Chapter 1. What Is Ray, and Where Does It Fit?
Ray is primarily a Python tool for fast and simple distributed computing. Ray was created by the RISELab at the University of California, Berkeley. An earlier iteration of this lab created the initial software that eventually became Apache Spark. Researchers from the RISELab started the company Anyscale to continue developing and to offer products and services around Ray.
Note
You can also use Ray from Java. Like many Python applications, under the hood Ray uses a lot of C++ and some Fortran. Ray streaming also has some Java components.
The goal of Ray is to solve a wider variety of problems than its predecessors, supporting various scalable programing models that range from actors to machine learning (ML) to data parallelism. Its remote function and actor models make it a truly general-purpose development environment instead of big data only.
Ray automatically scales compute resources as needed, allowing you to focus on your code instead of managing servers. In addition to traditional horizontal scaling (e.g., adding more machines), Ray can schedule tasks to take advantage of different machine sizes and accelerators like graphics processing units (GPUs).
Since the introduction of Amazon Web Services (AWS) Lambda, interest in serverless computing has exploded. In this cloud computing model, the cloud provider allocates machine resources on demand, taking care of the servers on behalf of its customers. Ray provides a great foundation for general-purpose serverless platforms by providing the following features:
-
It hides servers. Ray autoscaling transparently manages servers based on the application requirements.
-
By supporting actors, Ray implements not only a stateless programming model (typical for the majority of serverless implementations) but also a stateful one.
-
It allows you to specify resources, including hardware accelerators required for the execution of your serverless functions.
-
It supports direct communications between your tasks, thus providing support for not only simple functions but also complex distributed applications.
Ray provides a wealth of libraries that simplify the creation of applications that can fully take advantage of Ray’s serverless capabilities. Normally, you would need different tools for everything, from data processing to workflow management. By using a single tool for a larger portion of your application, you simplify not only development but also your operation management.
In this chapter, we’ll look at where Ray fits in the ecosystem and help you decide whether it’s a good fit for your project.
Why Do You Need Ray?
We often need something like Ray when our problems get too big to handle in a single process. Depending on how large our problems get, this can mean scaling from multicore all the way through multicomputer, all of which Ray supports. If you find yourself wondering how you can handle next month’s growth in users, data, or complexity, our hope is you will take a look at Ray. Ray exists because scaling software is hard, and it tends to be the kind of problem that gets harder rather than simpler with time.
Ray can scale not only to multiple computers but also without you having to directly manage servers. Computer scientist Leslie Lamport has said, “A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.” While this kind of failure is still possible, Ray is able to automatically recover from many types of failures.
Ray runs cleanly on your laptop as well as at scale with the same APIs. This provides a simple starting option for using Ray that does not require you to go to the cloud to start experimenting. Once you feel comfortable with the APIs and application structure, you can simply move your code to the cloud for better scalability without needing to modify your code. This fills the needs that exist between a distributed system and a single-threaded application. Ray is able to manage multiple threads and GPUs with the same abstractions it uses for distributed computing.
Where Can You Run Ray?
Ray can be deployed in a variety of environments, ranging from your laptop to the cloud, to cluster managers like Kubernetes or Yarn, to six Raspberry Pis hidden under your desk.1 In local mode, getting started can be as simple as a pip install and a call to ray.init. Much of modern Ray will automatically initialize a context if one is not present, allowing you to skip even this part.
The ray up command, which is included as part of Ray, allows you to create clusters and will do the following:
-
Provision a new instance/machine (if running on the cloud or cluster manager) by using the provider’s software development kit (SDK) or access machines (if running directly on physical machines)
-
Execute shell commands to set up Ray with the desired options
-
Run any custom, user-defined setup commands (for example, setting environment variables and installing packages)
-
Initialize the Ray cluster
-
Deploy an autoscaler if required
In addition to ray up, if running on Kubernetes, you can use the Ray Kubernetes operator. Although ray up and the Kubernetes operator are preferred ways of creating Ray clusters, you can manually set up the Ray cluster if you have a set of existing machines—either physical or virtual machines (VMs).
Depending on the deployment option, the same Ray code will work, with large variances in speed. This can get more complicated when you need specific libraries or hardware for code, for example. We’ll look more at running Ray in local mode in the next chapter, and if you want to scale even more, we cover deploying to the cloud and resource managers in Appendix B.
Running Your Code with Ray
Ray is more than just a library you import; it is also a cluster management tool. In addition to importing the library, you need to connect to a Ray cluster. You have three options for connecting your code to a Ray cluster:
- Calling
ray.initwith no arguments -
This launches an embedded, single-node Ray instance that is immediately available to the application.
- Using the Ray Client
ray.init("ray://<head_node_host>:10001") -
By default, each Ray cluster launches with a Ray client server running on the head node that can receive remote client connections. Note, however, that when the client is located remotely, some operations run directly from the client may be slower because of wide area network (WAN) latencies. Ray is not resilient to network failures between the head node and the client.
- Using the Ray command-line API
-
You can use the
ray submitcommand to execute Python scripts on clusters. This will copy the designated file onto the head node cluster and execute it with the given arguments. If you are passing the parameters, your code should use the Pythonsysmodule that provides access to any command-line arguments viasys.argv. This removes the potential networking point of failure when using the Ray Client.
Where Does It Fit in the Ecosystem?
Ray sits at a unique intersection of problem spaces.
The first problem that Ray solves is scaling your Python code by managing resources, whether they are servers, threads, or GPUs. Ray’s core building blocks are a scheduler, distributed data storage, and an actor system. The powerful scheduler that Ray uses is general purpose enough to implement simple workflows, in addition to handling traditional problems of scale. Ray’s actor system gives you a simple way of handling resilient distributed execution state. Ray is therefore able to act as a reactive system, whereby its multiple components can react to their surroundings.
In addition to the scalable building blocks, Ray has higher-level libraries such as Serve, Datasets, Tune, RLlib, Train, and Workflows that exist in the ML problem space. These are designed to be used by folks with more of a data science background than necessarily a distributed systems background.
Overall, the Ray ecosystem is presented in Figure 1-2.
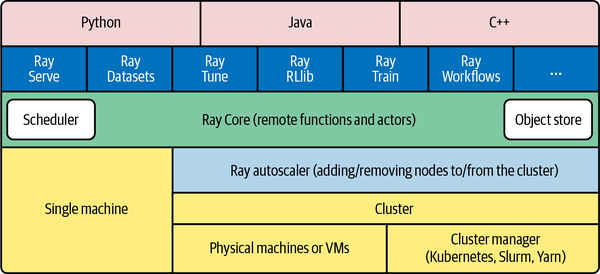
Figure 1-2. The Ray ecosystem
Let’s take a look at some of these problem spaces and see how Ray fits in and compares with existing tools. The following list, adapted from the Ray team’s “Ray 1.x Architecture” documentation, compares Ray to several related system categories:
- Cluster orchestrators
-
Cluster orchestrators like Kubernetes, Slurm, and Yarn schedule containers. Ray can leverage these for allocating cluster nodes.
- Parallelization frameworks
-
Compared to Python parallelization frameworks such as multiprocessing or Celery, Ray offers a more general, higher-performance API. In addition, Ray’s distributed objects support data sharing across parallel executors.
- Data processing frameworks
-
Ray’s lower-level APIs are more flexible and better suited for a “distributed glue” framework than existing data processing frameworks such as Spark, Mars, or Dask. Although Ray has no inherent understanding of data schemas, relational tables, or streaming dataflow, it supports running many of these data processing frameworks—for example, Modin, Dask on Ray, Mars on Ray, and Spark on Ray (RayDP).
- Actor frameworks
-
Unlike specialized actor frameworks such as Erlang, Akka, and Orleans, Ray integrates the actor framework directly into programming languages. In addition, Ray’s distributed objects support data sharing across actors.
- Workflows
-
When most people talk about workflows, they talk about UI or script-driven low-code development. While this approach might be useful for nontechnical users, it frequently brings more pain than value to software engineers. Ray uses programmatic workflow implementation, similar to Cadence. This implementation combines the flexibility of Ray’s dynamic task graphs with strong durability guarantees. Ray Workflows offers subsecond overhead for task launch and supports workflows with hundreds of thousands of steps. It also takes advantage of the Ray object store to pass distributed datasets between steps.
- HPC systems
-
Unlike Ray, which exposes task and actor APIs, a majority of high-performance computing (HPC) systems expose lower-level messaging APIs, providing a greater application flexibility. Additionally, many of the HPC implementations offer optimized collective communication primitives. Ray provides a collective communication library that implements many of these functionalities.
Big Data / Scalable DataFrames
Ray offers a few APIs for scalable DataFrames, a cornerstone of the big data ecosystem. Ray builds on top of the Apache Arrow project to provide a (limited) distributed DataFrame API called ray.data.Dataset. This is largely intended for the simplest of transformations and reading from cloud or distributed storage. Beyond that, Ray also provides support for a more pandas-like experience through Dask on Ray, which leverages the Dask interface on top of Ray.
We cover scalable DataFrames in Chapter 9.
Warning
In addition to the libraries noted previously, you may find references to Mars on Ray or Ray’s (deprecated) built-in pandas support. These libraries do not support distributed mode, so they can limit your scalability. This is a rapidly evolving area and something to keep your eye on in the future.
Machine Learning
Ray has multiple ML libraries, and for the most part, they serve to delegate much of the fancy parts of ML to existing tools like PyTorch, scikit-learn, and TensorFlow while using Ray’s distributed computing facilities to scale. Ray Tune implements hyperparameter tuning, using Ray’s ability to train many local Python-based models in parallel across a distributed set of machines. Ray Train implements distributed training with PyTorch or TensorFlow. Ray’s RLlib interface offers reinforcement learning with core algorithms.
Part of what allows Ray to stand out from pure data-parallel systems for ML is its actor model, which allows easier tracking of state (including parameters) and inter-worker communication. You can use this model to implement your own custom algorithms that are not a part of Ray Core.
We cover ML in more detail in Chapter 10.
Workflow Scheduling
Workflow scheduling is one of these areas which, at first glance, can seem really simple. A workflow is “just” a graph of work that needs to be done. However, all programs can be expressed as “just” a graph of work that needs to be done. New in 2.0, Ray has a Workflows library to simplify expressing both traditional business logic workflows and large-scale (e.g., ML training) workflows.
Ray is unique in workflow scheduling because it allows tasks to schedule other tasks without having to call back to a central node. This allows for greater flexibility and throughput.
If you find Ray’s workflow engine too low-level, you can use Ray to run Apache Airflow. Airflow is one of the more popular workflow scheduling engines in the big data space. The Apache Airflow Provider for Ray lets you use your Ray cluster as a worker pool for Airflow.
We cover workflow scheduling in Chapter 8.
Streaming
Streaming is generally considered to be processing “real-time-ish” data, or data “as-it-arrives-ish.” Streaming adds another layer of complexity, especially the closer to real time you try to get, as not all of your data will always arrive in order or on time. Ray offers standard streaming primitives and can use Kafka as a streaming data source and sink. Ray uses its actor model APIs to interact with streaming data.
Ray streaming, like many streaming systems bolted on batch systems, has some interesting quirks. Ray streaming, notably, implements more of its logic in Java, unlike the rest of Ray. This can make debugging streaming applications more challenging than other components in Ray.
We cover how to build streaming applications with Ray in Chapter 6.
Interactive
Not all “real-time-ish” applications are necessarily streaming applications. A common example is interactively exploring a dataset. Similarly, interacting with user input (e.g., serving models) can be considered an interactive rather than a batch process, but it is handled separately from the streaming libraries with Ray Serve.
What Ray Is Not
While Ray is a general-purpose distributed system, it’s important to note there are some things Ray is not (at least, not without your expending substantial effort):
-
Structured Query Language (SQL) or an analytics engine
-
A data storage system
-
Suitable for running nuclear reactors
-
Fully language independent
Ray can be used to do a bit of all of these, but you’re likely better off using more specialized tooling. For example, while Ray does have a key/value store, it isn’t designed to survive the loss of the leader node. This doesn’t mean that if you find yourself working on a problem that needs a bit of SQL, or some non-Python libraries, Ray cannot meet your needs—you just may need to bring in additional tools.
Conclusion
Ray has the potential to greatly simplify your development and operational overhead for medium- to large-scale problems. It achieves this by offering a unified API across a variety of traditionally separate problems while providing serverless scalability. If you have problems spanning the domains that Ray serves, or just are tired of the operational overhead of managing your own clusters, we hope you’ll join us on the adventure of learning Ray.
In the next chapter, we’ll show you how to get Ray installed in local mode on your machine. We’ll also look at a few Hello Worlds from some of the ecosystems that Ray supports (including actors and big data).
1 ARM support, including for Raspberry PIs, requires manual building for now.
Get Scaling Python with Ray now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

