Capítulo 1. Introducción a la gestióny calidad de los datos
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Hoy en día parece que los datos son la respuesta a todo: utilizamos los datos de las reseñas de productos y restaurantes para decidir qué comprar y dónde comer; las empresas utilizan los datos sobre lo que leemos, pulsamos y vemos para decidir qué contenido producir y qué anuncios mostrar; los reclutadores utilizan datos para decidir qué candidatos consiguen entrevistas de trabajo; el gobierno utiliza datos para decidir todo, desde cómo asignar la financiación de las autopistas hasta dónde va tu hijo a la escuela. Los datos -ya sean una tabla básica de números o la base de un sistema de "inteligencia artificial"- impregnan nuestras vidas. El impacto omnipresente que tienen los datos en nuestras experiencias y oportunidades diarias es precisamente la razón por la que el manejo de datos es -y seguirá siendo- una habilidad esencial para cualquier persona interesada en comprender e influir en el funcionamiento de los sistemas basados en datos. Del mismo modo, la capacidad de evaluar -e incluso mejorar- la calidad de los datos es indispensable para cualquier persona interesada en hacer que estos sistemas, a veces (profundamente) defectuosos, funcionen mejor.
Sin embargo, como los términos "gestión de datos" y " calidad de datos" significan cosas distintas para cada persona, comenzaremos este capítulo con una breve descripción general de los tres temas principales que se tratan en este libro: la gestión de datos, la calidad de datos y el lenguaje de programación Python. El objetivo de esta visión general es darte una idea de mi enfoque de estos temas, en parte para que puedas determinar si este libro es adecuado para ti. Después, dedicaremos algo de tiempo a la logística necesaria sobre cómo acceder y configurar las herramientas de software y otros recursos que necesitarás para seguir y completar los ejercicios de este libro. Aunque todos los recursos a los que este libro hará referencia son de uso gratuito, muchos libros y tutoriales de programación dan por sentado que los lectores codificarán en ordenadores (a menudo bastante caros) de su propiedad. Sin embargo, como realmente creo que cualquiera que lo desee puede aprender a manejar datos con Python, he querido asegurarme de que el material de este libro pueda servirte aunque no tengas acceso a un ordenador propio con todas las funciones. Para ayudar a garantizar esto, todas lassoluciones que encontrarás aquí y en los capítulos siguientes se escribieron y probaron en un Chromebook; también se pueden ejecutar utilizando herramientas gratuitas, sólo en línea, utilizando tu propio dispositivo o un ordenador compartido, por ejemplo, en la escuela o en una biblioteca pública. Espero que, al ilustrar lo accesibles que pueden ser no sólo los conocimientos, sino también las herramientas de manipulación de datos, te animes a explorar esta práctica apasionante y potenciadora.
¿Qué es la "gestión de datos"?
Tramitación de datos es el proceso de tomar datos "en bruto" o "encontrados" y transformarlos en algo que pueda utilizarse para generar conocimiento y significado. El motor de todo esfuerzo sustancial de manipulación de datos es una pregunta: algo sobre el mundo que quieres investigar o sobre lo que quieres aprender más. Por supuesto, si has llegado a este libro porque te entusiasma la idea de aprender a programar, la manipulación de datos puede ser una forma estupenda de empezar, pero permíteme instarte a que no intentes pasar directamente a la programación sin involucrarte en los procesos de calidad de datos de los capítulos siguientes. Porque, por mucho que la manipulación de datos pueda beneficiarse de las habilidades de programación, es mucho más que aprender a acceder a los datos y manipularlos; se trata de hacer juicios, inferencias y selecciones. Como se ilustrará en este libro, la mayoría de los datos disponibles no son de muy buena calidad, por lo que no hay forma de manipularlos sin tomar decisiones que influyan en el contenido de los datos resultantes. Intentar manejar datos sin tener en cuenta su calidad es como intentar conducir un coche sin dirección: puede que llegues a algún sitio -¡yrápido!-, pero probablemente no sea ningún sitio al que quieras llegar. Si vas a dedicar tiempo a procesar y analizar datos, debes asegurarte de que, al menos, el esfuerzo merezca la pena.
Pero igual de importante es que no hay mejor forma de aprender una nueva habilidad que relacionarla con algo que realmente quieras hacer "bien", porque ese interés personal es lo que te llevará a superar los inevitables momentos de frustración. Esto no significa que la pregunta que elijas tenga que ser algo de importancia mundial. Puede ser una pregunta sobre tus videojuegos, grupos de música o tipos de té favoritos. Puede ser una pregunta sobre tu colegio, tu barrio o tu vida en las redes sociales. Puede ser una pregunta sobre economía, política, fe o dinero. Sólo tiene que ser algo que te interese de verdad.
Una vez que tengas tu pregunta en la mano, estarás listo para comenzar el proceso de búsqueda de datos. Aunque puede ser necesario ajustar (o repetir) los pasos específicos en función de tu proyecto concreto, en principio la búsqueda de datos implica algunos o todos los pasos siguientes:
-
Localización o recogida de datos
-
Revisión de los datos
-
"Limpiar", normalizar, transformar y/o aumentar los datos
-
Analizar los datos
-
Visualizar los datos
-
Comunicar los datos
El tiempo y el esfuerzo necesarios para cada uno de estos pasos, por supuesto, pueden variar considerablemente: si lo que buscas es acelerar una tarea de tratamiento de datos que ya realizas para el trabajo, puede que ya tengas un conjunto de datos a mano y sepas básicamente lo que contiene. Por otra parte, si intentas responder a una pregunta sobre el gasto municipal en tu comunidad, la recopilación de datos puede ser la parte más difícil de tu proyecto.
Además, debes saber que, a pesar de haber numerado la lista anterior, el proceso de elaboración de datos es en realidad más un ciclo que un conjunto lineal de pasos. La mayoría de las veces, tendrás que volver sobre pasos anteriores a medida que aprendas más sobre el significado y el contexto de los datos con los que trabajas. Por ejemplo, al analizar un gran conjunto de datos, puedes encontrarte con patrones o valores sorprendentes que te hagan cuestionar las suposiciones que pudieras haber hecho al respecto durante el paso de "revisión". Esto casi siempre significará buscar más información -ya sea de la fuente de datos original o completamente nueva- para comprender lo que está ocurriendo realmente antes de poder seguir adelante con tu análisis o visualización. Por último, aunque no lo he incluido explícitamente en la lista, sería un poco más exacto comenzar cada uno de los pasos con Investigar y. Aunque las partes de nuestro trabajo relacionadas con la "manipulación" se centrarán en gran medida en el conjunto o conjuntos de datos que tenemos ante nosotros, la parte de la "calidad" tiene que ver casi exclusivamente con la investigación y el contexto, y ambos forman parte integrante de cada etapa del proceso de manipulación de datos.
Si todo esto te parece un poco abrumador ahora mismo, ¡no te preocupes! Los ejemplos de este libro se basan en conjuntos de datos reales, y a medida que sigas los procesos de codificación y evaluación de la calidad, todo esto empezará a parecer mucho más orgánico. Y si estás trabajando en tu propio proyecto de manipulación de datos y empiezas a sentirte un poco perdido, no dejes de recordar la pregunta a la que intentas responder. Eso no sólo te recordará por qué te molestas en aprender todas las minucias de los formatos de datos y las claves de acceso a la API,1 también te llevará casi siempre intuitivamente al siguiente "paso" en el proceso de manipulación, ya sea visualizar tus datos o investigar un poco más para mejorar su contexto y calidad.
¿Qué es la "calidad de los datos"?
Hay muchos datos en el mundo y muchas formas de acceder a ellos y recopilarlos. Pero no todos los datos son iguales. Comprender la calidad de los datos es una parte esencial de la gestión de datos, porque cualquier conocimiento basado en datos sólo puede ser tan bueno como los datos sobre los que se construyó.2 Así que si intentas utilizar los datos para comprender algo significativo sobre el mundo, primero tienes que asegurarte de que los datos que tienes reflejan con precisión ese mundo. Como veremos en capítulos posteriores (Capítulos 3 y 6, en particular), el trabajo de mejorar la calidad de los datos casi nunca es tan claro como las filas y columnas de datos, a menudo de aspecto ordenado y perfectamente etiquetadas, con las que trabajarás.
Ello se debe a que -a pesar del uso en de términos como aprendizaje automático e inteligencia artificial-lo único que pueden hacer las herramientas informáticas es seguir las instrucciones que se les dan, utilizando los datos proporcionados. E incluso los datos más complejos, sofisticados y abstractos son irrevocablemente humanos en su esencia, porque son el resultado de decisiones humanas sobre qué medir y cómo. Además, incluso las tecnologías informáticas más avanzadas de hoy en día hacen "predicciones" y toman "decisiones" mediante lo que equivale a una correspondencia de patrones a gran escala: patrones que existen en las selecciones concretas de datos que les proporcionan los humanos que los "entrenan". Los ordenadores no tienen ideas originales ni dan saltos creativos; son fundamentalmente malos en muchas tareas (como explicar la "esencia" de un argumento o la trama de una historia) que los humanos consideran intuitivas. Por otra parte, los ordenadores destacan en la realización de cálculos repetitivos, muy muy rápido, sin aburrirse, cansarse o distraerse. En otras palabras, aunque los ordenadores son un complemento fantástico del juicio y la inteligencia humanos, sólo pueden amplificarlos, no sustituirlos.
Lo que esto significa es que corresponde a los seres humanos implicados en la recogida, adquisición y análisis de datos garantizar su calidad, de modo que los resultados de nuestro trabajo con los datos signifiquen realmente algo. Aunque entraremos en detalles significativos sobre la calidad de los datos en el Capítulo 3, quiero introducir dos ejes distintos (aunque igualmente importantes) para evaluar la calidad de los datos: (1) la integridad de los propios datos, y (2) la "adecuación" o idoneidad de los datos con respecto a una pregunta concreta o problema.
Integridad de los datos
Para nuestros fines , la integridad de un conjunto de datos se evalúa utilizando los valores de los datos y los descriptores que lo componen. Si nuestro conjunto de datos incluye mediciones a lo largo del tiempo, por ejemplo, ¿se han registrado a intervalos constantes o esporádicamente? ¿Los valores representan lecturas individuales directas, o sólo se dispone de promedios? ¿Existe un diccionario de datos que proporcione detalles sobre cómo se recogieron, registraron o deben interpretarse los datos, por ejemplo, proporcionando las unidades pertinentes? En general, los datos completos, atómicos y bien anotados -entreotras cosas- se consideran de mayor integridad, porque estas características permiten realizar una gama más amplia de análisis más concluyentes. En la mayoría de los casos, sin embargo, te darás cuenta de que un conjunto de datos determinado tiene carencias en varias dimensiones de la integridad de los datos, lo que significa que depende de ti intentar comprender sus limitaciones y mejorarlo en lo que puedas. Aunque a menudo esto significa aumentar un determinado conjunto de datos encontrando otros que puedan complementarlo, contextualizarlo o ampliarlo, casi siempre significa mirar más allá de los "datos" de cualquier tipo y acudir a los expertos: las personas que diseñaron los datos, los recopilaron, han trabajado con ellos anteriormente o saben mucho sobre el tema que se supone que abordan tus datos.
Datos "Ajustados"
Sin embargo, incluso un conjunto de datos de que tenga una integridad excelente, no puede considerarse de alta calidad a menos que también sea apropiado para tu propósito concreto. Supongamos, por ejemplo, que estuvieras interesado en saber en qué estación de Citi Bike se han alquilado y devuelto más bicicletas en un período determinado de 24 horas. Aunque la API de Citi Bike en tiempo real contiene datos de alta integridad, es poco adecuada para responder a la pregunta concreta de qué estación de Citi Bike ha tenido la mayor rotación en una fecha determinada. En este caso, sería mucho mejor que intentaras responder a esta pregunta utilizando los datos del "historial de viajes" de Citi Bike.
Por supuesto, es raro que un problema de ajuste de datos pueda resolverse de forma tan sencilla; a menudo tenemos que hacer una cantidad significativa de trabajo de integridad antes de poder saber con confianza que nuestro conjunto de datos es realmente adecuado para nuestra pregunta o proyecto seleccionado. Sin embargo, no hay forma de eludir esta inversión de tiempo: los atajos cuando se trata de la integridad o el ajuste de los datos comprometerán inevitablemente la calidad y la relevancia de tu trabajo de manipulación de datos en general. De hecho, muchos de los daños causados por los sistemas informáticos actuales están relacionados con problemas de ajuste de los datos. Por ejemplo, utilizar datos que describen un fenómeno (como los ingresos) para intentar responder a preguntas sobre un fenómeno potencialmente relacionado, pero fundamentalmente diferente (como el nivel educativo), puede llevar a conclusiones distorsionadas sobre lo que ocurre en el mundo, con consecuencias a veces devastadoras. En algunos casos, por supuesto, es inevitable utilizar estas medidas indirectas. Un diagnóstico médico inicial basado en los síntomas observables de un paciente puede ser necesario para proporcionar un tratamiento de urgencia hasta que se disponga de los resultados de una prueba más definitiva. Sin embargo, aunque tales sustituciones son a veces aceptables a nivel individual, la distancia entre cualquier medida sustitutiva y el fenómeno real se multiplica con la escala de los datos y el sistema que se utiliza para alimentar. Cuando esto ocurre, acabamos teniendo una visión masivamente distorsionada de la propia realidad que nuestro manejo y análisis de datos esperaba iluminar. Afortunadamente, hay varias formas de protegerse contra este tipo de errores, como exploraremos más a fondo en el Capítulo 3.
¿Por qué Python?
Si estás leyendo este libro, lo más probable es que ya hayas oído hablar del lenguaje de programación Python, e incluso puede que estés bastante seguro de que es la herramienta adecuada para iniciar -o ampliar- tu trabajo en la manipulación de datos. Incluso en ese caso, creo que merece la pena repasar brevemente qué hace que Python sea especialmente adecuado para el tipo de trabajo de manipulación y calidad de datos que haremos en este libro. Por supuesto, si no has oído hablar de Python antes, considera esto una introducción a lo que lo convierte en uno de los lenguajes de programación más populares y potentes que se utilizan hoy en día.
Versatilidad
Quizás uno de los mayores puntos fuertes de Python como lenguaje de programación general sea su versatilidad: se puede utilizar fácilmente para acceder a API, raspar datos de la web, realizar análisis estadísticos y generar visualizaciones significativas. Aunque muchos otros lenguajes de programación hacen algunas de estas cosas, pocos las hacen todas tan bien como Python.
Accesibilidad
Uno de los objetivos del creador de Python, Guido van Rossum, al diseñar el lenguaje era hacer "código tan comprensible como el inglés sencillo". Python utiliza palabras clave en inglés, mientras que muchos otros lenguajes de programación (como R y JavaScript) utilizan signos de puntuación. Por tanto, para los lectores de lengua inglesa, Python puede ser más fácil e intuitivo de aprender que otros lenguajes de programación.
Legibilidad
Uno de los principios fundamentales de del lenguaje de programación Python es que "la legibilidad cuenta". En la mayoría de los lenguajes de programación, la disposición visual del código es irrelevante para su funcionamiento: mientras la "puntuación" sea correcta, el ordenador lo entenderá. Python, por el contrario, es lo que se conoce como "dependiente del espacio en blanco": sin los caracteres de tabulación y/o espacio adecuados que indentan el código, en realidad no hará nada excepto producir un montón de errores. Aunque puede costar un poco acostumbrarse, esto impone un nivel de legibilidad en los programas Python que puede hacer que leer el código de otras personas (o, más probablemente, tu propio código después de que haya pasado un poco de tiempo) sea mucho menos difícil. Otro aspecto de la legibilidad es comentar y documentar de otro modo tu trabajo, que trataré con más detalle en "Documentar, guardar y versionar tu trabajo".
Comunidad
Python tiene una comunidad de usuarios muy grande y activa, muchos de los cuales ayudan a crear y mantener "bibliotecas" de código que amplían enormemente lo que puedes lograr rápidamente con tu propio código Python. Por ejemplo, Python tiene bibliotecas de código populares y bien desarrolladas como NumPy y Pandas que pueden ayudarte a limpiar y analizar datos, así como otras como Matplotlib y Seaborn para crear visualizaciones. Incluso hay potentes bibliotecas como Scikit-Learn y NLTK que pueden hacer el trabajo pesado del aprendizaje automático y el procesamiento del lenguaje natural. Una vez que domines los aspectos esenciales del manejo de datos con Python que trataremos en este libro (en el que utilizaremos muchas de las bibliotecas que acabamos de mencionar), probablemente te sentirás ansioso por explorar lo que es posible con muchas de estas bibliotecas y sólo unas pocas líneas de código. Afortunadamente, las mismas personas que escriben el código de estas bibliotecas a menudo escriben entradas en sus blogs, hacen videotutoriales y comparten ejemplos de código que puedes utilizar para ampliar tu trabajo con Python.
Del mismo modo, el tamaño y el entusiasmo de la comunidad Python significa que encontrar respuestas a los problemas y errores comunes (e incluso a los no tan comunes) que te puedas encontrar es fácil: a menudo se publican soluciones detalladas en Internet. Como resultado, la resolución de problemas del código Python puede ser más fácil que para lenguajes más especializados con una comunidad más pequeña de usuarios de.
Alternativas a Python
Aunque Python tiene mucho que recomendar, es posible que también estés considerando otras herramientas para tus necesidades de tratamiento de datos. Lo que sigue es una breve descripción de algunas herramientas de las que quizá hayas oído hablar, junto con las razones por las que elegí Python para este trabajo:
- R
-
El lenguaje de programación R de es probablemente el competidor más cercano de Python para el trabajo con datos, y muchos equipos y organizaciones confían en R por su combinación de manejo de datos, modelado estadístico avanzado y capacidades de visualización. Al mismo tiempo, R carece de parte de la accesibilidad y legibilidad de Python.
- SQL
-
Lenguaje de consulta simple (SQL) es precisamente eso: un lenguaje diseñado para "trocear" datos de bases de datos. Aunque SQL puede ser potente y útil, requiere que los datos existan en un formato concreto para ser útil y, por tanto, tiene una utilidad limitada para "rebañar" datos en primer lugar.
- Scala
-
Aunque Scala es muy adecuado para tratar grandes conjuntos de datos, tiene una curva de aprendizaje mucho más pronunciada que Python, y una comunidad de usuarios mucho más reducida. Lo mismo ocurre con Julia.
- Java, C/C++
-
Aunque tienen grandes comunidades de usuarios y son muy versátiles, carecen del lenguaje natural y la facilidad de lectura de Python y están más orientados a la construcción de software que a la manipulación y el análisis de datos.
- JavaScript
-
En un entorno basado en la web, JavaScript tiene un valor incalculable, y muchas herramientas de visualización populares (por ejemplo, D3) se construyen utilizando variaciones de JavaScript. Al mismo tiempo, JavaScript no tiene la misma amplitud de funciones de análisis de datos que Python y, en general, es más lento.
Escribir y "ejecutar" Python
Para seguir los ejercicios de este libro, tendrás que familiarizarte con las herramientas que te ayudarán a escribir y ejecutar tu código Python; también querrás tener un sistema para hacer copias de seguridad y documentar tu código, de modo que no pierdas un trabajo valioso por una pulsación errónea de una tecla,5 y para que puedas recordarte fácilmente lo que puede hacer todo ese gran código, incluso cuando lleves tiempo sin mirarlo. Dado que existen múltiples conjuntos de herramientas para resolver estos problemas, te recomiendo que empieces por leer las secciones siguientes y luego elijas el enfoque (o la combinación de enfoques) que mejor se adapte a tus preferencias y recursos. A alto nivel, las decisiones clave serán si quieres trabajar "sólo online" -es decir, con herramientas y servicios a los que accedes a través de Internet- o si puedes y quieres poder hacer el trabajo de Python sin conexión a Internet, lo que requiere instalar estas herramientas en un dispositivo que túcontroles.
Todos escribimos de forma diferente según el contexto: probablemente utilices un estilo y una estructura diferentes cuando escribes un correo electrónico que cuando envías un mensaje de texto; para una carta de presentación de una solicitud de empleo puedes utilizar un tono totalmente distinto. Sé que yo también utilizo distintas herramientas para escribir en función de lo que necesite conseguir: Utilizo documentos en línea cuando necesito escribir y editar en colaboración con compañeros de trabajo y colegas, pero prefiero escribir libros y ensayos en un editor de texto superplano que vive en mi dispositivo. Los formatos de documentos más particulares, como los PDF, se suelen utilizar para contratos y otros documentos importantes que no queremos que otros puedan cambiar fácilmente.
Al igual que los lenguajes humanos naturales, Python puede escribirse en distintos tipos de documentos, cada uno de los cuales admite estilos ligeramente diferentes de escribir, probar y ejecutar tu código. Los principales tipos de documentos Python son los cuadernos y los archivos independientes. Aunque cualquiera de los dos tipos de documento puede utilizarse para la manipulación, el análisis y la visualización de datos, tienen puntos fuertes y requisitos ligeramente diferentes. Dado que es necesario realizar algunos ajustes para convertir un formato en otro, he hecho que los ejercicios de este libro estén disponibles en ambos formatos. Lo he hecho no sólo para darte la flexibilidad de elegir el tipo de documento que te resulte más fácil o útil, sino también para que puedas compararlos y ver por ti mismo cómo afecta al código el proceso de traducción. He aquí una breve descripción de estos tipos de documentos para ayudarte a hacer una primera elección:
- Cuadernos
-
Un cuaderno de Python es un documento interactivo que se utiliza para ejecutar trozos de código, utilizando una ventana de navegador web como interfaz. En este libro, utilizaremos una herramienta llamada "Jupyter" para crear, editar y ejecutar nuestros cuadernos Python.6 Una ventaja clave de utilizar cuadernos para programar en Python es que ofrecen una forma sencilla de escribir, ejecutar y documentar tu código Python, todo en un mismo lugar. Puede que prefieras los cuadernos si buscas una experiencia de programación más "apuntar y hacer clic" o si trabajar totalmente en línea es importante para ti. De hecho, los mismos cuadernos Python pueden utilizarse en tu dispositivo local o en un entorno de codificación en línea con cambios mínimos, lo que significa que esta opción puede ser la adecuada para ti si (1) no tienes acceso a un dispositivo en el que puedas instalar software, o (2) puedes instalar software pero también quieres poder trabajar en tu código cuando no tengas tu máquina contigo.
- Archivos independientes
-
Un archivo Python independiente es, en realidad cualquier archivo de texto plano que contenga código Python. Puedes crear estos archivos Python independientes utilizando cualquier editor de texto básico, aunque te recomiendo encarecidamente que utilices uno diseñado específicamente para trabajar con código, como Atom (te explicaré cómo configurarlo en "Instalación de Python, Jupyter Notebook y un editor de código"). Aunque el software que elijas para escribir y editar tu código depende de ti, en general el único lugar donde podrás ejecutar estos archivos independientes de Python es en un dispositivo físico (como un ordenador o un teléfono) que tenga instalado el lenguaje de programación Python. Tú (y tu ordenador) podréis reconocer los archivos Python independientes por su extensión de archivo .py. Aunque al principio puedan parecer más restrictivos, los archivos Python independientes pueden tener algunas ventajas. No necesitas una conexión a Internet para ejecutar archivos independientes, y no requieren que subas tus datos a la nube. Aunque ambas cosas también son válidas para los cuadernos ejecutados localmente , tampoco tienes que esperar a que se inicie ningún software cuando ejecutas archivos independientes. Una vez que tengas Python instalado, puedes ejecutar archivos independientes de Python instantáneamente desde la línea de comandos (hablaremos de esto más adelante), lo que resulta especialmente útil si tienes un script de Python que necesitas ejecutar con regularidad. Y aunque la capacidad de los blocs de notas de ejecutar fragmentos de código independientemente unos de otros puede hacerlos un poco más accesibles, el hecho de que los archivos Python independientes también ejecuten siempre tu código "desde cero" puede ayudarte a evitar los errores o resultados impredecibles que pueden producirse si ejecutas fragmentos de código del bloc de notas fuera de orden.
Por supuesto, no tienes por qué elegir sólo uno u otro; muchas personas consideran que los cuadernos son especialmente útiles para explorar o explicar datos (gracias a su formato interactivo y de fácil lectura), mientras que los archivos independientes son más adecuados para acceder a los datos , transformarlos y limpiarlos (ya que los archivos independientes pueden ejecutar más rápida y fácilmente el mismo código en diferentes conjuntos de datos, por ejemplo). Quizá la cuestión más importante sea si quieres trabajar en línea o localmente. Si no tienes un dispositivo en el que puedas instalar Python, tendrás que trabajar en blocs de notas basados en la nube; de lo contrario, puedes optar por utilizar cualquiera de los dos (¡o ambos!) blocs de notas o archivos independientes en tu dispositivo. Como se ha indicado anteriormente, para todos los ejercicios de este libro hay disponibles cuadernos que pueden utilizarse tanto en línea como localmente, así como archivos independientes de Python, para darte la mayor flexibilidad posible, ¡y también para que puedas comparar cómo se realizan las mismas tareas en en cada caso!
Trabajar con Python en tu propio dispositivo
Para entender y ejecutar código Python, tendrás que instalarlo en tu dispositivo. Dependiendo de tu dispositivo, puede haber un archivo de instalación descargable disponible, o puede que tengas que utilizar una interfaz basada en texto (que tendrás que utilizar en algún momento si utilizas Python en tu dispositivo) llamada línea de comandos. En cualquier caso, el objetivo es que te pongas en marcha con al menos Python 3.9.7 Una vez que tengas Python en funcionamiento, puedes pasar a instalar Jupyter notebook y/o un editor de código (las instrucciones incluidas aquí son para Atom). Si piensas trabajar sólo en la nube, puedes pasar directamente a "Trabajar con Python en línea" para obtener información sobre cómo empezar.
Primeros pasos con la línea de comandos
Si piensas utilizar Python localmente en tu dispositivo, tendrás que aprender a utilizar la línea de comandos (también denominada a veces terminal o símbolo del sistema), que es una forma basada en texto de proporcionar instrucciones a tu ordenador. Aunque en principio puedes hacer en la línea de comandos cualquier cosa que puedas hacer con el ratón, es particularmente eficaz para instalar código y software (especialmente las bibliotecas de Python que utilizaremos a lo largo del libro) y para hacer copias de seguridad y ejecutar código. Aunque puede costar un poco acostumbrarse, la línea de comandos suele ser más rápida y sencilla para muchas tareas relacionadas con la programación que utilizar el ratón. Dicho esto, te daré instrucciones para utilizar tanto la línea de comandos como el ratón cuando ambos sean posibles, y no dudes en utilizar el que te resulte más cómodo para una tarea concreta.
Para empezar, abramos una interfaz de línea de comandos (a veces también llamada terminal) y utilicémosla para crear una carpeta para nuestro trabajo de manipulación de datos. Si estás en una máquina Chromebook, macOS o Linux, busca "terminal" y selecciona la aplicación llamada Terminal; en un PC Windows, busca "powershell" y elige el programa llamado Windows PowerShell.
Consejo
Para activar Linux en tu Chromebook, sólo tienes que ir a la configuración de Chrome OS (haz clic en el icono de engranaje del menú Inicio, o busca "configuración" en el Launcher). Hacia la parte inferior del menú de la izquierda, verás un pequeño icono de pingüino con la etiqueta "Linux (Beta)". Haz clic en él y sigue las instrucciones para activar Linux en tu máquina. Puede que tengas que reiniciar antes de continuar.
Una vez que tengas un terminal abierto, ¡es hora de crear una nueva carpeta! Para ayudarte a empezar, aquí tienes un glosario rápido de términos útiles de la línea de comandos:
ls-
El comando "listar" de muestra los archivos y carpetas de la ubicación actual. Es una versión en texto de lo que verías en una ventana del buscador.
cdfoldername-
El comando "cambiar directorio" te mueve de la ubicación actual a
foldername, siempre y cuandofoldernamecuando utilices el comandols. Esto equivale a hacer "doble clic" con el ratón en una carpeta dentro de una ventana del buscador. cd ../-
"Cambiar directorio" una vez más, pero el
../desplaza tu posición actual a la carpeta o ubicación contenedora. cd ~/-
"Cambiar directorio", pero el
~/te devuelve a tu carpeta "home". mkdirfoldername-
"Hacer directorio" con nombre
foldername. Esto equivale a elegir Nuevo → Carpeta en el menú contextual con el ratón y luego nombrar la carpeta una vez que aparezca su icono.
Consejo
Cuando utilices en la línea de comandos, en realidad nunca tendrás que escribir el nombre completo de un archivo o carpeta; piensa en ello más bien como en una búsqueda, y empieza escribiendo los primeros caracteres del nombre (hay que admitir que distingue entre mayúsculas y minúsculas). Una vez hecho esto, pulsa la tecla Tabulador y el nombre se autocompletará en la medida de lo posible.
Por ejemplo, si tienes dos archivos en una carpeta, uno llamado xls_parsing.py y otro llamado xlsx_parsing.py (como harás cuando termines el Capítulo 4), y quisieras ejecutar este último, puedes escribir python xl
y luego pulsar Tabulador, lo que hará que la línea de comandos se autocomplete enpython xlsLlegados a este punto, como los dos nombres de archivo posibles son divergentes, tendrás que proporcionar un x o un _, después de lo cual, si vuelves a pulsar Tabulador, se completará el resto del nombre del archivo y ¡listo!
Cada vez que abras una nueva ventana de terminal en tu dispositivo, estarás en lo que se conoce como tu carpeta "home". En las máquinas macOS, Windows y Linux, ésta suele ser la carpeta "Usuario", que no es la misma que el área del "escritorio" que ves cuando te conectas por primera vez. Esto puede ser un poco desorientador al principio, ya que los archivos y carpetas que verás cuando ejecutes por primera vez ls en una ventana de terminal probablemente no te resulten familiares. No te preocupes; sólo tienes que dirigir tu terminal a tu escritorio habitual escribiendo:
cd ~/Desktop
en el terminal y pulsando Intro o Retorno (en aras de la eficacia, a partir de ahora me referiré a esto como la tecla Intro).
En los Chromebooks, Python (y los demás programas que necesitaremos) sólo puede ejecutarse desde dentro de la carpeta de archivos de Linux, por lo que no puedes navegar al escritorio y tendrás que abrir una ventana de terminal.
A continuación, escribe el siguiente comando en la ventana de tu terminal y pulsa Intro:
mkdir data_wrangling
¿Has visto aparecer la carpeta? Si es así, ¡enhorabuena por crear tu primera carpeta en la línea de comandos! Si no es así, comprueba dos veces el texto que aparece a la izquierda de la línea de comandos ($ en Chromebook, % en macOS, o > en Windows). Si no ves ahí la palabra Desktop, ejecuta cd ~/Desktop e inténtalo de nuevo.
Ahora que has adquirido un poco de práctica con la línea de comandos, vamos a ver cómo puede ayudarte a la hora de instalar y probar Python en tu máquina.
Instalar Python, Jupyter Notebook y un editor de código
Para simplificar las cosas , vamos a utilizar un gestor de distribución de software llamado Miniconda, que instalará automáticamente tanto Python como Jupyter Notebook. Aunque no pienses utilizar cuadernos para tu propia programación, son lo suficientemente populares como para que sea útil poder ver y ejecutar los cuadernos de otras personas, y no ocupan mucho espacio adicional en tu dispositivo. Además de poner en marcha tus herramientas Python y Jupyter Notebook, al instalar Miniconda también se creará una nueva función de línea de comandos llamada conda, que te proporcionará una forma rápida y sencilla de mantener actualizadas tus instalaciones de Python y Jupyter Notebook.8 Encontrarás más información sobre cómo realizar estas actualizaciones en el Apéndice A.
Si piensas realizar la mayor parte de tu programación Python en un cuaderno, también te recomiendo instalar un editor de código. Aunque nunca los utilices para escribir una sola línea de Python, los editores de código son indispensables para ver, editar e incluso crear tus propios archivos de datos de forma más eficaz y eficiente que el software de edición de texto incorporado en la mayoría de los dispositivos. Y lo que es más importante, los editores de código hacen algo que llama resaltado de sintaxis, que es básicamente una comprobación gramatical incorporada para el código y los datos. Aunque eso no parezca gran cosa, la realidad es que hará que tus procesos de codificación y depuración sean mucho más rápidos y fiables, porque sabrás (literalmente) dónde mirar cuando haya un problema. Esta combinación de características hace que un editor de código sólido sea una de las herramientas más importantes tanto para la programación en Python como para el manejo de datos en general.
En este libro utilizaré y haré referencia a el editor de código Atom(https://atom.io), que es gratuito, multiplataforma y de código abierto. Si juegas con la configuración, encontrarás muchas formas de personalizar tu entorno de codificación para adaptarlo a tus necesidades. Cuando hago referencia al color de ciertos caracteres o fragmentos de código en este libro, reflejan el tema por defecto "One Dark" de Atom, pero utiliza la configuración que mejor se adapte a ti.
Nota
Necesitarás una conexión a Internet fuerte y estable y unos 30-60 minutos para completar los siguientes procesos de configuración e instalación. También te recomiendo encarecidamente que tengas el dispositivo enchufado a una fuente de alimentación.
Chromebook
Para instalar tu conjunto de herramientas de gestión de datos en un Chromebook, lo primero que tendrás que saber es si tu versión del sistema operativo Chrome OS es de 32 o 64 bits.
Para encontrar esta información, abre la configuración de Chrome (haz clic en el icono de engranaje del menú Inicio o busca "configuración" en el Iniciador) y, a continuación, haz clic en "Acerca de Chrome OS" en la parte inferior izquierda. En la parte superior de la ventana, verás el número de versión seguido de (32-bit) o (64-bit), como se muestra en la Figura 1-1.

Figura 1-1. Detalle de la versión de Chrome OS
Toma nota de esta información antes de continuar con la configuración de.
Instalar Python y Jupyter Notebook
Para empezar , descarga el instalador de Linux que coincida con el formato de bits de tu versión de Chrome OS. A continuación, abre tu carpeta de Descargas y arrastra el archivo del instalador (terminará en .sh) a tu carpeta de archivos de Linux.
A continuación, abre una ventana de terminal, ejecuta el comando ls y asegúrate de queves el archivo .sh de Miniconda. Si es así, ejecuta el siguiente comando (recuerda quepuedes escribir el principio del nombre del archivo y pulsar la tecla Tabulador, ¡yse autocompletará!
bash _Miniconda_installation_filename_.sh
Sigue las instrucciones que aparezcan en tu ventana de terminal (acepta la licencia y la indicación conda init ), luego cierra y vuelve a abrir tu ventana de terminal. A continuación, tendrás que ejecutar lo siguiente:
conda init
A continuación, cierra y vuelve a abrir la ventana del terminal para poder instalar Jupyter Notebook con el siguiente comando:
conda install jupyter
Responde afirmativamente a las siguientes preguntas, cierra el terminal por última vez y ¡listo!
Instalar Atom
Para instalar Atom en tu Chromebook, tendrás que descargar el paquete .deb de https://atom.io y guardarlo en (o moverlo a) tu carpeta de archivos de Linux.
Para instalar el programa utilizando el terminal, abre una ventana de terminal y escribe
sudo dpkg -i atom-amd64.deb
Pulsa Intro.9 Una vez que el texto haya terminado de desplazarse y el símbolo del sistema (que termina con un $) esté de vuelta, la instalación habrá terminado.
Alternativamente, puedes hacer clic contextual en el archivo .deb de tu carpeta de archivos de Linux y elegir la opción "Instalar con Linux" en la parte superior del menú contextual, después haz clic en "Instalar" y "Aceptar". Deberías ver una barra de progreso en la parte inferior derecha de tu pantalla y recibir una notificación cuando se complete la instalación.
Sea cual sea el método que utilices, una vez finalizada la instalación, deberías ver aparecer el icono verde de Atom en tu burbuja de "aplicaciones Linux" en el lanzador .
macOS
Tienes dos opciones a la hora de instalar Miniconda en macOS: puedes utilizar el terminal para instalarlo mediante un archivo .sh, o puedes instalarlo descargando y haciendo doble clic en el instalador .pkg.
Instalar Python y Jupyter Notebook
Para empezar , ve a la página de enlaces del instalador de Miniconda. Si quieres hacer la instalación con el terminal, descarga el archivo "bash" de Python 3.9 que termina en .sh; si prefieres utilizar el ratón, descarga el archivo .pkg (puede que aparezca una notificación del sistema operativo durante el proceso de descarga advirtiendo: "Este tipo de archivo puede dañar tu ordenador"; elige "Conservar").
Sea cual sea el método que elijas, abre tu carpeta Descargas y arrastra el archivo a tu escritorio.
Si quieres probar a instalar Miniconda utilizando el terminal, empieza abriendo una ventana de terminal y utilizando el comando cd para dirigirlo a tu escritorio:
cd ~/Desktop
A continuación, ejecuta el comando ls y asegúrate de que ves el archivo .sh de Miniconda en la lista resultante. Si es así, ejecuta el siguiente comando (recuerda que puedes escribir el principio del nombre del archivo y pulsar la tecla Tabulador, ¡y se autocompletará!)
bash _Miniconda_installation_filename_.sh
Sigue las instrucciones que aparecen en la ventana de tu terminal:
-
Utiliza la barra espaciadora para desplazarte por el acuerdo de licencia página a página, y cuando veas
(END), pulsa Retorno. -
Escribe
yesseguido de Retorno para aceptar el acuerdo de licencia. -
Pulsa Retorno para confirmar la ubicación de la instalación y escribe
yesseguido de Intro para aceptar el mensajeconda init.
Por último, cierra la ventana del terminal.
Si prefieres hacer la instalación con el ratón, sólo tienes que hacer doble clic en el archivo .pkg y seguir las instrucciones de instalación.
Ahora que tienes Miniconda instalado, tienes que abrir una nueva ventana de terminal y escribir
conda init
A continuación, pulsa Retorno. A continuación, cierra y vuelve a abrir la ventana del terminal, y utiliza el siguiente comando (seguido de Intro) para instalar Jupyter Notebook:
conda install jupyter
Instalar Atom
Para instalar Atom en un Mac, visita https://atom.io y haz clic en el gran botón amarillo Descargar para descargar el instalador.
Haz clic en el archivo atom-mac.zip de tu carpeta Descargas y, a continuación, arrastra la aplicación Atom (que tendrá un icono verde al lado) a tu carpeta Aplicaciones (puede que te pida tu contraseña).
Windows 10+
Para instalar tu conjunto de herramientas de gestión de datos en Windows 10+, lo primero que necesitarás saber es si tu versión del sistema operativo Windows 10 es de 32 o 64 bits.
Para encontrar esta información, abre el menú Inicio y selecciona el icono del engranaje para ir al menú Configuración. En la ventana resultante, elige Sistema → Acerca de en el menú de la izquierda. En la sección titulada "Especificaciones del dispositivo", verás "Tipo de sistema", que especificará si tienes un sistema de 32 o 64 bits. Para las instrucciones oficiales, consulta las FAQ de Microsoft relacionadas.
Anota esta información antes de continuar con la configuración.
Instalar Python y Jupyter Notebook
Para poner en marcha , ve a la página de enlaces del instalador de Miniconda y descarga el instalador de Python 3.9 adecuado para tu sistema (de 32 o 64 bits). Una vez descargado el archivo .exe, haz clic en los menús del instalador, dejando las opciones preseleccionadas (puedes saltarte los tutoriales recomendados y el registro "Núcleo Anaconda" del final).
Una vez finalizada la instalación, deberías ver dos nuevos elementos en tu menú Inicio, en la lista "Añadidos recientemente" de la parte superior: "Anaconda Prompt (miniconda3)" y "Anaconda Powershell Prompt (miniconda3)", como se muestra en la Figura 1-2. Aunque ambos funcionarán para nuestros propósitos, te recomiendo que utilices Powershell como tu interfaz de "terminal" a lo largo de este libro.
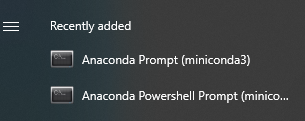
Figura 1-2. Opciones de Anaconda en el menú Inicio
Ahora que tienes Miniconda instalado, tienes que abrir una nueva ventana de terminal (Powershell) y escribir:
conda init
A continuación, pulsa Retorno. A continuación, cierra y vuelve a abrir la ventana del terminal como se indica, y utiliza el siguiente comando (seguido de Intro) para instalar Jupyter Notebook:
conda install jupyter
Responde afirmativamente (escribiendo y y pulsando la tecla Intro) a las siguientes preguntas.
Instalar Atom
Para instalar Atom en una máquina Windows 10+, visita https://atom.io y haz clic en el botón amarillo grande "Descargar" para descargar el instalador.
Haz clic en el archivo Atom-Setup-x64.exe 10 y espera a que termine la instalación; Atom debería iniciarse automáticamente. Puedes responder Sí a la ventana emergente azul que te pregunta si deseas registrarte como gestor de URI atom:// predeterminado.
Probar tu configuración
Para asegurarte de que tanto Python como Jupyter Notebook funcionan como es debido, empieza por abrir una ventana de terminal y dirigirla a la carpeta data_wrangling que creaste en "Introducción a la línea de comandos", y ejecuta el siguiente comando:11
cd ~/Desktop/data_wrangling
Luego, corre:
python --version
Si ves algo como
Python 3.9.4
significa que Python se ha instalado correctamente.
A continuación, prueba Jupyter Notebook ejecutando:
jupyter notebook
Si se abre una ventana del navegador12 que se parece a la imagen de la Figura 1-3, ¡ya está todo listo y preparado para funcionar!

Figura 1-3. Jupyter Notebook ejecutándose en una carpeta vacía
Trabajar con Python Online
Si quieres saltarte la molestia de instalar Python y el editor de código en tu máquina (y piensas utilizar Python sólo cuando tengas una conexión a Internet fuerte y constante), trabajar con cuadernos Jupyter en línea a través de Google Colab es una gran opción. Todo lo que necesitas para empezar es una cuenta de Google sin restricciones (puedes crear una nueva si lo prefieres-¡asegúrate de que conoces tu contraseña!) ¡Si dispones de esos elementos, ¡ya estás listo para ponerte manos a la obra con "Hello World!"!
¡Hola Mundo!
Ahora que ya tienes tus herramientas de manejo de datos, estás listo para empezar a escribir y ejecutar tu primer programa en Python. Para ello, nos inclinaremos ante la tradición de programación y crearemos un sencillo programa "Hola Mundo"; todo lo que está diseñado para hacer es imprimir las palabras "¡Hola Mundo!". Para empezar, necesitarás un nuevo archivo donde escribir y guardar tu código.
Utilizar Atom para crear un archivo Python independiente
Atom funciona como cualquier otro programa de edición de texto; puedes iniciarlo con el ratón o incluso con el terminal.
Para iniciarlo con el ratón, localiza el icono del programa en tu dispositivo:
- Chromebook
-
Dentro de la burbuja de aplicaciones "Aplicaciones Linux".
- Mac
-
En Aplicaciones o en el Launchpad en Mac.
- Windows
-
En el menú Inicio o a través de la búsqueda en Windows. Si Atom no aparece en el menú Inicio o en la búsqueda después de instalarlo por primera vez en Windows 10, puedes encontrar vídeos de solución de problemas en YouTube.
También puedes abrir Atom desde el terminal simplemente ejecutando
atom
La primera vez que abras Atom en un Chromebook, verás el mensaje "Elige una contraseña para el nuevo llavero". Como sólo vamos a utilizar Atom para editar código y datos, puedes hacer clic en Cancelar para cerrar este mensaje. En macOS, verás un aviso de que Atom se ha descargado de Internet; también puedes hacer clic para pasar de este aviso.
Ahora deberías ver una pantalla similar a la que se muestra en la Figura 1-4.
Por defecto, cuando Atom se inicia, muestra una o más pestañas de "Bienvenida"; puedes cerrarlas simplemente haciendo clic en el botón de cierre x que aparece a la derecha del texto cuando pasas el ratón por encima. Esto moverá la ficha sin título hacia el centro de tu pantalla (si quieres, también puedes contraer el panel Proyecto de la izquierda pasando el ratón por encima de su perímetro derecho hasta que aparezca < y haciendo clic sobre él).
Figura 1-4. Pantalla de bienvenida de Atom
Antes de empezar a escribir código, vamos a guardar nuestro archivo donde sepamos dónde encontrarlo: ¡en nuestra carpeta data_wrangling! En el menú Archivo, selecciona "Guardar como..." y guarda el archivo en tu carpeta data_wrangling con el nombre HolaMundo.py.
Consejo
Cuando guardes archivos Python independientes en , es esencial que te asegures de añadir la extensión .py. Aunque tu código Python seguirá funcionando correctamente sin ella, tener la extensión correcta permitirá a Atom hacer el superútil resaltado de sintaxis que mencioné en "Instalar Python, Jupyter Notebook y un editor de código". Esta función hará que sea mucho más fácil escribir tu código correctamente la primera vez.
Utilizar Jupyter para crear un nuevo cuaderno Python
Como habrás notado cuando probaste Jupyter Notebook, en "Probando tu configuración", la interfaz que estás utilizando es en realidad una ventana de navegador normal. Lo creas o no, cuando ejecutas el comando jupyter notebook, ¡tu ordenador normal está creando en realidad un pequeño servidor web en tu dispositivo!13 Una vez que la ventana principal de Jupyter esté en funcionamiento, ¡podrás utilizar el ratón para crear nuevos archivos Python y ejecutar otros comandos directamente en tu navegador web!
Para empezar, abre una ventana de terminal y utiliza el comando
cd ~/Desktop/data_wrangling/
en la carpeta data_wrangling de tu Escritorio. A continuación, ejecuta
jupyter notebook
Verás pasar un montón de código en la ventana del terminal, y tu ordenador debería abrir automáticamente una ventana del navegador que te mostrará un directorio vacío. En Nuevo, en la esquina superior derecha, elige "Python 3" para abrir un nuevo bloc de notas. Haz doble clic en la palabra Sin título que aparece en la esquina superior izquierda, junto al logotipo de Jupyter, para llamar a tu archivo HolaMundo.
Advertencia
Dado que Jupyter Notebook ejecuta un servidor web (sí, del mismo tipo que los sitios web normales) en tu ordenador local, es esencial que dejes esa ventana de terminal abierta y en funcionamiento mientras interactúes con tus cuadernos. Si cierras esa ventana de terminal en concreto, tus cuadernos se "colgarán".
Afortunadamente, los cuadernos Jupyter se guardan automáticamente cada dos minutos, así que aunque algo se bloquee, probablemente no perderás mucho trabajo. Dicho esto, puede que quieras minimizar la ventana del terminal que utilizas para iniciar Jupyter, para evitar cerrarla accidentalmente mientras estás trabajando.
Utilizar Google Colab para crear un nuevo cuaderno Python
En primer lugar, accede a la cuenta de Google que quieras utilizar para tu trabajo de manipulación de datos y, a continuación, visita el sitio web de Colab. Verás algo similar a la superposición que se muestra en la Figura 1-5.
Figura 1-5. Página de inicio de Google Colab (inicio de sesión)
En la esquina inferior derecha, elige Nueva libreta y, a continuación, haz doble clic en la parte superior izquierda para sustituir Sin título0.ipynb por HolaMundo.ipynb.14
Añadir el código
Ahora, en escribiremos nuestro primer fragmento de código, que está diseñado para imprimir las palabras "Hola Mundo". Independientemente del tipo de archivo Python que estés utilizando, el código que se muestra en el Ejemplo 1-1 es el mismo.
Ejemplo 1-1. hola_mundo.py
# the code below should print "Hello World!"("Hello World!")
En un archivo independiente
Todo lo que tienes que hacer es copiar (o escribir) el código del Ejemplo 1-1 en tu archivo y ¡guardarlo!
En un cuaderno
Cuando creas un nuevo archivo en , hay una "celda de código" vacía por defecto (en Jupyter Notebook, verás In [ ] a su izquierda; en Google Colab, hay un pequeño botón "play"). Copia (o escribe) el código del Ejemplo 1-1 en esa celda.
Ejecutar el código
Ahora que hemos añadido y guardado nuestro código Python en nuestro archivo, tenemos que ejecutarlo.
En un archivo independiente
Abre una ventana del terminal y muévelo a tu carpeta data_wrangling utilizando:
cd ~/Desktop/data_wrangling
Ejecuta el comando ls y asegúrate de que tu archivo HelloWorld.py aparece como respuesta. Por último, ejecuta
python HelloWorld.py
Deberías ver las palabras Hello World! impresas en su propia línea, antes de que vuelva el símbolo del sistema (lo que indica que el programa ha terminado de ejecutarse).
Documentar, guardar y versionar tu trabajo
Antes de sumergirnos de verdad en Python en el Capítulo 2, hay que hacer algunos preparativos más. Sé que pueden parecer tediosas, pero asegurarte de que has sentado las bases para documentar adecuadamente tu trabajo te ahorrará docenas de horas de esfuerzo y frustración. Es más, comentar, guardar y versionar cuidadosamente tu código es una parte crucial para "blindar" tu trabajo de manipulación de datos. Y aunque ahora mismo no sea precisamente tentador, muy pronto todos estos pasos serán una segunda naturaleza (¡lo prometo!), y verás cuánta velocidad y eficacia añaden a tu trabajo con datos.
Documentar
Puede que te hayas dado cuenta en de que la primera línea que escribiste en tu celda de código o archivo Python en "¡Hola Mundo!" no aparecía en la salida; lo único que se imprimía era Hello World!. Esa primera línea de nuestro archivo era un comentario, que proporciona una descripción en lenguaje llano de lo que hará el código de la(s) línea(s) siguiente(s). Casi todos los lenguajes de programación (¡y algunos tipos de datos!) permiten incluir comentarios, precisamente porque son una forma excelente de proporcionar a quien lea tu código15 el contexto y la explicación necesarios para comprender lo que hace el programa o la sección de código en cuestión.
Aunque muchos programadores individuales tienden a pasar por alto (léase: saltarse) el proceso de comentar, es probablemente el hábito de programación más valioso que puedes desarrollar. No sólo te ahorrará a ti -y a cualquiera con quien colabores- una enorme cantidad de tiempo y esfuerzo cuando revises un programa Python, sino que comentar es también la mejor manera de interiorizar realmente lo que estás aprendiendo sobre programación en general. Así que, aunque los ejemplos de código que se proporcionan con este libro ya tendrán comentarios, te animo encarecidamente a que los reescribas con tus propias palabras. Esto te ayudará a asegurarte de que, cuando en el futuro vuelvas a estos archivos, contendrán un claro recorrido sobre cómo entendiste cada reto de codificación concreto la primera vez.
El otro proceso de documentación esencial para la gestión de datos es llevar lo que yo llamo un "diario de datos". Al igual que un diario personal, tu diario de datos puede escribirse y organizarse como quieras; lo fundamental es capturar lo que haces mientras lo haces. Tanto si estás navegando por Internet en busca de datos, enviando correos electrónicos a expertos o diseñando un programa, necesitas un lugar donde registrarlo todo, porque te olvidarás.
La primera entrada de tu "diario" de cualquier proyecto de obtención de datos debe ser la pregunta que intentas responder. Aunque pueda resultar difícil, intenta escribir tu pregunta en una sola frase y ponla al principio del diario de tu proyecto de búsqueda de datos. ¿Por qué es importante que tu pregunta sea una sola frase? Porque el proceso de manipulación de datos reales te llevará inevitablemente por suficientes "madrigueras de conejo" -para responder a una pregunta sobre el origen de tus datos, por ejemplo, o para resolver algún problema de programación- que es muy fácil perder la pista de lo que intentabas conseguir originalmente (y por qué). Sin embargo, una vez que tengas esa pregunta en la parte superior de tu diario de datos, siempre podrás volver a ella para recordártela.
La pregunta de tu diario de datos también será muy valiosa para ayudarte a tomar decisiones sobre cómo emplear tu tiempo en la búsqueda de datos. Por ejemplo, tu conjunto de datos puede contener términos que no te resulten familiares: ¿deberías intentar averiguar el significado de cada uno de ellos? Sí, si hacerlo te ayuda a responder a tu pregunta. Si no, puede que sea el momento de pasar a otra tarea.
Por supuesto, una vez que consigas responder a tu pregunta (¡y lo conseguirás! al menos en parte), casi seguro que descubrirás que tienes más preguntas que quieres responder, o que quieres volver a responder a la misma pregunta, pero una semana, un mes o un año después. Tener a mano tu diario de datos como guía te ayudará a hacerlo mucho más rápido y con más facilidad la próxima vez. Eso no quiere decir que no suponga un esfuerzo: según mi experiencia, llevar un diario de datos minucioso hace que un proyecto tarde aproximadamente un 40% más en completarse la primera vez, pero hace que hacerlo de nuevo (con una nueva versión del conjunto de datos, por ejemplo) sea al menos el doble de rápido. Tener un diario de datos es también una valiosa prueba de trabajo: si alguna vez buscas el proceso por el que obtuviste los resultados de tu trabajo con los datos, tu diario de datos tendrá toda la información que tú (o cualquier otra persona) pueda necesitar.
Sin embargo, la forma de llevar tu diario de datos depende de ti. A algunas personas les gusta hacer un montón de formatos extravagantes; a otras les basta con utilizar un simple archivo de texto. Puede que incluso quieras utilizar un cuaderno de papel de verdad. Lo que te funcione a ti está bien. Aunque tu diario de datos será una referencia inestimable cuando llegue el momento de comunicarte con otros sobre tus datos (y el proceso de elaboración), debes organizarlo como mejor te convenga .
Guardar
Además de de documentar cuidadosamente tu trabajo mediante comentarios y diarios de datos, querrás asegurarte de guardarlo regularmente. Afortunadamente, el proceso de "guardar" está esencialmente integrado en nuestro flujo de trabajo: los blocs de notas se guardan automáticamente con regularidad, y para ejecutar el código en nuestro archivo independiente, primero tenemos que guardar nuestros cambios. Tanto si confías en los atajos de teclado (para mí, pulsar Ctrl+S es una especie de hábito nervioso) como si utilizas menúscontrolados por el ratón, probablemente querrás guardar tu trabajo cada 10 minutos más o menos, como mínimo.
Consejo
Si utilizas archivos independientes, una cosa con la que debes familiarizarte es cómo indica tu editor de código que un archivo tiene cambios sin guardar. En Atom, por ejemplo, aparece un pequeño punto de color en la pestaña del documento, justo a la derecha del nombre del archivo, cuando hay cambios sin guardar en el archivo. Si el código que estás ejecutando no se comporta como esperas, comprueba primero que lo tienes guardado y vuelve a intentarlo.
Versionado
La programación -como la mayor parte de la escritura- es un proceso iterativo. Mi enfoque preferido en siempre ha sido escribir un poco de código, probarlo y, si funciona, escribir un poco más y volver a probar. Uno de los objetivos de este enfoque es facilitar el retroceso en caso de que añada algo que "rompa" accidentalmente el código.16
Al mismo tiempo, no siempre es posible garantizar que tu código estará "funcionando" cuando tengas que alejarte de él, ya sea porque los niños acaban de llegar a casa, ha terminado la pausa de estudio o es hora de irse a la cama. Siempre quieres tener una copia "segura" de tu código a la que puedas volver. Aquí es donde entra en juego el control de versiones.
Primeros pasos con GitHub
Control de versiones es básicamente un sistema para hacer copias de seguridad de tu código, tanto en tu ordenador como en la nube. En este libro, utilizaremos GitHub para el control de versiones; es un sitio web muy popular donde puedes hacer copias de seguridad de tu código de forma gratuita. Aunque hay muchas formas distintas de interactuar con GitHub, utilizaremos la línea de comandos porque basta con unos pocos comandos rápidos para tener tu código a buen recaudo hasta que estés listo para volver a trabajar en él. Para empezar, tendrás que crear una cuenta en GitHub, instalar Git en tu ordenador y luego conectar las cuentas entre sí:
-
Visita el sitio web de GitHub en https://github.com y haz clic en "Registrarse". Introduce tu nombre de usuario preferido (puede que tengas que probar unos cuantos para encontrar uno que esté disponible), tu dirección de correo electrónico y la contraseña que hayas elegido (asegúrate de apuntarla o guardarla en tu gestor de contraseñas; la necesitarás pronto).
-
Una vez que te hayas identificado, haz clic en el botón Nuevo de la izquierda. Se abrirá la página "Crear un nuevo repositorio" que se muestra en la Figura 1-6.
-
Dale un nombre a tu repositorio. Puede ser cualquier cosa que quieras, pero te sugiero que sea algo descriptivo, como por ejemplo ejercicios_de_reorganización_de_datos.
-
Selecciona el botón de opción Privado, y marca la casilla situada junto a la opción que dice "Añadir un archivo README".
-
Pulsa el botón "Crear repositorio".
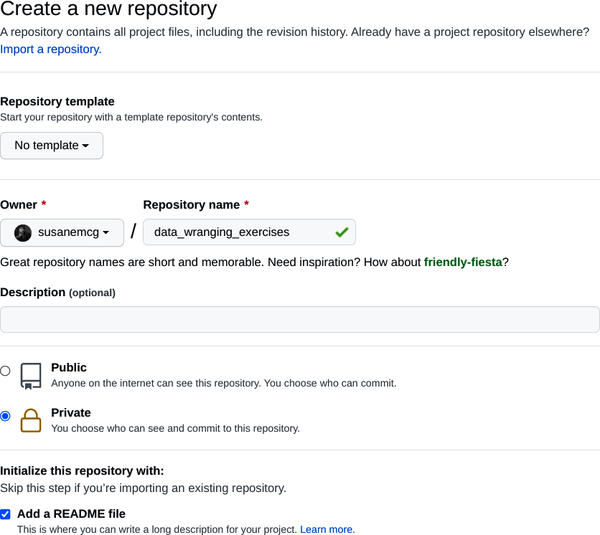
Figura 1-6. Crear un nuevo repositorio (o "repo") en GitHub.com
Ahora verás una página que muestra data_wrangling_exercises en letra grande, con un pequeño icono de un lápiz justo encima y a la derecha. Haz clic en el lápiz y verás una interfaz de edición en la que puedes añadir texto. Este es tu archivo README, que puedes utilizar para describir tu repositorio. Como utilizaremos este repositorio (o "repo" para abreviar) para almacenar ejercicios de este libro, puedes añadir simplemente una frase a tal efecto, como se muestra en la Figura 1-7.
Desplázate hasta la parte inferior de la página y verás el icono de tu perfil con un área editable a la derecha que dice "Confirmar cambios", y debajo un texto predeterminado que dice "Actualizar README.md". Sustituye ese texto por defecto por una breve descripción de lo que has hecho; éste es tu "mensaje de confirmación". Por ejemplo, yo escribí: "Añadida descripción del contenido del repositorio", como se muestra en la Figura 1-8. Luego haz clic en el botón "Confirmar cambios".
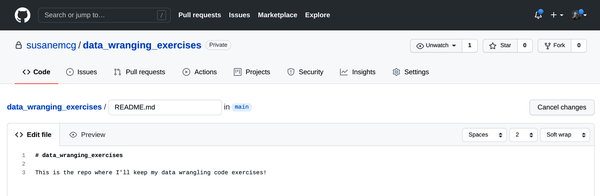
Figura 1-7. Actualizar el archivo README en GitHub
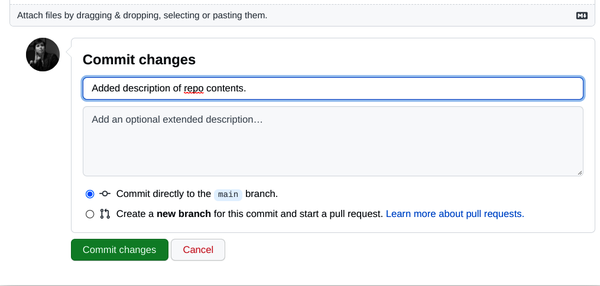
Figura 1-8. Añadir un mensaje de confirmación a los cambios del archivo README
Cuando se actualice la pantalla, verás el texto que has añadido al archivo principal debajo del título original de data_wrangling_exercises. Justo encima, deberías poder ver el texto de tu mensaje de confirmación, junto con el tiempo aproximado que ha pasado desde que hiciste clic en "Confirmar cambios". Si haces clic en el texto que dice "2 commits" a la derecha de eso, verás el "historial de commits", que te mostrará todos los cambios (hasta ahora sólo dos) que se han realizado en ese repositorio, como se muestra en la Figura 1-9. Si quieres ver cómo una confirmación ha cambiado un archivo concreto, haz clic en el código de seis caracteres de la derecha, y verás lo que se conoce como una vista diff (de "diferencia") del archivo. A la izquierda está el archivo tal y como existía antes de la confirmación, y a la derecha está la versión del archivo en esta confirmación.
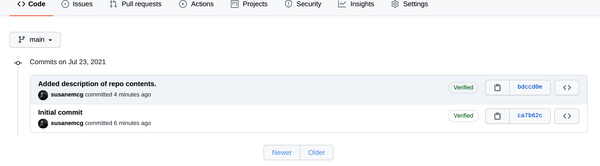
Figura 1-9. Un breve historial de confirmaciones de nuestro nuevo repositorio
Llegados a este punto, puede que te estés preguntando cómo se relaciona esto con hacer copias de seguridad del código, ya que todo lo que hemos hecho ha sido pulsar algunos botones y editar algo de texto. Ahora que hemos iniciado un "repositorio" en GitHub, podemos crear una copia del mismo en nuestra máquina local y utilizar la línea de comandos para hacer "commits" de código de trabajo y hacer copias de seguridad de ellos en este sitio web con sólo unos pocos comandos .
Para hacer copias de seguridad de archivos locales: instalar y configurar Git
Al igual que el propio Python, Git es un software que instalas en tu ordenador y ejecutas a través de la línea de comandos. Dado que el control de versiones es una parte integral de la mayoría de los procesos de codificación, Git viene incorporado en macOS y Linux; puedes encontrar instrucciones para máquinas Windows en GitHub, y para ChromeBooks, puedes instalar Git utilizando la aplicación Termux. Una vez que hayas completado los pasos necesarios, abre una ventana de terminal y escribe:
git --version
Seguido de "intro". Si se imprime algo, ¡ya tienes Git! Sin embargo, aún querrás establecer tu nombre de usuario y correo electrónico (puedes utilizar cualquier nombre y correo electrónico que desees) ejecutando los siguientes comandos:
git config --global user.email your_email@domain.com git config --global user.name your_username
Ahora que ya tienes instalado Git y has añadido tu nombre y correo electrónico preferidos a tu cuenta local de Git, tienes que crear una clave de autenticación en tu dispositivo para que, cuando hagas una copia de seguridad de tu código, GitHub sepa que realmente procede de ti (y no sólo de alguien al otro lado del mundo que averiguó tu nombre de usuario y contraseña).
Para ello, tendrás que crear lo que se conoce como una clave SSH, quees una cadena larga y única de caracteres almacenada en tu dispositivo que GitHub puede utilizar para identificarlo. Crear estas claves con la línea de comandos es fácil: sólo tienes que abrir una ventana de terminal y escribir:
ssh-keygen -t rsa -b 4096 -C "your_email@domain.com"
Cuando veas el aviso "Introduce un archivo en el que guardar la clave", pulsa la tecla Intro o Retorno, para que guarde la ubicación por defecto (así será más fácil encontrarla dentro de un minuto, cuando queramos añadirla a GitHub). Cuando veas el siguiente mensaje:
Enter passphrase (empty for no passphrase):
¡añade definitivamente una frase de contraseña! Y no hagas que sea la contraseña de tu cuenta de GitHub (o de cualquier otra). Sin embargo, como tendrás que proporcionar esta frase de contraseña cada vez que quieras hacer una copia de seguridad de tu código en GitHub,17 tiene que ser memorable: prueba con algo como las tres primeras palabras de la segunda estrofa de tu canción o poema favorito, por ejemplo. Mientras tenga al menos entre 8 y 12 caracteres, ¡listo!
Una vez que hayas vuelto a introducir tu frase de contraseña para confirmarla, puedes copiar tu clave en tu cuenta de GitHub; esto permitirá a GitHub hacer coincidir la clave de tu cuenta con la de tu dispositivo. Para ello, haz clic en el icono de tu perfil en la esquina superior derecha de GitHub y selecciona Configuración en el menú desplegable. A continuación, en la barra de navegación izquierda, haz clic en la opción "Claves SSH y GPG". Hacia la parte superior derecha, haz clic en el botón "Nueva clave SSH", como se muestra en la Figura 1-10.
Figura 1-10. Página de inicio de la clave SSH en GitHub.com
Para acceder a la clave SSH que acabas de generar, tendrás que ir a la carpeta de usuario principal de tu dispositivo (es la carpeta en la que se abrirá una nueva ventana de terminal) y configurarla (temporalmente) para que muestre archivos ocultos:
- Chromebook
-
Tu carpeta de usuario principal de es sólo la que se llama Archivos de Linux. Para mostrar los archivos ocultos, sólo tienes que hacer clic en los tres puntos apilados de la parte superior derecha de cualquier ventana de Archivos y elegir "Mostrar archivos ocultos."
- macOS
-
Utiliza el atajo de teclado Comando-Mayúsculas-. para mostrar/ocultar los archivos ocultos.
- Windows
-
Abre el Explorador de archivos en la barra de tareas y, a continuación, elige Ver → Opciones → "Cambiar opciones de carpeta y búsqueda". En la pestaña Ver de "Configuración avanzada", selecciona "Mostrar archivos, carpetas y unidades ocultos" y, a continuación, haz clic en Aceptar.
Busca la carpeta (¡en realidad es una carpeta!) llamada .ssh y haz clic en ella, luego, utilizando un editor de texto básico (como Atom), abre el archivo llamado id_rsa.pub. Utilizando el teclado para seleccionar y luego copiar todo lo que hay en el archivo, pégalo en el área de texto vacía llamada Clave, como se muestra en la Figura 1-11.
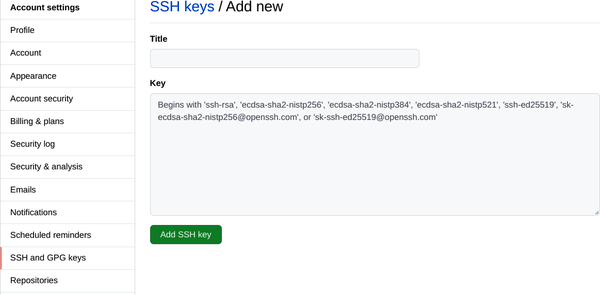
Figura 1-11. Subir tu clave SSH a tu cuenta de GitHub.com
Por último, dale un nombre a esta clave para que sepas a qué dispositivo está asociada, y haz clic en el botón "Añadir nueva clave SSH"; probablemente tendrás que volver a introducir tu contraseña principal de GitHub. Ya está. Ahora puedes volver a dejar ocultos los archivos ocultos y terminar de conectar tu cuenta de GitHub a tu dispositivo y/o cuenta de Colab.
Consejo
Te recomiendo que utilices atajos de teclado para copiar/pegar tu clave SSH porque la cadena exacta de caracteres (incluidos los espacios) realmente importa; si utilizas el ratón, puede que se arrastre algo. Sin embargo, si pegas tu clave y GitHub arroja un error, puedes probar un par de cosas:
-
Asegúrate de que estás subiendo el contenido del archivo .pub (en realidad nunca querrás hacer nada con el otro).
-
Cierra el archivo (sin guardarlo) e inténtalo de nuevo.
Si sigues teniendo problemas, siempre puedes borrar toda la carpeta .ssh y generar nuevas claves; como aún no se han añadido a nada, no pierdes nada con volver a empezar .
Unirlo todo
Nuestro último paso es crear una copia enlazada de nuestro repositorio de GitHub en nuestro ordenador local. Esto se hace fácilmente mediante el comando git clone:
-
Abre una ventana de terminal y navega hasta tu carpeta data_wrangling.
-
En GitHub, ve a
your_github_username/data_wrangling_exercises. -
Todavía en GitHub, haz clic en el botónCódigo situado en la parte superior de la página.
-
En la ventana emergente "Clonar con SSH", haz clic en el pequeño icono del portapapeles situado junto a la URL, como se muestra en la Figura 1-12.
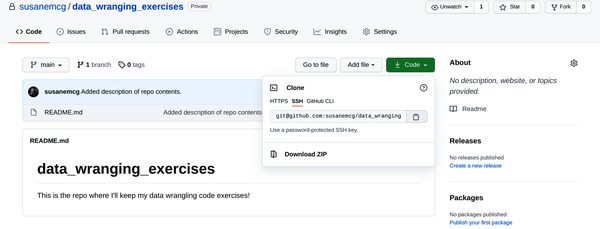
Figura 1-12. Recuperar la ubicación SSH del repositorio
-
De vuelta en tu ventana de terminal, escribe
git cloney luego pega la URL desde el portapapeles (o escríbela directamente si es necesario). Tendrá un aspecto parecido agit clone git@github.com:susanemcg/data_wrangling_exercises.git
-
Puede que aparezca un aviso preguntándote si quieres añadir el destino a la lista de hosts conocidos. Escribe
yesy pulsa Retorno. Si se te solicita, introduce tu contraseña SSH. -
Cuando veas el mensaje "hecho", escribe
ls. Ahora deberías ver data_wrangling_exercises en tu carpeta data_wrangling. -
Por último, escribe
cd data_wrangling_exercisesy pulsa Intro para mover tu terminal al repositorio copiado. Utiliza el comandolspara que el terminal muestre el archivo README.md.
¡Uf! Probablemente te parezca mucho, pero ten en cuenta que sólo tendrás que crear una clave SSH una vez, y que sólo tendrás que pasar por el proceso de clonación una vez por repositorio (y todos los ejercicios de este libro se pueden hacer en el mismo repositorio).
Ahora vamos a ver cómo funciona todo esto en acción añadiendo nuestro archivo Python a nuestro repositorio. En una ventana del buscador, navega hasta tu carpeta data_wrangling. Guarda y cierra tu archivo HelloWorld.py o HelloWorld.ipynb, y arrástralo a la carpeta data_wrangling_exercises. De vuelta en el terminal, utiliza el comando ls para confirmar que ves tu archivo Python.
Nuestro último paso es utilizar el comando add para que Git sepa que queremos que nuestro archivo Python forme parte de lo que se copia en GitHub. A continuación, utilizaremos commit para guardar la versión actual, seguido del comando push para subirla realmente a GitHub.
Para ello, vamos a empezar por ejecutando git status en la ventana del terminal. Esto debería generar un mensaje que mencione "archivos sin seguimiento" y muestre el nombre de tu archivo Python. Esto es lo que esperábamos (pero ejecutar git status es una buena forma de confirmarlo). Ahora haremos el proceso de añadir, confirmar y enviar descrito anteriormente. Observa que los comandos add producen mensajes de salida en el terminal:
-
En el terminal, ejecuta
git addyour_python_filename. -
A continuación, ejecuta
git commit -m "Adding my Hello World Python file."your_python_filenameEl comando-mindica que el texto entrecomillado debe utilizarse como mensaje de confirmación, el equivalente en la línea de comandos de lo que hemos introducido en GitHub para nuestra actualización del LÉAME hace unos minutos. -
Por último, ejecuta
git push.
El comando final es el que sube tus archivos a GitHub (ten en cuenta que esto claramente no funcionará si no tienes una conexión a Internet disponible, pero puedes hacer commits cuando quieras y ejecutar el comando push cuando vuelvas a tener Internet). Para confirmar que todo ha funcionado correctamente, vuelve a cargar la página de tu repositorio de GitHub, ¡y verás que se han añadido tu archivo Python y el mensaje de confirmación !
Para hacer copias de seguridad de archivos Python en línea: conectar Google Colab a GitHub
Si realizas toda tu gestión de datos en línea, puedes conectar Google Colab directamente a tu cuenta de GitHub. Asegúrate de que has iniciado sesión en tu cuenta de Google para la gestión de datos y visita https://colab.research.google.com/github. En la ventana emergente, te pedirá que inicies sesión en tu cuenta de GitHub y, a continuación, que "Autorices Colaboratorio". Una vez hecho esto, puedes seleccionar un repositorio de GitHub en el menú desplegable de la izquierda, y los cuadernos Jupyter que estén en ese repositorio aparecerán debajo.
Nota
La vista Google Colab de tus repositorios de GitHub sólo te mostrará cuadernos Jupyter (archivos que terminan en .ipynb). Para ver todos los archivos de un repositorio, tendrás que visitarlo en el sitio web de GitHub.
Unirlo todo
Si estás trabajando en Google Colab, todo lo que tienes que hacer para añadir un nuevo archivo a tu repositorio de GitHub es elegir Archivo → Guardar una copia en GitHub. Después de abrir y cerrar automáticamente algunas ventanas emergentes (se trata de Colab iniciando sesión en tu cuenta de GitHub en segundo plano), podrás elegir de nuevo el repositorio de GitHub en el que deseas guardar tu archivo en el menú desplegable de la parte superior izquierda. A continuación, puedes elegir mantener (o cambiar) el nombre de la libreta y añadir un mensaje de confirmación. Si dejas marcada la opción "Incluir un enlace a Colaboratorio" en esta ventana, el archivo de GitHub incluirá una pequeña etiqueta "Abrir en Colab", en la que podrás hacer clic para abrir automáticamente el cuaderno en Colab desde GitHub. Las libretas de las que no hagas una copia de seguridad explícita en GitHub de esta forma estarán en tu Google Drive, dentro de una carpeta llamada Libretas de Colab. También puedes encontrarlos visitando el sitio web de Colab y seleccionando la pestaña Google Drive en la parte superior de.
Conclusión
El objetivo de este capítulo era proporcionarte una visión general de lo que puedes esperar aprender en este libro: qué entiendo por manejo de datos y calidad de datos, y por qué creo que el lenguaje de programación Python es la herramienta adecuada para este trabajo.
Además, cubrimos toda la configuración que necesitarás para empezar (¡y seguir!) con Python para la manipulación de datos, ofreciendo instrucciones para configurar el entorno de programación que elijas: trabajar con archivos Python "independientes" o cuadernos Jupyter en tu propio dispositivo, o utilizar Google Colab para utilizar cuadernos Jupyter en línea. Por último, cubrimos cómo puedes utilizar el control de versiones (independientemente de la configuración que tengas) para hacer copias de seguridad, compartir y documentar tu trabajo.
En el próximo capítulo, iremos mucho más allá de nuestro programa "Hola Mundo", ya que trabajaremos con los fundamentos del lenguaje de programación Python e incluso abordaremos nuestro primer proyecto de manejo de datos: un día en la vida del sistema Citi Bike de Nueva York.
1 Los trataremos en detalle en los capítulos 4 y 5, respectivamente.
2 En el mundo de la informática, esto se expresa a menudo como "basura dentro/basura fuera".
3 Divulgación: muchos miembros del personal de ProPublica, incluido el reportero principal de esta serie, son antiguos compañeros míos.
4 La serie "Sesgo de las máquinas" generó un gran debate en la comunidad académica, donde algunos discreparon con la definición de sesgo de ProPublica. Sin embargo, lo que es mucho más importante, la polémica dio lugar a un ámbito de investigación académica totalmente nuevo: la imparcialidad y la transparencia en el aprendizaje automático y la inteligencia.
5 Recuerda que incluso un carácter de espacio mal colocado puede causar problemas en Python.
6 Este mismo software también puede utilizarse para crear cuadernos en R y otros lenguajes de programación.
7 Los números que aparecen aquí se denominan números de versión, y aumentan secuencialmente a medida que el lenguaje Python se modifica y actualiza con el tiempo. El primer número (3) indica la versión "mayor", y el segundo número (9) indica la versión "menor". A diferencia de los decimales normales, es posible que la versión menor sea superior a 9, por lo que en el futuro podrías encontrarte con una Python 3.12.
8 Miniconda es una versión más pequeña del popular software "Anaconda", pero como este último instala el lenguaje de programación R y otros elementos que no necesitaremos, utilizaremos Miniconda para ahorrar espacio en nuestro dispositivo.
9 Si tienes un Chromebook de 32 bits, el nombre del archivo puede ser ligeramente diferente.
10 El nombre del archivo de instalación puede tener un número diferente si estás en un sistema de 32 bits.
11 A menos que se indique lo contrario, todos los comandos de terminal deben ir seguidos de pulsar Intro o Retorno.
12 Si aparece un aviso preguntándote cómo quieres "abrir este archivo", te recomiendo que selecciones Google Chrome.
13 ¡No te preocupes, no es visible en Internet!
14 Las primeras versiones de Jupyter Notebook se conocían como "iPythonNotebook", de donde procede la extensión de archivo .ipynb.
15 ¡Especialmente "futuro tú"!
16 ¡Es decir, que ya no obtengo la salida que espero, o que obtengo errores y ninguna salida!
17 Dependiendo de tu dispositivo, puedes guardar esta contraseña en tu "llavero". Para más información, consulta la documentación en GitHub.
Get Tramitación práctica de datos y calidad de datos en Python now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

