Chapter 1. Zero Trust Fundamentals
In an age when network surveillance is ubiquitous, we find it difficult to trust anyone, and defining what trust is itself is equally difficult. Can we trust that our internet traffic will be safe from eavesdropping? Certainly not! What about that provider you leased your fiber from? Or that contracted technician who was in your datacenter yesterday working on the cabling?
Whistleblowers like Edward Snowden and Mark Klein have revealed the tenacity of government-backed spy rings. The world was shocked at the revelation that they had managed to get inside the datacenters of large organizations. But why? Isn’t it exactly what you would do in their position? Especially if you knew that traffic there would not be encrypted?
The assumption that systems and traffic within a datacenter can be trusted is flawed. Modern networks and usage patterns no longer echo those that made perimeter defense make sense many years ago. As a result, moving freely within a “secure” infrastructure frequently has a low barrier to entry once a single host or link there has been compromised.
You may think that the idea of using a cyberattack as a weapon to disrupt critical infrastructure like a nuclear plant or a power grid is far-fetched, but cyberattacks on the Colonial Pipeline in the United States and the Kudankulam Nuclear Power Plant in India serve as a stark reminder that critical infrastructure will continue to be a high-value target for attackers. So, what was common between the two attacks?
Well, in both cases, security was abysmal. Attackers took advantage of the fact that the VPN (virtual private network) connection to the Colonial Pipeline network was possible using a plain-text password without any multifactor authentication (MFA) in place. In the other example, malware was discovered on an Indian nuclear power plant employee’s computer that was connected to the administrative network’s internet servers. Once the attackers gained access, they were able to roam within the network due to the “trust” that comes with being inside the network.
Zero trust aims to solve the inherent problems in placing our trust in the network. Instead, it is possible to secure network communication and access so effectively that the physical security of the transport layer can be reasonably disregarded. It goes without saying that this is a lofty goal. The good news is that we’ve got pretty powerful cryptographic algorithms these days, and given the right automation systems, this vision is actually attainable.
What Is a Zero Trust Network?
A zero trust network is built upon five fundamental assertions:
-
The network is always assumed to be hostile.
-
External and internal threats exist on the network at all times.
-
Network locality alone is not sufficient for deciding trust in a network.
-
Every device, user, and network flow is authenticated and authorized.
-
Policies must be dynamic and calculated from as many sources of data as possible.
Traditional network security architecture breaks different networks (or pieces of a single network) into zones, contained by one or more firewalls. Each zone is granted some level of trust, which determines the network resources it is permitted to reach. This model provides very strong defense-in-depth. For example, resources deemed more risky, such as web servers that face the public internet, are placed in an exclusion zone (often termed a “DMZ”), where traffic can be tightly monitored and controlled. Such an approach gives rise to an architecture that is similar to some you might have seen before, such as the one shown in Figure 1-1.
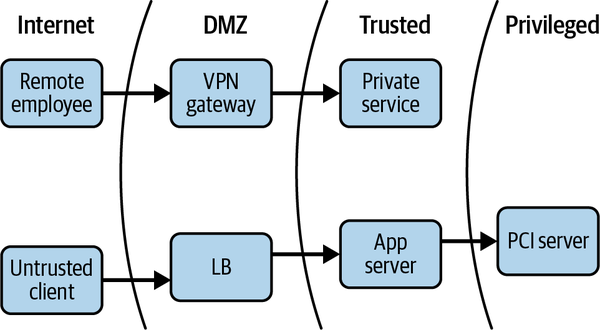
Figure 1-1. Traditional network security architecture
The zero trust model turns this diagram inside out. Placing stopgaps in the network is a solid step forward from the designs of yesteryear, but it is significantly lacking in the modern cyberattack landscape. There are many disadvantages:
-
Lack of intra-zone traffic inspection
-
Lack of flexibility in host placement (both physical and logical)
-
Single points of failure
It should be noted that, should network locality requirements be removed, the need for VPNs is also removed. A virtual private network (VPN) allows a user to authenticate in order to receive an IP address on a remote network. The traffic is then tunneled from the device to the remote network, where it is decapsulated and routed. It’s the greatest backdoor that no one ever suspected. If we instead declare that network location has no value, VPN is suddenly rendered obsolete, along with several other modern network constructs. Of course, this mandate necessitates pushing enforcement as far toward the network edge as possible, but at the same time it relieves the core from such responsibility. Additionally, stateful firewalls exist in all major operating systems, and advances in switching and routing have opened an opportunity to install advanced capabilities at the edge. All of these gains come together to form one conclusion: the time is right for a paradigm shift. By leveraging distributed policy enforcement and applying zero trust principles, we can produce a design similar to the one shown in Figure 1-2.
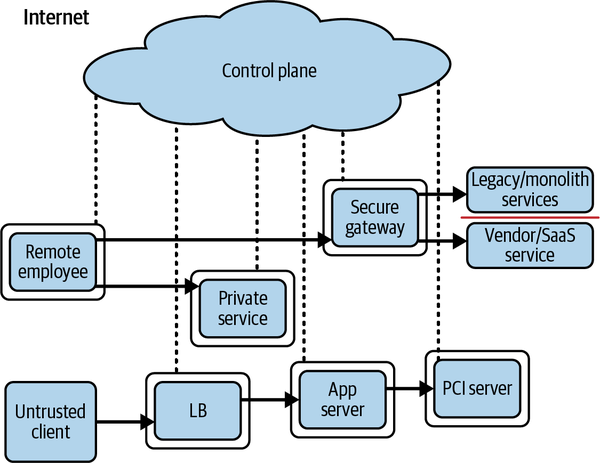
Figure 1-2. Zero trust architecture
Introducing the Zero Trust Control Plane
The supporting system is known as the control plane, while most everything else is referred to as the data plane, which the control plane coordinates and configures. Requests for access to protected resources are first made through the control plane, where both the device and user must be authenticated and authorized. Fine-grained policy can be applied at this layer, perhaps based on role in the organization, time of day, geo-location, or type of device. Access to more secure resources can additionally mandate stronger authentication.
Once the control plane has decided that the request will be allowed, it dynamically configures the data plane to accept traffic from that client (and that client only). In addition, it can coordinate the details of an encrypted tunnel between the requestor and the resource. This can include temporary one-time-use credentials, keys, and ephemeral port numbers.
It should be noted that the control plane decision to allow a request is time-bound rather than permanent. This means that if and when the factors that led the control plane decision to allow the request in the first place have changed, it may coordinate with the data plane to revoke the requested access to the resource.
While some compromises can be made on the strength of these measures, the basic idea is that an authoritative source, or trusted third party, is granted the ability to authenticate, authorize, and coordinate access in real time, based on a variety of inputs. We’ll discuss the control and data planes more in Chapter 2.
Evolution of the Perimeter Model
The traditional architecture described in this book is often referred to as the perimeter model, after the castle-wall approach used in physical security. This approach protects sensitive items by building lines of defenses that an intruder must penetrate before gaining access. Unfortunately, this approach is fundamentally flawed in the context of computer networks and no longer suffices. To fully understand the failure, it is useful to recall how the current model was arrived at.
Managing the Global IP Address Space
The journey that led to the perimeter model began with address assignment. Networks were being connected at an ever-increasing rate during the days of the early internet. If a network wasn’t being connected to the internet (remember, the internet wasn’t ubiquitous at the time), it was being connected to another business unit, another company, or perhaps a research network. Of course, IP addresses must be unique in any given IP network, and if the network operators were unlucky enough to have overlapping ranges, they would have a lot of work to do in changing them all. If the network you are connecting to happens to be the internet, then your addresses must be globally unique. So clearly some coordination is required here.
The Internet Assigned Numbers Authority (IANA), formally established in 1998, is the body that today provides that coordination. Prior to the establishment of the IANA, this responsibility was handled by Jon Postel, who created the internet map shown in Figure 1-3. He was the authoritative source for IP address ownership records, and if you wanted to guarantee that your IP addresses were globally unique, you would register with him. At this time, everybody was encouraged to register for IP address space, even if the network being registered was not going to be connected to the internet. The assumption was that even if a network was not connected now, it would probably be connected to another network at some point.
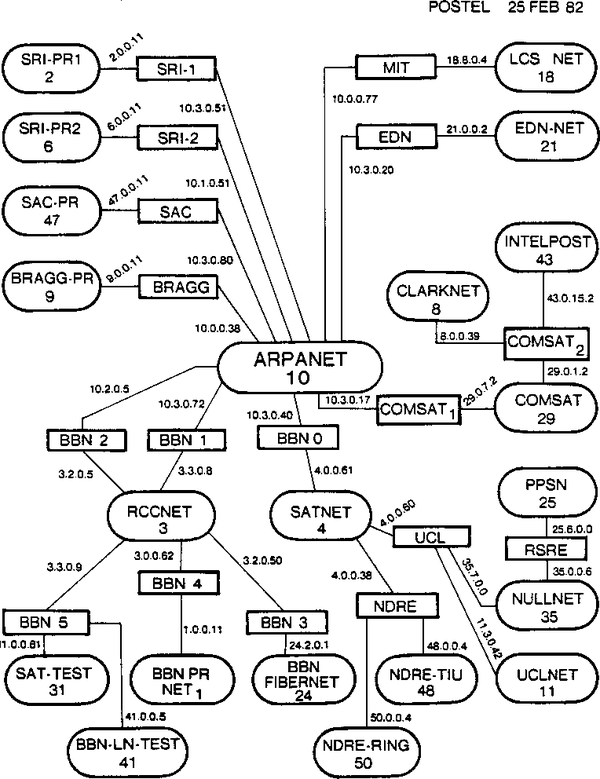
Figure 1-3. A map of the early internet created by Jon Postel, dated February 1982
Birth of Private IP Address Space
As IP adoption grew through the late 1980s and early 1990s, frivolous use of address space became a serious concern. Numerous cases of truly isolated networks with large IP address space requirements began to emerge. Networks connecting ATMs and arrival/departure displays at large airports were touted as prime examples. These networks were considered truly isolated for various reasons. Some devices might be isolated to meet security or privacy requirements (e.g., networks meant for ATMs). Some might be isolated because the scope of their function was so limited that having broader network access was seen as exceedingly unlikely (e.g., airport arrival and departure displays). RFC 1597, Address Allocation for Private Internets, was introduced to address this wasted public address space issue.
In March of 1994, RFC 1597 announced that three IP network ranges had been reserved with IANA for general use in private networks: 10.0.0.0/8, 172.16.0.0/12, and 192.168.0.0/16. This had the effect of slowing address depletion by ensuring that the address space of large private networks never grew beyond those allocations. It also enabled network operators to use nonglobally unique addresses where and when they saw fit. It had another interesting effect, which lingers with us today: networks using private addresses were more secure, because they were fundamentally incapable of joining other networks, particularly the internet.
At the time, very few organizations (relatively speaking) had an internet connection or presence, and as such, internal networks were frequently numbered with the reserved ranges. Additionally, security measures were weak to nonexistent because these networks were typically confined by the walls of a single organization.
Private Networks Connect to Public Networks
The number of interesting things on the internet grew fairly quickly, and soon most organizations wanted at least some sort of presence. Email was one of the earliest examples of this. People wanted to be able to send and receive email, but that meant they needed a publicly accessible mail server, which of course meant that they needed to connect to the internet somehow. With established private networks, it was often the case that this mail server would be the only server with an internet connection. It would have one network interface facing the internet, and one facing the internal network. With that, systems and people on the internal private network got the ability to send and receive internet email via their connected mail server.
It was quickly realized that these servers had opened up a physical internet path into their otherwise secure and private network. If one was compromised, an attacker might be able to work their way into the private network, since hosts there can communicate with it. This realization prompted strict scrutiny of these hosts and their network connections. Network operators placed firewalls on both sides of them to restrict communication and thwart potential attackers attempting to access internal systems from the internet, as shown in Figure 1-4. With this step, the perimeter model was born. The internal network became the “secure” network, and the tightly controlled pocket that the external hosts lay in became the DMZ, or the demilitarized zone.
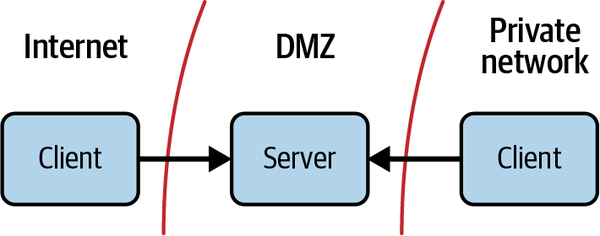
Figure 1-4. Both internet and private resources can access hosts in the DMZ; private resources, however, cannot reach beyond the DMZ, and thus do not gain direct internet access
Birth of NAT
The number of internet resources being accessed from internal networks was growing rapidly, and it quickly became easier to grant general internet access to internal resources than it was to maintain intermediary hosts for every application desired. NAT, or network address translation, solved that problem nicely.
RFC 1631, The IP Network Address Translator, defines a standard for a network device that is capable of performing IP address translation at organizational boundaries. By maintaining a table that maps public IPs and ports to private ones, it enabled devices on private networks to access arbitrary internet resources. This lightweight mapping is application agnostic, which meant that network operators no longer needed to support internet connectivity for particular applications; they needed only to support internet connectivity in general.
These NAT devices had an interesting property: because the IP mapping was many-to-one, it was not possible for incoming connections from the internet to access internal private IPs without specifically configuring the NAT to handle this special case. In this way, the devices exhibited the same properties as a stateful firewall. Actual firewalls began integrating NAT features almost instantaneously, and the two became a single function, largely indistinguishable. Supporting both network compatibility and tight security controls meant that eventually you could find one of these devices at practically every organizational boundary, as shown in Figure 1-5.
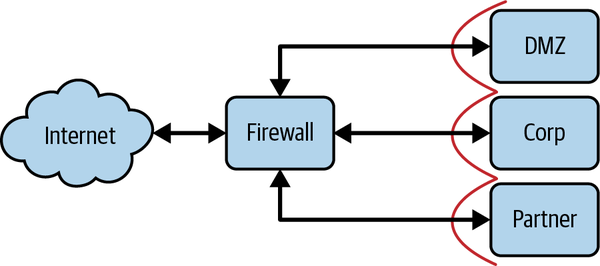
Figure 1-5. Typical (and simplified) perimeter firewall design
The Contemporary Perimeter Model
With a firewall/NAT device between the internal network and the internet, the security zones are clearly forming. There is the internal “secure” zone, the DMZ (demilitarized zone), and the untrusted zone (aka the internet). If at some point in the future, this organization needed to interconnect with another, a device would be placed on that boundary in a similar manner. The neighboring organization would likely become a new security zone, with particular rules about what kind of traffic can go from one to the other, just like the DMZ or the secure zone.
Looking back, we see the progression. We went from offline/private networks with just one or two hosts with internet access to highly interconnected networks with security devices around the perimeter. It is not hard to understand: network operators couldn’t afford to sacrifice the perfect security of their offline network because they had to open doors for various business purposes. Tight security controls at each door minimized the risk.
Evolution of the Threat Landscape
Even before the public internet, communicating with a remote computer system was highly desirable. This was commonly done over the public telephone system. Users and computer systems could dial in and, by encoding data into audible tones, gain connectivity to the remote machine. These dial-in interfaces were the most common attack vector of the day, since gaining physical access was much more difficult.
Once organizations had internet-connected hosts, attacks shifted from occurring over the telephone network to being launched over the dial-up internet. This triggered a change in most attack dynamics. Incoming calls to dial-in interfaces tied up a phone line, and were a notable occurrence when compared to a TCP connection coming from the internet. It was much easier to have a covert presence on an IP network than it was on a system that needed to be dialed into. Exploitation and brute force attempts could be carried out over long periods of time without raising too much suspicion...though an additional and more impactful capability arose from this shift: malicious code could then listen for internet traffic.
By the late 1990s, the world’s first (software) Trojan horses began to make their rounds. Typically, a user would be tricked into installing the malware, which would then open a port and wait for incoming connections. The attacker could then connect to the open port and remotely control the target machine.
It wasn’t long before that people realized it would be a good idea to protect those internet-facing hosts. Hardware firewalls were the best way to do it (most operating systems had no concept of a host-based firewall at the time). They provided policy enforcement, ensuring that only whitelisted/allowed-listed “safe” traffic was allowed in from the internet. If an administrator inadvertently installed something that exposed an open port (like a Trojan horse), the firewall would physically block connections to that port until explicitly configured to allow it. Likewise, traffic to the internet-facing servers from inside the network could be controlled, ensuring that internal users could speak to them, but not vice versa. This helped prevent movement into the internal network by a potentially compromised DMZ host.
DMZ hosts were of course a prime target (due to their connectivity), though such tight controls on both inbound and outbound traffic made it hard to reach an internal network through a DMZ. An attacker would first have to compromise the firewalled server, then abuse the application in such a way that it could be used for covert communication (they need to get data out of that network, after all). Dial-in interfaces remained the lowest-hanging fruit if one was determined to gain access to an internal network.
This is where things took an interesting turn. NAT was introduced to grant internet access to clients on internal networks. Due in some part to NAT mechanics and in some part to real security concerns, there was still tight control on inbound traffic, though internal resources wishing to consume external resources might freely do so. There’s an important distinction to be made when considering a network with NAT’d internet access against a network without it: the former has a relaxed (if any) outbound network policy.
This significantly transformed the network security model. Hosts on the “trusted” internal networks could then communicate directly with untrusted internet hosts, and the untrusted host was suddenly in a position to abuse the client attempting to speak with it. Even worse, malicious code could then send messages to internet hosts from within the internal network. Today, we know this as “phoning home.”
Phoning home is a critical component of most modern attacks. It allows data to be exfiltrated from otherwise-protected networks; but more importantly, since TCP is bidirectional, it allows data to be injected as well. A typical attack involves several steps, as shown in Figure 1-6. First, the attacker will compromise a single computer on the internal network by exploiting the user’s browser when they visit a particular page, by sending them an email with an attachment that exploits some local software, for example. The exploit carries a very small payload, just enough code to make a connection out to a remote internet host and execute the code it receives in the response. This payload is sometimes referred to as a dialer.
The dialer downloads and installs the real malware, which more often than not will attempt to make an additional connection to a remote internet host controlled by the attacker. The attacker will use this connection to send commands to the malware, exfiltrate sensitive data, or even to obtain an interactive session. This “patient zero” can act as a stepping stone, giving the attacker a host on the internal network from which to launch additional attacks.
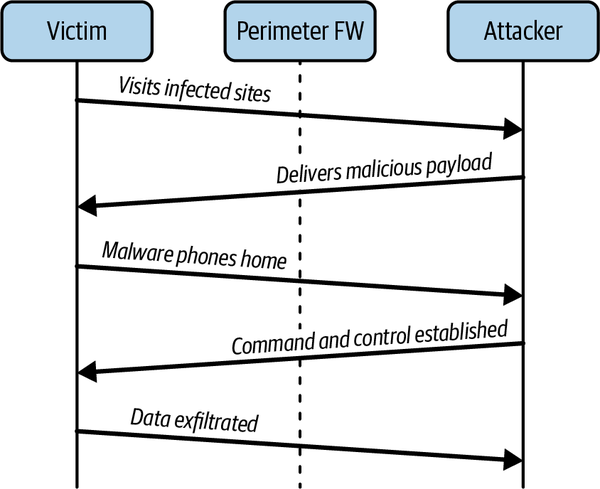
Figure 1-6. Client initiates all attack-related connections, easily traversing perimeter firewalls with relaxed outbound security
Outbound Security
Outbound network security is a very effective mitigation measure against dialer-based attacks, as the phone home can be detected and/or blocked. Oftentimes, however, the phone home is disguised as regular web traffic, possibly even to networks that are seemingly benign or “normal.” Outbound security tight enough to stop these attacks will oftentimes cripple web usability for users. This is a more realistic prospect for back-office systems.
The ability to launch attacks from hosts within an internal network is a very powerful one. These hosts almost certainly have permission to talk to other hosts in the same security zone (lateral movement) and might even have access to talk to hosts in zones more secure than their own. To this effect, by first compromising a low-security zone on the internal network, an attacker can move through the network, eventually gaining access to the high-security zones.
Taking a step back for a moment, it can be seen that this pattern very effectively undermines the perimeter security model. The critical flaw enabling attack progression is subtle, yet clear: security policies are defined by network zones, enforced only at zone boundaries, using nothing more than the source and destination details.
Other threats have risen as the world has become more ubiquitous over the years. Companies nowadays allow their workers to use their own devices for work in addition to the devices provided by the company, thanks to the popularity of Bring Your Own Device (BYOD). Employees can be more productive as a result of this, as they work from home more than ever before. During COVID-19, we discovered the advantages of BYOD when employees were no longer able to enter the workplace for extended periods of time. However, the attack surface area has grown because patching numerous devices with the most recent security fixes is significantly more difficult than patching a single device. One type of attack, among others, is the zero-click attack, which does not even require user interaction (more about it in the note below). Attackers deliberately look for devices that haven’t had their security patches updated in order to exploit vulnerabilities and obtain unauthorized access to them. In Chapter 5, we’ll look at the role of security patches and how to automate them to improve device trust.
Zero-Click Attack
A zero-click attack is a highly sophisticated attack that infects the user’s device without the user’s involvement. Zero-click attacks frequently take advantage of unpatched arbitrary code execution and buffer overflow security flaws. Because these attacks are conducted without user interaction, they can be incredibly effective. Popular apps like WhatsApp and Apple’s iMessage have been reported to be vulnerable to zero-click attacks. In 2021, Google provided a comprehensive investigation of the iMessage zero-click vulnerability, which describes the attack’s far-reaching ramifications. Patching all devices that have access to company resources and services is critical at all times.
Perimeter Shortcomings
Even though the perimeter security model still stands as the most prevalent model by far, it is increasingly obvious that the way we rely on it is flawed. Complex (and successful) attacks against networks with perfectly good perimeter security occur every day. An attacker drops a remote access tool (or RAT) into your network through one of a myriad of methods, gains remote access, and begins moving laterally. Perimeter firewalls have become the functional equivalent of building a wall around a city to keep out the spies.
The problem comes when architecting security zones into the network itself. Imagine the following scenario: you run a small ecommerce company. You have some employees, some internal systems (payroll, inventory, etc.), and some servers to power your website. It is natural to begin classifying the kind of access these groups might need: employees need access to internal systems, web servers need access to database servers, database servers don’t need internet access but employees do, and so on. Traditional network security would codify these groups as zones and then define which zone can access what, as shown in Figure 1-7. Of course, you need to actually enforce these policies; and since they are defined on a zone-by-zone basis, it makes sense to enforce them wherever one zone can route traffic into another.
As you might imagine, there are always exceptions to these generalized rules...they are, in fact, colloquially known as firewall exceptions. These exceptions are typically as tightly scoped as possible. For instance, your web developer might want SSH access to the production web servers, or your HR representative might need access to the HR software’s database in order to perform audits. In these cases, an acceptable approach is to configure a firewall exception permitting traffic from that individual’s IP address to the particular server(s) in question.
Now let’s imagine that your archnemesis has hired a team of hackers. They want to have a peek at your inventory and sales numbers. The hackers send emails to all the employee email addresses they can find on the internet, masquerading as a discount code for a restaurant near the office. Sure enough, one of them clicks the link, allowing the attackers to install malware. The malware phones home and provides the attackers with a session on the now-compromised employee’s machine. Luckily, it’s only an intern, and the level of access they gain is limited.
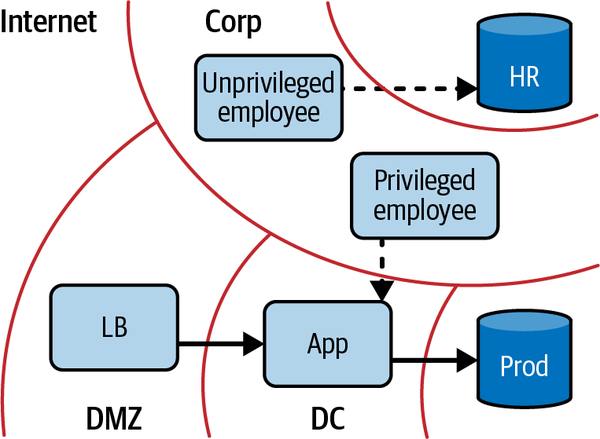
Figure 1-7. Corporate network interacting with the production network
They begin searching the network and find that the company is using file sharing software on its network. Out of all the employee computers on the network, none of them have the latest version and are vulnerable to an attack that was recently publicized.
One by one, the hackers begin searching for a computer with elevated access (this process of course can be more targeted if the attacker has advanced knowledge). Eventually they come across your web developer’s machine. A keylogger they install there recovers the credentials to log in to the web server. They SSH to the server using the credentials they gathered, and using the sudo rights of the web developer, they read the database password from disk and connect to the database. They dump the contents of the database, download it, and delete all the log files. If you’re lucky, you might actually discover that this breach occurred. They accomplished their mission, as shown in Figure 1-8.
Wait, what? As you can see, many failures at many levels led to this breach, and while you might think that this is a particularly contrived case, successful attacks just like this one are staggeringly common. The most surprising part, however, goes unnoticed all too often: what happened to all that network security? Firewalls were meticulously placed, policies and exceptions were tightly scoped and very limited, everything was done right from a network security perspective. So what gives?
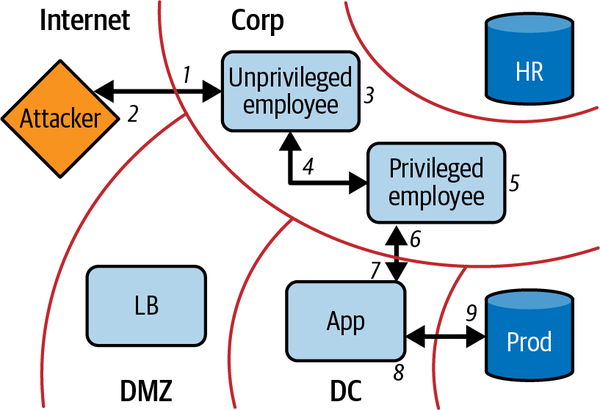
Figure 1-8. Attacker movement into corporate network, and subsequently production into network
When carefully examined, it is overwhelmingly obvious that this network security model is not enough. Bypassing perimeter security is trivial with malware that phones home, and firewalls between zones consider nothing more than source and destination when making enforcement decisions. While perimeters can still provide some value in network security, their role as the primary mechanism by which a network’s security stance is defined needs to be reconsidered.
Example Attack Progression
-
Employees targeted via phishing email
-
Corporate machine compromised, shell shoveled
-
Lateral movement through corporate network
-
Privileged workstation located
-
Local privilege escalation on workstation—keylogger installed
-
Developer password stolen
-
Compromised prod app host from privileged workstation
-
Developer password used to elevate privileges on prod app host
-
Database credentials stolen from app
-
Database contents exfiltrated via compromised app host
The first step, of course, is to search for existing solutions. Sure, the perimeter model is the accepted approach to securing a network, but that doesn’t mean we haven’t learned better elsewhere. What is the worst possible scenario network security-wise? It turns out that there is actually a level of absoluteness to this question, and the crux of it lies in trust.
Where the Trust Lies
When considering options beyond the perimeter model, one must have a firm understanding of what is trusted and what isn’t. The level of trust defines a lower limit on the robustness of the security protocols required. Unfortunately, it is rare for robustness to exceed what is required, so it is wise to trust as little as possible. Once trust is built into a system, it can be very hard to remove.
A zero trust network is just as it sounds. It is a network that is completely untrusted. Lucky for us, we interact with such a network very frequently: the internet. The internet has taught us some valuable security lessons. Certainly, an operator will secure an internet-facing server much differently than it secures its locally accessible counterpart. Why is that? And if the pains associated with such rigor were cured (or even just lessened), would the security sacrifice still be worth it?
The zero trust model dictates that all hosts be treated as if they’re internet facing. The networks they reside in must be considered compromised and hostile. Only with this consideration can you begin to build secure communication. With most operators having built or maintained internet-facing systems in the past, we have at least some idea of how to secure IP in a way that is difficult to intercept or tamper with (and, of course, how to secure those hosts). Automation enables us to extend this level of security to all of the systems in our infrastructure.
Automation as an Enabler
Zero trust networks do not require new protocols or libraries. They do, however, use existing technologies in novel ways. Automation systems are what allow a zero trust network to be built and operated.
Interactions between the control plane and the data plane are the most critical points requiring automation. If policy enforcement cannot be dynamically updated, zero trust will be unattainable; therefore, it is critical that this process be automatic and rapid.
There are many ways that this automation can be realized. Purpose-built systems are most ideal, though more mundane systems like traditional configuration management can fit here as well. Widespread adoption of configuration management represents an important stepping stone for a zero trust network, as these systems often maintain device inventories and are capable of automating network enforcement configuration in the data plane.
Due to the fact that modern configuration management systems can both maintain a device inventory and automate the data plane configuration, they are well positioned to be a first step toward a mature zero trust network.
Perimeter Versus Zero Trust
The perimeter and zero trust models are fundamentally different from each other. The perimeter model attempts to build a wall between trusted and untrusted resources (i.e., the local network and the internet). On the other hand, the zero trust model basically throws the towel in and accepts the reality that the “bad guys” are everywhere. Rather than build walls to protect the soft bodies inside, it turns the entire population into a militia.
The current approaches to perimeter networks assign some level of trust to the protected networks. This notion violates the zero trust model and leads to some bad behavior. Operators tend to let their guard down a bit when the network is “trusted” (they are human). Rarely are hosts that share a trust zone protected from themselves. Sharing a trust zone, after all, seems to imply that they are equally trusted. Over time, we have come to learn that this assumption is false, and it is not only necessary to protect your hosts from the outside, but it is also necessary to protect them from each other.
Since the zero trust model assumes the network is fully compromised, you must also assume that an attacker can communicate using any arbitrary IP address. Thus, protecting resources by using IP addresses or physical location as an identifier is not enough. All hosts, even those that share “trust zones,” must provide proper identification. Attackers are not limited to active attacks, though. They can still perform passive attacks in which they sniff your traffic for sensitive information. In this case, even host identification is not enough—strong encryption is also required.
There are three key components in a zero trust network: user/application authentication and authorization, device authentication and authorization, and trust. The first component has some duality in it due to the fact that not all actions are taken by users. So in the case of automated action (inside the datacenter, for instance), we look at qualities of the application in the same way that we would normally look at qualities of the user.
Authenticating and authorizing the device is just as important as doing so for the user/application. This is a feature rarely seen in services and resources protected by perimeter networks. It is often deployed using VPN or NAC technology, especially in more mature networks, but finding it between endpoints (as opposed to network intermediaries) is uncommon.
NAC as a Perimeter Technology
NAC, or Network Access Control, represents a set of technologies designed to strongly authenticate devices in order to gain access to a sensitive network. These technologies, which include protocols like 802.1X and the Trusted Network Connect (TNC) family, focus on admittance to a network rather than admittance to a service and as such are independent of the zero trust model. An approach more consistent with the zero trust model would involve similar checks located as close to the service being accessed as possible (something which TNC can address—more on this in Chapter 5). While NAC can still be employed in a zero trust network, it does not fulfill the zero trust device authentication requirement due to its distance from the remote endpoint.
Finally, a “trust score” is computed, and the application, device, and score are bonded to form an agent. Policy is then applied against the agent in order to authorize the request. The richness of information contained within the agent allows very flexible yet fine-grained access control, which can adapt to varying conditions by inclusion of the score component in your policies.
If the request is authorized, the control plane signals the data plane to accept the incoming request. This action can configure encryption details as well. Encryption can be applied at the device level, application level, or both. At least one is required for confidentiality.
With these authentication/authorization components, and the aid of the control plane in coordinating encrypted channels, we can assert that every single flow on the network is authenticated and expected. Hosts and network devices drop traffic that has not had all of these components applied to it, ensuring sensitive data can never leak out. Additionally, by logging each of the control plane events and actions, network traffic can be easily audited on a flow-by-flow or request-by-request basis.
Perimeter networks can be found that have similar capability, though these capabilities are enforced at the perimeter only. VPNs famously attempt to provide these qualities in order to secure access to an internal network, but the security ends as soon as your traffic reaches a VPN concentrator. It is apparent that operators know what internet-strength security is supposed to look like; they just fail to implement those strong measures throughout.
If one can imagine a network that applies these measures homogeneously, a brief thought experiment can shed a lot of light on this new paradigm. Identity can be proven cryptographically, meaning it no longer matters what IP address any given connection is originating from (technically, you can still associate risk with it—more on that later). With automation removing the technical barriers, the VPN is essentially obsolete. “Private” networks no longer mean anything special: the hosts there are just as hardened as the ones on the internet. Thinking critically about NAT and private address space, perhaps zero trust makes it more obvious that the security arguments for it are null and void.
Ultimately, the perimeter model flaw is its lack of universal protection and enforcement. Secure cells with soft bodies inside. What we’re really looking for is hard bodies, bodies that know how to check IDs and speak in a way they can’t be overheard. Having hard bodies doesn’t necessarily preclude you from also maintaining the security cells. In very sensitive installations, this would still be encouraged. It does, however, raise the security bar high enough that it wouldn’t be unreasonable to lessen or remove those cells. Combined with the fact that the majority of the zero trust function can be done with transparency to the end user, the model almost seems to violate the security/convenience trade-off: stronger security, more convenience. Perhaps the convenience problem (or lack thereof) has been pushed onto the operators.
Applied in the Cloud
There are many challenges in deploying infrastructure into the cloud, one of the larger being security. Zero trust is a perfect fit for cloud deployments for an obvious reason: you can’t trust the network in a public cloud! The ability to authenticate and secure communication without relying on IP addresses or the security of the network connecting them means that compute resources can be nearly commoditized. Since zero trust advocates that every packet be encrypted, even within the same datacenter, operators need not worry about which packets traverse the internet and which don’t. This advantage is often understated. Cognitive load associated with when, where, and how to encrypt traffic can be quite large, particularly for developers who may not fully understand the underlying system. By eliminating special cases, we can also eliminate the human error associated with them.
Some might argue that intra-datacenter encryption is overkill, even with the reduction in cognitive load. History has proven otherwise. At large cloud providers like AWS, a single “region” consists of many datacenters, with fiber links between them. To the end user, this subtlety is often obfuscated. The NSA was targeting precisely links like these in rooms like the one shown in Figure 1-9.

Figure 1-9. Room 641A—NSA interception facility inside an AT&T datacenter in San Francisco
There are additional risks in the network implementation of the provider itself. It is not impossible to think that a vulnerability might exist in which neighbors can see your traffic. A more likely case is network operators inspecting traffic while troubleshooting. Perhaps the operator is honest, but how about the person who stole their laptop a few hours later with your captures on the disk? The unfortunate reality is that we can no longer assume that our traffic is protected from snooping or modification while in the datacenter.
Role of Zero Trust in National Cybersecurity
In 2021, the United States White House released Executive Order (EO) 14028, calling out the need to improve national cybersecurity on an urgent basis. The backdrop of this EO was ever increasingly sophisticated cyberattacks over the span of many years, predominantly from foreign adversaries, putting national security at risk. EO 14028 specifically calls out advancement toward zero trust architecture as a critical step in improving national cybersecurity:
The Federal Government must adopt security best practices; advance toward Zero Trust Architecture; …..
Excerpt from EO 14028
Adoption of zero trust is not just exclusive to the United States government by any means. Governments across the globe have been embracing it to improve the security posture. Another example is United Kingdom’s National Cyber Security Centre zero trust architecture design principles.
In later chapters, we’ll cover efforts from various governmental and non-governmental organizations like the National Institute of Standards and Technology (NIST), the Cybersecurity & Infrastructure Security Agency (CISA), The Open Group, etc., in publishing zero trust architecture, principles, and guidelines.
Summary
This chapter explored the high-level concepts that have led us toward the zero trust model. The zero trust model does away with the perimeter model, which attempts to ensure that bad actors stay out of the trusted internal network. Instead, the zero trust system recognizes that this approach is doomed to failure, and as a result, starts with the assumption that malicious actors are within the internal network and builds up security mechanisms to guard against this threat.
To better understand why the perimeter model is failing us, we reviewed how the perimeter model came into being. Back at the internet’s beginning, the network was fully routable. As the system evolved, some users identified areas of the network that didn’t have a credible reason to be routable on the internet, and thus the concept of a private network was born. Over time, this idea took hold, and organizations modeled their security around protecting the trusted private network. Unfortunately, these private networks aren’t nearly as isolated as the original private networks were. The end result is a very porous perimeter, which is frequently breached in regular security incidents.
With the shared understanding of perimeter networks, we are able to contrast that design against the zero trust design. The zero trust model carefully manages trust in the system. These types of networks lean on automation to realistically manage the security control systems that allow us to create a more dynamic and hardened system. We introduced some key concepts like the authentication of users, devices, and applications, and the authorization of the combination of those components. We will discuss these concepts in greater detail throughout the rest of this book.
Finally, we talked about how the move to public cloud environments and the pervasiveness of internet connectivity have fundamentally changed the threat landscape. “Internal” networks are now increasingly shared and sufficiently abstracted away in such a way that end users don’t have as clear an understanding of when their data is transiting more vulnerable long-distance network links. The end result of this change is that data security is more important than ever when constructing new systems. The next chapter will discuss the high-level concepts that need to be understood in order to build systems that can safely manage trust.
Get Zero Trust Networks, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

