Chapter 1. Introduction to Robust Python
This book is all about making your Python more manageable. As your codebase grows, you need a specific toolbox of tips, tricks, and strategies to build maintainable code. This book will guide you toward fewer bugs and happier developers. Youâll be taking a hard look at how you write code, and youâll learn the implications of your decisions. When discussing how code is written, I am reminded of these wise words from C.A.R. Hoare:
There are two ways of constructing a software design: One way is to make it so simple that there are obviously no deficiencies, and the other way is to make it so complicated that there are no obvious deficiencies. The first method is far more difficult.1
This book is about developing systems the first way. It will be more difficult, yes, but have no fear. I will be your guide on your journey to leveling up your Python game such that, as C.A.R. Hoare says above, there are obviously no deficiencies in your code. Ultimately, this is a book all about writing robust Python.
In this chapter weâre going to cover what robustness means and why you should care about it. Weâll go through how your communication method implies certain benefits and drawbacks, and how best to represent your intentions. âThe Zen of Pythonâ states that, when developing code, âThere should be one -- and preferably only one -- obvious way to do it.â Youâll learn how to evaluate whether your code is written in an obvious way, and what you can do to fix it. First, we need to address the basics. What is robustness in the first place?
Robustness
Every book needs at least one dictionary definition, so Iâll get this out of the way nice and early. Merriam-Webster offers many definitions for robustness:
-
having or exhibiting strength or vigorous health
-
having or showing vigor, strength, or firmness
-
strongly formed or constructed
-
capable of performing without failure under a wide range of conditions
These are fantastic descriptions of what to aim for. We want a healthy system, one that meets expectations for years. We want our software to exhibit strength; it should be obvious that this code will stand the test of time. We want a strongly constructed system, one that is built upon solid foundations. Crucially, we want a system that is capable of performing without failure; the system should not become vulnerable as changes are introduced.
It is common to think of a software like a skyscraper, some grand structure that stands as a bulwark against all change and a paragon of immortality. The truth is, unfortunately, messier. Software systems constantly evolve. Bugs are fixed, user interfaces get tweaked, and features are added, removed, and then re-added. Frameworks shift, components go out of date, and security bugs arise. Software changes. Developing software is more akin to handling sprawl in city planning than it is constructing a static building. With ever changing codebases, how can you make your code robust? How can you build a strong foundation that is resilient to bugs?
The truth is, you have to accept change. Your code will be split apart, stitched together, and reworked. New use cases will alter huge swaths of codeâand thatâs OK. Embrace it. Understand that itâs not enough that your code can easily be changed; it might be best for it to be deleted and rewritten as it goes out of date. That doesnât diminish its value; it will still have a long life in the spotlight. Your job is to make it easy to rewrite parts of the system. Once you start to accept the ephemeral nature of your code, you start to realize that itâs not enough to write bug-free code for the present; you need to enable the codebaseâs future owners to be able to change your code with confidence. That is what this book is about.
You are going to learn to build strong systems. This strength doesnât come from rigidity, as exhibited by a bar of iron. It instead comes from flexibility. Your code needs to be strong like a tall willow tree, swaying in the wind, flexing but not breaking. Your software will need to handle situations you would never dream of. Your codebase needs to be able to adapt to new circumstances, because it wonât always be you maintaining it. Those future maintainers need to know they are working in a healthy codebase. Your codebase needs to communicate its strength. You must write Python code in a way that reduces failure, even as future maintainers tear it apart and reconstruct it.
Writing robust code means deliberately thinking about the future. You want future maintainers to look at your code and understand your intentions easily, not curse your name during late-night debugging sessions. You must convey your thoughts, reasoning, and cautions. Future developers will need to bend your code into new shapesâand will want to do so without worrying that each change may cause it to collapse like a teetering house of cards.
Put simply, you donât want your systems to fail, especially when the unexpected happens. Testing and quality assurance are huge parts of this, but neither of those bake quality completely in. They are more suited to illuminating gaps in expectations and offering a safety net. Instead, you must make your software stand the test of time. In order to do that, you must write clean and maintainable code.
Clean code expresses its intent clearly and concisely, in that order. When you look at a line of code and say to yourself, âah, that makes complete sense,â thatâs an indicator of clean code. The more you have to step through a debugger, the more you have to look at a lot of other code to figure out whatâs happening, the more you have to stop and stare at the code, the less clean it is. Clean code does not favor clever tricks if it makes the code unreadable to other developers. Just like C.A.R. Hoare said earlier, you do not want to make your code so obtuse that it will be difficult to understand upon visual inspection.
Maintainable code is code thatâ¦âwell, can be easily maintained. Maintenance begins immediately after the first commit and continues until not a single developer is looking at the project anymore. Developers will be fixing bugs, adding features, reading code, extracting code for use in other libraries, and more. Maintainable code makes these tasks frictionless. Software lives for years, if not decades. Focus on your maintainability today.
You donât want to be the reason systems fail, whether you are actively working on them or not. You need to be proactive in making your system stand the test of time. You need a testing strategy to be your safety net, but you also need to be able to avoid falling in the first place. So with all that in mind, I offer my definition of robustness in terms of your codebase:
A robust codebase is resilient and error-free in spite of constant change.
Why Does Robustness Matter?
A lot of energy goes into making software do what itâs supposed to, but itâs not easy to know when youâre done. Development milestones are not easily predicted. Human factors such as UX, accessibility, and documentation only increase the complexity. Now add in testing to ensure that youâve covered a slice of known and unknown behaviors, and you are looking at lengthy development cycles.
The purpose of software is to provide value. It is in every stakeholderâs interests to deliver that full value as early as possible. Given the uncertainty around some development schedules, there is often extra pressure to meet expectations. Weâve all been on the wrong end of an unrealistic schedule or deadline. Unfortunately, many of the tools to make software incredibly robust only add onto our development cycle in the short term.
Itâs true that there is an inherent tension between immediate delivery of value and making code robust. If your software is âgood enough,â why add even more complexity? To answer that, consider how often that piece of software will be iterated upon. Delivering software value is typically not a static exercise; itâs rare that a system provides value and is never modified again. Software is ever-evolving by its very nature. The codebase needs to be prepared to deliver value frequently and for long periods of time. This is where robust software engineering practices come into play. If you canât painlessly deliver features quickly and without compromising quality, you need to re-evaluate techniques to make your code more maintainable.
If you deliver your system late, or broken, you incur real-time costs. Think through your codebase. Ask yourself what happens if your code breaks a year from now because someone wasnât able to understand your code. How much value do you lose? Your value might be measured in money, time, or even lives. Ask yourself what happens if the value isnât delivered on time? What are the repercussions? If the answers to these questions are scary, good news, the work youâre doing is valuable. But it also underscores why itâs so important to eliminate future errors.
Multiple developers work on the same codebase simlutaneously. Many software projects will outlast most of those developers. You need to find a way to communicate to the present and future developers, without having the benefit of being there in person to explain. Future developers will be building off of your decisions. Every false trail, every rabbit hole, and every yak-shaving2 adventure will slow them down, which impedes value. You need empathy for those who come after you. You need to step into their shoes. This book is your gateway to thinking about your collaborators and maintainers. You need to think about sustainable engineering practices. You need to write code that lasts. The first step to making code that lasts is being able to communicate through your code. You need to make sure future developers understand your intent.
Whatâs Your Intent?
Why should you strive to write clean and maintainable code? Why should you care so much about robustness? The heart of these answers lies in communication. Youâre not delivering static systems. The code will continue to change. You also have to consider that maintainers change over time. Your goal, when writing code, is to deliver value. Itâs also to write your code in such a way that other developers can deliver value just as quickly. In order to do that, you need to be able to communicate reasoning and intent without ever meeting your future maintainers.
Letâs take a look at a code block found in a hypothetical legacy system. I want you to estimate how long it takes for you to understand what this code is doing. Itâs OK if youâre not familiar with all the concepts here, or if you feel like this code is convoluted (it intentionally is!).
# Take a meal recipe and change the number of servings# by adjusting each ingredient# A recipe's first element is the number of servings, and the remainder# of elements is (name, amount, unit), such as ("flour", 1.5, "cup")defadjust_recipe(recipe,servings):new_recipe=[servings]old_servings=recipe[0]factor=servings/old_servingsrecipe.pop(0)whilerecipe:ingredient,amount,unit=recipe.pop(0)# please only use numbers that will be easily measurablenew_recipe.append((ingredient,amount*factor,unit))returnnew_recipe
This function takes a recipe and adjusts every ingredient to handle a new number of servings. However, this code prompts many questions.
-
What is the
popfor? -
What does
recipe[0]signify? Why is that the old servings? -
Why do I need a comment for numbers that will be easily measurable?
This is a bit of questionable Python, for sure. I wonât blame you if you feel the need to rewrite it. It looks much nicer written like this:
defadjust_recipe(recipe,servings):old_servings=recipe.pop(0)factor=servings/old_servingsnew_recipe={ingredient:(amount*factor,unit)foringredient,amount,unitinrecipe}new_recipe["servings"]=servingsreturnnew_recipe
Those who favor clean code probably prefer the second version (I certainly do). No raw loops. Variables do not mutate. Iâm returning a dictionary instead of a list of tuples. All these changes can be seen as positive, depending on the circumstances. But I may have just introduced three subtle bugs.
-
In the original code snippet, I was clearing out the original recipe. Now I am not. Even if itâs just one area of calling code that is relying on this behavior, I broke that calling codeâs assumptions.
-
By returning a dictionary, I have removed the ability to have duplicate ingredients in a list. This might have an effect on recipes that have multiple parts (such as a main dish and a sauce) that both use the same ingredient.
-
If any of the ingredients are named âservingsâ Iâve just introduced a collision with naming.
Whether these are bugs or not depends on two interrelated things: the original authorâs intent and calling code. The author intended to solve a problem, but I am unsure of why they wrote the code the way they did. Why are they popping elements? Why is âservingsâ a tuple inside the list? Why is a list used? Presumably, the original author knew why, and communicated it locally to their peers. Their peers wrote calling code based on those assumptions, but as time wore on, that intent became lost. Without communication to the future, I am left with two options of maintaining this code:
-
Look at all calling code and confirm that this behavior is not relied upon before implementing. Good luck if this is a public API for a library with external callers. I would spend a lot of time doing this, which would frustrate me.
-
Make the change and wait to see what the fallout is (customer complaints, broken tests, etc.). If Iâm lucky, nothing bad will happen. If Iâm not, I would spend a lot of time fixing use cases, which would frustrate me.
Neither option feels productive in a maintenance setting (especially if I have to modify this code). I donât want to waste time; I want to deal with my current task quickly and move on to the next one. It gets worse if I consider how to call this code. Think about how you interact with previously unseen code. You might see other examples of calling code, copy them to fit your use case, and never realize that you needed to pass a specific string called âservingsâ as the first element of your list.
These are the sorts of decisions that will make you scratch your head. Weâve all seen them in larger codebases. They arenât written maliciously, but organically over time with the best intentions. Functions start simple, but as use cases grow and multiple developers contribute, that code tends to morph and obscure original intent. This is a sure sign that maintainability is suffering. You need to express intent in your code up front.
So what if the original author made use of better naming patterns and better type usage? What would that code look like?
defadjust_recipe(recipe,servings):"""Take a meal recipe and change the number of servings:param recipe: a `Recipe` indicating what needs to be adusted:param servings: the number of servings:return Recipe: a recipe with serving size and ingredients adjustedfor the new servings"""# create a copy of the ingredientsnew_ingredients=list(recipe.get_ingredients())recipe.clear_ingredients()foringredientinnew_ingredients:ingredient.adjust_proportion(Fraction(servings,recipe.servings))returnRecipe(servings,new_ingredients)
This looks much better, is better documented, and expresses original intent clearly. The original developer encoded their ideas directly into the code. From this snippet, you know the following is true:
-
I am using a
Recipeclass. This allows me to abstract away certain operations. Presumably, inside the class itself there is an invariant that allows for duplicate ingredients. (Iâll talk more about classes and invariants in Chapter 10.) This provides a common vocabulary that makes the functionâs behavior more explicit. -
Servings are now an explicit part of a
Recipeclass, rather than needing to be the first element of the list, which was handled as a special case. This greatly simplifies calling code, and prevents inadvertent collisions. -
It is very apparent that I want to clear out ingredients on the old recipe. No ambiguous reason for why I needed to do a
.pop(0). -
Ingredients are a separate class, and handle fractions rather than an explicit
float. Itâs clearer for all involved that I am dealing with fractional units, and can easily do things such aslimit_denominator(), which can be called when people want to restrict measuring units (instead of relying on a comment).
Iâve replaced variables with types, such as a recipe type and an ingredient type. Iâve also defined operations (clear_ingredients, adjust_proportion) to communicate my intent. By making these changes, Iâve made the codeâs behavior crystal clear to future readers. They no longer have to come talk to me to understand the code. Instead, they comprehend what Iâm doing without ever talking to me. This is asynchronous communication at its finest.
Asynchronous Communication
Itâs weird writing about asynchronous communication in a Python book without mentioning async and await. But Iâm afraid I have to discuss asynchronous communication in a much more complex place: the real world.
Asynchronous communication means that producing information and consuming that information are independent of each other. There is a time gap between the production and consumption. It might be a few hours, as is the case of collaborators in different time zones. Or it might be years, as future maintainers try to do a deep dive into the inner workings of code. You canât predict when somebody will need to understand your logic. You might not even be working on that codebase (or for that company) by the time they consume the information you produced.
Contrast that with synchronous communication. Synchronous communication is the exchange of ideas live (in real time). This form of direct communication is one of the best ways to express your thoughts but unfortunately, it doesnât scale, and you wonât always be around to answer questions.
In order to evaluate how appropriate each method of communication is when trying to understand intentions, letâs look at two axes: proximity and cost.
Proximity is how close in time the communicators need to be in order for that communication to be fruitful. Some methods of communication excel with real-time transfer of information. Other methods of communication excel at communicating years later.
Cost is the measure of effort to communicate. You must weigh the time and money expended to communicate with the value provided. Your future consumers then have to weigh the cost of consuming the information with the value they are trying to deliver. Writing code and not providing any other communication channels is your baseline; you have to do this to produce value. To evaluate additional communication channelsâ cost, here is what I factor in:
- Discoverability
-
How easy was it to find this information outside of a normal workflow? How ephemeral is the knowledge? Is it easy to search for information?
- Maintenance cost
-
How accurate is the information? How often does it need to be updated? What goes wrong if this information is out of date?
- Production cost
-
How much time and money went into producing the communication?
In Figure 1-1, I plot some common communication methodsâ cost and proximity required, based on my own experience.
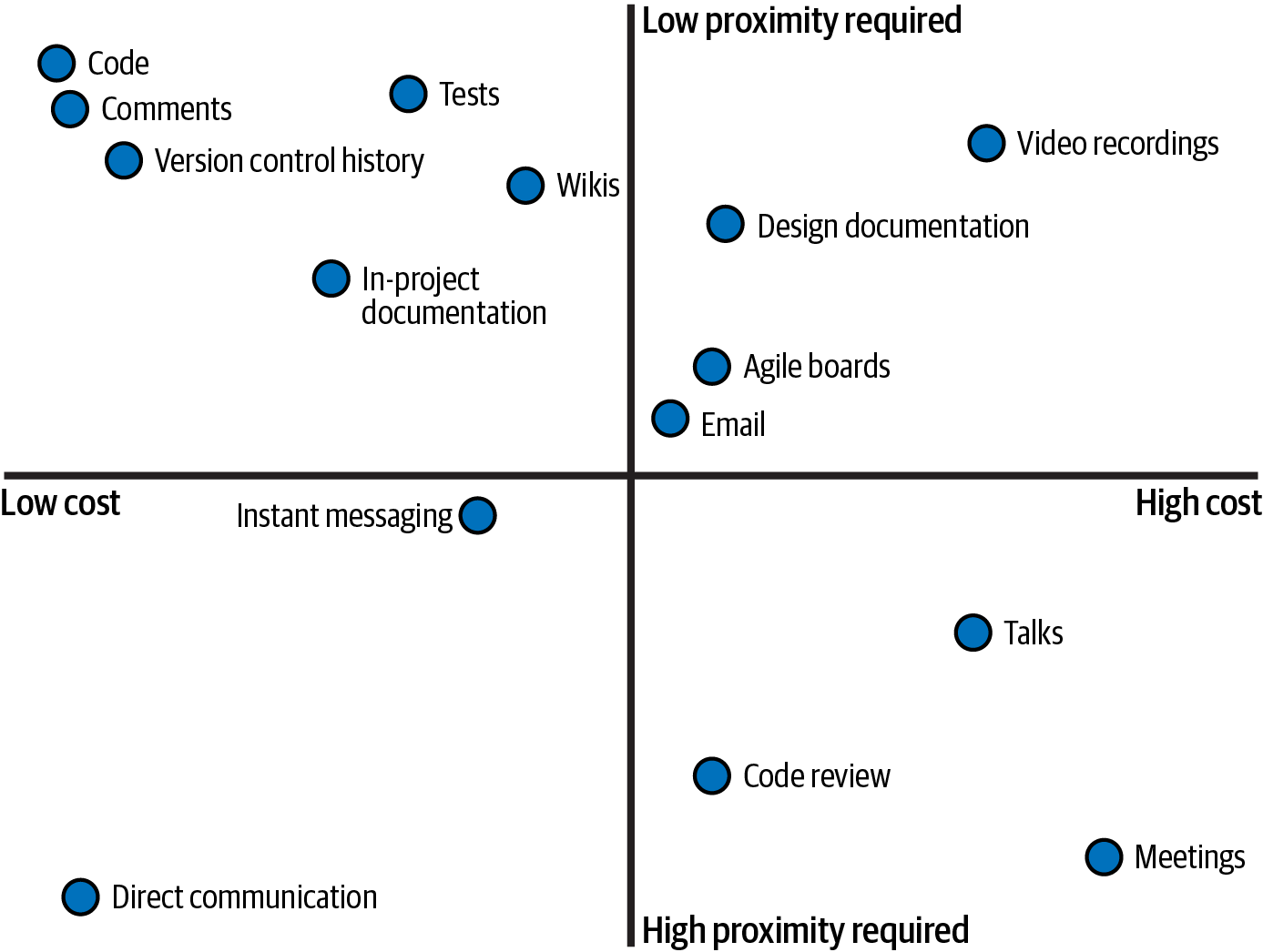
Figure 1-1. Plotting cost and proximity of communcation methods
There are four quadrants that make up the cost/proximity graph.
- Low cost, high proximity required
-
These are cheap to produce and consume, but are not scalable across time. Direct communication and instant messaging are great examples of these methods. Treat these as snapshots of information in time; they are only valuable when the user is actively listening. Donât rely on these methods to communicate to the future.
- High cost, high proximity required
-
These are costly events, and often only happen once (such as meetings or conferences). These events should deliver a lot of value at the time of communication, because they do not provide much value to the future. How many times have you been to a meeting that felt like a waste of time? Youâre feeling the direct loss of value. Talks require a multiplicative cost for each attendee (time spent, hosting space, logistics, etc.). Code reviews are rarely looked at once they are done.
- High cost, low proximity required
-
These are costly, but that cost can be paid back over time in value delivered, due to the low proximity needed. Emails and agile boards contain a wealth of information, but are not discoverable by others. These are great for bigger concepts that donât need frequent updates. It becomes a nightmare to try and sift through all the noise just to find the nugget of information you are looking for. Video recordings and design documentation are great for understanding snapshots in time, but are costly to keep updated. Donât rely on these communication methods to understand day-to-day decisions.
- Low cost, low proximity required
-
These are cheap to create, and are easily consumable. Code comments, version control history, and project READMEs all fall into this category, since they are adjacent to the source code we write. Users can view this communication years after it was produced. Anything that a developer encounters during their day-to-day workflow is inherently discoverable. These communication methods are a natural fit for the first place someone will look after the source code. However, your code is one of your best documentation tools, as it is the living record and single source of truth for your system.
Discussion Topic
This plot in Figure 1-1 was created based on generalized use cases. Think about the communication paths you and your organization use. Where would you plot them on the graph? How easy is it to consume accurate information? How costly is it to produce information? Your answers to these questions may result in a slightly different graph, but the single source of truth will be in the executable software you deliver.
Low cost, low proximity communication methods are the best tools for communicating to the future. You should strive to minimize the cost of production and of consumption of communication. You have to write software to deliver value anyway, so the lowest cost option is making your code your primary communication tool. Your codebase becomes the best possible option for expressing your decisions, opinions, and workarounds clearly.
However, for this assertion to hold true, the code has to be cheap to consume as well. Your intent has to come across clearly in your code. Your goal is to minimize the time needed for a reader of your code to understand it. Ideally, a reader does not need to read your implementation, but just your function signature. Through the use of good types, comments and variable names, it should be crystal clear what your code does.
Examples of Intent in Python
Now that Iâve talked through what intent is and how it matters, letâs look at examples through a Python lens. How can you make sure that you are correctly expressing your intentions? I will take a look at two different examples of how a decision affects intentions: collections and iteration.
Collections
When you pick a collection, you are communicating specific information. You must pick the right collection for the task at hand. Otherwise, maintainers will infer the wrong intention from your code.
Consider this code that takes a list of cookbooks and provides a mapping between authors and the number of books written:
defcreate_author_count_mapping(cookbooks:list[Cookbook]):counter={}forcookbookincookbooks:ifcookbook.authornotincounter:counter[cookbook.author]=0counter[cookbook.author]+=1returncounter
What does my use of collections tell you? Why am I not passing a dictionary or a set? Why am I not returning a list? Based on my current usage of collections, hereâs what you can assume:
-
I pass in a list of cookbooks. There may be duplicate cookbooks in this list (I might be counting a shelf of cookbooks in a store with multiple copies).
-
I am returning a dictionary. Users can look up a specific author, or iterate over the entire dictionary. I do not have to worry about duplicate authors in the returned collection.
What if I wanted to communicate that no duplicates should be passed into this function? A list communicates the wrong intention. Instead, I should have chosen a set to communicate that this code absolutely will not handle duplicates.
Choosing a collection tells readers about your specific intentions. Hereâs a list of common collection types, and the intention they convey:
- List
-
This is a collection to be iterated over. It is mutable: able to be changed at any time. Very rarely do you expect to be retrieving specific elements from the middle of the list (using a static list index). There may be duplicate elements. The cookbooks on a shelf might be stored in a list.
- String
-
An immutable collection of characters. The name of a cookbook would be a string.
- Generator
-
A collection to be iterated over, and never indexed into. Each element access is performed lazily, so it may take time and/or resources through each loop iteration. They are great for computationally expensive or infinite collections. An online database of recipes might be returned as a generator; you donât want to fetch all the recipes in the world when the user is only going to look at the first 10 results of a search.
- Tuple
-
An immutable collection. You do not expect it to change, so it is more likely to extract specific elements from the middle of the tuple (either through indices or unpacking). It is very rarely iterated over. The information about a specific cookbook might be represented as a tuple, such as
(cookbook_name, author, pagecount). - Set
-
An iterable collection that contains no duplicates. You cannot rely on ordering of elements. The ingredients in a cookbook might be stored as a set.
- Dictionary
-
A mapping from keys to values. Keys are unique across the dictionary. Dictionaries are typically iterated over, or indexed into using dynamic keys. A cookbookâs index is a great example of a key to value mapping (from topic to page number.)
Do not use the wrong collection for your purposes. Too many times have I come across a list that should not have had duplicates or a dictionary that wasnât actually being used to map keys to values. Every time there is a disconnect between what you intend and what is in code, you create a maintenance burden. Maintainers must pause, work out what you really meant, and then work around their faulty assumptions (and your faulty assumptions, too).
These are basic collections, but there are more ways to express intent. Here are some special collection types that are even more expressive in communicating to the future:
frozenset-
A set that is immutable.
OrderedDict-
A dictionary that preserves order of elements based on insertion time. As of CPython 3.6 and Python 3.7, built-in dictionaries will also preserve order of elements based on insertion of time.
defaultdict-
A dictionary that provides a default value if the key is missing. For example, I could rewrite my earlier example as follows:
fromcollectionsimportdefaultdictdefcreate_author_count_mapping(cookbooks:list[Cookbook]):counter=defaultdict(lambda:0)forcookbookincookbooks:counter[cookbook.author]+=1returncounterThis introduces a new behavior for end usersâif they query the dictionary for a value that doesnât exist, they will receive a 0. This might be beneficial in some use cases, but if itâs not, you can just return
dict(counter)instead. Counter-
A special type of dictionary used for counting how many times an element appears. This greatly simplifies our above code to the following:
fromcollectionsimportCounterdefcreate_author_count_mapping(cookbooks:list[Cookbook]):returnCounter(book.authorforbookincookbooks)
Take a minute to reflect on that last example. Notice how using a Counter gives us much more concise code without sacrificing readability. If your readers are familiar with Counter, the meaning of this function (and how the implementation works) is immediately apparent. This is a great example of communicating intent to the future through better selection of collection types. Iâll explore collections further in Chapter 5.
There are plenty of additional types to explore, including array, bytes, and range. Whenever you come across a new collection type, built-in or otherwise, ask yourself how it differs from other collections and what it conveys to future readers.
Iteration
Iteration is another example where the abstraction you choose dictates the intent you convey.
How many times have you seen code like this?
text="This is some generic text"index=0whileindex<len(text):(text[index])index+=1
This simple code prints each character on a separate line. This is perfectly fine for a first pass at Python for this problem, but the solution quickly evolves into the more Pythonic (code written in an idiomatic style that aims to emphasize simplicity and is recognizable to most Python developers):
forcharacterintext:(character)
Take a moment and reflect on why this option is preferable. The for loop is a more appropriate choice; it communicates intentions more clearly. Just like collection types, the looping construct you select explicitly communicates different concepts. Hereâs a list of some common looping constructs and what they convey:
forloops-
forloops are used for iterating over each element in a collection or range and performing an action/side effect.forcookbookincookbooks:print(cookbook) whileloops-
whileloops are used for iterating as long as a certain condition is true.whileis_cookbook_open(cookbook):narrate(cookbook) - Comprehensions
-
Comprehensions are used for transforming one collection into another (normally, this does not have side effects, especially if the comprehension is lazy).
authors=[cookbook.authorforcookbookincookbooks] - Recursion
-
Recursion is used when the substructure of a collection is identical to the structure of a collection (for example, each child of a tree is also a tree).
deflist_ingredients(item):ifisinstance(item,PreparedIngredient):list_ingredients(item)else:print(ingredient)
You want each line of your codebase to deliver value. Furthermore, you want each line to clearly communicate what that value is to future developers. This drives a need to minimize any amount of boilerplate, scaffolding, and superfluous code. In the example above, I am iterating over each element and performing a side effect (printing an element), which makes the for loop an ideal looping construct. I am not wasting code. In contrast, the while loop requires us to explicitly track looping until a certain condition occurs. In other words, I need to track a specific condition and mutate a variable every iteration. This distracts from the value the loop provides, and provides unwanted cognitive burden.
Law of Least Surprise
Distractions from intent are bad, but thereâs a class of communication that is even worse: when code actively surprises your future collaborators. You want to adhere to the Law of Least Surprise; when someone reads through the codebase, they should almost never be surprised at behavior or implementation (and when they are surprised, there should be a great comment near the code to explain why it is that way). This is why communicating intent is paramount. Clear, clean code lowers the likelihood of miscommunication.
Note
The Law Of Least Surprise, also known as the Law of Least Astonishment, states that a program should always respond to the user in the way that astonishes them the least.3 Surprising behavior leads to confusion. Confusion leads to misplaced assumptions. Misplaced assumptions lead to bugs. And that is how you get unreliable software.
Bear in mind, you can write completely correct code and still surprise someone in the future. There was one nasty bug I was chasing early in my career that crashed due to corrupted memory. Putting the code under a debugger or putting in too many print statements affected timing such that the bug would not manifest (a true âheisenbugâ).4 There were literally thousands of lines of code that related to this bug.
So I had to do a manual bisect, splitting the code in half, see which half actually had the crash by removing the other half, and then do it all over again in that code half. After two weeks of tearing my hair out, I finally decided to inspect an innocuous sounding function called getEvent. It turns out that this function was actually setting an event with invalid data. Needless to say, I was very surprised. The function was completely correct in what it was doing, but because I missed the intent of the code, I overlooked the bug for at least three days. Surprising your collaborators will cost their time.
A lot of this surprise ends up coming from complexity. There are two types of complexity: necessary complexity and accidental complexity. Necessary complexity is the complexity inherent in your domain. Deep learning models are necessarily complex; they are not something you browse through the inner workings of and understand in a few minutes. Optimizing objectârelational mapping (ORM) is necessarily complex; there is a large variety of possible user inputs have to be accounted for. You wonât be able to remove necessary complexity, so your best bet would be to try and contain it, lest it sprawls across your codebase and ends up becoming accidental complexity instead.
In contrast, accidental complexity is complexity that produces superfluous, wasteful, or confusing statements in code. Itâs what happens when a system evolves over time and developers are jamming features in without reevaluating old code to determine whether their original assertions hold true. I once worked on a project where adding a single command-line option (and associated means of programmatically setting it) touched no fewer than 10 files. Why would adding one simple value ever need to require changes all over the codebase?
You know you have accidental complexity if youâve ever experienced the following:
-
Things that sound simple (adding users, changing a UI control, etc.) are non-trivial to implement.
-
Difficulty onboarding new developers into understanding your codebase. New developers on a project are your best indicators of how maintainable your code is right nowâno need to wait years.
-
Estimates for adding functionality are always high, yet you slip the schedule nonetheless.
Remove accidental complexity and isolate your necessary complexity wherever possible. Those will be the stumbling blocks for your future collaborators. These sources of complexity compound miscommunication, as they obscure and diffuse intent throughout the codebase.
Discussion Topic
What accidental complexities do you have in your codebase? How challenging would it be to understand simple concepts if you were dropped into the codebase with no communication to other developers? What can you do to simplify complexities identified in this exercise (especially if they are in often-changing code)?
Throughout the rest of the book, I will look at different techniques for communicating intent in Python.
Closing Thoughts
Robust code matters. Clean code matters. Your code needs to be maintainable for the entire lifetime of the codebase, and in order to ensure that outcome, you need to put active foresight into what you are communicating and how. You need to clearly embody your knowledge as close to the code as possible. It will feel like a burden to continuously look forward, but with practice it becomes natural, and you start reaping the benefits as you work in your own codebase.
Every time you map a real-world concept to code, you are creating an abstraction, whether it is through the use of a collection or your decision to keep functions separate. Every abstraction is a choice, and every choice communicates something, whether intentional or not. I encourage you to think about each line of code you are writing and ask yourself, âWhat will a future developer learn from this?â You owe it to future maintainers to enable them to deliver value at the same speed that you can today. Otherwise, your codebase will get bloated, schedules will slip, and complexity will grow. It is your job as a developer to mitigate that risk.
Look for potential hotspots, such as incorrect abstractions (such as collections or iteration) or accidental complexity. These are prime areas where communication can break down over time. If these types of hotspots are in areas that change often, they are a priority to address now.
In the next chapter, youâre going to take what you learned from this chapter and apply it to a fundamental Python concept: types. The types you choose express your intent to future developers, and picking the correct types will lead to better maintainability.
1 Charles Antony Richard Hoare. âThe Emperorâs Old Clothes.â Commun. ACM 24, 2 (Feb. 1981), 75â83. https://doi.org/10.1145/358549.358561.
2 Yak-shaving describes a situation where you frequently have to solve unrelated problems before you can even begin to tackle the original problem. You can learn about the origins of the term at https://oreil.ly/4iZm7.
3 Geoffrey James. The Tao of Programming. https://oreil.ly/NcKNK.
4 A bug that displays different behavior when being observed. SIGSOFT â83: Proceedings of the ACM SIGSOFT/SIGPLAN software engineering symposium on High-level debugging.
Get Robust Python now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

