Chapter 1. A Brief Introduction to Edge AI
Welcome on board! In this chapter, we’ll be taking a comprehensive tour of the edge AI world. We’ll define the key terms, learn what makes “edge AI” different from other AI, and explore some of the most important use cases. Our goal for this chapter is to answer these two important questions:
-
What is edge AI, anyway?
-
Why would I ever need it?
Defining Key Terms
Each area of technology has its own taxonomy of buzzwords, and edge AI is no different. In fact, the term edge AI is a union of two buzzwords, fused together into one mighty term. It’s often heard alongside its siblings, embedded machine learning and TinyML.
Before we move on, we better spend some time defining these terms and understanding what they mean. Since we’re dealing with compound buzzwords, let’s deal with the most fundamental parts first.
Embedded
What is “embedded”? Depending on your background, this may be the most familiar of all the terms we’re trying to describe. Embedded systems are the computers that control the electronics of all sorts of physical devices, from Bluetooth headphones to the engine control unit of a modern car. Embedded software is software that runs on them. Figure 1-1 shows a few places where embedded systems can be found.

Figure 1-1. Embedded systems are present in every part of our world, including the home and the workplace
Embedded systems can be tiny and simple, like the microcontroller that controls a digital watch, or large and sophisticated, like the embedded Linux computer inside a smart TV. In contrast to general-purpose computers, like a laptop or smartphone, embedded systems are usually meant to perform one specific, dedicated task.
Since they power much of our modern technology, embedded systems are extraordinarily widespread. In fact, there were over 28 billion microcontrollers shipped in the year 20201—just one type of embedded processor. They’re in our homes, our vehicles, our factories, and our city streets. It’s likely you are never more than a few feet from an embedded system.
It’s common for embedded systems to reflect the constraints of the environments into which they are deployed. For example, many embedded systems are required to run on battery power, so they’re designed with energy efficiency in mind—perhaps with limited memory or an extremely slow clock rate.
Programming embedded systems is the art of navigating these constraints, writing software that performs the task required while making the most out of limited resources. This can be incredibly difficult. Embedded systems engineers are the unsung heroes of the modern world. If you happen to be one, thank you for your hard work!
The Edge (and the Internet of Things)
The history of computer networks has been a gigantic tug of war. In the first systems—individual computers the size of a room—computation was inherently centralized. There was one machine, and that one machine did all the work.
Eventually, however, computers were connected to terminals (as shown in Figure 1-2) that took over some of their responsibilities. Most of the computation was happening in the central mainframe, but some simple tasks—like figuring out how to render letters onto a cathode-ray tube screen—were done by the terminal’s electronics.
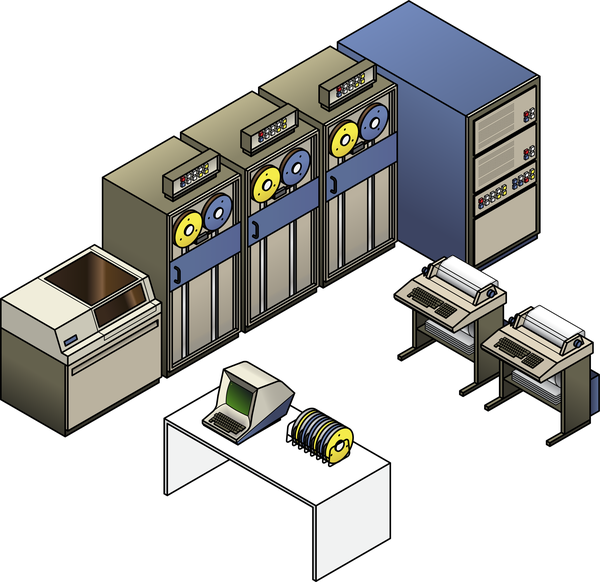
Figure 1-2. Mainframe computers performed the bulk of the computation, while simple terminals processed input, printed output, and rendered basic graphics
Over time, terminals became more and more sophisticated, taking over more and more functions that were previously the job of the central computer. The tug-of-war had begun! Once the personal computer was invented, small computers could do useful work without even being connected to another machine. The rope had been pulled to the opposite extreme—from the center of the network to the edge.
The growth of the internet, along with web applications and services, made it possible to do some really cool stuff—from streaming video to social networking. All of this depends on computers being connected to servers, which have gradually taken over more and more of the work. Over the past decade, most of our computing has become centralized again—this time in the “cloud.” When the internet goes down, our modern computers aren’t much use!
But the computers we use for work and play are not our only connected devices. In fact, it is estimated that in 2021 there were 12.2 billion assorted items connected to the internet,2 creating and consuming data. This vast network of objects is called the Internet of Things (IoT), and it includes everything you can think of: industrial sensors, smart refrigerators, internet-connected security cameras, personal automobiles, shipping containers, fitness trackers, and coffee machines.
Tip
The first ever IoT device was created in 1982. Students at Carnegie Mellon University connected a Coke vending machine to the ARPANET—an early precursor to the internet—so they could check whether it was empty without leaving their lab.
All of these devices are embedded systems containing microprocessors that run software written by embedded software engineers. Since they’re at the edge of the network, we can also call them edge devices. Performing computation on edge devices is known as edge computing.
The edge isn’t a single place; it’s more like a broad region. Devices at the edge of the network can communicate with each other, and they can communicate with remote servers, too. There are even servers that live at the edge of the network. Figure 1-3 shows how this looks.
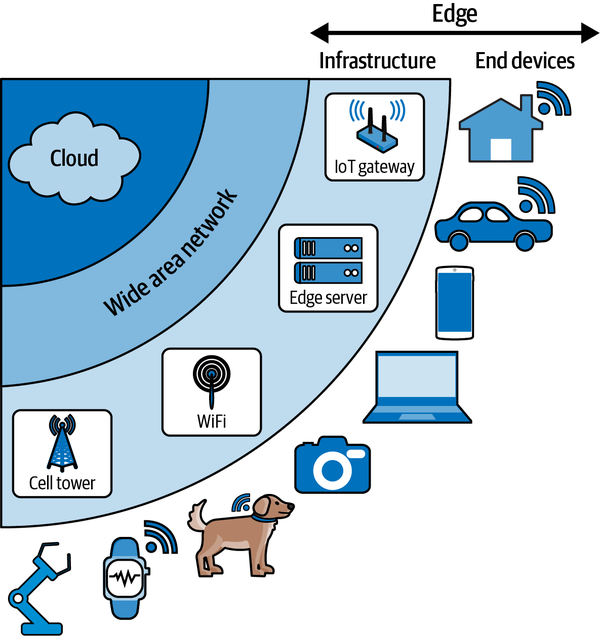
Figure 1-3. Devices at the edge of the network can communicate with the cloud, with edge infrastructure, and with each other; edge applications generally span multiple locations within this map (for example, data might be sent from a sensor-equipped IoT device to a local edge server for processing)
There are some major benefits to being at the edge of the network. For one, it’s where all the data comes from! Edge devices are our link between the internet and the physical world. They can use sensors to collect data based on what is going on around them, be that the heart rate of a runner or the temperature of a cold drink. They can make decisions on that data locally and send it to other locations. Edge devices have access to data that nobody else does.
Are Mobile Phones and Tablets Edge Devices?
As portable computers that live at the edge of the network, mobile phones, tablets, and even personal computers are all edge devices. Mobile phones were one of the first platforms to feature edge AI: modern mobile phones use it for many purposes, from voice activation to smart photography.3
We’ll come back to edge devices later (since they’re the focus of this book). Until then, let’s continue to define some terms.
Artificial Intelligence
Phew! This is a big one. Artificial intelligence (AI) is a very big idea, and it’s terribly hard to define. Since the dawn of time, humans have dreamed of creating intelligent entities that can help us in our struggle to survive. In the modern world we dream of robot sidekicks who assist with our adventures: hyperintelligent, synthetic minds that will solve all of our problems, and miraculous enterprise products that will optimize our business processes and guarantee us rapid promotion.
But to define AI, we have to define intelligence—which turns out to be particularly tough. What does it mean to be intelligent? Does it mean that we can talk, or think? Clearly not—just ask the slime mold (see Figure 1-4), a simple organism with no central nervous system that is capable of solving a maze.
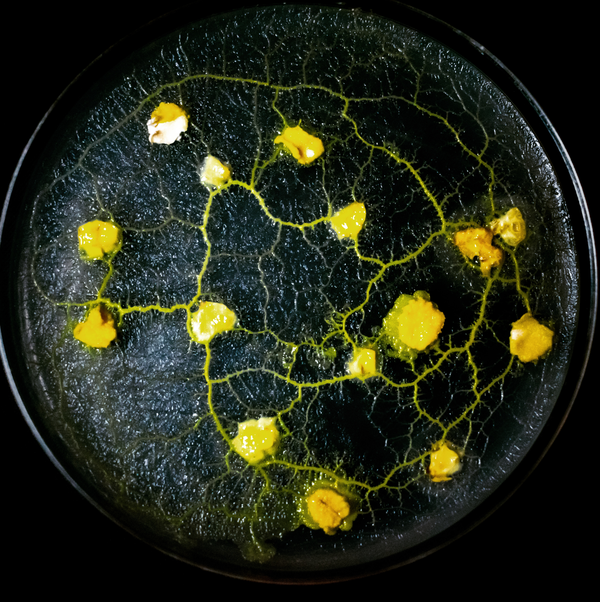
Figure 1-4. Slime molds are single-celled organisms that have been documented as being able to solve mazes in order to locate food, via a process of biological computation—as shown in “Slime Mould Solves Maze in One Pass Assisted by Gradient of Chemo-Attractants” (Andrew Adamatzky, arXiv, 2011)
Since this isn’t a philosophy book, we don’t have the time to fully explore the topic of intelligence. Instead, we want to suggest a quick-and-dirty definition:
Intelligence means knowing the right thing to do at the right time.
This probably doesn’t stand up to academic debate, but that’s fine with us. It gives us a tool to explore the subject. Here are some tasks that require intelligence, according to our definition:
-
Taking a photo when an animal is in the frame
-
Applying the brakes when a driver is about to crash
-
Informing an operator when a machine sounds broken
-
Answering a question with relevant information
-
Creating an accompaniment to a musical performance
-
Turning on a faucet when someone wants to wash their hands
Each of these problems involves both an action (turning on a faucet) and a precondition (when someone wants to wash their hands). Within their own context, most of these problems sound relatively simple—but, as anyone who has used an airport restroom knows, they are not always straightforward to solve.
It’s pretty easy for most humans to perform most of these tasks. We’re highly capable creatures with general intelligence. But it’s possible for smaller systems with more narrow intelligence to perform the tasks, too. Take our slime mold—it may not understand why it is solving a maze, but it’s certainly able to do it.
That said, the slime mold is unlikely to also know the right moment to turn on a faucet. Generally speaking, it’s a lot easier to perform a single, tightly scoped task (like turning on a faucet) than to be able to perform a diverse set of entirely different tasks.
Creating an artificial general intelligence, equivalent to a human being, would be super difficult—as decades of unsuccessful attempts have shown. But creating something that operates at slime mold level can be much easier. For example, preventing a driver from crashing is, in theory, quite a simple task. If you have access to both their current speed and their distance from a wall, you can do it with simple conditional logic:
current_speed=10# In meters per seconddistance_from_wall=50# In metersseconds_to_stop=3# The minimum time in seconds required to stop the carsafety_buffer=1# The safety margin in seconds before hitting the brakes# Calculate how long we’ve got before we hit the wallseconds_until_crash=distance_from_wall/current_speed# Make sure we apply the brakes if we’re likely to crash soonifseconds_until_crash<seconds_to_stop+safety_buffer:applyBrakes()
Clearly, this simplified example doesn’t account for a lot of factors. But with a little more complexity, a modern car with a driver assistance system based on this conditional logic could arguably be marketed as AI.4
There are two points we are trying to make here: the first is that intelligence is quite hard to define, and many rather simple problems require a degree of intelligence to solve. The second is that the programs that implement this intelligence do not necessarily need to be particularly complex. Sometimes, a slime mold will do.
So, what is AI? In simple terms, it’s an artificial system that makes intelligent decisions based on some kind of input. And one way to create AI is with machine learning.
Machine Learning
At its heart, machine learning (ML) is a pretty simple concept. It’s a way to discover patterns in how the world works—but automatically, by running data through algorithms.
We often hear AI and machine learning used interchangeably, as if they are the same thing—but this isn’t the case. AI doesn’t always involve machine learning, and machine learning doesn’t always involve AI. That said, they pair together very nicely!
The best way to introduce machine learning is through an example. Imagine you’re building a fitness tracker—it’s a little wristband that an athlete can wear. It contains an accelerometer, which tells you how much acceleration is happening on each axis (x, y, and z) at a given moment in time—as shown in Figure 1-5.
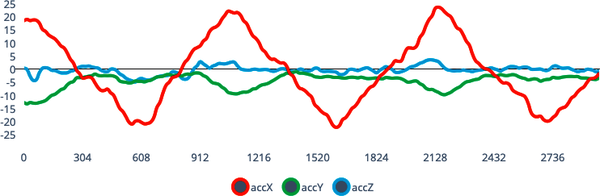
Figure 1-5. The output of a three-axis accelerometer sampled at 6.25 Hz
To help your athletes, you want to keep an automatic log of the activities they are doing. For example, an athlete might spend an hour running on Monday and then an hour swimming on Tuesday.
Since our movements while swimming are quite different from our movements while running, you theorize that you might be able to tell these activities apart based on the output of the accelerometer in your wristband. To collect some data, you give prototype wristbands to a dozen athletes and have them perform specific activities—either swimming, running, or doing nothing—while the wristbands log data (see Figure 1-6).
Now that you have a dataset, you want to try to determine some rules that will help you understand whether a particular athlete is swimming, running, or just chilling out. One way to do this is by hand: analyzing and inspecting the data to see if anything stands out to you. Perhaps you notice that running involves more rapid acceleration on a particular axis than swimming. You can use this information to write some conditional logic that determines the activity based on the reading from that axis.
Analyzing data by hand can be tricky, and it generally requires expert knowledge about the domain (such as human movements during sport). An alternative to manual analysis might be to use machine learning.
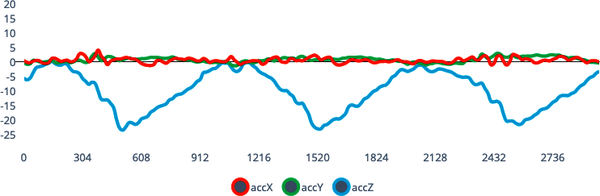
Figure 1-6. The output of a three-axis accelerometer showing a different activity than in Figure 1-5; each activity can be characterized by a pattern of changes in acceleration on each axis over time
With an ML approach, you feed all of your athletes’ data into a training algorithm. When provided with both the accelerometer data and information about which activity the athlete is currently performing, the algorithm does its best to learn a mapping between the two. This mapping is called a model.
Hopefully, if the training was successful, your new machine learning model can take a brand new, never-seen-before input—a sample of accelerometer data from a particular window in time—and tell you which activity an athlete is performing. This process is known as inference.
This ability to understand new inputs is called generalization. During training, the model has learned the characteristics that distinguish running from swimming. You can then use the model in your fitness tracker to understand fresh data, in the same way that you might use the conditional logic we mentioned earlier.
There are lots of different machine learning algorithms, each with their own strengths and drawbacks—and ML isn’t always the best tool for the job. Later in this chapter we’ll discuss the scenarios where machine learning is the most helpful. But a nice rule of thumb is that machine learning really shines when our data is really complex.
Edge AI
Congratulations, we’ve made it to our first compound buzzword! Edge AI is, unsurprisingly, the combination of edge devices and artificial intelligence.
As we discussed earlier, edge devices are the embedded systems that provide the link between our digital and physical worlds. They typically feature sensors that feed them information about the environment they are close to. This gives them access to a metaphorical fire hose of high-frequency data.
We’re often told that data is the lifeblood of our modern economy, flowing throughout our infrastructure and enabling organizations to function. That’s definitely true—but all data is not created equally. The data obtained from sensors tends to have a very high volume but a relatively low informational content.
Imagine the accelerometer-based wristband sensor we described in the previous section. The accelerometer is capable of taking a reading many hundreds of times per second. Each individual reading tells us very little about the activity currently taking place—it’s only in aggregate, over thousands of readings, that we can begin to understand what is going on.
Typically, IoT devices have been viewed as simple nodes that collect data from sensors and then transmit it to a central location for processing. The problem with this approach is that sending such large volumes of low-value information is extraordinarily costly. Not only is connectivity expensive, but transmitting data uses a ton of energy—which is a big problem for battery-powered IoT devices.
Because of this problem, the vast majority of data collected by IoT sensors has usually been discarded. We’re collecting a ton of sensor data, but we’re unable to do anything with it.
Edge AI is the solution to this problem. Instead of having to send data off to some distant location for processing, what if we do it directly on-device, where the data is being generated? Now, instead of relying on a central server, we can make decisions locally—no connectivity required.
And if we still want to report information back to upstream servers, or the cloud, we can transmit just the important information instead of having to send every single sensor reading. That should save a lot of cost and energy.
There are many different ways to deploy intelligence to the edge. Figure 1-7 shows the continuum from cloud AI to fully on-device intelligence. As we’ll see later in this book, edge AI can be spread across entire distributed computing architectures—including some nodes at the very edge, and others in local gateways or the cloud.
As we’ve seen, artificial intelligence can mean many different things. It can be super simple: a touch of human insight encoded in a little simple conditional logic. It can also be super sophisticated, based on the latest developments in deep learning.
Edge AI is exactly the same. At its most basic, edge AI is about making some decisions on the edge of the network, close to where the data is made. But it can also take advantage of some really cool stuff. And that brings us nicely to the next section!
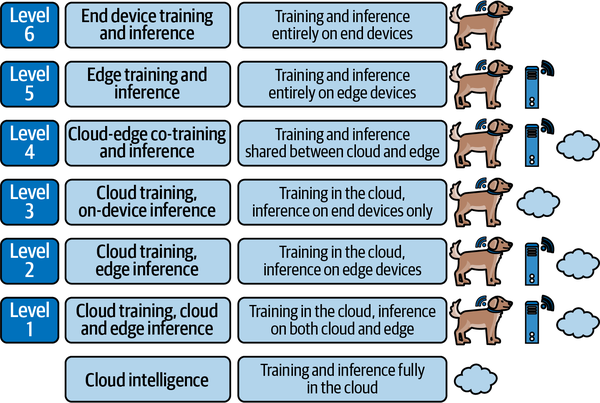
Figure 1-7. The continuum between cloud intelligence and fully on-device intelligence; these six levels were described by “Edge Intelligence: Paving the Last Mile of Artificial Intelligence with Edge Computing” (Zhou et. al., Proceedings of the IEEE, 2019)
Embedded Machine Learning and Tiny Machine Learning
Embedded ML is the art and science of running machine learning models on embedded systems. Tiny machine learning, or TinyML,5 is the concept of doing this on the most constrained embedded hardware available—think microcontrollers, digital signal processors, and small field programmable gate arrays (FPGAs).
When we talk about embedded ML, we’re usually referring to machine learning inference—the process of taking an input and coming up with a prediction (like guessing a physical activity based on accelerometer data). The training part usually still takes place on a conventional computer.
Embedded systems often have limited memory. This raises a challenge for running many types of machine learning models, which often have high requirements for both read-only memory (ROM) (to store the model) and RAM (to handle the intermediate results generated during inference).
They are often also limited in terms of computation power. Since many types of machine learning models are quite computationally intensive, this can also raise problems.
Luckily, over the past few years there have been many advances in optimization that have made it possible to run quite large and sophisticated machine learning models on some very small, low-power embedded systems. We’ll learn about some of those techniques over the next few chapters!
Embedded machine learning is often deployed alongside its trusty companion, digital signal processing. Before we move on, let’s define that term, too.
Digital Signal Processing
In the embedded world we often work with the digital representations of signals. For example, an accelerometer gives us a stream of digital values that correspond to acceleration on three axes, and a digital microphone gives us a stream of values that correspond to sound levels at a particular moment in time.
Digital signal processing (DSP) is the practice of using algorithms to manipulate these streams of data. When paired with embedded machine learning, we often use DSP to modify signals before feeding them into machine learning models. There are a few reasons why we might want to do this:
-
Cleaning up a noisy signal
-
Removing spikes or outlying values that might be caused by hardware issues
-
Extracting the most important information from a signal
-
Transforming the data from the time domain to the frequency domain6
DSP is so common for embedded systems that often embedded chips have super fast hardware implementations of common DSP algorithms, just in case you need them.
We now share a solid understanding of the most important terms in this book. Figure 1-8 shows how they fit together in context.
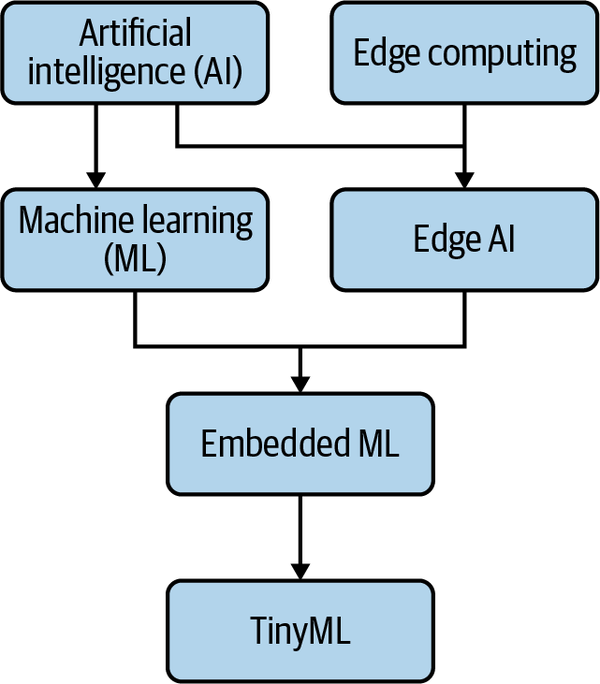
Figure 1-8. This diagram shows some of the most important concepts in edge AI in context with each other—from most general at the top to most specific at the bottom
In the next section, we’ll dive deep into the topic of edge AI and start to break down what makes it such an important technology.
Why Do We Need Edge AI?
Imagine that this morning you went on a trail run through Joshua Tree National Park, a vast expanse of wilderness in the Southern California desert. You listened to music the whole time, streamed to your phone via an uninterrupted cellular connection. At a particularly beautiful spot, deep in the mountains, you snapped a photograph and sent it to your partner. A few minutes later you received their reply.
In a world where even the most remote places have some form of data connection, why do we need edge AI? What is the point of tiny devices that can make their own decisions if the internet’s beefy servers are only a radio burst away? With all of the added complication, aren’t we just making life more difficult for ourselves?
As you may have guessed, the answer is no! Edge AI solves some very real problems that otherwise stand in the way of making our technology work better for human beings. Our favorite framework for explaining the benefits of edge AI is a rude-sounding mnemonic: BLERP.
To Understand the Benefits of Edge AI, Just BLERP
BLERP? Jeff Bier, founder of the Edge AI and Vision Alliance, created this excellent tool for expressing the benefits of edge AI. It consists of five words:
-
Bandwidth
-
Latency
-
Economics
-
Reliability
-
Privacy
Armed with BLERP, anyone can easily remember and explain the benefits of edge AI. It’s also useful as a filter to help decide whether edge AI is well suited for a particular application.
Let’s go through it, word by word.
Bandwidth
IoT devices often capture more data than they have bandwidth to transmit. This means the vast majority of sensor data they capture is not even used—it’s just thrown away! Imagine a smart sensor that monitors the vibration of an industrial machine to determine if it is operating correctly. It might use a simple thresholding algorithm to understand when the machine is vibrating too much, or not enough, and then communicate this information via a low bandwidth radio connection.
This already sounds useful. But what if you could identify patterns in the data that give you a clue that the machine might be about to fail? If we had a lot of bandwidth, we could send the sensor data up to the cloud and do some kind of analysis to understand whether a failure is imminent.
In many cases, though, there isn’t enough bandwidth or energy budget available to send a constant stream of data to the cloud. That means that we’ll be forced to discard most of our sensor data, even though it contains useful signals.
Bandwidth limitations are very common. It’s not just about available connectivity—it’s also about power. Networked communication is often the most energy-intensive task an embedded system can perform, meaning that battery life is often the limiting function. Some machine learning models can be quite compute intensive, but they tend to still use less energy than transmitting a signal.
This is where edge AI comes in. What if we could run the data analysis on the IoT device itself, without having to upload the data? In that case, if the analysis showed that the machine was about to fail, we could send a notification using our limited bandwidth. This is much more feasible than trying to stream all of the data.
Of course, it’s also quite common for devices to have no network connection at all! In this case, edge AI enables a whole galaxy of use cases that were previously impossible. We’ll hear more about this later.
Latency
Transmitting data takes time. Even if you have a lot of available bandwidth it can take tens or hundreds of milliseconds for a round-trip from a device to an internet server. In some cases, latency can be measured in minutes, hours, or days—think satellite communications, or store-and-forward messaging.
Some applications demand a faster response. For example, it might be impractical for a moving vehicle to be controlled by a remote server. Controlling a vehicle as it navigates an environment requires constant feedback between steering adjustments and the vehicle’s position. Under significant latency, steering becomes a major challenge!
Edge AI solves this problem by removing the round-trip time altogether. A great example of this is a self-driving car. The car’s AI systems run on onboard computers. This allows it to react nearly instantly to changing conditions, like the driver in front slamming on their brakes.
One of the most compelling examples of edge AI as a weapon against latency is in robotic space exploration. Mars is so distant from Earth that it takes minutes for a radio transmission to reach it at the speed of light. Even worse, direct communication is often impossible due to the arrangement of the planets. This makes controlling a Mars rover very hard. NASA solved this problem by using edge AI—their rovers use sophisticated artificial intelligence systems to plan their tasks, navigate their environments, and search for life on the surface of another world. If you have some spare time, you can even help future Mars rovers navigate by labeling data to improve their algorithms!
Economics
Connectivity costs a lot of money. Connected products are more expensive to use, and the infrastructure they rely on costs their manufacturers money. The more bandwidth required, the steeper the cost. Things get especially bad for devices deployed on remote locations that require long-range connectivity via satellite.
By processing data on-device, edge AI systems reduce or avoid the costs of transmitting data over a network and processing it in the cloud. This can unlock a lot of use cases that would have previously been out of reach.
In some cases, the only “connectivity” that works is sending out a human being to perform some manual task. For example, it’s common for conservation researchers to use camera traps to monitor wildlife in remote locations. These devices take photos when they detect motion and store them to an SD card. It’s too expensive to upload every photo via satellite internet, so researchers have to travel out to their camera traps to collect the images and clear the storage.
Because traditional camera traps are motion activated, they take a lot of unnecessary photos—they might be triggered by branches moving in the wind, hikers walking past, and creatures the researchers aren’t interested in. But some teams are now using edge AI to identify only the animals they care about, so they can discard the other images. This means they don’t have to fly out to the middle of nowhere to change an SD card quite so often.
In other cases, the cost of connectivity might not be a concern. However, for products that depend on server-side AI, the cost of maintaining server-side infrastructure can complicate your business model. If you have to support a fleet of devices that need to “phone home” to make decisions, you may be forced into a subscription model. You’ll also have to commit to maintaining servers for a long period of time—at the risk of your customers finding themselves with “bricked” devices if you decide to pull the plug.7
Don’t underestimate the impact of economics. By reducing the cost of long-term support, edge AI enables a vast number of use cases that would otherwise be infeasible.
Reliability
Systems controlled by on-device AI are potentially more reliable than those that depend on a connection to the cloud. When you add wireless connectivity to a device, you’re adding a vast, overwhelmingly complex web of dependencies, from link-layer communications technologies to the internet servers that may run your application.
Many pieces of this puzzle are outside of your control, so even if you make all the right decisions you will still be exposed to the reliability risk associated with technologies that make up your distributed computing stack.
For some applications, this might be tolerable. If you’re building a smart speaker that responds to voice commands, your users might understand if it stops recognizing their commands when their home internet connection goes down. That said, it can still be a frustrating experience!
But in other cases, safety is paramount. Imagine an AI-based system that monitors an industrial machine to make sure that it is being operated within safe parameters. If it stops working when the internet goes down, it could endanger human lives. It would be much safer if the AI is based entirely on-device, so it still operates in the event of a connectivity problem.
Reliability is often a compromise, and the required level of reliability varies depending on use case. Edge AI can be a powerful tool in improving the reliability of your products. While AI is inherently complex, it represents a different type of complexity than global connectivity, and its risk is easier to manage in many situations.
Privacy
Over the past few years, many people have begrudgingly resigned themselves to a trade-off between convenience and privacy. The theory is that if we want our technology products to be smarter and more helpful, we have to give up our data. Because smart products traditionally make decisions on remote servers, they very often end up sending streams of sensor data to the cloud.
This may be fine for some applications—for example, we might not worry that an IoT thermostat is reporting temperature data to a remote server.8 But for other applications, privacy is a huge concern. For example, many people would hesitate to install an internet-connected security camera inside their home. It might provide some reassuring security, but the trade-off—that a live video and audio feed of their most private spaces is being broadcast to the internet—does not seem worth it. Even if the camera’s manufacturer is entirely trustworthy, there’s always a chance of the data being exposed through security vulnerabilities.9
Edge AI provides an alternative. Rather than streaming live video and audio to a remote server, a security camera could use some onboard intelligence to identify that an intruder is present when the owners are out at work. It could then alert the owners in an appropriate way. When data is processed on an embedded system and is never transmitted to the cloud, user privacy is protected and there is less chance of abuse.
The ability of edge AI to enable privacy unlocks a huge number of exciting use cases. It’s an especially important factor for applications in security, industry, childcare, education, and healthcare. In fact, since some of these fields involve tight regulations (or customer expectations) around data security, the product with the best privacy is one that avoids collecting data altogether.
Using BLERP
As we’ll start to see in Chapter 2, BLERP can be a handy tool for understanding whether a particular problem is well suited for edge AI. There doesn’t have to be a strong argument for every word of the acronym: even meeting just one or two criteria, if compelling enough, can give merit to a use case.
Edge AI for Good
The unique benefits of edge AI provide a new set of tools that can be applied to some of our world’s biggest problems. Technologists in areas like conservation, healthcare, and education are already using edge AI to make a big impact. Here are just a few examples we’re personally excited about:
-
Smart Parks is using collars running machine learning models to better understand elephant behavior in wildlife parks around the world.
-
Izoelektro’s RAM-1 helps prevent forest fires caused by power transmission hardware by using embedded machine learning to detect upcoming faults.
-
Researchers like Dr. Mohammed Zubair Shamim from King Khalid University in Saudi Arabia are training models that can screen patients for life-threatening medical conditions such as oral cancer using low-cost devices.
-
Students across the world are developing solutions for their local industries. João Vitor Yukio Bordin Yamashita, from UNIFEI in Brazil, created a system for identifying diseases that affect coffee plants using embedded hardware.
The properties of edge AI make it especially well-suited for application to global problems. Since reliable connectivity is expensive and not universally available, many current generation smart technologies only benefit people living in industrialized, wealthy, and well-connected regions. By removing the need for a reliable internet connection, edge AI increases access to technologies that can benefit people and the planet.
When machine learning is part of the mix, edge AI generally involves small models—which are often quick and cheap to train. Since there’s also no need to maintain expensive backend server infrastructure, edge AI makes it possible for developers with limited resources to build cutting-edge solutions for the local markets that they know better than anyone. To learn more about these opportunities, we recommend watching “TinyML and the Developing World”, an excellent talk given by Pete Warden at the TinyML Kenya meetup.
As we saw in “Privacy”, edge AI also creates an opportunity to improve privacy for users. In our networked world, many companies treat user data as a valuable resource to be extracted and mined. Consumers and business owners are often required to barter away their privacy in order to use AI products, putting their data in the hands of unknown third parties.
With edge AI, data does not need to leave the device. This enables a more trusting relationship between user and product, giving users ownership of their own data. This is especially important for products designed to serve vulnerable people, who may feel skeptical of services that seem to be harvesting their data.
As we’ll see in later sections, there are many potential pitfalls that must be navigated in order to build ethical AI systems. That said, the technology provides a tremendous opportunity to make the world a better place.
Note
If you’re thinking about using edge AI to solve problems for your local community, the authors would love to hear from you. We’ve provided support for a number of impactful projects and would love to identify more. Send an email to the authors at hello@edgeaibook.com.
Key Differences Between Edge AI and Regular AI
Edge AI is a subset of regular AI, so a lot of the same principles apply. That said, there are some special things to consider when thinking about artificial intelligence on edge devices. Here are our top points.
Training on the edge is rare
A lot of AI applications are powered by machine learning. Most of the time, machine learning involves training a model to make predictions based on a set of labeled data. Once the model has been trained, it can be used for inference: making new predictions on data it has not seen before.
When we talk about edge AI and machine learning, we are usually talking about inference. Training models requires a lot more computation and memory than inference does, and it often requires a labeled dataset. All of these things are hard to come by on the edge, where devices are resource-constrained and data is raw and unfiltered.
For this reason, the models used in edge AI are often trained before they are deployed to devices, using relatively powerful compute and datasets that have been cleaned and labeled—often by hand. It’s technically possible to train machine learning models on the edge devices themselves, but it’s quite rare—mostly due to the lack of labeled data, which is required for training and evaluation.
There are two subtypes of on-device training that are more widespread. One of these is used commonly in tasks such as facial or fingerprint verification on mobile phones, to map a set of biometrics to a particular user. The second is used in predictive maintenance, where an on-device algorithm learns a machine’s “normal” state so that it can act if the state becomes abnormal. There’ll be more detail on the topic of on-device learning in “On-Device Training”.
The focus of edge AI is on sensor data
The exciting thing about edge devices is that they live close to where the data is made. Often, edge devices are equipped with sensors that give them an immediate connection to their environments. The goal of an edge AI deployment is to make sense of this data, identifying patterns and using them to make decisions.
By its nature, sensor data tends to be big, noisy, and difficult to manage. It arrives at a high frequency—potentially many thousands of times per second. An embedded device running an edge AI application has a limited time frame in which to collect this data, process it, feed it into some kind of AI algorithm, and act on the results. This is a major challenge, especially given that most embedded devices are resource-constrained and don’t have the RAM to store large amounts of data.
The need to tame raw sensor data makes digital signal processing a critical part of most edge AI deployments. In any efficient and effective implementation, the signal processing and AI components must be designed together as a single system, balancing trade-offs between performance and accuracy.
A lot of traditional machine learning and data science tools are focused on tabular data—things like company financials or consumer product reviews. In contrast, edge AI tools are built to handle constant streams of sensor data. This means that a whole different set of skills and techniques is required for building edge AI applications.
ML models can get very small
Edge devices are often designed to limit cost and power consumption. This means that, generally, they have much slower processors and smaller amounts of memory than personal computers or web servers.
The constraints of the target devices mean that, when machine learning is used to implement edge AI, the machine learning models must be quite small. On a midrange microcontroller, there may only be a hundred kilobytes or so of ROM available to store a model, and some devices have far smaller amounts. Since larger models take more time to execute, the slow processors of devices can also push developers toward deploying smaller models.
Making models smaller involves some trade-offs. To begin with, larger models have more capacity to learn. When you make a model smaller, it starts to lose some of its ability to represent its training dataset and may not be as accurate. Because of this, developers creating embedded machine learning applications have to balance the size of their model against the accuracy they require.
Various technologies exist for compressing models, reducing their size so that they fit on smaller hardware and take less time to compute. These compression technologies can be very useful, but they also impact models’ accuracy—sometimes in subtle but risky ways. “Compression and optimization” will talk about these techniques in detail.
That said, not all applications require big, complex models. The ones that do tend to be around things like image processing, since interpreting visual information involves a lot of nuance. Often, for simpler data, a few kilobytes (or less) of model is all you need.
Learning from feedback is limited
As we’ll see later, AI applications are built through a series of iterative feedback loops. We do some work, measure how it performs, and then figure out what’s needed to improve it.
For example, imagine we build a fitness monitor that can estimate your 10K running time based on data collected from onboard sensors. To test whether it’s working well, we can wait until you run an actual 10K and see whether the prediction was correct. If it’s not, we can add your data to our training dataset and try to train a better model.
If we have a reliable internet connection, this shouldn’t be too hard—we can just upload the data to our servers. But part of the magic of edge AI is that we can deploy intelligence to devices that have limited connectivity. In this case, we might not have the bandwidth to upload new training data. In many cases, we might not be able to upload anything at all.
This presents a big challenge for our application development workflow. How do we make sure our system is performing well in the real world when we have limited access to it? And how can we improve our system when it’s so difficult to collect more data? This is a core topic of edge AI development and something we’ll be covering heavily throughout this book.
Compute is diverse and heterogeneous
The majority of server-side AI applications run on plain old x86 processors, with some graphics processing units (GPUs) thrown in to help with any deep learning inference. There’s a small amount of diversity thanks to Arm’s recent server CPUs, and exotic deep learning accelerators such as Google’s TPUs (tensor processing units), but most workloads run on fairly ordinary hardware.
In contrast, the embedded world includes a dizzying array of device types:
-
Microcontrollers, including tiny 8-bit chips and fancy 32-bit processors
-
System-on-chip (SoC) devices running embedded Linux
-
General-purpose accelerators based on GPU technology
-
Field programmable gate arrays (FPGAs)
-
Fixed architecture accelerators that run a single model architecture blazing fast
Each category includes countless devices from many different manufacturers, each with a unique set of build tools, programming environments, and interface options. It can be quite overwhelming.
The diversity of hardware means there are likely to be multiple suitable systems for any given use case. The hard part is choosing one! We’ll cover this challenge over the course of the book.
“Good enough” is often the goal
With traditional AI, the goal is often to get the best possible performance—no matter the cost. Production deep learning models used in server-side applications can potentially be gigabytes in size, and they lean on powerful GPU compute to be able to run in a timely manner. When compute is not an obstacle, the most accurate model is often the best choice.
The benefits of edge AI come with some serious constraints. Edge devices have less capable compute, and there are often tricky choices involved with trading off between on-device performance and accuracy.
This is certainly a challenge—but it’s not a barrier. There are huge benefits to running AI at the edge, and for a vast number of use cases they easily outweigh the penalty of a little reduced accuracy. Even a small amount of on-device intelligence can be infinitely better than none at all.
The goal is to build applications that make the most of this “good enough” performance—an approach described elegantly by Alasdair Allan as Capable Computing. The key to doing this successfully is using tools that help us understand the performance of our applications in the real world, once any performance penalties have been factored in. We’ll be covering this topic at length.
Tools and best practices are still evolving
As a brand-new technology that has only begun to reach mass adoption, edge AI still depends on tools and approaches that were developed for large-scale, server-side AI. In fact, the majority of AI research is still focused on building large models on giant datasets. This has a couple of implications.
First, as we’ll see in Chapter 5, we’ll often find ourselves using existing development tools from the fields of data science and machine learning. On the positive side, this means we can draw from a rich ecosystem of libraries and frameworks that is proven to work well. However, few of the existing tools prioritize things that are important on the edge—like small model sizes, computational efficiency, and the ability to train on small amounts of data. We often have to do some extra work to make these the focus.
Second, since edge AI research is fairly new we’re likely to see extremely rapid evolution. As the field grows, and more researchers and engineers turn to focus on it, new approaches for improving efficiency are emerging—along with best practices and techniques for building effective applications. This promise of rapid change makes edge AI a very exciting field to work in.
Summary
In this chapter, we’ve explored the terminology that defines edge AI, learned a handy tool for reasoning about its benefits, explored how moving compute to the edge can increase access to technology, and outlined the factors that make edge AI different from traditional AI.
From the next chapter onward, we’ll be dealing with specifics. Get ready to learn about the use cases, devices, and algorithms that power edge AI today.
1 As reported by Business Wire.
2 Expected to grow to 27 billion by 2025, according to IoT Analytics.
3 Embedded engineering and mobile development are typically separate disciplines. Even within a mobile device, the embedded firmware and operating system are distinct from mobile applications. This book focuses on embedded engineering, so we won’t talk much about building mobile apps—but we will cover techniques that are relevant in both cases.
4 For many years it was hoped that artificial general intelligence could be achieved by complex conditional logic, hand-tuned by engineers. It has turned out to be a lot more complicated than that!
5 The term TinyML is a registered trademark of the TinyML Foundation.
6 This will be explained in “Spectral analysis”.
7 Not all edge AI applications are immune to this since it’s often necessary to monitor devices and push updates to algorithms. That said, there are certainly many cases where edge AI can reduce the burden of maintenance.
8 Even in this innocuous example, a malicious person accessing your thermostat data could use it to recognize when you’re on vacation so they can break into your house.
9 This exact scenario unfolded in 2022 with the Ring home security system, which was found to be vulnerable to an attack (“Amazon’s Ring Quietly Fixed Security Flaw That Put Users’ Camera Recordings at Risk of Exposure”, TechCrunch, 2022).
Get AI at the Edge now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

