Kapitel 1. Was ist eigentlich Serverless?
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Serverless wurde auf als transformative Technologie gehypt, von verschiedenen Entwicklungsplattformen als Marke genutzt und von den großen Cloud-Providern als Label auf Dutzende von Diensten geklebt. Sie verspricht die Möglichkeit, Code mehrmals am Tag auszuliefern, neue Anwendungen mit ein paar Dutzend Codezeilen zu prototypisieren und auf die größten Anwendungsprobleme zu skalieren. Unternehmen wie Snap (die Haupt-App von Snapchat), iRobot (für die Kommunikation von Hunderttausenden von Haushaltsgeräten) und Microsoft (für eine Vielzahl von Websites und Portalen) haben sie bereits erfolgreich für ihre Produktionsanwendungen eingesetzt.
Wie bereits im Vorwort erwähnt, wird der Begriff "serverlos" nicht nur für Recheninfrastrukturdienste, sondern auch für Speicherung, Messaging und andere Systeme verwendet. Die Definitionen auf helfen zu erklären, was serverlos ist und was nicht. Da sich dieses Buch darauf konzentriert, wie man Anwendungen mit einer serverlosen Infrastruktur erstellt, konzentrieren sich viele Kapitel darauf, wie man die Rechenschichten entwirft und programmiert. Unsere Definition soll aber auch Infrastrukturteams helfen, die darüber nachdenken, serverlose Abstraktionen zu entwickeln, die nicht auf Computern basieren. Zu diesem Zweck werde ich die folgende Definition von Serverless verwenden:
Serverless ist ein Muster für die Entwicklung und Ausführung verteilter Anwendungen, das die Last in unabhängige Arbeitseinheiten aufteilt und diese Arbeit dann automatisch auf einer automatisch skalierten Anzahl von Instanzen plant und ausführt.
Generell gilt,1 besteht das serverlose Muster darin, die Anzahl der Rechenprozesse automatisch an die verfügbare Arbeitsmenge anzupassen, wie in Abbildung 1-1 dargestellt.

Abbildung 1-1. Das serverlose Modell
Du wirst feststellen, dass diese Definition sehr weit gefasst ist. Sie umfasst nicht nur FaaS-Plattformen wie AWS Lambda oder Cloudflare Workers, sondern könnte auch Systeme wie GitHub Actions (Build- und Continuous-Integration-Aktionen), Service Worker in Chrome (Hintergrund-Threads, die zwischen Browser und Server koordinieren) oder sogar benutzerdefinierte Funktionen auf einer Abfrageplattform wie Googles BigQuery (verteiltes SQL-Warehouse) umfassen. Dazu gehören auch Plattformen für die Speicherung von Objekten wie Amazon Simple Storage Service (S3) (eine Arbeitseinheit ist die Speicherung eines Blob) und sogar Actor-Frameworks, die die Anzahl der Instanzen zur Verwaltung des Actor-Status automatisch skalieren.
In diesem Buch werde ich in der Regel Beispiele aus demOpen-Source-Projekt Knative heranziehen, um die Serverless-Prinzipien zu veranschaulichen, aber ich werde gelegentlich auch auf andere Serverless-Plattformen eingehen, wenn es Sinn macht. Ich werde mich aus drei Gründen auf Knative konzentrieren:
-
Als Open-Source-Projekt ist es auf einer Vielzahl von Plattformen verfügbar, von Cloud-Providern bis hin zu Einplatinencomputern wie dem Raspberry Pi.
-
Da es sich um ein Open-Source-Projekt handelt, ist der Quellcode zum Experimentieren verfügbar. Du kannst Debugging-Zeilen hinzufügen oder es in ein größeres bestehendes Projekt oder eine Plattform integrieren. Bei vielen serverlosen Plattformen handelt es sich um kommerzielle Cloud-Angebote, die an einen bestimmten Anbieter gebunden sind und bei denen du ihrePlattform in der Regel nicht verändern oder ersetzen kannst.
-
Es steht im Titel des Buches und ich nehme an, einige von euch wären enttäuscht, wenn ich es nicht erwähnen würde. Außerdem habe ich fünf Jahre lang mit der Knative-Community zusammengearbeitet, Software und Community aufgebaut und Fragen beantwortet. Mein Fachwissen über Knative ist mindestens genauso groß wie meine Erfahrung mit anderen Plattformen.
Warum nennt man es Serverless?
Sesselkritiker von Serverless weisen gerne auf einen Fehler im Namen hin - auch wenn der Name "Serverless" lautet, handelt es sich in Wirklichkeit um eine Möglichkeit, deinen Anwendungscode irgendwo auf Servern auszuführen. Wie kam es also zu diesem Namen und wie passt Serverless in die Entwicklung von Computersystemen in den letzten 50 Jahren?
In den 1960er und 1970er Jahren waren Großrechner selten, teuer und das Herzstück der Informatik. In den 70er und 80er Jahren wurden die Computer immer kleiner und billiger, so dass es Mitte der 90er Jahre oft billiger war, mehrere kleinere Computer miteinander zu vernetzen, um eine Aufgabe zu bewältigen, als einen einzelnen teureren Computer zu kaufen. Die effiziente Koordinierung dieser Computer ist die Grundlage des verteilten Computings. (Eine ausführlichere Geschichte des Serverless Computing findest du in Kapitel 11. Einen Überblick über die Entwicklung des Begriffs "Serverless" findest du unter "Cloud-Hosted Serverless").
Während es viele Möglichkeiten gibt, Computer miteinander zu verbinden, um Probleme durch verteiltes Rechnen zu lösen, konzentriert sich Serverless darauf, die Lösung von Problemen zu erleichtern, die in bekannte Muster für die Verteilung von Arbeit fallen. Vieles davon deckt sich mit der Microservices-Bewegung, die um 2010 begann und darauf abzielte, bestehende monolithische Anwendungen in unabhängige Komponenten aufzuteilen, die von kleineren Teams geschrieben und verwaltet werden können. Serverless ergänzt eine Microservices-Architektur, indem es die Implementierung einzelner Microservices vereinfacht (aber nicht voraussetzt).
Tipp
Das Ziel von Serverless ist es, dass Entwickler beim Erstellen und Skalieren von Anwendungen nicht mehr in Servereinheiten denken müssen,2 sondern stattdessen Skalierungseinheiten zu verwenden, die für die Anwendung sinnvoll sind.
Indem sie bekannte Muster übernehmen, können serverlose Plattformen schwierige, aber gängige Prozesse wie Failover, Replikation oder Request Routing automatisieren - die "undifferenzierte Schwerstarbeit" des verteilten Computings (ein Begriff, den Jeff Bezos 2006 prägte, als er die Vorteile der Cloud-Computing-Plattform von Amazon beschrieb). Ein beliebtes serverloses Modell aus dem Jahr 2011 ist das Zwölf-Faktoren-Anwendungsmodell, das mehrere Muster beschreibt, die von den meisten serverlosen Plattformen übernommen werden, darunter zustandslose Anwendungen, bei denen die Speicherung von externen Diensten oder der Plattform übernommen wird, sowie eine klare Trennung von Konfiguration und Anwendungscode.
Inzwischen sollte klar sein, dass eine serverlose Entwicklungsphilosophie nicht bedeutet, einen ganzen Haufen teurer Hardware aus dem Fenster zu werfen - im Gegenteil, serverlose Plattformen müssen oft mit bestehenden Softwaresystemen zusammenarbeiten und sich in diese integrieren, einschließlich Mainframe-Systemen, deren Ursprünge in den 1960er Jahren liegen.
Knative ( ) ist eine gute Wahl für die Integration von Serverless-Funktionen in eine bestehende Computing-Plattform, da es auf den Fähigkeiten von Kubernetes aufbaut und diese nativ integriert. Auf diese Weise überbrückt Knative die Frage "Serverless versus Container", die seit der Einführung von AWS Lambda und Kubernetes im Jahr 2014 ein beliebter Streitpunkt ist.
Ein bisschen Terminologie
Auf beschreibe ich serverlose Systeme und vergleiche sie mit traditionellen Computersystemen. Ich werde im Laufe des Buches ein paar spezifische Begriffe verwenden. Ich werde versuchen, diese Begriffe einheitlich zu verwenden, denn es gibt viele Möglichkeiten, ein serverloses System zu implementieren, und es lohnt sich, eine präzise Sprache zu verwenden, die sich von spezifischen Produkten unterscheidet und mit der wir beschreiben können, wie unsere mentalen Modelle auf eine bestimmte Implementierung zutreffen:
- Prozess
-
Ich verwende den Begriff Prozess im Sinne von Unix: ein ausführendes Programm mit einem oder mehreren Threads, die sich einen gemeinsamen Speicherbereich und eine Schnittstelle mit einem Kernel teilen. Die meisten serverlosen Systeme basieren auf dem Linux-Kernel, da dieser sowohl beliebt als auch kostenlos ist. Andere serverlose Systeme basieren jedoch auf dem Windows-Kernel oder der JavaScript-Laufzeit, die über WebAssembly (Wasm) offengelegt wird. Der zum Zeitpunkt der Erstellung dieses Buches am weitesten verbreitete serverlose Prozessmechanismus ist der Linux-Kernel über das Container-Subsystem, das sowohl von Lambda über die Firecracker-VM-Bibliothek als auch von verschiedenen Open-Source-Projekten wie Knative über das Zeitplannungsprogramm Kubernetes und das Container Runtime Interface (CRI) genutzt wird.
- Instanz
-
Eine Instanz ist eine serverlose Ausführungsumgebung zusammen mit der externen Systeminfrastruktur, die für die Verwaltung des Root-Prozesses in dieser Umgebung benötigt wird. Die Instanz ist die kleinste verfügbare Einheit für Planung und Berechnung in einem serverlosen System und wird oft als Schlüssel in Systemen wie Logging, Monitoring und Tracing verwendet, um Korrelationen zu ermöglichen. Serverlose Systeme behandeln Instanzen als kurzlebig und erstellen und zerstören sie automatisch als Reaktion auf die Systemauslastung. Je nach Serverless-Umgebung kann es möglich sein, mehrere Prozesse innerhalb einer einzigen Instanz auszuführen, aber das äußere Serverless-System betrachtet die Instanz als die Einheit für Skalierung und Ausführung.
- Artefakt
-
Ein Artefakt (oder Code-Artefakt) ist ein Satz von Computercode, der bereit ist, von einer Instanz ausgeführt zu werden. Das kann eine ZIP-Datei mit Quellcode, ein kompiliertes JAR, ein Container-Image oder ein Wasm-Snippet sein. Normalerweise führt jede Instanz den Code mit einem bestimmten Artefakt aus. Wenn ein neues Artefakt bereit ist, werden neue Instanzen gestartet und die alten Instanzen gelöscht. Diese Methode des Ausrollens von Code unterscheidet sich von traditionellen Systemen, die VMs bereitstellen und diese VMs dann wiederverwenden, um viele verschiedene Artefakte oder Versionen eines Artefakts auszuführen, und sie hat vorteilhafte Eigenschaften, auf die wir später eingehen werden.
- Bewerbung
-
Eine Anwendung ist eine konzipierte und koordinierte Reihe von Prozessen und Speichersystemen, die zusammengefügt werden, um einen bestimmten Nutzwert zu erzielen. Während einfache Anwendungen nur eine Art von Instanz enthalten können, enthalten die meisten serverlosen Anwendungen mehrere Microservices, von denen jeder seine eigene Art von Instanz ausführt. Es ist auchüblich, dass Anwendungen mit einer Mischung aus serverlosen und nicht-serverlosen Komponenten erstellt werden - in Kapitel 5 erfährst du mehr darüber, wie du serverlose und traditionelle Architekturen in eine einzige Anwendung integrieren kannst.
Diese Komponenten sowie einige andere, wie das Zeitplannungsprogramm, sind inAbbildung 1-2 dargestellt.

Abbildung 1-2. Komponenten einer serverlosen Anwendung
Was ist eine "Einheit der Arbeit"?
Serverless skaliert nach Arbeitseinheiten und kann auf null Instanzen skalieren, wenn es keine Arbeit gibt. Du fragst dich vielleicht, was eine Arbeitseinheit ist? Eine Arbeitseinheit ist eine zustandslose, unabhängige Anfrage, die von einer einzelnen Instanz mit einer bestimmten Menge an Rechenleistung (und weiteren Netzwerkanfragen) erfüllt werden kann. Lasst uns das mal aufschlüsseln:
- Zustandslos
-
Jede Anfrage enthält alle zu erledigenden Aufgaben und hängt nicht davon ab, ob die Instanz bereits frühere Teile der Anfrage bearbeitet hat oder ob andere Anfragen im Gange sind. Das bedeutet auch, dass ein serverloser Prozess keine Daten für zukünftige Aufgaben im Speicher ablegen kann oder davon ausgeht, dass zwischen den Arbeitseinheiten Prozesse laufen, um z. B. prozessinterne Timer zu verwalten. Diese Definition lässt viel Spielraum - du kannst auf die Ergebnisse von Arbeitseinheiten verweisen, die bereits verarbeitet wurden, oder deine Arbeit kann ein Datenstrom sein, wie z. B. "Hier ist ein Videosegment, das Bewegung enthält (bis die Bewegung aufhört)". Wenn du die Eingaben in die Funktion ohne lokalen Zustand verarbeiten kannst (z. B. eine Funktion, die nicht mit einer Klasse oder globalen Werten verbunden ist), dann bist du zustandslos genug, um serverlos zu sein.
- Unabhängig
-
Da nur Arbeit referenziert werden kann, die an anderer Stelle abgeschlossen ist, können serverlose Systeme durch Hinzufügen weiterer Knoten horizontal skaliert werden, da jede Arbeitseinheit nicht direkt von der Ausführung einer anderen abhängt. Darüber hinaus bedeutet Unabhängigkeit, dass Arbeit an eine Instanz weitergeleitet werden kann, die bereit ist, die Arbeit zu erledigen (einschließlich einer neu erstellten Instanz), und Instanzen können geschlossen werden, wenn nicht genug Arbeit vorhanden ist, um sie zu verteilen.
- Anfragen
-
Wie reaktive Systeme sollten auch serverlose Systeme nur dann arbeiten, wenn sie darum gebeten werden. Diese Arbeitsanfragen können viele Formen annehmen: Es kann sich um zu verarbeitende Ereignisse, HTTP-Anfragen, zu verarbeitende Zeilen oder sogar um E-Mails handeln, die im System ankommen. Das Wichtigste dabei ist, dass die Arbeit in einzelne Teile zerlegt werden kann. Das System kann messen, wie viele Teile es gibt, und anhand dieser Messung bestimmen, wie viele Instanzen bereitgestellt werden müssen.
Hier sind einige Beispiele für Arbeitseinheiten,auf die serverlose Systemeskalieren können.
Verbindungen
Ein System könnte jede eingehende TCP-Verbindungsanfrage als eine Arbeitseinheit behandeln. Wenn eine Verbindung eintrifft, wird sie einer Instanz zugeordnet, und diese Instanz spricht ein (proprietäres) Protokoll, bis die eine oder andere Seite die Verbindung aufgibt.
Wie in Abbildung 1-3 dargestellt, verwendet CockroachDB das folgende Modell, um die "Köpfe" von PostgreSQL (Postgres) in ihrer Datenbank zu verwalten3Jede Datenbankverbindung eines Kunden wird von einem speziellen Verbindungsproxy an einen SQL-Prozessor für diesen Kunden weitergeleitet, der das Postgres-Protokoll spricht, die SQL-Abfragen interpretiert, sie in Abfragepläne für die (gemeinsam genutzte) Backend-Speicherung umwandelt, die Abfragepläne ausführt und dann die Ergebnisse wieder in das Postgres-Protokoll einträgt und an den Kunden zurückgibt. Wenn für einen bestimmten Kunden keine Verbindungen geöffnet sind, wird der Pool der SQL-Prozessoren auf Null reduziert.
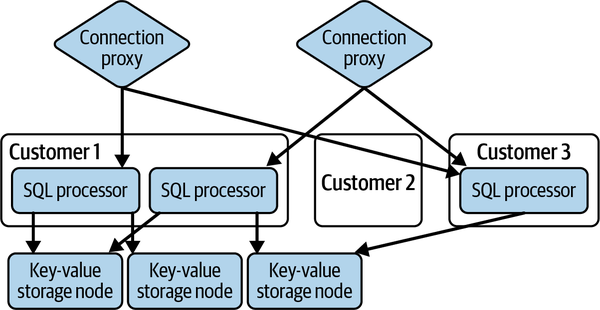
Abbildung 1-3. CockroachDB serverlose Architektur
Durch die Verwendung des serverlosen Paradigmas kann CochroachDB die Nutzung nur dann in Rechnung stellen, wenn eine Datenbankverbindung tatsächlich aktiv ist, und einen angemessenen kostenlosen Dienst für kleine Kunden anbieten, die den Dienst meist nicht nutzen. Natürlich ist der Backend-Speicherdienst dafür nicht serverlos - die Daten werden in einem gemeinsam genutzten Key-Value-Store gespeichert, und die Datenspeicherung wird den Kunden auf monatlicher Basis unabhängig von der Anzahl der Verbindungen und ausgeführten Abfragen in Rechnung gestellt. Mehr über dieses Modell erfährst du unter "Key-Value Storage".
Anfragen
Auf einer höheren Ebene könnte ein serverloses System ein bestimmtes Anwendungsprotokoll wie HTTP, SMTP (E-Mail) oder einen RPC-Mechanismus verstehen und jeden Protokollaustausch als einzelne Arbeitseinheit interpretieren. Viele Protokolle unterstützen die Wiederverwendung oder das Multiplexen von Anwendungsanfragen auf einer einzigen TCP-Verbindung. Wenn das serverlose System die Anwendungsnachrichten versteht, kann die Arbeit in kleinere Teile zerlegt werden, was folgende Vorteile hat:
-
Bei kleineren Anfragen ist die Wahrscheinlichkeit größer, dass sie gleichmäßig groß und zeitlich enger begrenzt sind. Bei Protokollen, die es erlauben, mehr als eine Anfrage über einen TCP-Stream zu übertragen, werden die meisten Anfragen vermutlich vor dem TCP-Stream beendet, und die Arbeit für die Ausführung einer Anfrage ist kleiner, was einen feineren Lastausgleich zwischen den Instanzen ermöglicht.
-
Die Interpretation von Anwendungsanfragen ermöglicht es, die Lebensdauer von Verbindungen und Instanzen zu entkoppeln. Wenn eine TCP-Verbindung die Arbeitseinheit ist, müssen für die Bereitstellung eines neuen Code-Artefakts neue Instanzen für neue Verbindungen gestartet und dann gewartet werden, bis die bestehenden Verbindungen abgeschlossen sind (dies wird beschwörend als "Entleeren" der Instanzen bezeichnet). Wenn das Entleeren der Instanzen fünf Minuten statt einer Minute dauert, brauchen Anwendungsrollouts und Konfigurationsänderungen fünfmal so lange, um abgeschlossen zu werden. Viele Einstellungen (z. B. Umgebungsvariablen) können nur gesetzt werden, wenn ein Prozess (eine Instanz) gestartet wird, was die Geschwindigkeit einschränkt, mit der Teams Code oder Konfigurationen ändern können.
-
Je nach Protokoll ist es möglich, dass eine einzelne Verbindung null, eine oder viele Anfragen auf einmal hat. Durch die Interpretation von Anwendungsanfragen bei der Planung von Arbeitseinheiten können serverlose Systeme eine höhere Effizienz und geringere Latenzzeiten erreichen - indem sie Anfragen auf mehrere Instanzen aufteilen, wenn Anfragen parallel gestellt werden, oder indem sie vermeiden, Instanzen für Verbindungen zu starten, für die derzeit keine Anfragen vorliegen.
-
Indem sie die Grenzen von Anfragen auf Anwendungsebene definieren, können serverlose Systeme qualitativ hochwertigere Telemetriedaten und Dienste bereitstellen. Wenn das System die Dauer einer Anfrage messen kann, kann es die Latenzzeit, die Größe der Anfrage und andere Metriken messen, und es kann Fristen und die Nachverfolgung von Anfragen auf Anwendungsebene außerhalb des spezifischen Prozesses, der eine Anfrage bearbeitet, ermöglichen und durchsetzen. Auf diese Weise können serverlose Systeme auf Anwendungsfehler genauso reagieren wie API-Gateways und andere HTTP-Router.
Veranstaltungen
Auf einer hohen Ebene sind Ereignisse und Anfragen fast dasselbe. Auf einer anderen Ebene sind Ereignisse ein grundlegender Baustein für reaktive und asynchrone Architekturen. Ereignisse sagen aus: "Zu diesem Zeitpunkt ist diese Sache passiert." Es wäre möglich, ein ganzes serverloses System auf Basis von Ereignissen zu modellieren; du könntest ein Ereignis für "Diese HTTP-Anfrage ist passiert", "Diese Datenbankzeile wurde gescannt" oder "Dieses Element in der Arbeitswarteschlange wurde empfangen" haben. Das ist eine sehr clevere Methode, um sowohl synchrone als auch asynchrone Kommunikation in einem einzigen Modell unterzubringen. Leider führt die Umwandlung von synchronen Anfragen in asynchrone Ereignisse und "Antwortereignisse", die mit dem Anfrageereignis korreliert sind, zu einigen Problemen:
- Zeitüberschreitungen
-
Die Durchsetzung von Zeitüberschreitungen in asynchronen Systemen kann viel schwieriger sein, vor allem wenn eine Nachricht, die eine Zeitüberschreitung benötigt, irgendwo in einer Nachrichtenwarteschlange stehen könnte und darauf wartet, dass ein Prozess bemerkt, dass die Zeitüberschreitung beendet ist.
- Fehlerberichterstattung
-
Abgesehen von Timeouts und Anwendungsabstürzen können synchrone Anfragen manchmal auch Fehlerbedingungen in der zugrunde liegenden Anwendung auslösen. Fehlerbedingungen können alles sein, von "Du hast eine Datei angefordert, für die du keine Berechtigung hast" über "Du hast eine Suchanfrage ohne Abfrage gesendet" bis hin zu "Diese Eingabe hat aufgrund eines Programmierfehlers eine Ausnahme ausgelöst." Alle diese Fehlerbedingungen müssen dem ursprünglichen Aufrufer so zurückgemeldet werden, dass er verstehen kann, was er mit seiner Anfrage falsch gemacht hat und wie er weiter vorgehen kann.
- Kardinalität und Korrelation
-
Es mag zwar Vorteile haben, "Eine Anfrage wurde empfangen" und "Eine Antwort wurde gesendet" als Ereignisse zu modellieren, aber diese Ereignisse als Nachrichtenbus zu verwenden, um zu sagen: "Bitte senden Sie diese Antwort auf dieses Ereignis", geht am Sinn von Ereignissen als Beobachtungen eines externen Systems vorbei. Praktischer gefragt: Welche Bedeutung hat ein zweites "Bitte sende diese Antwort zu diesem Ereignis", das mit demselben Anfrageereignis korreliert? Wenn man davon ausgeht, dass das Anwendungsprotokoll nur eine einzige Antwort vorsieht, wird das zweite Ereignis wahrscheinlich verworfen. Das Verwerfen des Ereignisses kann wiederum eine zusätzliche Benachrichtigung des Verursachers erforderlich machen, um ihm mitzuteilen, dass seine Nachricht ignoriert wurde - ein weiterer Fall des bereits erwähnten Problems der Fehlerberichterstattung.
Meiner Meinung nach sind diese Kosten die Vorteile eines "großen, einheitlichen Ereignismodells von Serverless" nicht wert. Manchmal sind synchrone Aufrufe die richtige Antwort, manchmal sind asynchrone Aufrufe die richtige Antwort, und es liegt an den Anwendungsentwicklern, auf intelligente Weise zwischen beiden zu wählen.
Es geht nicht (nur) um die Waage
Die automatische Skalierung ist schön, aber eine Laufzeitumgebung um Arbeitseinheiten herum aufzubauen, hat mehr Vorteile. Sobald die Infrastrukturebene versteht, warum die Anwendung ausgeführt wird, ist es möglich, ein zusätzliches Gerüst um die Anwendung herum aufzubauen, um zu messen und zu verwalten, wie gut sie ihre Arbeit erledigt. Je feinkörniger die Arbeitseinheiten sind, desto mehr Unterstützung kann die Plattform bieten, um die Anwendung zu verstehen, zu kontrollieren und sogar zu sichern.
In der Welt der Desktop- und Webbrowser-Anwendungen fand diese Revolution in den späten 1990er (Desktop) und 2000er Jahren (Browser) statt, als Anwendungsereignis- oder Nachrichtenschleifen langsam durch Frameworks ersetzt wurden, die Callback-basierte Systeme verwendeten, um Benutzereingaben automatisch an die entsprechenden Widgets und Steuerelemente innerhalb eines Fensters weiterzuleiten. Für HTTP-Server wurde in den 90er Jahren ein ähnliches Single-System-Framework namens CGI (Common Gateway Interface) entwickelt. In vielerlei Hinsicht war dies der Vorläufer der modernen serverlosen Systeme - es ermöglichte das Schreiben eines Programms, das auf eine einzige HTTP-Anfrage antwortet und viele Details der Netzwerkkommunikation automatisch abwickelt. (Mehr über CGI und seinen Einfluss auf serverlose Systeme erfährst du inKapitel 11).
Ähnlich wie bei der CGI-Spezifikation können moderne serverlose Systeme viele der bewährten Methoden der Routineprogrammierung vereinfachen, wenn es um die Handhabung einer Arbeitseinheit geht, und zwar auf eine programmierunabhängige Weise. Cloud Computing nennt diese Art von Hilfen "undifferenziertes Heavy Lifting" - das heißt, jedes Programm braucht sie, aber jedes Programm ist in Ordnung, wenn sie auf die gleiche Weise ausgeführt werden.
Die folgende Liste ist nicht erschöpfend; es ist durchaus möglich, dass die Anzahl der Funktionen, die durch das Verstehen von Arbeitseinheiten ermöglicht werden, weiter zunimmt, wenn weitere Werkzeuge und Funktionen zu den Laufzeitumgebungen hinzugefügt werden.
Blau und Grün: Rollout, Rollback und Day-to-Day
Die meisten serverlosen Systeme beinhalten ein Konzept zur koordinierten Aktualisierung oder Änderung des Code-Artefakts oder der Konfiguration der Instanzausführung. Das System weiß auch, was eine Arbeitseinheit ist, und verfügt über eine (interne) Möglichkeit, Anfragen an eine oder mehrere Instanzen weiterzuleiten, auf denen ein bestimmtes Code-Artefakt ausgeführt wird. Einige Systeme legen diese Details für Anwendungsbetreiber offen und ermöglichen es diesen Betreibern, die Verteilung der eingehenden Arbeit auf verschiedene Versionen eines Code-Artefakts explizit zu steuern.
Wenn man herauszoomt, sieht der serverlose Prozess, bei dem neue Instanzen mit einer bestimmten Version eines Code-Artefakts gestartet und alte Instanzen eingesammelt werden, wenn sie nicht mehr gebraucht werden, sehr ähnlich aus wie das Serverful Blue-Green Deployment-Muster: Eine zweite Bank von Servern wird mit dem "grünen" Code gestartet, während die "blauen" Server weiterlaufen, bis die grünen Server hochgefahren sind und der Datenverkehr von den blauen Servern auf die grünen umgeleitet wurde. Mit serverlosem Request Routing und automatischer Skalierung können diese Übergänge sehr schnell erfolgen, manchmal in weniger als einer Sekunde bei kleinen Anwendungen und in weniger als fünf Minuten selbst bei sehr großen Anwendungen.
Neben dem blau-grünen Rollout-Muster ist es auch möglich, die Verteilung der Arbeit auf die verschiedenen Versionen einer Anwendung prozentual (proportional) zu steuern. Diese ermöglicht sowohl inkrementelle Rollouts (die Arbeit wird langsam von einer Version auf eine andere verlagert, z. B. um die Caches der neuen Version zu füllen) als auch Canary Deployments (ein kleiner Prozentsatz der Arbeit wird an eine neue Anwendung weitergeleitet, um zu sehen, wie die Anwendung auf echte Nutzeranfragen reagiert).
Während es bei inkrementellen Rollouts vor allem darum geht, die Skalierung zu steuern, geht es bei Blue-Green- und Canary-Rollouts vor allem darum, das Bereitstellungsrisiko zu steuern. Einer der risikoreicheren Aspekte beim Betrieb eines Dienstes ist die Bereitstellung von neuem Anwendungscode oder neuer Konfiguration - die Änderung eines bereits funktionierenden Systems birgt das Risiko, dass der neue Systemzustand nicht funktioniert. Da es einfach ist, neue Instanzen mit einer bestimmten Version schnell zu starten, ist es mit Serverless schneller und einfacher, zu einer bestehenden (funktionierenden) Version zurückzukehren. Dies führt zu einer geringeren mittleren Wiederherstellungszeit (MTTR), einer gängigenKennzahl für die Notfallwiederherstellung.
Indem einzelne Instanzen ephemer sind und automatisch auf Basis der eingehenden Arbeit skaliert werden, kann Serverless das Risiko von "Infrastruktur-Schneeflocken" reduzieren -Systeme, die speziell von Hand mit handwerklichen Konfigurationen eingerichtet werden, die schwer zu replizieren oder zu reparieren sind. Wenn Instanzen im Rahmen des regulären Infrastrukturbetriebs automatisch ersetzt und neu bereitgestellt werden, werden die Wiederherstellung und die Initialisierung der Instanzen kontinuierlich getestet, wodurch sichergestellt wird, dass etwaige Mängel relativ schnell behoben werden.
Das kontinuierliche Ersetzen oder Erneuern von Infrastrukturinstanzen kann auch Sicherheitsvorteile haben: Eine Instanz, die von einem Angreifer beschädigt wurde, wird genauso zurückgesetzt wie eine Instanz, die durch einen Softwarefehler beschädigt wurde. Ephemere Instanzen können die Verteidigungsposition einer Anwendung verbessern, indem sie es Angreifern erschweren, die Persistenz aufrechtzuerhalten und sie zwingen, dieselbe Infrastruktur wiederholt zu kompromittieren. Die Notwendigkeit, eine Kompromittierung wiederholt durchzuführen, erhöht die Wahrscheinlichkeit, dass der Angriff entdeckt und die Schwachstelle geschlossen wird.
Tipp
Serverless behandelt einzelne Instanzen als fungibel - dasheißt, jede Instanz ist gleichermaßen durch eine andere ersetzbar. Die Lösung für eine defekte Instanz ist einfach, sie wegzuwerfen und eine neue zu besorgen. Die Antwort auf die Frage "Wie viele Instanzen für X?" lautet immer "So viele, wie du brauchst", denn es ist einfach, Instanzen hinzuzufügen oder zu entfernen. Wenn du dich an dieses Muster der austauschbaren Instanzen hältst, vereinfachst du viele betriebliche Probleme.
Creature Comforts: Undifferenziertes Heavy Lifting
Wie bereits in "Warum heißt es Serverless?" beschrieben hat , besteht einer der Vorteile einer serverlosen Plattform darin, dass sie gemeinsame Funktionen bereitstellt, die in jeder Anwendung nur schwer oder immer wieder neu implementiert werden können.
Wie in "It's Not (Just) About the Scale" erwähnt , ist es einfach, das Gerüst zu nutzen, um die undifferenzierten Aufgaben zu übernehmen, für die sonst Anwendungscode erforderlich wäre, sobald die eingehende Arbeit in das System aufgeschlüsselt und von der Infrastruktur erkannt wurde. Ein Beispiel dafür ist die Beobachtbarkeit: Eine herkömmliche Anwendung benötigt Instrumente, die jedes Mal messen, wenn eine Anfrage (Arbeitseinheit) gestellt wird und wie lange es dauert, diese Anfrage abzuschließen. Mit einer serverlosen Infrastruktur, die die Arbeitseinheiten für dich verwaltet, ist es für die Infrastruktur ein Leichtes, eine Uhr ticken zu lassen, wenn die Arbeit an deine Anwendung übergeben wird, und eine Latenzmessung aufzuzeichnen, wenn deine Anwendung die Arbeit abgeschlossen hat.
Es kann zwar immer noch notwendig sein, detailliertere Metriken aus deiner Anwendung heraus bereitzustellen (z. B. die Anzahl der gescannten Datensätze zur Beantwortung einer Arbeitsanfrage), aber die automatische Überwachung, Visualisierung und sogar Alarmierung zu Durchsatz und Latenz von Arbeitseinheiten kann Anwendungsteams eine einfache "Null-Aufwand"-Überwachungsgrundlage bieten. Monitoring-Basis. Das spart nicht nur Zeit bei der Anwendungsentwicklung, sondern kann auch Teams, die keine Zeit oder Lust haben, Fachwissen über Überwachung und Beobachtung zu entwickeln, bei der Anwendungsbereitstellung unterstützen.
Ebenso kann es sein, dass Serverless-Infrastrukturen eine Anwendungsnachverfolgung für die von der Infrastruktur verwalteten Arbeitseinheiten benötigen und implementieren möchten. Dieses Tracing dient zwei verschiedenen Zwecken:
-
Es bietet Infrastrukturbenutzern die Möglichkeit, die Quelle der Anwendungslatenz zu untersuchen und zu bestimmen, einschließlich der plattformbedingten Latenz und der Latenz aufgrund des Anwendungsstarts (falls zutreffend).
-
Es liefert Infrastrukturbetreibern umfassendere Informationen über zugrunde liegende Plattformengpässe, einschließlich der Anwendungsskalierung und der beobachteten Gesamtlatenz.
Weitere gängige Beobachtungsfunktionen sind die Sammlung und Aggregation von Protokollen, Performance-Profiling und Stack-Tracing. In Kapitel 10 wird die Verwendung dieser Tools zum Debuggen von serverlosen Anwendungen in der ephemeren Live-Umgebung näher erläutert. Durch die Kontrolle der angrenzenden Umgebung (und in einigen Fällen des Erstellungsprozesses der Anwendung) können Serverless-Umgebungen problemlos Observability Agents parallel zum Anwendungsprozess ausführen, um diese Arten von Daten zu sammeln.
Abbildung 1-4 zeigt eine Visualisierung der Messpunkte, die in einem serverlosen System implementiert werden können.

Abbildung 1-4. Gemeinsame Fähigkeiten
Creature Comforts: Inputs verwalten
Da serverlose Umgebungen einen infrastrukturgesteuerten Ingress-Punkt für Arbeitseinheiten bieten, kann die Infrastruktur selbst genutzt werden, um bewährte Methoden für die Bereitstellung von Diensten für den Rest der Welt zu implementieren. Ein Beispiel dafür ist die automatische Konfiguration von TLS (einschließlich der unterstützten Chiffren und der Beschaffung und Rotation gültiger Zertifikate, falls erforderlich) für serverlose Dienste, die über HTTPS oder andere Serverprotokolle aufgerufen werden können. Durch die Verlagerung dieser Aufgaben auf die serverlose Schicht kann der Infrastrukturanbieter ein spezialisiertes Team beschäftigen, das die Einhaltung bewährter Methoden sicherstellt; die Arbeit dieses Teams verteilt sich dann auf alle serverlosen Verbraucher, die die Plattform nutzen. Zu den weiteren gängigen Funktionen, die über "undifferenzierte Schwerstarbeit" hinausgehen, gehören Autorisierung, Durchsetzung von Richtlinien undProtokollübersetzung.
Eine visuelle Darstellung der von Knative durchgeführten Eingabetransformationen findest du in Abbildung 1-5.
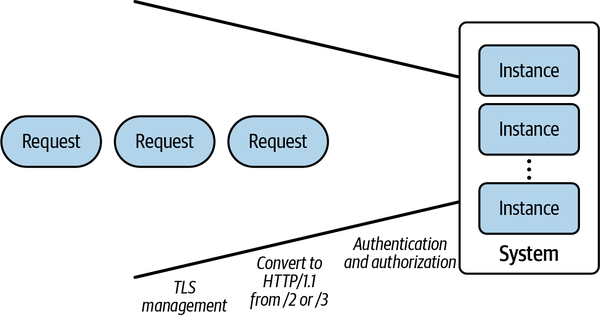
Abbildung 1-5. Eingaben verwalten
Die Durchsetzung von Berechtigungen und Richtlinien ist in vielen Anwendungsszenarien eine entscheidende Fähigkeit. In einer traditionellen Architektur könnte diese Ebene an eine äußere Anwendungsfirewall oder einen Proxy oder eine sprachspezifische Middleware delegiert werden. Middleware eignet sich gut für einsprachige Ökosysteme, aber es ist schwierig, ein einheitliches Leistungsniveau in der Middleware für mehrere Sprachen aufrechtzuerhalten. Firewalls und Proxys extrahieren diese Middleware in eine gemeinsame Dienstebene, aber die geschützte Anwendung muss immer noch überprüfen, ob die Anfragen von der Firewall und nicht von einem anderen internen Angreifer gesendet wurden. Da serverlose Plattformen den Weg der Anfrage bis zur Auslieferung der Arbeit an dieAnwendung kontrollieren, müssen sich die Anwendungsautoren nicht darum kümmern, obdie Anfragen von der Infrastruktur ordnungsgemäß bearbeitet wurden - eine weitere Verbesserung der Lebensqualität.
Die letzte Verbesserung der Lebensqualität von Anwendungsentwicklern besteht in der Möglichkeit, externe Anfragen in Arbeitseinheiten zu übersetzen, die von den Zielanwendungen leichter verarbeitet werden können. Viele moderne Protokolle sind kompliziert und erfordern umfangreiche Bibliotheken, um sie korrekt und effizient zu implementieren. Durch die Implementierung der Protokollübersetzung von einem komplexen Protokoll (wie HTTP/3 über UDP) in ein einfacheres (z. B. HTTP/1.1, das weithin verstanden wird), können Anwendungsentwickler aus einer größeren Auswahl an Anwendungsbibliotheken und Programmiersprachen wählen.
Creature Comforts: Prozesslebenszyklus verwalten
Als Teil der Skalierung und Arbeitsverteilung übernehmen serverlose Instanzen eine aktive Rolle bei der Verwaltung des Lebenszyklus des Anwendungsprozesses sowie aller Hilfsprozesse, die von der Plattform selbst erzeugt werden. Abhängig von der Plattform und der Menge der anfallenden Arbeit muss die Plattform diese Arbeit möglicherweise zurückhalten (in eine Warteschlange stellen), bis eine Instanz verfügbar ist, die die Anfrage bearbeiten kann. Dies wird als Kaltstart bezeichnet und kann selbst dann auftreten, wenn es bereits aktive Anwendungsinstanzen gibt (z. B. könnte ein plötzlicher Arbeitsansturm die Kapazität der bereitgestellten Instanzen übersteigen). Einige Serverless-Plattformen entscheiden sich für eine Überprovisionierung von Instanzen, um einen Puffer für solche Fälle zu schaffen, während andere die Anzahl zusätzlicher Instanzen minimieren, um die Kosten zu senken.
Normalerweise durchläuft ein Anwendungsprozess innerhalb einer serverlosen Instanz die folgenden Lebenszyklusphasen:
- 1. Platzierung
Bevor ein Prozess gestartet werden kann, muss die Instanz einem tatsächlichen Serverknoten zugewiesen werden. Es ist ein alter Witz, dass es in Serverless tatsächlich Server gibt, aber Serverless-Plattformen berücksichtigen mehrere der folgenden Bedingungen:
- Ressourcenverfügbarkeit: Je nach Modell und Grad der zulässigen Überzeichnung sind einige Knotenpunkte möglicherweise kein geeignetes Ziel für eine neue Instanz.
- Gemeinsame Artefakte: In der Regel können sich zwei Instanzen auf demselben Serverknoten Anwendungscode-Artefakte teilen. Je nach Größe der kompilierten Anwendung kann dies zu einer wesentlich schnelleren Startzeit der Anwendung führen, da weniger Daten zum Knoten geholt werden müssen.
- Adjacency: Wenn sich zwei Instanzen derselben Anwendung auf demselben Knoten befinden, kann es möglich sein, einige Ressourcen auf dem Knoten zu teilen (Speicherzuordnungen für gemeinsam genutzte Bibliotheken, just-in-time [JIT] kompilierter Code usw.). Je nach Sprache und Implementierung können diese Einsparungen beträchtlich oder fast nicht vorhanden sein.
- Wettstreit und gegnerische Effekte: In einer Umgebung mit mehreren Anwendungen konkurrieren einige Anwendungen möglicherweise um begrenzte Knotenressourcen (z. B. L2-Cache oder Speicherbandbreite). Ausgefeilte serverlose Plattformen können diese Anwendungen erkennen und sie auf verschiedene Knoten verteilen. Beachte, dass eine besonders optimierte Anwendung zu ihrem eigenen Gegner werden kann, wenn sie einen großen Teil einer nicht gemeinsam genutzten Ressource verwendet.
- Zeitplannungsprogramm für Tenants: In manchen Umgebungen kann es strenge Regeln dafür geben, welche Tenants physische Ressourcen mit anderen Tenants teilen dürfen. Starke Sandbox-Kontrollen innerhalb eines physischen Knotens können dennoch nicht vor neuartigen Angriffen wie Spectre oder Rowhammer schützen, die das Sicherheitsmodell umgehen.
- 2. Initialisierung
Nachdem die Instanz auf einem Knoten platziert wurde, muss die Instanz die Anwendungsumgebung vorbereiten. Dies kann Folgendes beinhalten:
- Holen von Code-Artefakten: Falls noch nicht vorhanden, müssen die Code-Artefakte abgerufen werden, bevor der Bewerbungsprozess beginnen kann.
- Abrufen der Konfiguration: Zusätzlich zum Code benötigen einige Instanzen bestimmte Konfigurationsinformationen (einschließlich Instance-Level oder Shared Secrets), die in das lokale Dateisystem geladen werden.
- Dateisysteme mounten: Einige serverlose Systeme unterstützen das Mounten von gemeinsamen Dateisystemen (entweder schreibgeschützt oder schreibgeschützt) auf Instanzen, um gemeinsame Daten zu verwalten. Bei anderen muss die Instanz die Daten beim Start abrufen.
- Netzwerkkonfiguration: Die neu erstellten Instanzen müssen auf irgendeine Weise bei dem ankommenden Load Balancer registriert werden, um Datenverkehr zu empfangen. Je nach Anzahl der Load Balancer kann dies ein Broadcast-Problem sein. In einigen Systemen müssen sich die Instanzen auch bei einem NAT-Anbieter (Network Address Translation) für den ausgehenden Datenverkehr registrieren.
- Ressourcenisolierung: Die Instanz muss möglicherweise Isolationsmechanismen wie Linux
cgroupskonfigurieren, um sicherzustellen, dass die Anwendung eine angemessene Menge an Knotenressourcen nutzt. - Sicherheitsisolierung: In einem mandantenfähigen System kann es notwendig sein, Sandboxen oder leichtgewichtige VMs einzurichten, um zu verhindern, dass Nutzer benachbarte Mandanten gefährden.
- Hilfsprozesse: Die serverlose Umgebung kann zusätzliche Dienste anbieten, wie z. B. die Sammlung von Protokollen oder Metriken, Service-Proxys oder Identitätsagenten. In der Regel sollten diese Prozesse konfiguriert und bereit sein, bevor der Hauptprozess der Anwendung startet.
- Sicherheitsrichtlinien: Diese können sowohl Richtlinien für den eingehenden als auch für den ausgehenden Netzwerkverkehr umfassen, die einschränken, welche Dienste der Anwendungsprozess im Netzwerk sehen kann.
- 3. Inbetriebnahme
Sobald die Umgebung bereit ist, wird der Anwendungsprozess gestartet. Normalerweise muss die Anwendung eine Art von Setup und interner Initialisierung durchführen, bevor sie bereit ist, Arbeit zu erledigen. Dies wird oft durch eine Bereitschaftsprüfung angezeigt, die entweder ein Aufruf des Prozesses an die äußere Umgebung oder eine Anfrage der Umgebung an den Prozess zur Gesundheitsprüfung sein kann.
Während die Platzierungs- und Initialisierungsphase größtenteils in der Verantwortung der serverlosen Plattform liegt, ist für die Startphase größtenteils der Anwendungsprogrammierer verantwortlich. Bei einigen Sprachimplementierungen kann die Startphase der Anwendung den Großteil der Verzögerung ausmachen, die auf Kaltstarts zurückzuführen ist.
- 4. Servieren
Sobald der Bewerbungsprozess signalisiert hat, dass er bereit ist, Arbeit zu empfangen, erhält er Arbeitseinheiten, die auf den Richtlinien der Plattform basieren. Einige Plattformen beschränken die Arbeit in einem Prozess auf eine einzige Anfrage, während andere mehrere Arbeitseinheiten auf einmal zulassen.
Sobald ein Prozess in den Serving-Status eintritt, bearbeitet er in der Regel mehrere Aufgaben (entweder parallel oder nacheinander), bevor er beendet wird. Die Wiederverwendung eines aktiven Serving-Prozesses trägt dazu bei, die Kosten für die Platzierung, Initialisierung und den Start zu amortisieren und die Anzahl der Kaltstarts der Anwendung zu reduzieren.
- 5. Abschalten
Sobald der Anwendungsprozess nicht mehr benötigt wird, signalisiert die Plattform, dass der Prozess beendet werden soll. Eine Plattform kann einige dieser Garantien bieten:
- Entleeren: Bevor die Instanz die Beendigung signalisiert, stellt sie sicher, dass sich keine Arbeitseinheiten mehr in der Luft befinden. Das vereinfacht das Herunterfahren der Anwendung, da sie keine aktive Arbeit mehr blockieren muss.
- Anständiges Herunterfahren: Einige Serverless-Plattformen bieten einem laufenden Prozess die Möglichkeit, vor dem Herunterfahren Aktionen auszuführen, wie z. B. das Leeren des Caches, das Aktualisieren von Snapshots oder das Aufzeichnen der letzten Anwendungsmetriken. Nicht alle Serverless-Plattformen bieten eine "Graceful Shutdown"-Phase an. Daher ist es wichtig zu wissen, ob diese Art von Aktivitäten auf der von dir gewählten Plattform garantiert ist.
- 6. Beendigung
Sobald das Shutdown-Signal gesendet wurde und eine eventuelle Graceful Shutdown-Phase verstrichen ist, wird der Prozess beendet und alle Hilfsprozesse, Sicherheitsrichtlinien und andere Ressourcen, die während der Initialisierung zugewiesen wurden, werden bereinigt (und durchlaufen möglicherweise ihre eigenen Graceful Shutdown-Phasen). Auf Plattformen, die nach verbrauchten Ressourcen abrechnen, ist dies oft der Zeitpunkt, an dem die Abrechnung endet. Bis zur Beendigung gelten die Ressourcen der Instanz im Allgemeinen als vom Zeitplannungsprogramm "beansprucht", so dass ein schneller Wechsel der Instanzen die Entscheidungen des serverlosen Zeitplannungsprogramms beeinflussen kann.
Zusammenfassung
Serverless Computing und Serverless-Plattformen setzen ein bestimmtes Anwendungsverhalten voraus. Sie werden bestehende Systeme nicht vollständig ersetzen und sind möglicherweise nicht für alle Anwendungen geeignet. Für eine Reihe von gängigen Anwendungsmustern bieten serverlose Plattformen erhebliche technische Vorteile, und ich erwarte, dass der Anteil der Unternehmen und Anwendungen, die serverlos arbeiten, weiter steigen wird. Im nächsten Kapitel geht es darum, eine kleine serverlose Anwendung zu erstellen, damit du ein Gefühl dafür bekommst, wie diese Theorie in der Praxis funktioniert.
1 In "Aufgaben-Warteschlangen" werden wir kurz über die Skalierung der Arbeit über die Zeit und nicht über die Anzahl der Instanzen sprechen.
2 "Servereinheiten" können entweder virtuelle/physische Maschinen oder Serverprozesse sein, die auf einer einzigen Instanz laufen. In beiden Fällen zielt Serverless darauf ab, dass sich die Entwickler nicht mehr um beides kümmern müssen!
3 Dies wird in Andy Kimballs Blogbeitrag "How We Built a Serverless SQL Database" beschrieben , in dem die Architektur von CockroachDB Serverless beschrieben wird (ich habe ihn zusammengefasst).
Get Serverlose Anwendungen auf Knative aufbauen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

