Capítulo 4. Eficiencia operativa
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
¡La resistencia es inútil!
Los Borg
En realidad, la resistencia no es inútil. Es mucho peor que eso.
La batalla contra las máquinas
Algún día, los servidores superconductores que funcionen en centros de datos superenfriados eliminarán la resistencia, y nuestros centros de datos funcionarán con una fracción de la electricidad que consumen ahora. Quizá nuestros futuros señores de la inteligencia general artificial (AGI) ya estén trabajando en ello. Pero, por desgracia, los humanos enclenques no podemos esperar.
Hoy en día, al alimentar las máquinas de los centros de datos, éstas se calientan. Esa energía -con demasiada frecuencia generada a un coste climático significativo- se pierde entonces para siempre. Luchar contra la resistencia es lo que hace la gente cuando se esfuerza por mejorar la eficacia del uso de la energía (PUE) en los centros de datos (como comentamos en el Capítulo 2). También es el motivo que subyace al concepto de eficiencia operativa, que es de lo que vamos a hablar en este capítulo.
Nota
Esos CC superconductores podrían estar en el espacio, porque así se resolvería el problema del frío (los superconductores tienen que estar muy, muy fríos, fríos en el espacio, no fríos en un chaleco). Sin embargo, los CC superconductores fuera del planeta están a un siglo vista. Demasiado tarde para resolver nuestros problemas inmediatos.
Durante las tres últimas décadas, hemos luchado contra el despilfarro de electricidad en los CC utilizando avances en el diseño de las CPU y otras mejoras en la eficiencia del hardware. Éstas han permitido a los desarrolladores conseguir el mismo rendimiento funcional con cada vez menos máquinas y menos energía. Sin embargo, esas mejoras de la ley de Moore ya no nos bastan. La ley de Moore se está ralentizando. Incluso podría detenerse (aunque probablemente no lo haga).
Afortunadamente, sin embargo, la eficiencia del hardware no es la única arma que tenemos para luchar contra la resistencia. La eficiencia operativa es la forma en que la gente verde de DevOps o SRE, como Sarah, reducen el derroche de electricidad en sus centros de datos. Pero, ¿qué es la eficiencia operativa?
Consejo
Ten en cuenta también que el calor liberado debido a la resistencia eléctrica de todos los aparatos eléctricos del mundo no contribuye significativamente al calentamiento global. Es nuestro sol, combinado con las propiedades físicas de los gases de efecto invernadero, el que produce el calentamiento real en el cambio climático. También es el sol el que, en última instancia, proporciona el calor suministrado por las bombas de calor, que es como consiguen una eficiencia >100%. La electricidad simplemente ayuda a las bombas de calor a conseguir esa energía solar.
En un futuro lejano, si conseguimos crear energía casi ilimitada a partir de la fusión o de paneles solares espaciales, quizá tengamos que preocuparnos por el calentamiento directo. Sin embargo, ése es un problema para otro siglo. Será excelente llegar a él. Significará que la humanidad ha sobrevivido a esta ronda.
Cosas calientes
La eficiencia operativa consiste en conseguir el mismo resultado funcional para la misma aplicación o servicio, incluido el rendimiento y la resistencia, utilizando menos recursos de hardware como servidores, discos y CPU. Eso significa que se necesita menos electricidad, que se disipa en forma de calor, que se necesita menos refrigeración para gestionar ese calor y que se emite menos carbono como parte de la creación y eliminación del equipo.
Puede que la eficiencia operativa no sea la opción más glamurosa. Tampoco puede tener el mayor potencial teórico para reducir el derroche de energía. Sin embargo, en este capítulo vamos a intentar convencerte de que es un paso práctico y alcanzable que casi todo el mundo puede dar para construir un software más ecológico. No sólo eso, sino que argumentaremos que, en muchos aspectos, patea el trasero de las alternativas.
Técnicas
Como hemos comentado en la introducción, AWS calcula que una buena eficiencia operativa puede reducir entre cinco y diez veces las emisiones de carbono de los sistemas. No es nada desdeñable.
"¡Espera! ¡¿No decías que la eficacia del código podría centuplicarlos! Eso es 10 veces mejor!"
Efectivamente. Sin embargo, el problema de la eficiencia del código es que puede chocar con algo que preocupa mucho a la mayoría de las empresas: la productividad de los desarrolladores. Y tienen razón en preocuparse por ello.
Estamos de acuerdo en que la eficiencia operativa es menos eficaz que la eficiencia del código, pero tiene una ventaja significativa para la mayoría de las empresas. Por un esfuerzo comparativamente bajo y utilizando herramientas disponibles en el mercado, puedes conseguir grandes mejoras en ella. Es una fruta al alcance de la mano, y es por donde la mayoría de nosotros tenemos que empezar.
La eficiencia del código es asombrosa, pero su inconveniente es que también supone un gran esfuerzo y, con demasiada frecuencia, es muy personalizado (con suerte, eso es algo que se está abordando, pero aún no hemos llegado a ese punto). No te conviene hacerlo a menos que vayas a tener muchos usuarios. Incluso entonces, necesitas experimentar primero para comprender tus necesidades.
Nota
Te darás cuenta de que 10 veces las mejoras operativas más 100 veces la eficiencia del código nos dan las 1000 veces que realmente queremos. Dentro de cinco años necesitaremos ambas cosas mediante herramientas y servicios básicos, es decir, plataformas ecológicas.
En cambio, las bibliotecas estandarizadas y los servicios básicos ya ofrecen una mayor eficacia operativa. Así que en este capítulo podemos incluir ejemplos de buenas prácticas ampliamente aplicables, que no pudimos darte en el anterior.
Pero antes de empezar a hacerlo, demos un paso atrás. Cuando hablamos de eficiencia operativa moderna, ¿en qué conceptos de alto nivel nos apoyamos?
Creemos que se reduce a una sola noción fundamental: la utilización de la máquina.
Utilización de la máquina
Utilización de la máquina, densidad del servidor o empaquetamiento. Hay montones de nombres para esta idea, y probablemente nos hayamos dejado alguno, pero el motivo que hay detrás de todos ellos es el mismo. La utilización de la máquina consiste en concentrar el trabajo en una sola máquina o en un clúster de forma que se maximice el uso de recursos físicos como la CPU, la memoria, el ancho de banda de la red, la E/S del disco y la energía.
Una gran utilización de la máquina es al menos tan fundamental para ser ecológico como la eficiencia del código.
Por ejemplo, supongamos que reescribes tu aplicación en C y reduces sus requisitos de CPU en un 99%. ¡Hurra! Eso ha sido doloroso y ha llevado meses. Hipotéticamente, ahora la ejecutas exactamente en el mismo servidor que antes. Por desgracia, todo ese esfuerzo de reescritura no te habrá ahorrado tanta electricidad. Como veremos en el Capítulo 6, una máquina parcialmente utilizada consume una gran proporción de la electricidad de una totalmente utilizada, y el impacto de carbono incorporado del hardware es el mismo.
En resumen, si no reduces tu máquina (lo que se llama rightsizing) al mismo tiempo que reduces tu aplicación, la mayor parte de tus esfuerzos de optimización del código se habrán desperdiciado. El problema es que el rightsizing puede ser complicado.
Redimensionamiento
Desde el punto de vista operativo, una de las acciones ecológicas más baratas que puedes emprender es no sobreaprovisionar tus sistemas. Eso significa reducir el tamaño de las máquinas que sean más grandes de lo necesario. Como ya hemos dicho (pero vale la pena repetirlo), una mayor utilización de las máquinas significa que la electricidad se utiliza de forma más eficiente y se reduce la sobrecarga de carbono incorporado. Las técnicas de redimensionamiento pueden aplicarse tanto in situ como en la nube.
Desgraciadamente, hay problemas para asegurarte de que tus aplicaciones se ejecutan en máquinas que no son ni demasiado grandes ni demasiado pequeñas (llamémosla la Zona Ricitos de Oro de DevOps): el sobreaprovisionamiento se hace a menudo por excelentes razones.
El sobreaprovisionamiento es una técnica de gestión de riesgos habitual y exitosa. A menudo es difícil predecir cuál será el comportamiento de un nuevo servicio o las demandas que se le harán. Por lo tanto, un enfoque perfectamente sensato es colocarlo en un clúster de servidores mucho más grande de lo que crees que necesita. Así, al menos, te asegurarás de que no se encuentre con limitaciones de recursos. También reduce la posibilidad de que se produzcan condiciones de carrera difíciles de depurar. Sí, te costará un poco más de dinero, pero es menos probable que tu servicio se caiga, y para la mayoría de las empresas, ese compromiso es obvio. Todos tenemos la intención de volver más tarde y redimensionar nuestras máquinas virtuales, pero rara vez lo hacemos debido al segundo problema de la redimensión: nunca tienes tiempo para hacerlo.
La solución obvia es el autoescalado. Por desgracia, como vamos a ver, tampoco es perfecta.
Autoescalado
El autoescalado es una técnica utilizada a menudo en la nube, pero también puedes hacerlo on prem. La idea subyacente es ajustar automáticamente los recursos asignados a un sistema en función de la demanda actual. Todos los proveedores de la nube tienen servicios de autoescalado, y también está disponible como parte de Kubernetes. En teoría, es increíble.
El problema es que, en la práctica, el autoescalado puede plantear problemas similares al sobreaprovisionamiento manual. Escalar hasta el máximo está bien, pero volver a escalar hacia abajo es mucho más arriesgado y aterrador, por lo que a veces no se configura para que ocurra automáticamente. Puedes volver a reducir manualmente, pero ¿quién tiene tiempo para hacer algo manual? Esa era la razón por la que utilizabas el autoescalado en primer lugar. Como resultado, el autoescalado no siempre resuelve tu problema de infrautilización.
Afortunadamente, existe otra solución potencial en las nubes públicas. Las instancias ráfagas ofrecen un compromiso entre resistencia y ecologismo. Están diseñadas para cargas de trabajo que no requieren un alto nivel de CPU de forma constante, pero que ocasionalmente necesitan ráfagas de CPU para evitar las molestas caídas.
Las instancias ráfagas vienen con un nivel básico de rendimiento de CPU, pero, cuando la carga de trabajo lo exige, pueden "ráfagas" a un nivel superior durante un periodo limitado. La cantidad de tiempo que la instancia puede mantener la ráfaga viene determinada por los créditos de CPU acumulados que tenga. Cuando la carga de trabajo vuelve a la normalidad, la instancia vuelve a su nivel básico de rendimiento y comienza a acumular créditos de CPU de nuevo.
Las instancias reventables tienen múltiples ventajas:
-
Son más baratas (léase: más eficientes desde el punto de vista de la máquina para los proveedores de la nube) que los tipos de instancia que ofrecen un alto rendimiento de CPU más constante.
-
Son más ecológicos, ya que permiten que tus sistemas gestionen picos ocasionales de demanda sin tener que aprovisionar por adelantado más recursos de los que sueles necesitar. También se reducen automáticamente.
-
Lo mejor de todo es que hacen que la gestión de la densidad del servidor sea problema de tu proveedor de la nube y no tuyo.
Por supuesto, siempre hay aspectos negativos:
-
La cantidad de tiempo que tu instancia puede alcanzar un nivel de rendimiento superior está limitada por los créditos de CPU que tengas. Aún puedes caer si te quedas sin ellos.
-
Si tu carga de trabajo exige una CPU elevada y constante, sería más barato utilizar simplemente un tipo de instancia grande.
-
No es tan seguro como elegir una instancia sobredimensionada. El rendimiento de las instancias reventables puede ser variable, por lo que es difícil predecir el nivel exacto que obtendrás. Si hay suficiente demanda de ellas, es de esperar que mejore con el tiempo a medida que los hiperescaladores sigan invirtiendo para mejorarlas.
-
Gestionar los créditos de CPU añade complejidad a tu sistema. Tienes que llevar un registro de los créditos acumulados y planificar las ráfagas.
El resultado es que dimensionar es estupendo, pero no hay una forma trivial de hacerlo. Utilizar la energía eficientemente sin sobreaprovisionar requiere una inversión inicial de tiempo y nuevas habilidades, incluso con instancias autoescalables o reventables.
Una y otra vez, se ha demostrado que la Rana Gustavo tenía razón. Nada es fácil cuando se trata de ser ecológico, o ya lo estaríamos haciendo. Sin embargo, además de ser más sostenible, evitar el sobreaprovisionamiento puede ahorrarte un montón de dinero, así que merece la pena estudiarlo. Quizás manejar las dificultades del rightsizing sea una razón para poner en marcha un proyecto de infraestructura como código o GitOps...
Infraestructura como código
La infraestructura como código (IaC) es el principio según el cual defines, configuras e implementas la infraestructura utilizando código en lugar de hacerlo manualmente. La idea es proporcionarte una mejor automatización y repetibilidad, además del control de versiones. Utilizando lenguajes específicos de dominio y archivos de configuración, describes cómo quieres que sean tus servidores, redes y almacenamiento. Esta representación basada en código se convierte entonces en la única versión de la verdad para tu infraestructura.
GitOps es una versión de IaC que utiliza Git como sistema de control de versiones. Cualquier cambio, incluidos los de aprovisionamiento como el autoescalado, se gestionan a través de Git, y la configuración actual de tu infraestructura se concilia continuamente con el estado deseado definido en tu repositorio. El objetivo es proporcionar una pista de auditoría de cualquier cambio en la infraestructura, permitiéndote rastrear, revisar y revertir.
La buena noticia es que las comunidades de IaC y GitOps han empezado a pensar en las operaciones verdes, y las llamadas GreenOps ya son un objetivo del Grupo de Sostenibilidad Medioambiental de la Fundación de Computación Nativa en la Nube (CNCF). La fundación vincula el concepto a las técnicas de reducción de costes (también conocidas como FinOps, de las que hablaremos más en el Capítulo 11, sobre los beneficios colaterales de los sistemas ecológicos), y la fundación tiene razón (véase la Figura 4-1). Desde el punto de vista operativo, más ecológico es más barato.
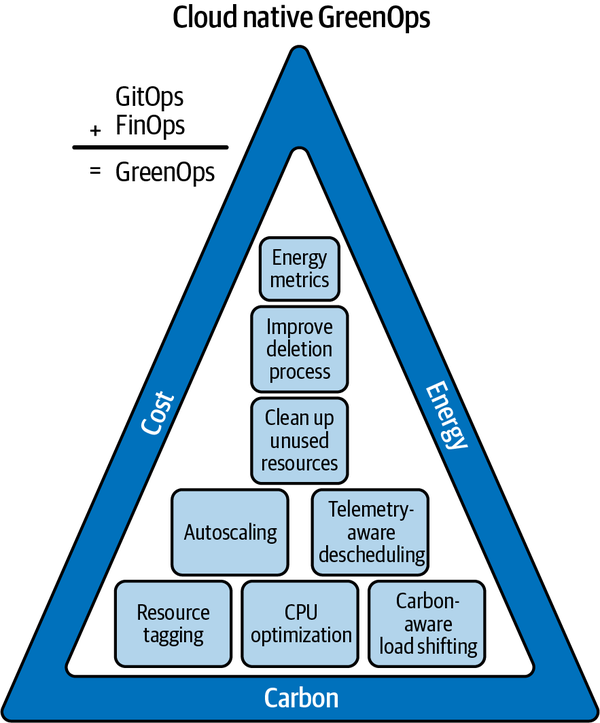
Figura 4-1. Definición CNCF de GreenOps como GitOps + FinOps
Creemos que la implicación de es que empieces por la parte superior del triángulo y trabajes hacia abajo, lo que parece sensato porque lo de abajo es ciertamente más complicado.
Cualquier cosa que automatice las tareas de rightsizing y autoscaling hace que sea más probable que ocurran, y eso sugiere que IaC y GitOps deberían ser algo bueno para Green. Que haya una comunidad CNCF IaC impulsando GreenOps también es una señal excelente.
En el momento de escribir este artículo, los autores hablaron con Alexis Richardson, director general de Weaveworks, y con algunos miembros del equipo. Weaveworks acuñó el término GitOps en 2017 y estableció los principios fundamentales junto con FluxCD, una implementación compatible con Kubernetes. La empresa considera que el próximo gran reto para las GreenOps es el seguimiento automatizado de las emisiones de gases de efecto invernadero. Estamos de acuerdo, y es un problema que trataremos en el Capítulo 10.
Programación de grupos
Las técnicas operativas estándar, como el rightsizing y el autoscaling, están muy bien, pero si realmente quieres ser inteligente en la utilización de las máquinas, también deberías considerar el concepto más radical de la programación de clusters.
La idea que subyace a la programación en clústeres es que las cargas de trabajo de formas diferentes se pueden empaquetar programáticamente en servidores como piezas en un juego de Tetris DevOps (ver Figura 4-2). El objetivo es ejecutar la misma cantidad de trabajo en el grupo de máquinas más pequeño posible. Es, quizás, lo último en eficiencia operativa automatizada, y supone un gran cambio respecto a la forma en que solíamos aprovisionar los sistemas. Tradicionalmente, cada aplicación tenía su propia máquina física o VM. Con la programación en clúster, esas máquinas se comparten entre las aplicaciones.
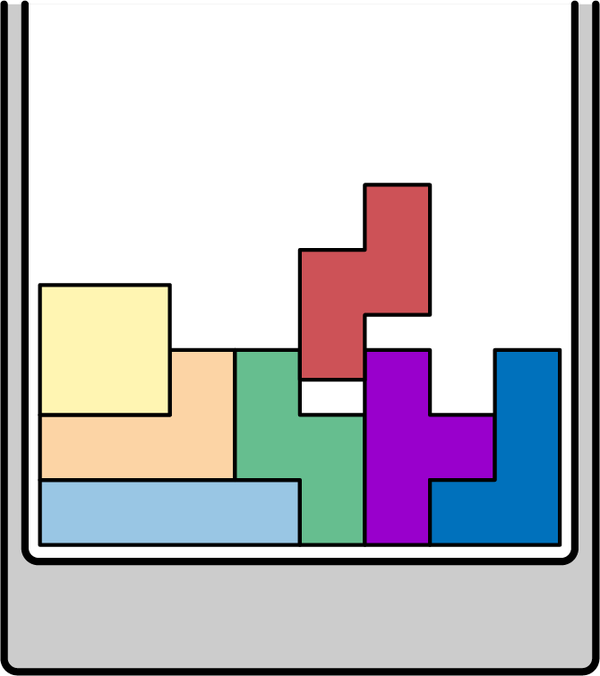
Figura 4-2. Tetris DevOps
Por ejemplo, imagina que tienes una aplicación con una alta necesidad de E/S y una baja necesidad de CPU. Un programador de clústeres podría ubicar tu trabajo en el mismo servidor que una aplicación que requiere mucho procesador pero no utiliza mucha E/S. El objetivo del programador es siempre hacer el uso más eficiente de los recursos locales, garantizando al mismo tiempo que tus trabajos se completen en el plazo requerido y con la calidad y disponibilidad deseadas.
La buena noticia es que existen muchas herramientas y servicios de programación de clústeres , normalmente como parte de plataformas de orquestación. El más popular es un componente de la plataforma de código abierto Kubernetes, y es una versión muy simplificada del programador de clústeres interno de Google, que se llama Borg. Como mencionamos en la introducción, Borg se utiliza en Google desde hace casi dos décadas.
Para probar la programación de clusters, podrías utilizar el programador de Kubernetes u otro como Nomad de HashiCorp en tu DC on-prem. También puedes utilizar un servicio gestionado de Kubernetes en la nube, como EKS, GKS o AKS (de AWS, Google y Azure, respectivamente), o una opción que no sea Kubernetes, como AWS Container Service (ECS). La mayoría de los programadores de clústeres ofrecen una funcionalidad similar, por lo que lo más probable es que utilices el que viene con la plataforma operativa que hayas seleccionado; es poco probable que sea un factor diferenciador que te haga elegir una plataforma en lugar de otra. Sin embargo, la falta de esta funcionalidad de utilización de máquinas podría indicar que la plataforma en la que estás no es lo suficientemente verde.
La programación en clúster suena muy bien, y lo es, ya que puede proporcionar hasta un 80% de utilización de la máquina. Si estas herramientas no te ahorran dinero/carbono, probablemente no las estés utilizando correctamente. Sin embargo, sigue habiendo un gran problema.
Subcarga de información
Para que estos programadores de clusters muevan los trabajos de máquina a máquina para conseguir un empaquetamiento óptimo, necesitan tres cosas:
-
Los trabajos deben encapsularse junto con todas sus bibliotecas prerrequisito, de modo que puedan desplazarse para empaquetarse al máximo sin dejar de funcionar de repente porque les falta una dependencia clave.
-
La herramienta de encapsulación debe admitir una instanciación rápida (es decir, debe ser posible que el trabajo encapsulado se apague en una máquina y se vuelva a encender en otra rápidamente). Si eso tarda una hora (o incluso unos minutos), la programación en clúster no funcionará: el servicio no estaría disponible durante demasiado tiempo.
-
Los trabajos encapsulados deben etiquetarse para que el programador sepa qué hacer con ellos (para que sepa si tienen requisitos de alta disponibilidad, por ejemplo).
Las partes de encapsulación e instanciación rápida pueden hacerse envolviéndolas en un contenedor como Docker o Containerd, y esa tecnología ya está ampliamente disponible. ¡Viva!
Nota
Internamente, muchos de los servicios de AWS utilizan VM ligeras como envoltorio de los trabajos, en lugar de contenedores. No pasa nada. El concepto sigue siendo el mismo.
Sin embargo, toda esta tecnología inteligente sigue chocando con la necesidad de información. Cuando un programador comprende las cargas de trabajo que está programando, puede utilizar los recursos de forma más eficaz. Si no sabe nada, no puede hacer un buen trabajo.
En el caso de Kubernetes, el programador puede actuar basándose en las restricciones especificadas en la definición del pod de la carga de trabajo, en particular las solicitudes (mínimas) y los límites (máximos) de CPU y memoria, pero eso significa que tienes que especificarlos. El problema es que eso puede ser complicado.
Según el veterano profesional de GreenOps Ross Fairbanks, "El problema tanto de la autoescalabilidad como de la definición de restricciones es que establecerlas es difícil". Afortunadamente, ahora existen algunas herramientas que lo facilitan. Fairbanks opina: " El Autoescalador de Vainas Verticales de Kubernetes puede ser de ayuda. Tiene un modo de recomendación para que puedas acostumbrarte a usarlo, así como un modo automatizado. Es un buen punto de partida si utilizas Kubernetes y quieres mejorar la utilización de las máquinas".1
¿Y la nube?
Si tus sistemas están alojados en la nube, aunque no utilices un orquestador de contenedores como Kubernetes, normalmente te beneficiarás de la programación de clusters, porque los proveedores de la nube utilizan sus propios programadores.
Puedes comunicar las características de tu carga de trabajo eligiendo el tipo de instancia de nube adecuado, y los programadores de la nube utilizarán tu elección para optimizar la utilización de sus máquinas. Por eso, desde una perspectiva ecológica, no debes sobreespecificar tus requisitos de recursos o disponibilidad (por ejemplo, pidiendo una instancia dedicada cuando bastaría con una bursátil o incluso sólo una no dedicada).
De nuevo, esto requiere reflexión, planificación y observación. Las nubes públicas son bastante buenas a la hora de detectar cuándo has sobreaprovisionado y estás utilizando disimuladamente algunos de esos recursos para otros usuarios (también conocido como sobresuscripción), pero la forma más eficiente de utilizar una plataforma es siempre tal y como fue concebida. Si lo que necesitas es una instancia bursátil, la forma más eficiente de utilizar la nube es elegir una.
Cargas de trabajo mixtas
La programación de clústeres es más eficaz (puedes conseguir un empaquetamiento realmente denso) si dispone de una amplia gama de tareas diferentes y bien etiquetadas para programar en un montón de grandes máquinas físicas. Por desgracia, esto significa que es menos eficaz -o incluso completamente ineficaz- para configuraciones más pequeñas, como la ejecución de Kubernetes on prem para un puñado de nodos o para un par de máquinas virtuales dedicadas en la nube.
Sin embargo, puede ser estupendo para los hiperescaladores. Tienen que hacer malabarismos con una amplia gama de trabajos para lograr un empaquetamiento óptimo y, en parte, eso explica los elevados porcentajes de utilización de servidores de los que informan. Los porcentajes de utilización que arroja AWS implican que AWS requiere menos de una cuarta parte del hardware que utilizarías en Prem para el mismo trabajo. Las cifras reales son difíciles de obtener, pero la cifra de AWS es más que plausible (probablemente sea una subestimación del ahorro potencial de AWS).
Ese menor número de servidores significa mucha menos electricidad utilizada y carbono incorporado. En consecuencia, el paso más fácil que puedes dar en materia de sostenibilidad suele ser trasladar tus sistemas a la nube y utilizar bien sus servicios, incluida toda la gama de tipos de instancias. Sólo utilizando sus servicios y programadores optimizados podrás conseguir esas cifras. No te traslades a servidores dedicados y esperes mucho valor ecológico, aunque utilices Kubernetes como un profesional.
Como hemos dicho antes, la escala y la eficiencia van de la mano. Los hiperescaladores pueden invertir el enorme esfuerzo de ingeniería para ser hipereficientes porque es su negocio principal. Si tu empresa se dedica a vender seguros, nunca tendrás el incentivo económico para construir una sala de servidores on-prem hipereficiente, aunque fuera posible. De hecho, no actuarías en tu propio interés si lo hicieras, porque no sería un elemento diferenciador.
Desplazamiento temporal e instancias puntuales
Los programadores mencionados anteriormente adquieren una dimensión extra de flexibilidad si añadimos el tiempo a la mezcla. Las arquitecturas que reconocen y pueden gestionar trabajos de baja prioridad o retrasables son especialmente operativas con una alta utilización de la máquina y, como veremos en el capítulo siguiente, esas arquitecturas son vitales para la conciencia del carbono. Según el experto en tecnología verde Paul Johnston, de, "estar siempre encendido es insostenible".
Lo que nos lleva a un giro interesante en la programación de clusters: el concepto en la nube de instancias puntuales (como se conocen en AWS y Azure; se llaman Instancias Preemptibles en el más literal GCP).
Los proveedores de nubes públicas utilizanlas instancias puntuales para conseguir una utilización aún mejor de las máquinas, utilizando la capacidad sobrante. Puedes poner tu trabajo en una instancia puntual, y puede que se complete o puede que no. Si sigues intentándolo, probablemente se realizará en algún momento, sin garantía de cuándo. En otras palabras, los trabajos tienen que ser muy cambiantes en el tiempo. A cambio de este enfoque laissez faire de la programación, los usuarios obtienen un 90% de descuento sobre el precio estándar del alojamiento.
Una instancia puntual combina varios de los conceptos de programación inteligente que acabamos de comentar. Es una forma de:
-
Envolver tu trabajo en una VM
-
Etiquetarlo como insensible al tiempo
-
Dejar que tu proveedor de la nube lo programe cuando y donde quiera
Potencialmente (es decir, dependiendo de los factores que intervienen en las decisiones de programación de la nube), el uso de instancias puntuales podría ser una de las formas más ecológicas de operar un sistema. Nos encantaría que los hiperescaladores tuvieran en cuenta la intensidad de carbono de la red local a la hora de programar las cargas de trabajo de las instancias puntuales, y esperamos que eso ocurra para 2025. Google ya está hablando de este tipo de medidas.
Multiarrendamiento
En un capítulo sobre eficiencia operativa, sería una parodia si no mencionáramos el concepto de multitenencia.
Multiarrendamiento es cuando una única instancia de un servidor se comparte entre varios usuarios, y es vital para una utilización realmente alta de la máquina. Fundamentalmente, cuanto más diversos sean tus usuarios (también conocidos como inquilinos), mejor será tu utilización.
¿Por qué? Pues consideremos lo contrario. Si todos tus inquilinos fueran minoristas de comercio electrónico, todos querrían más recursos el Viernes Negro y en vísperas de Navidad. También querrían procesar más solicitudes por las tardes y a la hora de comer (hora punta de las compras en casa). Una demanda correlacionada así es mala para la utilización.
No quieres tener que aprovisionar suficientes máquinas para las Navidades y luego tenerlas paradas el resto del año. Eso es muy poco ecológico. Sería más eficiente para la máquina si el minorista pudiera compartir sus recursos de hardware con alguien que tuviera mucho trabajo que hacer que fuera menos sensible al tiempo que las compras (por ejemplo, la formación en ML). Sería aún más óptimo compartir esos recursos con alguien que experimentara la demanda en diferentes fechas o a diferentes horas del día. Tener una amplia mezcla de clientes es otra forma de que las nubes públicas consigan sus elevadas cifras de utilización.
Servicios sin servidor
Los servicios sin servidor como AWS Lambda, Azure Functions y Google Cloud Functions son multiusuario. También tienen trabajos encapsulados, se preocupan por la instanciación rápida y ejecutan trabajos que son lo suficientemente cortos y sencillos como para que un programador sepa qué hacer con ellos (ejecutarlos lo más rápido posible y luego olvidarse de ellos). También tienen suficiente escala como para que a los proveedores de nubes públicas les merezca la pena esforzarse en hiperoptimizarlas.
Por tanto, los servicios sin servidor tienen un enorme potencial para ser baratos y ecológicos. Lo están haciendo decentemente, pero creemos que tienen margen para mejorar mucho. Cuanta más gente los utilice, más eficientes serán.
Hiperescaladores y beneficios
No hay ningún secreto mágico para ser ecológico en tecnología. Se trata sobre todo de ser mucho más eficiente y mucho menos derrochador, lo que coincide con los deseos de cualquiera que quiera gestionar sus costes de alojamiento.
Según el ex-Azure DevRel Adam Jackson, "el secreto no tan sucio de los proveedores de la nube pública es que cuanto más barato es un servicio, mayores son los márgenes. Los proveedores de la nube quieren que elijas la opción más barata porque es donde ganan más dinero".
Esos servicios son baratos porque son eficientes y funcionan a gran escala. Como señaló el economista del siglo XVII Adam Smith: "No es de la benevolencia del carnicero, el cervecero o el panadero de quien esperamos nuestra cena, sino de su atención a su propio interés". En la misma línea, los proveedores de la hipernube hacen que sus sistemas sean eficientes en su propio beneficio. Sin embargo, en este caso también es en nuestro beneficio, porque sabemos que, aunque la eficiencia no es un indicador exacto de la ecología, no es mala.
Reducir tus facturas de alojamiento utilizando los servicios más baratos, eficientes y comoditizados que puedas encontrar no sólo redunda en tu interés y en el del planeta, sino también en el de tu anfitrión. Ganará más dinero, y eso es bueno. Ganar dinero no está mal. Ser ineficiente energéticamente en medio de una crisis climática impulsada por la energía, sí lo es. También pone de relieve la razón por la que la eficiencia operativa puede ser la forma ganadora de eficiencia: puede hacer ganar mucho dinero a los operadores de centros de distribución. Está en consonancia con sus intereses, y debes elegir a los que tengan la conciencia para verlo y el capital para respaldarlo.
Nota
El servicio sin servidor AWS Lambda es un ejemplo excelente de cómo se mejora la eficiencia de un servicio cuando se hace evidente que hay suficiente demanda para que merezca la pena. Cuando Lambda se lanzó por primera vez, utilizaba muchos recursos. Definitivamente, no era ecológico. Sin embargo, cuando la demanda latente se hizo evidente, AWS invirtió y construyó la plataforma de código abierto Firecracker para ello, que utiliza máquinas virtuales más ligeras para aislar los trabajos y también mejora los tiempos de instanciación y la programación. Mientras exista una demanda sin explotar, es probable que continúe esta mercantilización. Eso hará que sea más barato y ecológico , además de más rentable para AWS.
Prácticas de SRE
La ingeniería de fiabilidad del sitio (SRE) es un concepto que originalmente procedía de otro hiperescalador obsesionado por la eficiencia: Google. Los SRE son responsables de diseñar, construir y mantener sistemas fiables y robustos que puedan soportar un tráfico elevado y seguir funcionando sin problemas. La buena noticia es que las operaciones ecológicas están alineadas con los principios de la SRE, y si tienes una organización SRE, ser ecológico debería ser más fácil.
Práctica de los ESR:
-
Monitoreo (que debe incluir las emisiones de carbono; véase el Capítulo 9 para nuestras opiniones sobre el tema de la medición de las emisiones de carbono y el Capítulo 10 para nuestras opiniones sobre cómo utilizar esas mediciones).
-
Integración y entrega continuas (que pueden ayudar a entregar y probar las reducciones de emisiones de carbono de forma más rápida y segura).
-
Automatización (por ejemplo, IaC, que ayuda a reducir el tamaño)
-
Containerización y microservicios (que son más automatizables y significan que todo tu sistema no está obligado a estar bajo demanda y puede ser más consciente del carbono).
Éste no es un libro sobre las buenas prácticas y principios de la SRE, así que no vamos a entrar en ellos en detalle, aunque los tratamos más a fondo en el Capítulo 11. Sin embargo, hay muchos libros disponibles en O'Reilly que las tratan de forma excelente y en profundidad.
LightSwitchOps
La mayor parte de lo que hemos hablado hasta ahora han sido cosas inteligentes de alta tecnología. Sin embargo, en hay algunas ideas sencillas de eficiencia operativa que cualquiera puede poner en práctica, y una de las más inteligentes que hemos oído es la de Holly Cummins, de Red Hat. Se llama LightSwitchOps (ver Figura 4-3).
Figura 4-3. LightSwitchOps ilustrado por Holly
Cerrar las cargas de trabajo zombis (término de Cummins para las aplicaciones y servicios que ya no hacen nada) debería ser una obviedad para ahorrar energía.
En un reciente experimento de la vida real, un importante proveedor de máquinas virtuales que trasladó uno de sus centros de distribución descubrió que dos tercios de sus servidores ejecutaban aplicaciones que ya apenas se utilizaban. De hecho, se trataba de cargas de trabajo zombis.
Según Martin Lippert, Spring Tools Lead & Sustainability Ambassador en VMware, "En 2019, VMware consolidó un centro de datos en Singapur. El equipo quería trasladar todo el centro de datos y, por tanto, investigó qué necesitaba exactamente una migración. El resultado fue algo chocante: el 66% de todas las máquinas host eran zombis".3
Este tipo de residuos ofrece un enorme potencial de ahorro de carbono. La triste realidad es que muchas de tus máquinas también pueden estar ejecutando aplicaciones y servicios que ya no aportan valor.
El problema es, ¿cuáles son exactamente?
Hay varias formas de averiguar si un servicio sigue importando a alguien. La más eficaz es algo llamado prueba del grito. Dejaremos como ejercicio para el lector deducir cómo funciona. Otra es que los recursos tengan una vida útil fija. Por ejemplo, podrías intentar aprovisionar sólo instancias que se apaguen solas al cabo de seis meses, a menos que alguien solicite activamente que sigan funcionando.
Son ideas estupendas, pero hay una razón por la que la gente no hace ninguna de estas cosas. Les preocupa que si apagan una máquina, no sea tan fácil volver a encenderla, y ahí es donde entra LightSwitchOps.
Para las operaciones ecológicas, es vital que puedas apagar las máquinas con la misma confianza con la que apagas las luces del salón, es decir, con la seguridad de que cuando pulses el interruptor para volver a encenderlas, lo harán. El consejo de Holly Cummins es que te asegures de que puedes apagar cualquier cosa. Si no lo estás, entonces si tu servidor no forma parte hoy del ejército de los muertos vivientes, puedes estar seguro de que algún día lo será.
Ross Fairbanks, profesional de GreenOps, sugiere que un buen punto de partida con LightSwitchOps es apagar automáticamente tus sistemas de prueba y desarrollo durante la noche y el fin de semana.
Apocalipsis zombi
Además de ahorrar carbono, hay razones de seguridad en para apagar esos servidores zombis. Ed Harrison, antiguo responsable de seguridad de en Metaswitch Networks (ahora parte de Microsoft), nos dijo: "Algunos de los mayores incidentes de ciberseguridad de los últimos tiempos han tenido su origen en sistemas que nadie conocía y que nunca deberían haber estado encendidos". Y añadió: "Los equipos de seguridad siempre intentan reducir la superficie de ataque. El equipo de sostenibilidad será su mejor amigo si se centra en apagar los sistemas que ya no son necesarios".4
Ubicación, ubicación, ubicación
Nos queda una cosa increíblemente importante de la que hablar. Se trata de un movimiento que es potencialmente incluso más fácil que LightSwitchOps, y podría ser el lugar adecuado para que empieces, sobre todo si te trasladas a un nuevo centro de datos.
Tienes que elegir el anfitrión y la región adecuados.
La realidad es que en algunas regiones es más fácil alimentar los centros de distribución con electricidad baja en carbono que en otras. Por ejemplo, Francia tiene un enorme parque nuclear, y Escandinavia tiene energía eólica e hidráulica. Los CC de esas zonas son más limpios.
Te lo repetimos, elige bien tus regiones. En caso de duda, pregunta a tu anfitrión.
Nota
La publicación empresarial global en línea Financial Times ofrece un buen ejemplo de un cambio de ubicación que conduce a una infraestructura más ecológica. El equipo de ingenieros del FinancialTimes pasó la mayor parte de una década trasladándose a regiones de la UE predominantemente sostenibles en la nube desde centros de datos locales que no tenían objetivos de sostenibilidad.
Anne habló con el Financial Times en 2018 (cuando la empresa había realizado el 75% del cambio) sobre el efecto que estaba teniendo en sus propios objetivos de sostenibilidad operativa. En ese momento, el resultado era que el ~67% de su infraestructura estaba en consecuencia en servidores "neutros en carbono", y la empresa esperaba que esto aumentara a casi el 90% cuando se produjera la transición a la Nube en 2020 (como así fue).
Puede que todo el mundo haya abandonado la frase "carbono neutral", pero el Financial Times hereda ahora el objetivo de AWS de alimentar sus operaciones con un 100% de energía renovable para 2025, lo cual es estupendo. La lección aquí es que elegir proveedores con objetivos de sostenibilidad sólidos con los que parezcan comprometidos (es decir, plataformas ecológicas) te quita ese trabajo duro de encima: simplemente ocurrirá bajo tus pies.
¡Oh No! ¡La Resistencia contraataca!
Por desgracia, la eficiencia y la resiliencia siempre han tenido una relación incómoda. La eficiencia añade complejidad y, por tanto, fragilidad a un sistema, y eso es un problema.
Eficiencia frente a resistencia
En la mayoría de los casos, no puedes hacer que un servicio sea más eficiente sin trabajar también para hacerlo más resistente, o se te caerá encima. Por desgracia, esto vuelve a poner en conflicto la eficacia con la productividad de los desarrolladores.
Por ejemplo:
-
Los programadores de clústeres son bestias complicadas que pueden ser difíciles de configurar y utilizar con éxito.
-
Hay muchos modos de fallo en el multiarrendamiento: la privacidad y la seguridad se convierten en problemas, y siempre existe el riesgo de que un problema de otro arrendatario en tu máquina se extienda y afecte a tus propios sistemas.
-
Incluso apagar las cosas no está exento de riesgos. La prueba del grito de la que hablamos antes hace exactamente lo que pone en la lata.
-
Por si fuera poco, el sobreaprovisionamiento es una forma probada de añadir robustez a un sistema de forma barata en términos de tiempo de desarrollo (a costa de un aumento de las facturas de alojamiento, pero la mayoría de la gente está dispuesta a hacer ese trueque).
Yendo al grano, la eficacia es un reto para la resiliencia.
Hay algunos argumentos en contra. Aunque un programador de clústeres es bueno para la eficiencia operativa, también tiene ventajas en cuanto a resiliencia. Una de las principales razones por las que la gente utiliza un programador de clústeres es para reiniciar automáticamente los servicios ante fallos de nodo, hardware o red. Si un nodo se cae o deja de estar disponible por cualquier motivo, un programador puede trasladar automáticamente las cargas de trabajo afectadas a otros nodos del clúster. No sólo consigues una utilización eficiente de los recursos, sino también una mayor disponibilidad, siempre que no haya sido el programador del clúster el que se haya caído, claro.
Sin embargo, la realidad es que ser más eficiente puede ser un negocio arriesgado. Manejar sistemas más complejos requiere nuevas habilidades. En el caso de Microsoft, que mejoró la eficacia de Teams durante la pandemia de COVID, la empresa no podía limitarse a introducir cambios en su eficacia. También tuvo que mejorar sus pruebas adoptando técnicas de ingeniería del caos en la producción para eliminar los errores de su nuevo sistema.
Al igual que Microsoft, si realizas tú mismo alguna mejora directa de la eficiencia, probablemente tendrás que hacer más pruebas y más arreglos. En el ejemplo de Skyscanner, el uso de instancias puntuales aumentó la resiliencia de sus sistemas y también redujo sus facturas de alojamiento y aumentó su ecologismo, pero toda la motivación de la empresa para adoptar instancias puntuales fue forzarse a sí misma a realizar pruebas adicionales de resiliencia.
La eficiencia suele ir de la mano de la especialización, y es más eficaz a gran escala, pero la escala también tiene peligros. La Unión Europea teme que estemos poniendo todos nuestros huevos computacionales en la cesta de unos pocos hiperescaladores estadounidenses, lo que podría conducir a un mundo frágil. La UE tiene razón, y formó la Alianza para una Infraestructura Digital Sostenible(SDIA) para intentar combatir ese riesgo.
Por otro lado, sabemos que la misma concentración se traducirá en menos máquinas y menos electricidad utilizada. Será difícil que los proveedores más pequeños que componen la SDIA alcancen las eficiencias de escala de los hiperescaladores, aunque se alineen en opciones sensatas de tecnología de alojamiento de código abierto, como recomienda la SDIA.
Puede que no nos guste la idea de los enormes centros de datos que están construyendo Amazon, Google, Microsoft y Alibaba, pero es casi seguro que serán mucho más eficientes que un millar de centros de datos más pequeños, aunque éstos calienten unas cuantas piscinas municipales o distritos instagrammables, como exige actualmente la UE.
Ten en cuenta que nos encantan los nuevos mandatos de la UE sobre transparencia en las emisiones. No nos burlamos de la UE, aunque por una u otra pequeña razón ninguno de nosotros vive ya en ella. No obstante, preferiríamos que los centros de distribución estuvieran situados cerca de aerogeneradores o granjas solares, donde podrían utilizar un exceso inesperado de energía en lugar de competir con los hogares por la preciada electricidad en las zonas urbanas de la red.
Herramientas y técnicas operativas ecológicas
Dando un paso atrás, repasemos las principales medidas de eficiencia operativa que puedes tomar. Algunas son difíciles, pero la buena noticia es que muchas son sencillas, sobre todo si se comparan con la eficiencia del código. Recuerda, todo gira en torno a la utilización de la máquina.
-
Apaga las cosas si apenas se usan o mientras no se utilizan, como los sistemas de prueba durante el fin de semana (LightSwitchOps de Holly Cummins).
-
No sobreaprovisiones (utiliza rightsizing y autoscaling, instancias burstables en la nube). Recuerda autoescalar tanto hacia abajo como hacia arriba, ¡o sólo será útil la primera vez!
-
Recorta tus facturas de alojamiento en la medida de lo posible utilizando, por ejemplo, el Explorador de costes de AWS o el análisis de costes de Azure, o un servicio no hiperescalador como CloudZero, ControlPlane o Harness. Una simple auditoría también puede identificar a menudo servicios zombis. Más barato es casi siempre más verde.
-
Las arquitecturas de microservicios en contenedores que reconocen las tareas de baja prioridad y/o retrasables pueden funcionar con una mayor utilización de la máquina. Sin embargo, ten en cuenta que aumentar la complejidad de la arquitectura exagerando el número de microservicios también puede provocar un aprovisionamiento excesivo. Sigues necesitando seguir las buenas prácticas de diseño de microservicios, así que, por ejemplo, lee Building Microservices (O'Reilly) de Sam Newman.
-
Si estás en la nube, los tipos de instancia dedicados no tienen conciencia del carbono y la utilización de la máquina es baja. Elegir tipos de instancia que den más flexibilidad al anfitrión aumentará la utilización y reducirá las emisiones de carbono y los costes.
-
Adopta la multitenencia desde las máquinas virtuales compartidas a las plataformas de contenedores gestionadas.
-
Utiliza servicios en la nube y tipos de instancias eficientes, a gran escala y preoptimizados (como instancias reventables, bases de datos gestionadas y servicios sin servidor). O utiliza productos equivalentes de código abierto con un compromiso con las prácticas ecológicas o eficientes, una comunidad enérgica que les obligue a cumplir esos compromisos, y la escala para cumplirlos de forma realista.
-
Recuerda que las instancias puntuales en AWS o Azure (instancias preferentes en GCP) son geniales: baratas, eficientes, ecológicas y una plataforma que fomenta la resiliencia de tus sistemas.
-
Nada de esto es fácil, pero los principios de la SRE pueden ayudar: CI/CD, monitoreo y automatización.
Por desgracia, nada de esto está exento de trabajo. Incluso funcionar menos o apagar cosas requiere una inversión de tiempo y atención. Sin embargo, lo bueno de ser ecológico es que al menos te ahorrará dinero. Así que el primer sistema que hay que tener en cuenta desde el punto de vista ecológico debería ser también el más fácil de convencer a tu jefe: el más caro.
Dicho esto, cualquier cosa que no esté libre de trabajo, aunque ahorre mucho dinero, va a ser difícil de vender. Será más fácil conseguir la inversión si puedes alinear tu paso a las operaciones ecológicas con una entrega más rápida o con el ahorro de tiempo del desarrollador o de operaciones en el futuro, porque esas ideas son atractivas para las empresas.
Eso significa que los más eficaces de los pasos sugeridos son los cinco últimos. Fíjate en los principios de la SRE, el multiarrendamiento, los servicios gestionados, las bibliotecas ecológicas de código abierto y las instancias puntuales. Todos ellos están diseñados para ahorrar tiempo de desarrollo y operaciones a largo plazo, y resultan ser baratos y ecológicos porque son productos básicos y escalables. No luches contra la máquina. Ser ecológico sin destruir la productividad de los desarrolladores consiste en elegir plataformas ecológicas.
Para sobrevivir a la transición energética, calculamos que todo va a tener que volverse mil veces más eficiente en carbono a través de una combinación de, inicialmente, eficiencia operativa y desplazamiento de la demanda y, finalmente, eficiencia del código, todo ello conseguido utilizando plataformas ecológicas. Aunque suene ambicioso, debería ser factible. Se trata de liberar la mayor capacidad de hardware que hemos utilizado para la productividad de los desarrolladores en los últimos 30 años, manteniendo al mismo tiempo la productividad de los desarrolladores.
Puede que tarde una década, pero ocurrirá. Tu trabajo consiste en asegurarte de que todos tus proveedores de plataformas, ya sean de nube pública, de código abierto o de código cerrado, tienen una estrategia creíble para conseguir este tipo de ecologismo. Esta es la pregunta que debes hacerte constantemente: "¿Es ésta una plataforma ecológica?"
Get Software ecológico para la construcción now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

