Chapter 4. Concurrency and Parallelism
Writing multithreaded programs is one of the most difficult tasks many programmers will face. They are difficult to reason about, and often exhibit nondeterministic behavior: a typical program that utilizes concurrency facilities will sometimes yield different results given the same inputs, a result of ill-defined execution order that can additionally produce race conditions and deadlocks. Some of these conditions are hard to detect, and none of them are easy to debug.
Most languages give us paltry few resources to cope with the cognitive burden of concurrency. Threads and locks, in all their forms, are often the only real tools at our disposal, and we are often victims of how difficult they are to use properly and efficiently. In which order should locks be acquired and released? Does a reader have to acquire a lock to read a value another thread might be writing to? How can multithreaded programs that rely upon locks be comprehensively tested? Complexity spirals out of control in a hurry; meanwhile, you are left debugging a race condition that only occurs in production or a deadlock that happens on this machine, but not that one.
Considering how low-level they are, the continued reliance upon threads, locks, and pale derivatives as the sole “user-facing” solution to the varied complexities of concurrency is a remarkable contrast to the never-ending stampede of activity seen over the years in developing more effective and less error-prone abstractions. Clojure’s response to this has many facets:
As we discussed in Chapter 2, minimize the amount of mutable state in your programs, with the help of immutable values and collections with reliable semantics and efficient operations.
When you do need to manage changing state over time and in conjunction with concurrent threads of execution, isolate that state and constrain the ways in which that state can be changed. This is the basis of Clojure’s reference types, which we’ll discuss shortly.
When you absolutely have no other choice—and are willing to shrug off the benefits of the semantic guarantees of Clojure’s reference types—make it straightforward to drop back to bare locks, threads, and the high-quality concurrency APIs provided by Java.
Clojure provides no silver bullet that makes concurrent programming instantly trivial, but it does provide some novel and now battle-tested tools to makes it far more tractable and reliable.
Shifting Computation Through Time and Space
Clojure provides a number of entities—delays, futures, and promises—that encapsulate discrete use cases for controlling when and how computations are performed. While only futures are solely concerned with concurrency, they are all often used to help implement specific concurrent semantics and mechanics.
Delays
A delay is a construct that suspends
some body of code, evaluating it only upon demand, when it is
dereferenced:
(def d (delay (println "Running...")
:done!))
;= #'user/d
(deref d)
; Running...
;= :done!Note
The deref abstraction is
defined by Clojure’s clojure.lang.IDeref interface; any type
that implements it acts as a container for a value. It may be
dereferenced, either via deref,
or the corresponding reader syntax, @.[124] Many Clojure entities are dereferenceable, including
delays, futures, promises, and all reference types, atoms, refs,
agents, and vars. We talk about them all in this chapter.
You can certainly accomplish the same sort of thing just by using functions:
(def a-fn (fn []
(println "Running...")
:done!))
;= #'user/a-fn
(a-fn)
; Running...
;= :done!However, delays provide a couple of compelling advantages.
Delays only evaluate their body of code
once, caching the return value. Thus,
subsequent accesses using deref
will return instantly, and not reevaluate that code:[125]
@d ;= :done!
A corollary to this is that multiple threads can safely attempt to dereference a delay for the first time; all of them will block until the delay’s code is evaluated (only once!), and a value is available.
When you may want to provide a value that contains some expensive-to-produce or optional data, you can use delays as useful (if crude) optimization mechanisms, where the end “user” of the value can opt into the costs associated with that data.
(defn get-document
[id]
; ... do some work to retrieve the identified document's metadata ...
{:url "http://www.mozilla.org/about/manifesto.en.html"
:title "The Mozilla Manifesto"
:mime "text/html"
:content (delay (slurp "http://www.mozilla.org/about/manifesto.en.html"))})  ;= #'user/get-document
(def d (get-document "some-id"))
;= #'user/d
d
;= {:url "http://www.mozilla.org/about/manifesto.en.html",
;= :title "The Mozilla Manifesto",
;= :mime "text/html",
;= :content #<Delay@2efb541d: :pending>}
;= #'user/get-document
(def d (get-document "some-id"))
;= #'user/d
d
;= {:url "http://www.mozilla.org/about/manifesto.en.html",
;= :title "The Mozilla Manifesto",
;= :mime "text/html",
;= :content #<Delay@2efb541d: :pending>} 
-
We can use
delayto cheaply suspend some potentially costly code or optional data.-
That
delay’s code will remain unevaluated until we (or our code’s caller) opt to dereference its value.
Some parts of our program may be perfectly satisfied with the
metadata associated with a document and not require its content
at all, and so can avoid the costs associated with retrieving that
content. On the other hand, other parts of our application may
absolutely require the content, and still others might make use of
it if it is already available. This latter use
case is made possible with realized?, which polls a delay to see if its value has been
materialized yet:
(realized? (:content d)) ;= false @(:content d) ;= "<!DOCTYPE html><html>..." (realized? (:content d)) ;= true
Note
Note that realized? may
also be used with futures, promises, and lazy sequences.
realized? allows you to
immediately use data provided by a delay that has already been
dereferenced, but perhaps opt out of forcing the evaluation of a
delay if you know that doing so will be too expensive an operation
than you’re willing to allow at that point in time and can do
without its eventual value.
Futures
Before getting to more sophisticated topics like reference types, Clojure programmers often start off asking, “How do I start a new thread and run some code in it?” Now, you can use the JVM’s native threads if you have to (see Using Java’s Concurrency Primitives), but Clojure provides a kinder, gentler option in futures.
A Clojure future evaluates a body of code in another thread:[126]
(def long-calculation (future (apply + (range 1e8)))) ;= #'user/long-calculation
future returns immediately,
allowing the current thread of execution (such as your REPL) to
carry on. The result of evaluation will be retained by the future,
which you can obtain by dereferencing it:
@long-calculation ;= 4999999950000000
Just like a delay, dereferencing a future will block if the code it is evaluating has not completed yet; thus, this expression will block the REPL for five seconds before returning:
@(future (Thread/sleep 5000) :done!) ;= :done!
Also like delays, futures retain the value their body of code
evaluated to, so subsequent accesses via deref will return that value immediately.
Unlike delays, you can provide a timeout and a “timeout value”
when dereferencing a future, the latter being what deref will return if the specified timeout
is reached:[127]
(deref (future (Thread/sleep 5000) :done!)
1000
:impatient!)
;= :impatient!Futures are often used as a device to simplify the usage of
APIs that perform some concurrent aspect to their operation. For
example, say we knew that all users of the get-document function from Example 4-1 would need the :content value. Our first impulse might be
to synchronously retrieve the document’s :content within the scope of the get-document call, but this would make
every caller wait until that content is retrieved fully, even if the
caller doesn’t need the content immediately. Instead, we can use a
future for the value of :content;
this starts the retrieval of the content in another thread right
away, allowing the caller to get back to work without blocking on
that I/O. When the :content value
is later dereferenced for use, it is likely to block for less time
(if any), since the content retrieval had already been in
motion.
(defn get-document
[id]
; ... do some work to retrieve the identified document's metadata ...
{:url "http://www.mozilla.org/about/manifesto.en.html"
:title "The Mozilla Manifesto"
:mime "text/html"
:content (future (slurp "http://www.mozilla.org/about/manifesto.en.html"))}) -
The only change from Example 4-1 is replacing
delaywithfuture.
This requires no change on the part of clients (since they
continue to be interested only in dereferencing the value of
:content), but if callers are
likely to always require that data, this small change can prove to
be a significant improvement in throughput.
Futures carry a couple of advantages compared to starting up a native thread to run some code:
Clojure futures are evaluated within a thread pool that is shared with potentially blocking agent actions (which we discuss in Agents). This pooling of resources can make futures more efficient than creating native threads as needed.
Using
futureis much more concise than setting up and starting a native thread.Clojure futures (the value returned by
future) are instances ofjava.util.concurrent.Future, which can make it easier to interoperate with Java APIs that expect them.
Promises
Promises share many of the mechanics of delays and futures: a promise may be dereferenced with an optional timeout, dereferencing a promise will block until it has a value to provide, and a promise will only ever have one value. However, promises are distinct from delays and futures insofar as they are not created with any code or function that will eventually define its value:
(def p (promise)) ;= #'user/p
promise is initially a
barren container; at some later point in time, the promise may be
fulfilled by having a value delivered to it:
(realized? p) ;= false (deliver p 42) ;= #<core$promise$reify__1707@3f0ba812: 42> (realized? p) ;= true @p ;= 42
Thus, a promise is similar to a one-time, single-value pipe:
data is inserted at one end via deliver and retrieved at the other end by
deref. Such things are sometimes
called dataflow variables and are the building blocks of declarative
concurrency. This is a strategy where relationships between
concurrent processes are explicitly defined such that derivative
results are calculated on demand as soon as their inputs are
available, leading to deterministic behavior. A simple example would
involve three promises:
(def a (promise)) (def b (promise)) (def c (promise))
We can specify how these promises are related by creating a future that uses (yet to be delivered) values from some of the promises in order to calculate the value to be delivered to another:
(future (deliver c (+ @a @b)) (println "Delivery complete!"))
In this case, the value of c will not be delivered until both
a and b are available (i.e., realized?); until that time, the future
that will deliver the value to
c will block on dereferencing
a and b. Note that attempting to dereference
c (without a timeout) with the
promises in this state will block your REPL thread
indefinitely.
In most cases of dataflow programming, other threads will be
at work doing whatever computation that will eventually result in
the delivery of values to a and
b. We can short-circuit the
process by delivering values from the REPL;[128] as soon as both a
and b have values, the future
will unblock on dereferencing them and will be able to deliver the
final value to c:
(deliver a 15) ;= #<core$promise$reify__5727@56278e83: 15> (deliver b 16) ; Delivery complete! ;= #<core$promise$reify__5727@47ef7de4: 16> @c ;= 31
Promises don’t detect cyclic dependencies
This means that (deliver p
@p), where p is a
promise, will block indefinitely.
However, such blocked promises are not locked down, and the situation can be resolved:
(def a (promise)) (def b (promise)) (future (deliver a @b));= #<core$promise$reify__5727@6156f1b0: 42> @a ;= 42 @b ;= 42
-
Futures are used there to not block the REPL.
-
aandbare not delivered yet.-
Delivering
aallows the blocked deliveries to resume—obviously(deliver a @b)is going to fail (to returnnil) but(deliver b @a)proceeds happily.
An immediately practical application of promises is in easily making callback-based APIs synchronous. Say you have a function that takes another function as a callback:
(defn call-service [arg1 arg2 callback-fn] ; ...perform service call, eventually invoking callback-fn with results... (future (callback-fn (+ arg1 arg2) (- arg1 arg2))))
Using this function’s results in a synchronous body of code
requires providing a callback, and then using any number of
different (relatively unpleasant) techniques to wait for the
callback to be invoked with the results. Alternatively, you can
write a simple wrapper on top of the asynchronous, callback-based
API that uses a promise’s blocking behavior on deref to enforce the synchronous semantics
for you. Assuming for the moment that all of the asynchronous
functions you’re interested in take the callback as their last
argument, this can be implemented as a general-purpose higher-order
function:
(defn sync-fn
[async-fn]
(fn [& args]
(let [result (promise)]
(apply async-fn (conj (vec args) #(deliver result %&)))
@result)))
((sync-fn call-service) 8 7)
;= (15 1)Parallelism on the Cheap
We’ll be examining all of Clojure’s flexible concurrency facilities in a bit, one of which—agents—can be used to orchestrate very efficient parallelization of workloads. However, sometimes you may find yourself wanting to parallelize some operation with as little ceremony as possible.
The flexibility of Clojure’s seq abstraction[129] makes implementing many routines in terms of processing sequences very easy. For example, say we had a function that uses a regular expression to find and return phone numbers found within other strings:
(defn phone-numbers
[string]
(re-seq #"(\d{3})[\.-]?(\d{3})[\.-]?(\d{4})" string))
;= #'user/phone-numbers
(phone-numbers " Sunil: 617.555.2937, Betty: 508.555.2218")
;= (["617.555.2937" "617" "555" "2937"] ["508.555.2218" "508" "555" "2218"])Simple enough, and applying it to any seq of strings is easy,
fast, and effective. These seqs could be loaded from disk using
slurp and file-seq, or be coming in as messages from a
message queue, or be the results obtained by retrieving large chunks
of text from a database. To keep things simple, we can dummy up a seq
of 100 strings, each about 1MB in size, suffixed with some phone
numbers:
(def files (repeat 100
(apply str
(concat (repeat 1000000 \space)
"Sunil: 617.555.2937, Betty: 508.555.2218"))))Let’s see how fast we can get all of the phone numbers from all of these “files”:
(time (dorun (map phone-numbers files)))
This is parallelizable though, and trivially so. There is a
cousin of map—pmap – that will parallelize the application of a function
across a sequence of values, returning a lazy seq of results just like
map:
(time (dorun (pmap phone-numbers files)))
Run on a dual-core machine, this roughly doubles the throughput
compared to the use of map in the
prior example; for this particular task and dataset, roughly a 4x
improvement could be expected on a four-core machine, and so on. Not
bad for a single-character change to a function name! While this might
look magical, it’s not; pmap is
simply using a number of futures—calibrated to suit the number of CPU
cores available—to spread the computation involved in evaluating
phone-numbers for each file across
each of those cores.
This works for many operations, but you still must use pmap judiciously. There
is a degree of overhead associated with
parallelizing operations like this. If the operation being
parallelized does not have a significant enough runtime, that overhead
will dominate the real work being performed; this can make a naive
application of pmap
slower than the equivalent use of map:
(def files (repeat 100000
(apply str
(concat (repeat 1000 \space)
"Sunil: 617.555.2937, Betty: 508.555.2218"))))
(time (dorun (map phone-numbers files)))
; "Elapsed time: 2649.807 msecs"
(time (dorun (pmap phone-numbers files)))
; "Elapsed time: 2772.794 msecs"The only change we’ve made here is to the data: each string is
now around 1K in size instead of 1MB in size. Even though the total
amount of work is the same (there are more “files”), the
parallelization overhead outstrips the gains we get from putting each
evaluation of phone-numbers onto a
different future/core. Because of this overhead, it is very common to
see speedups of something less than Nx (where N is the number of CPU cores available) when
using pmap. The lesson is clear:
use pmap when the operation you’re
performing is parallelizable in the first place, and is significant
enough for each value in the seq that its workload will eclipse the
process coordination inherent in its parallelization. Trying to force
pmap into service where it’s not
warranted can be disastrous.
There is often a workaround for such scenarios, however. You can
often efficiently parallelize a relatively trivial operation by
chunking your dataset so that each unit of parallelized work is
larger. In the above example, the unit of work is just 1K of text;
however, we can take steps to ensure that the unit of work is larger,
so that each value processed by pmap is a seq of 250 1K strings, thus
boosting the work done per future dispatch and cutting down on the
parallelization overhead:
(time (->> files
(partition-all 250)
(pmap (fn [chunk] (doall (map phone-numbers chunk))))
(apply concat)
dorun))
; "Elapsed time: 1465.138 msecs"-
mapwill return a lazy seq, so we usedoallto force the realization of that lazy seq within the scope of the function provided topmap. Otherwise,phone-numberswould never be called at all in parallel, leaving the work of applying it to each string to whatever process might have consumed the lazy seq later.
By changing the chunk size of our workload, we’ve regained the benefits of parallelization even though our per-operation computation complexity dropped substantially when applied to many more smaller strings.
Two other parallelism constructs are built on top of pmap: pcalls and pvalues. The former evaluates any number of
no-arg functions provided as arguments, returning a lazy sequence of
their return values; the latter is a macro that does the same, but for
any number of expressions.
State and Identity
In Clojure, there is a clear distinction between state and identity. These concepts are almost universally conflated; we can see that conflation in its full glory here:
class Person {
public String name;
public int age;
public boolean wearsGlasses;
public Person (String name, int age, boolean wearsGlasses) {
this.name = name;
this.age = age;
this.wearsGlasses = wearsGlasses;
}
}
Person sarah = new Person("Sarah", 25, false);Nothing particularly odd, right? Just a Java class[130] with some fields, of which we can create instances. Actually, the problems here are legion.
We have established a reference to a Person, meant to represent "Sarah", who is apparently 25 years old.
Over time, Sarah has existed in many different states: Sarah as a
child, as a teenager, as an adult. At each point in time—say, last
Tuesday at 11:07 a.m.—Sarah has
precisely one state, and each state in time is
inviolate. It makes absolutely no sense to talk about changing one of
Sarah’s states. Her characteristics last Tuesday don’t change on
Wednesday; her state may change from one point in time to another, but
that doesn’t modify what she was previously.
Unfortunately, this Person
class and low-level references (really, just pointers) provided by
most languages are ill-suited to representing even this trivial—we
might say fundamental—concept. If Sarah is to turn 26 years old, our
only option is to clobber the particular state we have
available:[131]
sarah.age++;
Even worse, what happens when a particular change in Sarah’s state has to modify multiple attributes?
sarah.age++; sarah.wearsGlasses = true;
At any point in time between the execution of these two lines of code, Sarah’s age has been incremented, but she does not yet wear glasses. For some period of time (technically, an indeterminate period of time given the way modern processor architectures and language runtimes operate), Sarah may exist in an inconsistent state that is factually and perhaps semantically impossible, depending on our object model. This is the stuff that race conditions are made of, and a key motivator of deadlock-prone locking strategies.
Note that we can even change this sarah object to represent a completely
different person:
sarah.name = "John";
This is troublesome. The sarah object does not represent a single
state of Sarah, nor even the concept of Sarah as an identity. Rather,
it’s an unholy amalgam of the two. More generally, we cannot make any
reliable statements about prior states of a Person reference, particular instances of
Person are liable to change at any
time (of particular concern in programs with concurrent threads of
execution), and not only is it easy to put instances into inconsistent
states, it is the default.
The Clojure approach. What we really want to be able to say is that Sarah has an identity that represents her; not her at any particular point in time, but her as a logical entity throughout time. Further, we want to be able to say that that identity can have a particular state at any point in time, but that each state transition does not change history; thinking back to On the Importance of Values and the contrast between mutable objects and immutable values, this characterization of state would seem to carry many practical benefits as well as being semantically more sound. After all, in addition to wanting to ensure that a state of some identity is never internally inconsistent (something guaranteed by using immutable values), we may very well want to be able to easily and safely refer to Sarah as she was last Tuesday or last year.
Unlike most objects, Clojure data structures are immutable. This makes them ideal for representing state:
(def sarah {:name "Sarah" :age 25 :wears-glasses? false})
;= #'user/sarahThe map we store in the sarah
var is one state of Sarah at some point in time. Because the map is
immutable, we can be sure that any code that holds a reference to that
map will be able to safely use it for all time regardless of what
changes are made to other versions of it or to the state held by the
var. The var itself is one of Clojure’s reference
types, essentially a container with defined concurrency and
change semantics that can hold any value, and be used as a stable
identity. So, we can say that Sarah is represented by the sarah var, the state of which may change
over time according to the var’s semantics.
This is just a glimpse of how Clojure treats identity and state and how they relate over time as distinct concepts worthy of our attention.[132] The rest of this chapter will be devoted to exploring the mechanics of that treatment. In large part, this will consist of exploring Clojure’s four reference types, each of which implement different yet well-defined semantics for changing state over time. Along with Clojure’s emphasis on immutable values, these reference types and their semantics make it possible to design concurrent programs that take maximum advantage of the increasingly capable hardware we have available to us, while eliminating entire categories of bugs and failure conditions that would otherwise go with the territory of dealing with bare threads and locks.
Clojure Reference Types
Identities are represented in Clojure using four
reference types: vars, refs, agents, and atoms. All of these are very different in
certain ways, but let’s first talk about what they have in
common.
At their most fundamental level, references are just boxes that hold a value, where that value can be changed by certain functions (different for each reference type):

All references always contain some value
(even if that value is nil);
accessing one is always done using deref or @:
@(atom 12)
;= 12
@(agent {:c 42})
;= {:c 42}
(map deref [(agent {:c 42}) (atom 12) (ref "http://clojure.org") (var +)])
;= ({:c 42} 12 "http://clojure.org" #<core$_PLUS_ clojure.core$_PLUS_@65297549>)Dereferencing will return a snapshot of the
state of a reference when deref was
invoked. This doesn’t mean there’s copying of any sort when you obtain
a snapshot, simply that the returned state—assuming you’re using
immutable values for reference state, like Clojure’s collections—is
inviolate, but that the reference’s state at later points in time may
be different.
One critical guarantee of deref within the context of Clojure’s reference types is that
deref will never
block, regardless of the change semantics of the reference
type being dereferenced or the operations being applied to it in other
threads of execution. Similarly, dereferencing a reference type will
never interfere with other operations. This is in contrast with
delays, promises, and futures—which can block on deref if their value is not yet realized—and
most concurrency primitives in other languages, where readers are
often blocked by writers and vice versa.
“Setting” the value of a reference type is a more nuanced affair. Each reference type has its own semantics for managing change, and each type has its own family of functions for applying changes according to those semantics. Talking about those semantics and their corresponding functions will form the bulk of the rest of our discussion.
In addition to all being dereferenceable, all reference types:
May be decorated with metadata (see Metadata). Rather than using
with-metaorvary-meta, metadata on reference types may only be changed withalter-meta!, which modifies a reference’s metadata in-place.[133]Can notify functions you specify when the their state changes; these functions are called watches, which we discuss in Watches.
Can enforce constraints on the state they hold, potentially aborting change operations, using validator functions (see Validators).
Classifying Concurrent Operations
In thinking about Clojure’s reference types, we’ll repeatedly stumble across a couple of key concepts that can be used to characterize concurrent operations. Taken together, they can help us think clearly about how each type is best used.
Coordination. A coordinated operation is one where multiple actors must cooperate (or, at a minimum, be properly sequestered so as to not interfere with each other) in order to yield correct results. A classic example is any banking transaction: a process that aims to transfer monies from one account to another must ensure that the credited account not reflect an increased balance prior to the debited account reflecting a decreased balance, and that the transaction fail entirely if the latter has insufficient funds. Along the way, many other processes may provoke similar transactions involving the same accounts. Absent methods to coordinate the changes, some accounts could reflect incorrect balances for some periods, and transactions that should have failed (or should have succeeded) would succeed (or fail) improperly.
In contrast, an uncoordinated operation is one where multiple actors cannot impact each other negatively because their contexts are separated. For example, two different threads of execution can safely write to two different files on disk with no possibility of interfering with each other.
Synchronization. Synchronous operations are those where the caller’s thread of execution waits or blocks or sleeps until it may have exclusive access to a given context, whereas asynchronous operations are those that can be started or scheduled without blocking the initiating thread of execution.
Just these two concepts (or, four, if you count their duals) are sufficient to fully characterize many (if not most) concurrent operations you might encounter. Given that, it makes sense that Clojure’s reference types were designed to implement the semantics necessary to address permutations of these concepts, and that they can be conveniently classified according to the types of operations for which each is suited:[134]

When choosing which reference type(s) to use for a given problem, keep this classification in mind; if you can characterize a particular problem using it, then the most appropriate reference type will be obvious.
Note
You’ll notice that none of Clojure’s reference types are slated as implementing coordinated and asynchronous semantics. This combination of characteristics is more common in distributed systems, such as eventually consistent databases where changes are only guaranteed to be merged into a unified model over time. In contrast, Clojure is fundamentally interested in addressing in-process concurrency and parallelism.
Atoms
Atoms are the most basic reference type; they are identities that implement synchronous, uncoordinated, atomic compare-and-set modification. Thus, operations that modify the state of atoms block until the modification is complete, and each modification is isolated—on their own, there is no way to orchestrate the modification of two atoms.
Atoms are created using atom.
swap! is the most common modification operation used with
them, which sets the value of an atom to the result of applying some
function to the atom’s value and any additional arguments provided to
swap!:
(def sarah (atom {:name "Sarah" :age 25 :wears-glasses? false}))
;= #'user/sarah
(swap! sarah update-in [:age] + 3)
;= {:age 28, :wears-glasses? false, :name "Sarah"} -
Here, when
swap!returns, the value held by thesarahatom will have been set to the result of(update-in @sarah [:age] + 3).-
swap!always returns the new value that was swapped into the atom.
Atoms are the minimum we need to do right by Sarah: every modification of an atom occurs atomically, so it’s safe to apply any function or composition of functions to an atom’s value. You can be sure that no other threads of execution will ever see an atom’s contents in an inconsistent or partially applied state:
(swap! sarah (comp #(update-in % [:age] inc)
#(assoc % :wears-glasses? true)))
;= {:age 29, :wears-glasses? true, :name "Sarah"}One thing you must keep in mind when using swap! is that, because atoms use
compare-and-set semantics, if the atom’s value changes before your
update function returns (as a
result of action by another thread of execution), swap! will retry, calling your update
function again with the atom’s newer value. swap! will continue to retry the
compare-and-set until it succeeds:
(def xs (atom #{1 2 3}))
;= #'user/xs
(wait-futures 1 (swap! xs (fn [v]
(Thread/sleep 250)
(println "trying 4")
(conj v 4)))
(swap! xs (fn [v]
(Thread/sleep 500)
(println "trying 5")
(conj v 5))))
;= nil
; trying 4
; trying 5
; trying 5
@xs
;= #{1 2 3 4 5}-
The thread of execution that aimed to
conj5into the set held inxsended up retrying the application of the function passed toswap!; while it was sleeping, the other thread was able to modify the atom (conjing4into the set), so the compare-and-set failed the first time.
We can visualize the retry semantics of swap! like so:

If the value of atom a
changes between the time when function g is invoked and the time when it returns a
new value for a (a1 and a2, respectively),
swap! will discard that new value
and reevaluate the call with the latest available state of a. This will continue until the return value
of g can be set on a as the immediate successor of the state of
a with which it was invoked.
There is no way to constrain swap!’s retry semantics; given this, the
function you provide to swap!
must be pure, or things will surely go awry in
hard-to-predict ways.
Being a synchronous reference type, functions that change atom values do not return until they have completed:
(def x (atom 2000)) ;= #'user/x (swap! x #(Thread/sleep %))
-
This expression takes at least two seconds to return.
A “bare” compare-and-set!
operation is also provided for use with atoms, if you already think
you know what the value of the atom being modified is; it returns
true only if the atom’s value was
changed:
(compare-and-set! xs :wrong "new value") ;= false (compare-and-set! xs @xs "new value") ;= true @xs ;= "new value"
Warning
compare-and-set! does
not use value semantics; it requires that the
value in the atom be identical[135] to the expected value provided to it as its second
argument:
(def xs (atom #{1 2}))
;= #'user/xs
(compare-and-set! xs #{1 2} "new value")
;= falseFinally, there is a “nuclear option”: if you want to set the
state of an atom without regard for what it contains currently, there
is reset!:
(reset! xs :y) ;= :y @xs ;= :y
Now that we know about atoms, this is a good time to look at two facilities that all reference types support, since some later examples will use them.
Notifications and Constraints
We already learned about one common operation in Clojure Reference Types—dereferencing—which allows us to obtain the current value of a reference regardless of its particular type. There are certain other common things you’ll sometimes want to do with every type of reference that involve being able to monitor or validate state changes as they happen. All of Clojure’s reference types provide hooks for these, in the form of watches and validators.
Watches
Watches are functions that are called whenever the state of a reference has changed. If you are familiar with the “observer” design pattern, you will recognize the applicable use cases immediately, although watches are decidedly more general: a watch can be registered with any reference type, and all watches are functions—there are no special interfaces that must be implemented, and the notification machinery is provided for you.
All reference types start off with no watches, but they can be registered and removed at any time. A watch function must take four arguments: a key, the reference that’s changed (an atom, ref, agent, or var), the old state of the reference, and its new state:
(defn echo-watch
-
Our watch function prints to stdout every time the atom’s state may have changed.
-
If we add the same watch function under a new key…
-
It’ll now be called twice for each state change.
Warning
Watch functions are called synchronously on the same thread that effected the reference’s state change in question. This means that, by the time your watch function has been called, the reference it is attached to could have been updated again from another thread of execution. Thus, you should rely only on the “old” and “new” values passed to the watch function, rather than dereferencing the host ref, agent, atom, or var.
The key you provide to add-watch can be used to remove the watch later on:
(remove-watch sarah :echo2)
;= #<Atom@418bbf55: {:name "Sarah", :age 27}>
(swap! sarah update-in [:age] inc)
; :echo {:name Sarah, :age 27} => {:name Sarah, :age 28}
;= {:name "Sarah", :age 28}Note that watches on a reference type are called whenever the reference’s state has been modified, but this does not guarantee that the state is different:
(reset! sarah @sarah)
; :echo {:name Sarah, :age 28} => {:name Sarah, :age 28}
;= {:name "Sarah", :age 28}Thus, it’s common for watch functions to check if the old and new states of the watched reference are equal before proceeding.
Generally speaking, watches are a great mechanism for triggering the propagation of local changes to other references or systems as appropriate. For example, they make it dead easy to keep a running log of a reference’s history:
(def history (atom ()))
(defn log->list
[dest-atom key source old new]
(when (not= old new)
(swap! dest-atom conj new)))
(def sarah (atom {:name "Sarah", :age 25}))
;= #'user/sarah
(add-watch sarah :record (partial log->list history))
;= #<Atom@5143f787: {:age 25, :name "Sarah"}>
(swap! sarah update-in [:age] inc)
;= {:age 26, :name "Sarah"}
(swap! sarah update-in [:age] inc)
;= {:age 27, :name "Sarah"}
(swap! sarah identity)
;= {:age 27, :name "Sarah"}
(swap! sarah assoc :wears-glasses? true)
;= {:age 27, :wears-glasses? true, :name "Sarah"}
(swap! sarah update-in [:age] inc)
;= {:age 28, :wears-glasses? true, :name "Sarah"}
(pprint @history)
;= ;= nil
;= ; ({:age 28, :wears-glasses? true, :name "Sarah"}
;= ; {:age 27, :wears-glasses? true, :name "Sarah"}
;= ; {:age 27, :name "Sarah"}
;= ; {:age 26, :name "Sarah"})-
We use
partialhere to bind in the atom to which the watch function will always log history.-
Since
identityalways returns its sole argument unchanged, thisswap!will result in a state change in the reference, but the old and new states will be equal.log->listonly adds an entry if the new state is different, so this “repeated” state will not appear in the history.
Depending on how clever you get in your use of watches, you can also make the behavior of the watch function vary depending upon the key it’s registered under. A simple example would be a watch function that logged changes, not to an in-memory sink but to a database identified by its registered key:
(defn log->db
[db-id identity old new]
(when (not= old new)
(let [db-connection (get-connection db-id)]
...)))
(add-watch sarah "jdbc:postgresql://hostname/some_database" log->db)We’ll combine watches with refs and agents to great effect in Persisting reference states with an agent-based write-behind log.
Validators
Validators enable you to constrain a reference’s state however you like. A validator is a function of a single argument that is invoked just before any proposed new state is installed into a reference. If the validator returns logically false or throws an exception, then the state change is aborted with an exception.
A proposed change is the result of any change function you
attempt to apply to a reference. For example, the map of sarah that has had its :age slot incremented, but before swap! installs that updated state into the
reference. It is at this point that a validator function—if any has
been set on the affected reference—has a chance to veto it.
(def n (atom 1 :validator pos?)) ;= #'user/n (swap! n + 500) ;= 501 (swap! n - 1000) ;= #<IllegalStateException java.lang.IllegalStateException: Invalid reference state>
Because validator functions take a single argument, you can
readily use any applicable predicate you might have available
already, like pos?.
While all reference types may have a validator associated with
them, atoms, refs, and agents may be created
with them by providing the validator function as a :validator option to atom, ref, or agent. To add a validator to a var, or to
change the validator associated with an atom, ref, or agent, you can
use the set-validator!
function:
(def sarah (atom {:name "Sarah" :age 25}))
;= #'user/sarah
(set-validator! sarah :age)
;= nil
(swap! sarah dissoc :age)
;= #<IllegalStateException java.lang.IllegalStateException: Invalid reference state>You can make the message included in the thrown exception more
helpful by ensuring that the validator you use throws its own
exception, instead of simply returning false or nil upon a validation failure:[136]
(set-validator! sarah #(or (:age %)
-
Remember that validators must return a logically true value, or the state change will be vetoed. In this case, if we implemented the validator using, for example,
#(when-not (:age %) (throw ...)), the validator would returnnilwhen the state did have an:ageslot, thus causing an unintentional validation failure.
While validators are very useful in general, they hold a special status with regard to refs, as we’ll learn about next and in particular in Enforcing local consistency by using validators.
Refs
Refs are Clojure’s coordinated reference type. Using them, you can ensure that multiple identities can participate in overlapping, concurrently applied operations with:
No possibility of the involved refs ever being in an observable inconsistent state
No possibility of race conditions among the involved refs
No manual use of locks, monitors, or other low-level synchronization primitives
No possibility of deadlocks
This is made possible by Clojure’s implementation of software transactional memory, which is used to manage all change applied to state held by refs.
Software Transactional Memory
In general terms, software transactional memory (STM) is any method of coordinating multiple concurrent modifications to a shared set of storage locations. Doing this in nearly any other language means you have to take on the management of locks yourself, accepting all that comes along with them. STM offers an alternative.
Just as garbage collection has largely displaced the need for manual memory management—eliminating a wide range of subtle and not-so-subtle bugs associated with it in the process—so has STM often been characterized as providing the same kind of systematic simplification of another error-prone programming practice, manual lock management. In both instances, using a proven, automated solution to address what is otherwise an error-prone manual activity both frees you from having to develop expertise in low-level details unrelated to your domain, and often produces end results with more desirable runtime characteristics than those attainable by experts in those low-level details.[137]
Clojure’s STM is implemented using techniques that have been relied upon by database management systems for decades.[138] As the name implies, each change to a set of refs has transactional semantics that you are sure to be familiar with from your usage of databases; each STM transaction ensures that changes to refs are made:
Atomically, so that all the changes associated with a transaction are applied, or none are.
Consistently, so that a transaction will fail if the changes to affected refs do not satisfy their respective constraints.
In isolation, so that an in-process transaction does not affect the states of involved refs as observed from within other transactions or other threads of execution in general.
Clojure’s STM therefore satisfies the A, C, and I properties of ACID (https://en.wikipedia.org/wiki/ACID), as you may understand it from the database world. The “D” property, durability, is not something that the STM is concerned with since it is purely an in-memory implementation.[139]
The Mechanics of Ref Change
With that background out of the way, let’s see what refs can do for us. Earlier in Classifying Concurrent Operations, we talked about banking transactions being an example of an operation that requires coordination among multiple identities and threads of execution. While this is true, banking is perhaps an overwrought example when it comes to demonstrating transactional semantics. It might be more enlightening (and entertaining!) to explore refs and Clojure’s STM as an ideal foundation for implementing a multiplayer game engine.
While some problems are rightfully described as “embarrassingly parallel” because of their potential to be parallelized given suitable facilities, we can say that multiplayer games are embarrassingly concurrent: the datasets involved are often massive, and it’s possible to have hundreds or thousands of independent players each provoking changes that must be applied in a coordinated, consistent fashion so as to ensure the game’s rules are reliably enforced.
Our “game”[140] will be in the fantasy/role-playing genre, the sort that contains classes like wizards and rangers and bards. Given that, we’ll represent each player’s character as a ref holding a map, which will contain all of the data relevant to the player’s character’s class and abilities. Regardless of their class, all characters will have a minimal set of attributes:
:name, the character’s name within the game.:health, a number indicating the character’s physical well-being. When:healthdrops to0, that character will be dead.:items, the set of equipment that a character is carrying.
Of course, specific character classes will have their own
attributes. character is a
function that implements all this, with default values for :items and :health:
(defn character
[name & {:as opts}]
(ref (merge {:name name :items #{} :health 500}
opts)))With this available, we can now define some actual characters that different players could control:[141]
(def smaug (character "Smaug" :health 500 :strength 400 :items (set (range 50))))
-
We’ve created
smaugwith a set of items; here, just integers, which might correspond to item IDs within a static map or external database.
In a game like this, if Bilbo and Gandalf were to defeat Smaug in a battle, they would be able to “loot” Smaug of the items he’s carrying. Without getting into gameplay details, all this means is that we want to take some item from Smaug and transfer it to another character. This transfer needs to occur so that the item being transferred is only in one place at a time from the perspective of any outside observers.
Enter Clojure’s STM and transactions. dosync establishes the scope of a transaction.[142] All modifications of refs must occur within
a transaction, the processing of which happens synchronously. That
is, the thread that initiates a transaction will “block” on that
transaction completing before proceeding in its execution.
Similar to atoms’ swap!, if
two transactions attempt to make a conflicting change to one or more
shared refs, one of them will retry. Whether two concurrently
applied transactions are in conflict depends entirely upon which
functions are used to modify refs shared between those transactions.
There are three such functions—alter, commute, and ref-set—each of which has different
semantics when it comes to producing (or avoiding) conflict.
With all that said, how do we implement looting of items among
characters in our game? The loot
function transfers one value from (:items
@from) to (:items @to)
transactionally, assuming each is a set,[143] and returns the new state of from:
(defn loot
[from to]
(dosync
(when-let [item (first (:items @from))]
(alter to update-in [:items] conj item)
(alter from update-in [:items] disj item))))-
If
(:items @from)is empty,firstwill returnnil, the body ofwhen-letwill remain unevaluated, the transaction will be a no-op, andlootitself will returnnil.
Again, assuming Smaug is dead, we can cause Bilbo and Gandalf to loot his items:
(wait-futures 1
(while (loot smaug bilbo))
(while (loot smaug gandalf)))
;= nil
@smaug
;= {:name "Smaug", :items #{}, :health 500}
@bilbo
;= {:name "Bilbo", :items #{0 44 36 13 ... 16}, :health 500}
@gandalf
;= {:name "Gandalf", :items #{32 4 26 ... 15}, :health 500}Right, so Gandalf and Bilbo have now taken all of Smaug’s
items. The important point to notice is that the bilbo and gandalf characters divvied up Smaug’s loot
from different futures (therefore, threads), and that all the
looting occurred atomically: no items are unaccounted for, no item
references were duplicated, and at no point was an item owned by
multiple characters.
(map (comp count :items deref) [bilbo gandalf])
-
If these counts were to add up to anything other than
50(the original number of items held by Smaug), or…-
…if Gandalf ended up with any items that Bilbo also held, then the effect of our
loottransactions would have been cumulatively inconsistent.
This was accomplished without the manual management of locks, and this process will scale to accommodate transactions involving far more refs and far more interleaving transactions applied by far more separate threads of execution.
Understanding alter
loot uses alter,
which is similar to swap!
insofar as it takes a ref, a function ƒ, and additional arguments
to that function. When alter
returns, the in-transaction value of the ref
in question will have been changed to the return of a call to ƒ,
with the ref’s value as the first argument, followed by all of the
additional arguments to alter.
The notion of an in-transaction value is an important one. All the functions that modify the state of a ref actually operate on a speculative timeline for the ref’s state, which starts for each ref when it is first modified. All later ref access and modification works on this separate timeline, which only exists and can only be accessed from within the transaction. When control flow is to exit a transaction, the STM attempts to commit it. In the optimistic case, this will result in the in-transaction, speculative states of each affected ref being installed as the refs’ new shared, non-transaction state, fully visible to the rest of the world. However, depending upon the semantics of the operation(s) used to establish those in-transaction values, any change made to the refs’ state outside of the transaction may conflict with the transaction’s modifications, resulting in the transaction being restarted from scratch.
Throughout this process, any thread of execution that is solely reading (i.e., dereferencing) refs involved in a transaction can do so without being blocked or waiting in any circumstance. Further, until a given transaction commits successfully, its changes will not affect the state of refs seen by readers outside of that transaction, including readers operating within the scope of entirely different transactions.
The unique semantic of alter is that, when the transaction is to be committed,
the value of the ref outside of the transaction must be the same
as it was prior to the first in-transaction application of
alter. Otherwise, the
transaction is restarted from the beginning with the new observed
values of the refs involved.
This dynamic can be visualized as the interaction between
two transactions, t1 and t2, which both
affect some shared ref a using
alter:

Even though t1 starts before
t2, its
attempt to commit changes to a
fails because t2 has already
modified it in the interim: the current state of a (a2) is different
than the state of a (a1) when it was
first modified within t1. This conflict
aborts the commit of any and all in-transaction modifications to
refs affected by t1 (e.g.,
x, y, z,
…). t1
then restarts, using up-to-date values for all of the refs it
touches.
Depicted and described this way, you can think of Clojure’s STM as a process that optimistically attempts to reorder concurrent change operations so they are applied serially. Unsurprisingly, the same semantics are found in the database world as well, often called serializable snapshot isolation (https://en.wikipedia.org/wiki/Serializability).
Minimizing transaction conflict with commute
Because it makes no assumptions about the
reorderability of the modifications made to affected refs,
alter is the safest mechanism
for effecting ref change. However, there are
situations where the modifications being made to refs can be
reordered safely; in such contexts, commute can be used in place of alter, potentially minimizing conflicts
and transaction retries and therefore maximizing total
throughput.
As its name hints, commute has to do with
commutative functions (https://en.wikipedia.org/wiki/Commutative_property)—those
whose arguments may be reordered without impacting results, such
as +, *, clojure.set/union…—but it doesn’t
mandate that the functions passed to it be commutative. What
really matters is that the function applications performed using
commute are reorderable without
violating program semantics. It follows that in such cases, it is
the final result of all commutable function applications that
matters, and not any intermediate results.
For example, although division is not commutative, it may be
often used with commute when
you are not concerned with intermediate results:
(= (/ (/ 120 3) 4) (/ (/ 120 4) 3)) ;= true
Thus, commute can be used
when the functional composition is commutative for the functions
involved:
(= ((comp #(/ % 3) #(/ % 4)) 120) ((comp #(/ % 4) #(/ % 3)) 120)) ;= true
Generally, commute should
only be used to apply changes to ref states where reordering of
that application is acceptable.
commute differs from
alter in two ways. First, the
value returned by alter on a
ref will be the committed value of this ref; in other words, the
in-transaction value is the eventual committed value. On the other
hand, the in-transaction value produced by commute is not guaranteed to be the
eventual committed value, because the commuted function will be applied again
at commit time with the latest value for the commuted ref.
Second, a change made to a ref by using commute will never
cause a conflict, and therefore never cause a transaction to
retry. This obviously has potentially significant performance and
throughput implications: transaction retries are fundamentally
rework and time that a thread is “blocked” waiting for a
transaction to complete successfully instead of moving on to its
next task.
We can demonstrate this very directly. Given some ref
x:
(def x (ref 0)) ;= #'user/x
We’ll beat on it with 10,000 transactions that do some small
amount of work (just obtaining the sum of some integers), and then
alter x’s value:
(time (wait-futures 5
(dotimes [_ 1000]
(dosync (alter x + (apply + (range 1000)))))
(dotimes [_ 1000]
(dosync (alter x - (apply + (range 1000)))))))
; "Elapsed time: 1466.621 msecs"At least some of the time taken to process these
transactions was spent in retries, thus forcing the resumming of
the integer sequence. However, the operations used with alter here (addition and subtraction)
can safely be used with commute:
(time (wait-futures 5
(dotimes [_ 1000]
(dosync (commute x + (apply + (range 1000)))))
(dotimes [_ 1000]
(dosync (commute x - (apply + (range 1000)))))))
; "Elapsed time: 818.41 msecs"Even though it applies the change function to the ref’s
value twice—once to set the in-transaction value (so x would have an updated value if we were
to refer to it again later in the transaction), and once again at
commit-time to make the “real” change to the (potentially
modified) value of x—our
cumulative runtime is cut nearly in half because commute will never retry.
commute is not magic
though: it needs to be used judiciously, or it can produce invalid
results. Let’s see what happens if we carelessly use commute instead of alter in the loot function from Example 4-2:
(defn flawed-loot
[from to]
(dosync
(when-let [item (first (:items @from))]
(commute to update-in [:items] conj item)
(commute from update-in [:items] disj item))))Let’s reset our characters and see what our new looting function does:
(def smaug (character "Smaug" :health 500 :strength 400 :items (set (range 50))))
(def bilbo (character "Bilbo" :health 100 :strength 100))
(def gandalf (character "Gandalf" :health 75 :mana 750))
(wait-futures 1
(while (flawed-loot smaug bilbo))
(while (flawed-loot smaug gandalf)))
;= nil
(map (comp count :items deref) [bilbo gandalf])
;= (5 48)
(filter (:items @bilbo) (:items @gandalf))
;= (18 32 1)Using the same checks from Example 4-3, we can see that
flawed-loot has produced some
problems: Bilbo has 5 items while Gandalf has 48 (with 18, 32, and 1 being the three duplicated items), a
situation that should never happen since Smaug started with 50.
What went wrong? In three instances, the same value was
pulled from Smaug’s set of :items and conjed into both Bilbo’s and Gandalf’s
:items. This is prevented in
the known-good implementation of loot because using alter properly guarantees that the
in-transaction and committed values will be identical.
In this peculiar case, we can safely
use commute to add the looted
item to the recipient’s set (since the order in which items are
added to the set is of no importance); it is the removal of the
looted item from its source that requires the use of alter:
(defn fixed-loot
[from to]
(dosync
(when-let [item (first (:items @from))]
(commute to update-in [:items] conj item)
(alter from update-in [:items] disj item))))
(def smaug (character "Smaug" :health 500 :strength 400 :items (set (range 50))))
(def bilbo (character "Bilbo" :health 100 :strength 100))
(def gandalf (character "Gandalf" :health 75 :mana 750))
(wait-futures 1
(while (fixed-loot smaug bilbo))
(while (fixed-loot smaug gandalf)))
;= nil
(map (comp count :items deref) [bilbo gandalf])
;= (24 26)
(filter (:items @bilbo) (:items @gandalf))
;= ()On the other hand, commute is perfect for other functions
in our game. For example, attack and heal functions are just going to be
incrementing and decrementing various character attributes, so
such changes can be made safely using commute:
(defn attack
[aggressor target]
(dosync
(let [damage (* (rand 0.1) (:strength @aggressor))]
(commute target update-in [:health] #(max 0 (- % damage))))))
(defn heal
[healer target]
(dosync
(let [aid (* (rand 0.1) (:mana @healer))]
(when (pos? aid)
(commute healer update-in [:mana] - (max 5 (/ aid 5)))
(commute target update-in [:health] + aid)))))With a couple of additional functions, we can simulate a player taking some action within our game:
Now we can have duels:
(wait-futures 1
(play bilbo attack smaug)
(play smaug attack bilbo))
;= nil
(map (comp :health deref) [smaug bilbo])
;= (488.80755445030337 -12.0394908759935)-
All by his lonesome, Bilbo understandably cannot hold his own against Smaug.
…or, “epic” battles:
(dosync
Clobbering ref state with ref-set
ref-set will set the in-transaction state of a ref to the
given value:
(dosync (ref-set bilbo {:name "Bilbo"}))
;= {:name "Bilbo"}Just like alter, ref-set will provoke a retry of the
surrounding transaction if the affected ref’s state changes prior
to commit-time. Said differently, ref-set is semantically equivalent to using alter with a function that returns a
constant value:
(dosync (alter bilbo (constantly {:name "Bilbo"})))
; {:name "Bilbo"}Since this change is made without reference to the current
value of the ref, it is quite easy to change a ref’s value in a
way that is consistent with regard to the STM’s transactional
guarantees, but that violates application-level contracts. Thus,
ref-set is generally used only
to reinitialize refs’ state to starting values.
Enforcing local consistency by using validators
If you’ll notice, Bilbo has a
very high :health value at the end of Example 4-7. Indeed, there is no limit to how
high a character’s :health can
go, as a results of heals or other restorative actions.
These sorts of games generally do not allow a character’s health to exceed a particular level. However, from both a technical and management perspective—especially given a large team or codebase—it may be too onerous to guarantee that every function that might increase a character’s health would not produce a health “overage.” Such functions may, as part of their own semantics, attempt to avoid such an illegal condition, but we must be able to protect the integrity of our model separately. Maintaining local consistency like this—the C in “ACID”—in the face of concurrent changes is the job of validators.
We talked about validators already in Validators. Their use and semantics with refs is entirely the same as with other reference types, but their interaction with the STM is particularly convenient: if a validator function signals an invalid state, the exception that is thrown (just like any other exception thrown within a transaction) causes the current transaction itself to fail.
With this in mind, we should refactor our game’s
implementation details a bit. First, character should be changed so
that:
A common set of validators is added to every character.
Additional validators can be provided for each character, so as to enforce constraints related to a character’s class, level, or other status in the game:
(defn- enforce-max-health
-
enforce-max-healthreturns a function that accepts a character’s potential new state, throwing an exception if the new:healthattribute is above the character’s original health level.-
We record the character’s initial
:healthas their:max-health, which will come in handy later.-
In addition to always ensuring that a character’s maximum health is never exceeded, it is easy to allow individual characters to be created with their own additional set of validator functions…

…which can be easily rolled into the validation of their containing refs.
Now, no character can ever be healed past his original health level:
(def bilbo (character "Bilbo" :health 100 :strength 100))
;= #'user/bilbo
(heal gandalf bilbo)
;= #<IllegalStateException java.lang.IllegalStateException: Bilbo is already at max
health!>One limitation of validators is that they are strictly local; that is, their charter does not extend past ensuring that the next state held by a reference satisfies the constraints they check:
(dosync (alter bilbo assoc-in [:health] 95))
;= {:max-health 100, :strength 100, :name "Bilbo", :items #{}, :health 95, :xp 0}
(heal gandalf bilbo)
;= #<IllegalStateException java.lang.IllegalStateException: Bilbo is already at max
health!>Here, Bilbo’s :health is
set just short of his :max-health, so he really should be
heal-able. However, the implementation of heal does not yet take :max-health into account, and there is
no way for the relevant validator to “tweak” Bilbo’s new state to
suit its constraints—in this case, to make his :health the lesser of his :max-health or the sum of his current
:health and Gandalf’s heal amount. If validators
were allowed to make changes like this, then
it would be difficult to avoid introducing inconsistency into the
refs modified within a transaction. Validators exist solely to
maintain invariants within your model.
A tweak to heal is
warranted to ensure that “partial” heals are possible, up to a
character’s maximum health:
(defn heal
[healer target]
(dosync
(let [aid (min (* (rand 0.1) (:mana @healer))
(- (:max-health @target) (:health @target)))]
(when (pos? aid)
(commute healer update-in [:mana] - (max 5 (/ aid 5)))
(alter target update-in [:health] + aid)))))Now heal will improve a
character’s health up to his maximum health,
returning nil when the
character’s health is already at that level:
(dosync (alter bilbo assoc-in [:health] 95))
;= {:max-health 100, :strength 100, :name "Bilbo", :items #{}, :health 95}
(heal gandalf bilbo)
;= {:max-health 100, :strength 100, :name "Bilbo", :items #{}, :health 100}
(heal gandalf bilbo)
;= nilNote that our modification to target now potentially depends upon its
prior state, so we use alter
instead of commute. This isn’t
strictly required: perhaps you would be happy enough to have the
validator catch errant heals, which would happen only if some
other concurrently applied transaction also increased the health
of the target character. This points to a potential downside to
how we’ve modeled our characters, as all-encompassing bags of
state (maps in this case) held by a single ref: if concurrent
transactions modify unrelated parts of that state using alter, a transaction will retry
unnecessarily.[144]
The Sharp Corners of Software Transactional Memory
As we said at the beginning of this chapter, Clojure does not offer any silver bullet to solve the problem of concurrency. Its STM implementation may sometimes seem magical—and, compared to the typical alternatives involving manual lock management, it sorta is—but even the STM has its own sharp corners and rough edges of which you should be aware.
Side-effecting functions strictly verboten
The only operations that should ever be performed
within the scope of a transaction are things that are safe to
retry, which rules out many forms of I/O. For example, if you
attempt to write to a file or database inside a dosync block, you will quite possibly end up writing the
same data to the file or database multiple times.
Clojure can’t detect that you’re attempting to perform an
unsafe operation inside a transaction; it will happily and
silently retry those operations, perhaps with disastrous results.
For this reason, Clojure provides an io! macro, which will throw an error if
it is ever evaluated within a transaction. Thus, if you have a
function that may be used within a transaction, you can wrap the
side-effecting portion of its body in an io! form to help guard against
accidentally calling unsafe code:
(defn unsafe [] (io! (println "writing to database..."))) ;= #'user/unsafe (dosync (unsafe)) ;= #<IllegalStateException java.lang.IllegalStateException: I/O in transaction>
Warning
As a corollary, operations on atoms should generally be considered side-effecting,
insofar as swap!, et al., do
not participate in the STM’s transactional semantics. Thus, if a
transaction is retried three times, and it contains a swap! call, swap! will be invoked three times and
the affected atom will be modified three times…rarely what you
want, unless you’re using an atom to count transaction
retries.
Note also that the values held by refs must be immutable.[145] Clojure isn’t going to stop you from putting mutable objects into a ref, but things like retries and the usual foibles associated with mutability will likely result in undesirable effects:
(def x (ref (java.util.ArrayList.)))
;= #'user/x
(wait-futures 2 (dosync (dotimes [v 5]
(Thread/sleep (rand-int 50))
(alter x #(doto % (.add v))))))
;= nil
@x
;= #<ArrayList [0, 0, 1, 0, 2, 3, 4, 0, 1, 2, 3, 4]> -
The randomized
sleepcall ensures that the two transactions will overlap; at least one of them will retry, leading to…-
…hopelessly flawed results.
Minimize the scope of each transaction
Remember from the discussion around Figure 4-2 that the STM’s job is to ensure that all of the work encapsulated as transactions be applied to affected refs in a serial fashion, reordering that work and those ref state changes if necessary. This implies that, the shorter each transaction is, the easier it will be for the STM to schedule that transaction, thus leading to faster application and higher total throughput.
What happens if you have out-sized transactions, or
transactions with a mix of scopes and scales? In general, the
largest transactions will be delayed (along with whatever else the
thread waiting on that transaction would otherwise be doing).
Consider a bunch of transactions, all affecting some ref a:
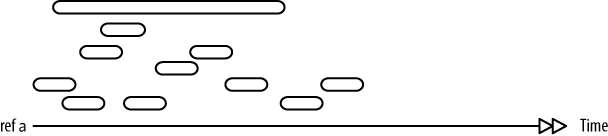
Assuming each of them is altering a, the execution of those transactions
will be retried until they can be applied serially. The
longest-running transaction will end up being retried repeatedly,
with the likely result that it will be delayed until a long enough
slot opens up in the contended ref’s timeline for it to
fit:
Note
Remember that commute (discussed in Minimizing transaction conflict with commute) does not provoke change
conflicts and retries. Therefore, if you can use it safely with
the change functions applicable to your state’s domain, you will
effectively sidestep any potential hazards associated with
long-running transactions.
Doing a lot of time-consuming computation can result in a long-running transaction, but so can retries prompted by contention over other refs. For example, the long-running transaction depicted above may be performing some complex computation, which may need to be restarted repeatedly due to contention over another ref. Thus, you should aim to minimize the scope of transactions in general as much as possible both in terms of the computational runtime involved and in the number of affected refs.
Live lock. You might wonder: what happens if, particularly in times of heavy load, a large transaction never gets a chance to commit due to ref contention? This is called live lock, the STM equivalent to a deadlock, where the thread(s) driving the transactions involved are blocked indefinitely attempting to commit their respective transactions. Without suitable fallbacks, and we’d be no better off than if we were manually managing locks and causing our own deadlocks!
Thankfully, Clojure’s STM does have a couple of fallbacks. The first is called barging, where an older transaction is allowed to proceed in certain circumstances, forcing newer transactions to retry. When barging fails to push through the older transaction in a reasonable amount of time, the STM will simply cause the offending transaction to fail:
(def x (ref 0)) ;= #'user/x (dosync @(future (dosync (ref-set x 0))) (ref-set x 1)) ;= #<RuntimeException java.lang.RuntimeException: ;= Transaction failed after reaching retry limit> @x ;= 0
The transaction running in the REPL thread above always starts a new future, itself running a transaction that modifies the state of the contended ref. Dereferencing that future ensures that the REPL thread’s transaction waits until the future’s transaction has completed, thus ensuring a retry—and therefore the spawning of a new future, and so on.
Clojure’s STM will permit a transaction to retry only so many times before throwing an exception. An error thrown with a stack trace you can examine is infinitely better than an actual deadlock (or live lock), where the only solution is to forcibly kill the application’s process with little to no information about the problem’s locale.
Readers may retry
In the case of reference types, deref is guaranteed to never block.
However, inside a transaction dereferencing a ref may trigger a transaction
retry!
This is because, if a new value is committed by another transaction since the beginning of the current transaction, the value of the ref as of the start of the transaction cannot be provided.[146] Helpfully, the STM notices this problem and maintains a bounded history of the states of refs involved in a transaction, where the size of the history is incremented by each retry. This increases the chance that—at some point—the transaction won’t have to retry anymore because, while the ref is concurrently updated, the desired value is still present in the history.
History length can be queried (and tuned) with
ref-history-count, ref-max-history, and ref-min-history. Minimum and maximum history sizes can also be
specified when a ref is created by using the named arguments
:min-history and :max-history:
(ref-max-history (ref "abc" :min-history 3 :max-history 30)) ;= 30
This allows you to potentially tune a ref to suit expected workloads.
Retries on deref
generally occur in the context of read-only transactions, which
attempt to snapshot a lot of very active refs. We can visualize
this behavior with a single ref and a slow reading
transaction:
(def a (ref 0)) (future (dotimes [_ 500] (dosync (Thread/sleep 200) (alter a inc)))) ;= #<core$future_call$reify__5684@10957096: :pending> @(future (dosync (Thread/sleep 1000) @a)) ;= 28
-
The read value being 28 means that the reader transaction has been able to complete before all the writers have been run.
So, the a ref has grown
its history to accommodate the needs of the slow reading
transaction. What happens if the writes occur even faster?
(def a (ref 0)) (future (dotimes [_ 500] (dosync (Thread/sleep 20) (alter a inc)))) ;= #<core$future_call$reify__5684@10957096: :pending> @(future (dosync (Thread/sleep 1000) @a)) ;= 500 (ref-history-count a) ;= 10
This time the history has been maxed out and the reader transaction has only been executed after all the writers. This means that the writers blocked the reader in the second transaction. If we relax the max history, the problem should be fixed:
(def a (ref 0 :max-history 100)) (future (dotimes [_ 500] (dosync (Thread/sleep 20) (alter a inc)))) ;= #<core$future_call$reify__5684@10957096: :pending> @(future (dosync (Thread/sleep 1000) @a)) ;= 500 (ref-history-count a) ;= 10
It didn’t work because by the time there’s enough history, the writers are done. So, the key is to set the minimum history to a good value:
(def a (ref 0 :min-history 50 :max-history 100))
-
We choose 50 because the reader transaction is 50 times slower than the writer one.
This time the reader transaction completes quickly and successfully with no retry!
Write skew
Clojure’s STM provides for the transactional
consistency of ref state, but so far we’ve only seen that to be
the case for refs that are modified by the transactions involved.
If a ref isn’t modified by a transaction, but the consistency of
that transaction’s changes depend upon the state of a ref that is
read but not modified, there is no way for the STM to know about
this through calls to alter,
commute, and set-ref. If the read ref’s state happens
to change mid-transaction, that transaction’s effects on other
refs may end up being inconsistent with the read ref; this state
of affairs is called write skew.
Such a circumstance is rare; generally, refs involved in a
transaction are all being modified in some way. However, when
that’s not the case, ensure may
be used to prevent write skew: it is a way to dereference a ref
such that that read will conflict with any modifications prompted
by other transactions, causing retries as necessary.
An example of this within the game’s context might be the
current amount of daylight. It’s safe to say that attacks made
with the benefit of mid-day sun will be more successful than those
made at night, so a modification to attack to take into consideration the
current amount of daylight would make sense:
(def daylight (ref 1))
(defn attack
[aggressor target]
(dosync
(let [damage (* (rand 0.1) (:strength @aggressor) @daylight)]
(commute target update-in [:health] #(max 0 (- % damage))))))However, if the state of daylight is changed between the time it
is read within a transaction and when that transaction commits its
changes, those changes may be inconsistent. For example, a
separate game process may shift daylight to reflect a sunset-appropriate
amount of light (e.g., (dosync (ref-set
daylight 0.3))). If attack is running while that change is
being made, and uses the old value of daylight, more damage will be attributed
to an attack action than is appropriate.

Formally, if the state b2 that a
transaction t1 writes to ref
b depends upon the state of ref
a at a1, and t1 never writes
to a, and another transaction
t2
modifies a to hold some state
a2 prior
to t1
committing, then the world will be inconsistent: b2 corresponds
with a past state a1, not the
current state a2. This is write
skew.
Simply changing attack to
(ensure daylight) instead of
dereferencing via @daylight
will avoid this by guaranteeing that daylight will not change before the
reading transaction commits successfully.

When a transaction t1 reads a ref
a using ensure instead of deref, any changes to that ref’s state
by any other transaction t2 prior to
t1
completing will retry until t1 has
successfully committed. This will avoid write skew: the change to
b will always be consistent
with the latest state of a,
even though t1 never changes
the state of a.
Note
In terms of avoiding write skew, (ensure a) is semantically equivalent to (alter a identity) or (ref-set a @a)—both effectively
dummy writes—which
end up requiring that the read value persist until commit time.
Compared to dummy writes, ensure will generally minimize the
total number of transaction retries involving read-only
refs.
Vars
You’ve already used and worked with vars a great deal. Vars differ from Clojure’s other reference types in that their state changes are not managed in time; rather, they provide a namespace-global identity that can optionally be rebound to have a different value on a per-thread basis. We’ll explain this at length starting in Dynamic Scope, but first let’s understand some of their fundamentals, since vars are used throughout Clojure, whether concurrency is a concern or not.
Evaluating a symbol in Clojure normally results in looking for a var with that name in the current namespace and dereferencing that var to obtain its value. But we can also obtain references to vars directly and manually dereference them:
map ;= #<core$map clojure.core$map@501d5ebc> #'map
-
Recall from Referring to Vars: var that
#'mapis just reader sugar for(var map).
Defining Vars
Vars make up one of the fundamental building blocks of
Clojure. As we mentioned in Defining Vars: def, top
level functions and values are all stored in vars, which are defined
within the current namespace using the def
special form or one of its derivatives.
Beyond simply installing a var into the namespace with the
given name, def copies the
metadata[147] found on the symbol provided to name the new (or
to-be-updated) var to the var itself. Particular metadata found on
this symbol can modify the behavior and semantics of vars, which
we’ll enumerate here.
Private vars
Private vars are a basic way to delineate parts of a library or API that are implementation-dependent or otherwise not intended to be accessed by external users. A private var:
Can only be referred to using its fully qualified name when in another namespace.
Its value can only be accessed by manually dereferencing the var.
A var is made private if the symbol that names it has a
:private slot in its metadata
map with a true
value. This is a private var, holding some useful constant value
our code might need:
(def ^:private everything 42)
Recall from Metadata that this notation is equivalent to:
(def ^{:private true} everything 42)We can see that everything is available outside of its
originating namespace only with some effort:
(def ^:private everything 42) ;= #'user/everything (ns other-namespace) ;= nil (refer 'user) ;= nil everything ;= #<CompilerException java.lang.RuntimeException: ;= Unable to resolve symbol: everything in this context, compiling:(NO_SOURCE_PATH:0)> @#'user/everything ;= 42
You can declare a private function by using the defn- form, which is entirely identical to the familiar
defn form, except that it adds
in the ^:private metadata for
you.
Docstrings
Clojure allows you to add documentation to top-level vars via docstrings, which are usually string literals that immediately follow the symbol that names the var:
(def a "A sample value." 5) ;= #'user/a (defn b "A simple calculation using `a`." [c] (+ a c)) ;= #'user/b (doc a) ; ------------------------- ; user/a ; A sample value. (doc b) ; ------------------------- ; user/b ; ([c]) ; A simple calculation using `a`.
As you can see, docstrings are just more metadata on the var
in question; def is doing a
little bit of work behind the scenes to pick up the optional
docstring and add it to the var’s metadata as necessary:
(meta #'a)
;= {:ns #<Namespace user>, :name a, :doc "A sample value.",
;= :line 1, :file "NO_SOURCE_PATH"}This means that, if you want, you can add documentation to a
var by specifying the :doc
metadata explicitly, either when the var is defined, or even
afterward by altering the var’s metadata:
(def ^{:doc "A sample value."} a 5)
;= #'user/a
(doc a)
; -------------------------
; user/a
; A sample value.
(alter-meta! #'a assoc :doc "A dummy value.")
;= {:ns #<Namespace user>, :name a, :doc "A dummy value.",
;= :line 1, :file "NO_SOURCE_PATH"}
(doc a)
; -------------------------
; user/a
; A dummy value.This is a rare requirement, but can be very handy when writing var-defining macros.
Constants
It is common to need to define constant values, and
using top level def forms to do
so is typical. You can add ^:const metadata to a var’s name symbol in order to declare it as a
constant to the compiler:
(def ^:const everything 42)
While a nice piece of documentation on its own, ^:const does have a functional impact:
any references to a constant var aren’t resolved at runtime (as
per usual); rather, the value held by the var is retained
permanently by the code referring to the var when it is compiled.
This provides a slight performance improvement for such references
in hot sections of code, but more important, ensures that your
constant actually remains constant, even if
someone stomps on a var’s value.
This certainly isn’t what we’d like to have happen:
(def max-value 255) ;= #'user/max-value (defn valid-value? [v] (<= v max-value)) ;= #'user/valid-value? (valid-value? 218) ;= true (valid-value? 299) ;= false (def max-value 500)
-
max-valueis redefined, after which pointvalid-value?implements different semantics due to its reliance on our “constant.”
We can prevent such mishaps using ^:const:
(def ^:const max-value 255) ;= #'user/max-value (defn valid-value? [v] (<= v max-value)) ;= #'user/valid-value? (def max-value 500) ;= #'user/max-value (valid-value? 299) ;= false
Because max-value is
declared ^:const, its value is
captured by the valid-value?
function at compile-time. Any later modifications to max-value will have no effect upon the
semantics of valid-value? until
it is itself redefined.
Dynamic Scope
For the most part, Clojure is lexically scoped: that is, names have values as defined by the forms that circumscribe their usage and the namespace within which they are evaluated. To demonstrate:
(let [a 1
b 2]
(println (+ a b))
(let [b 3
+ -]
(println (+ a b))))
;= 3
;= -2-
aandbare names of locals established bylet;+andprintlnare names of vars containing functions defined in theclojure.corenamespace, which are available within our current namespace.-
The local
bhas been bound with a different value, as has+; since these definitions are more lexically local than the outer local binding ofband the original var named+, they shadow those original values when evaluated within this context.
The exception to this rule is dynamic
scope, a feature provided by vars. Vars have a
root binding; this is the value bound to a var when it is defined
using def or some derivative, and
the one to which references to that var will evaluate in general.
However, if you define a var to be dynamic
(using ^:dynamic
metadata),[148] then the root binding can be overridden and shadowed
on a per-thread basis using the binding form.
(def ^:dynamic *max-value* 255) ;= #'user/*max-value* (defn valid-value? [v] (<= v *max-value*)) ;= #'user/valid-value? (binding [*max-value* 500] (valid-value? 299)) ;= true
Note
Dynamic vars intended to be rebound with binding should be surrounded with
asterisks — like *this*—also known as
“earmuffs.” This is merely a naming convention, but is helpful
to alert a reader of some code that dynamic scope is
possible.
Here we are able to change the value of *max-value* outside of the lexical scope
of its usage within valid-value?
by using binding. This is only a
thread-local change though; we can see that *max-value* retains its original value in
other threads:[149]
(binding [*max-value* 500]
(println (valid-value? 299))
(doto (Thread. #(println "in other thread:" (valid-value? 299)))
.start
.join))
;= true
;= in other thread: falseDynamic scope is used widely by libraries and in Clojure itself[150] to provide or alter the default configuration of an API without explicitly threading context through each function call. You can see very practical examples in both Chapters 15 and 14, where dynamic scope is used to provide database configuration information to a library.
Visualizing dynamic scope. To illustrate, consider a var: it has a root value,
and for each thread, it may have any number
of thread-local bindings, which stack up as nested dynamic scopes
come into effect via binding.

Only the heads of these stacks may be accessed (shown bolded
above). Once a binding is established, the prior binding is shadowed
for the duration of the dynamic scope put into place by binding. So within the innermost dynamic
scope here, *var* (and therefore,
(get-*var*)) will never evaluate
to :root, :a, or :b:
(def ^:dynamic *var* :root)
;= #'user/*var*
(defn get-*var* [] *var*)
;= #'user/get-*var*
(binding [*var* :a]
(binding [*var* :b]
(binding [*var* :c]
(get-*var*))))
;= :cEach level of dynamic scope pushes a new “frame” onto the stack for the var being bound:

(binding [*var* :a]
(binding [*var* :b]
(binding [*var* :c]
(binding [*var* :d]
(get-*var*)))))
;= :dWe’ve seen how dynamic scope can be used to control the behavior of functions at a distance, essentially allowing callers to provide an implicit argument to functions potentially many levels down in a call tree. The final piece of the puzzle is that dynamic scope can also work in reverse, to allow functions to provide multiple side-channel return values to callers potentially many levels up in a call tree.
For example, while Clojure provides some incredibly convenient
IO functions to simply retrieve the content of a URL (e.g., slurp and others in the clojure.java.io namespace), such methods
provide no easy way to retrieve the corresponding HTTP response code
when you require it (a necessary thing sometimes, especially when
using various HTTP APIs). One option would be to
always return the response code in addition to
the URL’s content in a vector of [response-code url-content]:
(defn http-get
[url-string]
(let [conn (-> url-string java.net.URL. .openConnection)
response-code (.getResponseCode conn)]
(if (== 404 response-code)
[response-code]
[response-code (-> conn .getInputStream slurp)])))
(http-get "http://google.com/bad-url")
;= [404]
(http-get "http://google.com/")
;= [200 "<!doctype html><html><head>..."]That’s not horrible, but as users of http-get, this approach forces us to deal
with the response code for every call in every context, even if we
aren’t interested in it.
As an alternative, we could use dynamic scope to establish a
binding that http-get can set
only when we’re interested in the HTTP response
code:
(def ^:dynamic *response-code* nil)
-
We define a new var,
*response-code*; users ofhttp-getopt into accessing the response code it obtains by binding this var.-
We use
thread-bound?to check if the caller ofhttp-gethas established a thread-local binding on*response-code*. If not, we do nothing with it.-
set!is used to change the value of the current thread-local binding on*response-code*so that the caller can access that value as desired.-
Now that
http-getcan use the optional dynamic scope around*response-code*to communicate auxiliary information to its callers, it can simply return the string content loaded from the URL instead of the compound vector of[response-code url-content](assuming the URL is not404).
Again, to illustrate:

Because set! acts on a var’s binding by replacing the current
thread-local value, a caller within the dynamic scope established by
binding—whether a direct one or
one 50 frames up the call stack—can access that new value without it
having been threaded back through the return values of all the
intervening function calls. This works for any number of vars, any
number of bindings, and any number or type of set!-ed values, including functions. Such
flexibility enables simple API extensions like auxiliary returns as
we’ve demonstrated here, up to more elaborate and powerful things
like non-local return mechanisms.
Dynamic scope propagates through Clojure-native concurrency
forms. The thread-local nature of dynamic scope is
useful—it allows a particular execution context to remain isolated
from others—but without mitigation, it would cause undue
difficulty when using Clojure facilities that by necessity move
computation from one thread to another. Thankfully, Clojure does
propagate dynamic var bindings across threads—called binding
conveyance—when using agents (via send and send-off), futures, as well as pmap and its variants:
(binding [*max-value* 500] (println (valid-value? 299)) @(future (valid-value? 299))) ; true ;= true
Even though valid-value? is
invoked on a separate thread than the one that originally set up the
dynamic scope via binding,
future propagates that scope
across to the other thread for the duration of its operation.
Note that, while pmap does
support binding conveyance, the same does not
hold true for lazy seqs in general:
(binding [*max-value* 500] (map valid-value? [299])) ;= (false)
The workaround here is to ensure that you push the dynamic scope required for each step in the lazy seq into the code that will actually be evaluated when values in the seq are to be realized:
(map #(binding [*max-value* 500]
(valid-value? %))
[299])
;= (true)Vars Are Not Variables
Vars should not be confused with variables in other languages. Coming from a language like Ruby, where code usually looks like this:
def foo x = 123 y = 456 x = x + y end
It’s incredibly tempting for new Clojure users to try to write code like this:
(defn never-do-this [] (def x 123) (def y 456) (def x (+ x y) x))
This is very poor form in Clojure. But, what’s the worst that could happen?
(def x 80) ;= #'user/x (defn never-do-this [] (def x 123) (def y 456) (def x (+ x y)) x) ;= #'user/never-do-this (never-do-this) ;= 579 x
-
“Waitaminute, I declared
xto be80at the start!”
def always defines
top level vars—it is not
an assignment operation affecting some local scope. x and y
in this example are globally accessible throughout your namespace,
and will clobber any other x and
y vars already in your
namespace.
With the exception of dynamic scope, vars are fundamentally
intended to hold constant values from the time they are defined
until the termination of your application, REPL, etc. Use one of
Clojure’s other reference types for identities that provide useful
and proper semantics for changing state in place, if that is what
you are looking for. Define a var to hold one of those, and use the
appropriate function (swap!,
alter, send, send-off, et al.) to modify the state of
those identities.
Changing a var’s Root Binding. Despite our various warnings against using vars as
variables as understood in other languages, there is value in
mutating their root bindings occasionally and with great care. To
change a var’s root binding as a function of its current value,
there’s alter-var-root:
(def x 0) ;= #'user/x (alter-var-root #'x inc) ;= 1
When the var in question contains a function, this provides a superset of the functionality found in most aspect-oriented programming frameworks. Concrete examples in that vein are provided in Aspect-Oriented Programming and Building mixed-source projects.
You can also temporarily change the root binding of a bunch of
vars with with-redefs, which will restore the vars’ root bindings upon
exiting its scope; this can be very useful in testing, for mocking
out functions or values that depend upon environment-specific
context. See Mocking for an
example.
Forward Declarations
You can opt not to provide a value for a var; in this case, the var is considered “unbound,” and dereferencing it will return a placeholder object:
(def j) ;= #'user/j j ;= #<Unbound Unbound: #'user/j>
This is useful for when you need to refer to a var that you haven’t defined a value for yet. This can happen when implementing certain types of algorithms that benefit from alternating recursion—or, you may simply want to have the implementation of a function to come after where it is used as a matter of style or in an attempt to call attention to primary or public API points. Clojure compiles and evaluates forms in the order presented in your source files, so any vars you refer to must at least be declared prior to those references. Assuming such vars’ values are only required at runtime (e.g., if they are placeholders for functions), then you can redefine those vars later with their actual values. This called a forward declaration.
In such cases, the declare macro is somewhat more idiomatic. Using it instead of
def alone makes explicit your
intention to define an unbound var (rather than leaving open the
possibility that you simply forgot to provide a value), and it
allows you to define many unbound vars in a single
expression:
(declare complex-helper-fn other-helper-fn)
Agents
Agents are an uncoordinated, asynchronous reference type. This means that changes to an agent’s state are independent of changes to other agents’ states, and that all such changes are made away from the thread of execution that schedules them. Agents further possess two characteristics that uniquely separate them from atoms and refs:
I/O and other side-effecting functions may be safely used in conjunction with agents.
Agents are STM-aware, so that they may be safely used in the context of retrying transactions.
Agent state may be altered via two functions, send and send-off. They follow the same pattern as other reference state
change functions, accepting another function that will determine the
agent’s new state that accepts as arguments the agent’s current state
along with optional additional arguments to pass to the
function.
Taken together, each function + optional set of arguments passed to
send or send-off is called an agent
action, and each agent maintains a queue of
actions. Both send and send-off return immediately after queueing
the specified action, each of which are evaluated serially, in the
order in which they are “sent,” on one of many threads dedicated to
the evaluation of agent actions. The result of each evaluation is
installed as the agent’s new state.
The sole difference between send and send-off is the type of action that may be
provided to each. Actions queued using send are evaluated within a fixed-size
thread pool that is configured to not exceed the parallelizability of
the current hardware.[151] Thus, send
must never be used for actions that might perform I/O or other
blocking operations, lest the blocking action prevent other
nonblocking, CPU-bound actions from fully utilizing that
resource.
In contrast, actions queued using send-off are evaluated within an unbounded
thread pool (incidentally, the same one used by futures), which allows
any number of potentially blocking, non-CPU-bound actions to be
evaluated concurrently.
Knowing all this, we can get a picture of how agents work in general:

Actions are queued for an agent using either send or send-off (represented in Figure 4-7 as different-colored units of work).
The agent applies its state to those actions in order, performing that
evaluation on a thread from the pool associated with the function used
to queue the action. So, if the black actions are CPU-bound, then
threads t2
and t3 are
from the dedicated, fixed-size send
thread pool, and t9 and t18 are from the
unbounded send-off thread pool. The
return value of each action becomes the agent’s new state.
While the semantics of agents may be subtle, using them is extraordinarily easy:
(def a (agent 500))
-
An agent is created with an initial value of
500.-
We
sendan action to the agent, consisting of therangefunction and an additional argument1000; in another thread, the agent’s value will be set to the result of(range @a 1000).
Both send and send-off return the agent involved. When
sending actions in the REPL, it is possible that you’ll see the result of the sent
action’s evaluation immediately in the printing of the agent;
depending on the complexity of the action and how quickly it can be
scheduled to be evaluated, it may be complete by the time the REPL has
a chance to print the agent returned from send or send-off:
(def a (agent 0)) ;= #'user/a (send a inc) ;= #<Agent@65f7bb1f: 1>
On the other hand, you may find yourself needing the result of a
pending action’s evaluation, and polling the agent for the result
would be daft. You can block on an agent(s) completing evaluation of
all actions sent from your current thread using await:[153]
(def a (agent 5000)) (def b (agent 10000)) (send-off a #(Thread/sleep %)) ;= #<Agent@da7d7b5: 5000> (send-off b #(Thread/sleep %)) ;= #<Agent@c0cd75b: 10000> @a
-
The function sent to
awill take five seconds to complete, so its value has not been updated yet.-
We can use
awaitto block until all of the actions sent to the passed agents from this thread have completed. This particular call will block for up to 10 seconds, since that is how long the function sent tobwill take to evaluate.-
After
awaithas returned, the sent actions will have been evaluated, and the agent(s) values will have been updated. Note that another action could have modifieda’s value before you dereference it!
await-for does the same but allows you to provide a
timeout.
Dealing with Errors in Agent Actions
Because agent actions are run asynchronously, an exception thrown in the course of their evaluation cannot be dealt with in the same thread of execution that dispatches the offending action. By default, encountering an error will cause an agent to fail silently: you’ll still be able to dereference its last state, but further actions will fail to queue up:
(def a (agent nil)) ;= #'user/a (send a (fn [_] (throw (Exception. "something is wrong")))) ;= #<Agent@3cf71b00: nil> a ;= #<Agent@3cf71b00 FAILED: nil> (send a identity)
A failed agent can be salvaged with restart-agent, which will reset the
agent’s state to the provided value and enable it to receive actions
again. An optional flag to restart-agent, :clear-actions, will clear any pending
actions on the agent. Otherwise those pending actions will be
attempted immediately.
(restart-agent a 42) ;= 42 (send a inc)
-
Restarting an agent will reset its failed status and allow it to receive actions again.
-
However, if an agent’s queue contains other actions that will cause further errors…
-
…then
restart-agentwould need to be called once per erroring action.-
Adding the
:clear-actionsoption to arestart-agentcall will clear the agent’s queue prior to resetting its failed status, ensuring that any doomed actions in the queue will not immediately fail the agent.
This default error-handling mode—where agents drop into a failed status and need to be resuscitated again—is most useful when you can rely upon manual intervention, usually via a REPL.[154] More flexible and potentially hands-off error handling can be had by changing the defaults for each agent as appropriate.
Agent error handlers and modes
The default behavior where an error causes an agent
to enter a failed status is one of two failure modes supported by
agents. agent accepts an
:error-mode option of :fail (the default) or :continue;[155] an agent with a failure mode of :continue will simply ignore an error
thrown by the evaluation of an agent action, carrying on with
processing any actions in its queue and receiving new actions
without difficulty:
(def a (agent nil :error-mode :continue)) ;= #'user/a (send a (fn [_] (throw (Exception. "something is wrong")))) ;= #<Agent@44a5b703: nil> (send a identity) ;= #<Agent@44a5b703: nil>
This makes restart-agent
unnecessary, but dropping errors on the floor by default and
without any possible intervention is generally not a good idea.
Thus, the :continue error mode
is almost always paired with an error handler, a function of two
arguments (the agent, and the precipitating error) that is called
any time an agent action throws an exception; an error handler can
be specified for an agent by using the :error-handler option:[156]
(def a (agent nil
:error-mode :continue
:error-handler (fn [the-agent exception]
(.println System/out (.getMessage exception)))))
;= #'user/a
(send a (fn [_] (throw (Exception. "something is wrong"))))
;= #<Agent@bb07c59: nil>
; something is wrong
(send a identity)
:= #<Agent@bb07c59: nil>Of course, far more sophisticated things can be done within
an :error-handler function beyond simply dumping information about
the exception to the console: some data in the application may be
changed to avoid the error, an action or other operation might be
retried, or the agent’s :error-mode can be switched back to
:fail if you know that shutting
down the agent is the only safe course of action:
(set-error-handler! a (fn [the-agent exception]
(when (= "FATAL" (.getMessage exception))
(set-error-mode! the-agent :fail))))
;= nil
(send a (fn [_] (throw (Exception. "FATAL"))))
;= #<Agent@6fe546fd: nil>
(send a identity)
;= #<Exception java.lang.Exception: FATAL>I/O, Transactions, and Nested Sends
Unlike refs and atoms, it is perfectly safe to use agents to coordinate I/O and perform other blocking operations. This makes them a vital piece of any complete application that use refs and Clojure’s STM to maintain program state over time. Further, thanks to their semantics, agents are often an ideal construct for simplifying asynchronous processing involving I/O even if refs are not involved at all.
Because agents serialize all actions sent to them, they
provide a natural synchronization point for necessarily side-effecting operations. You
can set up an agent to hold as its state a handle to some context—an
OutputStream to a file or network socket, a connection to a
database, a pipe to a message queue, etc.—and you can be sure that
actions sent to that agent will each have exclusive access to that
context for the duration of their evaluation. This makes it easy to
integrate the Clojure sphere—including refs and atoms—which
generally aims to minimize side effects with the rest of the world
that demands them.
You might wonder how agents could possibly be used from within STM transactions. Sending an agent action is a side-effecting operation, and so would seem to be just as susceptible to unintended effects due to transaction restarts as other side-effecting operations like applying change operations to atoms or writing to a file. Thankfully, this is not the case.
Agents are integrated into Clojure’s STM implementation such
that actions dispatched using send and send-off from within the scope of a
transaction will be held in reserve until that transaction is
successfully committed. This means that, even if a transaction
retries 100 times, a sent action is only dispatched once, and that
all of the actions sent during the course of a transaction’s runtime
will be queued at once after the transaction commits. Similarly,
calls to send and send-off made within the scope of
evaluation of an agent action—called a nested
send—are also held until the action has completed. In both
cases, sent actions held pending the completion of an action
evaluation or STM transaction may be discarded entirely if a
validator aborts the state change associated with either.
To illustrate these semantics and see what they enable, let’s take a look at a couple of examples that use agents to simplify the coordination of I/O operations in conjunction with refs and the STM, and as part of a parallelized I/O-heavy workload.
Persisting reference states with an agent-based write-behind log
The game we developed in The Mechanics of Ref Change using refs to maintain character state in the face of relentlessly concurrent player activity proved the capabilities of Clojure’s STM in such an environment. However, any game like this, especially those providing multiplayer capabilities, will track and store player activity and the impact it has on their characters. Of course, we wouldn’t want to stuff any kind of logging, persistence, or other I/O into the core game engine: any persistence we want to perform may itself end up being inconsistent because of transaction restarts.
The simplest way to address this is to use watchers and
agents to implement a write-behind log for characters in the game.
First, let’s set up the agents that will hold our output sinks;
for this example, we’ll assume that all such agents will contain
java.io.Writers, the Java
interface that defines the API of character output streams:
(require '[clojure.java.io :as io]) (def console (agent *out*)) (def character-log (agent (io/writer "character-states.log" :append true)))
One of these agents contains *out* (itself an instance of Writer), the other a Writer that drains to a character-states.log file in the
current directory. These Writer
instances will have content written to them by an agent action,
write:
(defn write
[^java.io.Writer w & content]
(doseq [x (interpose " " content)]
(.write w (str x)))
(doto w
(.write "\n")
.flush))write takes as its first
argument a Writer (the state of
one of the agents it will be queued for), and any number of other
values to write to it. It writes each value separated by a space,
then a newline, and then flushes the Writer so outputted content will
actually hit the disk or console rather than get caught up in any
buffers that might be in use by the Writer.
Finally, we need a function that will add a watcher to any
reference type, which we’ll use to connect our character refs with
the agents that hold the Writer
instances:
(defn log-reference
[reference & writer-agents]
(add-watch reference :log
(fn [_ reference old new]
(doseq [writer-agent writer-agents]
(send-off writer-agent write new)))))Every time the reference’s state changes, its new state will
be sent along with our write
function to each of the agents provided to log-reference. All we need to do now is
add the watcher for each of the characters for which we want to
log state changes, and fire up a battle:
(def smaug (character "Smaug" :health 500 :strength 400))
(def bilbo (character "Bilbo" :health 100 :strength 100))
(def gandalf (character "Gandalf" :health 75 :mana 1000))
(log-reference bilbo console character-log)
(log-reference smaug console character-log)
(wait-futures 1
(play bilbo attack smaug)
(play smaug attack bilbo)
(play gandalf heal bilbo))
; {:max-health 500, :strength 400, :name "Smaug", :items #{}, :health 490.052618}
; {:max-health 100, :strength 100, :name "Bilbo", :items #{}, :health 61.5012391}
; {:max-health 100, :strength 100, :name "Bilbo", :items #{}, :health 100.0}
; {:max-health 100, :strength 100, :name "Bilbo", :items #{}, :health 67.3425151}
; {:max-health 100, :strength 100, :name "Bilbo", :items #{}, :health 100.0}
; {:max-health 500, :strength 400, :name "Smaug", :items #{}, :health 480.990141}
; ...-
You can see the healing effects of Gandalf made concrete each time Bilbo’s
:healthgoes up in the log.
You’ll find this same content in the character-states.log file as well. Fundamentally, we’re logging states to the console and a file because they’re the most accessible sinks; this approach will work just as well if you were to stream updates to a database, message queue, and so on.
Using a watcher like this gives us the opportunity to make each state change to our characters’ refs durable (e.g., by writing them to disk or to a database) without modifying the functions used to implement those changes.
In order to track and persist in-transaction
information—like the amount of each attack and heal, who did what
to whom, and so on—we just need to dispatch a write action to our writer agents within
the body of any function that makes a change we might want to
persist:
(defn attack
[aggressor target]
(dosync
(let [damage (* (rand 0.1) (:strength @aggressor) (ensure daylight))]
(send-off console write
(:name @aggressor) "hits" (:name @target) "for" damage)
(commute target update-in [:health] #(max 0 (- % damage))))))
(defn heal
[healer target]
(dosync
(let [aid (min (* (rand 0.1) (:mana @healer))
(- (:max-health @target) (:health @target)))]
(when (pos? aid)
(send-off console write
(:name @healer) "heals" (:name @target) "for" aid)
(commute healer update-in [:mana] - (max 5 (/ aid 5)))
(alter target update-in [:health] + aid)))))
(dosync
(alter smaug assoc :health 500)
(alter bilbo assoc :health 100))
; {:max-health 100, :strength 100, :name "Bilbo", :items #{}, :health 100}
; {:max-health 500, :strength 400, :name "Smaug", :items #{}, :health 500}
(wait-futures 1
(play bilbo attack smaug)
(play smaug attack bilbo)
(play gandalf heal bilbo))
; {:max-health 500, :strength 400, :name "Smaug", :items #{}, :health 497.414581}
; Bilbo hits Smaug for 2.585418463393845
; {:max-health 100, :strength 100, :name "Bilbo", :items #{}, :health 66.6262521}
; Smaug hits Bilbo for 33.373747881474934
; {:max-health 500, :strength 400, :name "Smaug", :items #{}, :health 494.667477}
; Bilbo hits Smaug for 2.747103668676348
; {:max-health 100, :strength 100, :name "Bilbo", :items #{}, :health 100.0}
; Gandalf heals Bilbo for 33.37374788147494
; ...The end result of composing these small pieces together with our character refs is a fire-and-forget persistence mechanism that is safe to use in conjunction with the retries that are inevitable when using atoms and transactions over refs. We wrote to the console and a logfile to keep the example simple, but you can just as easily write ref state updates to a database. In any case, this demonstrates how, just as with the general usage of atoms and refs, even things like sharing I/O resources within a concurrent environment can be done without touching a single low-level lock and taking on the risks inherent in their management.
Using agents to parallelize workloads
It may initially seem unnecessary or inconvenient to have to segregate agent actions into two sorts. However, without the separation between blocking and nonblocking actions, agents would lose their ability to efficiently utilize the resources needed to service the different kinds of workloads—CPU, disk I/O, network throughput, and so on.
For example, say our application was dedicated to processing messages pulled from a queue; reading messages from the queue would likely be a blocking operation due to waiting on the network if the queue was not in-process, and depending on the semantics of the queue, waiting for work to be available. However, processing each message is likely to be CPU-bound.
This sounds a lot like a web crawler. Agents make building one that is efficient and flexible quite easy. The one we’ll build here will be extraordinarily basic,[157] but it will demonstrate how agents can be used to orchestrate and parallelize potentially very complicated workloads.
First, we need some basic functions for working with the
content of web pages we crawl. links-from takes a base URL and that
URL’s HTML content, returning a seq of the links found within that
content; words-from takes some
HTML content and extracts its text, returning a seq of the words
found therein, converted to lowercase:
(require '[net.cgrand.enlive-html :as enlive])
(use '[clojure.string :only (lower-case)])
(import '(java.net URL MalformedURLException))
(defn- links-from
[base-url html]
(remove nil? (for [link (enlive/select html [:a])]
(when-let [href (-> link :attrs :href)]
(try
(URL. base-url href)
; ignore bad URLs
(catch MalformedURLException e))))))
(defn- words-from
[html]
(let [chunks (-> html
(enlive/at [:script] nil)
(enlive/select [:body enlive/text-node]))]
(->> chunks
(mapcat (partial re-seq #"\w+"))
(remove (partial re-matches #"\d+"))
(map lower-case))))This code uses Enlive, a web templating and scraping library that we discuss in detail in Enlive: Selector-Based HTML Transformation, but its details aren’t key to our main focus, the use of agents to soak up all of the resources we have to maximize crawling throughput.
There will be three pools of state associated with our web crawler:
One of Java’s thread-safe queues will hold URLs that are yet to be crawled, which we’ll call
url-queue. Then, for each page we retrieve, we will…Find all of the links in the page so as to crawl them later; these will all be added to a set held within an atom called
crawled-urls, and URLs we haven’t visited yet will be queued up inurl-queue. Finally…We’ll extract all of the text of each page, which will be used to maintain a count of cumulative word frequencies observed throughout the crawl. This count will be stored in a map of words to their respective counts, held in an atom called
word-freqs:
(import '(java.util.concurrent BlockingQueue LinkedBlockingQueue))
(def url-queue (LinkedBlockingQueue.))
(def crawled-urls (atom #{}))
(def word-freqs (atom {}))We’ll set up a bunch of agents in order to fully utilize all the resources we have available,[158] but we need to think through what state they’ll hold and what actions will be used to transition those states. In many cases, it is useful to think about agent state and the actions applied to it as forming a finite state machine; we’ve already walked through the workflow of our crawler, but we should formalize it.

The state of an agent at each point in this process should be obvious: prior to retrieving a URL, an agent will need a URL to retrieve (or some source of such URLs); prior to scraping, an agent will need a page’s content to scrape; and, prior to updating the cumulative crawler state, it will need the results of scraping. Since we don’t have very many potential states, we can simplify things for ourselves by allowing each action implementing these transitions to indicate the next action (transition) that should be applied to an agent.
To see what this looks like, let’s define our set of agents;
their initial state, corresponding with the initial state
preceding the “Retrieve URL” transition in Figure 4-8, is a map containing the
queue from which the next URL may be retrieved, and the next
transition itself, a function we’ll call get-url:
(declare get-url)
(def agents (set (repeatedly 25 #(agent {::t #'get-url :queue url-queue})))) The three transitions shown in Figure 4-8 are implemented by three
agent actions: get-url,
process, and handle-results.
get-url will wait on a
queue (remember, each of our agents has url-queue as its initial value) for URLs
to crawl. It will leave the state of the agent set to a map
containing the URL it pulls off the queue and its content:
(use '[clojure.java.io :only (as-url)]) (declare run process handle-results)
-
We’ll show
runand explain what it’s doing in a little bit.-
If we’ve already crawled the URL pulled off the queue (or if we encounter an error while loading the URL’s content), we leave the agent’s state untouched. This implementation detail in our finite state machine adds a cycle to it where
get-urlwill sometimes be invoked on a single agent multiple times before it transitions states.
process will parse a
URL’s content, using the links-from and words-from functions to obtain the URL’s
content’s links and build a map containing the frequencies of each
word found in the content. It will leave the state of the agent
set to a map containing these values as well as the originating
URL:
(defn process
[{:keys [url content]}]
(try
(let [html (enlive/html-resource (java.io.StringReader. content))]
{::t #'handle-results
:url url
:links (links-from url html)
:words (reduce (fn [m word]
(update-in m [word] (fnil inc 0)))
{}
(words-from html))})
(finally (run *agent*))))-
The
:wordsmap associates found words with their count within the retrieved page, which we produce by reducing a map through the seq of those words.fnilis a HOF that returns a function that uses some default value(s) (here,0) in place of anynilarguments when calling the function provided tofnil; this keeps us from having to explicitly check if the value in the words map isnil, and returning1if so.
handle-results will
update our three key pieces of state: adding the just-crawled URL
to crawled-urls, pushing each
of the newfound links onto url-queue, and merging the URL’s
content’s word frequency map with our cumulative word-freqs map. handle-results returns a state map
containing url-queue and the
get-url transition, thus
leaving the agent in its original state.
(defn ^::blocking handle-results
[{:keys [url links words]}]
(try
(swap! crawled-urls conj url)
(doseq [url links]
(.put url-queue url))
(swap! word-freqs (partial merge-with +) words)
{::t #'get-url :queue url-queue}
(finally (run *agent*))))You may have noticed that each of the functions we’ll use as
agent actions has a try form
with a finally clause that
contains a sole call to run
with *agent* as its sole
argument.[161] We didn’t define *agent* anywhere; usually unbound, it is
a var provided by Clojure that, within the scope of the evaluation
of an agent action, is bound to the current
agent. So, (run
*agent*) in each of these actions is calling run with a single argument, the agent
that is evaluating the action.
This is a common idiom used with agents that allow them to
run continuously. In our web crawler’s case, run is a function that queues up the
next transition function to be applied to an agent based on that
agent’s ::t state. If each
action already knows which transition function should be applied
next, why add a level of indirection in calling run? Two reasons:
While it is reasonable to expect each function used as an agent action to know what the next transition should be given the new agent state it is returning, there’s no way for it to know whether that next transition is a blocking action or not. This is something that is best left up to the transitions themselves (and their informed authors); thus,
runwill use the presence (or, absence) of::blockingmetadata on each transition to determine whether to usesendorsend-offto dispatch transition functions.[162]runcan check to see if the agent has been marked as being paused—a condition indicated simply by the presence of a logically true::pausedvalue in the agent’s metadata.
(defn paused? [agent] (::paused (meta agent)))
(defn run
([] (doseq [a agents] (run a)))
([a]
(when (agents a)
(send a (fn [{transition ::t :as state}]
(when-not (paused? *agent*)
(let [dispatch-fn (if (-> transition meta ::blocking)
send-off
send)]
(dispatch-fn *agent* transition)))
state)))))run doubles as a way to
start all of our (unpaused) agents when called with no arguments.
The pausing capability is particularly important, as we
wouldn’t want to have the crawler run without interruption. With
the use of metadata to indicate that run should not dispatch the next
transition for an agent’s state, pause and restart give us a way to pause or
restart the agents’ operation just from changing their
metadata:
(defn pause
([] (doseq [a agents] (pause a)))
([a] (alter-meta! a assoc ::paused true)))
(defn restart
([] (doseq [a agents] (restart a)))
([a]
(alter-meta! a dissoc ::paused)
(run a)))Now we can crawl some web pages! We’ll want to run the
crawler repeatedly from a fresh state, so it will be handy to have
a testing function that will reset the crawler state. test-crawler does this, as well as
adding a starting URL to url-queue, and letting the agents run
for just 60 seconds so we can make some informal throughput
comparisons:
(defn test-crawler
"Resets all state associated with the crawler, adds the given URL to the
url-queue, and runs the crawler for 60 seconds, returning a vector
containing the number of URLs crawled, and the number of URLs
accumulated through crawling that have yet to be visited."
[agent-count starting-url]
(def agents (set (repeatedly agent-count
#(agent {::t #'get-url :queue url-queue}))))
(.clear url-queue)
(swap! crawled-urls empty)
(swap! word-freqs empty)
(.add url-queue starting-url)
(run)
(Thread/sleep 60000)
(pause)
[(count @crawled-urls) (count url-queue)])-
We warned you against redefining vars within the body of a function in Vars Are Not Variables, but this may be one of the few contexts where doing so is okay: a function that is never called outside of the REPL, used solely for experimentation and testing.
To establish a baseline, let’s first try it with a single agent, using the BBC’s news page as a crawl root:
(test-crawler 1 "http://www.bbc.co.uk/news/") ;= [86 14598]
Eighty-six pages crawled in a minute. Surely we can do better; let’s use 25 agents, which will parallelize both the blocking retrieval workload as well as the CPU-bound scraping and text processing workload:
(test-crawler 25 "http://www.bbc.co.uk/news/") ;= [670 81775]
Not bad, 670 pages crawled in 60 seconds, a very solid order of magnitude gained simply by tweaking the number of agents being applied to the problem.[163]
Let’s check on the word frequencies being calculated. We can get a selection of the most and least common terms with their frequencies quite easily:
(->> (sort-by val @word-freqs) reverse (take 10)) ;= (["the" 23083] ["to" 14308] ["of" 11243] ["bbc" 10969] ["in" 9473] ;= ["a" 9214] ["and" 8595] ["for" 5203] ["is" 4844] ["on" 4364]) (->> (sort-by val @word-freqs) (take 10)) ;= (["relieved" 1] ["karim" 1] ["gnome" 1] ["brummell" 1] ["mccredie" 1] ;= ["ensinar" 1] ["estrictas" 1] ["arap" 1] ["forcibly" 1] ["kitchin" 1])
Looks like we have a fully functioning crawler that does some marginally interesting work. It’s surely not optimal—as we’ve said, it’s quite basic, and would need a variety of subtle enhancements in order to be used at scale, but the foundation is clearly there.
Now, remember what we were saying earlier in this section,
that the division of agent actions into those that may block (due
to I/O or other wait conditions) and those that won’t (i.e.,
CPU-bound processing) enables the maximal utilization of all of
the resources at our disposal. We can test this; for example, by
marking process as a blocking
operation, we will ensure that it is always sent to agents using
send-off, and thus handled
using the unbounded thread pool:
(alter-meta! #'process assoc ::blocking true)
;= {:arglists ([{:keys [url content]}]), :ns #<Namespace user>,
;= :name process, :user/blocking true}The practical effect of this is that all of the HTML parsing, searching for links, and text processing associated with the word frequency calculations will happen without limit.
(test-crawler 25 "http://www.bbc.co.uk/news/") ;= [573 80576]
This actually has a negative impact on throughput—approaching 15 percent overall—as now there can be up to 25 active (and hungry) agents contending for CPU cores, which can cumulatively slow our CPU-bound workload.
Using Java’s Concurrency Primitives
Now that we’ve done a deep dive into Clojure’s extensive
concurrency and state-management features, it’s worth pointing out
that Java’s native threads, primitive lock mechanisms, and its own
very useful concurrency libraries—especially the java.util.concurrent.* packages—are quite usable in Clojure. In
particular, the latter are used extensively in the implementation of
Clojure’s own concurrency primitives, but Clojure does not wrap or
subsume them, so you should learn about them and use them as
appropriate in your applications.
We’ve not yet explored all the mechanics of Clojure’s Java interoperability—we’ll get to that in Chapter 9—but the examples we show here should be basic enough for you to understand before you dig into that.
Java defines a couple of key interfaces—java.lang.Runnable and java.util.concurrent.Callable—which are implemented by Clojure functions that take no
parameters. This means you can pass no-arg Clojure functions to any
Java API that requires an object that implements one of these
interfaces, including native Threads:
(.start (Thread. #(println "Running..."))) ;= Running... ;= nil
The java.util.concurrent.* packages offer a number of concurrency
facilities that are used in the implementation of Clojure’s own
features, many of which you should take advantage when appropriate. We
already demonstrated the operation of one type of thread-safe queue
implementation in Using agents to parallelize workloads,
LinkedBlockingQueue; there are many
others like it but with subtle yet important differences in semantics
and performance. Then there are thread pools, thread-safe concurrent data structures (a better
fallback than the vanilla, e.g., java.util.HashMap if your Clojure program
needs to share a mutable-in-place data structure with some Java code),
and special-purpose objects like CountDownLatch, which allow you block a
thread (or future, or agent action dispatched with send-off) until some number of other events
have occurred.
If you would like to know how to use these facilities effectively and develop a thorough understanding of concurrency at the lower levels of the JVM, we recommend Java Concurrency in Practice by Goetz, et al.
Locking
Even given all of the (safer) concurrency primitives
provided by Clojure, you may still occasionally need a primitive
lock, often when working with mutable Java entities such as arrays.
Of course, once you make this decision, you’re on your own: you are
no longer benefiting from the defined semantics that those
primitives guarantee. In any case, you can use the locking macro to obtain and hold a lock on
a given object for the duration of execution within the body of the
locking form.
So, this Clojure code:
(defn add
[some-list value]
(locking some-list
(.add some-list value)))is equivalent to this code in Java, Ruby, and Python, respectively:
// Java
public static void add (java.util.List someList, Object value) {
synchronized (someList) {
someList.add(value);
}
}
# Ruby
require 'thread'
m = Mutex.new
def add (list, value)
m.synchronize do
list << value
end
end
# Python
import threading
lock = threading.Lock()
def add (list, value):
lock.acquire()
list.append(value)
lock.release()Final Thoughts
Concurrent programming is hard, and many popular programming languages are set up in such a way to make it harder. By having a clear separation of identity and state, promoting immutability, and offering built-in constructs for safe multithreaded programming, Clojure goes a long way to making concurrent programming easier and more accessible.
[124] @foo is nearly always
preferred to (deref foo),
except when using deref
with higher-order functions (to, for example, dereference all
of the delays in a sequence) or using deref’s timeout feature, available
only with promises and futures.
[125] And, therefore, not cause any potential side effects associated with the code provided to create the delay.
[126] future-call is also
available if you happen to have a zero-argument function you’d
like to have called in another thread.
[127] This option is not available when using the @ reader sugar.
[128] Which, technically, is in another thread!
[130] Note that this discussion is by no means limited to Java. Many—really, nearly all—other languages conflate state and identity, including Ruby, Python, C#, Perl, PHP, and so on.
[131] Don’t get hung up on the lack of accessors and such; whether you work with fields or getters and setters has no impact on the semantics involved.
[132] Rich Hickey gave a talk in 2009 on the ideas of identity, state, and time and how they informed the design of Clojure. We highly recommend you watch the video of that talk: http://www.infoq.com/presentations/Are-We-There-Yet-Rich-Hickey.
[133] atom, ref, and agent all accept an optional
:meta keyword argument,
allowing you to provide an initial metadata map when creating
those references.
[134] Vars do not fit into this particular classification; their primary mode of change is thread-local, and thus are orthogonal to notions of coordination or synchronization.
[135] As defined by identical?; see Object Identity (identical?).
[136] Alternatively, you can use a library like Slingshot to throw values, instead of encoding useful information in a paltry string: https://github.com/scgilardi/slingshot.
[137] Modern garbage collection implementations can enable programs to outperform alternatives written using manual memory management in many contexts; and, each time a new garbage collector implementation or optimization is added to the JVM, every program everywhere benefits from it without any involvement from individual programmers. The same dynamic has played out with Clojure’s STM.
[138] In particular, multiversion concurrency control (often abbreviated MVCC): https://en.wikipedia.org/wiki/Multiversion_concurrency_control.
[139] We present a way to address durability of ref state with the help of agents in Persisting reference states with an agent-based write-behind log.
[140] We’re not game designers, and what we build here is obviously a contrivance, but there’s no reason the mechanisms we demonstrate here could not be utilized and extended to implement a thoroughly capable game engine.
[141] In a real game engine, you would almost surely not use
vars to hold characters; rather, it would make sense to use a
single map containing all online players’ characters, itself
held within a ref. As players were to go on- and offline, their
characters would be assoced
and dissoced from that
map.
[142] Note that nested transaction scopes—either due to
lexically nested dosync
forms, or the joining of scopes in, for example, different
functions thanks to the flow of execution—are joined into a
single logical transaction that commits or retries as a unit
when control flows out of the outermost
dosync.
[144] Determining ideal ref granularity for your particular model is an optimization step that you’ll have to figure through benchmarking, experimentation, and some degree of forethought. Always start with the simplest approach—all-encompassing values are just fine most of the time—only reaching for a more complicated solution when necessary. See http://clj-me.cgrand.net/2011/10/06/a-world-in-a-ref/ for one such potential direction.
[145] Or, at the very least, effectively mutable due to your usage of them. For example, it is possible to use a mutable Java list as the state of a ref with proper transactional semantics if you strictly copy-on-write when producing modified lists, but this is both bad form and almost always unnecessary.
[146] See Write skew for more
subtleties on the value returned by deref inside a transaction.
[148] Attempting to use binding on a var that is not :dynamic will result in an exception
being thrown.
[149] Please excuse the momentary slew of Java interop; it is necessary to use a native thread in order to demonstrate this characteristics of dynamic vars. See Using Java’s Concurrency Primitives and Chapter 9 for explanations of what’s going on here.
[150] Examples include *warn-on-reflection* as detailed in
Type Hinting for Performance and Type errors and warnings. *out*, *in*, and *err*, and indirect usages of binding, like with-precision are discussed in Scale and Rounding Modes for Arbitrary-Precision Decimals
Ops.
[151] For example, a two-core CPU will have a send thread pool configured to contain a
maximum of four threads, a four-core CPU will have a pool of eight
threads, etc.
[152] Many thousands of agents may be created without strain with a default heap configuration; millions may be created by tweaking the JVM’s heap settings.
[153] It is an implementation detail—and so may change in the
future—but you can call (.getQueueCount
some-agent) in order to check the current size of an
some-agent’s action
queue.
[154] That is, via a REPL connected to your environment, wherever it may be; see Debugging, Monitoring, and Patching Production in the REPL.
[155] You can change an agent’s error mode with set-error-mode!.
[156] You can change an agent’s error handler with set-error-handler!.
[157] And not very well-behaved, especially insofar as it doesn’t throttle connections, a key point of politeness when crawling web content. Our apologies to the BBC for (ab)using them as an example crawl root!
[158] Another shortcoming of our basic web crawler: at nearly any scale, a useful web crawler would use a message queue and suitable database instead of maintaining all state in memory. This thankfully does not affect the semantics of our example, which could be adapted to use such things with relative ease.
[159] We use a namespaced keyword to avoid any potential naming clashes with other parts of state that might be added to the agents, if this crawler implementation were to ever be extended outside of its own namespace.
[160] Depending on the range of states that are to be held by your agents, sending a multimethod or protocol function to them can be an elegant, efficient option to discriminate between a number of different potential agent state transitions. We talk about multimethods and protocols in Chapter 7 and Protocols, respectively.
[161] We’ve repeated this pattern in three functions at this point; any more, and it would be a no-brainer to write a macro that would eliminate that boilerplate.
[162] This metadata access explains in part why we’re using the functions’ vars to denote transitions instead of the functions themselves. Beyond that, using vars helps make it easier to modify the behavior of the web crawler; see Limitations to Redefining Constructs for why.
[163] Of course, your specific results will vary greatly depending upon the CPU power you have available and the speed and latency of your Internet connection; however, the relative improvement from 1 to 25 agents should be similar.
Get Clojure Programming now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

