Chapter 4. Forces Behind Serverless
This chapter is focused primarily on understanding the ingredients that have come together to make serverless successful now and in the future. (I don’t have a crystal ball, but the structural advantages of serverless seem likely to continue until someone figures out an even better way to help developers build scalable applications.)
Three main forces have combined to enable serverless to become a popular paradigm. Today, many organizations still have large, business-critical monoliths—even mainframe applications are a critical part of many industries! Over the next 20 years, I expect to see serverless take a larger role in many of these existing applications, living alongside the existing monoliths and mainframes. This is great—most technologies don’t completely replace their predecessors but offer new options that are better for new requirements. I expect serverless to become the dominant paradigm for new applications (including low- and no-code applications) and for clever technologists to find ways for serverless to integrate with existing technology stacks. The mice and the elephants will be living together, so to speak (Figure 4-1).

Figure 4-1. Serverless and the monolith
The two main drivers of serverless adoption are as follows:
- Reduced drag on innovation
-
All infrastructure has some friction on its use, but serverless reduces the wasted energy in running software.
- Microbilling
-
Focusing on units of work enables a clearer relation between service costs and value delivered.
On first adoption of serverless, these benefits may be small, but each new serverless component increases the payoff for the application as a whole. Once the benefits reach a tipping point, serverless becomes the default for an organization, and tools and infrastructure start to leverage these capabilities in a built-in way. Let’s take a look at how each of these drivers works and why the value adds up.
Top Speed: Reducing Drag
Most service projects start out with one or a small number of main server processes—this is called the monolith model of development. Over time, the monolith accumulates more and more functionality, until it is the combined work of twenty, fifty, or even hundreds of developers—a total investment of hundreds or thousands of engineering-years (not to mention product-manager years, testing years, etc.). Eventually, monoliths reach the point where they are so large and sophisticated that no one person understands the entire application, and large-scale changes become very difficult. Even small changes may need careful planning and consideration, and working on the monolith becomes more akin to major public works projects than a stroll in the park.
In reaction to this tendency toward slowing velocity in large projects, the microservice model was born. This model favors separating each piece of functionality into a separate service and stitching them together with a mix of explicit remote invocations or asynchronous messages. By building smaller services, it becomes harder for one service to entangle another in its implementation details, and it becomes simpler to reason about changing the behavior of a particular service while holding the other services constant. The exact size of each microservice is a matter of taste; what’s critical is that the contracts among microservices are expressed by clear APIs that change slowly and carefully.1
In addition to the antientropy properties of separating the implementations of disjoint services, microservices allow application teams to choose the best set of implementation languages and tools for each job. For example, an order database might be represented by a Java frontend and a backing Postgres database, while a product catalog might be implemented in TypeScript with storage in MongoDB. By separating each microservice into a separate process, teams are better able to choose technologies that match the problem space—Python for AI problems, Java for complex domain logic, JavaScript or TypeScript for presentation and UI, and Erlang for parallel highly available messaging.
Continuing this trend, the FaaS model decomposes each microservice into a set of even smaller units: each separate invocation endpoint or event handler is built and deployed as its own separate computational unit. In this model, even two different methods on the same API do not share the same compute process and might not even be implemented in the same language. This separation has a few benefits:
- Component changes can be shipped independently
-
Because each function is a separate service and set of server processes, it’s possible to upgrade one function without impacting the rest of the system (assuming that the “upgrade” actually still works). This means that rollouts (and rollbacks) have the smallest possible blast radius when things go wrong—look at what you last changed, and undo that change to get back to working. It’s amazing how often a simple “undo” can get a system back to up and running. Functions make that undo as simple as possible.
- Resource allocations can be sized per method
-
When you put a bunch of related but different operations into the same server process, you need to plan for the worst-case combination of those operations. Maybe the List operation needs to allocate 50 MB of RAM to deserialize, format, and assemble a response, but takes only 0.1 seconds of CPU to do the computation. Meanwhile, the Predict operation needs 20 seconds of CPU to compute a response and caches a shared 200 MB model in memory. If you want each server to be able to handle 10 requests, you need to plan on 200 + 10 × 50 = 700 MB of RAM to be able to handle 10 Lists, and allocate 10 CPUs to handle 10 Predicts. You’ll never have both happening at once, but you need to plan for the worst case of each.
If you allocate separate functions for List and Predict, the List method may need 500 MB of RAM for 10 requests (they don’t need to load the prediction model at all), but only 1 CPU. Meanwhile, the Predict method needs 200 MB of RAM and 10 CPUs for each instance. Since you’re separating the two types of requests, you can reduce the size of Predict instances by lowering the requests in-flight per instance. Assuming you’re using a serverless model and automatically scaling these two methods, then a mix of 34 Lists and 23 Predicts would require 6 servers in the classic model, and 4 List and 5 half-sized Predict servers in the FaaS model. Even though FaaS is running an extra instance, the total resources required are 60% to 70% higher for the traditional microservice model. Monoliths suffer from this even more; capacity planning for monoliths can be a substantial closed box depending on the degree of interaction between components. Table 4-1 can help visualize these two scenarios.
| Component | Methods | Worst-case CPU | Worst-case memory | Instances | Resources |
|---|---|---|---|---|---|
Shared instance |
List and Predict, 10 concurrent requests |
10 × 1.0 (Predict) |
200 MB (model) + 10 × 50 MB (List) |
6 |
10 CPU, 700 MB RAM per instance |
Total |
6 |
100 CPUs, 7 GB RAM |
|||
List instances |
List, 10 concurrent requests |
10 × 0.1 |
10 × 50 MB |
4 |
1 CPU, 500 MB RAM per instance |
Predict instances |
Predict, 5 concurrent requests |
5 × 1.0 |
200 MB |
5 |
5 CPUs, 200 MB RAM per instance |
Total |
9 |
29 CPUs, 3000 MB RAM |
|||
Given these obvious benefits, why aren’t microservices and FaaS even more popular than they are today? As you might have guessed by the title of this section, an opposing force drives teams toward monoliths: friction. For all the benefits of deploying microservices instead of monoliths, one major drawback of microservices is the proliferation of little services, as in Figure 4-2. Each service requires care and feeding—wouldn’t it be easier to just feed and care for one large hippo, rather than hundreds of little hamsters that each need separate vet appointments?
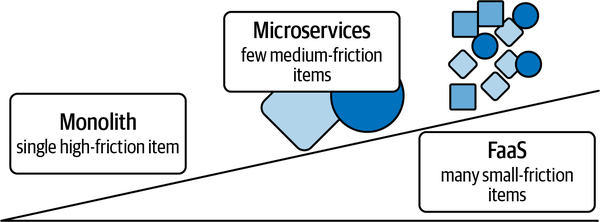
Figure 4-2. Code size and maintenance effort
This friction has many sources; some are intrinsic to live services, and others are imposed by various organizational processes. Intrinsic costs are things like writing application configurations, uptime monitoring, maintaining API compatibility, and artifact builds. External costs from organizational processes are launch reviews, application acceptance testing, or compliance audits. External costs are not necessarily bad—they are tools for achieving business goals that aren’t required by the underlying technology. Serverless can help reduce the intrinsic costs of running an application by simplifying configuration and automating monitoring. Tools like continuous delivery can help reduce both intrinsic and external costs by simplifying build, test, and even audit processes.
Each team makes these trade-offs every time it looks at adding a new feature or capability—whether this should live inside an existing delivery unit like a microservice, or live in its own unit, adding a new instance of “running a service” cost to the burden paid by the team. (Remember, the team has a number of ongoing burdens, including “keep the unit tests green” and “communicate with stakeholders.” Adding “maintain 273 microservices” to that burden contributes to fatigue and burnout.) By reducing the cost of “maintain a service,” it becomes easier for a team to shift right along the spectrum of Figure 4-2 into smaller units of delivery.
Continuously Delivering Value
So, microservices can be easier to run and maintain and make it easier to change one component without cascading consequences. In exchange, they require more discipline when making changes that cross microservices. But why are we talking about microservices here? Do I need to adopt serverless to run microservices?
You don’t need serverless to run microservices, and you don’t need microservices to run serverless. But the two do go together like peanut butter and jelly (or whatever your two favorite sandwich fillings are). From here on out, we’ll generally assume that you’ve chosen to run your microservices on serverless to take advantage of the operational benefits described in Chapter 1, as well as the benefits I’ll describe next.
In general, microservices make it easier to implement a number of modern deployment practices, including data separation, progressive delivery, and continuous delivery. Microservices make it easier to change the deployment practices for each small piece of the delivery puzzle without needing to coordinate across several handfuls of teams and dozens of individuals. These improvements build on one another, with data separation and progressive delivery each providing capabilities toward the ultimate goal of continuous delivery:
- Data separation
-
Well-architected microservices interact with one another through explicit APIs, either direct RPC or via asynchronous messaging. This allows each microservice to manage its own datastore through the team’s chosen abstractions. For example, a team responsible for managing shopping carts in an online store might expose an API in terms of orders and line items. The checkout system might expose a separate API that consumed orders and payment instruments to execute a transaction.
Letting teams choose the abstractions they expose to other teams allows them to define interfaces in terms of business domain concepts, rather than tables and relations. Hiding the implementation of those abstractions behind an API allows the microservice team to change the storage and implementation choices behind the microservice without affecting other teams. This could mean adding a cache to an existing query API or migrating from a single-instance relational database to a scale-up NoSQL database to deal with increased storage and I/O demand.
Data separation enables the following practices; without data separation, application changes become coupled across microservices, making it harder to implement progressive or continuous delivery.
- Progressive delivery
-
Once teams are able to deliver changes to their microservice implementation without affecting the APIs they use to coordinate with other services, their next challenge is to make that application delivery safe and repeatable. Progressive delivery is a technique for applying changes in smaller, safer steps. Rather than rolling out the whole microservice at once, a subset of requests is routed to the new version, with the ability to evaluate the performance and stability of the new version before sending most application traffic to the new version. Blue-green and canary deployments are popular examples of progressive delivery, but this can also manifest as traffic mirroring or “dark launch” of new code paths, where both new and old services are invoked.
The goal of progressive delivery is to make delivering software safer by reducing the impact of bad changes and reducing the time to recover when a bad change happens. As a rough rule of thumb, the overall damage of an outage is a product of blast radius (the number of users affected) times the duration of the outage. Progressive delivery aims to reduce the damage of a bad rollout, making it safer and quicker to roll out software.
- Continuous delivery
-
With teams able to independently roll out changes and to reduce the impact of bad configuration changes, they can start to implement continuous delivery. Whole books have been written on this topic, but roughly speaking, continuous delivery is the practice of automating software delivery such that software can be delivered safely on a frequent basis—daily or even on each code change in a repository. Implementing continuous delivery often means automating all aspects of the software build-and-release cycle and connecting the automated delivery mechanism with application monitoring such that a bad release can be detected and rolled back automatically.
We’ve already talked about how serverless can simplify application management and continuous operations, but serverless often has benefits in reaching continuous delivery nirvana as well.
Tip
Continuous delivery is not about never having an outage or failing to roll out software. The goal is to reduce the risk of rolling out software by reducing the damage potential of an individual rollout. Small, rapid rollouts reduce the pressure of combining must-fix patches with large new features. Splitting up the push scope reduces the risk of all-at-once failure. Automation reduces the risk of failure due to process variations.
While serverless does not require data separation (and a microservice might actually be implemented as several coordinating serverless processes sharing a common database), the API surface provided via direct RPC calls or asynchronous messaging lends itself well to the serverless unit-of-work model. By motivating teams to define APIs that can drive serverless scaling metrics, teams also end up implementing scalable APIs in front of their application data sources, and it becomes easier to define subsets of the application that interact with a given data source and need to be pushed together.
Progressive delivery is often directly supported by the serverless runtime; because the serverless runtime is already aware of the units of work, mechanisms are often built into the framework to enable splitting or routing those units to specific application versions. For example, Knative and many FaaS offerings provide the option to split traffic between application revisions that are tracked by runtime automatically on deployment.
Capping off the acceleration of application deployment, serverless platforms can assist in continuous delivery because they are well placed to track high-level application metrics at the unit-of-work level. Latency, throughput, and error rate should all be accessible to deployment automation based on integration with the platform monitoring stack. Obviously, some deployment metrics (such as the number of successful shopping cart orders) may not be available to the deployment machinery without application-level metrics, but generic unit-of-work monitoring can provide a basic performance envelope suitable for many teams. I’ll talk more about the monitoring capabilities of serverless platforms in Chapter 10.
Winning the (Business) Race
It’s fun to push code and have it show up live on the production site within 30 or 60 minutes, but the real benefit to continuous delivery is removing the technological limits on organizational reaction time. By providing a supporting scaffold for implementing continuous delivery, organizations that implement a serverless-first development model can react more quickly to changes in customer needs and experiment in more agile ways than organizations that need to tend to a monolith.
Summing up, organizations benefit in two ways from adopting a serverless-first microservices architecture:
- Reduced operational toil
-
Historically, the main benefit of monoliths was that a single operations team could specialize and focus on building an execution platform that managed all of the applications on one or a fixed fleet of servers (think cgi-bin or J2EE application servers loading dozens of microapplications onto a single server). Microservices mean maintaining dozens of servers, each with only a single application, leading to increased operational burden as each server is unique to the installed application. By simplifying application operations and automating some of the common day-to-day monitoring tasks, much of the toil of a microservices architecture can be avoided.
- Scaffolding for continuous delivery
-
If reduced toil is the aerodynamic shell for applications, continuous delivery is the turbocharger. Reducing the lead time for change is one of the key metrics used by DevOps Research and Assessment in identifying organizations that are elite performers in software execution. With software making its way into more and more aspects of business, continuous delivery allows faster reaction time to uncertain world events. Tightening the observe-decide-act loop helps organizations keep up with whatever the world throws their way.
Hopefully, these arguments explain how serverless can help organizations make better, faster decisions. The next section explains how serverless can help organizations make smarter decisions as well.
Microbilling
The previous section talked about splitting up monolithic applications into microservices from the point of view of application delivery and development team comfort. We’re about to talk about something that can make development teams distinctly uncomfortable but that can shine a fascinating light on an organization’s economic status—the cost of delivering goods and services (aka cost of goods sold, or COGS for all you business majors out there).
It may surprise some of you to learn that many businesses don’t understand their computing costs. The rest of you are nodding along and saying, “Evan, just cut to the punchline.” By splitting monoliths into microservices and tracking units of work, it becomes possible to allocate computing costs for individual lines of business, sometimes down to the transaction level!
Even though costs can be measured at a fine-grained level, return on investment (ROI) may be much harder to calculate. For example, customer loyalty programs may have an easily measurable cost but a difficult-to-measure contribution to customer loyalty and repeat sales.
By splitting out costs on a fine-grained level, it becomes easier to understand which services drive profit as well as revenue. If it costs $0.50 to engage a user via a text-chat application, for example, you can compare that cost with the cost of hiring a human operator at $15/hour to answer text questions; if the human can answer more than 30 customers per hour, they are actually cheaper than the application, ignoring training costs and app development costs. Furthermore, you might be able to zero in on a particular AI component that contributes $0.30 of the interaction price and optimize it—either moving it to CPU to GPU or vice versa, or changing the model itself to optimize for costs.
A Deal with the Cloud
Billing down to the individual unit of work is simplest with cloud-provided serverless platforms, which often bill directly for the work performed, sometimes down to the millisecond of CPU or RAM. With cloud-provider serverless offerings, the cloud provider is responsible for provisioning sufficient capacity and managing the extra unused capacity. In turn, the cloud provider captures some of the extra value of having the illusion of infinite capacity. Some studies have suggested that serverless compute is approximately four times the cost of standard IaaS instances like Amazon Elastic Compute Cloud (EC2) (which, in turn, command a premium over on-premises installations). While cloud providers can and do change their pricing, the value provided by serverless is likely to continue to make serverless offerings more expensive per capacity than less flexible infrastructure.
Because cloud providers typically charge on either the basis of units of work performed (i.e., function executions) or on CPU or memory occupancy time while processing requests, it’s easy to map costs for a particular microservice to that service’s callers and up into the related application stacks. It is possible to take advantage of scaling to zero to deploy multiple copies of a microservice, one for each application, but this is typically unnecessary because it’s easy to determine a per-request cost from the cloud-provider pricing.
While mapping per-request charges to application usage works quite well for single-threaded applications with one request in-flight per instance, the billing can get somewhat more complicated with platforms like Google’s Cloud Run (or Knative), where multiple requests can be processed by an instance at once. The main benefit of the more complex execution model offered by Cloud Run or Knative is that many serverless applications end up spending a considerable amount of wall time waiting on API or service responses. Since wall time is often used as a billing metric for both memory and CPU occupancy, this can make multithreading and handling multiple requests in a single instance an attractive capability even if it makes billing somewhat harder. The efficiency gains of enabling request multiplexing can be seen in Figure 4-3, where a double-sized instance may be able to handle four times as many work units—this would be a cost savings of 50%!
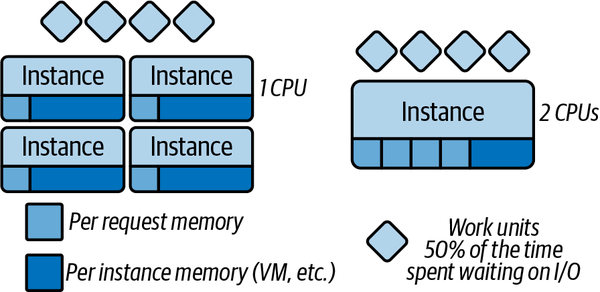
Figure 4-3. Handling multiple requests per instance
Even if you’re using a more complex multithreaded model like Knative, averaging
costs across all requests will generally work well unless you combine requests
with very different execution profiles into one microservice. One common
example is Get versus List requests—typically, the former read a
single database row, while the latter might read thousands of database rows,
possibly filtering out the results or marshaling large amounts of data.
Separating Get and List into different functions or microservices can reduce
contention between the two, but can also contribute to operational complexity
for limited value, so test before you blindly apply this advice.
One final warning: using serverless services may have hidden costs that are harder to account for in determining request costs. Here are a few examples:
- Network egress
-
Nearly every cloud provider charges separately for network bytes sent. Hopefully, your serverless platform can report the fraction of total sent bytes that are due to your serverless applications, but accounting for all this traffic can sometimes be difficult.
- Data systems
-
While a few database systems can truly call themselves “serverless,” most are still attached to a fairly fixed set of servers or a primary/replica topology. Because serverless systems generally externalize their storage, data services can be a hidden cost of serverless that is difficult to account for in your cost of goods and services.
- Multitier services
-
When an application is decomposed into multiple software layers, additional work is required to understand how the backend costs should be attributed based on frontend operations. If all the systems are serverless, distributed tracing (see “Tracing”) can provide the mapping from frontend to backend costs. If the backends are not serverless, costs can become opaque in the same way as data services.
Clouding on Your Own
There are many good reasons why you might choose to build a serverless platform on your own rather than relying on a cloud-provider offering—existing investments or cost sensitivity, missing cloud capabilities (for example, GPU support or specific feature integrations), edge and physical or regulatory computing requirements, or a desire for consistent tools across different clouds are all good reasons. Does this mean that you need to abandon the dream of serverless cost models and understanding your cost of providing services? Obviously not!
If the cloud providers can do it, it’s not magic. At most, it’s a bit complicated, but it’s possible to build your own cost model for computation—tools like Kubecost allow Kubernetes platforms to compute costs based on metrics and cloud economics around VMs, networking, and storage. With these platforms, you can use monitoring information to determine the resources used by each pod, sum them up by component (across both serverless and more serverful services), and then allot those costs to individual groups.
It’s also possible to have these tools amortize (share) the costs of the underlying platform: load balancers, node agents, monitoring, log collection, etc. all have a cost that is typically run in a multitenant fashion for the benefit of all users. These costs can be split by many policies—equal cost per application, equal cost per used compute-minute, or cost per reserved/provisioned compute-second are all reasonable approaches that have been used in practice.
Accounting for provisioned but unused capacity can be tricky in this world; physical or virtual machines that are on but are not running application code can either be apportioned as supporting platform costs or accepted by the organization as a “loss leader” to attract internal customers to the platform. In some cases, organizations can recoup some or a lot of this cost by overprovisioning (selling the same cores or memory twice, assuming some known inefficiencies) or with opportunistic work described in the next section.
What Happens When You’re Not Running
So far, we’ve talked about how serverless works for running your application, but we haven’t talked much about what happens to the servers when there’s no application work to be done. One option is simply to allow the processors to enter low-power states; this can save hundreds of watts of power on recent x86 processors. The hardware is still sitting there, and other components like RAM, disk, and add-in cards also consume nontrivial amounts of power, generating heat and load on datacenter systems like cooling, networking, and power distribution. It really feels like we should be able to do something better with that capacity. (And no, I’m not talking about mining Bitcoin!)
As I suggested in the previous section, one use for this baseline capacity is opportunistic computing. Systems like Kubernetes allow work to be scheduled at different priority levels; CPUs that are idle with high-priority tasks can allocate time slices to low-priority work while being ready to pause that work when a new high-priority task comes in.
Depending on your operational comfort, you can capitalize on this idle capacity in several ways:
- Batch computation
-
Many organizations collect large amounts of data for later analysis; this analysis is often needed “next business day” or under similarly loose time constraints. By running this work at lower priority on the same resources consumed by serverless, the batch work can be completed during times when real-time interactive demand for work is less. Batch workloads are often actually serverless as well—“map all these records” or “reduce across these combinations” are both scaled by units of work. This pattern works well for embarrassingly parallel problems, but can end up being very inefficient for batch workloads requiring each worker to directly connect to other workers. If these direct connections stall because of the sender or destination losing resources to a serverless process, it may lead to cascading stalls of hundreds of tasks.
- Build services
-
Software builds are another opportunity to parallelize work and improve development velocity. This can also extend to other compute-intensive processes such as 3D rendering or AI model training. Rather than provisioning expensive laptops and having the fans kick in and videoconferencing stutter, users can offload these tasks from their local machine onto spare capacity temporarily available between spikes of usage. This model works better for large builds or renders that may take tens of minutes to hours of time; it’s rarely worth offloading all the state for a one-minute build to the cloud.
- Development and research
-
With sufficient spare capacity and strong isolation of serverless tasks, an organization may decide to allow development teams to use the idle low-priority capacity for development environments or pet research projects. This can serve as both a perk for development teams and an opportunity for innovation within the organization.
The Gravitational Force of Serverless
Hopefully, I’ve convinced you that serverless is here to stay rather than a flash in the pan. Furthermore, the compelling advantages of serverless development will cause serverless to gain an increasing market share in the same way that minicomputers, desktop applications, web services, APIs, and cell phones have all grown market share alongside the preexisting models of application development.
If you believe that serverless will have an increasing impact on day-to-day computing and application development, then it stands to reason that other technologies will grow and evolve to better support serverless. In the same way that JavaScript became ubiquitous because of the rise of web- and browser-based applications, languages, tools, and computing infrastructure will put new pressures on computing. In turn, tools that address these challenges well will grow and flourish (for example, both Ruby on Rails and PHP were born for the web), while applications that aren’t well suited will retain their existing niches (in 40 years, we’ll still need COBOL programmers to help banks manage their mainframe applications).
Implications for Languages
Serverless’s emphasis on managing units of work connects to and externalizes two existing language patterns: inversion of control and reactive design principles. Inversion of control,2 popularized by the Spring framework, is a model in which the framework controls the flow of the program, calling application-specific code at specified times. In the reactive programming model, applications express themselves as a set of reactions to changes to upstream data sources.3 By externalizing these patterns from specific languages, serverless democratizes access to these capabilities without requiring the use of specific language frameworks or tools. For example, serverless systems are naturally elastic under varying amounts of work, and the units-of-work paradigm maps well to both “don’t call me, I’ll call you” control flows and a message-driven model of communication.
While serverless may provide scaffolding to support existing language and system design patterns, it introduces new requirements as well:
- Fast startup
-
Tying application execution to work available means that serverless systems tend to execute scaling up and down operations more frequently than traditional systems. In turn, this means that application startup (and shutdown) should both be fast and generate a low amount of load. Compiled languages and languages that have lightweight JIT processes have an advantage over languages with heavyweight JIT or module import processes that need to be run on each application start.
- Failure handling
-
Because serverless systems rely heavily on scaling based on units of work, they often employ external services to store state or as microservice boundaries. This means that applications built in a serverless style are exposed to many remote service calls, each of which may fail or time out because of networking issues.
- Network storage over disk storage
-
Local-disk storage in serverless environments tends to be highly ephemeral. Therefore, the ability to quickly access and manage files on local disk may be less important than in traditional applications, where caches or precomputed results may be stored on disk to avoid later work. At the same time, the ability to easily call network storage services and externalize state outside the serverless instance may be more important than in traditional systems—for example, the ability to easily access systems like Redis or object stores like S3 is more critical when local storage is truly ephemeral.
- Serialization
-
While all applications need to serialize and deserialize data, serverless applications may put additional weight on both the ease (for developers) and the speed and efficiency (for computers) of serializing and deserializing data. Because serverless architectures tend to be composed of microservices and backing data services that each have their own storage or network formats, the ability to efficiently and easily serialize and deserialize data across different endpoints is increasingly important.
Implications for Sandboxing
Traditional applications have used VMs and Linux containers to sandbox applications. These tools are well tested and understood but introduce substantial startup performance challenges as well as overhead for kernels, shared libraries, and network interfaces. Startup times for VMs with a general-purpose OS can be tens of seconds, while Linux containers can introduce hundreds of milliseconds of setup time.
Newer technologies like Wasm and service workers in the JavaScript runtime allow defining much more restrictive sandboxes (only a handful of custom-designed I/O methods exposed) that can spin up in ten milliseconds and have per-sandbox overheads of a megabyte or less. Platforms like Cloudflare Workers show some of the promise of this approach, though there are also substantial limitations that probably mean that all levels of sandboxing will live alongside each other for a long time.4
Implications for Tooling
The serverless paradigm is a great fit for developer tooling (and general tools for non-developers). Tools and automation generally nicely break down into units of work—building a binary, generating an API, handling a ticket, or responding to a text message. Given the size of a typical function, integration testing can be a feasible approach for much of the application coverage, rather than needing to maintain both unit and integration tests.
For developers, GitHub Actions is a great example of a serverless tooling platform. Developers can write actions that operate on a single commit, pull request, or release and don’t need to think about long-running servers, job scheduling and concurrency, or connecting platform components and services. For nondevelopers, services like IFTTT (If This Then That) that provide simple automations between packaged services offer a similar serverless experience without needing to write any code or automation scripts.
With an easy-to-operate platform for applications, tools like low-code and no-code application builders and integration platforms benefit from serverless as an underlying application substrate. As applications become less about large continuously running processes and more about small amounts of glue between existing services, low-code and serverless approaches complement each other by reducing the requirements for users to write and manage applications.
Implications for Security
Serverless processes tend to start up and shut down frequently across a pool of hosts. Instance-level security tools may struggle in a dynamic environment like this, making cluster-level tooling more important and relevant. At the same time, the ephemeral nature of serverless processes can give defenders an advantage as natural turnover of instances can erode attackers’ beachheads after the initial success of the attack.
Looking at historical trends, serverless seems likely to improve the ability of defenders to ensure consistent patching at the OS level. Consistent packaging formats such as OCI containers may also help with indexing and visibility of applications built with vulnerable libraries and data. Unfortunately, many of the high-impact security vulnerabilities tend to manifest as application-level defects like insufficient input validation, access control errors, and design errors. Serverless functionality is largely agnostic to these failures; they are equally serious for both ephemeral and persistent instances, and need to be addressed elsewhere in the software-design process.
Implications for Infrastructure
The most obvious challenges for infrastructure supporting serverless applications relate to application startup (particularly cold starts when a request is in-flight) and providing the illusion of infinite scale of capacity and speed. In addition to the language-level cold-start problems mentioned, infrastructure needs to get the application code to the cold-starting instance, and needs to handle this problem for many instances at once. Beyond startup times, serverless platforms also need to consider managing costs and efficiently provisioning and deprovisioning instances, as well as connectivity to and from the platform for all instances.
Beyond the day-to-day challenges of serverless platforms mentioned previously, a few larger challenges with serverless infrastructure have solutions that are not obvious or “do more of the same, but faster.”
One of the challenges of data processing is whether to “ship data to code” or “ship code to data.” Current serverless architectures mostly ship data to code, though improvements in sandboxing with Wasm may change that balance. While many applications are small enough that the two approaches have mostly similar overheads, most organizations have at least a few data-intensive applications for which the overhead of shipping and converting data between different formats dominates the overall cost. Being able to run these platforms in a serverless manner and derive the velocity, cost, and efficiency benefits thereof is an open problem.
Another related challenge with serverless is how to handle intertwining units of work. As long as each unit of work is independent, it is easy to understand how to scale and subdivide the problem so that different computers can work on different aspects. Unfortunately, some problems consist of a mix of easily divided work and work that synthesizes the easily divided parts into a more coherent whole. Physical simulations, stream processing, and neural network training are all examples where some work is highly independent, while other work requires tight coordination among computing components. While serverless can be used to handle the easily divided parts, having to cross platforms and paradigms to gain the benefits of serverless for only part of the solution is not very helpful. Mechanisms to bridge easily between serverless and more conventional computing patterns will help expand the range of problems that serverless can address.
Summary
Serverless is not just about making it easier to run software services. Simpler software services make new architectures feasible, which in turn allows teams and organizations to change their application development model. New ways of building applications (and new tools supporting these patterns) shift the constraints of delivering and testing software. New ways of running applications enable new business processes like evaluating the cost-per-operation and ROI of software initiatives. In the next part, we’ll see how to apply serverless to system architecture and software design to realize these benefits—but the software architecture serves the needs of the organization, not the other way around!
1 If the APIs among these components change rapidly and carelessly such that pushes between components need to be coordinated, you may have a distributed monolith. This is as much a cultural as a technical problem.
2 Sometimes described by the Hollywood principle, “Don’t call us, we’ll call you.”
3 While reactive programming doesn’t have as clear a tagline as inversion of control, it has shown impressive performance improvements compared with a traditional thread-per-request model.
4 For more details on Cloudflare Workers specifically, see Kenton Varda’s talk from QCon London in 2022: “Fine-Grained Sandboxing with V8 Isolates”.
Get Building Serverless Applications on Knative now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

