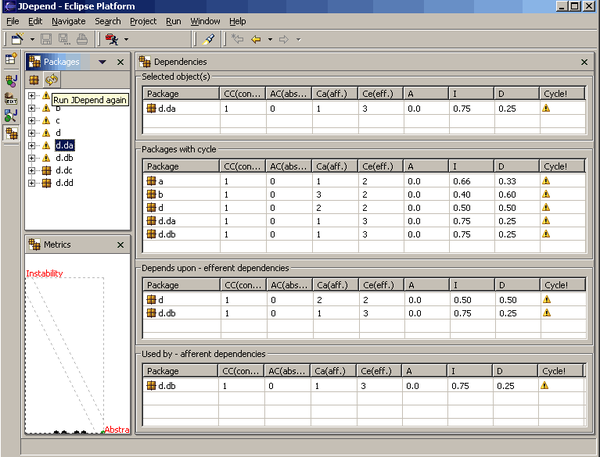
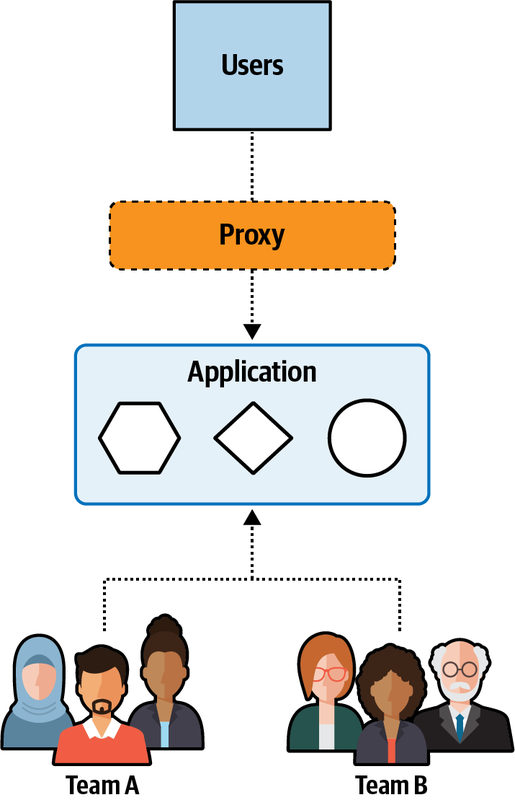
Now that Addison and Austen had the go-ahead to move to a distributed architecture and break apart the monolithic Sysops Squad application, they needed to determine the best approach for how to get started.
“The application is so big I don’t even know where to start. It’s as big as an elephant!” exclaimed Addison.
“Well,” said Austen. “How do you eat an elephant?”
“Ha, I’ve heard that joke before, Austen. One bite at a time, of course!” laughed Addison.
“Exactly. So let’s use the same principle with the Sysops Squad application,” said Austen. “Why don’t we just start breaking it apart, one bite at a time? Remember how I said reporting was one of the things causing the application to freeze up? Maybe we should start there.”
“That might be a good start,” said Addison, “but what about the data? Just making reporting a separate service doesn’t solve the problem. We’d need to break apart the data as well, or even create a separate reporting database with data pumps to feed it. I think that’s too big of a bite to take starting out.”
“You’re right,” said Austen. “Hey, what about the knowledge base functionality? That’s fairly standalone and might be easier to extract.”
“That’s true. And what about the survey functionality? That should be easy to separate out as well,” said Addison. “The problem is, I can’t help feeling like we should be tackling this with more of a methodical approach rather than just eating the elephant bite by bite.”
“Maybe Logan can give us some advice,” said Austen.
Addison and Austen met with Logan to discuss some of the approaches they were considering for how to break apart the application. They explained to Logan that they wanted to start with the knowledge base and survey functionality but weren’t sure what to do after that.
“The approach you’re suggesting,” said Logan, “is what is known as the Elephant Migration Anti-Pattern. Eating the elephant one bite at a time may seem like a good approach at the start, but in most cases it leads to an unstructured approach that results in a big ball of distributed mud, what some people also call a distributed monolith. I would not recommend that approach.”
“So, what other approaches exist? Are there patterns we can use to break apart the application?” asked Addison.
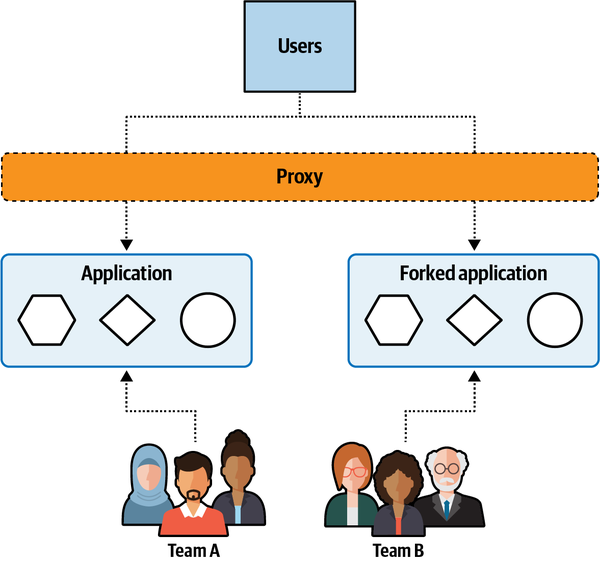
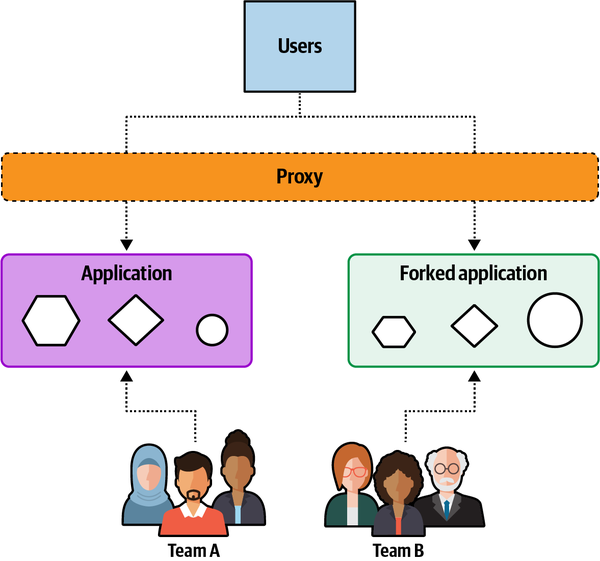
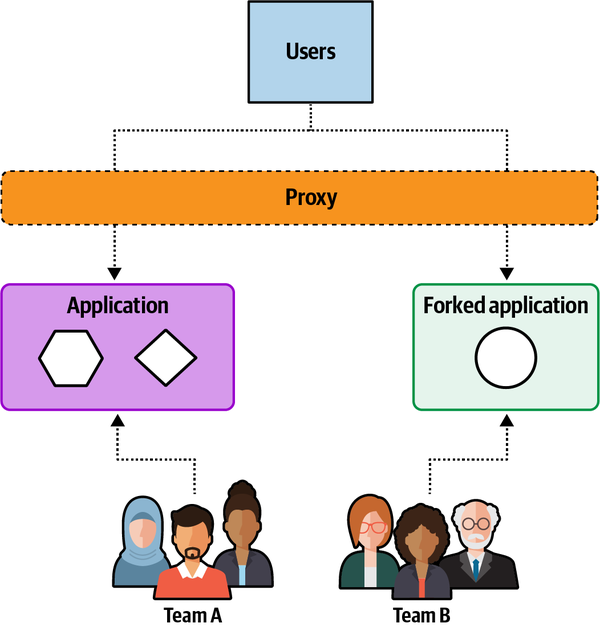
“You need to take a holistic view of the application and apply either tactical forking or component-based decomposition,” said Logan. “Those are the two most effective approaches I know of.”
Addison and Austen looked at Logan. “But how do we know which one to use?”