Chapter 4. Automated Threat Modeling
There didn’t seem to be any computer-driven process that couldn’t be improved upon by humans crawling around on the actual structure and writing on it with grease pencils.
Neal Stephenson, Atmosphæra Incognita
In Chapter 1 you got an in-depth look into the mechanics of building different types of system models “by hand,” by drawing on a whiteboard or using an application like Microsoft’s Visio or draw.io. You also saw the information you need to gather when constructing those models. In Chapter 3, you got an overview of threat modeling approaches that consume the system models you create, allowing you to identify areas of security concern within your system under evaluation. You learned of methods that find high-level threats, with a consideration for the adversaries who have the capability and intent to carry out an attack. You also saw methodologies that look deeper in the threat “stack” to analyze the underlying causes that lead to threats (and adversarial targets)—weaknesses and vulnerabilities, which alone or in combination result in disaster for your system’s functionality and data (as well as your reputation and brand).
These techniques and methodologies are an effective approach to both system and threat modeling, if you have the time and energy, and can convince your organization that this approach is important. However, in this age of continuous everything, and everything as code, a lot of pressure is placed on development teams to deliver more in less time. Therefore, security practices that were accepted as necessary evils because they consumed more than a few minutes of developer time are being abandoned as too costly (perceived or otherwise). That leaves people who focus on security in a difficult position. Do you try to influence your organization to bite the bullet and be more rigorous in applying security engineering practices, or do you try to get as much done as possible with your shrinking resources, knowing that the quality of your results (and, by extension, the security of the end product) may suffer? How do you maintain high security standards and the attention to detail that is necessary to create a well-engineered system?
One way you can facilitate good security engineering is to limit the need to build system and threat models by hand and turn to automation to help reduce the burden on you, to meet the needs of the business and the security team. While the human element is arguably an important part of a threat modeling activity, construction and analysis of system models is something a computer can accomplish with ease; you, of course, must supply the input.
Automation not only helps you to design the model, but also can assist with answering questions. For example, if you’re not sure whether data flow A between endpoints X and Y leaves your critical data exposed to the mythical Eve,1 you can use a program to figure that out.
In this chapter, we explore an evolution in the making. When it comes to creating the state of the art in threat modeling techniques, performing threat analysis and defect elicitation, you can use automation techniques dubbed threat modeling with code and threat modeling from code.2
You may be wondering—how will threat modeling automation make your life easier, and not one more tool/process/responsibility to care about in the long run? We wondered the same, too.
Why Automate Threat Modeling?
Let’s face it—threat modeling the traditional way is hard, for many reasons:
-
It takes rare and highly specialized talent—to do threat modeling well, you need to tease out the weaknesses in a system. This requires training (such as reading this or other primers on threat modeling) and a healthy dose of pessimism and critical thinking when it comes to what is and what could be (and how things could go wrong).
-
There is a lot to know, and that will require a breadth and depth of knowledge and experiences. As your system grows in complexity, or changes are introduced (such as the digital transformation many companies are going through these days), the changes in technologies brings an accelerating number of weaknesses: new weaknesses and threats are identified, and new attack vectors created; the security staff must be constantly learning.
-
There are myriad options to choose from.3 This includes tools and methodologies to perform threat modeling and analysis, as modeled representations, and how to record, mitigate, or manage findings.
-
Convincing stakeholders that threat modeling is important can be difficult, in part because of the following:
-
Everyone is busy (as mentioned previously).
-
Not everyone in the development team understands the system as specified and/or as designed. What is designed is not necessarily what was in the specification, and what is implemented may not match either. Finding the right individuals who can correctly describe the current state of the system under analysis can be challenging.
-
Not all architects and coders have a complete understanding of what they are working on; except in small, highly functioning teams, not all team members will have cross-knowledge of one another’s areas. We call this the Three Blind Men and the Elephant development methodology.
-
Some team members (hopefully, only a small number) have less-than-perfect intentions, meaning they may be defensive or provide intentionally misleading statements).
-
-
While you may be able to read the code, that does not show you the whole picture. If you have code to read, you may have missed your chance to avoid potentially serious mistakes introduced by the design that coding cannot mitigate. And sometimes it can be hard to derive the overlaying design from code only.
-
Creating a system model requires time and effort. And since nothing is ever static, maintaining a system model takes time. A system’s design will change as the system requirements are modified in response to implementation, and you need to keep the system model in sync with any changes.
These are some of the reasons that some long-time members of the security community have expressed concerns on the practical use of threat modeling as a defensive activity during the development life cycle.4 And to be honest, these reasons are challenging.
But fear not! The security community is a hardy bunch who are never shy to take on a challenge to address a real-world problem, especially those problems that cause you pain, anguish, and sleepless nights. And automation can help address these concerns (see Figure 4-1).
Figure 4-1. “Very small shell script” (source: https://oreil.ly/W0Lqo)
The difficult part of using automation is the complexity of systems and the relative inability for a program to do something the human brain can do better: pattern recognition.5 The difficulty is expressing the system in a way a computer can understand without actually creating the system. As a result, two related approaches are available:
- Threat modeling from code
-
Creating computer code in a programming language or in a newly defined domain-specific language (DSL) that results, when executed, in analysis of threats being performed on a model that represents the input data provided
- Threat modeling with code (aka threat modeling in code)
-
Using a computer program to interpret and process information provided to it to identify threats or vulnerabilities
Both approaches can be effective as long as you resolve the GIGO problem. The results you get must bear a direct relationship to the quality of your input (the description of the system and its attributes) for the automation. Both methods also require the algorithms and rules used in the analysis to be “correct,” such that a given set of inputs generates valid and justifiable outputs. Either implementation can eliminate the need for specialized talent to interpret a system model and understand information about elements, interconnections, and data to identify the indicators of a potential security concern. Of course, this does require that the framework or language supports this analysis and is programmed to do it correctly.
We will talk first about the construction of a system model in a machine-readable format, and then present the theories for each type of automated threat modeling and provide commercial and open source projects that implement them. Later in the chapter (and in the next chapter), we leverage these concepts to deliver information on further evolutionary threat modeling techniques that strive to work within the rapidly accelerating world of DevOps and CI/CD.
Fundamentally, threat modeling relies on input in the form of information that contains or encodes data sufficient for you to analyze; this information enables you to identify threats. When using code rather than human intelligence to perform threat modeling, you describe the system to be evaluated (e.g., the entities, flows, or sequences of events that make up a system, along with the metadata necessary to support analysis and documentation of findings), and the application renders and analyzes the system representation to produce results, and optionally render the representation as diagrams.
Threat Modeling from Code
Threat modeling from code processes information about a system stored in machine-readable form to generate output information related to weaknesses, vulnerabilities, and threats. It does this based on a database or set of rules of things it should be looking for, and needs to be resilient to unexpected input (since these types of applications take input data to interpret). In other words, threat modeling from code is an interpreted approach to create a system model from which to generate threats.
Threat modeling from code may also be referred to as threat modeling in code, such as in the case of Threatspec (described in “Threatspec”).
Note
The phrase “threat modeling from code” is an evolution of thought, combining two concepts of how a system captures, maintains, and processes information to identify threats. The idea of threat modeling in code came from conversations Izar had with Fraser Scott (the creator of Threatspec, described later) around the notion that code modules can store system representation and threat information alongside code or other documentation and can be maintained throughout the life cycle. Tooling that processes the information can be executed to output meaningful data. In threat modeling from code—came about from another conversation between Izar and the creator of ThreatPlaybook, Abhay Bhargav—threat information can be encoded but needs to be “wrangled” and correlated by something to be meaningful. Collectively, these paradigms form the basis for this evolving area of threat modeling as code, whereby interpretation and manipulation of data from various sources are the key operations.
How It Works
In threat modeling from code, you use a program (code) to analyze information created in a machine-readable format that describes a system model, its components, and data about those components. The program interprets the input system model and data, and uses a taxonomy of threats and weaknesses, and detection criteria, to (a) identify potential findings and (b) produce results that can be interpreted by a human. Usually, the output will be a text document or PDF-type report.
Threatspec
Threatspec is an open source project geared toward both development teams and security practitioners. It provides a convenient way to document threat information alongside code, allowing you to generate documentation or a report that enables informed risk decisions. Threatspec is authored and maintained by Fraser Scott at https://threatspec.org.
Note
Threatspec is called out here in this class of tool because of what it does versus what it does not do:
-
It does require code to exist.
-
It does make documentation of threat information easier.
-
It does not perform analysis or threat detection on its own.
Some of the benefits of using Threatspec include the following:
-
Brings security to coders by using code annotations (with which they are probably familiar)
-
Allows the organization to define a common lexicon of threats and other structures for development teams to use
-
Facilitates the security discussion of threat modeling and analysis
-
Automatically generates detailed and useful documentation, including diagrams and code snippets
On the other hand, while Threatspec is an excellent tool for giving coders a way to annotate their code with threat information and thus bring security closer into the development process, it has a couple of downsides to keep in mind.
First, the tool first requires code to exist, or to be created together with annotations, which may mean that the design is already solidified. In this case, the development team is mainly creating security documentation, which is highly valuable but different from threat modeling. Effectively, for these types of projects, threat modeling “shifts right,” which is in the wrong direction.
But the Threatspec documentation does make it clear that the most productive use of the tool is in environments that have bought into the everything-as-code mentality, such as DevOps. For those environments, the chicken-and-egg of design versus code development is not a concern. Threatspec has also recently added the capability to document threats and annotations without having written code, by putting this information into plain-text files that can be parsed. This may help mitigate this potential concern for teams that have more structure to their development life cycle or follow more stringent systems engineering practices.
Second, the development team requires expert knowledge. The team needs guidance from an expert, of what a threat is and how to describe it. This means you cannot address the problem of scalability directly. This approach lends itself, as described by the tool’s documentation, to discussions or guided exercises between the development team and security personnel. But in doing so, scalability is further challenged, by adding back the bottleneck of the security expert. Extensive training of development teams may overcome this hurdle, or having security embedded within the development group may help facilitate conversations closer to where and when code is being developed.
Note
In the future, Threatspec may be especially suited for taking the output of static code analysis tools and generating annotations describing threats from the nature of the code (rather than just what the coders are able or willing to document themselves). Because Threatspec has direct access to source code, it may, as an enhancement, perform verification activities and provide feedback directly into the source code when it discovers threats, risks, or weaknesses. Finally, extending threats into functional safety and privacy domains can produce a comprehensive view of the security, privacy, and safety posture of a system, which is especially important when dealing with compliance officers or regulators (e.g., for PCI-DSS compliance, GDPR, or other regulatory environments) or for guiding root cause or hazard analysis as follow-up activities.
You can obtain Threatspec from GitHub at https://oreil.ly/NGTI8. It requires Python 3 and Graphviz to run and generate reports. The creator/maintainer of Threatspec is active in the security community, especially the OWASP Threat Modeling working group and in the Threatspec Slack, and encourages contributions and feedback on the tool.
ThreatPlaybook
ThreatPlaybook is an open source project brought to you by the folks at we45, led by Abhay Bhargav. It is marketed as a “DevSecOps framework [for] collaborative Threat Modeling to Application Security Test Automation.” It is geared toward development teams to provide a convenient way to document threat information and to drive automation of security vulnerability detection and validation. ThreatPlaybook has a stable release (V1) and a beta release (V3); there is no V2 release.6
Note
ThreatPlaybook’s specialty is to facilitate the use of threat modeling information:
-
It makes documentation of threat information easier.
-
It connects with other security tools for orchestration and validation of vulnerabilities, such as through security test automation.
-
It does not perform analysis or threat detection on its own.
ThreatPlaybook uses GraphQL in MongoDB, and YAML-based descriptions of use cases and threats with descriptive constructs, to support test orchestration for vulnerability verification. It also offers a full API, a capable client application, and a decent report generator. For test automation integrations, it has two options: the original Robot Framework Libraries7 and in V3 its own Test Orchestration Framework functionality. The documentation suggests that ThreatPlaybook has good integration (via Robot Framework) with OWASP Zed Attack Proxy, Burp Suite from PortSwigger, and npm-audit.
You can obtain ThreatPlaybook from GitHub at https://oreil.ly/Z2DZd or via Python’s pip utility. A companion website has good, although somewhat sparse, documentation, and videos explaining how to install, configure, and use ThreatPlaybook.
Threat Modeling with Code
Unlike Threatspec and ThreatPlaybook described previously, which are examples of using code to facilitate the threat modeling activity in the system development life cycle, threat modeling with code takes an architecture or system description that is encoded in a form such as one of the description languages described previously, and performs analysis for automated threat identification and reporting. Utilities following the “with code” paradigm are tools that can read system model information and generate meaningful results that encapsulate the knowledge and expertise of security professionals, and enable security pros to scale across a larger development community.
How It Works
A user writes a program in a programming language to construct a representation of a system and its components, and information about those components. This program describes information about the system in code and provides constraints to performing the analysis. The resulting process uses a set of APIs (functions) to perform threat analysis on the modeled system state and properties. When the “source code” is compiled and executed (or interpreted, depending on the specifics of the language in use), the resulting program produces security threat findings based on the characteristics and constraints of the modeled system.
The concept of creating models without drawing on a whiteboard has been around since at least 1976, when A. Wayne Wymore, then a professor at the University of Arizona, published Systems Engineering Methodology for Interdisciplinary Teams (Wiley). This book, and others that followed, set the groundwork for the technical domain known as model-based systems engineering (MBSE). Lessons the industry learned from MBSE influenced the system-modeling constructs referenced in Chapter 1, and the languages of describing systems for computational analysis that we will briefly discuss.8
Architecture description languages (ADLs) describe representations of systems. Related to ADLs are system design languages, or SDLs. Within the set of ADLs, two related languages provide the ability to build and analyze system models that look for security threats:9
-
The Acme description language for component-based system modeling
Systems engineering uses AADL, which is larger and more expressive, when creating system models of embedded and real-time systems. This is true especially in the fields of avionics and automotive systems, which require functional safety—the property of preserving health and life of human occupants when it comes to system behavior. ACME is less expressive and therefore more applicable for systems that are less complex or smaller in size (defined by number of components and interactions). ACME is also a freely available language specification, while AADL requires a paid license, although some training material is available for free so you can become familiar with the language.10
These languages introduce simple concepts that system and software engineers still use today. You may notice similarities to the concepts we described in Chapter 1:
- Components
-
Represent functional units such as processes or data stores
- Connectors
-
Establish relationships and communication pipelines among components
- Systems
-
Represent specific configurations of components and connectors
- Ports
-
Points of interaction between components and connectors
- Roles
-
Provide useful insights into the function of elements within the system
- Properties, or annotations
-
Provide information regarding each construct that can be used for analysis or documentation
Note
In both ACME and AADL, ports exist as connection points between objects and flows. Our discussion of modeling techniques uses this concept, both through drawings and manual analysis techniques, and through automated methodologies using objects with properties. We recommend this as an enhancement on the traditional DFD (as described in Chapter 1) to improve readability of the system model. This concept also supports the inclusion of architectural constraints or capabilities into the system model, where holding protocols or protection schemes on the data flows alone is not easy to process for complex systems with multiple data flows that are harder to analyze. Using ports helps with this analysis and to render your diagram.
Minimalist architecture description language for threat modeling
What information is necessary to describe and analyze a system model? Let’s refresh your memory of what you learned in Chapter 1 about building a representative drawing “by hand.” You need information on the following:
-
The entities that exist in the system
-
How these entities interact—which elements connect to one another via data flows
-
Characteristics of the elements and data flows
These are the core requirements for describing a system model so that automation can identify patterns that represent potential weaknesses and threats. More specifically, the language or constructs that describe the system must allow you to specify basic entity relationships and describe the core units of elements (and collections of elements), ports, and data flows.
Additionally, you should include metadata in the properties of the objects—the who, what, and why—of the systems and its elements. There are multiple reasons that this is necessary when you build a representation of the system, as metadata does the following:
-
Metadata provides background information that helps to identify gaps in security controls and processes, as well as to generate a report or document that the development team will use. This metadata includes items such as the name of the object within the system model, application or process name, who or which team is responsible for its implementation and/or maintenance, and the object’s general purpose within the system.
-
Assigns each object a short identifier for easier reference in the future and to facilitate documentation and the rendering of diagrams.
-
Allows you to provide specific information such as the value (financial value, or the importance of the data for users of the system, for instance) of the data managed and/or stored by the system under consideration. You should also provide the value that the system’s functionality provides, how much the system supports risk identification and prioritization, and other information needed for documentation. This information is not strictly necessary to identify security concerns, but it should be considered necessary when you perform risk assessment, prioritization, and reporting.
Elements and collections
Objects connect to other objects within a system, and have properties pertinent for threat analysis; these objects are referred to as elements. Elements can represent a process, an object, or an individual (actor). Elements also represent data within a system. Data is associated with elements or data flows (for details, see “Data and data flows”).
Collections are a special form of element. Collections form an abstract relationship grouping of elements (and by extension their data flows or any arbitrary orphaned elements and/or ports) to establish commonality or a reference point for analysis. They allow you to create a representation of a group of items, where the value or purpose of the group is important to you in some way. Grouping may inform analysis independent of the members of the group—if certain elements operate or exist as part of a group, that may offer clues about their shared functionality that each element by itself would not indicate. Recommended collections include the following:
- System
-
This allows you to indicate that a set of elements comprises members of a larger compound element. For the purposes of drawing, and for analysis at varying degrees of granularity, a system can be represented both as a collection or as an element. As we discussed in Chapter 1, when drawing system models, a process exists for starting with an element and decomposing it into its representative parts. Recall when creating the context, or initial layer, showing the major components of the system, a single shape was used to represent a collection of sub-component parts; when drawn at a higher level of specificity (i.e., zoomed in), the representative parts become individualized. When creating a system model in a description language, the representative parts need to be specified individually and, for convenience, grouped together (usually by assigning a shared label or indicator of their relationships to one another).
- Execution context
-
It is critically important to be able to account for the context in which a process executes, or the scope of a unit of data, during analysis. Use an execution context collection to associate things like processes with other things such as virtual or physical CPUs, compute nodes, operating systems, etc., in the scope in which it operates. Understanding this helps you identify cross-context concerns and other opportunities for abuse.
- Trust boundary
-
A collection of elements may be purely abstract and/or arbitrary, not requiring physical or virtual adjacency, to have meaning to you. At the time of defining the objects in the system model, not all system components may be known. So it can be helpful to be able to associate a set of elements as a collection that shares a trust relationship, or for which trust changes between them and other elements not in the collection.
Information associated with nodes—another name for elements—is encoded as properties or characteristics of the object, and provides critical information for analysis and documentation. To support correct system model checking and threat analysis, elements need to have basic properties.11 A representative sample is shown here:
Element:containsexposescallsis_type:-cloud.saas-cloud.iaas-cloud.paas-mobile.ios-mobile.android-software-firmware.embedded-firmware.kernel_mod-firmware.driver-firmware-hardware-operating_system-operating_system.windows.10-operating_system.linux-operating_system.linux.fedora.23-operating_system.rtosis_containerizeddeploys_to:-windows-linux-mac_os_x-aws_ec2provides-protection-protection.signed-protection.encrypted-protection.signed.cross-protection.obfuscatedpackaged_as:-source-binary-binary.msi-archivesource_language:-c-cpp-pythonuses.technology:-cryptography-cryptography.aes128-identity-identity.oauth-secure_boot-attestationrequires:-assurance-assurance.privacy-assurance.safety-assurance.thread_safety-assurance.fail_safe-privileges.root-privileges.guestmetadata:-name-label-namespace-created_by-ref.source.source-ref.source.acquisition-source_type.internal-source_type.open_source-source_type.commercial-source_type.commercial.vendor-description
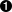
List (array or dictionary) of elements connected to this element (for a system of systems, for example), which may include data
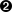
List of port nodes

One element to another, establishing a data flow

Elements have a type (generic or specific)

Boolean characteristics might be True or False, or (set) or (unset)

Generic protection scheme


What form is the element in use?

If the system is or contains software, what language(s) is in use?

Specific technology or capabilities that are used by the component

What does the component need, or assume, to exist?

Set only values that apply. Be careful of conflicting attributes

General information for reporting, reference, and other documentation

Reference to where source code or documentation resides

Reference to where this component came from (project site, perhaps)

This component was internally source

Elements should support particular relationships to other entities or objects:
-
Elements can contain other elements.
-
An element may expose a port (ports are described in the next section).
-
Ports are associated with data.
-
-
Elements can connect to other elements by way of a port, establishing a data flow.
-
An element can make a call to another element (such as when an executable makes a call into a shared library).
-
An element can read or write data. (Data objects are described in “Data and data flows”.)
Ports
Ports provide an entry or connection point where interactions between nodes occur. Ports are exposed by nodes (especially nodes representing processes) and are associated with a protocol. Ports also identify requirements on their security, such as any expectation of security in subsequent communications that pass through the port. Methods offered by the port protect exposed communication channels; some of these methods come from the node exposing the port (such as a node opening a port for traffic protected by TLS) or from the port itself (e.g., for a physically secure interface).
For consumption and readability by a computer program,12 it is imperative to identify and segregate communication flows per protocol. Since different protocols may offer varied configuration options that can impact the overall security of the design, try to avoid overloading communication flows. For example, an HTTPS server that allows RESTful interactions as well as WebSockets through the same service and the same port should use two communication flows. Likewise, a process that supports both HTTP and HTTPS through the same interface should be described in the model with distinct communication channels. This will facilitate analyzing the system.
Properties related to ports may include the following:
Port:requires:-security-security.firewallprovides:-confidentiality-integrity-qos-qos.delivery_receiptprotocol:-I2C-DTLS-ipv6-btle-NFSdata:-incoming-outbound-service_name-portmetadata:-name-label-description
What does this port require or expect?
When set, this means some form of security mechanism is expected to be in place to protect the port
This port must have a firewall in place to protect it (as a specific security protection example)
What capabilities does the port offer?
What protocol does the port use?13
Bluetooth Low Energy
Network File System
What data is associated with this port?
Data being communicated to this port (data nodes, list)
Data being communicated from this port (data nodes, list)
Describe the service that is exposed, especially if this object represents a well-known service14
Numeric port number, if known (not ephemeral)
General information for reporting, reference, and other documentation
Data and data flows
Data flows (see Chapter 1 for examples of data flows) are sometimes referred to as edges because they become connecting lines in a diagram.15 Data flows are the paths upon which data objects travel between elements (and through ports).
You may be wondering why it is important or useful to separate data from data flows. The answer is that a communication channel usually is just a path or pipe upon which arbitrary information can travel, similar to a highway. The data channel itself usually has no context regarding the sensitivity of the data that flows through it. Nor does it have any sense of business value, criticality, or other factors that may impact its use or protection requirements. By using data nodes and associating them with data flows, you can create an abstraction that represents a system that passes different types of data across data flows.
It may be obvious, but you should assign the most restrictive classification of the data going through the data flow as the data classification for the data flow itself, as this will drive the requirements on the data flow to protect the data that passes within it. This allows the system representation to be templated to support variant analysis, which means testing various combinations of data associated with the data flows to predict when a security issue may arise.
These are some suggested properties for data:
Data:encoding:-json-protobuf-ascii-utf8-utf16-base64-yaml-xmlprovides:-protection.signed-protection.signed.xmldsig-protection.encryptedrequires:-security-availability-privacy-integrityis_type:-personal-personal.identifiable-personal.health-protected-protected.credit_info-voice-video-securitymetadata:-name-label-description
Type of data this object represents
General information for reporting, reference, and other documentation
Arbitrary user-defined information
Services that expose the port define the capabilities and properties of the data flow (the data flow inherits properties represented by the port). Data flows may still benefit from having metadata, allowing them to differentiate each flow when, for example, generating a diagram or report.
Other model description languages
To round out your knowledge, let’s discuss a couple of other languages, some of which fit into the SDL category. We encourage you to investigate them if you are interested.
The Common Information Model, or CIM, is a Distributed Management Task Force (DMTF) standard for representing, at a granular level of detail, a computing system and its properties. You can use CIM, and variants like SBLIM for Linux systems, to understand and document the configuration of a system for tasks such as policy orchestration and configuration management. For a guide on the type of data to use when annotating system models, review the list of available properties the CIM offers for systems the specification describes.
Unified Modeling Language, or UML is an Object Management Group, or OMG, standard with a heavy lean toward describing software-centric systems. You may already be familiar with UML, as it is commonly taught as part of a computer science curriculum. The sequence diagram (which we discussed in Chapter 1) is a part of the UML specification. Recently, research has been presented at the academic level that uses UML more for the description of software systems when looking to identify threats than for the analysis to identify those threats.16
Systems Modeling Language (SysML) is also an OMG standard. This variant of UML is designed to be more directly applicable for systems engineering (rather than purely software) than UML. SysML adds two diagram types to UML, and slightly modifies a couple of the other diagram types to remove software-specific constructs, but overall reduces the diagrams available from 13 to 9.17 In theory, this makes SysML “lighter”-weight and more functional for general systems engineering use. Companies and organizations that rely on highly structured systems engineering processes, and of course academia, have published case studies on how to apply SysML for modeling systems for threats, although at the time of writing there is limited availability of case studies showing the automation of analysis for threats.18,19
The types of system models, or abstractions, available, and the data that can be associated with them, in both UML and SysML, are key for application in the area of threat modeling, and specifically threat modeling via code. Both provide a means to specify objects and interactions, and parameters about those objects and interactions. Both also use XML as their data interchange format. XML is designed to be processed by computer applications, which makes this ideal for creating system models that you can analyze for threats.
Analysis of graphs and metadata
Let’s consider for a moment the simple example shown in Figure 4-2.

Figure 4-2. Simple client/server system model
These annotations accompany the system diagram in Figure 4-2:
-
The client is written in C and calls out to the server on port 8080 to authenticate the user of the client.
-
The server checks an internal database, and if the information sent by the client matches what is expected, the server returns an authorization token to the client.
Put your security hat on (refer to the Introduction if you need to brush up on authentication and other applicable flaws) and identify the security concerns in this simple system model.20 Now, think about how you came to the conclusion you did. You (probably) looked at the system model, saw the information provided as annotations, and determined potential threats. You performed pattern analysis against a database of threat information stored in your memory. This is what security advisors for development teams do regularly, and is one of the challenges of scalability—not enough “memory” and “compute power” to go around.
This pattern analysis and extrapolation is easy for a human brain to do. Our brains, given the right knowledge, can easily see patterns and make extrapolations. We even have a subconscious that allows us to have “gut feelings” about our analysis. We make connections to and between things that seem random and ambiguous. We don’t even process all of the steps that our brains take when working; our thoughts “just happen.” Computers, unlike our brains, do things quickly, but they need to be aware of every step and process that’s needed. Computers can’t infer or assume. So, what we take for granted, computers need to be programmed to do.
So, how would a computer program analyze this scenario?
First, you need to develop a framework for analysis. This framework must be able to accept input (from the model) and perform pattern analysis, draw inferences, make connections, and occasionally guess, to produce an outcome that humans can interpret as meaningful. Ready with that AI yet?
Actually, it is not that much of a challenge, and has not been for quite some time. The basic approach is simple:
-
Create a format for describing a system representation with information, using something like an ADL.
-
Create a program to interpret the system model information.
-
Extend the program to perform analysis based on a set of rules that govern the patterns of information present in the system model.
So let’s look at that simple example again, in Figure 4-3.

Figure 4-3. Simple client/server system model revisited
Now, let’s use our idealized description language from earlier in the chapter to describe the information in the system model. To reference each object distinctly in the system model, we use a placeholder identifier for each object, and connect properties to that identifier:
# Describe 'Node1' (the client)Node1.name:clientNode1.is_type:softwareNode1.source_language:cNode1.packaged_type:binary# Describe 'Node2' (the server)Node2.name:serverNode2.is_type:software# Describe 'Node3' (an exposed port)Node3.is_type:portNode3.port:8080Node3.protocol:http# Establish the relationshipsNode2.exposes.port:Node3Node1.connects_to:Node3# Describe the data that will be passed on the channelData1.is_type:credentialData1.requires:[confidentiality,integrity,privacy]Data1.metadata.description:"Datacontainsacredentialtobecheckedbytheserver"Data2.is_type:credentialData2.requires:[confidentiality,integrity]Data2.metadata.description:"Datacontainsasessiontokenthatgives/authorizationtoperformactions"Node3.data.incoming = Data1Node3.data.outbound = Data2
Now, obviously, in the preceding example (which we completely made up and created only for the purpose of explanation), you may notice one or two things of concern. Your human brain is able to make inferences about the meaning of the properties and what the system might look like. In Chapter 3, you learned how to determine some of the vulnerabilities that may exist in a sample system.
But how will the computer program do this same task? It needs to be programmed to do so—it needs a set of rules, and structures to piece information together to achieve the results necessary for analysis.
Constructing rules means looking at available sources of threats and identifying the “indicators” that reveal a threat is possible. The CWE Architectural Concepts list or CAPEC Mechanisms of Attack are repositories that are excellent resources to consider.
Note
You may have noticed that we refer to the CWE and CAPEC databases multiple times throughout the book. We are particularly fond of using these as central resources because they are open, public, and filled with consumable and applicable information that has been contributed by experts across the security community.
For our demonstration, let’s take a look at two possible sources of a rule:
CWE-319 tells us the weakness occurs when “the software transmits sensitive or security-critical data in cleartext in a communication channel that can be sniffed by unauthorized actors.” From this simple description, you should be able to identify the indicators that need to be present for a potential threat to exist in a system:
-
A process: This performs an action.
-
“Transmits”: The software unit communicates with another component.
-
“Sensitive or security-critical data”: Data of value to an attacker.
-
Without encryption: On the channel or protecting the data packets directly (one of these conditions needs to exist).
-
Impact: Confidentiality.
CAPEC-157 describes an attack against sensitive information as “in this attack pattern, the adversary intercepts information transmitted between two third parties. The adversary must be able to observe, read, and/or hear the communication traffic, but not necessarily block the communication or change its content. Any transmission medium can theoretically be sniffed if the adversary can examine the contents between the sender and recipient.” From this description, we get details of how an attacker may perform this attack:
-
Traffic between two parties (endpoints) is intercepted.
-
The attack is passive; no modification or denial of service is expected.
-
The attacker (actor) requires access to the communication channel.
So with these two descriptions, we might consider the following unified rules (in text):
-
The source endpoint communicates to the destination endpoint.
-
The data flow between endpoints contains sensitive data.
-
The data flow is not protected for confidentiality.
The impact of having these conditions present in a system would enable a malicious actor to obtain sensitive data through sniffing.
The code to identify this pattern and to indicate the condition of threat existence might look like (in pseudocode, minus all the safety checks) the following:
defevaluate(noden,"Threat from CWE-319"):ifn.is_typeis"software":foriinrange(0,len(n.exposes)):return(n.exposes[i].p.data.incoming[0].requires.security)and(n.exposes[i].p.provides.confidentiality)
This is an extremely simplified example of what a tool or automation could accomplish. More efficient algorithms for performing this pattern matching certainly exist, but hopefully this example gives you an idea of how threat modeling uses code to perform automatic threat detection.
While threat modeling with code is a pretty neat trick, threat modeling from code makes the technology potentially more accessible. In this paradigm, instead of using code to assist in managing threat information, or using a program to analyze a textual description of a model “with code” to match constructs to rules to determine threats, an actual program is written that, when executed, performs the threat modeling analysis and rendering “automagically.”
For this to be possible, a program author needs to create program logic and APIs to describe elements, data flows, etc. and the rules by which they will be analyzed. Developers then use the APIs to create executable programs. Execution (with or without precompilation, dependent on the language choice for the APIs) of the program code results in these basic steps:
-
Translate the directives that describe objects to build a representation of the system (such as a graph, or just an array of properties, or in an other representation internal to the program).
-
Load a set of rules.
-
Walk the graph of objects performing pattern matching against the set of rules to identify findings.
-
Generate results based on templates for drawing the graph as a diagram that is (hopefully) visually acceptable to a human and for outputting details of findings.
Writing code to autogenerate threat information provides a few benefits:
-
As a coder, you are already used to writing code, so this offers an opportunity for you to have something actionable on your terms.
-
Threat modeling as code neatly aligns with the everything as code or DevOps philosophies.
-
You can check in code and keep it under revision control in tools you, as a developer, are already used to, which should help with adoption as well as management of the information.
-
If the APIs and libraries that are built to contain the knowledge and expertise of security professionals support the capability to dynamically load rules for analysis, the same program can service multiple domains. A program can re-analyze a system previously described in code as new research or threat intelligence reveals new threats so they are always up-to-date, without changing the model or having to redo any work.
This method has a few detractions to consider as well, however:
-
Developers such as yourself already write code every day to deliver value to your business or customers. Writing additional code to document your architecture may seem like an additional burden.
-
With so many programming languages available today, the likelihood of finding a code bundle that uses (or supports integration with) a language your development team uses may be a challenge.
-
The focus is still on developers who, as the keepers of code, need the skills to understand concepts like object-oriented programming and functions (and calling conventions, etc.).
These challenges are not insurmountable; however, the threat modeling from code space is still immature. The best example we can offer for a code module and API for performing threat modeling from code is pytm.
Note
Disclaimer: we are really, really, really biased toward pytm, as creators/leaders of the open source project. We want to be fair in this book to all the great innovations in the field of threat modeling automation. But we do honestly feel pytm has addressed a gap in methods that have been made available to security practitioners and development teams trying to make threat modeling actionable and effective for them.
pytm
One of the main reasons we wrote this book was the sincere desire for individuals involved with development to have immediately accessible information that helps them further develop their security capabilities in the secure software development life cycle. This is why we talk about training, the challenge of “thinking like a hacker,” attack trees and threat libraries, rules engines, and diagrams.
As experienced security practitioners, we have heard many arguments from development teams against the use of threat modeling tooling: “It is too heavy!”, “It is not platform-agnostic; I work in X, and the tool only works in Y!”, “I don’t have the time to learn one more application, and this one requires me to learn a whole new syntax!” Apart from the presence of a lot of exclamation points, a common pattern in these declarations is that the coder is asked to step outside their immediate comfort zone and add one more skill to their toolbox or interrupt a familiar workflow and add an extraneous process. So, we thought to ourselves, what if we were to instead try to approximate the threat modeling process to one already familiar to the coder?
Much as can be seen in continuous threat modeling (which we describe in depth in Chapter 5), reliance on tools and processes already known to the development team helps create commonality and trust in the process. You are already comfortable with these and use them every day.
Then we looked at automation. Which areas of threat modeling offered the most challenges to the development team? The usual suspects stepped forward: identifying threats, diagramming and annotating, and keeping the threat model (and by extension, the system model) current with minimum effort. We bantered about description languages, but they fell into the category of “one more thing for the team to learn,” and their application felt heavy in the development process, while the teams were trying to make it lighter. How could we help the development team meet its (efficiency/reliability) goal and still achieve our security education goal?
Then it struck us: why not describe a system as a collection of objects in an object-oriented way, using a commonly known, easy, accessible, existing programming language, and generate diagrams and threats from that description? Add Python, and there you have it: a Pythonic library for threat modeling.
Available at https://oreil.ly/nuPja (and at https://oreil.ly/wH-Nl as an OWASP Incubator project), in its first year of life, pytm has captured the interest of many in the threat modeling community. Internal adoption at our own companies and others, talks and workshops by Jonathan Marcil at popular security conferences like OWASP Global AppSec DC and discussions at the Open Security Summit and even use by Trail of Bits in its Kubernetes threat model indicate that we are moving in the right direction!
Note
pytm is an open source library that has profited immensely from the discussions, work, and additions of individuals including Nick Ozmore and Rohit Shambhuni, co-creators of the tool; and Pooja Avhad and Jan Was, responsible for many central patches and improvements. We look forward to the community’s active involvement in making it better. Consider this a call to action!
Here is a sample system description using pytm:
#!/usr/bin/env python3frompytm.pytmimportTM,Server,Datastore,Dataflow,Boundary,Actor,Lambdatm=TM("my test tm")tm.description="This is a sample threat model of a very simple system - a /web-basedcommentsystem.Theuserenterscommentsandtheseareaddedtoa/databaseanddisplayedbacktotheuser.Thethoughtisthatitis,though/simple,acompleteenoughexampletoexpressmeaningfulthreats."User_Web=Boundary("User/Web")Web_DB=Boundary("Web/DB")user=Actor("User")user.inBoundary=User_Webweb=Server("Web Server")web.OS="CloudOS"web.isHardened=Truedb=Datastore("SQL Database (*)")db.OS="CentOS"db.isHardened=Falsedb.inBoundary=Web_DBdb.isSql=Truedb.inScope=Falsemy_lambda=Lambda("cleanDBevery6hours")my_lambda.hasAccessControl=Truemy_lambda.inBoundary=Web_DBmy_lambda_to_db=Dataflow(my_lambda,db,"(λ)Periodically cleans DB")my_lambda_to_db.protocol="SQL"my_lambda_to_db.dstPort=3306user_to_web=Dataflow(user,web,"User enters comments (*)")user_to_web.protocol="HTTP"user_to_web.dstPort=80user_to_web.data='Comments in HTML or Markdown'user_to_web.order=1web_to_user=Dataflow(web,user,"Comments saved (*)")web_to_user.protocol="HTTP"web_to_user.data='Ack of saving or error message, in JSON'web_to_user.order=2web_to_db=Dataflow(web,db,"Insert query with comments")web_to_db.protocol="MySQL"web_to_db.dstPort=3306web_to_db.data='MySQL insert statement, all literals'web_to_db.order=3db_to_web=Dataflow(db,web,"Comments contents")db_to_web.protocol="MySQL"db_to_web.data='Results of insert op'db_to_web.order=4tm.process()
pytm is a Python 3 library. No Python 2 version is available.
In pytm, everything revolves around elements. Specific elements are
Process,Server,Datastore,Lambda, (Trust)Boundary, andActor. TheTMobject contains all metadata about the threat model as well as the processing power. Import only what your threat model will use, or extendElementinto your own specific ones (and then share them with us!)We instantiate a
TMobject that will contain all of our model description.Here we instantiate a trust boundary that we will use to separate distinct areas of trust of the model.
We also instantiate a generic actor to represent the user of the system.
And we immediately put it in the correct side of a trust boundary.
Each specific element has attributes that will influence the threats that may be generated. All of them have common default values, and we need to change only those that are unique to the system.
The
Dataflowelement links two previously defined elements, and carries details about the information flowing, the protocol used, and the communication ports in use.Apart from the usual DFD, pytm also knows how to generate sequence diagrams. By adding an
.orderattribute toDataflow, it is possible to organize them in a way that will make sense once expressed in that format.After declaring all our elements and their attributes, one call to
TM.process()executes the operations required in the command line.
Besides the line-by-line analysis, what we can learn from this piece of code is that each threat model is a separate individual script. This way, a large project can keep the pytm scripts small and colocated with the code that they represent, so that they can be more easily kept updated and version controlled. When a specific part of the system changes, only that specific threat model needs editing and change. This focuses effort on the description of the change, and avoids the mistakes made possible by editing one large piece of code.
By virtue of the process() call, every single pytm script has the same set of command-line switches and arguments:
tm.py[-h][--debug][--dfd][--reportREPORT][--excludeEXCLUDE][--seq]/[--lis][--describeDESCRIBE]optionalarguments:-h,--helpshowthishelpmessageandexit--debugdebugmessages--dfdoutputDFD(default)--reportREPORToutputreportusingthenamedtemplatefile/(sampletemplatefileisunderdocs/template.md)--excludeEXCLUDEspecifythreatIDstobeignored--seqoutputsequentialdiagram--listlistallavailablethreats--describeDESCRIBEdescribethepropertiesavailableforagivenelement
Of note are --dfd and --seq: these generate the diagrams in PNG format. The DFD is generated by pytm writing in Dot, a format consumed by Graphviz and the sequence diagram by PlantUML. also has multiplatform support. The intermediate formats are textual, so you can make modifications, and the layout is governed by the respective tools and not by pytm. Working this way, every tool can focus on what it does best.21
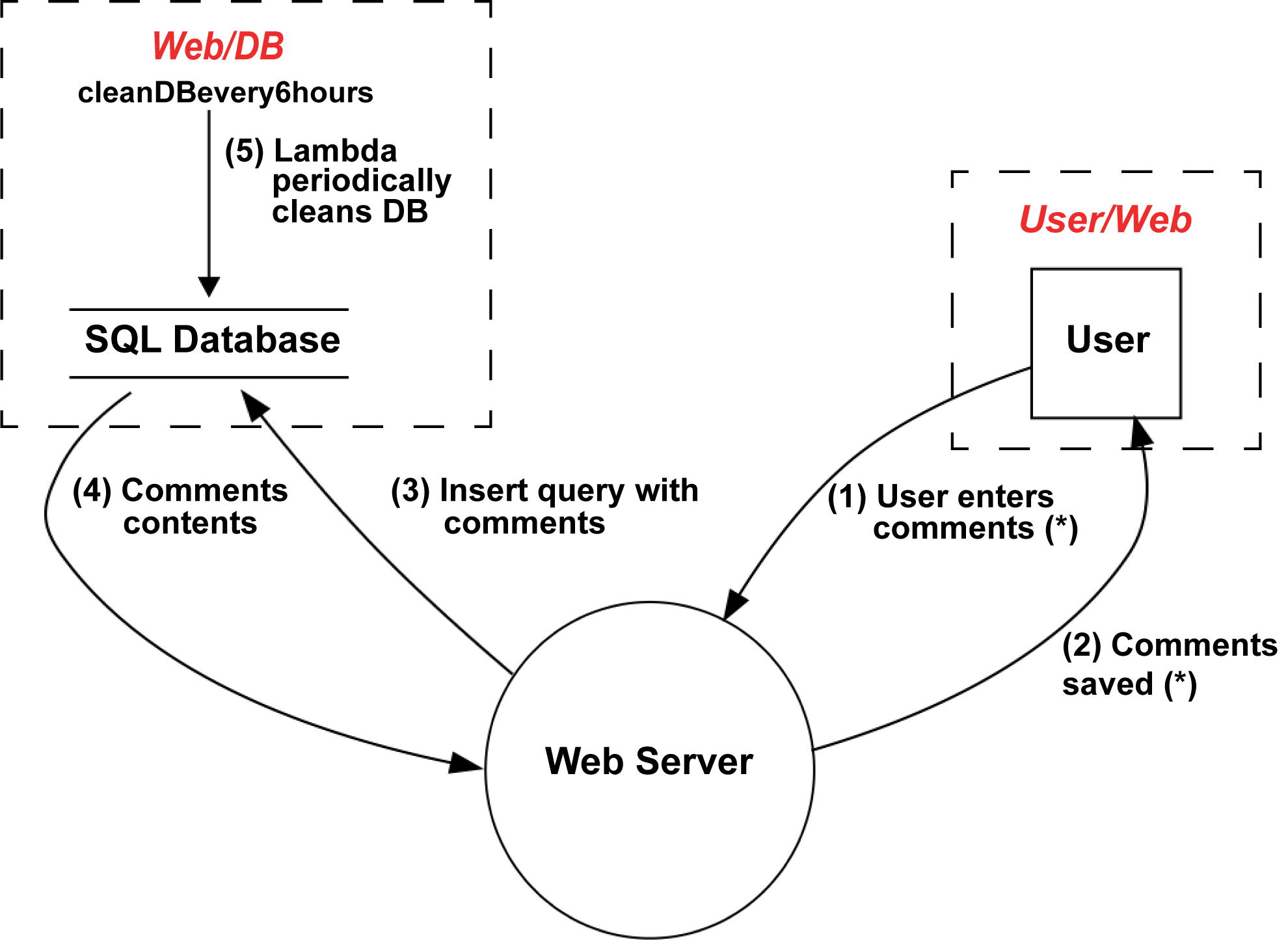
Figure 4-4. DFD representation of the sample code
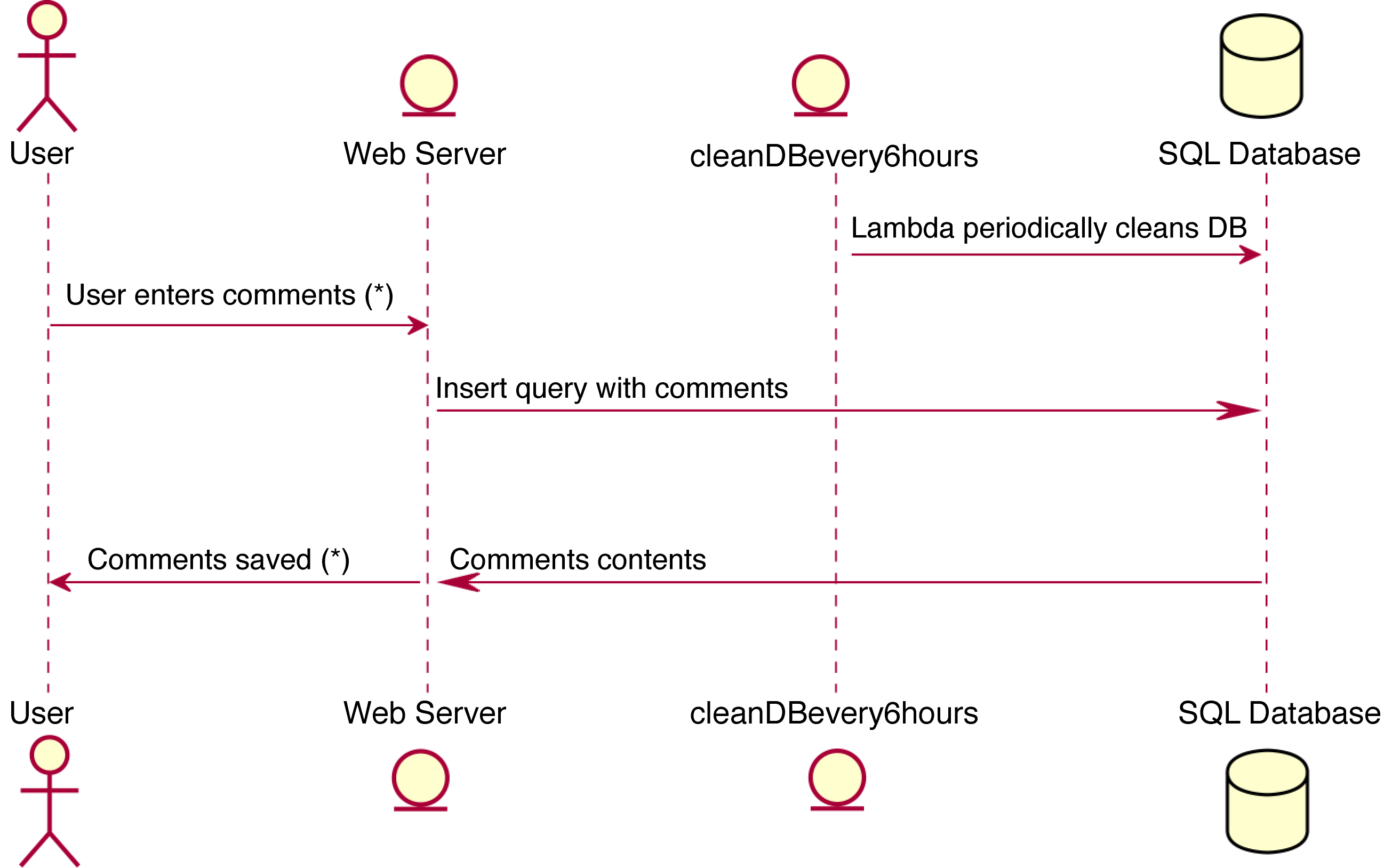
Figure 4-5. The same code, now represented as a sequence diagram
Being able to diagram at the speed of code has proven to be a useful property of pytm. We have seen code being jotted down during initial design meetings to describe the system in play. pytm allows team members to leave a threat modeling session with a functional representation of their idea that has the same value as a drawing on a whiteboard but can be shared, edited, and collaborated upon immediately. This approach avoids all the pitfalls of whiteboards (“Has anyone seen the markers? No, the black markers!”, “Can you move the camera a bit? The glare is hiding half of the view,” “Sarah is responsible for turning the drawing into a Visio file. Wait, who’s Sarah?”, and the dreaded “Do Not Erase” signs).
But while all of that is valuable, a threat modeling tool is quite lacking if it doesn’t, well, reveal threats. pytm does have that capability, albeit with a caveat: at this stage in its development, we are more concerned with identifying initial capabilities than being exhaustive in the threats identified. The project started with a subset of threats that roughly parallels the capabilities of the Microsoft Threat Modeling Tool described in this chapter, and added some lambda-related threats. Currently, pytm recognizes more than 100 detectable threats, based on a subset of CAPEC. You can see some of the threats pytm is able to identify here (and all threats can be listed by using the --list switch):
INP01-BufferOverflowviaEnvironmentVariablesINP02-OverflowBuffersINP03-ServerSideInclude(SSI)InjectionCR01-SessionSidejackingINP04-HTTPRequestSplittingCR02-CrossSiteTracingINP05-CommandLineExecutionthroughSQLInjectionINP06-SQLInjectionthroughSOAPParameterTamperingSC01-JSONHijacking(akaJavaScriptHijacking)LB01-APIManipulationAA01-AuthenticationAbuse/ByPassDS01-ExcavationDE01-InterceptionDE02-DoubleEncodingAPI01-ExploitTestAPIsAC01-PrivilegeAbuseINP07-BufferManipulationAC02-SharedDataManipulationDO01-FloodingHA01-PathTraversalAC03-SubvertingEnvironmentVariableValuesDO02-ExcessiveAllocationDS02-TryAllCommonSwitchesINP08-FormatStringInjectionINP09-LDAPInjectionINP10-ParameterInjectionINP11-RelativePathTraversalINP12-Client-sideInjection-inducedBufferOverflowAC04-XMLSchemaPoisoningDO03-XMLPingoftheDeathAC05-ContentSpoofingINP13-CommandDelimitersINP14-InputDataManipulationDE03-SniffingAttacksCR03-Dictionary-basedPasswordAttackAPI02-ExploitScript-BasedAPIsHA02-WhiteBoxReverseEngineeringDS03-FootprintingAC06-UsingMaliciousFilesHA03-WebApplicationFingerprintingSC02-XSSTargetingNon-ScriptElementsAC07-ExploitingIncorrectlyConfiguredAccessControlSecurityLevelsINP15-IMAP/SMTPCommandInjectionHA04-ReverseEngineeringSC03-EmbeddingScriptswithinScriptsINP16-PHPRemoteFileInclusionAA02-PrincipalSpoofCR04-SessionCredentialFalsificationthroughForgingDO04-XMLEntityExpansionDS04-XSSTargetingErrorPagesSC04-XSSUsingAlternateSyntaxCR05-EncryptionBruteForcingAC08-ManipulateRegistryInformationDS05-LiftingSensitiveDataEmbeddedinCache
As mentioned earlier, the format pytm uses to define threats is undergoing a revision to accommodate a better rule engine and provide more information. Currently, pytm defines a threat as a JSON structure with the following format:
{"SID":"INP01","target":["Lambda","Process"],"description":"Buffer Overflow via Environment Variables","details":"This attack pattern involves causing a buffer overflow through/manipulation of environment variables. Once the attacker finds that they can/modify an environment variable, they may try to overflow associated buffers./This attack leverages implicit trust often placed in environment variables.","Likelihood Of Attack":"High","severity":"High","condition":"target.usesEnvironmentVariables is True and target.sanitizesInput is False and target.checksInputBounds is False","prerequisites":"The application uses environment variables.An environment/variable exposed to the user is vulnerable to a buffer overflow.The vulnerable/environment variable uses untrusted data.Tainted data used in the environment/variables is not properly validated. For instance boundary checking is not /done before copying the input data to a buffer.","mitigations":"Do not expose environment variables to the user.Do not use /untrusted data in your environment variables. Use a language or compiler that /performs automatic bounds checking. There are tools such as Sharefuzz [R.10.3]/which is an environment variable fuzzer for Unix that support loading a shared/library. You can use Sharefuzz to determine if you are exposing an environment/variable vulnerable to buffer overflow.","example":"Attack Example: Buffer Overflow in $HOME A buffer overflow insccw allows local users to gain root access via the $HOMEenvironmental variable. Attack Example: Buffer Overflow in TERM Abuffer overflow in the rlogin program involves its consumption ofthe TERM environment variable.","references":"https://capec.mitre.org/data/definitions/10.html, CVE-1999-0906, CVE-1999-0046, http://cwe.mitre.org/data/definitions/120.html, http://cwe.mitre.org/data/definitions/119.html, http://cwe.mitre.org/data/definitions/680.html"},
The target field describes either a single or a tuple of possible elements that the threat acts upon. The condition field is a Boolean expression that evaluates to True (the threat exists) or False (the threat does not exist) based on the values of the attributes of the target element.
Warning
Interestingly enough, the use of Python’s eval() function to evaluate the Boolean expression in a condition introduces a possible vulnerability to the system: if pytm is installed system-wide, for example, but the threat file’s permissions are too permissive and any user can write new threats, an attacker could write and add their own Python code as a threat condition, which would happily be executed with the privileges of the user running the script. We aim to fix that in the near future, but until then, be warned!
To complete the initial set of capabilities, we added a template-based reporting capability.22 While simple and succinct, the templating mechanism is enough to provide a usable report. It enables the creation of reports in any text-based format, including HTML, Markdown, RTF, and simple text. We have opted for Markdown:
#Threat Model Sample ***##System Description {tm.description}##Dataflow Diagram ##Dataflows Name|From|To |Data|Protocol|Port ----|----|---|----|--------|---- {dataflows:repeat:{{item.name}}|{{item.source.name}}|{{item.sink.name}}/ |{{item.data}}|{{item.protocol}}|{{item.dstPort}} }##Potential Threats {findings:repeat:* {{item.description}} on element "{{item.target}}" }
This template, applied to the preceding script, would generate the report you can see in Appendix A.
We truly expect to continue growing and developing more capabilities in the near future, hopefully bringing down the entry barrier to threat modeling by development teams while providing useful results.
Threagile
A new (as of July 2020) entry in the threat-modeling-as-code space, Threagile by Christian Schneider is a promising system. It is currently in stealth mode but will soon be made available, open source!
Much like pytm, Threagile falls under the category of threat modeling with code, but uses a YAML file to describe the system it will evaluate. A development team is able to use the tools that team members already know, in their native IDE, and that can be maintained together with the code of the system it represents, version controlled, shared, and collaborated on. The tool is written in Go.
Since at the time of this writing the tool is still under development, we advise you to visit the Threagile’s author’s website to see examples of the reports and diagrams generated.
The main elements of the YAML file describing the target system are its data assets, technical assets, communication links, and trust boundaries. For example, a data asset definition looks like this:
Customer Addresses:id:customer-addressesdescription:Customer Addressesusage:businessorigin:Customerowner:Example Companyquantity:manyconfidentiality:confidentialintegrity:mission-criticalavailability:mission-criticaljustification_cia_rating:these have PII of customers and the system /needs these addresses for sending invoices
At this time, the data asset definition is the main difference in approach between Threagile and pytm, since the definitions of technical assets (in pytm, elements like Server, Process, etc.), trust boundaries, and communication links (pytm data flows) follow more or less the same breadth of information about each specific element in the system.
Differences are more marked in that Threagile considers different types of trust boundaries, like Network On Prem, Network Cloud Provider, and Network Cloud Security Group (among many others) explicitly, while pytm does not differentiate. Each type mandates different semantics that play a role in the evaluation of threats.
Threagile has a plug-in system to support rules that analyze the graph of the system described by the YAML input. At the time of this writing, it supports around 35 rules, but more are being added. A random pick of sample rules shows the following:
-
cross-site-request-forgery
-
code-backdooring
-
ldap-injection
-
unguarded-access-from-internet
-
service-registry-poisoning
-
unnecessary-data-transfer
Unlike pytm, which works as a command-line program, Threagile also provides a REST API that stores (encrypted) models, and allows you to edit and run them. The Threagile system will maintain the input YAML in a repository, together with the code the YAML describes, and the system can be told to perform processing either via the CLI or the API. Output of Threagile consists of the following:
-
A risk report PDF
-
A risk tracking Excel spreadsheet
-
A risk summary with risk detail as JSON
-
A DFD automatically laid out (with coloring expressing the classification of assets, data, and communication links)
-
A data asset risk diagram
This last diagram is of particular interest, as it expresses, for each data asset, where it is processed and where it is stored, with color expressing risk state per data asset and technical asset. To the best of our knowledge, this is the only tool offering that view right now.
The format of the generated PDF report is extremely detailed, containing all the information necessary to flow risk up to management or for developers to be able to mitigate it. The STRIDE classification of identified threats is present, as is an impact analysis of risks per category.
We look forward to seeing more of this tool and getting involved with its development, and heartily suggest you take a look at it after it is opened to the public.
An Overview of Other Threat Modeling Tools
We tried to represent these tools as impartially as we could, but overcoming confirmation bias can be difficult. Any errors, omissions, or misrepresentations are solely our responsibility. No vendor or project participated in this review, and we do not suggest one tool over another. The information presented here is simply for educational purposes and to help you start your own research.
IriusRisk
Methodologies implemented: Questionnaire-based, threat library
Main proposition: The free/community edition of IriusRisk (see Figure 4-6) provides the same functionality as the Enterprise version, with a limitation on the kinds of reports it can produce and the elements offered in its menu for inclusion in the system. The free edition also does not contain an API, but it is enough to show the capabilities of the tool. Figure 4-6 shows an example of the analysis results performed by IriusRisk on the model of a simple browser/server system. Its threat library appears to be based on CAPEC at least, with mentions of CWE; Web Application Security Consortium, or WASC; OWASP Top Ten; and the OWASP Application Security Verification Standard (ASVS) and OWASP Mobile Application Security Verification Standard (MASVS).
Freshness: Constantly updated
Obtain from: https://oreil.ly/TzjrQ

Figure 4-6. IriusRisk real-time analysis results
A typical finding on an IriusRisk report would contain the component where it was identified, the kind of flaw (“Access sensitive data”), a short explanation of the threat (“Sensitive data is compromised through attacks against SSL/TLS”) and a graphic/color representation of the risk and progress of countermeasures.
Drilling into a given threat shows a unique ID (containing CAPEC or other index information), a division of impact into confidentiality, integrity, and availability, a longer description and a list of references, associated weaknesses, and countermeasures that will inform the reader on how to address the identified issue.
SD Elements
Methodologies implemented: Questionnaire-based, threat library
Main proposition: At the time of writing in version 5, SD Elements aims to be a full-cycle security management solution for your enterprise. One of the capabilities it offers is questionnaire-based threat modeling. Given a predefined security and compliance policy, the application tries to verify the compliance of the system in development to that policy by suggesting countermeasures.
Freshness: Frequently updated commercial offering
Obtain from: https://oreil.ly/On7q2
ThreatModeler
Methodologies implemented: Process flow diagrams; Visual, Agile, Simple Threat (VAST); threat library
Main proposition: ThreatModeler is one of the first commercially available threat modeling diagramming and analysis tools. ThreatModeler uses process flow diagrams (which we briefly mention in Chapter 1) and implements the VAST modeling approach to threat modeling.
Freshness: Commercial offering
Obtain from: https://threatmodeler.com
OWASP Threat Dragon
Methodologies implemented: Rule-based threat library, STRIDE
Main proposition: Threat Dragon is a project recently out of incubator status at OWASP. It is an online and desktop (Windows, Linux, and Mac) threat modeling application that provides a diagramming solution (drag and drop), and a rule-based analysis of the elements defined, suggesting threats and mitigations. This cross-platform, free tool is usable and expandable (see Figure 4-7).
Freshness: In active development, led by Mike Goodwin and Jon Gadsden
Obtain from: https://oreil.ly/-n5uF

Figure 4-7. A sample system, available as a demonstration
Notice in Figure 4-7, that the DFD conforms to the simple symbology presented throughout the book; each element has a property sheet that provides details and context about it. The element is shown in the context of the full system, and basic information about whether it is in scope for the threat model, and what it contains, and how it is stored or processed, is available.
Users also can create their own threats, adding a level of customization that enables an organization or team to stress those threats that are particular to their environment or to the functioning of their system. There is a direct correlation with STRIDE threat elicitation and a simple High/Medium/Low criticality ranking without direct correlation to a CVSS score.
Threat Dragon offers a comprehensive reporting capability that keeps the system diagram in focus, and provides a list of all findings (with their mitigations, if available) sorted by elements, or the reason if a given element is part of the diagram but marked out of scope for the threat model.
Microsoft Threat Modeling Tool
Methodologies implemented: Draw and annotate, STRIDE
Main proposition: Another major contribution of Adam Shostack and the SDL Team at Microsoft, the Microsoft Threat Modeling Tool is one of the earliest appearances in the threat modeling tool space. Initially based on a Visio library (and thus requiring a license for that program), that dependency has been dropped, and now the tool is a standalone installation. Once installed, it offers options to add a new model or template, or load existing ones. The template defaults to an Azure-oriented one, with a generic SDL template for systems that are not Azure-specific. Microsoft also supports a library of templates, which, although not extensive at the moment, is surely a welcome contribution to the landscape. The tool uses an approximation of the DFD symbology we used in Chapter 1, and offers tools that let you annotate each element with attributes, both predefined and user-defined. Based on prepopulated rules (that live in an XML file and can, in theory, be user-edited), the tool generates a threat model report containing the diagram, the identified threats (classified based on STRIDE), and some mitigation advice. Although the elements and their attributes are heavily Windows oriented, the tool does have value for non-Windows users (see Figure 4-8).
Freshness: Seems to be updated every couple of years.
Obtain from: https://oreil.ly/YL-gI
Much as in other tools, each element can be edited to provide its properties. The main difference here is that some element properties are very Windows-related; for example, the OS Process element contains properties like Running As, with Administrator as a possible value, or Code Type: Managed. When the program generates threats, it will ignore options that won’t be applicable to the targeted environment.
Reporting in this tool is closely tied to STRIDE, with each finding having a STRIDE category, in addition to a description, a justification, a state of mitigation, and a priority.

Figure 4-8. DFD for sample demo system provided with the tool
CAIRIS
Methodologies implemented: Asset-driven and threat-driven security design
Main proposition: Created and developed by Shamal Faily, CAIRIS, which stands for Computer Aided Integration of Requirements and Information Security, is a platform to create representations of secure systems focusing on risk analysis that is based on requirements and usability. Once you define an environment (i.e., a container in which the system exists—an encapsulation of assets, tasks, personas and attackers, goals, vulnerabilities, and threats), you can define the contents of the environment. Personas define users, and tasks describe how personas interact with the system. Personas also have roles, which can be stakeholder, attacker, data controller, data processor, and data subject. Personas interact with assets, which have properties including Security and Privacy (like CIA), Accountability, Anonymity, and Unobservability, valued as None, Low, Medium, and High. Tasks model the work that one or more personas perform on the system in environment-specific vignettes. CAIRIS is able to generate UML DFDs with the usual symbology, as well as textual representations of a system. The system is complex, and our description will never do it justice, but during the course of our research, CAIRIS intrigued us enough to warrant further exploration. A book that expands on the tool and the ways it should be used, and that provides a complete course on security by design is Designing Usable and Secure Software with IRIS and CAIRIS, by Shamal Faily (Springer).
Freshness: Under active development
Obtain from: https://oreil.ly/BfW2l
Mozilla SeaSponge
Methodologies implemented: Visually driven, no threat elicitation
Main proposition: Mozilla SeaSponge is a web-based tool that works on any relatively modern browser and provides a clean, good-looking UI, which also promotes an intuitive experience. At this time, it does not offer a rule engine or a reporting capability, and development appears to have ended in 2015 (see Figure 4-9).
Freshness: Development seems to have stagnated.
Obtain from: https://oreil.ly/IOlh8
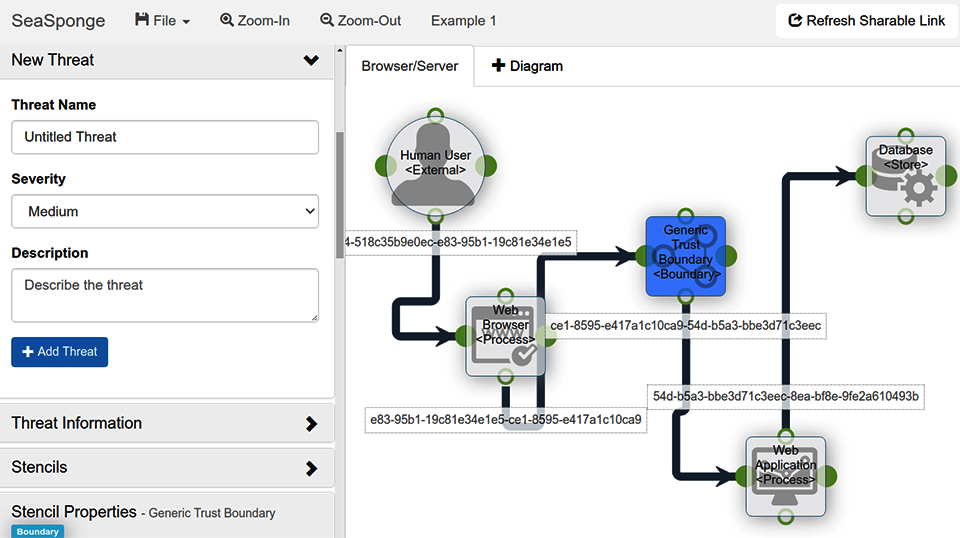
Figure 4-9. Mozilla SeaSponge user interface
Tutamen Threat Model Automator
Methodologies implemented: Visually driven, STRIDE, and threat libraries
Main proposition: Tutamen Threat Model Automator is a commercial software-as-a-service (SaaS) offering (as of October 2019, in free beta) with an interesting approach: upload a diagram of your system in draw.io or Visio formats, or an Excel spreadsheet, and receive your threat model. You must annotate your data with security-related metadata, zones of trust, and permissions you want to assign to elements. The generated report will identify the elements, the data flows, and the threats, and will propose mitigations.
Freshness: Frequently updated commercial offering
Obtain from: http://www.tutamantic.com
Threat Modeling with ML and AI
This is the age of “AI solves everything.”23 However, the state of the security industry is such that we’re not ready to make that leap (yet) for threat modeling.
Some research has been has been done in using machine learning (ML) and AI in threat modeling. This is natural, given that today’s AI is an advancement of the expert systems of the (recent) past. These systems were based on rules processed by inference engines trying to satisfy a set of requirements to bring the system being modeled into a satisfactory state. Or the systems would point out any discrepancies that deemed the solution impossible. Sounds familiar, no?
Machine learning is built on the premise that after you classify enough data, patterns emerge that allow you to classify any new data. Trying to translate that into the threat modeling domain can be tricky. For example, in the field of network security, it is easy to generate vast amounts of data carrying both “good” and “bad” traffic to train a classification algorithm. However, in threat modeling, a sufficient corpus of data may not exist, meaning you would be unable to train an algorithm to recognize threats with fidelity. That immediately takes you back to the approach where a threat is an expression of an unwanted state caused by the configuration of the system, in a specific constellation of elements and attributes.
Machine learning approaches to threat modeling are primarily still an academic exercise, with little in the way of published papers or proofs of concept that would allow us to demonstrate a functioning AI/ML system.24,25 At least one patent already addresses a generic machine learning threat modeling chain like the one described previously, but as of today, we are not aware of a working prototype of a tool or a dataset supporting it.
Even as they are called upon and leveraged to improve security in other systems, ML systems have a need to be modeled for threats. Here are some examples of research done in this area:
-
The NCC Group has provided results of its research into this area and has developed threat models for ML systems that highlight how they can be attacked or abused by unscrupulous adversaries.26 The researchers at NCC Group used one of the oldest non-ML tools available for threat modeling—Microsoft’s Threat Modeling Tool, 2018 Edition—in their research.
-
Researchers at the Institute of Computer Engineering, Vienna University of Technology, published their threat model for ML algorithm training and inference mechanisms, along with a good discussion on vulnerabilities, adversary goals, and countermeasures to mitigate the threats identified.27
-
Berryville Institute of Machine Learning, cofounded by famed security scientist Gary McGraw, PhD, published an architectural risk analysis of ML systems that reveals interesting areas of concern in the field of security when applied to ML systems (some of which may themselves be applied to detecting security issues in other systems).28
MITRE’s CWE is beginning to include security weaknesses for machine learning systems, with the addition of CWE-1039, “Automated Recognition Mechanism with Inadequate Detection or Handling of Adversarial Input Perturbations”.
Summary
In this chapter, we took a longer look at some of the existing challenges of threat modeling and how you can overcome them. You learned about architecture description languages and how they provided the foundation for the automation of threat modeling. You learned about the various options for automating threat modeling, from simply generating better threat documentation to performing full modeling and analysis by writing code.
We discussed tools that use techniques from threat modeling with code and threat modeling from code (collectively referred to in the industry as threat modeling as code) while implementing threat modeling methodologies from Chapter 3. Some of these tools also implement other features, such as security test orchestration. We showed you our threat-modeling-from-code tool, pytm, and we finished by briefly discussing the challenge of applying machine learning algorithms to threat modeling.
In the next chapter, you will get a glimpse into the near-future of threat modeling with exciting new techniques and technologies.
1 Randall Munroe, “Alice and Bob,” xkcd webcomic, https://xkcd.com/177.
2 Some people also use the encompassing phrase threat modeling as code to align to the DevOps jargon. Much like DevOps (and its jargon!) a couple of years ago, the whole vocabulary is in transition—many people mean many different things by it, but we feel that slowly a convention is coalescing.
3 At last check, we counted more than 20 methodologies and variations.
4 “DtSR Episode 362—Real Security Is Hard,” Down the Security Rabbit Hole Podcast, https://oreil.ly/iECWZ.
5 Ophir Tanz, “Can Artificial Intelligence Identify Pictures Better than Humans?” Entrepreneur, April 2017, https://oreil.ly/Fe9w5.
6 See the ThreatPlaybook documentation for more details, at https://oreil.ly/lhSPc.
7 See the Robot Framework, an open source framework for testing, at https://oreil.ly/GWGKP.
8 A. Wymore’s autobiography is available on this University of Arizona site.
9 A survey of ADLs is available from “Architecture Description Languages” by Stefan Bjornander, https://oreil.ly/AKo-w.
10 “AADL Resource Pages,” Open AADL, http://www.openaadl.org.
11 There are many possible ways to represent objects within a system; this shows an idealized or representative set of properties based on our research. The list has been modified for placement in this text, and the original can be found at https://oreil.ly/Vdiws.
12 As in any good code, simplicity is best to make the program flow intelligibly to the “next maintainer.”
13 For readers unfamiliar with I2C, see Scott Campbell’s “Basics of the I2C Communication Protocol” Circuit Basics page.
14 See “Service Name and Transport Protocol Port Number Registry,” IANA, https://oreil.ly/1XktB.
15 For a discussion on edges and graphs, see “Graph Theory” by Victor Adamchik, https://oreil.ly/t0bYp.
16 Michael N. Johnstone, “Threat Modelling with Stride and UML,” Australian Information Security Management Conference, November 2010, https://oreil.ly/QVU8c.
17 “What is the Relationship Between SysML and UML?” SysML Forum, accessed October 2020, https://oreil.ly/xL7l2.
18 Aleksandr Kerzhner et al., “Analyzing Cyber Security Threats on Cyber-Physical Systems Using Model-Based Systems Engineering,” https://oreil.ly/0ToAu.
19 Robert Oates et al., “Security-Aware Model-Based Systems Engineering with SysML,” https://oreil.ly/lri3g.
20 Hint: Using this system model carries at least five potential threats such as spoofing and credential theft.
21 Graphviz has packages for all major operating systems.
22 See “The World’s Simplest Python Template Engine” by Eric Brehault, https://oreil.ly/BEFIn.
23 Corey Caplette, “Beyond the Hype: The Value of Machine Learning and AI (Artificial Intelligence) for Business (Part 1),” Towards Data Science, May 2018, https://oreil.ly/324W3.
24 Mina Hao, “Machine Learning Algorithms Power Security Threat Reasoning and Analysis,” NSFOCUS, May 2019, https://oreil.ly/pzIQ9.
25 M. Choras and R. Kozik, ScienceDirect, “Machine Learning Techniques for Threat Modeling and Detection,” October 6, 2017, https://oreil.ly/PQfUt.
26 “Building Safer Machine Learning Systems—A Threat Model,” NCC Group, August 2018, https://oreil.ly/BRgb9.
27 Faiq Khalid et al., “Security for Machine Learning-Based Systems: Attacks and Challenges During Training and Inference,” Cornell University, November 2018, https://oreil.ly/2Qgx7.
28 Gary McGraw et al., “An Architectural Risk Analysis of Machine Learning Systems,” BIML, https://oreil.ly/_RYwy.
Get Threat Modeling now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

