Capítulo 1. Lo que la naturaleza y la historia nos han enseñado sobre la escala
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Lo que funciona a escala puede ser diferente de escalar lo que funciona.
-Rohini Nilekani
El objetivo principal de este libro es presentar información valiosa que te permita escalar de forma eficiente y eficaz tu carga de trabajo de aprendizaje profundo. En este capítulo introductorio, consideraremos qué significa escalar y cómo determinar cuándo empezar a escalar. Nos sumergiremos en la ley general del escalado y nos inspiraremos en la "naturaleza" como el sistema más escalable. También examinaremos la evolución de las tendencias en el aprendizaje profundo y analizaremos cómo la innovación en hardware, software, datos y algoritmos está convergiendo para potenciar el aprendizaje profundo a escala. Por último, exploraremos la filosofía que subyace a la escalabilidad y repasaremos los factores que debes tener en cuenta y las preguntas que debes hacerte antes de iniciar tu viaje de escalabilidad.
Este capítulo está cargado de filosofía e historia. Si prefieres material técnico, pasa a "Inteligencia Artificial: La evolución de los sistemas aprendibles".
La filosofía del escalado
Para escalar un sistema es aumentar su capacidad añadiéndole más recursos.1 Aumentar la capacidad de un puente añadiendo más carriles para dar cabida a más vehículos simultáneamente es un ejemplo de escalar el puente. Añadir más réplicas de un servicio para atender más peticiones simultáneas de usuarios y aumentar el rendimiento es un ejemplo de escalar el servicio. A menudo, cuando la gente habla de escalar, empieza con un objetivo de alto nivel, con la intención de escalar un escenario o una capacidad de orden superior. Añadir carriles adicionales a un puente o añadir más réplicas de un servicio puede parecer un objetivo sencillo, pero cuando empiezas a diseccionarlo y a desentrañar sus dependencias y el plan para ejecutarlo, empiezas a darte cuenta de los retos y complejidades que implica cumplir el objetivo original de escalar.
¿Cómo podemos evaluar estos retos específicos de tareas y dominios? Están recogidos en la ley general de la escala.
La Ley General de la Escala
La ley general de escalado , dada por y ∝ f(x), define la escalabilidad de y por su dependencia de la variable x. Se supone que la relación matemática dada por f(x) sólo se mantiene en un intervalo significativo de x, para esbozar que la escalabilidad por definición es limitada y que habrá un valor de x en el que se romperá dicha relación (de escalado) entre x e y. Estos valores de x definirán los límites de escalabilidad de y. La expresión genérica f(x) indica que la ley de escalabilidad adopta muchas formas y es muy específica de un dominio/tarea. La ley general de escalado también establece que dos variables pueden no compartir ninguna relación de escalado.
Por ejemplo, la longitud de una banda elástica es proporcional al tirón aplicado y a la elasticidad del material. La longitud de la banda aumenta a medida que se aplica más fuerza (tracción). Sin embargo, llega un momento en que, al aplicar más fuerza, el material alcanza su resistencia a la tracción y se rompe. Éste es el límite del material y define cuánto puede escalar la banda. Dicho esto, la elasticidad de la banda no comparte una relación de escala con algunas otras propiedades del material, como su color.
La historia del derecho de escalada es interesante y relevante incluso hoy, porque subraya los retos y limitaciones que conlleva la escalada.
Historia de la Ley de Escalado
En la Divina Comedia, el escritor y filósofo del siglo XIV Dante Alighieri hizo una descripción poética de su concepción del Infierno, describiéndolo como un cono invertido que desciende en nueve anillos concéntricos hasta el centro de la Tierra. Su descripción iba acompañada de una ilustración de Sandro Botticelli conocida como el Mapa del Infierno. Esta representación se tomó al pie de la letra, lo que dio lugar a una investigación para medir el diámetro del cono (la llamada Sala del Infierno). Galileo Galilei, un joven matemático, utilizó el verso poético de Dante "Ya el Sol estaba unido al horizonte / Cuyo círculo meridiano cubre / Jerusalén con su punto más alto" como base para su conclusión de que el diámetro del círculo de la cúpula debía ser igual al radio de la Tierra y que el centro del techo se encontraría en Jerusalén. Atendiendo al término "meridiano", Galileo dedujo también que el límite de la cúpula del tejado pasaría por Francia, en el punto que atraviesa el meridiano primo. Al situar la punta de la cúpula en Jerusalén y el perímetro en Francia, llegó a la conclusión de que el perímetro opuesto se encontraría en Uzbekistán. La deducción de Galileo sobre el tamaño de la Sala del Infierno dio como resultado una estructura bastante grande. Tomó como referencia la cúpula de la catedral de Florencia, que tiene 45,5 metros (149 pies) de ancho y 1,5 metros (5 pies) de grosor, y escaló sus medidas linealmente para deducir que el techo de la sala tendría que tener 600 km (373 millas) de grosor para soportar su propio peso. Su trabajo fue bien recibido, lo que le valió un puesto como profesor de matemáticas en la Universidad de Pisa.
En un giro interesante, Galileo se dio cuenta de que la estructura, con este grosor, no sería muy estable. Pronunció que el grosor de la cúpula tendría que aumentar mucho más deprisa que la anchura para mantener la resistencia de la estructura y evitar que se derrumbara. La conclusión de Galileo se inspiró en el estudio de los huesos de los animales, cuyo grosor, observó, aumenta proporcionalmente a un ritmo mucho más rápido que su longitud. Por ejemplo, el hueso más largo y también más fuerte de los humanos, el fémur, tiene una media de 48 cm de longitud y 2,34 cm de diámetro, y puede soportar hasta 30 veces el peso de un adulto. El fémur de un galgo, sin embargo, mide de media sólo 19 cm (7,48 pulg.) de longitud y 0,13 cm (0,05 pulg.) de grosor (véase la Figura 1-1).2 Entre las dos especies, esto supone una diferencia de longitud de sólo 2,5 veces, ¡mientras que el fémur humano es 18 veces más grueso que el de un galgo! Siguiendo con la comparación, el segundo animal más grande que se conoce en el mundo (sólo superado por la ballena azul), el Tyrannosaurus rex, tenía un fémur que medía 133 cm de largo, con un grosor aproximado de 43 cm.3
Basándose en sus estudios, Galileo identificó una limitación para el tamaño de los huesos de los animales, deduciendo que a partir de cierta longitud los huesos tendrían que ser imposiblemente gruesos para mantener la fuerza necesaria para sostener el cuerpo. Por supuesto, existen otros retos prácticos para la vida en la Tierra -por ejemplo, la agilidad y la movilidad- que, junto con los principios de Darwin, limitan el tamaño de los animales. Utilizo este ejemplo natural para demostrar las consideraciones implicadas en el escalado, tema central de este libro. Este contexto histórico ilustra maravillosamente que el escalado no es libre ni ilimitado, por lo que debe considerarse detenidamente el alcance del escalado. "¿Por qué escalar?" es una pregunta igualmente crucial. Aunque un hueso del fémur humano puede soportar 30 veces el peso de un adulto, un humano medio apenas puede levantar un peso dos veces superior al suyo. En cambio, ¡se sabe que las diminutas hormigas levantan 50 veces su peso!
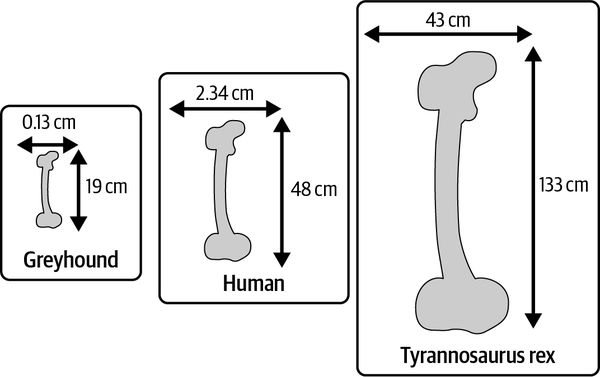
Figura 1-1. La escala de los huesos del fémur en tres especies: galgo, humano y Tyrannosaurus rex.
En última instancia, la investigación de Galileo condujo a la ley general de escalabilidad que constituye la base de muchos teoremas de escalabilidad en la ciencia y la ingeniería modernas. Leerás más sobre algunas de estas leyes aplicables a escenarios de aprendizaje profundo, como la ley de Moore, el escalado de Dennard, la ley de Amdahl, la ley de escalado universal de Gunther y la ley de escalado de modelos lingüísticos , en los capítulos 3, 5, 8 y 10, respectivamente.
Sistemas escalables
El ejemplo de comentado en la sección anterior demuestra por qué el escalado (aumentar el tamaño de un animal, por ejemplo) debe considerarse en el contexto de todo el sistema (teniendo en cuenta la calidad de vida del animal, por ejemplo) y sus capacidades deseadas (digamos, levantar grandes pesos). También demuestra que es esencial construir sistemas escalables.
En muchos sentidos, escalar consiste en comprender las limitaciones y dependencias del sistema y escalar proporcionalmente las dimensiones para alcanzar el estado óptimo. El escalado con optimización es más eficaz que el simple escalado. De hecho, todo se rompe a escala. Más adelante en este capítulo, hablaremos de las consideraciones para escalar eficazmente. Por ahora, repasemos brevemente la naturaleza como sistema escalable, y la tendencia natural a escalar.
La naturaleza como sistema escalable
La superficie del planeta Tierra es de unos 510 millones de km2(197 millones de millas cuadradas) y alberga al menos 8,7 millones de especies vivas únicas.4 Se calcula que la población total de una sola de esas 8,7 millones de especies, los humanos, es de unos 8.000 millones. Como humanos, poseemos una capacidad espectacular para digerir datos ilimitados a través de nuestros sentidos visuales y auditivos. Y lo que es aún más fascinante, ¡no hacemos ningún esfuerzo consciente para ello! En conjunto, nos comunicamos en más de 7.100 lenguas habladas.5 Si hay algo que demuestre que funcionamos a gran escala, es el mundo que nos rodea.
Con nuestro insaciable apetito de conocimiento y exploración de nuestro entorno y más allá, estamos ciertamente limitados por el número de horas de un día. Esta limitación ha dado lugar a un intenso deseo de automatizar las minucias de nuestra vida cotidiana y sacar tiempo para hacer más cosas dentro de los límites del día. El reto que plantea la automatización de las minucias es que está estratificada, es recursiva; una vez que automatizas la capa más baja y la sacas de escena, la siguiente capa se convierte aparentemente en la nueva capa más baja, y te encuentras esforzándote por automatizarlo todo.
Tomemos como ejemplo la comunicación. Históricamente, nuestros antepasados viajaban durante días o incluso meses para conversar en persona. El gran esfuerzo que suponía viajar era un obstáculo para lograr el objetivo (conversar). Más tarde, las formas escritas de comunicación eliminaron la dependencia de que viajara el comunicador principal; los mensajes podían ser entregados por un intermediario. Con el tiempo, los medios de propagación de las comunicaciones escritas a través de los canales también evolucionaron, desde las palomas mensajeras a los servicios postales, pasando por el código Morse y el telégrafo. A esto siguió la era digital de los mensajes, desde los faxes y los correos electrónicos hasta la comunicación social y la divulgación a través de programas de Internet, y todo ocurre en el orden de los milisegundos. Ahora estamos en una época de abundancia de comunicación, hasta el punto de que estamos buscando formas de priorizar automáticamente lo que digerimos de la plétora de información que hay ahí fuera e incluso considerando enfoques estocásticos para resumir el contenido con el fin de optimizar cómo utilizamos nuestro tiempo. En nuestra búsqueda por eliminar los obstáculos originales a la comunicación (tiempo y espacio), creamos un nuevo obstáculo que requiere una nueva solución. Ahora nos encontramos buscando ampliar la forma en que nos comunicamos, explorando activamente las vías de la interfaz cerebro-ordenador y pasando directamente a la lectura mental.6
Nuestro Sistema Visual: Una inspiración biológica
Escalar es complejo. Tus límites definen cómo escalas para alcanzar tus ambiciones. El sistema visual humano es un bello ejemplo de sistema escalable. Es capaz de procesar infinitas señales visuales -literalmente todo, desde la superficie de tu globo ocular hasta el horizonte y todo lo que hay en medio- a través de una diminuta lente con una longitud focal de unos dos tercios de pulgada (17 mm). Es sencillamente magnífico que podamos hacer todo eso instantáneamente, subconscientemente, sin ningún esfuerzo reconocible. Los científicos llevan más de cien años estudiando cómo funciona el sistema visual humano, y aunque se han realizado importantes avances por parte de personas como David Hubel y Torsten Weisel,7 estamos lejos de comprender plenamente el complejo mecanismo que nos permite percibir nuestro entorno.
Tu cerebro tiene unos 100.000 millones de neuronas. Cada neurona está conectada a otras 10.000 neuronas, y hay hasta 1.000 billones de sinapsis que transmiten información entre ellas. Un sistema tan complejo y escalable sólo puede prosperar si es práctico y eficiente. Tu sistema visual se coordina con unas1015 sinapsis, y sin embargo sólo consume aproximadamente la cantidad de energía utilizada por una bombilla LED (12 vatios más o menos).8 Teniendo en cuenta lo implícito y subconsciente que es este proceso, es un buen ejemplo de entrada mínima y salida máxima, pero a costa de la complejidad.
Como sistema adaptable de procesamiento de la información, el nivel de sofisticación que demuestra el sistema visual humano es fenomenal. Las células corticales del cerebro son masivamente paralelas. Cada célula cortical extrae información diferente de las mismas señales. Esta información extraída se agrega y procesa, dando lugar a decisiones, acciones y experiencias. Los recuerdos de tus experiencias se almacenan de forma extremadamente comprimida en el hipocampo. Nuestro sistema biológico es un gran ejemplo de sistema paralelizado y distribuido, diseñado para manejar la información de forma eficiente. Los científicos y los ingenieros de aprendizaje profundo se han inspirado mucho en la naturaleza y la biología, lo que subraya la importancia de la eficiencia y de apreciar las consideraciones de complejidad a la hora de escalar. Éste será también el principio rector a lo largo de este libro: Me centraré en los principios y técnicas de construcción de sistemas de aprendizaje profundo escalables, teniendo en cuenta al mismo tiempo la complejidad y la eficiencia de dichos sistemas.
Muchos de los avances en la construcción de sistemas inteligentes (IA) han estado motivados por el funcionamiento interno de los sistemas biológicos. El bloque de construcción fundamental del aprendizaje profundo, la neurona, se inspiró en la excitación de los sistemas nerviosos biológicos. Del mismo modo, la red neuronal convolucional (CNN), una técnica eficaz para procesar inteligentemente el contenido de la visión por ordenador, se inspiró originalmente en el sistema visual humano. En la siguiente sección, leerás sobre la evolución de los sistemas de aprendizaje y repasarás las tendencias evolutivas del aprendizaje profundo.
Inteligencia Artificial: La evolución de los sistemas aprendibles
En 1936, Alan Turing presentó la formulación teórica de un dispositivo informático imaginario capaz de reproducir los "estados mentales" y las capacidades de manipulación de símbolos de un ordenador humano.9 Este artículo, "On Computable Numbers, with an Application to the Entscheidungsproblem" (Sobre los números computables, con una aplicación al problema de Entscheidungs), dio forma al campo de la informática moderna. Doce años después de que Turing expusiera su visión de las "máquinas de computación", esbozó muchos de los conceptos básicos de las "máquinas inteligentes", o "[máquinas] que pueden aprender de la experiencia".10 Turing ilustró que memorizando el estado actual, considerando todas las jugadas posibles y eligiendo la de mayor recompensa y menor castigo, los ordenadores podían jugar al ajedrez. Sin embargo, sus pensamientos y teorías eran más avanzados que la capacidad del hardware computacional de la época, lo que limitó seriamente la realización de ordenadores que jugaran al ajedrez. Su visión de máquinas inteligentes jugando al ajedrez no se hizo realidad hasta 1997, unos 50 años después, cuando el Deep Blue de IBM venció a Garry Kasparov, entonces campeón del mundo, en un partido a seis partidas.
Se necesitan cuatro para bailar el tango
Aproximadamente en la última década, la visión de principios del siglo XX de realizar sistemas inteligentes ha empezado a parecer de repente mucho más realista. Esta evolución tiene sus raíces en la innovación en los ámbitos del hardware, el software y los datos, tanto como en los algoritmos de aprendizaje. En esta sección, leerás sobre el progreso colectivo en estas cuatro disciplinas y cómo ha ido conformando nuestro avance hacia la construcción de sistemas inteligentes .
El hardware
El ordenador Deep Blue de IBM contaba con 256 procesadores paralelos; podía examinar 200 millones de posibles jugadas de ajedrez por segundo y anticiparse 14 jugadas. El éxito del Deep Blue se atribuyó más a los avances del hardware que a las técnicas de IA, como expresó la observación de Noam Chomsky de que el acontecimiento era "tan interesante como un bulldozer ganando una competición olímpica de halterofilia".
Esta anécdota histórica subraya la importancia de la potencia de cálculo en el desarrollo de la IA y el aprendizaje automático (AM). Los datos históricos, como se muestra en la Figura 1-2, afirman la demanda intensamente creciente de computación acelerada para potenciar el desarrollo de la IA. También es testimonio de cómo la industria de hardware y dispositivos se ha puesto al día para satisfacer la demanda de miles de millones de cálculos en coma flotante por segundo.11 Este crecimiento se ha guiado en gran medida por la ley de Moore de, tratada en el Capítulo 3, que proyecta una duplicación del número de transistores (en el dispositivo) cada dos años. Más transistores permiten una multiplicación matricial más rápida a nivel de circuitos electrónicos. La creciente complejidad de construir ordenadores tan potentes es evidente, ya que se está observando la superación de la ley de Moore.12
NVIDIA ha sido la organización clave que ha impulsado la industria de la computación acelerada, alcanzando los 1.979 billones de operaciones en coma flotante por segundo (1.979 teraFLOPs) para tipos de datos bfloat16 con su chip Hopper. Google también ha contribuido significativamente a potenciar el cálculo de la IA con su Unidad de Procesamiento Tensorial (TPU), cuya versión 4 es capaz de alcanzar los 275 teraFLOPs (bfloat16). Otros chips de IA, como el Habana de Intel, las Unidades de Procesamiento Inteligente (IPU) de Graphcore y el Wafer Scale Engine (WSE) de Cerebras, también se han desarrollado activamente en los últimos años.13 El éxito (o fracaso) de muchas ideas de investigación se ha atribuido a la disponibilidad de hardware adecuado, lo que popularmente se conoce como la lotería del hardware.14
Las limitaciones y restricciones que surgen como resultado del uso intensivo y la emisión de energía son algunos de los retos clave para el hardware. Algunos proyectos muy interesantes, como Natick de Microsoft, están explorando formas sostenibles de satisfacer las crecientes demandas de computación intensiva. Leerás más sobre los aspectos de hardware del aprendizaje profundo en los Capítulos 3 y 5.
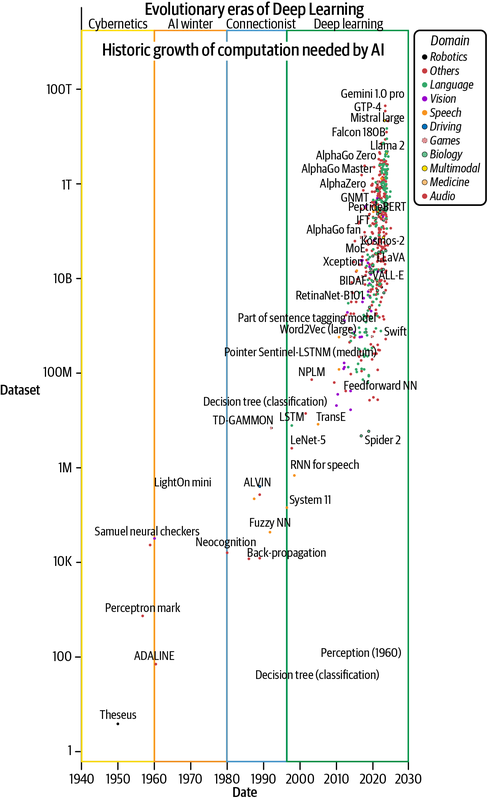
Figura 1-2. Crecimiento del cálculo necesario para desarrollar modelos de IA (trazado utilizando datos tomados de Sevilla et al., 2022)
Los datos
Después del hardware, los datos son el segundo combustible más crítico para el aprendizaje profundo. El tremendo crecimiento de los datos disponibles y el desarrollo de técnicas para obtenerlos, crearlos, gestionarlos y utilizarlos eficazmente han conformado el éxito de los sistemas de aprendizaje. Los algoritmos de aprendizaje profundo están hambrientos de datos, pero hemos conseguido alimentar a esta bestia con volúmenes cada vez mayores de datos para desarrollar mejores sistemas (véase la Figura 1-3). Esto es posible gracias al crecimiento exponencial de los contenidos creados digitalmente. Por ejemplo, sólo en el año 2020, se estima que se crearán 64,2e-9 TB (64,2 zettabytes) de datos-32 veces más que los 2e-9 TB (2 ZB) creados en 2010.15
Nota
Hablaremos más sobre el papel de los datos en el aprendizaje profundo en el Capítulo 2. Se han innovado toda una serie de técnicas para aprovechar el volumen, la variedad, la veracidad y el valor de los datos para desarrollar y escalar modelos de aprendizaje profundo. Estas técnicas se exploran en la "IA centrada en los datos", de la que hablaremos en el Capítulo 10.
Tradicionalmente, el desarrollo de sistemas inteligentes comenzaba con un conjunto de datos altamente curados y etiquetados. Más recientemente, técnicas innovadoras como el aprendizaje autosupervisado han demostrado ser bastante económicas y eficaces a la hora de aprovechar un corpus muy grande de datos no etiquetados ya disponibles: el conocimiento de forma libre que hemos creado a lo largo de la historia en forma de artículos de noticias, libros y otras publicaciones diversas.16 Por ejemplo, CoCa, un modelo de aprendizaje autosupervisado contrastivo, sigue este principio y, en el momento de escribir estas líneas, es el líder en precisión de ImageNet top-1, con un 91% (véase la Figura 1-6 más adelante en esta sección).17 Además, las aplicaciones de los medios sociales conservan automáticamente grandes cantidades de datos multimodales etiquetados (por ejemplo, datos de visión en forma de imágenes con pies de foto/comentarios y vídeos con imágenes y audio) que están impulsando modelos generalistas más potentes (que se tratan con más detalle en los Capítulos 12 y 13).
Nota
Precisión top-N es una medida de la frecuencia con la que la etiqueta correcta se encuentra entre las N mejores predicciones del modelo. Por ejemplo, la precisión top-1 indica la frecuencia con la que la predicción del modelo coincide exactamente con la respuesta esperada, y la precisión top-5 indica la frecuencia con la que la respuesta esperada se encuentra entre las 5 mejores predicciones del modelo.
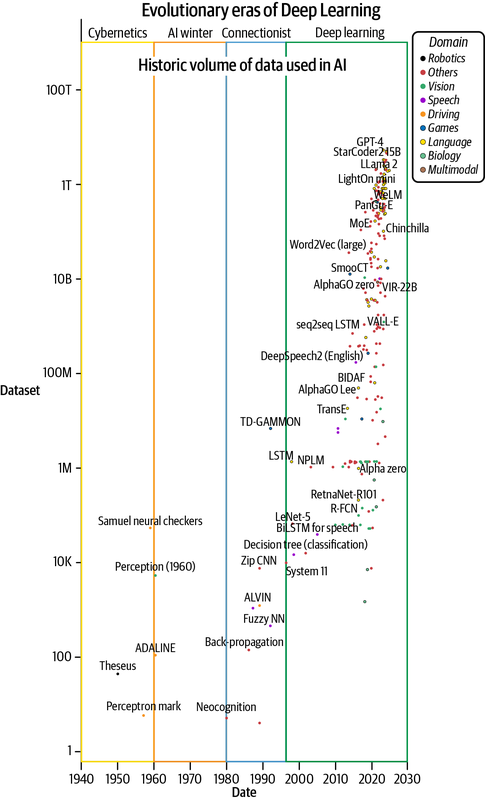
Figura 1-3. Crecimiento de los volúmenes de datos utilizados para entrenar modelos de IA (trazado con datos de Sevilla et al., 2022)
El programa
El panorama del software que apoya el desarrollo de soluciones de IA también ha ido creciendo. Durante la fase de creación de, alrededor del año 2000, sólo se disponía de marcos de software en fase inicial, como MATLAB y el Torch basado en Lua. A esto le siguió la fase de formación de, que comenzó en torno a 2012, cuando se desarrollaron marcos de aprendizaje automático como Caffe, Chainer y Theano (véase la Figura 1-4). tardó otros cuatro años en alcanzar la fase de madurez, que vio cómo marcos estables como Apache MXNet, TensorFlow y PyTorch proporcionaban API más amigables para el desarrollo de modelos. Gracias a las comunidades de código abierto de todo el mundo, que trabajan en colaboración para ampliar la postura de las herramientas de software para el aprendizaje profundo, ahora nos encontramos en una fase de expansión. La fase de expansión se define por el creciente ecosistema de software y herramientas para acelerar el desarrollo y la producción de software de IA .
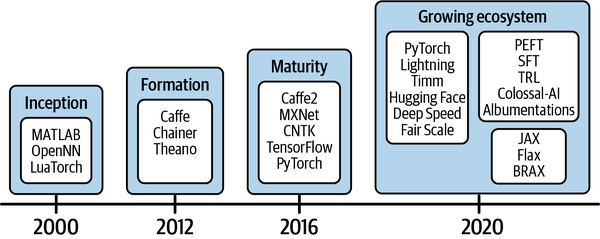
Figura 1-4. Las fases evolutivas del software y las herramientas para el aprendizaje profundo
El desarrollo de código abierto impulsado por la comunidad ha sido clave para reunir el software, los algoritmos y las personas necesarios para el crecimiento exponencial. Los proyectos de desarrollo de software de aprendizaje profundo de código abierto (como PyTorch, JAX y TensorFlow), las fundaciones como la Fundación Linux (responsable de PyTorch y su ecosistema) y los foros de intercambio de investigación como arXiv y Papers with Code han fomentado y permitido las contribuciones de personas de todo el mundo. El papel que han desempeñado las comunidades de código abierto en la ampliación de los esfuerzos de los sistemas inteligentes no es sino heroico.
Los algoritmos (de aprendizaje profundo)
La visión de los sistemas inteligentes que se pueden aprender comenzó con soluciones basadas en heurísticas y reglas, que evolucionaron rápidamente hacia sistemas estocásticos basados en datos. La Figura 1-5 traza la evolución y el correspondiente aumento de popularidad de los algoritmos de aprendizaje profundo a lo largo del tiempo, capturando la progresión desde el nacimiento del aprendizaje automático clásico a las redes neuronales superficiales basadas en perceptrones, hasta las capas más profundas y densas que dieron forma al aprendizaje profundo actual. (Para un contexto histórico más detallado, consulta la barra lateral "Historia del aprendizaje profundo". Ten en cuenta que se trata de un gráfico indicativo que muestra la popularidad y el crecimiento del aprendizaje profundo. No representa la popularidad absoluta). Como puedes ver, el crecimiento de la popularidad del aprendizaje profundo ha sido exponencial, pero a lo largo del camino ha habido algunas pausas -los llamados inviernos de la IA de - comoresultado de las restricciones y limitaciones que había que superar.
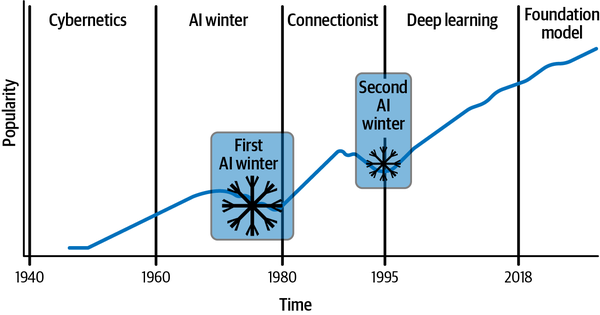
Figura 1-5. Evolución y crecimiento de la popularidad del aprendizaje profundo
El segundo invierno de la IA se prolongó hasta 1995. Llegados a este punto, los investigadores se dieron cuenta de que, para seguir teniendo éxito con las redes neuronales, necesitaban encontrar soluciones a los siguientes tres problemas:
- Escalar capas eficazmente
-
Durante la era conexionista, los investigadores del aprendizaje profundo descubrieron que los modelos eficaces para el aprendizaje profundo requieren un número muy elevado de capas. Añadir simplemente más capas a las redes neuronales no era una opción viable, debido al sobreajuste (como señalan Sepp Hochreiter y Yoshua Bengio et al.).18
- Escalar la eficiencia del cálculo
-
Por desgracia, ¡la suerte de la lotería del hardware estaba echada en esta época! Por ejemplo, se tardaron tres días en entrenar un modelo de 9.760 parámetros basado en la arquitectura LeNet-5 de Yann LeCun, propuesta en 1989, que tenía cinco capas entrenables.19 El mejor ordenador disponible en aquel momento no era lo bastante eficiente para proporcionar una retroalimentación rápida, y las limitaciones de hardware estaban estrangulando el desarrollo.
- Escalar la entrada
-
Como se muestra en la Figura 1-3, el volumen de datos utilizado en los experimentos de aprendizaje profundo apenas cambió desde la década de 1940 hasta aproximadamente 1995. La capacidad de capturar, almacenar y gestionar datos también seguía desarrollándose durante esta época.
Está claro que gestionar la escala es un reto crítico en cualquier sistema de aprendizaje profundo. La investigación histórica que aceleró el crecimiento del aprendizaje profundo fue la red de creencias profunda y densamente conectada desarrollada por Hinton et al. en 2006,20 que tiene tantos parámetros como 0,002 mm3 de corteza de ratón. Fue la primera vez que el aprendizaje profundo se acercó a modelar un sistema biológico, por pequeño que fuera. Como se muestra en las Figuras 1-2 y 1-3, éste fue también el año histórico en que los datos y el hardware cobraron impulso en sus respectivos crecimientos. Los esfuerzos colaborativos de código abierto también han impulsado el crecimiento; esto es evidente por la evolución que siguió a la publicación del conjunto de datos ImageNet en 2009, denominado el "momento ImageNet". Este conjunto de datos, que contiene más de 14 millones de imágenes anotadas de objetos cotidianos en unas 20.000 categorías, se puso a disposición de los investigadores para que compitieran en el ImageNet Large Scale Visual Recognition Challenge (ILSVRC) e inventaran algoritmos para la tarea a escala.21
Bajo la supervisión de Hinton, en 2017 Alex Krizhevsky produjo una solución para el ILSVRC que superó a la competencia por un enorme margen del 10,8% (con un error del 15,3% en el top-5).22 Este trabajo, ahora conocido popularmente como AlexNet, aplicó novedosas técnicas de entrenamiento distribuido para escalar el desarrollo de la solución en dos GPU con memoria muy limitada. La Figura 1-6 muestra la trayectoria de éxito (tasa creciente de la precisión top-5) de ImageNet desde este desarrollo pionero.
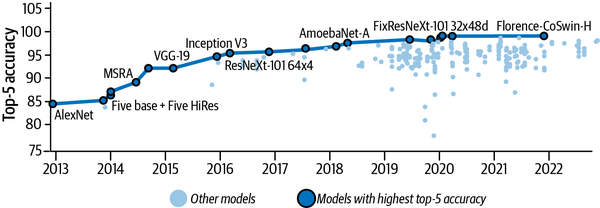
Figura 1-6. Precisión de los 5 mejores modelos de aprendizaje profundo en el conjunto de datos ImageNet desde la creación de AlexNet (gráfico basado en datos obtenidos de https://oreil.ly/mYfbq)
Más o menos en esa época, la industria también empezó a interesarse seriamente por el aprendizaje profundo y su producción; unas bases industriales sólidas lo posicionaron para una inyección de dinero, y la financiación de riesgo aceleró no sólo la comercialización, sino también la investigación futura. Los fondos han estado fluyendo hacia el aprendizaje profundo a un gran ritmo desde 2013, cuando la adquisición de DNNresearch de Hinton por parte de Google abrió las compuertas, convirtiéndolo (a partir de 2023) en una industria de 27.000 millones de dólares.23 La abundancia de recursos y apoyo ha sobrealimentado el auge del aprendizaje profundo en la última década, y con el apoyo de la industria llegó el crecimiento interdisciplinar que ha impulsado el desarrollo colectivo de los aspectos científicos del aprendizaje profundo y los algoritmos, junto con todo lo demás que se encuentra en la intersección del hardware, el software y los datos.
Ahora que ya conoces un poco la historia, en la siguiente sección examinaremos las tendencias actuales del aprendizaje profundo y veremos cómo la capacidad de escalar está influyendo en la investigación en curso y en la adaptación de la industria.
Tendencias en evolución del aprendizaje profundo
Veinte años después del éxito de Deep Blue, el aprendizaje profundo ha evolucionado hasta sustituir por completo a las soluciones basadas en reglas y está superando cada vez más el rendimiento humano en tareas específicas. AlphaGo24 por ejemplo, alcanzó este nivel tras unas cuatro horas de entrenamiento en una sola máquina de 44 núcleos con una TPU y puede lograr una convergencia aproximada en unas nueve horas gracias a sus novedosos algoritmos e implementaciones de software. Ha derrotado a Stockfish, uno de los mejores motores de ajedrez del mundo que ha ganado varias competiciones de ajedrez. Esta mayor capacidad para ofrecer mejores soluciones que el software basado en reglas/lógica está reconocida por la migración al Software 2.0 (que se analiza con más detalle en el Capítulo 2), donde el software tradicional se está convirtiendo en software basado en modelos.
Evolución general del aprendizaje profundo
La aplicación del aprendizaje profundo a la visión por ordenador, que comenzó con la red de reconocimiento de dígitos de Yann LeCun25 se ha extendido hoy a muchas tareas de visión, como la clasificación de imágenes, la detección y segmentación de objetos, la comprensión de escenas, el subtitulado, etc. Estas soluciones se desarrollan y utilizan habitualmente en todo el mundo. La eficiencia fue la motivación clave de la arquitectura de red neuronal convolucional mencionada anteriormente en este capítulo, y dada la naturaleza voluminosa de los datos de visión, ha seguido siendo una consideración clave. Los modelos basados en CNN, como ResNet y EfficientNet, han tenido mucho éxito en tareas de visión, alcanzando una precisión top-1 de alrededor del 90%, al tiempo que aplicaban cuidadosamente consideraciones de eficiencia y escalado. Estos modelos son excelentes para contextos espaciales pequeños, pero no se adaptan a contextos espaciales más amplios.
La arquitectura Transformer de Google26 que presta atención a los tokens en secuencias largas de forma paralelizada, ha sido pionera. Los requisitos para escalar los modelos de visión para un contexto global han llevado a explorar el uso de arquitecturas basadas en Transformer. Un ejemplo de ello es el Transformador de Visión (ViT)27 que tokeniza las imágenes en trozos pequeños y memoriza dónde se encuentran estos trozos en el espacio global de la imagen. En los últimos años, la mayor parte de la investigación en visión se ha basado en la arquitectura Transformer. CoAtNet, una combinación de arquitecturas CNN y Transformer , tiene 2.440 millones de parámetros y alcanza un 90,88% de precisión top-1 en tareas ImageNet. MaxViT, una arquitectura basada en ViT, se aproxima a CoAtNet en la referencia de precisión, pero tiene unas cinco veces menos parámetros (475 millones).28 Aun así, escalar el tamaño del contexto de los Transformadores ha seguido siendo un reto debido a las limitaciones de memoria y computación. Esto ha dado lugar a técnicas interesantes e innovadoras como MEGABYTE y LongViT, que pueden procesar tamaños de contexto muy grandes (por ejemplo, secuencias de millones de bytes o las imágenes gigapíxel utilizadas en patología).29 Sin embargo, el escalado no sólo tiene que ver con el número de parámetros; las economías de datos, energía y costes también son fundamentales.
Fue la arquitectura Transformer la que reavivó la innovación en el ámbito del procesamiento del lenguaje, que se había estancado antes de 2017. A pesar de sufrir ineficiencias de cálculo (debido al cálculo cuadrático en el módulo de atención), esta arquitectura revolucionó por completo el procesamiento del lenguaje natural. Como se muestra en la Figura 1-7, los modelos lingüísticos basados en esta arquitectura fueron capaces de escalar sus capacidades escalando el número de parámetros, una tendencia conocida como la ley de escalado de los modelos lingüísticos.30El Codex de OpenAI es uno de esos modelos escalables; entrenado con código fuente abierto de GitHub, está revolucionando la forma en que los desarrolladores codifican hoy en día. Esta tendencia continuó al menos hasta mediados de 2021. Lo que siguió a finales de 2021 fue una seria reconsideración del escalado, principalmente mediante el escalado del número de parámetros, y se produjo una meseta con algunas caídas significativas causadas por modelos que utilizaban un número considerablemente menor de parámetros, pero que seguían superando a sus homólogos. Chinchilla es uno de esos modelos que se escala principalmente en función del volumen de datos; a pesar de tener 2,5 veces menos parámetros, sigue superando a GPT-3. LLaMA, otro modelo comparable de Meta, también ha ganado popularidad y se utiliza ampliamente. Esta tendencia puede verse en la Figura 1-7, que destaca la zona de concentración de modelos en torno al intervalo 7B-200B, a pesar de que se están desarrollando modelos con parámetros >1T.
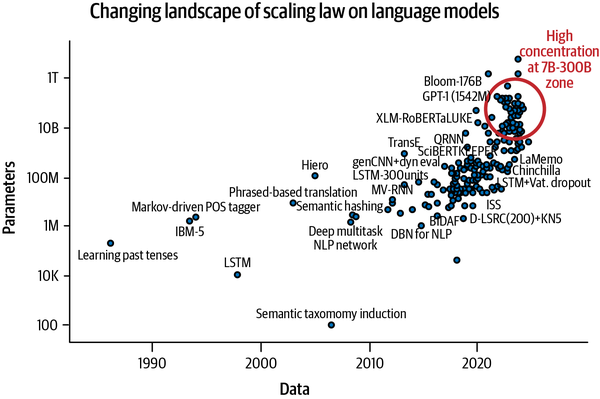
Figura 1-7. El paisaje cambiante de la ley de escala de los modelos lingüísticos (trazado con datos de Sevilla et al., 2022)
La ley de escalado de los modelos de aprendizaje profundo ha fomentado el desarrollo de modelos sobreparametrizados y redes cada vez más profundas y densas.31 Esta tendencia se observa en todas las modalidades de datos: visión, lenguaje, habla, etc. Como ya se ha mencionado, una innovación importante en la intersección de los datos y los algoritmos es el desarrollo de modelos autosupervisados.32 Juntos, estos avances están apoyando la creación de grandes modelos de propósito más general que muestran capacidades emergentes, lo que les permite realizar tareas sin ser entrenados explícitamente para ellas. Estos grandes modelos, más conocidos como modelos de base, aprovechan un conjunto de técnicas de entrenamiento distribuido complejas y bien diseñadas para utilizar eficazmente los recursos disponibles y producir los mejores modelos posibles. Otra tendencia emergente es el desarrollo de grandes modelos multimodales (LMM) que pueden trabajar con datos de distintas modalidades (como texto, audio e imágenes), como CLIP y DALL-E, GPT-4, Gemini y Flamingo. Esto, a su vez, ha provocado un rápido crecimiento del arte generativo, con modelos como Sora, GLIDE, Imagen y Stability .ai's Stable Diffusion, que han provocado una conmoción en la industria del arte.33
Ninguno de estos desarrollos habría sido posible sin los avances en algoritmos, hardware, software y datos. Leerás sobre estos avances en la Parte I. En la Parte II veremos los detalles del entrenamiento distribuido, y en la Parte III profundizaremos en el desarrollo eficiente y eficaz de modelos a gran escala, incluidos los modelos fundacionales.
Evolución en dominios especializados
Aparte del progreso de propósito general, el aprendizaje profundo también ha influido masivamente en los procesos y técnicas de dominios especializados como los que se tratan en esta sección.
Matemáticas y cálculo
Durante siglos, los matemáticos creyeron que el algoritmo estándar de multiplicación de matrices era el más eficiente. Entonces, en 1969, Volker Strassen demostró que otro algoritmo era superior. El esfuerzo por optimizar el cálculo matricial ha sido continuo. La superación de la ley de Moore de hizo necesaria la exploración de técnicas alternativas para escalar la multiplicación de matrices, lo que condujo a la multiplicación por aproximación de, que produce un aumento de velocidad de 100x, pero es menos práctica para escenarios en los que importa la precisión.34 El descubrimiento más reciente, liderado por DeepMind, identificó mejoras en el algoritmo de Strassen por primera vez desde su descubrimiento hace medio siglo mediante el uso del sistema de aprendizaje profundo AlphaTensor.35
Plegamiento de proteínas
Otro ejemplo de del éxito del código abierto y del trabajo impulsado por la comunidad es el esfuerzo por resolver problemas en la investigación del plegamiento de proteínas mediante la predicción automática de secuencias de proteínas evolutivas de extremo a extremo. AlphaFold, otro sistema de aprendizaje profundo de DeepMind, escaló el conjunto de datos de proteínas de 190K estructuras derivadas empíricamente a 0,2B estructuras de proteínas generadas por IA.36 Un gran ejemplo de escala es ProGen2, un modelo de 6.400 millones de parámetros desarrollado utilizando técnicas de aprendizaje profundo distribuido para escalar el entrenamiento a través de 256 nodos en TPU.37 La acalorada competición dio lugar a ESMFold, un modelo de 15B parámetros para cuyo desarrollo se necesitaron unas 2.000 GPUs NVIDIA V100, que funciona seis veces más rápido que AlphaFold2 en el momento de la inferencia.38 Con estas innovaciones, la comunidad investigadora del plegamiento de proteínas pasó básicamente de "el problema del plegamiento de proteínas no tiene solución actualmente" a "el aprendizaje profundo lo ha resuelto (en su mayor parte)".
Mundo simulado
El aprendizaje profundo ha tenido un gran impacto en la realidad virtual y la simulación guiada por la física, incluso en el diseño y la planificación de tejidos, y en otras industrias relacionadas. La ponencia principal de CVPR 2022 "Comprender la apariencia visual desde la micra hasta la escala global", de Kavita Bala, Decana de Informática y Ciencias de la Información de la Universidad de Cornell, es una charla excelente que pone de relieve cómo el aprendizaje profundo está cambiando las industrias de todo el mundo.
En este capítulo has leído mucho sobre la historia y la evolución del aprendizaje profundo. En la siguiente sección, cambiaré el enfoque hacia consideraciones prácticas y principios generales que son esenciales para el escalado. Creo que es fundamental comprender estas cuestiones antes de empezar a hablar de cómo escalar tu carga de trabajo de aprendizaje profundo, aunque la orientación que proporciono aquí es tan genérica que se aplica no sólo al aprendizaje profundo, sino al escalado de cualquier tarea, de ingeniería o de otro tipo.
La escala en el contexto del aprendizaje profundo
El escalado, en el contexto del aprendizaje profundo, es multidimensional, y a grandes rasgos consiste en los tres aspectos siguientes:
- Generalizabilidad
-
Aumentar la capacidad de los modelos para generalizarse a diversas tareas o grupos demográficos
- Formación y desarrollo
-
Ampliación de la técnica de entrenamiento de modelos para acortar el tiempo de desarrollo y satisfacer al mismo tiempo las necesidades de recursos
- Inferencia
-
Aumentar la capacidad de servicio del modelo desarrollado durante el servicio
Todas ellas tienen matices y requieren diferentes estrategias para escalar. Este libro, sin embargo, se centrará principalmente en las dos primeras; la inferencia (implementación, servicio y mantenimiento) está fuera del alcance del libro.
Seis consideraciones sobre el desarrollo
Hay seis consideraciones que es crucial explorar al desarrollar una solución de aprendizaje profundo. Tomemos un caso de uso realista como base para explorar estas consideraciones y decidir cuándo puede ser necesario escalar y cómo prepararse para ello. Utilizaré este ejemplo a lo largo de esta sección y a menudo en todo el libro.
Supongamos que has construido un sistema que analiza imágenes de satélite para predecir si hay tejados y, en caso afirmativo, qué tipo de materiales de tejado se han utilizado. Supongamos también que este sistema se ha desarrollado originalmente para Sydney, Australia. Tu modelo es un modelo supervisado basado en la visión. Por lo tanto, tienes un conjunto de datos reales representativos de los tejados y los materiales utilizados en Sydney, y el modelo se ha entrenado con este conjunto de datos. Ahora quieres ampliar tu solución para que funcione con cualquier tejado del mundo.
Cuando empieces a descomponer esta misión, pronto te darás cuenta de que para poder alcanzar este objetivo tendrás que tener en cuenta los seis aspectos que se exponen en los siguientes apartados.
Problema bien definido
Para soluciones basadas en datos, como el aprendizaje profundo, es realmente importante comprender el problema exacto que hay que resolver y si se dispone de los datos adecuados para ese problema.
Por tanto, para que tu solución funcione en cualquier tejado del mundo, hay que definir bien el problema. Plantéate preguntas como
-
¿Seguimos detectando sólo la presencia de un tejado y los materiales utilizados? ¿O estamos ampliando para determinar también el estilo del tejado (por ejemplo, a cuatro aguas, a dos aguas, plano)?
-
¿Cómo varían los materiales y las formas de los tejados según las zonas geográficas?
-
¿Nuestros criterios de éxito son uniformes, o tenemos que sopesar la sensibilidad frente a la especificidad según las circunstancias (para determinados tejados o zonas geográficas concretas, por ejemplo)?
-
¿Cómo se definen y cuáles son los umbrales de error mínimo y máximo aceptables? ¿Existen otros criterios de éxito?
Estas cuestiones son cruciales porque, por ejemplo, si detectar correctamente los tejados de iglú es igual de importante que detectar correctamente los tejados de hormigón, puede que tengas la complejidad añadida del desequilibrio de datos, dado que los tejados de hormigón son muy comunes, pero es probable que los iglúes estén infrarrepresentados en tu conjunto de datos. Los matices geográficos, como los tejados canadienses que suelen estar cubiertos de nieve, también tendrán que gestionarse con cuidado. Este ejercicio de comprender completamente tu problema te ayuda a extrapolar las limitaciones de tu sistema y a planificar cómo gestionarlas eficazmente con tus restricciones. Al fin y al cabo, ¡el escalado está limitado!
Conocimiento del dominio (también conocido como restricciones)
Como ya hemos comentado en, el escalado para la detección de tejados y materiales de tejado requiere una muy buena comprensión de factores como los siguientes:
-
¿Qué define un tejado? ¿Existen ciertas dimensiones mínimas? ¿Se reconocen sólo determinadas formas o materiales?
-
¿Qué se incluye y qué se excluye, y por qué? ¿Consideramos tejado el techo de la marquesina de una parada de autobús? ¿Y las pérgolas?
-
¿Cuáles son las restricciones específicas del dominio que debe seguir la solución?
Es crucial determinar cómo se relacionan entre sí los tejados y los materiales de los tejados, y cómo las geografías limitan los tipos de materiales de los tejados. Por ejemplo, los tejados de caucho aún no han penetrado en el mercado australiano, pero el caucho es un material popular en Canadá por su capacidad para proteger los tejados de condiciones climáticas extremas. Desde el punto de vista de la apariencia y el material, los tejados de caucho y tejas son mucho más parecidos que los tejados metálicos o de aglomerado de color, por ejemplo. El conocimiento del dominio derivado de una amplia comprensión del espacio del problema suele ser muy útil para crear restricciones y aplicar la validación. Por ejemplo, con el conocimiento del dominio, el modelo que predice probabilidades relativas de 0,5 y 0,5 respectivamente para los materiales de tejado de tejas y caucho es comprensible; sin embargo, predecir las mismas probabilidades para las tejas y el hormigón sería menos comprensible, ya que el aspecto de estos materiales es muy distinto. Del mismo modo, predecir que el caucho es el material de los tejados australianos será probablemente erróneo. Un buen sistema siempre entiende las expectativas del usuario, peroéstas pueden ser difíciles de cumplir en un sistema basado en datos, como una solución de aprendizaje profundo. Pueden probarse y aplicarse más fácilmente como estrategias de adaptación al dominio.
La verdad sobre el terreno
Tu conjunto de datos es la base de la base de conocimientos para tu solución de aprendizaje profundo. Al planificar y construir tu conjunto de datos, debes plantearte preguntas como las siguientes:
-
¿Cómo podemos conservar el conjunto de datos para que sea representativo de los tejados de todo el mundo?
-
¿Cómo garantizamos la calidad y la generalización?
Tus esfuerzos de etiquetado y obtención de datos tendrán que escalar en consecuencia, y esto puede resultar realmente caro muy rápidamente. A medida que escalas un sistema de aprendizaje profundo, la capacidad de iterar rápidamente sobre los datos se vuelve crucial. Andrej Karpathy, investigador independiente y anterior director de IA en Tesla, habla de esto en términos de "motor de datos": "La ventaja competitiva en IA no es tanto para los que tienen datos, sino para los que tienen un motor de datos: adquisición iterada de datos, reentrenamiento, evaluación, implementación, telemetría. Y quien pueda hacerlo girar más rápido".
A medida que escalas, también empiezas a ver interesantes escenarios extraños del "mundo real". Los tejados de tepes escandinavos, por ejemplo, son un tipo muy interesante de tejado específico de una región. El tepe es un material de cubierta menos común para los habitantes de muchas otras partes del mundo. En las zonas donde se utiliza, tienes que considerar cuestiones como la forma de delimitar estos tejados de los de hormigón con césped artificial. Cómo identificas y captas esos valores atípicos también se convierte en un reto interesante. Tener claro dónde trazas los límites y qué riesgos aceptas es importante para escalar tu sistema. En el Capítulo 10 encontrarás más información sobre técnicas para afrontar estos retos.
Desarrollo de modelos
Tu objetivo es ampliar la capacidad del modelo para identificar tejados y materiales de tejado en todo el mundo. Por tanto, puede que tus esfuerzos de escalado tengan que ir más allá del escalado del conjunto de datos (para una mejor representación y generalización) y pasar al escalado de la capacidad del modelo y de las técnicas implicadas. Como ya hemos dicho, si globalizas, tu modelo tendrá que conocer una mayor variedad de estilos y tipos de materiales de tejado. Si tu modelo no está diseñado para esta escala, puede existir el riesgo de un ajuste insuficiente.
Puedes preguntar:
-
¿Cómo planificamos los experimentos para llegar al modelo óptimo para la solución a escala?
-
¿Qué enfoque debemos adoptar para desarrollarnos rápidamente y acelerar la acumulación?
-
¿Cómo podemos improvisar con nuestras metodologías de formación para que sean las más óptimas? ¿Cuándo necesitamos formación distribuida? ¿Qué estrategias de formación eficientes son relevantes para nuestro caso de uso?
-
¿Debemos desarrollar con todos los datos, o utilizar técnicas centradas en los datos como el muestreo y los aumentos para acelerar el desarrollo?
Los planes para la evaluación de modelos también requieren consideraciones similares, al igual que la estructuración de la base de código y la planificación y escritura de pruebas de automatización en torno al desarrollo de modelos para apoyar una iteración rápida y fiable. A lo largo del libro leerás sobre el desarrollo de modelos a escala y las técnicas de entrenamiento, con un enfoque explícito en la planificación de experimentos en el Capítulo 11.
Implementación
Ampliar un sistema para que llegue a todo el mundo requiere también escala y sofisticación en las estrategias de implementación. Aunque la implementación va más allá del alcance de este libro, recomiendo considerar las circunstancias de la implementación desde las primeras fases de desarrollo.
Aquí tienes algunas preguntas que deberías plantearte:
-
¿Qué limitaciones tendrá nuestro entorno de implementación?
-
¿Podemos obtener suficiente computación y proporcionar la latencia deseada sin comprometer la capacidad de servicio de las solicitudes de los usuarios para las técnicas a las que nos dirigimos?
-
¿Cómo obtenemos métricas de calidad de los entornos implementados con fines de asistencia?
-
¿Cómo optimizamos el modelo para distintos equipos antes de su implementación?
-
¿Apoyará esto nuestra elección de herramientas?
La velocidad de procesamiento de los datos y el paso adelante del modelo tienen implicaciones directas en la capacidad de servicio del sistema. El retraso en el calentamiento y el arranque de los servicios del modelo repercute directamente en las estrategias de escalabilidad que deben adoptar los servicios para un tiempo de actividad adecuado. Se trata de datos importantes para compartir como aportación a la planificación del desarrollo del modelo.
Comentarios
El feedback es crucial para mejorar, y no hay mejor feedback que el directo en tiempo real, directamente de tus usuarios. Un gran ejemplo de recogida de opiniones es GitHub Copilot. Copilot recoge opiniones varias veces después de que se hagan sugerencias de código para reunir métricas precisas sobre la utilidad de las sugerencias proporcionadas, si las sugerencias se siguen utilizando y, en caso afirmativo, con qué nivel de ediciones. Esta es una gran oportunidad para crear un motor de datos.
A medida que aumenta la escala, aumenta también la importancia de los sistemas de retroalimentación y apoyo. En esencia, cuando pienses en la retroalimentación, las preguntas que deberías hacerte son:
-
¿Cómo vamos a recoger las opiniones de los usuarios para mejorar continuamente nuestro sistema?
-
¿Podemos automatizar la recogida de información? ¿Cómo podemos integrarlo con el flujo de trabajo de desarrollo del modelo para realizar una configuración similar a la del motor de datos?
La retroalimentación necesita acción; de lo contrario, el sistema de retroalimentación carece de sentido. En el contexto de un motor de datos, medir las lagunas e iterar continuamente para cerrarlas proporciona ventajas significativas a la hora de construir cualquier sistema basado en datos, como una solución de aprendizaje profundo. Aquí es donde reside la ventaja competitiva.
Consideraciones sobre la ampliación
Escalar es complicado. La mítica "carga de trabajo vergonzosamente paralela", en la que se requiere poco o ningún esfuerzo para dividir y paralelizar tareas, no existe en realidad. Por ejemplo, las unidades de procesamiento gráfico (GPU) se comercializan como dispositivos vergonzosamente paralelos para cálculos matriciales, pero su capacidad de procesamiento está estrangulada por su ancho de banda de memoria, lo que limita el rendimiento práctico del cálculo (véase el Capítulo 3). Como ya se ha comentado, el verdadero reto del escalado reside en comprender las limitaciones de los subsistemas y trabajar con ellos para escalar todo el sistema.
Esta sección trata de las preguntas que debes hacerte antes de intentar escalar, y del marco para hacerlo.
Preguntas que hay que hacerse antes de escalar
El dicho proverbial "Todos los caminos conducen a Roma" se aplica también en el escalado. A menudo, puede haber muchas formas de alcanzar la escala deseada. El objetivo debe ser tomar la ruta más óptima.
Por ejemplo, para reducir a la mitad la latencia de tu proceso de entrenamiento, puede que necesites escalar. Podrías
-
Amplía tu hardware adquiriendo dispositivos informáticos más potentes.
-
Amplía tu proceso de formación utilizando la formación distribuida.
-
Reduce el presupuesto de cálculo de tu proceso o programa a costa de la exactitud/precisión.
-
Optimiza la entrada, por ejemplo, comprimiendo el conjunto de datos mediante la destilación de datos (tratada en el Capítulo 10).
Si tienes limitaciones económicas y no puedes financiar más dispositivos o dispositivos más potentes, entonces es probable que la ruta óptima sea la opción 3 ó 4. Si no puedes comprometer la precisión, entonces la opción 4 es la más óptima por eliminación. De lo contrario, la opción 3 puede ser la más económica para reducir la latencia.
Los temas tratados anteriormente en este capítulo pueden destilarse en el siguiente conjunto de preguntas que es fundamental plantearse antes de iniciar tus esfuerzos de ampliación. Responder a estas preguntas te ayudará a definir tus opciones y te permitirá escalar con mayor eficacia:
-
¿Qué estamos escalando?
-
¿Cómo mediremos el éxito?
-
¿Realmente necesitamos escalar?
-
¿Cuáles son los efectos dominó (es decir, las implicaciones posteriores)?
-
¿Cuáles son las limitaciones?
-
¿Cómo escalaremos?
-
¿Es óptima nuestra técnica de escalado?
Considerar estas cuestiones no sólo te obligará a asegurarte de que comprendes bien el alcance y los límites de la ampliación, sino que también te garantizará que has definido unas buenas métricas para medir tu éxito. Cassie Kozyrkov, directora general de Data Scientific y anteriormente científica jefe de decisiones en Google, tiene un excelente artículo titulado "Metric Design for Data Scientists and Business Leaders" (Diseño de métricas para científicos de datos y líderes empresariales)39 que destaca la importancia de definir primero las métricas antes de tomar decisiones. La navaja de Occam, el principio de parsimonia, destaca la importancia de la simplicidad, pero no a expensas de la necesidad. Es la regla nº 1 para escalar eficazmente, que te ves obligado a considerar cuando te preguntas: "¿Realmente necesitamos escalar?". Los siguientes capítulos de este libro están diseñados para profundizar en los enfoques y técnicas de escalado y ayudarte a determinar si la técnica de escalado que has elegido es óptima para tu caso de uso.
Características de los sistemas escalables
Ian Gorton trata a fondo los principios de un sistema escalable, los patrones de diseño utilizados en los sistemas escalables y los retos asociados al escalado en su libro Fundamentos de los sistemas escalables: Diseño de Arquitecturas Distribuidas. El libro de Gorton no es un requisito previo para este libro, pero es una lectura recomendada si tienes alguna formación en ingeniería de software. En esta sección se esbozan cuatro características de un sistema escalable que es útil tener en cuenta cuando te preparas para escalar tu carga de trabajo.
Fiabilidad
La característica más importante de un sistema escalable es la fiabilidad. Un sistema fiable rara vez falla. En los momentos inoportunos en que lo hace, falla de forma predecible, permitiendo al sistema dependiente y a los usuarios afrontar con gracia dicho fallo. En otras palabras, un sistema fiable es capaz de hacer frente a fallos (poco frecuentes) y recuperarse de los escenarios de fallo con elegancia. He aquí un ejemplo: todos los 224,641e+18 FLOPs que has realizado hasta ahora se perdieron cuando, debido a un fallo de la red, el entrenamiento se detuvo después de funcionar durante dos meses utilizando 500 nodos GPU A100. Cuando el sistema vuelve a funcionar, ¿es capaz de reanudar desde el último estado de cálculo completado y recuperarse con elegancia? Un sistema fiable será capaz de hacer frente a este fallo y recuperarse con elegancia.
Las métricas comúnmente conocidas para definir un sistema fiable son las siguientes:
- Objetivo de punto de recuperación (RPO)
-
RPO se define como la distancia hacia atrás que puedes recorrer para recuperar los datos tras un fallo. Por ejemplo, con el checkpointing, el intervalo que decidas -la frecuencia con la que almacenas los pesos intermitentes y los estados de entrenamiento (optimizadores, etc.)- definirá tu RPO. Puede establecerse en función del número de pasos o épocas.
- Objetivo de tiempo de recuperación (RTO)
-
RTO se define como el tiempo que se tarda en recuperarse y volver al estado de justo antes de la caída.
- Tasa de inactividad
-
Tasa de inactividad es el porcentaje de tiempo durante el cual se observa que el sistema no está disponible o no responde.
Disponibilidad
Disponibilidad define la probabilidad de que un sistema esté operativo y funcional. La norma de referencia para los sistemas de alta disponibilidad es cinco nueves, esdecir, el sistema está disponible y funciona el 99,999% del tiempo. Gestionar la disponibilidad de un sistema basado en el aprendizaje profundo hasta cinco nueves es un proceso complicado. TikTok, el servicio de procrastinación de vídeos compartidos en formato pequeño de ByteDance Ltd, está operativo internacionalmente desde 2017. En cinco años, ha ampliado sus servicios de personalización de contenidos de usuario a 150 países, albergando a más de 1.000 millones de usuarios. La arquitectura del sistema, denominada Monolith40 combina el aprendizaje online y offline para servir contenido relevante para el usuario, creando usuarios fieles mediante técnicas de predicción de la tasa de clics (DeepFM) y funcionando a escala. Aunque la disponibilidad general de TikTok es alta, en ocasiones se ha enfrentado a situaciones de interrupción (hasta cinco horas de interrupción).
Adaptabilidad
Adaptabilidad habla de lo resistente que es un sistema para satisfacer las crecientes demandas de escalado. ¿Es capaz de escalar el entrenamiento sobre el número de GPUs disponibles? ¿Es capaz el código de entrenamiento de hacer frente a fallos como la pérdida de un nodo durante el entrenamiento? Estas son algunas de las consideraciones que entran en el ámbito de la adaptabilidad. Algunos retos de ingeniería de software de fácil solución aparecen como problemas increíblemente difíciles en el espacio del aprendizaje profundo.
Rendimiento
Rendimiento se define de muchas maneras, especialmente para los sistemas basados en el aprendizaje profundo. Por un lado, tienes métricas que indican lo buena que es la estocasticidad de tu sistema de aprendizaje profundo y si cumple la norma deseada. Por otro lado, tienes métricas técnicas sobre el rendimiento del sistema -relacionadas con cuántos recursos consume (RAM, CPU), cuál es la tasa de rendimiento, etc.- que puedes monitorear cuando se realiza el escalado. Idealmente, el escalado es un acontecimiento favorable para las métricas estocásticas y las métricas que dirigen las expectativas y el comportamiento del sistema. Por ejemplo, no querrás que la precisión de la detección de tejados disminuya cuando escales tu sistema de detección de tejados en distintas zonas geográficas. Dicho esto, se espera que las métricas técnicas se alineen siguiendo sus respectivas leyes de escalado. Si escalas la API que sirve al modelo para que tenga el doble de tasa de rendimiento, entonces es de esperar que cambien los requisitos de memoria, aunque es de esperar que esto tenga un impacto mínimo en la latencia.
Consideraciones sobre los sistemas escalables
En un crudo recordatorio de la ley de Murphy, el famoso dicho "¡Todo se rompe a escala!" casi siempre se cumple. Esto no debería sorprender, porque escalar consiste en trabajar con las limitaciones, ya sea para resolverlas o para eludirlas. Hacerlo con eficacia requiere un alto nivel de cuidado y consideración. Las siguientes secciones abordan algunos de los factores que hay que tener en cuenta al diseñar sistemas escalables y algunos patrones de diseño de utilidad común para el escalado.
Evitar puntos únicos de fallo
Un punto único de fallo (SPOF) es un componente cuyo fallo puede paralizar todo el sistema. Supongamos que se está entrenando un modelo a escala, a través de 1.000 GPUs A100. Todas estas máquinas se comunican con un almacén de datos distribuido para leer los datos necesarios para el entrenamiento. Si este almacén de datos falla, se detendrá el entrenamiento; por tanto, el almacén de datos es un único punto de fallo. Está claro que es importante minimizar la presencia de SPOF, si es posible erradicarlos.
Diseñar para alta disponibilidad
En la sección anterior, hablamos de por qué la disponibilidad es una característica importante de un sistema escalable. Ampliando ese debate, todos los componentes de un sistema escalable deben diseñarse para tener una alta disponibilidad. La alta disponibilidad se consigue mediante las tres R: fiabilidad, resistencia y redundancia. Es decir, los componentes del sistema deben diseñarse para que sean fiables (es decir, que rara vez fallen y, si fallan, que lo hagan de forma predecible), resistentes (es decir, que puedan hacer frente con elegancia a fallos posteriores sin que todo el sistema se detenga) y redundantes (es decir, que tengan redundancia incorporada para que, en caso de fallo, un componente redundante pueda hacerse cargo sin afectar a todo el sistema).
Paradigmas de escala
Hoy en día se utilizan habitualmente los tres paradigmas de escalado siguientes:
- Horizontal
-
En escalado horizontal, el mismo sistema se replica varias veces. A continuación, las réplicas deben coordinarse entre sí para prestar el mismo servicio a escala. El entrenamiento distribuido, en el que se añaden varios nodos y cada uno de ellos sólo examina partes específicas independientes de un conjunto de datos mayor, es un muy buen ejemplo de escalado horizontal. Este tipo de entrenamiento a escala se conoce como paralelismo de datos distribuido; hablaremos de él con más detalle en los Capítulos 6 y 7.
- Vertical
-
En el escalado vertical, las capacidades del sistema se escalan añadiendo más recursos a un componente existente. Añadir más tarjetas de memoria para aumentar la RAM en un 50% es un ejemplo de escalado vertical desde el punto de vista del nodo. Este tipo de escalado se tratará con más detalle en los Capítulos 8 y 9.
- Híbrido
-
En el escalado híbrido, se aplican técnicas de escalado horizontal y vertical para escalar en ambas dimensiones. Este tipo de formación a escala se tratará más adelante, en los Capítulos 8 y 9.
Coordinación y comunicación
La coordinación y la comunicación están en el corazón de cualquier sistema. El escalado de cualquier sistema crea presión sobre la columna vertebral de comunicación que utiliza el sistema. Existen dos paradigmas principales de comunicación:
- Sincrónico
-
Comunicación síncrona se produce en tiempo real, con dos o más componentes que comparten información simultáneamente. Este tipo de comunicación es intensiva en rendimiento. A medida que aumenta la escala (por ejemplo, el número de componentes), este paradigma de comunicación se convierte rápidamente en un cuello de botella.
- Asíncrono
-
En la comunicación asíncrona, dos o más componentes comparten información a lo largo del tiempo. La comunicación asíncrona proporciona flexibilidad y relaja la carga de comunicación, pero se produce a expensas de la discontinuidad.
La comunicación y la coordinación también son fundamentales en el escalado de los sistemas de aprendizaje profundo. Por ejemplo, el descenso de gradiente estocástico (SGD), una técnica aplicada para encontrar los pesos óptimos del modelo, era originalmente síncrona. Esta técnica se convirtió rápidamente en un cuello de botella a la hora de escalar el entrenamiento, lo que llevó a proponer su homólogo asíncrono, el SGD asíncrono (ASGD).41 Leerás más sobre los retos de coordinación y comunicación en los Capítulos 5 y 6.
Almacenamiento en caché e intermitente
La recuperación de información requiere la comunicación en cualquier sistema, pero los viajes para acceder a la información desde el almacenamiento suelen ser caros. Esto se intensifica en los escenarios de aprendizaje profundo porque la información está repartida entre nodos de cálculo y dispositivos GPU, lo que hace que la recuperación de información sea complicada y costosa. El almacenamiento en caché es una técnica muy popular que se utiliza para guardar la información que se necesita con frecuencia en un almacenamiento ineficiente, con el fin de eliminar los cuellos de botella en esta parte de la información. Los sistemas actuales están más limitados por la memoria y la comunicación que por la potencia de cálculo; por eso el almacenamiento en caché también puede ser útil para conseguir una latencia menor.
Estado del proceso
Conocer el estado actual de un proceso o sistema es fundamental para pasar a la siguiente fase. La cantidad de información contextual que necesita un componente define si tiene o no estado: los procesos y operaciones sin estado no necesitan ningún tipo de información contextual, mientras que los procesos con estado sí la necesitan. El sin estado simplifica el escalado. Por ejemplo, calcular el producto punto de dos matrices es una operación completamente sin estado, ya que sólo requiere una operación elemento a elemento sobre los índices de la matriz. El sin estado de la multiplicación de matrices permite la llamada paralelización vergonzosa de los cálculos tensoriales. Por el contrario, la acumulación de gradiente, una técnica de aprendizaje profundo utilizada para escalar el tamaño de los lotes con restricciones de memoria, es altamente apátrida. Utilizar componentes y técnicas lo más sin estado posible reduce la complejidad del sistema y minimiza los cuellos de botella en el escalado.
Recuperación graceful y checkpointing
Los fallos ocurren, como demuestra el hecho de que el estándar de oro de la disponibilidad del servicio es de cinco nueves (es decir, 99,999% de tiempo de actividad). Esto reconoce que, incluso en los sistemas de más alta disponibilidad, siempre se producirá algún tipo de fallo en algún momento. La sofisticación de un sistema escalable reside en disponer de una vía eficaz de recuperación cuando se produce un fallo, como ya se ha comentado. El checkpointing es una técnica comúnmente utilizada para preservar el estado intermitente, almacenándolo como punto de control para permitir la recuperación desde el último estado bueno conocido y maximizar el RPO.
Mantenibilidad y observabilidad
La mantenibilidad de cualquier sistema es importante, porque está directamente asociada a su continuidad. A medida que aumenta la complejidad de un sistema, como es de esperar al escalarlo, aumenta también el coste de su mantenimiento. La observabilidad, conseguida mediante herramientas de monitoreo y notificación de forma significativa, aumenta la comodidad de trabajar y mantener sistemas complejos. Además, cuando se producen fallos, identificarlos y remediarlos se convierte en una operación mucho más sencilla, lo que se traduce en un RTO más corto.
Escalar eficazmente
A lo largo de este capítulo, has comprendido la importancia de escalar eficazmente. Como has visto, es fundamental comprender cuál es tu objetivo de escalado, cuáles son tus limitaciones y cuáles serán tus cuellos de botella, y trabajar cuidadosamente dentro de tu marco de escalado para alcanzar ese objetivo.
El viejo proverbio de carpintería "medir dos veces, cortar una" se ha adoptado ampliamente en muchos ámbitos y ha demostrado su valía en las prácticas de desarrollo de software. Si quieres construir sistemas de calidad minimizando el riesgo de errores y fallos catastróficos, ¡es muy útil tenerlo en cuenta! El mismo principio se aplica también a los sistemas basados en el aprendizaje profundo. "Medir dos veces y cortar una" es una estrategia importante para escalar con eficacia. Proporciona un marco muy necesario para:
-
Conoce los puntos de referencia actuales y destaca las limitaciones conocidas.
-
Pon a prueba ideas y teorías sobre la solución en un entorno simulado y proporciona información rápida.
-
Gana confianza en la solución, reduciendo el riesgo de errores/ganancias accidentales.
-
Identifica pronto los cuellos de botella sutiles y no evidentes.
-
Cuantificar los puntos de referencia revisados con la solución implantada.
-
Repite rápidamente las estrategias de mejora aplicándolas de forma incremental.
La eficiencia también tiene que ver con el uso eficaz de los recursos disponibles. El coste de las prácticas ineficaces de aprendizaje profundo es demasiado alto, aunque dejar que las GPU "hagan burrr" tenga una ley de potencia asociada al pico de adrenalina que provoca en cualquier profesional del aprendizaje profundo. Y ese coste no se limita al dinero y al tiempo; también hay que tener en cuenta los efectos medioambientales y sociales, debido a la enorme cantidad de emisiones de carbono asociadas al consumo energético de estas operaciones y al consiguiente impacto adverso e irreversible sobre el cambio climático. Entrenar un gran modelo lingüístico como el GPT3 puede producir 500 toneladas métricas de emisiones de dióxido de carbono, el equivalente a unos 600 vuelos entre Londres y Nueva York. Los ordenadores más respetuosos con el medio ambiente, como el superordenador francés utilizado para entrenar BLOOM, que funciona principalmente con energía nuclear, emiten menos carbono que las GPU tradicionales; aun así, se calcula que BLOOM produce 25 toneladas métricas de emisiones de dióxido de carbono (el equivalente a 30 vuelos Londres-Nueva York) durante el entrenamiento.42 Técnicas como el preentrenamiento, el aprendizaje de pocos disparos y el aprendizaje por transferencia hacen hincapié en reducir el tiempo de entrenamiento y reutilizar los aprendizajes del modelo para otras tareas. El preentrenamiento, en particular, sienta las bases para mejorar la eficacia mediante la reutilización. Implementaciones de aprendizaje contrastivo como CoCa, CLIP y SigLIP son grandes ejemplos de preentrenamiento a escala conseguido mediante autosupervisión.43 Los puntos de referencia de modelos de entrenamiento con presupuestos fijos de GPU pueden proporcionar información muy útil para la selección de modelos, permitiéndote escalar eficientemente.44
Sin embargo, cuando se trata del cambio climático, limitar las emisiones de carbono en el momento del entrenamiento es sólo una medida para sentirse bien: es grande, pero es sólo un gasto puntual. Hugging Face estimó que, mientras realiza la inferencia, BLOOM emite unas 42 libras (19 kg) de dióxido de carbono al día. Se trata de un gasto continuo que se irá acumulando, hasta superar los gastos de formación en unos tres años y medio.45 Son preocupaciones serias, y lo menos que podemos hacer es asegurarnos de que utilizamos los recursos de que disponemos de la forma más eficiente posible, planificando los experimentos de forma que se minimicen los ciclos de entrenamiento desperdiciados y utilizando toda la capacidad de las GPU y las CPU. A lo largo de este libro, exploraremos estos conceptos y diversas técnicas para desarrollar modelos de aprendizaje profundo de forma eficaz y eficiente.
Resumen
Según Forbes, en 2021 el 76% de las empresas estaban dando prioridad a la IA.46 McKinsey informa de que el aprendizaje profundo representa hasta el 40% de los ingresos anuales creados por la analítica y predice que la IA podría generar 13 billones de dólares de producción económica adicional para 2030.47 Mediante el código abierto y la participación de la comunidad, la IA y el aprendizaje profundo se están democratizando cada vez más. Sin embargo, cuando se trata de escalar, debido a los gastos que conlleva, el apalancamiento se queda principalmente en las MAANG (antes FAANG) y las organizaciones con financiación masiva. El escalado es uno de los mayores retos para los profesionales del ML.48 Esto no debería sorprender, porque ampliar cualquier solución de aprendizaje profundo requiere no sólo un conocimiento profundo del aprendizaje automático y la ingeniería de software, sino también experiencia en datos y conocimientos de hardware. La creación de soluciones a escala estándar de la industria se encuentra en la intersección del hardware, el software, los algoritmos y los datos.
Para orientarte para el resto del libro, en este capítulo se han tratado la historia y los orígenes de la ley de escalado y la evolución del aprendizaje profundo. Has leído sobre las tendencias actuales y has explorado cómo el crecimiento del aprendizaje profundo se ha visto impulsado por los avances en hardware, software y datos, tanto como por los propios algoritmos. También conociste las consideraciones clave que debes tener en cuenta al escalar tus soluciones de aprendizaje profundo y exploraste las implicaciones de la escala en el contexto del desarrollo del aprendizaje profundo. La complejidad que conlleva el escalado es enorme y el coste que conlleva no es intrascendente. Una cosa es cierta: ¡escalar es una aventura, y muy divertida! Estoy deseando ayudarte a comprender mejor el escalado del aprendizaje profundo en este libro. En los tres capítulos siguientes, empezarás cubriendo los conceptos fundamentales del aprendizaje profundo y adquiriendo conocimientos prácticos sobre el funcionamiento interno de la pila de aprendizaje profundo.
1 Bondi, André B. 2000. "Características de la escalabilidad y su impacto en el rendimiento". En Actas del Segundo Taller Internacional sobre Software y Rendimiento (WOSP '00), 195-203. https://doi.org/10.1145/350391.350432.
2 Hutchinson, John R., Karl T. Bates, Julia Molnar, Vivian Allen y Peter J. Makovicky. 2011. "Un análisis computacional de las dimensiones de las extremidades y el cuerpo en el Tyrannosaurus rex con implicaciones para la locomoción, la ontogenia y el crecimiento". PLoS One 6, nº 10: e26037. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3192160.
3 Hutchinson et al., "Un análisis computacional", e26037; Persons, W. Scott IV, Philip J. Currie y Gregory M. Erickson. 2019. "Un espécimen adulto antiguo y excepcionalmente grande de Tyrannosaurus rex". The Anatomical Record 303, no. 4: 656-72. https://doi.org/10.1002/ar.24118.
4 National Geographic. s.f. "Biodiversidad". Consultado el 9 de febrero de 2024. https://education.nationalgeographic.org/resource/biodiversity.
5 Ethnologue. s.f. Lenguas del Mundo. Consultado el 9 de febrero de 2024. https://www.ethnologue.com.
6 Fields, R. Douglas. 2020. "Llegan las tecnologías de lectura y control mental". Observaciones (blog), 10 de marzo de 2020. https://blogs.scientificamerican.com/observations/mind-reading-and-mind-control-technologies-are-coming.
7 Wurtz, Robert H. 2009. "Recuento del impacto de Hubel y Wiesel". The Journal of Physiology 587: 2817-23. https://doi.org/10.1113%2Fjphysiol.2009.170209.
8 Jorgensen, Timothy J. 2022. "¿Es el cerebro humano un ordenador biológico?" Princeton University Press, 14 de marzo de 2022. https://press.princeton.edu/ideas/is-the-human-brain-a-biological-computer.
9 Turing, Alan. 1936. "Sobre números computables, con una aplicación al Entscheidungsproblem". En Proceedings of the London Mathematical Society s2-43, 544-46. https://doi.org/10.1112/plms/s2-43.6.544.
10 Turing, Alan. 1948. "Maquinaria Inteligente". Informe para el Laboratorio Nacional de Física. Reimpreso en Mechanical Intelligence: Collected Works of A. M. Turing, vol. 1, editado por D.C. Ince, 107-27. Amsterdam: North Holland, 1992. https://weightagnostic.github.io/papers/turing1948.pdf.
11 Sevilla, Jaime, Lennart Heim, Anson Ho, Tamay Besiroglu, Marius Hobbhahn y Pablo Villalobos. 2022. "Compute Trends Across Three Eras of Machine Learning". arXiv, 9 de marzo de 2022. https://arxiv.org/abs/2202.05924.
12 Heffernan, Virginia. 2022. "¿Está realmente muerta la Ley de Moore?" WIRED, 22 de noviembre de 2022. https://www.wired.com/story/moores-law-really-dead.
13 Heffernan, "¿Está realmente muerta la Ley de Moore? " https://www.wired.com/story/moores-law-really-dead.
14 Hooker, Sara. 2020. "La lotería del hardware". arXiv, 21 de septiembre de 2020. https://arxiv.org/abs/2009.06489.
15 Taylor, Petroc. 2023. "Volumen de datos/información creada, capturada, copiada y consumida en todo el mundo de 2010 a 2020, con previsiones de 2021 a 2025". Statista, 16 de noviembre de 2023. https://www.statista.com/statistics/871513/worldwide-data-created.
16 Chen, Ting, Simon Kornblith, Mohammad Norouzi y Geoffrey Hinton. 2020. "Un marco sencillo para el aprendizaje contrastivo de representaciones visuales". arXiv, 1 de julio de 2020. https://arxiv.org/abs/2002.05709.
17 Yu, Jiahui, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini y Yonghui Wu. 2022. "CoCa: Contrastive Captioners Are Image-Text Foundation Models". arXiv, 14 de junio de 2022. https://arxiv.org/abs/2205.01917.
18 Hochreiter, S. 1990. "Implementierung und Anwendung eines 'neuronalen' Echtzeit-Lernalgorithmus für reaktive Umgebungen". Instituto de Informática, Universidad Técnica de Múnich. https://www.bioinf.jku.at/publications/older/fopra.pdf; Bengio, Y., P. Simard y P. Frasconi. 1994. "Aprender dependencias a largo plazo con el ascenso gradiente es difícil". IEEE Transactions on Neural Networks 5, nº 2: 157-66. https://doi.org/10.1109/72.279181.
19 LeCun, Y., B. Boser, J.S. Denker, D. Henderson, R.E. Howard, W. Hubbard y L.D. Jackel. 1989. "Retropropagación aplicada al reconocimiento de códigos postales escritos a mano". Computación neuronal 1, no. 4: 541-51. https://doi.org/10.1162/neco.1989.1.4.541.
20 Hinton, Geoffrey E., Simon Osindero y Yee-Whye Teh. 2006. "Un algoritmo de aprendizaje rápido para redes de creencia profundas". Neural Computation 18, nº 7: 1527-54. https://doi.org/10.1162/neco.2006.18.7.1527.
21 Deng, Jia, Wei Dong, Richard Socher, Li-Jia Li, Kai Li y Fei-Fei Li. 2009. "ImageNet: Una base de datos jerárquica de imágenes a gran escala". En Actas de la Conferencia IEEE sobre Visión por Ordenador y Reconocimiento de Patrones (CVPR), 248-55. http://dx.doi.org/10.1109/CVPR.2009.5206848.
22 Krizhevsky, Alex, Ilya Sutskever y Geoffrey E. Hinton. 2012. "Clasificación de ImageNet con redes neuronales convolucionales profundas". En Advances in Neural Information Processing Systems (NIPS 2012) 25, nº 2. https://papers.nips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf.
23 Thomas, Owen. 2013. "Google ha comprado una startup que le ayudará a reconocer voces y objetos". Business Insider, 13 de marzo de 2013. https://www.businessinsider.com/google-buys-dnnresearch-2013-3; Saha, Rachana. 2024. "Se espera que el mercado del aprendizaje profundo alcance los 127.000 millones de dólares en 2028". Analytics Insight, 19 de febrero de 2024. https://www.analyticsinsight.net/deep-learning-market-expected-to-reach-us127-billion-by-2028.
24 Silver, David, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, et al. 2018. "Un algoritmo general de aprendizaje por refuerzo que domina el ajedrez, el shogi y el go jugando solo". Science 362, nº 6419: 1140-1144. https://doi.org/10.1126/science.aar6404.
25 Turing, "Máquinas inteligentes", 107-27.
26 Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser e Illia Polosukhin. 2017. "Attention Is All You Need". arXiv, 6 de diciembre de 2017. https://arxiv.org/abs/1706.03762.
27 Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, et al. 2021. "Una imagen vale 16x16 palabras: Transformers for Image Recognition at Scale" arXiv, 3 de junio de 2021. https://arxiv.org/abs/2010.11929.
28 Silver y otros, "Un algoritmo general de aprendizaje por refuerzo", 1140-1144; Tu, Zhengzhong, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik y Yinxiao Li. 2022. MaxViT: Transformador de Visión Multieje. arXiv, 9 de septiembre de 2022. https://arxiv.org/abs/2204.01697.
29 Yu, Lili, Dániel Simig, Colin Flaherty, Armen Aghajanyan, Luke Zettlemoyer y Mike Lewis. 2023. "MEGABYTE: Predicting Million-Byte Sequences with Multiscale Transformers" arXiv, 19 de mayo de 2023. https://arxiv.org/abs/2305.07185; Wang, Wenhui, Shuming Ma, Hanwen Xu, Naoto Usuyama, Jiayu Ding, Hoifung Poon y Furu Wei. 2023. "Cuando una imagen vale 1.024 x 1.024 palabras: A Case Study in Computational Pathology". arXiv, 6 de diciembre de 2023. https://arxiv.org/abs/2312.03558.
30 Kaplan, Jared, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, et al. 2020. "Scaling Laws for Neural Language Models" arXiv, 23 de enero de 2020. https://arxiv.org/abs/2001.08361.
31 Kaplan et al., "Leyes de escalado para modelos lingüísticos neuronales ", https://arxiv.org/abs/2001.08361
32 Gorton, Ian. 2022. Fundamentos de los Sistemas Escalables: Diseño de Arquitecturas Distribuidas. Sebastopol, CA: O'Reilly Media.
33 Heikkilä, Melissa. 2022. "Dentro de un nuevo proyecto radical para democratizar la IA". MIT Technology Review, 12 de julio de 2022. https://www.technologyreview.com/2022/07/12/1055817/inside-a-radical-new-project-to-democratize-ai/amp.
34 Blalock, Davis y John Guttag. 2021. "Multiplicar matrices sin multiplicar". arXiv, 21 de junio de 2021. https://arxiv.org/abs/2106.10860.
35 Fawzi, Alhussein, Matej Balog, Aja Huang, Thomas Hubert, Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, et al. 2022. "Descubriendo algoritmos de multiplicación de matrices más rápidos con aprendizaje por refuerzo". Nature 610: 47-53. https://doi.org/10.1038/s41586-022-05172-4.
36 Hassabis, Demis. 2022. AlphaFold revela la estructura del universo de las proteínas. Blog de DeepMind, 28 de julio de 2022. https://deepmind.google/discover/blog/alphafold-reveals-the-structure-of-the-protein-universe.
37 Nijkamp, Erik, Jeffrey Ruffolo, Eli N. Weinstein, Nikhil Naik y Ali Madani. 2022. "ProGen2: Exploring the Boundaries of Protein Language Models" arXiv, 27 de junio de 2022. https://arxiv.org/abs/2206.13517.
38 Lin, Zeming, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Nikita Smetanin, et al. 2023. "Predicción a escala evolutiva de la estructura de las proteínas a nivel atómico con un modelo lingüístico". Science 379, nº 6637: 1123-30. https://doi.org/10.1126/science.ade2574.
39 Kozyrkov, Cassie. 2022. "Diseño de métricas para científicos de datos y líderes empresariales". Towards Data Science, 23 de octubre de 2022. https://towardsdatascience.com/metric-design-for-data-scientists-and-business-leaders-b8adaf46c00.
40 Liu, Zhuoran, Leqi Zou, Xuan Zou, Caihua Wang, Biao Zhang, Da Tang, Bolin Zhu, et al. 2022. "Monolito: Real Time Recommendation System With Collisionless Embedding Table" arXiv, 27 de septiembre de 2022. https://arxiv.org/abs/2209.07663.
41 Dean, Jeffrey, y Luiz André Barroso. 2013. "La cola a escala". Communications of the ACM 56, nº 2: 74-80. https://doi.org/10.1145/2408776.2408794; Chen, Jianmin, Xinghao Pan, Rajat Monga, Samy Bengio y Rafal Jozefowicz. 2017. "Revisiting Distributed Synchronous SGD". arXiv, 21 de marzo de 2017. https://arxiv.org/abs/1604.00981.
42 Heikkilä, Melissa. 2022. "Por qué tenemos que medir mejor la huella de carbono de la IA". MIT Technology Review, 15 de noviembre de 2022. https://www.technologyreview.com/2022/11/15/1063202/why-we-need-to-do-a-better-job-of-measuring-ais-carbon-footprint.
43 Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, et al. 2021. "Learning Transferable Visual Models from Natural Language Supervision" arXiv, 26 de febrero de 2021. https://arxiv.org/abs/2103.00020; Zhai, Xiaohua, Basil Mustafa, Alexander Kolesnikov y Lucas Beyer. 2023. Sigmoid Loss for Language Image Pre-Training. arXiv, 27 de septiembre de 2023. https://arxiv.org/abs/2303.15343.
44 Geiping, Jonas, y Tom Goldstein. 2022. "Cramming: Training a Language Model on a Single GPU in One Day" arXiv, 28 de diciembre de 2022. https://arxiv.org/abs/2212.14034.
45 Heikkilä, "Why We Need to Do a Better Job of Measuring AI's Carbon Footprint", https://www.technologyreview.com/2022/11/15/1063202/why-we-need-to-do-a-better-job-of-measuring-ais-carbon-footprint.
46 Colón, Luis. 2021. "El 76% de las empresas priorizan la IA y el aprendizaje automático en los presupuestos de TI de 2021". Forbes, 17 de enero de 2021. https://www.forbes.com/sites/louiscolumbus/2021/01/17/76-of-enterprises-prioritize-ai--machine-learning-in-2021-it-budgets.
47 Bughin, Jacques, Jeongmin Seong, James Manyika, Michael Chui y Raoul Joshi. 2018. "Notas desde la frontera de la IA: Modelización del impacto de la IA en la economía mundial". Documento de debate del Instituto Global McKinsey. https://www.mckinsey.com/featured-insights/artificial-intelligence/notes-from-the-ai-frontier-modeling-the-impact-of-ai-on-the-world-economy.
48 Thormundsson, Bergur. 2022. "Retos a los que se enfrentan las empresas al implementar y utilizar el aprendizaje automático en 2018, 2020 y 2021". Statista, 6 de abril de 2022. https://www.statista.com/statistics/1111249/machine-learning-challenges.
Get Aprendizaje profundo a escala now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

