Chapter 6. Web Remoting
NOW THAT WE’VE SEEN HOW AJAX APPS CAN MANIPULATE THE DISPLAY, IT WOULD BE USEFUL IF THEY could use that capability to show data arriving from the server. We’d also like to accept input and upload it to the server. The Web Remoting patterns let JavaScript directly issue calls to the server. The point is to let the browser make a query or upload some data, without actually refreshing the page.
The first pattern is Web Service, which explains how the server side exposes functionality to be accessed by the browser.
The remaining patterns are the most useful and most common
mechanisms for web remoting.[*] XMLHttpRequest Call is a clean way
for the browser script to invoke and catch responses from the server.
IFrame Call provides a similar use by exploiting IFrame
functionality. HTTP Streaming, also known as “Push” (or “Comet”), allows the server to
continue streaming new data down the pipe, without the browser having to
issue new requests. On-Demand JavaScript is a fairly broad-scoped pattern and is included in this
section because one style, Script Tag
Generation, is a distinctive technology that’s becoming a
popular way to directly access external domains.
Of the four techniques, XMLHttpRequest Call
is the cleanest, because XMLHttpRequest is specifically designed for
web remoting. Nevertheless, all of the techniques are effective, and
each has a certain set of situations where it’s the superior choice. See
the "Alternatives" section
for XMLHttpRequest Call for a comparison of the
various techniques.
Web Service
⊙⊙⊙ API, HTTP, Microcontent, REST, RPC, Share, SOAP, Platform
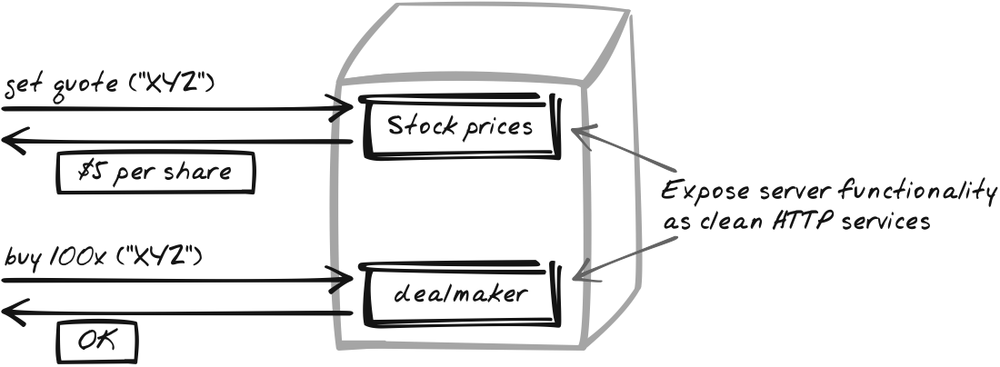
Goal Story
In a financial forecasting app, Tracy runs an algorithm to
forecast the next four interest rates. The browser script uploads
the parameters to an “Interest Rate Forcaster” web service, which
eventually outputs a concise list of future rates, free of any HTML
markup: 4.5, 3.4, 4.0,
4.1.
Problem
What will Ajax Apps call on the server?
Forces
Ajax Apps can access the server directly and require well-scoped services instead of the conventional-style scripts that output an entire HTML page.
Many organizations like to expose their functionality and data for third parties to access. The API needs to be clean and easy to use.
Solution
Expose server-side functionality as fine-grained, easy-to-use Web Services. "Web Service" is an overloaded term, and the Ajax Patterns use a fairly broad definition:
A Web Service is a standard HTTP service.
A Web Service has a well-defined, consistent interface—input and output assumptions, message formats, and exception handling are all clearly understood by its developers and ideally documented in some manner.
A Web Service accepts fine-grained input parameters and outputs fine-grained responses, such as an XML document, a simple string, or a snippet of HTML. If it outputs an entire HTML document, it’s probably not a Web Service.
Under this definition, there is considerable flexibility involved in creating a Web Service:
A Web Service might be open to the public, might be protected by a secure authentication mechanism, or might be hidden from the public by a firewall.
A Web Service might be built by a tool or handwritten.
A Web Service might use messages according to any protocol, such as SOAP, or might use custom messages.
Deciding on all these things is the main task involved in creating a Web Service.
Web services are the latest in a long tradition of distributed computing, with technologies like SunRPC, CORBA, and EJB along the way. They’ve arisen quite separately from Ajax, as a general-purpose way to expose services to interested clients. These clients are usually standalone processes with no user interface as well as desktop clients and web server scripts. Until recently, they were irrelevant to anything inside a web browser, which could only communicate with services capable of returning an entire HTML page. But thanks to remoting technologies, JavaScript can now make use of such services. Indeed, a clean Web Service is actually the best thing for remoting technologies to call—it makes the call easier, and having a fine-grained response is good for the response handler. Thus, there’s a strong synergy between Ajax and web services.
Here’s the PHP code for a one-liner web service to perform a sum (imaginative, I know):
<?
echo $_GET["figure1"] + $_GET["figure2"];
?>You can try the service by entering http://ajaxify.com/run/xmlHttpRequestCall/sumGet.phtml?figure1=5&figure2=10 in your browser’s address bar. The entire response will be “15.” As the example shows, a web service’s response can be as simple as a single value. Other times, it might be some HTML, but even then, it will usually only be a snippet rather than an entire page. For example, the above service could be refactored to show the result as a heading:
<?
echo "<h1>" . ($_GET["figure1"] + $_GET["figure2"]) . "</h1>";
?>A collection of related services like these forms an HTTP-based API that exposes server functionality. Most Ajax Apps will access the API from the browser via the XMLHttpRequest Call and alternative remoting techniques. In addition, third parties can access Web Services and use them for their own applications, web or not.
This section introduces only the concept of web services. There are a number of decisions you need to make when designing such services for your own application. Will the service output XML to be processed in the browser, HTML to be displayed directly, or some other format? How will the URLs look? What sort of input will it take? All these issues are discussed in Chapter 9.
Decisions
How will the web service be used?
The single most important decision about a web service, as with any form of API, is to know how it will be used. In particular, will it be available for third-parties as a generic interface to your system, or are you developing it purely for an Ajax browser app to access? If the latter, then you might want to practice feature-driven development and let the browser app drive web service design—see Simulation Service (Chapter 19).
If there are third parties involved, it becomes a balancing act between their needs and the needs of your browser app. Since they will probably be accessing your server from more powerful environments than the average web browser, you might need to add some redundancy to support each type of client. The API for third parties might be more general, whereas the browser sometimes needs an API that knows something about the application. In an extreme case, it tracks application state and outputs the actual HTML to be shown to the user.
How will you prevent third-party usage?
Web services are seen as having a kind of synergy with Ajax, as Ajax Apps can talk to the same interface already being offered to third-party clients. However, sometimes you want the web service to be closed to third parties. That’s going to be difficult on the public Web, since pretty much anything a browser can access will also be available to third-party clients. So, you might have spent ages designing a nice, clean web service to make browser scripting as painless as possible, only to discover that third parties are reaping the benefits. There’s no magic bullet, but here are a few suggestions:
Require users to be logged in, with an authenticated email address, in order for the application to make use of web services. You can then use cookies or upload unique session IDs to authenticate the user.
Consider using a system like Captcha (http://www.captcha.net/), where the user is forced to perform a challenge that should be about impossible for an automated script to do. You might require a challenge be solved once an hour, say.
Use standard filtering techniques, like blocking certain IP addresses and refusing requests if they arrive too frequently.
Use obfuscation and encryption. This idea is based on a tricky little anti-spam plugin for Wordpress, HashCash (http://wp-plugins.net/plugin/wp-hashcash/). By outputting a customized piece of obfuscated JavaScript that’s used to decrypt web service content, you force any client programmer to do two things: first, hook into a JavaScript engine in order to execute the code; second, consume resources performing the decryption. Neither is impossible, but they do make the task less appealing. Unfortunately, they also break the clean nature of web services, though you should be able to abstract the messy details with a suitable JavaScript API.
Real-World Examples
Just about any Ajax App has some kind of web service. In these examples, we’ll look at a public API designed for third-party usage, then at a couple of services accessed only from a corresponding Ajax browser script.
Technorati API
Technorati (http://technorati.com) exposes its search capability for third-party use. To perform a query, run an HTTP GET on the following URL: http://api.technorati.com/search?key=1234&query=serendipity, where “1234” is your personal technorati key and “serendipity” is the search query. You’ll get an XML document that lists the results.
NetVibes
NetVibes (http://netvibes.com) is an Ajax portal that gets it content from several web services. To get weather data, the browser invokes a service like this:
http://netvibes.com/xmlProxy.php?url=http%3A//xoap.weather.com/weather/local/
USNY0996%3Fcc%3D*%26unit%3Dd%26dayf%3D4The service is actually a proxy because it passes through to a real weather service at weather.com. As the URL shows, you can specify parameters such as location (USDNYC0996), units (d), and number of days ahead (4). The output is an XML document without any HTML markup:
<weather ver="2.0">
<head>
<locale>en_US</locale>
<form>MEDIUM</form>
...
</head>
<dayf>
...
<hi>N/A</hi>
<low>46</low>
<sunr>7:18 AM</sunr>
<suns>4:34 PM</suns>
...
</dayf>
...
</weather>Wish-O-Matic
Alexander Kirk’s Wish-O-Matic (http://wish-o-matic.com) provides Amazon recommendations. The browser posts the following information to a service at http://alexander.kirk.at/wish-o-matic/search=grand&catalog=Books&page=1&locale=US&_=. The service then responds with a list of books. Unlike the previous service, the data is pure HTML, ready for immediate display in the browser.
search=grand&catalog=Books&page=1&locale=US&_=
<table><tr><td style="width: 500px">
<b>Author:</b> Kevin Roderick<br/><b>Title:</b>
Wilshire Boulevard:
The Grand Concourse of Los Angeles<br/><b>ISBN:</b>
1883318556<br/><a
href="javascript:void(add_item('1883318556', 'Wilshire Boulevard: The Grand
Concourse of Los Angeles',
'http://images.amazon.com/images/P/1883318556.01._SCTHUMBZZZ_.jpg'))">My
friend likes this item!</a></td>
...
</td></tr>
</table>
<br/>
<a href="javascript:void(prev_page( ))">< prev</a> |
<a href="javascript:void(next_page( ))">next ></a>Code Example: AjaxPatterns testAjaxCaller
AjaxCaller is a JavaScript HTTP client used in examples
throughout this book (explained later in this chapter in "Code Example: AjaxPatterns
TestAjaxCaller" for XMLHttpRequest Call). Here,
we’ll look at a web service used in the testAjaxCaller application (http://ajaxlocal/run/testAjaxCaller/), a
very simple service that just echoes its input.
httpLogger begins by
outputting a request method (e.g., “GET” or “POST”), its own request
URL, and CGI variables present in the URL and body:
echo "<p>Request Method: $requestMethod</p>"; echo "<p>Request URL: ".$_SERVER['REQUEST_URI']."</p>"; echo "<p>Vars in URL: ".print_r($_GET, TRUE)."</p>"; echo "<p>Vars in Body: ".print_r($_POST, TRUE)."</p>";
A separate function is used to read the body, which can also
be outputted with a regular print
or echo statement:
function readBody( ) {
$body="";
$putdata = fopen("php://input", "r");
while ($block = fread($putdata, 1024)) {
$body = $body.$block;
}
fclose($putdata);
return $body;
}Related Patterns
Web Services patterns
All the patterns in Web Services (Chapter 9) explain various strategies for designing Web Services with clean, maintainable interfaces.
Web Remoting patterns
The remaining Web Remoting patterns explain how the browser invokes a server-side Web Service.
Cross-Domain Proxy
The main point of this pattern is to guide on designing your own Web Services pattern. However, there are times when your server script will need to call on an external web service, as explained in Cross-Domain Proxy (Chapter 10).
Simulation Service
A Simulation Service (Chapter 19) is a “dummy” service that produces canned responses, a useful device while developing the browser-side of an Ajax App.
Service Test
The nice thing about web services, compared to most aspects of web development, is that it’s easy to write automated tests, as described in Service Test (Chapter 19).
XMLHttpRequest Call
⊙⊙⊙ Call, Callback, Download, Grab, Live, Query, Remoting, RemoteScripting, Synchronise, Synchronize, Upload, XMLHttpRequest
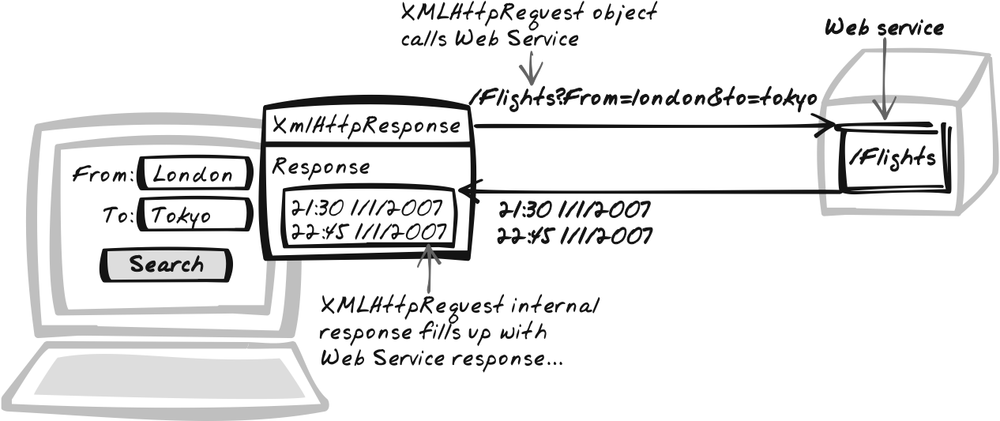
Goal Story
Reta’s purchasing some items from a wholesaler’s web
site. Each time she adds an item to the shopping cart, the web site
issues an XMLHttpRequest to save
the latest cart contents. There’s no form submission, so the item is
added instantaneously, which saves Reta time as well as helping her
understand what’s going on.
Problem
How can the browser communicate with the server?
Forces
Ajax Apps require browser-server communication. User-generated information must be uploaded and new server information must be downloaded.
Because Ajax Apps should have a smooth and continuous feel, browser-server communication must be unobtrusive.
Ajax Apps should be highly responsive, so calls should involve minimal data transfer.
As the network is often unreliable and performance is inconsistent, calls should be asynchronous, allowing the user to keep working while network calls are in progress.
Solution
Use XMLHttpRequest objects for
browser-server communication. JavaScript lacks a portable
mechanism for general network communication, a restriction that’s
always been in place for security reasons and will probably remain.
But thanks to the XMLHttpRequest
object—now available in all major browsers—JavaScript code
can make HTTP calls back to its originating
server and get hold of the results. Doing so enables you to make
fine-grained server calls and deal with responses as you wish,
unlike conventional form submissions, which cause a complete page
refresh. Note: an online demo (http://ajaxify.com/run/xmlHttpRequestCall)
illustrates the code concepts throughout this Solution and the code
snippets loosely follow from the demo.
This pattern uses the sum web service described earlier in Web Service, with a URL like http://ajaxify.com/run/xmlHttpRequestCall/sumGet.phtml?figure1=5&figure2=10. It returns just the sum, “15” in this case. You can test that by typing the full URL in the browser, but here we want to call it from JavaScript and catch the result. Here’s a very basic example:
var xhReq = new XMLHttpRequest( );
xhReq.open("GET", "sumGet.phtml?figure1=5&figure2=10", false);
xhReq.send(null);
var serverResponse = xhReq.responseText;
alert(serverResponse); // Shows "15"The sequence begins by creating a new instance of XMLHttpRequest. xhReq.open( ) then
prepares a call on the test service, sumGet.phtml (the code’s running from the
same path, so the domain and path need not be qualified). The GET
signifies the request method to be used. The false argument says the call is
synchronous, meaning that the code will block until a response comes
back. The send command completes
the request. Because the call is synchronous, the result is ready as
soon as the next line is executed. The XMLHttpRequest object has saved the
response from the server, and you can access it with the responseText field.
The above example shows that the fundamental technology is pretty simple. However, be aware that it’s a very basic usage that’s not yet fit for production. Fundamental questions remain, which are answered throughout this Solution:
How do you get hold of an
XMLHttpRequest?How do asynchronous calls work?
How do you handle errors?
What if the service requires a POST or PUT request rather than a GET?
What constraints apply to external domains?
How can you deal with XML responses?
What’s the API?
As you read all this, be aware that many, many libraries are
available to handle remoting (see Appendix A). Most developers shouldn’t need to touch
XMLHttpRequest directly. Having said that, it’s good to be
aware of the capabilities and limitations of XMLHttpRequest Calls,
along with the other web-remoting techniques. This knowledge will
help you select the most appropriate library and help with any bugs
you might encounter.
Creating XMLHttpRequest objects
In most browsers, XMLHttpRequest is a standard JavaScript
class, so you just create a new instance of XMLHttpRequest. However, Microsoft is
the inventor of XMLHttpRequest,
and until IE7, IE offered it only as an ActiveX object. To make
things even more fun, there are different versions of that object.
The following code shows a factory function that works on all
browsers that support XMLHttpRequest:
function createXMLHttpRequest( ) {
try { return new ActiveXObject("Msxml2.XMLHTTP"); } catch (e) {}
try { return new ActiveXObject("Microsoft.XMLHTTP"); } catch (e) {}
try { return new XMLHttpRequest( ); } catch(e) {}
alert("XMLHttpRequest not supported");
return null;
}
...
var xhReq = createXMLHttpRequest( );You really need to use a function like this for maximum portability. Once you have the object, its basic functionality and API are pretty consistent across browsers, but be sure to test carefully as there are a few subtle implementation differences in some browsers. (If you’re curious, the "Solution" in HTTP Streaming [later in this chapter] highlights one such inconsistency.)
You can also reuse an XMLHttpRequest; it’s worthwhile doing so
in order to prevent memory leaks. To be safe, start a new call
only when there’s not one already in progress. As explained below,
it’s possible to inspect the status of a call, and you should only
start a call if the status is 0 or 4. So if it’s anything else,
first call the abort( ) method
to reset status.
Asynchronous calls
I previously mentioned in the "Solution" that under synchronous mode, “the code will block until a response comes back.” Some hardened readers probably writhed uncomfortably at the thought. We all know that some requests take a long time to process, and some don’t come back at all. Pity the user when a server script is buried in an infinite loop.
In practice, XMLHttpRequest Calls should almost always be
asynchronous. That means the browser and the user can continue
working on other things while waiting for a response to come back.
How will you know when the response is ready? The XMLHttpRequest’s readyState always reflects the current
point in the call’s lifecycle. When the object is born, it’s at 0.
After open( ) has been called,
it’s 1. The progression continues until the response is back, at
which point the value is 4.
So, to catch the response, you need to watch for a readyState of 4. That’s easy enough,
because XMLHttpRequest fires
readystatechange events. You
can declare a callback function using the onreadystatechange field. The callback
will then receive all state changes. The states below 4 aren’t
especially useful and are somewhat inconsistent across browser
types anyway (http://www.quirksmode.org/blog/archives/2005/09/xmlhttp_notes_r_2.html).
So most of the time, all we’re interested in is, “Are you in state
4 (i.e., complete) or not?”
Based on all that, here’s an asynchronous version of the code shown earlier:
var xhReq = createXMLHttpRequest( );
xhReq.open("GET", "sumGet.phtml?figure1=5&figure2=10", true);
xhReq.onreadystatechange = onSumResponse;
xhReq.send(null);
...
function onSumResponse( ) {
if (xhReq.readyState != 4) { return; }
var serverResponse = xhReq.responseText;
...
}As shown, you declare the callback method in XMLHttpRequest’s onreadystatechange property. In
addition, the third argument of open(
) is now true. This argument is actually called the
“asynchronous flag,” which explains why we’re now setting it to
true. The callback function, onSumResponse, is registered using
onreadystatechange and contains
a guard clause to ensure the readyState is 4 before any processing
can occur. At that point, we have the full response in responseText.
JavaScript also supports “closures”—a form of anonymous function—which suggests a more concise boilerplate structure for asynchronous calls:
var xhReq = createXMLHttpRequest( );
xhReq.open("get", "sumget.phtml?figure1=10&figure2=20", true);
xhReq.onreadystatechange = function( ) {
if (xhReq.readyState != 4) { return; }
var serverResponse = xhReq.responseText;
...
};
xhReq.send(null);Use closures sparingly, because you’re defining a new function each time. It’s slower than referring to an existing one and might also lead to memory leaks.
Asynchronous calls are essential, but also more error-prone.
If you look at the callback mechanism, you might notice the
potential for a subtle, but serious, bug. The problem arises when
the same instance of XMLHttpRequest is simultaneously used
for different calls. If Call 2 is issued while the object is still
waiting for the response of Call 1, what will the callback
function receive? In fact, it’s even possible the callback
function itself is changed before the first call returns. There
are ways to deal with this problem, and they’re the topic of the
Call Tracking (Chapter 10)
pattern.
Detecting errors
Sometimes, a request doesn’t come back as you expected it, or maybe not at all. You scripted the call wrong, or there’s a bug in the server, or some part of the infrastructure just screwed up. Thinking asynchronously is the first step to dealing with these problems, because at least your application isn’t blocked. But you need to do more than that.
To detect a server error, you can check the response status
using XMLHttpRequest’s status flag. This is just a standard
HTTP code. For example, if the resource is missing, XMLHttpRequest.status will take on the
famous “404” value. In most cases, you can assume anything other
than 200 is an error situation. This suggests adding a new check
to the callback function of the previous section:
xhReq.onreadystatechange = function( ) {
if (xhReq.readyState != 4) { return; }
if (xhReq.status != 200) {
var serverResponse = xhReq.responseText;
...
};That’s great if the browser knows a problem occurred, but
sometimes the request will be lost forever. Thus, you usually want
some kind of timeout mechanism (http://ajaxblog.com/archives/2005/06/01/async-requests-over-an-unreliable-network)
as well. Establish a Scheduling timer to
track the session. If the request takes too long, the timer will
kick in and you can then handle the error. XMLHttpRequest has an abort( ) function that you should also
invoke in a timeout situation. Here’s a code sample:
var xhReq = createXMLHttpRequest( );
xhReq.open("get", "infiniteLoop.phtml", true); // Server stuck in a loop.
var requestTimer = setTimeout(function( ) {
xhReq.onreadystatechange = function( ) {
if (xhReq.readyState != 4) { return; }
clearTimeout(requestTimeout);
if (xhReq.status != 200) {
// Handle error, e.g. Display error message on page
return;
}
var serverResponse = xhReq.responseText;
...
};Compared to the previous example, a timer has been
introduced. The onreadystatechange(
) callback function will clear the timer once it
receives the full response (even if that response happens to be
erroneous). In the absence of this clearance, the timer will fire,
and in this case, the setTimeout sequence stipulates that
abort( ) will be called and
some recovery action can then take place.
Handling POSTs and other request types
Up to this point, requests have been simple
GET queries—pass in a URL and grab the response. As
discussed in the RESTful Service (Chapter 9), real-world projects need
to work with other request types as well. POST, for example, is suited to calls that affect server
state or upload substantial quantities of data. To illustrate,
let’s now create a new service, sumPostGeneric.phtml, that does the same
thing as postGet.phtml but with
a POST message. It’s called “generic” because it reads the full
message body text, as opposed to a CGI-style form submission. In
this case, it expects a body such as “Calculate this sum: 5+6” and
returns the sum value:
<?
$body = readBody( );
ereg("Calculate this sum: ([0-9]+)\+([0-9]+)", $body, $groups);
echo $groups[1] + $groups[2];
// A PHP method to read arbitrary POST body content.
function readBody( ) {
$body="";
$putData = fopen("php://input", "r");
while ($block = fread($putData, 1024)) {
$body = $body.$block;
}
fclose($putData);
return $body;
}
?>To POST an arbitrary body, we give XMLHttpRequest a request type of POST
and pass the body in as an argument to send( ). (Note that with GET queries,
the send( ) argument is null as
there’s no body content).
var xhreq = createxmlhttprequest( );xhreq.open("post", "sumPostGeneric.phtml", true);xhreq.onreadystatechange = function( ) { if (xhreq.readystate != 4) { return; } var serverResponse = xhreq.responsetext; ... };xhreq.send("calculate this sum: 5+6");
Quite often, though, you’ll be posting key-value pairs, so
you want the message to look as if it were submitted from a
POST-based form. You’d do that because it’s more standard, and
server-side libraries make it easy to write web services that
accept standard form data. The service shown in the code example
following the next one, sumPostForm.php, shows how PHP makes
light work of such submissions, and the same is true for most
languages:
<?
echo $_POST["figure1"] + $_POST["figure2"];
?>For the browser script to make a CGI-style upload, two
additional steps are required. First, declare the style in a
“Content-Type” header; as the example below shows, XMLHttpRequest lets you directly set
request headers. The second step is to make the body a set of
name-value pairs:
var xhreq = createxmlhttprequest( );
xhreq.open("post", "sumPostForm.phtml", true);
xhReq.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
xhreq.onreadystatechange = function( ) {
if (xhreq.readystate != 4) { return; }
var serverresponse = xhreq.responsetext;
...
};
xhreq.send("calculate this sum: 5+6");GET and POST are virtually ubiquitous, but RESTful
Service points out there’s a time and place for other
request methods too, such as PUT and DELETE. You don’t have to do
anything special with those other methods; just set the request
type in the open( ) call and
send( ) an appropriate body
(the item you’re putting in the case of PUT; a null argument in
the case of DELETE).
Constraints on external domains
On discovering XMLHttpRequest, a common reaction is to
start dreaming up an interface that pulls in content from popular
web sites and mashes it altogether to into one big Web 2.0
soufflé. Unfortunately, it’s not so simple because of a key
security rule imposed by all major browsers: XMLHttpRequest can only access content
from the originating server. If your application lives at
http://ajax.shop/admin, then your XMLHttpRequest objects can happily reach
http://ajax.shop/admin/products.html and
http://ajax.shop/products/contents.html,
shouldn’t be able to reach http://books.ajax.shop/contents.html, and
definitely won’t have access to http://google.com.
This “same-origin policy” (or “same-domain policy”) (http://www.mozilla.org/projects/security/components/same-origin.html) will be familiar to developers of Java applets and Flash, where the policy has always been in place. It’s there to prevent all kinds of abuse, such as a malicious script grabbing confidential content from one server and uploading it to another server under their own control. Some have suggested it’s possibly overkill, that most of the risks it tries to prevent are already possible by other means (http://spaces.msn.com/members/siteexperts/Blog/cns!1pNcL8JwTfkkjv4gg6LkVCpw!2085.entry). However, restrictions like this won’t be lifted lightly; the rule’s likely to be around for the long term, so we had better learn to work with it.
Given same-origin restrictions, then, how do all those Ajax
mashup sites work (http://housingmaps.com)? The answer is
that the cross-domain transfers usually run through the
originating server, which acts as a kind of proxy—or
tunnel—allowing XMLHttpRequests
to communicate with external domains. Cross-Domain
Proxy (Chapter 10)
elaborates on the pattern, and its "Alternatives" section
lists some clever workarounds that do allow the originating server
to be bypassed.
XML responses
The discussion here has swiftly ignored the big
elephant in the room: XML. XMLHttpRequest, as its name suggests,
was originally designed with, yes, XML in mind. As we’ve already
seen, it will actually accept any kind of response, so what’s
special about XML? With XMLHttpRequest, any responses can be
read via the responseText
field, but there’s also an alternative accessor: responseXML. If the response header
indicates the content is XML, and the response text is a valid XML
string, then responseXML will
be the DOM object that results from parsing the XML.
The Display Maniputlation (Chapter 5) patterns have already illustrated how JavaScript supports manipulation of DOM objects. In those patterns, we were only interested in one particular DOM object, the HTML (or XHTML) document representing the current web page. But you can manipulate any other DOM object just as easily. Thus, it’s sometimes convenient to have a web service output XML content and manipulate the corresponding DOM object.
The prerequisite here is a Web Service (see earlier in this chapter) that outputs valid XML. There are many libraries and frameworks around for automatically generating XML from databases, code objects, files, or elsewhere. But don’t think you have to start learning some fancy XML library in order to create XML web services, because it’s fairly easy to hand code them too, at least for simple data. The service just needs to output an XML Content-type header followed by the entire XML document. Here’s an XML version of the sum service shown earlier—it outputs an XML document containing the input figures as well as the sum result:
<?
header("Content-Type: text/xml");
$sum = $_GET["figure1"] + $_GET["figure2"];
echo <<< END_OF_FILE
<sum>
<inputs>
<figure id="1">{$_GET["figure1"]}</figure>
<figure id="2">{$_GET["figure2"]}</figure>
</inputs>
<outputs>$sum</outputs>
</sum>
END_OF_FILE
?>The call sequence is the same as before, but the callback
function now extracts the result using responseXML. It then has a first-class
DOM object and can interrogate it using the standard DOM
API:
var xhReq = createXMLHttpRequest( );
xhReq.open("GET", "sumXML.phtml?figure1=10&figure2=20", true);
xhReq.onreadystatechange = function( ) {
if (xhReq.readyState != 4) { return; }
xml = xhReq.responseXML;
var figure1 = xml.getElementsByTagName("figure")[0].firstChild.nodeValue;
var figure2 = xml.getElementsByTagName("figure")[1].firstChild.nodeValue;
var sum = xml.getElementsByTagName("outputs")[0].firstChild.nodeValue;
...
};
xhReq.send(null);
});The name “XMLHttpRequest” relates to its two primary functions: handling HTTP requests and converting XML responses. The former function is critical and the latter is best considered a bonus. There are certainly good applications for XML responses—see XML Message (Chapter 9), and XML Data Island and Browser-Side XSLT (Chapter 11)—but keep in mind that XML is not a requirement of Ajax systems.
You can also upload XML from browser to server. In this
case, XMLHttpRequest doesn’t
offer any special XML functionality; you just send the XML message
as you would any other message, and with an appropriate request
type (e.g., POST or PUT). To support the receiving web service,
the JavaScript should generally declare the XML content type in a
request header:
xhReq.setRequestHeader('Content-Type', "text/xml");The XMLHttpRequest API: a summary
We’ve looked at how to achieve typical tasks with
XMLHttpRequest, and now here’s
a quick summary of its properties and methods based on an Apple
Developer Connection article (http://developer.apple.com/internet/webcontent/xmlhttpreq.html).
The API is supported by IE5+, the Mozilla family (including all
Firefox releases), and Safari 1.2+.
XMLHttpRequest has the
following properties:
onreadystatechangeThe callback function that’s notified of state changes. 0=UNINITIALIZED, 1=LOADING, 2=LOADED, 3=INTERACTIVE, and 4=COMPLETE. (As explained earlier in "Asynchronous calls,” states 1-3 are ambiguous and interpretations vary across browsers.)
readyStateThe state within the request cycle.
responseTextThe response from the server, as a String.
responseXMLThe response from the server, as a Document Object Model, provided that the response “Content-Type” header is “text/html,” and the
responseTextis a valid XML string.statusHTTP response code (http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html) received from the server. This should normally be 200; most values indicate an error.
statusTextThe HTTP response code description received from the server; e.g., “Not Found.”
And these are XMLHttpRequest’s methods:
abort( )Stops the request and resets its
readyStateback to zero. (See "Detecting errors,” earlier in this chapter.)getAllResponseHeaders( )Returns a string of all response headers, separated by a newline as in the original message.
getResponseHeader(headerField)Returns the value for a particular header field.
open(requestMethod, url, asynchronousFlag, username, password)Prepares
XMLHttpRequest(See the "Solution,” earlier.). Only the first two parameters are optional.usernameandpasswordcan be used for authentication.send(bodyContent)Sends the message along with specified body content (null if no body content is to be sent; e.g., for GET requests). (See the "Solution,” earlier.)
setRequestHeader(headerField, headerValue)Sets a request header. (See "Handling POSTs and other request types,” earlier.)
Decisions
What kind of content will web services provide?
As mentioned in the solution, XML is not the only
kind of content that XMLHttpRequest can deal with. As long as
you can parse the message in JavaScript, there are various
response types possible. The patterns on web services highlight a
number of response types, including HTML, XML, JSON, and
plain-text.
How will caching be controlled?
It’s possible that an XMLHttpRequest response will be cached
by the browser. Sometimes, that’s what you want and sometimes it’s
not, so you need to exert some control over caching.
With cache control, we’re talking about GET-based requests. Use GET for read-only queries and other request types for operations that affect server state. If you use POST to get information, that information usually won’t be cached. Likewise, if you use GET to change state, you run the risk that the call won’t always reach the server, because the browser will cache the call locally. There are other reasons to follow these this advice too; see RESTful Service (Chapter 9).
Often, you want to suppress caching in order to get the latest server information, in which case, a few techniques are relevant. Since browsers and servers vary, the standard advice is spread the net as wide as possible by combining some of these techniques:
You can make the URL unique by appending a timestamp (http://www.howtoadvice.com/StopCaching) (a random string, or a string from an incrementing sequence, is sometimes used too). It’s a cheap trick, but surprisingly robust and portable:
var url = "sum.phtml?figure1=5&figure2=1×tamp=" + new Date().getTime( );
You can add a header to the request:
xhReq.setRequestHeader("If-Modified-Since", "Sat, 1 Jan 2005 00:00:00 GMT");In the Web Service set response headers to suppress caching (http://www.stridebird.com/articles/?showarticle=1&id=33). In PHP, for example:
header("Expires: Sat, 1 Jan 2005 00:00:00 GMT"); header("Last-Modified: ".gmdate( "D, d M Y H:i:s")."GMT"); header("Cache-Control: no-cache, must-revalidate"); header("Pragma: no-cache");Use POST instead of GET. Requests that are of POST type will sometimes cause caching to be suppressed. However, this particular technique is not recommended because, as explained in RESTful Service, GET and POST have particular connotations and shouldn’t be treated as interchangeable. In any event, it won’t always work, because it’s possible some resources will actually cache POST responses.
On the other hand, caching is a good thing when the service is time-consuming and unlikely to have changed recently. To encourage caching, you can reverse the above advice; e.g., set the Expires headers to a suitable time in the future. In addition, a good approach for smaller data is to cache it in the program itself, using a JavaScript data structure. Browser-Side Cache (Chapter 13) explains how.
How will you deal with errors?
The section on error detection left open the question of what to do once we discover a server timeout or nonstandard error code. There are three possible actions:
- Try again
Retry a few times before giving up.
- Inform the user
Tell the user what’s gone wrong and what the consequences are. For instance, inform him that his data hasn’t been submitted and he should try again in a few minutes.
- Do nothing
Sometimes, you have the luxury of ignoring the response (or lack thereof). That might be because you’re issuing low-importance Fire-and-Forget calls (http://www.ajaxian.com/archives/2005/09/ajaxian_fire_an.html), where you’re uploading some data without waiting for any response.
Real-World Examples
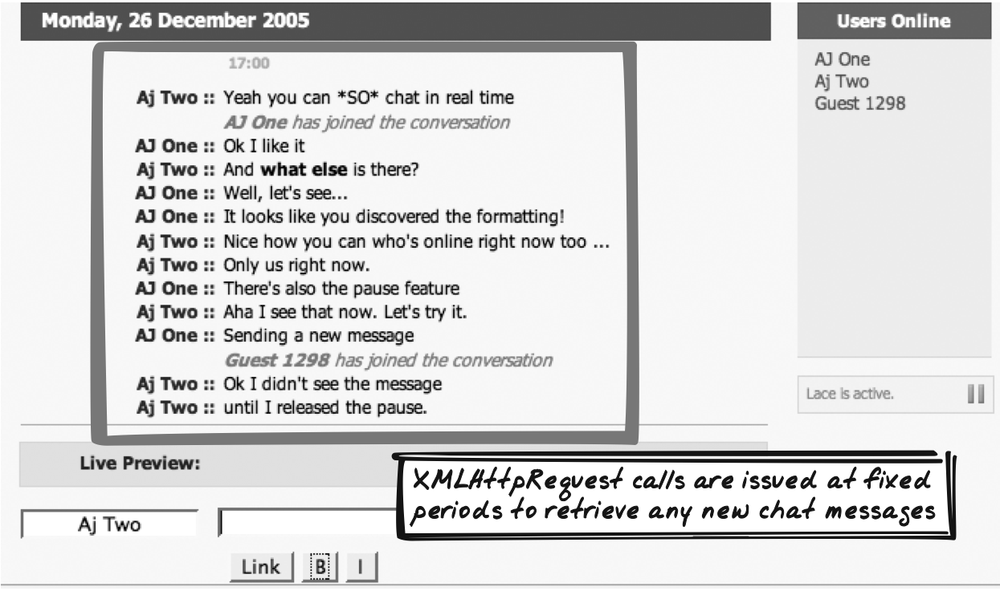
Lace Chat
Brett Stimmerman’s Lace Chat (http://www.socket7.net/lace/) is an Ajax
chat application that uses XMLHttpRequest in two ways: to upload
messages you type and to download all the latest messages from the
server (Figure
6-3).
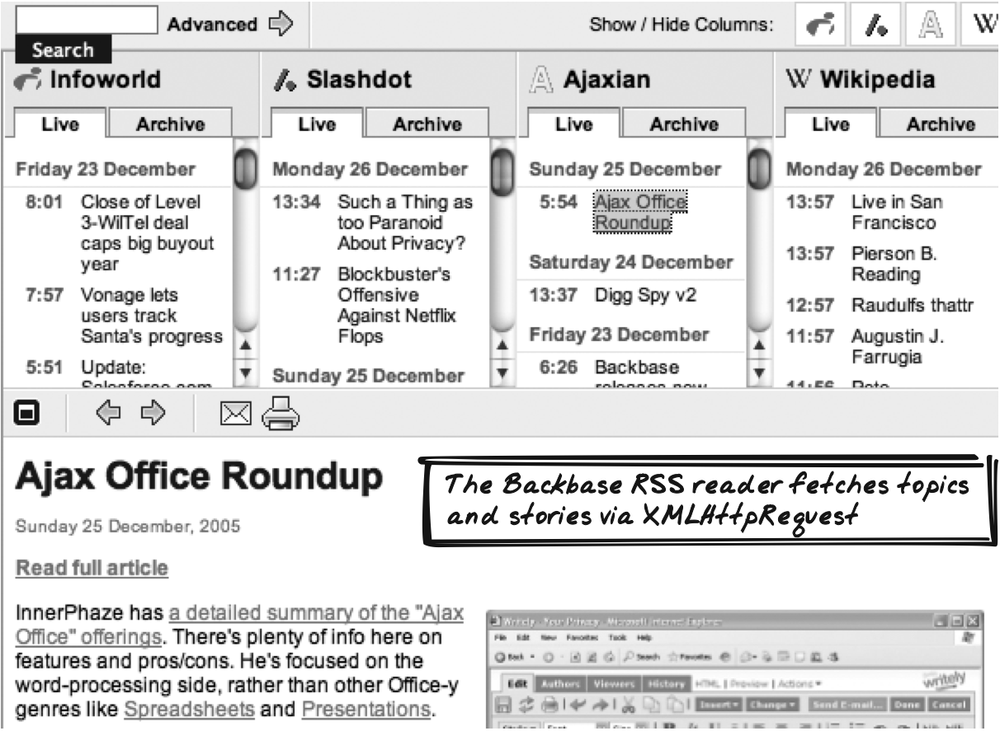
Backbase
Backbase’s Demo RSS Reader (http://www.backbase.com/demos/RSS) uses
XMLHttpRequest to pull down
titles of recent articles (Figure 6-4). When you click on
one of those titles, a new XMLHttpRequest will pull down the entire
content.
Anyterm
Phil Endecott’s Anyterm (http://anyterm.org/demos.html) is an Ajax terminal emulator allowing you to run telnet or SSH within the browser. It uses XMLHttpRequest Calls to upload keystrokes and download the latest screen state.
Mint
Mint (http://haveamint.com/) is a web site
statistics package. Site owners include Mint JavaScript on each
page, which quietly inspects the user’s browser settings and
uploads them using an XMLHttpRequest.
Code Example: AjaxPatterns TestAjaxCaller
The example (http://ajaxpatterns.org/xmlHttpRequestCall/)
referenced in the "Solution,” earlier, covers
most typical XMLHttpRequest
usage. In practice, many people adopt Ajax frameworks and libraries
rather than calling XMLHttpRequest directly. That’s the
approach taken with all of the Ajax Patterns demos, which use a
library called ajaxCaller.js that was developed
in parallel to the demos themselves. It’s a fairly basic library,
but offers a simple interface for the functionality that’s typically
required of XMLHttpRequest. In
this section, I’ll introduce the library by showing a few usages
within the AjaxCaller Test Demo (http://ajaxify.com/run/testAjaxCaller).
The simplest call is getting some plain-text: just specify the URL and the callback function.
ajaxCaller.getPlainText(url, onResponse);
For all calls, the callback function always takes three
arguments. The first argument is the result, either a string or a
DOM object. The second is an associative array mapping header fields
to header values. The third is a “calling context.” Think of calling
context as an optional value that travels alongside the request and
the corresponding response, returned to the callback function in
exactly the same form as you passed it in when the call was issued.
Usually it holds information about the call; e.g., if the call was
made to send off a purchase order, the calling context might contain
the item that was ordered. Then, ajaxCaller will pass the context into the
callback function, which can mark the item as successfully ordered.
In reality, the calling context is not actually passed to and from
the server; ajaxCaller keeps it
locally and tracks each pending request. If this all sounds a bit
complicated, check out Call Tracking (Chapter 10).
The callback function looks as follows:
function onResponse(text, headers, callingContext) {
// Use text (a string), headers, and callingContext
}And since it’s only the text that’s used most of the time, the function can also be declared in a simpler form.[*]
function onResponse(text) {
// Use text (a String)
}getPlainText( ) is one of
four commonly used methods. The others are getXML( ), postForPlainText( ), and
postForXML( ). Together, these
four cover both common request types (GET and POST) and both
response types (text and XML).
ajaxCaller.getXML(url, callbackFunction); ajaxCaller.postForXML(url, vars, callbackFunction); ajaxCaller.getPlainText(url, callbackFunction, callbackContext); ajaxCaller.postForPlainText(url, callbackFunction, callbackContext);
There are also a number of more general methods—for example,
get( ) provides more flexible GET
requests. In addition to a URL and a callback function, get( ) lets you specify some variables to
be appended to the URL, a flag to indicate whether the response is
XML, and the callingContext as
discussed above.
var vars = {
flavour: "chocolate",
topping: "nuts"
};
ajaxCaller.get("httpLogger.php", vars, onResponse, false, "iceCreamRequest");There are general operations for other request types too.
postVars( ) creates a CGI-style
POST upload and postBody( )
creates an arbitrary-body POST upload. There are similar methods for
other request types; e.g., PUT, TRACE, OPTIONS, DELETE, and
HEAD.
Alternatives
This section lists all alternatives I’m aware of, some more limited than others. The more obscure techniques are included for the sake of completeness and also in the hope they might spark a few ideas.
Page refreshes
The conventional way to communicate with the server is for the browser to request an entirely new page, which is pretty extreme when you stop and think about it. It might be appropriate if the user’s navigating to a completely different part of a web site, but it’s overkill if you want to update a football score at the bottom of the page or upload some user input. The most familiar kind of full page refresh is the hyperlink, which causes the browser to issue a GET request, clear the current page, and output the response. The other kind of full page refresh is a form submission, which causes the browser to pass some parameters with the request—which will be GET, POST, or some other method—and, as with a hyperlink, replace the previous page with the new response. With web remoting, any user-interface changes are completely at the discretion of the script running inside the page. These conventional techniques are still available, but most server communication uses XMLHttpRequest Call and related technologies.
IFrame Call
IFrame Call (see later in this
chapter) is the main alternative to XMLHttpRequest. Like XMLHttpRequest, it allows for remote
calls using GET, POST, and other request types. But whereas
XMLHttpRequest is designed
specifically for web remoting, IFrame Call exploits the IFrame to
do something it was never really intended to do, and the code
shows it. Here’s a summary of XMLHttpRequest’s strengths over IFrame
Calls:
Being designed specifically for web remoting, the
XMLHttpRequestAPI is easier to use, especially when it comes to non-GET request types. However, this is no great advantage as it’s generally recommended that you use a wrapper library to avoid working with either API. (XMLHttpRequest’s API may be better, but it’s not great!)XMLHttpRequestoffers functionality not available to IFrame Call, such as the ability to abort a call and track the call’s state. This can have important performance implications (http://www.ajaxian.com/archives/2005/09/ajaxian_fire_an.html).XMLHttpRequestis typically faster, especially with shorter responses (http://me.eae.net/archive/2005/04/02/xml-http-performance-and-caching/).XMLHttpRequestparses XML in a simple, portable, manner; IFrame is unrelated to XML.On those browsers that do support
XMLHttpRequest, the API is more consistent than that of IFrame.XMLHttpRequestis rapidly gaining the virtue of widespread familiarity. This not only helps other developers understand your code, but also means you benefit from tools such as those which monitorXMLHttpRequesttraffic (see Traffic Sniffing [Chapter 18]).
For all these reasons, XMLHttpRequest should be the default
choice. However, there are some specialized situations where
IFrame Call is superior:
IFrame works on many older browsers that don’t actually support
XMLHttpRequest.IFrame happens to have some specialized properties (if only by complete fluke) for browser history and bookmarkability, at least for IE, as discussed in Unique URLs (Chapter 17).
XMLHttpRequeston IE won’t work if security measures disable ActiveX, a policy sometimes enforced in the enterprise (http://verens.com/archives/2005/08/12/ajax-in-ie-without-activex/).IFrame may offer a more portable solution for HTTP Streaming as discussed in that pattern.
HTTP Streaming
HTTP Streaming (see later in
this chapter) also allows for web remoting, and unlike XMLHttpRequest, the connection remains
open. Functionally, the key advantage over XMLHttpRequest is that the server can
continuously push new information to the browser. From a resource
perspective, streaming is good insofar as there’s less starting
and stopping of connections, but there are serious scaleability
issues as it’s rarely feasible to keep open a huge amounts of
connections and maintain numerous server-side scripts.
Richer Plugin
The Richer Plugin (Chapter 8) pattern discusses Java, Flash, and other plugins and extensions. These components often have permission to call the server programmatically. and in some cases, can be used as proxies available to JavaScript code.
On-Demand JavaScript
On-Demand JavaScript (see
later in this chapter) describes a couple of ways to download
JavaScript on the fly. One involves XMLHttpRequests (and therefore isn’t
foundational in itself), but the other is an alternative transport
mechanism, a different technique for web remoting. It works by
adding a script element to the
document body, which has the effect of automatically pulling down
a named JavaScript file.
Image-Cookie Call
Brent Ashley’s RSLite library (http://www.ashleyit.com/rs/rslite/) is an unusual alternative based on images and cookies. An image’s source property is set to the service URL, which is simply a means of invoking the service. The service writes its response into one or more cookies, which will then be accessible from the JavaScript once the call has completed.
Stylesheet Call
Another way to get at server state is to dynamically change
a CSS stylesheet. Just like setting a new JavaScript or image
source, you set a stylesheet’s href property to point to the web
service. In Julien Lamarre’s demo of this technique (http://zingzoom.com/ajax/ajax_with_stylesheet.php),
the web service actually outputs a stylesheet, and the response is
embedded in the URL of a background-image property!
204 Response
An old—and pretty much obsolete—trick is to have the server respond with a 204 “No Content” response code. Browsers won’t refresh the page when they see this code, meaning that your script can quietly submit a form to such a service with no impact on the page. However, you can only use the 204 trick for "fire-and-forget" calls—while the response may contain information embedded in the headers, there’s no way for a browser script to access it.
Import XML Document
There’s a technique specifically for retrieving XML
documents that uses similar technology to XMLHttpRequest. Peter-Paul Koch
described the technique back in 2000 (http://www.quirksmode.org/dom/importxml.html),
and recently suggested it can now be written off (http://www.quirksmode.org/blog/archives/2005/01/with_httpmapsea.html).
Metaphor
An XMLHttpRequest Call is like the browser having a side conversation with the server while carrying on the main conversation with the user.
IFrame Call
⊙ Call, Callback, Download, Frame, IFrame, Live, Query, Remoting, RemoteScripting, Upload
Goal Story
Bill’s ordering a car online and the price is always
synchronized with his choice. This happens because of a hidden
IFrame. Each time he changes something, the browser populates a form
in the IFrame and submits it. The IFrame soon contains the new
price, which the browser copies into the visible display. XMLHttpRequest could have accomplished the
feat too, but it’s not supported in Bill’s outdated browser.
Problem
How can the browser communicate with the server?
Forces
Refer to the section "Forces" in XMLHttpRequest Call.
Solution
Use IFrames for
browser-server communication. Much of the fuss in Ajax
concerns the XMLHttpRequest
object, but sometimes other remoting techniques are more
appropriate, and IFrame Call is one of those (see the "Alternatives" section of
XMLHttpRequest Call, earlier in this chapter,
for a comparison). IFrames are page-like elements that can be
embedded in other pages. They have their own source URL, distinct
from their parent page, and the source URL can change dynamically.
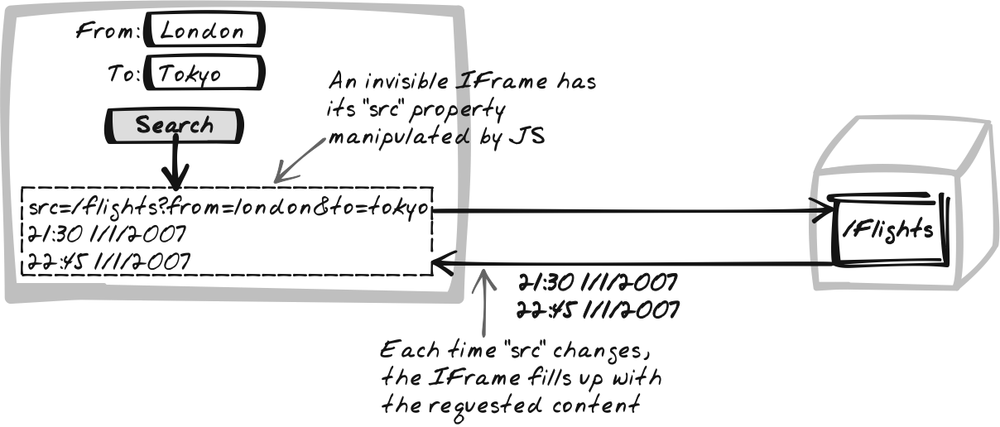
IFrame Calls work by making the IFrame point to a URL we’re
interested in, and then reading the IFrame’s contents once the new
content has loaded. Note: an online demo (http://ajaxify.com/run/iframe) illustrates
most of the code concepts throughout this Solution and the code
snippets loosely follow from the demo.
To begin with, you need an IFrame in the initial HTML, and an
event handler registered to catch the onload event. (It would be less obtrusive
to register the handler with JavaScript, but due to certain browser
“features,” that doesn’t always work.)
<iframe id='iFrame' onload='onIFrameLoad( );'></iframe>
We’re using the IFrame as a data repository, not as a user
interface, so some CSS is used to hide it. (The more natural choice
would be display: none, but as an
experimental demo shows [http://ajaxlocal/run/iframe/displayNone/],
browser strangeness makes it infeasible.)
#iFrame {
visibility: hidden;
height: 1px;
}On the server, we’re initially going to use the web service
discussed in XMLHttpRequest Call: sumGet.phtml. To call the service, we’ll
change the IFrame’s source:
$("iFrame").src = "sumGet.phtml?figure1=5&figure2=1";We already registered an onload handler in the initial HTML. The
handler will be called when the new content has loaded, and at that
stage, the IFrame’s body will reflect the content we’re after. The
following code calls a function, extractIFrameBody( ), which extracts the
body in a portable manner (based on http://developer.apple.com/internet/webcontent/iframe.html).
function onIFrameLoad( ) {
var serverResponse = extractIFrameBody($("iFrame")).innerHTML;
$("response").innerHTML = serverResponse;
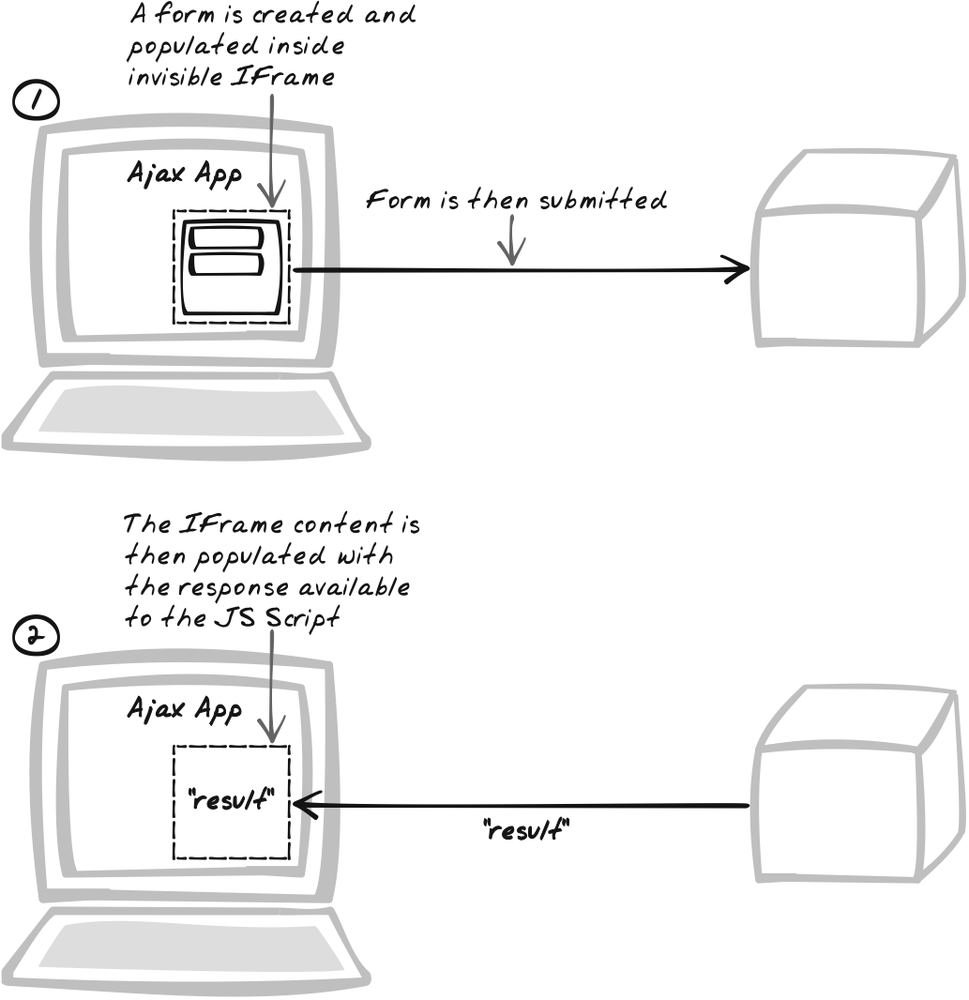
}That covers the GET call. To illustrate POSTing, we’ll invoke
the sumPost.phtml service, also
discussed in XMLHttpRequest Call. POST calls
are a bit more complicated because we can’t just change the source.
Instead, we dynamically inject a form into the IFrame and submit it.
In this example, the arguments ('5' and '2') are hardcoded, but they could easily
be scripted by manipulating the input elements.
var iFrameBody = extractIFrameBody($("iFrame"));
iFrameBody.innerHTML =
"<form action='sumPostForm.phtml' method='POST'>" +
"<input type='text' name='figure1' value='5'>" +
"<input type='text' name='figure2' value='2'>" +
"</form>";
var form = iFrameBody.firstChild;
form.submit( );As with conventional form submission, the IFrame will be
refreshed with the output of the form recipient. Thus, the previous
onLoad handler will work fine.
Figure 6-6 illustrates the
overall process.
Another approach with IFrames is to have the server output
some JavaScript that alters the parent or calls a function defined
in the parent. The code will automatically be called when the page
loads, so there’s no need for an onload handler. Unfortunately, this
approach creates substantial coupling between the server and
browser. In contrast, note how the examples above used completely
generic web services—the services only know how to add numbers
together and nothing about the calling context. That’s possible
because all behavior was encapsulated in the onload( ) function.
As Call Tracking (Chapter 10) discusses, there are problems—and suitable workarounds—with simultaneous XMLHttpRequest Calls, and the same is true for IFrames. First, you need to create a separate IFrame for each parallel call—you don’t want to change an IFrame’s source while it’s waiting for a response. Second, you need to investigate and test limitations, because the application can grind to a halt if too many calls are outstanding.
There’s one last problem with IFrame Call: browser UIs aren’t really built with this application in mind, so some things might seem funny to users. In particular, Alex Russell has pointed out two issues that arise with IFrame Calls under IE: the “phantom click” and the “throbber of doom” (http://alex.dojotoolkit.org/?p=538). The former repeats a clicking sound every time an IFrame request takes place, and the latter keeps animating the throbber icon while the IFrame is loading. These devices are great for a full page refresh, like when you click on a link, but they suck when a script is trying to quietly talk with the server behind the scenes. In Alex’s article, he explains how he unearthed a fantastic hack inside Gmail’s (http://gmail.com) chat application. The hack suppresses the annoying behavior by embedding the IFrame inside an obscure ActiveX component called “htmlfile,” which is basically a separate web page. As the IFrame isn’t directly on the web page anymore, IE no longer clicks and throbs. See Alex’s blog post (http://alex.dojotoolkit.org/?p=538) for full details.
Make no mistake: IFrame Call is a pure hack. IFrames were never intended to
facilitate browser-server communication. It’s likely the technique
will slowly fade away as XMLHttpRequest gains popularity and as
legacy browsers are retired. Nevertheless, it does retain a few
advantages over XMLHttpRequest Call, mentioned
in the "Alternatives"
section of that pattern.
Real-World Examples
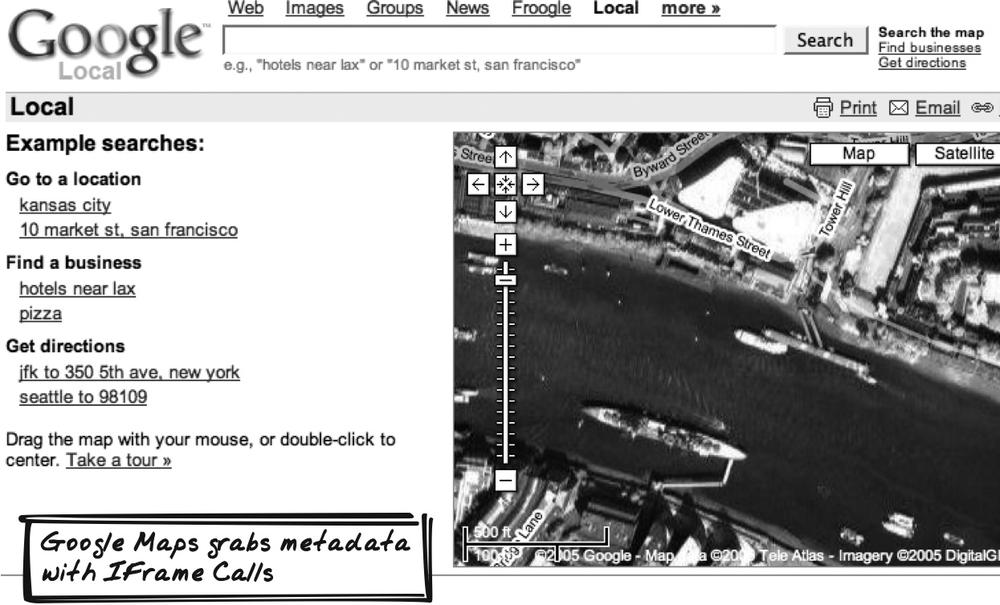
Google Maps
Google Maps (http://maps.google.com), perhaps the most
famous Ajax App, lets you navigate through a map of the world
(Figure 6-7). Location
and metadata is required from the server, and this content is
retrieved using IFrames. Google also uses XMLHttpRequest for downloading XSLT
stylesheets (a technique described in Browser-Side
XSLT [Chapter
11]).
Scoop framework, Kuro5hin
Scoop (http://scoop.kuro5hin.org), an open source content management system, uses IFrames for discussion areas (Figure 6-8). Using the “dynamic comments” module, users can drill down a discussion thread without reloading the whole page. Scoop powers the popular Kuro5hin web site (http://kuro5hin.org) among others.

PXL8 Demo
Michele Tranquilli has an excellent tutorial on IFrames with embedded examples (http://www.pxl8.com/iframes.html).
HTMLHttpRequest Library
Angus Turnbull’s HTMLHttpRequest (http://www.twinhelix.com/javascript/htmlhttprequest/)
is a portable web-remoting library that initially attempts to use
XMLHttpRequest, and if that
fails, falls back to IFrame. The tool is documented in the Code
Examples section of Cross-Browser Component
(Chapter 12).
Code Refactoring: AjaxPatterns Sum Demo
The Basic Sum Demo (http://ajaxify.com/run/sum) uses XMLHttpRequest, and there’s a version
available that’s been refactored to use IFrame (http://ajaxify.com/run/sum/iframe). There’s
no walkthrough here, as it’s very similar to the GET component of
the demo discussed earlier in the "Solution.”
Alternatives
XMLHttpRequest Call
XMLHttpRequest Call (see earlier in this chapter) is the natural alternative to IFrame Call. The "Alternatives" section of that pattern, earlier in this chapter, compares the two approaches.
Frame Call
Before IFrames, there were plain old frames. As a user-interface concept, they’ve had a few public relations problems over the years, but they do at least provide a means of remote scripting similar to IFrame Calls (even if it was accidental). Since IFrames are now widely supported, it’s unlikely you’ll ever need to use frames for remote scripting (or anything else, for that matter).
Metaphor
A hidden IFrame is an invisible friend you can delegate queries to.
HTTP Streaming
⊙ Connection, Duplex, Live, Persistent, Publish, Push, RealTime, Refresh, Remoting, RemoteScripting, Stateful, ReverseAjax, Stream, TwoWay, Update
Goal Story
Tracy’s trading application contains a section showing the
latest announcements. It’s always up-to-date because the
announcements are streamed directly from the server. Suddenly, an
important announcement appears, which triggers her to issue a new
trade. The trade occurs with a new XMLHttpRequest, so the announcement stream
continues unaffected.
Problem
How can the server initiate communication with the browser?
Forces
The state of many Ajax Apps is inherently volatile. Changes can come from other users, external news and data, completion of complex calculations, and triggers based on the current time and date.
HTTP connections can only be created within the browser. When a state change occurs, there’s no way for a server to create a physical connection to notify any interested client.
Solution
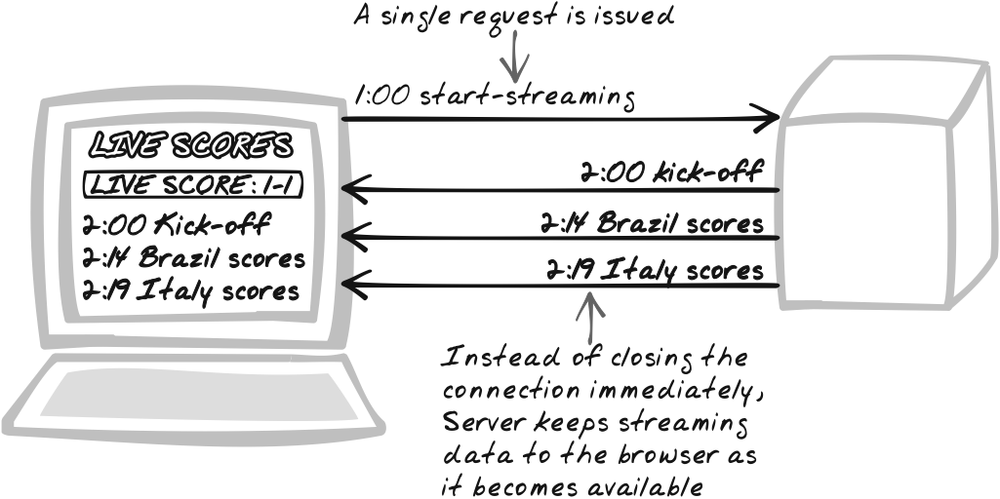
Stream server data in the response of a long-lived HTTP connection. Most web services do some processing, send back a response, and immediately exit. But in this pattern, they keep the connection open by running a long loop. The server script uses event registration or some other technique to detect any state changes. As soon as a state change occurs, it pushes new data to the outgoing stream and flushes it, but doesn’t actually close it. Meanwhile, the browser must ensure the user interface reflects the new data. This pattern discusses a couple of techniques for Streaming HTTP, which I refer to as “page streaming” and “service streaming.”
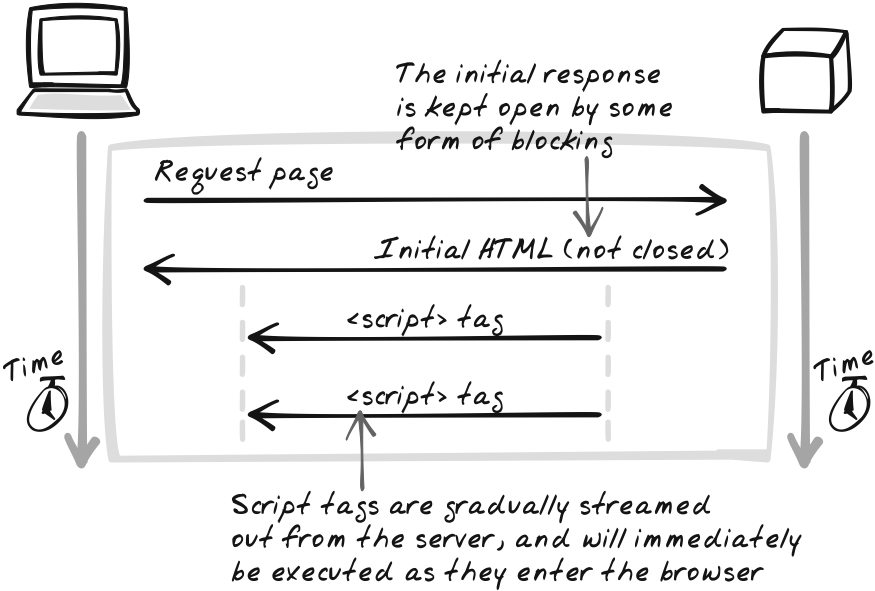
Page streaming involves streaming the original page response
(Figure 6-10). Here, the
server immediately outputs an initial page and flushes the stream,
but keeps it open. It then proceeds to alter it over time by
outputting embedded scripts that manipulate the DOM. The browser’s
still officially writing the initial page out, so when it encounters
a complete <script> tag, it
will execute the script immediately. A simple demo is available at
http://ajaxify.com/run/streaming/.
For example, the server can initially output a div that will always contain the latest
news:
print ("<div id='news'></div>");But instead of exiting, it starts a loop to update the item every 10 seconds (ideally, there would be an interrupt mechanism instead of having to manually pause):
<?
while (true) {
?>
<script type="text/javascript">
$('news').innerHTML = '<?= getLatestNews( ) ?>';
</script>
<?
flush( ); // Ensure the Javascript tag is written out immediately
sleep(10);
}
?>That illustrates the basic technique, and there are some
refinements discussed next and in the "Decisions" section, later in
this chapter. One burning question you might have is how the browser
initiates communication, since the connection is in a perpetual
response state. The answer is to use a “back channel”; i.e., a
parallel HTTP connection. This can easily be accomplished with an
XMLHttpRequest Call or an IFrame Call. The streaming service will be able to effect a
subsequent change to the user interface, as long as it has some
means of detecting the call—for example, a session object, a global
application object (such as the applicationContext in a Java Servlet
container), or the database.
Page streaming means the browser discovers server changes almost immediately. This opens up the possibility of real-time updates in the browser, and allows for bi-directional information flow. However, it’s quite a departure from standard HTTP usage, which leads to several problems. First, there are unfortunate memory implications, because the JavaScript keeps accumulating and the browser must retain all of that in its page model. In a rich application with lots of updates, that model is going to grow quickly, and at some point a page refresh will be necessary in order to avoid hard drive swapping or worse. Second, long-lived connections will inevitably fail, so you have to prepare a recovery plan. Third, most servers can’t deal with lots of simultaneous connections. Running multiple scripts is certainly going to hurt when each script runs in its own process, and even in more sophisticated multithreading environments, there will be limited resources.
Another problem is that JavaScript must be used, because it’s the only way to alter page elements that have already been output. In its absence, the server could only communicate by appending to the page. Thus, browser and server are coupled closely, making it difficult to write a rich Ajaxy browser application.
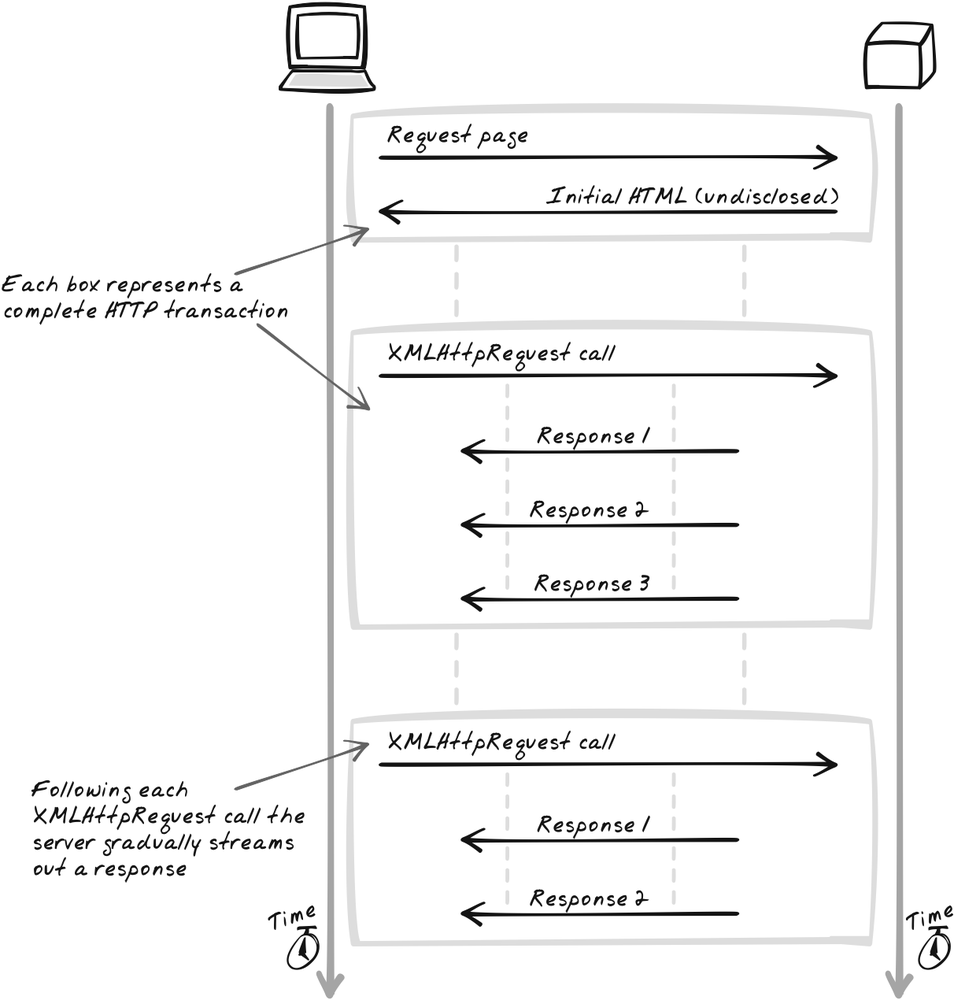
Service streaming is a step towards solving these problems
(Figure 6-11). The
technique relies on XMLHttpRequest Call (or a
similar remoting technology like IFrame Call).
This time, it’s an XMLHttpRequest
connection that’s long-lived, instead of the initial page load.
There’s more flexibility regarding length and frequency of
connections. You could load the page normally, then start streaming
for 30 seconds when the user clicks a button. Or you could start
streaming once the page is loaded, and keep resetting the connection
every 30 seconds. Flexibility is valuable, given that HTTP Streaming
is constrained by the capabilities of the server, the browsers, and
the network.
As for the mechanics of service streaming, the server uses the same trick of looping
indefinitely to keep the connection open, and periodically flushing
the stream. The output can no longer be HTML script tags, because the web browser
wouldn’t automatically execute them, so how does the browser deal
with the stream? The answer is that it polls for the latest response
and uses it accordingly.
The responseText property
of XMLHttpRequest always contains
the content that’s been flushed out of the server, even when the
connection’s still open. So the browser can run a periodic check;
e.g., to see if its length has changed. One problem, though, is
that, once flushed, the service can’t undo anything its output. For
example, the responseText string
arising from a timer service might look like this: “12:01:00
12:01:05 12:01:10,” whereas it would ideally be just “12:01:00,”
then just “12:01:05,” then just “12:01:10.” The solution is to parse
the response string and look only at the last value—to be more
precise, the last complete value, since it’s
possible the text ends with a partial result. An example of this
technique (http://www.ajaxify.com/run/streaming/xmlHttpRequest/countdown/)
works in this way. To ease parsing, the service outputs each message
delimited by a special token, @END@ (an XML tag would be an alternative
approach). Then, a regular expression can be run to grab the latest
message, which must be followed by that token to ensure it’s
complete:
function periodicXHReqCheck( ) {
var fullResponse = util.trim(xhReq.responseText);
var responsePatt = /^(.*@END@)*(.*)@END@.*$/;
if (fullResponse.match(responsePatt)) { // At least one full response so far
var mostRecentDigit = fullResponse.replace(responsePatt, "$2");
$("response").innerHTML = mostRecentDigit;
}
}That’s great if you only care about the last message, but what if the browser needs to log all messages that came in? Or process them in some way? With a polling frequency of 10 seconds, the previous sequence would lead to values being skipped; the browser would skip from 12:01 to 12:01:10, ignoring the second value. If you want to catch all messages, you need to keep track of the position you’ve read up to. Doing so lets you determine what’s new since the previous poll, a technique used in "Code Refactoring: AjaxPatterns Streaming Wiki,” later in this chapter.
In summary, service streaming makes streaming more flexible, because you can stream
arbitrary content rather than JavaScript commands, and because you
can control the connection’s lifecycle. However, it combines two
concepts that aren’t consistent across browsers—XMLHttpRequest and HTTP Streaming—with
predictable portability issues. Experiments suggest that the
page-streaming technique does work on both IE
and Firefox (http://ajaxify.com/run/streaming/), but
service streaming only works properly on Firefox, whether XMLHTTPRequest (http://ajaxify.com/run/streaming/xmlHttpRequest/)
or IFrame (http://ajaxify.com/run/streaming/xmlHttpRequest/iframe/)
is used. In both cases, IE suppresses the response until it’s
complete. You could claim that’s either a bug or a feature; but
either way, it works against HTTP Streaming. So for portable page
updates, you have a few options:
Use a hybrid (http://ajaxlocal/run/streaming/xmlHttpRequest/iframe/scriptTags/) of page streaming and IFrame-based service streaming, in which the IFrame response outputs
scripttags, which include code to communicate with the parent document (e.g.,window.parent.onNewData(data);). As with standard page streaming, the scripts will be executed immediately. It’s not elegant, because it couples the remote service to the browser script’s structure, but it’s a fairly portable and reliable way to achieve HTTP Streaming.Use a limited form of service streaming, where the server blocks until the first state change occurs. At that point, it outputs a message and exits. This is not ideal, but certainly feasible (see "Real-World Examples" later in this chapter).
Use Periodic Refresh (Chapter 10) instead of HTTP Streaming.
Decisions
How long will you keep the connection open?
It’s impractical to keep a connection open forever. You need to decide on a reasonable period of time to keep the connection open, which will depend on:
The resources involved: server, network, browsers, and supporting software along the way.
How many clients will be connecting at any time. Not just averages, but peak periods.
How the system will be used—how much data will be output, and how the activity will change over time.
The consequences of too many connections at once. For example, will some users miss out on critical information? It’s difficult to give exact figures, but it seems fair to assume a small intranet application could tolerate a connection of minutes or maybe hours, whereas a public dotcom might only be able to offer this service for quick, specialized situations, if at all.
How will you decide when to close the connection?
The web service has several ways to trigger the closing of a connection:
A time limit is reached.
The first message is output.
A particular event occurs. For example, the stream might indicate the progress of a complex calculation (see Progress Indicator [Chapter 14]) and conclude with the result itself.
Never. The client must terminate the connection.
How will the browser distinguish between messages?
As the "Solution" mentions, the service can’t erase what it’s already output, so it often needs to output a succession of distinct messages. You’ll need some protocol to delineate the messages; e.g., the messages fit a standard pattern, the messages are separated by a special token string, or the messages are accompanied by some sort of metadata—for example, a header indicating message size.
Real-World Examples
LivePage
LivePage (http://twisted.sourceforge.net/TwistedDocs-1.2.0/howto/livepage.html)
is part of Donovan Preston’s Nevow framework (http://nevow.com), a
Python-based framework, built on the Twisted framework
(http://twistedmatrix.com/). Events are
pushed from the server using XMLHttpRequest-based service streaming.
For compatibility reasons, Nevow uses the technique mentioned in
the "Solution" in
which the connection closes after first output. Donovan explained
the technique to me:
When the main page loads, an XHR (XMLHttpRequest) makes an “output conduit” request. If the server has collected any events between the main page rendering and the output conduit request rendering, it sends them immediately. If it has not, it waits until an event arrives and sends it over the output conduit. Any event from the server to the client causes the server to close the output conduit request. Any time the server closes the output conduit request, the client immediately reopens a new one. If the server hasn’t received an event for the client in 30 seconds, it sends a noop (the javascript “null”) and closes the request.
Jotspot Live
Jotspot Live (http://jotlive.com/) is a live, multiuser wiki environment that uses HTTP Streaming to update message content (Figure 6-12). In an interview with Ajaxian.com (http://www.ajaxian.com/archives/2005/09/jotspot_live_li.html), developer Abe Fettig explained the design is based on LivePage (see the previous example).

Realtime on Rails
Martin Scheffler’s Realtime on Rails (http://www.uni-weimar.de/~scheffl2/wordpress/?p=19) is a real-time chat application that uses service streaming on Firefox and, because of the restrictions described in the earlier "Solution,” Periodic Refresh on other browsers.
Lightstreamer engine
Lightstreamer (http://www.lightstreamer.com/) is a commercial “push engine” used by companies in finance and other sectors to perform large-scale HTTP Streaming. Because it works as a standalone server, there are many optimizations possible; the company states that 10,000 concurrent users can be supported on a standard 2.4GHz Pentium 4 (http://www.softwareas.com/http-streaming-an-alternative-to-polling-the-server#comment-3078).
Pushlets framework
Just van den Broecke’s Pushlets framework (http://www.pushlets.com/doc/whitepaper-s4.html) is a Java servlet library based on HTTP Streaming that supports both page-streaming and service-streaming mechanisms.
Code Refactoring: AjaxPatterns Streaming Wiki
The Basic Wiki Demo (http://ajaxify.com/run/wiki) updates messages with Periodic Refresh, polling the server every five seconds. The present Demo (http://ajaxify.com/run/wiki/streaming) replaces that mechanism with service streaming. The AjaxCaller library continues to be used for uploading new messages, which effectively makes it a back-channel.
The Web Service remains generic, oblivious to the type of client that connects to it. All it has to do is output a new message each time it detects a change. Thus, it outputs a stream like this:
<message>content at time zero</message> <message>more content a few seconds later</message> <message>even more content some time after that </message> ... etc. ...
To illustrate how the server can be completely independent of the client application, it’s up to the client to terminate the service (in a production system, it would be cleaner for the service to exit normally; e.g., every 60 seconds). The server detects data changes by comparing old messages to new messages (it could also use an update timestamp if the message table contained such a field):
while (true) {
...
foreach ($allIds as $messageId) {
...
if ($isNew || $isChanged) {
print getMessageXML($newMessage); // prints "<message>...</message>"
flush( );
}
}
sleep(1);
}The browser sets up the request using the standard open( ) and send(
) methods. Interestingly, there’s no onreadystatechange handler because we’re
going to use a timer to poll the text. (In Firefox, a handler might
actually make sense, because onreadystatechange seems to be called whenever the response
changes.)
xhReq.open("GET", "content.phtml", true);
xhReq.send(null);
// Don't bother with onreadystatechange - it shouldn't close
// and we're polling responsetext anyway
...
pollTimer = setInterval(pollLatestResponse, 2000);pollLatestResponse( )
keeps reading the outputted text. It keeps track of
the last complete message it detected using nextReadPos. For example, if it’s
processed two 500-character messages so far, nextReadPos will be 1001. That’s where the
search for a new message will begin. Each complete message after
that point in the response will be processed sequentially. Think of
the response as a work queue. Note that the algorithm doesn’t assume
the response ends with </message>; if a message is
half-complete, it will simply be ignored.
function pollLatestResponse( ) {
var allMessages = xhReq.responseText;
...
do {
var unprocessed = allMessages.substring(nextReadPos);
var messageXMLEndIndex = unprocessed.indexOf("</message>");
if (messageXMLEndIndex!=-1) {
var endOfFirstMessageIndex = messageXMLEndIndex + "</message>".length;
var anUpdate = unprocessed.substring(0, endOfFirstMessageIndex);
renderMessage(anUpdate);
nextReadPos += endOfFirstMessageIndex;
}
} while (messageXMLEndIndex != -1);After some time, the browser will call xhReq.abort( ). In this case, it’s the
browser that stops the connection, but as mentioned earlier, it
could just as easily be the server.
Finally, note that the uploading still uses the AjaxCaller library. So if the user uploads a new message, it will soon be streamed out from the server, which the browser will pick up and render.
Alternatives
Periodic Refresh
Periodic Refresh (Chapter 10) is the obvious alternative to HTTP Streaming. It fakes a long-lived connection by frequently polling the server. Generally, Periodic Refresh is more scalable and easier to implement in a portable, robust manner. However, consider HTTP Streaming for systems, such as intranets, where there are fewer simultaneous users, you have some control over the infrastructure, and each connection carries a relatively high value.
TCP connection
Using a Richer Plugin like Flash or Java, the browser can initiate a TCP connection. The major benefit is protocol flexibility—you can use a protocol that’s suitable for long-lived connections, unlike HTTP, whose stateless nature means that servers don’t handle long connections very well. One library that facilitates this pattern is Stream (http://www.stormtide.ca/Stream/), consisting of an invisible Flash component and a server, along with a JavaScript API to make use of them.
Related Patterns
Distributed Events
You can use Distributed Events (Chapter 10) to coordinate browser activity following a response.
Metaphor
Think of a “live blogger” at a conference, continuously restating what’s happening each moment.
Want To Know More?
Donovan Preston on his creation of LivePage (http://ulaluma.com/pyx/archives/2005/05/multiuser_progr.html)
Alex Russell on Comet (http://alex.dojotoolkit.org/?p=545)
Acknowledgments
Thanks to Donovan Preston and Kevin Arthur for helping to clarify the pattern and its relationship to their respective projects, LivePage and Stream.
On-Demand JavaScript
⊙⊙ Behaviour, Bootstrap, CrossDomain, Dynamic, JavaScript, LazyLoading, OnDemand, ScriptTag
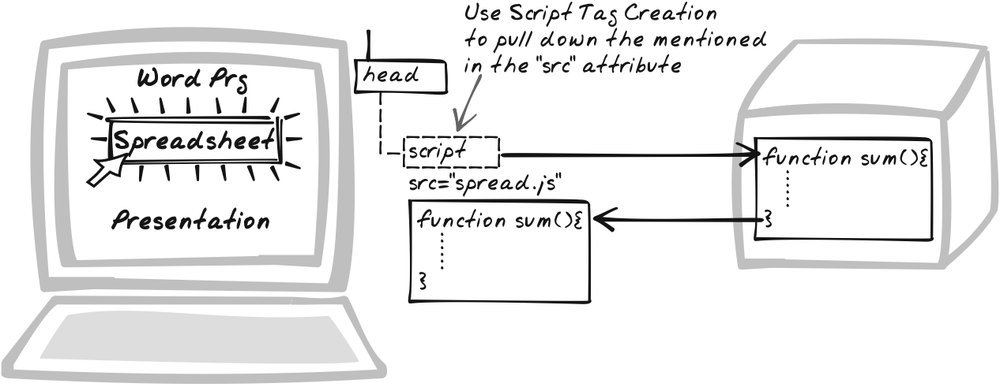
Goal Story
Bill’s logging into his bank web site. The login form comes up straight away, and as he types in his username and password, the browser is quietly downloading the JavaScript necessary for the rest of the application.
Problem
How can you deploy lots of JavaScript code?
Forces
Ajax Apps make heavy use of JavaScript. Richer browser behavior means bulkier JavaScript to download.
Downloading JavaScript has a performance impact. Interaction cannot fully begin until all initial JavaScript has been loaded.
Bandwidth is also a concern with heavy JavaScript content. Often, not all JavaScript that’s loaded is actually used, leading to a waste of bandwidth.
Solution
Download and run JavaScript snippets. The initial page load includes some JavaScript code, which—among other things—contains the bootstrapping code necessary to pull down further JavaScript. There are two techniques available: Script Tag Creation and Service Eval. Each will now be described, following by three main applications of the pattern.
With Script Tag Creation, use DOM
manipulation to inject a new script element into the page. Perhaps
surprisingly, the effect will be exactly the same as if the <script> tag had been encountered on
startup: the referenced JavaScript will be downloaded and executed
automatically. The tag can be attached to either the head or the
body, though the former is more common as that’s where you’d usually
find script tags:
var head = document.getElementsByTagName("head")[0];
script = document.createElement('script');
script.id = 'importedScriptId';
script.type = 'text/javascript';
script.src = "http://path.to.javascript/file.js";
head.appendChild(script);How will you know when the script has loaded? It seems
browsers vary in their behavior here, with some loading the script
synchronously and some not. In IE, you can be notified with a
mechanism similar to XMLHttprequest’s (http://www.xml.com/lpt/a/2005/11/09/fixing-ajax-xmlhttprequest-considered-harmful.htmlonreadystatechange).
With other browsers, you might need to keep polling for some
indication it’s loaded (where the indication depends on what the
script is meant to do). If you happen to control the server script,
you could implement a notification mechanism; i.e., complete the
script by calling back to a listener, if it exists. There’s actually
a promising proposal, JSONP (http://bob.pythonmac.org/archives/2005/12/05/remote-json-jsonp/),
which aims to have a simple, flexible mechanism like this, standard
across the entire industry.
Script Tag Creation doesn’t let you retrieve any old text; it has to be valid JavaScript. And your script won’t be able to read it directly because the browser will use it only for evaluation. So how can you get hold of some data from an external server? The most common way is for the remote JavaScript to assign a variable to the required data:
var characters = new Array("Mario", "Sonic", "Lara");The content is usually a data structure, just like a standard JSON Message, but it requires an assignment as well, in order to be referenced in the code. It could also be a function that returns the desired value. Either way, the browser code has to use whatever name is mentioned in the script, which isn’t ideal. Again, the idea of a flexible script mechanism like J is worth considering, as it would let the caller decide on the variable name.
Service Eval is the other technique for On-Demand
JavaScript, though not as prominent as Script Tag
Creation for reasons we’ll discuss later. Under
Service Eval, a Web
Service is called with a standard
XMLHttpRequest Call, it outputs some JavaScript as response content, and
the JavaScript is then executed with an eval( ) call. We’re just inspecting the
XMLHttpRequest Call’s responseText property, which we could
manipulate before evaluating, so the body doesn’t have to be a
complete, valid piece of JavaScript (unlike with Script
Tag Creation).
Any code not inside a function will be executed immediately. To add new functionality for later on, the JavaScript can add directly to the current window or to an object that’s already known to exist. For example, the following can be sent:
self.changePassword = function(oldPassword, newpassword) {
...
}The XMLHttpRequest callback
function just needs to treat the response as plain-text and pass it
to eval( ). A warning: here
again, asynchronicity rears its ugly head. You can’t assume the new
code will be available immediately after requesting it, so don’t do
this:
if (!self.changePassword) {
requestPasswordModuleFromServer( );
}
changePassword(old, new) // Won't work the first time because
// changePassword's not loaded yet.Instead, you either need to make a synchronous call to the server, add a loop to keep checking for the new function, or explicitly make the call in the response handler.
On-Demand JavaScript has three distinct applications:
- Lazy Loading
Defer loading of bulky JavaScript code until later on. Works with either On-Demand JavaScript technique (Service Eval or Script Tag Creation).
- Behavior Message
Have the server respond with a kind of “Behavior Message,” which dictates the browser’s next action. Works with either On-Demand JavaScript technique (Service Eval or Script Tag Creation).
- Cross-Domain Scripting
Using Script Tag Creation, bypass the standard “same-origin” policy that normally necessitates a Cross-Domain Proxy. Works only with Script Tag Creation.
Let’s look at Lazy Loading first. Conventionally, best practice has been to
avoid including JavaScript unobtrusively—by including it in one or
more script tags:
<html>
<head>
<script type="text/javascript" src="search.js"></script>
<script type="text/javascript" src="validation.js"></script>
<script type="text/javascript" src="visuals"></script>
</head>
...
</html>Lazy Loading builds on this approach to suggest just a minimal initialization module in the initial HTML:
<html>
<head>
<script type="text/javascript" src="init.js"></script>
</head>
...
</html>The initialization module declares whatever actions are required to start up the page and perhaps enough to cover typical usage. In addition, it must perform a bootstrapping function, pulling down new JavaScript on demand.
The second application, Behavior Message, is a variant of the
HTML Message pattern. Whereas Lazy Loading sets
up library code for ongoing use, Behavior Messages take some
transient code and runs eval( )
on it immediately—the script is not wrapped inside a function
(although it may define some functions that it calls). Effectively,
the browser is asking the server what to do next.
Cross-Domain Scripting is the third
application of this pattern. script tags have always been able to
include source JavaScript from external domains. The rule not only
applies to static <script>
tags, but also to dynamically created script tags as in the Script Tag
Creation technique. Thus, unlike with XMLHttpRequest and IFrame, your script can
directly access external content this way. And because the src property can be any URL, you can pass
in arguments as CGI variables. The idea is becoming rather popular,
with companies such as Yahoo! offering JavaScript APIs specifically
for this approach (see "Real-World Examples,” later
in this section).
Running a script from an external domain can be useful when you trust it, and ideally control it. Other times, it’s a definite security risk. Douglas Crockford, creator of JSON warns of the havoc an external script can wreak (http://www.mindsack.com/uxe/dynodes/) (emphasis mine):
That script can deliver the data, but it runs with the same authority as scripts on the base page, so it is able steal cookies or misuse the authorization of the user with the server. A rogue script can do destructive things to the relationship between the user and the base server.... The unrestricted script tag hack is the last big security hole in browsers. It cannot be easily fixed because the whole advertising infrastructure depends on the hole. Be very cautious.
Decisions
Will you use Service Eval or Script Tag Creation?
The choice is between Service Eval and Script Tag Creation depends on several factors. Service Eval has the following benefits over Script Tag Creation:
Being based on
XMLHttpRequest, there’s a standard mechanism for being notified when the script is ready, so there’s no risk of calling functions that don’t yet exist.You get access to the raw script code.
There’s more flexibility on the message format: you can, for example, send several JavaScript snippets inside different XML nodes, and have the browser script extract them out.
And Script Tag Creation has a couple of benefits over Service Eval:
You can load JavaScript from external domains. This is the only significant functional difference between the two styles.
The JavaScript will automatically be evaluated in much the same way as the JavaScript linked in the static HTML is evaluated when the
<script>tag is first encountered. Thus, you don’t have to explicitly add variables and functions to the document in order to use them later; you just declare them normally.
With Lazy Loading, how will you break modules down?
You’ll need to decide how to carve up your JavaScript. Standard principles of software development apply: a module should be well-focused, and intermodule dependencies should be avoided where possible. In addition, there are web-specific concerns:
Ideally, any given module is either not used at all, or used in entirety. What you don’t want is a 5000-line module that’s downloaded to retrieve a 3-line function. It’s a waste of bandwidth that defeats the main purpose of On-Demand JavaScript.
You need one or more modules present on startup. At least one is required to kick off further downloads as required.
Keep in mind that code will probably be cached locally. Alexander Kirk has done some experimentation with caching of On-Demand JavaScript (http://alexander.kirk.at/2005/10/11/caching-of-downloaded-code-testing-results/), and it turns out that all major browsers will cache code created with Script Tag Generation. You can usually ensure that responses from
XMLHttpRequestare also cached.
With Lazy Loading, at what stage will the script download the JavaScript?
It’s easiest to download the JavaScript just before it’s required, but that’s not always the best approach. There will be some delay in downloading the JavaScript, which means the user will be waiting around if you grab it at the last possible moment. When the user’s actions or the system state suggest some JavaScript will soon be needed, consider downloading it immediately.
Predicting if JavaScript is needed is an example of Predictive Fetch (Chapter 13)—grabbing something on the hunch that it might be needed. You need to make a trade-off about the likelihood it’s required against the hassle caused if you hold off until later. For example, imagine you have some JavaScript to validate a completed form. If you wait until the end, you’ll definitely not be wasting bandwidth, but it’s at the expense of the user’s satisfaction. You could download it when there’s one field to go, or two fields, or when the form’s first loaded. Each option increases the chance of a wasted download, but increases the chance of a smoother validation procedure.
Real-World Examples
MapBuilder
MapBuilder (http://mapbuilder.sourceforge.net) is a framework for mapping web sites (Figure 6-14). It uses On-Demand JavaScript to reduce the amount of code being downloaded. The application is based on a Model-View-Controller paradigm. Model information is declared in an XML file, along with the JavaScript required to load corresponding widgets. When the page starts up, only the required JavaScript is downloaded, instead of the entire code base. This is therefore a partial implementation of this pattern; it does ensure that only the minimal subset of JavaScript is ever used, but it doesn’t load pieces of the code in a lazy, on-demand style.
Delicious/Yahoo! APIs
Social bookmarking web site Delicious (http://del.icio.us), and its owner, Yahoo!, both offer JSON-based APIs, with appropriate hooks to allow direct access from the browser via Script Tag Creation. The Delicious API (http://del.icio.us/help/json) will create a new object with the result (or populate it if it’s already present). The Yahoo! API (http://developer.yahoo.net/common/json.html) allows you to specify a callback function in your script that the JSON will be passed to.
Dojo packaging framework
Dojo (http://dojotoolkit.org/download) is a comprehensive framework aiming to simplify JavaScript development. As such, it provides a number of scripts, of which an individual project might only use a subset. To manage the scripts, there’s a Java-like package system, which lets you pull in new JavaScript as required (http://dojo.jot.com/WikiHome/Documents/DojoPackageSystem). You need only include a single JavaScript file directly:
<script type="text/javascript" src="/dojo/dojo.js"></script>
You then pull in packages on demand with the Dojo API:
dojo.hostenv.moduleLoaded("dojo.aDojoPackage.*");Running the above command will cause Dojo to automatically
download the modules under dojo.aDojoPackage.[*]
JSAN import system
The JavaScript Archive Network (JSAN) (http://openjsan.org) is an online repository of scripts. As well, it includes a library for importing JavaScript modules, also a convention similar to Java. The following call:
JSAN.use('Module.To.Include');is mapped to Module/To/Include.js.
JSAN.includePath defines all
the possible top-level directories where this path can reside. If
the includePath is ["/","/js"],
JSAN will look for /Module/To/Include and /js/Module/To/Include.
Code Example, AjaxPatterns On-Demand JavaScript Wiki
Introducing On-Demand JavaScript to the Wiki Demo
In the Basic Wiki Demo (http://ajaxify.com/run/wiki), all JavaScript is downloaded at once. But many times, users will only read from the wiki—why download the code to write to it? So this demo refactors to On-Demand JavaScript in three stages:
The
uploadMessagefunction is extracted to a second JavaScript file, upload.js. There’s no On-Demand JavaScript yet because both files are included.A further refactoring introduces On-Demand JavaScript by ensuring that upload.js file is only downloaded if and when an upload occurs. This version uses Script Tag Creation.
In yet another refactoring, the Script Tag Creation technique is replaced with Service Eval.
Separate JavaScript: Extracting upload.js
In the first refactoring (http://ajaxlocal/run/wiki/separateJS/), the upload function is simply moved to a separate JavaScript file. The initial HTML includes the new file:
<script type="text/javascript" src="wiki.js"></script>
<script type="text/javascript" src="upload.js">The new upload.js now contains the
uploadMessage function.
Reflecting the separation, a couple of parameters are introduced
to help decouple the function from the main wiki script:
function uploadMessages(pendingMessages, messageResponseHandler) {
...
}The calling code is almost the same as before:
uploadMessages(pendingMessages, onMessagesLoaded);
We’ve thus far gained a bit of modularity, but don’t have a boost to performance yet, since both files must be downloaded on startup.
Script Tag Creation On-Demand JavaScript
With On-Demand JavaScript, the upload.js is no longer required on startup, so its reference no longer appears in the initial HTML, leaving just the main module, wiki.js:
<script type="text/javascript" src="wiki.js"></script>
A new function has been added to download the script. To
avoid downloading it multiple times, a guard clause checks if
uploadMessages already exists,
and if so, immediately returns. Following the Script Tag
Creation technique, it adds a script
element to the document’s head, initialized with the
upload.js URL and a standard JavaScript
type attribute:
function ensureUploadScriptIsLoaded( ) {
if (self.uploadMessages) { // Already exists
return;
}
var head = document.getElementsByTagName("head")[0];
script = document.createElement('script');
script.id = 'uploadScript';
script.type = 'text/javascript';
script.src = "upload.js";
head.appendChild(script);
}The calling script just has to invoke this function. However, as mentioned earlier in the "Solution,” it’s possibly downloaded asynchronously, so a check must be made here too:
ensureUploadScriptIsLoaded( );
if (self.uploadMessages) { // If not loaded yet, wait for next sync
uploadMessages(pendingMessages, onMessagesLoaded);
....If scripts are loaded asynchronously by the browser, the test will actually fail the first time, because the download function will return before the script’s been downloaded. But in this particular application, that doesn’t actually matter much—the whole synchronization sequence is run every five seconds anyway. If the upload function isn’t there yet, it should be there in five seconds, and that’s fine for our purposes.
Service Eval On-Demand JavaScript
The Script Tag Creation code is refactored here to use an Service
Eval instead, where an XMLHttpRequest
Call retrieves upload.js and
evals it. The initial
script—wiki.js differs only in its
implementation of the JavaScript retrieval. The text response is
simply passed to eval:
function ensureUploadScriptIsLoaded( ) {
if (self.uploadMessages) { // Already exists
return;
}
ajaxCaller.getPlainText("upload.js", function(jsText) { eval(jsText); });
}The JavaScript response must also change. If it simply defined a global function like before; i.e.:
function uploadMessages(pendingMessages, messageResponseHandler) {
...
}then the function would die when the evaluation completes. Instead, we can achieve the same effect by declaring the function as follows (this will attach the function to the current window, so it will live on after the script is evaluated).
uploadMessages = function(pendingMessages, messageResponseHandler) {
...
}Related Patterns
HTML Message
The Behavior Message usage of this pattern is a companion to HTML Message (Chapter 9) and follows a similar server-centric philosophy in which the server-side dynamically controls browser activity.
Predictive Fetch
Apply Predictive Fetch (Chapter 13) to On-Demand JavaScript by downloading JavaScript when you anticipate it will soon be required.
Multi-Stage Download
The Lazy Loading application of this pattern is a like Multi-Stage Download, which also defers downloading. The emphasis in Multi-Stage Download is downloading semantic and display content rather than downloading JavaScript. In addition, that pattern s more about downloading according to a prescheduled sequence rather than downloading on demand.
Want to Know More?
Dynamic Data Using the DOM and Remote Scripting, A Tutorial by Thomas Brattli (http://www.dhtmlcentral.com/tutorials/tutorials.asp?id=11)
[*] Other techniques do exist, and are mentioned in "Alternatives" in XMLHttpRequest Call later in this chapter.
[*] Because of the way JavaScript handles function calls, the library call will still go to the function in this form, even though the call contains three arguments.
[*] It’s possible not all modules will be downloaded, because the precise set can be defined by the package author and can be made dependent on the calling environment (whether browser or command line).
Get Ajax Design Patterns now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

