Chapter 1. Data Mesh Introduction
Youngsters think that at some point data architectures were easy, and then data volume, velocity, variety grew and we needed new architectures which are hard. In reality, data problems were always organization problems and therefore were never solved.
Gwen (Chen) Shapira, Kafka: The Definitive Guide (O’Reilly)
If you’re working at a growing company, you’ll realize that a positive correlation exists between company growth and the scale of ingress data. This could be from increased usage for existing applications or newly added applications and features. It’s up to the data engineer to organize, optimize, process, govern, and serve this growing data to the consumers while maintaining service-level agreements (SLAs). Most likely, these SLAs were guaranteed to the consumers without the data engineer’s input. The first thing you learn when working with such a large amount of data is that when the data processing starts to encroach toward the guarantees made by these SLAs, more focus is put on staying within the SLAs, and things like data governance are marginalized. This in turn generates a lot of distrust in the data being served and ultimately distrust in the analytics—the same analytics that can be used to improve operational applications to generate more revenue or prevent revenue loss.
If you replicate this problem across all lines of business in the enterprise, you start to get very unhappy data engineers trying to speed up data pipelines within the capacity of the data lake and data processing clusters. This is the position where I found myself more often than not.
So what is a data mesh? The term “mesh” in “data mesh” was taken from the term “service mesh,” which is a means of adding observability, security, discovery, and reliability at the platform level rather than the application layer. A service mesh is typically implemented as a scalable set of network proxies deployed alongside application code (a pattern sometimes called a sidecar). These proxies handle communication between microservices and also act as a point where service mesh features are introduced.
Microservice architecture is at the core of a streaming data mesh architecture, and introduces a fundamental change that decomposes monolithic applications by creating loosely coupled, smaller, highly maintainable, agile, and independently scalable services beyond the capacity of any monolithic architecture. In Figure 1-1 you can see this decomposition of the monolithic application to create a more scalable microservice architecture without losing the business purpose of the application.
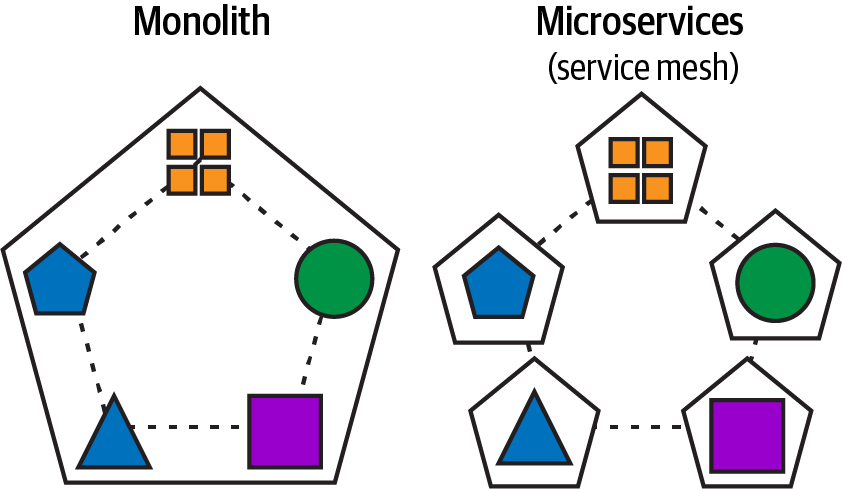
Figure 1-1. Decomposing a monolithic application into microservices that communicate with one another via a service mesh
A data mesh seeks to accomplish the same goals that microservices achieved for monolithic applications. In Figure 1-2 a data mesh tries to create the same loosely coupled, smaller, highly maintainable, agile, and independently scalable data products beyond the capacity of any monolithic data lake architecture.
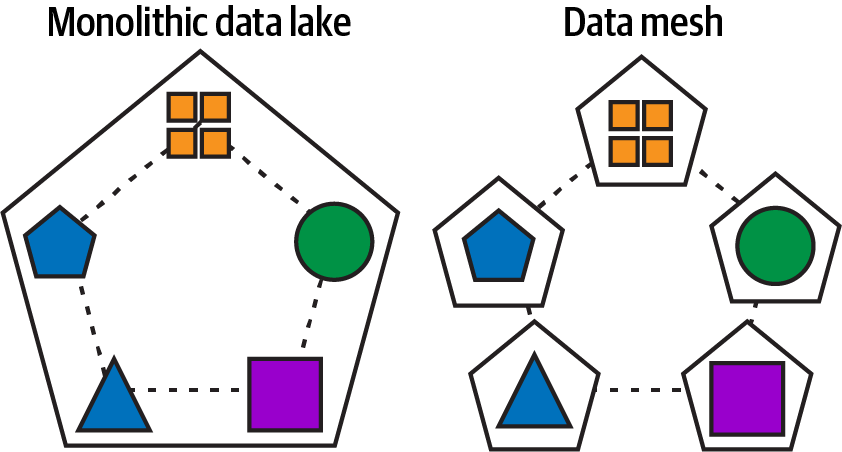
Figure 1-2. Monolithic data lake/warehouse decomposed to data products and domains that communicate via a data mesh
Zhamak Dehghani (whom I refer to as ZD in this book) is the pioneer of the data mesh pattern. If you are not familiar with ZD and her data mesh blog, I highly recommend reading it as well as her very popular book Data Mesh (O’Reilly). I will be introducing a simple overview to help you get a basic understanding of the pillars that make up the data mesh architectural pattern so that I can refer to them throughout the book.
In this chapter we will set up the basics of what a data mesh is before we introduce a streaming data mesh in Chapter 2. This will help lay a foundation for better understanding as we overlay ideas of streaming. We will then talk about other architectures that share similarities with data mesh to help delineate them. These other architectures tend to confuse data architects when designing a data mesh, and it is best to get clarity before we introduce data mesh to streaming.
Data Divide
ZD’s blog talks about a data divide, illustrated in Figure 1-3, to help describe the movement of data within a business. This foundational concept will help in understanding how data drives business decisions and the monolithic issues that come with it.
To summarize, the operational data plane holds data stores that back the applications that power a business.
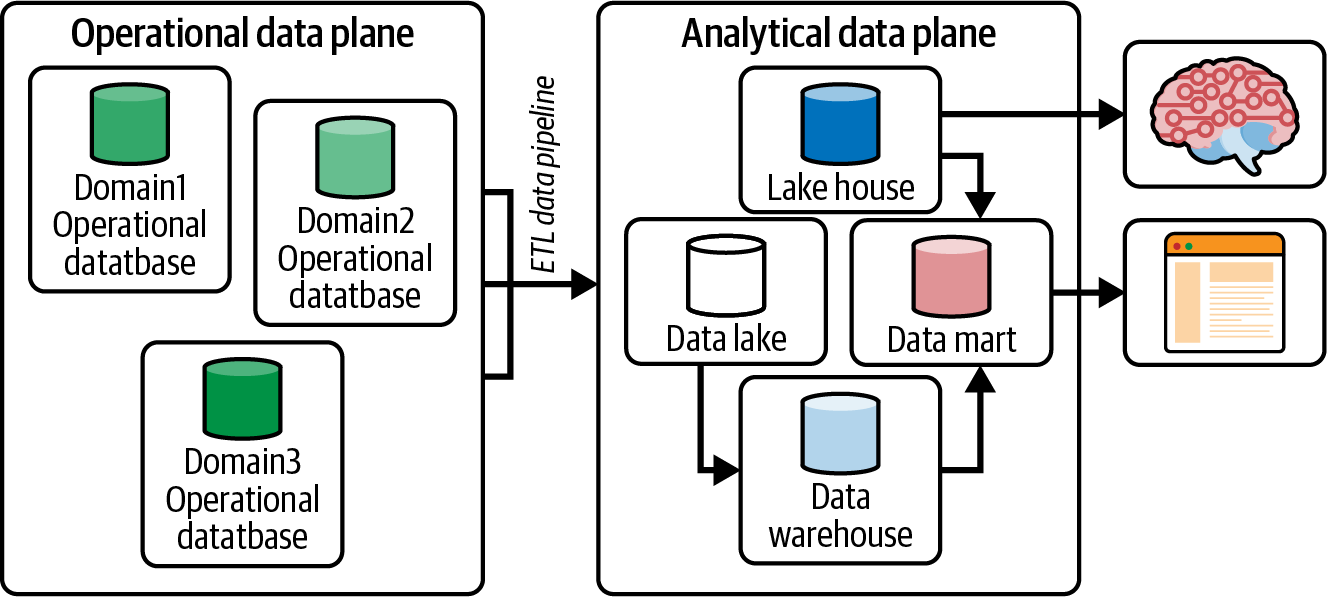
Figure 1-3. The data divide separating the operational data plane from the analytical data plane
An extract, transform, and load (ETL) process replicates the operational data to the analytical data plane, since you do not want to execute analytical queries on operational data stores, taking away compute and storage resources needed to generate revenue for your business. The analytical plane contains data lakes/warehouses/lake-houses to derive insights. These insights are fed back to the operational data plane to make improvements and grow the business.
With the help of Kubernetes on the operational plane, applications have evolved from sluggish and monolithic applications to agile and scalable microservices that intercommunicate, creating a service mesh. The same cannot be said for the analytical plane. The goal of the data mesh is to do just that: to break up the monolithic analytical plane to a decentralized solution to enable agile, scalable, and easie-to-manage data. We will refer to the operational plane and analytical plane throughout the book, so it’s important to establish this understanding early as we start to build a streaming data mesh example.
Data Mesh Pillars
The foundation of the data mesh architecture is supported by the pillars defined in Table 1-1. We will quickly summarize them in the following sections, covering the salient concepts of each, so that we can focus on the implementation of a streaming data mesh in later chapters.
| Data ownership | Data as a product | Self-service data platform | Federated computational data governance |
|---|---|---|---|
Decentralization and distribution of responsibility to people who are closest to the data in order to support continuous change and scalability. |
Discovering, understanding, trusting, and ultimately using quality data. |
Self-service data infrastructure as a platform to enable domain autonomy. |
Governance model that embraces decentralization, domain self-sovereignty, and interoperability through global standardization. A dynamic topology and most importantly automated execution of decisions by the platform. |
Data ownership and data as a product make up the core of the data mesh pillars. Self-service data platform and federated computational data governance exist to support the first two pillars. We’ll briefly discuss these four now and devote a whole chapter to each pillar beginning with Chapter 3.
Data Ownership
As mentioned previously, the primary pillar of a data mesh is to decentralize the data so that its ownership is given back to the team that originally produced it (or at least know and care about it the most). The data engineers within this team will be assigned a domain—one in which they are experts in the data itself. Some examples of domains are analytics, inventory, and application(s). They are the groups who likely were previously writing to and reading from the monolithic data lake.
Domains are responsible for capturing data from its true source. Each domain transforms, enriches, and ultimately provides that data to its consumers.
There are three types of domains:
- Producer only
-
Domains that only produce data and don’t consume it from other domains
- Consumer only
- Producer and consumer
-
Domains that produce and consume data to and from other domains, respectively
Note
Following the domain-driven design (DDD) approach, which models domain objects defined by the business domain’s experts and implemented in software, the domain knows the specific details of its data, such as schema and data types that adhere to these domain objects. Since data is defined at the domain level, it is the best place to define specifics about its definition, transformation, and governance.
Data as a Product
Since data now belongs to a domain, we require a way to serve data between domains. Since this data needs to be consumable and usable, it needs to be treated as any other product so consumers will have a good data experience. From this point forward, we will call any data being served to other domains data products.
Defining what a “good experience” is with data products is a task that has to be agreed upon among the domains in the data mesh. An agreed-to definition will help provide well-defined expectations among the participating domains in the mesh. Table 1-2 lists some ideas to think about that will help create a “good experience” for data product consumers and help with building data products in a domain.
| Considerations | Description |
|---|---|
Data products should be easily consumable. |
Some examples could be:
|
Engineers should have a generalist skill set. |
Engineers need to build data products without needing tools that require hyper-specialized skills. These are a possible minimum set of skills needed to build data products:
|
Data products should be searchable. |
When publishing a data product to the data mesh, a data catalog will be used for discovery, metadata views (usage, security, schema, and lineage), and access requests to the data product by domains that may want to consume it. |
Federated Computational Data Governance
Since domains are used to create data products, and sharing data products across many domains ultimately builds a mesh of data, we need to ensure that the data being served follows some guidelines. Data governance involves creating and adhering to a set of global rules, standards, and policies applied to all data products and their interfaces to ensure a collaborative and interoperable data mesh community. These guidelines must be agreed upon among the participating data mesh domains.
Note
Data mesh is not completely decentralized. The data is decentralized in domains, but the mesh part of data mesh is not. Data governance is critical in building the mesh in a data mesh. Examples of this include building self-services, defining security, and enforcing interoperability practices.
Here are some things to consider when thinking about data governance for a data mesh: authorization, authentication, data and metadata replication methods, schemas, data serialization, and tokenization/encryption.
Self-Service Data Platform
Because following these pillars requires a set of hyper-specialized skills, a set of services must be created in order to build a data mesh and its data products. These tools require compatibility with skills that are accessible to a more generalist engineer. When building a data mesh, it is necessary to enable existing engineers in a domain to perform the tasks required. Domains have to capture data from their operational stores, transform (join or enrich, aggregate, balance) that data, and publish their data products to the data mesh. Self-service services are the “easy buttons” necessary to make data mesh easy to adopt with high usability. In summary, the self-services enable the domain engineers to take on many of the tasks the data engineer was responsible for across all lines of the business. A data mesh not only breaks up the monolithic data lake, but also breaks up the monolithic role of the data engineer into simple tasks the domain engineers can perform.
Data Mesh Diagram
Figure 1-4 depicts there are three distinct domains: data science, mobile application, and inventory.
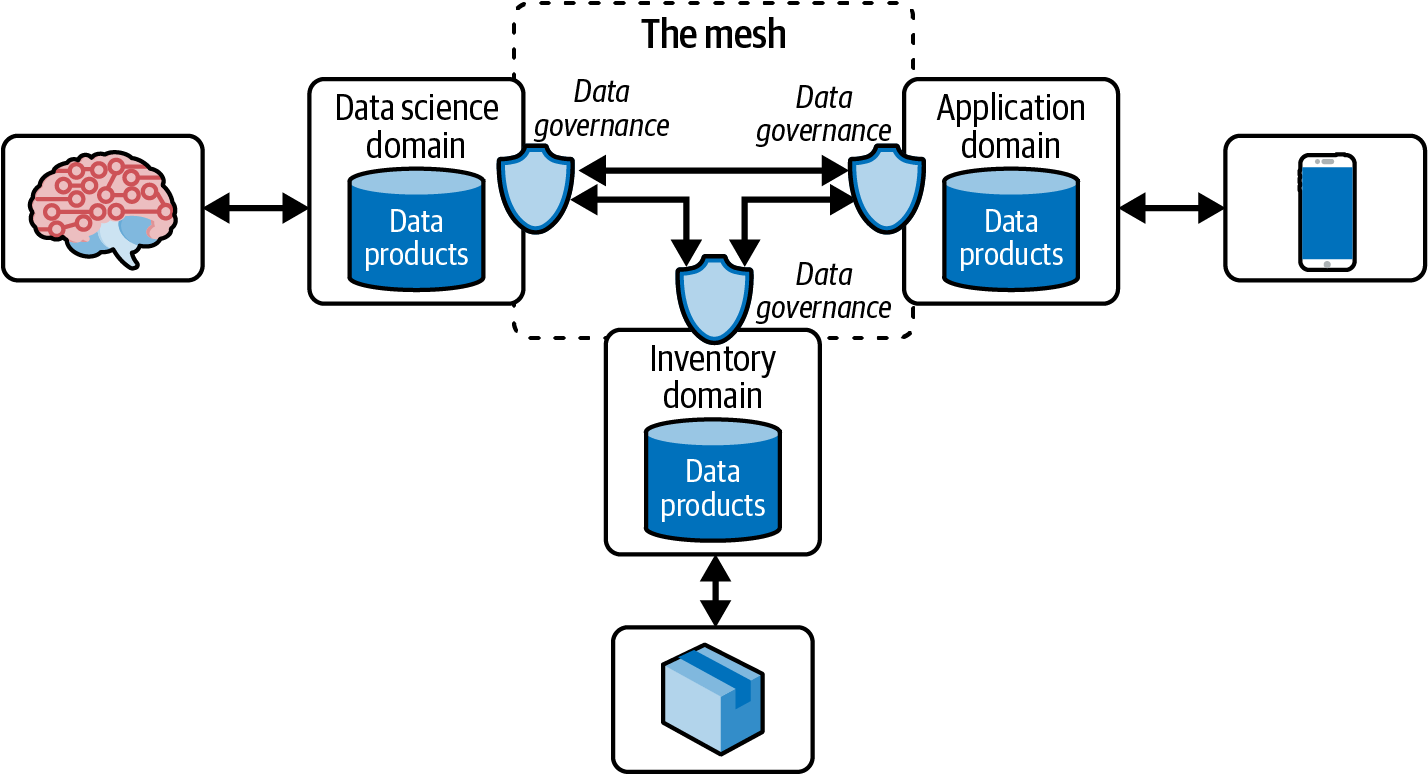
Figure 1-4. High-level view of a data mesh
The data science domain consumes data from the application domain, which owns the data coming from mobile applications. The inventory domain consumes data from data science for inventory logistics, like reducing distance or moving supply to locations with higher propensity to buy. Lastly, the application domain could be consuming references to newly trained models to load into its mobile applications that create updated personalized experiences.
Data governance creates access controls between the data product producer and consumer and provides metadata like schema definitions and lineages. In some cases, mastered data along with reference data may be relevant to the implementation. Data governance allows us to create appropriate access controls for these resources as well.
The edges that connect domains replicate data between them. They build the connections between domains, creating the “mesh.” Figure 1-4 is a high-level graph of a data mesh that we will dive deeper into in the following chapters.
In later chapters we will also talk about how to identify and build a domain by assembling a data team that follows the spirit of ZD’s vision of a decentralized data platform. Again, Figure 1-4 is a high-level view of a nonstreaming data mesh. Such an implementation does not imply that streaming is the solution for publishing data for consumption. Other alternatives can move data between and within a domain. Chapter 2 covers streaming data mesh specifically and its advantages.
Other Similar Architectural Patterns
The previous section summarized the data mesh architecture at a very high level as defined by ZD’s vision. Many data architects like to point out existing data architectures that have similar characteristics to a data mesh. These similarities may be enough for architects to label their existing implementations as already conforming to and meeting the data mesh pillars. These architects may be absolutely correct or partially correct. A few of these data architectures include data fabrics, data gateways, data as a service, data democratization, and data virtualization.
Data Fabric
A data fabric is a pattern that is very similar to a data mesh in that both provide solutions encompassing data governance and self-service: discovery, access, security, integration, transformation, and lineage (Figure 1-5).
At the time of this writing, consensus on the differences between data mesh and data fabric is unclear. In simple terms, a data fabric is a metadriven means of connecting disparate sets of data and related tools to provide a cohesive data experience and to deliver data in a self-service manner.

Figure 1-5. Data fabric pillars
While a data mesh seeks to solve many of the same problems that a data fabric addresses—namely, the ability to address data in a single, composite data environment—the approach is different. While a data fabric enables users to create a single, virtual layer on top of distributed data, a data mesh further empowers distributed groups of data producers to manage and publish data as they see fit. Data fabrics allow for a low-to-no-code data virtualization experience by applying data integration within APIs that reside within the data fabric. The data mesh, however, allows for data engineers to write code for APIs with which to interface further.
A data fabric is an architectural approach to provide data access across multiple technologies and platforms, and is based on a technology solution. One key contrast is that a data mesh is much more than just technology: it is a pattern that involves people and processes. Instead of taking ownership of an entire data platform, as in a data fabric, the data mesh allows data producers to focus on data production, allows data consumers to focus on consumption, and allows hybrid teams to consume other data products, blend other data to create even more interesting data products, and publish these data products—with some data governance considerations in place.
In a data mesh, data is decentralized, while in a data fabric, centralization of data is allowed. And with data centralization like data lakes, you get the monolithic problems that come with it. Data mesh tries to apply a microservices approach to data by decomposing data domains into smaller and more agile groups.
Fortunately, the tools that support a data fabric can support a data mesh. It’s also apparent that a data mesh will need additional self-services that support the domains in engineering data products and provision the infrastructure to build and serve data products. In Figure 1-6 we see that a data mesh has all the components of a data fabric but implemented in a mesh. Simply put, a data fabric is a subset of a data mesh.
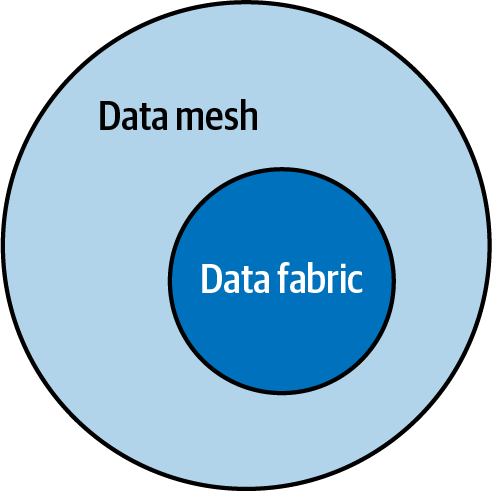
Figure 1-6. Data fabric is a subset of data mesh
Data Gateways and Data Services
Data gateways are like API gateways but serve data:
Data gateways act like API gateways but focusing on the data aspect. A data gateway offers abstractions, security, scaling, federation, and contract-driven development features.
Bilgin Ibryam, “Data Gateways in the Cloud Native Era” from InfoQ, May 2020
Similarly, data as a service (DaaS) is a pattern that serves data from its original source that is fully managed and consumable by following open standards and is served by software as a service (SaaS). Both architectural patterns serve data, but DaaS is focused more on serving the data from the cloud. You could say that DaaS enables data gateways in the cloud, where it previously may have been on only premises. Figure 1-7 shows an example.
Combining the concepts of both data gateways and DaaS, it is easier to qualify data as coming from the original source, especially if the data was immutable from the source. Replication of data that originated from an on-premises data center to a SaaS in the cloud would be a requirement.
All the requirements for DaaS are satisfied by data mesh except for being enabled by a SaaS. In data mesh, SaaS is an option, but currently there are no SaaS data mesh providers that make implementing a data mesh easy.

Figure 1-7. Data as a service (DaaS) has a similar goal as providing data products in a data mesh
Data Democratization
Data democratization is the process of making digital information accessible to the average nontechnical user of information systems without having to require the involvement of IT:
Data democratization means that everybody has access to data and there are no gatekeepers that create a bottleneck at the gateway to the data. It requires that we accompany the access with an easy way for people to understand the data so that they can use it to expedite decision-making and uncover opportunities for an organization. The goal is to have anybody use data at any time to make decisions with no barriers to access or understanding.
Bernard Marr, “What Is Data Democratization? A Super Simple Explanation and the Key Pros and Cons,” Forbes, July 2017
Data mesh satisfies this definition through its data products, self-service, and low-code approach to sharing and creating data. Simple access to data is critical in keeping a business data driven. Getting fast access to data to create analytical insights will enable faster response to operational changes that could save a business from high costs.
Data Virtualization
Data virtualization is a special kind of data integration technology that provides access to real-time data, across multiple sources and extremely large volumes, without having to move any data to a new location.1
Many have considered data virtualization as a solution to implementing a data mesh since it can satisfy all the pillars of a data mesh architecture, especially the idea of not having to move any data to a new location, which requires replication of the data using a separate ETL process. As we start to talk about streaming data mesh, we need to understand the difference between data virtualization and data replication, which is the approach a streaming data mesh takes.
As stated before, with data virtualization, the data isn’t moved to a new location and therefore is not copied multiple times when performing queries, unlike data replication. Depending on how far the data is spread out, this may be beneficial. However, if data exists in multiple global regions, performing queries across long distances will affect query performance significantly. The purpose of replicating data from operational to analytical planes using ETL is to not only prevent ad hoc queries from being executed on the operational data stores, which would affect the operational applications powering the business; but also bring the data closer to the tools performing the analytics. So ETL is still needed, and replication is inevitable:
Data virtualization comes from a world-view where data storage is expensive and networking is cheap (i.e., on premise). The problem it solved is making the data accessible no matter where it is and without having to copy it. Copies in databases are bad because of the difficulty in guaranteeing consistency. Data replication is based on the view that copies aren’t bad (because the data has been mutated). Which turns out to be more useful when it’s the network that’s expensive (the cloud).Mic Hussey, principal solutions engineer at Confluent
Consider a hybrid replication and virtualization. As the data starts to reside in different global regions, it could be better to replicate the data to a region and then implement data virtualization within a region.
Focusing on Implementation
Streaming is not a requirement in ZD’s definition of a data mesh. Serving data products in a data mesh can be implemented as batching or streaming APIs. ZD also states that data mesh should be used for only analytical use cases. We will take data mesh beyond analytical and apply it to architectures that provide solutions for DaaS and data fabrics. Chapter 2 highlights some of the advantages for streaming over batching data mesh.
Taking the fundamentals of data mesh and applying them to a streaming context will require us to make implementation choices so that we can build a streaming data mesh by example. The implementation choices made within this book are not necessarily requirements for a streaming data mesh but options chosen to help stitch the streaming solution together while adhering to ZD’s data mesh pillars. The two key technologies required for a streaming implementation will require (1) a streaming technology such as Apache Kafka, Redpanda, or Amazon Kinesis; and (2) a way to expose data as asynchronous resources, using a technology such as AsyncAPI. As this book progresses, we will focus on implementations using Kafka and AsyncAPI.
Apache Kafka
Apache Kafka as the implementation for streaming data platforms. This book doesn’t require you to know Apache Kafka but will cover just the important features that enable a proper streaming data mesh. Also, Kafka can be replaced with a similar streaming platform like Apache Pulsar or Redpanda, both of which follow the Apache Kafka producer and consumer framework. It is important to note that streaming platforms that are able to keep their data in a commit log will best implement the streaming data mesh pattern described in this book. Commit logs in a streaming platform are described in Chapter 2.
AsyncAPI
AsyncAPI is an open source project that simplifies asynchronous event-driven architecture (EDA). AsyncAPI is a framework that allows implementors to generate code or configurations, in whichever language or tool like, to produce or consume streaming data. It allows you to describe any streaming data in an AsyncAPI configuration in a simple, descriptive, and interoperable way. It will be one of the foundational components we’ll use to build a streaming data mesh. AsyncAPI alone is not enough to define data products in a streaming data mesh. However, since AsyncAPI is extensible, we will extend it to include the data mesh pillars previously defined. We will go over the details of AsyncAPI in later chapters.
With the data mesh and its defined pillars, let’s take a deeper look into how we can apply the pillars and concepts discussed in this chapter to streaming data to create a streaming data mesh.
1 Kriptos; “What is Data Virtualization? Understanding the Concept and its Advantages,” Data Virtualization, February 2022.
Get Streaming Data Mesh now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

