Chapter 4. Using Predefined Simple Datatypes
W3C XML Schema provides an extensive set of predefined datatypes. W3C XML Schema derives many of these predefined datatypes from a smaller set of “primitive” datatypes that have a specific meaning and semantic and cannot be derived from other types. We will see how we can use these types to define our own datatypes by derivation to meet more specific needs in the next chapter.
Figure 4-1 provides a map of predefined datatypes and the relationships between them.

Lexical and Value Spaces
W3C XML Schema introduced a decoupling between the data, as it can be read from the instance documents (the “lexical space”), and the value, as interpreted according to the datatype (the “value space”).
Before we can enter into the definition of these two spaces, we must examine the processing model and the transformations endured by a value written in a XML document before it is validated. Element and attribute content proceeds through the following steps during processing:
- Serialization space
The series of bytes that is actually stored in a document (either as the value of an attribute or as a text node) may be seen as belonging to a first space, which we may call the “serialization space.”
- Parsed space
The XML 1.0 Recommendation makes it clear that the serialization space is not directly meaningful to applications, and a first transformation is performed on the value by conforming XML parsers before the value reaches an application: characters are converted into Unicode, and ends of lines (for text nodes and attributes) and whitespaces (only for attributes) are normalized. The result of this transformation is what reaches the applications—including schema processors—and belongs to what we may call the “parsed space.”
- Lexical space
Before doing any validation, W3C XML Schema performs a second round of whitespace processing on this value reported by the XML parser. This depends on the value’s datatype and may either ignore, normalize, or collapse the whitespaces. The value after this whitespace processing belongs to the “lexical space” defined in the W3C XML Schema Recommendation.
- Value space
W3C XML Schema considers an item from the lexical space to be a representation of an abstract value whose meaning or semantic is defined by its datatype and can be a piece of text, and also a number, a date, or qualified name. The ensemble of abstract values is defined as the “value space.”
Each datatype has its own lexical and value spaces and its own rules
to associate a lexical representation with a value; for many
datatypes, a single value can have multiple lexical representations
(for instance, the <xs:float> value
“3.14116” can also be written
equivalently as “03.14116,”
“3.141160,” or
“.314116E1”). This distinction is
important since the basic operations performed on the values (such as
equality testing or sorting) are done on the value space.
“3.14116” is considered to be equal
to “03.14116” when the type is
xs:float and is different when the type is
xs:string . The same applies to sort orders: some
datatypes have a full order relation (every pair of values can be
compared), others have no order relation at all, and the remaining
types have a partial order relation (values cannot always be
compared).
Whitespace Processing
The handling of special characters (tab, linefeeds, carriage returns
and spaces, which are often used only to “pretty
print” XML documents) has always been very
controversial. W3C XML Schema has imposed a two-step generic
algorithm, which is applied to most of the predefined datatypes
(actually, on all of them except two, xs:string
and
xs:normalizedString).
- Whitespace replacement
This is the first step of whitespace processing applied to the parsed value. During whitespace replacement, all occurrences of any whitespace—#x9 (tab), #xA (linefeed), and #xD (carriage return)—are replaced with a space (#x20). The number of characters is not changed by this step, which is applied to all the predefined datatypes (except for
xs:string, since no whitespace replacement is performed on the parsed value for this).- Whitespace collapse
The second step removes the leading and trailing spaces, and replaces all contiguous occurrences of spaces by a single space character. This is applied on all the predefined datatypes (except for
xs:string, since no whitespace replacement is performed on the parsed value for this, and forxs:normalizedString, in which whitespaces are only normalized).
String Datatypes
This
section
discusses datatypes derived from the
xs:string
primitive datatype as well as other datatypes that have a similar
behavior (namely,
xs:hexBinary ,
xs:base64Binary ,
xs:anyURI ,
xs:QName , and
xs:NOTATION ). These
types are not expected to carry any quantifiable value (W3C XML
Schema doesn’t even expect to be able to sort them)
and their value space is identical to their lexical space except when
explicitly described otherwise. One should note that even though they
are grouped in this section because they have a similar behavior,
these primitive datatypes are considered quite different by the
Recommendation.
The datatypes covered in this section are shown in Figure 4-2.
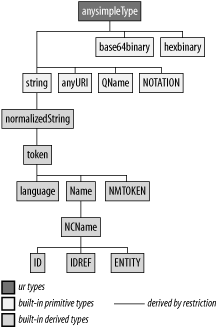
The two exceptions in whitespace processing (
xs:string and
xs:normalizedString ) are string
datatypes. One of the main differences between these types is the
applied whitespace processing. To stress this difference, we will
classify these types by their whitespace processing.
No Whitespace Replacement
-
xs:string This string datatype is the only predefined datatype for which no whitespace replacement is performed. As we will see in the next chapter, the whitespace replacement performed on user-defined datatypes derived from this type can be defined without restriction. On the other hand, a user datatype cannot be defined as having no whitespace replacement if it is derived from any predefined datatype other than
xs:string.As expected, a string is a set of characters matching the definition given by XML 1.0, namely, “legal characters are tab, carriage return, line feed, and the legal characters of Unicode and ISO/IEC 10646.”
The value of the following element:
<title lang="en"> Being a Dog Is a Full-Time Job </title>
is the full string:
Being a Dog Is a Full-Time Job
with all its tabs, and CR/LF if the title element is a type
xs:string.
Normalized Strings
-
xs:normalizedString The normalized string is the only predefined datatype in which whitespace replacement is performed without collapsing.
The lexical space of
xs:normalizedStringis the same as the lexical space ofxs:stringfrom which it is derived—except that since any occurrence of #x9 (tab), #xA (linefeed), and #xD (carriage return) are replaced by a #x20 (space), these three characters cannot be found in its lexical and value spaces.The value of the same element:
<title lang="en"> Being a Dog Is a Full-Time Job </title>
is now the string:
Being a Dog Is a Full-Time Job
in which all the whitespaces have been replaced by spaces if the title element is a type
xs:normalizedString.
Tip
There is no additional constraint on normalized strings. Any value
that is a valid as a
xs:string is also valid
xs:normalizedString but its
tabs, linefeed and CR will be replaces by spaces. The difference is the whitespace processing
that is applied when the lexical value is
calculated.
Collapsed Strings
Whitespace collapsing is performed after
whitespace replacement by trimming the leading and trailing spaces
and replacing all the contiguous occurrences of spaces with a single
space. All the predefined datatypes (except, as we have seen,
xs:string and
xs:normalizedString ) are
whitespace collapsed.
We will classify tokens, binary formats, URIs, qualified names, notations, and all their derived types under this category. Although these datatypes share a number of properties, we must stress again that this categorization is done for the purpose of explanation and does not directly appear in the Recommendation.
Tokenss
-
xs:token xs:tokenisxs:normalizedStringon which the whitespaces have been collapsed. Since whitespaces are accepted in the lexical space ofxs:token, this type is better described as a " tokenized” string than as a “token”!The same element:
<title lang="en"> Being a Dog Is a Full-Time Job </title>
is still a valid
xs:token, and its value is now the string:Being a Dog Is a Full-Time Job
in which all the whitespaces have been replaced by spaces, any trailing spaces are removed, and contiguous sequences of spaces are replaced by single spaces.
Tip
As is the case with
xs:normalizedString, there is no constraint onxs:token, and any value that is a validxs:stringis also a validxs:token. The difference is the whitespace processing that is applied when the lexical value is calculated. This is not true of derived datatypes that have additional constraints on their lexical and value space. The restriction on the lexical spaces ofxs:normalizedStringis, therefore, a restriction by projection of their parsed space (different values of their parsed space are transformed into a single value of their lexical space), and not a restriction by invalidating values of their lexical space, as is the case for all the other predefined datatypes.The predefined datatypes derived from
xs:tokenarexs:language,xs:NMTOKEN, andxs:Name.-
xs:language This was created to accept all the language codes standardized by RFC 1766. Some valid values for this datatype are
en,en-US,fr, orfr-FR.-
xs:NMTOKEN This corresponds to the XML 1.0 “Nmtoken” (Name token) production, which is a single token (a set of characters without spaces) composed of characters allowed in XML name. Some valid values for this datatype are "
Snoopy", "CMS","1950-10-04", or "0836217462". Invalid values include"brought classical music to the Peanuts strip" (spaces are forbidden) or "bold,brash"(commas are forbidden).-
xs:Name This is similar to
xs:NMTOKENwith the additional restriction that the values must start with a letter or the characters “:” or “-”. This datatype conforms to the XML 1.0 definition of a “Name.” Some valid values for this datatype areSnoopy,CMS, or-1950-10-04-10:00. Invalid values include0836217462(xs:Namecannot start with a number) orbold,brash(commas are forbidden). This datatype should not be used for names that may be “qualified” by a namespace prefix, since we will see another datatype (xs:QName) that has a specific semantic for these values.The datatypexs:NCNameis derived fromxs:Name.-
xs:NCName This is the "noncolonized name” defined by Namespaces in XML1.0, i.e., a
xs:Namewithout any colons (“:”). As such, this datatype is probably the predefined datatype that is closest to the notion of a “name” in most of the programming languages, even though some characters such as “-” or “.” may still be a problem in many cases. Some valid values for this datatype areSnoopy,CMS,-1950-10-04-10-00, or1950-10-04. Invalid values include-1950-10-04:10-00orbold:brash(colons are forbidden).xs:ID,xs:IDREF, andxs:ENTITYare derived fromxs:NCName.-
xs:ID This is derived from
xs:NCName. The one constraint added to its value space is that there must not be any duplicate values in a document. In other words, the values of attributes or simple type elements having this datatype can be used as unique identifiers, and this datatype emulates the XML 1.0 ID attribute type. We will see this feature in more detail in Chapter 9.-
xs:IDREF This is derived from
xs:NCName. The constraint added to its value space is it must match an ID defined in the same document. I will explain this feature in more detail in Chapter 9.-
xs:ENTITY Also provided for compatibility with XML 1.0 DTDs, this is derived from
xs:NCNameand must match an unparsed entity defined in a DTD.
Tip
XML 1.0 gives the following definition of unparsed entities: “an unparsed entity is a resource whose contents may or may not be text, and if text, may be other than XML. Each unparsed entity has an associated notation, identified by name. Beyond a requirement that an XML processor make the identifiers for the entity and notation available to the application, XML places no constraints on the contents of unparsed entities.” In practice, this mechanism has seldom been used, as the general usage is to define links to the resources that could be defined as unparsed entities.
Qualified names
-
xs:QName Following Namespaces in XML 1.0,
xs:QNamesupports the use of namespace-prefixed names. A namespace prefix xs:QName treats a shortcut to identify a URI. Each xs:QName effectively contains a set of tuples {namespace name, local part}, in which the namespace name is the URI associated to the prefix through a namespace declaration. Even though the lexical space ofxs:QNameis very close to the lexical space ofxs:Name(the only constraint on the lexical space is that there is a maximum of one colon allowed in anxs:QName, which cannot be the first character), the value spaces of these datatypes are completely different (a scalar forxs:Nameand a tuple forxs:QName) andxs:QNameis defined as a primitive datatype. The constraint added by this datatype over anxs:Nameis the prefix must be defined as a namespace prefix in the scope of the element in which this datatype is used.W3C XML Schema itself has already given us some examples of QNames. When we write
<xs:attribute name="lang" type="xs:language"/>, the type attribute is anxs:QNameand its value is the tuple:{"http://www.w3.org/2001/XMLSchema", "language"}because the URI:
"http://www.w3.org/2001/XMLSchema"
was assigned to the prefix "
xs:“. If there is no namespace declaration for this prefix, the type attribute is considered invalid.The prefix of an
xs:QNameis optional. We are also able to write:<xs:element ref="book" maxOccurs="unbounded"/>
in which the ref attribute is also a
xs:QNameand its value the tuple:{NULL, "book"}because we haven’t defined any default namespace.
xs:QNamedoes support default namespaces; if a default namespace is defined in the scope of this element, the value of its URI is used for this tuple.
URIs
-
xs:anyURI This is another string datatype in which lexical and value spaces are different. This datatype tries to compensate for the differences of format between XML and URIs as specified in the RFCs 2396 and 2732. These RFCs are not very friendly toward non-ASCII characters and require many character escapings that are not necessary in XML. The W3C XML Schema Recommendation doesn’t describe the transformation to perform, noting only that it is similar to what is described for XLink link locators.
As an example of this transformation, the
hrefattribute of an XHTML link written as:<a href="http://dmoz.org/World/Français/"> Word/Français </a>
would be converted to the value:
http://dmoz.org/World/Fran%c3%a7ais/
in the value space.
The
xs:anyURIdatatype doesn’t pay any attention toxml:baseattributes that may have been defined in the document.
Notations
-
xs:NOTATION This is probably the most obscure of these string datatypes. This datatype was created to implement the XML 1.0 notations. It cannot be used directly in a schema; it must be used through user-defined derived datatypes. We will see more of it in the next chapter.
Binary string-encoded datatypes
XML 1.0 is unable to hold binary content, which must be string-encoded before it can be included in a XML document. W3C XML Schema has defined two primary datatypes to support two encodings that are commonly used (hexBinary and base64). These encodings may be used to include any binary content, including text formats whose content may be incompatible with the XML markup. Other binary text encodings may also be used (such as uuXXcode, Quote Printable, BinHex, aencode, or base85, to name a few), but their value would not be recognized by W3C XML Schema.
-
xs:hexBinary This defines a simple way to code binary content as a character string by translating the value of each binary octet into two hexadecimal digits. This encoding is different from the encoding method called BinHex (introduced by Apple, described by RFC 1741, and includes a mechanism to compress repetitive characters).
A UTF-8 XML header such as:
<?xml version="1.0" encoding="UTF-8"?>
that is encoded as
xs:hexBinarywould be:3f3c6d78206c657673726f693d6e3122302e20226e656f636964676e223d54552d4622383e3f
-
xs:base64Binary This matches the encoding known as “base64” and is described in RFC 2045. It maps groups of 6 bits into an array of 64 printable characters.
The same header encoded as
xs:base64Binarywould be:PD94bWwgdmVyc2lvbj0iMS4wIiBlbmNvZGluZz0iVVRGLTgiPz4NCg==
The W3C XML Schema Recommendation missed the fact that RFC 2045 requests a line break every 76 characters. This should be clarified in an errata. The consequence of these line breaks being thought of as optional by W3C XML Schema, is that the lexical and value spaces of
xs:base64Binarycannot be considered identical.
Numeric Datatypes
The
numeric
datatypes are built on top of four primitive datatypes:
xs:decimal for all the decimal types (including the
integer datatypes, considered decimals without a fractional part),
xs:double and
xs:float for
single and double precision floats, and
xs:boolean
for Booleans. Whitespaces are collapsed for all these datatypes.
The datatypes covered in this section are shown in Figure 4-3.
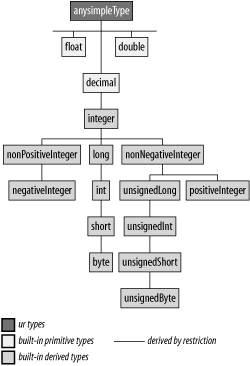
Decimal Types
All
decimal
types are derived from the
xs:decimal primary type
and constitute a set of predefined types that address the most common
usages.
-
xs:decimal This datatype represents the decimal numbers. The number of digits can be arbitrarily long (the datatype doesn’t impose any restriction), but obviously, since a XML document has an arbitrary but finite length, the number of digits of the lexical representation of a
xs:decimalvalue needs to be finite. Although the number of digits is not limited, we will see in the next chapter how the author of a schema can derive user-defined datatypes with a limited number of digits if needed.Leading and trailing zeros are not significant and may be trimmed. The decimal separator is always a dot (“.”); a leading sign (“+” or “-”) may be specified and any characters other than the 10 digits (including whitespaces) are forbidden. Scientific notation (“E+2”) is also forbidden and has been reserved to the float datatypes only.
Valid values for
xs:decimalinclude:123.456+1234.456-1234.456-.456-456The following values are invalid:
1 234.456(spaces are forbidden)1234.456E+2(scientific notation (“E+2”) is forbidden)+ 1234.456(spaces are forbidden)+1,234.456(delimiters between thousands are forbidden)xs:integeris the only datatype directly derived fromxs:decimal.-
xs:integer This integer datatype is a subset of
xs:decimal, representing numbers which don’t have any fractional digits in its lexical or value spaces. The characters that are accepted are reduced to 10 digits and an optional leading sign. Like its base datatype,xs:integerdoesn’t impose any limitation on the number of digits, and leading zeros are not significant.Valid values for
xs:integerinclude:123456+00000012-1-456The following values are invalid:
1234(spaces are forbidden)1.(the decimal separator is forbidden)+1,234(delimiters between thousands are forbidden).xs:integerhas given birth to three derived datatypes:xs:nonPositiveIntegerandxs:nonNegativeInteger(which have still an unlimited length) andxs:long(to fit in a 64-bit word).-
xs:nonPositiveIntegerandxs:negativeInteger The W3C XML Schema Working Group thought that it would be more clear that the value “0” was included if they used litotes as names, and used
xs:nonPositiveIntegerif the integers are negative or null.xs:negativeIntegeris derived fromxs:nonPositiveIntegerto represent the integers that are strictly negative. These two datatypes allow integers of arbitrary length.-
xs:nonNegativeIntegerandxs:positiveInteger Similarly,
xs:nonNegativeIntegeris the integers that are positive or equal to zero andxs:positiveIntegeris derived from this type. The “unsigned” family branch (xs:unsignedLong,xs:unsignedInt,xs:unsignedShort, andxs:unsignedByte) is also derived fromxs:nonNegativeInteger.-
xs:long,xs:int,xs:short, andxs:byte. The datatypes we have seen up to now have an unconstrained length. This approach isn’t very microprocessor-friendly. This subfamily represents signed integers that can fit into 8, 16, 32, and 64-bit words.
xs:longis defined as all of the integers between -9223372036854775808 and 9223372036854775807, i.e., the values that can be stored in a 64-bit word. The same process is applied again to derivexs:intwith a range between -2147483648 and 2147483647 (32 bits), to derivexs:shortwith a range between -32768 and 32767 (16 bits), and to derivexs:bytewith a range between -128 and 127 (8 bits).-
xs:unsignedLong,xs:unsignedInt,xs:unsignedShort, andxs:unsignedByte. The last of the predefined integer datatypes is the subfamily of unsigned (i.e., positive) integers that can fit into 8, 16, 32, and 64-bit words.
xs:unsignedLongis defined as the integers in a range between 0 and 18446744073709551615, i.e., the values that can be stored in a 64-bit word. The same process is applied again to derivexs:unsignedIntwith a range between 0 and 4294967295 (32 bits), to derivexs:unsignedShortwith a range between 0 and 65535 (16 bits), and to derivexs:unsignedBytewith a range between 0 and 255 (8 bits).
Float Datatypes
-
xs:floatandxs:double xs:floatandxs:doubleare both primitive datatypes and represent IEEE simple (32 bits) and double (64 bits) precision floating-point types. These store the values in the form of mantissa and an exponent of a power of 2 (m x 2^e), allowing a large scale of numbers in a storage that has a fixed length. Fortunately, the lexical space doesn’t require that we use powers of 2 (in fact, it doesn’t accept powers of 2), but instead lets us use a traditional scientific notation with integer powers of 10. Since the value spaces (powers of 2) don’t exactly match the values from the lexical space (powers of 10), the recommendation specifies that the closest value is taken. The consequence of this approximate matching is that float datatypes are the domain of approximation; most of the float values can’t be considered exact, and are approximate.These datatypes accept several “special” values: positive zero (0), negative zero (-0) (which is greater than positive 0 but less than any negative value), infinity (INF) (which is greater than any value), negative infinity (-INF) (which is less than any float, and “not a number” (NaN).
Valid values for
xs:floatandxs:doubleinclude:123.456+1234.456-1.2344e56-.45E-6INF-INFNaNThe following values are invalid:
1234.4E 56(spaces are forbidden)1E+2.5(the power of 10 must be an integer)+INF(positive infinity doesn’t expect a sign)NAN(capitalization matters in special values)
-
xs:boolean This is a primitive datatype that can take the values
trueandfalse(or 1 and 0).
Date and Time Datatypes
The datatypes covered in this section are shown in Figure 4-4.
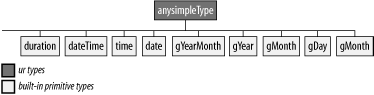
The Realm of ISO 8601
The W3C Recommendation, “XML Schema Part 2: Datatypes,” provides new confirmation of how difficult it is to fix time.
The support for date and time datatypes relies entirely on a subset of the ISO 8601 standard, which is the only format supported by W3C XML Schema. The purpose of ISO 8601 is to eliminate the risk of confusion between the various date and time formats used in different countries. In other words, W3C XML Schema does not support these local date and time formats, and imposes the usage of ISO 8601 for any datatype that has the semantic of a date or time. While this is a good thing for interchange formats, this is more questionable when XML is used to define user interfaces, since we will see that ISO 8601 is not very user friendly. The variations using the names of the months or different orders between year, month, and day are not the only victims of this decision: ISO 8601 imposes the usage of the Gregorian (Christian) calendar to the exclusion of calendars used by other cultures or religions.
ISO 8601 describes several formats to define date, times, periods, and recurring dates, with different levels of precision and indetermination. After many discussions, W3C XML Schema selected a subset of these formats and created a primitive datatype for each format that is supported.
The indeterminacy allowed in some of these formats adds a lot of difficulty, especially when comparisons or arithmetic are involved. For instance, it is possible to define a point in time without specifying the time zone, which is then considered undetermined. This undetermined time zone is identical all over the document (and between the schema and the instance documents) and it’s not an issue to compare two datetimes without a time zone. The problem arises when you need to compare two points in time, one with a time zone and the other without. The result of this comparison will be undetermined if these values are too close, since one of them may be between -13 hours and +12 hours of Coordinated Universal Time (UTC). Thus, the support of these datetime datatypes introduces a notion of “partial order relation.”
Another caveat with ISO 8601 is that time zones are only supported through the time difference from UTC, which ignores the notion of summer time. For instance, if an application working in British Summer Time (BST) wants to specify the time zone—and we have seen that this is necessary to be able to compare datetimes—the application needs to know if a date is in summer (the time zone will be one hour after UTC) or in winter (the time zone would then be UTC). ISO 8601 ignores the “named time zones” using the summer saving times (such as PST, BST, or WET) that we use in our day-to-day life; ignoring the time zones can be seen as a somewhat dangerous shortcut to specify that a datetime is on your “local time,” whatever it is.
Datatypes
- Point in time:
xs:dateTime The
xs:dateTimedatatype defines a “specific instant of time.” This is a subset of what ISO 8601 calls a “moment of time.” Its lexical value follows the format “CCYY-MM-DDThh:mm:ss,” in which all the fields must be present and may optionally be preceded by a sign and leading figures, if needed, and followed by fractional digits for the seconds and a time zone. The time zone may be specified using the letter “Z,” which identifies UTC, or by the difference of time with UTC.Tip
The value space of
xs:dateTimeis considered to be the moment of time itself. The time zone that defines the value (when there is one) is considered meaningless, which is a problem for some applications that complain that even though2002-01-18T12:00:00+00:00and2002-01-18T11:00:00-01:00refer to the same “moment of time,” they carry different time zone information, which should make its way into the value space.Valid values for
xs:dateTimeinclude:2001-10-26T21:32:522001-10-26T21:32:52+02:002001-10-26T19:32:52Z2001-10-26T19:32:52+00:00-2001-10-26T21:32:522001-10-26T21:32:52.12679The following values are invalid:
2001-10-26(all the parts must be specified)2001-10-26T21:32(all the parts must be specified)2001-10-26T25:32:52+02:00(the hours part (25) is out of range)01-10-26T21:32(all the parts must be specified)In the valid examples given above, three of them have identical value spaces:
2001-10-26T21:32:52+02:002001-10-26T19:32:52Z2001-10-26T19:32:52+00:00The first one (
2001-10-26T21:32:52), which doesn’t include a time zone specification, is considered to have an indeterminate value between2001-10-26T21:32:52-14:00and2001-10-26T21:32:52+14:00. With the usage of summer saving time, this range is subject to national regulations and may change. The range was between -13:00 and +12:00 when the Recommendation was published, but the Working Group has kept a margin to accommodate possible changes in the regulations.Despite the indeterminacy of the time zone when none is specified, the W3C XML Schema Recommendation considers that the values of datetimes without time zones implicitly refer to the same undetermined time zone and can be compared between them. While this is fine for “local” applications that operate in a single time zone, this is a source of potential confusion and errors for world-wide applications or even for applications that calculate a duration between moments belonging to different time saving seasons within a single time zone.
- Periods of time:
xs:date,xs:gYearMonthandxs:gYear. The lexical space of
xs:datedatatype is identical to the date part ofxs:dateTime. Likexs:dateTime, it includes a time zone that should always be specified to be able to compare two dates without ambiguity. As defined per W3C XML Schema, a date is a period one day in its time zone, “independent of how many hours this day has.” The consequence of this definition is that two dates defined in a different time zone cannot be equal except if they designate the same interval (2001-10-26+12:00and2001-10-25-12:00, for instance). Another consequence is that, like withxs:dateTime, the order relation between a date with a time zone and a date without a time zone is partial.Valid values for
xs:dateinclude:2001-10-262001-10-26+02:002001-10-26Z2001-10-26+00:00-2001-10-26-20000-04-01The following values are invalid:
2001-10(all the parts must be specified)2001-10-32(the days part (32) is out of range)2001-13-26+02:00(the month part (13) is out of range)01-10-26(the century part is missing)xs:daterepresents a day identified by a Gregorian calendar date (and could have been called "gYearMonthDay“).xs:gYearMonth(“g” for Gregorian) is a Gregorian calendar month andxs:gYearis a Gregorian calendar year. These three datatypes are fixed periods of time and optional time zones may be specified for each of them. The only differences between them really are their length (1 day, 1 month, and 1 year) and their format (i.e., their lexical spaces).The format of
xs:gYearMonthis the format ofxs:datewithout the day part. Valid values forxs:gYearMonthinclude:2001-102001-10+02:002001-10Z2001-10+00:00-2001-10-20000-04The following values are invalid:
2001(the month part is missing)2001-13(the month part is out of range)2001-13-26+02:00(the month part is out of range)01-10(the century part is missing)The format of
xs:gYearis the format ofxs:gYearMonthwithout the month part. Valid values forxs:gYearinclude:20012001+02:002001Z2001+00:00-2001-20000The following values are invalid:
01(the century part is missing)2001-13(the month part is out of range)This support of time periods is very restrictive: these periods can only match the Gregorian calendar day, month, or year, and cannot have an arbitrary length or start time.
- Recurring point in time:
xs:time The lexical space of
xs:timeis identical to the time part ofxs:dateTime. The semantic ofxs:timerepresents a point in time that recurs every day; the meaning of01:20:15is “the point in time recurring each day at 01:20:15 am.” Likexs:dateandxs:dateTime,xs:timeaccepts an optional time zone definition. The same issue arises when comparing times with and without time zones.Note
Despite the fact that: 01:20:15 is commonly used to represent a duration of 1 hour, 20 minutes, and 15 seconds, a different format has been chosen to represent a duration.
Valid values for
xs:timeinclude:21:32:5221:32:52+02:0019:32:52Z19:32:52+00:0021:32:52.12679The following values are invalid:
21:32(all the parts must be specified)25:25:10(the hour part is out of range)-10:00:00(the hour part is out of range)1:20:10(all the digits must be supplied)This support of a recurring point in time is also very limited: the recursion period must be a Gregorian calendar day and cannot be arbitrary.
- Recurring period of time:
xs:gDay,xs:gMonth, andxs:gMonthDay. We have already seen points in times and periods, as well as recurring points in time. This wouldn’t be complete without a description of recurring periods. W3C XML Schema supports three predefined recurring periods corresponding to Gregorian calendar months (recurring every year) and days (recurring each month or year). The support of recurring periods is restricted both in terms of recursion (the recursion period can only be a Gregorian calendar year or month) and period (the start time can only be a Gregorian calendar day or month, and the duration can only be a Gregorian calendar month or day).
xs:gDayis a period of a Gregorian calendar day recurring each Gregorian calendar month. The lexical representation ofxs:gDayis---DDwith an optional time zone specification. Valid values forxs:gDayinclude:---01---01Z---01+02:00---01-04:00---15---31The following values are invalid:
--30-(the format must be "---DD“)---35(the day is out of range)---5(all the digits must be supplied)15(missing the leading "---“)The rules of arithmetic between dates and durations apply in this case, and days are “pinned” in the range for each month. In our example,
--31, the selected dates will be January 31st, February 28th (or 29th), March 31st, April 30th, etc.xs:gMonthDayis a period of a Gregorian calendar day recurring each Gregorian calendar year. The lexical representation ofxs:gMonthDayis--MM-DDwith an optional time zone specification. Valid values forxs:gMonthDayinclude:--05-01--11-01Z--11-01+02:00--11-01-04:00--11-15--02-29The following values are invalid:
-01-30-(the format must be--MM-DD)--01-35(the day part is out of range)--1-5(one part is missing)01-15(the leading--is missing)xs:gMonthis a period of a Gregorian calendar month recurring each Gregorian calendar year. The lexical representation ofxs:gMonthdefined in the Recommendation is--MM--with an optional time zone specification. The W3C XML Schema Working Group has acknowledged that this was an error and that the format--MMdefined by ISO 8061 should be used instead. It has not been decided yet if the format described in the Recommendation will be forbidden or only deprecated, but it is advised to use the format--MM(assuming that the tools you are using already support it). Valid values forxs:gMonthinclude:--05--11Z--11+02:00--11-04:00--02The following values are invalid:
-01-(the format must be--MM)--13(the month is out of range)--1(both digits must be provided)01(the leading--is missing)-
xs:duration Naive programmers who think that the concept of duration is simple should read the Recommendation, which states:
xs:durationis defined as a six-dimensional space!” Mathematicians would object that this is not absolutely true since most of the axes of these dimension are parallel, but the fact is that when these programmers say that a development will last one month and 3 days, they define a duration that is comprised of between 31 and 34 days. The attempt of W3C XML Schema to deal with these issues on top of ISO 8601 has introduced a degree of indeterminacy in the comparisons between durations.The lexical space of
xs:durationis the format defined by ISO 8601 under the formPnYnMnDTnHnMnS, in which the capital letters are delimiters that can be omitted when the corresponding member is not used. An important difference with the format used forxs:dateTimeis none of these members are mandatory and none of them are restricted to a range. This gives flexibility to choose the units that will be used and to combine several of them—for instance,P1Y2MT123S(1 year, 2 months, and 123 seconds). This flexibility has a price; such a duration is not completely defined: a year may have 365 or 366 days, and a period of two months lasts between 59 and 62 days. Durations cannot always be compared and the order between durations is partial. We will see, in the next chapter, that user-defined datatypes can be derived fromxs:duration, which can restrict the components used to express durations and insure that these indeterminations do not happen.Since the value of a duration is fixed as soon as you give it a starting point, the schema Working Group has identified four datetimes:
1696-09-01T00:00:00Z1697-02-01T00:00:00Z1903-03-01T00:00:00Z1903-07-01T00:00:00ZThese cause the greatest deviations when durations mixing day, month, and other components are added. The Working Group has determined that the comparison of durations is undefined if—and only if—the result of the comparison is different when each of these dates is used as a starting point.
Valid values for
xs:durationinclude:PT1004199059SPT130SPT2M10SP1DT2S-P1YP1Y2M3DT5H20M30.123SThe following values are invalid:
1Y(the leadingPis missing)P1S(theTseparator is missing)P-1Y(all parts must be positive)P1M2Y(the parts order is significant andYmust precedeM)P1Y-1M(all parts must be positive)
List Types
These datatypes
are lists of whitespace-separated items.
The type of these items (called the item type) is defined during the
derivation process (which we will see in the next chapter) and list
datatypes can be derived from any simple type. Three predefined
datatypes are lists (
xs:NMTOKENS ,
xs:IDREFS , and
xs:ENTITIES ). For all
the list datatypes, the items must be separated by one or more
whitespaces.
-
xs:NMTOKENS This is a whitespace-separated list of
xs:NMTOKEN. Each item of the list must be in the lexical space ofxs:NMTOKEN.-
xs:IDREFS This is a whitespace-separated list of
xs:IDREF. Each item of the list must be in the lexical space ofxs:IDREFand must reference an existingxs:IDin the same document.-
xs:ENTITIES This is a whitespace-separated list of
xs:ENTITY. Each item of the list must be in the lexical space ofxs:ENTITYand must match an unparsed entity defined in a DTD.
What About anySimpleType?
We have now covered all the predefined datatypes except one, which is
an atypical type:
anySimpleType. This
datatype is a kind of wildcard, which means, as expected, that any
value is accepted and doesn’t add any constraint on
the lexical space.
anySimpleType has two other characteristics that
make it unique among simple types: users’ simple
types cannot be derived from it and its properties, and its canonical
form is not defined in the Recommendation! These characteristics make
it a type that should be avoided, except when the rules of a
derivation (which we will see in the next chapter) require its usage.
Back to Our Library
If we look back with a critical eye at our library, we see we used the following simple datatypes:
<xs:element name="name" type="xs:string"/>
<xs:element name="qualification" type="xs:string"/>
<xs:element name="born" type="xs:date"/>
<xs:element name="dead" type="xs:date"/>
<xs:element name="isbn" type="xs:string"/>
<xs:attribute name="id" type="xs:ID"/>
<xs:attribute name="available" type="xs:boolean"/>
<xs:attribute name="lang" type="xs:language"/>We are lucky that the elements born and
dead are ISO 8601 dates. The ISBN number is
composed of numeric digits and a final character which can be either
a digit or the letter “x"-and is
therefore represented as a string. We also did a good job with the
datatypes for the id, available
and lang attributes, but the choice of
xs:string for the elements name and
qualification is more controversial. They appear
in the instance document as:
<name>
Charles M Schulz
</name>
.../...
<qualification>
bold, brash and tomboyish
</qualification>This formatting suggests that whitespaces are probably not
significant and should be collapsed. This can be done by choosing the
datatype
xs:token instead of
xs:string ; the same applies to the
title element, which is a simple content derived
from
xs:string that would be better derived from
xs:token . This change will not have any impact on
the validation with our schema, but the document is more precisely
described and future derivations would be more easily built on
xs:token than on
xs:string . The
other datatype that could have been chosen better is
isbn, which can be represented as
xs:NMTOKEN. The new schema
would then be:
<?xml version="1.0"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="name" type="xs:token"/>
<xs:element name="qualification" type="xs:token"/>
<xs:element name="born" type="xs:date"/>
<xs:element name="dead" type="xs:date"/>
<xs:element name="isbn" type="xs:NMTOKEN"/>
<xs:attribute name="id" type="xs:ID"/>
<xs:attribute name="available" type="xs:boolean"/>
<xs:attribute name="lang" type="xs:language"/>
<xs:element name="title">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:token">
<xs:attribute ref="lang"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
<xs:element name="library">
<xs:complexType>
<xs:sequence>
<xs:element ref="book" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="author">
<xs:complexType>
<xs:sequence>
<xs:element ref="name"/>
<xs:element ref="born"/>
<xs:element ref="dead" minOccurs="0"/>
</xs:sequence>
<xs:attribute ref="id"/>
</xs:complexType>
</xs:element>
<xs:element name="book">
<xs:complexType>
<xs:sequence>
<xs:element ref="isbn"/>
<xs:element ref="title"/>
<xs:element ref="author" minOccurs="0" maxOccurs="unbounded"/>
<xs:element ref="character" minOccurs="0"
maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute ref="id"/>
<xs:attribute ref="available"/>
</xs:complexType>
</xs:element>
<xs:element name="character">
<xs:complexType>
<xs:sequence>
<xs:element ref="name"/>
<xs:element ref="born"/>
<xs:element ref="qualification"/>
</xs:sequence>
<xs:attribute ref="id"/>
</xs:complexType>
</xs:element>
</xs:schema>Get XML Schema now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

