Chapter 4. Trino Architecture
After the introduction to Trino, and an initial installation and usage in the earlier chapters, we now discuss the Trino architecture. We dive deeper into related concepts, so you can learn about the Trino query execution model, query planning, and cost-based optimizations.
In this chapter, we first discuss the Trino high-level architectural components. It is important to have a general understanding of the way Trino works, especially if you intend to install and manage a Trino cluster yourself, as discussed in Chapter 5.
In the later part of the chapter, we dive deeper into those components when we talk about the query execution model of Trino. This is most important if you need to diagnose or tune a slow performance query, all discussed in Chapter 8, or if you plan to contribute to the Trino open source project.
Coordinator and Workers in a Cluster
When you first installed Trino, as discussed in Chapter 2, you used only a single machine to run everything. For the desired scalability and performance, this deployment is not suitable.
Trino is a distributed SQL query engine resembling massively parallel processing (MPP) style databases and query engines. Rather than relying on vertical scaling of the server running Trino, it is able to distribute all processing across a cluster of servers horizontally. This means that you can add more nodes to gain more processing power.
Leveraging this architecture, the Trino query engine is able to process SQL queries on large amounts of data in parallel across a cluster of computers, or nodes. Trino runs as a single-server process on each node. Multiple nodes running Trino, which are configured to collaborate with each other, make up a Trino cluster.
Figure 4-1 displays a high-level overview of a Trino cluster composed of one coordinator and multiple worker nodes. A Trino user connects to the coordinator with a client, such as a tool using the JDBC driver or the Trino CLI. The coordinator then collaborates with the workers, which access the data sources.
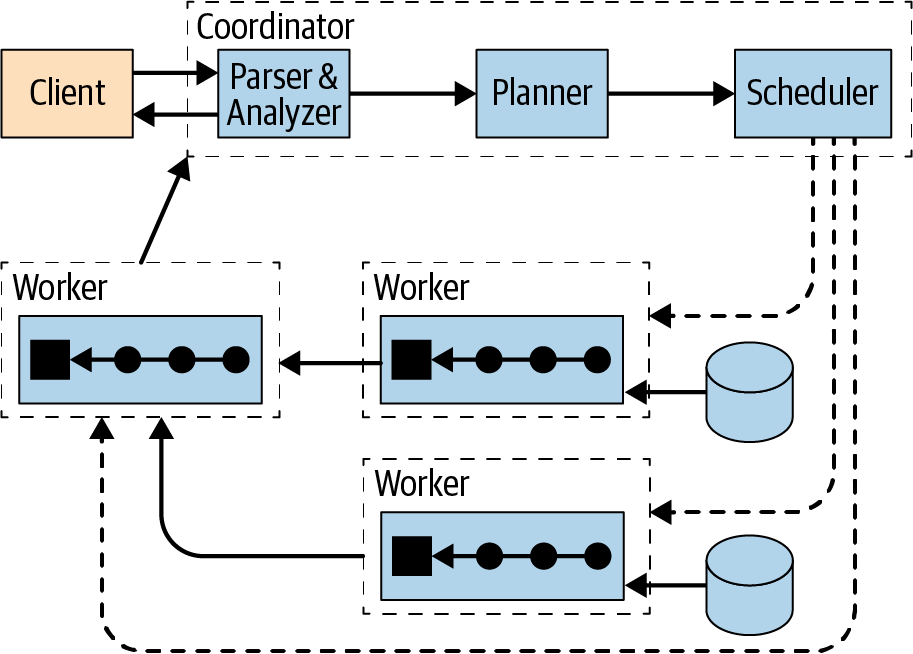
Figure 4-1. Trino architecture overview with coordinator and workers
A coordinator is a Trino server that handles incoming queries and manages the workers to execute the queries.
A worker is a Trino server responsible for executing tasks and processing data.
The discovery service runs on the coordinator and allows workers to register to participate in the cluster.
All communication and data transfer between clients, coordinator, and workers uses REST-based interactions over HTTP/HTTPS.
Figure 4-2 shows how the communication within the cluster happens between the coordinator and the workers, as well as from one worker to another. The coordinator talks to workers to assign work, update status, and fetch the top-level result set to return to the users. The workers talk to each other to fetch data from upstream tasks, running on other workers. And the workers retrieve result sets from the data source.
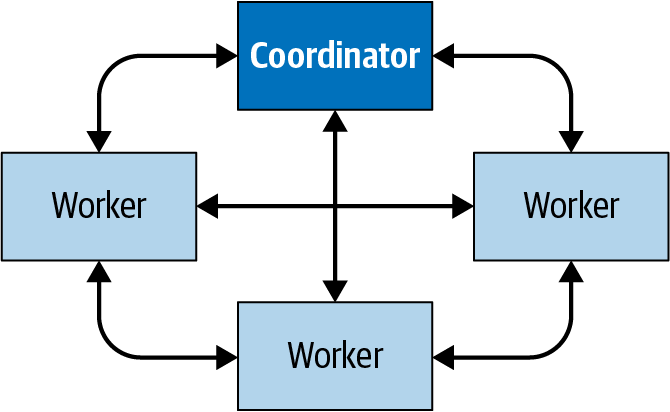
Figure 4-2. Communication between coordinator and workers in a Trino cluster
Coordinator
The Trino coordinator is the server responsible for receiving SQL
statements from the users, parsing these statements, planning queries, and
managing worker nodes. Itâs the brain of a Trino installation and the node to which a client connects. Users interact with the coordinator via the
Trino CLI, applications using the JDBC or ODBC
drivers, the Trino Python client, or any other client library for a variety of languages. The
coordinator accepts SQL statements from the client such as SELECT queries for
execution.
Every Trino installation must have a coordinator alongside one or more workers. For development or testing purposes, a single instance of Trino can be configured to perform both roles.
The coordinator keeps track of the activity on each worker and coordinates the execution of a query. The coordinator creates a logical model of a query involving a series of stages.
Once the coordinator receives an SQL statement, it is responsible for parsing, analyzing, planning, and scheduling the query execution across the Trino worker nodes. The statement is translated into a series of connected tasks running on a cluster of workers. As the workers process the data, the results are retrieved by the coordinator and exposed to the clients on an output buffer. When an output buffer is completely read by the client, the coordinator requests more data from the workers on behalf of the client. The workers, in turn, interact with the data sources to get the data from them. As a result, data is continuously requested by the client and supplied by the workers from the data source until the query execution is completed.
Coordinators communicate with workers and clients by using an HTTP-based protocol. Figure 4-3 displays the communication between client, coordinator, and workers.
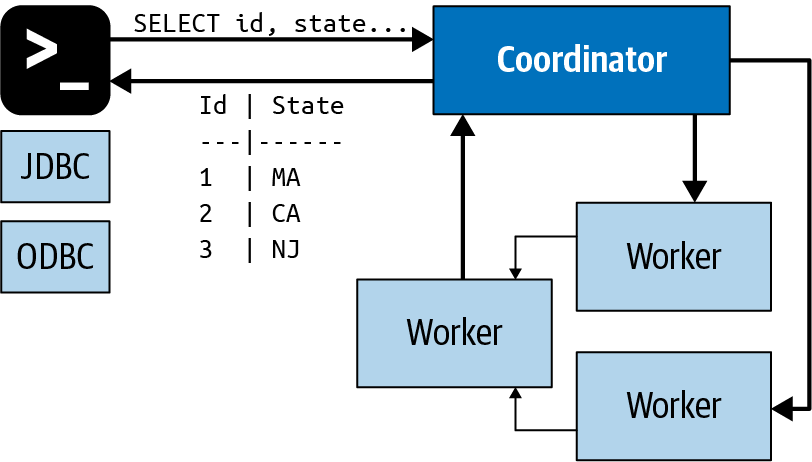
Figure 4-3. Client, coordinator, and worker communication processing an SQL statement
Discovery Service
Trino uses a discovery service to find all nodes in the cluster. Every Trino instance registers with the discovery service on startup and periodically sends a heartbeat signal. This allows the coordinator to have an up-to-date list of available workers and use that list for scheduling query execution.
If a worker fails to report heartbeat signals, the discovery service triggers the failure detector, and the worker becomes ineligible for further tasks.
The Trino coordinator runs the discovery service. It shares the HTTP server with Trino and thus uses the same port. Worker configuration of the discovery service therefore points at the hostname and port of the coordinator.
Workers
A Trino worker is a server in a Trino installation. It is responsible for executing tasks assigned by the coordinator, including retrieving data from the data sources and for processing data. Worker nodes fetch data from data sources by using connectors and then exchange intermediate data with each other. The final resulting data is passed on to the coordinator. The coordinator is responsible for gathering the results from the workers and providing the final results to the client.
During installation, workers are configured to know the hostname or IP address of the discovery service for the cluster. When a worker starts up, it advertises itself to the discovery service, which makes it available to the coordinator for task execution.
Workers communicate with other workers and the coordinator by using an HTTP-based protocol.
Figure 4-4 shows how multiple workers retrieve data from the data sources and collaborate to process the data, until one worker can provide the data to the coordinator.
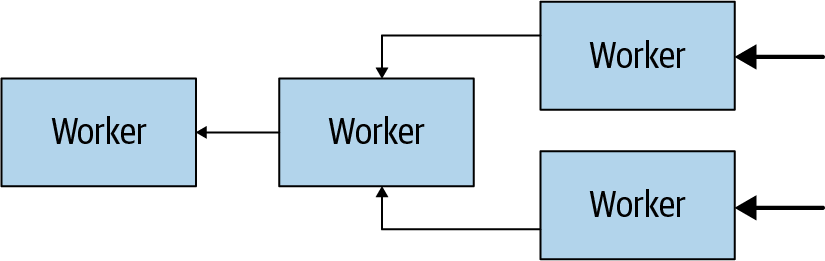
Figure 4-4. Workers in a cluster collaborate to process SQL statements and data
Connector-Based Architecture
At the heart of the separation of storage and compute in Trino is the connector-based architecture. A connector provides Trino an interface to access an arbitrary data source.
Each connector provides a table-based abstraction over the underlying data source. As long as data can be expressed in terms of tables, columns, and rows by using the data types available to Trino, a connector can be created and the query engine can use the data for query processing.
Trino provides a service provider interface (SPI), which defines the functionality a connector has to implement for specific features. By implementing the SPI in a connector, Trino can use standard operations internally to connect to any data source and perform operations on any data source. The connector takes care of the details relevant to the specific data source.
Every connector implements the three parts of the API:
-
Operations to fetch table/view/schema metadata
-
Operations to produce logical units of data partitioning, so that Trino can parallelize reads and writes
-
Data sources and sinks that convert the source data to/from the in-memory format expected by the query engine
Letâs clarify the SPI with an example. Any connector in Trino that supports
reading data from the underlying data source needs to implement the listTables
SPI. As a result, Trino can use the same method to ask any connector to check the list of available
tables in a schema. Trino does not have to know that some
connectors have to get that data from an information schema, others have to
query a metastore, and still others have to request that information via an API
of the data source. For the core Trino engine, those details are irrelevant. The
connector takes care of the details. This approach clearly separates the
concerns of the core query engine from the specifics of any underlying data
source. This simple, yet powerful approach provides large benefits for the ability to
read, expand, and maintain the code over time.
Trino provides many connectors to systems such as HDFS/Hive, Iceberg, Delta Lake, MySQL, PostgreSQL, MS SQL Server, Kafka, Cassandra, Redis, and many more. In Chapters 6 and 7, you learn about several of the connectors. The list of available connectors is continuously growing. Refer to the Trino documentation for the latest list of supported connectors.
Trinoâs SPI also gives you the ability to create your own custom connectors. This may be necessary if you need to access a data source without a compatible connector. If you end up creating a connector, we strongly encourage you to learn more about the Trino open source community, use our help, and contribute your connector. Check out âTrino Resourcesâ for more information. A custom connector may also be needed if you have a unique or proprietary data source within your organization. This is what allows Trino users to query any data source by using SQLâtruly SQL-on-Anything.
Figure 4-5 shows how the Trino SPI includes separate interfaces for metadata, data statistics, and data location used by the coordinator, and for data streaming used by the workers.

Figure 4-5. Overview of the Trino SPI
Trino connectors are plug-ins loaded by each server at startup. They are configured by specific parameters in the catalog properties files and loaded from the plug-ins directory. We explore this more in Chapter 6.
Note
Trino uses a plug-in-based architecture for numerous aspects of its functionality. Besides connectors, plug-ins can provide implementations for event listeners, access controls, and function and type providers.
Catalogs, Schemas, and Tables
The Trino cluster processes all queries by using the connector-based architecture described earlier. Each catalog configuration uses a connector to access a specific data source. The data source exposes one or more schemas in the catalog. Each schema contains tables that provide the data in table rows, with columns using different data types. For more details, see Chapter 8: specifically âCatalogsâ, âSchemasâ, and âTablesâ.
Query Execution Model
Now that you understand how any real-world deployment of Trino involves a cluster with a coordinator and many workers, we can look at how an actual SQL query statement is processed.
Understanding the execution model provides you the foundational knowledge necessary to tune Trinoâs performance for your particular queries.
Recall that the coordinator accepts SQL statements from the end user, from the CLI or applications using the ODBC or JDBC driver or other client libraries. The coordinator then triggers the workers to get all the data from the data source, creates the result data set, and makes it available to the client.
Letâs take a closer look into what happens inside the coordinator first. When a SQL statement is submitted to the coordinator, it is received in textual format. The coordinator takes that text and parses and analyzes it. It then creates a plan for execution by using an internal data structure in Trino called the query plan. This flow is displayed in Figure 4-6. The query plan broadly represents the needed steps to process the data and return the results per the SQL statement.
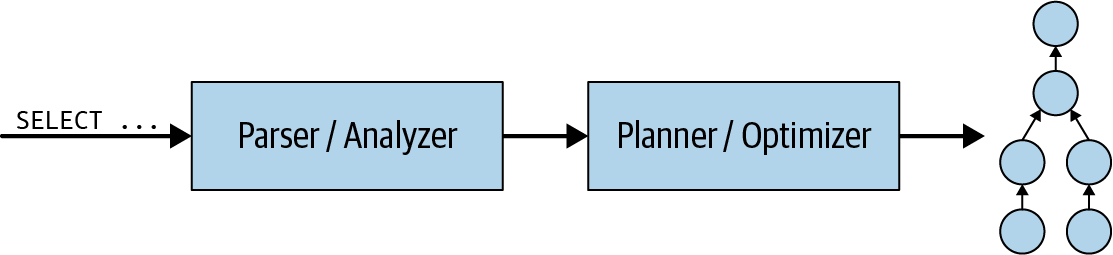
Figure 4-6. Processing an SQL query statement to create a query plan
As you can see in Figure 4-7, the query plan generation uses the metadata SPI and the data statistics SPI to create the query plan. So the coordinator uses the SPI to gather information about tables and other metadata connecting to the data source directly.
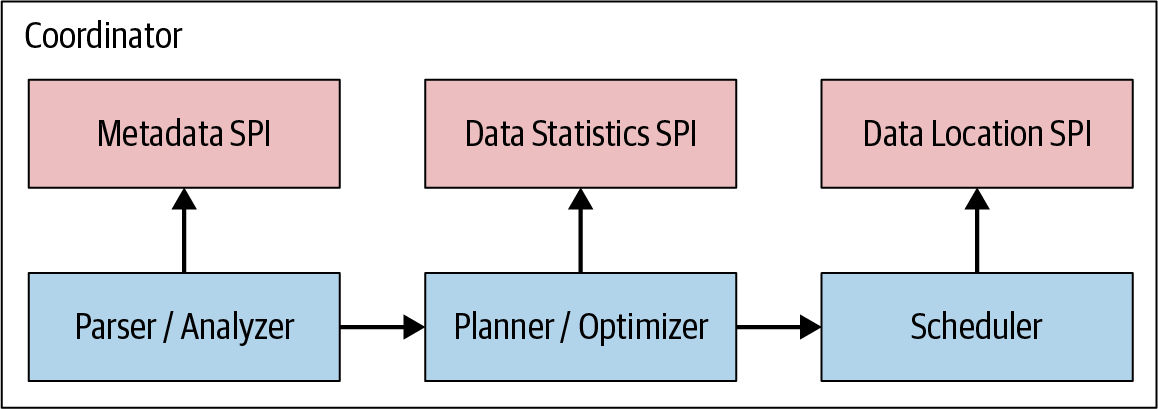
Figure 4-7. The SPIs for query planning and scheduling
The coordinator uses the metadata SPI to get information about tables, columns, and types. These are used to validate that the query is semantically valid and to perform type checking of expressions in the original query and security checks.
The statistics SPI is used to obtain information about row counts and table sizes to perform cost-based query optimizations during planning.
The data location SPI is then facilitated in the creation of the distributed query plan. It is used to generate logical splits of the table contents. Splits are the smallest unit of work assignment and parallelism.
Note
The various SPIs are more of a conceptual separation; the actual lower-level Java API is separated by multiple Java packages in a more fine-grained manner.
The distributed query plan is an extension of the simple query plan consisting of one or more stages. The simple query plan is split into plan fragments. A stage is the runtime incarnation of a plan fragment, and it encompasses all the tasks of the work described by the stageâs plan fragment.
The coordinator breaks up the plan to allow processing on clusters facilitating
workers in parallel to speed up the overall query. Having more than one stage results in
the creation of a dependency tree of stages. The number of stages depends on the
complexity of the query. For example, queried tables, returned columns, JOIN
statements, WHERE conditions, GROUP BY operations, and other SQL statements
all impact the number of stages created.
Figure 4-8 shows how the logical query plan is transformed into a distributed query plan on the coordinator in the cluster.
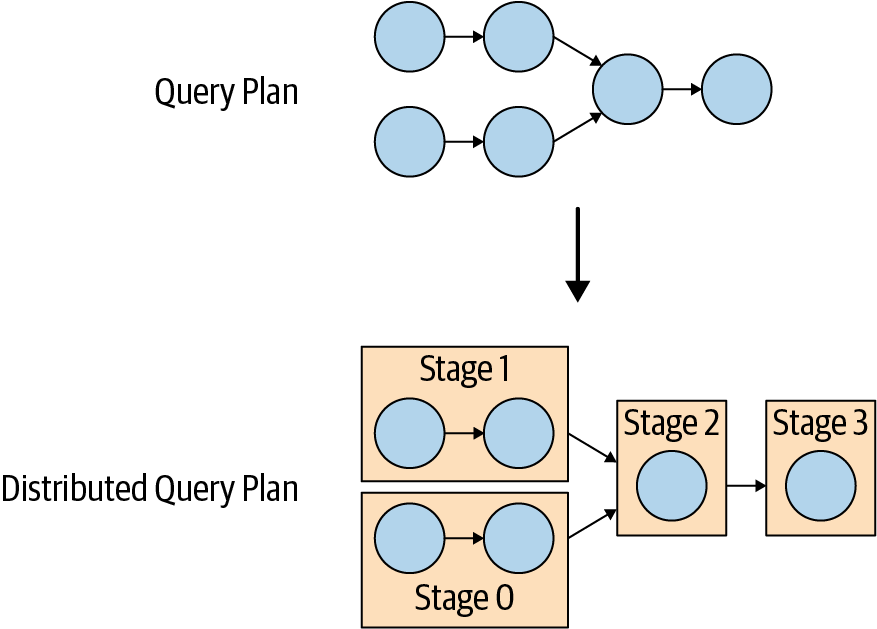
Figure 4-8. Transformation of the query plan to a distributed query plan
The distributed query plan defines the stages and the way the query is to execute on a Trino cluster. Itâs used by the coordinator to further plan and schedule tasks across the workers. A stage consists of one or more tasks. Typically, many tasks are involved, and each task processes a piece of the data.
The coordinator assigns the tasks from a stage out to the workers in the cluster, as displayed in Figure 4-9.
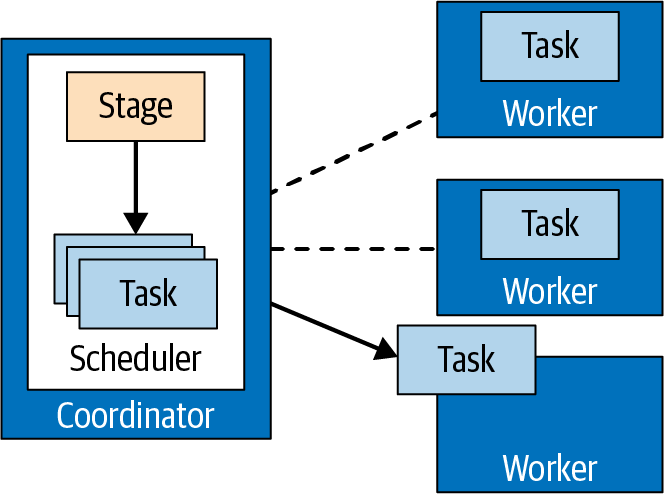
Figure 4-9. Task management performed by the coordinator
The unit of data that a task processes is called a split. A split is a descriptor for a segment of the underlying data that can be retrieved and processed by a worker. It is the unit of parallelism and work assignment.
The specific operations on the data performed by the connector depend on the underlying data source. For example, the Hive connector describes splits in the form of a path to a file with offset and length that indicate which part of the file needs to be processed.
Tasks at the source stage produce data in the form of pages, which are a collection of rows in columnar format. These pages flow to other intermediate downstream stages. Pages are transferred between stages by exchange operators, which read the data from tasks within an upstream stage.
The source tasks use the data source SPI to fetch data from the underlying data source with the help of a connector. This data is presented to Trino and flows through the engine in the form of pages. Operators process and produce pages according to their semantics. For example, filters drop rows, projections produce pages with new derived columns, and so on.
The sequence of operators within a task is called a pipeline. The last operator of a pipeline typically places its output pages in the taskâs output buffer. Exchange operators in downstream tasks consume the pages from an upstream taskâs output buffer. All these operations occur in parallel on different workers, as seen in Figure 4-10.
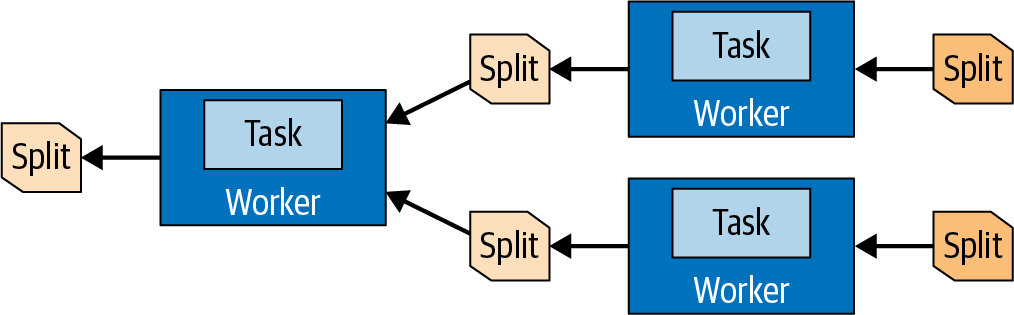
Figure 4-10. Data in splits is transferred between tasks and processed on different workers
So a task is the runtime incarnation of a plan fragment when assigned to a worker. After a task is created, it instantiates a driver for each split. Each driver is an instantiation of a pipeline of operators and performs the processing of the data in the split.
A task may use one or more drivers, depending on the Trino configuration and environment, as shown in Figure 4-11. Once all drivers are finished and the data is passed to the next split, the drivers and the task are finished with their work and are destroyed.
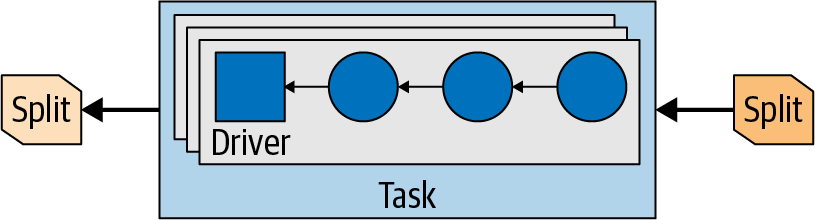
Figure 4-11. Parallel drivers in a task with input and output splits
An operator processes input data to produce output data for a downstream operator. Example operators are table scans, filters, joins, and aggregations. A series of these operators form an operator pipeline. For example, you may have a pipeline that first scans and reads the data, and then filters the data, and finally partially aggregates the data.
To process a query, the coordinator creates the list of splits with the metadata from the connector. Using the list of splits, the coordinator starts scheduling tasks on the workers to gather the data in the splits. During query execution, the coordinator tracks all splits available for processing and the locations where tasks are running on workers and processing splits.
As tasks finish processing and are producing more splits for downstream processing, the coordinator continues to schedule tasks until no splits remain for processing. Once all splits are processed on the workers, all data is available, and the coordinator can make the result available to the client.
Query Planning
Before diving into how the Trino query planner and cost-based optimizations work, letâs set up a stage that frames our considerations in a certain context. We present an example query as context for our exploration to help you understand the process of query planning.
Example 4-1 uses the TPC-H data setâsee âTrino TPC-H and TPC-DS Connectorsââto sum up the value of all orders per nation and list the top five nations.
Example 4-1. Example query to explain query planning
SELECT(SELECTnameFROMregionrWHEREregionkey=n.regionkey)ASregion_name,n.nameASnation_name,sum(totalprice)orders_sumFROMnationn,orderso,customercWHEREn.nationkey=c.nationkeyANDc.custkey=o.custkeyGROUPBYn.nationkey,regionkey,n.nameORDERBYorders_sumDESCLIMIT5;
Letâs try to understand the SQL constructs used in the query and their purpose:
-
A
SELECTquery using three tables in theFROMclause, implicitly defining aCROSS JOINbetween thenation,orders, andcustomertables -
A
WHEREcondition to retain the matching rows from thenation,orders, andcustomertables -
An aggregation using
GROUP BYto aggregate values of orders for each nation -
A subquery
(SELECT name FROM region WHERE regionkey = n.regionkey)to pull the region name from theregiontable; note that this query is correlated, as if it was supposed to be executed independently for each row of the containing result set -
An ordering definition,
ORDER BY orders_sum DESC, to sort the result before returning -
A limit of five rows defined to return only nations with the highest order sums and filter out all others
Parsing and Analysis
Before a query can be planned for execution, it needs to be parsed and analyzed. Details about SQL and the related syntactic rules for building the query can be found in Chapters 8 and 9. Trino verifies the text for these syntax rules when parsing it. As a next step, Trino analyses the query:
- Identifying tables used in a query
-
Tables are organized within catalogs and schemas, so multiple tables can have the same name. For example, TPC-H data provides
orderstables of various sizes in the different schemas assf10.orders,sf100.orders, etc. - Identifying columns used in a query
-
A qualified column reference
orders.totalpriceunambiguously refers to atotalpricecolumn within theorderstable. Typically, however, an SQL query refers to a column by name onlyâtotalprice, as seen in Example 4-1. The Trino analyzer can determine which table a column originates from. - Identifying references to fields within ROW values
-
A dereference expression
c.bonusmay refer to abonuscolumn in the table namedcor aliased withc. Or, it may refer to abonusfield in accolumn of row type (a struct with named fields). It is the job of the analyzer in Trino to decide which is applicable, with a table-qualified column reference taking precedence in case of ambiguity. Analysis needs to follow SQL languageâs scoping and visibility rules. The information collected, such as identifier disambiguation, is later used during planning, so that the planner does not need to understand the query language scoping rules again.
As you see, the query analyzer has complex, cross-cutting duties. Its role is very technical, and it remains invisible from the user perspective as long as the queries are correct. The analyzer manifests its existence whenever a query violates SQL language rules, exceeds the userâs privileges, or is unsound for some other reason.
Once the query is analyzed and all identifiers in the query are processed and resolved, Trino proceeds to the next phase, which is query planning.
Initial Query Planning
A query plan defines a program that produces query results. Recall that SQL is a declarative language: the user writes an SQL query to specify the data they want from the system. Unlike an imperative program, the user does not specify how to process the data to get the result. This part is left to the query planner and optimizer to determine the sequence of steps to process the data for the desired result.
This sequence of steps is often referred to as the query plan. Theoretically, an exponential number of query plans could yield the same query result. The performance of the plans varies dramatically, and this is where the Trino planner and optimizer try to determine the optimal plan. Plans that always produce the same results are called equivalent plans.
Letâs consider the query shown previously in Example 4-1. The most straightforward query plan for this query is the one that most closely resembles the queryâs SQL syntactical structure. This plan is shown in Example 4-2. For the purposes of this discussion, the listing should be self-explanatory. You just need to know that the plan is a tree, and its execution starts from leaf nodes and proceeds up along the tree structure.
Example 4-2. Manually condensed, straightforward textual representation of the query plan for the example query
- Limit[5]
- Sort[orders_sum DESC]
- LateralJoin[2]
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- Filter[c.nationkey = n.nationkey AND c.custkey = o.custkey]
- CrossJoin
- CrossJoin
- TableScan[nation]
- TableScan[orders]
- TableScan[customer]
- EnforceSingleRow[region_name := r.name]
- Filter[r.regionkey = n.regionkey]
- TableScan[region]Each element of the query plan can be implemented in a straightforward,
imperative fashion. For example, TableScan accesses a table in its underlying
storage and returns a result set containing all rows within the table. Filter
receives rows and applies a filtering condition on each, retaining only the rows
that satisfy the condition. CrossJoin operates on two data sets that it
receives from its child nodes. It produces all combinations of rows in those data
sets, probably storing one of the data sets in memory, so that the underlying
storage does not have to be accessed multiple times.
Warning
The latest Trino releases have changed the names of the operations in a query
plan. For example, TableScan is equivalent to ScanProject with a table
specification. The Filter operation has been renamed to FilterProject. The ideas
presented, however, remain the same.
Letâs now consider the computational complexity of this query plan. Without
knowing all the nitty-gritty details of the actual implementation, we cannot
fully reason about the complexity. However, we can assume that the lower bound
for the complexity of a query plan node is the size of the data set it produces.
Therefore, we describe complexity by using Big Omega notation, which describes the
asymptotic lower bound. If N, O, C, and R represent the number of rows
in nation, orders, customer, and region tables, respectively, we can
observe the following:
-
TableScan[orders]reads theorderstable, returning O rows, so its complexity is Ω(O). Similarly, the other twoTableScanoperations return N and C rows; thus their complexity is Ω(N) and Ω(C), respectively. -
CrossJoinaboveTableScan[nation]andTableScan[orders]combines the data fromnationandorderstables; therefore, its complexity is Ω(N à O). -
The
CrossJoinabove combines the earlierCrossJoin, which produced N à O rows, withTableScan[customer], so with data from thecustomertable; therefore, its complexity is Ω(N à O à C). -
TableScan[region]at the bottom has complexity Ω(R). However, because of theLateralJoin, it is invoked N times, with N as the number of rows returned from the aggregation. Thus, in total, this operation incurs Ω(R à N) computational cost. -
The
Sortoperation needs to order a set of N rows, so it cannot take less time than is proportional to N Ã log(N).
Disregarding other operations for a moment as no more costly than the ones we have analyzed so far, the total cost of the preceding plan is at least Ω[N + O
+ C + (N Ã O) + (N Ã O Ã C) + (R Ã N) + (N Ã log(N))]. Without knowing the
relative table sizes, this can be simplified to Ω[(N à O à C) + (R à N)
+ (N Ã log(N))]. Adding a reasonable assumption that region is the smallest
table and nation is the second smallest, we can neglect the second and third parts of the result and get the simplified result of Ω(N à O à C).
Enough of algebraic formulas. Itâs time to see what this means in practice!
Letâs consider an example of a popular shopping site with 100 million customers
from 200 nations who placed 1 billion orders in total. The CrossJoin of these
two tables needs to materialize 20 quintillion (20,000,000,000,000,000,000)
rows. For a moderately beefy 100-node cluster, processing 1 million rows a
second on each node, it would take over 63 centuries to compute the
intermediate data for our query.
Of course, Trino does not even try to execute such a naive plan. But this initial plan serves as a bridge between two worlds: the world of SQL language and its semantic rules, and the world of query optimizations. The role of query optimization is to transform and evolve the initial plan into an equivalent plan that can be executed as fast as possible, at least in a reasonable amount of time, given finite resources of the Trino cluster. Letâs talk about how query optimizations attempt to reach this goal.
Optimization Rules
In this section, you get to take a look at a handful of the many important optimization rules implemented in Trino.
Predicate Pushdown
Predicate pushdown is probably the single most important optimization and
easiest to understand. Its role is to move the filtering condition as close to
the source of the data as possible. As a result, data reduction happens as early
as possible during query execution. In our case, it transforms a Filter into a
simpler Filter and an InnerJoin above the same CrossJoin condition,
leading to a plan shown in Example 4-3. Portions of the plan
that didnât change are excluded for readability.
Example 4-3. Transformation of a CrossJoin and Filter into an InnerJoin
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- Filter[c.nationkey = n.nationkey AND c.custkey = o.custkey] // original filter
- CrossJoin
- CrossJoin
- TableScan[nation]
- TableScan[orders]
- TableScan[customer]
...
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- Filter[c.nationkey = n.nationkey] // transformed simpler filter
- InnerJoin[o.custkey = c.custkey] // added inner join
- CrossJoin
- TableScan[nation]
- TableScan[orders]
- TableScan[customer]
...The âbiggerâ join that was present is now converted into InnerJoin on an
equality condition. Without going into details, letâs assume for now that such
a join can be efficiently implemented in a distributed system, with
computational complexity equal to the number of produced rows. This means that
predicate pushdown replaced an âat leastâ Ω(N à O à C)
CrossJoin with a Join that is âexactlyâ Î(N Ã O).
However, predicate pushdown could not improve the CrossJoin between the nation
and orders tables because no immediate condition is joining these
tables. This is where cross join elimination comes into play.
Cross Join Elimination
In the absence of the cost-based optimizer, Trino joins the tables contained in
the SELECT query in the order of their appearance in the query text. The one
important exception to this occurs when the tables to be joined have no joining
condition, which results in a cross join. In almost all practical cases, a cross join is unwanted, and all the multiplied rows are later filtered out, but the cross join itself has so much work to do that it may never complete.
Cross join elimination reorders the tables being joined to minimize the number
of cross joins, ideally reducing it to zero. In the absence of information about
relative table sizes, other than the cross join elimination, table join ordering
is preserved, so the user remains in control. The effect of cross join
elimination on our example query can be seen in Example 4-4.
Now both joins are inner joins, bringing overall computational cost of joins to
Î(C + O) = Î(O). Other parts of the query plan did not change since the initial plan, so the overall query computation cost is at least Ω[O + (R à N) + (N à log(N))]âof course, the O component representing the number of rows in the orders table
is the dominant factor.
Example 4-4. Reordering the joins to eliminate the cross join
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- Filter[c.nationkey = n.nationkey] // filter on nationkey first
- InnerJoin[o.custkey = c.custkey] // then inner join custkey
- CrossJoin
- TableScan[nation]
- TableScan[orders]
- TableScan[customer]
...
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[c.custkey = o.custkey] // reordered to custkey first
- InnerJoin[n.nationkey = c.nationkey] // then nationkey
- TableScan[nation]
- TableScan[customer]
- TableScan[orders]TopN
Typically, when a query has a LIMIT clause, it is preceded by an ORDER BY
clause. Without the ordering, SQL does not guarantee which result rows are
returned. The combination of ORDER BY followed by LIMIT is also present in
our query.
When executing such a query, Trino could sort all the rows produced and then
retain just the first few of them. This approach would have Î(row_count
à log(row_count)) computational complexity and Î(row_count) memory
footprint.
However, it is not optimal and is wasteful to sort the entire results only to keep a much smaller subset of the sorted results. Therefore, an optimization
rule rolls ORDER BY followed by LIMIT into a TopN plan node. During
query execution, TopN keeps the desired number of rows in a heap data structure,
updating the heap while reading input data in a streaming fashion. This brings
computational complexity down to Î(row_count à log(limit)) and memory
footprint to Î(limit). Overall query computation cost is now Ω[O + (R
à N) + N].
Partial Aggregations
Trino does not need to pass all rows from the orders table to the join
because we are not interested in individual orders.
Our example query computes an aggregate, the sum over totalprice for each
nation, so it is possible to pre-aggregate the rows as shown in Example 4-5.
We reduce the amount of data flowing into the downstream join
by aggregating the data. The results are not complete, which is why this is
referred to as a pre-aggregation. But the amount of data is potentially
reduced, significantly improving query performance.
Example 4-5. Partial pre-aggregation can significantly improve performance
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[c.custkey = o.custkey]
- InnerJoin[n.nationkey = c.nationkey]
- TableScan[nation]
- TableScan[customer]
- Aggregate[by custkey; totalprice := sum(totalprice)]
- TableScan[orders]For improved parallelism, this kind of pre-aggregation is implemented
differently, as a so-called partial aggregation. Here, we are presenting
simplified plans, but in an actual EXPLAIN plan, this is represented
differently than the final aggregation.
Note
The kind of pre-aggregation shown in Example 4-5 is not
always an improvement. It is detrimental to query performance when partial
aggregation does not reduce the amount of data.
For this reason, the
optimization is currently disabled by default and can be enabled with the
push_partial_aggregation_through_join session property or the
optimizer.push-partial-aggregation-through-join configuration property. By
default, Trino uses partial aggregations and places them above the join to
reduce the amount of data transmitted over the network between Trino nodes. To
fully appreciate the role of these partial aggregations, we would need to
consider nonsimplified query plans.
Implementation Rules
The rules we have covered so far are optimization rulesârules with a goal to reduce query processing time, a queryâs memory footprint, or the amount of data exchanged over the network. However, even in the case of our example query, the initial plan contained an operation that is not implemented at all: the lateral join. In the next section, we look at how Trino handles these kinds of operations.
Lateral Join Decorrelation
The lateral join could be implemented as a for-each loop that traverses all rows from a data set and executes another query for each of them. Such an implementation is possible, but this is not how Trino handles the cases like our example. Instead, Trino decorrelates the subquery, pulling up all the correlated conditions and forming a regular left join. In SQL terms, this corresponds to transformation of a query:
SELECT(SELECTnameFROMregionrWHEREregionkey=n.regionkey)ASregion_name,n.nameASnation_nameFROMnationn
into
SELECTr.nameASregion_name,n.nameASnation_nameFROMnationnLEFTOUTERJOINregionrONr.regionkey=n.regionkey
Even though we may use such constructs interchangeably, a cautious reader
familiar with SQL semantics immediately realizes that they are not fully
equivalent. The first query fails if duplicate entries in the
region table have the same regionkey, whereas the second query does not
fail. Instead, it produces more result rows. For this reason, lateral join
decorrelation uses two additional components besides the join. First, it
ânumbersâ all the source rows so that they can be distinguished. Second, after
the join, it checks whether any row was duplicated, as shown in
Example 4-6. If duplication is detected, the query processing is
failed in order to preserve the original query semantics.
Example 4-6. Lateral join decompositions require additional checks
- TopN[5; orders_sum DESC]
- MarkDistinct & Check
- LeftJoin[n.regionkey = r.regionkey]
- AssignUniqueId
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- ...
- TableScan[region]Semi-Join (IN) Decorrelation
A subquery can be used within a query not only to pull information, as we just
saw in the lateral join example, but also to filter rows by using the IN
predicate. In fact, an IN predicate can be used in a filter (the WHERE
clause), or in a projection (the SELECT clause). When you use IN in a
projection, it becomes apparent that it is not a simple Boolean-valued operator
like EXISTS. Instead, the IN predicate can evaluate to true, false, or
null.
Letâs consider a query designed to find orders for which the customer and item suppliers are from the same country, as shown in Example 4-7. Such orders may be interesting. For example, we may want to save shipping costs or reduce shipping environmental impact by shipping directly from the supplier to the customer, bypassing our own distribution centers.
Example 4-7. Semi-join (IN) example query
SELECTDISTINCTo.orderkeyFROMlineitemlJOINordersoONo.orderkey=l.orderkeyJOINcustomercONo.custkey=c.custkeyWHEREc.nationkeyIN(-- subquery invoked multiple timesSELECTs.nationkeyFROMpartpJOINpartsupppsONp.partkey=ps.partkeyJOINsuppliersONps.suppkey=s.suppkeyWHEREp.partkey=l.partkey);
As with a lateral join, this could be implemented with a loop over rows from the outer query, where the subquery to retrieve all nations for all suppliers of an item gets invoked multiple times.
Instead of doing this, Trino decorrelates the subqueryâthe subquery is
evaluated once, with the correlation condition removed, and then is joined
back with the outer query by using the correlation condition. The tricky part
is ensuring that the join does not multiply result rows (so a deduplicating
aggregation is used) and that the transformation correctly retains the IN
predicateâs three-valued logic.
In this case, the deduplicating aggregation uses the same partitioning as the join, so it can be executed in a streaming fashion, without data exchange over the network and with minimal memory footprint.
Cost-Based Optimizer
In âQuery Planningâ, you learned how the Trino planner converts a query in textual form into an executable and optimized query plan. You learned about various optimization rules in âOptimization Rulesâ, and their importance for query performance at execution time. You also saw implementation rules in âImplementation Rulesâ, without which a query plan would not be executable at all.
We walked the path from the beginning, where query text is received from the user, to the end, where the final execution plan is ready. Along the way, we saw selected plan transformations, which are critical because they make the plan execute orders of magnitude faster, or make the plan executable at all.
Now letâs take a closer look at plan transformations that make their decisions based not only on the shape of the query but also, and more importantly, on the shape of the data being queried. This is what the Trino state-of-the-art cost-based optimizer (CBO) does.
The Cost Concept
Earlier, we used an example query as our work model. Letâs use a similar approach, again for convenience and to aid understanding. As you can see in Example 4-8, certain query clauses, which are not relevant for this section, are removed. This allows you to focus on the cost-based decisions of the query planner.
Example 4-8. Example query for cost-based optimization
SELECTn.nameASnation_name,avg(extendedprice)asavg_priceFROMnationn,orderso,customerc,lineitemlWHEREn.nationkey=c.nationkeyANDc.custkey=o.custkeyANDo.orderkey=l.orderkeyGROUPBYn.nationkey,n.nameORDERBYnation_name;
Without cost-based decisions, the query planner rules optimize the initial plan for this query to produce a plan, as shown in Example 4-9. This plan is determined solely by the lexical structure of the SQL query. The optimizer used only the syntactic information; hence it is sometimes called the syntactic optimizer. The name is meant to be humorous, highlighting the simplicity of the optimizations. Since the query plan is based only on the query, you can hand-tune or optimize the query by adjusting the syntactic order of the tables in the query.
Example 4-9. Query join order from the syntactic optimizer
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[o.orderkey = l.orderkey]
- InnerJoin[c.custkey = o.custkey]
- InnerJoin[n.nationkey = c.nationkey]
- TableScan[nation]
- TableScan[customer]
- TableScan[orders]
- TableScan[lineitem]Now letâs say the query was written differently, changing only the order of the
WHERE conditions:
SELECTn.nameASnation_name,avg(extendedprice)asavg_priceFROMnationn,orderso,customerc,lineitemlWHEREc.custkey=o.custkeyANDo.orderkey=l.orderkeyANDn.nationkey=c.nationkeyGROUPBYn.nationkey,n.name;
The plan ends up with a different join order as a result:
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[n.nationkey = c.nationkey]
- InnerJoin[o.orderkey = l.orderkey]
- InnerJoin[c.custkey = o.custkey]
- TableScan[customer]
- TableScan[orders]
- TableScan[lineitem]
- TableScan[nation]
The fact that a simple change of ordering conditions affects the query plan, and therefore the performance of the query, is cumbersome for the SQL analyst. Creating efficient queries then requires internal knowledge of the way Trino processes the queries. A query author should not be required to have this knowledge to get the best performance out of Trino. In addition, tools with Trino, such as Apache Superset, Tableau, Qlick, or Metabase, typically support many different databases and query engines and do not write optimized queries for Trino.
The cost-based optimizer ensures that the two variants of the query produce the same optimal query plan for processing by Trinoâs execution engine.
From a time-complexity perspective, it does not matter whether you join, for
example, the nation table with customerâor, vice versa, the customer
table with nation.
Both tables need to be processed, and in the case of hash-join implementation,
total running time is proportional to the number of output rows. However, time
complexity is not the only thing that matters. This is generally true for
programs working with data, but it is especially true for large database
systems. Trino needs to be concerned about memory usage and network traffic as
well. To reason about memory and network usage of the join, Trino needs to
better understand how the join is
implemented.
CPU time, memory requirements, and network bandwidth usage are the three dimensions that contribute to query execution time, both in single-query and concurrent workloads. These dimensions constitute the cost in Trino.
Cost of the Join
When joining two tables over the equality condition (=), Trino implements an
extended version of the algorithm known as a
hash join. One of the joined tables
is called the build side. This table is used to build a lookup hash table with
the join condition columns as the key. Another joined table is called the
probe side. Once the lookup hash table is ready, rows from the probe side are
processed, and the hash table is used to find matching build-side rows in
constant time. By default, Trino uses three-level hashing in order to
parallelize processing as much as possible:
-
Both joined tables are distributed across the worker nodes, based on the hash values of the join condition columns. Rows that should be matched have the same values on join condition columns, so they are assigned to the same node. This reduces the size of the problem by the number of nodes being used at this stage. This node-level data assignment is the first level of hashing.
-
At a node level, the build side is further scattered across build-side worker threads, again using a hash function. Building a hash table is a CPU-intensive process, and using multiple threads to do the job greatly improves throughput.
-
Each worker thread ultimately produces one partition of the final lookup hash table. Each partition is a hash table itself. The partitions are combined into a two-level lookup hash table so that we avoid scattering the probe side across multiple threads as well. The probe side is still processed in multiple threads, but the threads get their work assigned in batches, which is faster than partitioning the data by using a hash function.
As you can see, the build side is kept in memory to facilitate fast, in-memory data processing. Of course, a memory footprint is also associated, proportional to the size of the build side. This means that the build side must fit into the memory available on the node. This also means that less memory is available to other operations and to other queries. This is the memory cost associated with the join. There is also the network cost. In the algorithm described previously, both joined tables are transferred over the network to facilitate node-level data assignment.
The cost-based optimizer can select which table should be the build table, controlling the memory cost of the join. Under certain conditions, the optimizer can also avoid sending one of the tables over the network, thus reducing network bandwidth usage (reducing the network cost). To do its job, the cost-based optimizer needs to know the size of the joined tables, which is provided as the table statistics.
Table Statistics
In âConnector-Based Architectureâ, you learned about the role of connectors. Each table is provided by a connector. Besides table schema information and access to actual data, the connector can provide table and column statistics:
-
Number of rows in a table
-
Number of distinct values in a column
-
Fraction of
NULLvalues in a column -
Minimum and maximum values in a column
-
Average data size for a column
Of course, if some information is missingâfor example, the average text length
in a varchar column is not knownâa connector can still provide other
information, and the cost-based optimizer uses what is available.
With an estimation of the number of rows in the joined tables and, optionally,
average data size for columns, the cost-based optimizer already has sufficient
knowledge to determine the optimal ordering of the tables in our example query.
The CBO can start with the biggest table (lineitem) and subsequently join the
other tablesâorders, then customer, then nation:
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[l.orderkey = o.orderkey]
- InnerJoin[o.custkey = c.custkey]
- InnerJoin[c.nationkey = n.nationkey]
- TableScan[lineitem]
- TableScan[orders]
- TableScan[customer]
- TableScan[nation]
Such a plan is good and should be considered because every join has the smaller relation as the build side, but it is not necessarily optimal. If you run the example query, using a connector that provides table statistics, you can enable the CBO with the session property:
SETSESSIONjoin_reordering_strategy='AUTOMATIC';
With the table statistics available from the connector, Trino may come up with a different plan:
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[l.orderkey = o.orderkey]
- TableScan[lineitem]
- InnerJoin[o.custkey = c.custkey]
- TableScan[orders]
- InnerJoin[c.nationkey = n.nationkey]
- TableScan[customer]
- TableScan[nation]
This plan was chosen because it avoids sending the biggest table (lineitem)
three times over the network. The table is scattered across the nodes only
once.
The final plan depends on the actual sizes of joined tables and the number of nodes in a cluster, so if youâre trying this out on your own, you may get a different plan than the one shown here.
Cautious readers notice that the join order is selected based only on the join conditions, the links between tables, and the data size of the tables, including number of rows and average data size for each column. Other statistics are critical for optimizing more involved query plans, which contain intermediate operations between table scans and the joinsâfor example, filters, aggregations, and non-inner joins.
Filter Statistics
As you just saw, knowing the sizes of the tables involved in a query is
fundamental to properly reordering the joined tables in the query plan. However,
knowing just the table sizes is not enough. Consider a modification of our
example query, in which the user added another condition like
l.partkey = 638, in order to drill down in their data set for information about orders for a particular item:
SELECTn.nameASnation_name,avg(extendedprice)asavg_priceFROMnationn,orderso,customerc,lineitemlWHEREn.nationkey=c.nationkeyANDc.custkey=o.custkeyANDo.orderkey=l.orderkeyANDl.partkey=638GROUPBYn.nationkey,n.nameORDERBYnation_name;
Before the condition was added, lineitem was the biggest table, and the query
was planned to optimize handling of that table. But now, the filtered lineitem
is one of the smallest joined relations.
Looking at the query plan shows that the filtered lineitem table is now small
enough. The CBO puts the table on the build side of the join, so that it
serves as a filter for other tables:
- Aggregate[by nationkey...; orders_sum := sum(totalprice)]
- InnerJoin[l.orderkey = o.orderkey]
- InnerJoin[o.custkey = c.custkey]
- TableScan[customer]
- InnerJoin[c.nationkey = n.nationkey]
- TableScan[orders]
- Filter[partkey = 638]
- TableScan[lineitem]
- TableScan[nation]
To estimate the number of rows in the filtered lineitem table, the CBO again
uses statistics provided by a connector: the number of distinct values in a
column and fraction of NULL values in a column. For the partkey = 638
condition, no NULL value satisfies the condition, so the optimizer knows that
the number of rows gets reduced by the fraction of NULL values in the
partkey column. Further, if you assume roughly uniform distribution of values
in the column, you can derive the final number of rows:
filtered rows = unfiltered rows * (1 - null fraction) / number of distinct values
Obviously, the formula is correct only when the distribution of values is uniform. However, the optimizer does not need to know the number of rows; it just needs to know the estimation of it, so in general being somewhat off is not a problem. Of course, if an item is bought much more frequently than othersâsay, Starburst candiesâthe estimation may be too far off, and the optimizer may choose a bad plan. Currently, when this happens, you have to disable the CBO.
In the future, connectors will be able to provide information about the data distribution to handle cases like this. For example, if a histogram were available for the data, then the CBO could more accurately estimate the filtered rows.
Table Statistics for Partitioned Tables
One special type of filtered table deserves special mention: partitioned tables. Data may be organized into partitioned tables in a Hive/HDFS warehouse accessed by the Hive connector or a modern lakehouse using the Iceberg or Delta Lake table formats and connectors; see âHive Connector for Distributed Storage Data Sourcesâ and âModern Distributed Storage Management and Analyticsâ. When the data is filtered by a condition on partitioning keys, only matching partitions are read during query executions. Furthermore, since the table statistics are stored on a per partition basis, the CBO gets statistics information only for partitions that are read, so itâs more accurate.
Of course, every connector can provide this kind of improved stats for filtered relations. We are referring only to the way the Hive connector provides statistics here.
Broadcast Versus Distributed Joins
In the previous section, you learned about the hash join implementation and the importance of the build and probe sides. Because Trino is a distributed system, joins can be done in parallel across a cluster of workers, where each worker processes a fraction of the join. For a distributed join to occur, the data may need to be distributed across the network, and different strategies are available that vary in efficiency, depending on the data shape.
Broadcast join strategy
In a broadcast join strategy, the build side of the join is broadcast to all the worker nodes that are performing the join in parallel. In other words, each join gets a complete copy of the data for the build side, as displayed in Figure 4-12. This is semantically correct only if the probe side remains distributed across the workers without duplication. Otherwise, duplicate results are created.
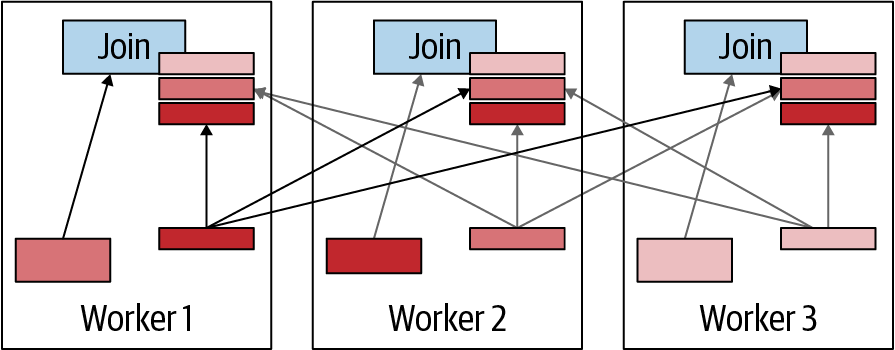
Figure 4-12. Broadcast join strategy visualization
The broadcast join strategy is advantageous when the build side is small, allowing for cost-effective transmission of data. The advantage is also greater when the probe side is very large because it avoids having to redistribute the data as is necessary in the distributed join.
Distributed join strategy
In a distributed join strategy, the input data to both the build side and the probe side is redistributed across the cluster such that the workers perform the join in parallel. The difference in data transmission over the network is that each worker receives a unique fraction of the data set, rather than a copy of the data as performed in the broadcast join. The data redistribution must use a partitioning algorithm such that the matching join key values are sent to the same node. For example, say we have the following data sets of join keys on a particular node:
Probe: {4, 5, 6, 7, 9, 10, 11, 14}
Build: {4, 6, 9, 10, 17}
Consider a simple partitioning algorithm:
if joinkey mod 3 == 0 then send to Worker 1 if joinkey mod 3 == 1 then send to Worker 2 if joinkey mod 3 == 2 then send to Worker 3
The partitioning results in these probes and builds on Worker 1:
Probe:{6, 9}
Build:{6, 9}
Worker 2 deals with different probes and builds:
Probe: {4, 7, 10}
Build: {4, 10}
And, finally, Worker 3 deals with a different subset:
Probe:{5, 11, 14}
Build: {17}
By partitioning the data, the CBO guarantees that the joins can be computed in parallel without having to share information during the processing. The advantage of a distributed join is that it allows Trino to compute a join whereby both sides are very large and there is not enough memory on a single machine to hold the entirety of the probe side in memory. The disadvantage is the extra data being sent over the network.
The decision between a broadcast join and distributed join strategy must be costed. Each strategy has trade-offs, and we must take into account the data statistics in order to cost the optimal one. Furthermore, this also needs to be decided during the join reordering process. Depending on the join order and where filters are applied, the data shape changes. This could lead to cases in which a distributed join between two data sets may work best in one join order scenario, but a broadcast join may work better in a different scenario. The join enumeration algorithm takes this into consideration.
Note
The join enumeration algorithm used by Trino is rather complex and beyond the scope of this book. It is documented in detail on a Starburst blog post. It breaks the problem into subproblems with smaller partitions, finds the correct join usage with recursions, and aggregates the results to a global result.
Working with Table Statistics
In order to leverage the CBO in Trino, your data must have statistics. Without data statistics, the CBO cannot do much; it requires data statistics to estimate rows and costs of the different plans.
Because Trino does not store data, producing statistics for Trino is connector-implementation dependent. As of the time of this writing, the Hive, Delta Lake, and Iceberg connectors for object storage systems, as well as a number of RDBMS connectors including PostgreSQL and others, provide data statistics to Trino. We expect that, over time, more connectors will support statistics, and you should continue to refer to the Trino documentation for up-to-date information.
Table statistics gathering and maintenance depend on the underlying data source. Letâs look at the Hive connector as an example of ways to collect statistics:
-
Use Trinoâs
ANALYZEcommand to collect statistics. -
Enable Trino to gather statistics when writing data to a table.
-
Use Hiveâs
ANALYZEcommand to collect statistics.
It is important to note that Trino and the Hive connector stores statistics in the Hive metastore, the same place that Hive uses to store statistics. Other connectors use the metadata storage as used by the connected data sourceâfor example, metadata files in the Iceberg table format or the information schema in some relational databases. So if youâre sharing the same tables between Hive and Trino, they overwrite each otherâs statistics. This is something you should consider when determining how to manage statistics collection.
Trino ANALYZE
Trino provides an ANALYZE command to collect statistics for a connector (for
example, the Hive connector). When run, Trino computes column-level statistics
by using its execution engine and stores the statistics in the Hive metastore.
The syntax is as follows:
ANALYZEtable_name[WITH(property_name=expression[,...])]
For example, if you want to collect and store statistics from the flights
table, you can run this:
ANALYZEdatalake.ontime.flights;
In the partitioned case, we can use the WITH clause if we want to analyze only
a particular partition:
ANALYZEdatalake.ontime.flightsWITH(partitions=ARRAY[ARRAY['01-01-2019']])
The nested array is needed when you have more than one partition key and youâd like each key to be an element in the next array. The topmost array is used if you have multiple partitions you want to analyze. The ability to specify a partition is very useful in Trino. For example, you may have some type of ETL process that creates new partitions. As new data comes in, statistics could become stale, as they do not incorporate the new data. However, by updating statistics for the new partition, you donât have to reanalyze all the previous data.
Gathering Statistics When Writing to Disk
If you have tables for which the data is always written through Trino,
statistics can be collected during write operations. For example, if you run a
CREATE TABLE AS, or an INSERT SELECT query, Trino collects the statistics
as it is writing the data to disk (HDFS or S3, for example) and then stores the
statistics in the Hive metastore.
This is a useful feature, as it does not require you to run the manual step
of ANALYZE. The statistics are never stale. However, for this to work properly
and as expected, the data in the table must always be written by Trino.
The overhead of this process has been extensively benchmarked and tested, and it shows negligible impact to performance. To enable the feature, you can add the following property into your catalog properties file by using the Hive connector:
hive.collect-column-statistics-on-write=true
Hive ANALYZE
Outside of Trino, you can still use the Hive ANALYZE command to collect the
statistics for Trino. The computation of the statistics is performed by the
Hive execution engine and not the Trino execution engine, so the results may
vary, and there is always the risk of Trino behaving differently when using
statistics generated by Hive versus Trino. Itâs generally recommended to use
Trino to collect statistics. But there may be reasons for using Hive, such as
if the data lands as part of a more complex pipeline and is shared with other
tools that may want to use the statistics. To collect statistics by using Hive,
you can run the following commands:
hive>ANALYZETABLEdatalake.ontime.flightsCOMPUTESTATISTICS;hive>ANALYZETABLEdatalake.ontime.flightsCOMPUTESTATISTICSFORCOLUMNS;
For complete information on the Hive ANALYZE command, you can refer to
the official Hive documentation.
Displaying Table Statistics
Once you have collected the statistics, it is often useful to view them. You may want to do this to confirm that statistics have been collected, or perhaps you are debugging a performance issue and want to see the statistics being used.
Trino provides a SHOW STATS command:
SHOWSTATSFORdatalake.ontime.flights;
Alternatively, if you want to see the statistics on a subset of data, you can provide a filtering condition. For example:
SHOWSTATSFOR(SELECT*FROMdatalake.ontime.flightsWHEREyear>2010);
Conclusion
Now you understand the Trino architecture, with a coordinator receiving user requests and then using workers to assemble all the data from the data sources.
Each query is translated into a distributed query plan of tasks in numerous stages. The data is returned by the connectors in splits and processed in multiple stages until the final result is available and provided to the user by the coordinator.
If you are interested in the Trino architecture in even more detail, you can dive into the paper âTrino: SQL on Everythingâ by the Trino creators, published at the IEEE International Conference on Data Engineering (ICDE) and available on the Trino website.
Next, you are going to learn more about deploying a Trino cluster in Chapter 5, hooking up more data sources with different connectors in Chapters 6 and 7, and writing powerful queries in Chapter 8.
Get Trino: The Definitive Guide, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

