Chapter 1. Designing Compute for Data Pipelines
When you’re developing applications that run on dedicated hardware, whether an on-premises data center, laptop, or phone, you have a predetermined, fixed amount of resources. In the cloud, on the other hand, you can configure virtual hardware to best meet workload needs, rather than working in a predefined resource envelope.
Compute design for data pipelines is about determining what resources you need for performant and reliable operation. Along with CPU, memory, disk space, and bandwidth, cloud compute has an additional axis of purchasing options, giving you the power to trade off cost against performance.
This can be a daunting topic, with millions of possible permutations across compute instance types, sizes, and purchasing plans. In this chapter, I’ll show you how to navigate this space, winnowing down options based on data pipeline performance characteristics and refining your choices with performance benchmarking.
The first thing to keep in mind is that cloud compute is a shared, distributed system. As a result, there are times when capacity is not available to fulfill your resource requests. I’ll begin this chapter by highlighting different scenarios where you can experience resource shortfalls, because ultimately it doesn’t matter how well you’ve designed your cluster if the resources you need aren’t available.
Next, you’ll see advice on various purchasing options for cloud compute and how to best leverage these options in data pipeline design.
Another step in homing in on the right compute configuration comes when you consider the business and architectural requirements of the design space. To illustrate this process, I’ll walk through a scenario that starts with a business problem and takes you through identifying relevant compute options at a high level.
Having filtered down the millions of compute options to a relevant subset, in the last section of the chapter you’ll see how to benchmark the performance of different cluster configurations. This is an exciting part of the chapter, where you’ll begin to understand the multifaceted dependencies that go into optimizing compute, including how more cluster nodes does not necessarily mean better performance. At the end of the chapter, I’ll bring purchasing options back into the picture to show you how to trade off performance against cost.
Even if you work in an environment where you don’t own the infrastructure, this chapter will give you important insight into robust pipeline design, cost–performance trade-offs, and even a little architecture, which, frankly, I think is indispensable for good pipeline design.
Understanding Availability of Cloud Compute
While significant capacity is offered by the cloud, there’s more to consider when it comes to the availability of compute resources. Something I try to keep in mind is that cloud resources are backed by physical hardware. It’s easy to overlook the fact that the server farms and networking that back virtual compute are susceptible to capacity and reliability considerations like what you would have when running your own on-premises system. There are also aspects to consider with how cloud service providers (CSPs) make compute resources available to customers.
Outages
As more computing moves to the cloud, the impact of CSP outages can have a wide reach that includes government websites, meal delivery services, and even robot vacuum cleaner scheduling.
CSPs provide service level agreements (SLAs) that guarantee a certain percentage of uptime, as you can see in the Google Cloud and Amazon EC2. If these SLAs are not met, you can be reimbursed for a portion of the compute spend that was impacted.
This might sound fine at first; if you can’t deploy resources due to an outage, you don’t have to pay for them. But consider the financial impact of your service being offline as a result of an outage. From a business perspective, you should be losing significantly more money from service disruptions than the cost of deploying cloud resources. To that point, a 2018 report from Lloyd’s of London estimates that an incident taking down one of the top three CSPs for three to six days would result in up to $15 billion in revenue losses. Given the expansion of businesses in the cloud since the time of that publication, revenue losses for a similar event today would be costlier.
One way to stem the impact of outages is to diversify where you launch compute resources. When outages occur, they can impact a subset of regions and Availability Zones (AZs) on a CSP’s network, as was the case with this outage Amazon Web Services (AWS) suffered in 2021. Building in the option to run pipelines in multiple AZs can help reduce exposure to outages.
Keep in mind that this also has a cost: supporting multi-AZ deployments requires additional infrastructure. Furthermore, networking costs can be a consideration, as well as data pipeline performance impacts if workloads span multiple AZs.
Note
Failover systems, as their name indicates, provide coverage in the event of a failure in the primary system. They can be implemented in a variety of ways based on how urgently you need to keep the system online. A hot failover is a live, redundant system that can be switched to quickly, at the cost of always keeping a redundant system online and ready.
From here, there are varying degrees of failover readiness, down to a cold failover system, where resources are brought online when a failure occurs. In this case, you trade system availability for cost, as you don’t incur the cost of running a redundant system but you sacrifice system availability while the cold system comes online.
While failover systems can provide additional coverage in the event of an outage, these systems can be very costly. A failover strategy that runs your pipeline in a different region will require data to be replicated across multiple regions, significantly increasing your data storage and access costs.
Capacity Limits
Something that can be overlooked when working with cloud services is that resources are often shared. Unless you specifically purchase dedicated hardware, you will be sharing compute with other customers. This means that when you provision a cluster, you are making a request for those resources. It’s not a guarantee of availability.
When you launch a compute instance or cluster, you are making a request for specific instance types and sizes. Whether this request can be fulfilled depends on the capacity available in the region and AZ you select.
If all resources are consumed when you need to initiate a batch job or add more capacity to a streaming pipeline, your resource request will go unfulfilled. I’ve seen this behavior when requesting compute capacity during popular times to run workloads, such as the hours after the close of business in the United States eastern time zone. Even if you have reserved dedicated compute resources, you can create this issue for yourself if you attempt to provision more capacity than you’ve purchased.
Segmentation can help you mute capacity impacts by splitting pipeline workloads into those that are time critical and those that can be run as resources are available. You’ll learn more about this in “Architectural Requirements”.
Account Limits
There can be limits on the amount of capacity available based on your subscription level. For example, you could have access to only a limited amount of CPU capacity. Requests exceeding this amount will be unfulfilled and can result in an error. If you are aware of these account limits ahead of time, you may be able to mitigate this situation by upgrading your subscription level, but keep in mind that you may not have access to additional resources immediately. Depending on the kind of increase you request, you may have to wait for approval from your CSP.
Infrastructure
Whether compute is available also depends on how you set up the environment where you are running pipelines. The availability of a particular instance type and size varies based on compute region and AZ, with some options being unavailable across different regions. If you are using a service like AWS Elastic MapReduce (EMR), there can be restrictions on the types of instances that are supported.
Note
I mentioned a few strategies for blunting the impacts of cloud availability issues including failover systems, multi-AZ operation, and job segmentation. Fundamentally, your pipelines need to operate in an environment where these situations can pop up. Good design techniques such as idempotency, data deduplication strategies, and retry mechanisms will help limit the impacts to pipeline uptime and data quality that can arise from unexpected resourcing shortfalls. These topics are covered in Chapter 4.
Leveraging Different Purchasing Options in Pipeline Design
At a high level, compute purchasing options come in three choices—on demand, interruptible/spot, and contractual discounts such as reserved instances and committed use. Table 1-1 shows the breakdown of the different prices for a fictitious instance INST3, based on an AWS pricing model.
| On demand | Reserved | Spot minimum | Spot maximum |
|---|---|---|---|
| $0.4 | $0.2 | $0.1 | $0.2 |
Note
In this book, I focus on instance hours–based purchasing options, where the underlying compute instances provide a fixed amount of resources and are charged by the number of hours used.
On Demand
As you can see in Table 1-1, on-demand pricing is the most expensive option because it allows you to request an instance whenever you need it and to retain it for the duration of your workload. It’s important to remember that you can make requests for compute at any time, but there is no guarantee that what you request will be available, as you saw earlier in this chapter.
On demand is a nice option when you’re trying to get a sense of your compute needs and can’t tolerate service disruption or if your workloads are short, infrequent, or unpredictable. Of the available purchasing options, on demand is the easiest to manage because you don’t need to evaluate reservations or handle the loss of spot instances.
Spot/Interruptible
Spot instances, also known as interruptible instances, are excess compute that a CSP has available. These instances offer a significant discount over on demand, as seen in the “Spot minimum” price in Table 1-1, but their price and availability are highly volatile. If demand increases, spot prices will increase (see “Spot maximum” in Table 1-1) and availability will decrease. At this point, a CSP will invoke a call-in of outstanding spot instances, providing a warning to spot consumers that the instance is about to terminate. Spot instances can be good choices for low-priority, non–time critical workloads and can also be used to provide additional cluster capacity.
Spot instances are often comingled with other purchasing options to improve performance and reduce cost based on system requirements. If you have a high-performance pipeline where interruption cannot be tolerated, you can use a baseline of on-demand or contractual provisioning, supplementing with spot instances as available to improve performance.
Some services can manage the interruption of spot instance termination for you. If you use spot instances as task nodes in your EMR cluster, you can configure settings to prevent job failure if the interruptible instances are terminated. AWS also provides instance fleets, where a mixture of on-demand and spot instances are configured to meet a target capacity. This gives you the benefit of lower-cost interruptible instances without the overhead of configuring them yourself. If you use an approach like this where a CSP is managing the provisioning choices, make sure to run some test workloads to validate that the choices being made for you are meeting your needs.
It’s possible that interrupting a pipeline job is a reasonable trade-off. If cost is a higher consideration than performance and data availability, spot instances can be a good choice as your primary resourcing strategy. You’ll see techniques for handling interrupted pipeline jobs in Chapter 4.
Other opportunities to use spot instances include development, testing, and short maintenance workloads.
Contractual Discounts
There are a variety of options for you to receive a discount in exchange for committing to purchase compute over a fixed period of time. AWS reserved instances, savings plans, and Google committed use discounts are some offerings that fall into this category. Outside of these options, companies can also negotiate private pricing agreements directly with CSPs.
Contractual discounts can be a good option if both of the following are true: you have predictable compute needs, and the way you use compute is consistent with the way the discount is applied. Understanding how the discounts are applied is very important; in the next section, I’ll share a story of a time when misunderstanding this aspect of reserved instance purchases resulted in unexpected costs. So long as you are clear on this, you can save substantially over on demand, as shown in Table 1-1. Pipelines with 24-7 operation and a baseline fixed workload can be good candidates for this option.
Typically, the more rigid the reservation, the greater the discount. For example, if you commit to reserving a specific instance type in a single AZ, you can get a better discount than if you need more flexibility, such as multiple instance types.
Something to consider with reserved contractual discounts is the historical decrease in instance hour cost. If prices drop below what you paid for with your reserved instance purchase, you do not get a refund of the difference. Committing to the minimum time period can help insulate you from overpaying in this scenario.
The area of contractual discounts is constantly evolving. To help you determine whether this is a good option, ask the following questions:
- What exactly am I reserving?
- Beyond the period of time you need to reserve to qualify for the discount, you want to be aware of what exactly you are committing to. Are you reserving a specific compute instance type and/or size, or are you reserving a number of CPU cores or an amount of memory? Does the contract allow you to change these choices or are they fixed?
- Is availability guaranteed?
- Are you reserving availability? Despite what you might think from the name, for some CSPs “reservation” does not mean that what you reserve will be available. For example, an AWS reserved instance purchase does not guarantee availability unless you also have a capacity reservation by specifying a single AZ for your reserved instance purchase.
- What if I no longer need my reservation?
- As resourcing needs change, you may find yourself with unused reservations. In some cases, you may be able to sell unused reservations to recoup the expense, such as on the Amazon EC2 marketplace. Additionally, some contracts allow you to convert to a different instance configuration.
- How is the discount applied?
- You might think that reserving a certain amount of capacity means the discount will be applied anytime you use resources matching what you reserved. This isn’t necessarily the case.
Contractual Discounts in the Real World: A Cautionary Tale
To illustrate the importance of understanding how contractual discounts are applied, consider a pipeline with two workers, WORKER1 and WORKER2, using an instance type INST3. Over the past year, the pipeline was consistently using 10 instance hours per month. The pipeline is expected to process as much or more data in subsequent years, so reducing costs through a reserved instance purchase seems attractive. Based on historical use, you commit to purchasing 10 instance hours per month, for a total of 120 instance hours of INST3 over the period of one year.
The reserved instance purchase is set to start in January. In the first few months of the year, your instance hour usage is as depicted in Figure 1-1.
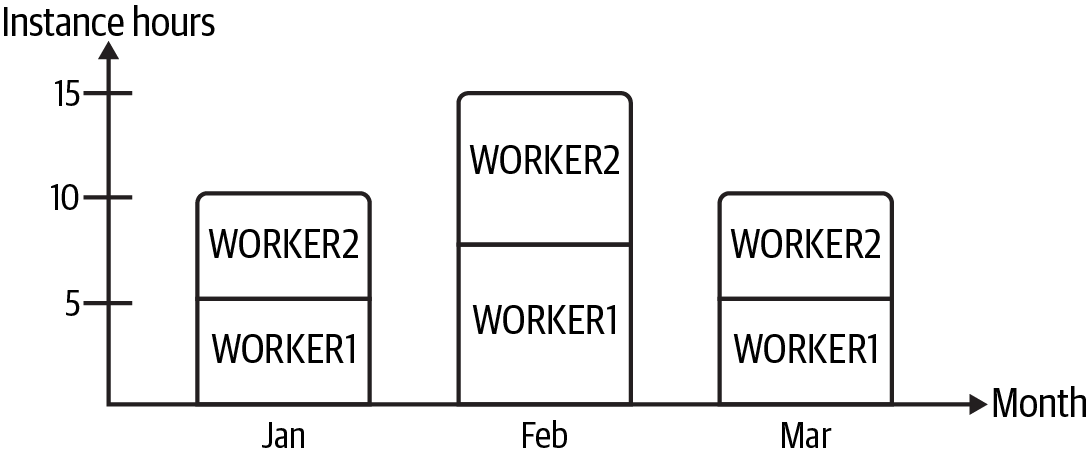
Figure 1-1. INST3 instance hours used by month
In January and March, each worker used five instance hours, adding up to the 10 you anticipated based on past use. In February, you had a bit more data to process than usual, so each node used eight instance hours, for a total of 16 instance hours. You aren’t too worried; you know that if you use more than your reserved capacity, you will be charged an on-demand price for the excess. As a result, you expect the quarterly cloud bill to look something like Table 1-2.
| Hours | Cost per hour | Total | |
|---|---|---|---|
| INST3—reserved | 30 | 0.2 | $6.00 |
| INST3—on demand | 6 | 0.4 | $2.40 |
| Quarterly total: | $8.40 |
Instead, you get the bill depicted in Table 1-3.
| Hours | Cost per hour | Total | |
|---|---|---|---|
| INST3—reserved | 30 | 0.2 | $6.00 |
| INST3—on demand | 18 | 0.4 | $7.20 |
| Quarterly total: | $13.20 |
What happened? You were using the number of instance hours you reserved for 30 out of 36 hours, so why are you getting charged on-demand pricing for over half of the total time? And why are you charged for 48 hours?1
Sadly, this is not a billing mistake. The reservation is for a single instance, so the discount only gets applied to one INST3 instance at a time. The filled portions of Figure 1-2 show the application of the reserved instance hours. Only WORKER1 received the discount. In addition, reserving instance capacity means you pay for the instance hours reserved even if they are unused, which is why you were charged for 30 hours over three months.
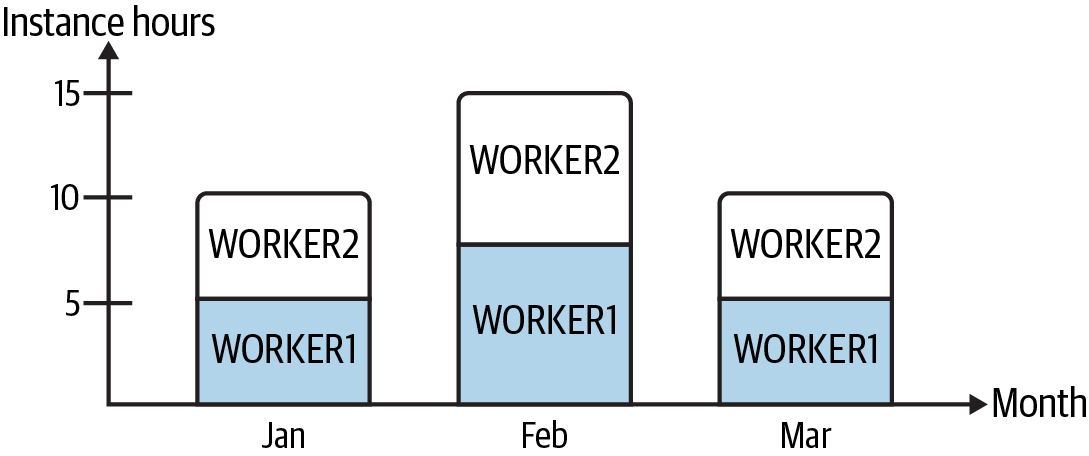
Figure 1-2. Reserved instance capacity used by WORKER1
To get the pricing you had assumed you were getting, you would have needed to purchase two reserved instances, committing to 60 hours per year for each one.
Requirements Gathering for Compute Design
As engineers, when we think about resourcing, we tend to focus on what is needed to accomplish a particular task, such as performing a set of data transformations. That is definitely part of the equation, but understanding the big, system-level picture elucidates where we can make trade-offs to harness all the options the cloud gives us.
Business Requirements
Understanding the business problems that need to be solved can help you get a sense of high-level pipeline requirements. This can include identifying the data sources, setting the ingestion schedule, and specifying the desired result data. This is the time to get a sense of system uptime requirements, which will help you determine whether you need to plan for a failover system. Business requirements can also include restrictions on which regions you can use and possibly which cloud services and software you can use.
The speed at which ingestion needs to complete can also be defined at this time. Part of this is understanding how performance trades off against cloud spend; is the application something that requires real-time, zero-downtime operation, or is ingestion runtime not as critical, enabling you to trade performance and availability for reduced cost?
With the data sources and result data defined, you can get a sense of the complexity of pipeline operation. Thinking of the three Vs of big data—variety, velocity, and volume—will help you determine pipeline architecture and resourcing needs. For example, if you are working with data sources that have significant changes in data volume over time, you will want to consider how to handle that, either by provisioning the maximum amount of compute needed or by adopting a scaling strategy to reduce waste when data loads are low.
Architectural Requirements
Architectural requirements translate business requirements into technical specifications, providing a picture of what needs to be built to realize the business needs. This can include setting performance specifications, uptime requirements, and data processing engine choice.
You want to consider compute design and data processing engines together, as the configuration possibilities between the two are tightly coupled. In addition, think about the environment in which the pipeline will run. For example, in a Kubernetes environment where a single cluster is servicing several different processes, make sure you have the right namespacing in place to limit contention. This will be important to ensure that the pipeline has sufficient resources while not impairing other parts of the system.
Architectural requirements can help you identify opportunities to split pipeline operation into processes where performance is critical and processes where performance is not as much of a concern. This presents an opportunity to use some cost-saving strategies.
High-performance workloads can require a significant percentage of free memory and CPU. While this unused capacity is critical for performance, it is wasteful: you’re paying for resources you don’t use. One way you can recoup these unused resources without impacting performance is by using priority scheduling. Low-priority processes can run in the background to use spare cycles and can be reduced or suspended when the higher-priority processes start to ramp up. Uber used this strategy to improve utilization in its big data platform.
Workload segmentation can also help you reduce pipeline runtime by running some tasks during off-hours or in the background. For example, if the cost of deduplicating data during pipeline execution is too expensive, you can consider deduplicating post ingestion. Uber used this approach to recompress Parquet files in the background to a higher level of compression, enabling the company to take advantage of lower storage costs without impacting pipeline runtime.
Offline processes are also an opportunity to use low-cost interruptible instances. If you have a pipeline that generates numerous small files throughout the day, you can run a compaction job offline to mitigate the impacts. I’ll discuss the small-files problem and mitigation strategies in Chapter 3.
Requirements-Gathering Example: HoD Batch Ingest
Recalling the running example from the Preface, the Herons on Demand (HoD) team begins working with a university lab to help them collect and analyze migratory bird data through surveys. It is hoped that new migration sites can be identified by combining the bird sighting data from HoD users with the survey data collected by the researchers. The pipeline for processing this data is pictured in Figure 1-3.
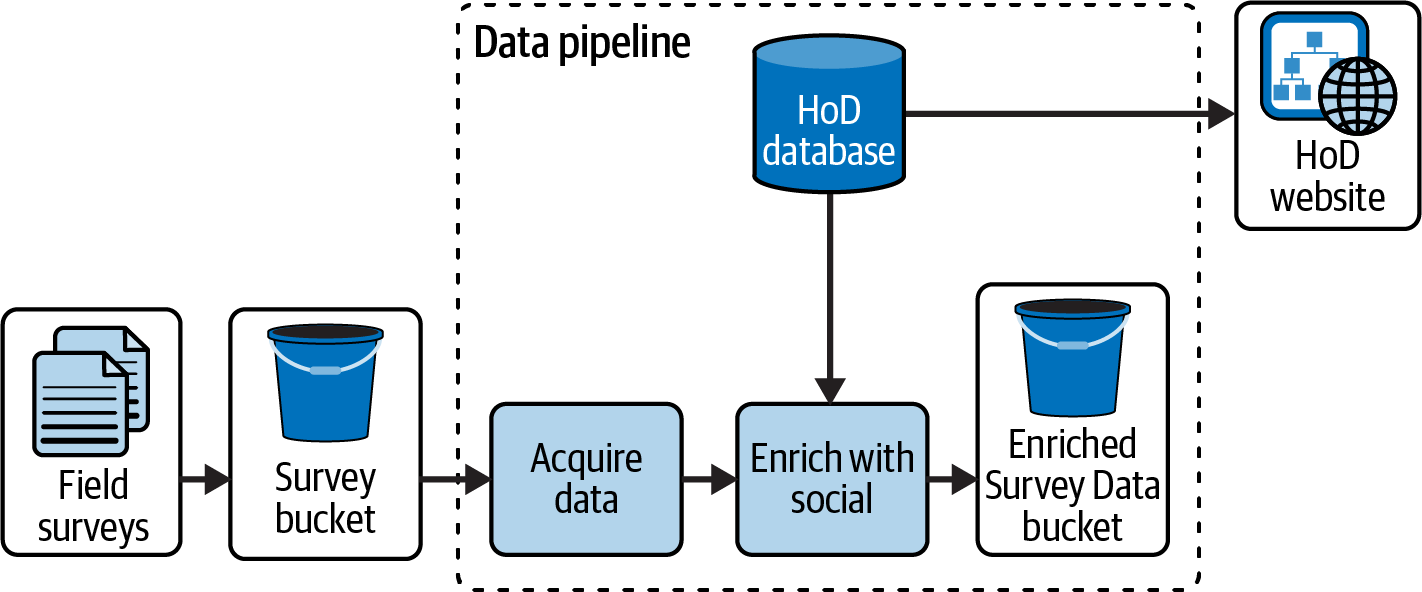
Figure 1-3. HoD batch architecture: survey pipeline
Field surveys are collected using an app that uploads survey results to cloud storage as compressed JSON. The pipeline brings in the survey data and joins it with social media collected by HoD, storing the result in Parquet format for analysis by the university researchers.
Let’s first consider some of the business requirements for the survey data pipeline. The data produced by this pipeline will be used by the researchers for grant proposals and dissertations. The researchers would like to get the data as quickly as possible, particularly leading up to these important deadlines, but they also need to be judicious stewards of the grant money that will be used for cloud compute. This sounds like a potential cost–performance trade-off opportunity.
The researchers agree to receive batches of data every two weeks, or biweekly. Given the infrequent ingest cycle, the HoD team proposes to handle any pipeline failures through monitoring and rerunning within the same day the failure occurred, rather than spending additional money to build a more sophisticated solution that can detect and mitigate these issues in real time.
The HoD team gets access to an existing dataset of surveys from the researchers, spanning the preceding year. To get a sense of the survey data batch size, they plot the data size across biweekly bins, as shown in Figure 1-4.
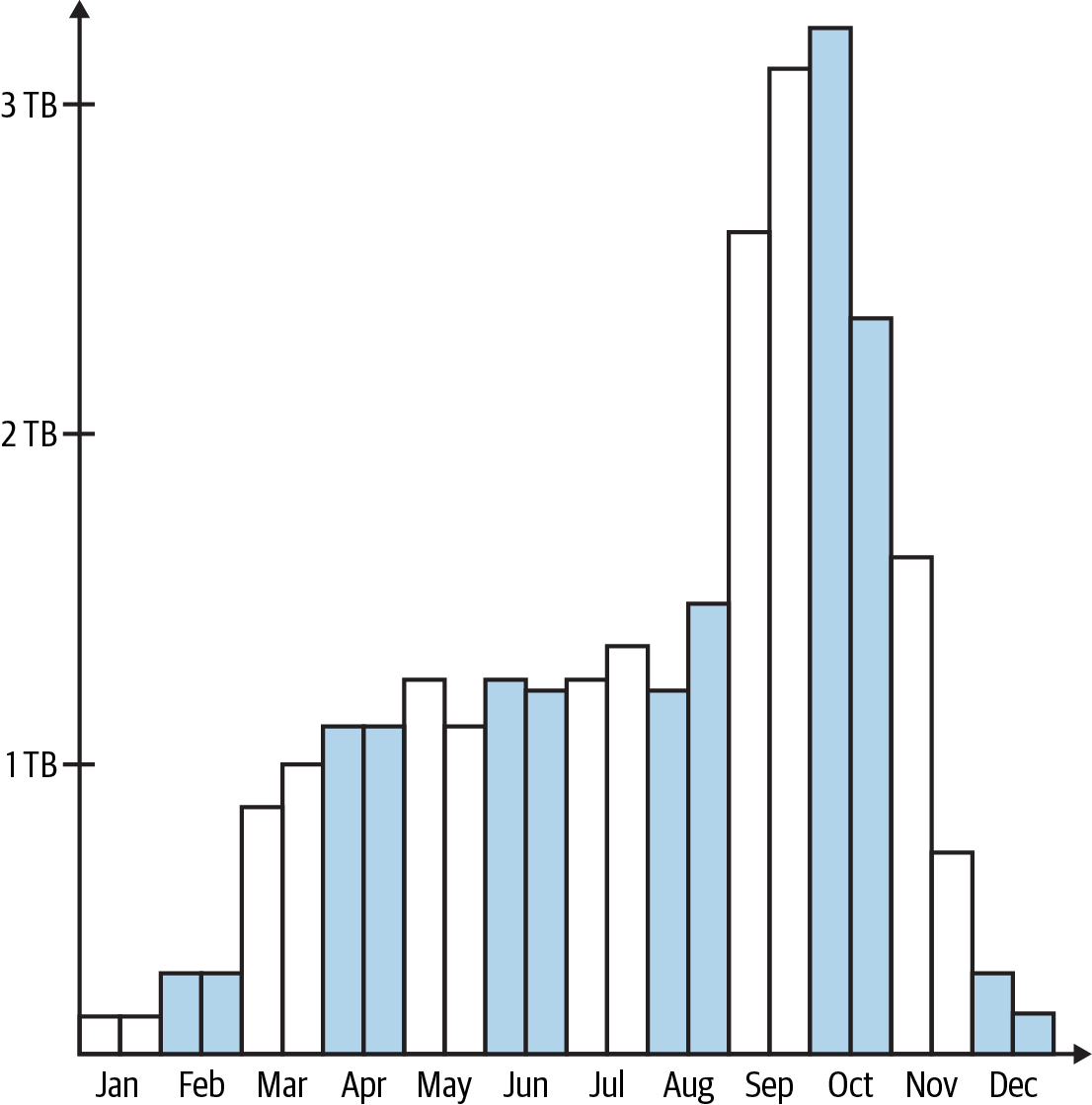
Figure 1-4. Bird survey data bucketed biweekly
From an architectural point of view, the team is already running some pipelines using Spark on EMR. They already are comfortable with that system, and the large amount of data and number of enhancements seem like a good fit for in-memory processing, so they decide to run the survey pipeline using the same tooling.
Given this scenario, let’s take a look at what we know regarding the survey pipeline.
Data
The survey data is static, with a volume of a few TB of compressed JSON in cloud storage. Cloud storage provides bandwidth in the hundreds of Gbps, which we would be well below given the expected data size per batch.
The other data source is the HoD social media database, which will be both serving content for the HoD website and providing data for the pipeline. Because there are multiple demands on this resource, contention and performance impacts are a concern for both the website and the pipeline. There may be a need to increase database resources to serve both purposes. Because the data pipeline runs biweekly, another option is to create a snapshot of the database just prior to ingestion that can be used by the pipeline.
In either case, you would want to make sure retries are built in when accessing the data, whether it comes from a cloud storage location or the HoD database.
Performance
There wasn’t a specific performance spec given in the requirements, just the desire to have the data quickly but without significant cost. We will revisit this in “Benchmarking” to get a sense of performance–cost trade-offs.
As a starting point, the Spark documentation suggests allocating at most 75% of the available memory for Spark. Depending on pipeline resource needs and desired speed of ingest, you may need to target utilization at a lower percentage. The same applies for CPU, disk, and network utilization. This is something you will get a better sense of over time as you monitor pipeline performance.
Purchasing options
An on-demand purchasing model makes sense to start out, as this provides a fixed set of resources while getting the pipeline up and running reliably. It’s too early to explore contractual discounts such as reserved instances, because you’re not sure what the load looks like over the long term.
With the ability to trade cost for performance, spot instances can be added to the mix once you have a solid sense of resourcing needs. There isn’t a particular time of the day or day of the week the pipeline needs to run, providing additional latitude in scheduling to run the job when spot instances are available or on-demand prices are lower.
Benchmarking
Now that you’ve got a sense of the subset of relevant compute options, it’s time to take them for a test drive. Benchmarking is the process of evaluating cluster design and compute options while running a sample workload, helping you identify optimal configurations.
Something that really frustrated me early in my career was how little information I could find about benchmarking and cluster sizing, either online, in books, or by talking to more experienced data engineers. The answer was always some form of “it depends.”
While I’ve seen some general formulas for assessing resource needs, such as the Packt approach for sizing a Hadoop cluster for data processing, my experience has been that it really does depend (sorry!) on many things that are interrelated and that can change over time in data pipelines.
While I can’t give you a magic formula, I can walk you through the process of estimating and evaluating different compute configurations, pointing out when various aspects of pipeline design impact the decisions you’re making. I’ll continue the example from the prior section, making some choices about different data processing engines, techniques, and cluster sizes and illustrating how they impact one another.
Because data processing engines have a significant impact on compute needs but a discussion of the topic is beyond the scope of this book, I’ve included pointers to resources in “Recommended Readings”.
Note
As you read through this section, keep in mind that not only will benchmarking workloads give you insight into cluster design, they are also a helpful tool for characterizing and debugging workloads. This can be handy if you’re considering using serverless to run a process but you’re unsure what kinds of resources it would need (and therefore have poor visibility into potential serverless costs). One of the trade-offs when using serverless is reduced visibility into how resources are being used, which can hide the impacts of suboptimal data processing engine configurations, low performance queries, and subpar data structures. If you find yourself in this situation, it can be worthwhile to spin up a cluster where you can monitor and introspect performance.
Even if you’re using managed services, it’s helpful to understand this process. You have the option to specify cluster configuration properties such as instance family, size, and number of workers in many popular managed solutions, including Google Dataproc, AWS Glue, Databricks, and Snowflake.
Instance Family Identification
Determining which instance family to use is a combination of assessing the relative needs of CPU, memory, and bandwidth and analyzing cluster performance. Once you’ve gone through this process a few times, you’ll start to develop a sense of which families work well for different applications.
Returning to the HoD bird survey pipeline example, Spark will be used for processing the data, which primarily works with data in-memory. Another aspect of this pipeline is the join performed between the survey data and the HoD database. Joining large datasets in-memory points to a memory-optimized family or potentially a general-purpose instance with a lot of memory.
Tip
This is a great time to consider the interdependencies among the data you are working with, how you process it, and the compute resources you need. Notice that I mentioned joining large datasets in-memory. You could choose to create this data in another way: you could minimize the size of the data being joined to reduce the amount of data in memory and disk space needed for shuffle, or perhaps forgo the join altogether by instead performing a lookup on a sorted key-value store.
There are many knobs to optimize how data is processed. The challenge with data pipelines is that these knobs can be infrastructure design, data formatting, and data processing engine configuration, to name a few.
Because the pipeline is running in EMR, only a subset of instance types are available. Some additional guidance from the Spark documentation suggests a configuration of eight to 16 cores per machine2 and a 10 Gb or higher bandwidth, further slimming down the potential options.
The AWS instances that meet these requirements are shown in Table 1-4.3
| API name | Memory (GB) | vCPUs | Network performance | Linux on demand cost |
|---|---|---|---|---|
| m4.2xlarge | 32 | 8 | High | $0.40 |
| m4.4xlarge | 64 | 16 | High | $0.80 |
| m5.xlarge | 16 | 4 | Up to 10 Gb | $0.19 |
| m5.2xlarge | 32 | 8 | Up to 10 Gb | $0.38 |
| m5.4xlarge | 64 | 16 | Up to 10 Gb | $0.77 |
| r4.xlarge | 30.5 | 4 | Up to 10 Gb | $0.27 |
| r4.2xlarge | 61 | 8 | Up to 10 Gb | $0.53 |
| r4.4xlarge | 122 | 16 | Up to 10 Gb | $1.06 |
| r5.xlarge | 32 | 4 | Up to 10 Gb | $0.25 |
| r5.2xlarge | 64 | 8 | Up to 10 Gb | $0.50 |
| r5.4xlarge | 128 | 16 | Up to 10 Gb | $1.01 |
| r5.12xlarge | 384 | 48 | 10 Gb | $3.02 |
Note
According to Datacenters.com, vCPU is calculated as (Threads × Cores) × Physical CPU = Number vCPU. vCPU is effectively the number of threads available. More vCPUs can enable more parallelism by enabling more Spark executors, or they can provide a fixed set of executors with more resources.
In the comparison, I’ve selected a few general-purpose types, m4 and m5, and two memory-optimized types, r4 and r5. Notice that for the same vCPU there’s twice as much memory in the memory-optimized instances and a corresponding increase in hourly cost.
Cluster Sizing
Another common question in compute design is how many nodes you should have in your cluster. At a minimum, a cluster should have two workers for reliability and performance. To reach a desired capacity you can choose to configure a cluster with many smaller instances or use fewer larger instances. Which is better? Well, it depends. This is another case where infrastructure design, data processing engine configuration, code, and data structure come together.
The types of purchasing options you use for the cluster nodes is another consideration. In “Benchmarking Example”, you’ll see some examples of mixing interruptible and on-demand instances.
Let’s consider a case where you design a cluster that has a few nodes using instances with a large amount of memory per instance. When working with Spark, you can incur long garbage collection times if each worker node has a large amount of memory. If this leads to unacceptable performance and reliability impacts for your workload, you would be better off provisioning more nodes with a smaller amount of memory per node to get the desired memory capacity.
On the other hand, if your workload has significant shuffle, having more workers means there are more instances you may need to move data between. In this case, designing the cluster to have a few nodes with a larger memory footprint would be better for performance, as described in recent guidance from Databricks.
You’ll see an example of working through this trade-off in the upcoming section, “Benchmarking Example.”
Monitoring
To evaluate the efficacy of a given cluster configuration, you need to monitor performance. This is covered in more detail in Chapter 11, so for now I will only highlight some of the specific monitoring areas that relate to benchmarking workloads.
Cluster resource utilization
Monitoring the usage of memory, disk, CPU, and bandwidth over the course of a workload can help you identify whether you are under- or over-provisioned. In EMR, you can inspect these metrics using Ganglia. Prometheus and Grafana are other monitoring tools that enable you to combine metrics from multiple deployments into a single dashboard.
Data processing engine introspection
When working with Spark, the Spark UI provides additional diagnostic information regarding executor load, how well balanced (or not) your computation is across executors, shuffles, spill, and query plans, showing you how Spark is running your query. This information can help you tune Spark settings, data partitioning, and data transformation code.
Benchmarking Example
To show you how to do benchmarking in practice, I’ll walk through some example cluster configurations for the bird survey batch pipeline in Figure 1-3, describing how you would discern how the cluster is performing under load.
Looking at the data distribution in Figure 1-4, most batches have 1 to 2 TB of data. Starting the estimation using a batch in this range will provide a configuration that works in the largest number of cases. It also has the advantage of not overfitting to very large or very small jobs, which may have different performance characteristics.
Undersized
I’ll start with the cluster configuration in Table 1-5. This configuration is undersized, and I want to illustrate it so that you know how to identify this scenario. GP1 denotes the general-purpose cluster configuration, and M1 is the memory-optimized configuration.
| Name | Instance type | Instance count | Total vCPU | Total memory (GB) | Bandwidth (GB) |
|---|---|---|---|---|---|
| GP1 | m5.xlarge | 3 | 12 | 48 | Up to 10 |
| M1 | r5.xlarge | 3 | 12 | 96 | Up to 10 |
When working with large-scale data, it can take a long time to finish a single run. However, you don’t have to wait until a job completes to inspect the results. In fact, it’s better when benchmarking if you can check on the health of the cluster from time to time using the monitoring tools I mentioned earlier.
Distributed systems, including distributed data processing engines like Spark, will attempt to retry a variety of failure conditions such as rerunning a failed task and retrying on a communication timeout. This is a fundamental aspect of fault tolerance in distributed systems, and for your data processing jobs it means that in the presence of insufficient resources, a job could be retried several times before it is officially declared failed.
Let’s consider a hypothetical scenario for running the survey data pipeline against a 2 TB batch using either of the cluster configurations in Table 1-5, as in this case they will both perform about the same.
You launch the cluster and the pipeline starts chugging away, spending quite a bit of time in the “Enrich with social” step where the join is happening. You ran a smaller batch size through the “Enrich with social” step on your laptop and it took a few minutes, whereas on the cluster it’s been running for over an hour. It’s time to take a look at some performance monitoring to see what’s going on.
When you look at the Spark UI, you see several failed tasks and “out of memory” messages in the executor logs. You check Ganglia, and you see that 85% of the available memory has been consumed and the load on the workers is high. You also see that some cluster nodes have failed, having been replaced by EMR to keep the cluster at the requested resource level. The job continues to run as Spark tries to rerun the failed tasks, but ultimately the job fails.
Oversized
Moving on to another configuration option, GP2 and M2 in Table 1-6 add significantly more workers but retain the xlarge instance size. Fewer memory-optimized instances are used in M2 versus the general-purpose instances in GP2 given the additional memory available with this instance type.
| Name | Instance type | Instance count | Total vCPU | Total memory (GB) | Bandwidth (GB) |
|---|---|---|---|---|---|
| GP2 | m5.xlarge | 40 | 160 | 640 | Up to 10 |
| M2 | r5.xlarge | 30 | 120 | 960 | Up to 10 |
In the hypothetical 2 TB batch example, you see that these configurations perform significantly better. The metrics are well within limits throughout job execution—no out-of-memory or failed-node issues. When you look at the Spark UI, you notice there is a lot of shuffling going on. The job completes successfully, with a runtime of 8 hours for GP2 and 6.5 hours for M2.
Right-Sized
Right-sizing refers to having the optimal number of resources to perform a task. This means there are limited excess resources (waste) and that you are not under-resourced, which can lead to reliability and performance issues.
Warning
While this exercise goes straight into right-sizing as part of the benchmarking process, you want to be cautious about spending time too early in the design process trying to find the optimal compute configuration.
Right-sizing is something that comes over time as you gain insight into pipeline performance and resource utilization. When you are initially getting a pipeline up and running, it can be desirable to over-provision, that is, provide more resources than are necessary. This eliminates the issues of under-resourcing, allowing you to focus on working out bugs in other areas. Once you feel like you’ve got things running reliably, then you can start to consider right-sizing.
Given the shuffling you saw with configurations GP2 and M2, swapping out the small-sized instances for fewer larger instances might improve performance, giving the configuration in Table 1-7.
| Name | Instance type | Instance count | Total vCPU | Total memory (GB) | Bandwidth (GB) |
|---|---|---|---|---|---|
| GP3 | m5.4xlarge | 10 | 160 | 640 | Up to 10 |
| M3 | r5.2xlarge | 8 | 64 | 512 | Up to 10 |
Running with this configuration, you see a reduction in shuffling versus GP2 and M2 and reduced runtimes. GP3 runs in 7 hours and M3 runs in 4.75 hours. This is an interesting outcome, as M3 has fewer resources than M2 but runs faster due to reducing shuffling overhead through fewer workers.
Now that you’ve identified some working configurations, let’s take a look at costs in Table 1-8.
| Name | Instance count | Hours | On demand | 40% spot | 60% spot |
|---|---|---|---|---|---|
| GP2 | 40 | 8 | $77 | $62 | $54 |
| M2 | 30 | 6.5 | $58 | $49 | $44 |
| GP3 | 10 | 7 | $67 | $56 | $51 |
| M3 | 8 | 4.75 | $24 | $20 | $19 |
Starting with GP2, it’s probably not surprising that this is the costliest option given the number of instances and the runtime. Remember that GP2 and M2 both ran the pipeline successfully. If it hadn’t been for inspecting cluster performance, it wouldn’t have been apparent that the configuration was suboptimal.
You can see the cost advantage of the memory-optimized instances for this application in comparing M3 to GP3. Not only were fewer memory-optimized instances needed, but the job runtime was lower. As a result, the M3 on-demand cost is about 35% of the GP3 cost. With 60% of the instance hours provided by spot instances, the M3 cost could be reduced an additional 20%.
Tip
When you’re prototyping and testing out different configurations, it’s very easy to forget to shut down resources when you’re done with them. Look for auto-shutdown options when you launch resources; typically you can set this to shut down the resource after a certain period of idle time.
Another way to help keep track of resources is to use tags or labels, which are also set up when you launch a resource. For example, you could use the tag DEV-TEMP to identify ephemeral development resources that can be shut down if idle for more than 24 hours.
Summary
The numerous ready-to-use compute configurations available in the cloud give you tremendous power to design compute that provides an optimal balance of performance, cost, and uptime for your data pipelines. Rather than feeling overwhelmed by the millions of choices, you can confidently design compute by evaluating pricing, instance configuration, and cluster design options, and use benchmarking to refine these choices.
This understanding equips you to evaluate services and products that manage compute design for you. This includes third-party products and services that reduce cloud compute costs; CSP offerings that manage compute for you, such as AWS Fargate; and service options that manage different pricing plans under the hood, such as AWS Instance Fleets.
As with any system design, a key part of compute design is understanding how things can go wrong. When working with cloud compute, being familiar with the sources of potential resourcing issues helps you design robust pipelines and plan for contingencies. Outages, capacity and account limits, and infrastructure design are areas to keep in mind, especially if you are working with shared tenancy compute.
Depending on the cost–availability trade-off of your application, you have a variety of ways to handle availability issues, including failover systems, job segmentation, and running pipelines in multiple AZs. Keep cost versus business need in mind when evaluating failover systems or multiregional deployments, particularly the cost of data replication.
The understanding you’ve gained about different pricing options will help you save costs where you can tolerate some ambiguity in compute capacity with interruptible/spot instances, and where you can comfortably commit to reservations—both strategies for saving significant costs over on-demand pricing. Interruptible instances are a great choice for development activities, opportunistically adding additional capacity, testing, or low-priority maintenance workloads. When you evaluate reservations, make sure you read the fine print! You will pay for your reserved capacity whether you use it or not, so make sure you understand how reserved capacity is applied to your workload.
To start getting a sense of what compute options are right for you, evaluate your business needs and architectural requirements. This will help you zero in on the right mixture of purchasing plans and cluster configuration possibilities for your pipelines.
Business requirements help you identify data, performance, cost, and reliability needs, while architectural requirements provide insight about data processing engines and infrastructure. During this process, acquiring sample data and gaining an understanding of where costs can be traded for system operation will give you important information to start exploring compute design options.
As you saw in this chapter, the learnings you gain from business and architectural requirements will get you ready to evaluate different cluster configurations by estimating required resources, deploying clusters to run your pipeline, and monitoring performance, resource utilization, and data processing engine behavior. Along the way, you also saw in this chapter how compute design is intertwined with many other aspects of data pipeline operation, including data processing engine configurations, approaches for transforming data, and decisions about data structure. Another element that impacts compute performance is how data is stored, which you will learn more about in Chapter 3.
As you saw in the benchmarking example, more compute power does not necessarily provide better performance. Monitoring and iterating on compute configurations is an essential practice for cost-effective design, helping you discern what configurations are most effective for a specific workload. While I focused on benchmarking to home in on cluster configurations in this chapter, this skill is indispensable for debugging and will be helpful in guiding infrastructure decisions regardless of whether you will be taking on infrastructure design yourself.
Moving on from managing cloud compute to get the best value for your money, in the next chapter you’ll see how to leverage the elasticity of the cloud to increase or reduce cloud resources to accommodate different workloads and cost–performance trade-offs.
Recommended Readings
Spark optimization resources
High Performance Spark by Holden Karau and Rachel Warren (O’Reilly)
Chapter 7 of Learning Spark, 2nd Edition, by Jules S. Damji, Brooke Wenig, Tathagata Das, and Denny Lee (O’Reilly)
Chapter 19 of Spark: The Definitive Guide by Bill Chambers and Matei Zaharia (O’Reilly)
Dask optimization resources
Scaling Python with Dask by Holden Karau and Mika Kimmins (O’Reilly)
Dask: The Definitive Guide by Matthew Rocklin, Matthew Powers, and Richard Pelgrim (O’Reilly)
1 In the scenario that inspired this story, the extra cost was well over a few dollars.
2 This is also very dependent on how you configure Spark and your workload.
3 Data from https://instances.vantage.sh.
Get Cost-Effective Data Pipelines now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

