Chapter 4. Hypermedia Clients
The good news about computers is that they do what you tell them to do. The bad news is that they do what you tell them to do.
Ted Nelson
Writing applications that use APIs to consume external services on the web requires a mix of specificity (what to do) and generality (how to do it) that can be challenging. The recipes in this chapter are focused on both what we tell client applications to do using local code and how we tell them via the protocol and messages we send back and forth. This combination of âwhatâ and âhowâ makes up the foundation of stable, yet flexible, API consumer apps.
Tip
For more information on the art of creating API consumers, check out âIncreasing Resilience with Hypermedia Clientsâ.
As a general rule, being very explicit about what clients can and cannot do will result in applications that are easy to break and hard to reuse. A better approach is to create API consumer apps that make only a few basic assertions about how they communicate (e.g., protocol, message model, and vocabulary) with servers and let the server supply all the other details (the what) at runtime. As shown in Figure 4-1, the recipes in this chapter focus on using hypermedia formats over HTTP protocol to support validation, state management, and the creation of goal-oriented client applications. This is what HTML browsers have done for 30+ years. We need to take a similar approach with our API consumers, too.
That doesnât mean we need to duplicate the HTML browser. That client application is focused on a high degree of usability that relies on humans to be the âbrainsâ behind the interface (or in front of the interface, really). The HTML message format is designed to make it possible to control the visual rendering of messages as well as the animation of content using inline scripting. This focus on UI and humans is not needed for most web service API consumers.

Figure 4-1. Hypermedia client recipes
Instead, for web services, we need to focus on M2M interactions and how to make up for the âmissing elementââthe human. The recipes in this chapter have been selected because they lead to a high level of reusability without depending on humans to be involved in every step of the client-server interaction. To that end, there is an emphasis on four elements of resilient hypermedia-driven clients:
-
Taking advantage of protocols and formats
-
Relying on runtime metadata
-
Solving the M2M interface challenge
-
Using semantic profiles as shared understanding between client and server
With that as a backdrop, letâs dig into our set of client-side recipes for RESTful web APIs.
4.1 Limiting the Use of Hardcoded URLs
Changing URLs on the server can cause annoying problems for client applications. Sometimes URL changes occur due to adding or removing featuresâit is a challenge to protect your client application from these kinds of problems. Sometimes the service URLs change due to âre-homingâ or moving the service from one platform or implementation group to another. How can you limit the impact of server URL changes on your client application?
Problem
How can you reduce the chances of a client application failing when service URLs are changed?
Solution
The best way to limit the impact of service URL changes in your client applications is to âabstract awayâ the actual URL values:
- Use named URL variables.
-
First, you should code your client so that any URL reference within the application is a named variable, not an actual URL. This is a similar pattern to how you can âlocalizeâ your client application for a single language (French, Arabic, Korean, etc.).
- Store URL values in configuration files.
-
Second, once you have a set of URL variable names, move the actual strings out of the source code and into a configuration file. This makes it possible to update the URLs without changing the source code or recompiling the application. Depending on your platform, you may still need to redeploy your client application after changing the configuration file.
- Reduce the number of URLs you need to âmemorizeâ to one.
-
If at all possible, limit the total number of URLs your application needs to âknow aboutâ in the first place. If youâre accessing a service that supports hypermedia formats (Collection+JSON, SIREN, HAL, etc.), your client application will likely only need to âmemorizeâ one URLâthe starting or âhomeâ URL (see Recipe 5.1).
- Convince the service teams to use hypermedia or configuration files.
-
Lastly, if you have influence over the people who are writing the services you use (e.g., your enterprise colleagues), try to convince them to use hypermedia formats that supply URLs at runtime, or at least provide a downloadable configuration file where the service team can store all the named URL variables that your client will need at runtime.
Example
To recap, the four ways you can reduce the impact of service URL changes are:
-
Use named URL variables in your code.
-
Move the URLs into client configuration files.
-
Limit the number of URLs your client needs to know ahead of time.
-
Get services to provide the URLs for you.
Using named URL variables
The following is an example of a code snippet showing the list of named URL variables stored in client code:
// initializing named variables for service URLsvarserviceURLs={};serviceURLs.home="http://service.example.org/";serviceURLs.list="http://service.example.org/list/";serviceURLs.filter="http://service.example.org/filter/";serviceURLs.read="http://service.example.org/list/{id}/";serviceURLs.update="http://service.example.org/list/{id}/";serviceURLs.remove="http://service.example.org/list/{id}/";serviceURLs.approve="http://service.example.org/{id}/status";serviceURLs.close="http://service.example.org/{id}/status";serviceURLs.pending="http://service.api.example.org/{id}/status";/* later in your client code... */// using named URL variablesconsthttp=newXMLHttpRequest();// Send a requesthttp.open("GET",serviceURLs.list);http.send();// handle responseshttp.onload=function(){switch(http.responseURL){caseserviceURLs.home:...break;...}}
Note that some URL values are shared for different names variables. This is often the case when the important information is passed via an HTTP body and/or HTTP method (e.g., HTTP PUT versus HTTP DELETE). Youâll also notice that some URLs contain a templated value (e.g., http://api.example.org/list/{id}/). This means that both client and server MUST share a similar standard for encoding templated URLs. I recommend using libraries that conform to the IETFâs RFC 6570.
Loading named URL variables from configuration
Once you have your code set up for only using named URL variables, it is a short step to moving all those URLs outside your codebase into a configuration file:
<html><head><scripttype="text/javascript"src="client.example.org/js/service-urls-config.js"></script><scripttype="text/javascript">...// using named URL variablesconsthttp=newXMLHttpRequest();// Send a requesthttp.open("GET",serviceURLs.list);http.send();// handle responseshttp.onload=function(){switch(http.responseURL){caseserviceURLs.home:...break;...}}...</script></head><body>...</body></html>
The configuration file (which looks just like the code in the previous example) is stored at the same location as the client code (http://client.example.org/js/). However, it could be stored anywhere the client application can access, including a local file system that is supported by the client platform.
Limit memorized client URLs to one with hypermedia
If your service is using hypermedia formats that automatically supply URLs at runtime, you can limit the number of URLs your client application needs to know ahead of time to possibly one URL: the starting or âhomeâ URL. Then your client can âfindâ any other URLs based on inline information found in id, name, rel, and/or tags (see Recipe 5.1):
/* find-rel.js */varstartingURL="http://service.example.org/";varthisURL="";varlink={};// using named URL variablesconsthttp=newXMLHttpRequest();// Send a requesthttp.open("GET",serviceURLs.list);http.send();// handle responseshttp.onload=function(){switch(http.responseURL){casestartingURL:link=findREL("list");if(link.href){thisURL=link.href;...}...break;...}}
Finally, if you can influence the service teams, try to convince them to either use hypermedia types so that client applications need to remember only their starting URL, or have the server team provide a remote configuration file that holds all the named variables that define the static URLs the client will need.
Discussion
The best way to limit the client-side impact of service URL changes is to keep the URLs out of the client application code. The most effective way to do that is for services to use hypermedia formats that provide URLs at runtime, or for services to provide configuration information that contains a list of URLs as named variables. If you canât get that from the service, then it is up to the client application programmers to come as close to that as possible. That means using a client-side configuration file or, if loading configuration data is not viable (e.g., security reasons), then create your own client-side named variable collection in code.
Warning
It is important to acknowledge that relying on client-side configuration files is not an ideal solution. Changes in service URLs need to be communicated to the client developer so that the client-side information (config or code) can be updated. This presents a possible lag between service changes and client changes. You can set up client-side monitoring of changes, but thatâs just adding more work and can only shorten the client applicationâs reaction time to unannounced changes.
It was noted earlier that some URL variables may share the same URL data, but have very different uses. For example, the service URLs for read, update, and delete may be the same (http://service.example.org/{id}). This leads to the next step of client applications keeping the entire collection of request metadata in code, too (URL, method, headers, query string, and/or body information). See Recipe 4.10 for more on this option and when to use it.
4.2 Coding Clients to Be HTTP Aware
Sometimes helper libraries, wrappers, and/or API software developer kits (SDKs) can make it harder for API client applications to solve their problems instead of making it easier. For this reason it is important to make sure your API client applications are able to âconverseâ with services in HTTP (or whatever the target protocol might be).
Problem
In cases where services offer help classes or SDKs, there are times when the client cannot find the exact local function needed to solve a problem. How can you make sure that client applications can work around any limitations of any helper libraries or SDKs supplied by the service?
Solution
The best way to create API client applications that are both effective and nimble is to make sure they are âprotocol-awareââthat they can, when needed, speak directly to a service using the HTTP protocol (or whatever protocol the service is using). To do that, even when your client app takes advantage of SDKs and helper libraries, you should make sure your client app also knows how to âspeak HTTPâ directly. That will ensure your application can use the service in ways the original service authors had not thought about when creating the initial release.
It is perfectly acceptable to mix the use of available service SDKs with direct HTTP calls when needed. In fact, it is a good idea to create your own high-level HTTP library that can easily be invoked on demand.
Example
While most modern languages supply HTTP libraries and functions, it is a good idea to create your own high-level HTTP support library. That means handling both the HTTP request and HTTP response details. Hereâs a simple example of a client-side JavaScript helper library for HTTP calls:
varajax={// setup code here.../************************************************************** PUBLIC METHODS ***args = {url:string, headers:{}, queryString:{}, body:{},callback:function, context:string}***********************************************************/httpGet:function(args){...},httpGetXML:function(args){...},httpGetJSON:function(args){...},httpGetPlainText:function(args){...},httpPost:function(args){...},httpPostVars:function(args){...},httpPostForXML:function(args){...},httpPostForJSON:function(args){...},httpPostForPlainText:function(args){...},httpPut:function(args){...},httpHead:function(args){...},httpDelete:function(args){...},httpOptions:function(args){...},httpTrace:function(args){...},// implementation details below ...}
This library can then be called using the following code:
functiongetDocument(url){varargs={};args.url=url;args.callbackFunction=ajaxComplete;args.context="processLinks";args.headers={'accept':'application/vnd.collection+json'}ajax.httpGet(args}// later ...functionajaxComplete(response,headers,context,status,msg){switch(status){...}// handle statusswitch(context){...}// dispatch to context}
This example is psuedocode from a client-side JavaScript implementation focused on browser-based applications. The exact details of your library are not important. What is important is that your client application can quickly and safely craft an HTTP request and handle the HTTP response. Notice that the library is designed to make HTTP calls easier to deal with and does not limit access to the protocol.
Discussion
Not only is it important to offer API client apps direct access to the HTTP protocol, it is important to code the application so that the developer is always aware that HTTP calls are taking place. It might seem like a good idea to âhide the HTTPâ under semantic methods like this:
varserviceClient={findUser:function(userId){...},assignUserWorkTickets(userId,ticketArray){...}}
The second call in this example (assignUserWorkTickets) might be a minefield. How many HTTP calls are involved? Just one? Maybe one per item in the ticketArray? Are the ticket calls sequential, or are they run in parallel? Developers should be able to âseeâ what they are getting into when they use an SDK or library. Even something as simple as changing the helper library calls from assignUserWorkTickets to sendHttpRequests({ requestList:WorkTickets, parallel:true }) can help developers get a sense of the consequences of their actions.
Also, an HTTP-aware API client doesnât need to be complicated, either. Client-side browser applications can get quite a bit done with the XMLHttpRequest object without getting too deep into the weeds of HTTP. See Recipe 4.1 for an example.
The downside of using this approach is that some services might want to protect themselves against inexperienced or possibly malicious client-side developers. They want to use SDKs to control the way client applications interact with the service. This never works to deter malicious actors and often just frustrates well-meaning developers trying to solve their own problems in ways the service provider had not imagined. Iâve seen many cases where client-side teams have abandoned an API because the required SDK was deemed unsuitable.
4.3 Coding Resilient Clients with Message-Centric Implementations
To extend the life of the client application and improve its stability, it is a good idea to code client applications to âspeakâ in well-known media types.
Problem
How can you ensure your client application is more resilient to small changes and not coupled too tightly to a specific domain or running service?
Solution
A great way to build resilient client applications is to code your client app to bind tightly to the message returned by the service, not to a particular service or domain problem. That way, if there are minor changes in the service, as long as the media type response stays the same, your client application is likely to continue to operate correctly.
Example
You have lots of options when coding your API client. You can bind it directly to the service and its documented objects, or you can bind your client to the structured media types that the service emits. In almost all cases, it is better to bind to media types than to service interface types.
Here is an example of a ToDo domain application. This client is implemented by binding to all the actions described in the API documentation:
/* to-do-functions.js */varthisPage=function(){functioninit(){}functionmakeRequest(href,context,body){}functionprocessResponse(ajax,context){}functionrefreshList(){}functionsearchList(){}functionaddToList(){}functioncompleteItem(){}functionshowList(){}functionattachEvents(){}};
The details of what goes on within each function are not important here. What is key is that each action in the domain (refresh, search, add, etc.) is described in the source code of the client. When the service adds any new features (e.g., the ability to setDueDate for a task), this client application code will be out-of-date and will not be able to adapt to the new feature. And it would be more challenging if the details changed, such as arguments or other action metadata (e.g., change POST to PUT, modify the URLs, etc.).
Now, look at the following client that is focused on a message-centric coding model. In this case, the code is not focused on the ToDo domain actions but on the messages (e.g., HTML, HAL, SIREN, etc.) the client sends and receives. In fact, this message-centric approach would be the same no matter the service domain or topic:
/* to-do-messages.js */varthisPage=function(){functioninit(){}functionmakeRequest(href,context,body){}functionprocessResponse(ajax,context){}functiondisplayResponse(){}functionrenderControls(){}functionhandleClicks(){}};
Again, details are missing but the point here is that the functionality of the client application is rooted in the work of making requests, processing the response message, displaying the results, the input controls, and then catching any click events. Thatâs it. The actual domain-specific actions (refresh, search, add, etc.) will be described in the response message via hypermedia control, not the code. That means when the service adds a new feature (like the setDueDate operation), this client will âseeâ the new actions described in the message and automatically render that action. There will be no need to write new code to support new operations.
Binding to the message means that new actions and most modifications of existing actions are âfreeââthere is no need for additional coding.
Discussion
Shifting your client code from domain specific to message centric is probably the more effective way to create resilient applications for the web. This is the approach of the HTML-based web browser, which has been around for close to 30 years without any significant interface changes. This is despite the fact that the internal coding for HTML browsers has been completely replaced more than once, there are multiple, competing editions of the browser from various vendors, and the features of HTML have changed over time, too.
Much like the recipe to make your API clients âHTTP-awareâ (see Recipe 4.2), making them message centric adds an additional layer of resilience to your solution. As weâll see later in this chapter (see Recipe 4.5), there are more layers to this âclient resilience cakeâ to deal with, too. Each layer added creates a more robust and stable foundation upon which to build your specific solution.
One of the downsides of this approach is that it depends on services to properly support strong typed message models for resource responses (see Recipe 4.3). If the service you need to connect with only responds with unstructured media types like XML and JSON, it will be tough to take advantage of a message-centric coding model for your client applications. If you have any influence over your service teams (e.g., youâre in a corporate IT department), it can really pay dividends if you can convince them to use highly structured media types like HTML, HAL, SIREN, Collection+JSON, and others. See Chapter 3 for several recipes focused on the value of media types as a guiding principle for web services.
4.4 Coding Effective Clients to Understand Vocabulary Profiles
Just as it is important to code clients to be able to âspeakâ HTTP and bind to message formats, it is also important to code your client applications to be able to âconverseâ in the vocabulary of the service and/or domain. To do that, you need to code client applications to recognize and utilize domain vocabularies expressed as external profile documents.
Problem
How can you make sure that your client application will be able to âunderstandâ the vocabulary (names of call properties and actions) of the services it will interact with, even when some of the services themselves might change over time?
Solution
To make sure clients and servers are âtalking the same languageâ at runtime, you should make sure both client and server are coded to understand the same vocabulary terms (e.g., data names and action names). You can accomplish this by relying on one of the well-known vocabulary formats, including:
Since I am a coauthor on the ALPS specification, youâll see lots of examples of using ALPS as the vocabulary standards document. You may also be using a format not listed hereâand thatâs just fine. The important thing is that you and the services your client application interacts with agree on a vocabulary format as a way to describe the problem domain.
Example
Expressing a serviceâs domain as a set of vocabulary terms allows both client and service to share understanding in a generic, stable manner. This was covered in Recipe 3.4. Hereâs a set of vocabulary terms for a simple domain:
# Simple ToDo ## Purpose We need to track 'ToDo' records in order to improve both timeliness and accuracy of customer follow-up activity. ## Data In this first pass at the application, we need to keep track of the following data properties: * **id** : a globally unique value for each ToDo record * **body** : the text content of the ToDo record ## Actions This edition of the application needs to support the following operations: * **Home** : starting location of the service * **List** : return a list of all active ToDo records in the system * **Add** : add a new ToDo record to the system * **Remove** : remove a completed ToDo record from the system
Next, after translating that story document into ALPS, it looks like this:
{"$schema":"https://alps-io.github.io/schemas/alps.json","alps":{"version":"1.0","title":"ToDo List","doc":{"value":"ALPS ToDo Profile (see [ToDo Story](to-do-story.md))"},"descriptor":[{"id":"id","type":"semantic","tag":"ontology"},{"id":"title","type":"semantic","tag":"ontology"},{"id":"home","type":"semantic","tag":"taxonomy","descriptor":[{"href":"#goList"}]},{"id":"list","type":"semantic","tag":"taxonomy","descriptor":[{"href":"#id"},{"href":"#title"},{"href":"#goHome"},{"href":"#goList"},{"href":"#doAdd"},{"href":"#doRemove"}]},{"id":"goHome","type":"safe","rt":"#home","tag":"choreography"},{"id":"goList","type":"safe","rt":"#list","tag":"choreography"},{"id":"doAdd","type":"unsafe","rt":"#list","tag":"choreography","descriptor":[{"href":"#id"},{"href":"#title"}]},{"id":"doRemove","type":"idempotent","rt":"#list","tag":"choreography","descriptor":[{"href":"#id"}]}]}}
This ALPS document contains all the possible data elements and action elements, along with additional metadata on how to craft requests to the service and what to expect in response. This ALPS document can be the source material for creating client applications that will be able to successfully interact with any service that supports this profile. This is especially true for services that support hypermedia responses.
For example, assuming a ToDo-compliant service is running at localhost:8484, a ToDo-compliant client might do the following:
# data to work with
STACK PUSH {"id":"zaxscdvf","body":"testing"}
# vocabulary and format supported
CONFIG SET {"profile":"http://api.examples.org/profiles/todo-alps.json"}
CONFIG SET {"format":"application/vnd.mash+json"}
# write to service
REQUEST WITH-URL http://api.example.org/todo/list WITH-PROFILE WITH-FORMAT
REQUEST WITH-FORM doAdd WITH-STACK
REQUEST WITH-LINK goList
REQUEST WITH-FORM doRemove WITH-STACK
EXIT
Tip
Check out Appendix D for a short review of how to program in HyperLANG with the HyperCLI.
Note that the client only needs to know the starting URL, along with the names of the actions (doAdd, goList, and doRemove) and the names of the data properties (id and body). The client also needs to tell the service what vocabulary (profile) and media type (format) will be used during the interaction. These are all decisions made when coding the application. With that done, the remainder of the script invokes actions and sends data that the client knows ahead of time will be validâbased on the published vocabulary. Since, in this case, the service is known to support hypermedia responses, the client can safely assume that the vocabulary links and forms will be found in the service response and coded accordingly.
Discussion
Vocabulary documents are the glue that binds API producers and API consumers without resorting to tight coupling. As we have seen in the last example, reliance on clear vocabularies and well-known media type formats does a great deal to reduce the coupling between client and service without losing any detail.
Services often publish API definition documents (e.g., OpenAPI, AsyncAPI, RAML, etc.). This is handy for people who want to implement a single instance of the API service, but it has limited value for API consumers. When API client applications use the service implementation specification to create an API consumer, that application will be tightly bound to this particular service implementation. Any changes to the service implementation are likely to break that client application. A better approach is to bind the API consumer to a published profile document instead.
If the service you are working with does not publish a stable vocabulary document, it is a good idea to create your own. Use the API definition documentation (OpenAPI, etc.) as a guide to craft your own ALPS document (or some other format, if you wish), and then publish that document for your team (and others) to use when creating an API client for that service. It is also a good idea to include that ALPS document in your client applicationâs source code repository for future reference.
As shown in the last example, you get the greatest benefit of vocabulary profiles when the service you are working with returns hypermedia responses. When that is not the case (and you donât have the ability to influence the service teams), you can still code your client as if hypermedia was in the response (see Recipe 4.10 for details).
See Also
-
Recipe 3.4, âDescribing Problem Spaces with Semantic Profilesâ
-
Recipe 3.3, âSharing Domain Specifics via Published Vocabulariesâ
-
Recipe 4.5, âNegotiating for Profile Support at Runtimeâ
-
Recipe 4.7, âUsing Schema Documents as a Source of Message Metadataâ
-
Recipe 5.7, âPublishing Complete Vocabularies for Machine Clientsâ
4.5 Negotiating for Profile Support at Runtime
Client applications that depend on services that provide responses using pre-determined semantic profiles need a way to make sure those services will be âspeakingâ in the required vocabulary.
Problem
Youâve coded your client to work with any service that complies with, for example, the ToDo semantic profile. How can you confirmâat runtimeâthat the service you are about to use supports the to-do vocabulary?
Solution
A client application can dependably check for semantic profile support in a service using the âprofile negotiationâ pattern. Clients can use the accept-profile request header to indicate the expected semantic profile, and services can use the content-profile response header to indicate the supporting semantic profile.
Like content negotiation (see Recipe 5.6), profile negotiation allows clients and servers to share metadata details about the resource representation and make decisions on whether the serverâs response is acceptable for the client. When services return resource profiles that do not match the clientâs request, the client can reject the response with an error, request more information from the server, or continue anyway.
Example
Clients can determine the supported semantic profiles for a service resource in a number of ways. Profile negotiation is the most direct way for clients to indicate and validate a serviceâs profile support.
The following is a simple example of profile negotiation:
*** REQUEST GET /todo/list HTTP/1.1 Host: api.example.org Accept-Profile: <http://profiles.example.org/to-do> *** RESPONSE HTTP/2.0 200 OK Content-Profile: http://profiles/example.org/to-do ...
In this example, the client uses the accept-profile header to indicate the desired vocabulary, and the service uses the content-profile header to tell the client what profile was used to compose the resource representation that was returned.
Servers may also return a 406 HTTP status code (Not Acceptable) when a client requests a semantic profile the service does not support. When doing so, the service should return metadata that indicates which profiles that service is prepared to support instead:
*** REQUEST GET /todo/list HTTP/1.1 Host: api.example.org Accept-Profile: <http://profiles.example.org/to-do/v3> *** RESPONSE HTTP/2.0 406 Not Acceptable Content-Type: application/vnd.collection+json
{"collection":{"links":[{"rel":"profile","href":"http://profiles.example.org/todo/v1"},{"rel":"profile","href":"http://profiles.example.org/todo/v2"},]},"error":{"title":"Unsupported Profile","message":"See links for supported profiles for this resource."}}
It is also possible for services to provide a way for client applications to preemptively request details on the supported semantic profiles. To do this, services can offer one or more links with the relation value of âprofile,â with each link pointing to a supported semantic profile document. For example:
{"collection":{"title":"Supported Semantic Profiles","links":[{"rel":"profile","href":"http://profiles.example.org/todo/v1"},{"rel":"profile","href":"http://profiles.example.org/todo/v2"},{"rel":"profile","href":"http://profiles.example.org/todo/v3"}]}}
These links can appear in any resource representation that supports that profile. Even when only one semantic profile is supported, it is a good idea to emit profile links in responses to help clients (and their developers) recognize the supported vocabularies. In this case, clients can look at the collection of profile links to see if their semantic profile identifier is among those listed in the response.
The list of supported profiles can be reported as HTTP headers too:
*** REQUEST GET /todo/list HTTP/1.1 Host: api.example.org Accept-Profile: <http://profiles.example.org/to-do/v3> *** RESPONSE HTTP/2.0 406 Not Acceptable Content-Type: application/vnd.collection+json Links <http://profiles.example.org/todo/v3>; rel="profile", <http://profiles.example.org/todo/v2>; rel="profile", <http://profiles.example.org/todo/v1>; rel="profile"
Discussion
Itâs a good idea for client applications that are âcoded to the profileâ to validate all incoming responses to make sure the client will be able to process the resource correctly. Since servers may actually report more than one profile link in responses, client applications should assume all profile metadata is reported as a collection and search for the desired profile identifier within that collection.
Negotiating for semantic profiles with accept-profile and content-profile is not very common. The specification that outlines that work is still a draft document and, as of this writing, the most recent WC3 work on profiles is still a work in progress. However, within a closed system (e.g., enterprise IT), implementing profile negotiation can be a good way to promote and encourage the use of semantic profiles in
general.
I donât recommend getting too granular with identifying semantic profile versions (v1, v1.1, v1.1.1, etc.), as it only makes for more work at runtime for both client applications and remote services. When changes to profiles need to be made, it is a good idea to keep the variations backward compatible for as long as possible. If a profile update results in a breaking change, you should update the identifier to indicate a new version (v1 â v2).
See Also
-
Recipe 3.3, âSharing Domain Specifics via Published Vocabulariesâ
-
Recipe 3.4, âDescribing Problem Spaces with Semantic Profilesâ
-
Recipe 4.4, âCoding Effective Clients to Understand Vocabulary Profilesâ
-
Recipe 4.7, âUsing Schema Documents as a Source of Message Metadataâ
-
Recipe 5.7, âPublishing Complete Vocabularies for Machine Clientsâ
-
Recipe 5.8, âSupporting Shared Vocabularies in Standard Formatsâ
4.6 Managing Representation Formats at Runtime
Client applications that need to interact with more than one service may need to be coded to âconverseâ in more than one message format (HTML, HAL, SIREN, Collection+JSON, etc.). That means recognizing and dealing with multiple message formats at runtime.
Problem
How do client applications that need to be able to process more than one message type request and validate the message types they receive from services and process information from varying formats consistently?
Solution
Applications that operate should be able to manage the resource representation formats (HTML, HAL, SIREN, Collection+JSON, etc.) using the HTTP Accept and Content-Type headers. This focus on message-centric coding (see Recipe 4.3) will give stability to your client code without banding it closely to the specific domain of the service(s) you are using.
Whenever your client makes an API request, you should include an HTTP Accept header to indicate the structured format(s) your application âunderstands.â Then, when the server replies, you should check the Content-Type header to confirm which of your supported formats was returned. If the format returned is not one your client can handle, you should stop processing and report the problem. In human-driven apps, this is usually done with a pop-up message or inline content. For M2M apps, this can be done as an error message back to the calling machine and/or a log message sent to some supervising authority:
*** REQUEST GET /todo/list HTTP/1.1 Host: api.example.org Accept: application/vnd.collection+json *** RESPONSE HTTP/1.1 200 OK Content-Type: application/vnd.collection+json ...
The client applications also need to be coded in a way that creates a separation of concern (SoC) between the message formats exchanged with services and the internal representation of the information. When the server returns a response, the client application can route the message body to the proper handler for processing. This is where the message is translated into an internal model that the client application can use to inspect and manipulate the response.
That means implementing the Message Translator pattern internally so that clients can consistently translate between internal object models and external messages.
Example
Here is an example of code that validates the media type of the service response and handles it accordingly:
functionhandleResponse(ajax,url){varctypeif(ajax.readyState===4){try{ctype=ajax.getResponseHeader("content-type").toLowerCase();switch(ctype){case"application/vnd.collection+json":cj.parse(JSON.parse(ajax.responseText));break;case"application/vnd.siren+json":siren.parse(JSON.parse(ajax.responseText));break;case"application/vnd.hal+json":hal.parse(JSON.parse(ajax.responseText));break;default:dump(ajax.responseText);break;}}catch(ex){alert(ex);}}}
Notice that the client can âconverseâ in three message formats: Collection+JSON, SIREN, and HAL. If the service returns anything else, the application sends it to the dump() routine for additional processing.
Discussion
Organizing your client code to be driven by message formats works best when services support highly structured formats like HTML, HAL, SIREN, Collection+JSON, etc. When services use unstructured response formats like XML and JSON, youâll need additional metadata to support message-driven client code. In that case, schema documents like XML Schema and JSON Schema can be handy. See Recipe 4.7 for more on using schema documents on the client side.
Recognizing the incoming message format is just the first step. You also need to be able to parse and often translate that message for internal use. For web browsers, you can build a single JavaScript library that converts incoming JSON formats (HAL, SIREN, Collection+JSON) into HTML for rendering. The following are the high-level methods for converting JSON-based API messages into HTML:
// collection+JSON-->HTMLfunctionparse(collection){varelm;g.cj=collection;title();content();links();items();queries();template();error();elm=d.find("cj");if(elm){elm.style.display="block";}}// HAL --> HTMLfunctionparse(hal){g.hal=hal;title();setContext();if(g.context!==""){selectLinks("app","toplinks");selectLinks("list","h-links");content();embedded();properties();}else{alert("Unknown Context, can't continue");}elm=d.find("hal");if(elm){elm.style.display="block";}}// SIREN --> HTMLfunctionparse(msg){varelm;g.siren=msg;title();getContent();links();entities();properties();actions();elm=d.find("siren");if(elm){elm.style.display="block";}}
Each message parser is designed specifically to convert the selected message format into HTML to render in the browser. This is an implementation of the Message Translator pattern. Writing these one-way translators is not very challenging for highly structured formats. Since the target (HTML) is not domain specific, a single translator can be effective for any application topic or domain. I always keep a stable browser-based media type parser on hand for quickly building rendering applications for services that use these formats.
The work gets more challenging if you need to translate the incoming message into a domain-specific internal object model or graph. In these cases, itâs a good idea to use other metadata like semantic profiles (see Recipe 4.4) or schema documents (see Recipe 4.7) as your guide for translating the incoming message.
The work gets exponentially more difficult when all your client has to work with is an unstructured document like XML or JSON and there is no reliable schema or profile supplied. In these cases, youâll need to spend time creating custom-built translators based on the human-readable documentation. It is also likely that small changes in the documentation can cause big problems for your custom-built translator.
See Also
-
Recipe 3.2, âEnsuring Future Compatibility with Structured Media Typesâ
-
Recipe 3.4, âDescribing Problem Spaces with Semantic Profilesâ
-
Recipe 4.3, âCoding Resilient Clients with Message-Centric Implementationsâ
-
Recipe 4.4, âCoding Effective Clients to Understand Vocabulary Profilesâ
-
Recipe 4.7, âUsing Schema Documents as a Source of Message Metadataâ
4.7 Using Schema Documents as a Source of Message Metadata
When services do not support semantic profiles or structured media types, client applications may still be able to code to a semantic specification if that service returns references to schema documents that describe the contents of the message:
-
Use schema where profiles and media types are not sufficient or are missing
-
Do not use schema documents to validate incoming messages
-
Do use schema to validate outgoing messages
Problem
How can we build resilient client applications based on message schema for unstructured media types (XML or JSON) instead of semantic profiles?
Solution
In cases where services consistently return schema documents with unstructured messages formats (XML or JSON) as runtime responses, you may be able to code a resilient client application without the support of semantic profiles. To do this, you need to organize client code that is driven solely by schema information.
The most common examples of these schema formats are XML Schema and JSON Schema.
Example
When services provide them, you can also use schema documents as additional metadata information for the incoming message. This works best when the response itself contains a pointer to the schema. At runtime, it is not a good idea to validate incoming messages against a schema document unless you plan on rejecting invalid inputs entirely. Usually, runtime responses will have minor differences (e.g., added fields not found in the schema, rearranged order of elements in the response, etc.), and these minor changes are not good reasons to reject the input. However, it is handy to use the provided schema URI/URL as an identifier to confirm that the service has returned a response with the expected semantic metadata.
Warning
Using schema documents to validate incoming messages runs counter to Postelâs Law, which states: âbe conservative in what you do, be liberal in what you accept from others.â Strong typing incoming messages (instead of âbe[ing] liberal in what you acceptâ) is likely to result in rejected responses that might otherwise work well for both client and server. The specification document RFC 1122, authored by Robert Braden, goes into great detail on how to design and implement features that can safely allow for minor variations in message and protocol details. See Recipes 4.12 and 4.13 for more on this challenge.
Negotiating for schemas
It is possible for client applications to engage in schema negotiation with the service. This is useful when both client and server know ahead of time that there are multiple editions of the same general schema (user-v1, user-v2, etc.) and you want to confirm both are working with the same edition. An expired proposal from the W3C suggested the use of accept-schema and schema HTTP headers:
*** REQUEST GET /todo/list HTTP/1.1 Host: api.example.org Accept-Schema: <urn:example:schema:e-commerce-payment> *** RESPONSE HTTP/1.1 200 OK Schema: <urn:example:schema:e-commerce-payment ...
Iâve not encountered this negotiation approach âin the wild.â If it is offered by a service, it is worth looking into as a client developerâany semantic metadata is better than none.
Schema identifier in the Content-Type header
The schema identifier may also be passed from server to client in the Content-Type header:
*** REQUEST GET /todo/list HTTP/1.1 Host: api.example.org Accept: application/vnd.hal+json *** RESPONSE HTTP/1.1 200 OK Content-Type: \ application/vnd.hal+json;schema=urn:example:schema:e-commerce-payment ...
It is important to point out that adding additional facets (those after the â;â) to the media type string can complicate message format validation. Also, some media type definitions expressly forbid including additional metadata in the media type identifier string (for example, JSON has this rule).
Schema identifier in the document
It is most common to see the schema identifier provided as part of the message body:
{"$schema":"https://alps-io.github.io/schemas/alps.json","alps":{"version":"1.0","title":"ToDo List","doc":{"value":"A suggested ALPS profile for a ToDo service"},"descriptor":[{"id":"id","type":"semantic","def":"http://schema.org/identifier"},{"id":"title","type":"semantic","def":"http://schema.org/title"},{"id":"completed","type":"semantic","def":"http://mamund.site44.com/alps/def/completed.txt"}]}}
The schema identifier does not need to be a dereferenceable URL (https://alps-io.github.io/schemas/alps.json). It may just be a URI or URN identifier string (urn:example:schema:e-commerce-payment). The value of using a dereferenceable URL is that humans can follow the link to get additional information.
Coding schema-aware clients
Once you know how to identify schema information, you can use it to drive your client application code:
functionhandleSchema(ajax,schemaIdentifier){varschemaTypetry{schemaType=schemaIdentifier.toLowerCase()switch(ctype){case"https://api.example.com/schemas/task":task.parse(JSON.parse(ajax.responseText));break;case"https://api.example.com/schemas/task-v2":task.parse(JSON.parse(ajax.responseText));break;case"https://api.example.com/schemas/user":case"https://api.example.com/schemas/user-v2":user.parse(JSON.parse(ajax.responseText));break;case"https://api.example.com/schemas/note":note.parse(JSON.parse(ajax.responseText));break;default:dump(ajax.responseText);break;}}catch(ex){alert(ex);}}
Note that organizing code around schema definitions is often much more work than relying on semantic profile formats like ALPS. Schemas are usually domain specific and are more likely to change over time than semantic profiles. In this example, you can see that there are two (apparently) incompatible schema references for the task object. Also, the example shows that while there are two different user schema documents, they are (at least as far as this client is concerned) compatible versions.
Discussion
The primary value of schema documents comes into play when you are creating and sending messages (see Recipe 4.12). However, client applications can also use the schema document identifiers themselves (URLs or URIs) as advisory values for processing incoming messages. Essentially, schema identifiers become confirmation values that the response received by the client will contain the information the client will need to perform its work.
Note
I wonât be talking about maintaining schema registries in this edition of the cookbook. I do, however, cover the power of registered vocabularies (much less constrained than schema documents) in Recipes 3.4 and 4.4.
Negotiating for schema identifiers has limited value as well. It can be a good way for clients to preemptively tell services what schema they can support. This allows services to reject requests using HTTP status code 406 Not Acceptable. But this, too, runs afoul of Postelâs Law.
Client applications that are coded to be âschema awareâ are likely to be more of a challenge than client applications coded as âmedia type awareâ (see Recipe 4.3) or âprofile awareâ (see Recipe 4.4). That is because schema documents typically are at a much more granular level (objects), and object schema usually changes more often than the overall vocabulary or message formats.
JSON Schema has a feature that allows for successful validation of a sample document even if that document contains additional properties not found in the schema (additionalProperties:true|false). By default, this is set to true, which allows for additional properties to appear without triggering a schema validation error. Also, altering the order of the properties within an object will not trigger a schema validation error.
Warning
Including âunknownâ properties in an incoming message is not, by itself, a security problem. For example, this can be quite common in the HTML format. However, attempting to consume and process unknown properties may be a security hole. As youâll see in Recipe 4.13, it is best for client applications to ignore unknown properties and only process the values the application was designed to deal with.
In XML documents, schema validators are rather demanding. To be passed as valid, the elements within the XML messages need to be in the same order as indicated in the schema document, and in most cases, the appearance of a new element or property will trigger a validation error.
See Also
-
Recipe 3.4, âDescribing Problem Spaces with Semantic Profilesâ
-
Recipe 4.3, âCoding Resilient Clients with Message-Centric Implementationsâ
-
Recipe 4.4, âCoding Effective Clients to Understand Vocabulary Profilesâ
-
Recipe 4.12, âUsing Document Schemas to Validate Outgoing Messagesâ
-
Recipe 4.13, âUsing Document Queries to Validate Incoming Messagesâ
4.8 Every Important Element Within a Response Needs an Identifier
Just as every important resource in a RESTful API has an identifier (URL), every important action and/or data element within a response deserves its own identifier. A client needs to be able to locate the right resource, and find and use the right action or data collection in the resource response.
Problem
How do you make sure that client applications can find the actions and/or data they are looking for within a response? In addition, how can you make sure the ability to find these important elements doesnât degrade over time as the service evolves?
Solution
The key to ensuring stable, meaningful identifiers within API responses is to select media types that support a wide range of identifier types as structural elements. HTML does a good job at this. I created the Machine Accessible Semantic Hypermedia (MASH) format as an example of a media type that supports multiple structural identifiers.
The four kinds of identifiers are:
ID-
A document-wide unique single-value element (e.g.,
id=1q2w3e4r) NAME-
An application-wide unique single-value element (e.g.,
name=createUserForm) REL-
A system-wide unique multivalue element (e.g.,
rel=create-form self) TAG-
A solution-specific nonunique multivalue element (e.g.,
tag=users page-level)
Another example of the last item (solution-specific nonunique multivalue element) is the HTML CLASS element.
Client applications should be coded to be able to find the desired FORM, LINK, or DATA block using at least one of these types of identifiers.
Example
For an example of the importance of using media types that support structured identifiers, consider the following challenge:
-
Access the starting URL of the
usersservice . -
Within the response to that request, find the form for searching for existing users.
-
Fill out the form to find the user with the nickname âmingles,â and execute the request.
-
Store the resulting properties of this response to client memory.
-
Within the response to that request, find the form for updating this resource.
-
Using the data in the response, fill in the update form, change the email address to âmingles@example.org,â and execute the request.
While we, as humans, could do this rather easily (e.g., in an HTML browser), getting a machine to do this takes some additional effort. Consider, for example, that you need to update the email addresses of 10 or more user accounts. Now add to this challenge that you need to deal with multiple versions of the user service, or one that uses multiple response formats, or one that has evolved over time. In these cases, the client might use a script like this:
# hyper-cli example
ECHO Updating email address for mingles
ACTIVATE http://api.example.org/users
ACTIVATE WITH-FORM nickSearch
WITH-QUERY {"nick":"mingles"}
ACTIVATE WITH-FORM userUpdate
WITH-BODY {"name":"Miguelito","nick":"mingles","email":"mingles@example.org"}
ACTIVATE WITH-FORM emailSearch
WITH-QUERY {"email":"mingles@example.org"}
ECHO Update Confirmed
EXIT
# eof
Tip
Check out Appendix D for more on how to use the HyperCLI and HyperLANG as a hypermedia client application.
Note in this example that the client application is relying on identifiers for three actions (nickSearch, userUpdate, and emailSearch) and for a collection of properties (name, nick, and email). The actual representation format (HTML, MASH, SIREN, etc.) does not matter for the scriptâthat is handled internally by the client. Also note that the only URL supplied is the initial one to contact the service. The rest of the URLs are supplied in the responses (as part of the forms).
Discussion
Most HTTP design practices make it clear that every resource deserves its own identifier (in the form of a URL). This is easy to see when you look at typical HTTP API requests:
http://api.example.org/customers/123 http://api.example.org/users?customer=123
This is also true when it comes to describing interactions within a single response. For example, consider the following response from /users?customer=123:
{"id":"aqswdefrgt","href":"http://api.example.org/customers/123","name":"customer-record","rel":"item http://rels.example.org/customer","tags":"item customer read-only","data":["identifier":"123","companyName":"Ajax Brewing","address":"123 Main St, Byteville, MD","users":"http://api.example.org/users?customer=123"]}
Note that the record metadata is as follows:
id-
A document-wide unique ID that clients can use to locate this record in any list
href-
A system-wide URL that clients can use to retrieve this record from the service
name-
A semantic application-wide name that clients can use to return records of this âtypeâ
rel-
A collection of system-wide names that clients can use to return records of this âtypeâ or instance
tags-
A collection of application-wide names that clients can use to filter records in various ways
The added href example here shows that the system-wide identifier (http://api.example.org/customers/123) does not need to be the same as the internal id (aqswdefrgt). In fact, it is a good idea to assume they are decoupled in order to avoid problems when the URL changes due to service migration, installation of new proxies, etc.
4.9 Relying on Hypermedia Controls in the Response
One of the principles of REST-based services is the reliance on âhypermedia as engine of application stateâ or, as Roy Fielding has called it, âThe Hypermedia Constraint.â Services that emit hypermedia formats as their responses make it much easier for client applications to determine what actions are possibleâand how to commit those actionsâat runtime. And the hypermedia information that appears within a response can be context sensitive. Context examples include the current state of the service (does a record already exist?), the user context (does this user have permission to edit the record?), and the context of the request itself (has someone else already edited this data?).
Problem
When service providers are emitting hypermedia-based responses, how can the API consumer best take advantage of the included information to improve both the human-agent and machine-agent experience?
Solution
It is best to write API consumers to âunderstandâ response formats (see Recipe 4.3 in this chapter). In the case of hypermedia types, each format has its own âhypermedia signatureââthe list of hypermedia elements (called hypermedia factors or H-Factors) that this media type can express. Creating client applications that know the media type and understand the nine H-Factors will greatly improve the flexibility and resilience of the client application. Nine H-Factors can appear within a RESTful service response, which is described in Tables 4-1 and 4-2.
| Title | Description | Example | |
|---|---|---|---|
LE |
Link Embedded |
Brings content into the current view |
HTML |
LO |
Link Outbound |
Navigates the client to a new view |
HTML |
LT |
Link Template |
Supports additional parameters before executing |
URI templates |
LN |
Link Nonidempotent |
Describes a nonidempotent action |
|
LI |
Link Idempotent |
Describes an idempotent action |
SIREN |
| Title | Description | Example | |
|---|---|---|---|
CR |
Control for Read Requests |
Describes read details |
|
CU |
Control for Update Requests |
Describes write details |
|
CM |
Control for HTTP Methods |
Describes the HTTP method to use |
|
CL |
Control for Link Relations |
Describes the link relation for an action |
|
Each hypermedia format has its own H-Factor signature.
In Figure 4-2, you can see three media types: SVG, Atom, and HTML. Note that the SVG format only supports the LE and LO factors. SVG, for example, supports embedded links like <IMAGE href="â¦"â¦>, and outbound links such as <A href="â¦">Go Home</a>.
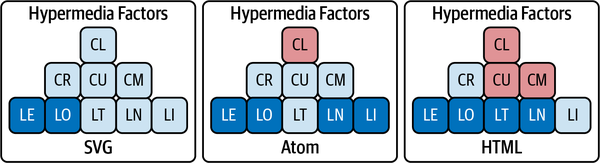
Figure 4-2. Visualizing the hypermedia factors of various media types
Example
Knowing which formats your client is likely to encounter allows the client to recognize and, where appropriate, offer options to human- and machine-driven agents in order for them to accomplish tasks.
For example, the HyperCLI client (see Appendix D) supports a number of hypermedia formats. When using a format like SIREN, you can script the HyperCLI client to add, search, modify, or remove content based on the hypermedia controls in the responses. The following is a short SIREN script written in HyperLANG:
#
# SIREN Edit Session
# read a record, save it, modify it, write it back to the server
#
# ** make initial request
REQUEST WITH-URL http://rwcbook10.herokuapp.com
# ** retreive the first record in the list
REQUEST WITH-PATH $.entities[0].href
# ** push the item properties onto the stack
STACK PUSH WITH-PATH $.properties
# ** modify the tags property value on the stack
STACK SET {"tags":"fishing,\.\skiing,\.\hiking"}
# ** use the supplied edit form and updated stack to send update
REQUEST WITH-FORM taskFormEdit WITH-STACK
# ** confirm the change
SIREN PATH $.entities[0]
# ** exit session
EXIT
Note
See Appendix D for a short introduction to programming in HyperLANG with the Hyper CLI.
Note that in this example, only the starting URL was supplied. The remaining actions were committed by relying on the hypermedia metadata supplied in each service response.
Discussion
This recipe covers the principle of using that hypermedia data to solve problems directly. It relies on details supplied by services and, for that reason, this recipe is only helpful when services support hypermedia formats in the response.
The advantage of relying on supplied hypermedia in your scripts is that you reduce the amount of hardcoding you need to do within your client application. You can make it easier for services to modify hypermedia details (e.g., URLs, HTTP methods, supported formats, etc.) without breaking the client application. In the preceding example, the script does not hardcode the HTTP URL, method, or encoding type for the taskFormEdit action. It simply uses the details supplied by the service.
This recipe works best when the client application understands not only the response format (e.g., SIREN) but also the semantic profile (the topic domain) used by the
service. For instance, in the preceding example, the client knows ahead of time that there is a possible taskFormEdit hypermedia control that it can use to modify an existing record. See Recipe 4.4 for more on semantic profiles.
The H-Factor signature of hypermedia formats varies widely and will affect how hardcoding is (or is not) required for an API client. For example, the SIREN format supports the full range of H-Factors, and HAL supports just a few of them. In contrast, a nonhypermedia format like application/json supports no built-in H-Factors, making it difficult to write a resilient API client for services that support only plain JSON responses.
In general, the more H-Factors supported by a media type, the more likely you can write an API client that will survive changes in hypermedia details in the future.
See Also
-
Recipe 3.2, âEnsuring Future Compatibility with Structured Media Typesâ
-
Recipe 3.5, âExpressing Actions at Runtime with Embedded Hypermediaâ
-
Recipe 4.3, âCoding Resilient Clients with Message-Centric Implementationsâ
-
Recipe 4.7, âUsing Schema Documents as a Source of Message Metadataâ
-
Recipe 5.4, âExpressing Internal Functions as External Actionsâ
4.10 Supporting Links and Forms for Nonhypermedia Services
There are times when you need to interact with services that do not offer clear links and formsâhypermedia-style responses. There is a handy approach you can take on the client side to make up for this lack of support.
Problem
How can you get the advantages of API decoupling and the clearly described interactions available with hypermedia-style responses when the service you are working with does not offer hypermedia response formats as an option?
Solution
When youâre working with services that donât offer hypermedia-style responses and you still want to be able to rely on clearly described links and forms on the client side, you can code your client application to supply its own links and forms at runtime, based on the original API documentation.
Example
A hypermedia-based API client consumes the response, identifies the action items (links and forms) in the message, and renders them (in the case of the human UI solution) along with any data that is received. A high-level look at that kind of client code would be:
// low-level HTTP stufffunctionreq(url,method,body){varajax=newXMLHttpRequest();ajax.onreadystatechange=function(){rsp(ajax)};ajax.open(method,url);ajax.setRequestHeader("accept",g.atype);if(body&&body!==null){ajax.setRequestHeader("content-type",g.ctype);}ajax.send(body);}functionrsp(ajax){if(ajax.readyState===4){g.msg=JSON.parse(ajax.responseText);showTitle();showToplinks();showItems();showActions();}}
When a response is received, the client looks through the message body and handles all the key tasks. For example, hereâs what the showTopLinks() method might look like:
// emit links for all viewsfunctionshowToplinks(){varact,actions;varelm,coll;varmenu,a;elm=d.find("toplinks");d.clear(elm);menu=d.node("div");actions=g.actions[g.object];// get the link metadatafor(varactinactions){link=actions[act]if(link.target==="app"){a=d.anchor({href:link.href,rel:(link.rel||"collection"),className:"action item",text:link.prompt});a.onclick=link.func;d.push(a,menu);}}d.push(menu,elm);}
This example renders the top links on a user interface. The source of that rendering is the link metadata. This client gets that in a single line of code. In hypermedia responses, that link metadata is in the body of the message. But even if you only get simple JSON data responses, you can use this same code. You just need to modify where the link metadata comes from.
In the following example, the link metadata comes from an internal structure that holds all the links and forms for a particular context (âusers,â âtasks,â etc.). All the metadata was gleaned from the APIs human-centric documentation. All the rules for possible actions and arguments were translated from the API docs into this client-code structure:
// user object actionsg.actions.user={home:{target:"app",func:httpGet,href:"/home/",prompt:"Home"},tasks:{target:"app",func:httpGet,href:"/task/",prompt:"Tasks"},users:{target:"app",func:httpGet,href:"/user/",prompt:"Users"},byNick:{target:"list",func:jsonForm,href:"/user",prompt:"By Nickname",method:"GET",args:{nick:{value:"",prompt:"Nickname",required:true}}},byName:{target:"list",func:jsonForm,href:"/user",prompt:"By Name",method:"GET",args:{name:{value:"",prompt:"Name",required:true}}},add:{target:"list",func:jsonForm,href:"/user/",prompt:"Add User",method:"POST",args:{nick:{value:"",prompt:"Nickname",required:true,pattern:"[a-zA-Z0-9]+"},password:{value:"",prompt:"Password",required:true,pattern:"[a-zA-Z0-9!@#$%^&*-]+"},name:{value:"",prompt:"Full Name",required:true},}},item:{target:"item",func:httpGet,href:"/user/{id}",prompt:"Item"},edit:{target:"single",func:jsonForm,href:"/user/{id}",prompt:"Edit",method:"PUT",args:{nick:{value:"{nick}",prompt:"Nickname",readOnly:true},name:{value:"{name}",prompt:"Full Name",required:true}}},changepw:{target:"single",func:jsonForm,href:"/task/pass/{id}",prompt:"Change Password",method:"POST",args:{nick:{value:"{nick}",prompt:"NickName",readOnly:true},oldPass:{value:"",prompt:"Old Password",required:true,pattern:"[a-zA-Z0-9!@#$%^&*-]+"},newPass:{value:"",prompt:"New Password",required:true,pattern:"[a-zA-Z0-9!@#$%^&*-]+"},checkPass:{value:"",prompt:"Confirm New",required:true,pattern:"[a-zA-Z0-9!@#$%^&*-]+"},}},assigned:{target:"single",func:httpGet,href:"/task/?assignedUser={id}",prompt:"Assigned Tasks"}};
Now you can use links and forms for services that donât provide them at runtime.
Discussion
This recipe relies on someone doing the work of translating the rules buried in the API documentation into a machine-readable form. Thatâs what hypermedia-compliant services do. If the service doesnât automatically do this work, client developers can save a lot of time by doing it once and sharing the results. Consider placing all link and form metadata for a service in a separate module or an external configuration file. Even better, if you can, convince your server teams to do this for you.
Some formats are designed specifically to make capturing and sharing link and form metadata. One is the Web Service Transition Language (WSTL). You may also be able to use JSON HyperSchema. Check out âHypermedia Supporting Typesâ for details.
There are some additional challenges not covered in the example, the biggest being user-context management. It could be that admin users should see or do things that guest users do not. In that case, a solid approach is to create a separate set of action metadata for each security role your application supports.
Another challenge youâll need to deal with is when the service changes but your local metadata information does not keep up. This is another case of versioning problems that come up when clients operate on static metadata at runtime. The good news is that, when action rules change on the server, at least the client application only needs to update configuration metadata and not the entire application codebase.
See Also
-
Recipe 3.2, âEnsuring Future Compatibility with Structured Media Typesâ
-
Recipe 3.5, âExpressing Actions at Runtime with Embedded Hypermediaâ
-
Recipe 4.3, âCoding Resilient Clients with Message-Centric Implementationsâ
-
Recipe 4.6, âManaging Representation Formats at Runtimeâ
-
Recipe 5.3, âConverting Internal Models to External Messagesâ
-
Recipe 5.4, âExpressing Internal Functions as External Actionsâ
4.11 Validating Data Properties at Runtime
When supporting the collection of inputs for client applications, it can be a challenge to properly describe valid input values at runtime. However, relying on predefined input rules documented only in human-readable prose can limit the adaptability of the client application and reduce its usefulness over time.
Problem
How can API clients consistently enforce the right data properties on input values at runtime? Also, how can we make sure that changes in the input rules over time continue to be honored by API clients and that these rule changes do not break already-deployed API clients?
Solution
An effective approach for API clients to support data property validation at runtime is to recognize and honor rich input descriptions (RIDs) within HTTP responses. A great example of RIDs can be found in the HTML format. HTML relies upon the INPUT element and a collection of attributes to describe expected inputs (INPUT.type) and define valid values (INPUT.pattern, INPUT.required, INPUT.size, etc.).
Client applications should support any or all data property quality checks provided by the incoming message format (HAL, SIREN, Collection+JSON, etc.).
Example
The HAL-FORMS specification is a good example of an API format that supports RIDs. HAL-FORMS is an extension of the HAL media type designed specifically to add RID support to the HAL format. The HAL-FORMS specification splits RIDs into three key groups: Core, Additional, and a special category: Options.
The Core section lists the following elements that clients should support: readOnly, regex, required, and templated. The Additional section lists elements that clients may support: cols, max, maxLength, min, minLength, placeholder, rows, step, and type. The Options support is a special class of input validation that implements describing enumerators (e.g., small, medium, large, etc.).
Here is an example of a HAL-FORMS Options description:
{"_templates":{"default":{..."properties":[{"name":"shipping","type":"radio","prompt":"Select Shipping Method","options":{"selectedValues":["FedEx"],"inline":[{"prompt":"Federal Express","value":"FedEx"},{"prompt":"United Parcel Service","value":"UPS"},{"prompt":"DHL Express","value":"DHL"}]}}]}}}
Discussion
The SIREN format supports a wide range of RIDs. It does this by simply referring to the HTML specification for input types.
The RID can often be used to determine the rendering of the input control (e.g., a drop-down list, date-picker, etc.). This is common when the response message is consumed by an API client that is designed for human use, but can be ignored when the client application is designed for M2M interactions.
At a minimum, supporting a regular expression property to describe valid inputs can work in many cases and limits the implementation burden on the client application. This is especially true for M2M interactions where there is no need for user interface rendering hints.
If the service response does not include inline/runtime RIDs, client application developers should review the human-readable documentation and implement the API consumer to support the same kinds of RIDs described here. Usually that means creating either an inline code implementation of RIDs or a configuration-based approach. No matter the implementation details, it is a good idea to turn the human-readable input validation rules into machine-readable algorithms. See Recipe 4.10 for details on this strategy.
See Also
-
Recipe 3.4, âDescribing Problem Spaces with Semantic Profilesâ
-
Recipe 4.4, âCoding Effective Clients to Understand Vocabulary Profilesâ
-
Recipe 4.8, âEvery Important Element Within a Response Needs an Identifierâ
-
Recipe 4.10, âSupporting Links and Forms for Nonhypermedia Servicesâ
-
Recipe 4.12, âUsing Document Schemas to Validate Outgoing Messagesâ
-
Recipe 4.13, âUsing Document Queries to Validate Incoming Messagesâ
4.12 Using Document Schemas to Validate Outgoing Messages
It is important for client applications to do their very best to send valid messages (especially message bodies) to servers. One way to ensure you are sending valid message bodies is to validate those bodies with a schema document. But is it always a good idea to use schema validations when sending request bodies?
Problem
How can a client application make sure it is sending a well-formed and valid request body when invoking service requests?
Solution
Sending well-formed and valid request bodies with HTTP methods like POST, PUT, and PATCH is important. To reduce the chance your request is rejected, you should validate the structure and content of your request bodies before sending them to the service for processing. Essentially, it is the responsibility of the client application to properly craft a valid request body, and it is the role of the service to do its best to process all valid requests. This is the embodiment of Postelâs Law (aka the robustness principle).
A very effective way to meet this requirement is to use schema documents to confirm the validity of your message body. Both JSON and XML have strong schema specifications, and there is a wide array of tooling to support them.
There are two levels of confirmation that clients need to handle: is the document well-formed, and is the document valid? Well-formed documents have the proper structure. This means they can be successfully parsed. Valid documents are not only well-formed, but both the structural elements (e.g., street_name, purchase_price) and the values of the those elements are of the right data type and within acceptable value ranges (e.g., purchase_price is a numerical value greater than zero and less than one thousand).
For any cases where client applications are expected to send request message bodies, those clients should perform some type of validation before committing the request to the internet. If the body format is in JSON or XML format, using schema documents and validator libraries is the way to go. For other formats (application/x-www-form-urencoded, etc.), client applications should rely on their own local validation routines to confirm the message body is well-formed and valid.
Example
Hereâs an example of a simple message body described in FORMS+JSON format:
{
id: "filter",
name: "filter",
href: "http://company-atk.herokuapp.com/filter/",
rel: "collection company filter",
title: "Search",
method: "GET",
properties: [
{name: "status",value: ""},
{name: "companyName",value: ""},
{name: "stateProvince",value: ""},
{name: "country",value: ""}
]
}
And hereâs a basic JSON Schema document that can be used to validate the message body:
{"$schema":"http://json-schema.org/draft-04/schema#","type":"object","properties":{"status":{"type":"string","enum":["pending","active","closed"]},"companyName":{"type":"string"},"stateProvince":{"type":"string"},"country":{"type":"string"}}}
Note
The topic of JSON Schema is too large for this book to cover. To dig more into this topic, I recommend you check out https://json-schema.org.
Here is a possible body a client might send:
{
"status":"pending",
"country":"CA"
}
Finally, hereâs an example using a popular JSON validator (ajv) that I frequently use:
/** load the schema file from external source* pass in the JSON message to send* process and return results/errors*/functionjsonMessageCheck(schema,message){varschemaCheck=ajv.compile(schema);varstatus=schemaCheck(message);return{status:status,errors:schemaCheck.errors};}
Validating XML messages with XML Schema
There are similar options for handling XML validations, too, via XML Schema documents and tooling. There are a handful of approaches, depending on your platform.
Using the same example, hereâs the XML Schema for filtering company records:
<xs:schemaattributeFormDefault="unqualified"elementFormDefault="qualified"xmlns:xs="http://www.w3.org/2001/XMLSchema"><xs:elementname="message"><xs:complexType><xs:all><xs:elementname="status"type="xs:string"minOccurs="0"maxOccurs="1"/><xs:elementname="companyName"type="xs:string"minOccurs="0"maxOccurs="1"/><xs:elementname="stateProvince"type="xs:string"minOccurs="0"maxOccurs="1"/><xs:elementname="country"type="xs:string"minOccurs="0"maxOccurs="1"/></xs:all></xs:complexType></xs:element></xs:schema>
Note
For more on the world of XML and XSD, check out XML Schema and XML Schema 1.1.
And hereâs a sample XML message:
<message> <status>pending</status> <country>CA</country> </message>
And then hereâs a simple example of runtime validation in client code:
varxsd=require('libxmljs2-xsd');functionxmlMessageCheck(schema,message){varschemaCheck;varerrors;varstatus=false;try{schemaCheck=xsd.parseFile(schema);status=true;}catch{status=false;errors=schemaCheck.validate(message);}return{status:status,errors:errors}}
This sample relies on a node module based on the Linux xmllib library.
Validating FORMS with JSON Schema
Validating application/x-www-form-urlencoded message bodies takes a bit more work, but as long as the message bodies are simple, you can convert the application/x-www-form-urlencoded messages into JSON and then apply a JSON Schema document against the results:
constqs=require('querystring');/** read JSON schema doc from external source* send in form-urlencoded string* convert data into JSON and forward to json checker* return results from json checker*/functionformJSONValidator(schema,formData){varjsonData=qs.parse(formData);varresults=jsonMessageCheck(schema,jsonData);returnresults// {status:status,schema.errors}}
Notice that this routine depends on the jsonMessageCheck method seen earlier in this section.
Discussion
Services should make all required schemas available online and link to them in every interaction that relies on validated messages. This means that client applications should look for schema references in services responses. Common locations are shown here.
In the HTTP link header:
**** REQUEST
GET /api.example.org/users/search HTTP/1.1
Accept: application/forms+json;
*** RESPONSE
200 OK HTTP/1.1
Content-Type: application/forms+json;
Link: <schemas.example.org/service1/user-schema.json>; profile=schema
{...}
As part of the response body:
{"id":"za1xs2cd3","type":"search","schema":"api.example.org/schemas/user-search.json","links":[{"id":"q1w2e3r4""name":"user","href":"http://api.example.org/q1w2e3r4","title":"User Search","method":"GET","properties":[{"name":"familyName","value":""},{"name":"givenName","value":""},{"name":"sms","value":""},]}],...}
Validating message bodies using JSON/XML Schema can be tricky. For example, JSON Schema is much more forgiving than XML Schema. While there are some tools that support converting XML Schema to JSON Schema at runtime, it rarely works out well. It is best to continue to write schemas in their native format.
The trick of converting application/x-www-form-urlencoded to JSON works well as long as the resulting JSON is treated as simple name/value pairs. Most FORMs-formatted messages follow this pattern, but there are cases where services get creative with FORM field names that imply a nested hierarchy. For example:
user.familyName=mamund&user.givenName=ramund&user.sms=+12345678901
implies a server-side message that looks like this:
{"user":{"familyName":"mamund","givenName":"ramund","sms":"+12345678901"}}
As the service get more clever with naming patterns, the suggested trick of converting FORM strings to JSON documents gets less reliable. To avoid the problem, it may be better to write a code-based validator instead.
In the best case, services will supply client application developers with properly written (and up-to-date) schema documents to use at runtime. If the target service does not do this, application developers should review the human-readable documentation for the service API and craft their own schema documents for use at runtime. These documents should be posted somewhere online (possibly behind a secured URL) that is reachable by client applications. Care must also be taken to keep these schema documents up-to-date as the service changes over time.
Warning
When in doubt, write your own custom message checking code directly to avoid any problems with poorly written or inadequately maintained schema documents.
Well-crafted services will make sure that any schema changes to production services will remain backward compatible with previous editions of the service. However, client applications should be prepared for services that do not follow this principle. If the target service is particularly bad at maintaining backward compatibility, client applications may need to abandon runtime validation based on schema documents and instead write code-based validators to ensure compatibility going forward.
4.13 Using Document Queries to Validate Incoming Messages
When API client applications receive a response from a service, it is important that they validate the incoming data to make sure the response contains the expected data in the requested format. This is especially true for M2M interactions where the human agent rarely gets a chance to view and validate incoming messages.
Problem
How can an API client application consistently and safely confirm that the incoming service response contains the expected data in the requested format?
Solution
API client applications should inspect incoming service responses on three levels:
- Protocol
-
Does the response include the expected HTTP protocol-level details (HTTP status code, content-type, and any other important headers)?
- Structure
-
Is the response body (if it exists) made up of the expected structural elements? For example, is there an expected
titleproperty? Does the body contain one or morelinkelements with the expectedrel,name, or other properties, and so forth? - Value
-
Assuming the expected structural elements exist (e.g., links, forms, data properties), do those elements contain the expected values (e.g.,
rel="self")? In the case of data properties, do the elements contain the expected data types (string, integer, etc.), and are the values of the data properties within acceptable ranges? For example, doDatetype properties contain valid calendar dates? Are numerical values within acceptable upper and lower bounds?
Tip
For details on how to use schema documents to validate outgoing messages, see Recipe 4.12.
Example
Here is a simplified version of validating the incoming message for protocol, structure, and values:
varresponse=httpRequest(url,options);varchecks={};varmessage={};// protocol-level checkschecks.statusOK=(response.statusCode===200?true:false)checks.contentTypeCollectionJSON=(response.headers["content-type"].toLowercase().indexOf("vnd.collection+json")?true:false);checks.semanticTypeTaxes=(response.headers["profile-type"].toLowercase().indexOf("taxes.v1.alps")?true:false);// structural checkschecks.body=JSON.parse(response.body);checks.submitLink=(body.filter("submit").length>0?true:false);checks.rejectLink=(body.filter("reject").length>0?true:false);checks.countryCode=(body.filter("countryCode").length>0?true:false);checks.stateProvince=(body.filter("stateProvince").length>0?true:false);checks.salesTotal=(body.filter("salesTotal").length>0?true:false);// value checkschecks.submit=checkProperties(submitLink,["href","method","encoding"]);checks.reject=checkProperties(rejectLink,["href","method","encoding"]);checks.country=checkProperties(countryCode,["value"],filters.taxRules);checks.stateProv=checkProperties(stateProvince,["value"],filters.taxRules);checks.salesTotal=checkProperties(salesTotal,["value"],filters.taxRules);// do computationif(validMessage(checks){vartaxes=computeTaxes(checks);checks.taxes=checkProperties(taxes,filters.taxRules);}// send resultsif(validMessage(checks){message=formBody(checks.submit,checks.taxes);}else{message=formBody(checks.reject,checks.taxes);}response=httpRequest(taxMessage);
You can also see that, after all the checks are made (and assuming they all pass), the code performs the expected task (computing taxes) and submits the results. It is easy to see from this example that most of the coding effort is in safely validating the incoming message before doing a small bit of work. This is a feature of well-built API client applications, especially in M2M cases.
Discussion
Although the example is verbose, it should be noted that much of this code can be generated instead of handcoded. This can greatly reduce the effort needed to compose a well-formed API client, and improve the safety and consistency of the application at runtime.
Do not rely on schemas
You may be surprised to see that I am not suggesting the use of schema documents (JSON Schema, XML Schema, etc.) for validating incoming messages. In my experience, applying schemas (particularly strict schemas) to incoming messages results in too many false negativesârejections of messages that fail the schema but could still be successfully and safely processed by the client. This is especially true in the case of XML Schema, which is strict by default. Even valid items in a different order in the document can result in a failed schema review. Schemas also donât cover the protocol-level checks that are needed.
Consider using JSON/XML path queries
The example relies on some features of JavaScript to perform filtering checks. These lines of code can be replaced by a more generic solution using JSON Path queries. I use a JavaScript/NodeJS library called JSON Path-Plus for this task. However, caution is advised here since, as of this writing, the JSONPath specification at IETF is still incomplete and will likely change significantly.
The XML Path specification, however, is quite mature and a very reliable source for checking XML-formatted messages. There is even ongoing work at the W3C to expand the scope of XML Path version 3.1 to include support for JSON queries.
See more on filtering incoming messages in Recipe 4.14.
4.14 Validating Incoming Data
When creating API clients it is important to know how to deal with incoming messages. Essentially, every service response should be assumed to be dangerous until proven otherwise. The message may contain malicious data, smuggled scripts for execution, and/or just plain bad data that might cause the client application to misbehave.
Having a strategy for safely dealing with incoming payloads is essential to building a successful API ecosystem. This is especially true in ecosystems where M2M communication exists, since humans will have reduced opportunities to inspect and correct or reject questionable content.
Problem
How can client applications make sure the incoming message does not contain dangerous or malicious content?
Solution
API client applications should carefully inspect incoming messages (service responses) and remove or ignore any dangerous content. This can be done by relying on a few basic principles when coding the client application:
-
Always filter incoming data.
-
Rely on the âallow listâ model instead of âdeny listâ for approving content.
-
Maintain a âmin/maxâ for all data values and reject any data outside that range.
These general rules are supported by another line of defense for client applications: syntactic validation (based on the expected data type) and semantic validation (based on the expected value of that data type). Examples of syntactic validation are complex types such as postal codes, telephone numbers, personal identity numbers (US Social Security numbers, etc.) and other similar predefined types. Your client application should be able to identify when these types of data are expected to appear and know how to validate the structure of these data types. For example, US postal codes are made up of two sets of digits: first a required five digits and thenâoptionallyâa dash and four more digits. Well-designed message formats provide this kind of data type information in the response at runtime.
Warning
The basic premise that API clients should adopt is âdefend yourself at all costsâincluding to the point of refusing to process the request altogether.â This flies a bit in the face of Postelâs Law (aka the robustness principle), but for a good reason. API clients should only pay attention to content values they already understand, should make sure the values are reasonable, and only perform predetermined operations on those fields.
Client applications should also do their best to validate the semantic value of the message content. For example, if a date range is providedâfor example: startDate and stopDateâit is important to validate that the value for startDate is earlier than the value supplied for stopDate.
Example
Collection+JSON is an example of this kind of support for syntactic type information:
{"collection" :
{
...
"items" : [
{
"rel" : "item person"
"href" : "http://example.org/friends/jdoe",
"data" : [
{"name" : "full-name", "value" : "J. Doe",
"prompt" : "Full Name", "type" : "string"},
{"name" : "email", "value" : "jdoe@example.org",
"prompt" : "Email", "type" : "email"},
{"name" : "phone", "value" : "123-456-7890",
"prompt" : "Telephone", "type" : "telephone"}
{"name" : "birthdate", "value" : "1990-09-30",
"prompt" : "Birthdate", "type" : "date"}
]
}
]
...
}
}
Discussion
Not many representation formats automatically include data type and range metadata for content values. Where possible, try to convince the services your client application uses to add this information as runtime metadata. Formats that do a pretty good job at this are JSON-LD, UBER, Collection+JSON, and any of the RDF formats.
For cases where the type/range metadata is not available at runtime, client developers should scan the existing human-readable documentation and create their own content metadata to apply to incoming messages. While this external source might fall out of sync over time (when the human-readable documents are updated), having a machine-readable set of content filtering rules is still quite valuable.
Here is an example of possible type and range metadata for a client that computes sales and VAT taxes:
varfilters={}filters.taxRules={country:{"type":"enum","value":["CA","GL","US"}],stateProvince:{"type":"enum","value":[...]},salesTotal:{"type":"range","value":{"min":"0","max":"1000000"}}
When receiving a response message, it is a good practice to create an internal, filtered representation of that message and only allow your own code to operate on the filtered representationânot the original. This reduces the chances that your application will mistakenly ingest improperly formed data and limits the possible risk to your application.
// make request, pull body, and scrubvarreponse=httpRequest(url,options);varmessage=filterResponse(response.body,filters.taxRules);
In this example, the message variable contains content deemed safe for the application to use. Note that the filterResponse() routine can perform a number of operations. First, it should only look for content that is interesting for this client application. For example, if this client computes sales or value-added taxes, it might only need to pay attention to the fields country, stateProvince, and salesTotal. This filter may only return those fields while making sure the values in them are âsafe.â For example, the country field contains one of a list of valid ISO country codes, etc. The results can be used to format another message to use in future requests.
Note that in this example, additional semantic validation is needed to make sure that both the country and stateProvince values are compatible. For example, country="CA" and stateProvince="KY" would be semantically invalid.
Finally, there may be cases where an API client has the job of accepting a working document, performing some processing on that document, updating it, and sending the document along to another application or service. In these instances, it is still a good idea to filter the content of the document down to just the fields your API client needs to deal with, validate those values, perform the operation, and then update the original document with the results before passing it along. Your API client is not in charge of scrubbing the whole document that is to be passed along, however. Your only responsibility is to pull the fields, clean them, do the work, and then update the original document. You should assume that any other applications that work on this document are doing the same level of self-protection.
Here is a simplified example:
functionprocessTaxes(args){varresults={};varresponse=httpRequest(args.readUrl,args.readOptions);varmessage=filterResponse(response.body,args.rules);if(message.status!=="error"){results=computeTaxes(message);}else{results=invalidMessage(message)}options.requestBody=updateBody(response.body,message);response=httpRequest(args.writeUrl,args.writeOptions);}
For more on scrubbing incoming data, check out the OWASP Input Validation Cheat Sheet.
4.15 Maintaining Your Own State
In a RESTful system, it can be a challenge to locate and access the transient state of requests and responses. There are only three possible places for this kind of information: server, client, and messages passed between server and client. Which option is best under what circumstances?
Problem
How can a client successfully track the transient state of server and client interactions? Where does the application state reside when a single client application is talking to multiple server-side components?
Solution
The safest place to keep the transient stateâthe state of the application as defined by runtime requests and responsesâis in the client. The client is responsible for selecting which servers are engaged in interactions, and the client is initiating HTTP requests. It is the client, and only the client, that has the most accurate picture of the state of the application. This is especially true when the client has enlisted multiple services (services unrelated to each other) to accomplish a task or goal.
The easiest way to do this is for the client application to keep a detailed history of each request/response interaction and select (or compute) important application state data from that history. Most programming tools support serializing HTTP streams.
Typically, the following elements should be captured and stored by the client:
- Request elements
-
-
URL
-
Method
-
Headers
-
Query string
-
Request body
-
- Response elements
-
-
URL
-
Status
-
Content-type
-
Headers
-
Body
-
Note that the URL value from the request might not be the same as the URL of the response. This might be due to an incomplete request URL (e.g., missing the protocol element: api.example.org/users) or as a result of server-side redirection.
Example
The following is a snippet of code from the HyperCLI client application that manages the request and response elements of HTTP interactions:
...// collect request info for laterrequestInfo={};requestInfo.url=url;requestInfo.method=method;requestInfo.query=query;requestInfo.headers=headers;requestInfo.body=body;// make the actual callif(body&&method.toUpperCase()!=="GET"){if(method.toUpperCase()==="DELETE"){response=request(method,url,{headers:headers});}else{response=request(method,url,{headers:headers,body:body});}}else{if(body){url=url+querystring.stringify(body);}response=request(method,url,{headers:headers});}response.requestInfo=requestInfo;responses.push(response);...
This code creates a push-down stack that holds information on each HTTP interaction. The same client application can now recall the history of interactions and use the request and response details to make decisions on how to proceed.
Here is the SHOW HELP output for the DISPLAY command that returns details on the available HTTP interaction history:
DISPLAY|SHOW (synonyms) REQUEST (returns request details - URL, Headers, querystring, method, body) URL (returns the URL of the current response) STATUS|STATUS-CODE (returns the HTTP status code of the current response) CONTENT-TYPE (returns the content-type of the current response) HEADERS (returns the HTTP headers of the current response) PEEK (displays the most recent response on the top of the stack) POP (pops off [removes] the top item on the response stack) LENGTH|LEN (returns the count of the responses on the response stack) CLEAR|FLUSH (clears the response stack) PATH <jsonpath-string|$#> (applies the JSON Path query to current response)
Tip
For more on HyperLANG and the HyperCLI, see Appendix D.
Discussion
Keeping track of HTTP requests and responses takes a bit of work to set up but results in a very powerful feature for client applications. To lower the cost of supporting this functionality, it can be helpful to create a reusable library that just handles the request/response stack and share that in all client-side HTTP applications.
Just tracking the interactions on the stack is usually not enough functionality for clients. Youâll also need to monitor selected values and keep track of them as âstate variables.â You can see from the previous example that the suggested functionality includes the use of JSON Path as a way to inspect and select properties from within a single request/response pair. You can use something like this to monitor important state values, too. See Recipe 4.16 for more on tracking important client-side variables.
If you are working with a client application that does not manage its own file space (e.g., a web browser), you can set up an external service that will track the HTTP interactions and serve them up remotely (via HTTP!). This offers the same functionality but relies on a live HTTP connection between the client and the interaction service. That means the service might be a bit slower than a native file-based system and the service might be unavailable due to network problems between the client and the interaction service.
4.16 Having a Goal in Mind
There are times when the client application needs to continue running (making requests, performing work, sending updates, etc.) until a certain goal is reached (a queue is empty, the total has reached the proper level, etc.). This is especially true for client apps that have some level of autonomy or automated processing. There are some challenges to this, including cases where the client knows the goal but the service(s) being used by that client do not.
Problem
How do you program a client application to continue processing until some goal is reached? Also, what does it take to create client applications that have a goal that is âprivateâ and not shared or understood by any services?
Solution
To build client applications that can continue operations until a goal is reached, you need to program some level of autonomy for that client. The application needs to know what property (or properties) to monitor, know the target value(s) for the selected properties, be able to locate and monitor the values over time, and know when an end has been reached and how to effect a stop in processing.
Programming this solution is essentially the work of most gaming engines or autonomous robot systems. Client applications can follow the classic artificial intelligence PAGE model:
- Percepts
-
The properties that need to be monitored.
- Actions
-
The tasks clients can commit to affect the values of the properties (read, write, compute).
- Goals
-
The desired end values.
- Environment
-
The playing field or game space in which the client operates. In our case, this would be the services with which the client interacts in order to see and affect the Percepts on the way to achieving the Goals.
Example
There are a couple of different types of goal models you are likely to need: a defined exit goal (DEG) and a defined state goal (DSG). Each takes a slightly different programming construct.
Defined exit goal
With DEGs, you write a program that halts or exits some process once the defined goal is reached. The following example was taken from an autonomous hypermedia client that navigates its way out of an undetermined maze:
functionprocessLinks(response,headers){varxml,linkItem,i,rel,url,href,flg,links,rules;flg=false;links=[];rules=[];// get all the links in this documentg.linkCollection=[];xml=response.selectNodes('//link');for(i=0;i<xml.length;i++){rel=xml[i].getAttribute('rel');url=xml[i].getAttribute('href');linkItem={'rel':rel,'href':url};g.linkCollection[g.linkCollection.length]=linkItem;}// is there an exit?href=getLinkElement('exit');if(href!=''){printLine('*** Done! '+href);g.done=true;return;}// is there an entrance?if(flg==false&&g.start==false){href=getLinkElement('start');if(href!=''){flg=true;g.start=true;g.href=href;g.facing='north';printLine(href);}}// ok, let's go through a doorrules=g.rules[g.facing];for(i=0;i<rules.length;i++){if(flg==false){href=getLinkElement(rules[i]);if(href!=''){flg=true;g.facing=rules[i];printLine(href);continue;}}}// update pointer, handle next moveif(href!=''){g.href=href;nextMove();}}
Note that the client application has a goal of âfinding the exitâ and continues to move from room to room until that goal is reached.
Defined state goal
There are cases when you need to program a client application to maintain a desired stateâa DSG. For example, you need a client app to monitor the temperature of a room and activate heating/cooling units to maintain that state. Here is a snippet of code designed to do that:
// set control valuesvarroomURL="http://api.example.org/rooms/13";varmin=18;varmax=22;varwait=(15*60*1000);// set up periodic checkssetInterval(checkTemp(roomURL,min,max),wait));// do the checkfunctioncheckTemp(roomURL,minTemp,maxTemp){varrtn,temp;rtn="";response=httpRequest(roomURL);printLine(req)if(response.temp<minTemp){rtn=response.form("heat");}if(response.temp>maxTemp){rtn=response.form("cool");}if(rtn!==""){response=httpRequest(rtn);printLine();}}
In the simple DSG, the application is tasked to maintain a room temperature between 18ºC and 22ºC. The temperature is monitored every 15 minutes and, if needed, adjusted accordingly. Of course the service used by this client doesnât know what the client has in mind, it just responds with the information about the requested room when asked. You can see in this example that the response from the service includes data on the temperature (req.temp) as well as hypermedia controls to modify the state of the temperature (req.form("heat") and req.form("cool")). It is worth pointing out that the monitoring service (http://api.example.org/rooms) might not know anything about how to adjust the room temperatureâthat might be handled by separate services, too.
Discussion
Coding goal-oriented clients (DEGs and DSGs) assumes a few key things. First, that the client âknowsâ the end goal ahead of time. Second, that the client already knows how to achieve this goal (finding the exit, adjusting the temp, etc.). Third, the client can find an accurate representation of the current state, and fourth, is able to properly evaluate the current state against the desired goal. All of these elements must be present for the goal-oriented client to be successful.
Tip
For this recipe, the client examples (DEG and DSG) assume that all the planning and criteria for evaluation are determined ahead of time and/or supplied when the client starts (via a config file). No machine learning or planning skills are built into the client application here.
In the DSG temperature example, the client knows that the end goal is a room temp between 18ºC and 22ºC. It also knows it can use the âheatâ and âcoolâ forms in an HTTP response to achieve the goal. The client also knows that it can use the room URL to check on the current temperature, and knows how to evaluate the returned temp to its own internal minimum and maximum values.
Sometimes the evaluation step is more involved. For example, in the temperature management case, maybe the temperature settings are different at different times of the day, or if there are (or are not) people in the room, or based on the current cost per kilowatt per hour, etc. In these cases, there may be more values to monitor and use in a more involved comparison routine before taking the determined action.
It might also be the case that the evaluation is handled by another service (not the client). For example, a stock buy/sell decision might come from a service that accepts a wide range of inputs (which your client may supply), then returns an action recommendation that the client application then executes.
Whenever possible, it is a good idea to make both the properties to monitor and the local evaluation values a configurable set of data points. This avoids hardcoding decision-making data into the client application itself. You could, for example, provide the client with the control data via a configuration file or even a remote HTTP call to another service that holds configuration data.
Finally, it is important to add an escape option for goal-oriented client applications. For example, if the DEG canât find an exit to the maze, it will probably need to give up after some point or be forever trapped in a loop. This escape value should be completely controlled by the client, too. Depending on some other service for the decision to escape could fail if the remote service is unavailable or sending bad data to the client.
The same is true for DSG-style client applications. In our temperature monitor example, imagine that the service that returns the sensor data is broken or unavailable. What does the client do? Does it just keep checking in vain? A better option is to add some code that triggers an alert when the sensors are not responding or if they report data far outside the assumed boundaries.
Get RESTful Web API Patterns and Practices Cookbook now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

