Kapitel 1. Data Mesh Einführung
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Die Jüngeren denken, dass Datenarchitekturen irgendwann einmal einfach waren, und dann wuchsen Datenvolumen, Geschwindigkeit und Vielfalt und wir brauchten neue Architekturen, die schwierig sind. In Wirklichkeit waren Datenprobleme immer auch Organisationsprobleme und wurden daher nie gelöst.
Gwen (Chen) Shapira, Kafka: The Definitive Guide (O'Reilly)
Wenn du in einem wachsenden Unternehmen arbeitest, wirst du feststellen, dass eine positive Korrelation zwischen dem Unternehmenswachstum und dem Umfang der Ingress-Daten besteht. Das kann an der zunehmenden Nutzung bestehender Anwendungen oder an neu hinzukommenden Anwendungen und Funktionen liegen. Es ist die Aufgabe des Dateningenieurs, diese wachsenden Daten zu organisieren, zu optimieren, zu verarbeiten, zu verwalten und den Verbrauchern zur Verfügung zu stellen und dabei die Service Level Agreements (SLAs) einzuhalten. Höchstwahrscheinlich wurden diese SLAs den Verbrauchern auch ohne das Zutun des Dateningenieurs garantiert. Das erste, was du lernst, wenn du mit einer so großen Datenmenge arbeitest, ist, dass, wenn die Datenverarbeitung anfängt, die Garantien dieser SLAs zu überschreiten, du dich mehr darauf konzentrierst, die SLAs einzuhalten, und Dinge wie Data Governance an den Rand drängst. Das wiederum führt zu großem Misstrauen gegenüber den Daten, die verarbeitet werden, und letztlich auch gegenüber den Analysen - dieselben Analysen, die zur Verbesserung der betrieblichen Anwendungen genutzt werden können, um mehr Umsatz zu erzielen oder Umsatzverluste zu verhindern.
Wenn du dieses Problem auf alle Geschäftsbereiche des Unternehmens überträgst, wirst du sehr unzufriedene Dateningenieure bekommen, die versuchen, Datenpipelines innerhalb der Kapazität des Data Lake und der Datenverarbeitungscluster zu beschleunigen. Das ist die Position, in der ich mich am häufigsten wiederfand.
Was ist also ein Datengitter? Der Begriff "Mesh" in "Data Mesh" wurde von dem Begriff "Service Mesh" übernommen, der ein Mittel ist, um Beobachtbarkeit, Sicherheit, Erkennung und Zuverlässigkeit auf der Plattformebene und nicht auf der Anwendungsebene hinzuzufügen. Ein Service Mesh wird in der Regel als skalierbarer Satz von Netzwerk-Proxys implementiert, die neben dem Anwendungscode eingesetzt werden (ein Muster, das manchmal als Sidecar bezeichnet wird). Diese Proxies wickeln dieKommunikation zwischen Microservices ab und fungieren auch als Ausgangspunkt für dieEinführung von Service-Mesh-Funktionen.
Die Microservice-Architektur ist das Herzstück einer Streaming-Data-Mesh-Architektur und führt eine grundlegende Veränderung ein, die monolithische Anwendungen zerlegt, indem sie lose gekoppelte, kleinere, hochgradig wartbare, agile und unabhängig skalierbare Dienste schafft, die die Kapazität jeder monolithischen Architektur übersteigen. In Abbildung 1-1 siehst du diese Zerlegung der monolithischen Anwendung, um eine skalierbarere Microservice-Architektur zu schaffen, ohne den Geschäftszweck der Anwendung zu verlieren.
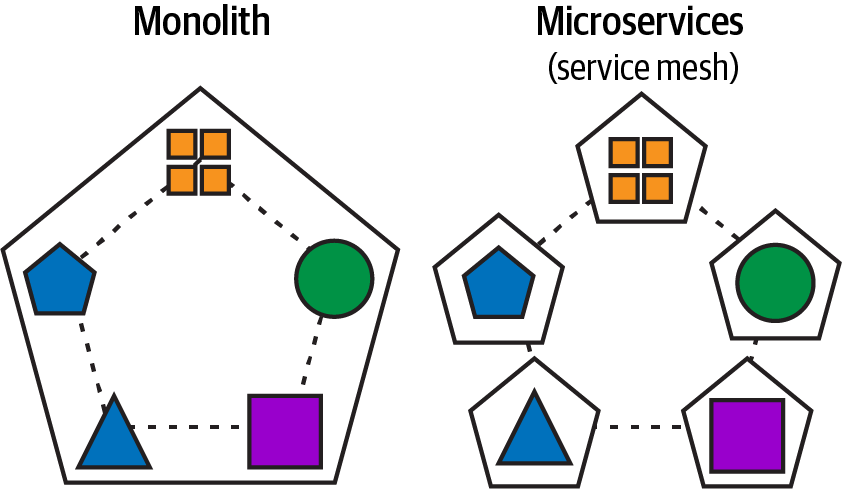
Abbildung 1-1. Zerlegung einer monolithischen Anwendung in Microservices, die über ein Servicenetz miteinander kommunizieren
Ein Datengeflecht versucht, die gleichen Ziele zu erreichen, die Microservices für monolithische Anwendungen erreicht haben. In Abbildung 1-2 versucht ein Data Mesh, die gleichen lose gekoppelten, kleineren, hochgradig wartbaren, agilen und unabhängig skalierbaren Datenprodukte zu schaffen, die über die Kapazität von jeder monolithischen Data Lake-Architektur hinausgehen.
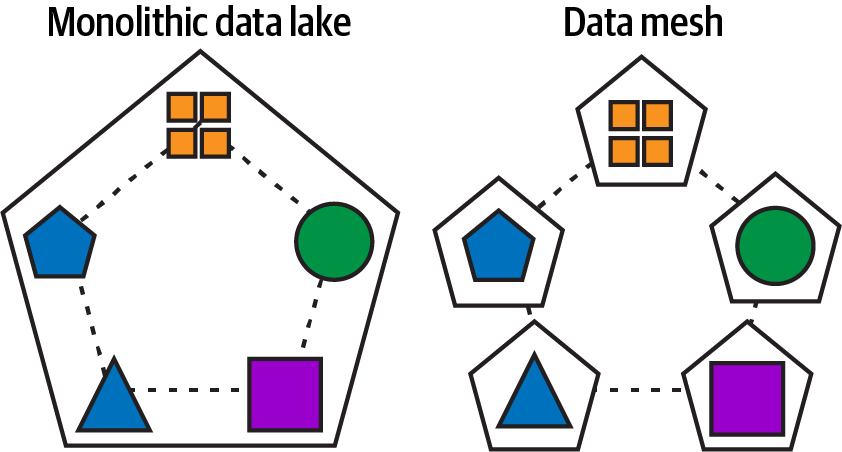
Abbildung 1-2. Monolithischer Data Lake/Lagerhaus, aufgeteilt in Datenprodukte und Domänen, die über ein Datennetz kommunizieren
Zhamak Dehghani (die ich in diesem Buch ZD nenne) ist die Pionierin des Data Mesh Pattern. Wenn du ZD und ihren Data-Mesh-Blog noch nicht kennst, empfehle ich dir dringend, ihn sowie ihr sehr beliebtes Buch Data Mesh (O'Reilly) zu lesen. Ich werde einen einfachen Überblick geben, damit du ein grundlegendes Verständnis für die Säulen des Data Mesh-Architekturmusters bekommst, damit ich im Laufe des Buches darauf verweisen kann.
In diesem Kapitel werden wir die Grundlagen eines Datennetzes erläutern, bevor wir in Kapitel 2 ein Streaming-Datennetz vorstellen. So schaffen wir eine Grundlage für ein besseres Verständnis, wenn wir die Ideen des Streaming überlagern. Anschließend werden wir über andere Architekturen sprechen, die Ähnlichkeiten mit Datenmaschen aufweisen, um sie voneinander abzugrenzen. Diese anderen Architekturen verwirren Datenarchitekten oft, wenn sie ein Datengeflecht entwerfen, und es ist das Beste, sich Klarheit zu verschaffen, bevor wir das Datengeflecht mit dem Streaming verbinden.
Datenteilung
Der Blog von ZD spricht von einer Datenkluft, die in Abbildung 1-3 dargestellt ist, um die Bewegung von Daten innerhalb eines Unternehmens zu beschreiben. Dieses grundlegende Konzept hilft zu verstehen, wie Daten Geschäftsentscheidungen beeinflussen und welche monolithischen Probleme damit verbunden sind.
Unter findest du eine Zusammenfassung: Die operative Datenebene enthält die Datenspeicher, die die Anwendungen unterstützen, die ein Unternehmen betreiben.
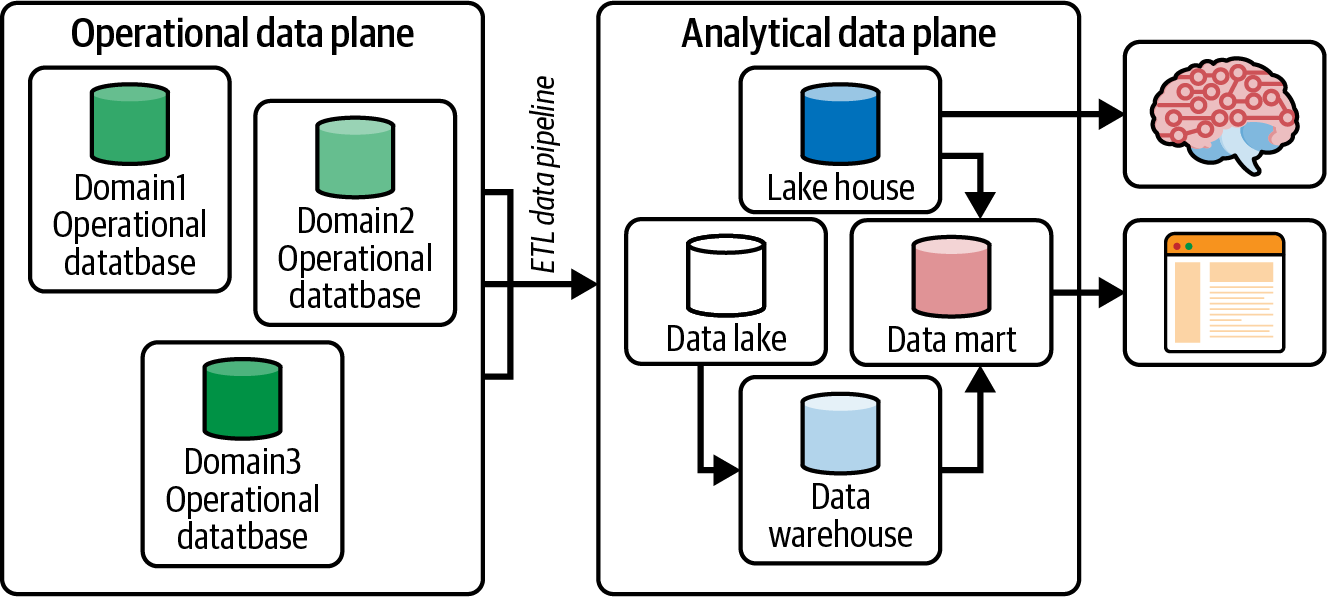
Abbildung 1-3. Die Datentrennung, die die operative Datenebene von der analytischen Datenebene trennt
Ein Extraktions-, Transformations- und Ladeprozess (ETL) repliziert die operativen Daten auf die analytische Datenebene, da du keine analytischen Abfragen auf operativen Datenspeichern ausführen möchtest, die Rechen- und Speicherressourcen beanspruchen, die du für die Umsatzgenerierung deines Unternehmens benötigst. Die analytische Ebene enthält Data Lakes/Warehouses/Seehäuser, um Erkenntnisse abzuleiten. Diese Erkenntnisse werden an die operative Datenebene zurückgegeben, um Verbesserungen vorzunehmen und das Unternehmen zu vergrößern.
Mithilfe von Kubernetes auf der operativen Ebene haben sich die Anwendungen von trägen und monolithischen Anwendungen zu agilen und skalierbaren Microservices entwickelt, die miteinander kommunizieren und ein Dienstnetz bilden. Das Gleiche gilt für die analytische Ebene. Das Ziel des Data Mesh ( ) ist es, genau das zu tun: die monolithische analytische Ebene zu einer dezentralen Lösung aufzubrechen, um agile, skalierbare und einfach zu verwaltende Daten zu ermöglichen. Wir werden im Laufe des Buches immer wieder auf die operative Ebene und die analytische Ebene Bezug nehmen, daher ist es wichtig, dieses Verständnis frühzeitig zu entwickeln, wenn wir mit dem Aufbau eines Streaming Data Mesh-Beispiels beginnen.
Säulen des Datennetzes
Die Grundlage der Datenmaschenarchitektur wird durch die in Tabelle 1-1 definierten Säulen gestützt. In den folgenden Abschnitten fassen wir sie kurz zusammen und erläutern die wichtigsten Konzepte, damit wir uns in späteren Kapiteln auf die Implementierung eines Streaming Data Mesh konzentrieren können.
| Dateneigentum | Daten als Produkt | Selbstbedienungs-Datenplattform | ComputergestützteDatenverwaltung im Verbund |
|---|---|---|---|
Dezentralisierung und Verteilung der Verantwortung an Personen, die den Daten am nächsten sind, um kontinuierliche Veränderungenund Skalierbarkeit zu unterstützen. |
Qualitätsdaten entdecken, verstehen, ihnen vertrauen und sieschließlich nutzen. |
Self-Service-Dateninfrastruktur als Plattform für die Autonomie der Domäne. |
Ein Governance-Modell, das Dezentralisierung, Eigenständigkeit der Domäne und Interoperabilität durch globale Standardisierung umfasst. Eine dynamische Topologie und vor allem die automatische Ausführungvon Entscheidungen durch die Plattform. |
Dateneigentum und Daten als Produkt bilden den Kern der Säulen des Datengeflechts. Die ersten beiden Säulen werden durch die Self-Service-Datenplattform und die föderale Datenverwaltung unterstützt. Wir werden jetzt kurz auf diese vier Säulen eingehen und ab Kapitel 3 jeder Säule ein ganzes Kapitel widmen.
Dateneigentum
Wie bereits erwähnt, besteht die wichtigste Säule eines Datennetzes darin, die Daten zu dezentralisieren, damit sie wieder in den Besitz des Teams übergehen, das sie ursprünglich erstellt hat (oder sich zumindest am besten mit ihnen auskennt und für sie interessiert). Die Dateningenieure in diesem Team werden einem Bereich zugewiesen - einem Bereich, in dem sie Experten für die Daten selbst sind. Beispiele für Bereiche sind Analyse, Inventarisierung und Anwendung(en). Sie sind die Gruppen, die wahrscheinlich vorher in den monolithischen Data Lake geschrieben und aus ihm gelesen haben.
Die Domains sind dafür verantwortlich, die Daten an ihrer eigentlichen Quelle zu erfassen. Jede Domäne wandelt die Daten um, reichert sie an und stellt sie schließlich den Verbrauchern zur Verfügung.
Es gibt drei Arten von Domains:
- Nur Produzent
-
Domains die nur Daten produzieren und nicht von anderen Domains konsumieren
- Nur für Verbraucher
- Erzeuger und Verbraucher
-
Domains, die Daten für andere Domains produzieren und von anderen Domains konsumieren.
Hinweis
Nach dem Ansatz des domain-driven design (DDD), bei dem von den Experten der Geschäftsdomäne definierte und in Software implementierte Domänenobjekte modelliert werden, kennt die Domäne die spezifischen Details ihrer Daten, z. B. das Schema und die Datentypen, die zu diesen Domänenobjekten gehören. Da die Daten auf der Domänenebene definiert werden, ist dies der beste Ort, um die Einzelheiten ihrer Definition, Umwandlung und Verwaltung festzulegen.
Daten als Produkt
Da die Daten von jetzt zu einer Domäne gehören, brauchen wir eine Möglichkeit, Daten zwischen den Domänen zu übermitteln. Da diese Daten konsumierbar und nutzbar sein müssen, müssen sie wie jedes andere Produkt behandelt werden, damit die Verbraucher ein gutes Datenerlebnis haben. Von nun an werden wir alle Daten, die anderen Domänen zur Verfügung gestellt werden, als Datenprodukte bezeichnen.
Die Definition dessen, was eine "gute Erfahrung" mit Datenprodukten ist, ist eine Aufgabe, auf die sich die Bereiche im Datennetz einigen müssen. Eine einvernehmliche Definition wird dazu beitragen, dass die Erwartungen der beteiligten Bereiche im Netz klar definiert sind. In Tabelle 1-2 sind einige Ideen aufgelistet, die dabei helfen, ein "gutes Erlebnis" für die Nutzer von Datenprodukten zu schaffen und die Entwicklung von Datenprodukten in einem Bereich zu unterstützen.
| Überlegungen | Beschreibung |
|---|---|
Datenprodukte sollten leicht konsumierbar sein. |
Einige Beispiele könnten sein:
|
Ingenieurinnen und Ingenieure sollten generalistische Fähigkeiten haben. |
Ingenieure müssen Datenprodukte erstellen können, ohne dass sie Werkzeuge benötigen, die hochspezialisierte Fähigkeiten voraussetzen. Dies ist ein mögliches Minimum an Fähigkeiten, die für die Erstellung von Datenprodukten erforderlich sind:
|
Die Datenprodukte sollten durchsuchbar sein. |
Bei der Veröffentlichung eines Datenprodukts im Datennetz wird ein Datenkatalog für die Erkennung, Metadatenansichten (Verwendung, Sicherheit, Schema und Herkunft) und Zugriffsanfragen auf das Datenprodukt durch Domänen, die es nutzen möchten, verwendet. |
Computergestützte Datenverwaltung im Verbund
Da für die Erstellung von Datenprodukten verwendet wird und die gemeinsame Nutzung von Datenprodukten über viele Bereiche hinweg letztlich ein Datengeflecht bildet, müssen wir sicherstellen, dass die Daten, die bereitgestellt werden, bestimmten Richtlinien folgen. Data Governance beinhaltet die Erstellung und Einhaltung einer Reihe von globalen Regeln, Standards und Richtlinien, die auf alle Datenprodukte und ihre Schnittstellen angewendet werden, um eine kollaborative und interoperable Data Mesh Community zu gewährleisten. Diese Richtlinien müssen zwischen den beteiligten Bereichen des Datennetzes vereinbart werden.
Hinweis
Das Datennetz ist nicht vollständig dezentralisiert. Die Daten sind in den Domänen dezentralisiert, aber der Mesh-Teil des Data Mesh ist es nicht. Data Governance ist entscheidend für den Aufbau des Netzes in einem Data Mesh. Beispiele dafür sind der Aufbau von Self-Services, die Definition von Sicherheit und die Durchsetzung von Interoperabilitätspraktiken.
Hier sind einige Dinge, die bei der Data Governance für ein Datengeflecht zu beachten sind: Autorisierung, Authentifizierung, Methoden zur Replikation von Daten und Metadaten, Schemata, Datenserialisierung und Tokenisierung/Verschlüsselung.
Self-Service-Datenplattform
Da nach diesen Säulen eine Reihe von hochspezialisierten Fähigkeiten erfordert, muss eine Reihe von Diensten geschaffen werden, um ein Datennetz und seine Datenprodukte aufzubauen. Diese Werkzeuge müssen mit Fähigkeiten kompatibel sein, die für einen eher generalistischen Ingenieur zugänglich sind. Beim Aufbau eines Datennetzes ist es notwendig, die vorhandenen Ingenieure in einem Bereich in die Lage zu versetzen, die erforderlichen Aufgaben zu erfüllen. Die Fachbereiche müssen Daten aus ihren operativen Speichern erfassen, diese Daten umwandeln (zusammenführen oder anreichern, aggregieren, abgleichen) und ihre Datenprodukte im Datennetz veröffentlichen. Self-Service-Dienste sind die "einfachen Knöpfe", die notwendig sind, um das Data Mesh einfach und benutzerfreundlich zu machen. Zusammenfassend lässt sich sagen, dass die Self-Services es den Domain Engineers ermöglichen, viele der Aufgaben zu übernehmen, für die der Data Engineer in allen Geschäftsbereichen zuständig war. Ein Data Mesh bricht nicht nur den monolithischen Data Lake auf, sondern zerlegt auch die monolithische Rolle des Data Engineers in einfache Aufgaben, die die Domain Engineers übernehmen können.
Daten-Netzdiagramm
Abbildung 1-4 zeigt, dass es drei verschiedene Bereiche gibt: Datenwissenschaft, mobile Anwendungen und Inventarisierung.
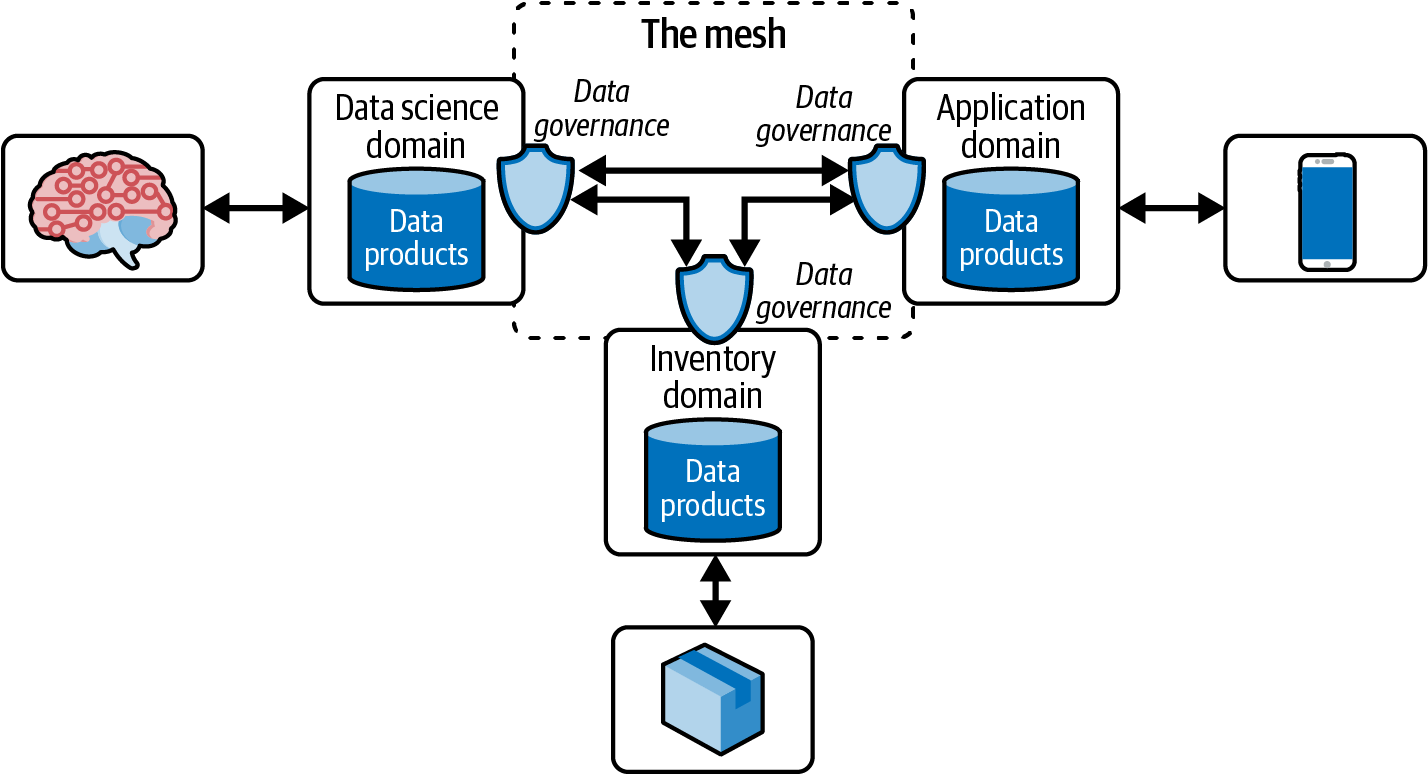
Abbildung 1-4. High-Level-Ansicht eines Datennetzes
Die Data-Science-Domäne konsumiert Daten aus der Anwendungsdomäne, die die Daten aus den mobilen Anwendungen enthält. Die Domäne inventory nutzt Daten aus der Datenwissenschaft für die Bestandslogistik, z. B. zur Verringerung von Entfernungen oder zur Verlagerung von Lieferungen an Orte mit höherer Kaufbereitschaft. Schließlich könnte die Anwendungsdomäne Verweise auf neu trainierte Modelle nutzen, um sie in ihre mobilen Anwendungen zu laden, die aktualisierte personalisierte Erfahrungen schaffen.
Data Governance schafft Zugriffskontrollen zwischen Datenproduzenten und -verbrauchern und stellt Metadaten wie Schemadefinitionen und Abstammungslinien bereit. In einigen Fällen können auch Stammdaten und Referenzdaten für die Umsetzung relevant sein. Data Governance ermöglicht es uns, auch für diese Ressourcen geeignete Zugriffskontrollen zu schaffen.
Die Kanten, die Domains verbinden, replizieren Daten zwischen ihnen. Sie stellen die Verbindungen zwischen den Domänen her und bilden das "Netz". Abbildung 1-4 ist ein übersichtliches Diagramm eines Datennetzes, auf das wir in den folgenden Kapiteln näher eingehen werden.
In späteren Kapiteln werden wir auch darüber sprechen, wie man eine Domäne identifiziert und aufbaut, indem man ein Datenteam zusammenstellt, das dem Geist von ZDs Vision einer dezentralen Datenplattform folgt. Abbildung 1-4 ist eine Übersicht über ein nicht streamingfähiges Datennetz. Eine solche Implementierung bedeutet nicht, dass Streaming die Lösung für die Veröffentlichung von Daten zum Konsum ist. Es gibt auch andere Alternativen, um Daten zwischen und innerhalb einer Domain zu bewegen. Kapitel 2 befasst sich speziell mit Streaming Data Mesh und seinen Vorteilen.
Andere ähnliche architektonische Muster
Der vorangegangene Abschnitt fasst die Datenmaschenarchitektur auf einer sehr hohen Ebene zusammen, wie sie in der Vision von ZD definiert ist. Viele Datenarchitekten verweisen gerne auf bestehende Datenarchitekturen, die ähnliche Merkmale wie ein Data Mesh aufweisen. Diese Ähnlichkeiten können für die Architekten ausreichen, um ihre bestehenden Implementierungen als konform mit den Säulen des Data Mesh zu bezeichnen. Diese Architekten können absolut richtig oder teilweise richtig liegen. Einige dieser Datenarchitekturen sind Data Fabrics, Data Gateways, Data as a Service, Data Democratization und Data Virtualization.
Data Fabric
Eine Data Fabric ist ein Muster, das einem Data Mesh sehr ähnlich ist, denn beide bieten Lösungen, die Data Governance und Self-Service umfassen: Erkennung, Zugriff, Sicherheit, Integration, Transformation und Abstammung(Abbildung 1-5).
Zum Zeitpunkt der Erstellung dieses Artikels ist der Konsens über die Unterschiede zwischen Data Mesh und Data Fabric noch unklar. Vereinfacht ausgedrückt ist eine Data Fabric ein metagestütztes Mittel zur Verbindung unterschiedlicher Datensätze und zugehöriger Tools, um ein kohärentes Datenerlebnis zu bieten und Daten in einer Selbstbedienungsweise bereitzustellen.
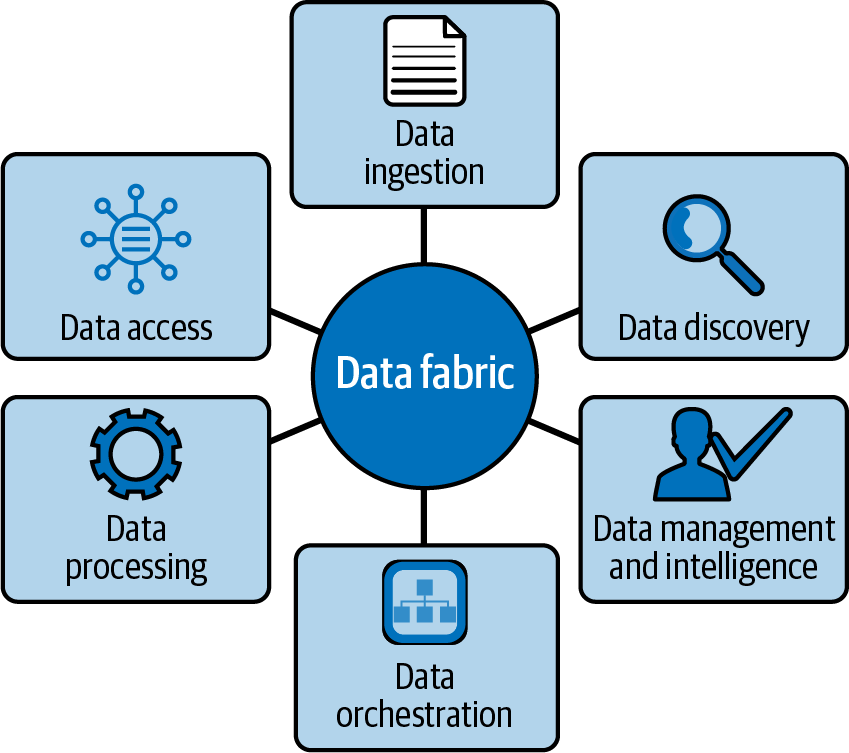
Abbildung 1-5. Säulen der Datenstruktur
Während ein Data Mesh viele der gleichen Probleme lösen soll wie eine Data Fabric - nämlich die Möglichkeit, Daten in einer einzigen, zusammengesetzten Datenumgebung zu verwalten - ist der Ansatz ein anderer. Während eine Data Fabric es den Nutzern ermöglicht, eine einzige virtuelle Schicht über verteilten Daten zu erstellen, gibt ein Data Mesh verteilten Gruppen von Datenproduzenten die Möglichkeit, Daten nach eigenem Ermessen zu verwalten und zu veröffentlichen. Data Fabrics ermöglichen eine Datenvirtualisierung mit wenig bis gar keinem Code, da die Datenintegration über APIs erfolgt, die sich innerhalb der Data Fabric befinden. Das Datengeflecht ermöglicht es Dateningenieuren jedoch, Code für APIs zu schreiben, mit denen sie weitere Schnittstellen bilden können.
Ein Datengeflecht ist ein architektonischer Ansatz, um den Datenzugriff über mehrere Technologien und Plattformen hinweg zu ermöglichen, und basiert auf einer technischen Lösung. Ein wesentlicher Unterschied ist, dass ein Data Mesh viel mehr ist als nur Technologie: Es ist ein Muster, das Menschen und Prozesse einbezieht. Anstatt wie bei einer Data Fabric die gesamte Datenplattform zu übernehmen, können sich die Datenproduzenten auf die Datenproduktion und die Datenkonsumenten auf den Datenkonsum konzentrieren und hybride Teams können andere Datenprodukte konsumieren, andere Daten mischen, um noch interessantere Datenprodukte zu erstellen, und diese Datenprodukte veröffentlichen - mit einigen Überlegungen zur Data Governance.
In einem Data Mesh sind die Daten dezentralisiert, während in einer Data Fabric eine Zentralisierung der Daten möglich ist. Und bei einer Zentralisierung von Daten wie bei Data Lakes treten die damit verbundenen monolithischen Probleme auf. Data Mesh versucht, einen Microservices-Ansatz auf Daten anzuwenden, indem es die Datenbereiche in kleinere und flexiblere Gruppen aufteilt.
Glücklicherweise können die Tools, die eine Data Fabric unterstützen, auch ein Data Mesh unterstützen. Es ist auch klar, dass ein Data Mesh zusätzliche Self-Services benötigt, die die Domänen bei der Entwicklung von Datenprodukten unterstützen und die Infrastruktur für die Erstellung und Bereitstellung von Datenprodukten bereitstellen. In Abbildung 1-6 sehen wir, dass ein Data Mesh alle Komponenten einer Data Fabric hat, aber in einem Mesh implementiert ist. Einfach ausgedrückt, ist eine Data Fabric eine Teilmenge eines Data Mesh.
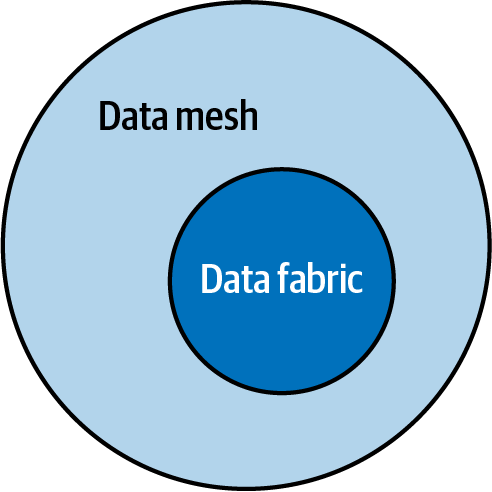
Abbildung 1-6. Data Fabric ist eine Untermenge von Data Mesh
Daten-Gateways und Datendienste
Daten-Gateways sind wie API-Gateways, liefern aber Daten:
Daten-Gateways funktionieren wie API-Gateways, konzentrieren sich aber auf den Datenaspekt. Ein Daten-Gateway bietet Abstraktionen, Sicherheit, Skalierung, Föderation und vertragsgesteuerte Entwicklungsfunktionen.
Bilgin Ibryam, "Data Gateways in the Cloud Native Era" aus InfoQ, Mai 2020
In ähnlicher Weise ist data as a service(DaaS) ein Muster, das Daten aus ihrer ursprünglichen Quelle bereitstellt, die vollständig verwaltet und konsumiert werden können, indem offene Standards befolgt werden, und das durch Software as a Service(SaaS) bereitgestellt wird. Beide Architekturmuster dienen der Bereitstellung von Daten, aber DaaS konzentriert sich mehr auf die Bereitstellung der Daten aus der Cloud. Man könnte sagen, dass DaaS Daten-Gateways in der Cloud ermöglicht, wo sie vorher vielleicht nur in den Räumlichkeiten waren. Abbildung 1-7 zeigt ein Beispiel.
Durch die Kombination der Konzepte von Datengateways und DaaS ist es einfacher, die Daten als aus der ursprünglichen Quelle stammend zu qualifizieren, insbesondere wenn die Daten von der Quelle aus unveränderlich waren. Die Replikation von Daten, die aus einem Rechenzentrum vor Ort stammen, in ein SaaS in der Cloud wäre eine Voraussetzung.
Alle Anforderungen an DaaS werden von Data Mesh erfüllt, außer dass es durch ein SaaS ermöglicht wird. Bei Data Mesh ist SaaS eine Option, aber derzeit gibt es keine SaaS Data Mesh-Anbieter, die die Implementierung eines Data Mesh einfach machen.
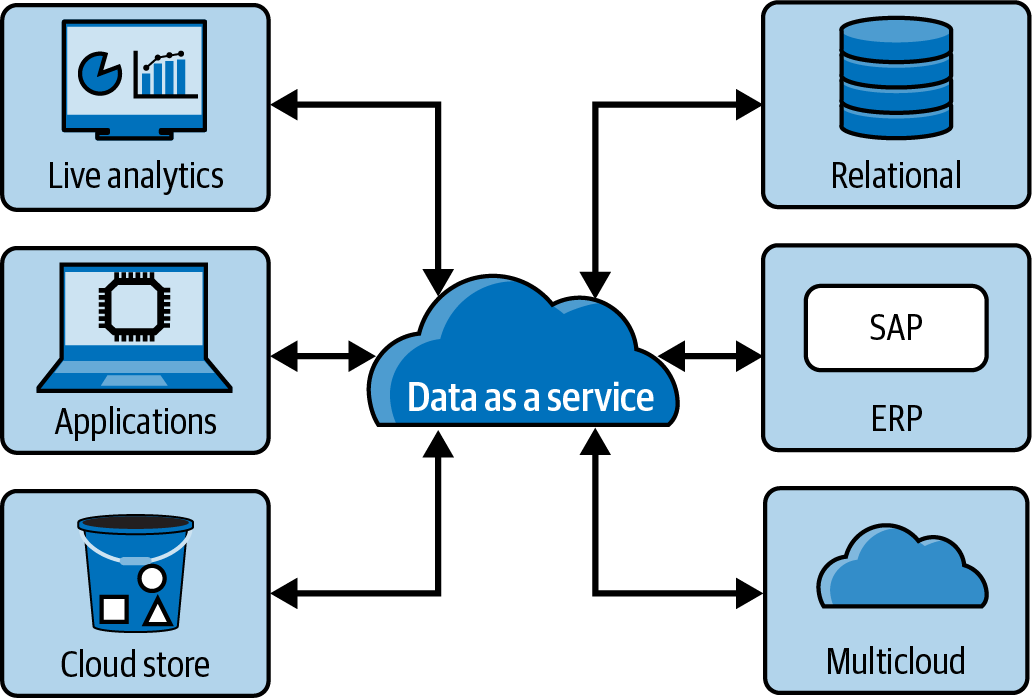
Abbildung 1-7. Data as a Service (DaaS) hat ein ähnliches Ziel wie die Bereitstellung von Datenprodukten in einem Datennetz
Daten-Demokratisierung
Daten-Demokratisierung ist der Prozess, digitale Informationen für den durchschnittlichen nicht-technischen Nutzer von Informationssystemen zugänglich zu machen, ohne dass die IT-Abteilung involviert sein muss:
Datendemokratisierung bedeutet, dass jeder Zugang zu den Daten hat und es keine Pförtner gibt, die einen Engpass am Tor zu den Daten schaffen. Wir müssen den Zugang zu den Daten mit einer einfachen Methode verbinden, die es den Menschen ermöglicht, die Daten zu verstehen, damit sie sie nutzen können, um die Entscheidungsfindung zu beschleunigen und Chancen für ein Unternehmen aufzudecken. Das Ziel ist, dass jeder die Daten jederzeit nutzen kann, um Entscheidungen zu treffen, ohne dass der Zugang oder das Verständnis behindert werden.
Bernard Marr, "Was ist Datendemokratisierung? Eine super einfache Erklärung und die wichtigsten Vor- und Nachteile", Forbes, Juli 2017
Data Mesh erfüllt diese Definition durch seine Datenprodukte, den Self-Service und den Low-Code-Ansatz zur gemeinsamen Nutzung und Erstellung von Daten. Ein einfacher Zugang zu Daten ist entscheidend, damit ein Unternehmen datengesteuert bleibt. Ein schneller Zugriff auf Daten, um analytische Erkenntnisse zu gewinnen, ermöglicht eine schnellere Reaktion auf betriebliche Veränderungen, die ein Unternehmen vor hohen Kosten bewahren können.
Datenvirtualisierung
Datenvirtualisierung ist eine besondere Art von Datenintegrationstechnologie, die den Zugang zu Echtzeitdaten aus verschiedenen Quellen und extrem großen Datenmengen ermöglicht, ohne dass die Daten an einen neuen Ort verschoben werden müssen.1
Viele haben die Datenvirtualisierung als Lösung für die Implementierung eines Datengeflechts in Betracht gezogen, da sie alle Säulen einer Datengeflecht-Architektur erfüllen kann, insbesondere die Idee, keine Daten an einen neuen Ort verschieben zu müssen, was eine Replikation der Daten über einen separaten ETL-Prozess erfordert. Wenn wir über das Streaming Data Mesh sprechen, müssen wir den Unterschied zwischen Datenvirtualisierung und Datenreplikation verstehen, denn das ist der Ansatz, den ein Streaming Data Mesh verfolgt.
Wie bereits erwähnt, werden die Daten bei der Datenvirtualisierung nicht an einen neuen Ort verschoben und daher bei Abfragen nicht mehrfach kopiert, anders als bei der Datenreplikation. Je nachdem, wie weit die Daten verstreut sind, kann das von Vorteil sein. Wenn die Daten jedoch in mehreren globalen Regionen vorhanden sind, beeinträchtigt die Durchführung von Abfragen über große Entfernungen die Abfrageleistung erheblich. Der Zweck der Replikation von Daten aus der operativen in die analytische Ebene mithilfe von ETL besteht nicht nur darin zu verhindern, dass Ad-hoc-Abfragen auf den operativen Datenspeichern ausgeführt werden, die sich auf die operativen Anwendungen auswirken würden, sondern auch darin, die Daten näher an die Analysetools zu bringen. ETL ist also nach wie vor erforderlich, und eine Replikation ist unvermeidlich:
Datenvirtualisierung kommt aus einer Welt, in der die Speicherung von Daten teuer und die Vernetzung billig ist (d.h. vor Ort). Das Problem, das damit gelöst wird, ist, dass die Daten unabhängig von ihrem Standort zugänglich sind, ohne dass man sie kopieren muss. Kopien in Datenbanken sind schlecht, weil es schwierig ist, die Konsistenz zu gewährleisten. Die Datenreplikation basiert auf der Ansicht, dass Kopien nicht schlecht sind (weil die Daten verändert wurden). Das erweist sich als sinnvoller, wenn das Netzwerk teuer ist (die Cloud).Mic Hussey, Principal Solutions Engineer bei Confluent
Betrachte eine hybride Replikation und Virtualisierung. Da sich die Daten in verschiedenen globalen Regionen befinden, könnte es besser sein, die Daten in eine Region zu replizieren und dann eine Datenvirtualisierung innerhalb einer Region zu implementieren.
Konzentration auf die Umsetzung
Streaming ist keine Voraussetzung in der ZD-Definition eines Datennetzes. Die Bereitstellung von Datenprodukten in einem Datengeflecht kann als Batching- oder Streaming-APIs implementiert werden. Das ZD sagt auch, dass Data Mesh nur für analytische Anwendungsfälle verwendet werden sollte. Wir werden Data Mesh über den analytischen Bereich hinaus auf Architekturen anwenden, die Lösungen für DaaS und Data Fabrics bieten. In Kapitel 2 werden einige der Vorteile von Streaming gegenüber Batching Data Mesh hervorgehoben.
Wenn wir die Grundlagen der Datenvernetzung auf einen Streaming-Kontext anwenden, müssen wir Entscheidungen zur Implementierung treffen, damit wir ein Streaming-Datennetz anhand von Beispielen aufbauen können. Die in diesem Buch getroffenen Implementierungsentscheidungen sind nicht notwendigerweise Voraussetzungen für ein Streaming Data Mesh, sondern Optionen, die dabei helfen, die Streaming-Lösung zusammenzufügen und dabei die Säulen des ZD Data Mesh einzuhalten. Die zwei Schlüsseltechnologien, die für eine Streaming-Implementierung benötigt werden, sind (1) eine Streaming-Technologie wie Apache Kafka, Redpanda oder Amazon Kinesis und (2) eine Möglichkeit, Daten als asynchrone Ressourcen mit einer Technologie wie der AsyncAPI bereitzustellen. Im weiteren Verlauf dieses Buches werden wir uns auf Implementierungen mit Kafka und AsyncAPI konzentrieren.
Apache Kafka
Apache Kafka als die Implementierung für Streaming-Data-Plattformen. Dieses Buch setzt nicht voraus, dass du Apache Kafka kennst, sondern behandelt nur die wichtigen Funktionen, die ein richtiges Streaming Data Mesh ermöglichen. Außerdem kann Kafka durch eine ähnliche Streaming-Plattform wie Apache Pulsar oder Redpanda ersetzt werden, die beide dem Apache Kafka Producer- und Consumer-Framework folgen. Wichtig ist, dass Streaming-Plattformen, die in der Lage sind, ihre Daten in einem Commit-Log zu speichern, das in diesem Buch beschriebene Streaming-Data-Mesh-Muster am besten umsetzen. Commit-Logs in einer Streaming-Plattform werden in Kapitel 2 beschrieben.
AsyncAPI
AsyncAPI ist ein Open-Source-Projekt, das die asynchrone ereignisgesteuerte Architektur (EDA) vereinfacht. AsyncAPI ist ein Framework, das es Implementierern ermöglicht, Code oder Konfigurationen in einer beliebigen Sprache oder einem beliebigen Tool zu erstellen, um Streaming-Daten zu produzieren oder zu konsumieren. Es ermöglicht dir, beliebige Streaming-Daten in einer AsyncAPI-Konfiguration auf einfache, beschreibende und interoperable Weise zu beschreiben. Sie wird eine der grundlegenden Komponenten sein, die wir für den Aufbau eines Streaming Data Mesh verwenden werden. Die AsyncAPI allein reicht nicht aus, um Datenprodukte in einem Streaming Data Mesh zu definieren. Da die AsyncAPI jedoch erweiterbar ist, werden wir sie um die zuvor definierten Säulen des Datennetzes ergänzen. Wir werden die Details der AsyncAPI in späteren Kapiteln erläutern.
Mit dem Datengeflecht und seinen definierten Säulen wollen wir uns nun genauer ansehen, wie wir die in diesem Kapitel besprochenen Säulen und Konzepte auf Streaming-Daten anwenden können, um ein Streaming-Datengeflecht zu erstellen.
1 Kriptos; "Was ist Datenvirtualisierung? Das Konzept und seine Vorteile verstehen", Datenvirtualisierung, Februar 2022.
Get Streaming Data Mesh now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

