Chapter 5. Ray Design Details
Now that you’ve created and worked with remote functions and actors, it’s time to learn what’s happening behind the scenes. In this chapter, you will learn about important distributed system concepts, like fault tolerance, Ray’s resource management, and ways to speed up your remote functions and actors. Many of these details are most important when using Ray in a distributed fashion, but even local users benefit. Having a solid grasp of the way Ray works will help you decide how and when to use it.
Fault Tolerance
Fault tolerance refers to how a system will handle failures of everything from user code to the framework itself or the machines it runs on. Ray has a different fault tolerance mechanism tailored for each system. Like many systems, Ray cannot recover from the head node failing.1
Warning
Some nonrecoverable errors exist in Ray, which you cannot (at present) configure away. If the head node, GCS, or connection between your application and the head node fails, your application will fail and cannot be recovered by Ray. If you require fault tolerance for these situations, you will have to roll your own high availability, likely using ZooKeeper or similar lower-level tools.
Overall, Ray’s architecture (see Figure 5-1) consists of an application layer and a system layer, both of which can handle failures.
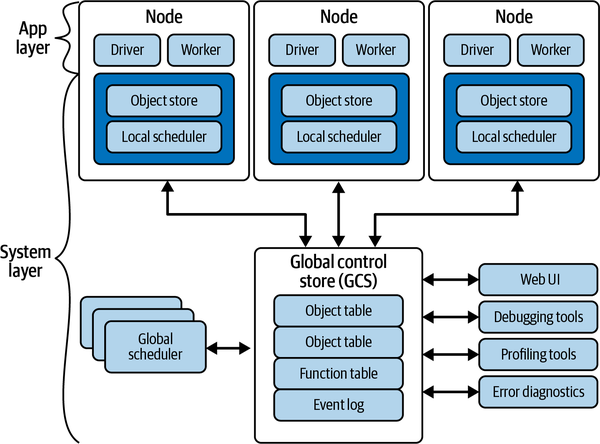
Figure 5-1. Overall Ray architecture ...
Get Scaling Python with Ray now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

