Capítulo 1. El panorama del aprendizaje automático
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
No hace tanto tiempo, si hubieras cogido el teléfono y le hubieras preguntado el camino a casa, te habría ignorado y la gente se habría cuestionado tu cordura. Pero el aprendizaje automático ya no es ciencia ficción: miles de millones de personas lo utilizan cada día. Y la verdad es que existe desde hace décadas en algunas aplicaciones especializadas, como el reconocimiento óptico de caracteres (OCR). La primera aplicación de ML que realmente se generalizó, mejorando la vida de cientos de millones de personas, se impuso en la década de 1990: el filtro de spam. No es exactamente un robot autoconsciente, pero técnicamente se puede considerar aprendizaje automático: de hecho, ha aprendido tan bien que ya casi nunca es necesario marcar un correo electrónico como spam. Le siguieron cientos de aplicaciones de ML que ahora impulsan silenciosamente cientos de productos y funciones que utilizas habitualmente: indicaciones de voz, traducción automática, búsqueda de imágenes, recomendaciones de productos y muchas más.
¿Dónde empieza y dónde acaba el aprendizaje automático? ¿Qué significa exactamente que una máquina aprenda algo? Si descargo una copia de todos los artículos de Wikipedia, ¿mi ordenador ha aprendido realmente algo? ¿De repente es más inteligente? En este capítulo empezaré aclarando qué es el aprendizaje automático y por qué te puede interesar utilizarlo.
A continuación, antes de lanzarnos a explorar el continente del aprendizaje automático, echaremos un vistazo al mapa y conoceremos las principales regiones y los hitos más notables: aprendizaje supervisado frente a aprendizaje no supervisado y sus variantes, aprendizaje en línea frente a aprendizaje por lotes, aprendizaje basado en instancias frente a aprendizaje basado en modelos. Luego veremos el flujo de trabajo de un proyecto típico de ML, discutiremos los principales retos a los que puedes enfrentarte y veremos cómo evaluar y ajustar un sistema de aprendizaje automático.
Este capítulo introduce un montón de conceptos fundamentales (y jerga) que todo científico de datos debería conocer de memoria. Será una visión general de alto nivel (es el único capítulo sin mucho código), todo bastante sencillo, pero mi objetivo es asegurarme de que todo te quede meridianamente claro antes de continuar con el resto del libro. Así que, ¡toma un café y empecemos!
Consejo
Si ya estás familiarizado con los fundamentos del aprendizaje automático, quizá quieras pasar directamente al Capítulo 2. Si no estás seguro, intenta responder a todas las preguntas que figuran al final del capítulo antes de seguir adelante.
¿Qué es el aprendizaje automático?
El aprendizaje automático es la ciencia (y el arte) de programar ordenadores para que puedan aprender de los datos.
He aquí una definición un poco más general:
[El aprendizaje automático es el] campo de estudio que da a los ordenadores la capacidad de aprender sin ser programados explícitamente.
Arthur Samuel, 1959
Y una más orientada a la ingeniería:
Se dice que un programa informático aprende de la experiencia E con respecto a alguna tarea T y alguna medida de rendimiento P, si su rendimiento en T, medido por P, mejora con la experiencia E.
Tom Mitchell, 1997
Tu filtro de spam es un programa de aprendizaje automático que, dados ejemplos de correos spam (marcados por los usuarios) y ejemplos de correos normales (no spam, también llamados "jamón"), puede aprender a marcar el spam. Los ejemplos que el sistema utiliza para aprender se denominan conjunto de entrenamiento. Cada ejemplo de entrenamiento se denomina instancia (o muestra ) de entrenamiento. La parte de un sistema de aprendizaje automático que aprende y hace predicciones se llama modelo. Las redes neuronales y los bosques aleatorios son ejemplos de modelos.
En este caso, la tarea T es marcar el spam de los nuevos correos electrónicos, la experiencia E son los datos de entrenamiento, y hay que definir la medida de rendimiento P; por ejemplo, puedes utilizar la proporción de correos electrónicos clasificados correctamente. Esta medida de rendimiento concreta se denomina precisión, y se utiliza a menudo en tareas de clasificación.
Si te limitas a descargar una copia de todos los artículos de Wikipedia, tu ordenador tiene muchos más datos, pero de repente no es mejor en ninguna tarea. Esto no es aprendizaje automático.
¿Por qué utilizar el aprendizaje automático?
Piensa en cómo escribirías un filtro de spam utilizando técnicas de programación tradicionales(Figura 1-1):
-
Primero examina qué aspecto suele tener el spam. Podrías observar que algunas palabras o frases (como "4U", "tarjeta de crédito", "gratis" y "asombroso") tienden a aparecer mucho en el asunto. Quizá también observes otros patrones en el nombre del remitente, el cuerpo del correo electrónico y otras partes del mismo.
-
Escribirías un algoritmo de detección para cada uno de los patrones que observaras, y tu programa marcaría los correos electrónicos como spam si se detectaran varios de estos patrones.
-
Probarías tu programa y repetirías los pasos 1 y 2 hasta que fuera lo suficientemente bueno como para lanzarlo.
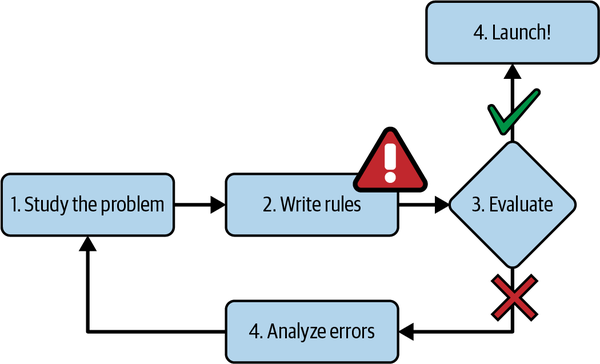
Figura 1-1. El enfoque tradicional
Como el problema es difícil, es probable que tu programa se convierta en una larga lista de reglas complejas, muy difíciles de mantener.
En cambio, un filtro de spam basado en técnicas de aprendizaje automático aprende automáticamente qué palabras y frases son buenos predictores de spam detectando patrones de palabras inusualmente frecuentes en los ejemplos de spam en comparación con los ejemplos de spam(Figura 1-2). El programa es mucho más corto, más fácil de mantener y, muy probablemente, más preciso.
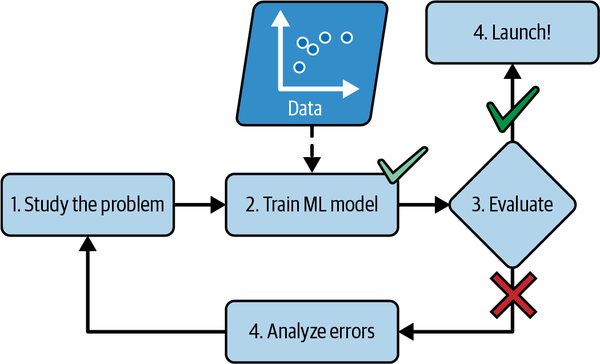
Figura 1-2. El enfoque del aprendizaje automático
¿Qué pasa si los spammers se dan cuenta de que todos sus correos que contienen "4U" están bloqueados? Podrían empezar a escribir "Para U" en su lugar. Un filtro de spam que utilice técnicas de programación tradicionales tendría que actualizarse para marcar los correos "Para U". Si los spammers siguen eludiendo tu filtro de spam, tendrás que seguir escribiendo reglas nuevas para siempre.
En cambio, un filtro de spam basado en técnicas de aprendizaje automático se da cuenta automáticamente de que "Para U" se ha vuelto inusualmente frecuente en el spam marcado por los usuarios, y empieza a marcarlos sin tu intervención(Figura 1-3).
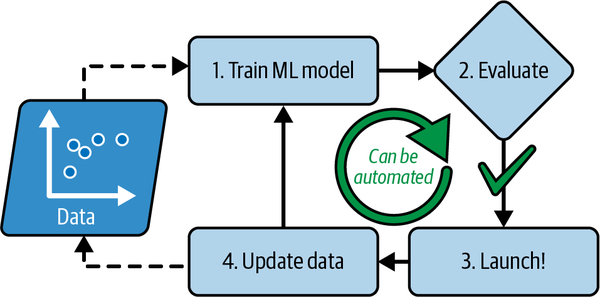
Figura 1-3. Adaptarse automáticamente al cambio
Otra área en la que brilla el aprendizaje automático es en los problemas que son demasiado complejos para los enfoques tradicionales o que no tienen un algoritmo conocido. Por ejemplo, considera el reconocimiento del habla. Supongamos que quieres empezar de forma sencilla y escribir un programa capaz de distinguir las palabras "uno" y "dos". Puede que te des cuenta de que la palabra "dos" empieza con un sonido agudo ("T"), así que podrías codificar un algoritmo que midiera la intensidad del sonido agudo y utilizarlo para distinguir los unos de los dos, pero obviamente esta técnica no se adaptará a miles de palabras pronunciadas por millones de personas muy diferentes en entornos ruidosos y en docenas de idiomas. La mejor solución (al menos hoy) es escribir un algoritmo que aprenda por sí mismo, dadas muchas grabaciones de ejemplo para cada palabra.
Por último, el aprendizaje automático puede ayudar a los humanos a aprender(Figura 1-4). Los modelos de ML pueden inspeccionarse para ver lo que han aprendido (aunque para algunos modelos esto puede ser complicado). Por ejemplo, una vez que un filtro de spam se ha entrenado con suficiente spam, puede inspeccionarse fácilmente para revelar la lista de palabras y combinaciones de palabras que cree que son los mejores predictores de spam. A veces esto revelará correlaciones insospechadas o nuevas tendencias, y por lo tanto conducirá a una mejor comprensión del problema. Excavar en grandes cantidades de datos para descubrir patrones ocultos se denomina minería de datos, y el aprendizaje automático destaca en ello.
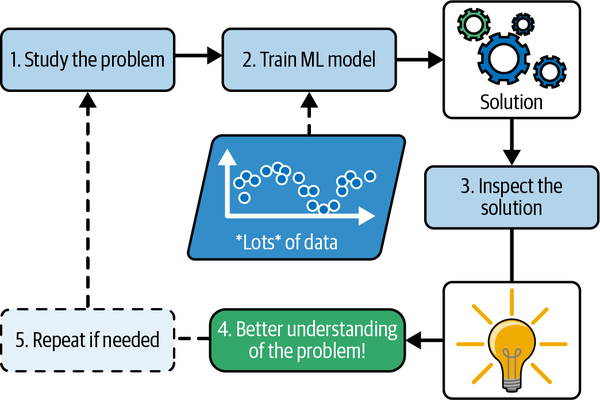
Figura 1-4. El aprendizaje automático puede ayudar a los humanos a aprender
En resumen, el aprendizaje automático es estupendo para:
-
Problemas para los que las soluciones existentes requieren muchos ajustes o largas listas de reglas (un modelo de aprendizaje automático a menudo puede simplificar el código y funcionar mejor que el enfoque tradicional)
-
Problemas complejos para los que el uso de un enfoque tradicional no da una buena solución (las mejores técnicas de aprendizaje automático tal vez puedan encontrar una solución)
-
Entornos fluctuantes (un sistema de aprendizaje automático puede reentrenarse fácilmente con nuevos datos, manteniéndose siempre actualizado)
-
Obtener información sobre problemas complejos y grandes cantidades de datos
Ejemplos de aplicaciones
Veamos algunos ejemplos concretos de tareas de aprendizaje automático, junto con las técnicas que pueden abordarlas:
- Analizar imágenes de productos en una línea de producción para clasificarlos automáticamente
-
Se trata de la clasificación de imágenes, que suele realizarse utilizando redes neuronales convolucionales (CNN; véase el Capítulo 14) o, a veces, transformadores (véase el Capítulo 16).
- Detección de tumores en escáneres cerebrales
-
Se trata de la segmentación semántica de imágenes, en la que se clasifica cada píxel de la imagen (ya que queremos determinar la ubicación y la forma exactas de los tumores), normalmente utilizando CNN o transformadores.
- Clasificar automáticamente los artículos de noticias
-
Se trata del procesamiento del lenguaje natural (PLN), y más concretamente de la clasificación de textos, que puede abordarse mediante redes neuronales recurrentes (RNN) y CNN, pero los transformadores funcionan aún mejor (véase el Capítulo 16).
- Marcar automáticamente los comentarios ofensivos en los foros de debate
-
Esto también es clasificación de textos, utilizando las mismas herramientas de PNL.
- Resumir documentos largos automáticamente
-
Se trata de una rama de la PNL llamada resumen de texto, que también utiliza las mismas herramientas.
- Crear un chatbot o un asistente personal
-
Esto implica muchos componentes de PNL, incluidos módulos de comprensión del lenguaje natural (NLU) y de respuesta a preguntas.
- Previsión de los ingresos de tu empresa el año que viene, basada en muchas métricas de rendimiento
-
Se trata de una tarea de regresión (es decir, de predicción de valores) que puede abordarse utilizando cualquier modelo de regresión, como un modelo de regresión lineal o de regresión polinómica (véase el Capítulo 4), una máquina de vectores de soporte de regresión (véase el Capítulo 5), un bosque aleatorio de regresión (véase el Capítulo 7) o una red neuronal artificial (véase el Capítulo 10). Si quieres tener en cuenta secuencias de métricas de rendimiento anteriores, puedes utilizar RNNs, CNNs o transformadores (ver Capítulos 15 y 16).
- Hacer que tu aplicación reaccione a los comandos de voz
-
Se trata del reconocimiento del habla, que requiere procesar muestras de audio: como son secuencias largas y complejas, suelen procesarse mediante RNNs, CNNs o transformadores (véanse los Capítulos 15 y 16).
- Detectar el fraude con tarjetas de crédito
-
Se trata de la detección de anomalías, que puede abordarse mediante bosques de aislamiento, modelos de mezcla gaussiana (véase el Capítulo 9) o autocodificadores (véase el Capítulo 17).
- Segmentar a los clientes en función de sus compras para que puedas diseñar una estrategia de marketing diferente para cada segmento
-
Se trata de la agrupación, que puede conseguirse mediante k-means, DBSCAN, etc. (véase el Capítulo 9).
- Representar un conjunto de datos complejo y de alta dimensión en un diagrama claro y perspicaz
-
Se trata de la visualización de datos, que a menudo implica técnicas de reducción de la dimensionalidad (véase el Capítulo 8).
- Recomendar un producto que pueda interesar a un cliente, basándose en compras anteriores
-
Se trata de un sistema de recomendación. Un enfoque consiste en alimentar una red neuronal artificial (véase el Capítulo 10) con compras anteriores (y otra información sobre el cliente), y hacer que emita la siguiente compra más probable. Esta red neuronal suele entrenarse con secuencias de compras anteriores de todos los clientes.
- Construir un bot inteligente para un juego
-
Esto se aborda a menudo utilizando el aprendizaje por refuerzo (RL; véase el Capítulo 18), que es una rama del aprendizaje automático que entrena a agentes (como los bots) para que elijan las acciones que maximizarán sus recompensas a lo largo del tiempo (por ejemplo, un bot puede obtener una recompensa cada vez que el jugador pierde algunos puntos de vida), dentro de un entorno determinado (como el juego). El famoso programa AlphaGo que venció al campeón del mundo en el juego del Go se construyó utilizando RL.
Esta lista podría seguir y seguir, pero espero que te dé una idea de la increíble amplitud y complejidad de las tareas que puede abordar el aprendizaje automático, y de los tipos de técnicas que utilizarías para cada tarea.
Tipos de sistemas de aprendizaje automático
Hay tantos tipos diferentes de sistemas de aprendizaje automático que resulta útil clasificarlos en categorías amplias, basándose en los siguientes criterios:
-
Cómo se les supervisa durante el entrenamiento (supervisado, no supervisado, semi-supervisado, auto-supervisado y otros)
-
Si pueden o no aprender de forma incremental sobre la marcha (aprendizaje en línea frente a aprendizaje por lotes).
-
Si funcionan simplemente comparando los nuevos puntos de datos con los puntos de datos conocidos, o si, por el contrario, detectan patrones en los datos de entrenamiento y construyen un modelo predictivo, al igual que hacen los científicos (aprendizaje basado en instancias frente a aprendizaje basado en modelos).
Estos criterios no son excluyentes; puedes combinarlos como quieras. Por ejemplo, un filtro de spam de última generación puede aprender sobre la marcha utilizando un modelo de red neuronal profunda entrenado con ejemplos de spam y jamón proporcionados por humanos; esto lo convierte en un sistema de aprendizaje supervisado en línea basado en modelos.
Veamos cada uno de estos criterios un poco más de cerca.
Supervisión de la formación
Los sistemas de ML pueden clasificarse según la cantidad y el tipo de supervisión que reciben durante el entrenamiento. Hay muchas categorías, pero hablaremos de las principales: aprendizaje supervisado, aprendizaje no supervisado, aprendizaje autosupervisado, aprendizaje semisupervisado y aprendizaje por refuerzo.
Aprendizaje supervisado
En el aprendizaje supervisado, el conjunto de entrenamiento que alimentas al algoritmo incluye las soluciones deseadas, llamadas etiquetas(Figura 1-5).
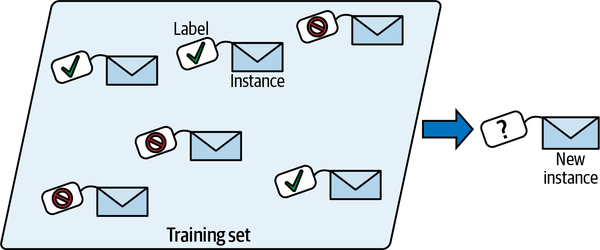
Figura 1-5. Un conjunto de entrenamiento etiquetado para la clasificación del spam (un ejemplo de aprendizaje supervisado)
Una tarea típica de aprendizaje supervisado es la clasificación. El filtro de spam es un buen ejemplo de ello: se entrena con muchos emails de ejemplo junto con su clase (spam o jamón), y debe aprender a clasificar los nuevos emails.
Otra tarea típica es predecir un valor numérico objetivo, como el precio de un coche, dado un conjunto de características (kilometraje, antigüedad, marca, etc.). Este tipo de tarea se denomina regresión(Figura 1-6).1 Para entrenar al sistema, tienes que darle muchos ejemplos de coches, incluyendo tanto sus características como sus objetivos (es decir, sus precios).
Ten en cuenta que algunos modelos de regresión también pueden utilizarse para la clasificación, y viceversa. Por ejemplo, la regresión logística se utiliza habitualmente para la clasificación, ya que puede dar como resultado un valor que corresponde a la probabilidad de pertenecer a una clase determinada (por ejemplo, 20% de probabilidades de ser spam).
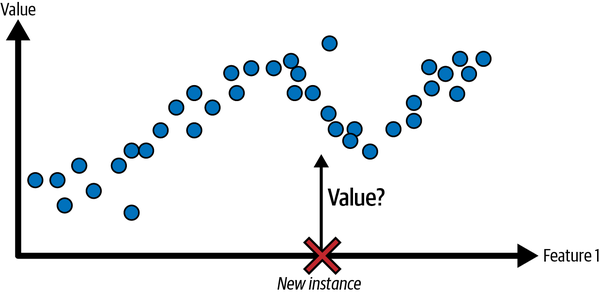
Figura 1-6. Un problema de regresión: predecir un valor, dada una característica de entrada (normalmente hay múltiples características de entrada, y a veces múltiples valores de salida)
Nota
Las palabras objetivo y etiqueta suelen tratarse como sinónimos en el aprendizaje supervisado, pero objetivo es más común en tareas de regresión y etiqueta es más común en tareas de clasificación. Además, las características a veces se denominan predictores o atributos. Estos términos pueden referirse a muestras individuales (por ejemplo, "la característica kilometraje de este coche es igual a 15.000") o a todas las muestras (por ejemplo, "la característica kilometraje está fuertemente correlacionada con el precio").
Aprendizaje no supervisado
En el aprendizaje no supervisado, como puedes suponer, los datos de entrenamiento no están etiquetados(Figura 1-7). El sistema intenta aprender sin un maestro.
Por ejemplo, supongamos que tienes muchos datos sobre los visitantes de tu blog. Tal vez quieras ejecutar un algoritmo de agrupación para intentar detectar grupos de visitantes similares(Figura 1-8). En ningún momento le dices al algoritmo a qué grupo pertenece un visitante: él encuentra esas conexiones sin tu ayuda. Por ejemplo, podría darse cuenta de que el 40% de tus visitantes son adolescentes a los que les encantan los cómics y que suelen leer tu blog después de clase, mientras que el 20% son adultos a los que les gusta la ciencia ficción y que te visitan durante los fines de semana. Si utilizas un algoritmo de agrupación jerárquica, también puede subdividir cada grupo en grupos más pequeños. Esto puede ayudarte a dirigir tus posts a cada grupo.

Figura 1-7. Un conjunto de entrenamiento sin etiquetar para el aprendizaje no supervisado
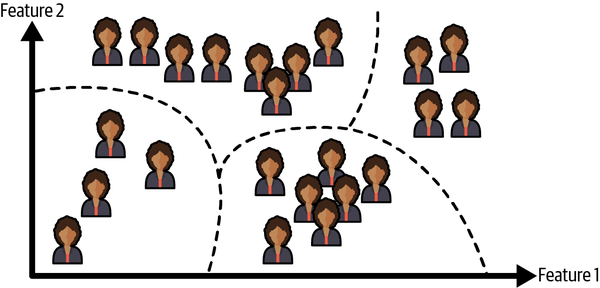
Figura 1-8. Agrupación
Los algoritmos devisualización también son buenos ejemplos de aprendizaje no supervisado: los alimentas con un montón de datos complejos y sin etiquetar, y dan como resultado una representación 2D o 3D de tus datos que se puede trazar fácilmente(Figura 1-9). Estos algoritmos intentan preservar toda la estructura que pueden (por ejemplo, tratando de evitar que los clusters separados en el espacio de entrada se solapen en la visualización) para que puedas entender cómo están organizados los datos y quizás identificar patrones insospechados.
Una tarea relacionada es la reducción de la dimensionalidad, en la que el objetivo es simplificar los datos sin perder demasiada información. Una forma de hacerlo es fusionar varias características correlacionadas en una sola. Por ejemplo, el kilometraje de un coche puede estar fuertemente correlacionado con su edad, por lo que el algoritmo de reducción de la dimensionalidad los fusionará en una característica que represente el desgaste del coche. Esto se llama extracción de características.

Figura 1-9. Ejemplo de visualización t-SNE que destaca los grupos semánticos2
Consejo
A menudo es una buena idea intentar reducir el número de dimensiones de tus datos de entrenamiento utilizando un algoritmo de reducción de la dimensionalidad antes de alimentarlos con otro algoritmo de aprendizaje automático (como un algoritmo de aprendizaje supervisado). Se ejecutará mucho más rápido, los datos ocuparán menos espacio en disco y memoria y, en algunos casos, también puede rendir mejor.
Otra tarea no supervisada importante es la detección de anomalías:por ejemplo, detectar transacciones inusuales con tarjetas de crédito para evitar fraudes, detectar defectos de fabricación o eliminar automáticamente los valores atípicos de un conjunto de datos antes de pasarlo a otro algoritmo de aprendizaje. Al sistema se le muestran la mayoría de los casos normales durante el entrenamiento, para que aprenda a reconocerlos; entonces, cuando ve un nuevo caso, puede decir si se parece a uno normal o si es probable que sea una anomalía (ver Figura 1-10). Una tarea muy similar es la detección de novedades: su objetivo es detectar nuevas instancias que parezcan diferentes de todas las instancias del conjunto de entrenamiento. Esto requiere tener un conjunto de entrenamiento muy "limpio", desprovisto de cualquier instancia que quieras que detecte el algoritmo. Por ejemplo, si tienes miles de fotos de perros, y el 1% de esas fotos representan chihuahuas, entonces un algoritmo de detección de novedades no debería tratar las nuevas fotos de chihuahuas como novedades. En cambio, los algoritmos de detección de anomalías pueden considerar que estos perros son tan raros y tan diferentes de los demás perros que probablemente los clasificarían como anomalías (sin ánimo de ofender a los chihuahuas).

Figura 1-10. Detección de anomalías
Por último, otra tarea no supervisada habitual es el aprendizaje de reglas de asociación, en el que el objetivo es indagar en grandes cantidades de datos y descubrir relaciones interesantes entre atributos. Por ejemplo, supongamos que tienes un supermercado. Ejecutar una regla de asociación en tus registros de ventas puede revelar que las personas que compran salsa barbacoa y patatas fritas también suelen comprar filetes. Por tanto, puede que quieras colocar estos artículos cerca unos de otros.
Aprendizaje semisupervisado
Como etiquetar los datos suele llevar tiempo y ser costoso, a menudo tendrás muchos casos sin etiquetar y pocos casos etiquetados. Algunos algoritmos pueden tratar con datos parcialmente etiquetados. Esto se denomina aprendizaje semisupervisado(Figura 1-11).
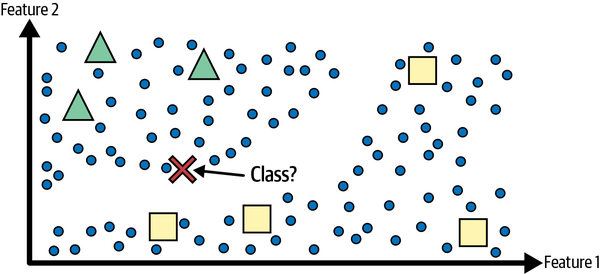
Figura 1-11. Aprendizaje semisupervisado con dos clases (triángulos y cuadrados): los ejemplos no etiquetados (círculos) ayudan a clasificar una nueva instancia (la cruz) en la clase de los triángulos y no en la de los cuadrados, aunque esté más cerca de los cuadrados etiquetados
Algunos servicios de alojamiento de fotos, como Google Fotos, son buenos ejemplos de ello. Una vez que subes todas tus fotos familiares al servicio, éste reconoce automáticamente que la misma persona A aparece en las fotos 1, 5 y 11, mientras que otra persona B aparece en las fotos 2, 5 y 7. Esta es la parte no supervisada del algoritmo (agrupación). Ahora lo único que necesita el sistema es que le digas quiénes son esas personas. Sólo tienes que añadir una etiqueta por persona3 y será capaz de nombrar a todas las personas de cada foto, lo que resulta útil para buscar fotos.
La mayoría de los algoritmos de aprendizaje semisupervisado son combinaciones de algoritmos no supervisados y supervisados. Por ejemplo, se puede utilizar un algoritmo de agrupación para agrupar instancias similares, y luego cada instancia sin etiquetar se puede etiquetar con la etiqueta más común de su agrupación. Una vez etiquetado todo el conjunto de datos, es posible utilizar cualquier algoritmo de aprendizaje supervisado.
Aprendizaje autosupervisado
Otro enfoque del aprendizaje automático consiste en generar realmente un conjunto de datos totalmente etiquetado a partir de otro totalmente sin etiquetar. De nuevo, una vez etiquetado todo el conjunto de datos, se puede utilizar cualquier algoritmo de aprendizaje supervisado. Este enfoque se denomina aprendizaje autosupervisado.
Por ejemplo, si tienes un gran conjunto de datos de imágenes sin etiquetar, puedes enmascarar aleatoriamente una pequeña parte de cada imagen y luego entrenar un modelo para recuperar la imagen original(Figura 1-12). Durante el entrenamiento, las imágenes enmascaradas se utilizan como entradas del modelo, y las imágenes originales se utilizan como etiquetas.

Figura 1-12. Ejemplo de aprendizaje autosupervisado: entrada (izquierda) y objetivo (derecha)
El modelo resultante puede ser bastante útil en sí mismo: por ejemplo, para reparar imágenes dañadas o borrar objetos no deseados de las fotos. Pero la mayoría de las veces, un modelo entrenado mediante aprendizaje autosupervisado no es el objetivo final. Normalmente querrás ajustar y afinar el modelo para una tarea ligeramente distinta, una que realmente te interese.
Por ejemplo, supongamos que lo que realmente quieres es tener un modelo de clasificación de mascotas: dada una foto de cualquier mascota, te dirá a qué especie pertenece. Si tienes un gran conjunto de datos de fotos de mascotas sin etiquetar, puedes empezar entrenando un modelo de reparación de imágenes mediante aprendizaje autosupervisado. Una vez que funcione bien, debe ser capaz de distinguir las distintas especies de mascotas: cuando repara una imagen de un gato cuyacara está enmascarada, debe saber que no debe añadir la cara de un perro. Suponiendo que la arquitectura de tu modelo lo permita (y la mayoría de las arquitecturas de redes neuronales lo permiten), entonces es posible ajustar el modelo para que prediga especies de mascotas en lugar de reparar imágenes. El último paso consiste en afinar el modelo en un conjunto de datos etiquetados: el modelo ya sabe qué aspecto tienen los gatos, los perros y otras especies de mascotas, así que este paso sólo es necesario para que el modelo pueda aprender la correspondencia entre las especies que ya conoce y las etiquetas que esperamosde él.
Nota
Transferir conocimientos de una tarea a otra se denomina aprendizaje por transferencia, y es una de las técnicas más importantes del aprendizaje automático actual, especialmente cuando se utilizan redes neuronales profundas (es decir, redes neuronales compuestas por muchas capas de neuronas). Hablaremos de ello en detalle en la Parte II.
Algunas personas consideran que el aprendizaje autosupervisado forma parte del aprendizaje no supervisado, ya que trata con conjuntos de datos totalmente sin etiquetar. Pero el aprendizaje autosupervisado utiliza etiquetas (generadas) durante el entrenamiento, así que en ese sentido está más cerca del aprendizaje supervisado. Y el término "aprendizaje no supervisado" se utiliza generalmente cuando se trata de tareas como la agrupación, la reducción de la dimensionalidad o la detección de anomalías, mientras que el aprendizaje autosupervisado se centra en las mismas tareas que el aprendizaje supervisado: principalmente la clasificación y la regresión. En resumen, es mejor tratar el aprendizaje autosupervisado como una categoría propia.
Aprendizaje por refuerzo
El aprendizaje por refuerzo es una bestia muy diferente. El sistema de aprendizaje, llamado agente en este contexto, puede observar el entorno, seleccionar y realizar acciones, y obtener recompensas a cambio (o penalizaciones en forma de recompensas negativas, como se muestra en la Figura 1-13). Luego debe aprender por sí mismo cuál es la mejor estrategia, llamada política, para obtener la mayor recompensa a lo largo del tiempo. Una política define qué acción debe elegir el agente cuando se encuentra en una situación determinada.
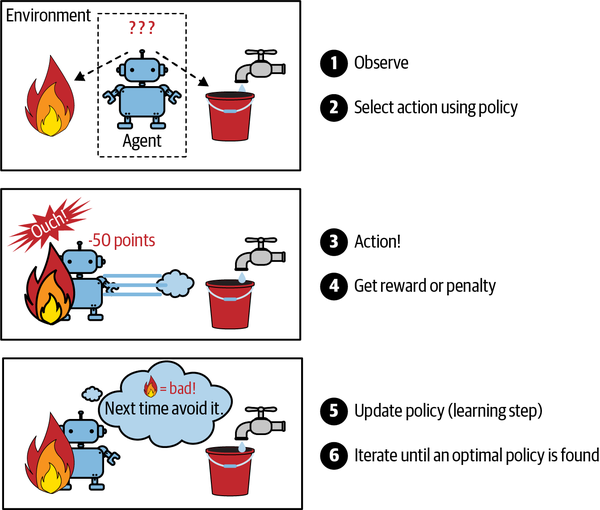
Figura 1-13. Aprendizaje por refuerzo
Por ejemplo, muchos robots aplican algoritmos de aprendizaje por refuerzo para aprender a caminar. El programa AlphaGo de DeepMind también es un buen ejemplo de aprendizaje por refuerzo: saltó a los titulares en mayo de 2017 cuando venció a Ke Jie, el jugador número uno del mundo en ese momento, en el juego del Go. Aprendió su política ganadora analizando millones de partidas, y luego jugando muchas partidas contra sí mismo. Ten en cuenta que el aprendizaje se desactivó durante las partidas contra el campeón; AlphaGo sólo aplicaba la política que había aprendido. Como verás en la siguiente sección, esto se llama aprendizaje fuera de línea.
Aprendizaje por lotes frente a aprendizaje en línea
Otro criterio utilizado para clasificar los sistemas de aprendizaje automático es si el sistema puede o no aprender de forma incremental a partir de un flujo de datos entrantes.
Aprendizaje por lotes
En el aprendizaje por lotes, el sistema es incapaz de aprender de forma incremental: debe entrenarse utilizando todos los datos disponibles. Esto suele llevar mucho tiempo y recursos informáticos, por lo que suele hacerse fuera de línea. Primero se entrena el sistema, y luego se lanza a producción y funciona sin aprender más; sólo aplica lo que ha aprendido. Esto se llama aprendizaje fuera de línea.
Por desgracia, el rendimiento de un modelo tiende a decaer lentamente con el tiempo, simplemente porque el mundo sigue evolucionando mientras el modelo permanece inalterado. A este fenómeno se le suele llamar putrefacción del modelo o deriva de los datos. La solución es volver a entrenar periódicamente el modelo con datos actualizados. La frecuencia con la que tengas que hacerlo dependerá del caso de uso: si el modelo clasifica fotos de gatos y perros, su rendimiento decaerá muy lentamente, pero si el modelo se ocupa de sistemas que evolucionan con rapidez, por ejemplo haciendo predicciones sobre el mercado financiero, entonces es probable que decaiga bastante rápido.
Advertencia
Incluso un modelo entrenado para clasificar fotos de gatos y perros puede necesitar un reentrenamiento regular, no porque los gatos y los perros muten de la noche a la mañana, sino porque las cámaras cambian continuamente, junto con los formatos de imagen, la nitidez, el brillo y las proporciones de tamaño. Además, puede que el año que viene a la gente le gusten razas diferentes, o que decidan vestir a sus mascotas con sombreritos: ¿quién sabe?
Si quieres que un sistema de aprendizaje por lotes conozca datos nuevos (como un nuevo tipo de spam), tienes que entrenar una nueva versión del sistema desde cero en el conjunto de datos completo (no sólo los datos nuevos, sino también los antiguos), y luego sustituir el modelo antiguo por el nuevo. Afortunadamente, todo el proceso de entrenamiento, evaluación y lanzamiento de un sistema de aprendizaje automático puede automatizarse con bastante facilidad (como vimos en la Figura 1-3), por lo que incluso un sistema de aprendizaje por lotes puede adaptarse a los cambios. Basta con actualizar los datos y entrenar una nueva versión del sistema desde cero tantas veces como sea necesario.
Esta solución es sencilla y suele funcionar bien, pero entrenar utilizando el conjunto completo de datos puede llevar muchas horas, por lo que normalmente entrenarías un nuevo sistema sólo cada 24 horas o incluso sólo semanalmente. Si tu sistema necesita adaptarse a datos que cambian rápidamente (por ejemplo, para predecir los precios de las acciones), entonces necesitas una solución más reactiva.
Además, el entrenamiento sobre el conjunto completo de datos requiere muchos recursos informáticos (CPU, espacio de memoria, espacio de disco, E/S de disco, E/S de red, etc.). Si tienes muchos datos y automatizas tu sistema para que se entrene desde cero cada día, acabará costándote mucho dinero. Si la cantidad de datos es enorme, puede ser incluso imposible utilizar un algoritmo de aprendizaje por lotes.
Por último, si tu sistema tiene que ser capaz de aprender de forma autónoma y dispone de recursos limitados (por ejemplo, una aplicación para smartphone o un vehículo explorador en Marte), cargar con grandes cantidades de datos de entrenamiento y consumir muchos recursos para entrenar durante horas todos los días es un obstáculo.
Una opción mejor en todos estos casos es utilizar algoritmos capaces de aprender de forma incremental.
Aprendizaje en línea
En el aprendizaje en línea, entrenas al sistema de forma incremental, alimentándolo con instancias de datos secuencialmente, ya sea individualmente o en pequeños grupos llamados minilotes. Cada paso de aprendizaje es rápido y barato, de modo que el sistema puede aprender sobre la marcha, a medida que llegan nuevos datos (ver Figura 1-14).
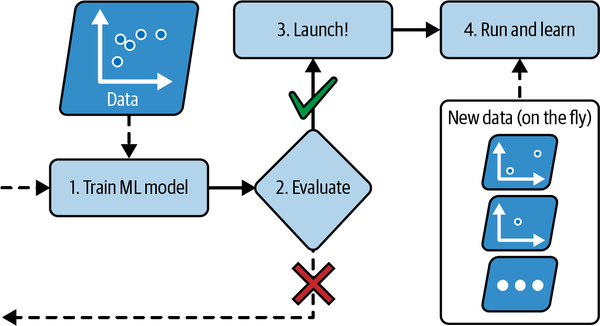
Figura 1-14. En el aprendizaje en línea, un modelo se entrena y se pone en producción, y luego sigue aprendiendo a medida que llegan nuevos datos
El aprendizaje en línea es útil para los sistemas que necesitan adaptarse a los cambios con extrema rapidez (por ejemplo, para detectar nuevos patrones en el mercado de valores). También es una buena opción si tienes recursos informáticos limitados; por ejemplo, si el modelo se entrena en un dispositivo móvil.
Además, los algoritmos de aprendizaje en línea pueden utilizarse para entrenar modelos en enormes conjuntos de datos que no caben en la memoria principal de una máquina (esto se denomina aprendizaje fuera del núcleo ). El algoritmo carga parte de los datos, ejecuta un paso de entrenamiento en esos datos y repite el proceso hasta que se haya ejecutado en todos los datos (ver Figura 1-15).
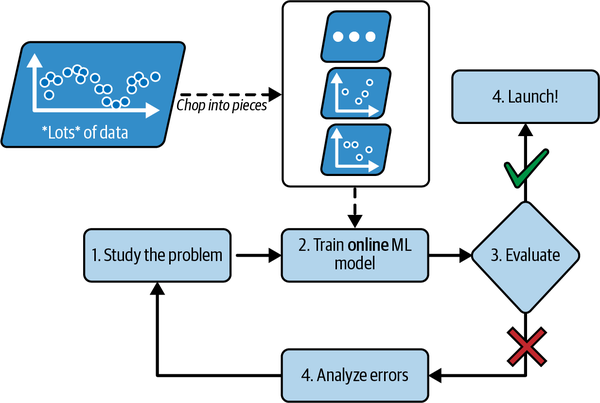
Figura 1-15. Utilizar el aprendizaje en línea para manejar conjuntos de datos enormes
Un parámetro importante de los sistemas de aprendizaje en línea es la rapidez con que deben adaptarse a los datos cambiantes: se denomina tasa de aprendizaje. Si fijas una tasa de aprendizaje alta, tu sistema se adaptará rápidamente a los nuevos datos, pero también tenderá a olvidar rápidamente los datos antiguos (y no querrás que un filtro de spam marque sólo los últimos tipos de spam que se le mostraron). Por el contrario, si fijas una tasa de aprendizaje baja, el sistema tendrá más inercia; es decir, aprenderá más lentamente, pero también será menos sensible al ruido en los nuevos datos o a las secuencias de puntos de datos no representativos (valores atípicos).
Advertencia
El aprendizaje fuera del núcleo suele hacerse fuera de línea (es decir, no en el sistema en vivo), por lo que el aprendizaje en línea puede ser un nombre confuso. Piensa en él como aprendizaje incremental.
Un gran reto del aprendizaje en línea es que si se introducen datos malos en el sistema, el rendimiento de éste disminuirá, posiblemente con rapidez (dependiendo de la calidad de los datos y del ritmo de aprendizaje). Si se trata de un sistema en vivo, tus clientes lo notarán. Por ejemplo, los datos erróneos pueden proceder de un error (por ejemplo, el mal funcionamiento de un sensor en un robot), o de alguien que intenta engañar al sistema (por ejemplo, enviando spam a un motor de búsqueda para intentar aparecer en los primeros puestos de los resultados de búsqueda). Para reducir este riesgo, debes monitorizar de cerca tu sistema y desactivar rápidamente el aprendizaje (y posiblemente volver a un estado de funcionamiento anterior) si detectas una caída en el rendimiento. También puedes monitorizar los datos de entrada y reaccionar ante datos anómalos; por ejemplo, utilizando un algoritmo de detección de anomalías (ver Capítulo 9).
Aprendizaje basado en instancias frente a aprendizaje basado en modelos
Otra forma de clasificar los sistemas de aprendizaje automático es por cómo generalizan. La mayoría de las tareas de aprendizaje automático consisten en hacer predicciones. Esto significa que, dados una serie de ejemplos de entrenamiento, el sistema tiene que ser capaz de hacer buenas predicciones para (generalizar a) ejemplos que nunca ha visto antes. Tener una buena medida del rendimiento en los datos de entrenamiento es bueno, pero insuficiente; el verdadero objetivo es tener un buen rendimiento en nuevas instancias.
Hay dos enfoques principales para la generalización: el aprendizaje basado en instancias y el aprendizaje basado en modelos.
Aprendizaje basado en instancias
Posiblemente la forma más trivial de aprender sea simplemente aprender de memoria. Si crearas un filtro de spam de esta forma, se limitaría a marcar todos los correos electrónicos idénticos a los que ya han sido marcados por los usuarios: no es la peor solución, pero desde luego no es la mejor.
En lugar de marcar sólo los correos electrónicos que son idénticos a los correos spam conocidos, tu filtro antispam podría programarse para marcar también los correos electrónicos que son muy similares a los correos spam conocidos. Esto requiere una medida de similitud entre dos correos electrónicos. Una medida de similitud (muy básica) entre dos correos electrónicos podría ser contar el número de palabras que tienen en común. El sistema marcaría un correo como spam si tiene muchas palabras en común con un correo spam conocido.
Es lo que se denomina aprendizaje basado en instancias: el sistema aprende los ejemplos de memoria, y luego generaliza a nuevos casos utilizando una medida de similitud para compararlos con los ejemplos aprendidos (o con un subconjunto de ellos). Por ejemplo, en la Figura 1-16 la nueva instancia se clasificaría como un triángulo porque la mayoría de las instancias más similares pertenecen a esa clase.
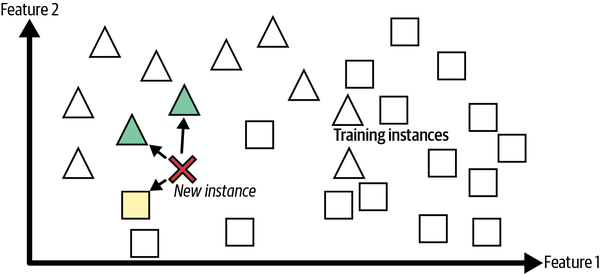
Figura 1-16. Aprendizaje basado en instancias
Aprendizaje basado en modelos y un flujo de trabajo típico de aprendizaje automático
Otra forma de generalizar a partir de un conjunto de ejemplos es construir un modelo de esos ejemplos y luego utilizar ese modelo para hacer predicciones. Esto se denomina aprendizaje basado en modelos(Figura 1-17).
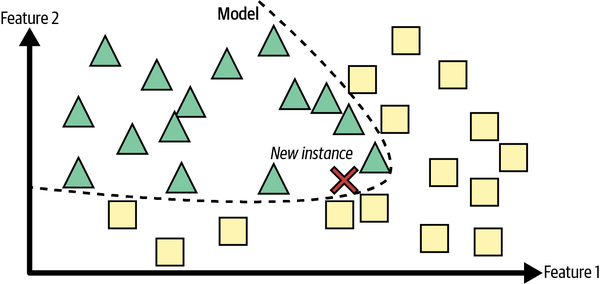
Figura 1-17. Aprendizaje basado en modelos
Por ejemplo, supongamos que quieres saber si el dinero hace feliz a la gente, así que descargas los datos del Índice para una Vida Mejor del sitio web de la OCDE y las estadísticas del Banco Mundial sobre el producto interior bruto (PIB) per cápita. Luego unes las tablas y las ordenas por PIB per cápita. La Tabla 1-1 muestra un extracto de lo que obtienes.
| País | PIB per cápita (USD) | Satisfacción vital |
|---|---|---|
Turquía |
28,384 |
5.5 |
Hungría |
31,008 |
5.6 |
Francia |
42,026 |
6.5 |
Estados Unidos |
60,236 |
6.9 |
Nueva Zelanda |
42,404 |
7.3 |
Australia |
48,698 |
7.3 |
Dinamarca |
55,938 |
7.6 |
Vamos a trazar los datos de estos países(Figura 1-18).
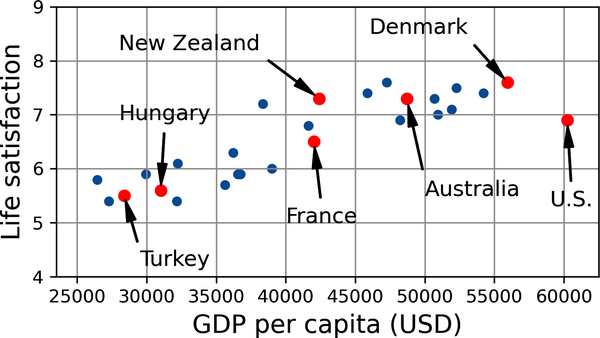
Figura 1-18. ¿Ves alguna tendencia?
¡Parece que hay una tendencia! Aunque los datos son ruidosos (es decir, en parte aleatorios), parece que la satisfacción vital aumenta de forma más o menos lineal a medida que aumenta el PIB per cápita del país. Así que decides modelizar la satisfacción vital como una función lineal del PIB per cápita. Este paso se denomina selección del modelo: seleccionas un modelo lineal de satisfacción vital con un solo atributo, el PIB per cápita(Ecuación 1-1).
Ecuación 1-1. Un modelo lineal simple
Este modelo tiene dos parámetros, θ0 y θ1.4 Ajustando estos parámetros, puedes hacer que tu modelo represente cualquier función lineal, como se muestra en la Figura 1-19.
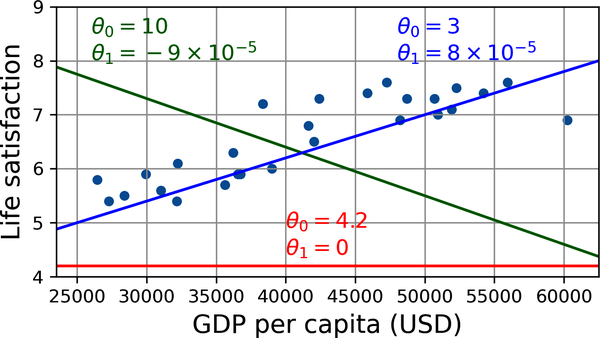
Figura 1-19. Algunos modelos lineales posibles
Antes de poder utilizar tu modelo, tienes que definir los valores de los parámetros θ0 y θ1. ¿Cómo puedes saber qué valores harán que tu modelo funcione mejor? Para responder a esta pregunta, tienes que especificar una medida de rendimiento. Puedes definir una función de utilidad (o función de adecuación) que mida lo bueno que es tu modelo, o puedes definir una función de coste que mida lo malo que es. Para los problemas de regresión lineal, se suele utilizar una función de coste que mide la distancia entre las predicciones del modelo lineal y los ejemplos de entrenamiento; el objetivo es minimizar esta distancia.
Aquí es donde entra en juego el algoritmo de regresión lineal: le das tus ejemplos de entrenamiento y encuentra los parámetros que hacen que el modelo lineal se ajuste mejor a tus datos. A esto se le llama entrenar el modelo. En nuestro caso, el algoritmo encuentra que los valores óptimos de los parámetros son θ0 = 3,75 y θ1 = 6,78 × 10-5.
Advertencia
De forma confusa, la palabra "modelo" puede referirse a un tipo de modelo (p. ej., regresión lineal), a una arquitectura de modelo totalmente especificada (p. ej., regresión lineal con una entrada y una salida), o al modelo final entrenado listo para ser utilizado en predicciones (p. ej., regresión lineal con una entrada y una salida, utilizando θ0 = 3,75 y θ1 = 6,78 × 10-5). La selección del modelo consiste en elegir el tipo de modelo y especificar completamente su arquitectura. Entrenar un modelo significa ejecutar un algoritmo para encontrar los parámetros del modelo que harán que se ajuste mejor a los datos de entrenamiento, y es de esperar que haga buenas predicciones sobre nuevos datos.
Ahora el modelo se ajusta lo más posible a los datos de entrenamiento (para un modelo lineal), como puedes ver en la Figura 1-20.
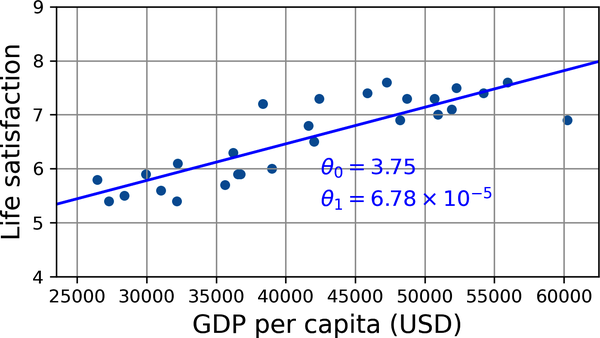
Figura 1-20. El modelo lineal que mejor se ajusta a los datos de entrenamiento
Por fin estás preparado para ejecutar el modelo y hacer predicciones. Por ejemplo, supongamos que quieres saber lo felices que son los chipriotas, y los datos de la OCDE no tienen la respuesta. Afortunadamente, puedes utilizar tu modelo para hacer una buena predicción: buscas el PIB per cápita de Chipre, encuentras 37.655 $, y luego aplicas tu modelo y descubres que es probable que la satisfacción vital esté en torno a 3,75 + 37.655 × 6,78 × 10-5 = 6,30.
Para abrirte el apetito, el Ejemplo 1-1 muestra el código Python que carga los datos, separa las entradas X de las etiquetas y, crea un gráfico de dispersión para su visualización y, a continuación, entrena un modelo lineal y realiza una predicción.5
Ejemplo 1-1. Entrenar y ejecutar un modelo lineal con Scikit-Learn
importmatplotlib.pyplotaspltimportnumpyasnpimportpandasaspdfromsklearn.linear_modelimportLinearRegression# Download and prepare the datadata_root="https://github.com/ageron/data/raw/main/"lifesat=pd.read_csv(data_root+"lifesat/lifesat.csv")X=lifesat[["GDP per capita (USD)"]].valuesy=lifesat[["Life satisfaction"]].values# Visualize the datalifesat.plot(kind='scatter',grid=True,x="GDP per capita (USD)",y="Life satisfaction")plt.axis([23_500,62_500,4,9])plt.show()# Select a linear modelmodel=LinearRegression()# Train the modelmodel.fit(X,y)# Make a prediction for CyprusX_new=[[37_655.2]]# Cyprus' GDP per capita in 2020(model.predict(X_new))# output: [[6.30165767]]
Nota
Si en su lugar hubieras utilizado un algoritmo de aprendizaje basado en instancias, habrías descubierto que Israel tiene el PIB per cápita más parecido al de Chipre (38.341 $), y como los datos de la OCDE nos dicen que la satisfacción vital de los israelíes es de 7,2, habrías predicho una satisfacción vital de 7,2 para Chipre. Si te alejas un poco y miras a los dos países más próximos, encontrarás a Lituania y Eslovenia, ambos con una satisfacción vital de 5,9. Haciendo la media de estos tres valores, obtienes 6,33, que se aproxima bastante a tu predicción basada en el modelo. Este sencillo algoritmo se denomina regresión k-vecinos más próximos (en este ejemplo, k = 3).
Sustituir el modelo de regresión lineal por la regresión k-vecinos más próximos del código anterior es tan fácil como sustituir estas líneas:
fromsklearn.linear_modelimportLinearRegressionmodel=LinearRegression()
con estos dos:
fromsklearn.neighborsimportKNeighborsRegressormodel=KNeighborsRegressor(n_neighbors=3)
Si todo ha ido bien, tu modelo hará buenas predicciones. Si no, puede que necesites utilizar más atributos (tasa de empleo, salud, contaminación atmosférica, etc.), obtener más datos de entrenamiento o de mejor calidad, o quizá seleccionar un modelo más potente (por ejemplo, un modelo de regresión polinómica).
En resumen:
-
Estudiaste los datos.
-
Has seleccionado un modelo.
-
Lo entrenaste con los datos de entrenamiento (es decir, el algoritmo de aprendizaje buscó los valores de los parámetros del modelo que minimizan una función de coste).
-
Por último, aplicaste el modelo para hacer predicciones sobre nuevos casos (esto se llama inferencia), esperando que este modelo generalice bien.
Este es el aspecto de un proyecto típico de aprendizaje automático. En el Capítulo 2 experimentarás esto de primera mano recorriendo un proyecto de principio a fin.
Hemos cubierto mucho terreno hasta ahora: ya sabes en qué consiste realmente el aprendizaje automático, por qué es útil, cuáles son algunas de las categorías más comunes de sistemas de ML y cómo es el flujo de trabajo de un proyecto típico. Ahora veamos qué puede fallar en el aprendizaje e impedirte hacer predicciones precisas.
Principales retos del aprendizaje automático
En resumen, como tu tarea principal es seleccionar un modelo y entrenarlo con unos datos, las dos cosas que pueden salir mal son "mal modelo" y "malos datos". Empecemos con ejemplos de datos malos.
Cantidad insuficiente de datos de entrenamiento
Para que un niño pequeño aprenda lo que es una manzana, basta con que señales una manzana y digas "manzana" (posiblemente repitiendo este procedimiento unas cuantas veces). Ahora el niño es capaz de reconocer manzanas de todo tipo de colores y formas. Una genialidad.
El aprendizaje automático aún no ha llegado a su fin; se necesitan muchos datos para que la mayoría de los algoritmos de aprendizaje automático funcionen correctamente. Incluso para problemas muy sencillos se suelen necesitar miles de ejemplos, y para problemas complejos, como el reconocimiento de imágenes o del habla, puedes necesitar millones de ejemplos (a menos que puedas reutilizar partes de un modelo existente).
Datos de entrenamiento no representativos
Para generalizar bien, es crucial que tus datos de entrenamiento sean representativos de los nuevos casos a los que quieres generalizar. Esto es así tanto si utilizas el aprendizaje basado en instancias como el basado en modelos.
Por ejemplo, el conjunto de países que utilizaste anteriormente para entrenar el modelo lineal no era perfectamente representativo; no contenía ningún país con un PIB per cápita inferior a 23.500 $ ni superior a 62.500 $. La Figura 1-22 muestra el aspecto de los datos cuando añades esos países.
Si entrenas un modelo lineal con estos datos, obtienes la línea continua, mientras que el modelo antiguo está representado por la línea de puntos. Como puedes ver, no sólo el hecho de añadir unos cuantos países que faltan altera significativamente el modelo, sino que deja claro que un modelo lineal tan simple probablemente nunca va a funcionar bien. Parece que los países muy ricos no son más felices que los países moderadamente ricos (de hecho, ¡parecen ligeramente más infelices!), y a la inversa, algunos países pobres parecen más felices que muchos países ricos.
Al utilizar un conjunto de entrenamiento no representativo, entrenaste un modelo que probablemente no hará predicciones precisas, especialmente para los países muy pobres y muy ricos.
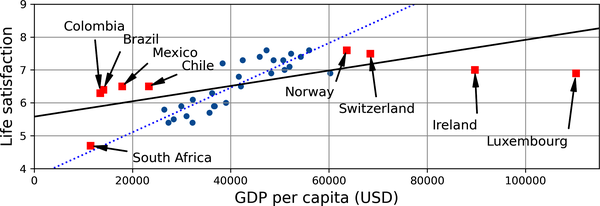
Figura 1-22. Una muestra de entrenamiento más representativa
Es crucial utilizar un conjunto de entrenamiento que sea representativo de los casos a los que quieres generalizar. Esto suele ser más difícil de lo que parece: si la muestra es demasiado pequeña, tendrás ruido de muestreo (es decir, datos no representativos como resultado del azar), pero incluso las muestras muy grandes pueden ser no representativas si el método de muestreo es defectuoso. Esto se denomina sesgo de muestreo.
Datos de baja calidad
Obviamente, si tus datos de entrenamiento están llenos de errores, valores atípicos y ruido (por ejemplo, debido a mediciones de mala calidad), al sistema le resultará más difícil detectar los patrones subyacentes, por lo que es menos probable que tu sistema funcione bien. A menudo merece la pena dedicar tiempo a limpiar tus datos de entrenamiento. La verdad es que la mayoría de los científicos de datos dedican una parte importante de su tiempo a hacer precisamente eso. Los siguientes son un par de ejemplos de cuándo te conviene limpiar los datos de entrenamiento:
-
Si algunos casos son claramente atípicos, puede ayudar simplemente descartarlos o intentar corregir los errores manualmente.
-
Si a algunas instancias les faltan algunas características (por ejemplo, el 5% de tus clientes no especificaron su edad), debes decidir si quieres ignorar este atributo por completo, ignorar estas instancias, rellenar los valores que faltan (por ejemplo, con la mediana de edad), o entrenar un modelo con la característica y otro sin ella.
Características irrelevantes
Como dice el refrán: basura entra, basura sale. Tu sistema sólo será capaz de aprender si los datos de entrenamiento contienen suficientes características relevantes y no demasiadas irrelevantes. Una parte fundamental del éxito de un proyecto de aprendizaje automático es conseguir un buen conjunto de características con las que entrenar. Este proceso, llamado ingeniería de características, implica los siguientes pasos:
-
Selección de características (seleccionar las características más útiles para entrenar entre las existentes)
-
Extracción de rasgos (combinar los rasgos existentes para producir uno más útil -como vimos antes, los algoritmos de reducción de la dimensionalidad pueden ayudar-)
-
Crear nuevas funciones recopilando nuevos datos
Ahora que hemos visto muchos ejemplos de datos malos, veamos un par de ejemplos de algoritmos malos.
Sobreajuste de los datos de entrenamiento
Supongamos que visitas un país extranjero y el taxista te estafa. Podrías tener la tentación de decir que todos los taxistas de ese país son ladrones. Generalizar en exceso es algo que los humanos hacemos con demasiada frecuencia y, por desgracia, las máquinas pueden caer en la misma trampa si no tenemos cuidado. En el aprendizaje automático esto se llama sobreadaptación: significa que el modelo funciona bien en los datos de entrenamiento, pero no generaliza bien.
La Figura 1-23 muestra un ejemplo de un modelo de satisfacción vital polinómico de alto grado que se ajusta en exceso a los datos de entrenamiento. Aunque funciona mucho mejor en los datos de entrenamiento que el modelo lineal simple, ¿te fiarías realmente de sus predicciones?
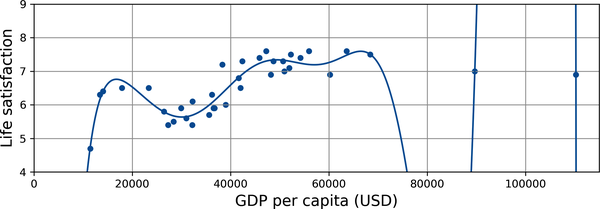
Figura 1-23. Sobreajuste de los datos de entrenamiento
Los modelos complejos, como las redes neuronales profundas, pueden detectar patrones sutiles en los datos, pero si el conjunto de entrenamiento es ruidoso, o si es demasiado pequeño, lo que introduce ruido de muestreo, entonces es probable que el modelo detecte patrones en el propio ruido (como en el ejemplo del taxista). Obviamente, estos patrones no se generalizarán a nuevas instancias. Por ejemplo, supongamos que alimentas tu modelo de satisfacción vital con muchos más atributos, incluidos los no informativos, como el nombre del país. En ese caso, un modelo complejo puede detectar patrones como el hecho de que todos los países de los datos de entrenamiento con una w en su nombre tienen una satisfacción vital superior a 7: Nueva Zelanda (7,3), Noruega (7,6), Suecia (7,3) y Suiza (7,5). ¿Hasta qué punto estás seguro de que la regla de la satisfacción w se generaliza a Ruanda o Zimbabue? Obviamente, este patrón se produjo en los datos de entrenamiento por pura casualidad, pero el modelo no tiene forma de saber si un patrón es real o simplemente el resultado del ruido en los datos.
Advertencia
El sobreajuste se produce cuando el modelo es demasiado complejo en relación con la cantidad y el ruido de los datos de entrenamiento. Aquí tienes posibles soluciones:
-
Simplifica el modelo seleccionando uno con menos parámetros (por ejemplo, un modelo lineal en lugar de un modelo polinómico de alto grado), reduciendo el número de atributos en los datos de entrenamiento o restringiendo el modelo.
-
Reúne más datos de entrenamiento.
-
Reduce el ruido de los datos de entrenamiento (por ejemplo, corrige los errores de los datos y elimina los valores atípicos).
Restringir un modelo para simplificarlo y reducir el riesgo de sobreajuste se denomina regularización. Por ejemplo, el modelo lineal que hemos definido antes tiene dos parámetros, θ0 y θ1. Esto da al algoritmo de aprendizaje dos grados de libertad para adaptar el modelo a los datos de entrenamiento: puede ajustar tanto la altura(θ0) como la pendiente(θ1) de la recta. Si forzáramos θ1 = 0, el algoritmo sólo tendría un grado de libertad y le costaría mucho más ajustarse correctamente a los datos: lo único que podría hacer es mover la recta hacia arriba o hacia abajo para acercarse lo más posible a las instancias de entrenamiento, por lo que acabaría en torno a la media. Sin duda, ¡un modelo muy simple! Si permitimos que el algoritmo modifique θ1 pero le obligamos a mantenerlo pequeño, entonces el algoritmo de aprendizaje tendrá efectivamente entre uno y dos grados de libertad. Producirá un modelo más simple que uno con dos grados de libertad, pero más complejo que uno con sólo uno. Lo que quieres es encontrar el equilibrio adecuado entre ajustarse perfectamente a los datos de entrenamiento y mantener el modelo lo suficientemente simple como para garantizar una buena generalización.
La Figura 1-24 muestra tres modelos. La línea de puntos representa el modelo original que se entrenó con los países representados como círculos (sin los países representados como cuadrados), la línea continua es nuestro segundo modelo entrenado con todos los países (círculos y cuadrados), y la línea discontinua es un modelo entrenado con los mismos datos que el primer modelo pero con una restricción de regularización. Puedes ver que la regularización obligó al modelo a tener una pendiente menor: este modelo no se ajusta a los datos de entrenamiento (círculos) tan bien como el primer modelo, pero en realidad generaliza mejor a los nuevos ejemplos que no vio durante el entrenamiento (cuadrados).
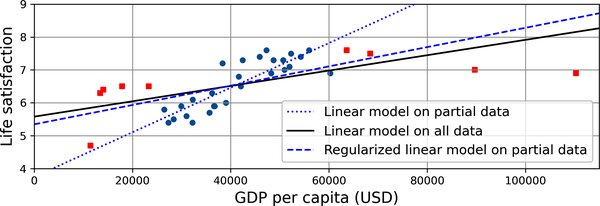
Figura 1-24. La regularización reduce el riesgo de sobreajuste
La cantidad de regularización a aplicar durante el aprendizaje puede controlarse mediante un hiperparámetro. Un hiperparámetro es un parámetro de un algoritmo de aprendizaje (no del modelo). Como tal, no se ve afectado por el propio algoritmo de aprendizaje; debe fijarse antes del entrenamiento y permanece constante durante éste. Si ajustas el hiperparámetro de regularización a un valor muy grande, obtendrás un modelo casi plano (una pendiente cercana a cero); es casi seguro que el algoritmo de aprendizaje no sobreajustará los datos de entrenamiento, pero tendrá menos probabilidades de encontrar una buena solución. Ajustar los hiperparámetros es una parte importante de la construcción de un sistema de aprendizaje automático (verás un ejemplo detallado en el próximo capítulo).
Ajuste insuficiente de los datos de entrenamiento
Como puedes suponer, el infraajuste es lo contrario del sobreajuste: se produce cuando tu modelo es demasiado simple para aprender la estructura subyacente de los datos. Por ejemplo, un modelo lineal de satisfacción vital es propenso al infraajuste; la realidad es simplemente más compleja que el modelo, por lo que sus predicciones serán inexactas, incluso en los ejemplos de entrenamiento.
Aquí tienes las principales opciones para solucionar este problema:
-
Selecciona un modelo más potente, con más parámetros.
-
Introduce mejores características en el algoritmo de aprendizaje (ingeniería de características).
-
Reduce las restricciones del modelo (por ejemplo, reduciendo elhiperparámetro de regularización).
Un paso atrás
A estas alturas ya sabes mucho sobre el aprendizaje automático. Sin embargo, hemos repasado tantos conceptos que puede que te sientas un poco perdido, así que demos un paso atrás y veamos el panorama general:
-
El aprendizaje automático consiste en hacer que las máquinas mejoren en alguna tarea aprendiendo de los datos, en lugar de tener que codificar reglas explícitamente.
-
Hay muchos tipos diferentes de sistemas de ML: supervisados o no, por lotes o en línea, basados en instancias o en modelos.
-
En un proyecto de ML reúnes datos en un conjunto de entrenamiento, y alimentas con el conjunto de entrenamiento a un algoritmo de aprendizaje. Si el algoritmo se basa en un modelo, afina algunos parámetros para ajustar el modelo al conjunto de entrenamiento (es decir, para hacer buenas predicciones sobre el propio conjunto de entrenamiento), y luego es de esperar que también sea capaz de hacer buenas predicciones sobre nuevos casos. Si el algoritmo se basa en instancias, simplemente aprende los ejemplos de memoria y generaliza a nuevas instancias utilizando una medida de similitud para compararlas con las instancias aprendidas.
-
El sistema no funcionará bien si tu conjunto de entrenamiento es demasiado pequeño, o si los datos no son representativos, tienen ruido o están contaminados con características irrelevantes (basura dentro, basura fuera). Por último, tu modelo no debe ser ni demasiado simple (en cuyo caso se ajustará mal) ni demasiado complejo (en cuyo caso se ajustará demasiado).
Hay un último tema importante que tratar: una vez que has entrenado un modelo, no quieres limitarte a "esperar" que generalice a nuevos casos. Quieres evaluarlo y ajustarlo si es necesario. Veamos cómo hacerlo.
Probar y validar
La única forma de saber lo bien que un modelo se generalizará a nuevos casos es probarlo realmente en nuevos casos. Una forma de hacerlo es poner tu modelo en producción y monitorear su rendimiento. Esto funciona bien, pero si tu modelo es horriblemente malo, tus usuarios se quejarán: no es la mejor idea.
Una opción mejor es dividir tus datos en dos conjuntos: el conjunto de entrenamiento y el conjunto de prueba. Como estos nombres implican, entrenas tu modelo utilizando el conjunto de entrenamiento, y lo pruebas utilizando el conjunto de prueba. La tasa de error en los nuevos casos se denomina error de generalización (o error fuera de muestra), y al evaluar tu modelo en el conjunto de prueba, obtienes una estimación de este error. Este valor te indica lo bien que funcionará tu modelo en instancias que nunca ha visto antes.
Si el error de entrenamiento es bajo (es decir, tu modelo comete pocos errores en el conjunto de entrenamiento) pero el error de generalización es alto, significa que tu modelo está sobreajustando los datos de entrenamiento.
Consejo
Es habitual utilizar el 80% de los datos para el entrenamiento y reservar el 20% para las pruebas. Sin embargo, esto depende del tamaño del conjunto de datos: si contiene 10 millones de instancias, retener el 1% significa que tu conjunto de prueba contendrá 100.000 instancias, probablemente más que suficiente para obtener una buena estimación del error de generalización.
Ajuste de hiperparámetros y selección de modelos
Evaluar un modelo es bastante sencillo: basta con utilizar un conjunto de pruebas. Pero supongamos que dudas entre dos tipos de modelos (digamos, un modelo lineal y un modelo polinómico): ¿cómo puedes decidir entre ellos? Una opción es entrenar a ambos y comparar lo bien que generalizan utilizando el conjunto de pruebas.
Supón ahora que el modelo lineal generaliza mejor, pero quieres aplicar cierta regularización para evitar el sobreajuste. La pregunta es, ¿cómo eliges el valor del hiperparámetro de regularización? Una opción es entrenar 100 modelos diferentes utilizando 100 valores distintos para este hiperparámetro. Supón que encuentras el mejor valor de hiperparámetro que produce un modelo con el menor error de generalización, digamos, sólo un 5% de error. Pones este modelo en producción, pero por desgracia no funciona tan bien como esperabas y produce errores del 15%. ¿Qué acaba de ocurrir?
El problema es que mediste el error de generalización varias veces en el conjunto de pruebas, y adaptaste el modelo y los hiperparámetros para producir el mejor modelo para ese conjunto concreto. Esto significa que es poco probable que el modelo funcione igual de bien con datos nuevos.
Una solución habitual a este problema se denomina validación por retención(Figura 1-25): simplemente retiras parte del conjunto de entrenamiento para evaluar varios modelos candidatos y seleccionar el mejor. El nuevo conjunto retenido se denomina conjunto de validación (o conjunto de desarrollo). Más concretamente, entrenas varios modelos con distintos hiperparámetros en el conjunto de entrenamiento reducido (es decir, el conjunto de entrenamiento completo menos el conjunto de validación), y seleccionas el modelo que obtiene mejores resultados en el conjunto de validación. Tras este proceso de validación en espera, entrenas el mejor modelo en el conjunto de entrenamiento completo (incluido el conjunto de validación), con lo que obtienes el modelo final. Por último, evalúa este modelo final en el conjunto de pruebas para obtener una estimación del error de generalización.
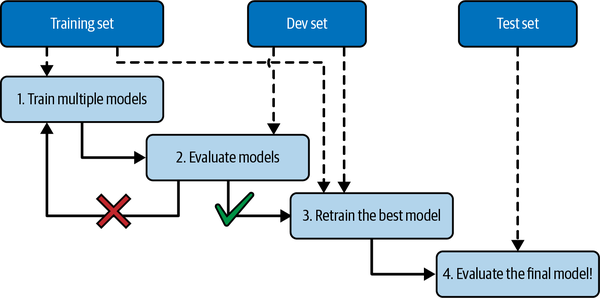
Figura 1-25. Selección del modelo mediante validación de la retención
Esta solución suele funcionar bastante bien. Sin embargo, si el conjunto de validación es demasiado pequeño, las evaluaciones del modelo serán imprecisas: puedes acabar seleccionando un modelo subóptimo por error. A la inversa, si el conjunto de validación es demasiado grande, el conjunto de entrenamiento restante será mucho menor que el conjunto de entrenamiento completo. ¿Por qué es malo esto? Bueno, como el modelo final se entrenará con el conjunto de entrenamiento completo, no es ideal comparar modelos candidatos entrenados con un conjunto de entrenamiento mucho más pequeño. Sería como seleccionar al velocista más rápido para participar en un maratón. Una forma de resolver este problema es realizar una validación cruzada repetida, utilizando muchos conjuntos de validación pequeños. Cada modelo se evalúa una vez por conjunto de validación, después de entrenarlo con el resto de los datos. Al promediar todas las evaluaciones de un modelo, obtienes una medida mucho más precisa de su rendimiento. Sin embargo, hay un inconveniente: el tiempo de entrenamiento se multiplica por el número de conjuntos de validación.
Desajuste de datos
En algunos casos, es fácil obtener una gran cantidad de datos para el entrenamiento, pero estos datos probablemente no serán perfectamente representativos de los datos que se utilizarán en la producción. Por ejemplo, supongamos que quieres crear una aplicación móvil para hacer fotos de flores y determinar automáticamente su especie. Puedes descargar fácilmente millones de fotos de flores en la web, pero no serán perfectamente representativas de las fotos que se tomarán realmente utilizando la app en un dispositivo móvil. Quizá sólo tengas 1.000 fotos representativas (es decir, tomadas realmente con la app).
En este caso, la regla más importante que debes recordar es que tanto el conjunto de validación como el conjunto de prueba deben ser lo más representativos posible de los datos que esperas utilizar en producción, por lo que deben estar compuestos exclusivamente por imágenes representativas: puedes barajarlas y poner la mitad en el conjunto de validación y la otra mitad en el conjunto de prueba (asegurándote de que no haya duplicados o casi duplicados en ambos conjuntos). Después de entrenar tu modelo con las fotos de la web, si observas que el rendimiento del modelo en el conjunto de validación es decepcionante, no sabrás si se debe a que tu modelo ha sobreajustado el conjunto de entrenamiento, o si se debe simplemente a la falta de correspondencia entre las fotos de la web y las fotos de la aplicación móvil.
Una solución es guardar algunas de las imágenes de entrenamiento (de la web) en otro conjunto al que Andrew Ng denominó conjunto entrenar-desarrollar(Figura 1-26). Una vez entrenado el modelo (en el conjunto de entrenamiento, no en el conjunto de entrenamiento-desarrollo), puedes evaluarlo en el conjunto de entrenamiento-desarrollo. Si el modelo funciona mal, debe de haber sobreajustado el conjunto de entrenamiento, por lo que debes intentar simplificar o regularizar el modelo, obtener más datos de entrenamiento y limpiar los datos de entrenamiento. Pero si funciona bien en el conjunto de entrenamiento y desarrollo, entonces puedes evaluar el modelo en el conjunto de desarrollo. Si funciona mal, entonces el problema debe provenir del desajuste de los datos. Puedes intentar resolver este problema preprocesando las imágenes de la web para que se parezcan más a las fotos que tomará la aplicación móvil, y luego volver a entrenar el modelo. Una vez que tengas un modelo que funcione bien tanto en el conjunto de entrenamiento como en el conjunto de desarrollo, puedes evaluarlo una última vez en el conjunto de prueba para saber cómo de bien es probable que funcione en producción.
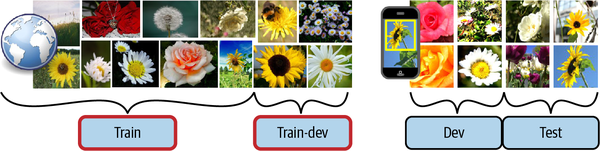
Figura 1-26. Cuando los datos reales son escasos (derecha), puedes utilizar datos abundantes similares (izquierda) para el entrenamiento y retener algunos de ellos en un conjunto de entrenamiento-desarrollo para evaluar el sobreajuste; los datos reales se utilizan entonces para evaluar el desajuste de los datos (conjunto de desarrollo) y para evaluar el rendimiento del modelo final (conjunto de prueba).
Ejercicios
En este capítulo hemos tratado algunos de los conceptos más importantes del aprendizaje automático. En los próximos capítulos profundizaremos más y escribiremos más código, pero antes asegúrate de que puedes responder a las siguientes preguntas:
-
¿Cómo definirías el aprendizaje automático?
-
¿Puedes nombrar cuatro tipos de aplicaciones en las que brilla?
-
¿Qué es un conjunto de entrenamiento etiquetado?
-
¿Cuáles son las dos tareas supervisadas más habituales?
-
¿Puedes nombrar cuatro tareas comunes no supervisadas?
-
¿Qué tipo de algoritmo utilizarías para permitir a un robot caminar por diversos terrenos desconocidos?
-
¿Qué tipo de algoritmo utilizarías para segmentar a tus clientes en varios grupos?
-
¿Enmarcarías el problema de la detección de spam como un problema de aprendizaje supervisado o como un problema de aprendizaje no supervisado?
-
¿Qué es un sistema de aprendizaje online?
-
¿Qué es el aprendizaje complementario?
-
¿Qué tipo de algoritmo se basa en una medida de similitud para hacer predicciones?
-
¿Cuál es la diferencia entre un parámetro del modelo y un hiperparámetro del modelo?
-
¿Qué buscan los algoritmos basados en modelos? ¿Cuál es la estrategia más común que utilizan para tener éxito? ¿Cómo hacen predicciones?
-
¿Puedes nombrar cuatro de los principales retos del aprendizaje automático?
-
Si tu modelo funciona muy bien en los datos de entrenamiento, pero generaliza mal a las nuevas instancias, ¿qué está ocurriendo? ¿Puedes nombrar tres posibles soluciones?
-
¿Qué es un conjunto de pruebas y por qué querrías utilizarlo?
-
¿Para qué sirve un conjunto de validación?
-
¿Qué es el conjunto tren-dev, cuándo lo necesitas y cómo lo utilizas?
-
¿Qué puede ir mal si ajustas los hiperparámetros utilizando el conjunto de pruebas?
Las soluciones a estos ejercicios están disponibles al final del cuaderno de este capítulo, en https://homl.info/colab3.
1 Dato curioso: este curioso nombre es un término estadístico introducido por Francis Galton cuando estudiaba el hecho de que los hijos de personas altas tienden a ser más bajos que sus padres. Como los hijos eran más bajos, lo llamó regresión a la media. Este nombre se aplicó después a los métodos que utilizaba para analizar las correlaciones entre variables.
2 Observa cómo los animales están bastante separados de los vehículos y cómo los caballos están cerca de los ciervos pero lejos de los pájaros. Figura reproducida con permiso de Richard Socher et al., "Zero-Shot Learning Through Cross-Modal Transfer", Proceedings of the 26th International Conference on Neural Information Processing Systems 1 (2013): 935-943.
3 Eso es cuando el sistema funciona perfectamente. En la práctica, suele crear unos cuantos conglomerados por persona, y a veces mezcla a dos personas que se parecen, por lo que puede que tengas que proporcionar unas cuantas etiquetas por persona y limpiar manualmente algunos conglomerados.
4 Por convención, la letra griega θ (theta) se utiliza frecuentemente para representar los parámetros del modelo.
5 No pasa nada si aún no entiendes todo el código; te presentaré Scikit-Learn en los capítulos siguientes.
6 Por ejemplo, saber si hay que escribir "a", "dos" o "también", según el contexto.
7 Peter Norvig y otros, "La irrazonable eficacia de los datos", IEEE Intelligent Systems 24, nº 2 (2009): 8-12.
8 Figura reproducida con permiso de Michele Banko y Eric Brill, "Scaling to Very Very Large Corpora for Natural Language Disambiguation", Actas de la 39ª Reunión Anual de la Asociación de Lingüística Computacional (2001): 26-33.
9 David Wolpert, "La falta de distinciones a priori entre algoritmos de aprendizaje", Neural Computation 8, nº 7 (1996): 1341-1390.
Get Aprendizaje automático práctico con Scikit-Learn, Keras y TensorFlow, 3ª edición now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

