Chapter 4. Algorithms for Edge AI
There are two main categories of algorithms that are important in edge AI: feature engineering and artificial intelligence. Both types have numerous subcategories; in this chapter we’re going to explore a cross-section of them.
The goal is to provide an overview for each algorithm type from an engineering perspective, highlighting their typical usage, strengths, weaknesses, and suitability for deployment on edge hardware. This should give you a place to start when planning real-world projects, which we’ll walk through in the coming chapters.
Feature Engineering
In data science, feature engineering is the process of turning raw data into inputs usable by the statistical tools we use to describe and model situations and processes. Feature engineering involves using your domain expertise to understand which parts of the raw data contain the relevant information, then extracting that signal from the surrounding noise.
From an edge AI perspective, feature engineering is all about transforming raw sensor data into usable information. The better your feature engineering, the easier life is for the AI algorithms that are attempting to interpret it. When working with sensor data, feature engineering naturally makes use of digital signal processing algorithms. It can also involve chopping the data into manageable chunks.
Working with Data Streams
As we’ve seen, the majority of sensors produce time series data. The goal of an edge AI application is to take these streams of time series data and make sense of them.
The most common way to manage streams is to chop a time series into chunks, often called windows, then analyze the chunks one at a time.1 This produces a time series of results that you can interpret in order to understand what is going on. Figure 4-1 shows how a window is taken from a stream of data.
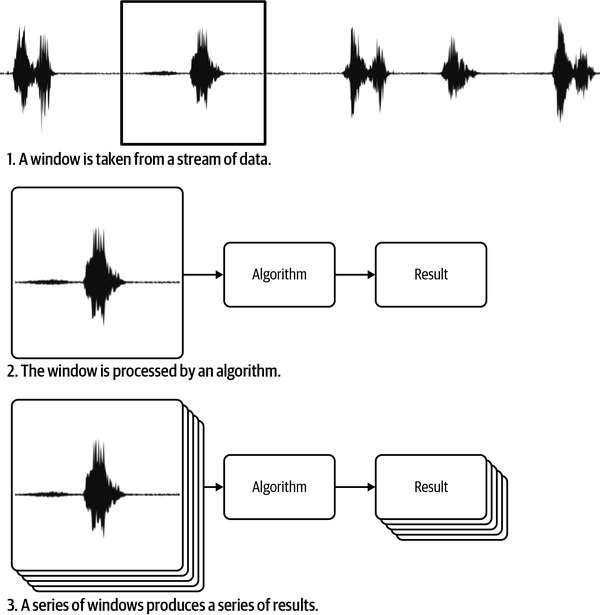
Figure 4-1. A time series is often broken into chunks, called windows, which are analyzed one at a time
It takes a certain amount of time to process a single chunk of data—we can call this the latency of our system. This limits how often we can take and process a window of data. The rate at which we can capture and process data is known as the frame rate of a system, often expressed in the number of windows that can be processed per second. Frames may be sequential or they may overlap, as shown in Figure 4-2.
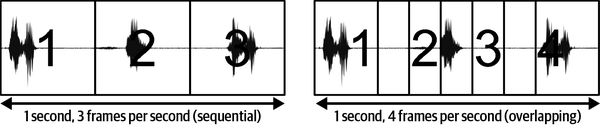
Figure 4-2. Depending on the frame rate, windows can potentially overlap; overlapping is desirable for data that contains events because it increases the chance that an entire event will fall within a window, rather than being cut short
The lower the latency, the more windows of data can be analyzed in a given period of time. The more analysis you can do, the more reliable the results. For example, imagine we are using a machine learning model to recognize a command. If the windows are too far apart, we might miss critical parts of a spoken command and not be able to recognize it (see Figure 4-3).
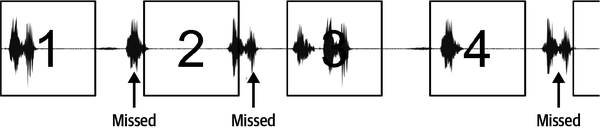
Figure 4-3. If the frame rate is too low, some parts of the signal will not be processed; if you are trying to detect short-lived events, this might mean that some events are missed
The choice of window size is very important. The larger the window, the longer it takes to process the data within it. However, larger windows contain more information about the signal—meaning they may make life easier for the signal processing and AI algorithms being used. The trade-off between window size and frame rate is an important thing to explore when you are developing a system.
As we’ll see later, there are many different AI algorithms—and some of them are more sensitive to window size than others. Some algorithms (typically those that maintain an internal memory of what is occurring in a signal) are able to work well with very small window sizes, while others require large window sizes in order to properly parse a signal. Algorithm choice also impacts latency, which also constrains window size. It’s a complex system of trade-offs between window size, latency, and algorithm choice.
Windowing also applies to video streams: in this case, each “window” of the video is a certain number of still images—typically a single one, but some AI algorithms can potentially analyze several images at the same time.
More sophisticated techniques for dealing with streams of data fall into the category of digital signal processing. These techniques can be combined with windowing in order to create data that feeds AI algorithms.
Digital Signal Processing Algorithms
There are hundreds of different signal processing algorithms that can help digest the signals produced by sensors. In this section, we’ll cover some of the DSP algorithms that are most important for edge AI.
Resampling
All time series signals have a sample rate (also known as a frequency), often described in terms of the number of data samples per second (Hz). It’s often necessary to change the sample rate of a signal. For example, you might want to reduce the rate of a signal (known as downsampling) if it is producing data faster than you can process it. On the other hand, you may want to increase the rate of a signal (upsampling) so that it can be conveniently analyzed alongside another signal that has a higher frequency.
Downsampling works by “throwing away” some of the samples in order to achieve the target frequency. For example, if you threw away every other frame of a 10 Hz (10 samples per second) signal it would become a 5 Hz signal. However, due to a phenomenon called aliasing, reducing the frequency in this way can lead to distortion in the output. To help combat this, signals must have some high-frequency information removed before they are downsampled. This is achieved using a low-pass filter, described in the next section.
Upsampling works in the opposite way—new samples are created and inserted to increase the frequency of a signal. For example, if an extra sample was inserted after every sample in a 10 Hz signal, it would become a 20 Hz signal. The difficult part is knowing what to insert! There’s no way to know what would actually have been happening during the time between two samples, but a technique known as interpolation can be used to fill in the blanks with an approximation.
In addition to time series, images can also be upsampled and downsampled. In this case, it’s the spatial resolution (pixels per image) that is being increased or decreased. Like time series resampling, the resizing of images also requires anti-aliasing or interpolation techniques.
Both upsampling and downsampling are important, but downsampling is more commonly encountered in edge AI. It’s typical for sensors to produce an output at a set frequency, leaving it to the developer to downsample and obtain the frequency that best suits the rest of their signal processing pipeline.
For edge AI applications, upsampling is mostly useful if you wish to combine two signals with different frequencies into a single time series. However, this can also be achieved by downsampling the higher frequency signal, which might be computationally cheaper.
Filtering
A digital filter is a function that, applied to a time series signal, transforms it in certain ways. Many different types of filters exist, and they can be very useful in preparing data for edge AI algorithms.
Low-pass filters are designed to allow low-frequency elements of a signal to pass through, while removing high-frequency elements. The cutoff frequency of the filter describes the frequency beyond which high-frequency signals will be affected, and the frequency response describes how much those signals will be affected.
High-pass filters are the same thing in reverse, allowing frequencies above a cutoff frequency to pass, and attenuating (reducing) those below. A band-pass filter combines the two, allowing frequencies within a certain band but attenuating those outside of it.
The purpose of filtering in edge AI is to isolate the useful parts of a signal, removing parts that do not contribute to solving the problem. For example, a speech recognition application could use a band-pass filter to allow frequencies in the normal range of human speech (125 Hz to 8 kHz) while rejecting information in other frequencies. This could make it easier for a machine learning model to interpret the speech without being distracted by other information in the signal.
Filters can be applied to any type of data. For example, if a low-pass filter is applied to an image, it has a blurring or smoothing effect. If a high-pass filter is applied to the same image, it will “sharpen” details.
One type of low-pass filter is a moving average filter. Given a time series, it calculates a moving average of values within a certain window. In addition to smoothing the data, it has the effect of making a single value represent information from a wide range of time.
If several moving averages are calculated and stacked together, each with differing window lengths, a momentary snapshot of the signal (containing several different moving averages) contains information about changes in the signal across a window of time and a number of different frequencies. This can be a helpful technique in feature engineering, since it means an AI algorithm can observe a broad window of time using relatively few data points.
Filtering is an extremely common signal processing operation. Many embedded processors provide hardware support for some types of filtering, which reduces latency and energy usage.
Spectral analysis
A time series signal can be said to be in the time domain, meaning it represents how a set of variables change over time. Using some common mathematical tools, it’s possible to transform a time series signal into the frequency domain. The values obtained through transformation describe how much of the signal lies in various frequency bands over a range of frequencies—a spectrum.
By slicing a signal into multiple, thin windows and then transforming each window into the frequency domain, as shown in Figure 4-5, it’s possible to create a map of how the signal’s frequencies change over time. This map, known as a spectrogram, serves as a very effective input to machine learning models.
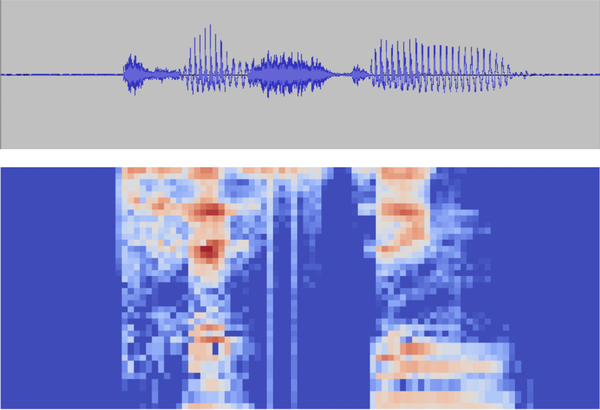
Figure 4-5. The same clip of audio represented as a waveform in the time domain (top) and a spectrogram in the frequency domain (bottom)
Spectrograms are commonly used in real-world applications, especially around audio. Separating the data into windowed frequency bands allows relatively small and simple models to interpret it.2 It’s also possible for humans to visually distinguish one word from another while looking at spectrograms—some people have even learned to read them.
There are many algorithms that can transform a signal from the time to the frequency domain, but the most common is the Fourier transform. It’s a very common operation, and there’s often hardware support (or at least optimized implementations) available for performing Fourier transforms on embedded devices.
There are a huge number of algorithms and techniques for digital signal processing and time series analysis; they’re major fields of engineering and study. Some great resources on the subjects are:
-
The Scientist and Engineer’s Guide to Digital Signal Processing, by Steven W. Smith (California Technical, 1997)
-
Practical Time Series Analysis, by Aileen Nielsen (O’Reilly, 2019)
Image feature detection
A whole subset of signal processing algorithms are concerned with the extraction of useful features3 from images. These have traditionally been referred to as computer vision algorithms. Some common examples include:
- Edge detection
-
Used to identify boundaries in an image (see Figure 4-6)
- Corner detection
-
Used to find points in an image that have an interesting two-dimensional structure
- Blob detection
-
Used to identify regions of an image that have something in common
- Ridge detection
-
Used to identify curves within an image

Figure 4-6. Edge detection algorithms find boundaries between areas with different colors or intensities
Image feature detection reduces a big, messy image into a more compact representation of the visual structures that are present within it. This can potentially make life easier for any AI algorithms that are operating downstream.
Feature detection is not always necessary when working with images. Typically, deep learning models are able to learn their own ways of extracting features, reducing the utility of preprocessing. However, it’s still common to perform feature detection when interpreting image data using other types of edge AI algorithm.
The OpenCV project provides a set of libraries for feature detection (and other image-processing tasks) that will run on most SoC devices. For microcontrollers, OpenMV provides an open source library of feature detection algorithm implementations along with hardware designed to run them.
Combining Features and Sensors
There’s nothing stopping you from combining several different features and signals as the input to your AI algorithms. For example, you could calculate several moving averages of a time series over several different windows and pass them all into a machine learning model together. There are no hard-and-fast rules, so feel free to experiment and be creative with the way you slice and dice your data. The following chapters will provide a framework for experimentation.
Going beyond combining features from the same signal, sensor fusion is the concept of integrating data from multiple sensors together. For example, an edge AI fitness tracker could combine information from an accelerometer, gyroscope, and heart rate sensor to try to detect which sport a wearer is playing.
In a more complex edge AI scenario, the sensors don’t even have to be integrated with the same device. Imagine a smart climate control system that makes use of temperature and occupancy sensors distributed throughout a building to optimize air conditioning usage.
There are three categories of sensor fusion:
- Complementary
-
Where multiple sensors combine to deliver a more complete understanding of a situation than would be possible with a single sensor—for example, the various sensors on our hypothetical fitness tracker.
- Competitive
-
Where multiple sensors measure the same exact thing in order to reduce the likelihood of bad measurements—for example, multiple redundant sensors monitoring the temperature of a critical piece of equipment.
- Cooperative
-
Where information from multiple sensors combines to create a signal that was not otherwise available—for example, two cameras producing a stereo image that provides depth information.
The challenge inherent in sensor fusion is how to combine multiple signals that may even occur at different rates. You should consider the following:
-
Aligning the signals in time. For many algorithms, it’s important that all of the signals we intend to fuse are sampled at the same frequency, and that the values reflect simultaneous measurements. This can be achieved through resampling—for example, upsampling a low-frequency signal so that it has the same rate as the high-frequency signal it is being fused with.
-
Scaling the signals. It’s critical that the signals’ values are on the same scale, so that a signal with typically large values does not overwhelm a signal with typically smaller ones.
-
Numerically combining the signals. This can be done using simple mathematical operations (addition, multiplication, or averaging) or with more sophisticated algorithms such as the Kalman filter (covered later)—or simply by concatenating the data together and passing it into the algorithm as a single matrix.
You can perform sensor fusion before or after other stages of feature engineering. For an arbitrary example: if you intended to fuse two time series, you might choose to run a low pass over one of them first, then scale them to the same scale, combine the two through averaging, and transform the combined values into the frequency domain. Don’t be afraid to experiment!
We now have some serious tools for processing data. In the next section, we’ll explore the AI algorithms that will help us understand it.
Artificial Intelligence Algorithms
There are two ways to think about AI algorithms. One is based on functionality: what are they designed to do? The other is based on implementation: how do they work? Both aspects are important. Functionality is critical to the application you are trying to build, and implementation is important when thinking about your constraints—which generally means your dataset and the device you will be deploying to.
Algorithm Types by Functionality
First up, let’s look at the most important types of algorithm from a functional perspective. Mapping the problem you are trying to solve to these algorithm types is known as framing, and we’ll be diving deep into framing in Chapter 6.
Classification
Classification algorithms try to solve the problem of distinguishing between various types, or classes, of things. This could mean:
-
A fitness monitor with an accelerometer classifying walking versus running
-
A security system with an image sensor classifying an empty room versus a room with a person present
-
A wildlife camera classifying four different species of animal
Figure 4-7 shows a classifier being used to determine whether a forklift truck is idle or moving, based on data collected by an accelerometer.
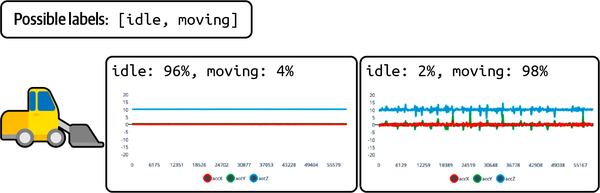
Figure 4-7. A classifier typically outputs a probability distribution including each possible class
Classification can be categorized in a few different ways, depending on the task:
- Binary classification
-
The input belongs to one of two classes.
- Multiclass classification
-
The input belongs to one of more than two classes.
- Multilabel classification
-
The input belongs to zero or more of any number of classes.
The most common forms of classification are binary and multiclass. With these forms of classification, you always need at least two classes. Even if there’s only one thing you care about (for example, a person in the room), you also need a class that represents everything that you don’t care about (for instance, rooms that don’t have people in them). Multilabel classification is comparatively rare.
Regression
Regression algorithms try to come up with numbers. This could mean:
-
A smart thermostat that predicts the temperature in an hour’s time
-
A virtual scale that estimates the weight of a food product using a camera
-
A virtual sensor that estimates a motor’s speed of rotation based on its sound
Virtual sensors, like the latter two examples, are a particularly interesting case of regression. They can use available sensor data to predict measurements from different types of sensor—without actually requiring those sensors to be present.
Object detection and segmentation
Object detection algorithms take an image or video and identify the locations of specific objects within them, often by drawing bounding boxes around them. They combine classification and regression, identifying specific types of objects and predicting their numeric coordinates—as seen in Figure 4-8.

Figure 4-8. A common output for object detection models consists of bounding boxes drawn around detected objects, each with an individual confidence score
Specialized object detection algorithms exist for particular types of objects. For example, pose estimation models are designed to recognize human body parts and identify their locations within an image—as shown in Figure 4-9.

Figure 4-9. Pose estimation identifies key points on a human body, the position of which can be used as input for other processes
Segmentation algorithms are similar to object detection algorithms, but they classify images at a pixel level. This results in a segmentation map, as seen in Figure 4-10, which attempts to label areas of the input with their content.

Figure 4-10. This street scene has been labeled with a segmentation map. Different areas, such as people and the road surface, are shown in different shades. A segmentation algorithm aims to predict which pixels belong to which type of object.
Here are some example use cases for object detection and segmentation:
Anomaly detection
Anomaly detection algorithms recognize when a signal has deviated from its normal behavior. They are useful in many applications:
-
An industrial predictive maintenance system that can recognize when a motor has started to break down by its current draw
-
A robot vacuum that can identify when it is driving on an unusual surface using an accelerometer
-
A trail camera that knows when an unknown animal has walked past
Anomaly detection algorithms are very useful for predictive maintenance. They’re also very helpful when paired with machine learning models. Many machine learning models will produce spurious, random results if they are presented with an input that isn’t in their training set.
To avoid this, an ML model can be paired with an anomaly detection algorithm that tells it when something is out of distribution so that its spurious results can be discarded. Some types of models can also be calibrated so that their output represents a true probability distribution that can be interpreted to recognize when the model is uncertain.
Clustering
Clustering algorithms try to group inputs by similarity and can recognize when an input is not similar to what it has seen before. They are often used when an edge AI device needs to learn from its environment, including for anomaly detection applications. For example, consider:
-
A voice assistant that learns which voice belongs to each of its users
-
A predictive maintenance application that learns a “normal” state of operation and can detect deviations from it
-
A vending machine that can recommend drinks based on a user’s previous choices
A clustering algorithm can either learn its clusters on the fly (after deployment) or have them configured ahead of time.
Dimensionality reduction
Dimensionality reduction algorithms take a signal and produce a representation of it that contains equivalent information but takes up a lot less space. The representations of two signals can then be compared to one another easily. Here are some example applications:
-
Compression of audio, to make it cheaper to transmit sounds from a remote device
-
Fingerprint recognition, ensuring a fingerprint matches the owner of a device
-
Facial recognition, recognizing individual faces in a video feed
Dimensionality reduction tends to be used alongside other AI algorithms, as opposed to being used on its own. For example, it can be used in conjunction with a clustering algorithm to identify similar signals in complex data types, like audio and video.
Transformation
Transformation algorithms take one signal and output another. Here are some examples:
-
Noise-canceling headphones that identify and remove specific noises in a signal
-
A car reversing camera that enhances the image in dark or rainy conditions
-
A speech recognition device that takes an audio signal and outputs a transcription
The input and output of transformation algorithms can be extremely different. In the case of transcription, the input is a stream of audio data and the output is a sequence of words.
Combining Algorithms
There’s no reason you can’t mix different types of algorithms in the same application. Later in this section we’ll explore techniques for combining algorithms (see “Combining algorithms”).
Algorithm Types by Implementation
Exploring algorithms by functionality helps us understand what they are used for, but from an engineering perspective it’s important to get a sense for the different ways these functionalities can be implemented. There are hundreds of different ways to build a classification algorithm, for example, resulting from decades of computer science research. Each method has its own unique strengths and weaknesses that are amplified by the constraints posed by edge AI hardware.
In the following section, we’ll explore the most important ways that edge AI algorithms are implemented. Bear in mind that this isn’t an exhaustive list—we’re focused on edge AI, so we’re focused on technologies that work well on-device.
Conditionals and heuristics
The simplest type of AI algorithms are based on conditional logic: simple if statements that result in decisions. Let’s look back at the code snippet we explored in “Artificial Intelligence”:
current_speed=10# In meters per seconddistance_from_wall=50# In metersseconds_to_stop=3# The minimum time in seconds required to stop the carsafety_buffer=1# The safety margin in seconds before hitting the brakes# Calculate how long we’ve got before we hit the wallseconds_until_crash=distance_from_wall/current_speed# Make sure we apply the brakes if we’re likely to crash soonifseconds_until_crash<seconds_to_stop+safety_buffer:applyBrakes()
This simple algorithm does a basic calculation using some human-defined values (seconds_to_stop, etc.) and decides whether to apply a car’s brakes. Does this count as AI? It’s a question that might stimulate debate—but the answer is emphatically yes.4
The common understanding of artificial intelligence is that it’s a quest to create machines that can think like human beings. The engineering definition is much more realistic: AI allows computers to do tasks that typically require human intelligence. In this case, controlling a car’s brakes to avoid a collision is definitely something that has typically required human intelligence. It would have been considered extremely impressive twenty years ago, but automatic braking is a common feature in modern vehicles.
Note
Before you laugh at the idea that if statements can be artificial intelligence, consider that decision trees—one of the most popular and effective categories of machine learning algorithms—are just if statements under the hood. These days, even deep learning models can be implemented as binary neural networks, which are essentially conditional logic. Intelligence comes from the application, not the implementation!
The conditional logic in our car braking algorithm is actually an implementation of classification. Given an input (the speed of the car and the distance from a wall), the algorithm classifies the situation into one of two types: safe driving or impending crash. Conditional logic is naturally used for classification since its output is categorical; an if statement gives us either one output or another.
Conditional logic is connected to the idea of heuristics. A heuristic is a handcrafted rule that can be applied to a situation in order to help understand or react to it. For example, our car braking algorithm uses the heuristic that if we have less than four seconds before hitting a wall, we should apply the brakes.
Heuristics are designed by human beings using domain knowledge. This domain knowledge can be built on data that has been collected about a real-world situation. In that respect, our seemingly simple car braking algorithm might actually represent some deep, well-researched understanding of the real world. Perhaps the value of seconds_to_stop was arrived at after millions of dollars’ worth of crash tests and represents the ideal value for the constant. With this in mind, it’s easy to see how even an if statement can represent a significant amount of human intelligence and knowledge, captured and distilled into a simple and elegant piece of code.
Our car braking example is very simple—but when paired with signal processing, conditional logic can make some quite sophisticated decisions. For example, imagine you are building a predictive maintenance system that aims to alert workers of the health of an industrial machine based on the sounds it makes. Perhaps the machine makes a characteristic high-pitched whine when it is about to break down. If you capture audio and translate it into the frequency domain using a Fourier transform, you can use a simple if statement to determine when the whine is happening and let the workers know.
Beyond if statements, you can use more complex logic to interpret situations based on known rules. For example, an industrial machine may use a handcoded algorithm to avoid damage by varying its speed based on measurements of internal temperature and pressure. The algorithm might take the temperature and pressure and directly calculate an RPM, using human insight that is captured in the code.
If it works for your situation, conditional logic and other handcoded algorithms can be amazing. It is easy to understand, easy to debug, and easy to test. There’s no risk of unspecified behavior: the code either branches one way or another, and all paths can be exercised with automated tests. It runs incredibly fast and will work on any imaginable device.
There are two major downsides of heuristics. First, developing them may require significant domain knowledge and programming expertise. Domain knowledge is not always available—for example, a small company might not have the resources to conduct the expensive research necessary to understand the fundamental mathematical rules of a system. In addition, even given domain knowledge, not everyone has the expertise required to design and implement a heuristic algorithm in efficient code.
The second big downside is the idea of combinatorial explosion. The more variables that are present in a situation, the more difficult it is to model with traditional computer algorithms. A good example of this is the game of chess: there are so many pieces, and so many possible moves, that deciding what to do next requires a vast amount of computation. Even the most advanced chess computers built using conditional logic can easily be beaten by expert human players.
Some edge AI problems are far more complex than games of chess. For example, imagine trying to handwrite conditional logic that can determine whether a camera image shows an orange or a banana. With some tricks (“yellow means banana, orange means orange”) you might succeed for some categories of images—but it would be impossible to make it generalize beyond the simplest of scenes.
A good rule of thumb for handcoded logic is that the more data values you have to deal with, the more difficult it is going to be to get a satisfactory solution. Fortunately, there are plenty of algorithms that can step in when a handcoded approach fails.
Classical machine learning
Machine learning is a special approach to creating algorithms. Where heuristic algorithms are created by handcoding logic based on known rules, machine learning algorithms discover their own rules—by exploring large amounts of data.
The following description, taken from the book TinyML, introduces the basic ideas behind machine learning:
To create a machine learning program, a programmer feeds data into a special kind of algorithm and lets the algorithm discover the rules. This means that as programmers, we can create programs that make predictions based on complex data without having to understand all of the complexity ourselves. The machine learning algorithm builds a model of the system based on the data we provide, through a process we call training. The model is a type of computer program. We run data through this model to make predictions, in a process called inference.
TinyML (O’Reilly, 2019)
Machine learning algorithms can perform all of the functional tasks described earlier in this chapter, from classification to transformation. The key requirement for using machine learning is that you have a dataset. This is a large store of data, generally collected under real-world conditions, that is used to train the model.
Typically, the data needed to train a machine learning model is gathered during the development process, aggregated from as many sources as possible. As we’ll see in later chapters, a large and varied dataset is critical for working with edge AI—but especially machine learning.
Since machine learning depends on large datasets, and because training a machine learning model is computationally expensive, the training part generally happens before deployment, with inference happening on the edge. It’s certainly possible to train machine learning models on-device, but the lack of data combined with the small amount of compute make it a challenge.
In edge AI, there are two main ways to work with machine learning datasets:
- Supervised learning
-
Where the dataset has been labeled by an expert to assist the machine learning algorithm in understanding it
- Unsupervised learning
-
Where the algorithm identifies structures in the data without human help
Machine learning has a major dataset-related drawback. ML algorithms depend entirely on their training data to know how to respond to inputs. As long as they are receiving inputs that are similar to their training data, they should work well. However, if they receive an input that is significantly dissimilar from their training dataset—known as an out-of-distribution input—they will produce an output that is completely useless.
The tricky part is that there is no obvious way of telling, from the output, that an input was out of distribution. This means that there’s always a risk that a model is providing useless predictions. Avoiding this problem is a core concern when working with machine learning.
There are many different types of machine learning algorithms. Classical machine learning encompasses the vast majority of them used in practice, with the major exception of deep learning (which we’ll explore in the next section).
Here are some of the most useful types of classical ML algorithms for edge AI. The title indicates whether they are supervised or unsupervised algorithms:
- Regression analysis (supervised)
-
Learns the mathematical relationships between input and output to predict a continuous value. Easy to train, fast to run, low data requirements, and highly interpretable, but can only learn simple systems.
- Logistic regression (supervised)
-
A classification-oriented type of regression analysis, logistic regression learns the relationship between input values and categories of output—for relatively simple systems.
- Support vector machine (supervised)
-
Uses fancy mathematics to learn much more complex relationships than basic regression analysis. Low data requirements, fast to run, can learn complex systems, but difficult to train and low interpretability.
- Decision trees and random forests (supervised)
-
Uses an iterative process to construct a series of
ifstatements that predict an output category or value. Easy to train, fast to run, highly interpretable, can learn complex systems but may require a lot of training data. - Kalman filter (supervised)
-
Predicts the next datapoint given a history of measurements. Can factor in multiple variables to improve precision. Often trained on-device, low data requirements, fast to run, easy to interpret, but can only model relatively simple systems.
- Nearest neighbors (unsupervised)
-
Classifies data by how similar it is to known data points. Often trained on-device, low data requirements, easy to interpret, but can only model relatively simple systems and can be slow with lots of data points.
- Clustering (unsupervised)
-
Learns to group inputs by similarity but does not require labels. Often trained on-device, low data requirements, fast to run, easy to interpret, but can only model relatively simple systems.
Classical ML algorithms are an incredible set of tools for interpreting the output of your feature engineering pipeline and making decisions with data. They cover the spectrum from highly efficient to highly flexible, and they can perform many functional tasks. Another major benefit is that they tend to be very explainable—it’s easy to understand how they are making their decisions. And depending on the algorithm, the data requirements can be quite low (deep learning typically requires very large datasets).
The diverse pool of classical ML algorithms (there are literally hundreds) are both a blessing and a curse for edge AI. On the one hand, there are algorithms well suited to many different situations, which makes it possible to find one that is—theoretically—ideal for a particular use case. On the other hand, the large constellation of algorithms can be challenging to explore.
While libraries like scikit-learn make it easy to try out many different algorithms, there’s an art and a science to tuning each one to perform optimally, and to interpreting their results. In addition, if you’re hoping to deploy to a microcontroller, you may have to write your own efficient implementation of an algorithm—there are not many open source versions available yet.
A major downside of classical ML algorithms is that they run into a relatively low ceiling in terms of complexity of the systems they can model. This means that to get the best results, they often have to be paired with heavy feature engineering—which can be complex to design and computationally costly. Even with feature engineering, there are some tasks—such as the classification of image data—where classical ML algorithms just don’t perform well.
That said, classical ML algorithms are a fantastic set of tools for making on-device decisions. But if you hit their limitations, deep learning might help.
Deep learning
Deep learning is a type of machine learning that focuses on neural networks. These have proven such an effective tool that deep learning has grown into a gigantic field, with deep neural networks being applied to many types of application.
Note
This book focuses on the important properties of deep learning algorithms from an engineering perspective. The underlying mechanics of deep learning are interesting, but they’re not required knowledge for building an edge AI product. Using modern tools, any engineer can deploy deep learning models without a formal background in machine learning. We’ll share some of the tools for doing that in the tutorial chapters later on.
Deep learning shares the same principles as classical ML. A dataset is used to train a model, which can be implemented on a device to perform inference. There isn’t anything magical about a model—it’s just a combination of an algorithm and a collection of numbers that are fed into it, along with the model’s input, in order to produce the desired output.
The numbers in the model are called weights, or parameters, and they’re generated during the training process. The term neural network refers to the way that the model combines its input with its parameters, which was inspired by the way neurons in an animal brain connect to one another.
Many of the most mind-blowing feats of AI engineering that we’ve seen over the past decade have made use of deep learning models. Here are some popular highlights:
-
AlphaGo, a computer program that used deep learning to beat the best players at Go, an ancient game once thought impossible for computers to master
-
GPT-3, a model that can generate written language that is indistinguishable from human writing
-
Fusion reactor control, using deep learning to control the shape of plasma within a fusion reactor
-
DALL•E, a model that can generate realistic images and abstract art based on text prompts
-
GitHub Copilot, software that assists software engineers by automatically writing code
Beyond the fancy stuff, deep learning excels at all of the tasks in our subsections of algorithm types (see “Algorithm Types by Functionality”). It has proven to be flexible, adaptable, and an incredibly useful tool in allowing computers to understand and influence the world.
Deep learning models are effective because they work as universal function approximators. It’s been mathematically proven that, as long as you can describe something as a continuous function, a deep learning network can model it. This basically means that for any dataset that shows various inputs and desired outputs, there’s a deep learning model out there that can convert one into the other.
A really exciting result of this ability is that during training, deep learning models can figure out how to do their own feature engineering. If a special transformation is needed to help interpret the data, a deep learning model can potentially learn how to do it. This doesn’t make feature engineering obsolete, but it definitely reduces the burden on the developer to get things exactly right.
The reason deep learning models are so good at approximating functions is that they can have very large numbers of parameters. With each parameter, the model gets a little bit more flexibility, allowing it to describe a slightly more complex function.
This property leads to the two major drawbacks of deep learning models. First, finding the ideal values for all of these parameters is a difficult process. It involves training a model with lots of data. Data is often a rare and precious resource, difficult and expensive to obtain, so this can be a major obstacle. Fortunately, there are many techniques that can help make the most of limited data—we’ll cover them later in the book.
The second major drawback is the risk of overfitting. Overfitting is when a machine learning model learns a dataset too well. Instead of modeling the general rules that lead from outputs to inputs in its dataset, it memorizes the dataset completely. This means that it won’t perform well on data that it hasn’t seen before.
Overfitting is a risk with all machine learning models, but it’s especially a challenge for deep learning models because they can have so many parameters. Each additional parameter provides the model with slightly more ability to memorize its dataset.
There are a lot of different types of deep learning models. Here are some of the most important for edge AI:
- Fully connected models
-
The simplest type of deep learning model, fully connected models consist of stacked layers of neurons. The input of a fully connected model is fed directly in as a long series of numbers. Fully connected models are capable of learning any function, but they are mostly blind to spatial relationships in their inputs (for example, which values in an input are next to one another).
In an embedded context, this means they work well for discrete values (for example, if the input features are a set of statistics about a time series) but they aren’t as great with raw time series or image data.
Fully connected models are very well supported on embedded devices, with hardware and software optimizations commonly available.
- Convolutional models
-
Convolutional models are designed to make use of the spatial information in their inputs. For example, they can learn to recognize shapes in images, or the structures of signals within time series sensor data. This makes them extremely useful in embedded applications since spatial information is important in so many of the signals we deal with.
Like fully connected models, convolutional models are very well supported on embedded devices.
- Sequence models
-
Sequence models were designed originally for use on sequences of data, like time series signals or even written language. To help them recognize long-term patterns in time series, they often include some internal “memory.”
It turns out that sequence models are very flexible, and there’s increasing evidence that they can be very effective on any signal where spatial information is important. Many people believe they will eventually take over from convolutional models.
Sequence models are currently less well supported than convolutional and fully connected models on embedded devices; there are few open source libraries that provide optimized implementations for them. This is more due to inertia than technical limitations, so the situation is likely to change over the next couple of years.
- Embedding models
-
An embedding model is a pretrained deep learning model that is designed for dimensionality reduction—it takes a big, messy input and represents it as a smaller set of numbers that describes it within a certain context. They are used in the same way a signal processing algorithm would be: they produce features that can be interpreted by another ML model.
Embedding models are available for many tasks, from image processing (turning a big messy image into a numeric description of its contents) to speech recognition (turning raw audio into a numeric description of the vocal sounds within it).
The most common use for embedding models is transfer learning, which is a way of reducing the amount of data required to train a model. We’ll learn more about that later.
Embedding models can be fully connected, convolutional, or sequence models, so their support on embedded devices varies—but convolutional embedding models are the most common.
It’s only in recent years that deep learning models have been brought to edge AI hardware. Since they are often large and involve significant computation to run, it’s been the advent of high-end MCUs and SoCs with relatively powerful processors and large amounts of ROM and RAM that have enabled them to make the leap.
It’s possible to run a small deep learning model using just a few kilobytes of memory, but for models that do more complex things—from audio classification to object detection—it is common for models to require dozens or hundreds of kilobytes as a minimum.
This is already impressive since traditional server-side machine learning models can be anywhere from tens of megabytes to several terabytes in size. Using clever optimization, and by limiting scope, embedded models can be made much smaller—we’ll introduce some of these techniques shortly.
There are various ways to run a deep learning model on an embedded device. Here’s a quick summary:
- Interpreters
-
Deep learning interpreters, like TensorFlow Lite for Microcontrollers, use an interpreter to execute a model that is stored as a file. They are flexible and easy to work with, but they come with some computational and memory overhead, and they don’t support every type of model.
- Code generation
-
Code generation tools, like EON, take a trained deep learning model and translate it into optimized embedded source code. This is more efficient than an interpreter-based approach, and the code is human-readable so it can still be debugged, but it still doesn’t support every possible model type.
- Compilers
-
Deep learning compilers, like microTVM, take a trained model and generate optimized bytecode that can be included into embedded applications. The implementation they generate can be highly efficient, but it’s not as easy to debug and maintain as actual source code. They can support model types not explicitly supported by interpreters and code generation. It’s common for embedded hardware vendors to provide custom interpreters or compilers to assist with running deep learning models on their hardware.
- Handcoding
-
It’s possible to implement a deep learning network by writing code by hand, incorporating the parameter values from a trained model. This is a difficult and time-consuming process, but it allows full control over optimization and allows you to support any model type.
The environment for deploying deep learning models is very different between SoCs and microcontrollers. Since SoCs run full, modern operating systems, they also support most of the tools that are used to run deep learning models on servers. This means that pretty much any type of model will run on a Linux SoC. That said, the latency of the model will vary depending on the architecture of the model and the SoC’s processor.
There are also interpreters designed specifically for SoC devices. For example, TensorFlow Lite provides tools that allow deep learning models to be run more efficiently on SoCs—typically those that are used in smartphones. They include optimized implementations of deep learning operations that make use of features available in some SoCs, such as GPUs.
The SoCs that have integrated deep learning accelerators are a special case. Typically, the hardware vendor will provide a special compiler or interpreter that allows the model to make use of hardware acceleration. Accelerators typically only accelerate certain operations, so the amount of speedup depends on the architecture of the model.
Since microcontrollers don’t run full operating systems, the standard tools for running deep learning models aren’t available. Instead, frameworks like TensorFlow Lite for Microcontrollers provide a baseline of model support. They tend to lag behind the standard tools a little in terms of operator support, meaning they will not run some model architectures.
Operators and Kernels
In edge machine learning, an operator, or kernel, is an implementation of a particular mathematical operation used to run a deep learning model. These are overloaded terms with different meanings in other fields, including elsewhere in deep learning.
Typical high-end microcontrollers have hardware features such as SIMD instructions that will drastically improve the performance of deep learning models. TensorFlow Lite for Microcontrollers includes optimized implementations of operators, making use of these instructions, for several vendors. Like with SoCs, the vendors of microcontroller-based hardware accelerators often provide custom compilers or interpreters that allow models to run on their hardware.
The core advantages of deep learning are its flexibility, reduced requirements for feature engineering, and ability to make use of large amounts of data due to the high parameter counts of models. Deep learning is noteworthy for its ability to approximate complex systems, going beyond simple prediction to perform tasks such as generating art and accurately recognizing objects in images. Deep learning provides a lot of freedom, and researchers have only just begun to explore its potential.
The core disadvantages are its high data requirements, its propensity toward overfitting, the relatively large size and computational complexity of deep learning models, and the complexity of the training process. Additionally, deep learning models can be hard to interpret—it can be challenging to explain why they make one prediction over another. That said, there are tools and techniques that help mitigate most of these drawbacks.
Combining algorithms
A single edge AI application can make use of multiple different types of algorithms. Here are some typical ways this is done:
- Ensembles
-
An ensemble is a collection of machine learning models that are fed the same input. Their outputs are combined mathematically in order to make a decision. Since every ML model has its own strengths and weaknesses, an ensemble of models is often more accurate together than its constituent parts. The downside of ensembles is the additional complexity, memory, and compute required to store and run multiple models.
- Cascades
-
A cascade is a set of ML models that are run in sequence. For example, in a cellphone with a built-in digital assistant, a small, lightweight model is run constantly to detect any signs of human speech. Once speech is detected, a larger, more computationally expensive model is woken up in order to determine what was said.
Cascades are a great way of saving energy since they allow you to avoid unnecessary computation. In a heterogeneous compute environment, where multiple types of processor are available, the individual components of a cascade can even be run on different processors.
- Feature extractors
-
As we learned earlier, embedding models take a high-dimensional input, like an image, and distill it down to a set of numbers that describe its content. The output of an embedding model can be fed into another model, designed to make predictions based on what the embedding model describes about the original input. In this case, the embedding model is being used as a feature extractor.
If a pretrained embedding model is used, this technique—known as transfer learning—can massively reduce the amount of data required to train a model. Instead of learning how to interpret the original high-dimensional input, the model only needs to learn how to interpret the simple output returned by the feature extractor.
For example, imagine you wish to train a model to identify different species of birds from photographs. Rather than train an entire model from scratch, you could use the output of a pretrained feature extractor as the input to your model. This could reduce the amount of data and training time required in order to get good results.
Many pretrained deep learning feature extractors are available under open source licenses. They are commonly used for image related tasks, since large public image datasets are available for pretraining.
- Multimodal models
-
A multimodal model is a single model that takes inputs of multiple types of data simultaneously. For example, a multimodal model might accept both audio and accelerometer data together. This technique can be used as a mechanism for sensor fusion, using a single model to combine disparate data types.
Postprocessing algorithms
On edge AI devices, we typically work with streams of data—for example, a continuous time series of audio data. When we run an edge AI algorithm on that stream of data, it will produce a second time series that represents the outputs of the algorithm over time.
This poses a problem. How do we interpret this second time series in order to decide? For example, imagine we are analyzing audio to detect when somebody says a keyword so that we can trigger some functionality on a product. What we really want to know is when did we hear the keyword?
Unfortunately, the time series of inference results is not ideal for this purpose. First, it contains many events that do not represent a keyword being detected. To clean these up, we can ignore any whose confidence that a keyword was spotted is below a certain threshold.
Second, the model may occasionally (and briefly) detect a keyword when a keyword was not actually spoken. We need to filter out these blips to clean up our output. This is equivalent to running a low-pass filter on the time series.
Finally, instead of telling us each time the keyword was spoken, the raw time series tells us at a set rate whether the keyword is currently being spoken. This means we need to do some output gating to get the information we really want.
After cleaning up the raw output, we now have a signal that tells us when a keyword was actually spotted. This is something we can use in our application logic to control our device.
This sort of postprocessing is extremely common in edge AI applications. The exact postprocessing algorithm used, and its particular parameters—for example, the threshold for considering something a match—can be determined on a case-by-case basis. Tools like Edge Impulse’s Performance Calibration (covered in “Performance Calibration”) allow developers to automate discovery of the ideal postprocessing algorithm for their application.
Fail-safe design
There are many things that can go wrong with an edge AI application, so it’s critical that there are always safeguards in place to protect against unexpected issues.
For example, imagine a wildlife camera that uses a deep learning model to identify when an animal of interest has been photographed and uploads the animal’s image via a satellite connection. Under normal operation, it may send a few photographs a day—not costing very much in data fees.
But out in the field, a physical problem with the camera hardware—such as dirt or reflections on the lens—might result in images being taken that are very different from those in the original training dataset. These out-of-distribution images could lead to unspecified behavior from the deep learning model—which could mean that the model begins to constantly report that the animal of interest is present.
These false positives, caused by out-of-distribution inputs, might result in hundreds of images being uploaded via satellite connection. Not only would the camera be rendered useless, but it could potentially cost large amounts in data transfer fees.
In real-world applications, there’s no way to avoid things like damage to sensors or unexpected behavior from algorithms. Instead, it’s important that you design your application to be fail-safe. This means that if part of the system were to fail, the application would minimize harm.
The best way to do this varies between situations. In the case of a wildlife camera, it could be wise to build in a rate limit that kicks in if an unreasonable number of photographs are being uploaded. In another application, you might shut a system down entirely rather than risk harm being caused.
Building fail-safe applications is an important part of responsible AI—and good engineering in general. It is something to think about from the very beginning of any project.
Optimization for Edge Devices
With machine learning models, and particularly deep learning models, there’s often a trade-off between how well a model performs its task and how much memory and compute the model requires.
This trade-off is extremely important for edge AI. Edge devices are typically computationally constrained. They are designed to minimize cost and energy usage, not to maximize compute. At the same time, they are expected to deal with real-time sensor data, often at high frequencies, and potentially react in real time to events in the data stream.
Larger machine learning models tend to be better at complex tasks, since they have more capacity—which is helpful for learning complicated relationships between inputs and outputs. This extra capacity means they may require more ROM and RAM, and it also means they take longer to compute. The additional compute time results in higher power consumption, as we’ll learn in “Duty cycle”.
Finding the correct balance between task performance and computational performance is essential in any application. It’s a matter of juggling constraints. On the one hand, there’s a minimum standard for performance at a given task. On the other hand, hardware choices create hard limits on available memory, latency, and energy.
Managing this trade-off is one of the difficult—but fascinating—parts of edge AI development. It’s part of what makes the field uniquely interesting, and why tools for things like AutoML (which we’ll learn about in “Automated machine learning (AutoML)”) need to be redesigned for edge AI.
Here are some of the factors that can help us minimize compute requirements while maximizing task performance.
Choice of algorithm
Every edge AI algorithm has a slightly different profile of memory usage and computational complexity. The constraints of your target hardware should inform your choice of algorithm. Typically, classical ML algorithms are smaller and more efficient than deep learning algorithms.
However, it’s commonly the case that feature engineering algorithms use vastly more compute than either, making the choice between classical ML and deep learning less significant. The exception to this rule is the analysis of image data, which typically requires little feature engineering but relatively large deep learning models.
Here are some common ways to reduce the latency and memory required by your choice of algorithms:
-
Reduce the complexity of feature engineering. More math means higher latency.
-
Reduce the amount of data that reaches the AI algorithm.
-
Use classical ML instead of deep learning.
-
Trade complexity between feature engineering and machine learning model, depending on which runs more efficiently on your device.
-
Reduce the size (the number of weights and layers) of deep learning models.
-
Choose model types that have accelerator support on your device of choice.
Compression and optimization
There are many optimization techniques designed to reduce the amount of data and computation required by a given algorithm. Here are some of the most important types:
- Quantization
-
One way to reduce the amount of memory and computation required by an algorithm or model is to decrease the precision of its numeric representations. As mentioned in “How Are Values Represented?”, there are many different ways to represent numbers in computation—some that have more precision than others.
Quantization is the process of taking a set of values and reducing their precision while preserving the important information they contain. It can be done for both signal processing algorithms and ML models. It’s especially useful for deep learning models, which by default tend to have 32-bit floating-point weights. By reducing the weights to 8-bit integers you can reduce a model to 1/4th its size—typically without much reduction in accuracy.
Another advantage of quantization is that the code to perform integer math is faster and more portable than the code for floating-point math. This means that quantization results in a significant speedup on many devices, and that quantized algorithms will run on devices that lack floating-point units.
Quantization is a lossy optimization, meaning that it typically reduces the task performance of the algorithm. In ML models, this can be mitigated by training at a lower precision so that the model learns to compensate.
- Operator fusion
-
In operator fusion, a computation-aware algorithm is used to inspect the operators that are used when a deep learning model is run. When certain groups of operators are used together, it’s possible to replace them with a single fused implementation that has been written to maximize computational efficiency.
Operator fusion is a lossless technique: it improves computational performance without causing any reduction in task performance. The downside is that fused implementations are only available for certain combinations of operators, so its impact depends greatly on the architecture of a model.
- Pruning
-
Pruning is a lossy technique applied during the training of a deep learning model. It forces many of the model’s weights to have a value of zero, creating what is known as a sparse model. In theory, this should allow for faster computation since any multiplication involving a zero weight will invariably result in a zero.
However, at this point in time there is very little edge AI hardware and software designed to take advantage of sparse weights. This will change over the next few years, but for now the main benefit of pruning is that sparse models are easier to compress, due to their large blocks of identical values. This is helpful when models need to be sent over the air.
- Knowledge distillation
-
Knowledge distillation is another lossy deep learning training technique that enables a large “teacher” model to help train a smaller “student” model to reproduce its functionality. It takes advantage of the fact that there is typically a lot of redundancy in the weights of a deep learning model, meaning that it’s possible to find an equivalent model that is smaller but performs almost as well.
Knowledge distillation is a bit fiddly, so it’s not yet a common technique—but it’s likely to become a best practice over the next few years.
- Binary neural networks (BNNs)
-
BNNs are deep learning models where every weight is a single binary number. Since binary arithmetic is extremely fast on computers, binary neural networks can be very efficient to run. However, they are a relatively new technology and the tooling for training and running inference with them is not yet in broad use. Binarization is similar to quantization and is therefore a lossy technique.
- Spiking neural networks (SNNs)
-
A spiking neural network is an artificial neural network where the signals transmitted through the network have a time component. As “neuromorphic” systems, they are designed to more closely resemble the way biological neurons work. They have different trade-offs compared to traditional deep learning models, offering improved performance and efficiency for some tasks. However, they require specialized hardware (in the form of an accelerator) in order to offer a benefit.
SNNs can either be trained directly or be created from a traditional deep learning model in a conversion process. This process may be lossy.
Model compression has two major downsides. The first is that running compressed models often requires specific software, hardware, or a combination of the two. This can limit the devices that a compressed model can be deployed to.
The second downside is more dangerous. The lossy nature of compression often results in a subtle degradation of a model’s predictive performance that can be difficult to spot. The reduction in precision can bias a model to perform well in common cases, but to lose performance in the “long tail” of less frequently encountered inputs.
This problem can amplify the biases inherent in datasets and algorithms. For example, if a dataset collected for training an ML-powered health wearable contains fewer examples from people in minority groups, model compression may lead to degraded performance for people in these groups. Since they are a minority, the impact on the model’s overall accuracy might be hard to spot. This makes it extremely important to evaluate your system’s performance on every subgroup within your dataset (see “Collecting Metadata”).
There are two excellent scientific papers on this topic from researcher Sara Hooker et al. One is “What Do Compressed Deep Neural Networks Forget?”, and the other is “Characterising Bias in Compressed Models”.
On-Device Training
In the vast majority of cases, machine learning models used in edge AI are trained before being deployed to a device. Training requires large amounts of data, typically annotated with labels, and involves significant computation—the equivalent of hundreds or thousands of inferences per data point. This limits the utility of on-device training, since by nature edge AI applications are subject to severe constraints in memory, compute, energy, and connectivity.
That said, there are a few scenarios where on-device training makes sense. Here’s an overview:
- Predictive maintenance
-
A common example of on-device training happens in predictive maintenance when a machine is being monitored to determine whether it is functioning normally. A small on-device model can be trained with data that represents a “normal” state. If the machine’s signals start to deviate from that baseline, the application can notice and take action.
This use case is only possible when it can be assumed that abnormal signals are rare, and that at any given moment the machine is likely to be operating normally. This allows the device to treat the data being collected as having an implicit “normal” label. If abnormal states were common, it would be impossible to make assumptions about the state at any given moment.
- Personalization
-
Another example where on-device training makes sense is when a user is asked to deliberately provide labels. For example, some smartphones use facial recognition as a security method. When the user sets up the device, they are asked to enroll images of their face. A numeric representation of these facial images is stored.
These types of applications tend to use carefully designed embedding models that convert raw data into compact numeric representations of their content. The embeddings are designed in such a way that the Euclidean distance between two embeddings5 corresponds to the similarity between them. In our face recognition example, this makes it easy to determine whether a new face matches the representations stored during setup: the distance between the new face and the enrolled face is calculated, and if it is sufficiently close then the faces are considered the same.
This form of personalization works well because, typically, the algorithm used to determine embedding similarity can be very simple; either a distance calculation or a nearest neighbors algorithm. The embedding model has done all the hard work.
- Implicit association
-
A further example of on-device training is when labels are available by association. For example, battery management features such as Apple’s Optimized Battery Charging train models on-device to predict what time a user is likely to be using their device. One way to do this would be to train a forecasting model to output a probability of usage at a specific time, given a log of the previous few hours’ usage.
In this case, it’s easy to collect and label training data on a single device. Usage logs are collected in the background, and labels are applied according to some metric (such as whether the screen was activated). The implicit association between time and log content allow the data to be labeled. A simple model can then be trained.
- Federated learning
-
One of the obstacles to training on-device is a lack of training data. In addition, on-device data is often private and users are not comfortable with it being transmitted. Federated learning is a way of training models in a distributed manner, across many devices, while preserving privacy. Instead of raw data being transmitted, partially trained models are passed around between devices (or between each device and a central server). The partially trained models can be combined and distributed back to devices once they are ready.
Federated learning often seems attractive since it appears to provide a way for models to learn and improve while in the field. However, it has some serious limitations. It is computationally expensive and requires large amounts of data transfer, which runs counter to the core benefits of edge AI. The training process is very complex and requires both on-device and server-side components, which increases project risk.
Since data is not stored globally, there is no way to validate that the trained model is performing well across the entire deployment. The fact that models are uploaded from local devices presents a vector for security attacks. Finally, and most importantly, it does not solve the problem of labels. If labeled data is not available, federated learning is useless.
- Over-the-air updates
-
Although not actually an on-device training technique, the most common way to update models in the field is via over-the-air updates. A new model can be trained in the lab, using data collected from the field, and distributed to devices via firmware updates.
This depends on network communication, and it doesn’t solve the problem of obtaining labeled data, but it’s the most common way to keep models up to date over time.
1 The chunks can be discrete or overlapping, or even have gaps between them.
2 One reason for this is that the raw audio shown in Figure 4-5 consists of 44,100 samples, while the equivalent spectrogram only has 3,960 elements. The smaller input means a smaller model.
3 In image processing, a feature is a particular piece of information about an image, such as the positions of certain visual structures. The Wikipedia page titled “Feature (computer vision)” lists many common image features.
4 There’s a well-documented phenomenon known as the “AI effect”, where the moment AI researchers figure out how to make a computer do a task, critics no longer consider that task representative of intelligence.
5 An embedding can be thought of as a coordinate in a multidimensional space. The Euclidean distance between two embeddings is the distance between the two coordinates.
Get AI at the Edge now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

