Chapter 1. Introducing RESTful Web APIs
Leverage global reach to solve problems you havenât thought of for people you have never met.
The RESTful web APIs principle
In the Preface, I called out the buzzword-y title of this book as a point of interest. Hereâs where we get to explore the thinking behind RESTful web APIs and why I think it is important to both use this kind of naming and grok the meaning behind it.
To start, Iâll talk a bit about just what the phrase âRESTful web APIsâ means and why I opted for what seems like a buzzword-laden term. Next, weâll spend a bit of time on what I claim is the key driving technology that can power resilient and reliable services on the open webâhypermedia. Finally, thereâs a short section exploring a set of shared principles for implementing and using REST-based service interfacesâsomething that guides the selection and description of the patterns and recipes in this book.
Hypermedia-based implementations rely on three key elements: messages, actions, and vocabularies (see Figure 1-1). In hypermedia-based solutions, messages are passed using common formats like HTML, Collection+JSON, and SIREN. These messages contain content based on a shared domain vocabulary, such as PSD2 for banking, ACORD for insurance, or FIHR for health information. And these same messages include well-defined actions such as save, share, approve, and so forth.
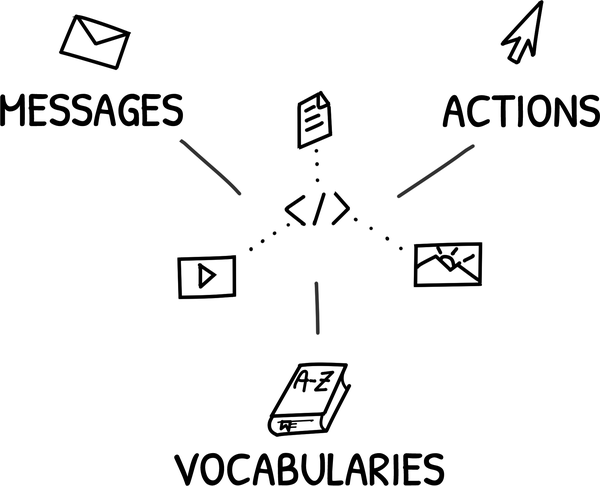
Figure 1-1. Elements of hypermedia
With these three concepts, I hope to engage you in thinking about how we build and use services over HTTP today, and how, with a slight change in perspective and approach, we can update the design and implementation of these services in a way that improves their usability, lowers the cost of creating and accessing them, and increases the ability of both service producers and consumers to build and sustain viable API-led businessesâeven when some of the services we depend upon are unreliable or unavailable.
To start, weâll explore the meaning behind the title of the book.
What Are RESTful Web APIs?
Iâve used the phrase âRESTful web APIsâ in articles, presentations, and training materials for several years. My colleague, Leonard Richardson, and I wrote a whole book on the topic in 2013. Sometimes the term generates confusion, even skepticism, but almost always it elicits curiosity. What are these three words doing together? What does the combination of these three ideas mean as a whole? To answer these questions, it can help to take a moment to clarify the meaning of each idea individually.
So, in this section, weâll visit:
- Fieldingâs REST
-
The architectural style that emphasizes scalability of component interactions, generality of interfaces, and independent deployment of components.
- The web of Tim Berners-Lee
-
The World Wide Web was conceived as a universal linked information system, in which generality and portability are paramount.
- Alan Kayâs extreme late binding
-
The design aesthetic that allows you to build systems that you can safely change while they are still up and running.
Fieldingâs REST
As early as 1998, Roy T. Fielding made a presentation at Microsoft explaining his concept of Representational State Transfer (or REST as it is now known). In this talk, and his PhD dissertation that followed two years later (âArchitectural Styles and the Design of Network-based Software Architecturesâ), Fielding put forth the idea that there was a unique set of software architectures for network-based implementations, and that one of the six styles he outlinedâRESTâwas particularly suited for the World Wide Web.
Tip
Years ago I learned the phrase, âOften cited, never read.â That snarky comment seems to apply quite well to Fieldingâs dissertation from 2000. I encourage everyone working to create or maintain web-based software to take the time to read his dissertationâand not just the infamous Chapter 5, âRepresentational State Transferâ. His categorization of general styles over 20 years ago correctly describes styles that would later be known as gRPC, GraphQL, event-driven, containers, and others.
Fieldingâs method of identifying desirable system-level properties (like availability, performance, simplicity, modifiability, etc.), as well as a recommended set of constraints (client-server, statelessness, cacheability, etc.) selected to induce these properties, is still, more than two decades later, a valuable way to think about and design software that needs to be stable and functional over time.
A good way to sum up Fieldingâs REST style comes from the dissertation itself:
REST provides a set of architectural constraints that, when applied as a whole, emphasizes scalability of component interactions, generality of interfaces, independent deployment of components, and intermediary components to reduce interaction latency, enforce security, and encapsulate legacy systems.
The recipes included in this book were selected to lead to designing and building services that exhibit many of Fieldingâs âarchitectural properties of key interestâ. The following is a list of Fieldingâs architectural properties along with a brief summary of their use and meaning:
- Performance
-
The performance of a network-based solution is bound by physical network limitations (throughput, bandwidth, overhead, etc.) and user-perceived performance, such as request latency and the ability to reduce completion time through parallel requests.
- Scalability
-
The ability of the architecture to support large numbers of components, or interactions among components, within an active configuration.
- Simplicity
-
The primary means of inducing simplicity in your solutions is by applying the principle of separation of concerns to the allocation of functionality within components, and the principle of generality of interfaces.
- Modifiability
-
The ease with which a change can be made to an application architecture via evolvability, extensibility, customizability, configurability, and reusability.
- Visibility
-
The ability of a component to monitor or mediate the interaction between two other components using things like caches, proxies, and other mediators.
- Portability
-
The ability to run the same software in different environments, including the ability to safely move code (e.g., JavaScript) as well as data between runtime systems (e.g., Linux, Windows, macOS, etc.)
- Reliability
-
The degree to which an implementation is susceptible to system-level failures due to the failure of a single component (machine or service) within the network.
The key reason weâll be using many of Fieldingâs architectural principles in these recipes: they lead to implementations that scale and can be safely modified over long distances of space and time.
The Web of Tim Berners-Lee
Fieldingâs work relies on the efforts of another pioneer in the the online world, Sir Tim Berners-Lee. More than a decade before Fielding wrote his dissertation, Berners-Lee authored a 16-page document titled âInformation Management: A Proposalâ (1989 and 1990). In it, he offered a (then) unique solution for improving information storage and retrieval for the CERN physics laboratory where he worked. Berners-Lee called this idea the World Wide Web (see Figure 1-2).
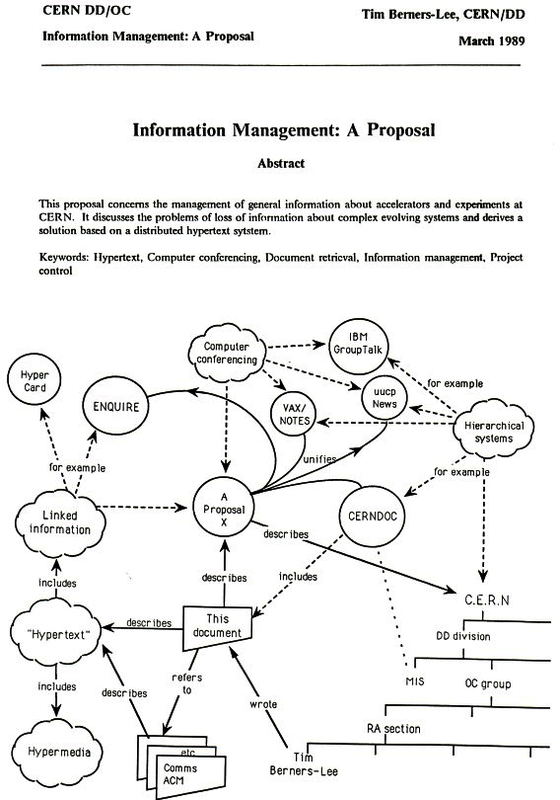
Figure 1-2. Berners-Leeâs World Wide Web proposal (1989)
The World Wide Web (WWW) borrowed from the thinking of Ted Nelson, who coined the term hypertext, by connecting related documents via links andâlaterâforms that could be used to prompt users to enter data that was then sent to servers anywhere in the world. These servers could be quickly and easily set up with free software running on common desktop computers. Fittingly, the design of the WWW followed the âRule of Least Power,â which says that we should use the least powerful technology suitable for the task. In other words, keep the solution as simple as possible (and no simpler). This was later codified in a W3C document of the same name. This set up a low barrier of entry for anyone who wished to join the WWW community, and helped fuel its explosive popularity in the 1990s and early 2000s.
On the WWW, any document could be edited to link to (point to) any other document on the web. This could be done without having to make special arrangements at either end of the link. Essentially, people were free to make their own connections, collect their own favorite documents, and author their own contentâwithout the need for permissions from anyone else. All of this content was made possible by using links and forms within pages to create unique pathways and experiencesâones that the original document authors (the ones being connected) knew nothing about.
Weâll be using these two aspects of the WWW (the Rule of Least Power and being free to make your own connections) throughout the recipes in this book.
Alan Kayâs Extreme Late Binding
Another important aspect of creating reliable, resilient services that can âlive on the webâ comes from US computer scientist Alan Kay. He is often credited with popularizing the notion of object-oriented programming in the 1990s.
In 2019, Curtis Poe wrote a blog post exploring Kayâs explanation of OOP and, among other things, Poe pointed out: âExtreme late-binding is important because Kay argues that it permits you to not commit too early to the one true way of solving an issue (and thus makes it easier to change those decisions), but can also allow you to build systems that you can change while they are still running!â (emphasis Poeâs).
Tip
For a more direct exploration of the connections between Roy Fieldingâs REST and Alan Kayâs OOP, see my 2015 article, âThe Vision of Kay and Fielding: Growable Systems that Last for Decades".
Just like Kayâs view of programming using OOP, the webâthe internet itselfâis always running. Any services we install on a machine attached to the internet are actually changing the system while it is running. Thatâs what we need to keep in mind when we are creating our services for the web.
It is the notion that extreme late binding supports changing systems while they are still running that we will be using as a guiding principle for the recipes in this book.
So, to sum up this section, weâll be:
-
Using Fieldingâs notions of architecting systems to safely scale and modify over time
-
Leveraging Berners-Leeâs âRule of Least Powerâ and the ethos of lowering the barrier of entry to make it easy for anyone to connect to anyone else easily
-
Taking advantage of Kayâs extreme late binding to make it easier to change parts of the system while it is still running
An important technique we can use to help achieve these goals is called hypermedia.
Why Hypermedia?
In my experience, the concept of hypermedia stands at the crossroads of a number of important tools and technologies that have positively shaped our information society. And it can, I think, help us improve the accessibility and usability of services on the web in general.
In this section weâll explore:
-
A century of hypermedia
-
The value of messages
-
The power of vocabularies
-
Richardsonâs magic strings
The history of hypermedia reaches back almost 100 years and it comes up in 20th century writing on psychology, human-computer interactions, and information theory. It powers Berners-Leeâs World Wide Web (see âThe Web of Tim Berners-Leeâ), and it can power our âweb of APIs,â too. And thatâs why it deserves a bit of extended exploration here. First, letâs define hypermedia and the notion of hypermedia-driven applications.
Hypermedia: A Definition
Ted Nelson is credited with coining the terms hypertext and hypermedia as early as the 1950s. He used these terms in his 1965 ACM paper âComplex Information Processing: A File Structure for the Complex, the Changing and the Indeterminateâ. In its initial design, according to Tomas Isakowitz in 2008, a hypertext system âconsists of nodes that contain information, and of links, that represent relationships between the nodes.â Hypermedia systems focus on the connections between elements of a system.
Essentially, hypermedia provides the ability to link separate nodes, also called resources, such as documents, images, services, even snippets of text within a document, to each other. On the network, this connection is made using universal resource identifiers (URIs). When the connection includes the option of passing some data along, these links are expressed as forms that can prompt human users or scripted machines to supply inputs, too. HTML, for example, supports links and forms through tags such as <A>, <IMG>, <FORM>, and others. There are several formats that support hypermedia links and forms.
These hypermedia elements can also be returned as part of the request results. The ability to provide links and forms in responses gives client applications the option of selecting and activating those hypermedia elements in order to progress the application along a path. This makes it possible to create a network-based solution that is composed entirely of a series of links and forms (along with returned data) that, when followed, provide a solution to the designed problem (e.g., compute results; retrieve, update, and store data at a remote location; etc.).
Links and forms provide a generality of interfaces (use of hypermedia documents over HTTP, for example) that powers hypermedia-based applications. Hypermedia-based client applications, like the HTML browser, can take advantage of this generality to support a wide range of new applications without ever having their source code modified or updated. We simply browse from one solution to the next by following (or manually typing) links, and use the same installed client application to read the news, update our to-do list, play an online game, etc.
The recipes in this book take advantage of hypermedia-based designs in order to power not just human-driven client applications like HTML browsers, but also machine-drive applications. This is especially helpful for clients that rely on APIs to access services on the network. In Chapter 4, Iâll be introducing a command-line application that allows you to quickly script hypermedia-driven client applications without changing the installed client application code base (see Appendix D).
A Century of Hypermedia
The idea of connecting people via information has been around for quite a while. In the 1930s, Belgiumâs Paul Otlet imagined a machine that would allow people to search and select a custom blend of audio, video, and text content, and view the results from anywhere. It took almost one hundred years, but the streaming revolution finally arrived in the 21st century.
Paul Otlet
Otletâs 1940 view (see Figure 1-3) of how his home machines could connect to various sources of news, entertainment, and informationâsomething he called the âWorld Wide Networkââlooks very much how Ted Nelson (introduced later in this section) and Tim Berners-Lee (see âThe Web of Tim Berners-Leeâ) would imagine the connect world, too.
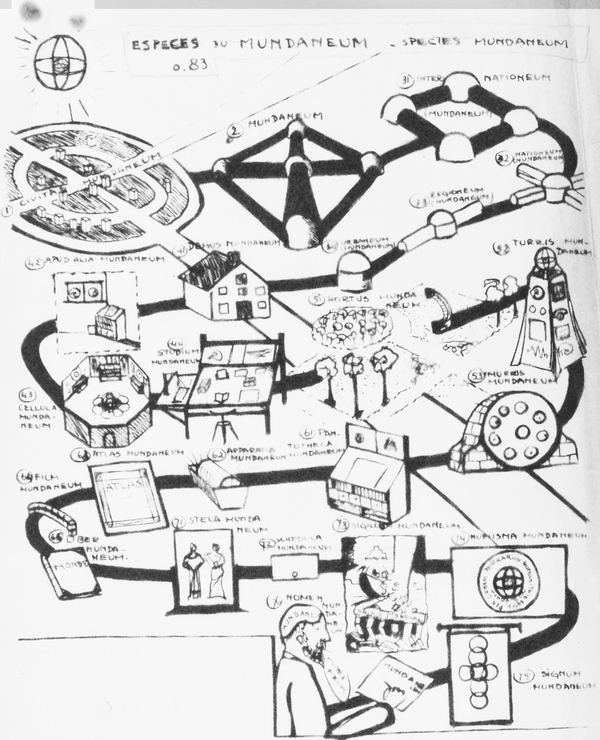
Figure 1-3. Otletâs World Wide Network (1940)
Vannevar Bush
While working as a manager for the Manhattan Project, Vannevar Bush noted that when teams of individuals got together to work out problems in a creative setting, they often bounced ideas off each other, leaping from one research idea to another and making new connections between scientific papers. He wrote up his observations in a July 1945 article, âAs We May Thinkâ, and described an information workstation similar to Otletâs that relied on microfiche and a âpointingâ device mounted on the readerâs head.
Douglas Engelbart
Reading that article sparked a junior military officer serving in East Asia to think about how he could make Bushâs workstation a reality. It took almost 20 years, but in 1968 that officer, Douglas Engelbart, led a demonstration of what he and his team had been working on in what is now known as âThe Mother of All Demosâ. That session showed off the then unheard of âinteractive computerâ that allowed the operator to use a pointing device to highlight text and click to follow âa link.â Engelbart had to invent the âmouseâ pointer to make his demo work.
Ted Nelson
A contemporary of Engelbart, Ted Nelson, had been writing about the power of personal computing as early as 1965 using terms he coined, such as hyperlinks, hypertext, hyperdata, and hypermedia. By 1974, his book Computer Lib/Dream Machines (Tempus Books) laid out a world powered by personal electronic devices connected to each other via the internet. At this same time, Alan Kay (see âAlan Kayâs Extreme Late Bindingâ) had described the Dynabook device that looked very much like the small laptops and tablets of today.
All these early explorations of how information could be linked and shared had a central idea: the connections between things would enable people and power creativity and innovation. By the late 1980s, Tim Berners-Lee had put together a successful system that embodied all the ideas of those who came before him. Berners-Leeâs WWW made linking pages of documents safe, easy, and scalable.
This is what using service APIs is all aboutâdefining the connections between things to enable new solutions.
James J. Gibson
Around the same time Ted Nelson was introducing the term hypertext to the world, another person was creating terms, too. Psychologist James J. Gibson, writing in his 1966 book The Senses Considered as Perceptual Systems (Houghton-Mifflin), on how humans and other animals perceive and interact with the world around them, created the term affordance. From Gibson:
[T]he affordances of the environment are what it offers the animal, what it provides or furnishes.
Gibsonâs affordances support interaction between animals and the environment in the same way Nelsonâs hyperlinks allow people to interact with documents on the network. A contemporary of Gibson, Donald Norman, popularized the term affordance in his 1988 book The Design of Everyday Things (Doubleday). Norman, considered the grandfather of the Human-Computer Interaction (HCI) movement, used the term to identify ways in which software designers can understand and encourage human-computer interaction. Most of what we know about usability of software comes from the work of Norman and others in the field.
Hypermedia depends on affordances. Hypermedia elements (links and forms) are the things within a web response that afford additional actions such as searching for existing documents, submitting data to a server for storage, and so forth. Gibson and Norman represent the psychological and social aspects of computer interaction weâll be relying upon in our recipes. For that reason, youâll find many recipes involve using links and forms to enable the modification of application state across multiple services.
The Value of Messages
As we saw earlier in this chapter, Alan Kay saw object-oriented programming as a concept rooted in passing messages (see âAlan Kayâs Extreme Late Bindingâ). Tim Berners-Lee adopted this same point of view when he outlined the message-centric Hypertext Transfer Protocol (HTTP) in 1992 and helped define the message format of Hypertext Markup Language (HTML) the following year.
By creating a protocol and format for passing generalized messages (rather than for passing localized objects or functions), the future of the web was established. This message-centric approach is easier to constrain, easier to modify over time, and offers a more reliable platform for future enhancements, such as entirely new formats (XML, JSON, etc.) and modified usage of the protocol (documents, websites, web apps, etc.).
Message-centric solutions online have parallels in the physical world, too. Insect colonies such as termites and ants, famous for not having any hierarchy or leadership, communicate using a pheromone-based message system. Around the same time that Nelson was talking about hypermedia and Gibson was talking about affordances, American biologist and naturalist E. O. Wilson (along with William Bossert) was writing about ant colonies and their use of pheromones as a way of managing large, complex communities.
With all this in mind, you probably wonât be surprised to discover that the recipes in this book all rely on a message-centric approach to passing information between machines.
The Power of Vocabularies
A message-based approach is fine as a platform. But even generic message formats like HTML need to carry meaningful information in an understandable way. In 1998, about the same time that Roy Fielding was crafting his REST approach for network applications (see âFieldingâs RESTâ), Peter Morville and his colleague Louis Rosenfeld published the book Information Architecture for the World Wide Web (OâReilly). This book is credited with launching the information architecture movement. University of Michigan professor Dan Klyn explains information architecture using three key elements: ontology (particular meaning), taxonomy (arrangement of the parts), and choreography (rules for interaction among the parts).
These three things are all part of the vocabulary of network applications. Notably, Tim Berners-Lee, not long after the success of the World Wide Web, turned his attention to the challenge of vocabularies on the web with his Resource Description Framework (RDF) initiatives. RDF and related technologies such as JSON-LD are examples of focusing on meaning within the messages, and weâll be doing that in our recipes, too.
For the purposes of our work, Klynâs choreography is powered by hypermedia links and forms. The data passed between machines via these hypermedia elements is the ontology. Taxonomy is the connections between services on the network that, taken as a whole, create the distributed applications weâre trying to create.
Richardsonâs Magic Strings
One more element worth mentioning here is the use and power of ontologies when youâre creating and interacting with services on the web. While it makes sense that all applications need their own coherent, consistent terms (e.g., givenName, familyName, voicePhone, etc.), it is also important to keep in mind that these terms are essentially what Leonard Richardson called âmagic stringsâ in the book RESTful Web APIs from 2015.
The power of the identifiers used for property names has been recognized for quite some time. The whole RDF movement (see âThe Power of Vocabulariesâ) was based on creating network-wide understanding of well-defined terms. At the application level, Eric Evansâs 2014 book Domain-Driven Design (Addison-Wesley) spends a great deal of time explaining the concepts of âubiquitous languageâ (used by all team members to connect all the activities within the application) and âbounded contextâ (a way to break up large application models into coherent subsections where the terms are well understood).
Evans was writing his book around the same time Fielding was completing his dissertation. Both were focusing on how to get and keep stable understanding across large applications. While Evans focused on coherence within a single codebase, Fielding was working to achieve the same goals across independent codebases.
It is this shared context across separately built and maintained services that is a key factor in the recipes within this book. Weâre trying to close Richardsonâs âsemantic gapâ through the design and implementation of services on the web.
In this section weâve explored the hundred-plus years of thought and effort (see âA Century of Hypermediaâ) devoted to using machines to better communicate ideas across a network of services. We saw how social engineering and psychology recognized the power of affordances (see âJames J. Gibsonâ) as a way of supporting a choice of action within hypermedia messages (see âThe Value of Messagesâ). Finally, we covered the importance, and power, of well-defined and maintained vocabularies (see âThe Power of Vocabulariesâ) to enable and support semantic understanding across the network.
These concepts make up a kind of toolkit or set of guidelines for identifying helpful recipes throughout the book. Before diving into the details of each of the patterns, thereâs one more side trip worth taking. One that provides an overarching, guiding set of principles for all the content here.
Shared Principles for Scalable Services on the Web
To wrap up this introductory chapter, I want to call out some base-level shared principles that acted as a guide when selecting and defining the recipes I included in this book. For this collection, Iâll call out a single, umbrella principle:
Leverage global reach to solve problems you havenât thought of for people you have never met.
We can break this principle down a bit further into its three constituent parts.
Leverage Global Reachâ¦
There are lots of creative people in the world, and millions of them have access to the internet. When weâre working to build a service, define a problem space, or implement a solution, there is a wealth of intelligence and creativity within reach through the web. However, too often our service models and implementation tooling limit our reach. It can be very difficult to find what weâre looking for and, even in cases where we do find a creative solution to our problem by someone else, it can be far too costly and complicated to incorporate that invention into our own work.
For the recipes in this book, I tried to select and describe them in ways that increase the likelihood that others can find your solution, and lower the barrier of entry for using your solution in other projects. That means the design and implementation details emphasize the notions of context-specific vocabularies applied to standardized messages and protocols that are relatively easy to access and implement.
Good recipes increase our global reach: the ability to share our solutions and to find and use the solutions of others.
â¦to Solve Problems You Havenât Thought ofâ¦
Another important part of our guideline is the idea that weâre trying to create services that can be used to build solutions to problems that we havenât yet thought about. That doesnât mean weâre trying to create some kind of âgeneric serviceâ that others can use (e.g., data storage as a service or access control engines). Yes, these are needed, too, but thatâs not what Iâm thinking about here.
To quote Donald Norman (from his 1994 video):
The value of a well-designed object is when it has such as rich set of affordances that the people who use it can do things with it that the designer never imagined.
I see these recipes as tools in a craftpersonâs workshop. Whatever work you are doing, it often goes better when you have just the right tool for the job. For this book, I tried to select recipes that can add depth and a bit of satisfaction to your toolkit.
Good recipes make well-designed services available for others to use in ways we hadnât thought of yet.
â¦for People You Have Never Met
Finally, since weâre aiming for services that work on the webâa place with global reachâwe need to acknowledge that it is possible that weâll never get to meet the people who will be using our services. For this reason, it is important to carefully and explicitly define our service interfaces with coherent and consistent vocabularies. We need to apply Eric Evansâs ubiquitous language across services. We need to make it easy for people to understand the intent of the service without having to hear us explain it. Our implementations need to beâto borrow Fieldingâs phraseââstate-lessâ; they need to carry with them all the context needed to understand and successfully use the service.
Good recipes make it possible for âstrangersâ (services and/or people) to safely and successfully interact with each other in order to solve a problem.
Dealing with Timescales
Another consideration we need to keep in mind is that systems have a life of their own and they operate on their own timescales. The internet has been around since the early 1970s. While its essential underlying features have not changed, the internet itself has evolved over time in ways few could have predicted. This is a great illustration of Normanâs âwell-designed objectâ notion.
Large-scale systems not only evolve slowlyâeven the features that are rarely used persist for quite a long time. There are features of the HTML language (e.g., <marquee>, <center>, <xmp>, etc.) that have been deprecated, yet you can still find instances of these language elements online today. It turns out it is hard to get rid of something once it gets out onto the internet. Things we do today may have long-term effects for years to come.
Of course, not all solutions may need to be designed to last for a long time. You may find yourself in a hurry to solve a short-term problem that you assume will not last for long (e.g., a short service to perform a mass update to your product catalog). And thatâs fine, too. My experience has been, donât assume your creations will always be short-lived.
Good recipes promote longevity and independent evolution on a scale of decades.
This Will All Change
Finally, it is worth saying that, no matter what we do, no matter how much we plot and plan, this will all change. The internet evolved over the decades in unexpected ways. So did the role of the HTTP protocol and the original HTML message format. Software that we might have thought would be around forever is no longer available, and applications that were once thought disposable are still in use today.
Whatever we buildâif we build it wellâis likely to be used in unexpected ways, by unknown people, to solve as yet unheard-of problems. For those committed to creating network-level software, this is our lot in life: to be surprised (pleasantly or not) by the fate of our efforts.
Iâve worked on projects that have taken more than 10 years to become noticed and useful. And Iâve thrown together short-term fixes that have now been running for more than two decades. For me, this is one of the joys of my work. I am constantly surprised, always amazed, and rarely disappointed. Even when things donât go as planned, I can take heart that eventually, all this will change.
Good recipes recognize that nothing is permanent, and things will always change over time.
With all this as a backdrop, letâs take some time to more deeply explore the technology and design thinking behind the selected recipes in this book. Letâs explore the art of âthinking in hypermedia.â
Get RESTful Web API Patterns and Practices Cookbook now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

