Capítulo 1. Introducción a la Ciencia de Datos y al Trading
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
La mejor forma de empezar a aprender sobre un tema complejo es dividirlo en partes más pequeñas y comprender primero esas piezas. Entender el aprendizaje profundo para las finanzas requiere conocimientos de ciencia de datos y mercados financieros.
Este capítulo sienta las bases necesarias para comprender a fondo la ciencia de datos y sus usos, así como para entender los mercados financieros y cómo la negociación y la previsión pueden beneficiarse de la ciencia de datos.
Al final del capítulo, deberías saber qué es la ciencia de datos, cuáles son sus aplicaciones y cómo puedes utilizarla en finanzas para extraer valor.
Comprender los datos
Es imposible comprender el campo de la ciencia de datos sin entender primero los tipos y estructuras de los datos. Al fin y al cabo, la primera palabra del nombre de este inmenso campo es datos. Entonces, ¿qué son los datos? Y lo que es más importante, ¿qué puedes hacer con ellos?
Los datos , en su forma más simple y pura, son una colección de información en bruto que puede ser de cualquier tipo (numérica, texto, booleana, etc.).
El objetivo final de la recogida de datos es la toma de decisiones. Esto se hace mediante un proceso complejo que va desde el acto de recoger y procesar los datos hasta interpretarlos y utilizar los resultados para tomar una decisión.
Pongamos un ejemplo de utilización de datos para tomar una decisión. Supongamos que tienes una cartera compuesta por cinco acciones diferentes que pagan dividendos con la misma ponderación, como se detalla en la Tabla 1-1.
| Acciones | Rendimiento de los dividendos |
|---|---|
| A | 5.20% |
| B | 3.99% |
| C | 4.12% |
| D | 6.94% |
| E | 5.55% |
Nota
Un dividendo es el pago que se hace a los accionistas con los beneficios de una empresa. La rentabilidad por dividendo es la cantidad distribuida en unidades monetarias sobre el precio actual de las acciones de la empresa.
Analizar estos datos puede ayudarte a comprender la rentabilidad media por dividendo que estás recibiendo de tu cartera. La media es básicamente la suma dividida por la cantidad, y da una instantánea rápida de la rentabilidad por dividendo global de la cartera:
Por tanto, la rentabilidad media por dividendos de tu cartera es del 5,16%. Esta información puede ayudarte a comparar tu rentabilidad media por dividendos con la de otras carteras, para saber si tienes que hacer algún ajuste.
Otra métrica que puedes calcular es el número de acciones mantenidas en la cartera. Esto puede proporcionar el primer ladrillo informativo para construir un muro de diversificación. Aunque estos dos datos (la rentabilidad media de los dividendos y el número de acciones de la cartera) son muy sencillos, el análisis de datos complejos comienza con métricas sencillas y a veces no requiere modelos sofisticados para interpretar correctamente la situación.
Las dos métricas que calculaste en el ejemplo anterior se llaman media y recuento . Forman parte de un campo llamado estadística descriptiva que se trata en el Capítulo 3, y que también forma parte de la ciencia de datos.
Tomemos otro ejemplo de análisis de datos con fines inferenciales. Supongamos que has calculado una medida de correlación anual entre dos materias primas, y quieres predecir si la próxima correlación anual será positiva o negativa. La Tabla 1-2 contiene los detalles de los cálculos.
| Año | Correlación |
|---|---|
| 2015 | Positivo |
| 2016 | Positivo |
| 2017 | Positivo |
| 2018 | Negativo |
| 2019 | Positivo |
| 2020 | Positivo |
| 2021 | Positivo |
| 2022 | Positivo |
| 2023 | Positivo |
Nota
La correlación es una medida de la relación lineal entre dos series temporales. Una correlación positiva significa generalmente que las dos series temporales se mueven por término medio en la misma dirección, mientras que una correlación negativa significa generalmente que las dos series temporales se mueven por término medio en direcciones opuestas. La correlación se trata en el Capítulo 3.
Según la Tabla 1-2, la correlación histórica entre las dos materias primas fue mayoritariamente (es decir, un 88%) positiva. Teniendo en cuenta las observaciones históricas, puedes decir que hay un 88% de probabilidad de que la próxima medida de correlación sea positiva. Esto también significa que hay un 12% de probabilidad de que la próxima medida de correlación sea negativa:
Este es otro ejemplo básico de cómo utilizar los datos para extraer conclusiones de las observaciones y tomar decisiones. Por supuesto, el supuesto aquí es que los resultados históricos reflejarán exactamente los resultados futuros, lo que es poco probable en la vida real, pero en ocasiones, para predecir el futuro todo lo que tienes es el pasado.
Ahora, antes de hablar de la ciencia de datos, repasemos qué tipos de datos pueden utilizarse y segmentémoslos en diferentes grupos:
- Datos numéricos
-
Este tipo de datos se compone de cifras que reflejan un determinado tipo de información que se recoge a intervalos regulares o irregulares. Algunos ejemplos son los datos de mercado (OHLC,1 volumen, diferenciales, etc.) y datos de estados financieros (activos, ingresos, costes, etc.).
- Datos categóricos
-
Los datos categóricos son datos que pueden organizarse en grupos o categorías utilizando nombres o etiquetas. Son más cualitativos que cuantitativos. Por ejemplo, el grupo sanguíneo de los pacientes es un tipo de dato categórico. Otro ejemplo es el color de los ojos de distintas muestras de una población.
- Datos de texto
-
Los datos de texto han ido en aumento en los últimos años con el desarrollo del procesamiento del lenguaje natural (PLN). Los modelos de aprendizaje automático utilizan los datos de texto para traducir, interpretar y analizar el sentimiento del texto.
- Datos visuales
-
Las imágenes y los vídeos también se consideran datos, y puedes procesarlos y transformarlos en información valiosa. Por ejemplo, una red neuronal convolucional (CNN) es un tipo de algoritmo (tratado en el Capítulo 8) que puede reconocer y categorizar fotos por etiquetas (por ejemplo, etiquetar las fotos de gatos como gatos).
- Datos de audio
-
Los datos de audio son muy valiosos y pueden ayudar a ahorrar tiempo en las transcripciones. Por ejemplo, puedes utilizar algoritmos sobre el audio para crear subtítulos y crear subtítulos automáticamente. También puedes crear modelos que interpreten el sentimiento del orador utilizando el tono y el volumen del audio.
La ciencia de datos es un campo transdisciplinar que trata de extraer inteligencia y conclusiones de los datos utilizando diferentes técnicas y modelos, ya sean simples o complejos. El proceso de la ciencia de datos se compone de muchos pasos, además del mero análisis de los datos. A continuación se resumen estos pasos:
- Recogida de datos: Este proceso implica la obtención de datos de fuentes fiables y precisas. Una frase muy conocida en informática, generalmente atribuida a George Fuechsel, dice "Basura dentro, basura fuera", y se refiere a la necesidad de disponer de datos de calidad en los que puedas confiar para realizar un análisis adecuado. Básicamente, si tienes datos inexactos o defectuosos, todos tus procesos serán inválidos.
- Preprocesamiento de datos: En ocasiones, los datos que adquieres pueden estar en bruto, y es necesario preprocesarlos y limpiarlos para que los modelos de ciencia de datos puedan utilizarlos. Por ejemplo, eliminar datos innecesarios, añadir valores que faltan o eliminar datos no válidos y duplicados puede formar parte del paso de preprocesamiento. Otros ejemplos más complejos pueden incluir la normalización y eliminación de ruido de los datos. El objetivo de este paso es preparar los datos para el análisis.
- Exploración de datos: Durante este paso, se realiza una investigación estadística básica para encontrar tendencias y otras características en los datos. Un ejemplo de exploración de datos es calcular la media de los datos.
- Visualización de los datos: Este es un paso importante que se añade al anterior. Incluye la creación de visualizaciones como histogramas y mapas de calor para ayudar a identificar pautas y tendencias y facilitar la interpretación.
- Análisis de datos: Este es el enfoque principal del proceso de la ciencia de datos. Es cuando ajustas (entrenas) los datos utilizando diferentes modelos de aprendizaje para que interpreten y predigan el resultado futuro basándose en los parámetros dados.
- Interpretación de los datos: Este paso se ocupa de comprender la información y las conclusiones presentadas por los modelos de la ciencia de datos. La optimización también puede formar parte de este paso; en esos casos, volvemos al paso 5 y ejecutamos de nuevo los modelos con los parámetros actualizados antes de reinterpretarlos y evaluar el rendimiento.
Tomemos un ejemplo sencillo en Python que aplique los pasos del proceso de la ciencia de datos. Supongamos que quieres analizar y predecir el VIX(índice de volatilidad), un indicador de series temporales de volatilidad que representa la volatilidad implícita del índice bursátil S&P 500. El VIX está disponible desde 1993 y lo emite el Chicago Board Options Exchange (CBOE).
Nota
También hay un paso oculto en el proceso de la ciencia de datos al que me refiero como paso cero, y se produce cuando te formas una idea basada en qué proceso debe iniciarse. Al fin y al cabo, no aplicarías el proceso si antes no tuvieras un motivo. Por ejemplo, creer que los números de la inflación pueden impulsar los rendimientos de ciertas materias primas es una idea y un motivo para empezar a explorar los datos en busca de números reales que demuestren esta hipótesis.
Dado que su objetivo es medir el nivel de miedo o incertidumbre en el mercado bursátil, el VIX se denomina con frecuencia índice del miedo. Es un porcentaje que se calcula utilizando el precio de las opciones sobre el S&P 500. Un valor más alto del VIX se correlaciona con una mayor turbulencia e incertidumbre del mercado, mientras que un valor más bajo se correlaciona con una mayor estabilidad media.
El primer paso es la recopilación de datos, que en este caso puede automatizarse utilizando Python. El siguiente bloque de código se conecta al sitio web de la Reserva Federal de San Luis y descarga los datos históricos del VIX entre el 1 de enero de 1990 y el 23 de enero de 2023(el Capítulo 6 está dedicado a la introducción de Python y a la escritura de código; de momento, no es necesario que entiendas el código, ya que ése no es todavía el objetivo):
# Importing the required libraryimportpandas_datareaderaspdr# Setting the beginning and end of the historical datastart_date='1990-01-01'end_date='2023-01-23'# Creating a dataframe and downloading the VIX datavix=pdr.DataReader('VIXCLS','fred',start_date,end_date)# Printing the latest five observations of the dataframe(vix.tail())
El código utiliza la biblioteca pandas para importar la función DataReader, que obtiene los datos históricos en línea de diversas fuentes. La función DataReader toma el nombre de los datos como primer argumento, seguido de la fuente y las fechas. El resultado de print(vix.tail()) se muestra en la Tabla 1-3.
| FECHA | VIXCLS |
|---|---|
| 2023-01-17 | 19.36 |
| 2023-01-01 | 20.34 |
| 2023-01-19 | 20.52 |
| 2023-01-20 | 19.85 |
| 2023-01-23 | 19.81 |
Pasemos al segundo paso: el preprocesamiento de los datos. Divido esta parte en la comprobación de datos no válidos y la transformación de los datos para que estén listos para su uso. Cuando tratas con series temporales, especialmente series temporales descargadas, a veces puedes encontrarte con valores nan. NaN significa Not a Number (No es un número), y los valores de nan se producen porque faltan datos, no son válidos o están corruptos.
Puedes tratar los valores nan de muchas formas. Para este ejemplo, vamos a utilizar la forma más sencilla de tratar estos valores no válidos, que es eliminarlos. Pero antes, vamos a escribir un código sencillo que muestre el número de valores nan que hay en el marco de datos, para que tengas una idea de cuántos valores vas a eliminar:
# Calculating the number of nan valuescount_nan=vix['VIXCLS'].isnull().sum()# Printing the result('Number of nan values in the VIX dataframe: '+str(count_nan))
El código utiliza la función isnull() y suma el número que obtiene, lo que da el número de valores nan. El resultado del fragmento de código anterior es el siguiente:
NumberofnanvaluesintheVIXdataframe:292
Ahora que tienes una idea de cuántas filas vas a eliminar, puedes utilizar el código siguiente para eliminar las filas no válidas:
# Dropping the nan values from the rowsvix=vix.dropna()
La segunda parte del segundo paso consiste en transformar los datos. Los modelos de la ciencia de datos suelen requerir datos estacionarios , es decir, datos con propiedades estadísticas estables, como la media.
Nota
El concepto de estacionariedad y las métricas estadísticas necesarias se tratan en detalle en el Capítulo 3. Por ahora, todo lo que necesitas saber es que es probable que tengas que transformar tus datos brutos en datos estacionarios cuando utilices modelos de ciencia de datos.
Para transformar los datos del VIX en datos estacionarios, basta con tomar las diferencias de un valor respecto al valor anterior. El siguiente fragmento de código toma la trama de datos del VIX y la transforma en datos estacionarios teóricamente implícitos:2
# Taking the differences in an attempt to make the data stationaryvix=vix.diff(periods=1,axis=0)# Dropping the first value of the dataframevix=vix.iloc[1:,:]
El tercer paso es la exploración de datos, que consiste en comprender los datos que tienes ante ti, estadísticamente hablando. Como verás las métricas estadísticas en detalle en el Capítulo 3, me limitaré a calcular la media del conjunto de datos.
La media es simplemente el valor que pueden representar los demás valores del conjunto de datos si eligieran un líder. Es la suma de los valores dividida por su cantidad. La media es la estadística más sencilla del mundo de la estadística descriptiva, y sin duda la más utilizada. La fórmula siguiente muestra la representación matemática de la media de un conjunto de valores:
Puedes calcular fácilmente la media del conjunto de datos del siguiente modo:
# Calculating the mean of the datasetmean=vix["VIXCLS"].mean()# Printing the result('The mean of the dataset = '+str(mean))
El resultado del fragmento de código anterior es el siguiente:
Themeanofthedataset=0.0003
El siguiente paso es la visualización de los datos, que en la mayoría de los casos se considera el paso divertido. Vamos a trazar los valores diferenciados del VIX a lo largo del tiempo. El siguiente fragmento de código traza los datos del VIX que se muestran en la Figura 1-1:
# Importing the required libraryimportmatplotlib.pyplotasplt# Plotting the latest 250 observations in black with a labelplt.plot(vix[–250:],color='black',linewidth=1.5,label='Change in VIX')# Plotting a red dashed horizontal line that is equal to meanplt.axhline(y=mean,color='red',linestyle='dashed')# Calling a grid to facilitate the visual componentplt.grid()# Calling the legend function so it appears with the chartplt.legend()# Calling the plotplt.show()
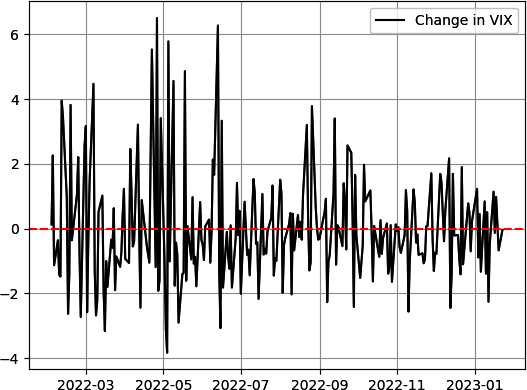
Figura 1-1. Variación del VIX desde principios de 2022
Los pasos 5 y 6, análisis e interpretación de datos, son los que vas a estudiar a fondo en este libro, así que vamos a saltárnoslos por ahora y a concentrarnos en la parte introductoria de la ciencia de datos.
Volvamos al problema de los datos no válidos o ausentes antes de continuar. A veces los datos están incompletos y faltan celdas. Aunque esto tiene el potencial de obstaculizar la capacidad predictiva del algoritmo, no debe impedirte continuar con el análisis, ya que hay soluciones rápidas que ayudan a disminuir el impacto negativo de las celdas vacías. Por ejemplo, considera la Tabla 1-4.
| Cuarto | PIB |
|---|---|
| Q1 2020 | 0.9% |
| Q2 2020 | 1.2% |
| Q3 2020 | 0.5% |
| Q4 2020 | 0.4% |
| Q1 2021 | #N/A |
| Q2 2021 | 1.0% |
| Q3 2021 | 1.1% |
| Q4 2021 | 0.6% |
La tabla contiene el producto interior bruto (PIB) trimestral3 de un país hipotético. Observa que en la tabla falta el valor del 1T 2021. Hay tres formas básicas de resolver este problema:
- Elimina la celda que contiene el valor que falta.
Esta es la técnica utilizada en el ejemplo del VIX. Simplemente considera que la marca de tiempo no existe. Es la solución más sencilla.
- Supón que la casilla que falta es igual a la casilla anterior.
-
También se trata de una corrección sencilla que tiene por objeto suavizar los datos en lugar de ignorar por completo el problema.
- Calcula la media o la mediana de las casillas alrededor del valor vacío.
-
Esta técnica lleva el suavizado un paso más allá y supone que el valor que falta es igual a la media entre el valor anterior y el siguiente. Además, puede ser la media de algunas observaciones anteriores.
La ciencia de datos comprende una serie de conceptos matemáticos y estadísticos y requiere un profundo conocimiento de los algoritmos de aprendizaje automático. En este libro, estos conceptos se tratan en detalle, pero también de una manera fácil de comprender, para beneficiar tanto a los lectores técnicos como a los no técnicos. Se supone que muchos modelos son cajas misteriosas, y hay algo de verdad en ello, pero el trabajo de un científico de datos consiste en comprender los modelos antes de interpretar sus resultados. Esto ayuda a comprender las limitaciones de los modelos.
Este libro utiliza Python como lenguaje de programación para crear los algoritmos. Como se ha mencionado, el Capítulo 6 introduce Python y los conocimientos necesarios para manipular y analizar los datos, pero también proporciona las bases para crear los distintos modelos, que, como verás, son más sencillos de lo que cabría esperar.
Antes de pasar a la siguiente sección, echemos un vistazo al concepto de almacenamiento de datos. Al fin y al cabo, los datos son valiosos, pero necesitas almacenarlos en un lugar donde se puedan obtener y analizar fácilmente.
El almacenamiento de datos se refiere a las técnicas y áreas utilizadas para almacenar y organizar datos para futuros análisis. Los datos se almacenan en muchos formatos, como CSV y XLSX. Otros tipos de formatos pueden ser XML, JSON e incluso JPEG para las imágenes. El formato se elige en función de la estructura y organización de los datos.
Los datos también pueden almacenarse en la nube o in situ, en función de tu capacidad de almacenamiento y costes. Por ejemplo, puede que quieras guardar los datos históricos de un minuto de las acciones de Apple en la nube, en lugar de en un archivo CSV, para ahorrar espacio en tu ordenador local.
Cuando trabajes con series temporales en Python, vas a tratar principalmente con dos tipos de almacenamiento de datos: matrices y marcos de datos. Veamos en qué consisten:
- Matriz
-
Una matriz se utiliza para almacenar elementos del mismo tipo. Normalmente, un conjunto de datos homogéneo (como números) se guarda mejor en una matriz.
- Marco de datos
-
Un marco de datos es una estructura bidimensional que puede contener datos de varios tipos. Puede compararse a una tabla con columnas y filas.
En general, las matrices deben utilizarse siempre que sea necesario almacenar eficazmente una colección homogénea de datos. Cuando se trate de datos heterogéneos o cuando necesites editar y analizar datos de forma tabular, debes utilizar dataframes.
Comprender la Ciencia de Datos
La ciencia de datos desempeña un papel esencial en la tecnología y el progreso. Los algoritmos se basan en la información proporcionada por las herramientas de la ciencia de datos para realizar sus tareas. Pero, ¿qué son los algoritmos?
Un algoritmo es un conjunto de procedimientos ordenados que están diseñados para completar una determinada actividad o abordar una cuestión concreta. Un algoritmo puede ser tan sencillo como lanzar una moneda al aire o tan sofisticado como el algoritmo de Risch.4
Tomemos un algoritmo muy sencillo que actualice una plataforma de gráficos con los datos financieros necesarios. Este algoritmo seguiría estos pasos
- Conecta el servidor y el proveedor de datos online.
- Copia los datos financieros con la marca de tiempo más reciente.
- Pega los datos en la plataforma de gráficos.
- Vuelve al paso 1 y rehaz todo el proceso.
Ésa es la naturaleza de los algoritmos: ejecutar un determinado conjunto de instrucciones con un objetivo finito o infinito.
Nota
Los seis pasos de la ciencia de datos comentados en el apartado anterior también pueden considerarse un algoritmo.
Las estrategias de negociación también son algoritmos, ya que tienen reglas claras para el inicio y la liquidación de posiciones. Un ejemplo de estrategia de negociación es el arbitraje de mercado.
El arbitraje es un tipo de estrategia de negociación que pretende beneficiarse de las diferencias de precio de un mismo activo cotizado en distintas bolsas. Estas diferencias de precios son anomalías que los arbitrajistas borran mediante sus actividades de compra y venta. Consideremos una acción que se negocia en la bolsa A y en la bolsa B de países diferentes (por razones de simplicidad, los dos países utilizan la misma moneda). Naturalmente, la acción debe cotizar al mismo precio en ambas bolsas. Cuando esta condición no se cumple, los arbitrajistas salen de sus guaridas a la caza.
Compran la acción en la bolsa más barata y la venden inmediatamente en la bolsa más cara, asegurándose así un beneficio prácticamente sin riesgo. Estas operaciones se realizan a la velocidad del rayo, ya que las diferencias de precios no duran mucho debido a la enorme potencia y rapidez de los arbitrajistas. Para aclararnos, he aquí un ejemplo:
- El precio de la acción en la bolsa A = 10,00 $.
- El precio de la acción en la bolsa B = 10,50 $.
El algoritmo del arbitrajista en este caso hará lo siguiente:
- Compra la acción en la bolsa A por 10,00 $.
- Vende la acción inmediatamente en la bolsa B por 10,50 $.
- Embolsa la diferencia (0,50 $) y repite hasta cerrar la brecha.
Nota
Los algoritmos de negociación y ejecución pueden ser muy complejos y requieren conocimientos especializados y un cierto perímetro de mercado.
Llegados a este punto, deberías ser consciente de los dos usos principales de la ciencia de datos, la interpretación de datos y la predicción de datos:
- Interpretación de los datos
-
También se suele denominar inteligencia empresarial o, simplemente, inteligencia de datos. El objetivo de la implementación de los algoritmos es comprender el qué y el cómo de los datos.
- Predicción de datos
-
También se suele denominar análisis predictivo o simplemente previsión. El objetivo de la implementación de los algoritmos es comprender el futuro de los datos.
El principal objetivo de utilizar algoritmos de aprendizaje en los mercados financieros es predecir los precios futuros de los activos, de modo que puedas tomar una decisión de negociación informada que produzca una revalorización del capital con un porcentaje de éxito superior al aleatorio. En este libro hablo de muchos algoritmos de aprendizaje simples y complejos. Estos algoritmos o modelos de aprendizaje pueden clasificarse como sigue:
- Aprendizaje supervisado
-
Los algoritmos de aprendizaje supervisado son modelos que necesitan datos etiquetados para funcionar. Esto significa que debes proporcionar datos para que el modelo se entrene en esos valores pasados y comprenda los patrones ocultos, de modo que pueda ofrecer salidas futuras cuando se encuentre con nuevos datos. Algunos ejemplos de aprendizaje supervisado son los algoritmos de regresión lineal y los modelos de bosque aleatorio.
- Aprendizaje no supervisado
-
Los algoritmos de aprendizaje no supervisado son modelos que no necesitan datos etiquetados para funcionar. Esto significa que pueden hacer el trabajo con datos no etiquetados, ya que están construidos para encontrar patrones ocultos por sí mismos. Algunos ejemplos son los algoritmos de agrupación y el análisis de componentes principales (ACP).
- Aprendizaje por refuerzo
-
Los algoritmos de aprendizaje por refuerzo son modelos que no necesitan datos en absoluto, ya que descubren su entorno y aprenden de él por sí solos. A diferencia de los modelos de aprendizaje supervisado y no supervisado, los modelos de aprendizaje por refuerzo adquieren conocimientos a través de la retroalimentación obtenida del entorno mediante un sistema de recompensas. Como esto se aplica generalmente a situaciones en las que un agente interactúa con el entorno y aprende a adoptar comportamientos que maximizan la recompensa a lo largo del tiempo, puede que no sea el algoritmo adecuado para la regresión de series temporales. Por otra parte, puede utilizarse para desarrollar una política que pueda aplicarse a los datos de series temporales para crear predicciones.
Como habrás observado, el título del libro es Aprendizaje profundo para finanzas. Esto significa que, además de cubrir otros modelos de aprendizaje, dedicaré una parte considerable del libro a discutir los modelos de aprendizaje profundo para la predicción de series temporales. El aprendizaje profundo gira principalmente en torno al uso de redes neuronales, un algoritmo que se analiza en profundidad en el Capítulo 8.
Los modelos profundos de aprendizaje supervisado (como las redes neuronales profundas) pueden aprender representaciones jerárquicas de los datos porque incluyen muchas capas, en las que cada capa extrae características a un nivel diferente de abstracción. Como resultado, los modelos profundos aprenden patrones ocultos y complejos que pueden ser difíciles de aprender para los modelos superficiales (no profundos).
Por otra parte, los modelos superficiales de aprendizaje supervisado (como la regresión lineal) tienen una capacidad limitada para aprender relaciones complejas y no lineales. Pero requieren menos esfuerzo computacional y, por tanto, son más rápidos.
Hoy en día, los algoritmos de la ciencia de datos se implementan prácticamente en todas partes, no sólo en las finanzas. Algunas aplicaciones son las siguientes:
- Análisis empresarial: Optimizar los precios, predecir la rotación de clientes o mejorar las iniciativas de marketing mediante el análisis de datos.
- Sanidad: Mejorar los resultados de los pacientes, encontrar terapias innovadoras o reducir los costes sanitarios mediante el análisis en profundidad de los datos de los pacientes.
- Deportes: Análisis de datos deportivos para mejorar el rendimiento de los equipos, la búsqueda de jugadores o las apuestas
- Investigar: Analizar datos para apoyar la investigación científica, demostrar teorías u obtener nuevos conocimientos.
Cuando alguien habla de aplicaciones de la ciencia de datos, ayuda saber qué hace un científico de datos. Un científico de datos debe evaluar y comprender datos complejos para obtener información y proporcionar orientación para la toma de decisiones. Entre las tareas más comunes a este respecto se incluyen el desarrollo de modelos estadísticos, la aplicación de técnicas de aprendizaje automático y la visualización de datos. Apoyan la aplicación de soluciones basadas en datos e informan a las partes interesadas de sus resultados.
Nota
Los científicos de datos son diferentes de los ingenieros de datos. Mientras que un científico de datos se ocupa de la interpretación y el análisis de los datos, un ingeniero de datos se ocupa de las herramientas y la infraestructura necesarias para recopilar, almacenar y analizar los datos.
A estas alturas ya deberías comprender todo lo que necesitas para iniciarte en la ciencia de datos. Presentemos el segundo tema principal del libro: los mercados financieros.
Introducción a los Mercados Financieros y al Trading
El objetivo de este libro es presentar un enfoque práctico para aplicar distintos modelos de aprendizaje a la previsión de datos de series temporales financieras. Para ello, es imprescindible adquirir conocimientos sólidos sobre el funcionamiento de los mercados financieros y de negociación.
Los mercados financieros son lugares donde las personas pueden negociar instrumentos financieros, como acciones, bonos y divisas. El acto de comprar y vender se denomina negociación. El principal objetivo de la compra de un instrumento financiero, aunque no el único, es la revalorización del capital. El comprador cree que el valor del instrumento es mayor que su precio; por tanto, compra la acción(va largo) y vende cuando cree que el precio actual es igual al valor actual. Por el contrario, los operadores también pueden ganar dinero si el precio del instrumento baja. Este proceso se denomina venta en corto y es habitual en determinados mercados, como el de futuros y el de divisas (FX).
El proceso de venta en corto implica tomar prestado el instrumento financiero de un tercero, venderlo en el mercado y volver a comprarlo, antes de devolvérselo al tercero. Lo ideal es que, como esperas que el precio del instrumento baje, lo vuelvas a comprar a un coste más bajo (tras la bajada del precio) y se lo devuelvas al tercero al precio de mercado, embolsándote así la diferencia. Los siguientes ejemplos explican mejor estos conceptos:
- Ejemplo de posición larga (compra)
-
Un operador espera que el precio de las acciones de Microsoft aumente en los próximos dos años debido a la mejora de las normativas tecnológicas, lo que aumentaría los beneficios. Compra una serie de acciones a 250 $ y pretende venderlas a 500 $. Por tanto, el operador tiene una posición larga en acciones de Microsoft (lo que también se denomina ser alcista).
- Ejemplo de posición corta (venta)
-
Un operador espera que el precio de las acciones de Lockheed Martin baje en los próximos días debido a las señales de una estrategia técnica. Vende en corto una serie de acciones a 450 $ y pretende recomprarlas a 410 $. Por tanto, el operador tiene una posición corta en acciones de Lockheed Martin (también se dice que es bajista).
Nota
Los mercados que tienden al alza se denominan alcistas. Derivado de la palabra toro y de la naturaleza agresiva del toro, ser alcista está relacionado con el optimismo, la euforia y la codicia.
Los mercados que tienden a la baja se denominan bajistas. Derivado de la palabra oso y de su naturaleza defensiva, ser bajista está relacionado con el pesimismo, el pánico y el miedo.
Los instrumentos financieros pueden presentarse en su forma bruta (al contado) o en forma de derivados. Los derivados son productos que los operadores utilizan para operar en los mercados de determinadas maneras. Por ejemplo, un contrato a plazo o de futuros es un contrato derivado en el que un comprador fija el precio de un activo para comprarlo más adelante.
Otro tipo de derivado es una opción. Una opción es el derecho, pero no la obligación, de comprar un determinado activo a un precio específico en el futuro pagando una prima ahora (el precio de la opción). Cuando un comprador quiere comprar la acción subyacente, ejerce su opción para hacerlo; de lo contrario, puede dejar que la opción venza.
La actividad comercial también puede producirse con fines de cobertura, ya que no se limita a la mera especulación. Un ejemplo de ello es Air France (la principal compañía aérea francesa) que cubre sus operaciones comerciales comprando futuros del petróleo. La compra de futuros del petróleo protege a Air France de la subida de los precios del petróleo que puede perjudicar a sus operaciones principales (aviación). El aumento de los costes derivados del uso de combustible para propulsar los aviones se compensa con las ganancias de los futuros. Esto permite a la aerolínea centrarse en su actividad principal. Todo este proceso se denomina cobertura.
Otro ejemplo: supongamos que una compañía aérea prevé consumir una determinada cantidad de combustible en los próximos seis meses, pero le preocupa el posible aumento del precio del petróleo en ese periodo. Para protegerse contra este riesgo de precios, la compañía aérea puede suscribir un contrato de futuros para comprar petróleo a un precio fijo en una fecha futura.
Si el precio del petróleo aumenta durante ese tiempo, la compañía aérea seguiría pudiendo comprar el petróleo al precio fijo más bajo acordado en el contrato de futuros. Si el precio del petróleo baja, la compañía aérea estaría obligada a pagar el precio fijo más alto, pero el precio de mercado más bajo del petróleo compensaría ese coste.
De este modo, la aerolínea puede mitigar el riesgo de las fluctuaciones de los precios en el mercado del petróleo y estabilizar sus costes de combustible. Esto puede ayudar a la compañía aérea a gestionar mejor su presupuesto y prever sus futuros beneficios. Como puedes ver, el objetivo no es obtener beneficios económicos de las operaciones comerciales, sino simplemente estabilizar sus costes fijando un precio conocido para el petróleo.
Normalmente, los instrumentos financieros se agrupan en clases de activos en función de su tipo:
- Mercados bursátiles
-
Un mercado de valores es un lugar de intercambio (electrónico o físico) donde las empresas emiten acciones para conseguir dinero para sus negocios. Cuando las personas compran acciones de una empresa, se convierten en copropietarios de esa empresa y pueden tener derecho a dividendos según la política de la empresa. Dependiendo de las acciones, también pueden obtener el derecho a votar en las reuniones del consejo de administración.
- Renta fija
-
Los gobiernos y las empresas pueden pedir dinero prestado en el mercado de renta fija. Cuando una persona compra un bono, en realidad está prestando dinero al prestatario, que ha acordado devolver el préstamo junto con los intereses. Dependiendo de la solvencia del prestatario y de los tipos de interés vigentes, el valor del bono puede aumentar o disminuir.
- Divisas
-
El mercado de divisas, también conocido como mercado de divisas, es un lugar donde la gente puede comprar y vender diversas divisas. El valor de la moneda de un país puede aumentar o disminuir en función de diversas variables, como la economía, los tipos de interés y la estabilidad política del país.
- Materias primas
-
Los productos agrícolas, el oro, el petróleo y otros activos físicos con usos industriales o de otro tipo se denominan materias primas. Suelen ofrecer un medio para beneficiarse de las tendencias económicas mundiales, además de ser una forma de cobertura contra la inflación.
- Inversiones alternativas
-
En el mundo de las finanzas, las inversiones no tradicionales, como los bienes inmuebles, los fondos de capital riesgo/inversión y los fondos de cobertura, se denominan clases de activos alternativos. Estas clases de activos tienen el potencial de ofrecer mejores rendimientos que los activos tradicionales y ofrecen la ventaja de la diversidad, pero también tienden a ser menos líquidos y pueden ser más difíciles de evaluar.
Es crucial recordar que cada una de estas clases de activos tiene cualidades únicas y diversos niveles de riesgo, por lo que los inversores deben hacer sus deberes antes de invertir en cualquiera de estos activos.
Los mercados financieros permiten a las empresas y a los gobiernos recaudar el dinero que necesitan para funcionar. También permiten a los inversores ganar dinero especulando e invirtiendo en oportunidades interesantes. Las actividades de negociación proporcionan liquidez a los mercados. Y cuanto más líquido es un mercado, más fácil y menos costoso es negociar en él. Pero, ¿cómo funcionan realmente los mercados? ¿Qué hace que los precios suban y bajen?
Lamicroestructura del mercado es la investigación que se ocupa de la negociación de valores en los mercados financieros. Examina cómo funciona la negociación y cómo se comportan los operadores, los inversores y los creadores de mercado. Comprender la formación de los precios y las variables que afectan a los costes de negociación es el objetivo de la investigación de la microestructura del mercado.
El flujo de órdenes, la liquidez, la eficacia del mercado y la formación de precios son sólo algunos de los muchos temas que abarca la investigación de la microestructura del mercado. Además, esta investigación examina cómo afectan a la dinámica del mercado las distintas técnicas de negociación, incluidas las órdenes limitadas, las órdenes de mercado y la negociación algorítmica. La liquidez es posiblemente el concepto de microestructura de mercado más importante. Describe la facilidad con la que un activo puede comprarse o venderse sin que cambie materialmente su precio. La liquidez puede variar entre instrumentos financieros y a lo largo del tiempo. Puede verse afectada por una serie de variables, como el volumen de negociación y la volatilidad.
Por último, quiero hablar de otra área importante de la microestructura del mercado: la determinación de precios. Se refiere al método utilizado para fijar los precios en un mercado. Los precios pueden verse afectados por elementos como el flujo de órdenes, la actividad de los creadores de mercado y la presencia de diversos métodos de negociación.
Imagina que quieres comprar un número considerable de acciones de dos valores: el valor A y el valor B. El valor A es muy líquido, mientras que el valor B es muy ilíquido. Si quieres ejecutar la orden de compra en la acción A, es probable que te la ejecuten al precio de mercado deseado, con un impacto mínimo o nulo. Sin embargo, con la acción B, es probable que obtengas un precio peor, ya que no hay suficientes vendedores dispuestos a vender al precio de compra que deseas. Por lo tanto, al crear más demanda con tus pedidos, el precio sube para igualar los precios de los vendedores, y así, comprarás a un precio más alto (peor). Éste es el impacto que la liquidez puede tener en tu negociación.
Aplicaciones de la Ciencia de Datos en Finanzas
Empecemos a echar un vistazo a las principales áreas de la ciencia de datos para las finanzas. Cada campo tiene sus retos y problemas que necesitan soluciones simples y complejas. Las finanzas no son diferentes. En los últimos años se ha producido un aumento gigantesco del uso de la ciencia de datos para mejorar el mundo de las finanzas, desde el mundo corporativo hasta el de los mercados. Analicemos algunas de estas áreas:
- Predecir la dirección del mercado
-
El objetivo de utilizar la ciencia de datos en series temporales financieras es descubrir patrones, tendencias y relaciones en los datos históricos del mercado que puedan utilizarse para hacer predicciones sobre los movimientos futuros del mercado.
- Detección del fraude financiero
-
Las transacciones financieras pueden examinarse en busca de patrones y anomalías utilizando modelos de ciencia de datos, que intentan detectar posibles fraudes. Una forma de utilizar la ciencia de datos para detener el fraude financiero es examinar los datos de las transacciones con tarjeta de crédito en busca de patrones de gasto inusuales o sospechosos, como numerosas compras menores realizadas en rápida sucesión o compras importantes o frecuentes realizadas en la misma tienda.
- Gestión de riesgos
-
La ciencia de datos puede utilizarse para examinar datos financieros y detectar riesgos potenciales para las carteras. Esto puede implicar el análisis de grandes cantidades de datos históricos utilizando métodos como el modelado estadístico, el aprendizaje automático y la inteligencia artificial para detectar patrones y tendencias que puedan utilizarse para predecir factores de riesgo.
- Calificación crediticia
-
La ciencia de datos puede utilizarse para examinar datos financieros e historial crediticio, pronosticar la solvencia de una persona o empresa y tomar decisiones sobre préstamos. Utilizar datos financieros, como los ingresos y el historial crediticio, para predecir la solvencia de una persona es un ejemplo de aplicación de la ciencia de datos a la investigación de la puntuación crediticia. Esto puede implicar el uso de técnicas como el modelado estadístico y el aprendizaje automático para desarrollar un modelo de predicción que pueda utilizar una serie de indicadores, como el rendimiento crediticio anterior, los ingresos y el historial laboral, para evaluar la probabilidad de que una persona devuelva un préstamo.
- Procesamiento del lenguaje natural
-
Para juzgar mejor, la PNL analiza y extrae ideas de datos financieros no estructurados, como artículos de noticias, informes y publicaciones en redes sociales. La PNL utiliza el sentimiento del texto para extraer posibles oportunidades de negociación derivadas de las intenciones y sentimientos de los participantes y expertos del mercado. La PNL entra en el campo del análisis de sentimientos (con ayuda del aprendizaje automático).
Resumen
El campo de la ciencia de datos sigue creciendo cada día con la introducción continua de nuevas técnicas y modelos para mejorar la interpretación de los datos. Este capítulo ofrece una sencilla introducción a lo que necesitas saber sobre la ciencia de datos y cómo puedes utilizarla en finanzas.
Los tres capítulos siguientes presentan los conocimientos en estadística, probabilidad y matemáticas que puedes necesitar cuando intentes comprender los modelos de la ciencia de datos. Aunque el objetivo del libro es presentar un enfoque práctico para crear y aplicar los distintos modelos utilizando Python, te ayudará a comprender con qué estás tratando en lugar de aplicarlos ciegamente a los datos.
Si necesitas un repaso de Python, consulta el Capítulo 6, que es una introducción básica. Sienta las bases de lo que vendrá después en el libro. No es necesario que te conviertas en un maestro de Python, pero debes entender el código y a qué se refiere, y sobre todo cómo depurar y detectar errores en el código.
1 OHLC se refiere a los cuatro datos esenciales del mercado: precio de apertura, precio máximo, precio mínimo y precio de cierre.
2 La razón por la que digo "implícita" es que la estacionariedad debe verificarse mediante comprobaciones estadísticas que verás en el Capítulo 3. De momento, se supone que al diferenciar los datos se obtienen series temporales estacionarias.
3 La medida del PIB se analiza con más detalle en el Capítulo 12.
4 El algoritmo de Risch es una técnica de integración indefinida utilizada para encontrar antiderivadas, concepto que verás en el capítulo 4.
Get Aprendizaje profundo para las finanzas now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

