Chapter 17. Functionality
THIS CHAPTER CONTAINS A NUMBER OF HIGHER-LEVEL PATTERNS THAT ARE MORE GEARED TOWARD offering new functionality than modifying the user interface. Technical barriers have prevented these from being used much on the Web, but Ajax technologies are helping to break down the barrier.
Lazy Registration addresses the issue of managing the lifecycle of a user profile. Instead of a binary “you’re registered or you’re not” perspective, Lazy Registration advocates a more gradual accumulation of user data and authentication credentials. A related pattern is Direct Login, which explains how to let the user securely log in without forcing a page refresh. It incorporates browser-side encryption, a theme at the heart of the next pattern, Host-Proof Hosting. The purpose of this pattern is to encrypt and decrypt data within the browser so that it can’t be inspected by the hosting organization.
The next two patterns address monitoring the user’s activity level. Timeout uses event-handling and scheduling to decide when the user is no longer active. Heartbeat is similar, but it brings the server into the equation; the browser keeps sending a heartbeat message to tell the server that the user is still active and that the application is still sitting in the browser.
Finally, Unique URLs restores some functionality that Ajax, to some degree, takes away. Bookmarkable URLs and browser history have always been an issue on the Web, but Ajax exacerbates the problem when developers choose not to use page refreshes. The Unique URLs pattern identifies a range of tricks to handle bookmarking, deep linking, the Back button, and related concerns.
Lazy Registration
⊙⊙ Account, Authentication, Customisation, Customization, Incremental, Login, Password, Personalisation, Personalization, Profiling, Registration, User, Verification
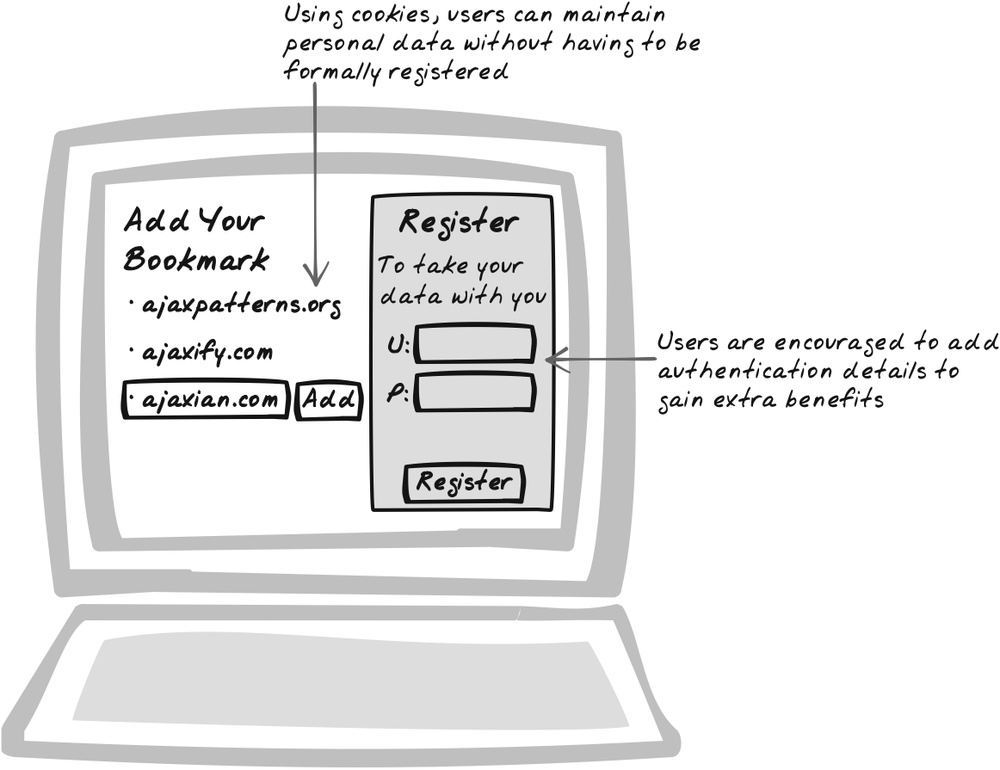
Goal Story
It’s Saturday afternoon, and Stuart is busy planning the evening’s activities. He visits a band listings web site, where he clicks on a map to zoom into his local area. Even though he has never visited the site before, a profile, which he can see on the top of the site is already being constructed. At this stage, the profile guesses at his location based on his actions so far. As he browses some of the jazz bands, the profile starts to show an increasing preference for jazz bands, and some of the ads reflect that. Since the jazz thing is a one-time idea, he goes into his profile and tweaks some of those genre preferences but leaves the location alone since the system’s guess was correct. Finally, he decides to make a booking, at which point he establishes a password for future access to the same profile including his address, which is posted back to the profile.
Forces
Public web sites thrive on registered users. Registered users receive personalized content, which means that the web site is able to deliver greater value per user. And registered users can also receive more focused advertising material.
For nonpublic web sites, such as extranets used by external customers, registration may be a necessity.
Most users don’t like giving their personal information to a web server. They have concerns about their own privacy and the security of the information. Furthermore, the registration process is often time consuming.
Many users spend time familiarizing themselves with a site before registering. In some cases, a user might interact with a site for years before formally establishing an account. There is a lot of valuable information that can be gained from this interaction that will benefit both the web site owner and the user.
Solution
Accumulate bits of information on the user as they interact while deferring formal registration. As soon as the user visits the web site, a user account with auto-generated ID is immediately created for her and set in a cookie that will remain in the browser. It doesn’t matter if she never return; unused IDs can be cleared after a few months.
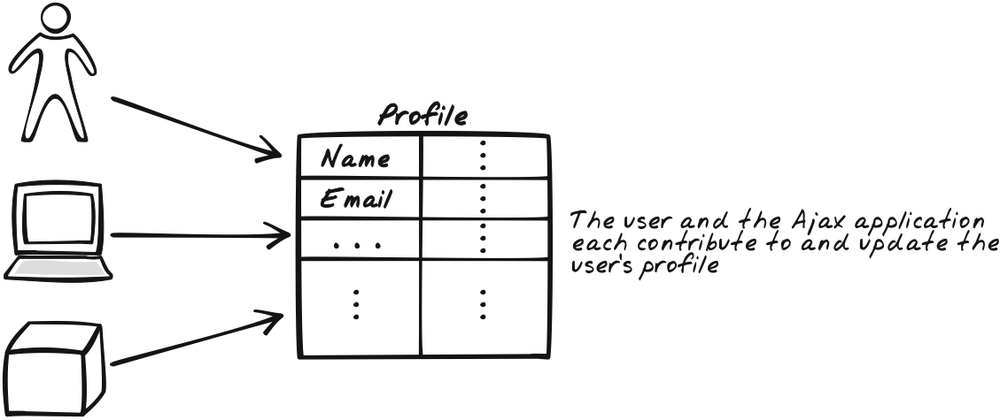
As the user interacts with the application, the account accumulates data. In many cases, the data is explicitly contributed by the user, and it’s advisable to expose this kind of information so that the user can actually populate it. In this way, the initial profile may be seen as a structure with lots of holes. Some holes are eventually filled out automatically and others by the user himself. The user is also free to correct any of the filled-in data at any time (Figure 17-2).
Two particularly notable “holes” are a unique user identifier and a password. It is this combination of attributes that allows the user to access the profile from another machine or a different browser. They will also preserve the profile in the case that cookies are deleted from the user’s browser. So, while this pattern is generally about gradual accumulation of profile data, there remains a significant milestone in the user/application relationship—the moment at which user ID and password are established.
Do the user ID and password have to be provided simultaneously? No. Even that can be incremental as long as you make the email address the unique identifier. In fact, this is pretty common nowadays. Email is usually required anyway, and it’s unique, so why not make it the user ID? In the context of Lazy Registration, though, there’s an additional benefit, as the email might be accumulated in the natural flow of events—the site might add the user to an announcements list, for example. In some cases, the email might even be verified during this process.
Sceptics may wonder why a user would want to actively work with her profile. The answer was formulated in a web usability pattern called “Carrot and a Stick” (http://jerry.cs.uiuc.edu/~plop/plop99/proceedings/Kane/perzel_kane.pdf):
Determine what users consider to be a “valuable” carrot. Offer the end user a portion of that carrot before you request personal information. The content is withheld (“the stick”) until the requested information is provided.
Thus, users will only enter information if there is a perceived benefit to them. There is plenty of evidence that this occurs—witness the social bookmarking phenomenon, where thousands of users make public their personal links. By exposing their profiles, many of those users are hoping the system will point them in the direction of related resources they have not yet heard of.
Some web sites have used this pattern for years, so what does it have to do with Ajax? Lazy Registration aims for a smooth approach in which the barrier is low for each new user contribution. For instance, you sign up for a web site’s mailing list, and your email is automatically added to your profile and shown on the side of the page. With Ajax, there’s no need to break the flow. No more “just go over there for a few minutes, then come back here, and if you’re lucky, you might be looking at something similar to what you can see now.” That’s a big win for web sites aiming to drop the barrier of registration, and it’s great for users, too.
It’s standard practice for web sites to collect data about users. The aim of this pattern is to empower them to contribute to this. Instead of covertly building up a corpus of data on a user, you invite him to add value to his own experience by contributing and maintaining the data himself.[*]
Several technologies are involved in Lazy Registration:
- Database
You clearly need a persistent data store in order to retain user profiles.
XMLHttpRequestPassing profile information back and forth with XMLHttpRequest Calls is the key to the smooth interaction mode you are seeking to achieve with this pattern.
- Cookie manipulation and session tracking
A cookie, associated with your domain and identifying a unique session ID, must reside in the user’s browser. The session ID can serve as a key on the server side to locate details about the user each time she accesses the web site. In conventional applications, the cookie is pushed from the browser to the server as a header in the response. That’s fine for Ajaxian Lazy Registration when the user first accesses the system, though sometimes it may be convenient to use a more Ajax-oriented approach. The first such approach is to manipulate the cookie in JavaScript (http://www.netspade.com/articles/javascript/cookies.xml). The second is to set the cookie using the response from an XMLHttpRequest Call, which all browsers are apparently happy to deal with in the same way as they deal with cookies in regular page reloads. In practice, you’re unlikely to be playing with cookies anyway. Most modern environments contain session-tracking frameworks that do the low-level cookie manipulation for you (also see Direct Login ). They generally use either URL rewriting or cookie manipulation, and you need the latter to make this pattern work most effectively. Since responses from
XMLHttpRequestset cookies in the same way as do entire page reloads, you should be able to change session data while servicing XMLHttpRequest Calls.
Decisions
What kind of data will the profile contain?
Usability and functionality concerns will drive decisions on what data is accumulated. By envisioning how users will interact with the web site, you can decide what kind of data must be there to support the interaction. For example:
Do you want to provide localized ads? You’ll need to know where the user lives.
Do you want to use collaborative filtering? You’ll need to capture the user’s preferences.
In addition, consider that some users, such as employees working on an intranet web site, use certain Ajax Apps all day long. For that reason, the profile might also contain preferences similar to those on conventional desktop applications. Many options will be application-specific, but a few generic examples include:
Enabling and disabling visual effects, such as One-Second Spotlight (Chapter 16).
Setting Heartbeat-related (see earlier in this chapter) parameters, e.g., setting how long timeout will be and whether the system will prompt the user when it’s coming up.
Customizing Status Area (Chapter 15) display.
One issue that arises with Lazy Registration is the clearing of data. What if a user visits once and never comes back? You probably don’t want to keep that data sitting there forever. Typically, you will probably have a script running daily to delete (or archive) the records of users whose last login was, say, three months ago.
How can the profile be accumulated?
You might know what data you need, but are users willing to give it to you? This comes back to the carrot-and-stick argument: you need to provide users a service that will make it worthwhile for them to provide that data. In addition, you need to communicate the benefit, and you must be able to assure them that the data will be safe and secure.
The least imaginative way to gain user data is to pay them for it, or, more deviously, pay others for it. Giving away a T-shirt in exchange for data was fine during the dot-com boom, but hopefully you can do better than that. Give the user a service they really need. For example:
If you want the user to provide his email, offer to send email notifications.
If you want the user to provide an ID and password, help him understand the benefits: he can log in from anywhere and the data will survive a hard-drive crash.
If you want the user to provide his physical address, provide localized search features.
If you want the user to rate your product, provide recommendations based on his ratings.
How much data should be stored in cookies?
How much you store in cookies depends on your general approach to the Ajax implementation: is the application browser-centric or server-centric? A browser-centric choice would be to pack as much as possible into the browser’s local state so as to optimize performance, while running a full-fledged JavaScript application with a little server-side synchronization. A server-centric approach would rely only on data held server-side, with the browser accessing additional data on a need-to-know basis using XMLHttpRequest Calls.
One special concern is the security of cookies. If users access the application from a public PC, there’s the risk of unauthorized access. In this case, it’s especially advisable not to store sensitive information in the browser and to offer the possibility of cleaning cookies at the end of the session. (For instance, call the option “I’m on a public terminal.”)
Real-World Examples
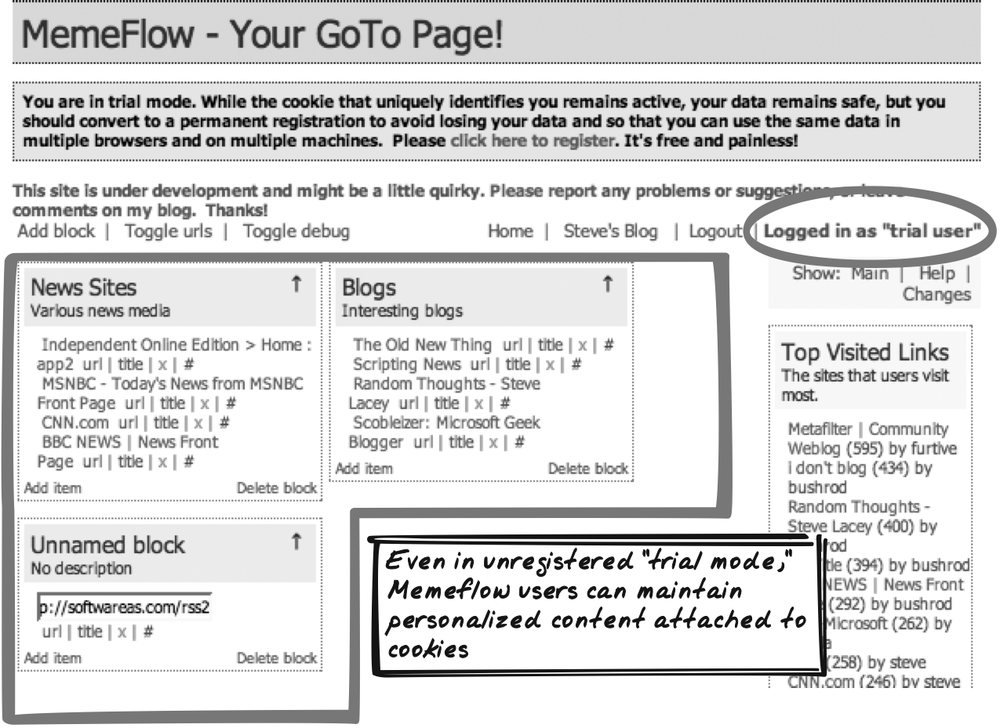
Memeflow
Steve Lacey’s MemeFlow (http://memeflow.com) is a portal with RSS-backed Portlets. Its use of Lazy Registration is characteristic of several other portals (Figure 17-3). You can immediately build up a collection of your favorite feeds, and when you provide your username and password later on, those feeds will remain.
Blummy
Alexander Kirk’s Blummy (http://blummy.com) is a bookmarklet manager (Figure 17-4). You can start adding bookmarklets to a personal "Blummy" container straightaway (this has a unique URL). When you register, you’ll get a URL with your own name, but the old URL remains valid, so you can keep the bookmark you created before registering.

Kayak
Kayak (http://kayak.com) is a travel search engine that retains queries you’ve made. A query history is available for nonregistered users and becomes part of your profile once registered.
Palmsphere
Palmsphere (http://palmsphere.com/store/home) showcases Palm applications for download and purchase. Each item has a Favorite button—if checked, the item is one of your Favorites. The Favorites list is summarized in your Member Center area, even if you’ve never registered, and retained in a cookie for the next time you visit.
Amazon.com
Amazon (http://amazon.com) has begun incorporating Ajax features only recently, but it blazed the trail for Lazy Registration a long time ago. Visit Amazon (http://amazon.com) as a new user, browse for just a few seconds, and here’s what you’ll see before even beginning to register or log in:
Shopping cart, to which you can add items
Recently Viewed Items
Page You Made—showing recent views and bookmarks related to those
Ability to update your history by deleting items you viewed
Ability to turn off Page You Made
Ability to search for a friend’s public wish list
Code Example: AjaxPatterns Shop Demo
The Ajax Shop Demo (http://ajaxify.com/shop) illustrates the kind of user interface described by this pattern (Figure 17-5).

When you run the demo, you’ll notice a few things:
You can add items to your cart right away.
The application guesses your favorite category by watching what you’re looking at. If you prefer, you can override the application’s guess, and the application will no longer attempt to adjust it.
By offering you the ability to send the cart contents to your email address, the application provides you with an incentive to add your email to the profile without yet formally registering.
The password and email verification process itself is unintrusive—the main flow of the site is uninterrupted. Even while you’re waiting for verification mail, you can continue to play around with the main content. Figure 17-6 shows the application when the user has gone as far as entering an email address and password.

To keep things simple, it doesn’t actually use a persistent data store; all information is held in the session. That’s definitely not advisable for a real system, because you don’t want to store passwords and other sensitive data there. Also, it means that the user, in theory, could bypass the email verification by inspecting the cookie. Nevertheless, the application demonstrates Lazy Registration from the user’s perspective, and the underlying code provides some illustration of what’s required to develop such an application.
Following are some of the features and how they were achieved.
Retrieval of categories and items
The application maintains the flow by avoiding any page reloads when categories and items are accessed. No information about categories or items is hardcoded; generic REST services are used to extract the data and are rendered locally in JavaScript.
Cart management
Again, the only real relevance of cart management is that page reloads are avoided. The cart contents are tracked in the session, so they should be present when the user resumes using the web site. When the user adds something to the cart, the JavaScript cart is not directly altered. Instead, the new item is posted to the server as XML:
function onAddItemClicked(item) {
var vars = {
command: 'add',
item: item
}
ajaxCaller.postForXML("cart.phtml", vars, onCartResponse);
}And likewise when the cart is cleared:
function onCartClearClicked( ) {
var vars = {
command: 'clear'
}
ajaxCaller.postForXML("cart.phtml", vars, onCartResponse);
}For both operations, the server retrieves the session cart and alters its state:
$cart = $_SESSION['cart'];
if (isset($_POST["command"]) && $_POST["command"]=="add") {
$item = $_POST["item"];
$cart->add($item);
} else if (isset($_POST["command"]) && $_POST["command"]=="clear") {
$cart->clear( );
}Then, the server outputs the final state as an XML response:
header("Content-type: text/xml");
echo "<cart>";
$contents = $cart->getContents( );
foreach (array_keys($contents) as $itemName) {
echo "<item>";
echo "<name>$itemName</name>";
echo "<amount>".$contents[$itemName]."</amount>";
echo "</item>";
}
echo "</cart>";In the browser, onCartResponse is registered to render
the cart based on the resulting XML.
Mailing cart contents
The profile block contains, along with several other fields, the user’s email. There’s also a clickable Mail field on the cart:
<div>
<div class="userLabel">Email:</div>
<input type="text" id="email" name="email" />
</div>
...
<span id="cartMail">Mail Contents</span>
....
$("cartMail").onclick = onCartMailClicked;When the user clicks on cartMail, the server checks that the
email has been filled in and simply uploads a POST message for the
mail to occur. In this case, there’s no feedback to the web user,
so the callback function is blank:
vars = {
command: "mailCart",
email: email
}
ajaxCaller.postForPlainText("cart.phtml", vars, function( ) {});The server receives not only the command, but the email address itself, since this might not be in the user’s profile yet. Just prior to sending the mail, the server retains the address as part of the user’s session:[*]
function mailCart( ) {
...
$email = $_POST["email"];
// Add mail to the profile - it's part of the Lazy Registration.
$_SESSION['email'] = $email;
...
}Then, it’s a simple matter of constructing a message from the server-side cart state and sending the email to the specified address using standard server-side libraries.
Tracking favorite categories
There’s a fixed “favorite category” selector in the HTML. It begins empty and is populated when the categories are loaded:
<div id="favoriteCategoryInfo">
My Best Category: <select id="favoriteCategory"></select>
</div>
function onAllCategoriesResponse(xml, ignoredHeaders, ignoredContext) {
...
categoryExplores[category] = 0;
favoriteCategoryOption = document.createElement("option");
...
}There’s also a mode variable to indicate whether the favorite category selection is automated. It begins in automated mode:
var isFavoriteCategoryAutomated = true;
If in automated mode, the script watches each time the user explores an item. Each category is tracked according to how many times the item was explored, and the selector is altered if a new maximum is reached:
var categoryExplores = new Array( );
...
function onExploreClicked(category) {
...
if (isFavoriteCategoryAutomated) {
categoryExplores[category]++;
favoriteCategory = $("favoriteCategory").value;
favoriteCategoryExplores = categoryExplores[favoriteCategory];
if (categoryExplores[category] > favoriteCategoryExplores) {
$("favoriteCategory").value = category;
}
}
}If the user decides to overwrite this Guesstimate by manually setting the preference, it will stay manual permanently:
$("favoriteCategory").onclick = function( ) {
isFavoriteCategoryAutomated = false;
}For the sake of simplicity, this field is not actually tracked in the server, though it could easily be incorporated into the user’s profile.
Verifying password and email
Now for the most important part. The user is finally willing to verify her password and email. These could potentially be broken into two separate verification activities, but since they fit together as a formal registration step, they are combined in the demo.
The trick is to manage the process with a little state transition logic. The registration is broken into a few states with transitions between them. Each state requires you to handle events in a slightly different way. Each transition involves altering the UI a little to reflect what the user can do.
registerState holds the
current state:
/*
"start": When page is loaded
"mustSendMail": When instructions and verify password field shown
"mustVerifySecretNumber": When email sent and user must enter secret
number inside email
"verified": When user is successfully logged in
*/
var registerState = "start";The HTML for this demo contains all the necessary fields and buttons. Their visibility is toggled based on the current state. For example, following are the password and password verification fields. The password field is always shown until the user is at the “verified” stage, whereas the “verify password” field is only shown after the user initiates the registration process:
<div id="passwordInfo">
<div class="userLabel">Password:</div>
<input type="password"ael id="password" name="password"/>
</div>
<div id="verifyPasswordInfo">
<div id="regHeader">Demo Registration</div>
<div class="regInstructions">
<strong>1.</strong> Please ensure email address is correct and
password is <strong>not</strong> confidential, then verify your
password below.
</div>
<div class="userLabel">Verify Password:</div>
<input id="verifyPassword" type="password" name="verifyPassword" />
</div>All three buttons are declared and, again, their visibility will change depending on the current state:
<input type="button" id="login" value="Login"></button> <input type="button" id="register" value="Register"></button> <input type="button" id="cancel" value="Cancel"></button>
What’s most important here is the Register button, which drives the process through each state. The Cancel button returns the state back to start, which causes the display to return to its initial state too. The purpose of the Login button is purely for demonstration. The Register button is present until the user is verified, and its label changes at each stage of the registration process. Its event handler remains the same throughout; the handler decides what to do based on the current state:
function onRegisterClicked( ) {
if (registerState=="start") {
registerState = "mustSendMail";
} else if (registerState=="mustSendMail") {
var submissionOK = sendMail( );
if (submissionOK) {
registerState = "mustVerifySecretNumber";
} else {
return;
}
} else if (registerState=="mustVerifySecretNumber") {
verifySecretNumber( );
}
onRegistrationStateChanged( );
}And onRegistrationStateChanged(
) exists purely to reveal and hide fields, and to change
the button label based on the current state:
function onRegistrationStateChanged( ) {
if (registerState=="start") {
$("userForm").reset( );
$("login").style.display = "inline";
$("verifyPasswordInfo").style.display = "none";
$("secretNumberInfo").style.display = "none";
$("verifiedInfo").style.display="none";
$("cancel").style.display = "none";
$("register").value="Register";
} else if (registerState=="mustSendMail") {
...
} else if (registerState=="mustVerifySecretNumber") {
...
} else if (registerState=="verified") {
...
}Related Patterns
Direct Login
Direct Login (see the next pattern) is a companion pattern, since some dynamic behavior can allow for login and registration to appear on the same form.
Live Form
It’s useful to maintain the profile details in a Live Form (Chapter 14) so that the user can easily add to them and the server can synchronize state and provide opportunities for further enhancement to the profile.
Timeout
When data is held in cookies, it’s important to expire the cookies if there’s a risk that others may gain access to the browser. Timeout (see later) helps the server decide whether the client is still active. If it’s not, it may be wise to ensure that any sensitive data is wiped from the cookies held in the browser.
Guesstimate
Lazy Registration can sometimes involve inferring information about the user’s profile by monitoring his behavior. Thus, it embraces the same nebulous principles as Guesstimate (Chapter 13), where a guess is acknowledged to be imprecise but better than no guess at all.
Metaphor
A good salesperson works the same way. While assumptions might be made based on a prospect’s behavior, the salesperson is always listening; her assumptions are always open to challenge. (Malcolm Gladwell depicted this pattern of successful salespeople in Blink [Little, Brown, 2005]).
Want to Know More?
OECD privacy guidelines (http://www.oecd.org/document/18/0,2340,en_2649_201185_1815186_1_1_1_1,00.html)
Personalization versus Customization (http://www.clickz.com/experts/archives/mkt/precis_mkt/article.php/814811)
Acknowledgments
The idea to handle Lazy Registration in this Ajaxian manner was originally proposed by Chris Were (“Tahpot”)(http://tahpot.blogspot.com/2005/06/lazy-registration-with-ajax.html).
Direct Login
⊙⊙ Access, Account, Authentication, Login
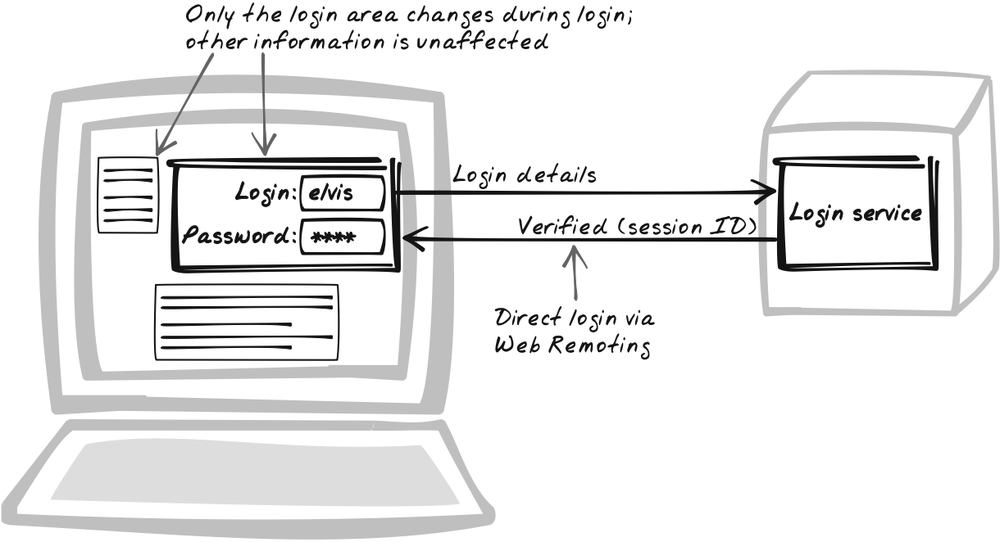
Goal Story
When Stuart logs in to perform an online exam, he is presented with a standard username-password form. He enters his username and password, but a few seconds later, the form becomes red and shows an error message underneath. He switches off Caps Lock and re-enters his credentials. This time, they’re accepted. The form morphs to show his name and balance, and a new menu appears alongside it.
Forces
Login is a necessary evil—it should be as transparent as possible.
Casual users may not bother to log in if the process interrupts their browsing experience.
Login requires the browser to interact with the server in order to validate the username and password.
The password should not travel in plain-text; it could be intercepted while traveling to the server.
Solution
Authenticate the user with an XMLHttpRequest Call instead of with a form-based submission, hashing in the browser for improved security. The essence of this pattern is a routine transformation from a submission-based approach to an Ajaxian, Web Remoting (Chapter 6) interaction style. But, in this pattern, I also discuss a very useful, though optional, technique that involves JavaScript-based hashing and is specific to the login process.
Conventional authentication usually requires the user and password to be uploaded as a standard form submission. The server usually converts the password to a hash (or “validator”) value and checks it against a stored hash value in the database. If they match, the user is in.
There are two problems with this approach. Firstly, flushing the page can be a distraction. It might not take long, but it will usually leave the user in a different context, which will discourage her from logging in. Even more troublesome is the stream of pages that ensue when a password must be recovered (e.g., having to provide your maiden name, last purchase date, and the name of your favorite pet canary), especially in this security-conscious era. The other problem relates to security of the transmission; if the password is uploaded as plain-text, there’s a risk of interception.
Direct Login addresses the page refresh problem and,
optionally, the transmission problem too. In the simplest approach,
you can implement Direct Login by simply
sending the username and password in plain-text to the validation
service using an XMLHttpRequest
POST. Then, the server behaves similarly to a conventional server:
it checks whether the password matches using a hash function and
prepares for session management. XMLHttpRequest deals with cookies as it
does regular form handling; this allows the session to be
established in the same way as a conventional form submission. The
only difference is the response content: instead of outputting a new
HTML page, the server outputs an XML or plain-text acknowledgment,
as well as any personalized content.
Passing the credentials over with XMLHttpRequest will improve usability, but
as long as the password is being transferred in plain-text, there’s
still a security threat. Ensuring the whole transaction runs overs
HTTPS is always the best measure, as this generally makes the
transaction secure from interception. However, many web sites don’t
provide such a facility. Fortunately, there’s a compromise that can
prevent transmission of plain-text passwords. The technique,
strictly speaking, is orthogonal to the Direct Login approach; you could apply it to conventional
submission-based authentication as well. But since it makes heavy
use of browser-side processing, it fits nicely with Direct
Login.
The trick is to perform hashing in the browser. JavaScript is fast enough to transform the password into a hash value (not to mention that it’s capable of doing it), and there are libraries available to implement popular algorithms.
The naïve way of hashing is to simply hash the password to match what should be in the database. But any interceptor would then be able to perform a replay attack—it could log in using the same details. So we need a more sophisticated approach, such as the following double hashing algorithm.
With double hashing, the server generates a one-time random seed (S). The browser then hashes twice: first, it hashes the password (P), hopefully to yield what is stored on the database (Ha; Hash attempt). But instead of sending that, the browser combines it with the one-time seed to form a new hash (Da; Double-hash attempt). This new hash is sent to the server. The server then pulls out the stored hash (H) from the database and combines it with the original one-time seed (S) to form a new hash, which must match the hash (Da) that was uploaded. This works because, in both cases, the initial password (P) has been passed through the same two hash functions. In the browser, the user’s attempt is passed through a fixed hash function, and the result is immediately passed to a new hash function with one-time seed. In the server, the database already holds the result of hashing the real password using the fixed hash function. As long as the server uses the same seed and algorithm as the browser used to perform a second hashing, the two results should match. The server is also responsible for clearing the one-time seed after a successful login; otherwise, an interceptor could log in later on by uploading the same data. Here’s a summary of the algorithm:
User visits web site
Server outputs initial page.
Server generates one-time seed (S) and stores it.
Server outputs page, including login form, with one-time seed embedded somewhere on the page (e.g., in a JavaScript variable).
User enters username (U) and password (P)
Browser handles submission.
Browser hashes password (P) using permanent hash function in order to arrive at the attempted hash value (Ha), which should be held in the database.
Browser combines attempted hash (Ha) with one-time seed (S) to create one-time, double-hashed value (Da).
Browser uploads username (U), double-hashed value (Da), and one-time seed (S).
Server authenticates
Verifies that one-time seed (S) is valid.
Server extracts stored hash for this user (H) and combines it with the seed (S) to get one-time, double-hashed value (D).
Server compares the double-hashed values (D and Da). If successful, it logs the user in (e.g., creates a new session and outputs a successful response code) and clears the one-time seed (S). If it is not successful, it either generates a new seed or decrements a usage counter on the existing seed.
Decisions
What hashing algorithm will be used?
You’re going to be hashing in the browser as well as in the server, so you’ll need a portable algorithm. Two popular standards are MD5 and SHA-1; both have implementations on JavaScript and on just about any server-side language you’re likely to use.
How will you manage the one-time seed?
The double-hashing algorithm hinges on the one-time seed being used only once and on ensuring that the user authenticates with the seed that the server provided. You have to make a few decisions regarding this:
- How does the seed expire?
In theory, the seed’s lifetime shouldn’t matter much since it will only be used once—there’s no risk of someone intercepting a successful upload and reusing that data to authenticate. However, you’ll probably want to clear any unused seeds periodically, e.g., once a day. More important than lifetime is number of validation attempts—perhaps you want to allow only three login attempts against the same seed. In this case, you’ll need to associate a counter with the seed.
- Is the seed uploaded back to the server?
The algorithm above requires that the seed be uploaded, but the server could instead track the session with a unique session ID and use that to look up the most recent seed it sent out. It’s probably better to upload the seed in most cases, as it keeps the conversation as stateless as possible. With the seed having already been downloaded in plain-text, there’s no significant threat posed by uploading it again.
Real-World Examples
NetVibes
The NetVibes (http://netvibes.com) portal handles the entire login process without any page refreshes.
Protopage
The Protopage (http://protopage.com) portal pops up a login box without opening a new page, though it sends you to a new page after the credentials are submitted.
Treehouse
Treehouse Magazine (http://treehousemagazine.com/), has a sidebar with a login Microlink. When clicked, it expands to form a login area, which can in turn morph into a registration area. It also degrades to use standard form submission if JavaScript is disabled.
Code Examples: Ajax Login Demo
James Dam’s Ajax Login (http://www.jamesdam.com/ajax_login/login.html) presents a standard HTML form (Figure 17-8). Submission is disabled and handled instead by callback methods registered on initialization:

<form action="post" onsubmit="return false">
<div id="login" class="login">
<label for="username">Username: </label>
<input name="username" id="username" size="20" type="text">
<label for="password">Password: </label>
<input name="password" id="password" size="20" type="password">
<p id="message">Enter your username and password to log in.</p>
</div>
<label for="comments">Comments:</label>
<textarea rows="6" cols="80" id="comments"></textarea>
</form>As soon as the user signals his intent to authenticate, which is indicated by form field focus, a random, one-time seed is retrieved from the server if there isn’t already one present. The response comes in two parts: an ID for the seed and the seed itself, both of which are saved as JavaScript variables. The server can later use the ID to retrieve the seed it sent:
function getSeed( ) {
...
if (!loggedIn && !hasSeed) {
http.open('GET', LOGIN_PREFIX + 'task=getseed', true);
http.onreadystatechange = handleHttpGetSeed;
http.send(null);
}
...
}
function handleHttpGetSeed( ) {
...
if (http.readyState == NORMAL_STATE) {
results = http.responseText.split('|');
// id is the first element
seed_id = results[0];
// seed is the second element
seed = results[1];
}
...
}The seed is then used to hash the password upon submission.
Notice that hex_md5( ), the
double-hashing operation, is used twice.
// validateLogin method: validates a login request
function validateLogin( ) {
...
// compute the hash of the password and the seed
hash = hex_md5(hex_md5(password) + seed);
// open the http connection
http.open('GET',
LOGIN_PREFIX +
'task=checklogin&username='+username+'&id='+seed_id+'&hash=
'+hash, true);
...
}The server then validates by locating the seed that it previously sent out, and checking if the hash value matches a hash of the seed and the stored password hash. If it does, the server deletes the seed to ensure that it’s used only once:
sql = 'SELECT * FROM seeds WHERE id=' . (int)$_GET['id'];
...
if (md5($user_row['password'] . $seed_row['seed']) == $_GET['hash']) {
echo('true|' . $user_row['fullname'']);
...
mysql_query('DELETE FROM s WHERE id=' . (int)$_GET['id']);
}After calling for validation, the browser receives a response and the form is morphed to show whether login was successful.
Related Patterns
Lazy Registration
Lazy Registration (see earlier) is geared toward first-time registration as well as deferred login, and it makes use of Direct Login.
Acknowledgments
The idea for this pattern comes from James Dam’s demo and write-up (http://www.jamesdam.com/ajax_login/login.html).
Peter Curran of Close Consultants (http://closeconsultants.com) provided valuable feedback that helped me clarify my explanation of the algorithm.
Host-Proof Hosting
○ ASP, DataCloud, Key, Secure, Untrusted
Goal Story
Reta is dismayed to learn that a malicious hacker managed to download a chunk of the company’s database containing personal details about all the customers in her store. Fortunately, she also learns that the pass-phrase she always entered was actually used to encrypt all that data, so the hacker won’t be able to make sense of any of the contents.
Problem
How can you mitigate the effects of unauthorized access to your application data?
Forces
Web apps require that some form of persistent data hold information about users, business state, past events, and so on.
Security restrictions—using standard web technologies—prohibit users from storing web apps on the user’s own hard drives. Even with Richer Plugins that allow it, many benefits of using a web app in the first place are lost. This means that persistent data is usually stored server side.
Cookies allow some data storage within the browser, but cookie data is also transmitted to the server where it’s vulnerable.
Server-side storage is open to abuse: the administrators, along with anyone who is able to gain access to it, are able to extract sensitive information by reading the data, as well as effect malicious changes by tampering with it. The abuse can occur within an organization’s own IT department or be inflicted by a third-party hosting company entrusted with the data.
Solution
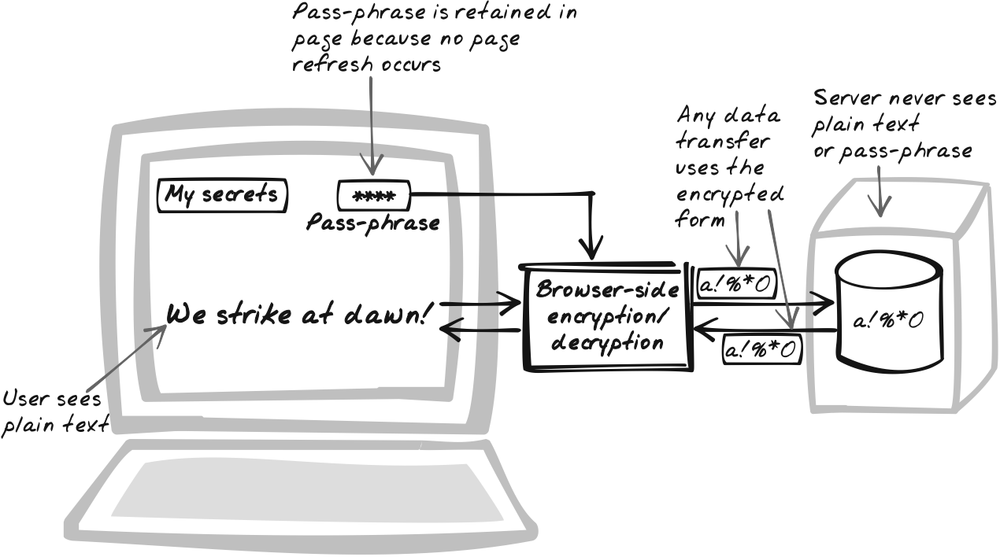
Host sensitive data in encrypted form so that clients can only access and manipulate it by providing a pass-phrase that is never transmitted to the server. The server is limited to persisting and retrieving whatever encrypted data the browser sends it and never actually sees the sensitive data in its plain form. All encryption and decryption takes place inside the browser itself.
Just what does secure hosting have do with Ajax? The Ajaxian twist comes in the maintenance of the pass-phrase. You could use the browser-side encryption with a conventional application, but the pass-phrase would have to be entered upon each page refresh, since no JavaScript state survives a reload. With page refreshes occurring every few seconds, the pass-phrase is completely unusable. However, using Ajax to avoid page refresh means you can retain all session state in the browser, so the pass-phrase only needs to be entered at the start. After being entered, it can be retained as a standard JavaScript string and will disappear from the browser when the user quits the browser or visits another site. Suddenly, Host-Proof Hosting becomes usable.
Incidentally, don’t take this pattern to be a new “Ajax-HTTPS” protocol. The issue here is how the data is actually stored, not how it’s transmitted. In theory, the data itself need not travel over a secure connection because it’s already encrypted. In practice, a secure connection might be worthwhile in order to reduce some of the vulnerabilities described later in this section.
Before you rush off to upload all your trade secrets to Shonky Hosting Inc., you should be aware that this idea isn’t foolproof. On the one hand, the host is assumed to be inherently untrustworthy. But on the other hand, the script for the browser application is held right there on the server, and the browser runs whatever scripts come down from that URL. This leaves open the possibility that the host will tamper—to evil ends—with either the code itself or the outgoing HTML and JavaScript.
What if a rogue administrator from the hosting company decided
to quietly add a small monitoring function to a JavaScript file and
append its execution to a window.onload function. Then, the evil
monitoring function could be made to run once a minute within the
browser. It might, for instance, serialize the entire DOM and upload
a summary back to the server with Web Remoting (Chapter 6), where more malicious code
would log it somewhere convenient. A third-party hacker sitting
between the browser and the server could also inject a script and
could upload data to a remote site with one of several established
techniques—for instance, by exporting browser data as CGI variables
on the source URL of an external image under the hacker’s control.
In both scenarios, the application can continue as normal, and the
poor user is none the wiser.
The threat of script injection certainly weakens the claim for this pattern, but it doesn’t invalidate it altogether. While script injection is theoretically possible, it does require some skill on the host’s part and is also detectable if you know what the code should and should not be doing. If you happened to discover that your application is uploading DOM details every sixty seconds (using a tool similar to those described in Traffic Sniffing [Chapter 18]), there’s a good chance that something’s blatantly wrong.
For practical purposes, also consider what happens if a hacker gains unauthorized access for a short time. She might well grab as much data as possible, but the data will be safely encrypted. In the unlikely event such a hacker was sophisticated enough to use script injection, she would only be able to gain pass-phrases of users who happen to be logged in during the time the server is under her control.
So pragmatic considerations suggest that the technique is safer than hosting the data in plain form, though it’s by no means perfect. But is it so much safer as to warrant the extra performance overhead and coding effort and the constraint of zero page refreshes? That’s a decision you’ll need to make on a case-by-case basis, bearing in mind the critical nature of the data—the likelihood of the various types of attack.
In theory, there’s an even stronger claim in favor of this approach. It might be possible to develop a general-purpose plugin to detect script injection. For a given application, such a plugin would have access to a certified copy of the source code. Then, it could monitor traffic and caution you about any unexpected activity. If such a plugin could be developed, the only way for script injection to succeed would be a conspiracy between the host, the code certifier, and the plugin manufacturer.
Decisions
What encryption algorithm and framework will be used?
You’ll need an algorithm that’s available in JavaScript as well as in your server-side environment. If the data is accessed by other clients, they obviously must have access to the algorithm too. A search reveals that several algorithm implementations are available, each with its own strengths and weaknesses. All of the following are open source.
RC4, AES, Serpent, Twofish, Caesar and RSA are provided by Michiel Van Everdigen’s open source package (http://home.zonnet.nl/MAvanEverdingen/Code/).
TEA (Tiny Encryption Algorithm) is provided by Moveable Type UK (http://www.movable-type.co.uk/scripts/TEAblock.html).
Blowfish is provided by farfarfar.com (http://www.farfarfar.com/scripts/encrypt/encrypt.js).
When will the pass-phrase be requested?
The browser will need to query for the pass-phrase as soon as encrypted data must be rendered. However, that might not be immediately. To make the encryption less intrusive, you might consider using something like the Lazy Registration pattern, where regular data is shown as soon as the user accesses the application, with encrypted data only accessible after the pass-phrase has been entered.
Real-World Examples
There are no public real-world examples to my knowledge. One precedent is Hushmail (http://hushmail.com), which uses a Java applet to allow access to email encrypted on the server.
Code Example: Host-Proof-Hosting Proof-Of-Concept
Richard Schwartz provides a proof-of-concept demo (http://smokey.rhs.com/web/test/AjaxCryptoConceptProof.nsf/blowfish?OpenPage)(Figure 17-10). For encryption, it delegates to a JavaScript Blowfish library. The application accepts a pass-phrase, a message key, and some message content. It then encrypts the message and uploads it. It also uploads the key, along with an encrypted version of the key, which can be used later to check that the user has the correct pass-phrase. The application then shows that the server is holding only the encrypted content and the key. You can then pull the encrypted content back down and decrypt it with the original pass-phrase.

The application itself is quite simple: it manipulates the “display” style settings of a series of forms in order to show or hide them. Thus, the user’s pass-phrase remains in the pass-phrase input field at all times. This is the important thing about the demo; there’s no form submission, so the pass-phrase needs to be entered only once.
When the application is ready to upload the encrypted data, it
sets up the global variables required by the Blowfish library
(ideally, the library would accept these as parameters). encodetext( ) is called (with “2” to
specify the Blowfish algorithm), and it outputs the encrypted
version in the form of a global variable:
saveCryptoText( ) {
...
inpdata=window.document.inputForm.plaintextInput.value;
passwd=window.document.inputForm.password.value;
// invoke blowfish
encodetext(2);
data = data + "&check=" + outdata ;
...
}The encrypted key is also attached:
inpdata=window.document.inputForm.check.value; encodetext(2); data = data + "&check=" + outdata ;
The data can now be sent to the server:[*]
url = "http://smokey.rhs.com/web/test/AjaxCryptoConceptProof.nsf/SaveBlowfishDoc ?OpenAgent" + data httpPost(url)
Later on, the application provides a list of message keys that have been sent to the server. When the user chooses one, the application requests an XML document from the server containing the message and key details (in practice, the message key could be verified before the body is downloaded). It first performs a check that the key is valid for this pass-phrase, then decrypts the message itself. Finally, a DOM object is morphed to display the decrypted text:
inpdata = ""; inpdata = getElementText(valuenode); outdata = "" decodetext(2); ... window.document.all.decryptedText.innerHTML = stripNulls(outdata);
Alternatives
Richer Plugin
You might consider exploiting the increased permissions of a Richer Plugin (Chapter 8) to access a local data store. However, with this there is still a risk of malicious script injection from the server. Furthermore, you’ll lose several key benefits of holding the data server side:
Users will not be able to access the data from remote locations.
Each local data store will need its own backup process. Uploading to a backup server will defeat the purpose of the local store.
Each local data store must be protected against unauthorized access.
The data stores will sometimes need to be migrated as the system changes.
Another application of Richer Plugin would be to hold the data server side but use the Richer Plugin in place of the JavaScript code to manage the local encryption and decryption. A plugin like this could also retain the pass-phrase.
Related Patterns
Metaphor
Caesar wonders whether he can entrust his aide with the top-secret recipe for victory wine. Fortunately, he’s a pioneer of cryptography, so he just hands over the recipe in encrypted form.
Want to Know More?
Check out Richard Schwartz’s blog entries:
Overview of the idea and pertinent conversation in the comments section (http://smokey.rhs.com/web/blog/PowerOfTheSchwartz.nsf/d6plinks/RSCZ-6C5G54)
Practical implementation issues (http://smokey.rhs.com/web/blog/PowerOfTheSchwartz.nsf/plinks/RSCZ-6CCMCD)
Introducing the proof-of-concept application (http://smokey.rhs.com/web/blog/PowerOfTheSchwartz.nsf/plinks/RSCZ-6CATX6)
A hypothetical scenario elaborating the idea (http://smokey.rhs.com/web/blog/PowerOfTheSchwartz.nsf/plinks/RSCZ-6CHL5J)
My blog entry summarizing the idea (http://www.softwareas.com/ajax-and-the-great-data-cloud-in-the-sky)
Chris Hammond-Thrasher comments on Ajax as a general solution to encryption issues, e.g., digital signatures and secure timestamps (http://thrashor.blogspot.com/2005/05/more-on-ajax-and-secure-web.html)
Acknowledgments
Richard Schwartz’s blog entries provided the idea for this pattern, and its name is attributed to Richard Schwartz, Michael Griffes, and their colleagues at eVelocity. I am also grateful to others who have commented on the approach, notably Alex Russell, who has cautioned on the vulnerabilities of this approach, such as script injection.
Timeout
⊙⊙ Logout, Screensaver, Session, Suspend, Timeout
Goal Story
Tracy was so keen on leaving the office Friday afternoon that she forgot to shut down the market news web site. Fortunately, the web site monitors mouse movements, meaning that if she doesn’t interact with the page for an hour, it will suspend itself, saving a lot of wasted refreshes. On Monday morning, Tracy walks in and sees a screensaver-like animation in the browser, with a message indicating that updates have ceased. She clicks a mouse button and sees the screen update with the latest prices.
Forces
Users often leave an application in a browser window for hours or days without interacting with it. Many times, they abandon it altogether. The practice is becoming more prevalent as all major browsers now support multitab browsing.
Ajax Apps often use Periodic Refresh or HTTP Streaming to keep informed about server state. The user may not care about the application anymore, but if it’s still in the browser, a naïeve implementation will continue to poll the server indefinitely—a massive waste of bandwidth and resources.
Ajax Apps often contain sensitive data which is at risk if the user forgets to log out when leaving a public terminal.
Ajax Apps often involve collaboration and communication between users. To cultivate an awareness of other users and their activities, the server must track the state of individual browsers.
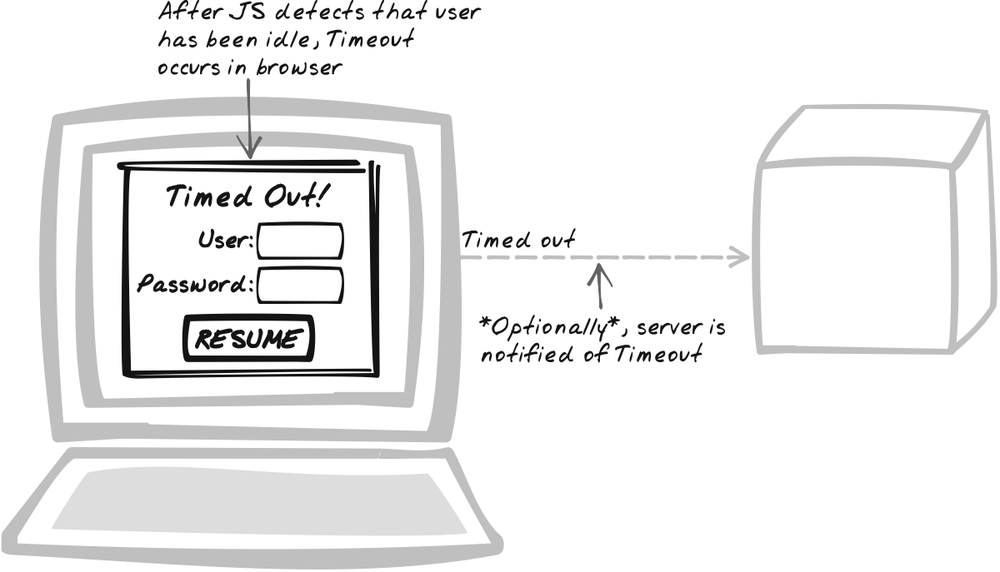
Solution
Have the browser Timeout the user after a period of inactivity and, optionally, inform the server. After a period of inactivity, the application is either suspended, requiring the user to manually resume it or shut down, requiring the user to restart.
This pattern raises the whole question of sessions in Ajax. Conventional applications usually have server-side session objects which represent the user’s current session. Typically, this means short-lived information such as shopping cart contents or recently viewed items.
In Ajax, server-side sessions are not so useful. In fact, if you rely solely on RESTful Services, you may not need those session objects at all. In browser-centric Ajax Apps, the browser is a full-fledged application with all of the session state held within. So the browser state is the session. The server-side session, if used at all, is only relevant to authentication and has no impact on the response to any particular query. See RESTful Service (Chapter 9) for more details.
How is all of this relevant to Timeout? Well, consider this familiar nightmare scenario:
The user opens up a form, spends two hours populating it while researching the answers, and clicks submit. The browser then responds with “Your session has expired” and adds insult to injury by presenting a new blank form.
Stories like this are all too common because server-side session Timeouts ignore what’s happening in the browser. If the user hasn’t submitted a form in, say, 30 minutes, the session times out and all the data is lost. That’s a problem if the user has been actively working on the browser side. With an Ajax App, the server has a better chance of staying in sync with the browser thanks to XMLHttpRequest Calls (Chapter 6). In most environments, the server-side session will be automatically refreshed when an XMLHttpRequest Call comes in. However, this is not optimal either because the server still doesn’t know why browser calls are occurring. For applications using Periodic Refresh (Chapter 10), for example, a server-side session will stay alive indefinitely even if the user has left the building.
By relying instead on browser-based Timeout detection, you can be more intelligent about how Timeouts will occur. Browser-based Timeout detection is based on Scheduling (Chapter 7). A timer is established to count down to Timeout state. Each significant activity cancels the timer and starts a new one in its place.
What activities are significant enough to restart the timer? Mouse movement is one candidate. You can monitor each mouse movement on the page; one of the following Code Refactoring illustrations below does exactly that. Mouse movements are a very broad indicator, and you might be concerned about “false positives”: These may be suggestions that a user is still working with an application when they’re in fact not, e.g., they just happened to move the mouse across the browser window while cycling through each open window. You’ll also get some “false negatives”: A user working only with the keyboard is liable to be timed out. If you’d prefer to keep the session going only if the user is actively changing data, you can instead catch events such as button clicks and keypresses within input fields.
Sudden Timeouts can be frustrating for users, so consider these feedback measures:
Unobtrusively show Timeout status, e.g., number of minutes remaining. You might highlight the status as Timeout approaches, and also offer some background and instruction on avoiding the Timeout.
When Timeout is approaching, offer a warning and an opportunity to explicitly restart the timer.
Once you’ve detected that the user is inactive, what do you do? Timeout can be used in several ways:
- Stop Periodic Refresh
Conventional applications tend to do nothing when the user is idle, but many Ajax Apps continuously poll the server. Thus, the Timeout should trigger cancellation of any Periodic Refresh timers.
- Clear data
Sometimes an inactive application is a hint that the user may no longer be in control of a terminal. There’s a risk that someone else could gain access to the user’s data and permissions. After a Timeout,
document.urlcan be pointed to the main application URL in order to refresh the page. In addition, you might decide to delete cookies holding sensitive data.- Save data
If you clear data, you might also consider first saving it on the server. There’s nothing more annoying than arriving back from lunch and finding that a partly filled-out form has been cleared for security purposes. With an XMLHttpRequest Call, you have the option of saving the user’s progress as a “draft.”
- Inform user
If you’re performing Timeout activities, you’ll need to provide some feedback to the user about what’s happening and what he should do about it.
- Inform server
Although the browser controls session Timeouts, the server can nevertheless be kept informed, and it can use server-side sessions for this purpose. There are quite a few applications of server-side session tracking:
- Invalidating server-side session
The server can invalidate any server-side session data for security purposes.
- Historical records
The server can retain Timeout data to help personalize the web site, to provide feedback to users, and also to inform you, the site operator.
- Multiuser awareness
In multiuser systems and especially in any sites hoping to foster a community, users should be aware of each others’ activities. Indeed, the “live web”—or, as Technorati puts it, “What’s Happening on the Web Right Now?”—is becoming a key phenomenon on the Web. If the server is able to track what users are working on and how long they have been idle, this information (subject to privacy considerations) can be conveyed to other users. That’s especially important when users are collaborating on the same workspace—for instance, in an Ajaxian wiki environment.
- Pessimistic locking
Pessimistic locking is a technique used to prevent two users from working on the same thing at once. In a wiki, for example, a user can lock the article and thereby have sole access to it until it’s saved or until the user is idle for a while. While this can be open to abuse on the public web, it would actually be quite a good model for many intranet applications. However, it hasn’t been practical because of the risk that the user might walk away and leave the lock intact. Server-side session Timeouts don’t help much because the user might be busily working in the browser but not be ready yet to submit content. But once the server is aware of what the user is doing in the browser, pessimistic locking starts to become practical. If the user hasn’t done anything for the last 30 minutes, for example, she loses the lock. Again, Ajax helps with this, because with Periodic Refresh (Chapter 10), you can immediately inform the user that she has lost the lock.
- Work scheduling
With this variant of Predictive Fetch (Chapter 13), it’s possible for the server to proactively prepare for future actions. By tracking active users, the process becomes more focused. For example, a blog aggregator could run a periodic background process to build a list of unread articles for each active user should they decide to view the list.
So informing the server of a Timeout is a good thing. But there’s still a small problem with this approach: What if the user quits the browser or moves away to another site? Then a Timeout will never occur and the server will blissfully continue assuming that the user is logged in for all eternity. To alleviate this problem, have the server refresh the user’s record upon each incoming request that suggests user activity. The rest remains, however, of inadvertently timing out a user who is performing browser-only activity. So what we need is a way for the browser to keep telling the server that the user is still active, explicitly noting that a Timeout hasn’t actually occurred. That’s exactly what the Heartbeat pattern is about—see later in this chapter for more details.
Decisions
How long will the Timeout period be?
The Timeout period will depend on the purpose for having the Timeout period in the first place. For example, if the purpose is primarily to stop Periodic Refresh (Chapter 10), you need to weigh the benefits of reduced bandwidth and server costs against the frustration caused to users who will have to reactivate the page and wait a few seconds for the latest data. In practice, there are probably several reasons to use Timeout, and the needs in each situation must be taken into consideration.
How will Timeout affect the user interface?
A Timeout can impact the interface in different ways. You may choose to use any of the following:
Wipe the entire display and show a message that the user was timed out or the session suspended. This is worthwhile if the data is sensitive.
As a variant on the previous option, reload the entry point for the application (as if the user had typed in the main URL).
Perform a Page Rearrangement to insert a message about the Timeout into the page.
In addition, if you want to be really sure that users know they’ve been timed out, you could produce an alert. Use Timeout alerts with caution: it’s quite obtrusive, and you could probably make the Timeout equally obvious with a carefully considered page element. A Popup (Chapter 15) is a less obtrusive mechanism.
Real-World Examples
Many conventional web sites have a session Timeout feature, though it’s implemented server side rather than the way I’ve described in this section.
Lace Chat
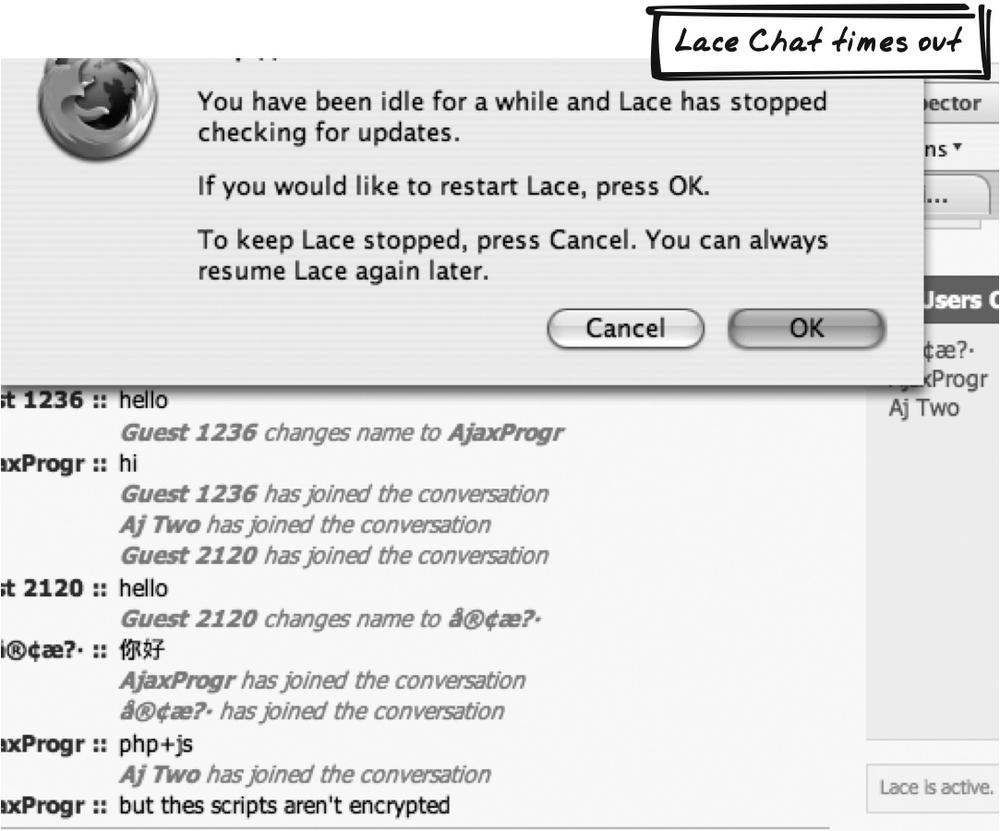
Brett Stimmerman’s Lace Chat (http://www.socket7.net/lace/) is an Ajax chat app. As such, it requires a Periodic Refresh in order to keep showing new messages, a serious bandwidth concern if the user is no longer interested in the conversation. So after some idle time, a dialog box appears indicating that Lace has stopped; it includes a button allowing the user to resume (Figure 17-12). Lace also has a Status Area (Chapter 15) that always shows whether the application is running—i.e., whether the server is being polled. In fact, you can pause and resume it manually too. The Timeout mechanism hooks into this state by forcing the application to pause upon Timeout.
Pandora
Pandora uses Flash to stream music into a browser. After a long idle period, it stops playing and produces a dialog to confirm that the user is still listening.
Session Warning Demo
Eric Pascarello has explained a demo system which has a standard server-side session Timeout but which also pops up a warning near Timeout allowing the user to renew the Timeout (http://radio.javaranch.com/pascarello/2005/07/05/1120592884938.html). There are implementations in both VB.net and JSP.
Operating system Timeouts
A precursor to Ajaxian Timeout is evident in operating systems, such as Apple OSX, that show a warning when they are about to enter standby mode. A pop-up dialog says something like “You haven’t used the mouse or keyboard for 15 minutes. Standby mode will start in 30 seconds.” The dialog will count down, and the user can prevent the Timeout with a keyboard or mouse action or by explicitly hitting a Cancel button. A similar precursor is present in remote terminal systems that output an idle warning to the console.
Code Refactoring: AjaxPatterns Timeout Wiki
Introducing Timeout to the wiki
Timeout is a very useful pattern for a wiki on several counts. Firstly, it cuts down on Periodic Refresh (Chapter 10) wastage. Secondly, it helps users understand what others are up to. Thirdly, it improves security if users are logged on. For all of these reasons, we will now add some Timeout functionality to the Basic Wiki Demo (http://ajaxify.com/run/wiki). (The Periodic Refresh Time Demo [http://ajaxify.com/run/time/periodicRefresh] also has a couple of similar Timeout refactorings under it.)
Initial refactoring: unconditional Timeout
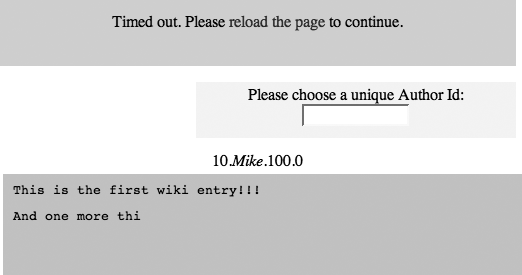
This initial version, Timeout Wiki Demo (http://ajaxify.com/run/wiki/timeout), is merciless. Log into the wiki and, no matter what you do, you’re timed out a few seconds later (Figure 17-13). The point, of course, is to introduce and prove the basic Timeout functionality, which can be built on later.
A Timeout message that will initially be hidden is added to the initial HTML:
<div id="timeoutMessage">
Timed out. Please <a href=".">reload the page</a> to continue.<br/>
</div>The script begins by hiding the Timeout message and kicking off a Timeout timer:
window.onload = function( ) {
...
$("timeoutMessage").style.display = "none";
timeoutTimer = setTimeout(onTimeout, TIMEOUT_TIME);
}When Timeout occurs, the Timeout message is made visible (with some fanfare, courtesy of a Scriptaculous effect [http://script.aculo.us]). Most importantly, the periodic sync stops, so the server is no longer polled. All the messages are removed from the page as well:
function onTimeout( ) {
new Effect.BlindDown($("timeoutMessage"));
stopPeriodicSync( );
removeMessages( );
}
...
function removeMessages( ) {
while ($("messages").hasChildNodes( )) {
$("messages").removeChild($("messages").firstChild);
}
}Warning that Timeout is pending
If only for the selfish reason that we want to avoid being flamed by the user, it would be nice to warn them that a Timeout is about to occur. And nicer still to let them prevent it from occurring. So this demo (http://ajaxify.com/run/wiki/timeout/warning) introduces a warning mechanism.
To the previous Timeout message we add a warning
message. Both are initially invisible. The warning includes
a renew button, which will invoke renewSession( ).
<div id="warningMessage">
Near timeout. Please <button id="renew">Renew</button> your session now.
</div>
window.onload = function( ) {
...
$("renew").onclick=renewSession;
...
}renewSession( ) is not
only used on renew but also on startup. It resets both the
timeoutTimer and the warningTimer. Note that these timers
have been introduced as variables in the script, precisely so that
we can cancel them in this method. In addition, renewSession( ) kicks off the standard
wiki sync timer and hides the warning and Timeout messages in the
case that either is showing:
var timeoutTimer = null;
var warningTimer = null;
...
function renewSession( ) {
$("warningMessage").style.display = "none";
$("timeoutMessage").style.display = "none";
clearInterval(warningTimer);
clearInterval(timeoutTimer);
warningTimer = setTimeout(onWarning, WARNING_TIME);
timeoutTimer = setTimeout(onTimeout, TIMEOUT_TIME);
startPeriodicSync( );
}So as long as the user clicks on the renew button while it’s
showing, he can force all timers to be restarted. But if he
doesn’t click on it, Timeout will proceed. We simply have to
ensure that the warning message is shown before the Timeout
message, i.e., WARNING_TIME
must fall short of TIMEOUT_TIME. When Timeout occurs, we
can assume that the warning is already being shown, so we replace
it with the Timeout message. And as before, we stop
synchronization and remove all messages:
function onTimeout( ) {
new Effect.BlindUp($("warningMessage"));
new Effect.Appear($("timeoutMessage"));
stopPeriodicSync( );
removeMessages( );
}Monitoring mouse movements
A warning’s better than nothing, but it does have the slight odor of techno-centeredness. From the user’s perspective, why should she have to explicitly renew the session. What’s this Timeout business anyway? For most users, it’s better to handle Timeout on their behalf. This demo (http://ajaxify.com/run/wiki/timeout/monitoring/) builds on the initial Timeout demo to suspend activity when the user is idle.
Here, we’ll make an assumption that the user is working with the mouse. That is, we can assume that the user is idle if (and only if) he hasn’t used the mouse for a while. As before, we have only one Timeout message, which we’ve altered to help the user understand how to bring all of those messages back again:
<div id="timeoutMessage">
Timed out. Please wiggle your mouse to continue.<br/>
</div>The key to this pattern is watching for mouse movements on the page and renewing the session when one occurs. Actually, that’s easy enough to achieve:
window.onload = function( ) {
...
document.getElementsByTagName("body")[0].onmouseover = function(event) {
renewSession( );
}
...
}Calling a function on each mouse movement could get grossly
inefficient. In real life, you might want to be just a little more
intelligent about this. For example, use some sort of throttling
algorithm to ensure that renewSession(
) isn’t called more than once every few seconds.
renewSession( ) itself
works similarly to the preceding warning demo: it hides the
Timeout message and kicks off sync and Timeout
timers.
function renewSession( ) {
if ($("timeoutMessage").style.display!="none") {
new Effect.BlindUp($("timeoutMessage"));
}
clearInterval(timeoutTimer);
if (!syncTimer) {
startPeriodicSync( );
}
timeoutTimer = setTimeout(onTimeout, TIMEOUT_TIME);
}Related Patterns
Heartbeat
Heartbeat (see the next pattern) is a companion pattern that helps the server monitor whether the user is still working in the browser.
Periodic Refresh
For Ajax Apps, a big motivation for Timeout functionality is the prospect of reducing Periodic Refreshes (Chapter 10).
Progress Indicator
Progress Indicator (Chapter 14) is normally used for feedback during an XMLHttpRequest Call. However, another application of it would be to count down toward the Timeout. The display could be present as a permanent fixture, or, alternatively, you could introduce it near Timeout.
Direct Login
If your Timeout requires reauthentication for users to continue working with the system, you probably want to offer a Direct Login (see earlier).
Status Area
You can show Timeout-related messages and countdowns in a Status Area (Chapter 15).
Popup
You can show Timeout-related messages and countdowns in Popups (Chapter 15).
Metaphor
If a car engine remains idle long enough, you’re probably going to assume that it’s dead and give up trying to start it. To keep going would only be a waste of energy.
Heartbeat
○ ACK, Announcement, Flash, Heartbeat, Monitor, Signal
Goal Story
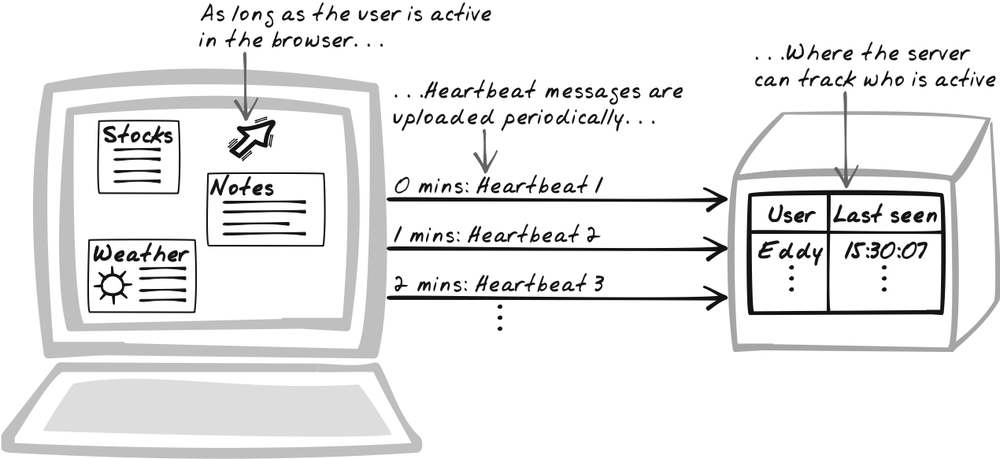
For auditing purposes, Frank must run the factory decision support system all day long, so the server needs to ensure that it’s always alive in the browser. But requests won’t come in very often because it’s a fat client, with the business logic in JavaScript. To ensure that the server keeps getting requests, the browser explicitly uploads a Heartbeat message every 10 minutes.
Problem
How do you know the user still has an application in the browser and is actively working with it?
Forces
It’s useful for the server to track whether the user is active, with several applications highlighted in the Solution of Timeout.
Due to the stateless nature of HTTP, the server doesn’t know when the user has quit the browser, experienced a browser crash, or surfed away to a different URL. Note that you could use the JavaScript
onunloadevent to catch the last of these, but it won’t work for the first two. In tracking the user’s activity, the server may assume the user is still active when he has in fact abandoned the application.The user sometimes spends a long time working in the browser, but in a manner which yields no calls to the server—for example, filling out a long form or playing a game. The server has no way of knowing that the user’s still around if no calls are made.
Solution
Have the browser periodically upload Heartbeat messages to indicate that the application is still loaded in the browser and the user is still active. The server keeps track of each user’s “last Heartbeat.” If the Heartbeat interval is 10 minutes and the user’s last Heartbeat was longer than 10 minutes ago, the server knows that the user is no longer active. The objective is to help the server track which users are active. Session tracking isn’t essential in Ajax Apps, where it’s possible to hold all session data as JavaScript state, but, as described in the Solution of Timeout, there are still reasons to do it.
Heartbeat messages are uploaded to a special "Heartbeat service" using XMLHttpRequest Calls. Because they affect server state, they should be POSTed in. The Heartbeat service will update the user’s last Heartbeat record, but how does it associate a Heartbeat message with a user? Heartbeat relies on some form of session management. One approach is to use cookies, either directly or via a cookie-based session framework. However, if you do that, the conversation will be stateful, thus violating a fundamental RESTful Service principle. A cleaner approach is to explicitly include the session ID in the Heartbeat body. Note that you shouldn’t just upload the user ID, as others could easily fake the user ID.
Heartbeat is closely related to Timeout, but they work in different ways. You can use either independently, but Heartbeat works best as a supplement to Timeout. The point of Timeout is to stop the browser application after an idle period for security and bandwidth reduction. Notifying the server of Timeout events yields extra benefits, but it only works if the application is still sitting in the browser and working fine. That’s why we use Heartbeat messages, which are, in a sense, the inverse of Timeouts, and therefore a good supplement. Whereas a Timeout message has the browser announce when a timeout has occurred (Figure 17-15), a Heartbeat message has it continuously announced that a Timeout hasn’t occurred (Figure 17-16). As soon as the server detects a missed Heartbeat, it can assume the application is no longer running.
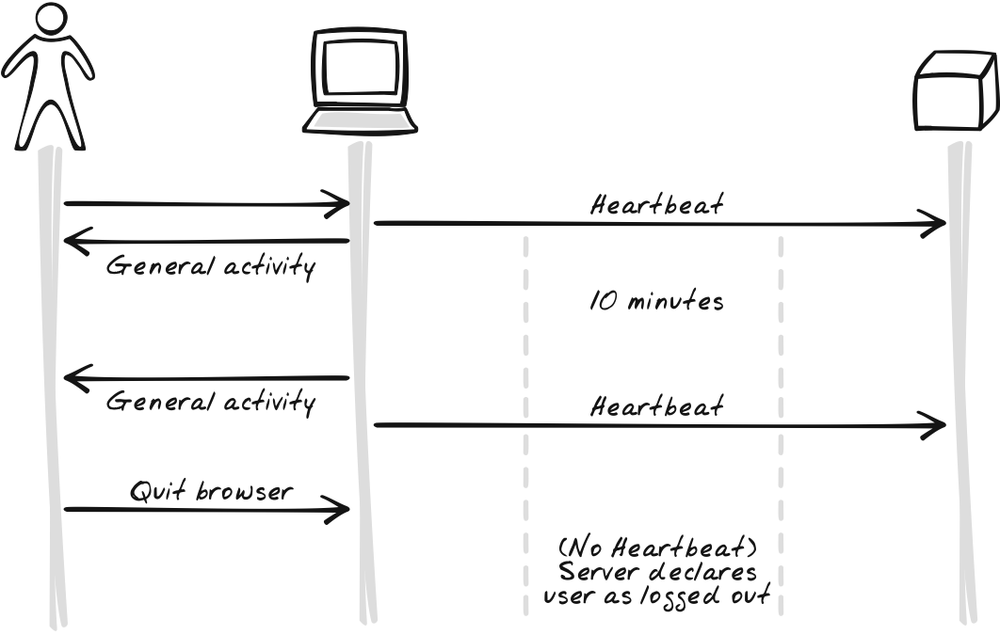
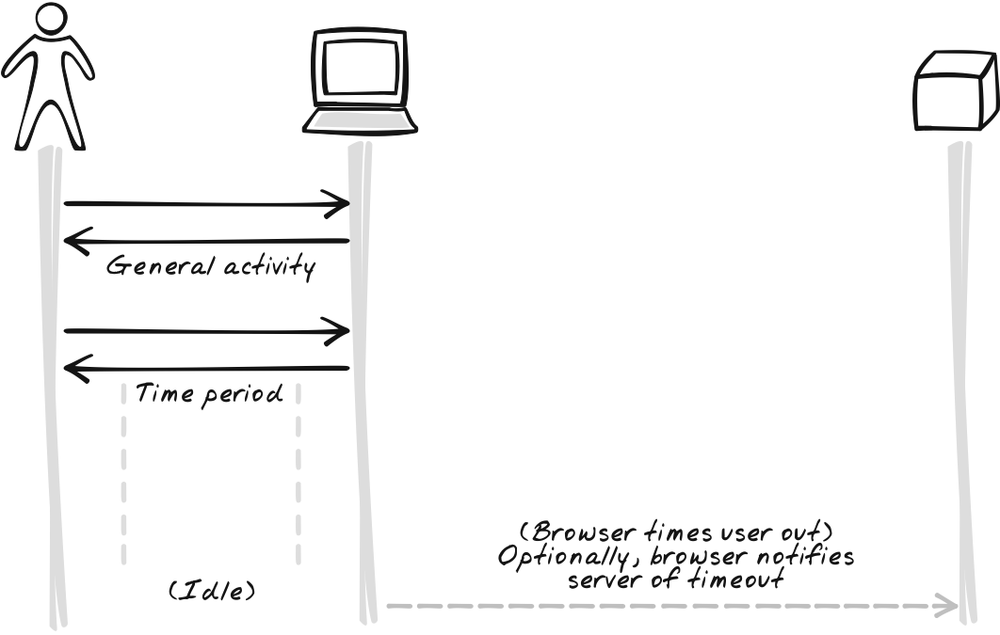
As an alternative to Heartbeat, you can maintain a “Last Seen” or “Last Request” field to track the last time the user issued a request. Thus, not only Heartbeat messages but any other messages will refresh the user’s record. The Heartbeat is just a backup. Using these fields might paint a more meaningful picture if you’re showing the timestamp to other users or feeding it into analysis.
This pattern is purely speculative in the context of Ajax applications. However, Heartbeats are commonplace in enterprise messaging systems, where they are used to monitor the status of components throughout a network.
Decisions
How will you maintain user records?
There are two main ways to maintain user records:
- In memory
The data is not persisted and will be lost once the user is timed out. In most environments, this will happen if you rely on standard session objects.
- Directly in the database
Within persistent user records. There’s some extra storage and data maintenance involved, but the benefit is that you always know when the user was last seen.
What, if anything, will cause the browser application to stop sending Heartbeats?
One option is for the browser application to always send Heartbeats. This lets the server track whether the application is still sitting in the browser, which may be useful for analysis purposes. More likely, though, you probably want to send Heartbeats only if the user is actively working with the browser. Thus, as mentioned in the preceding Solution, the Heartbeat is effectively a message that says “the user has not yet timed out.”
How much time between Heartbeats? How much delay until a user is declared inactive?
You need to decide on the time period between Heartbeats. If it’s too long, the information will not be very useful. If it’s too short, you’ll be placing a strain on the network, as well as impacting browser and server performance.
The appropriate figure could vary from subseconds to up to 30 minutes or more depending on the following factors:
- Application
In some applications, up-to-the-second information is more critical. In a multiuser system, for example, users’ work may be dictated by whoever else is present. If you wait 10 minutes to tell Alice that Bob has quit the chess game, she might be annoyed that she wasted the last 10 minutes thinking about her next move.
- Available resources
Ideally, the period should be as short as possible, though you can’t always justify this. For an intranet application, you’re likely to use a shorter period in recognition of better resources per user.
Real-World Examples
As this pattern is speculative, there are no real-world examples at this time.
Code Refactoring: AjaxPatterns Heartbeat Wiki
The Timeout pattern (see earlier in this chapter) refactored the wiki to produce the Timeout Wiki Demo (http://ajaxify.com/run/wiki/timeout), and two further refactorings from there. The present refactoring (http://ajaxify.com/run/wiki/timeout/heartbeat), as seen in Figure 17-17, creates a third version of the basic Timeout demo, introducing a Heartbeat. Note that Heartbeat can work independently of Timeout but works better in tandem, as this pattern demonstrates.

To illustrate Heartbeat, I’ll show one of its main applications—an application that lets users see who else is “currently online”, i.e., who else has a recent Heartbeat registered. Thus, each user is assigned a random ID, and a Heartbeat mechanism is used to maintain the “Currently Online” list.
But first, let’s look at the Heartbeat mechanism. Server side,
the Author class contains a
lastRequest property:
class Author {
private $id;
...
private $lastRequest;
...
}The Heartbeat service accepts a message with an author ID and
updates the user’s lastRequest.
Note that a production system should accept a session ID rather than
a user ID. The service extracts the author from the database and
updates its lastRequest. If the
author does not yet exist, a new record is created with lastRequest set to the present. Finally,
the record is persisted:
if (isset($_POST['renew']) && $_POST['renew']=="true") {
$authorId = $_POST['author'];
$now = time( );
$author = $authorDAO->fetch($authorId);
logInfo("Got author record for $authorId");
if ($author) {
logInfo("Updating timestamp for user $authorId");
$author->setLastRequest($now);
} else {
logInfo("Adding author $authorId");
$author = new Author($authorId, $now, $now);
}
$authorDAO->persist($author);
}A periodic loop is set up to access the Heartbeat service. Because the Heartbeat call is "fire-and-forget,” an empty callback function is used:
window.onload = function( ) {
...
heartbeatTimer = setInterval(sendHeartbeat, HEARTBEAT_PERIOD);
...
}
function sendHeartbeat( ) {
vars = {
renew: true,
author: authorId
};
ajaxCaller.postForPlainText("session.phtml", vars, function( ) {});
}And that’s the basic Heartbeat pattern. But there’s a bit more
to do because we’re integrating it into
Timeout. We want to stop sending Heartbeats
when a timeout has occurred in the browser. In the preceding code,
we created a variable, heartbeatTimer, to track the periodic
Heartbeat calls. Since we have a handle on the periodic process, we
are able to cancel it upon timeout:
function onTimeout( ) {
...
clearInterval(heartbeatTimer);
...
}The other feature here is the list of online users, which illustrates one way to use the Heartbeat data.
session.phtml exposes an XML list
of currently online users (http://ajaxify.com/run/wiki/timeout/heartbeat/session.phtml?current).
The fetchRecentlyActive method
accepts a parameter indicating just how
recently active the records should be. In this case, we ask for
users with a request in the past 10 seconds:
if ($_GET="current") {
header("Content-type: text/xml");
echo "<authors>";
foreach ($authorDAO->fetchRecentlyActive(10) as $author) {
echo "<author>{$author->getId( )}</author>";
}
echo "</authors>";In the browser, there’s a div to contain the list:
<h1>Who's Online?</h1>
<div id="currentlyOnline"></div>A timer is established to perform a Periodic Refresh on the current data. Every few seconds, the XML is requested and the callback function transforms it into HTML for display:
currentlyOnlineTimer = setInterval(updateCurrentlyOnline, CURRENTLY_ONLINE_PERIOD);
function updateCurrentlyOnline( ) {
ajaxCaller.getXML("session.phtml?current", function(xml) {
$("currentlyOnline").innerHTML = "<ul>";
var authors = xml.getElementsByTagName("author");
for (var i=0; i<authors.length; i++) {
var authorName = authors[i].firstChild.nodeValue;
$("currentlyOnline").innerHTML += "<li> " + authorName + "</li>";
}
$("currentlyOnline").innerHTML += "</ul>";
});
}As with the Heartbeat timer, the “currently online” timer is cancelled upon timeout, so no more Periodic Refreshes will occur:
function onTimeout( ) {
...
clearInterval(currentlyOnlineTimer);
...
}Related Patterns
Timeout
Timeout (see earlier) is a companion pattern, as discussed in the preceding "Solution.”
Submission Throttling
Heartbeat resembles Submission Throttling and Periodic Refresh (Chapter 6) insofar as all have a continuous XMLHttpRequest Call cycle. However, Heartbeat has a more specific aim—namely, informing the server of browser state.
Metaphor
The name "Heartbeat" is, of course, taken from a metaphor with the biological heart.
Want to Know More?
Go to http://www.mindspring.com/~mgrand/pattern_synopses3.htm#Heartbeat for a brief summary of Enterprise Java Heartbeat pattern. See Mark Grand’s “Java Enterprise Design Patterns” for the full pattern.
Unique URLs
⊙ Address, Bookmarks, Cut-And-Paste, Distinct, Favorites, Hyperlink, Location, Link, Mail, Share, Unique, URL
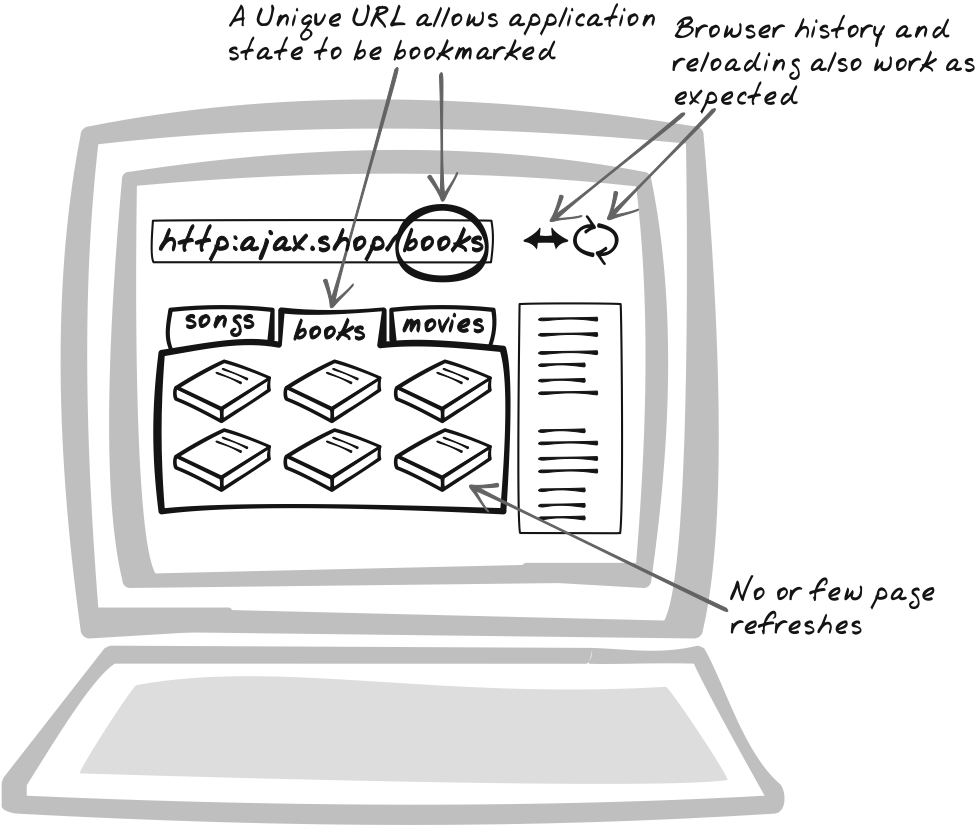
Goal Story
Sasha is exploring a recent news event by browsing a map of the area. There’s a Unique URL for each location, so she’s able to link to it in her blog and add it to her social bookmarking account.
Problem
How can you assign distinct URLs to different parts of your application?
Forces
Expressive URLs are vital. The ability to link from one site to another is arguably what made the Web successful. Furthermore, web surfers like to bookmark pages for later on. And these bookmarks are now a social phenomenon, with the advent of “linkblogs” and social bookmarking software like del.icio.us (http://del.icio.us).
Browsers retain URLs in their histories, and the Back button will only work if URLs vary. The Back button is a big habit for many users. It can mean “Go back to where I was a minute ago.” For many users, it can also mean “Undo my last action,” and that mental model must be respected even though some experts deem it to be technically incorrect.
A single address for your whole site is not enough; you need to support deep linking for links to be effective. That is, each distinct component of a web site should have its own URL.
In conventional web sites, the URL changes when the page is refreshed—e.g., when the user submits a form or follows a link. But in Ajax Apps, the page never refreshes, so the browser won’t change the URL.
Solution
Provide Unique URLs for significant application states. Each time a significant state change occurs—e.g., the user opens a new product in an e-commerce system—the application’s URL changes accordingly. The objective is straightforward, but as discussed later in this section, the implementation requires a few unusual tricks. This Solution is fairly complex, because it delves into the details of building Unique URLs. Increasingly, though, reusable libraries will save you the effort, so be sure to check out what’s available before directly applying any of the techniques here. The Real-World Examples identifies a couple of resources, and there will doubtless be others by the time you read this.
In Ajax, most server communication occurs with XMLHttpRequest. Since
XMLHttpRequest Calls don’t affect the page URL,
the URL is, by default, permanently stuck on the same URL that was
used to launch the Ajax App, no matter how many transfers occur. The
only option you have to manipulate the URL is to use JavaScript.
And, in fact, it’s very easy to do that with the window.location.href property:
window.location.href = newURL; // Caution - Read on before using this.
Very easy, but there’s one big problem: under normal circumstances, the browser will automatically clear the page and load the new URL, which sort of defeats the purpose of using Ajax in the first place. Fortunately, there’s a cunning workaround you can use. It was originally conceived in the Flash world and has more recently been translated to an Ajax context. Mike Stenhouse’s demo and article (http://www.contentwithstyle.co.uk/Articles/38/fixing-the-back-button-and-enabling-bookmarking-for-ajax-apps) provides a good summary of the approach, and the Solution here is based heavily on his work.
The cunning workaround relies on fragment
identifiers —those optional components of URLs that follow the
hash character (#). In
http://ajaxpatterns.org/Main_Page#Background,
for example, the fragment identifier is Background. The point of fragment
identifiers has traditionally been to get browsers scrolling to
different points on a page, which is why they are sometimes called
“in-page links” or “named links.” If you’re looking at the Table of
Contents on AjaxPatterns.org (http://ajaxpatterns.org#toc) and you click
on the Background link—http://ajaxpatterns.org/#Background—the
address bar will update and the browser will scroll to the
Background section. Here’s the point: no reload actually occurs. And
yet, the browser behaves as if you clicked on a standard link: the
URL in the address bar changes and the Back button sends you back
from whence you came (at least for some browsers; more on
portability later).
You can probably see where this is going. We want Ajax Apps to
change the page URL without forcing a reload, and it turns out that
changes to fragment identifiers do exactly that. The solution, then,
is for our script to change only the fragment component. We could do
this by munging the window.location.href property, but there’s
actually a more direct route: window.location.hash. So when a state
change is significant enough, just adjust the URL property:
window.location.hash = summary;
Throughout this pattern, summary refers
to a string representation of the current browser state—at least
that portion of the state that’s worth keeping. For example, imagine
that you have an Ajax interface containing several tabs: Books,
Songs, and Movies. You want to assign a Unique URL to each tab, so
the summary will be the name of any of these tabs. If there were
other significant variables, they would be integrated into the
summary string. To keep the fragment synchronized with the current
state, you need to identify when state changes occur and update the
fragment accordingly. In the following tab example, you can do this
by making the onclick handler set
the hash property in addition to
changing the actual content:
songTab.onclick = function( ) {
window.location.hash = "songs".
// ... now open up the tab
}So now the URL changes from http://ajax.shop/ to http://ajax.shop/#songs. That was easy enough, but what happens when you mail the URL to a friend? That friend’s browser will open up http://ajax.shop and assume songs is an innocent, old-fashioned, in-page link. It will try to scroll to a songs element and won’t find one, but it won’t complain about it either; it will simply show the main page as before. We’ve made the URL change after a state change, but so far we haven’t built in any logic to make the state change after a URL change.
State and URL need to be in sync. If one changes, the other must change as well. Effectively, there’s a mini-protocol specific to your application that defines how state and URL map to each other. In the preceding example, the protocol says “The fragment always represents the currently open tab.” Setting the fragment is one side of the protocol; the other side is reading it. After your friend opens http://ajax.shop/#songs, and after his browser unsuccessfully tries to scroll to the nonexistent songs element, we need to read the fragment and update the interface accordingly:
window.onload = function( ) {
initializeStateFromURL( );
}
initializeStateFromURL( ) {
var initialTab = window.location.hash;
openTab(initialTab);
}Good. Now you can mail the link, bookmark it, and link to it from another page. In some browsers at least, it will also go into your history, which means the Back button will work as expected. For a simple implementation, that’s good enough.
However, the solution still isn’t ideal, because what will happen if the application is already loaded? The most likely situations occur when clicking the Back button to revert to a previous state and when retrieving a bookmark while already on that application. In both cases, the URL will change in the address bar, but the application will do absolutely nothing!
Remember, we’re making the application manipulate fragments
precisely because the browser doesn’t reload the page when they
change. When it comes to Back buttons and bookmarks and the like,
we’re talking about changes that are initiated by the user, yet the
browser treats these with exactly the same inaction as when our
script initiates them. So our onload won’t be called and the application
won’t be affected in anyway.
To make Unique URLs work properly, we
have to resort to something of a cheap trick: continuously
polling the fragment property. Whenever the fragment happens
to change, the browser script will notice a short time later and
update state accordingly. In this example, we could schedule a check
every second using setInterval(
):
window.onload = function( ) {
initializeStateFromURL( );
setInterval(initializeStateFromURL, 1000);
}In fact, we should only perform an action if the hash has recently changed, so we perform a
check in initializeStateFromURL(
) to see if the hash has recently changed:
var recentHash = "";
function pollHash( ) {
if (window.location.hash==recentHash) {
return; // Nothing has changed since last polled.
}
recentHash = window.location.hash;
// URL has changed. Update the UI accordingly.
openTab(initialTab);
}The polling adds to performance overhead, but we now have a URL setup that feels like the real thing.
One last thing on this technique. I mentioned earlier that you
can set window.location.hash
manually after state changes. Now that we’ve considered the polling
technique, you can see that it’s also possible to do the reverse:
change the URL in response to user events, then let the polling
mechanism pick it up and change state accordingly. That adds a
delay, but one big benefit is that you can easily add a hyperlink on
the page to affect the system state.
Here’s a quick summary of the technique just described, which I’ll call the “page-URL” technique:
Ensure that
window.location.hashalways reflects application state.Create a function, e.g.,
initializeStateFromURL( ), to set application state fromwindow.location.hash.Run
initializeStateFromURLon startup and at periodic intervals.
But wait, there’s more! I mentioned earlier that each URL goes into history, but only “for some browsers.” IE is one of the outliers here, so the above technique will fail IE’s history mechanism, and the Back button won’t work as expected. The good news is there’s a workaround for it. The bad news is that it’s a different technique and won’t work properly on Firefox. So if you can live with everything working but IE history, go with the hash-rewrite technique. Otherwise, read on . . . .
The IE-specific solution relies on IFrames and on their source URLs, so I’ll call it the “IFrame-URL” technique. While IE won’t consider a fragment change historically significant, it will recognize changes to the source URL of an embedded IFrame. Each time you change the source URL of an IFrame, the entire page will be added to the history. Think of each page in the history as not just the main URL but the combination of main URL and URLs of any IFrames. Its the combination that must vary in order to create a new history entry.
So to get IE history working, we can embed a dummy IFrame and keep changing its source URL to reflect the current state. When the user clicks Back, the source will change to its previous state. In theory, the browser could keep polling the IFrame’s source URL to find out when it’s updated, but, for some reason, reverted IFrames don’t seem to provide the correct source URL. So a workaround is to make the actual IFrame body contain the summary of browser state, i.e., the string which was in the fragment identifier for the previous algorithm. Then, the polling mechanism looks at the IFrame body rather than its source URL.
For example, if the user clicks on the Songs tab, the IFrame
source will change to dummy.phtml?summary=Songs. The body of
dummy.phtml will be made (by the
server) to contain this argument verbatim, i.e., the body of the
IFrame will be “Songs.” When the user later clicks somewhere else
and then clicks the Back button, the browser will reset the IFrame’s
URL to dummy.phtml?summary=Songs and the body
will once again be “Songs.” The polling mechanism will soon detect
the change and open the Songs tab.
Now we have history, but we haven’t done anything about the URLs. So when the user clicks on the Songs tab, we not only change the IFrame source but also the main document URL using a fragment identifier like before. We also have to make sure that the polling mechanism looks at the URL as well as the IFrame source. If either has changed since last poll, the application state must be updated. In addition, the one that hasn’t changed must also be updated, i.e., if the IFrame source has changed, the URL must be updated, and vice versa.
Here’s a quick summary of the IFrame-URL technique:
Embed an IFrame in your document.
On each significant state change, update the IFrame’s source URL using a query string (
dummy.phtml?summary=Songs), and update the main page URL using a fragment identifier (http://ajax.shop/#Songs).Continuously poll the IFrame source URL and the main page URL. If either has changed, update the other one and update the application state according to the new value.
Note that this won’t work on Firefox, because Firefox will include URL changes as well as IFrame changes in the history. Thus, each state change will actually add two entries to Firefox’s history. As mentioned earlier, you’ll probably need to implement both algorithms in order to fully support both browsers. A modified version of the second technique will do it as well. Also, be careful when using both approaches because there’s a risk your polling mechanism will revert states too eagerly. If the user has begun changing a value and the polling mechanism kicks in, it’s possible that the value will change back. If you separate input and output carefully enough, that can be avoided. A workaround is to suspend the polling mechanism at certain times. None of this is ideal, but a Unique URL mechanism is worth fighting for.
As a variant on changing the IFrame’s source, Brad Neuberg—based on a hack by Danny Goodman—has pointed out that browsers will retain form field data (http://codinginparadise.org/weblog/2005/08/ajax-tutorial-saving-session-across.html). Instead of changing the IFrame source, you set the value of a hidden text field in the IFrame. That will solve the history problem, but you’ll still need to do something about the main page URL to give the page a Unique URL.
To summarize all of this, here are all the things we’d want from Unique URLs and an explanation of how each can be achieved in Ajax.
- Bookmarkable, linkable, and type-in-able
window.location.hashmakes the URL unique, so a user can bookmark it, link to it, and type it directly into her browser.window.onloadensures that the bookmark is used to set state. Polling or IFrame ensures that this will work even when the base URL (before the hash) is the same.- History and Back button
window.location.hashwill change, and polling ithis property will let you detect changes to the URL in most browers. A hidden IFrame is also required for portability; it can be polled too.- Back to Ajax App
After leaving an Ajax App, the user should be able to click the Back button and return to the final state just prior to signing off. The techniques in Heartbeat will support this behavior.
URL handling is one of the greatest complaints about Ajax, with myths abounding about how “Ajax breaks the Back button” and how “You can’t bookmark Ajax Apps.” That an Ajax App can include full page refreshes is enough to debunk these myths. But this pattern shows that even without page refreshes, Unique URLs are still do-able, even if somewhat complicated. This pattern identifies some of the current thinking on Unique URLs, but the problem has not yet been solved in a satisfactory manner. The best advice is to watch for new ideas and delegate to a good library where applicable.
Decisions
How will you support search engine indexing?
Search engines point “robot” scripts to a web site and have them accumulate a collection of pages. The robot works by scooting through the web site, finding standard links to standard URLs, and following them. It won’t click on buttons or type in values as a user would, and it probably won’t distinguish among fragment identifiers, either. So if it sees links to http://ajax.shop/#Songs and http://ajax.shop/#Movies, it will follow one or the other, but not both. That’s a big problem, because it means an entire Ajax App will only have one search link associated with it, and you’ll miss out on a lot of potential visits.
The simplest approach is to live with a single page and do
whatever you can with the initial HTML. Ensure that it contains
all of the info required for indexing, focusing on meta tags, headings, and initial
content.
A more sophisticated technique is to provide a Site Map page that is linked from the main page and that links to all URLs you want indexed with the link text containing suitable descriptions. There is one catch here: you can’t link to URLs with fragment identifiers, so you’ll need to come up with a way to present search engines with standard URLs even though your application would normally present these using fragment identifiers. For example, have the Site Map link to http://ajax.shop/Movies and configure your server to redirect to http://ajax.shop/#Movies. It’s probably reasonable to explicitly check if a robot is performing the search, and if it is, to preserve the URL—i.e., when the robot requests http://ajax.shop/Movies, simply output the same contents as the user would see on http://ajax.shop/#Movies. Thus, the search engine will index http://ajax.shop/Movies with the correct content, and when the user clicks on a search result, the server will know (because the client is not a robot) to redirect to http://ajax.shop/#Movies.
Search engine strategies for Ajax Apps has been discussed in a http://www.backbase.com/#dev/tech/001_designing_rias_for_sea.xml: detailed paper by Jeremy Hartlet of Backbase. See that paper for more details, though note that some advice is Backbase-specific.
What will be the polling interval?
The solutions here involve polling either the main page URL, the IFrame URL, or both. What sort of polling interval is appropriate? Anything more than a few hundred milliseconds will cause a noticeable delay (though that’s not a showstopper because users are used to delays in loading pages). From a responsiveness perspective, the delay should ideally be as short as possible, but there are two forces at work that will lengthen it:
- Performance overhead
Continuous polling will have an impact on overall application performance, so consider 10 milliseconds the bare minimum. Somewhere between 10 and 100 milliseconds is probably the best trade-off.
- Overeager synchronization
This is only a problem for the IFrame-URL approach and not the Page-URL approach. The IFrame-URL approach, as described in the Solution above, keeps Page URL, IFrame URL, and application state synchronized. Thus, there’s the possibility that you will begin to change one of those things and it will “snap back” during a synchronization checkpoint. For example, you might begin changing application state and suddenly see it “snap back” because it’s different than URL state. There are various pragmatic ways to avoid this sort of thing, but as long as you have to rely on polling, the problem might still arise for certain combinations of events. While far from ideal, a longer polling period will at least diminish the problem.
What state differences warrant Unique URLs?
In this pattern, I discuss “state changes” abstractly. When I say a “state change” should result in a new URL and a new entry in the browser’s history, what kind of state change am I discussing? In an Ajax App, some changes will be significant enough to warrant a new URL, and some won’t. Here are some guidelines:
User preferences shouldn’t change the URL—e.g., if a user opts for a yellow background, it shouldn’t appear in the URL.
When there’s a particular thing the user is looking at—for example, a product in an e-commerce catalogue, or a general category—that thing is a logical candidate for a Unique URL.
When it’s possible to open several things at once, you’ll probably need to capture the entire collection.
What will the URLs look like?
Unique URLs requires you to make like an information architect and do some URL design work. Possibly, you’ll be controlling only the fragment identifier rather than the entire URL, but even the fragment identifier has usability implications. Here are some guidelines:
Users sometimes hack URLs, which suggests that, in some cases, you might want to make the variable explicit. So instead of /#Movies, consider #category=Movies if you want to make the URLs more hack-friendly. Also, this format is more like a CGI-style URL, which may be more familiar to users. The downside is that you’ll need a little more coding to parse such URLs.
As mentioned earlier, search engine indexing is also a consideration, and the fragment identifier will sometimes be mapped to a search engine-friendly URL. Therefore, ensure that the fragment identifier is as descriptive as possible in order to attract searchers. For example, favor a product name over a product ID, since the name is what users are likely to search for.
Real-World Examples
PairStairs
Nat Pryce’s PairStairs (http://nat.truemesh.com/stairmaster.html)
is an Extreme Programming tool that accepts a list of programmer
initials and outputs a corresponding matrix (Figure 17-19). The URL stays
synchronized with the initials that are being entered—e.g., if you
enter “ap ek kc mm,” the URL will update so that it ends with
#ap_ek_kc_mm.
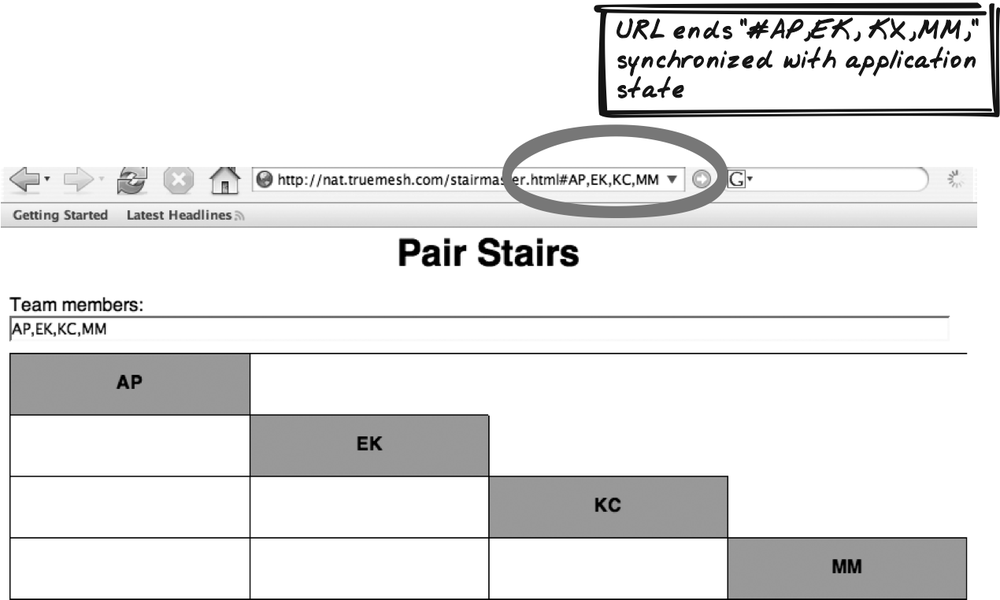
Dojo binding library
Dojo Toolkit’s dojo.io.bind (http://dojotoolkit.org/docs/intro_to_dojo_io.html) lets you specify (or autogenerate) a fragment-based URL as part of a web remoting call. After the response arrives, the application’s URL will change accordingly.
Really Simple History library
Really Simple History (http://codinginparadise.org/weblog/2005_09_20_archive.html)
is a framework that lets you explicitly manage browser history
(Figure 17-20). A call
to dhtmlHistory.add(fragment,
state) will set the URL’s fragment identifier to
fragment and set a state
variable to state. A callback
function can be registered to determine when the history has
changed (e.g., the Back button was pressed), and it will receive
the corresponding location and state. The library has recently
been incorporated into the Dojo project.
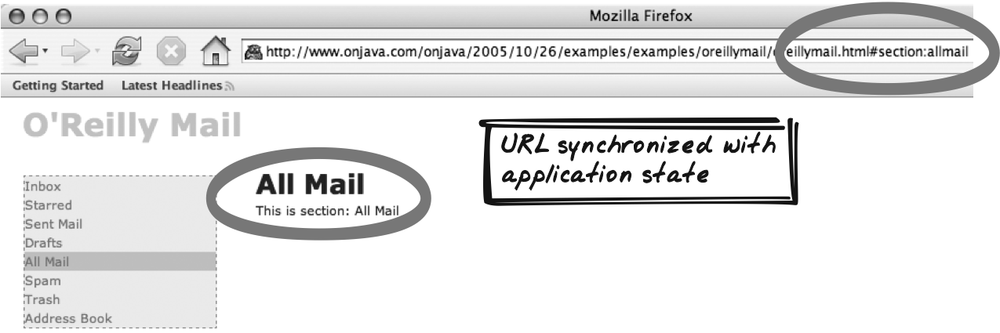
Code Refactoring: AjaxPatterns Unique URL Sum
This example refactors the Basic Sum Demo (http://ajaxify.com/run/sum) using both the Page-URL and IFrame-URL techniques. There are actually four implementations here:
Unique URL Sum Demo (http://ajaxify.com/run/sum/uniqueURL) uses the Page-URL technique so that when state changes, the URL will change.
Polling URL Sum Demo (http://ajaxify.com/run/sum/uniqueURL/pollURL) enhances the Unique URL Sum Demo by adding a polling mechanism, so that when the URL changes, the state will also change. Thus, the URL-state synchronization occurs in both directions.
IFrame URL Sum Demo (http://ajaxify.com/run/sum/uniqueURL/iFrame) alters the Unique URL Sum Demo to use the IFrame-URL technique. In this version, the history will work correctly because the IFrame source is changed, but the main page URL is not actually updated.
Full IFrame URL Sum Demo (http://ajaxify.com/run/sum/uniqueURL/iFrame/updateURL/) completes the IFrame-URL implementation by making the main page URL unique.
Unique URL Sum Demo
This first refactoring changes the fragment identifier
(hash) when a sum is submitted.
The fragment identifier always contains the main page state,
which, in this case, is a comma-separated list of the three sum
figures (e.g., #3,5,10):
function submitSum( ) {
definedFigures = {
figure1: $("figure1").value,
figure2: $("figure2").value,
figure3: $("figure3").value
}
hash = "#" + definedFigures.figure1 + "," + definedFigures.figure2
+ "," +definedFigures.figure3;
window.location.hash = hash;
ajaxCaller.get("sum.phtml", definedFigures, onSumResponse, false, null);
}This is only useful if the startup routine actually takes
the fragment identifier into account. Thus, a new function,
setInitialFigures( ), is called
on initialization. It inspects the fragment identifier, sets the
parameters, and calls submitSum(
) to update the sum result:
function setInitialFigures( ) {
figuresRE = /#([-]*[0-9]*),([-]*[0-9]*),([-]*[0-9]*)/;
figuresSpec = window.location.hash;
if (!figuresRE.test(figuresSpec)) {
return; // ignore url if invalid
}
$("figure1").value = figuresSpec.replace(figuresRE, "$1");
$("figure2").value = figuresSpec.replace(figuresRE, "$2");
$("figure3").value = figuresSpec.replace(figuresRE, "$3");
submitSum( );
}Polling URL Sum Demo
The previous version will update the URL upon state
change, but not vice versa. This demo rectifies the problem by
polling the URL and updating state if the URL changes. The
functionality for updating state from URL is already present in
the setInitialFigures( )
function of the previous version. We simply need to keep running
it instead of just calling it on startup. So, setInitialFigures( ) has been renamed to
pollHash( ) and is run
periodically:
window.onload = function( ) {
...
setInterval(pollHash, 1000);
}The function is the same as before, but with just one
change: a recentHash variable
is maintained to ensure that we only change state if the hash has
actually changed. We don’t want to change state more times than
are necessary:
var recentHash = "";
function pollHash( ) {
if (window.location.hash==recentHash) {
return; // Nothing has changed since last polled.
}
recentHash = window.location.hash;
// ... Same code as in previous setInitialFigures( ) function ...
}IFrame Sum Demo
The previous versions won’t work on IE because a fragment identifier change is not significant enough to get into IE’s history. So here, we’ll introduce an IFrame and change its source URL whenever the document changes.
The initial HTML includes an IFrame. This is the IFrame whose source URL we’ll manipulate in order to add entries to browser history. It’s backed by a PHP file that simply mimics the summary argument; the body of the IFrame always matches the source URL, so we can find the summary by inspecting the body. In fact, we should be able to just inspect the source URL directly, but there seems to be some bug in IE that fails to update the source property when you go back to a previous IFrame (even though it actually fetches the content according to that URL). Incidentally, the IFrame would normally be hidden via CSS but is kept visible for demonstration purposes.
<iframe id='iFrame' name='iFrame' src='summary.phtml?summary='></iframe>
Each time a sum is submitted, the IFrame’s source is updated:
function submitSum( ) {
...
$("iFrame").src = "summary.phtml?summary=" + summary;
}Instead of polling the URL, we’re now polling the IFrame’s body, which contains the state summary. Remember that in this version, the main page URL is fixed—we’re only making IE history work, and not yet making the application bookmarkable. Whenever we notice that the IFrame source has been changed, we assume that it’s because the Back button has been clicked. Thus, we pull out the summary from the IFrame body and adjust the application state accordingly:
window.onload = function( ) {
...
setInterval(pollSummary, 1000);
}
function pollSummary( ) {
summary = window["iFrame"].document.body.innerHTML;
if (summary==recentSummary) {
return; // Nothing has changed since last polled.
}
recentSummary = summary;
// Set figures according to summary string and call submitSum( )
// to set the result ...
}The Back button will now work as expected on both Firefox and IE.
Full IFrame Sum Demo
This final version builds on the previous version by including Unique URLs for the main page so that you can bookmark a particular combination of figures. Note that this is an “IFrame URL” demo and won’t work properly on Firefox for reasons explained in the preceding Solution.
The page contains an IFrame as before, and since we’re now synchronizing the URL as well, there are actually three things to keep in sync:
The application state, i.e., the three sum figures
The page URL
The IFrame URL
The algorithm is this: when one of these three changes, change the other two and update the sum result. To facilitate this, some convenience functions exist to read and write these properties:
function getURLSummary( ) {
var url = window.location.href;
return URL_RE.test(url) ? url.replace(/.*#(.*)/, "$1") : "";
}
function getIFrameSummary( ) {
return util.trim(window["iFrame"].document.body.innerHTML);
}
function getInputsSummary( ) {
return $("figure1").value +","+ $("figure2").value +","+ $("figure3").value;
}
function setURL(summaryString) {
window.location.hash = "#" + summaryString;
document.title = "Unique URL Sum: " + summaryString;
}
function setIFrame(summaryString) {
$("iFrame").src = "summary.phtml?summary=" + summaryString;
}The updateSumResult( ) is
also straightforward:
function updateSumResult( ) {
definedFigures = {
figure1: $("figure1").value,
figure2: $("figure2").value,
figure3: $("figure3").value
}
ajaxCaller.get("sum.phtml", definedFigures, onSumResponse, false, null);
}
function onSumResponse(text, headers, callingContext) {
self.$("sum").innerHTML = text;
}Now for the actual synchronization logic. The first thing that might change is the application state itself. This occurs when the Submit button is clicked and will cause the IFrame and page URL to update:
window.onload = function( ) {
self.$("addButton").onclick = function( ) {
onSubmitted( );
}
...
}
function onSubmitted( ) {
var inputsSummary = getInputsSummary( );
setIFrame(inputsSummary);
setURL(inputsSummary);
updateSumResult( );
}The other two things that can change are the IFrame source (e.g., if the Back button is clicked) or the URL (e.g., if a bookmark is selected). There’s no way to notice these directly, so, as before, we poll for them. A single polling function suffices for both:
window.onload = function( ) {
...
pollTimer = setInterval(pollSummary, POLL_INTERVAL);
}
function pollSummary( ) {
var iframeSummary = getIFrameSummary( );
var urlSummary = getURLSummary( );
var inputsSummary = getInputsSummary( );
if (urlSummary != inputsSummary) { // URL changed, e.g., bookmark
setInputs(urlSummary);
setIFrame(urlSummary);
updateSumResult( );
} else if (iframeSummary != inputsSummary) { //IFrame changed,e.g., Back button
setInputs(iframeSummary);
setURL(iframeSummary);
updateSumResult( );
}
}One final point: The timer is suspended while the user edits a field in order to prevent the URL or IFrame source from reverting the application state:[*]
window.onload = function( ) {
...
// Prevent iframe from triggering URL change during editing. The URL
// change would in turn trigger changing of the values currently under edit,
// which is why it needs to be stopped.
for (var i=1; i<=3; i++) {
$("figure"+i).onfocus = function( ) {
clearInterval(pollTimer);
}
$("figure"+i).onblur = function( ) {
pollTimer = setInterval(pollSummary, POLL_INTERVAL);
}
}
...
}The application is now bookmarkable and has a working history. It’s still not ideal, because if you unfocus an edit field, the figures will revert to a previous state. Also, there seems to be a browser issue (in both IE and Firefox), which means that the document URL isn’t updated after you manually edit it. Thus, you can change the URL using a bookmark, but if you change it manually, it will not change again in response to an update of application state.
Alternatives
Occasional refresh
Some Ajax Apps perform page refreshes when a major state change occurs. For example, A9 (http://a9.com) uses a lot of Display Morphing (Chapter 5) and Web Remoting (Chapter 6) but nevertheless performs a standard submission for searches, leading to clean URLs such as http://a9.com/ajax. Usually, that’s enough granularity, so no special URL manipulation needs to occur.
“Here” link
Some early Ajax offerings, like Google Maps and MSN Earth, keep the same URL throughout but offer a dynamic link within the page in case the user needs it. In some cases, there’s a standard link to “the current page”; in other cases, the link is generated on demand. Various text is used, such as “Bookmark this Page” or “Link to this page.” It’s very easy to implement this but, unfortunately, it breaks the URL model that users are familiar with; thus users might not be able to use it. Time will tell whether users will adapt to this new style or whether it will fade away as Ajax developers learn how to deal with Unique URLs.
Want to Know More?
“Uniform Resource Identifier (URI) Generic Syntax,” by Tim Berners-Lee, Roy Fielding, and Larry Masinter for the Internet Engineering Task Force (http://www.gbiv.com/protocols/uri/rfc/rfc3986.html)
“Designing RIAs For Search Engine Accessibility,” by Jeremy Hartley of Backbase (http://www.backbase.com/#dev/tech/001_designing_rias_for_sea.xml)
“Bookmarks and the Back Button in AJAX Applications,” by Laurens Holst of Backbase (http://www.backbase.com/#dev/tech/002_bookmarks.xml)
“Ajax History Libraries,” by Brad Neuberg (http://codinginparadise.org/weblog/2005_09_20_archive.html)
“Fixing the Back Button and Enabling Bookmarking for Ajax Apps,” by Mike Stenhouse (http://www.contentwithstyle.co.uk/Articles/38/fixing-the-back-button-and-enabling-bookmarking-for-ajax-apps)
Acknowledgments
The Solution is based heavily on Mike Stenhouse’s article (http://www.contentwithstyle.co.uk/Articles/38/fixing-the-back-button-and-enabling-bookmarking-for-ajax-apps).
[*] The Attention Trust (http://www.attentiontrust.org/about) is an organization which promotes this idea.
[*] Again, this is a simplification, because retaining the address would not be necessary—or desirable—if the user was already logged in.
[*] RESTful principles suggest that, in practice, the data would be uploaded with a POST, because the data would affect the server state. Another reason to use POST is that it’s not practical to encode an entire message in the URL. However, this application is a proof-of-concept, so GET is used here instead.
[*] It’s probably feasible to do something more sophisticated by tracking the history of URL, IFrame, and application state independently.
Get Ajax Design Patterns now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

