Einführung: Was ist verteiltes Tracing?
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Wenn du dieses Buch liest, hast du vielleicht schon eine Vorstellung davon, was die verteilten Wörter bedeuten. Es kann aber auch sein, dass du keine Ahnung hast, was sie bedeuten - vielleicht bist du auch einfach nur ein Fan von Bandicoots (dem Tier auf dem Cover). Wir werden nicht urteilen, versprochen.
Wie auch immer, du liest dies, um einen Einblick zu bekommen, was verteiltes Tracing ist und wie du es nutzen kannst, um die Leistung und den Betrieb deiner Microservices und anderer Software zu verstehen. Beginnen wir also mit einer einfachen Definition.
Verteiltes Tracing (auch verteiltes Request Tracing genannt) ist eine Art der korrelierten Protokollierung, die dir hilft, Einblicke in den Betrieb eines verteilten Softwaresystems zu gewinnen, z. B. für die Leistungsprofilerstellung, die Fehlersuche in der Produktion und die Ursachenanalyse von Fehlern oder anderen Vorfällen. Es gibt dir die Möglichkeit, genau zu verstehen, was ein bestimmter einzelner Dienst als Teil des Ganzen tut. So kannst du Fragen zur Leistung deiner Dienste und deines verteilten Systems als Ganzes stellen und beantworten.
Das war einfach - bis zum nächsten Buch!
Was ist das? Warum verlangen alle eine Rückerstattung? Oh...
Uns wird gesagt, dass du ein bisschen mehr als das brauchst. Gehen wir einen Schritt zurück und reden wir über Software, insbesondere über verteilte Software, damit wir die Probleme besser verstehen können, die durch verteiltes Tracing gelöst werden.
Verteilte Architekturen und du
Die Kunst und Wissenschaft der Entwicklung, des Einsatzes und des Betriebs von Software ist ständig in Bewegung. Neue Fortschritte bei der Computerhardware und -software haben die Grenzen dessen, wie eine Anwendung aussieht, im Laufe der Jahre dramatisch verschoben. Es gibt zwar einen interessanten Exkurs darüber, dass "alles Alte wieder neu ist", aber der Kürze halber wollen wir uns auf die Veränderungen in den letzten zwei Jahrzehnten konzentrieren.
Vor den Fortschritten in der Virtualisierung und Containerisierung brauchte man für die Bereitstellung einer webbasierten Anwendung einen physischen Server, möglicherweise einen, der nur für die Anwendung selbst bestimmt war. Wenn der Datenverkehr mit deiner Anwendung zunahm, musstest du entweder die physischen Ressourcen des Servers erhöhen (z. B. mehr Arbeitsspeicher) oder du brauchtest mehrere Server, auf denen jeweils eine eigene Kopie deiner Anwendung lief.
Bei einem monolithischen Serverprozess führte diese horizontale Skalierung oft zu ungünstigen Kompromissen bei Kosten, Leistung und organisatorischem Aufwand. Der Betrieb mehrerer Instanzen deines Servers bedeutete, dass du alle Funktionen des Servers dupliziert hast, anstatt einzelne Teilkomponenten unabhängig voneinander zu skalieren. Bei der traditionellen Infrastruktur musstest du oft entscheiden, wie viele Minuten (oder Stunden!) Leistungseinbußen du in Kauf nehmen konntest, während du zusätzliche Kapazitäten online gestellt hast - der Betrieb von Servern ist nicht billig, also warum solltest du die Spitzenkapazität nutzen, wenn du es nicht musst? Und schließlich wurde es mit zunehmender Größe und Komplexität deiner Anwendung und der Anzahl der daran arbeitenden Entwickler/innen immer schwieriger, neue Änderungen zu testen und zu validieren. Je größer dein Unternehmen wurde, desto unzumutbarer wurde es für die Entwickler, eine einzelne Codebasis zu verstehen, ganz zu schweigen von der Form des gesamten Systems. Immer kleinere Änderungen erhöhten die Wahrscheinlichkeit eines Ripple-Effekts, der zu einem Totalausfall der Anwendung führte, da die Auswirkungen von einer Komponente auf die andere ausstrahlten.
Die Zeit schritt jedoch voran, und es wurden Lösungen für diese Probleme entwickelt. Es wurde Software entwickelt, die die Details der physischen Hardware abstrahierte, wie z. B. die Virtualisierung, mit der ein einzelner physischer Server in mehrere logische Server aufgeteilt werden kann. Docker und andere Technologien zur Containerisierung erweiterten dieses Konzept, indem sie eine leichtgewichtige und benutzerfreundliche Abstraktion über schwerere virtuelle Maschinen stellten und die Frage, wer diese Software einsetzt, von den Betreibern auf die Entwickler verlagerten. Mit der Verbreitung von Cloud Computing und dem Konzept der On-Demand-Computing-Ressourcen wurde das Problem der Ressourcenskalierung gelöst, da es möglich wurde, die Anzahl der RAM- oder CPU-Kerne eines bestimmten Servers auf Knopfdruck zu erhöhen. Schließlich entstand die Idee der Microservice-Architekturen, um der Komplexität immer größerer und komplizierterer softwareorientierter Unternehmen zu begegnen, indem große Anwendungen um lose gekoppelte unabhängige Dienste herum strukturiert werden.
Heutzutage sind wohl die meisten Anwendungen auf irgendeine Weise verteilt, auch wenn sie keine Microservices nutzen. Einfache Client-Server-Anwendungen sind selbst verteilt - man denke nur an die klassische Frage: "Ein Aufruf an meinen Server hat eine Zeitüberschreitung verursacht; ist die Antwort verloren gegangen oder wurde die Arbeit gar nicht erledigt?" Außerdem können sie eine Vielzahl verteilter Abhängigkeiten haben, z. B. Datenspeicher, die als Dienst eines Cloud-Providers genutzt werden, oder eine ganze Reihe von APIs von Drittanbietern, die alles von Analysen bis hin zu Push-Benachrichtigungen und mehr bereitstellen.
Warum ist verteilte Software so beliebt? Die Argumente für verteilte Software sind ziemlich klar:
- Skalierbarkeit
-
Eine verteilte Anwendung kann leichter auf die Nachfrage reagieren und ihre Skalierung kann effizienter sein. Wenn viele Leute versuchen, sich bei deiner Anwendung anzumelden, kannst du zum Beispiel nur die Anmeldedienste skalieren.
- Verlässlichkeit
-
Der Ausfall einer Komponente sollte nicht die gesamte Anwendung in Mitleidenschaft ziehen. Verteilte Anwendungen sind widerstandsfähiger, weil sie die Funktionen auf verschiedene Serviceprozesse und Hosts aufteilen. So wird sichergestellt, dass selbst wenn ein abhängiger Service ausfällt, dies keine Auswirkungen auf den Rest der Anwendung hat.
- Instandhaltbarkeit
-
Verteilte Software ist aus mehreren Gründen leichter zu warten. Die Trennung von Diensten kann die Wartungsfreundlichkeit jeder Komponente erhöhen, da sie sich auf einen kleineren Aufgabenbereich konzentrieren kann. Außerdem kannst du neue Funktionen und Fähigkeiten hinzufügen, ohne sie selbst zu implementieren (und zu warten) - z. B. kannst du eine Sprache-zu-Text-Funktion in eine Anwendung einbauen, indem du dich auf den Sprache-zu-Text-Dienst eines Cloud-Providers verlässt.
Das ist sozusagen die Spitze des Eisbergs, was die Vorteile von verteilten Architekturen angeht. Natürlich ist nicht alles eitel Sonnenschein, und in jedes Leben gehört auch ein bisschen Regen...
Tiefe Systeme
Eine verteilte Architektur ist ein Paradebeispiel für das, was Softwarearchitekten oft ein tiefes System nennen.1 Diese Systeme zeichnen sich nicht durch ihre Breite, sondern durch ihre Komplexität aus. Wenn du an bestimmte Dienste oder Diensteklassen in einer verteilten Architektur denkst, solltest du den Unterschied erkennen können. Ein Pool von Cache-Knoten skaliert breit (d.h. du fügst einfach mehr Instanzen hinzu, um die Nachfrage zu bewältigen), aber andere Dienste skalieren anders. Anfragen können durch drei, vier, vierzehn oder vierzig verschiedene Schichten von Diensten geleitet werden, und jede dieser Schichten kann andere Abhängigkeiten haben, die dir nicht bewusst sind. Selbst wenn du einen vergleichsweise einfachen Dienst hast, ist deine Software wahrscheinlich von Dutzenden von Codes abhängig, die du nicht geschrieben hast, oder von Diensten, die von einem Cloud-Provider verwaltet werden, oder sogar von der zugrunde liegenden Orchestrierungssoftware, die den Status verwaltet.
Das Problem mit tiefen Systemen ist letztlich ein menschliches. Es wird schnell unrealistisch, dass ein einziger Mensch oder sogar eine Gruppe von Menschen genug von den Diensten versteht, die sich im kritischen Pfad einer einzigen Anfrage befinden, und sie weiter pflegen kann. Der Umfang dessen, was du als Dienstverantwortlicher kontrollieren kannst, und das, wofür du implizit verantwortlich bist, ist in Abbildung P-1 dargestellt. Dieses Kalkül wird zu einem Rezept für Stress und Burnout, da du gezwungen bist, reaktiv auf andere Serviceverantwortliche zu reagieren, ständig Feuer zu bekämpfen und herauszufinden, wie deine Services miteinander interagieren.
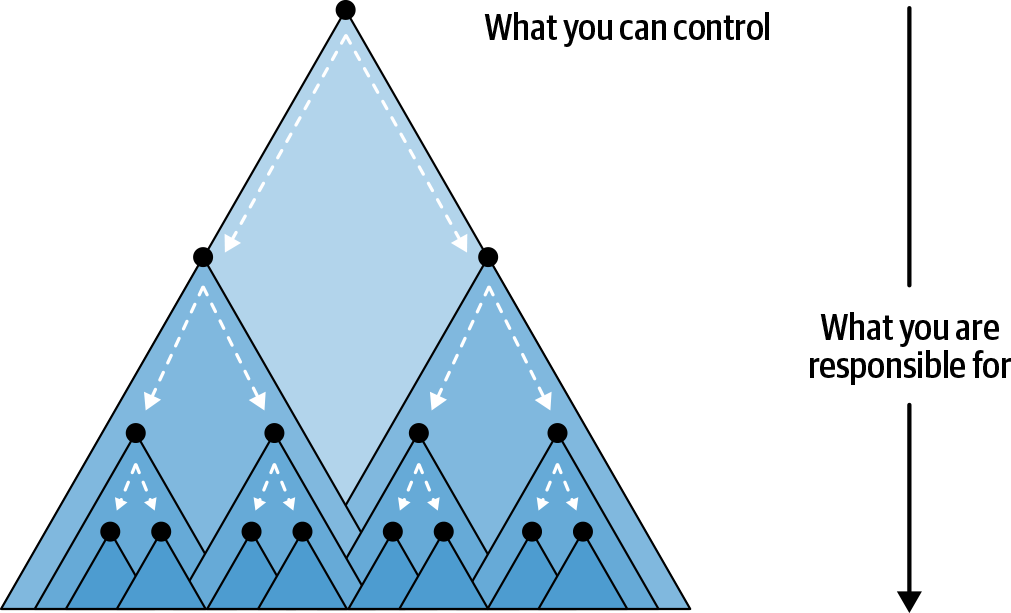
Abbildung P-1. Der Dienst, den du kontrollieren kannst, hat Abhängigkeiten, für die du verantwortlich bist, über die du aber keine direkte Kontrolle hast.
Verteilte Architekturen erfordern einen neuen Ansatz, um den Zustand und die Leistung von Software zu verstehen. Es reicht nicht aus, einen einzelnen Stack-Trace zu betrachten oder sich Diagramme zur CPU- und Arbeitsspeicherauslastung anzusehen. Da Software nicht nur in die Tiefe, sondern auch in die Breite skaliert, bieten Telemetriedaten wie Logs und Metriken allein nicht die nötige Klarheit, um Probleme in der Produktion schnell zu erkennen.
Die Schwierigkeiten, verteilte Architekturen zu verstehen
Die Verbreitung deiner Software stellt dich vor neue und spannende Herausforderungen. Plötzlich ist es schwieriger, Fehler und Abstürze festzustellen. Der Dienst, für den du verantwortlich bist, empfängt vielleicht fehlerhafte oder unerwartete Daten aus einer Quelle, die du nicht kontrollierst, weil dieser Dienst von einem Team am anderen Ende der Welt (oder einem Remote-Team) verwaltet wird. Ausfälle in Diensten, die du für sicher gehalten hast, führen plötzlich zu kaskadenartigen Ausfällen und Fehlern in allen deinen Diensten. Um es mit einem Satz von Twitter auszudrücken: Du hast es mit einem Microservices-Krimi zu tun (siehe Abbildung P-2).
Abbildung P-2. Es ist lustig, weil es wahr ist.
Um die Metapher zu erweitern: Die Überwachung hilft dabei herauszufinden, wo die Leiche ist, aber sie verrät nicht, warum der Mord geschehen ist. Die verteilte Rückverfolgung füllt diese Lücken, indem sie es dir ermöglicht, dein gesamtes System zu verstehen, indem sie Lösungen für drei wichtige Probleme bietet:
- Verschleierung
-
Je verteilter deine Anwendung wird, desto geringer wird die Kohärenz von Fehlern. Das heißt, dass der Abstand zwischen Ursache und Wirkung größer wird. Ein Ausfall der Blob-Speicherung deines Cloud-Providers kann sich ausbreiten und zu enormen Latenzzeiten für alle führen, oder ein einzelner, schwer zu diagnostizierender Ausfall eines bestimmten Dienstes, der viele Sprünge entfernt ist, verhindert, dass du die unmittelbare Ursache herausfinden kannst.
- Unstimmigkeiten
-
Verteilte Anwendungen sind zwar insgesamt zuverlässig, aber der Zustand der einzelnen Komponenten kann viel weniger konsistent sein als bei monolithischen oder nicht verteilten Anwendungen. Da jede Komponente einer verteilten Anwendung so konzipiert ist, dass sie in hohem Maße unabhängig ist, ist auch der Zustand dieser Komponenten uneinheitlich - was passiert zum Beispiel, wenn jemand eine Bereitstellung vornimmt? Wissen alle anderen Komponenten, was zu tun ist? Wie wirkt sich das auf die gesamte Anwendung aus?
- Dezentrales
-
Kritische Daten über die Leistung deiner Dienste werden per Definition dezentralisiert sein. Wie kannst du nach Fehlern in einem Dienst suchen, wenn vielleicht tausend Kopien dieses Dienstes auf Hunderten von Hosts laufen? Wie kannst du diese Ausfälle korrelieren? Die größte Stärke der Verteilung deiner Anwendung ist gleichzeitig das größte Hindernis, um zu verstehen, wie sie tatsächlich funktioniert!
Du fragst dich vielleicht: "Wie können wir diese Schwierigkeiten angehen?" Spoiler: Verteilte Rückverfolgung.
Wie hilft die verteilte Nachverfolgung?
Die verteilte Rückverfolgung ist ein wichtiges Instrument, um die explosionsartige Zunahme der Komplexität zu bewältigen, die unsere tiefen Systeme mit sich bringen. Es liefert Kontext, der sich über die gesamte Dauer einer Anfrage erstreckt, und kann genutzt werden, um die Interaktionen und die Form deiner Architektur zu verstehen. Diese einzelnen Traces sind jedoch nur der Anfang - in der Summe können Traces wichtige Erkenntnisse darüber liefern, was in deinem verteilten System tatsächlich vor sich geht. So kannst du nicht nur interessante Daten über deine Dienste korrelieren (z. B. dass die meisten Fehler auf einem bestimmten Host oder in einem bestimmten Datenbank-Cluster auftreten), sondern auch die Bedeutung anderer Arten von Telemetrie filtern und einordnen. Verteilte Traces liefern einen Kontext, der dir hilft, die Problemlösung auf die Dinge zu beschränken, die für deine Untersuchung relevant sind, damit du nicht raten und mehrere Logs und Dashboards überprüfen musst. Auf diese Weise steht das verteilte Tracing im Mittelpunkt einer modernen Observability-Plattform und wird zu einer wichtigen Komponente deiner verteilten Architektur und nicht zu einem isolierten Werkzeug.
Also, was ist ein Trace? Am einfachsten lässt sich das verstehen, wenn du dir deine Software in Form von Anfragen vorstellst. Jede deiner Komponenten erledigt eine bestimmte Aufgabe als Antwort auf eine Anfrage (auch bekannt als RPC, von Remote Procedure Call) von einem anderen Dienst. Dabei kann es sich um eine einfache Webseite handeln, die strukturierte Daten von einem Endpunkt eines Dienstes anfordert, um sie dem Benutzer zu präsentieren, oder um einen hochparallelen Suchprozess. Die eigentliche Art der Arbeit spielt dabei keine große Rolle, obwohl es bestimmte Muster gibt, die wir später besprechen werden und die sich für bestimmte Arten der Rückverfolgung eignen. Verteiltes Tracing kann zwar in den meisten verteilten Systemen funktionieren, wie wir in Kapitel 4 erläutern werden, aber seine Stärken kommen am besten bei der Modellierung der RPC-Beziehungen zwischen deinen Diensten zum Tragen.
Zusätzlich zu den RPC-Beziehungen solltest du dir überlegen, welche Aufgaben jeder dieser Dienste hat. Vielleicht authentifizieren und autorisieren sie Benutzerrollen, führen mathematische Berechnungen durch oder wandeln einfach Daten von einem Format in ein anderes um. Diese Dienste kommunizieren über RPCs miteinander, senden Anfragen und empfangen Antworten. Unabhängig davon, was sie tun, haben alle diese Dienste eines gemeinsam: Die Arbeit, die sie ausführen, dauert eine gewisse Zeit. Das Grundmuster der Dienste und RPCs ist in Abbildung P-3 dargestellt.

Abbildung P-3. Eine Anfrage von einem Client-Prozess an einen Service-Prozess.
Wir bezeichnen die Arbeit, die jeder Dienst verrichtet, als Spanne, d.h. als die Zeitspanne, die für die Arbeit benötigt wird. Diese Spans können mit Metadaten (bekannt als Attribute oder Tags) und Ereignissen (auch Logs genannt) kommentiert werden. Die RPCs zwischen den Diensten werden durch Beziehungen dargestellt, die die Art der Anfrage und die Reihenfolge, in der die Anfragen auftreten, modellieren. Diese Beziehungen werden über den trace context weitergegeben, also über Daten, die einen Trace und jeden einzelnen Span darin eindeutig identifizieren. Die Spandaten, die von jedem Dienst erstellt werden, werden dann an einen externen Prozess weitergeleitet, wo sie zu einem Trace zusammengefasst, für weitere Erkenntnisse analysiert und für weitere Analysen gespeichert werden können. Ein einfaches Beispiel für einen Trace ist in Abbildung P-4 zu sehen, die einen Trace zwischen zwei Diensten sowie einen Subtrace innerhalb des ersten Dienstes zeigt.
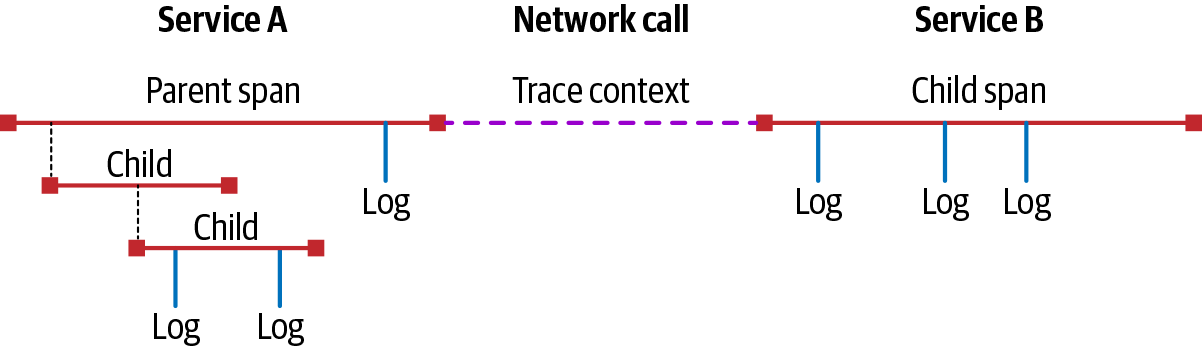
Abbildung P-4. Eine einfache Spur.
Verteiltes Tracing entschärft die Verschleierung in verteilten Architekturen, indem es sicherstellt, dass jede logische Anfrage durch deine Dienste als solche dargestellt wird - eine einzige logische Anfrage. Es stellt sicher, dass alle Daten, die für eine bestimmte Ausführung deiner Geschäftslogik relevant sind, an dem Punkt, an dem sie analysiert und dargestellt werden, gekoppelt bleiben. Das Problem der Inkonsistenz wird dadurch gelöst, dass Abfragen mit Hilfe von Beziehungen zwischen Diensten entlang bestimmter APIs oder anderer Routen gestellt werden können, so dass du Fragen stellen kannst wie "Was passiert mit meiner API, wenn dieser andere Dienst ausfällt? Schließlich wird das Problem der Dezentralisierung angegangen, indem eine Methode bereitgestellt wird, die sicherstellt, dass Prozesse unabhängig voneinander Trace-Daten an einen Collector senden können, der diese später zentralisiert.
Was kann man mit verteiltem Tracing alles machen? Was macht sie so wichtig für das Verständnis verteilter Systeme? Wir haben einige Beispiele aus der Praxis zusammengestellt:
-
Ein großes E-Mail- und Messaging-Unternehmen implementierte verteiltes Tracing in seiner Backend-Plattform, einschließlich der Tracing-Aufrufe an Redis. Diese Trace-Daten zeigten schnell, dass es eine unnötige Schleife in den Aufrufen an Redis gab, die mehr Daten aus dem Cache abrief als nötig. Durch das Entfernen dieses überflüssigen Aufrufs konnte das Unternehmen die Zeit, die für das Versenden einer E-Mail benötigt wurde, zwischen 100 und 1.000 Millisekunden reduzieren! Das bedeutete eine Zeitersparnis von etwa 85% für jede einzelne versendete E-Mail - und das bei einer Plattform, die täglich über eine Milliarde E-Mails versendet! Das Unternehmen war nicht nur in der Lage, diesen unnötigen Anruf zu entdecken, sondern auch die Auswirkungen der Beseitigung dieses Anrufs auf andere Dienste zu überprüfen und den Wert der Arbeit zu beziffern.
-
Ein Industriedatenunternehmen konnte verteilte Trace-Daten nutzen, um die Anfragen während eines Vorfalls, bei dem eine primäre Datenbank überlastet war, einfach mit einer früheren Basislinie zu vergleichen. Die Möglichkeit, aggregierte statistische Daten über die historische Leistung zusammen mit dem Kontext der einzelnen Anfragen während der Regression zu sehen, verkürzte die Zeit, die benötigt wurde, um die Grundursache des Vorfalls zu ermitteln, drastisch.
-
Ein großes Gesundheits- und Fitnessunternehmen führte verteiltes Tracing für seine Anwendungen ein. Als sie die Leistung ihrer Dokumentendatenbank analysierten, konnten die Ingenieure wiederholte Aufrufe identifizieren, die konsolidiert werden konnten, was zu geringeren Latenzzeiten und effizienterem Code führte.
-
Eine Videoplattform nutzte verteiltes Tracing, um Latenzprobleme bei verwalteten Diensten, auf die ihr System angewiesen war, zu beheben. Sie konnte ein Problem mit der Kafka-Pipeline ihres Cloud-Providers noch vor dem Anbieter identifizieren, so dass sie schnell auf den Vorfall reagieren und die gewünschte Leistung wiederherstellen konnte.
Dies sind nur einige wenige Beispiele - verteiltes Tracing hat sich auch für Teams bewährt, die versuchen, ihre kontinuierlichen Integrationssysteme besser zu verstehen, indem sie Einblick in ihre Testpipeline erhalten, in den Betrieb von Suchtechnologien im globalen Maßstab bei Google und als Eckpfeiler von Open-Source-Projekten wie OpenTelemetry. Die Frage ist wirklich: Was bedeutet verteiltes Tracing für dich?
Verteiltes Tracing und du
Verteiltes Tracing ist wiederum eine Methode, um verteilte Software zu verstehen. Das ist ungefähr so, als würde man sagen, dass Wasser nass ist - nicht sehr hilfreich und sehr verkürzend. Der beste Weg, verteiltes Tracing zu verstehen, ist, es in der Praxis zu erleben - und da kommt dieses Buch ins Spiel!
In den folgenden Kapiteln werden wir die drei wichtigsten Dinge behandeln, die du wissen musst, um mit der Implementierung von verteiltem Tracing für deine Anwendungen zu beginnen, und Strategien diskutieren, die du anwenden kannst, um die durch verteilte Architekturen verursachten Probleme zu lösen. Du lernst die verschiedenen Möglichkeiten kennen, wie du deine Software für verteiltes Tracing instrumentieren kannst und welche Arten von Tracing und Monitoring dir zur Verfügung stehen. Wir besprechen, wie du alle Daten sammelst, die deine Instrumente erzeugen, und welche Leistungsüberlegungen und Kosten mit der Sammlung und Speicherung von Tracedaten verbunden sind. Danach werden wir uns damit befassen, wie du aus deinen Trace-Daten einen Nutzen ziehen und sie in nützliche, betriebliche Erkenntnisse umwandeln kannst. Schließlich sprechen wir über die Zukunft der verteilten Rückverfolgung.
Am Ende dieses Buches solltest du die aufregende Welt des verteilten Tracings verstehen und wissen, wo, wie und wann du es für deine Software einsetzen kannst. Das Ziel von Distributed Tracing in der Praxis ist es, dass du deine Software einfacher erstellen, betreiben und verstehen kannst. Wir hoffen, dass die Lektionen in diesem Text dir dabei helfen werden, die nächste Generation der Überwachungs- und Beobachtungspraxis in deinem Unternehmen aufzubauen.
In diesem Buch verwendete Konventionen
In diesem Buch werden die folgenden typografischen Konventionen verwendet:
- Kursiv
-
Weist auf neue Begriffe, URLs, E-Mail-Adressen, Dateinamen und Dateierweiterungen hin.
Constant width-
Wird für Programmlistings sowie innerhalb von Absätzen verwendet, um auf Programmelemente wie Variablen- oder Funktionsnamen, Datenbanken, Datentypen, Umgebungsvariablen, Anweisungen und Schlüsselwörter zu verweisen.
Constant width bold-
Zeigt Befehle oder anderen Text an, der vom Benutzer wortwörtlich eingetippt werden sollte.
Constant width italic-
Zeigt Text an, der durch vom Benutzer eingegebene Werte oder durch kontextabhängige Werte ersetzt werden soll.
Hinweis
Dieses Element steht für einen allgemeinen Hinweis.
Code-Beispiele verwenden
Zusätzliches Material (Code-Beispiele, Übungen usw.) steht unter auf GitHub zum Download bereit.
Wenn du eine technische Frage oder ein Problem mit den Codebeispielen hast, sende bitte eine E-Mail an bookquestions@oreilly.com.
Dieses Buch soll dir helfen, deine Arbeit zu erledigen. Wenn in diesem Buch Beispielcode angeboten wird, darfst du ihn in deinen Programmen und deiner Dokumentation verwenden. Du musst uns nicht um Erlaubnis bitten ( ), es sei denn, du reproduzierst einen großen Teil des Codes. Wenn du zum Beispiel ein Programm schreibst, das mehrere Teile des Codes aus diesem Buch verwendet, brauchst du keine Erlaubnis. Der Verkauf oder die Verbreitung von Beispielen aus O'Reilly-Büchern erfordert jedoch eine Genehmigung. Die Beantwortung einer Frage mit einem Zitat aus diesem Buch und einem Beispielcode erfordert keine Genehmigung. Wenn du einen großen Teil des Beispielcodes aus diesem Buch in die Dokumentation deines Produkts aufnimmst, ist eine Genehmigung erforderlich.
Wir freuen uns über eine Namensnennung, verlangen sie aber in der Regel nicht. Eine Quellenangabe umfasst normalerweise den Titel, den Autor, den Verlag und die ISBN. Ein Beispiel: "Distributed Tracing in Practice" von Austin Parker, Daniel Spoonhower, Jonathan Mace, und Rebecca Isaacs mit Ben Sigelman (O'Reilly). Copyright 2020 Ben Sigelman, Austin Parker, Daniel Spoonhower, Jonathan Mace, and Rebecca Isaacs, 978-1-492-05663-8."
Wenn du der Meinung bist, dass die Verwendung von Code-Beispielen nicht unter die Fair-Use-Regelung oder die oben genannte Erlaubnis fällt, kannst du uns gerne unter permissions@oreilly.com kontaktieren .
O'Reilly Online Learning
Hinweis
Seit mehr als 40 Jahren bietet O'Reilly Media Schulungen, Wissen und Einblicke in Technologie und Wirtschaft, um Unternehmen zum Erfolg zu verhelfen.
Unser einzigartiges Netzwerk von Experten und Innovatoren teilt sein Wissen und seine Erfahrung durch Bücher, Artikel und unsere Online-Lernplattform. Die Online-Lernplattform von O'Reilly bietet dir On-Demand-Zugang zu Live-Trainingskursen, ausführlichen Lernpfaden, interaktiven Programmierumgebungen und einer umfangreichen Text- und Videosammlung von O'Reilly und über 200 anderen Verlagen. Besuche http://oreilly.com für weitere Informationen.
Wie du uns kontaktierst
Bitte richte Kommentare und Fragen zu diesem Buch an den Verlag:
- O'Reilly Media, Inc.
- 1005 Gravenstein Highway Nord
- Sebastopol, CA 95472
- 800-998-9938 (in den Vereinigten Staaten oder Kanada)
- 707-829-0515 (international oder lokal)
- 707-829-0104 (Fax)
Wir haben eine Webseite für dieses Buch, auf der wir Errata, Beispiele und zusätzliche Informationen auflisten. Du kannst diese Seite unter https://oreil.ly/distributed-tracing aufrufen .
Schreib eine E-Mail an bookquestions@oreilly.com, um Kommentare oder technische Fragen zu diesem Buch zu stellen.
Neuigkeiten und Informationen über unsere Bücher und Kurse findest du unter http://oreilly.com.
Finde uns auf Facebook: http://facebook.com/oreilly
Folge uns auf Twitter: http://twitter.com/oreillymedia
Schau uns auf YouTube: http://www.youtube.com/oreillymedia
Danksagungen
- Austin Parker
-
Ein besonderer Dank geht an alle bei O'Reilly, die dazu beigetragen haben, dass dieses Buch entstehen konnte - unsere Redakteurinnen Sarah Grey, Virginia Wilson und Katherine Tozer; die Produktionsmitarbeiterinnen und -mitarbeiter, die unermüdlich am Indexieren, Überarbeiten, Neuzeichnen und dafür gesorgt haben, dass alles auf die Seite passt. Danke an unsere technischen Prüfer für ihre Einsichten und ihr Feedback; ihr habt dieses Buch zu einem besseren gemacht! Ich möchte mich auch bei Ben Sigelman und dem restlichen Team von Lightstep für ihre Unterstützung bedanken - ohne euch wäre das alles nicht möglich gewesen.
Ich möchte mich bei meinen Eltern dafür bedanken, dass sie mich aufgenommen haben, und bei meinem Vater dafür, dass er mich täglich inspiriert. Ich liebe euch beide. An meine Frau: <3.
Aus Solidarität, Austin.
- Daniel Spoonhower
-
Ich möchte mich bei allen bei Lightstep bedanken, die Austin und mich bei dieser Arbeit unterstützt haben, vor allem bei denen, die meine vielen Fragen zu ihren Erfahrungen mit der Einführung und Nutzung von Tracing beantwortet haben. Ich möchte Bob Harper und Guy Blelloch dafür danken, dass sie mir geholfen haben, den Wert klarer Texte zu verstehen (und dass sie mir Übung im Schreiben unter Zeitdruck gegeben haben). Ich möchte auch meiner Familie dafür danken, dass sie mir geholfen hat, Zeit für die Arbeit an diesem Buch zu finden.
- Rebecca Isaacs
-
Ich möchte mich für die Erfahrung, die Ratschläge und die guten Ideen meiner Kolleginnen und Kollegen bedanken, von denen viele hohe Erwartungen an den Nutzen der verteilten Rückverfolgung in Produktionsumgebungen haben. Ich möchte auch Paul Barham für seine Einsichten und seine Weisheit in Bezug auf die Verfolgung und Analyse verteilter Systeme danken.
Get Verteilte Rückverfolgung in der Praxis now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

