Capítulo 4. Ponerlo todo junto: Aprendizaje profundo eficiente
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
En el Capítulo 2, leíste sobre los fundamentos y los flujos de datos de las aplicaciones de aprendizaje profundo. En el Capítulo 3, aprendiste sobre las diversas unidades de cálculo disponibles en la actualidad y cómo permiten el cálculo numérico a escala. Este capítulo se basa en el contenido de los dos capítulos anteriores, demostrando la aceleración proporcionada por el hardware informático especializado y proporcionando algunos ejemplos de cómo hacerlo. También presenta algunos consejos y trucos para entrenar eficazmente un modelo de aprendizaje profundo en una sola máquina con un máximo de un dispositivo acelerado.
En este capítulo hay dos ejercicios prácticos, uno que utiliza un modelo de lenguaje (GPT-2 de OpenAI) y el segundo un modelo de clasificación de imágenes (EfficientNet).1 El ejercicio GPT-2 te permite explorar el nivel de aceleración que proporciona una GPU y profundizar en los detalles de las herramientas de creación de perfiles para comprender las implicaciones subyacentes. En el segundo ejemplo práctico, explorarás la creación de una solución de segmentación de imágenes multiclase utilizando el conjunto de datos Scene Parsing Benchmark (SceneParse150) del MIT. Después de realizar estos ejercicios, verás varias técnicas que puedes aplicar para introducir eficiencia en tu código. Más concretamente, aprenderás sobre compilación de grafos, entrenamiento de precisión mixta, eficiencias obtenidas mediante trucos de gradiente, trucos de disposición de memoria y algunos trucos de DataLoader para gestionar la sobrecarga del canal de entrada del modelo. Este capítulo culmina con un pequeño ejemplo de núcleo personalizado para demostrar el aprovechamiento de la computación acelerada para operaciones personalizadas.
Ejercicio Práctico nº 1: GPT-2
ChatGPT es un influyente modelo de lenguaje generativo capaz de "conversar" mediante indicaciones de texto libre. La tecnología que hay detrás de ChatGPT es el Transformador Generativo Preentrenado (GPT) de OpenAI, un gran modelo de lenguaje basado en Transformadores. La escala ha sido un factor crucial para el éxito de GPT; es un modelo grande, entrenado con grandes volúmenes de datos, y emplea muchos trucos, algunos de los cuales son conocidos y se tratarán en el Capítulo 10. Fue la segunda versión de GPT, GPT-2, la que alcanzó un éxito impresionante. En este ejercicio, explorarás ese modelo.
La tarea para GPT-2 es predecir la palabra siguiente dadas las palabras anteriores dentro de un texto. La GPT-2 tiene más de 10 veces más parámetros y se entrena con 10 veces más datos que la GPT original. Más concretamente, GPT-2 tiene 1.500 millones de parámetros y se entrena a partir del texto extraído de 8 millones de páginas web.
Nota
GPT-2 se publicó a principios de 2019. Desde entonces (a principios de 2024) también se han publicado GPT-3, -3.5 y -4, aunque se mantienen en código cerrado (con un intercambio muy limitado de detalles de implementación). En la Tabla 4-1, en "Contribuidores clave a la escala", se ofrece una comparación de las versiones según distintos criterios .
Objetivos del ejercicio
Los objetivos de este ejercicio son los siguientes:
-
Revisa ejemplos de cómo escribir código agnóstico a la infraestructura. Esto te permite escalar fácilmente a otra infraestructura en caso de cuello de botella informático.
-
Perfila y monitoriza para medir el comportamiento de tu modelo y bucle de entrenamiento. Estas habilidades son útiles para comprender las limitaciones y proporcionan pistas para optimizar adecuadamente.
-
Conoce las técnicas para aprovechar las capacidades del hardware para desarrollar con eficacia.
-
Opcionalmente, aprende sobre Docker y otras cadenas de herramientas de construcción para construir tiempos de ejecución adecuados a tus necesidades de desarrollo, en lugar de utilizar entornos de navaja suiza como los contenedores NVIDIA GPU Cloud (NGC).
La siguiente sección explora la arquitectura del modelo y los detalles de implementación. (Para un recorrido más exhaustivo, consulta la explicación detallada de Jay Alammar sobre GPT-2, que explica conceptos intrincados como el Transformador, el bloque de atención, la autoatención enmascarada y la atención cruzada, y el papel que desempeñan la consulta, la clave y el valor en la predicción de la posible siguiente palabra/token).2 El código de este ejercicio está disponible en la carpeta chapter_4 del repositorio GitHub del libro.
Arquitectura Modelo
La técnica clave que emplea GPT consiste en enmascarar algunas palabras del corpus de texto y entrenar al modelo para que prediga las palabras enmascaradas explotando el corpus de texto restante. Por ejemplo, se puede mostrar al modelo el texto "He traído un libro a ___" y pedirle que prediga la palabra que falta, "leer". Como puedes ver, puede haber más de una palabra que podría encajar aquí (por ejemplo, "aprender"). Hay que puntuar estas posibles palabras para identificar la palabra recomendada. Con los bloques de atención, las arquitecturas Transformer pueden atender a secuencias más largas de tokens de forma paralela. Esto, combinado con esta capacidad de enmascaramiento, permite al modelo desarrollar una mejor comprensión del lenguaje y explotar el significado semántico del texto mediante la incrustación de palabras.
El GPT-2 es un modelo autorregresivo sólo de descodificador. La arquitectura completa se muestra en la Figura 4-1, incluido un desglose del bloque GPT (el componente descodificador). Esta figura muestra cómo fluyen la incrustación de texto y la codificación posicional a través de la red, que consiste en una serie de bloques de atención enmascarada de varias cabezas, compuestos junto con las capas LayerNorm (normalización de capas) y Conv1d (convolución 1D). Puedes observar que esta red tiene varias conexiones residuales a lo largo de toda ella. El bloque de atención tiene atención propia y cruzada, por lo que (como se muestra en la esquina inferior derecha de la figura) la consulta, la clave y el valor pueden proceder de la misma secuencia de texto, o bien la consulta puede proceder de una secuencia y la clave y el valor de otra.
Contribuyentes clave a la escala
Repasemos algunas de las características clave de la GPT-2 que contribuyeron al escalado de esta técnica.
Bloque de atención del transformador
Ashish Vaswani et al. propusieron inicialmente el bloque de atención multicabezal que se utiliza en GPT en su artículo seminal "Attention Is All You Need".3 La característica clave de esta arquitectura es que las palabras del texto se procesan como un todo. Otras arquitecturas contemporáneas, como las redes neuronales recurrentes (RNN) y las redes de memoria a corto plazo de larga duración (LSTM), procesan las palabras una a una en una secuencia temporal y recuerdan la representación de estas palabras mediante estados ocultos. La incapacidad de procesar palabras en paralelo era una razón clave por la que las capacidades de los modelos lingüísticos anteriores a los Transformadores no mejoraban rápidamente. Con la introducción del Transformador, se pudo proporcionar un contexto más amplio a través de una secuencia de tokens/palabras. En GPT-2, este tamaño de contexto era de 1.024 tokens, el doble que en GPT (ver Tabla 4-1). Desde entonces, el tamaño del contexto se ha ampliado hasta un tamaño inicial de 8.192 tokens en GPT-4,4 y la capacidad de razonamiento de esta red ha aumentado proporcionalmente.
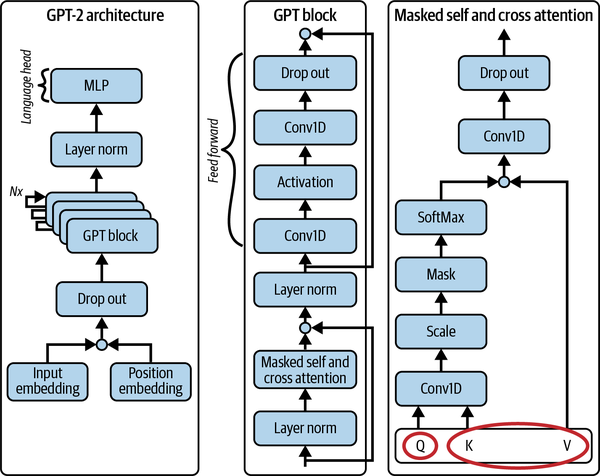
Figura 4-1. Arquitectura de GPT-2 y desglose detallado de su subred
| Nombre | Tamaño del contexto | Número de parámetros | Capas | Profundidad del modelo | Modelo comparable (en cuanto a capacidad) |
|---|---|---|---|---|---|
| GPT-2 pequeño | 1,024 | 117M | 12 | 768 | GPT (original) |
| Medio GPT-2 | 1,024 | 345M | 24 | 1,024 | BERT |
| GPT-2 grande | 1,024 | 762M | 36 | 1,280 | |
| GPT-2 XL | 1,024 | 1,542M | 48 | 1,600 | |
| GPT-3 pequeña | 2,048 | 125M | 12 | 768 | GPT-2 pequeño |
| Medio GPT-3 | 2,048 | 350M | 24 | 1,024 | Medio GPT-2 |
| GPT-3 grande | 2,048 | 760M | 24 | 1,536 | GPT-2 grande |
| GPT-3 XL | 2,048 | 1.3B | 24 | 2,048 | GPT-2 XL |
| GPT-3 2,7B | 2,048 | 2.7B | 32 | 2,560 | |
| GPT-3 6,7B | 2,048 | 6.7B | 32 | 4,096 | |
| GPT-3 13B | 2,048 | 13B | 40 | 5,140 | |
| GPT-3 175B | 2,048 | 175B | 96 | 12,288 | |
| GPT-4 | 8,192 | No revelado (se rumorea que 1,76T) | No revelado | No revelado | |
| GPT-4-32k | 32,768 | No revelado | No revelado | No revelado |
Entrenamiento no supervisado
Como ya hemos comentado en, el entrenamiento de GPT se consigue enmascarando ciertos tokens en el conjunto de datos de entrenamiento. Gracias a esta técnica, no es necesario etiquetar ni supervisar el entrenamiento de estos grandes modelos lingüísticos. Así, los datos de entrenamiento siguen siendo fáciles de obtener mediante un rastreador web. Dada la enorme cantidad de datos textuales disponibles en Internet, lo único que sigue preocupando es la calidad de las entradas. OpenAI emplea una técnica de filtrado para elegir páginas de texto que hayan recibido al menos tres upvotes ("me gusta" de la página) de usuarios más para garantizar la calidad del contenido utilizado para entrenar el modelo. Estos textos raspados formaron el vocabulario de GPT-2, que también se amplió a 50.257 a partir de los 40.478 tokens únicos utilizados para entrenar GPT.
Aprendizaje sin disparos
En la versión inicial de GPT, OpenAI se centró en entrenar un gran modelo lingüístico mediante el preentrenamiento y el ajuste fino de distintas versiones del modelo para diversos fines lingüísticos, como la respuesta a preguntas, el resumen de textos, la traducción lingüística y la comprensión lectora. Sin embargo, como las relaciones semánticas entre las palabras siguen siendo coherentes en todas las aplicaciones del lenguaje hablado, con GPT-2 se observó que el modelo podía reutilizarse para esas tareas mediante técnicas de cero o pocos disparos (que se tratan en los Capítulos 11, 12 y 13). En otras palabras, es posible entrenar un modelo lingüístico muy bueno y reutilizarlo para diversas tareas en el momento de la inferencia. Esto es posible porque las técnicas de disparo cero no requieren retropropagación; por tanto, la reutilización es muy eficiente en cuanto a costes, cálculos y tiempo.
Éste es un aspecto muy importante de la GPT que debe considerarse seriamente para el desarrollo de modelos en tareas relacionadas. Reutilizar un modelo existente para una tarea relacionada mediante el ajuste fino o la alineación del tiempo de inferencia, como en el metaaprendizaje y el aprendizaje de disparo cero, es un gran truco de optimización. Esto se tratará en detalle en el Capítulo 11.
Escala de parámetros
Como ya se ha comentado, GPT-2 es simplemente una versión a escala de GPT (con una ligera reordenación de las capas LayerNorm ). La escala en GPT-2 proviene del uso de un tamaño de contexto mayor y más bloques GPT(Figura 4-1 y Tabla 4-1). Las versiones posteriores del modelo siguieron escalando; el modelo GPT-3 más grande, por ejemplo, tiene 175.000 millones de parámetros.5 Como referencia, se calcula que los humanos tenemos 100 billones de sinapsis.
Aplicación
Aunque en OpenAI ha abierto el código de GPT-2, en este ejercicio utilizarás la biblioteca Transformers de Hugging Face, que proporciona una implementación en PyTorch de la arquitectura GPT-2 que se muestra en la Figura 4-1. En concreto, utilizarás la biblioteca GPT2LMHeadModel, un transformador de modelo GPT2 con un cabezal de modelado de lenguaje encima.
Para cablear el GPT-2 utilizarás PyTorch Lightning, como en el Capítulo 2. Utilizarás el conjunto de datos wikitexto Cara Abrazada para el entrenamiento.
Como ya se ha mencionado, el código para este ejercicio práctico está disponible en el repositorio GitHub del libro. La implementación se explica en las siguientes secciones.
modelo.py
La implementación del modelo en este script es sencilla, ya que la mayor parte de la complejidad del modelo se abstrae en GPT2LMHeadModel. El canal de entrada del modelo tokeniza el texto, y la llamada a forward se envía a GPT2LMHeadModel, que devuelve la pérdida de entropía cruzada entre el token predicho y el token verdadero. Este script envuelve el modelo de la biblioteca Transformers en la abstracción Lightning de LightningModule.
conjuntodatos.py
La implementación del conjunto de datos está en WikiDataModule, que envuelve la v2 del conjunto de datos wikitext. En este módulo, se descarga el texto en bruto, se preprocesa, se tokeniza y, a continuación, se agrupa según la capacidad de bloques del modelo. Los datos se dividen en conjuntos de entrenamiento, validación y prueba, y se crea un DataLoader respectivo para cada uno de los módulos.
app.py
El código del entrenador se incluye en app.py. Observa específicamente el método de punto de entrada train_gpt2, que define varios componentes integrados en el régimen de entrenamiento, incluidas las devoluciones de llamada y los perfiladores (muy parecido al ejercicio práctico PyTorch del Capítulo 2). Los perfiladores sólo deben utilizarse durante el desarrollo y las ejecuciones formales, ya que incurren en costes en términos de memoria y recursos informáticos. El código del entrenador es el siguiente
datamodule = WikiDataModule(name=model_name, batch_size=batch_size,
num_workers=num_workers)
model = GPT2Module(name=model_name)
trainer = PLTrainer(
accelerator="auto",
devices=="auto",
max_epochs=max_epochs,
callbacks=[
TQDMProgressBar(refresh_rate=refresh_rate),
ckpt_cb,
DeviceStatsMonitor(cpu_stats=True),
EarlyStopping(monitor="val/loss", mode="min"),
],
logger=[
exp_logger,
TensorBoardLogger(save_dir=result_dir / "logs"),
],
profiler=torch_profiler,
)
trainer.fit(model, datamodule)
Fíjate en los argumentos accelerator y devices de este código. Estos parámetros permiten escribir código independiente de la plataforma, de modo que el mismo código puede ejecutarse en CPU, GPU, TPU u otros aceleradores. También admite el cálculo en sombreadores Metal, disponibles en las GPU de la serie M de Apple. En otras palabras, este fragmento te permite marcar el primer objetivo de escribir código agnóstico de la plataforma que puedas ejecutar en cualquier lugar y escalar según tus necesidades.
Ejecutar el ejemplo
Para ejecutar el código en, ejecuta el siguiente comando desde tu entorno:
deep-learning-at-scale chapter_4 train_gpt2
A continuación se muestran algunos ejemplos de los resultados obtenidos tras entrenar este modelo en el conjunto de datos wikitext durante 50 épocas. La instrucción utilizada fue "Llevo toda la vida esperando un libro de aprendizaje profundo a escala. Ahora que tengo uno, lo leeré. Y yo". Aquí tienes parte del texto generado:
-
Tengo la sensación de que pasará mucho tiempo antes de que me retire de esto.
-
he aprendido mucho de ella.
-
No tengo ninguna duda de que va a cambiar mi vida.
-
Estaré dispuesta a hacer todo lo que pueda para ayudarla. Estaré en la...
-
' podré hacer cualquier cosa que haría normalmente en la vida.
-
ive para ver cómo se desarrolla todo.
-
Hace tiempo que esperaba un libro sobre aprendizaje profundo.
-
podré ver qué puedo hacer para conseguirlo.
Seguimiento de experimentos
Este ejercicio práctico de (y otros a lo largo de este libro) utiliza Aim, una solución de seguimiento de experimentos de código abierto, para monitorizar y visualizar el progreso y las métricas de las carreras de entrenamiento. Elegí Aim porque es de uso gratuito y sin compromiso por tu parte. Sin embargo, existen varias alternativas que puedes utilizar en su lugar, según te convenga. Algunas de estas alternativas se tratarán brevemente en el Capítulo 11 (ver "Configuración para la ejecución iterativa"). El siguiente fragmento se utiliza para activar el registrador de seguimiento de experimentos:
exp_logger = AimLogger(
experiment=exp_name,
train_metric_prefix="train/",
val_metric_prefix="val/",
test_metric_prefix="test/",
)
A continuación, este registrador se configura con la API del entrenador como logger: es decir, trainer = Trainer(... , logger=[exp_logger]), como se muestra en el fragmento anterior Trainer.
Nota
Tendrás que iniciar el servidor aim localmente ejecutando el comando aim up para visualizar los registros de ejecución en aumhub. Tus ejecuciones registrarán tanto los logs del perfilador como los logs de ejecución, que podrás visualizar utilizando tensorboard y aimhub respectivamente (como se hizo en el Capítulo 2). Los resultados mostrados en las Figuras 4-2 y 4-3 pueden visualizarse utilizando estas dos herramientas.
Medir para comprender las limitaciones y reducir la escala
Esta sección de presenta las medidas de rendimiento obtenidas ejecutando el código en una CPU de gama alta y en una GPU, y compara ambas para explorar las limitaciones.
Funcionando en una CPU
La Figura 4-2 muestra los resultados obtenidos al ejecutar este código en un ordenador no acelerado con una CPU de 10 núcleos y 32 GB de memoria (RAM). El tamaño del lote utilizado en esta ejecución se fijó en 12.
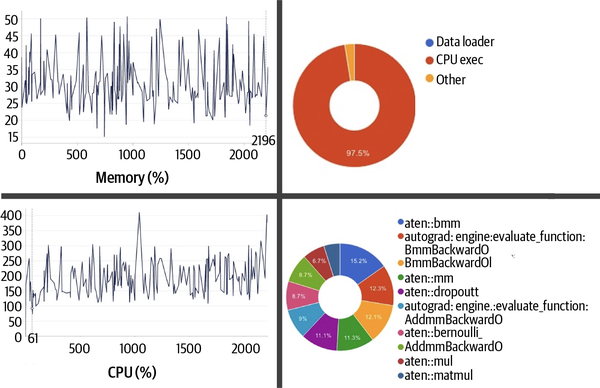
Figura 4-2. Capturas de pantalla del uso de recursos y perfiles de operador obtenidos de la ejecución de este ejemplo cuando se entrena en un ordenador de sólo CPU
El tiempo medio para dar un paso (es decir, procesar un lote de datos y hacer pasadas hacia delante y hacia atrás) fue de unos 304 segundos, de los cuales el 97,46% se empleó en ejecutar operaciones en la CPU y el 2,54% en operaciones fuera de la CPU. Cabe destacar que se dedicó un tiempo insignificante a las operaciones de carga de datos (por ejemplo, cargar el conjunto de datos de wikitextos en memoria para su ejecución).
El gráfico de consumo de memoria del perfilador indica un pico en 42,64 GB; sin embargo, si observas el monitoreo continuo del uso de memoria, en las métricas del sistema de Aim en este caso, puedes notar que el pico se sitúa en 50 GB.
Consejo
Los perfiladores se configuran para muestrear los pasos durante los cuales se debe ejecutar el perfilado. Puedes ver esto en la programación configurada para el perfilador en este ejemplo, torch.profiler.schedule(wait = 1, warmup = 1, active =5, repeat = 10, skip_first = True). Esto es útil para minimizar la sobrecarga del perfilado en la ejecución, pero plantea el riesgo de no capturar el uso adecuadamente. Por eso es útil el monitoreo continuo de alto nivel y ajustar la configuración de la programación para asegurarte de que obtienes una buena cobertura.
Las métricas del sistema también indican que la utilización de la CPU alcanzó un máximo del 410% en esta ejecución. La observación del proceso principal mediante una herramienta como htop muestra que tiene un tamaño virtual de la friolera de 453 GB, que incluye la memoria física, la memoria de intercambio, los archivos en disco que se han asignado al proceso (por ejemplo, las bibliotecas compartidas) y el espacio de memoria compartida (compartido con otros procesos, por ejemplo).
La Figura 4-2 muestra las 10 operaciones que más tiempo tardaron en calcularse, siendo la operación matriz-matriz por lotes aten::bmm la que representó el mayor porcentaje del tiempo, con un 15,2%. Aumentar el tamaño del lote te permitiría reducir el número total de pasos (es decir, el número total de veces que hay que llamar a esta operación por época).
Con un tamaño de lote de 12, el número total de pasos asciende a 184. Hipotéticamente hablando, si se duplicara el tamaño del lote a 24, el número de pasos se reduciría a 92. Dada la naturaleza vectorizada de la operación aten::bmm, si tuvieras más ciclos de cálculo disponibles, duplicar el tamaño del lote reduciría efectivamente a la mitad el coste de este cálculo. Sin embargo, a medida que aumentes el tamaño del lote, aumentarán los requisitos de memoria para mantener el tensor de entrada (la incrustación de tokens), y también la cantidad de memoria necesaria para mantener los gradientes. El requisito de memoria de los gradientes se escala linealmente con el tamaño del lote; es decir, la complejidad espacial viene dada por O(tamaño_lote). La implicación para las pérdidas y métricas por muestreo también aumentaría en el mismo orden.
Por esta razón, es importante encontrar el equilibrio óptimo entre CPU y memoria (tanto física como virtual). En este caso, con el hardware de CPU disponible, no era posible utilizar un tamaño de lote de 24, ya que el sistema tenía problemas de falta de memoria (OOM). De hecho, incluso con un tamaño de lote de 12, el sistema anfitrión no respondía esporádicamente. Existen técnicas de autoajuste, como los Algoritmos Adaptativos a la Memoria de la Antorcha (TOMA), que pueden encontrar el tamaño de lote más adecuado, reintentando con un tamaño inferior si se producen errores de OOM; el uso de estos trucos puede eliminar la sobrecarga manual de dimensionar correctamente el tamaño del lote, y pueden activarse fácilmente utilizando la APIlightning.pytorch.tuner.Tuner.scale_batch_size() .
Como se comenta en el Capítulo 3, gestionar los requisitos de memoria reduciendo la precisión de los tensores también es una opción; sin embargo, las CPU estándar no disponen de hardware especializado para los distintos formatos de coma flotante que allí se mencionan. Las unidades aceleradoras están más especializadas en el crujido de datos y disponen de hardware adicional para soportar el cálculo de menor precisión; las CPU son hardware de propósito general en el que este soporte está en gran medida ausente o emulado.
Dado que con un tamaño de lote de 12 el sistema no respondía esporádicamente y tardaba una media de 304 segundos en completar un paso, tardaría unas 15,5 horas en terminar una época (184 pasos). El rastreo de funciones, proporcionado por una herramienta de perfilado como el perfilador PyTorch utilizado en este ejemplo, es muy útil para comprender la duración y la naturaleza de las operaciones que están ocupando el espacio del proceso (ver Figura 4-3). Esto es útil para identificar las llamadas subóptimas para posteriores optimizaciones.
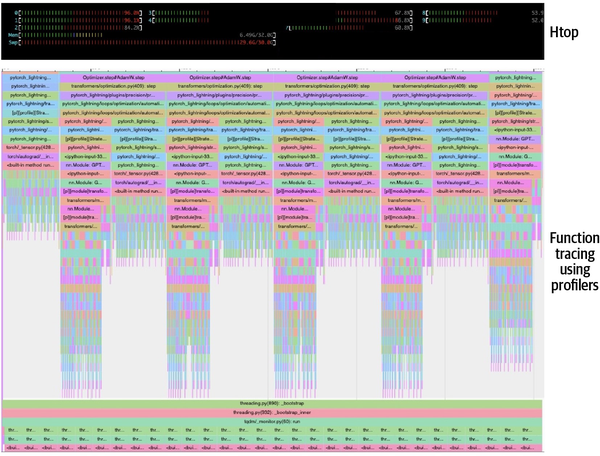
Figura 4-3. Trazado de funciones proporcionado por el perfilador PyTorch cuando este ejemplo se ejecuta en una CPU
La principal conclusión de este ejercicio es que dimensionar correctamente la memoria y el número de núcleos de la CPU y ajustar el tamaño del lote te ayudará a obtener lo mejor del entrenamiento basado en la CPU. Sin embargo, el tiempo de respuesta para el aprendizaje profundo en una CPU puede ser insuficiente: más de 15 horas para una época, como en este caso, es un ciclo de respuesta muy poco práctico para un desarrollo rápido y una buena experiencia de usuario.
En la sección siguiente, veremos cómo se puede ampliar este ejemplo en un ordenador heterogéneo utilizando una CPU similar a la utilizada en esta sección junto con una GPU NVIDIA A100 de 80 GB.
Funcionando en una GPU
En el Capítulo 3, leíste sobre el modelo de ejecución de la computación acelerada y aprendiste cómo el host/CPU facilita la ejecución del operador (es decir, el núcleo) en una GPU de forma paralela. También aprendiste los pasos necesarios para transferir datos del host a la memoria de la GPU y la sobrecarga que esto puede causar debido al ancho de banda limitado.
En este ejercicio, el canal de entrada del modelo (datos) carga los datos de texto en la memoria, realiza el preprocesamiento y la tokenización, y genera la incrustación, como se muestra en la Figura 4-1. Estas incrustaciones -los tensores matriciales- se cargan en la VRAM de la GPU. A continuación, a medida que avanza el cálculo, se invocan varias funciones del núcleo en la GPU para realizar las operaciones necesarias de forma vectorizada en sus miles de núcleos.
La Figura 4-4 es una captura de pantalla obtenida de una traza de función de una ejecución de entrenamiento de este ejemplo en una GPU NVIDIA A100 SXM de 80 GB. La traza superior corresponde a un hilo, generado por el proceso principal, que gestiona la comunicación entre el dispositivo y el host. Esta traza también muestra otro hilo en el mismo host que gestiona los cálculos ligados a la CPU (por ejemplo, el canal de entrada del modelo). La parte inferior de la figura muestra la pila del subproceso correspondiente al cálculo de la GPU. Observa la caída correspondiente en el multiprocesador de streaming cuando las operaciones de copia de memoria están en vuelo. La fila inferior indica el tiempo transcurrido para cada una de las funciones del núcleo invocadas durante las etapas del perfilado. Observa lo diferentes que son los trazados obtenidos de una CPU y una GPU (Figuras 4-3 y 4-4, respectivamente).
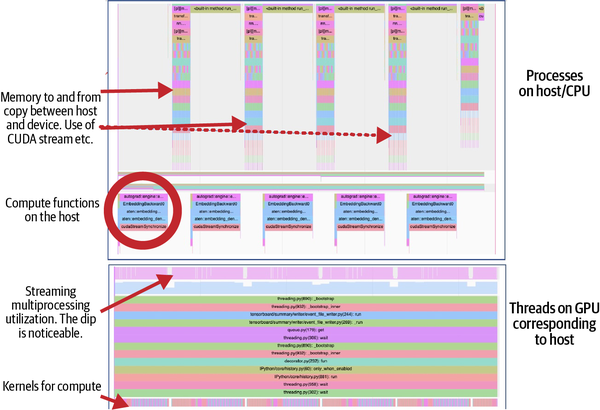
Figura 4-4. Trazado de funciones proporcionado por el perfilador PyTorch cuando se ejecuta en una GPU
Para ejecutar este ejemplo en una GPU, puedes utilizar el mismo comando que utilizaste para ejecutarlo en una CPU (ver "Ejecutar el ejemplo"). Como el código está escrito para ser agnóstico respecto a la plataforma, no es necesario realizar ningún cambio. Sin embargo, tendrás que asegurarte de que tu hardware tiene instalados un controlador y un tiempo de ejecución NVIDIA. Como uno de los objetivos de este ejercicio es poder monitorizar el uso, también necesitarás tener instalada la Interfaz de Herramientas de Perfilado CUDA (CUPTI). Para acceder a las instrucciones completas de configuración, consulta "Configuración de tu entorno para ejercicios prácticos".
Nota
Las herramientas de creación de perfiles del núcleo CUDA como CUPTI y NVProf son extremadamente útiles, pero sólo proporcionan perfiles a nivel de operador/núcleo. Por desgracia, no proporcionan una perspectiva de nivel superior, como la de la capa neuronal. Esta contextualización tiene que hacerla el usuario.
La primera observación que hay que hacer al ejecutar este ejercicio en una GPU A100 de 80 GB es que la utilización de la memoria del host ha descendido significativamente hasta ser marginal. Además, con un tamaño de lote de 12 sólo se utilizan unos 40 GB de VRAM en la GPU. También es digno de mención que el tiempo medio de paso ha bajado a 4 s desde los 304 s de una ejecución con CPU pura. Como puedes ver en la Figura 4-5, la utilización de la GPU es del 94,5%, con un 0,4% utilizado para la copia en memoria, un 1,5% para operaciones ligadas a la CPU y un 3,7% para otras operaciones. En particular, DataLoaders sigue representando una fracción marginal de este porcentaje.
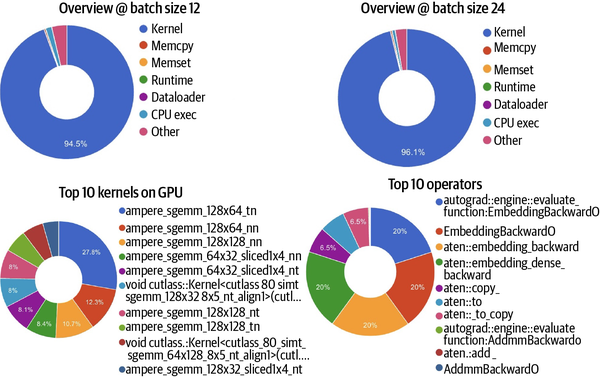
Figura 4-5. Capturas de pantalla del rastreo de funciones/operadores y del perfil del núcleo de la GPU obtenidas de la ejecución de este ejemplo cuando se entrena en computación heterogénea con una GPU NVIDIA.
Tenemos 80 GB y sólo se utiliza el 50%. Aumentemos ahora el tamaño del lote a 24. En teoría, la utilización ideal debería ser del 100%, lo que indica que todos los núcleos se están utilizando al máximo de su capacidad. Con un tamaño de lote de 24, hay un aumento de menos del 2% en la utilización de la GPU (hasta el 96,1%), como se muestra a la derecha en la Figura 4-5. Hay un descenso correspondiente en la ejecución de la CPU y en "otras" operaciones.
Si nos fijamos en la parte inferior de la Figura 4-5, podemos ver que cuando se introduce una GPU en la mezcla, el operador que más tarda ya no es aten::bmm (como en el caso de la ejecución sólo con CPU, mostrada en la Figura 4-2). Ahora, la operación más costosa es autograd::engine::evaluate_function:EmbeddingBackward0, que corresponde al cálculo del gradiente durante la diferenciación automática (es decir, la propagación hacia atrás). La razón de esta diferencia es que la operación de matriz a matriz por lotes aten::bmm es mucho más fácil de escalar en una GPU, y el tiempo de respuesta disminuye masivamente debido a la paralelización. Esto es esencialmente una buena aplicación de la ley de Amdahl, ya que la parte escalable del cálculo -la operación matriz- se paraleliza. Otras operaciones caras están relacionadas con la copia, lo que es indicativo de los retos que plantean las cargas de memoria.
Como era de esperar, a medida que aumenta el tamaño del lote, se observa un aumento de la utilización de la GPU y una disminución del tiempo de paso. Sin embargo, no hay ningún impacto en el orden de las operaciones principales. La traza, como se muestra en la Figura 4-5, sigue siendo similar, aunque con un aumento de las estadísticas de utilización.
Como se explica en el Capítulo 3, la mayoría de los aceleradores modernos, incluidas las GPUs NVIDIA, vienen con unidades de cálculo para varios formatos de precisión. El A100 específicamente viene con unidades Tensor Core capaces de estimar el nivel apropiado de precisión y ejecutar a ese nivel. Los tres modos disponibles, highest, high, y medium, pertenecen a órdenes decrecientes de precisión interna, con el nivel más alto garantizando el uso de números de coma flotante de precisión única (32 bits). Utilizando la siguiente configuración para activar esta capacidad, notarás un ahorro de tiempo de unos 0,7 s por paso en el nivel de precisión media, para un nuevo tiempo medio de paso de 3,3 s:
torch.backends.cuda.matmul.allow_tf32 = True
torch.set_float32_matmul_precision("medium")
Como indica el perfilador, sólo alrededor del 37,6% del cálculo de la GPU utilizó el Tensor Core, lo que indica que otros operadores quizá no eran compatibles con el formato tf32. Este nivel de comprensión es realmente útil para optimizar la ejecución del entrenamiento, porque aclara dónde está la mayor parte del gasto de cálculo y memoria y, si es crítico, permite explorar alternativas a éstos.
Si comparas la precisión del modelo con y sin la habilitación tf32, comprobarás que el impacto de la pérdida de precisión es insignificante en este caso. Sin embargo, dependiendo de tus circunstancias, puede merecer la pena hacer esta compensación. Este truco utiliza la arquitectura Tensor Core, que es específica de la serie de GPU Ampere y posteriores de NVIDIA. Si tu hardware no está equipado con la capacidad Tensor Core, simplificar utilizando formatos de precisión estándar como fp16 o mixto fp16 también puede proporcionar una ganancia significativa. Hablaremos más sobre esto en "Precisión mixta".
Transición del lenguaje a la visión
El ejercicio que aquí se comenta abarca muchos aspectos de los modelos lingüísticos. Antes de las arquitecturas Transformer, los matices de la modalidad de entrada (por ejemplo, texto, visión) impulsaban las técnicas básicas de modelado y requerían conocimientos especializados para tratar los dominios específicos de los distintos tipos de entrada. Al igual que los modelos secuenciales dominaban el dominio del lenguaje, las técnicas de convolución se utilizaban mucho en los modelos de visión por ordenador. Ahora se está reduciendo el uso de diferentes técnicas de modelado por modalidad de entrada, ya que los Transformadores están surgiendo como una técnica ubicua con aplicabilidad en todas las modalidades de entrada. Las arquitecturas basadas en Transformadores, como el Transformador de Visión (ViT)6 y el Transformador de Máscara de Atención Enmascarada (Mask2Former)7 están demostrando su rendimiento. Sin embargo, las redes de transformadores tienen una complejidad de cálculo cuadrática con respecto a la dimensión de entrada, lo que, aplicado a contenidos multimedia como imágenes pixeladas, dispara los requisitos de recursos. Dependiendo de la complejidad de la tarea, las arquitecturas convolucionales pueden proporcionar implementaciones computacionalmente menos exigentes pero eficientes.
La sección siguiente se centra en un ejercicio de visión por ordenador, utilizando la técnica de convolución.
Ejercicio Práctico nº 2: Modelo de Visión con Convolución
La tarea para este ejercicio consiste en generar resultados de segmentación para las imágenes del conjunto de datos MIT Scene Parsing Benchmark (SceneParse150), que están anotadas con 150 categorías de objetos. Teniendo en cuenta el fondo o lo desconocido, en total segmentarás para 151 clases. Este ejercicio demuestra el canal de escala, en el que el número de clases para las que segmentas es bastante grande.
Arquitectura Modelo
Este ejercicio aprovecha las redes neuronales convolucionales (CNN), una técnica de aprendizaje profundo basada en la visión por ordenador. Más concretamente, utilizarás EfficientNet como codificador de características y Convolve como bloqueador decodificador, ensamblados en una arquitectura basada en U-Net.8
Contribuyentes clave a la escala en el ejercicio de análisis de escenas
Echemos un vistazo más de cerca a algunas de las técnicas clave utilizadas en este ejercicio. Estas técnicas ayudan con el escalado a procesar grandes imágenes para un gran número de clases de forma eficiente y escalable.
Escalado con convoluciones
Uno de los principales retos al trabajar con imágenes es la escala de entrada. Una imagen de tres canales (color) de 512x512 tendrá un vector de entrada de tamaño 786.432. El tamaño del vector de entrada aumenta linealmente con el incremento de la altura o anchura de las imágenes. Sin embargo, estas entradas no son independientes; también existe una correlación estructural (espacial) y textural en las imágenes. Con la motivación de desarrollar técnicas más eficientes para aprender de las imágenes, se plantearon las redes convolucionales para explotar esta correlación de las propiedades de las características de las imágenes, aprovechando la dispersión y el reparto de parámetros.
Las CNN, propuestas por primera vez por Yann LeCun en los años 809 se inspiraron en la técnica de visión por ordenador "convolución", muy utilizada en técnicas de procesamiento de imágenes como la detección de perímetros, el desenfoque, etc. Estas técnicas aplican filtros predeterminados F de tamaño fxf sobre la imagen en una operación de ventana deslizante que se desplaza por pasos s, lo que reduce eficazmente el número de operaciones en un factor s. Esta operación de filtrado es invariante respecto a la traslación porque el mismo filtro -digamos, el filtro de detección de bordes F- puedeutilizarse para extraer un perímetro de cualquier parte de la imagen (en el centro, a lo largo de un perímetro o de otro modo). Los filtros de las capas de convolución (como en el aprendizaje profundo) se aprenden durante la retropropagación. La reutilización de estos filtros aprendidos F (ver Ecuación 4-1) hace que las CNN sean bastante interesantes y estén muy optimizadas, ya que no sólo se reduce masivamente el número de parámetros necesarios en una CNN, sino que además se comparten en cada paso. Este fenómeno se conoce comúnmente como reparto de pesos. Los apuntes de la clase Stanford CS230 de Andrew Ng y "Gentle Dive into Math Behind Convolutional Neural Networks" de Piotr Skalski son buenas fuentes para profundizar en el funcionamiento de las capas de convolución.10
Ecuación 4-1. Fórmula matemática utilizada por las capas de convolución para la extracción de rasgos de las imágenes
La arquitectura de la CNN de LeCun, LeNet-5, se muestra en la Figura 4-6.
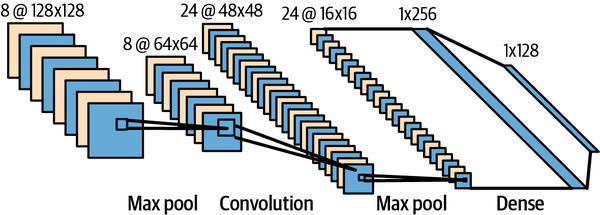
Figura 4-6. Arquitectura de LeNet-5 (Fuente: https://alexlenail.me/NN-SVG/LeNet.html)
Escalar con EfficientNet
EfficientNet, como indica su nombre, es una arquitectura de red neuronal que utiliza el escalado compuesto, como se muestra en la Figura 4-7, para escalar los modelos convolucionales de forma eficiente. Combina el escalado a través de la profundidad, la anchura y la resolución de una forma más eficaz para obtener un modelo de mayor rendimiento que maximice el uso de los recursos. EfficientNet se desarrolló utilizando una técnica llamada búsqueda de arquitectura neuronal (un subcampo de AutoML) sobre la que leerás en el Capítulo 11.
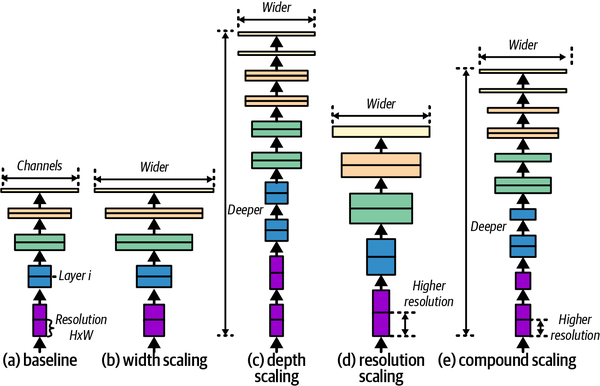
Figura 4-7. Arquitectura de EfficientNet (adaptado de Tan y Le, 2019)
Aplicación
Como ya se ha mencionado, la arquitectura final utilizada en el ejercicio es U-Net,11 que utiliza EfficientNet como red troncal (ver Figura 4-8).
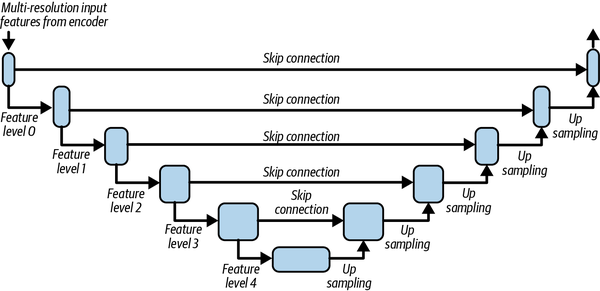
Figura 4-8. Arquitectura de U-Net (adaptado de Ronneberger et al., 2015)
El código de este ejercicio se encuentra en la carpetachapter_4 del repositorio de código del libro. Echemos un vistazo a la implementación:
- vision_model.py
-
La implementación del modelo está en
UNetSegmentationModel. Conecta el codificador EfficientNet de la biblioteca Cara Abrazadatimmy lo conecta con otro cabezal diseñado para la tarea de segmentación. Este cabezal, elDecoder, actúa como decodificador de características encargado de generar la salida de segmentación. El codificador EfficientNet proporciona características multinivel que se combinan con las salidas del decodificador de forma jerárquica, como se muestra en la arquitectura de conexión de salto U-Net (ver Figura 4-8).Como en el ejercicio anterior, este ejemplo utiliza PyTorch Lightning para aprovechar su capacidad de escribir código agnóstico de la infraestructura. La página
VisionSegmentationModuleproporciona la implementación deLightningModule. - conjuntodatos.py
-
La implementación del conjunto de datos está en
SceneParsingModule, que envuelve el conjunto de datos SceneParse150. Observa la transformación especializada utilizada en este caso para gestionar la conversión de las imágenes en tensores. - app.py
-
El punto de entrada a este ejercicio se define en app.py, en el método
train_vision_model. Observa el uso deVisionSegmentationModuleySceneParsingModuleaquí. Por lo demás, la implementación de este punto de entrada es muy similar a la del punto de entrada del ejercicio anterior,train_gpt2.
Ejecutar el ejemplo
Para ejecutar el código de este ejemplo, ejecuta el siguiente comando desde tu entorno:
deep-learning-at-scale chapter_4 train_efficient_unet
Observaciones
El número máximo de muestras que caben en la memoria de una GPU A100 de 80 GB es 85. En la ejecución base de este ejemplo, se puede alcanzar un tiempo medio de paso de 3,3 s por iteración. Esto es superior al tiempo de paso observado en el ejemplo GPT-2. Una razón de la alta latencia es que se lee, descodifica y procesa un volumen muy grande de datos (85 imágenes), lo que crea un proceso de E/S intensivo. Se trata de un reto habitual en las tareas de modelado basadas en la visión.
Ya hemos visto dos ejemplos prácticos y explorado diversas técnicas que emplean para desarrollar modelos eficientes y eficaces. En las secciones siguientes, conocerás algunas técnicas ortogonales para acelerar tu código de entrenamiento y explorarás las ventajas y desventajas de estas técnicas.
Compilación de gráficos con PyTorch 2.0
Como comentó en el Capítulo 2, PyTorch es un motor de cálculo de grafos dinámico que incurre en un coste adicional de compilación de grafos. Como viste en el Capítulo 3, este coste suele ser relativamente pequeño en comparación con el coste del cálculo matricial que requiere la red, pero a medida que los aceleradores se hacen más rápidos, esta diferencia se va reduciendo. Además, a medida que evolucionan las prácticas de aprendizaje profundo, más profesionales escriben kernels acelerados/GPU personalizados para acelerar su código. La facilidad de uso es el primer principio en el diseño del marco y las API de PyTorch. Sin embargo, el desarrollo en C++ necesario para los kernels CUDA redujo su facilidad de uso para los profesionales del aprendizaje profundo que necesitaban operadores CUDA personalizados.
PyTorch 2.0 aborda los dos retos mencionados a través de su enfoque innovador para proporcionar un mejor rendimiento y soportar formas tensoriales dinámicas, siendo al mismo tiempo compatible con versiones anteriores. Estas capacidades se consiguen realizando cambios a nivel de compilador para la ejecución de grafos. La API de evaluación de tramas añadida a CPython en Python 3.6 mediante la PEP 532 (también comentada en el Capítulo 2) ha sido fundamental en este diseño.
Nuevos componentes de PyTorch 2.0
Para proporcionar esta capacidad de compilación de grafos, en PyTorch 2.0 se añadieron cuatro nuevos componentes: PrimTorch, TorchDynamo, AOTAutograd y TorchInductor. PrimTorch es un conjunto mínimo simplificado de operadores primitivos que facilita la escritura de operadores complejos en Python. El principal objetivo de este componente es facilitar el desarrollo de funciones del núcleo específicas del hardware que, de otro modo, habrían requerido un complejo desarrollo en C++ con la correspondiente interfaz CPython para Python.
TorchDynamo es un esfuerzo por proporcionar capacidad de compilación de grafos sin perder usabilidad, trazando dinámicamente mediante la transformación de código de bytes Python. TorchScript, como se mencionó en el Capítulo 2, seguía una filosofía similar de trazar el grafo para obtener una variante más eficiente. Sin embargo, TorchScript está limitado en su capacidad para manejar flujos de control. PyTorch ofrece algunas otras utilidades de trazado, como torch.fx y PyTorch/XLA, pero la diferencia clave con TorchDynamo es el uso de la API de evaluación de tramas. De hecho, torch.fx se ha migrado ahora a TorchDynamo (ver Figura 4-9).
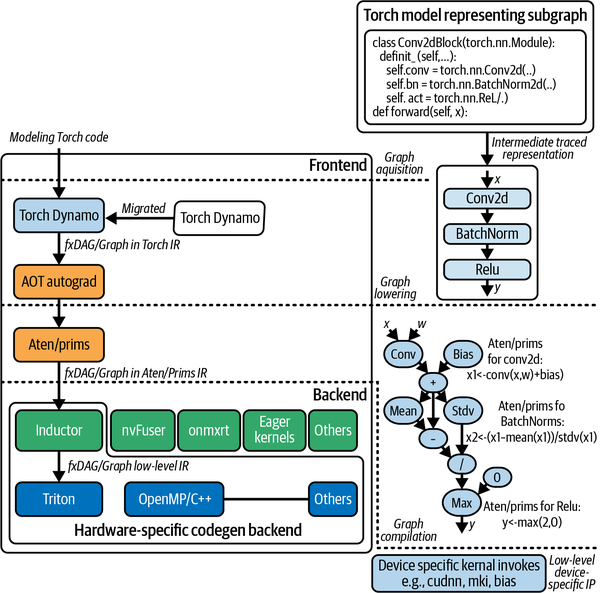
Figura 4-9. Componentes clave de PyTorch 2.0 que facilitan la capacidad de producir gráficos compilados
Ejecución de grafos en PyTorch 2.0
La ejecución de grafos en PyTorch 2.0 consta de tres pasos: adquisición del grafo, reducción y compilación. Veamos cada uno de ellos.
Adquisición de gráficos
El grafo de cálculo de tu modelo se compone utilizando un conjunto de implementaciones de subgrafos (es decir, torch.nn.Module). Estos subgráficos son compilados y consolidados (aplanados) por uno de los muchos backends de TorchDynamo (aot_ts_nvfuser, cudagraphs, inductor, ipex, nvprims_nvfuser, onnxrt, tvm), siempre que sea posible. Esta compilación ahorra la sobrecarga de generar gráficos dinámicamente en cada iteración (como se hace en PyTorch 1.x, según se comenta en el Capítulo 2). La advertencia aquí es que, debido a la naturaleza pitónica de PyTorch, no todas tus operaciones de flujo de control pueden compilarse en gráficos o subgráficos. Estas partes no compatibles de tu flujo de control se integran en la fase de ejecución volviendo al modo ansioso. Este cambio sin interrupciones, posible gracias a la API de evaluación de tramas, ofrece una técnica eficaz para aprovechar la capacidad de compilación de grafos de PyTorch 2.0. La eficiencia que proporciona sin perder facilidad de uso y sin dejar de ser Pythónica es genial. El hilo de discusión de PyTorch Dev "TorchDynamo: An Experiment in Dynamic Python Bytecode Transformation" (TorchDynamo: Un experimento en la transformación dinámica del código de bytes de Python) trata el funcionamiento interno con más detalle.
El siguiente fragmento demuestra cómo se realiza la traza utilizando conv_blockque utilizamos en los ejercicios de visión anteriores:
from torch.fx import symbolic_trace symbolic_traced : torch.fx.GraphModule = symbolic_trace(conv_block)
Aquí se muestra la representación interna obtenida mediante la traza de PyTorch. Se trata de otra representación del cálculo del grafo mostrado en la Figura 4-9:
print(symbolic_traced.graph)
graph():
%x : [#users=1] = placeholder[target=x]
%conv : [#users=1] = call_module[target=conv](args = (%x,), kwargs = {})
%bn : [#users=1] = call_module[target=bn](args = (%conv,), kwargs = {})
%act : [#users=1] = call_module[target=act](args = (%bn,), kwargs = {})
return act
Aquí se muestra el mismo gráfico, visualizado en formato tabular, indicando la conectividad entre las operaciones y las entradas y salidas:
symbolic_traced.graph.print_tabular()
opcode name target args kwargs
----------- ------ -------- ------- --------
placeholder x x () {}
call_module conv conv (x,) {}
call_module bn bn (conv,) {}
call_module act act (bn,) {}
output output output (act,) {}
Bajada del gráfico
En la etapa de reducción del grafo, todas las operaciones del grafo se descomponen en sus núcleos constituyentes, específicos del backend elegido. En este paso se obtiene la representación interna (RI) del grafo. Los componentes ATen y primitivos de PyTorch, también conocidos como prims, se encargan de esta etapa. En esta etapa, el grafo está más alineado/preparado para la invocación específica del hardware.
Recopilación de gráficos
La fase de compilación gráfica es cuando los kernels del IR obtenidos en la fase anterior se traducen a sus correspondientes operaciones específicas del dispositivo de bajo nivel. Esta fase requiere que el backend realice la compilación y también ejecute los núcleos específicos del dispositivo. TorchInductor (también conocido como inductor), el motor por defecto para la compilación, utiliza OpenAI Triton bajo el capó. Sin embargo, también se están desarrollando activamente otros backends (como aot_ts_nvfuser, cudagraphs, ipex, nvprims_nvfuser, onnxrt y tvm).
En el Capítulo 2, aprendiste sobre el flujo de datos del aprendizaje profundo y los requisitos de cálculo para las operaciones aritméticas. En esta sección, has visto mejoras inteligentes en PyTorch para mitigar las ineficiencias de los grafos dinámicos. En la siguiente sección, exploraremos trucos y técnicas, incluida la compilación de grafos, que pueden emplearse para entrenar modelos de forma eficiente en un único dispositivo.
Técnicas de modelado para escalar el entrenamiento en un único dispositivo
La mayoría de las técnicas descritas en esta sección son ortogonales y pueden aplicarse combinadas o independientemente. Estas técnicas pueden ayudarte a conseguir eficiencia aumentando la velocidad de cálculo o reduciendo los requisitos de memoria.
Recopilación de gráficos
Para aprovechar las ventajas de utilizar un grafo compilado, utiliza la API ortogonal torch.compile. Aplicar torch.compile sobre torch.nn.Module lo convierte al tipo OptimizedModule, una representación interna para módulos de grafos optimizados. Según los puntos de referencia documentados en PyTorch issue #93794, esto proporciona una ganancia de rendimiento de entre el 30% y el 200%, dependiendo del tipo de arquitectura y de la implementación subyacente.
El argumento fullgraph se utiliza para generar un grafo estático sin retroceso en modo ansioso entre los subgrafos. Si tu módulo no tiene flujo de control (if/else y otros flujos condicionales), tus posibilidades de obtener este tipo de grafo serán mayores. En general, utilizar fullgraph será un enfoque más eficiente siempre que sea posible. También puedes elegir tu backend, como ya se ha comentado; por defecto es inductor (ver Figura 4-9).
Hay tres modos de compilación:
default-
El modo por defecto compila el gráfico utilizando el backend elegido, pero lo hace de forma eficiente sin consumir demasiado tiempo ni memoria. En general, este modo será más ventajoso para modelos grandes.
reduce-overhead-
Este modo pretende eliminar la sobrecarga del marco subyacente, por lo que tarda más en compilarse y utiliza una pequeña cantidad de memoria adicional. El modo
reduce-overheades más eficaz si las entradas de tu modelo y de tus pasos son más pequeñas. max-autotune-
Como su nombre indica, este modo pretende proporcionar un gráfico compilado con el máximo ajuste, que es por tanto más rápido. Sin embargo, la fase de compilación será la más larga de las tres.
Para ver la diferencia antes y después de la compilación, ajusta el parámetro mode, como se muestra aquí:
torch.compile(self.model, mode = "max-autotune")
y ejecuta el siguiente comando desde tu entorno:
deep-learning-at-scale chapter_4 train_gpt2 ––use-compile
Para observar el comportamiento estándar del modo ansioso, que es también el comportamiento por defecto del script de ejemplo, ejecuta el mismo comando con -–no-use-compile en su lugar.
Consejo
Si tienes problemas con la compilación o notas un rendimiento subóptimo, utilizar la variable de entorno TORCH_LOGS="graph_breaks,recompiles" puede ayudarte con la depuración.
Al ejecutar este ejemplo en una GPU A100 SXM de 80 GB, puedes observar que con una sola precisión (fp32), 24 es el tamaño de lote óptimo para el entrenamiento. Un tamaño de lote superior a 24 provocará errores OOM. También verás que compilando el gráfico con la opción default, puedes obtener una ganancia del 5% en la eficiencia de tu entrenamiento en comparación con el cálculo de referencia en modo ansioso sin compilar. Si cambias el modo a max-autotune, la ganancia aumentará al 12%. Como pueden indicar los registros de errores de TorchDynamo, la red no es totalmente compatible con Dynamo (debido, por ejemplo, al uso de objetos de lista). Corregir estos errores proporcionará una mayor ganancia en eficiencia. En general, debe desaconsejarse el uso de listas en el entrenamiento, especialmente en DataLoaders, ya que pueden provocar una sobrecarga de memoria debido a la forma en que el multiprocesamiento de Python pica los objetos de lista (consulta el tema #13246 de PyTorch para una discusión sobre este tema).
Una de las técnicas que puedes utilizar para pasar de listas a tensores es apilarlos (es decir, utilizando torch.stack([...])), si tienen las mismas dimensiones. Si no, puedes añadir relleno para obtener un tensor apilado de tamaño máximo. Si tu caso de uso es especializado y ninguno de esos trucos te ayuda, puedes intentar escribir objetos personalizados con un manejo adecuado para implementar el método .to() para manejar la transferencia de dispositivos.
En esta sección, has aprendido un truco de una sola línea para ganar aproximadamente un 15% de eficiencia. En la siguiente sección, explorarás cómo ganar más velocidad a expensas de la precisión.
Entrenamiento de precisión reducida y mixta
La memoria consumida durante el entrenamiento puede clasificarse en dos categorías: memoria consumida por los estados del modelo y por los estados residuales. Hablaremos más sobre esto en el Capítulo 9, pero por ahora vamos a centrarnos en los requisitos de memoria durante el entrenamiento en forma absoluta. Éstas vienen determinadas por las siguientes categorías de datos numéricos, que se cargan en la memoria:
-
Parámetros del modelo (ponderaciones y sesgos)
-
Datos de entrada (generalmente cargados en trozos en la memoria)
-
Activaciones/mapa de características (los resultados de los cálculos; es decir, las características extraídas de los datos de entrada)
-
Gradientes (los gradientes de error necesarios para la retropropagación y la corrección de errores )
-
Estados del optimizador (se estima que ocupan entre el 33 y el 75% de la memoria)12
-
Métricas y pérdidas (valores numéricos para observar y monitorear el progreso del régimen de entrenamiento)
Aunque los requisitos de memoria para la activación son transitorios, aumentan linealmente con el número de parámetros del modelo y el tamaño de los datos de entrada. Del mismo modo, los requisitos de memoria para la retropropagación (es decir, los gradientes) aumentan linealmente con el tamaño del lote y el número de parámetros. Las métricas y las pérdidas, en general, tienen requisitos de memoria insignificantes. Sin embargo, dependiendo de la naturaleza de las métricas (por ejemplo, micro o macro), los requisitos pueden escalar en el orden del objetivo de la tarea del modelo. Por ejemplo, almacenar métricas para un clasificador binario simple requerirá mucho menos espacio que almacenar micrométricas para el clasificador multiclase/multietiqueta de 151 clases que hemos visto antes en este capítulo. Del mismo modo, para las tareas de detección/localización de objetos, como la segmentación semántica o de instancias, los requisitos de las métricas pueden ser extensos (por ejemplo, MaskIoU y cálculo de la media/precisión para varios tamaños de objeto, como se hace en los modelos Mask R-CNN).
El entrenamiento se suele realizar utilizando el formato estándar de coma flotante de precisión única (fp32). Se pueden utilizar varios formatos menos precisos, como los enumerados en la Tabla 3-1 en "Estándares de coma flotante", para acelerar el entrenamiento, tanto aumentando el tamaño del lote (reduciendo los requisitos de memoria como resultado de los contenedores de datos necesarios) como aprovechando las capacidades de los dispositivos de cálculo optimizados por hardware. Utilizar un formato de menor precisión (por ejemplo, fp16) puede dar lugar a modelos subóptimos. Sin embargo, en escenarios en los que un resultado altamente preciso no es crítico, la ganancia en eficiencia conseguida reduciendo la precisión puede ser enorme.
Precisión mixta
La precisión mixta, una técnica que combina formatos de coma flotante de precisión simple y media, también puede utilizarse para gestionar el compromiso entre eficiencia computacional y precisión numérica. El paquete Torch torch.cuda.amp proporciona una implementación que permite el uso de la precisión mixta para dispositivos compatibles con CUDA. La precisión mixta automática se realiza mediante la función torch.cuda.amp.autocast, que puede gestionar las conversiones de tipos de datos automáticamente. La arquitectura Tensor Core utilizada en la serie de GPU Ampere y posteriores de NVIDIA también puede multiplicar matrices de media precisión, acumulando el resultado en una salida de precisión simple o media. Todas estas técnicas facilitan el entrenamiento de precisión mixta.
Consejo
Cuando utilices la precisión mixta automática de, debes abstenerte de convertir explícitamente tus tensores a un tipo de datos concreto. La fundición explícita dificulta la conversión automática de precisión, lo que conduce a resultados subóptimos.
Hay una pequeña penalización de memoria asociada al entrenamiento con precisión mixta, porque se cargan dos copias de los pesos del modelo: una con precisión simple y otra con precisión media. En efecto, los requisitos de memoria equivalen a 1,5 veces los requisitos en precisión simple. La precisión mixta ya está implementada en las bibliotecas torch.cuda.amp y Lightning, así que puedes activarla simplemente llamando a Trainer(precision = "16-mixed").
Nota
La precisión mixta es principalmente una característica de los dispositivos acelerados. Los ordenadores con CPU estándar no ofrecen capacidades de cálculo de precisión inferior. Como resultado, observarás que la precisión mixta automática sólo suele admitirse para el entrenamiento en sistemas heterogéneos. La precisión mixta es también una implementación relativamente nueva (introducida alrededor de 2017); como resultado, las GPU más antiguas pueden no tener soporte incorporado para dicho entrenamiento.
El efecto de la precisión en los gradientes
Como los gradientes de se calculan en función del factor de error (es decir, la contribución de los parámetros al error), el valor puede ser demasiado pequeño o demasiado grande. Un gradiente demasiado grande da lugar a valores desbordantes, lo que provoca inestabilidad numérica en el cálculo. Este fenómeno se denomina problema de gradientes explosivos.13 A medida que disminuye la precisión numérica, se reduce la capacidad de mantener una mantisa mayor, lo que provoca un mayor riesgo de desbordamiento numérico. Del mismo modo, disminuye la capacidad de mantener diferencias en coma flotante muy precisas, lo que conlleva un mayor riesgo de desbordamiento. Ninguna de las dos situaciones es agradable. El escalado del gradiente y el recorte son dos técnicas que ayudan a evitar los problemas de desbordamiento y subdesbordamiento durante la propagación hacia atrás.
Escala de gradiente
El escalador de gradientes de PyTorch, como su nombre indica, escala los gradientes para gestionar la pérdida de precisión. Generalmente, el escalador se inicializa:
scaler = torch.cuda.amp.GradScaler()
y se utiliza durante el bucle de entrenamiento para escalar la pérdida antes de la retropropagación:
scaler.scale(loss).backward()
Los frameworks como Lightning se encargan automáticamente del escalado del gradiente cuando se utiliza precisión mixta. Por eso puedes observar que los ejemplos prácticos de este capítulo no incluyen un uso explícito de GradScaler.
Recorte de degradado
Recorte de gradiente se utiliza para mitigar la explosión de gradientes. Normalmente, el recorte se realiza sobre el valor del gradiente o sobre la norma del gradiente. En efecto, limita el valor máximo (o la norma) del gradiente durante el bucle de entrenamiento.
Lightning viene con una función clip_gradients que puede activarse a través del código de cableado de la infraestructura (por ejemplo, utilizando Trainer(gradient_clip_val = 0.5)) y puede personalizarse aún más utilizando la función configure_gradient_clipping de anulación de tu LightningModule. Puedes encontrar información más detallada en la documentación.
Optimizadores de 8 bits y cuantización
Como se ha comentado anteriormente en , los contenedores de datos para los gradientes, incluso en el entrenamiento de precisión mixta, se mantienen en fp32. Los esfuerzos por cambiar la precisión de los gradientes a fp16 han dado resultados poco deseables, porque la varianza de los gradientes puede ser grande (dependiendo de cómo contribuya cada uno de los parámetros al error). El reto con la escala de gradiente y el recorte es que ambos trucos se aplican de forma coherente en todo el tensor de gradiente.
Cuantización dinámica del árbol es otra técnica interesante que puede compensar los bits necesarios para representar la mantisa y el exponente (analizados en el Capítulo 3), utilizando un bit indicador para señalar el comienzo de la partición fraccionaria del número (véase la Figura 4-10). Esta cuantización dinámica permite dimensionar correctamente el tipo de datos, con lo que se obtienen resultados más precisos. Sin embargo, las estadísticas del gradiente (es decir, los estados del optimizador) se mantienen en formatos de menor precisión. La cuantización en bloques es otra técnica de cuantización que cuantiza los estados del optimizador en trozos, lo que proporciona una precisión mejor que la de media precisión y sólo ligeramente inferior a la de sus homólogos de precisión única.
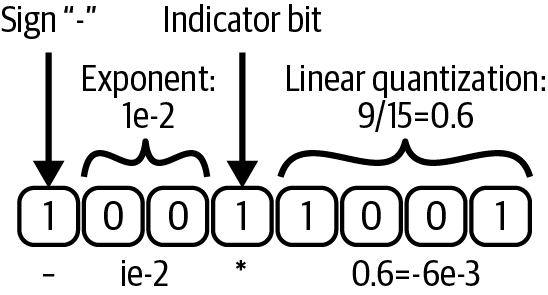
Figura 4-10. Cuantización dinámica en árbol utilizada en los optimizadores de 8 bits: el bit indicador se mueve dinámicamente y permite compensar las partes fraccionaria y decimal del número (adaptado de Dettmers et al., 2022)
La bibliotecabitsandbytes proporciona kernels CUDA personalizados que aprovechan la cuantización dinámica en árbol además de la cuantización en bloque para proporcionar una implementación más precisa y con mayor rendimiento de un conjunto de optimizadores, incluido Adam. Estas implementaciones (por ejemplo, bnb.optim.Adam8bit) pueden cambiarse por torch.optim.Adam con un solo cambio de línea. (Sin embargo, es posible que necesites una compilación personalizada de la biblioteca en función de tu versión del tiempo de ejecución de NVIDIA). Utilizarás esta biblioteca en los ejercicios prácticos de los Capítulos 7 y 9.
Un algoritmo de precisión mixta
Teniendo en cuenta los retos mencionados anteriormente, el algoritmo resumido para el entrenamiento de precisión mixta es el siguiente:
-
Empieza con una copia maestra de los pesos en precisión simple (
fp32). -
Obtén otra copia de media precisión (
fp16) de los pesos. -
Realiza un pase hacia delante utilizando
fp16pesos y activaciones. -
Escala la pérdida resultante por el factor de escala S.
-
Realiza una pasada hacia atrás utilizando los pesos (
fp16), las activaciones (fp16) y sus gradientes (fp32). -
Reduce los gradientes en un factor S (es decir, multiplícalos por 1/S).
-
Ejecuta trucos de degradado opcionales adicionales, como recorte de degradado, decaimiento del peso, etc.
-
Actualiza las estadísticas del gradiente (
fp16) en los estados del optimizador. -
Actualiza la copia maestra de pesos (en
fp32). -
Repite el bucle de iteración dado por los pasos 3-9 hasta la convergencia.
Trucos de memoria para la eficiencia
Como expuso en el Capítulo 1, la eficiencia es una consideración crucial en el escalado. En esta sección veremos algunos trucos de memoria que pueden ser útiles en el desarrollo de modelos en entornos con restricciones de memoria.
Disposición de la memoria
Los tensores n-dimensionales deben presentarse en un espacio de direcciones 1D en la memoria. La disposición en memoria define el almacenamiento de los tensores n-dimensionales, describiendo cómo se colapsarán los tensores en el espacio de direcciones. Fila-mayor y columna-mayor son dos formatos de uso común para disponer los tensores n-dimensionales de forma contigua en la memoria. Como se muestra en la Figura 4-11, la fila mayor es análoga al esquema basado en lote (N), canal (C), altura (H) y anchura (W) (es decir, NCHW, también conocido como canales primero), mientras que la columna mayor es análoga al esquema NHWC (canales en último lugar).
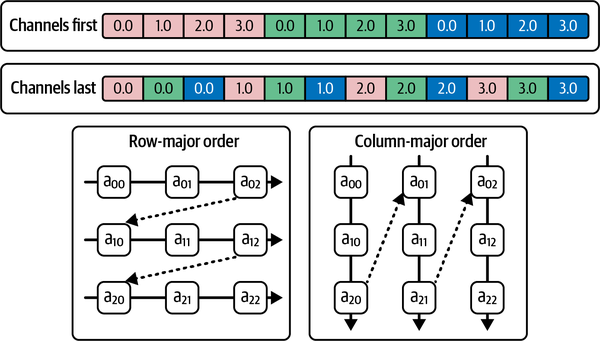
Figura 4-11. Disposición en memoria de los tensores canales-primero y canales-último
Si tu operación se paraleliza en el canal primero, entonces almacenar y acceder a los tensores utilizando la disposición de canales primero será más eficiente. Otras técnicas de modelado basadas en imágenes -en concreto, las convoluciones que operan y explotan la correlación espacial de las señales en las imágenes- acceden a los tensores de una forma más orientada al píxel. Por tanto, para las técnicas basadas en la convolución, los canales pueden ser la opción más eficiente. PyTorch permite cambiar opcionalmente a la disposición de memoria canales-último y admite el cálculo en los mismos formatos nativos implementando núcleos para una serie de operadores en formato canales-último, además del formato por defecto canales-primero.
Nota
Tanto PyTorch como NVIDIA cuDNN utilizan por defecto la disposición de canal primero (NCHW). Sin embargo, oneDNN y XNNPACK, las bibliotecas que PyTorch utiliza para el cálculo puro en la CPU, utilizan por defecto el último canal (NHWC). Alinear la disposición en toda la pila proporciona una ejecución más eficiente del bucle de entrenamiento; de lo contrario, el patrón de acceso a los datos se vuelve subóptimo, incurriendo en una penalización durante el acceso de los subtensores para las operaciones pertinentes.
En una CPU, el uso del formato canales-último para redes basadas en convolución puede proporcionar una ganancia de rendimiento temporal de hasta 1,8 veces mediante patrones de acceso a memoria apropiados implementados por las capas de convolución, agrupamiento y sobremuestreo.14
Para cambiar la disposición de la memoria, invoca .to(memory_format = torch.channels_last) en el tensor o en el módulo (para indicar la preferencia del operador).
En el segundo ejemplo práctico de este capítulo, puedes observar que se aplican images = images.to(memory_format = torch.channels_last) y self.model = self.model.to(memory_format = torch.channels_last) cuando se solicita la última ejecución de los canales. Pruébalo utilizando el siguiente comando:
deep-learning-at-scale chapter_4 train-efficient-unet --use-channel-last
En una única GPU A100 SXM de 80 GB, el uso del formato canales-último proporciona aproximadamente un 10% más de rendimiento en comparación con la configuración canales-primero.
Del mismo modo, al ejecutar el mismo ejemplo en la CPU con el backend mps, utilizar canales en último lugar proporciona un aumento del 17% en el rendimiento respecto a canales en primer lugar con la misma configuración de recursos (un tiempo de paso de 51,84 s por iteración, frente a 62,48 s).
Compresión de funciones
La omnipresencia de los problemas de memoria en la práctica del aprendizaje profundo ( ) viene indicada por la frecuencia con que se producen errores de OOM en la GPU.15 Se ha explorado el uso de la compresión de datos (con y sin pérdidas) para reducir la huella de memoria de los mapas de características desde el paso hacia delante hasta que se requieren de nuevo durante la propagación hacia atrás.16 Esta técnica puede reducir el requisito de memoria en una media de 1,8 veces; sin embargo, incurre en sobrecarga de rendimiento por la compresión/descompresión y el aumento de la comunicación CPU-GPU. En general, este enfoque puede ser útil si hay escasez o redundancia en los mapas de características, pero las ganancias observadas variarán mucho según la naturaleza del modelo y los datos.
Tensores meta y falsos
Los meta tensores son El mecanismo subyacente de PyTorch para representar la forma y el tipo de datos sin asignar realmente memoria para su almacenamiento. Los falsos tensores de PyTorch son muy similares a los metatensores, salvo que un metatensor se asigna a un dispositivo "meta" abstracto, mientras que los falsos tensores se asignan a dispositivos concretos (CPUs, GPUs, TPUs, etc.).
Un metatensor se inicializa como sigue:
meta_layer = torch.nn.Linear(100000, 100000, device = "meta")
Hablaremos más sobre los tensores meta y falsos en el capítulo 8, donde consideraremos su importancia en la gestión de la memoria en un entorno a escala.
Eficacia del optimizador
Así que hasta ahora has visto varias técnicas para mejorar la eficiencia de tus ejecuciones de entrenamiento, incluyendo el uso de la compilación de gráficos y el cambio de la disposición de la memoria y los formatos de datos. En esta sección, aprenderás algunos trucos de gradiente para escalar tu entrenamiento en un único host con un máximo de una GPU.
Descenso estocástico del gradiente (SGD)
Las primeras versiones de optimizadores de , como el descenso de gradiente, utilizaban todo el conjunto de datos de entrenamiento en un solo paso para derivar el gradiente. Pero cuando el tamaño del conjunto de datos empieza a aumentar, debido a las limitaciones de memoria de los dispositivos informáticos, el descenso de gradiente se convierte en un cuello de botella durante el entrenamiento. Para solucionarlo, se ideó una técnica de aproximación llamada descenso de gradiente estocástico (SGD). Con esta técnica, en lugar de derivar gradientes sobre toda la muestra, los gradientes se propagan por lotes para llegar a un modelo aproximadamente comparable.
El SGD y otras técnicas iterativas de descenso del gradiente se utilizan tan comúnmente hoy en día que se tiende a ignorar su importancia en el escalado de grandes conjuntos de datos. Estas técnicas sólo son eficaces si el tamaño del lote es adecuado para la aproximación universal. Para desarrollar un modelo que realice una tarea compleja que requiera aprender sobre un conjunto de datos muy variante, se necesitan tamaños de lote mayores que ayuden a la aproximación universal. Sin embargo, los presupuestos de memoria del hardware son limitados.
Acumulación de gradiente
Como se ha comentado en en la sección anterior, siempre son preferibles tamaños de lote mayores, ya que permiten una aproximación universal (que conduce a modelos bien generalizados). En situaciones en las que la capacidad de cálculo es limitada pero se desea escalar el tamaño del lote, se puede utilizar la acumulación de gradiente para simular lotes más grandes.
Con la acumulación de gradientes, el bucle estándar de entrenamiento del modelo, que se muestra aquí, se transforma para incluir pasos adicionales de normalización de la pérdida, acumulación de los gradientes y realización de los pasos de optimización cada x intervalo de pasos (en lugar de cada paso):
# Standard training loop
for epoch in range(...):
for idx, (inputs, labels) in enumerate(dataloader):
optimizer.zero_grad()
# Perform the forward pass
outputs = model(inputs)
# Compute loss
loss = loss_fn(outputs, labels)
# Perform backpropagation
loss.backward()
# Update the optimizer
optimizer.step()
A continuación se muestra el fragmento para la acumulación de gradiente, donde accumulation_step_count indica la frecuencia con la que se realiza el paso de optimización:
accumulation_step_count = ...
# Training loop with gradient accumulation enabled
for epoch in range(...):
for idx, (inputs, labels) in enumerate(dataloader):
optimizer.zero_grad()
# Perform the forward pass
outputs = model(inputs)
# Compute loss
loss = loss_fn(outputs, labels)
# Perform gradient normalization
loss = loss / accumulation_step_count
# Perform backpropagation
loss.backward()
# Update the optimizer
if ((idx + 1) % accumulation_step_count == 0) \
or (idx + 1 == len(dataloader)):
optimizer.step()
Esta técnica está diseñada principalmente para obtener modelos más precisos en entornos en los que los recursos de la GPU son limitados, más que para proporcionar eficiencia de cálculo.
Punto de control de gradiente
Más técnicas de optimización populares utilizadas hoy en día, como SGD y Adam, son stateful: guardan las estadísticas de los valores de gradiente pasados en el tiempo (por ejemplo, la suma suavizada exponencialmente en SGD con momentum y la suma al cuadrado en Adam). Algunos optimizadores necesitan más memoria que otros. Por ejemplo, AdamW guarda dos estados y, por tanto, necesita el doble de memoria que SGD.
Puedes comprobarlo intercambiando AdamW por SGD en la llamada a configure_optimizers en vision_model.py y observar la caída del requisito de memoria.
La comprobación de gradiente es una técnica que pretende ser más eficiente en memoria a expensas de la sobrecarga computacional. Si observas el DAG (analizado en el Capítulo 2) generado para un Conv2dReLUWithBN, como el utilizado en el ejercicio práctico nº 2, te darás cuenta de que algunos nodos comparten la ruta de propagación del gradiente. Tradicionalmente, los gradientes de estos nodos se guardan en memoria hasta que se han recorrido todos los descendientes en la dirección hacia atrás y se han calculado sus respectivos gradientes. El otro extremo de esta implementación es no guardar los gradientes y, en su lugar, volver a calcularlos bajo demanda. Si la latencia de cálculo no es muy grande, esta solución de compromiso puede proporcionar una mayor capacidad de memoria para entrenar el modelo o aumentar el tamaño del lote, por ejemplo. Estos enfoques son los dos extremos del espectro. El punto de control de gradiente, también conocido como punto de control de activación, ofrece un término medio: permite guardar gradientes en puntos de control conocidos, para encontrar un equilibrio óptimo entre liberar memoria y reducir la sobrecarga de cálculo redundante.
Esta capacidad está incluida en el módulo torch.utils.checkpoint.checkpoint de PyTorch. En el Capítulo 5, hay ejercicios prácticos que consisten en explorar la comprobación de gradientes.
Parche Gradiente Descenso
Patch Gradient Descent (PatchGD) es otra técnica muy interesante que puede utilizarse para escalar el entrenamiento de imágenes gigapíxel que no caben en una sola GPU (ver Figura 4-12).17 Es similar a la técnica de acumulación de gradientes, salvo que en PatchGD los gradientes se acumulan en las distintas ubicaciones espaciales de la misma imagen, en lugar de sobre muestras independientes. Con esta técnica, cada imagen se trocea en parches y los paquetes de parches se pasan por el bucle de entrenamiento en varios pasos. Durante estos pasos, los gradientes se acumulan en el vector de gradiente correspondiente hasta que se hayan pasado todos los parches.
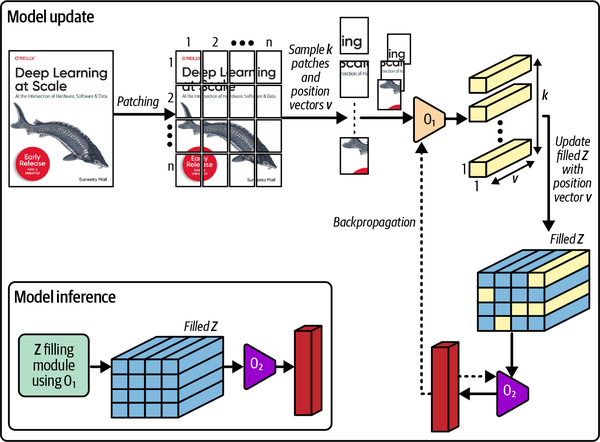
Figura 4-12. El flujo de trabajo de PatchGD mostrado sobre una muestra de imagen muy grande
Esta técnica sólo es eficaz para modelos de tipo clasificación, en los que el tamaño del gradiente es mucho menor que en los modelos utilizados para tareas más densas, como las detecciones. Con PatchGD, la entrada se trocea, pero el gradiente se mantiene en memoria en su tamaño completo. Por tanto, para que este truco funcione, el vector gradiente estimado debe caber en la memoria.
Tasa de aprendizaje y decaimiento del peso
La tasa de aprendizaje de es otro parámetro crucial, muy relacionado con el tiempo de convergencia. Como se expone en el Capítulo 2, con una tasa de aprendizaje más lenta, normalmente se tardará mucho más tiempo y se darán muchos más pasos para llegar a la convergencia o a los mínimos globales. Por el contrario, una tasa de aprendizaje muy alta puede llevar a navegar por la curvatura de pérdidas demasiado rápido, con lo que se perderían los mínimos globales y se llegaría a un modelo subóptimo. El decaimiento del peso también puede aplicarse mediante optimizadores para reforzar la regularización (mediante la normalización L2) y mitigar el sobreajuste. Tanto la velocidad de aprendizaje como el decaimiento del peso influyen en el tiempo de convergencia.
Por esta razón, dimensionar correctamente la tasa de aprendizaje es un ejercicio fructífero. Por desgracia, debido a su naturaleza estocástica, realizar un ajuste de hiperparámetros puede ser la única solución para optimizar la tasa de aprendizaje. En la Parte II de este libro, profundizaremos en el diseño experimental y la búsqueda de parámetros, y realizarás algunos ejercicios para afinar los parámetros del modelo.
Trucos de la tubería de entrada de modelos
En ambos ejemplos prácticos de este capítulo, una parte muy pequeña de los ciclos de cálculo fue utilizada por la canalización de entrada del modelo (es decir, los DataLoaders). A medida que aumenta el volumen y el tamaño de los datos por muestra, el aumento de la computación necesaria para cargar, descomprimir y leer y transformar aún más el conjunto de datos podría llegar a ser todo un reto. En el Capítulo 6, aprenderás sobre el entrenamiento con conjuntos de datos a escala masiva, incluyendo técnicas para desarrollar DataLoaders eficientes para mantener ocupadas las GPU y maximizar la utilización del SM. Algunas de estas técnicas implican elegir la compresión adecuada para tus datos, escalar las operaciones limitadas a la CPU con paralelismo de hilos y procesos (tratado en detalle en el Capítulo 3), y trasladar las transformaciones escalables a la GPU, ya sea mediante bibliotecas que proporcionen transformaciones compatibles con la GPU, como Kornia, o comprendiendo los cuellos de botella del ancho de banda de memoria CPU-GPU para dimensionar correctamente tus entradas. El Capítulo 7 incluirá un ejercicio práctico que se sumerge en los detalles de la escritura de canalizaciones de entrada eficientes.
En la siguiente sección, veremos un pequeño ejemplo de cómo escribir kernels CUDA personalizados en PyTorch 2.0 utilizando OpenAI Triton.
Escribir kernels personalizados en PyTorch 2.0 con Triton
El modelo de programación de Triton es análogo a la programación CUDA en el sentido de que ambos admiten el paralelismo SIMD(/T). Triton puede facilitar la construcción de núcleos de cálculo de alto rendimiento para redes neuronales utilizando paradigmas de programación de estilo SIMD. Sin embargo, su modelo de programación difiere del de CUDA en que los programas -en lugar de hilos- se bloquean.
Un ejemplo práctico para escribir un kernel personalizado para NVIDIA, custom_kernel_example.py, está disponible en el repositorio GitHub del libro.
En este código, se llama al núcleo multiply_kernel en un bloque de 1.024 elementos de los tensores para que realice la multiplicación y almacene el resultado en las posiciones correspondientes. En este ejemplo, MultiplyWithAutoGrad implementa una función con una característica de diferenciación automática. Esta función se puede invocar de la siguiente forma
MultiplyWithAutoGrad.apply(
torch.ones((1999, 1999, 10)).to(device),
torch.ones((10, 1999, 1999)).to(device)
)
Otro backend emergente del compilador PyTorch, Hidet, permite una optimización del compilador más detallada que Triton debido a su capacidad para operar a nivel de hilos (a diferencia de Triton, que opera a nivel de bloques) y al soporte de paradigmas adicionales como el mapeo de tareas y la fusión para optimizar aún más a nivel de operadores y tensores.18 Este compilador puede reducir aproximadamente un 50% del tiempo de cálculo en comparación con Triton/max-autotune. Sin embargo, actualmente se limita sólo a la inferencia, y el entrenamiento está en la hoja de ruta.
Resumen
En este capítulo, has aprendido sobre GPT-2 y EfficientNet como dos arquitecturas para dos formatos de entrada diferentes: texto e imágenes. Además de estos ejemplos prácticos, conociste diversas técnicas para desarrollar modelos de forma más eficiente. Este capítulo concluye la primera parte del libro, centrándose en la introducción de diversas técnicas fundamentales necesarias para acelerar y escalar el entrenamiento de tus modelos de aprendizaje profundo.
En la siguiente parte de este libro, aprenderás técnicas para ampliar el entrenamiento de modelos de uno a muchos dispositivos acelerados, utilizando muchos más hosts conectados a través de la red.
1 Radford, Alec, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei e Ilya Sutskever. 2019. "Los modelos lingüísticos son aprendices multitarea no supervisados ". https://paperswithcode.com/paper/language-models-are-unsupervised-multitask; Tan, Mingxing y Quoc V. Le. 2019. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks" arXiv, 28 de mayo de 2019. https://arxiv.org/abs/1905.11946.
2 Alammar, Jay. 2019. "El GPT-2 ilustrado (Visualizar modelos de lenguaje de transformación)". Blog de Jay Alammar, 12 de agosto de 2019. https://jalammar.github.io/illustrated-gpt2.
3 Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser e Illia Polosukhin. 2017. "Attention Is All You Need". arXiv, 6 de diciembre de 2017. https://arxiv.org/abs/1706.03762.
4 Bubeck, Sébastien, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, et al. 2023. "Chispas de Inteligencia General Artificial: Early Experiments with GPT-4." arXiv, 13 de abril de 2023. https://arxiv.org/abs/2303.12712.
5 Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. "Language Models Are Few-Shot Learners" arXiv, 28 de mayo de 2020. https://arxiv.org/abs/2005.14165.
6 Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, et al. 2021. "Una imagen vale 16x16 palabras: Transformers for Image Recognition at Scale" arXiv, 3 de junio de 2021. https://arxiv.org/abs/2010.11929.
7 Cheng, Bowen, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. 2022. "Masked-Attention Mask Transformer for Universal Image Segmentation" arXiv, 15 de junio de 2022. https://arxiv.org/abs/2112.01527.
8 Tan y Le, "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks ", https://arxiv.org/abs/1905.11946; Ronneberger, Olaf, Philipp Fischer y Thomas Brox. 2015. "U-Net: Convolutional Networks for Biomedical Image Segmentation" arXiv, 18 de mayo de 2015. https://arxiv.org/abs/1505.04597.
9 LeCun, Y., B. Boser, J.S. Denker, D. Henderson, R.E. Howard, W. Hubbard y L.D. Jackel. 1989. "Retropropagación aplicada al reconocimiento de códigos postales escritos a mano". Computación neuronal 1, no. 4: 541-51. https://doi.org/10.1162/neco.1989.1.4.541.
10 Ng, Andrew. s.f. Stanford CS230 lecture notes. https://cs230.stanford.edu/files/C4M1.pdf.; Skalski, Piotr. "Suave inmersión en las matemáticas tras las redes neuronales convolucionales". Towards Data Science, 12 de abril de 2019. https://oreil.ly/odnbI.
11 Ronneberger y otros, "U-Net: Redes convolucionales para la segmentación de imágenes biomédicas ", https://arxiv.org/abs/1505.04597.
12 Dettmers, Tim, Mike Lewis, Sam Shleifer y Luke Zettlemoyer. 2022. "8-Bit Optimizers via Block-wise Quantization" arXiv, 20 de junio de 2022. https://arxiv.org/abs/2110.02861.
13 Bengio, Y., P. Simard y P. Frasconi. 1994. "Aprender dependencias a largo plazo con el ascenso gradiente es difícil". IEEE Transactions on Neural Networks 5, nº 2: 157-66. https://doi.org/10.1109/72.279181.
14 Ma, Mingfei, Vitaly Fedyunin y Wei Wei. "Acelerando los Modelos de Visión de PyTorch con Canales Últimos en CPU". Blog de PyTorch, 24 de agosto de 2022. https://oreil.ly/Dr3Tt.
15 Zhang, Ru, Wencong Xiao, Hongyu Zhang, Yu Liu, Haoxiang Lin y Mao Yang. 2020. "Un estudio empírico sobre los fallos de programa de los trabajos de aprendizaje profundo". En Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering (ICSE '20), 1159-70. https://doi.org/10.1145/3377811.3380362.
16 Jain, Animesh, Amar Phanishayee, Jason Mars, Lingjia Tang y Gennady Pekhimenko. 2018. "Gist: Codificación eficiente de datos para el entrenamiento de redes neuronales profundas". En ACM/IEEE 45º Simposio Internacional Anual sobre Arquitectura de Ordenadores (ISCA), 776-89. https://doi.org/10.1109/ISCA.2018.00070.
17 Gupta, Deepak K., Gowreesh Mago, Arnav Chavan y Dilip K. Prasad. 2023. "Descenso gradiente de parches: Training Neural Networks on Very Large Images" arXiv, 31 de enero de 2023. https://arxiv.org/abs/2301.13817.
18 Ding, Yaoyao, Cody Hao Yu, Bojian Zheng, Yizhi Liu, Yida Wang y Gennady Pekhimenko. 2023. "Hidet: Task-Mapping Programming Paradigm for Deep Learning Tensor Programs" arXiv, 15 de febrero de 2023. https://arxiv.org/abs/2210.09603.
Get Aprendizaje profundo a escala now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

