Chapter 4. Databases
4.0 Introduction
You have a myriad of choices for using databases with AWS. Installing and running a database on EC2 provides you with the most choices of database engines and custom configurations, but brings about challenges like patching, backups, configuring high-availability, replication, and performance tuning. As noted on its product page, AWS offers managed database services that help address these challenges and cover a broad range of database types (relational, key-value/NoSQL, in-memory, document, wide column, graph, time series, ledger). When choosing a database type and data model, you must keep speed, volume, and access patterns in mind.
The managed database services on AWS integrate with many services to provide you additional functionality from security, operations, and development perspectives. In this chapter, you will explore Amazon Relational Database Service (RDS), NoSQL usage with Amazon DynamoDB, and the ways to migrate, secure, and operate these database types at scale. For example, you will learn how to integrate Secrets Manager with an RDS database to automatically rotate database user passwords. You will also learn how to leverage IAM authentication to reduce the application dependency on database passwords entirely, granting access to RDS through IAM permissions instead. You’ll explore autoscaling with DynamoDB and learn about why this is important from a cost and performance perspective.
Note
Some people think that Route 53 is a database but we disagree :-)
Note
Some database engines in the past have used certain terminology for replica configurations, default root user names, primary tables, etc. We took care to use inclusive terminology throughout this chapter (and the whole book) wherever possible. We support the movement to use inclusive terminology in these commercial and open source database engines.
Workstation Configuration
Follow the “General workstation setup steps for CLI recipes” to validate your configuration and set up the required environment variables. Then, clone the chapter code repository:
git clone https://github.com/AWSCookbook/Databases
Warning
During some of the steps in this chapter, you will create passwords and temporarily save them as environment variables to use in subsequent steps. Make sure that you unset the environment variables by following the cleanup steps when you complete the recipe. We use this approach for simplicity of understanding. A more secure method (such as the method used in Recipe 1.8) should be used in production environments.
4.1 Creating an Amazon Aurora Serverless PostgreSQL Database
Problem
You have a web application that receives unpredictable requests that require storage in a relational database. You need a database solution that can scale with usage and be cost-effective. You would like to build a solution that has low operational overhead and must be compatible with your existing PostgreSQL-backed application.
Solution
Configure and create an Aurora Serverless database cluster with a complex password. Then, apply a customized scaling configuration and enable automatic pause after inactivity. The scaling activity in response to the policy is shown in Figure 4-1.
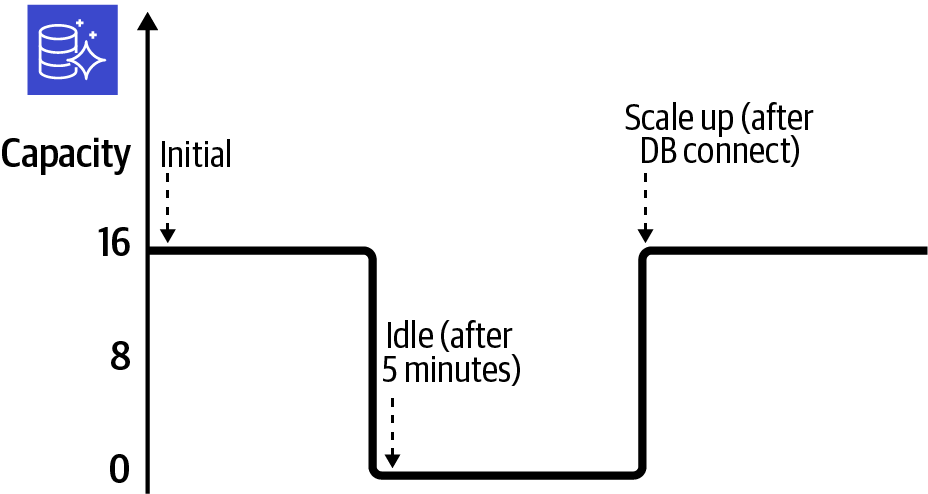
Figure 4-1. Aurora Serverless cluster scaling compute
Prerequisites
-
VPC with isolated subnets created in two AZs and associated route tables.
-
EC2 instance deployed. You will need the ability to connect to this for testing.
Preparation
Follow the steps in this recipe’s folder in the chapter code repository.
Steps
-
Use AWS Secrets Manager to generate a complex password:
ADMIN_PASSWORD=$(aws secretsmanager get-random-password \ --exclude-punctuation \ --password-length 41 --require-each-included-type \ --output text \ --query RandomPassword)Note
We are excluding punctuation characters from the password that we are creating because PostgreSQL does not support them. See the “Naming constraints in Amazon RDS” table.
-
Create a database subnet group specifying the VPC subnets to use for the cluster. Database subnet groups simplify the placement of RDS elastic network interfaces (ENIs):
aws rds create-db-subnet-group \ --db-subnet-group-name awscookbook401subnetgroup \ --db-subnet-group-description "AWSCookbook401 subnet group" \ --subnet-ids $SUBNET_ID_1 $SUBNET_ID_2You should see output similar to the following:
{ "DBSubnetGroup": { "DBSubnetGroupName": "awscookbook402subnetgroup", "DBSubnetGroupDescription": "AWSCookbook401 subnet group", "VpcId": "vpc-<<VPCID>>", "SubnetGroupStatus": "Complete", "Subnets": [ { "SubnetIdentifier": "subnet-<<SUBNETID>>", "SubnetAvailabilityZone": { "Name": "us-east-1b" }, "SubnetOutpost": {}, "SubnetStatus": "Active" }, ... -
Create a VPC security group for the database:
DB_SECURITY_GROUP_ID=$(aws ec2 create-security-group \ --group-name AWSCookbook401sg \ --description "Aurora Serverless Security Group" \ --vpc-id $VPC_ID --output text --query GroupId) -
Create a database cluster, specifying an
engine-modeofserverless:aws rds create-db-cluster \ --db-cluster-identifier awscookbook401dbcluster \ --engine aurora-postgresql \ --engine-mode serverless \ --engine-version 10.14 \ --master-username dbadmin \ --master-user-password $ADMIN_PASSWORD \ --db-subnet-group-name awscookbook401subnetgroup \ --vpc-security-group-ids $DB_SECURITY_GROUP_IDYou should see output similar to the following:
{ "DBCluster": { "AllocatedStorage": 1, "AvailabilityZones": [ "us-east-1f", "us-east-1b", "us-east-1a" ], "BackupRetentionPeriod": 1, "DBClusterIdentifier": "awscookbook401dbcluster", "DBClusterParameterGroup": "default.aurora-postgresql10", "DBSubnetGroup": "awscookbook401subnetgroup", "Status": "creating", ... -
Wait for the Status to read available; this will take a few moments:
aws rds describe-db-clusters \ --db-cluster-identifier awscookbook401dbcluster \ --output text --query DBClusters[0].Status -
Modify the database to automatically scale with new autoscaling capacity targets (8 min, 16 max) and enable
AutoPauseafter five minutes of inactivity:aws rds modify-db-cluster \ --db-cluster-identifier awscookbook401dbcluster --scaling-configuration \ MinCapacity=8,MaxCapacity=16,SecondsUntilAutoPause=300,TimeoutAction='ForceApplyCapacityChange',AutoPause=trueYou should see output similar to what you saw for step 4.
Note
In practice, you may want to use a different
AutoPausevalue. To determine what is appropriate for your use, evaluate your performance needs and Aurora pricing.Wait at least five minutes and observe that the database’s capacity has scaled down to 0:
aws rds describe-db-clusters \ --db-cluster-identifier awscookbook401dbcluster \ --output text --query DBClusters[0].Capacity -
Grant your EC2 instance’s security group access to the default PostgreSQL port:
aws ec2 authorize-security-group-ingress \ --protocol tcp --port 5432 \ --source-group $INSTANCE_SG \ --group-id $DB_SECURITY_GROUP_IDYou should see output similar to the following:
{ "Return": true, "SecurityGroupRules": [ { "SecurityGroupRuleId": "sgr-<<ID>>", "GroupId": "sg-<<ID>>", "GroupOwnerId": "111111111111", "IsEgress": false, "IpProtocol": "tcp", "FromPort": 5432, "ToPort": 5432, "ReferencedGroupInfo": { "GroupId": "sg-<<ID>>" } } ] }
Validation checks
List the endpoint for the RDS cluster:
aws rds describe-db-clusters \
--db-cluster-identifier awscookbook401dbcluster \
--output text --query DBClusters[0].Endpoint
You should see something similar to this:
awscookbook401dbcluster.cluster-<<unique>>.us-east-1.rds.amazonaws.com
Retrieve the password for your RDS cluster:
echo $ADMIN_PASSWORD
Connect to the EC2 instance by using SSM Session Manager (see Recipe 1.6):
aws ssm start-session --target $INSTANCE_ID
Install the PostgreSQL package so you can use the psql command to connect to the database:
sudo yum -y install postgresql
Connect to the database. This may take a moment as the database capacity is scaling up from 0. You’ll need to copy and paste the password (outputted previously):
psql -h $HOST_NAME -U dbadmin -W -d postgres
Here is an example of connecting to a database using the psql command:
sh-4.2$ psql -h awscookbook401dbcluster.cluster-<<unique>>.us-east-1.rds.amazonaws.com -U dbadmin -W -d postgres Password for user dbadmin:(paste in the password)
Quit psql:
\q
Exit the Session Manager session:
exit
Check the capacity of the cluster again to observe that the database has scaled up to the minimum value that you configured:
aws rds describe-db-clusters \
--db-cluster-identifier awscookbook401dbcluster \
--output text --query DBClusters[0].Capacity
Cleanup
Follow the steps in this recipe’s folder in the chapter code repository.
Tip
The default behavior of deleting an RDS cluster is to take a final snapshot as a safety mechanism. We chose to skip this behavior by adding the --skip-final-snapshot option to ensure you do not incur any costs for storing the snapshot in your AWS account. In a real-world scenario, you would likely want to retain the snapshot for a period of time in case you needed to re-create the existing database from the snapshot.
Discussion
The cluster will automatically scale capacity to meet the needs of your usage. Setting MaxCapacity=16 limits the upper bound of your capacity to prevent runaway usage and unexpected costs. The cluster will set its capacity to 0 when no connection or activity is detected. This is triggered when the SecondsUntilAutoPause value is reached.
When you enable AutoPause=true for your cluster, you pay for only the underlying storage during idle times. The default (and minimum) “inactivity period” is five minutes. Connecting to a paused cluster will cause the capacity to scale up to MinCapacity.
Warning
Not all database engines and versions are available with the serverless engine. At the time of writing, the Aurora FAQ states that Aurora Serverless is currently available for Aurora with MySQL 5.6 compatibility and for Aurora with PostgreSQL 10.7+ compatibility.
The user guide states that Aurora Serverless scaling is measured in capacity units (CUs) that correspond to compute and memory reserved for your cluster. This capability is a good fit for many workloads and use cases from development to batch-based workloads, and production workloads where traffic is unpredictable and costs associated with potential over-provisioning are a concern. By not needing to calculate baseline usage patterns, you can start developing quickly, and the cluster will automatically respond to the demand that your application requires.
If you currently use a “provisioned” capacity type cluster on Amazon RDS and would like to start using Aurora Serverless, you can snapshot your current database and restore it from within the AWS Console or from the command line to perform a migration. If your current database is not on RDS, you can use your database engine’s dump and restore features or use the AWS Database Migration Service (AWS DMS) to migrate to RDS.
Note
At the time of this writing, Amazon Aurora Serverless v2 is in preview.
The user guide mentions that Aurora Serverless further builds on the existing Aurora platform, which replicates your database’s underlying storage six ways across three Availability Zones. While this replication is a benefit for resiliency, you should still use automated backups for your database to guard against operational errors. Aurora Serverless has automated backups enabled by default, and the backup retention can be increased up to 35 days if needed.
Note
Per the documentation, if your database cluster has been idle for more than seven days, the cluster will be backed up with a snapshot. If this occurs, the database cluster is restored when there is a request to connect to it.
4.2 Using IAM Authentication with an RDS Database
Solution
First you will enable IAM authentication for your database. You will then configure the IAM permissions for the EC2 instance to use. Finally, create a new user on the database, retrieve the IAM authentication token, and verify connectivity (see Figure 4-2).
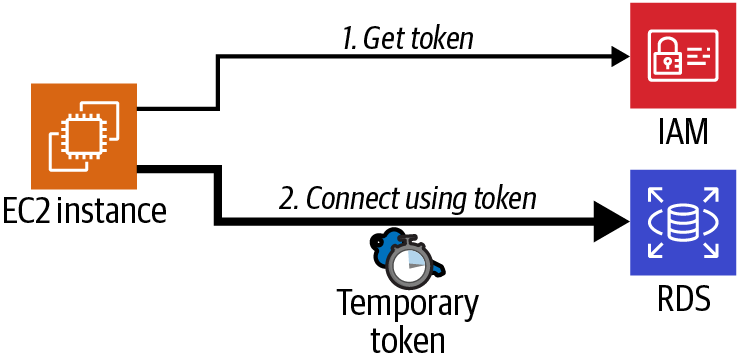
Figure 4-2. IAM authentication from an EC2 instance to an RDS database
Prerequisites
-
VPC with isolated subnets created in two AZs and associated route tables.
-
An RDS MySQL instance.
-
EC2 instance deployed. You will need the ability to connect to this for configuring MySQL and testing.
Preparation
Follow the steps in this recipe’s folder in the chapter code repository.
Steps
-
Enable IAM database authentication on the RDS database instance:
aws rds modify-db-instance \ --db-instance-identifier $RDS_DATABASE_ID \ --enable-iam-database-authentication \ --apply-immediatelyYou should see output similar to the following:
{ "DBInstance": { "DBInstanceIdentifier": "awscookbookrecipe402", "DBInstanceClass": "db.m5.large", "Engine": "mysql", "DBInstanceStatus": "available", "MasterUsername": "admin", "DBName": "AWSCookbookRecipe402", "Endpoint": { "Address": "awscookbookrecipe402.<<ID>>.us-east-1.rds.amazonaws.com", "Port": 3306, "HostedZoneId": "<<ID>>" }, ...Warning
IAM database authentication is available for only the database engines listed in this AWS article.
-
Retrieve the RDS database instance resource ID:
DB_RESOURCE_ID=$(aws rds describe-db-instances \ --query \ 'DBInstances[?DBName==`AWSCookbookRecipe402`].DbiResourceId' \ --output text) -
Create a file called policy.json with the following content (a policy-template.json file is provided in the repository):
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "rds-db:connect" ], "Resource": [ "arn:aws:rds-db:AWS_REGION:AWS_ACCOUNT_ID:dbuser:DBResourceId/db_user" ] } ] }Note
In the preceding example,
db_usermust match the name of the user in the database that we would like to allow to connect. -
Replace the values in the template file by using the
sedcommand with environment variables you have set:sed -e "s/AWS_ACCOUNT_ID/${AWS_ACCOUNT_ID}/g" \ -e "s|AWS_REGION|${AWS_REGION}|g" \ -e "s|DBResourceId|${DB_RESOURCE_ID}|g" \ policy-template.json > policy.json -
Create an IAM policy using the file you just created:
aws iam create-policy --policy-name AWSCookbook402EC2RDSPolicy \ --policy-document file://policy.jsonYou should see output similar to the following:
{ "Policy": { "PolicyName": "AWSCookbook402EC2RDSPolicy", "PolicyId": "<<ID>>", "Arn": "arn:aws:iam::111111111111:policy/AWSCookbook402EC2RDSPolicy", "Path": "/", "DefaultVersionId": "v1", "AttachmentCount": 0, "PermissionsBoundaryUsageCount": 0, "IsAttachable": true, "CreateDate": "2021-09-21T21:18:54+00:00", "UpdateDate": "2021-09-21T21:18:54+00:00" } } -
Attach the IAM policy
AWSCookbook402EC2RDSPolicyto the IAM role that the EC2 is using:aws iam attach-role-policy --role-name $INSTANCE_ROLE_NAME \ --policy-arn arn:aws:iam::$AWS_ACCOUNT_ID:policy/AWSCookbook402EC2RDSPolicy -
Retrieve the RDS admin password from Secrets Manager:
RDS_ADMIN_PASSWORD=$(aws secretsmanager get-secret-value \ --secret-id $RDS_SECRET_ARN \ --query SecretString | jq -r | jq .password | tr -d '"') -
Output text so that you can use it later when you connect to the EC2 instance.
List the endpoint for the RDS cluster:
echo $RDS_ENDPOINT
You should see output similar to the following:
awscookbookrecipe402.<<unique>>.us-east-1.rds.amazonaws.com
List the password for the RDS cluster:
echo $RDS_ADMIN_PASSWORD
-
Connect to the EC2 instance using SSM Session Manager (see Recipe 1.6):
aws ssm start-session --target $INSTANCE_ID
-
Install MySQL:
sudo yum -y install mysql
-
Connect to the database. You’ll need to copy and paste the password and hostname (outputted in steps 7 and 8):
mysql -u admin -p$DB_ADMIN_PASSWORD -h $RDS_ENDPOINT
You should see output similar to the following:
Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 18 Server version: 8.0.23 Source distribution Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]>
Note
In the
mysqlcommand in step 11, there is no space between the-pflag and the first character of the password. -
Create a new database user to associate with the IAM authentication:
CREATE USER db_user@'%' IDENTIFIED WITH AWSAuthenticationPlugin as 'RDS'; GRANT SELECT ON *.* TO 'db_user'@'%';
For both commands in step 12, you should see output similar to the following:
Query OK, 0 rows affected (0.01 sec)
-
Now, exit the
mysqlprompt:quit
Validation checks
While still on the EC2 instance, download the RDS Root CA (certificate authority) file provided by Amazon from the rds-downloads S3 bucket:
sudo wget https://s3.amazonaws.com/rds-downloads/rds-ca-2019-root.pem
Set the Region by grabbing the value from the instance’s metadata:
export AWS_DEFAULT_REGION=$(curl --silent http://169.254.169.254/latest/dynamic/instance-identity/document \
| awk -F'"' ' /region/ {print $4}')
Generate the RDS authentication token and save it as a variable. You’ll need to copy and paste the hostname (outputted in step 8):
TOKEN="$(aws rds generate-db-auth-token --hostname $RDS_ENDPOINT --port 3306 --username db_user)"
Connect to the database using the RDS authentication token with the new db_user. You’ll need to copy and paste the hostname (outputted in step 8):
mysql --host=$RDS_ENDPOINT --port=3306 \
--ssl-ca=rds-ca-2019-root.pem \
--user=db_user --password=$TOKEN
Run a SELECT query at the mysql prompt to verify that this user has the SELECT *.* grant that you applied:
SELECT user FROM mysql.user;
You should see output similar to the following:
MySQL [(none)]> SELECT user FROM mysql.user; +------------------+ | user | +------------------+ | admin | | db_user | | mysql.infoschema | | mysql.session | | mysql.sys | | rdsadmin | +------------------+ 6 rows in set (0.00 sec)
Exit the mysql prompt:
quit
Exit the Session Manager session:
exit
Cleanup
Follow the steps in this recipe’s folder in the chapter code repository.
Discussion
Instead of a password in your MySQL connection string, you retrieved and used a token associated with the EC2 instance’s IAM role. The documentation for IAM states that this token lasts for 15 minutes. If you install an application on this EC2 instance, the code can regularly refresh this token using the AWS SDK. There is no need to rotate passwords for your database user because the old token will be invalidated after 15 minutes.
You can create multiple database users associated with specific grants to allow your application to maintain different levels of access to your database. The grants happen within the database, not within the IAM permissions. IAM controls the db-connect action for the specific user. This IAM action allows the authentication token to be retrieved. That username is mapped from IAM to the GRANT(s) by using the same username within the database as in the policy.json file:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"rds-db:connect"
],
"Resource": [
"arn:aws:rds-db:AWS_REGION::dbuser:DBResourceId/db_user"
]
}
]
}
In this recipe, you also enabled encryption in transit by specifying the SSL certificate bundle that you downloaded to the EC2 instance in your database connection command. This encrypts the connection between your application and your database. This is a good security practice and is often required for many compliance standards. The connection string you used to connect with the IAM authentication token indicated an SSL certificate as one of the connection parameters. The certificate authority bundle is available to download from AWS and use within your application.
4.3 Leveraging RDS Proxy for Database Connections from Lambda
Solution
Create an RDS Proxy, associate it with your RDS MySQL database, and configure your Lambda to connect to the proxy instead of accessing the database directly (see Figure 4-3).
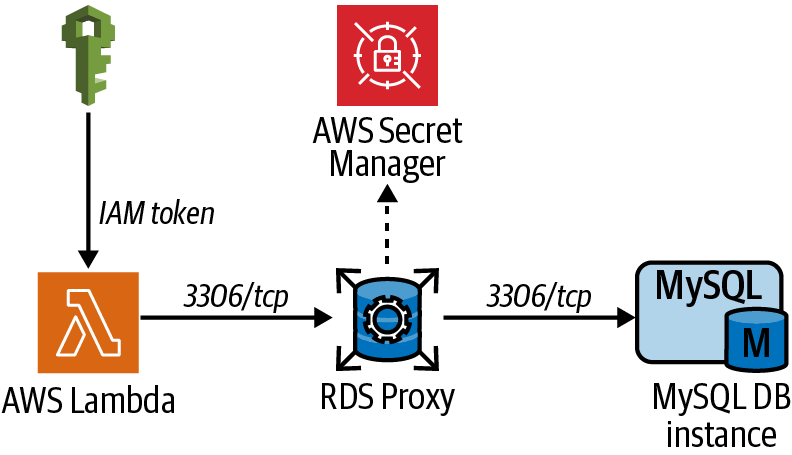
Figure 4-3. Lambda connection path to database via RDS Proxy
Prerequisites
-
VPC with isolated subnets created in two AZs and associated route tables
-
An RDS MySQL instance
-
A Lambda function that you would like to connect to your RDS database
Preparation
Follow the steps in this recipe’s folder in the chapter code repository.
Steps
-
Create a file called assume-role-policy.json with the following content (file provided in the repository):
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "rds.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } -
Create an IAM role for the RDS Proxy using the assume-role-policy.json file:
aws iam create-role --assume-role-policy-document \ file://assume-role-policy.json --role-name AWSCookbook403RDSProxyYou should see output similar to the following:
{ "Role": { "Path": "/", "RoleName": "AWSCookbook403RDSProxy", "RoleId": "<<ID>>", "Arn": "arn:aws:iam::111111111111:role/AWSCookbook403RDSProxy", "CreateDate": "2021-09-21T22:33:57+00:00", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "rds.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } } } -
Create a security group to be used by the RDS Proxy:
RDS_PROXY_SG_ID=$(aws ec2 create-security-group \ --group-name AWSCookbook403RDSProxySG \ --description "Lambda Security Group" --vpc-id $VPC_ID \ --output text --query GroupId) -
Create the RDS Proxy. This will take a few moments:
RDS_PROXY_ENDPOINT_ARN=$(aws rds create-db-proxy \ --db-proxy-name $DB_NAME \ --engine-family MYSQL \ --auth '{ "AuthScheme": "SECRETS", "SecretArn": "'"$RDS_SECRET_ARN"'", "IAMAuth": "REQUIRED" }' \ --role-arn arn:aws:iam::$AWS_ACCOUNT_ID:role/AWSCookbook403RDSProxy \ --vpc-subnet-ids $ISOLATED_SUBNETS \ --vpc-security-group-ids $RDS_PROXY_SG_ID \ --require-tls --output text \ --query DBProxy.DBProxyArn)Wait for the RDS Proxy to become available:
aws rds describe-db-proxies \ --db-proxy-name $DB_NAME \ --query DBProxies[0].Status \ --output text -
Retrieve the
RDS_PROXY_ENDPOINT:RDS_PROXY_ENDPOINT=$(aws rds describe-db-proxies \ --db-proxy-name $DB_NAME \ --query DBProxies[0].Endpoint \ --output text) -
Next you need an IAM policy that allows the Lambda function to generate IAM authentication tokens. Create a file called template-policy.json with the following content (file provided in the repository):
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "rds-db:connect" ], "Resource": [ "arn:aws:rds-db:AWS_REGION:AWS_ACCOUNT_ID:dbuser:RDSProxyID/admin" ] } ] } -
Separate out the Proxy ID from the RDS Proxy endpoint ARN. The Proxy ID is required for configuring IAM policies in the following steps:
RDS_PROXY_ID=$(echo $RDS_PROXY_ENDPOINT_ARN | awk -F: '{ print $7} ') -
Replace the values in the template file by using the
sedcommand with environment variables you have set:sed -e "s/AWS_ACCOUNT_ID/${AWS_ACCOUNT_ID}/g" \ -e "s|AWS_REGION|${AWS_REGION}|g" \ -e "s|RDSProxyID|${RDS_PROXY_ID}|g" \ policy-template.json > policy.json -
Create an IAM policy using the file you just created:
aws iam create-policy --policy-name AWSCookbook403RdsIamPolicy \ --policy-document file://policy.jsonYou should see output similar to the following:
{ "Policy": { "PolicyName": "AWSCookbook403RdsIamPolicy", "PolicyId": "<<Id>>", "Arn": "arn:aws:iam::111111111111:policy/AWSCookbook403RdsIamPolicy", "Path": "/", "DefaultVersionId": "v1", "AttachmentCount": 0, "PermissionsBoundaryUsageCount": 0, "IsAttachable": true, "CreateDate": "2021-09-21T22:50:24+00:00", "UpdateDate": "2021-09-21T22:50:24+00:00" } } -
Attach the policy to the DBAppFunction Lambda function’s role:
aws iam attach-role-policy --role-name $DB_APP_FUNCTION_ROLE_NAME \ --policy-arn arn:aws:iam::$AWS_ACCOUNT_ID:policy/AWSCookbook403RdsIamPolicyUse this command to check when the proxy enters the available status and then proceed:
aws rds describe-db-proxies --db-proxy-name $DB_NAME \ --query DBProxies[0].Status \ --output text -
Attach the
SecretsManagerReadWritepolicy to the RDS Proxy’s role:aws iam attach-role-policy --role-name AWSCookbook403RDSProxy \ --policy-arn arn:aws:iam::aws:policy/SecretsManagerReadWriteTip
In a production scenario, you would want to scope this permission down to the minimal secret resources that your application needs to access, rather than grant
SecretsManagerReadWrite, which allows read/write for all secrets. -
Add an ingress rule to the RDS instance’s security group that allows access on TCP port 3306 (the default MySQL engine TCP port) from the RDS Proxy security group:
aws ec2 authorize-security-group-ingress \ --protocol tcp --port 3306 \ --source-group $RDS_PROXY_SG_ID \ --group-id $RDS_SECURITY_GROUPYou should see output similar to the following:
{ "Return": true, "SecurityGroupRules": [ { "SecurityGroupRuleId": "sgr-<<ID>>", "GroupId": "sg-<<ID>>", "GroupOwnerId": "111111111111", "IsEgress": false, "IpProtocol": "tcp", "FromPort": 3306, "ToPort": 3306, "ReferencedGroupInfo": { "GroupId": "sg-<<ID>>" } } ] }Note
Security groups can reference other security groups. Because of dynamic IP addresses within VPCs, this is considered the best way to grant access without opening up your security group too wide. For more information, see Recipe 2.5.
-
Register targets with the RDS Proxy:
aws rds register-db-proxy-targets \ --db-proxy-name $DB_NAME \ --db-instance-identifiers $RDS_DATABASE_IDYou should see output similar to the following:
{ "DBProxyTargets": [ { "Endpoint": "awscookbook403db.<<ID>>.us-east-1.rds.amazonaws.com", "RdsResourceId": "awscookbook403db", "Port": 3306, "Type": "RDS_INSTANCE", "TargetHealth": { "State": "REGISTERING" } } ] }Check the status of the target registration with this command. Wait until the State reaches AVAILABLE:
aws rds describe-db-proxy-targets \ --db-proxy-name awscookbookrecipe403 \ --query Targets[0].TargetHealth.State \ --output text -
Add an ingress rule to the RDS Proxy security group that allows access on TCP port 3306 from the Lambda App function’s security group:
aws ec2 authorize-security-group-ingress \ --protocol tcp --port 3306 \ --source-group $DB_APP_FUNCTION_SG_ID \ --group-id $RDS_PROXY_SG_IDYou should see output similar to the following:
{ "Return": true, "SecurityGroupRules": [ { "SecurityGroupRuleId": "sgr-<<ID>>", "GroupId": "sg-<<ID>>", "GroupOwnerId": "111111111111", "IsEgress": false, "IpProtocol": "tcp", "FromPort": 3306, "ToPort": 3306, "ReferencedGroupInfo": { "GroupId": "sg-<<ID>>" } } ] } -
Modify the Lambda function to now use the RDS Proxy endpoint as the
DB_HOST, instead of connecting directly to the database:aws lambda update-function-configuration \ --function-name $DB_APP_FUNCTION_NAME \ --environment Variables={DB_HOST=$RDS_PROXY_ENDPOINT}You should see output similar to the following:
{ "FunctionName": "cdk-aws-cookbook-403-LambdaApp<<ID>>", "FunctionArn": "arn:aws:lambda:us-east-1:111111111111:function:cdk-aws-cookbook-403-LambdaApp<<ID>>", "Runtime": "python3.8", "Role": "arn:aws:iam::111111111111:role/cdk-aws-cookbook-403-LambdaAppServiceRole<<ID>>", "Handler": "lambda_function.lambda_handler", "CodeSize": 665, "Description": "", "Timeout": 600, "MemorySize": 1024, ...
Validation checks
Run the Lambda function with this command to validate that the function can connect to RDS using your RDS Proxy:
aws lambda invoke \
--function-name $DB_APP_FUNCTION_NAME \
response.json && cat response.json
You should see output similar to the following:
{
"StatusCode": 200,
"ExecutedVersion": "$LATEST"
}
"Successfully connected to RDS via RDS Proxy!"
Cleanup
Follow the steps in this recipe’s folder in the chapter code repository.
Discussion
Connection pooling is important to consider when you use Lambda with RDS. Since the function could be executed with a lot of concurrency and frequency depending on your application, the number of raw connections to your database can grow and impact performance. By using RDS Proxy to manage the connections to the database, fewer connections are needed to the actual database. This setup increases performance and efficiency.
Without RDS Proxy, a Lambda function might establish a new connection to the database each time the function is invoked. This behavior depends on the execution environment, runtimes (Python, NodeJS, Go, etc.), and the way you instantiate connections to the database from the function code. In cases with large amounts of function concurrency, this could result in large amounts of TCP connections to your database, reducing database performance and increasing latency. Per the documentation, RDS Proxy helps manage the connections from Lambda by managing them as a “pool,” so that as concurrency increases, RDS Proxy increases the actual connections to the database only as needed, offloading the TCP overhead to RDS Proxy.
SSL encryption in transit is supported by RDS Proxy when you include the certificate bundle provided by AWS in your database connection string. RDS Proxy supports MySQL and PostgreSQL RDS databases. For a complete listing of all supported database engines and versions, see this support document.
Tip
You can also architect to be efficient with short-lived database connections by leveraging the RDS Data API within your application, which leverages a REST API exposed by Amazon RDS. For an example on the RDS Data API, see Recipe 4.8.
4.4 Encrypting the Storage of an Existing Amazon RDS for MySQL Database
Solution
Create a read replica of your existing database, take a snapshot of the read replica, copy the snapshot to an encrypted snapshot, and restore the encrypted snapshot to a new encrypted database, as shown in Figure 4-4.
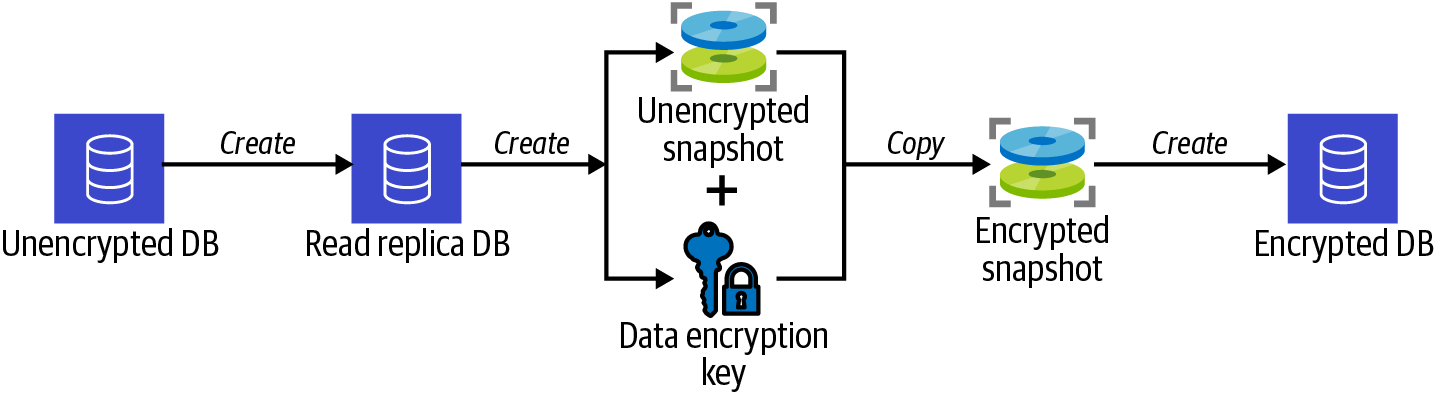
Figure 4-4. Process of encrypting an RDS database using a snapshot
Prerequisites
-
VPC with isolated subnets created in two AZs and associated route tables
-
An RDS MySQL instance with an RDS subnet group
Preparation
Follow the steps in this recipe’s folder in the chapter code repository.
Steps
-
Verify that the storage for the database is not encrypted:
aws rds describe-db-instances \ --db-instance-identifier $RDS_DATABASE_ID \ --query DBInstances[0].StorageEncryptedYou should see
falseoutputted. -
Create a KMS key to use to encrypt your database snapshot later. Store the key ID in an environment variable:
KEY_ID=$(aws kms create-key \ --tags TagKey=Name,TagValue=AWSCookbook404RDS \ --description "AWSCookbook RDS Key" \ --query KeyMetadata.KeyId \ --output text) -
Create an alias to easily reference the key that you created:
aws kms create-alias \ --alias-name alias/awscookbook404 \ --target-key-id $KEY_ID -
Create a read replica of your existing unencrypted database:
aws rds create-db-instance-read-replica \ --db-instance-identifier awscookbook404db-rep \ --source-db-instance-identifier $RDS_DATABASE_ID \ --max-allocated-storage 10You should see output similar to the following:
{ "DBInstance": { "DBInstanceIdentifier": "awscookbook404db-rep", "DBInstanceClass": "db.m5.large", "Engine": "mysql", "DBInstanceStatus": "creating", "MasterUsername": "admin", "DBName": "AWSCookbookRecipe404", "AllocatedStorage": 8, "PreferredBackupWindow": "05:51-06:21", "BackupRetentionPeriod": 0, "DBSecurityGroups": [], ...Note
By creating a read replica, you allow the snapshot to be created from it and therefore not affect the performance of the primary database.
Wait for the
DBInstanceStatusto become “available”:aws rds describe-db-instances \ --db-instance-identifier awscookbook404db-rep \ --output text --query DBInstances[0].DBInstanceStatus -
Take an unencrypted snapshot of your read replica:
aws rds create-db-snapshot \ --db-instance-identifier awscookbook404db-rep \ --db-snapshot-identifier awscookbook404-snapshotYou should see output similar to the following:
{ "DBSnapshot": { "DBSnapshotIdentifier": "awscookbook404-snapshot", "DBInstanceIdentifier": "awscookbook404db-rep", "Engine": "mysql", "AllocatedStorage": 8, "Status": "creating", "Port": 3306, "AvailabilityZone": "us-east-1b", "VpcId": "vpc-<<ID>>", "InstanceCreateTime": "2021-09-21T22:46:07.785000+00:00",Wait for the
Statusof the snapshot to become available:aws rds describe-db-snapshots \ --db-snapshot-identifier awscookbook404-snapshot \ --output text --query DBSnapshots[0].Status -
Copy the unencrypted snapshot to a new snapshot while encrypting by specifying your KMS key:
aws rds copy-db-snapshot \ --copy-tags \ --source-db-snapshot-identifier awscookbook404-snapshot \ --target-db-snapshot-identifier awscookbook404-snapshot-enc \ --kms-key-id alias/awscookbook404
You should see output similar to the following:
{ "DBSnapshot": { "DBSnapshotIdentifier": "awscookbook404-snapshot-enc", "DBInstanceIdentifier": "awscookbook404db-rep", "Engine": "mysql", "AllocatedStorage": 8, "Status": "creating", "Port": 3306, "AvailabilityZone": "us-east-1b", "VpcId": "vpc-<<ID>>", "InstanceCreateTime": "2021-09-21T22:46:07.785000+00:00", "MasterUsername": "admin", ...Tip
Specifying a KMS key with the
copy-snapshotcommand encrypts the copied snapshot. Restoring an encrypted snapshot to a new database results in an encrypted database.Wait for the
Statusof the encrypted snapshot to become available:aws rds describe-db-snapshots \ --db-snapshot-identifier awscookbook404-snapshot-enc \ --output text --query DBSnapshots[0].Status -
Restore the encrypted snapshot to a new RDS instance:
aws rds restore-db-instance-from-db-snapshot \ --db-subnet-group-name $RDS_SUBNET_GROUP \ --db-instance-identifier awscookbook404db-enc \ --db-snapshot-identifier awscookbook404-snapshot-encYou should see output similar to the following:
{ "DBInstance": { "DBInstanceIdentifier": "awscookbook404db-enc", "DBInstanceClass": "db.m5.large", "Engine": "mysql", "DBInstanceStatus": "creating", "MasterUsername": "admin", "DBName": "AWSCookbookRecipe404", "AllocatedStorage": 8, ...
Validation checks
Wait for DBInstanceStatus to become available:
aws rds describe-db-instances \
--db-instance-identifier awscookbook404db-enc \
--output text --query DBInstances[0].DBInstanceStatus
Verify that the storage is now encrypted:
aws rds describe-db-instances \
--db-instance-identifier awscookbook404db-enc \
--query DBInstances[0].StorageEncrypted
You should see true outputted.
Cleanup
Follow the steps in this recipe’s folder in the chapter code repository.
Discussion
When you complete the steps, you need to reconfigure your application to point to a new database endpoint hostname. To perform this with minimal downtime, you can configure a Route 53 DNS record that points to your database endpoint. Your application would be configured to use the DNS record. Then you would shift your database traffic over to the new encrypted database by updating the DNS record with the new database endpoint DNS.
Encryption at rest is a security approach left up to end users in the AWS shared responsibility model, and often it is required to achieve or maintain compliance with regulatory standards. The encrypted snapshot you took could also be automatically copied to another Region, as well as exported to S3 for archival/backup purposes.
Challenge
Create an RDS database from scratch that initially has encrypted storage and migrate your data from your existing database to the new database using AWS DMS, as shown in Recipe 4.7.
4.5 Automating Password Rotation for RDS Databases
Solution
Create a password and place it in AWS Secrets Manager. Configure a rotation interval for the secret containing the password. Finally, create a Lambda function using AWS-provided code, and configure the function to perform the password rotation. This configuration allows the password rotation automation to perform as shown in Figure 4-5.
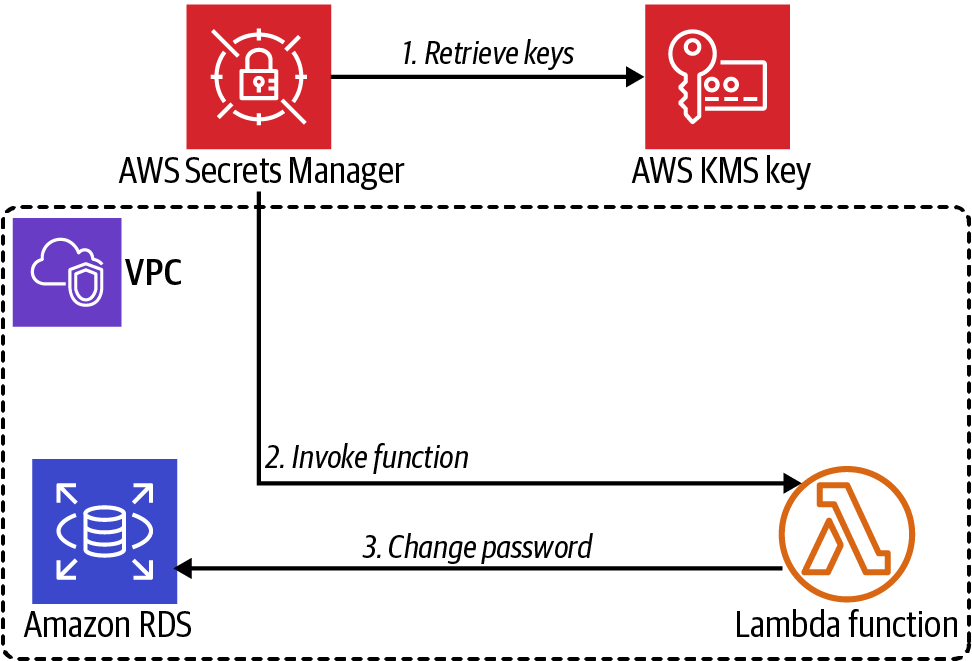
Figure 4-5. Secrets Manager Lambda function integration
Prerequisites
-
VPC with isolated subnets created in two AZs and associated route tables.
-
MySQL RDS instance and EC2 instance deployed. You will need the ability to connect to these for testing.
Preparation
Follow the steps in this recipe’s folder in the chapter code repository.
Steps
-
Use AWS Secrets Manager to generate a password that meets RDS requirements:
RDS_ADMIN_PASSWORD=$(aws secretsmanager get-random-password \ --exclude-punctuation \ --password-length 41 --require-each-included-type \ --output text --query RandomPassword)Tip
You can call the Secrets Manager GetRandomPassword API method to generate random strings of characters for various uses beyond password generation.
-
Change the admin password for your RDS database to the one you just created:
aws rds modify-db-instance \ --db-instance-identifier $RDS_DATABASE_ID \ --master-user-password $RDS_ADMIN_PASSWORD \ --apply-immediatelyYou should see output similar to the following:
{ "DBInstance": { "DBInstanceIdentifier": "awscookbook405db", "DBInstanceClass": "db.m5.large", "Engine": "mysql", "DBInstanceStatus": "available", "MasterUsername": "admin", "DBName": "AWSCookbookRecipe405", ... -
Create a file with the following content called rdscreds-template.json (file provided in the repository):
{ "username": "admin", "password": "PASSWORD", "engine": "mysql", "host": "HOST", "port": 3306, "dbname": "DBNAME", "dbInstanceIdentifier": "DBIDENTIFIER" } -
Use
sedto modify the values in rdscreds-template.json to create rdscreds.json:sed -e "s/AWS_ACCOUNT_ID/${AWS_ACCOUNT_ID}/g" \ -e "s|PASSWORD|${RDS_ADMIN_PASSWORD}|g" \ -e "s|HOST|${RdsEndpoint}|g" \ -e "s|DBNAME|${DbName}|g" \ -e "s|DBIDENTIFIER|${RdsDatabaseId}|g" \ rdscreds-template.json > rdscreds.json -
Download code from the AWS Samples GitHub repository for the Rotation Lambda function:
wget https://raw.githubusercontent.com/aws-samples/aws-secrets-manager-rotation- lambdas/master/SecretsManagerRDSMySQLRotationSingleUser/lambda_function.py
Note
AWS provides information and templates for different database rotation scenarios in this article.
-
Compress the file containing the code:
zip lambda_function.zip lambda_function.py
You should see output similar to the following:
adding: lambda_function.py (deflated 76%)
-
Create a new security group for the Lambda function to use:
LAMBDA_SG_ID=$(aws ec2 create-security-group \ --group-name AWSCookbook405LambdaSG \ --description "Lambda Security Group" --vpc-id $VPC_ID \ --output text --query GroupId) -
Add an ingress rule to the RDS instances security group that allows access on TCP port 3306 from the Lambda’s security group:
aws ec2 authorize-security-group-ingress \ --protocol tcp --port 3306 \ --source-group $LAMBDA_SG_ID \ --group-id $RDS_SECURITY_GROUPYou should see output similar to the following:
{ "Return": true, "SecurityGroupRules": [ { "SecurityGroupRuleId": "sgr-<<ID>>", "GroupId": "sg-<<ID>>", "GroupOwnerId": "111111111111", "IsEgress": false, "IpProtocol": "tcp", "FromPort": 3306, "ToPort": 3306, "ReferencedGroupInfo": { "GroupId": "sg-<<ID>>" } } ] } -
Create a file named assume-role-policy.json with the following content (file provided in the repository):
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "lambda.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } -
Create an IAM role with the statement in the provided assume-role-policy.json file using this command:
aws iam create-role --role-name AWSCookbook405Lambda \ --assume-role-policy-document file://assume-role-policy.jsonYou should see output similar to the following:
{ "Role": { "Path": "/", "RoleName": "AWSCookbook405Lambda", "RoleId": "<<ID>>", "Arn": "arn:aws:iam::111111111111:role/AWSCookbook405Lambda", "CreateDate": "2021-09-21T23:01:57+00:00", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ ... -
Attach the IAM managed policy for
AWSLambdaVPCAccessto the IAM role:aws iam attach-role-policy --role-name AWSCookbook405Lambda \ --policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaVPCAccessExecutionRole -
Attach the IAM managed policy for
SecretsManagerReadWriteto the IAM role:aws iam attach-role-policy --role-name AWSCookbook405Lambda \ --policy-arn arn:aws:iam::aws:policy/SecretsManagerReadWriteTip
The IAM role that you associated with the Lambda function to rotate the password used the
SecretsManagerReadWritemanaged policy. In a production scenario, you would want to scope this down to limit which secrets the Lambda function can interact with. -
Create the Lambda function to perform the secret rotation using the code:
LAMBDA_ROTATE_ARN=$(aws lambda create-function \ --function-name AWSCookbook405Lambda \ --runtime python3.8 \ --package-type "Zip" \ --zip-file fileb://lambda_function.zip \ --handler lambda_function.lambda_handler --publish \ --environment Variables={SECRETS_MANAGER_ENDPOINT=https://secretsmanager.$AWS_REGION.amazonaws.com} \ --layers $PyMysqlLambdaLayerArn \ --role \ arn:aws:iam::$AWS_ACCOUNT_ID:role/AWSCookbook405Lambda \ --output text --query FunctionArn \ --vpc-config SubnetIds=${ISOLATED_SUBNETS},SecurityGroupIds=$LAMBDA_SG_ID)Use this command to determine when the Lambda function has entered the Active state:
aws lambda get-function --function-name $LAMBDA_ROTATE_ARN \ --output text --query Configuration.State -
Add a permission to the Lambda function so that Secrets Manager can invoke it:
aws lambda add-permission --function-name $LAMBDA_ROTATE_ARN \ --action lambda:InvokeFunction --statement-id secretsmanager \ --principal secretsmanager.amazonaws.comYou should see output similar to the following:
{ "Statement": "{\"Sid\":\"secretsmanager\",\"Effect\":\"Allow\",\"Principal\":{\"Service\":\"secretsmanager.amazonaws.com\"},\"Action\":\"lambda:InvokeFunction\",\"Resource\":\"arn:aws:lambda:us-east-1:111111111111:function:AWSCookbook405Lambda\"}" } -
Set a unique suffix to use for the secret name to ensure you can reuse this pattern for additional automatic password rotations if desired:
AWSCookbook405SecretName=AWSCookbook405Secret-$(aws secretsmanager \ get-random-password \ --exclude-punctuation \ --password-length 6 --require-each-included-type \ --output text \ --query RandomPassword) -
Create a secret in Secrets Manager to store your admin password:
aws secretsmanager create-secret --name $AWSCookbook405SecretName \ --description "My database secret created with the CLI" \ --secret-string file://rdscreds.jsonYou should see output similar to the following:
{ "ARN": "arn:aws:secretsmanager:us-east-1:1111111111111:secret:AWSCookbook405Secret-T4tErs-AlJcLn", "Name": "AWSCookbook405Secret-<<Random>>", "VersionId": "<<ID>>" } -
Set up automatic rotation every 30 days and specify the Lambda function to perform rotation for the secret you just created:
aws secretsmanager rotate-secret \ --secret-id $AWSCookbook405SecretName \ --rotation-rules AutomaticallyAfterDays=30 \ --rotation-lambda-arn $LAMBDA_ROTATE_ARNYou should see output similar to the following:
{ "ARN": "arn:aws:secretsmanager:us-east-1:1111111111111:secret:AWSCookbook405Secret-<<unique>>", "Name": "AWSCookbook405Secret-<<unique>>", "VersionId": "<<ID>>" } -
Perform another rotation of the secret:
aws secretsmanager rotate-secret --secret-id $AWSCookbook405SecretName
You should see output similar to the output from step 17. Notice that the
VersionIdwill be different from the last command indicating that the secret has been rotated.
Validation checks
Retrieve the RDS admin password from Secrets Manager:
RDS_ADMIN_PASSWORD=$(aws secretsmanager get-secret-value --secret-id $AWSCookbook405SecretName --query SecretString | jq -r | jq .password | tr -d '"')
List the endpoint for the RDS cluster:
echo $RDS_ENDPOINT
Retrieve the password for your RDS cluster:
echo $RDS_ADMIN_PASSWORD
Connect to the EC2 instance by using SSM Session Manager (see Recipe 1.6):
aws ssm start-session --target $INSTANCE_ID
Install the MySQL client:
sudo yum -y install mysql
Connect to the database to verify that the latest rotated password is working. You’ll need to copy and paste the password (outputted previously):
mysql -u admin -p$password -h $hostname
Run a SELECT statement on the mysql.user table to validate administrator permissions:
SELECT user FROM mysql.user;
You should see output similar to the following:
+------------------+ | user | +------------------+ | admin | | mysql.infoschema | | mysql.session | | mysql.sys | | rdsadmin | +------------------+ 5 rows in set (0.00 sec)
Exit from the mysql prompt:
quit
Exit the Session Manager session:
exit
Cleanup
Follow the steps in this recipe’s folder in the chapter code repository.
Discussion
The AWS-provided Lambda function stores the rotated password in Secrets Manager. You can then configure your application to retrieve secrets from Secrets Manager directly; or the Lambda function you configured to update the Secrets Manager values could also store the password in a secure location of your choosing. You would need to grant the Lambda additional permissions to interact with the secure location you choose and add some code to store the new value there. This method could also be applied to rotate the passwords for nonadmin database user accounts by following the same steps after you have created the user(s) in your database.
The Lambda function you deployed is Python-based and connects to a MySQL engine-compatible database. The Lambda runtime environment does not have this library included by default, so you specified a Lambda layer with the aws lambda create-function command. This layer is required so that the PyMySQL library was available to the function in the Lambda runtime environment, and it was deployed for you as part of the preparation step when you ran cdk deploy.
See Also
4.6 Autoscaling DynamoDB Table Provisioned Capacity
Solution
Configure read and write scaling by setting a scaling target and a scaling policy for the read and write capacity of the DynamoDB table by using AWS application autoscaling, as shown in Figure 4-6.
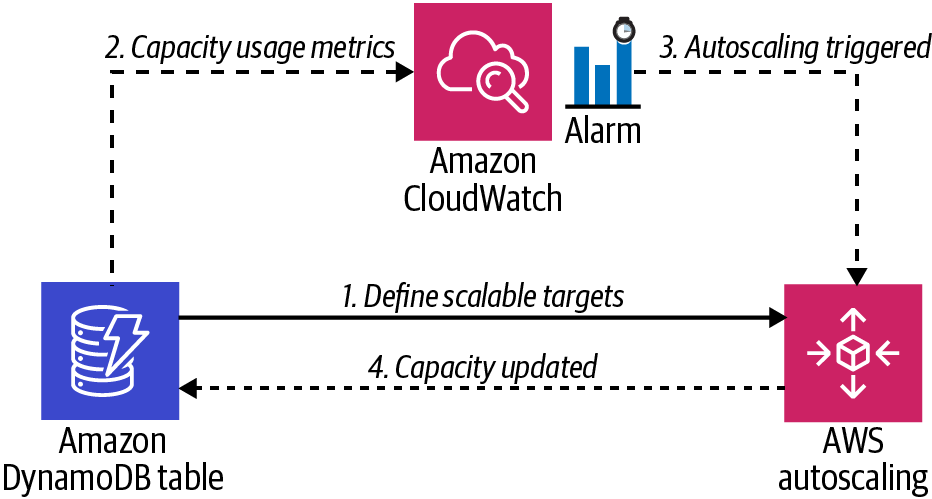
Figure 4-6. DynamoDB autoscaling configuration
Prerequisite
-
A DynamoDB table
Preparation
Follow the steps in this recipe’s folder in the chapter code repository.
Steps
-
Navigate to this recipe’s directory in the chapter repository:
cd 406-Auto-Scaling-DynamoDB
-
Register a
ReadCapacityUnitsscaling target for the DynamoDB table:aws application-autoscaling register-scalable-target \ --service-namespace dynamodb \ --resource-id "table/AWSCookbook406" \ --scalable-dimension "dynamodb:table:ReadCapacityUnits" \ --min-capacity 5 \ --max-capacity 10 -
Register a
WriteCapacityUnitsscaling target for the DynamoDB table:aws application-autoscaling register-scalable-target \ --service-namespace dynamodb \ --resource-id "table/AWSCookbook406" \ --scalable-dimension "dynamodb:table:WriteCapacityUnits" \ --min-capacity 5 \ --max-capacity 10 -
Create a scaling policy JSON file for read capacity scaling (read-policy.json provided in the repository):
{ "PredefinedMetricSpecification": { "PredefinedMetricType": "DynamoDBReadCapacityUtilization" }, "ScaleOutCooldown": 60, "ScaleInCooldown": 60, "TargetValue": 50.0 } -
Create a scaling policy JSON file for write capacity scaling (write-policy.json file provided in the repository):
{ "PredefinedMetricSpecification": { "PredefinedMetricType": "DynamoDBWriteCapacityUtilization" }, "ScaleOutCooldown": 60, "ScaleInCooldown": 60, "TargetValue": 50.0 }Note
DynamoDB-provisioned capacity uses capacity units to define the read and write capacity of your tables. The target value that you set defines when to scale based on the current usage. Scaling cooldown parameters define, in seconds, how long to wait to scale again after a scaling operation has taken place. For more information, see the API reference for autoscaling
TargetTrackingScalingPolicyConfiguration. -
Apply the read scaling policy to the table by using the read-policy.json file:
aws application-autoscaling put-scaling-policy \ --service-namespace dynamodb \ --resource-id "table/AWSCookbook406" \ --scalable-dimension "dynamodb:table:ReadCapacityUnits" \ --policy-name "AWSCookbookReadScaling" \ --policy-type "TargetTrackingScaling" \ --target-tracking-scaling-policy-configuration \ file://read-policy.json -
Apply the write scaling policy to the table using the write-policy.json file:
aws application-autoscaling put-scaling-policy \ --service-namespace dynamodb \ --resource-id "table/AWSCookbook406" \ --scalable-dimension "dynamodb:table:WriteCapacityUnits" \ --policy-name "AWSCookbookWriteScaling" \ --policy-type "TargetTrackingScaling" \ --target-tracking-scaling-policy-configuration \ file://write-policy.json
Validation checks
You can observe the autoscaling configuration for your table by selecting it in the DynamoDB console and looking under the “Additional settings” tab.
Cleanup
Follow the steps in this recipe’s folder in the chapter code repository.
Discussion
Tip
These steps will autoscale read and write capacities independently for your DynamoDB table, which helps you achieve the lowest operating cost model for your application’s specific requirements.
DynamoDB allows for two capacity modes: provisioned and on-demand. When using provisioned capacity mode, you are able to select the number of data reads and writes per second. The pricing guide notes that you are charged according to the capacity units you specify. Conversely, with on-demand capacity mode, you pay per request for the data reads and writes your application performs on your tables. In general, using on-demand mode can result in higher costs over provisioned mode for especially transactionally heavy applications.
You need to understand your application and usage patterns when selecting a provisioned capacity for your tables. If you set the capacity too low, you will experience slow database performance and your application could enter error and wait states, since the DynamoDB API will return ThrottlingException and ProvisionedThroughputExceededException responses to your application when these limits are met. If you set the capacity too high, you are paying for unneeded capacity. Enabling autoscaling allows you to define minimum and maximum target values by setting a scaling target, while also allowing you to define when the autoscaling trigger should go into effect for scaling up, and when it should begin to scale down your capacity. This allows you to optimize for both cost and performance while taking advantage of the DynamoDB service. To see a list of the scalable targets that you configured for your table, you can use the following command:
aws application-autoscaling describe-scalable-targets \
--service-namespace dynamodb \
--resource-id "table/AWSCookbook406"
For more information on DynamoDB capacities and how they are measured, see this support document.
4.7 Migrating Databases to Amazon RDS Using AWS DMS
Solution
Configure the VPC security groups and IAM permissions to allow AWS Database Migration Service (DMS) connectivity to the databases. Then, configure the DMS endpoints for the source and target databases. Next, configure a DMS replication task. Finally, start the replication task. An architecture diagram of the solution is shown in Figure 4-7.
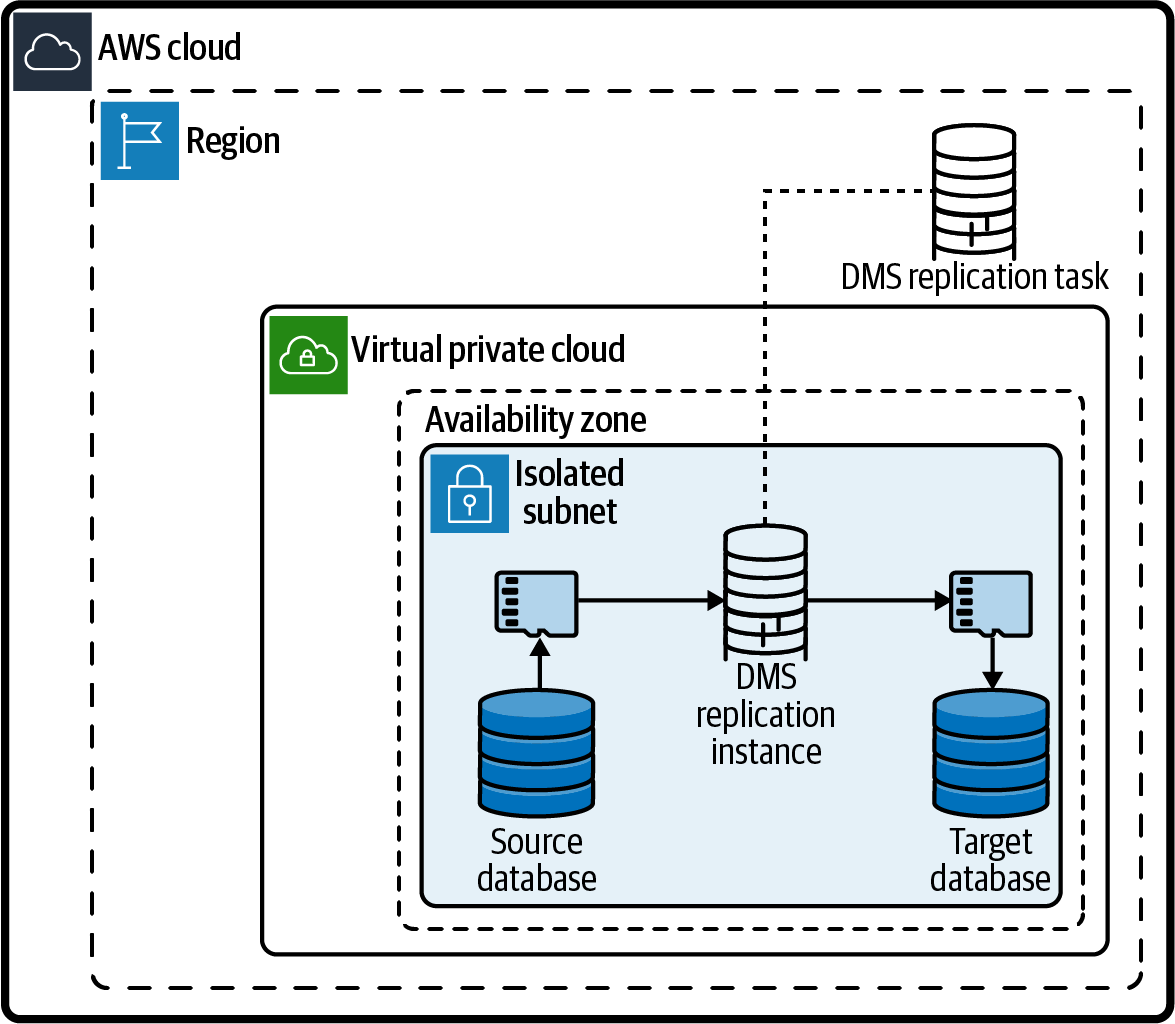
Figure 4-7. DMS network diagram
Preparation
Follow the steps in this recipe’s folder in the chapter code repository.
Steps
-
Create a security group for the replication instance:
DMS_SG_ID=$(aws ec2 create-security-group \ --group-name AWSCookbook407DMSSG \ --description "DMS Security Group" --vpc-id $VPC_ID \ --output text --query GroupId) -
Grant the DMS security group access to the source and target databases on TCP port 3306:
aws ec2 authorize-security-group-ingress \ --protocol tcp --port 3306 \ --source-group $DMS_SG_ID \ --group-id $SOURCE_RDS_SECURITY_GROUP aws ec2 authorize-security-group-ingress \ --protocol tcp --port 3306 \ --source-group $DMS_SG_ID \ --group-id $TARGET_RDS_SECURITY_GROUP -
Create a role for DMS by using the assume-role-policy.json provided:
aws iam create-role --role-name dms-vpc-role \ --assume-role-policy-document file://assume-role-policy.jsonWarning
The DMS service requires an IAM role with a specific name and a specific policy. The command you ran previously satisfies this requirement. You may also already have this role in your account if you have used DMS previously. This command would result in an error if that is the case, and you can proceed with the next steps without concern.
-
Attach the managed DMS policy to the role:
aws iam attach-role-policy --role-name dms-vpc-role --policy-arn \ arn:aws:iam::aws:policy/service-role/AmazonDMSVPCManagementRole
-
Create a replication subnet group for the replication instance:
REP_SUBNET_GROUP=$(aws dms create-replication-subnet-group \ --replication-subnet-group-identifier awscookbook407 \ --replication-subnet-group-description "AWSCookbook407" \ --subnet-ids $ISOLATED_SUBNETS \ --query ReplicationSubnetGroup.ReplicationSubnetGroupIdentifier \ --output text) -
Create a replication instance and save the ARN in a variable:
REP_INSTANCE_ARN=$(aws dms create-replication-instance \ --replication-instance-identifier awscookbook407 \ --no-publicly-accessible \ --replication-instance-class dms.t2.medium \ --vpc-security-group-ids $DMS_SG_ID \ --replication-subnet-group-identifier $REP_SUBNET_GROUP \ --allocated-storage 8 \ --query ReplicationInstance.ReplicationInstanceArn \ --output text)Wait until the
ReplicationInstanceStatusreaches available; check the status by using this command:aws dms describe-replication-instances \ --filter=Name=replication-instance-id,Values=awscookbook407 \ --query ReplicationInstances[0].ReplicationInstanceStatusWarning
You used the
dms.t2.mediumreplication instance size for this example. You should choose an instance size appropriate to handle the amount of data you will be migrating. DMS transfers tables in parallel, so you will need a larger instance size for larger amounts of data. For more information, see this user guide document about best practices for DMS. -
Retrieve the source and target DB admin passwords from Secrets Manager and save to environment variables:
RDS_SOURCE_PASSWORD=$(aws secretsmanager get-secret-value --secret-id $RDS_SOURCE_SECRET_NAME --query SecretString --output text | jq .password | tr -d '"') RDS_TARGET_PASSWORD=$(aws secretsmanager get-secret-value --secret-id $RDS_TARGET_SECRET_NAME --query SecretString --output text | jq .password | tr -d '"')
-
Create a source endpoint for DMS and save the ARN to a variable:
SOURCE_ENDPOINT_ARN=$(aws dms create-endpoint \ --endpoint-identifier awscookbook407source \ --endpoint-type source --engine-name mysql \ --username admin --password $RDS_SOURCE_PASSWORD \ --server-name $SOURCE_RDS_ENDPOINT --port 3306 \ --query Endpoint.EndpointArn --output text) -
Create a target endpoint for DMS and save the ARN to a variable:
TARGET_ENDPOINT_ARN=$(aws dms create-endpoint \ --endpoint-identifier awscookbook407target \ --endpoint-type target --engine-name mysql \ --username admin --password $RDS_TARGET_PASSWORD \ --server-name $TARGET_RDS_ENDPOINT --port 3306 \ --query Endpoint.EndpointArn --output text) -
Create your replication task:
REPLICATION_TASK_ARN=$(aws dms create-replication-task \ --replication-task-identifier awscookbook-task \ --source-endpoint-arn $SOURCE_ENDPOINT_ARN \ --target-endpoint-arn $TARGET_ENDPOINT_ARN \ --replication-instance-arn $REP_INSTANCE_ARN \ --migration-type full-load \ --table-mappings file://table-mapping-all.json \ --query ReplicationTask.ReplicationTaskArn --output text)Wait for the status to reach ready. To check the status of the replication task, use the following:
aws dms describe-replication-tasks \ --filters "Name=replication-task-arn,Values=$REPLICATION_TASK_ARN" \ --query "ReplicationTasks[0].Status" -
Start the replication task:
aws dms start-replication-task \ --replication-task-arn $REPLICATION_TASK_ARN \ --start-replication-task-type start-replication
Validation checks
Monitor the progress of the replication task:
aws dms describe-replication-tasks
Use the AWS Console or the aws dms describe-replication-tasks operation to validate that your tables have been migrated:
aws dms describe-replication-tasks \
--query ReplicationTasks[0].ReplicationTaskStats
You can also view the status of the replication task in the DMS console.
Cleanup
Follow the steps in this recipe’s folder in the chapter code repository.
Discussion
Tip
You could also run full-load-and-cdc to continuously replicate changes on the source to the destination to minimize your application downtime when you cut over to the new database.
DMS comes with functionality to test source and destination endpoints from the replication instance. This is a handy feature to use when working with DMS to validate that you have the configuration correct before you start to run replication tasks. Testing connectivity from the replication instance to both of the endpoints you configured can be done through the DMS console or the command line with the following commands:
aws dms test-connection \
--replication-instance-arn $rep_instance_arn \
--endpoint-arn $source_endpoint_arn
aws dms test-connection \
--replication-instance-arn $rep_instance_arn \
--endpoint-arn $target_endpoint_arn
The test-connection operation takes a few moments to complete. You can check the status and the results of the operation by using this command:
aws dms describe-connections --filter \ "Name=endpoint-arn,Values=$source_endpoint_arn,$target_endpoint_arn"
The DMS service supports many types of source and target databases within your VPC, another AWS account, or databases hosted in a non-AWS environment. The service can also transform data for you if your source and destination are different types of databases by using additional configuration in the table-mappings.json file. For example, the data type of a column in an Oracle database may have a different format than the equivalent type in a PostgreSQL database. The AWS Schema Conversion Tool (SCT) can assist with identifying these necessary transforms, and also generate configuration files to use with DMS.
Challenge
Enable full load and ongoing replication to continuously replicate from one database to another.
4.8 Enabling REST Access to Aurora Serverless Using RDS Data API
Solution
First, enable the Data API for your database and configure the IAM permissions for your EC2 instance. Then, test from both the CLI and RDS console. This allows your application to connect to your Aurora Serverless database, as shown in Figure 4-8.
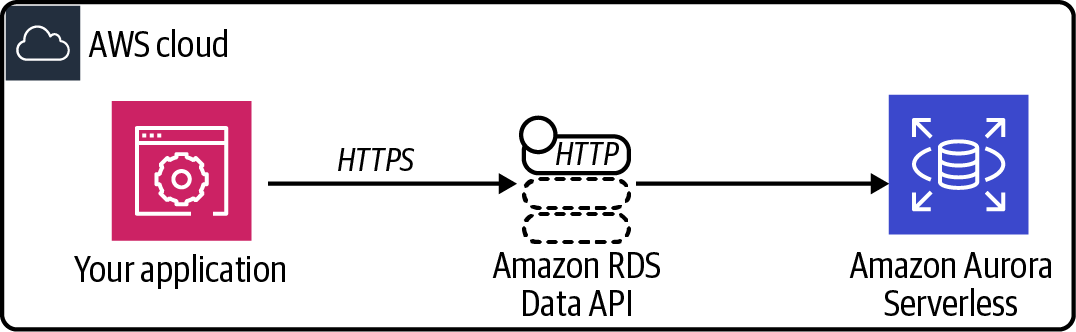
Figure 4-8. An application using the RDS Data API
Prerequisites
-
VPC with isolated subnets created in two AZs and associated route tables.
-
PostgreSQL RDS instance and EC2 instance deployed. You will need the ability to connect to these for testing.
Preparation
Follow the steps in this recipe’s folder in the chapter code repository.
Steps
-
Enable the Data API on your Aurora Serverless cluster:
aws rds modify-db-cluster \ --db-cluster-identifier $CLUSTER_IDENTIFIER \ --enable-http-endpoint \ --apply-immediately -
Ensure that
HttpEndpointEnabledis set totrue:aws rds describe-db-clusters \ --db-cluster-identifier $CLUSTER_IDENTIFIER \ --query DBClusters[0].HttpEndpointEnabled -
Test a command from your CLI:
aws rds-data execute-statement \ --secret-arn "$SECRET_ARN" \ --resource-arn "$CLUSTER_ARN" \ --database "$DATABASE_NAME" \ --sql "select * from pg_user" \ --output json(Optional) You can also test access via the AWS Console using the Amazon RDS Query Editor. First run these two commands from your terminal so you can copy and paste the values:
echo $SECRET_ARN echo $DATABASE_NAME
-
Log in to the AWS Console with admin permissions and go to the RDS console. On the lefthand sidebar menu, click Query Editor. Fill out the values and select “Connect to database,” as shown in Figure 4-9.
Figure 4-9. Connect to database settings
-
Run the same query and view the results below the Query Editor (see Figure 4-10):
SELECT * from pg_user;
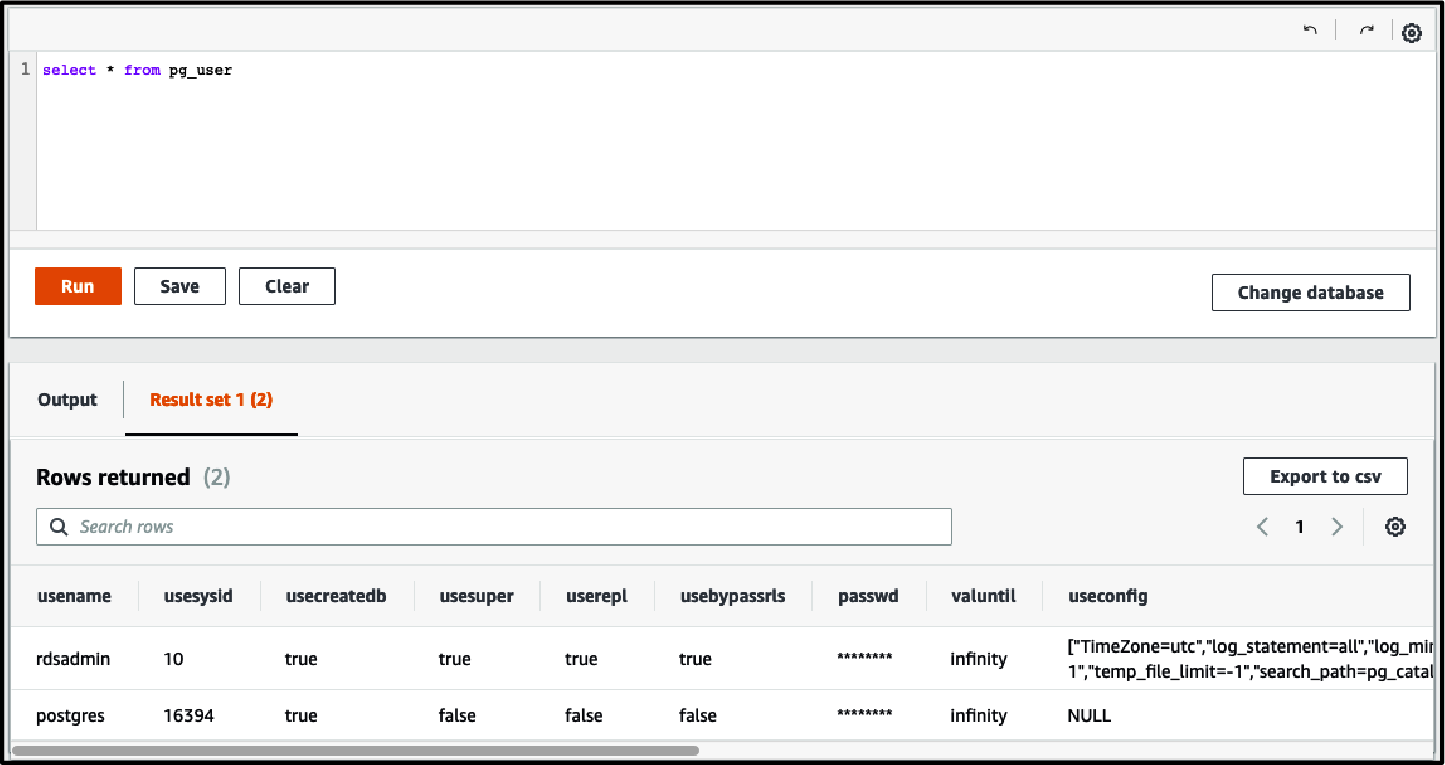
Figure 4-10. RDS Query Editor
-
Configure your EC2 instance to use the Data API with your database cluster. Create a file called policy-template.json with the following content (file provided in the repository):
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "rds-data:BatchExecuteStatement", "rds-data:BeginTransaction", "rds-data:CommitTransaction", "rds-data:ExecuteStatement", "rds-data:RollbackTransaction" ], "Resource": "*", "Effect": "Allow" }, { "Action": [ "secretsmanager:GetSecretValue", "secretsmanager:DescribeSecret" ], "Resource": "SecretArn", "Effect": "Allow" } ] } -
Replace the values in the template file by using the
sedcommand with environment variables you have set:sed -e "s/SecretArn/${SECRET_ARN}/g" \ policy-template.json > policy.json -
Create an IAM policy by using the file you just created:
aws iam create-policy --policy-name AWSCookbook408RDSDataPolicy \ --policy-document file://policy.json -
Attach the IAM policy for
AWSCookbook408RDSDataPolicyto your EC2 instance’s IAM role:aws iam attach-role-policy --role-name $INSTANCE_ROLE_NAME \ --policy-arn arn:aws:iam::$AWS_ACCOUNT_ID:policy/AWSCookbook408RDSDataPolicy
Validation checks
Create and populate some SSM parameters to store values so that you can retrieve them from your EC2 instance:
aws ssm put-parameter \
--name "Cookbook408DatabaseName" \
--type "String" \
--value $DATABASE_NAME
aws ssm put-parameter \
--name "Cookbook408ClusterArn" \
--type "String" \
--value $CLUSTER_ARN
aws ssm put-parameter \
--name "Cookbook408SecretArn" \
--type "String" \
--value $SECRET_ARN
Connect to the EC2 instance by using SSM Session Manager (see Recipe 1.6):
aws ssm start-session --target $INSTANCE_ID
Set the Region:
export AWS_DEFAULT_REGION=us-east-1
Retrieve the SSM parameter values and set them to environment values:
DatabaseName=$(aws ssm get-parameters \
--names "Cookbook408DatabaseName" \
--query "Parameters[*].Value" --output text)
SecretArn=$(aws ssm get-parameters \
--names "Cookbook408SecretArn" \
--query "Parameters[*].Value" --output text)
ClusterArn=$(aws ssm get-parameters \
--names "Cookbook408ClusterArn" \
--query "Parameters[*].Value" --output text)
Run a query against the database:
aws rds-data execute-statement \
--secret-arn "$SecretArn" \
--resource-arn "$ClusterArn" \
--database "$DatabaseName" \
--sql "select * from pg_user" \
--output json
Exit the Session Manager session:
exit
Cleanup
Follow the steps in this recipe’s folder in the chapter code repository.
Discussion
The Data API exposes an HTTPS endpoint for usage with Aurora and uses IAM authentication to allow your application to execute SQL statements on your database over HTTPS instead of using classic TCP database connectivity.
Tip
Per the Aurora user guide, all calls to the Data API are synchronous, and the default timeout for a query is 45 seconds. If your queries take longer than 45 seconds, you can use the continueAfterTimeout parameter to facilitate long-running queries.
As is the case with other AWS service APIs that use IAM authentication, all activities performed with the Data API are captured in CloudTrail to ensure an audit trail is present, which can help satisfy your security and audit requirements. You can control and delegate access to the Data API endpoint by using IAM policies associated with roles for your application. For example, if you wanted to grant your application the ability to only read from your database using the Data API, you could write a policy that omits the rds-data:CommitTransaction and rds-data:RollbackTransaction permissions.
The Query Editor within the RDS console provides a web-based means of access for executing SQL queries against your database. This is a convenient mechanism for developers and DBAs to quickly accomplish bespoke tasks. The same privileges that you assigned your EC2 instance in this recipe would need to be granted to your developer and DBA via IAM roles.
Get AWS Cookbook now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

