Chapter 4. Materialized Views
In the previous chapters, we only talked briefly about materialized views. Materialized views will be the most important concept to understand before you can begin to appreciate streaming databases. Materialized views in databases were first introduced in the early 1990s. They were initially developed as a feature in some OLTP databases to improve query performance by precomputing and storing the results of complex queries. Materialized views provide a way to store the results of a query as a physical table, which can be refreshed periodically or on demand to keep the data up-to-date. This approach helps to reduce the overhead of executing expensive queries repeatedly by allowing users to retrieve data from the materialized view instead.
In stream processing, materialized views are not only updated periodically or on demand. They’re always refreshed asynchronously in the background. As new data comes in, the materialized view gets updated immediately and the results are stored. We’ve highlighted this pattern in previous chapters. The asynchronous refresh closely corresponds to streaming, and synchronous refresh to batch.
Martin Kleppmann’s video titled “Turning the Database Inside-Out” describes materialized views as not only being preprocessed data but also directly built from writes to the transaction log. Materialized views have had a significant impact on stream processing by introducing the concept of precomputed and continuously, incrementally updated query results. Materialized views address some of the challenges in stream processing and provide benefits such as improved query performance, reduced data duplication, and simplified analytics.
Views, Materialized Views, and Incremental Updates
With materialized views, the processing logic for generating certain query results is separated from the mainstream processing pipeline. This separation can lead to more modular and manageable code, making it easier to maintain and extend the stream processing system.
To understand materialized views, we first need to understand traditional views. Both traditional views and materialized views live in a database. Traditional views (or just “views”) are defined by a SQL statement that gets executed when the client selects from the view. The results of a view don’t get stored. This increases the latency for queries that select from the view because the results are not preprocessed. To better understand this, let’s again use an analogy: you have a smart chipmunk named Simon (see Figure 4-1).
![][alt](/api/v2/epubs/9781098154820/files/assets/stdb_0401.png)
Figure 4-1. Chipmunk counting nuts, illustrating a traditional view
You ask Simon, “How many nuts are currently in my yard?” Simon runs out into your yard and counts the nuts, then comes back and tells you the number. When you ask Simon again what the count of the nuts in your yard is, he again runs out a second time to count all of the nuts and gives you a number. Both times, you had to wait for Simon to count the nuts before you received the number even if it did not change. This is akin to a traditional view and is represented mathematically in Figure 4-2.
![][alt](/api/v2/epubs/9781098154820/files/assets/stdb_0402.png)
Figure 4-2. The smart chipmunk can be represented as a function that aggregates the nuts in the yard and returns the count
You decide this isn’t efficient. Instead, you instruct Simon to write the total number of nuts on paper and store it in a box. You then ask Simon how many nuts there are, but he can’t answer because he’s too busy looking for changes in the number of nuts in the yard. So you employ another chipmunk that isn’t as smart as Simon to just tell you the number in the box. Let’s name him Alvin. This analogy is akin to a materialized view.
In this analogy, the chipmunks are SQL statements. The box in the second scenario is the storage that materializes views to save the results that have been precounted. In this same scenario, Simon (precounting the nuts) is smarter than Alvin presenting the value in the box (see Figure 4-3). Alvin presenting the value does so with low latency and can serve it to many clients concurrently without great effort.
![][alt](/api/v2/epubs/9781098154820/files/assets/stdb_0403.png)
Figure 4-3. Two chipmunks are used to describe a materialized view
An important part of the materialized view analogy is that Simon isn’t counting the nuts from the first to the last nut; he’s looking for incremental changes in the number of nuts. This includes how many were removed from the yard and how many were added (or fell from the trees).
Incremental changes refer to the process of making small, targeted changes to existing data rather than recomputing the entire dataset from scratch. These updates are typically applied to keep data consistent and up-to-date over time without incurring the computational overhead of reprocessing the entire dataset.
The incremental function is represented mathematically in Figure 4-4. X represents the current state of the nuts in the yard, and ∆* represents the incremental change to the nuts in the yard. X is already stored while the smart chipmunk captures ∆X and then adds to it the current state, X, to get to the next state.
To capture incremental changes, Simon always needs to be watching for new changes asynchronously—similar to what we have in a streaming setting.
![][alt](/api/v2/epubs/9781098154820/files/assets/stdb_0404.png)
Figure 4-4. The smart chipmunk adds incremental changes to the total nuts in the yard
Recall CDC (change data capture) from Chapter 1. CDC is a prime example of incremental changes. To review, CDC is a technique used to capture and track changes made to a database or data source over time by reading the WAL in an OLTP database. Instead of processing the entire dataset from scratch, CDC identifies and captures only the incremental changes: inserts, updates, and deletes.
Change Data Capture
There is a relationship between CDC and materialized views. Materialized views do the hard work of precomputing by watching for incremental changes and storing the results. Beforehand, CDC provides the incremental changes it captures from the WAL in an OLTP database. This means we can use a materialized view to preprocess the CDC containing incremental changes.
Going back to our chipmunk analogy, we had Simon provide a count of nuts in a yard. Let’s extend this example a bit to say there are many types of nuts in the yard. Each nut has these attributes:
-
Color
-
Location (latitude, longitude)
Nuts can change color as they age and may be moved or removed by other animals. Simon keeps track of these changes by inserting, updating, or deleting each nut on the list of nuts on the paper in the box. So when a client queries the list, the client only sees the latest status of each nut in the yard.
We illustrate this scenario technically in Figure 4-5. Here are some important points in the diagram:
-
The WAL in the primary/OLTP database on the far left is replicated to create a replica of the primary database.
-
Using a CDC connector, the WAL is also written into a topic in a streaming platform. The topic publishes the WAL of the primary database for other systems to subscribe to.
-
Sink connectors can consume from the topic and build replicas in other database systems.
-
Stream processors can build the same database replica in their cache.
![][alt](/api/v2/epubs/9781098154820/files/assets/stdb_0405.png)
Figure 4-5. Replication using incremental changes
With this technique, you can build a replica of the original OLTP database from a user-facing application in any downstream data store or stream processing engine. We will focus on the stream processing engine primarily because it satisfies the real-time use case and doesn’t force batch semantics.
In Chapter 3, we introduced push and pull queries. If we apply the chipmunk analogy, Simon is the push query and Alvin is the pull query.
Push Versus Pull Queries
Let’s expand on the chipmunk analogy. By leveraging the push query (aka Simon), we can query the result from Alvin without having to incur the latency we get when we compute the result synchronously.
We return to the original use case, where Simon is counting the number of nuts in the yard. To review, Simon works asynchronously, watching for changes in the nut count and storing any updates in the box. In a sense, Simon pushes the result into the box. Alvin serves the contents of the box to the client synchronously. Similarly, at query time, Alvin pulls the result from the box and serves it to the client. To summarize:
-
Simon is a push query that runs asynchronously.
-
Alvin is a pull query that runs synchronously.
Simon does most of the work calculating the result so that Alvin can focus on serving results with low latency as soon as he is queried. This works very nicely, but there’s one drawback: the client invoking the pull query doesn’t have much flexibility in asking more compelling questions. It only has the count of nuts to work with for building real-time insights. What if the client wants an average count, the maximum count, or to join multiple tables? In this case, the push query negates the ability of the client to ask deeper questions.
In Figure 4-6, to increase query flexibility, you’ll need to trade off latency because you’re forcing the serving engine to do more work. If a user-facing application invokes the query, you want it to execute with the lowest latency because the assumption is that many more end users will be using the application. Conversely, if you want the highest flexibility so that you can slice and dice the data to gain insights, then you should expect only a few expert end users to execute these queries.
![][alt](/api/v2/epubs/9781098154820/files/assets/stdb_0406.png)
Figure 4-6. A diagram showing pull queries trade-off when adding flexibility and the corresponding use cases
If you think about it, applications that require the lowest latencies would benefit the most from using push queries instead of pull queries. Figure 4-7 shows how you can balance between push and pull queries.
The box in the middle represents the materialized view. It balances the heavy lifting of push queries with the flexibility of the pull query. How you balance push and pull queries is up to your use case. If the box moves down along the line, the materialized view provides less flexible queries but is more performant. Conversely, as the box moves up, the more flexible the pull queries become, but the queries execute at higher latencies. Together, push and pull queries work to find the right balance between latency and flexibility (see Figure 4-8).
![][alt](/api/v2/epubs/9781098154820/files/assets/stdb_0407.png)
Figure 4-7. As query latency nears zero, push queries are preferred
![][alt](/api/v2/epubs/9781098154820/files/assets/stdb_0408.png)
Figure 4-8. Pull and push queries working together to balance latency and flexibility
But is there a way for us to have both high flexibility and low latency and without needing two SQL queries? We can do this by using materialized views that emit changes to a WAL. This would be the client experience:
-
The client submits a push query. This query creates a materialized view.
-
The client then subscribes to the changes in the materialized view just like subscribing to a WAL.
With this approach, the client is submitting a push query instead of a pull query. By allowing the client to also make changes to the push query, you get the flexibility needed for ad hoc queries. Also, by subscribing to the materialized view’s changes, query latency is no longer an issue because the incremental changes are being pushed to the client as they arrive. This means that the client no longer needs to invoke a pull query and wait for its result, bringing down latency. Only one SQL query is needed for the client to start receiving real-time analytical data.
This pattern is difficult today because push and pull queries are typically executed in separate systems. The push query is usually executed in the stream processor, while the pull query is executed in the OLAP system that serves to end users. Moreover, push and pull queries are typically authored by different teams of engineers. Streaming data engineers would write the push query, while analysts or the developers of user-facing applications invoke pull queries.
To get out of this dilemma, you’ll need a system that has:
-
Stream processing capabilities like building materialized views
-
The ability to expose the materialized views to topics in a streaming platform, akin to a WAL
-
The ability to store data in an optimal way to serve data
-
The ability to provide synchronous and asynchronous serving methods
These features are only available in streaming databases. They have the ability to marry stream processing platforms and databases together, using the same SQL engine for both data in motion and data at rest. We’ll talk about this in greater detail in Chapter 5.
The most common solution for real-time analytics is running a stream processing platform like Apache Flink and a RTOLAP data store like Apache Pinot (see Figure 4-9).
![][alt](/api/v2/epubs/9781098154820/files/assets/stdb_0409.png)
Figure 4-9. Common solution for real-time analytics
Figure 4-9 shows the path by which data in an OLTP database travels to an RTOLAP system for serving to a client. Let’s look closer at this architecture:
-
The entities are represented as tables in the OLTP database following domain-driven design.
-
The application inserts, updates, or deletes records in the table. These changes are recorded in the database WAL.
-
A CDC connector reads the WAL and writes the changes to a topic in a streaming platform. The streaming platform externalizes the OLTP WAL by publishing the changes into topics/partitions that mimic the WAL construct. These can be read by consumers to build replicas of the tables from the original OLTP database.
-
The stream processor is one such system that reads the topic and builds internal replicas of tables by using materialized views. As the materialized view gets updated asynchronously, it outputs its changes into another topic.
-
The RTOLAP data store reads the topic that contains the output of the materialized view and optimizes the data for analytical queries.
In Figure 4-9, the stream processor executes the push query at step 4 and the pull query gets invoked at step 5. Again, each query gets executed in separate systems and authored by different engineers.
Figure 4-10 drills down to show more of the complexity and division between the push and pull queries. The push query performs the arduous task of complex transformations and stores the result in a materialized view. The materialized view records its changes to its local store to a topic in a streaming platform that exposes the materialized view to the serving layer that holds the RTOLAP system.
![][alt](/api/v2/epubs/9781098154820/files/assets/stdb_0410.png)
Figure 4-10. A pull query pulling the result from two persisted tables through a view
As a result, the end user that interfaces with the RTOLAP system doesn’t have the flexibility to define the preprocessing logic needed to make the pull query run at low latency (see Figure 4-11).
Figure 4-11. End user trying to get a data engineer to optimize a query
Having the end user that authors the pull query also provide optimization logic to the streaming data would help avoid these scenarios. Unfortunately, these situations occur very often because of the current state of streaming architectures.
The problem is exacerbated when we try to directly replicate CDC data into an RTOLAP system.
CDC and Upsert
The term upsert is a portmanteau of the words update and insert to describe the logic an application employs when inserting and/or updating a database table.1 Upsert describes a logic that involves an application checking to see if a record exists in a database table. If the record exists by searching for its primary key, the record then invokes an update statement. Otherwise, if the record does not exist, the application invokes an insert statement to add the record to the table.
We learned that CDC data contains incremental changes like inserts, updates, and deletes. The upsert logic handles two out of the three types of changes in a CDC stream (we’ll come back to the delete change later).2
Upsert operations can indirectly improve select query performance and accuracy in certain scenarios. While upserts themselves are primarily focused on data modification, they can have positive impacts on select query performance and accuracy by maintaining data integrity and optimizing data storage. Here’s how upserts can contribute to these improvements:
- Data integrity and accuracy
-
Upserts help maintain data integrity by preventing duplicate records and ensuring the data is accurate and consistent. When select queries retrieve data from a database with proper upsert operations, they are more likely to return accurate and reliable information.
- Simplified pull queries
-
Selecting from a table with proper upsert operations simplifies the queries upon lookup. Having to perform deduplication or filtering for the latest records complicates the SQL and adds latency to its execution.
Upsert operations behave like a push query to help optimize and simplify the pull query. It is one of the factors to control the balance between push and pull queries. Let’s walk through a CDC scenario to help better understand this in Figure 4-12.
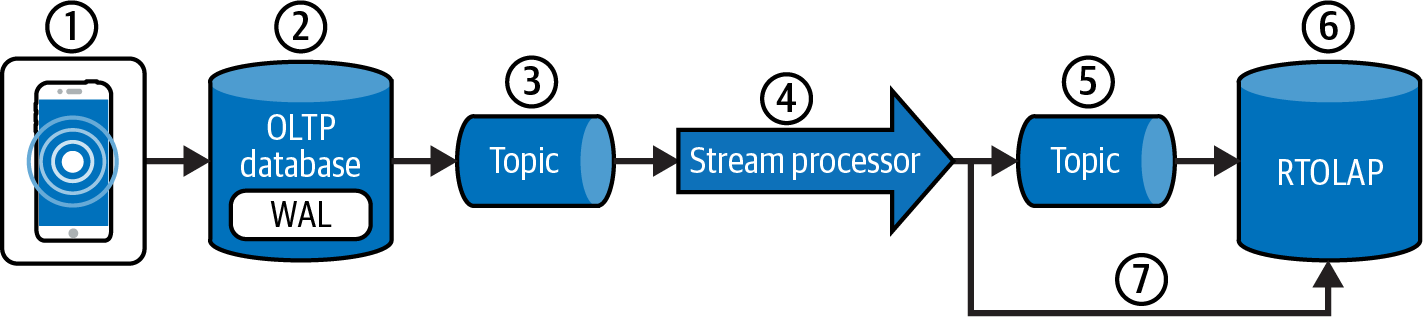
Figure 4-12. Steps outlining the replication to an RTOLAP data store
-
A transaction is sent from an application to either insert, update, or delete a record in a table in an OLTP database. Let’s assume the use case is updating the inventory of green T-shirts, so the table in question is the Products table.
-
The update is written into the WAL of the OLTP database.
-
Let’s assume that the connector reading the WAL was just started. This would require the connector to take a current snapshot of the Products table to get the current status.
-
If the connector doesn’t have this snapshot, the downstream systems cannot build an exact mirrored replica of the Products table.
-
By taking a snapshot of the table, the connector creates seed events that are logically equivalent to an insert for every record in the Products table.
-
Once this snapshot is available in the topic, we can build a table replica. You cannot build replicas with only incremental changes.
-
-
When the stream processor starts up, if it’s the first time consuming the topic, it reads it from the beginning. Otherwise, it starts reading from a stored offset. Reading the topic from the beginning allows the stream processor to build a replica of the Products table. Again, you cannot build a table replica with only incremental changes.
-
Complex transformations are implemented in the stream processor. They will require the stream processor to build a materialized view that represents a replica of the Products table.
-
Transformation operations are done on or between tabular constructs like materialized views. If no transformation is needed, creating a materialized view is not necessary, and the stream can pass through directly from the input topic to the output topic.
-
-
The output topic is similar to the input topic in that it holds a snapshot of the data to seed any downstream replicas. However, it has undergone transformations executed within the stream processor. For CDC data, the contents of the topics in this pipeline need to be able to seed downstream replicas.
-
If the RTOLAP data store reads from the topic directly, it will need to handle the upsert logic itself. To do so, it will also need to understand the data in the topic to identify insert, update, and delete operations so that it can subsequently apply them to the existing internal table.
-
This step is an alternative to step 6. In this case, the stream processor sends the data directly to the RTOLAP data store. For RTOLAPs that do not support upsert, the stream processor will have to execute the upsert logic instead of the RTOLAP system.
Since upsert operations, by definition, only support inserts and updates, deletes tend to be omitted. Some systems will implement upsert to also include delete logic. Others, like Apache Pinot, will only flag a deleted record so that its previous versions can be recovered. In these cases, it’s important to use the RTOLAP implementation of upsert, which requires the RTOLAP to read directly from the output topic. Some RTOLAPs may not expose the delete feature, and the work would have to be done in the stream processor.
Warning
Step 3 talks about holding the snapshot of the Product table in the topic. In Chapter 1, we talked about topics having a retention period after which older records are truncated. A different type of topic is necessary for CDC data called a compacted topic, where the truncation process preserves the latest record of each primary key. This allows older data to be preserved, enabling materialization of downstream table replicas, including the historical records.
In summary, there are two locations where the upsert logic can be implemented—in the RTOLAP system or the stream processor. The simpler and preferred approach is to have the RTOLAP read from the output topic and apply the upsert logic itself. The output topic also provides a buffer in cases where the stream processor produces data faster than the RTOLAP can consume.
Upsert highlights the pain of having two real-time systems grapple over or dodge ownership of such complex logic. These pains will create further contention between data engineers and analytical end users.
CDC can be hard to conceptualize in streaming because it takes part in so many constructs and complex logic. For example, it’s related to WALs in an OLTP database, it requires compacted topics in streaming platforms to keep history, it needs upsert to simplify and speed up pull queries, and it needs to be materialized in views. The difficulties go on when multiple systems are involved between the original OLTP source and the RTOLAP data store just to build a replica of the Products table. As we noted, there can be ways to consolidate these systems and help reduce redundancy and complexity. Streaming databases are one way to achieve this consolidation.
Transformations that include enrichment will require joining multiple streams in the stream processor. Recall the two types of streams: change streams and append-only streams. Change streams contain change data for entities in the business domain, like products and customers. Append-only streams contain events like the clickstream data from the application. Let’s walk through the streaming data pipeline again to see how to implement this.
Joining Streams
As previously stated, transformation operations are done on or between tabular constructs that hold change streams (materialized views) and append-only streams. Append-only streams are like change streams where the only changes allowed are inserts. In fact, you could consider all tabular constructs in databases to be sequences of changes going into and out of the tabular structure.
One of the main reasons you would not represent an append-only stream in a materialized view is that materialized views have to store results. Since append-only streams are inserts only and ever-growing, you would run out of storage space at some point, just like you would not write click events into a database because it too would run out of storage.
Since both change streams and append-only streams are represented as tabular constructs, many different streaming systems name these constructs differently. In this book, we will use the following terms with regard to tables in a stream processor:
- Append tables
-
A tabular construct that holds append-only streams. These constructs are not backed by a state store. These constructs represent data that passes through the stream processor.
- Change tables
-
A tabular construct that represents a materialized view. Change tables are backed by a state store.
We also need to differentiate topics in a streaming platform in the same way. Knowing the type of streaming data in the topics will indicate how they can be processed or represented in a tabular construct. We use these terms to identify topics in a streaming platform:
- Append topics
- Change topics
-
Topics containing change events or CDC events. Some Kafka engineers would also call these “table topics.”
With these terms, we can better describe how streams are joined together, as the logic can get confusing. It’s important to use SQL as the language to define joins and transformations because SQL is the universal language for manipulating data, and the SQL engine needs to combine streams and databases. Sharing a SQL engine to manipulate both data in motion and data at rest leads up to having a streaming database.
Apache Calcite
Let’s start with joining the append table and the change table we described in Chapter 2. The SQL in Example 4-1 is based on Apache Calcite, a data management framework used to build databases using relational algebra. Relational algebra is a formal and mathematical way of describing operations that can be performed on relational databases. It’s a set of rules and symbols that help us manipulate and query data stored in tables, also known as relations.
Apache Calcite contains many of the pieces that make up mathematical operations but omits some key functions: storage of data, algorithms for processing data, and a repository for storing metadata. If you want to build a database from scratch, Apache Calcite is one building block to do that. In fact, many of the existing real-time systems use Calcite: Apache Flink, Apache Pinot, Apache Kylin, Apache Druid, Apache Beam, and Apache Hive, to name a few.
Calcite intentionally stays out of the business of storing and processing data. ...[T]his makes it an excellent choice for mediating between applications and one or more data storage locations and data processing engines. It is also a perfect foundation for building a database: just add data.
Apache Calcite documentation
This is what we’ll do here—just add data. We bring back our clickstream use case where we have three sources of data, each in its own topic in a streaming platform.
Example 4-1. Joining to table topics
CREATESINKclickstream_enrichedASSELECTE.*,C.*,P.*FROMCLICK_EVENTSEJOINCUSTOMERSCONC.ip=E.ipandJOINPRODUCTSPONP.product_id=E.product_idWITH(connector='kafka',topic='click_customer_product',properties.bootstrap.server='kafka:9092',type='upsert',primary_key='id');
CLICK_EVENTSis an append table sourced from an append topic. It contains click events from a user-facing application.
CUSTOMERSis a change table sourced from a change topic. It contains change events from an OLTP database captured using a CDC connector.
PRODUCTSis a change table sourced from a change topic. It also contains change events from an OLTP database via CDC connector. Here, we will assume the product ID value was extracted from the click URL and placed into a separate column calledproduct_id.
As long as SQL is supported, stream processing platforms can represent data in topics in tabular structures, so SQL and tools like Calcite can be used to define complex transformations. Example 4-1 is an inner-join that joins together matching records that exist in all three tables—CLICK_EVENTS, CUSTOMERS, and PRODUCTS.
The output of any streaming SQL that aggregates or joins streams is a materialized view. In this case, we are joining:
CLICK_EVENTS-
An append table containing click events
CUSTOMERS-
A change table/materialized view of all customers
PRODUCTS-
Another change table/materialized view of products
Here are the properties of different types of table joins:
- Append table to append table
-
This is always windowed, or else the state store will run out of space.
- Change table to change table
-
A window is not required because the join result could fit in the state store if it’s appropriately sized.
- Change table to append table
-
This is also windowed, or else the state store will run out of space.3
Notice that whenever an append-only stream is part of a join, a window is needed to limit the data held in the state store.
In stream processing with SQL, when you perform a left join operation between streams corresponding to an append table and a change table, the result is driven by the append table.
In SQL, such a join looks as follows:
SELECT ... FROM append_table_stream LEFT JOIN change_table_stream ON join_condition;
Here, append_table_stream and change_table_stream represent the two input streams you want to join, and join_condition specifies the condition that determines how the two streams are matched.
The left stream (append_table_stream), which is specified first in the FROM clause, drives the result of the join. The result will contain all the events from the left stream, and for each event in the left stream, it will include the matching events from the right stream (change_table_stream) based on the join_condition.
Let’s illustrate this with two streams from our clickstream example: clicks and customers. Each event in the click stream represents a click with a customer ID and each event in the customers stream represents a customer with a customer ID. To join the two streams on the customer ID, you would write the SQL query as follows:
SELECTk.product_id,c.customer_nameFROMclickkLEFTJOINcustomerscONk.customer_id=c.customer_id;
In this example, the click stream is the left stream, and it drives the result of the join. For each customer event in the click stream, the query retrieves the corresponding customer name from the customers stream based on the matching customer ID.
It’s important to note that in stream processing, the join is continuous and dynamic. As new events arrive in the input streams, the join result is continuously updated and emitted as the result stream. This allows you to perform real-time processing and analysis on streaming data with SQL.
Clickstream Use Case
Let’s step back to be able to clearly understand the full diagram in Figure 4-13 step by step.
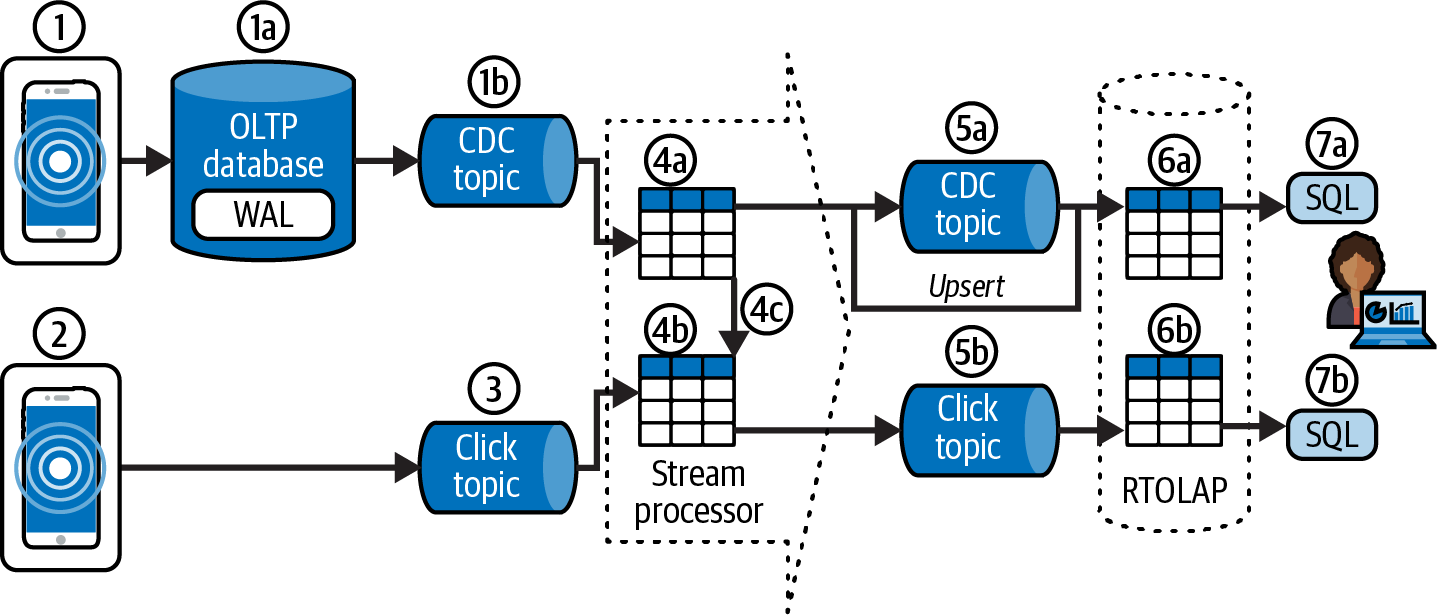
Figure 4-13. Path of CDC and append-only events from the application to the RTOLAP
-
A customer updates their information.
-
The information is saved in an OLTP database.
-
A CDC process runs on the OLTP database, capturing changes to the
CUSTOMERStable and writing them into a CDC topic. This topic is a compacted topic that can be considered a replica of theCUSTOMERStable. This will allow for other systems to build their replicas of theCUSTOMERStable.
-
-
The same customer clicks on a product on an e-commerce application.
-
The click event is written into a topic. We don’t write click events into an OLTP database because click events are only inserts. Capturing them in an OLTP database might eventually cause the database to run out of storage.
-
The stream processor reads from the CDC and click topics.
-
These are the messages from the
CUSTOMERSchange table topic in the stream processor. They are stored in a state store whose size depends on the window size (or, in the case of, for example, Kafka Streams or ksqlDB, fully stored in a KTable). -
These are the messages from the
CLICK_EVENTSappend table topic in the stream processor. -
A left-join is executed between the
CLICK_EVENTSappend table messages and theCUSTOMERSchange table messages. The result of the join isCLICK_EVENTSenriched with their correspondingCUSTOMERinformation (if it exists).
-
-
The stream processor writes its output to the topics below.
-
This is a change topic and contains the CDC
CUSTOMERchanges. This would be a redundant topic since the topic in 1b contains the same data. We keep it here to keep the diagram balanced. -
This is an append topic that contains the original
CLICK_EVENTdata enriched with theCUSTOMERdata.
-
-
Topics are pulled into the RTOLAP data store for real-time serving.
-
This is a replica of the original
CUSTOMERStable in the OLTP database and built from the change topic. -
This contains the enriched
CLICK_EVENTSdata.
-
-
The user invokes queries against the RTOLAP data store.
-
The user can query the
CUSTOMERStable directly. -
The user can query the enriched
CLICK_EVENTSdata without having to join the data themselves, as the join has already been done in the stream processor.
-
As we indicated earlier, you can either implement the join in the stream processor or by the user. In this case, we decided to prejoin the CLICK_EVENTS and CUSTOMER data to improve query performance from the user’s perspective. The hard work of joining is done by the stream processor so that the RTOLAP can focus on fast, low-latency queries. In this scenario, the stream processor is creating a materialized view that gets written to the topic in 5b. The RTOLAP builds a replica of the materialized view in itself from the topic in 5b. Within the RTOLAP database, we might have to implement a retention scheme that deletes older enriched CLICK_EVENTS to avoid running out of storage.
Alternatively, we could have just bypassed the stream processor and let the RTOLAP perform the joining when the user invokes the query. This would not require building a materialized view, and it would negate the need to manage another complex streaming system. But this query would be slow and put a lot of stress on the RTOLAP system.
So how can we reduce architectural complexity but still get the performance of materialized views? This is where we can converge stream processing with real-time databases—by using streaming databases.
Summary
I’m gonna make a very bold claim [that] all the databases you’ve seen so far are streaming databases.
Mihai Budiu, “Building a Streaming Incremental View Maintenance Engine with Calcite,” March 2023
Traditionally, stream processing and databases have been seen as distinct entities, with stream processing systems handling real-time, continuously flowing data, and databases managing persistent, queryable data. However, materialized views challenge this separation by bridging the gap between the two systems.
Materialized views enable the creation of precomputed, persistent summaries of data derived from streaming sources. These views serve as caches that store computed results or aggregations in a way that is easily queryable. This means that instead of solely relying on stream processing systems for real-time analysis, we can leverage materialized views to store and query summarized data without the need for continuous reprocessing.
By combining the benefits of stream processing and databases, materialized views offer several advantages. First, they provide the ability to perform complex analytics on streaming data in a more efficient and scalable manner. Rather than reprocessing the entire dataset for each query, materialized views store the precomputed results, allowing for faster and more responsive querying.
Moreover, materialized views facilitate the seamless integration of streaming and batch processing paradigms. They can be used to store intermediate results of stream processing pipelines, providing a bridge between the continuous flow of streaming data and the batch-oriented analytics typically performed on databases. This integration helps unify the processing models and simplifies the overall architecture of data-intensive systems.
Overall, materialized views blur the boundaries between stream processing and databases by allowing us to leverage persistent, queryable summaries of streaming data. By combining the benefits of both systems, they enable efficient and scalable real-time analytics, seamless integration of historical and real-time data, and the convergence of streaming and batch processing paradigms. The use of materialized views opens up exciting possibilities for building intelligent and responsive data systems that can handle the dynamic nature of streaming data while providing fast and flexible query capabilities.
We’ve now introduced two constructs in OLTP databases that bring them close to streaming technologies:
- The WAL
-
A construct that captures changes to database tables.
- The materialized view
-
An asynchronous query that preprocesses and stores data to enable low-latency queries.
In Chapter 1, we introduced Martin Kleppmann’s quote: “turning the database inside out.” We did, in fact, turn the database inside out by:
-
Taking the WAL construct in the OLTP and publishing it to the streaming platform, like Kafka.
-
Taking the materialized view feature and mimicking it in a stateful stream processing platform. This relinquished the need for complex transformations from the OLTP databases that needed to focus on capturing transactions and serving data by externalizing them to the streaming layer.
We now have the foundation to talk about streaming databases in the next chapter. This is where we will again turn the tables on the streaming paradigm by bringing WALs and materialized views back into the database. In other words, we’ll “turn streaming architectures outside in.”
1 A portmanteau is a word that results from blending two or more words, or parts of words, such that the portmanteau word expresses some combination of the meaning of its parts.
2 In many database systems the UPDATE operation consists of a DELETE and INSERT step; hence in these systems, UPSERT also involves a DELETE operation.
3 In Kafka Streams and ksqlDB, you can use materialized views (KTable or GlobalKTable) for the append table. In this case, a window is not required because the output is again a stream.
Get Streaming Databases now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

