Chapter 4. Decision Modeling: The Decision Asset Investigation Process
Are we drowning in data? The world is now creating more than 100 zettabytes (ZB)1 of data every year, “roughly equivalent to every human generating an entire copy of the Library of Congress each year,” according to Marc Warner in Computer Weekly. But is it really helping us? “If data-driven decision making was right,” Warner adds, “this growth should lead to vastly improved organizational performance.... Has that happened? Clearly not.” What’s going on?
Data can only help us think or do something more efficiently if it’s the right data, in the right form, at the right time. Zettabytes of the wrong data in the wrong form don’t help us meet our objectives; in fact, data can get in the way. This is why so many decision makers routinely say things like, “Please don’t send me any data. I’m simply not interested.”
Decision intelligence fixes this problem by changing your data into a more usable form. The Decision Asset Investigation process (Process B2, illustrated in Figure 4-1) is the first step on the path to building software simulation of the path(s) from actions to outcomes, to help you determine the best actions to take. The CDD serves as a “scaffold” that shows you where data supports that simulation. Decision Asset Investigation starts with your initial CDD and uses it as a guide to your investigation to find multiple assets that can be used to inform evidence-based decision making. In particular, this is where you’ll ask, “If I change the element(s) on the left of this dependency, what happens to the element on the right?”
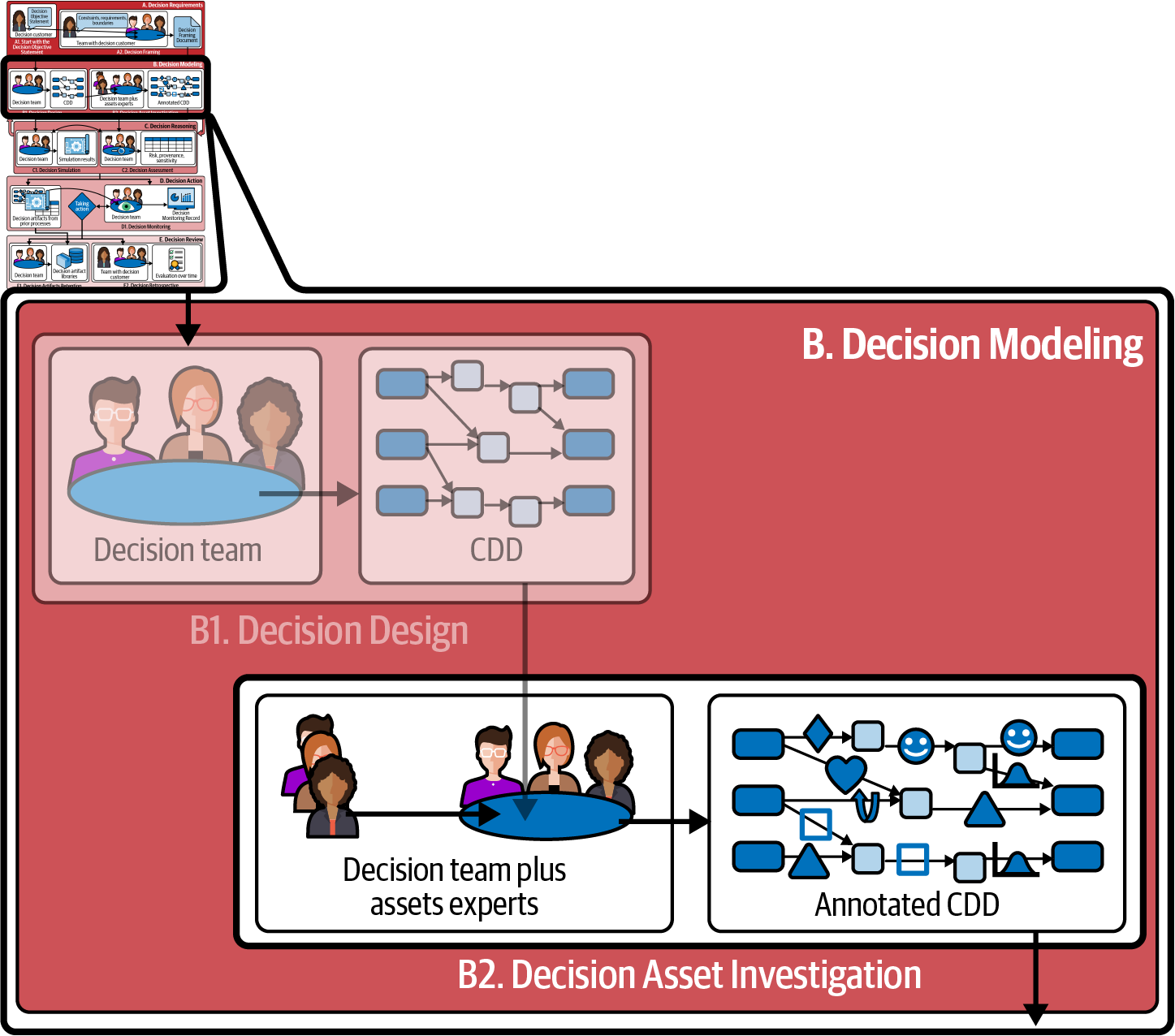
Figure 4-1. How Decision Asset Investigation relates to other processes in this book.
As you learned in Chapter 3, Process B1, Decision Design, focuses on aligning around the outcomes, identifying levers that can produce those outcomes, understanding externals that influence those outcomes, and building the causal chains from levers and externals to outcomes. Process B2, Decision Asset Investigation, in contrast, focuses on identifying the assets that will ultimately help you to implement those causal chains in software. Ultimately, you’ll have a tool that allows you to say, “If I make these lever choices and these assumptions about externals, here is what I expect to measure for this outcome.”
This chapter takes you step by step through the process of using and annotating your CDD to identify decision assets—data and other kinds of technology—that can support the simulation you’ll build in Chapter 5 and facilitate your conversation with your data team. This is a very different conversation from the more common “back-to-front” decision conversations. This work transforms your “decision blueprint” into a “decision digital twin” specification, ready for simulation.
Deciding to Go Digital
When is it worth the time to go beyond a CDD and to model a decision in software? The simple answer is that it depends on your expected return on investment (ROI) from this exercise. You might find—as have some of our customers—that the CDD alone is a giant benefit, and that your organization isn’t yet ready to take the next step. Or you might find, after you’ve had a chance to work with the CDD a bit, that either (a) your decision customers just aren’t “getting it” or (b) the decision is so complex and valuable that you think that it’s going to be worth building a simulation for it. If people’s livelihoods and/or large amounts of money depend on a decision, then our clients have found that investing in decision-software implementation can be worth the effort. And you can “dip your toe in the water” with a simple—sometimes called “low-fidelity”—simulation if you’d like before bringing in all the data and analytics bells and whistles.
If you choose to move forward, you’ll find a lot of variety in the levels of effort required to identify decision assets. Sometimes your decision asset is very simple—it’s just the knowledge that, if the element on the left goes up, then the one on the right goes up (or down). Other times, you can identify a decision asset like a statistical model; an ML model; a behavioral, cognitive, and/or mathematical model; or human expertise that can provide detailed information about a certain dependency. In fact, one of the most important questions you’ll answer in Decision Asset Investigation is: “Where is the model that informs this dependency arrow?”
Introduction to Process B2: Decision Asset Investigation
This chapter shows how decision teams can work with analysts to identify decision assets. You’ll learn how to use the Decision Asset Investigation process and maintain a Decision Asset Register, in which you’ll record the assets and the people responsible for them. In the “Try It Yourself” use case at the end of the chapter, you’ll practice identifying assets, attaching them to a CDD, and entering them on the register.
You might like to take a look at the Appendix for a complete list of how data can be used both during decision reasoning as well as while the decision is playing out in reality. You don’t need this full list to start collecting decision assets, however; feel free to get started without it. Basically, it says that data can inform many of the decision elements: providing predictions or assumptions about externals, providing expected ranges for intermediates, and (most important) driving the models that inform dependency arrows. This data is useful during decision reasoning and as the decision action plays out over time.
This process has two purposes. First, it guides you in documenting the decision assets (such as data, knowledge, and submodels) that will later inform your simulation. Second, it helps you identify missing assets so you can prioritize finding those assets or creating them by preparing and gathering new data, modeling, and/or researching initiatives.
It’s common for people to realize, as this process unfolds, that they’ve forgotten important elements in their CDD, such as an external that determines the value of an intermediate. Don’t hesitate to add those—effectively looping back to Decision Design from the last chapter—whenever you find them. If your organization has been doing DI for a while, you may find that someone else has modeled—and even simulated—part of your CDD, so you can see what data and models they used. The more you use DI and keep all the artifacts you create (see Chapter 8), the more you can build on the work of others and the easier it becomes.
From Simple to Sophisticated Assets
As you document your assets, you’ll probably find that their degrees of precision are all over the map. Maybe all you know is that “as this element goes up, this other one goes down.” Or—one level more sophisticated—maybe you can draw a simple X/Y graph (sketch graph) showing how the two are related. At the extreme end of sophistication, you could have a library of 30 research papers that bear on an asset—for instance, how nematodes respond to various treatments in different soil and weather conditions. You might have some software that calculates the dependency, or a simple or complicated mathematical function. Figure 4-2 illustrates assets at different levels of modeling sophistication. Table 4-2 lists icons for many types of sophisticated models.

Figure 4-2. A few different levels of sophistication of assets that can inform dependencies.
Documenting Decision Assets
As you identify decision assets, we recommend listing them in a Decision Asset Register. You can find a template (Phase B, Worksheet 2: Decision Asset Register) in the supplemental materials repository. Table 4-1 shows an example of a Decision Asset Register.
| Decision element | Decision asset | Asset type | Asset source and contact |
|---|---|---|---|
| <Here, enter either a description of the associated decision element, e.g., “Dependency from Pricing to Volume,” or you can label the CDD with numbers, and just include that number here, e.g., “(1)”> | <Name or description of the decision asset to be used, e.g., “Price/Volume curve” or “Model named PV_33B in the data warehouse”> | <This may be one of many types of assets, including a sketch graph, dataset, econometric model, observation, human knowledge, and many more> | <Who is responsible for maintaining/providing this asset?> |
| <include as many rows in the table as there are assets to track> |
|
|
|
CDD annotations
As you fill out the asset register, it’s a good idea to annotate your CDD to indicate the different kinds of assets that you’re bringing to bear. For visual impact, and to avoid cluttering the diagram too much, you might want to draw an icon indicating the nature of the asset. Table 4-2 provides examples of icons we have used before, and Figure 4-3 shows part of a decision model annotated with icons for a few different kinds of assets.
| Symbol | Type of decision asset |
|---|---|
| Mathematical model (financial or econometric) | |
| Mathematical model (not financial or econometric) | |
| ML model | |
| Statistical model | |
| Behavioral or psychological model | |
| Knowledge graph / inference model | |
| Medical model | |
| Digital-twin model (human or nonhuman expertise in a domain) | |
| Sketch graph incorporating human expertise | |
| Human expertise not incorporated into a model or sketch graph | |
| Data source for data not incorporated into a model or sketch graph | |
| Information source for information not incorporated into a model or sketch graph | |
| Agent-based human movement model | |
| Observation, data capture, measurement, or monitoring system | |
| Constraint | |
| Assumption (usually based on human knowledge, intuition, or an information source) | |
| Decision submodel |

Figure 4-3. Subset of a CDD, showing several different kinds of the data and technology assets that inform its structure. This behavioral model predicts how investing in a marketing program to promote social distancing will affect the social-distancing compliance. The econometric model shows how pricing leads to demand, and the ML model predicts how investing in a marketing program will affect the mask compliance. Please see the full decision model in Figure P-2 or the supplemental materials repository.
With all this in mind, please see “Formal Process Description: Process B2: Decision Asset Investigation” (including filling out the register and annotating the CDD), followed by some guidance on how to do this. Note that this process is different from step 12, which involves assessing expertise, from Process B1, Decision Design (Chapter 3), because it assumes a complete CDD as input to the process. It’s also about discovering technical elements that bridge the CDD from a diagram to a computerized model, not investigating new elements for the CDD. Both processes enhance the CDD, just in different ways.
Recording the decision assets
You need to record more information about each decision asset than you can show on a CDD. How you record it depends on how your organization manages data and knowledge. If you manage data and knowledge at the departmental level, you might use a spreadsheet or table like Table 4-3 as a Decision Asset Register to record the locations and owners of the assets associated with your CDD elements.
On the other hand, if you have a mature data governance architecture, your lexicon can precisely define each data term and document the authoritative source for obtaining or computing its value. You can reference lexicon entries in a spreadsheet, but as you create CDDs, you might consider building a dependency lexicon that documents elements that appear as intermediates or outcomes and their dependencies, the arrows into them and the elements on the left sides of those arrows with ties to your data lexicon for the data that informs those dependencies. This makes the dependencies easily available for future CDDs.
If you choose to take this more formal route, then a dependency lexicon will let you answer questions like, “Which organizational outcomes does this piece of data drive?” as well as the question addressed by Decision Asset Investigation, “Which data and knowledge affects this outcome?” If your organization has mature knowledge management (KM) systems, standards, and/or processes, you can similarly link your dependency lexicon to it for dependencies informed by human knowledge.
You might also think about investigating how LLMs like ChatGPT and/or semantic search tools can help you to locate elements within your formal lexicon: this may be the future of KM, which can now treat decision models as a valuable corporate asset to store and continuously improve. You might use LLMs and semantic search to identify decision elements stored within your knowledge base.
Formal Process Description: Process B2: Decision Asset Investigation
- Description
Identify and document existing and missing data, information, human knowledge, and other technology that inform decision elements on the CDD, in preparation for integrating these assets into a computerized decision model.
- Prerequisites
The CDD created during Decision Design.
A mandate (usually from the decision customer) to create an automated simulation based on the CDD.
Guidance regarding the time, effort, and fidelity required for this process.
Consider reading the Appendix.
Create a blank Decision Asset Register in which to record your findings, or use Phase B, Worksheet 2: Decision Asset Register, available in the supplemental materials repository, or understand how to use any organizational tools that link CDDs to your data governance system and your knowledge management system.
- Responsible role
Decision team leader. They will be assisted by people within and outside the decision team who can provide data, information, models, documents, or other forms of human knowledge related to the CDD.
- Steps
Read through this process and tailor it, as appropriate, to your team.
Examine the CDD you created during Decision Design as a first step:
Start by documenting the “low-hanging fruit”: the decision assets you’ve already identified during CDD elicitation (maybe you captured them in a “parking lot”). Add them to the Decision Asset Register.
Ask your team to look at the CDD again and identify the causal chains they think will have the biggest impact on the outcomes. Document them, including levers, externals, intermediates, and/or outcomes. As you did with outcomes and levers, you might also ask for what they think are the “top three” chains that make a difference.
For each intermediate and outcome, especially those along the “top three” causal chains, investigate whether there is some model or function that informs how it depends on the immediately preceding element(s). What data does each element supply to the model or function? Are any externals, levers, or intermediates missing?
For each intermediate, ask:
Are there any constraints on its allowed values? These will inform your simulation as well as how you monitor the decision as it plays out over time.
Are there systems that observe or measure that intermediate (such as a BI tool)?
Add your answers to the Decision Asset Register, and annotate the CDD so that you have a clear connection between each asset and the location within the CDD that it applies to.
For each external, document its:
Assumed value(s)
Constraints
Relevant datasets
Observations
Measurement or monitoring systems
Models (such as a predictive model for the GDP in India for the next five years)
Document where you think there are missing assets that are needed but not yet obtained.
- Deliverables
Decision Asset Investigation: A Sweet Potato CDD Drives Data Gathering and Research
As explained previously, the Decision Asset Investigation process has two purposes: to identify existing assets and to prioritize new data gathering or model building. Here’s a story about how this played out in a recent project.
A few years back, sweet potato growers in the United States were facing a new species of soilborne agricultural pest called a nematode. It’s basically an ugly sort of worm. Retail consumers tend to prefer unblemished produce, but nematodes cosmetically make them look unattractive. Even though the potatoes are perfectly edible, this “ugly” produce is unsuitable for sale to consumers and must be sold at a far lower price to canneries or pet-food manufacturers—a substantial financial blow to growers.
Growers can control nematodes in a number of ways. The most common methods are to rotate the crop (that is, to plant a different crop, like peanuts, in a nematode-heavy field for one season), apply pesticides, or both. These two approaches both have associated costs, and the rotation crops are substantially less profitable than sweet potato crops. Choosing the best step to take constitutes a complex decision in a volatile environment, and the decision can have a big financial impact.
As part of a United States Department of Agriculture (USDA) project to help sweet potato growers make better decisions using DI, we developed a decision model for this problem. Working with a group of sweet potato experts led by Dr. David Roberts and Dr. Michael Kudenov, along with plant pathologist Dr. Adrienne Gorny, we elicited outcomes, levers, and externals; wired up the CDD; and iterated a few times to make sure we hadn’t missed anything important. The result was the CDD shown in Figure 4-4.

Figure 4-4. The sweet potato nematodes model, with functions indicated (courtesy of USDA Agriculture and Food Research Initiative-funded DECIDE-SMARTER project, reproduced with permission).
After the Decision Design process, we moved on to Decision Asset Investigation. Our experts sent us several lists of data sources. We matched them to the CDD and found, to our great surprise, that there was a lot of research and data to support one part of the CDD, but no research at all to support some other parts. In particular, the nematicide concentration link (marked f5a in Figure 4-4) and the yield, price, and profit links (marked f6 through f13) were well researched, but the remaining links had very little research to support them.
As it turned out, without the CDD to visually show the decision-making structure, researchers hadn’t previously realized that they were only building data and conducting research to support some of it!
If you haven’t faced this situation before, then you might be surprised that it happened. We were surprised, too: with so much data out there, how could it not inform the entire decision model, and how could there be such big gaps between what’s needed by decision makers and what’s been investigated? But we’ve seen this pattern play out again and again: today’s data systems are designed to answer questions and provide insights, but not to connect actions to outcomes. Lacking the action/outcome perspective, they often fall short of what’s needed.
So, returning to the process at hand: the previous example shows that CDD analysis can tell you not only when you do have assets to support a decision, but can also point you to when you don’t: you’ll need to consider some new research, find a new data source, and/or use the CDD as a low-fidelity model for now.
Data for Externals
Previously, you learned how to investigate data that might help to inform dependencies. Externals need data as well. You can think of externals in four categories:
Things that never change, like the diameter of the earth
Single changing values that you can measure, like the current temperature
Values that will change in the future, and which you can predict, like tomorrow’s high temperature
Sets of values that you can predict for the future, like the daily high temperature for the next six months
Tip
We often call values that will change in the future and that you can predict for the future “assumptions” or “predictions.” Note that the English language also uses these words for intermediates and outcomes, for example, “We predict that our company will grow by 20% revenue next month.” But you know, as a decision modeler, that it’s really helpful to distinguish between things that you can influence through your actions (outcomes) and things over which you have no control (externals). So we recommend that you teach your teams to use the more unambiguous “intermediates” (or “leading indicator” or “key process indicator”) language instead of “assumption” or “prediction,” to avoid confusion.
But back to predictions about externals. Often, analysts and statisticians use information about the past which they extrapolate into the future to make these kinds of predictions. Sometimes this works, and sometimes it doesn’t.
To take just one famous example, toilet paper manufacturers had years of very stable data about consumer demand versus business demand. They had made years of data-driven decisions about production lines and distribution channels. They used their existing data to make predictions about what toilet paper supply and demand would be in 2020. Because of the Covid-19 pandemic, however, it would be hard to argue that 2020 was “just like” 2019! And because lots of decisions made in 2019 were playing out during 2020, lots of things changed—including a 40% increase in consumer demand versus commercial demand for toilet paper, not to mention panic buying and hoarding. The just-in-time retail distribution chains that toilet paper manufacturers rely on to get their product to consumers could not handle the increased load, and the system broke. The lesson is that big, stable datasets are only “hard data” if you’re discussing the past. In discussing the future, we can only make predictions.
Closely related to the idea of a prediction is the concept of an external assumption. An assumption is a guess about the value of an external that you’re uncertain about, either because it relates to an uncertain future, or because you’re not confident in your ability to accurately measure it in the present. For example, our sweet potato farmers may wish to assume that every field has some concentration of nematodes, because they decide that the cost of actually doing the testing isn’t worth it. All predictions are assumptions, but not all assumptions are predictions.
Here are some kinds of data you might find to help you with external assumptions:
Specific values or ranges of values, such as “Greenhouse gas emissions are assumed to be between 60 and 70 grams per revenue passenger kilometer”
Predictions and models, including predicted numerical values or probability distributions from mathematical or ML models
Datasets, such as the daily high and low temperatures for a specific location for the last 100 years
You may also find it useful to document constraints on externals: ranges or values that you believe will make it impossible to achieve your outcomes. For instance, “If the temperature goes outside the range of 0 degrees Celsius to 40 degrees Celsius for more than one hour, this plant will die.”
The Puzzle Toy Use Case: The Decision Asset Conversation
Congratulations! Your company’s new executive desk-toy product—a three-dimensional puzzle—is ready to launch! After you and your team celebrate meeting that milestone, you need to decide how to take your shiny new puzzle to market.
You’ve got a few decisions to make:
How much should you charge for each puzzle?
How many units should you order for the first production run?
How big an investment should you make in marketing the puzzle?
You need to submit your decisions to the senior management team for approval, and you know they’ll want hard evidence that your plan will be profitable and that your decisions won’t expose the company to unacceptable risks.
Luckily, you have access to your organization’s top-shelf analytics and data science team and state-of-the-art BI software. You call a “war room” meeting with your analyst team to explain the three decisions and start figuring it out. The analysts begin filling your whiteboard with diagrams of data lakes. They tell you about the AI algorithm they’re going to use and open their laptops to show you a spreadsheet with 20 worksheets, their amazing analytics tools, and the even more terrific insights they deliver. Over the next week, they put their best information together to create the dashboard in Figure 4-5.

Figure 4-5. A dashboard for the puzzle toy product launch.
It’s pretty impressive, but you have to ask: “How does this dashboard answer my three questions?” The data scientists look confused. Since the company’s never launched a product like this before, they don’t have any charts that can connect your three decision choices to the outcome you are measuring—profit.
The data scientists are puzzled and a bit frustrated. The company has spent a lot of money to collect, prepare, and manage a vast collection of data. After all, “Your decision is only as good as your data,” right? Surely somewhere, in all that tech, lie the answers to these seemingly simple questions. But where?
Fortunately, at the very start of the project, you used a CDD to decide what kind of toy to build. Now you realize that a new CDD can address your questions. The three questions suggest three things you control, your three levers: sales price, production order size, and marketing spend as a percent of profit. The outcome is easy: profit. Your objective is to maximize that profit. With a little help from your team, you quickly sketch the CDD shown in Figure 4-6.

Figure 4-6. The product launch CDD ready for Decision Asset Investigation.
Now you are ready to look at the dependency arrows and search for data and models that inform them. You quickly observe that unit cost is inversely related to production order size; the more you buy, the cheaper each unit is. You also realize that you don’t have control over production cost. That’s controlled by manufacturing, a different department within your company. So you have a new external: unit cost versus number produced. And your analytics team has manufacturing data that predicts cost versus number for other desktop toy products. In fact, it’s right there on the dashboard they gave you. So now you have added an external and its associated dataset to the CDD, as shown in Figure 4-7.

Figure 4-7. Adding an external and its associated data.
Next you look at the relationship between sales price and units sold. Units sold depends on another external, customer behavior. More specifically, it depends on a specific component of customer behavior, demand versus price. Your analytics team has an ML model that predicts demand for similar products, and they represented it on the dashboard graphically as Base Demand, a curve showing market penetration rate versus sales price. Market penetration rate is units sold divided by market size. So, to understand the relationship between sales price and units sold, you need one more external, market size. The analytics team found marketing information that estimates your market size at 500,000 units. The “sales price to units sold” part of the CDD now looks like Figure 4-8.

Figure 4-8. Adding externals and data that show the relationship between sales price and units sold.
You realize that marketing spend will also drive demand, and you turn to the causal chain that starts with marketing spend as a percent of profit. You need one more external: increased demand versus marketing spend. The analytics team has provided a predictive function, represented on the dashboard by the “Marketing-Driven Demand Uplift” graph. It shows percent increase in demand as a function of market spend. Adding that produces the CDD shown in Figure 4-9.

Figure 4-9. Adding the marketing uplift external.
Refining the CDD to show every place where the data is needed produces the annotated CDD in Figure 4-10.

Figure 4-10. The CDD at the end of Decision Asset Investigation.
Try It Yourself: Decision Asset Investigation for the Telecom Use Case
You built a CDD in “Try It Yourself: Decision Design for a Telecom Use Case”. In this section, you will complete a small Decision Asset Investigation process for that use case.
We’ll start with a very simple approach to identifying assets, which is to “find” knowledge inside your own brain about the directions of some dependencies.
In your next meeting, you lead the telecom decision team in reading through the Decision Asset Investigation process description together. As your first step in reviewing the CDD, you decide to look at the dependency arrows. You note that for most of the dependencies in this diagram, when the element on the left increases, the element on the right also increases (these are called direct dependencies). You ask the team to look for exceptions: are there any inverse dependencies, where the changes go in opposite directions? The team quickly identifies the arrow from “pricing” to “volume” as an inverse dependency and marks it in the CDD, as shown in Figure 4-11. The team then finds two additional inverse dependencies and marks them on the CDD.

Figure 4-11. The unlimited usage plan CDD with inverse dependencies annotated.
You may hear some disagreement about how certain dependencies work, such as the shape of the sketch graph. Depending on the type of link, resolving them will require different approaches: a link based on a simple formula may mean talking to experts in the finance department, while a link based on ML may require building a new model. You may also want to capture different sets of assets in two different lists so you can try them both to see if they lead to different decisions.
You ask the team if they know of existing assets that would provide more information about any of the dependencies in their CDD. A product manager points out that the relationship of price to volume is seldom a simple straight line. To illustrate, he creates a quick sketch graph like the one in Figure 4-12. You make a corresponding entry in row 1 of the Decision Asset Register, as shown in Table 4-3.

Figure 4-12. A sketch graph showing how price affects demand.
| Decision element | Decision asset | Asset type | Asset source and contact |
|---|---|---|---|
| Dependency from pricing to volume | Price/volume curve | Sketch graph | Joe Smith, Product Mgr., Marketing |
| Dependency from pricing to volume | Consumer price testing results | ML model, based on a dataset | Mary Brown, Sr. Data Scientist, ML Group |
| Marketing/advertising lever | Historical advertising effectiveness | Human knowledge | Shanice Johnson, Advertising Manager, Marketing |
| Macro economy external | Econ. Dept. Model 1042 | Econometric model | Prof. Sara García, Econ. Dept., UXY |
| Competitor behavior external | Competitive intelligence | Observation | John Wu, Sr. Research Analyst, Marketing |
The team’s ML expert responds, speaking up for the first time: “I have a dataset from a similar product where we price-tested different pricing levels on several thousand prospects with different characteristics. It shows that price to volume isn’t a simple straight line. In fact, I bet I could use that dataset to give you an initial model of how different pricing decisions would change product demand—kind of a machine-learning-based precision demand estimator.” The team is happy to identify an existing dataset that might be useful for the decision, and you label the dependency to show that, as shown in Figure 4-13, while making a corresponding entry in the Decision Asset Register, as shown in the second row of Table 4-3.

Figure 4-13. The unlimited usage plan CDD, annotated with decision assets.
The product manager speaks again, explaining that he’s just texted a colleague in the advertising department and asked her to drop in and join the group. When she arrives, she explains that it is “common knowledge” that a targeted advertising campaign will convince about 2% of potential customers to move to the company running the campaign. You annotate this piece of human expertise in the CDD and add the third row to the Decision Asset Register.
You now move on to looking at externals. You ask the team to identify assumptions in your externals, and to think of any assets that might support those assumptions. A data scientist recommends a publicly available macroeconomic model from a nearby university (row 4 of the Decision Asset Register); someone from marketing explains that their department includes a competitive research group that knows immediately whenever a competitor launches a similar product (row 5 of the Decision Asset Register). This is an observation you can use to track competitor behavior.
You add the assets to the CDD as shown in Figure 4-13 and congratulate the team on their work, but you note that they did not find every possible decision asset. You’ve just done the initial pass, which only looks for the easy-to-find assets: the “low-hanging fruit.” You’ll make another pass later to look for any additional decision assets that you need to build a decision simulation or make the decision; you might also send the CDD out to others in the company for their expertise. You might even assign an intern to research potential assets to support the CDD.
Conclusion
In this chapter about Process B2, Decision Asset Investigation, you’ve learned how to start collecting a list of assets that will help you to build a computer model of how actions lead to outcomes and ultimately work side by side with a computer to determine the best actions to choose. You’ve captured those assets by annotating the CDD from Chapter 3 and by listing them in an asset register. In Chapter 5, you’ll use the register and the annotated CDD to help you to simulate and track decisions.
1 This is a really, really big number: 1,000,000,000,000,000,000,000 (1021) bytes.
Get The Decision Intelligence Handbook now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

