Chapter 4. Protecting Workstations and Servers
If ransomware hits the desktop, even if it is stopped there, it already means that several security systems have failed. That failure could have happened at the mail server for not screening mail properly, or it could mean the web proxy or the intrusion detection system (IDS) did not know about a bad domain or a pattern of malicious traffic.
Fortunately, at the desktop level, there are a number things that can be done that make it harder for ransomware to execute and install successfully. A number of the suggestions in this chapter might sound expensive, and some will result in grumbling from end users, but security costs money, and it sometimes requires restricting access in a manner that occasionally inconveniences users. Security is often seen as a balancing act, where you the security professional must balance between creating an environment so restrictive that it encourages end users to seek ways around your restrictions and one that is so permissive that any attacker can simply walk away with your organization’s crown jewels. A big part of that balancing act is educating users about why certain changes are important. The more involved leadership and the users are with the changes the more likely they are to comply.
Furthermore, often the costs of these changes are less than the costs of paying a ransom or restoring multiple systems after an attack. Of course, that doesn’t mean getting approval to implement them will be any easier, but these security changes will significantly improve the chances of an organization surviving a ransomware attack unscathed.
Attack Vectors for Ransomware
Most modern cryptoransomware uses a few methods to gain entry into a system. Most gain access to networks by requiring user interaction through an infected file or malicious link sent via email or through malicious advertising injected into legitimate advertisement networks. The malvertising types of ransomware use JavaScript or Adobe Flash in the background while the ad downloads and runs the ransomware without any user interaction or knowledge (see Figure 4-1).
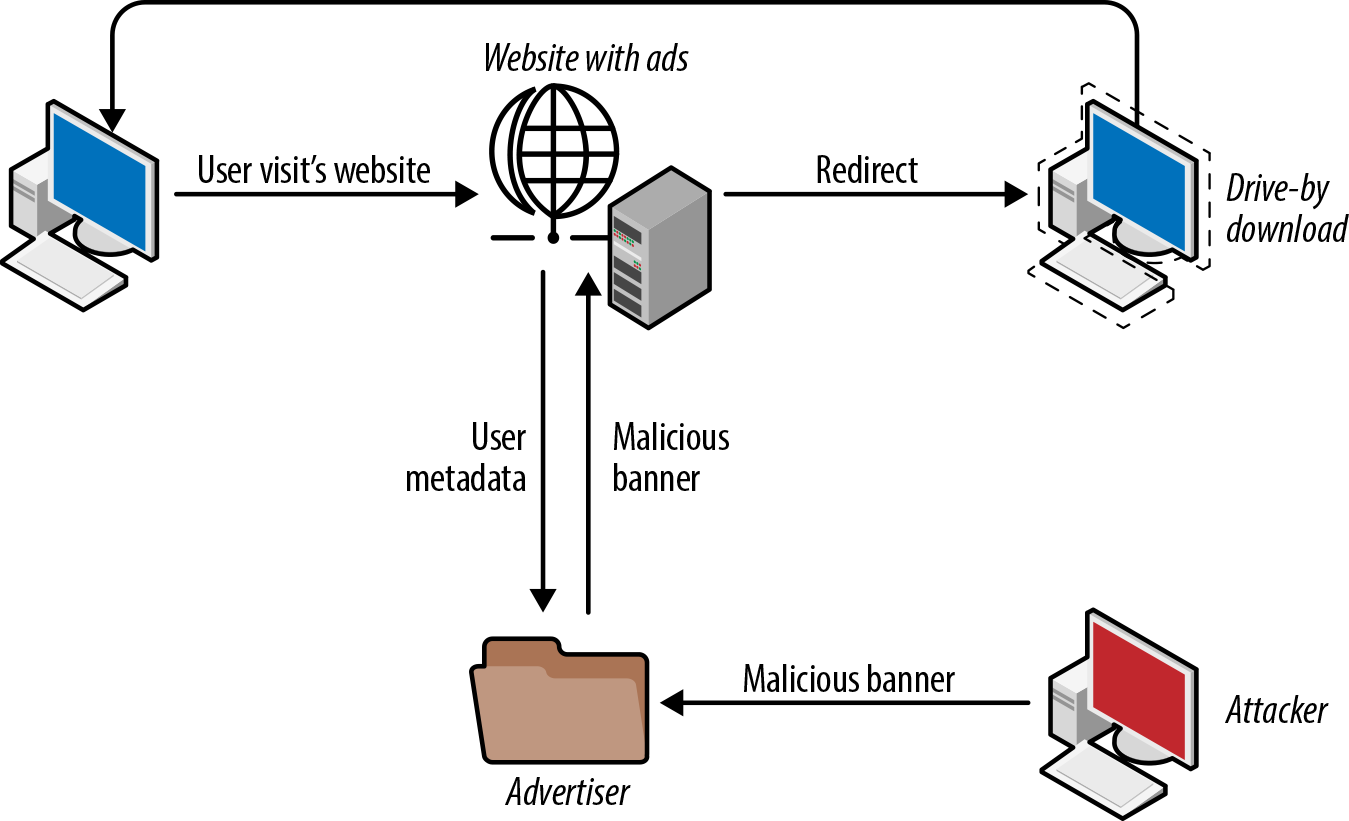
Figure 4-1. How malvertisements work
This means you have to find a way to prevent infected files from getting into your system through the most commonly used tools on your networks: the web browser and the email system.
Email is used by everyone, including hackers. It is in your best interest to aggressively scan all inbound files for malcode using an edge-detection mechanism like a FireEye NX, or a PaloAlto Firewall (with Wildfire enabled) for inbound email. This can scan all files, and even block files that don’t match specifically allowed types. For example, simply blocking .js and .wsf files is a good start but blocking older versions of Word documents (.doc), that can contain macros is also important. Another useful method is striping links from inbound emails and informing security teams when these types of malware files and links have been sent to end users.
Sandbox Functionality
Many advanced end-point security tools also have built-in sandbox functionality that create microvirtualized instances where inbound files including Office files are detonated and checked for malicious activity. This doesn’t help with virtual aware ransomware, but it does act as another layer in your protection cake.
Watch for New Tactics, Techniques, and Procedures (TTPs)
Attack groups are always changing up their delivery methods to take advantage of new avenues of exploitation. This section has already talked about macros embedded in Microsoft Word and Excel documents, but what about Microsoft Publisher files?1 Many security solutions don’t check for macros in Microsoft Publisher files, or in Microsoft Visio files. It is important to not only understand the threat landscape but to be aware of the capabilities (and limitations) of security tools in use in the network.
You should also install browser protection and ad blocking on your end-user devices. This type of sandboxing will prevent JavaScript-based malware from executing on the system and instead run in a virtual sandbox preventing execution on the system. In this way an malvertisment delivered piece of ransomware may never get down to the system to execute its tasks.
By avoiding the mapping of network drives, you will limit the spread of an infected system from an individual device to network resources. This allows an organization to recover quickly without having to pay the ransom should a piece of ransomware get past the protections in investigative measure you have put into place.
Hardening the System and Restricting Access
The first step in protecting workstations and servers in a network is to harden them. If an attacker cannot exploit a flaw in the workstation, it will be more difficult for that attacker to gain access and deliver the ransomware.
Discussion around stopping ransomware has to include stopping the delivery systems. Except in the case of spam deliveries, ransomware is installed on a victim machine by another piece of malware, most often an exploit kit in conjunction with a loader of some sort. Since the most effective way to stop ransomware is to never let it hit the target system, stopping these exploit kits should be the first goal.
Resources for Tracking Ransomware
While this book attempts to offer broad advice that is designed to stop all sorts of different types of ransomware, the fact is that new techniques are developed all the time. For organizations that don’t have a good relationship with a security vendor, there are a number of excellent resources for tracking what is going on in the world of ransomware. Using a few select news sites will help minimize the time the security team has to spend researching, while still providing critical information. Some of the best are:
It is also worth finding out if your industry has its own Information Sharing and Analysis Center (ISAC). These are great resources for industry-specific intelligence, as well as for security best practices that are industry specific. The most famous one is the Financial Services ISAC (FS-ISAC), but there are other ISACs for information technology companies, healthcare organizations, retail companies, the multistate ISAC, and many more.
Time to Ditch Flash
Any conversation about hardening a system also has to include a discussion about removing Adobe Flash across the network and preventing it from being installed. Adobe Flash is a common attack route and having it active in a network makes an organization more vulnerable to attack.
The Locky ransomware is often delivered via the Rig exploit kit, which has exploits against, among others, CVE-2014-0515 (affects Adobe Flash prior to 13.0.0.182), CVE-2014-0569 (affects Adobe Flash prior to 15.0.0.167), CVE-2016-4171 (affects Adobe Flash prior to 21.0.0.242), CVE-2016-4166 (affects Adobe Flash prior to 21.0.0.242), and many more. The fact is, almost as soon as the team at Adobe patches a Flash vulnerability, a new one is uncovered by hacker groups, or more accurately a new one is moved from use against high value targets to more commodity targets and quickly shared from one exploit kit to another.
This pattern repeats itself across exploit kits. The first version of Cerber was widely distributed using the Angler exploit kit, but in June 2016, after the arrest of nearly 50 people involved in underground activity in Russia by the Federal Security Service (FSB), Ceber is now most often delivered via Rig, Magnitude, and Nuclear exploit kits. These kits contain exploits against CVE-2015-0310 (affects Adobe Flash prior to 16.0.0.257), CVE-2015-0311 (affects Adobe Flash prior to 16.0.0.287), CVE-2015-0313 (affects Adobe Flash prior to 16.0.0.296), as well as the previously mentioned CVE-2016-4171 and CVE-2016-4166.
CryptXXX is also known to be distributed via the Rig exploit kit, using the Bedeep trojan as a loader, as is CTB-Locker.
There has a been tremendous growth in the distribution of ransomware via exploit kits. For better or worse, exploit kits like to target Adobe Flash. Given this information, the best course of action is disabling Flash or removing it entirely from workstations and servers. Alternatively, it is possible to administratively configure Adobe Flash so that it requires users to click a video in order to play it. Unfortunately, with the proper lure, it is very easy to get users to click a video.
Asset Management, Vulnerability, Scanning, and Patching
While Adobe Flash has been a consistent target of exploit kits, it is far from the only target. Exploit kits look for vulnerabilities in Microsoft’s Internet Explorer and Silverlight, Google Chrome, Mozilla’s Firefox, Apple Safari, Adobe PDF, and anything else that may interact with a website. But exploit kits rarely use zero-day vulnerabilities (vulnerabilities that have not been previously disclosed by the vendor or a third party). The developers of these exploit kit platforms are not necessarily security researchers, so they are not spending their time uncovering vulnerabilities. In fact, they don’t really need to spend time uncovering new vulnerabilities because there are so many unpatched systems out there.
Even if these developers had access to zero-day vulnerabilities, what would be the point in using them on targets that can be so easily compromised by taking advantage of existing vulnerabilities? Using a zero-day would simply alert the vendor to a new vulnerability that she could quickly patch. This is especially true given how closely these exploit kits are monitored.
It is not just applications that touch the Internet directly that security teams need to worry about. The single most exploited common vulnerabilities and exposures (CVEs) over the last few years has been CVE-2012-0158, a vulnerability in Microsoft Word. According to Sophos, in the fourth quarter of 2015, CVE-2012-0158 accounted for 48% of all exploits detected.2 This means a lot of organizations are not patching their Microsoft Office installations.
The single most important thing a security team can do to protect their network from ransomware is to keep any application that touches the Internet or interacts with email fully patched and updated to the latest version. Unfortunately, updates are often forgotten or ignored. While exploit kits rarely include exploits against zero-day vulnerabilities, they are very quick to add in new exploits once a vulnerability has been reported. Often within hours of a new vulnerability being reported a new exploit has been added to one of the exploit kits. That new exploit is then quickly shared across the different exploit kits. Waiting days or weeks to test and deploy a new patch can cost an organization a great deal of money.
Patching systems quickly isn’t possible if an organization does not have an accurate inventory of the software that is deployed throughout the network. Before talking about patching there needs to be a discussion about asset management. Using a software asset management tool like Corvil, TripWire, or Symantec’s End-point Management software to understand what versions of software are installed on every desktop, laptop, and server on the network is the first step. As part of these products, they also can interface with network access control (or NAC) products that not only validate compliance, but also enforce specific network access for devices that are not in compliance (either kicking them off of the network, or shunting them to a limited access network until they become compliant). You can also scan all devices that connect to your network to ensure they have the correct asset and configuration management software installed.
Once an organization has collected inventory information and developed a process to automate scanning of the network to update current version information the next step is to match threats against potential vulnerabilities that exist in the network. This allows the organization to prioritize patching those events that put the organization at the greatest risk. Prioritizing patching is not just a matter of matching scores—it also means understanding the risk.
For example, CVE-2016-4171 has a common vulnerability scoring system (CVSS) score of 9.8 (out of 10), and the vulnerability affects Adobe Flash with common platform enumeration (CPE) version cpe:/a:adobe:flash_player:21.0.0.242 and earlier. It is also being exploited in the wild. A software asset management tool that is up to date will allow a security team or system administrator to pull a list of all of the systems within the organization that are running Adobe Flash and check their CPE information against the vulnerability. Any systems that are not fully patched can either have an update pushed down or have the Adobe Flash service disabled.
There are also a number of vulnerability management tools, some with agents and others agentless, that can be used to audit systems for missing patches. Tools from Tenable, Rapid7, and McAfee can not only audit systems and provide regular and automated reports on outdated systems, but some of them can also tie into a network access controller to prevent an unpatched system from reaching the public Internet until it is brought back into compliance.
Chapter 6 will delve into more detail about ways to determine whether or not a vulnerability is being actively exploited, and especially ways to determine if it is being used by exploit kits that distribute ransomware. That is an important distinction, as vulnerability scoring is an inexact science. A vulnerability is only critical to an organization, irrespective of its CVSS score, if that organization has systems running the vulnerable code and if there is a risk of those systems being exploited. A system running an application that has a vulnerability that allows remote code execution with a CVSS score of 9 but doesn’t touch the Internet is less critical, in terms of patching, then one that does, at least around the discussion of ransomware.
Again, these checks should apply to any applications that reach directly out to the Internet, which is one of the main touch points for these attacker groups; and keeping browsers, plug-ins and other Internet-facing applications up to date goes a long way toward protecting the network.
Disrupting the Attack Chain
Of course, not all ransomware is delivered via a web-based attack. Often ransomware is delivered via spam or other methods that won’t be initially foiled by a fully updated system. However, email attacks still follow a similar attack pattern, e.g., an email attachment with a Microsoft Office document that contains a macro that downloads a trojan that, in turn, downloads the actual ransomware. If that is the case, the best thing to do is to try to stop the ransomware from executing, or at least from completing its installation.
Even after a ransomware attack has begun, there are still points in the attack where it can be stopped. To understand those points, let us review the steps most ransomware families follow during their installation process:
- The ransomware must execute and unpack itself and then collect system information.
- The ransomware has to change registry settings to maintain persistence.
- More advanced ransomware disables system restore and deletes everything in the Volume Shadow Copy (VSC).
- Most, but not all, ransomware has to call out to command-and-control infrastructure to get a public key that will be used to encrypt the files.
- The ransomware now has to enumerate the files.
- It then begins to read and encrypt the files.
- If each encrypted file is written to a new file, the original files must be deleted.
- Finally, the encryption key is removed from the local machine and sent back to the controller.
Notice that there are a number of potential break points in the the attack chain that a hardened system could disrupt and stop the installation process.
No One Loves the Security Team
Some of the changes that are going to be recommended over the next few pages are not going to be popular with users, starting with not allowing local admin privileges on workstations. All network users like this ability, but providing local administrative access to all users makes an organization less secure. Unfortunately, security is a tradeoff. While these changes will make an organization more secure, they may also have an impact on the ability of users to complete certain tasks. Each organization has to determine which tradeoffs are worth it.
One protection that exists prior to the outlined attack chain but is a good place to start is disabling macros in Microsoft Office. One common tactic for ransomware groups that use spam campaigns is to use macros embedded in Microsoft Office documents that reach out and download the ransomware. As discussed in Chapter 3, this is a surprisingly effective attack that doesn’t require any exploitation. By disabling macros in Microsoft Office documents, which can be done in custom additions to group policy, these types of simple attacks can be prevented before they have a chance to start.
Preventing ransomware from executing
The next thing to look at is limiting the directories in which programs can execute. Using the example of ransomware delivered via exploit kit, the ransomware code is most likely going to execute in the \Downloads, \Temp, or %AppData%\ directories. One possible way to stop the ransomware is to prevent any programs from executing in those directories, or really any directory outside \Program Files. Of course, that is one of those security policies that might generate a lot of complaints. Another option is to limit programs that can execute to only those that have been digitally signed.
To go even further, system administrators can set policy using the Microsoft Group Policy Management Console (GPMC) that prevents files from executing outside directories commonly used by ransomware. Some of these directories include:
Path: %localAppData%\*.exe Path: %localAppData%\*\*.exe Path: %localAppData%\Temp\*.zip\*.exe Path: %localAppData%\Temp\7z*\*.exe Path: %localAppData%\Temp\Rar*\*.exe Path: %localAppData%\Temp\wz*\*.exe
The problem with relying solely on digital signatures is that hacking groups know they can bypass a lot of security applications if their code is digitally signed. Therefore, these groups are constantly looking to steal legitimate keys in order to sign their code. Relying solely on digitally signed code as a litmus test opens the desktop to potential attack by more sophisticated ransomware families. A combination of limiting the ability to execute to certain directories and only allowing code that has been digitally signed offers the best protection.
One way to stop potential ransomware portable executables (PEs) from running is to use Microsoft Windows AppLocker. AppLocker is a tool that was introduced in Windows 7 and Windows Server 2008 that is specifically designed to stop unwanted programs from executing. AppLocker allows system administrators to control which files are allowed to execute and which aren’t. Specifically, AppLocker looks at the following sets of files:
- .com and .exe executables
- .dll and .ocx libraries
- .bat, .cmd, .js, .ps1, and .vbs scripts
- .msi and .msp Windows installers
System administrators can create rules based on Publisher, Installation Path, and File Hash for each of the categories of files and choose to allow or deny actions for a specific user, group, or everyone. While AppLocker does not offer everything needed to take advantage of the protections suggested in this chapter, it is a good start. It also has the advantage of native Windows logging, so anything that is stopped will automatically be logged as a Windows event. There are other tools like Carbon Black, TripWire, and SentinelOne that offer more advanced capabilities that are also worth investigating.
Figure 4-2 shows SentinelOne blocking an attack from TeslaCrypt. Like many of of the advanced end-point solutions, it can run in multiple modes; in this case, it is in blocking mode. When SentinelOne detects a threat in blocking mode, it automatically kills the malicious process, quarantines the file and, in this case, can restore any damaged files. These advanced end-point solutions do not rely on a signature set to detect ransomware; instead they look for the types of behavior outlined in the attack chain and can stop a ransomware attack very early on in the process.
More and more organizations are adopting whitelisting when it comes to application installs. By creating a list of applications that are allowed to be installed in the network, and blacklisting anything not on that list by default, organizations can improve their security posture, again at the expense of making things more difficult for users on their network. However, keep in mind that whitelisting is not a foolproof solution. Many of the exploit kits discussed here use process injection to bypass any application restrictions. There have also been a number of ransomware families that use valid (or stolen) keys to sign their malware, again bypassing some whitelisting restrictions. However, whitelisting is much better than the alternative of blacklisting only, which ostensibly becomes a game of cat and mouse with ransomware developers.
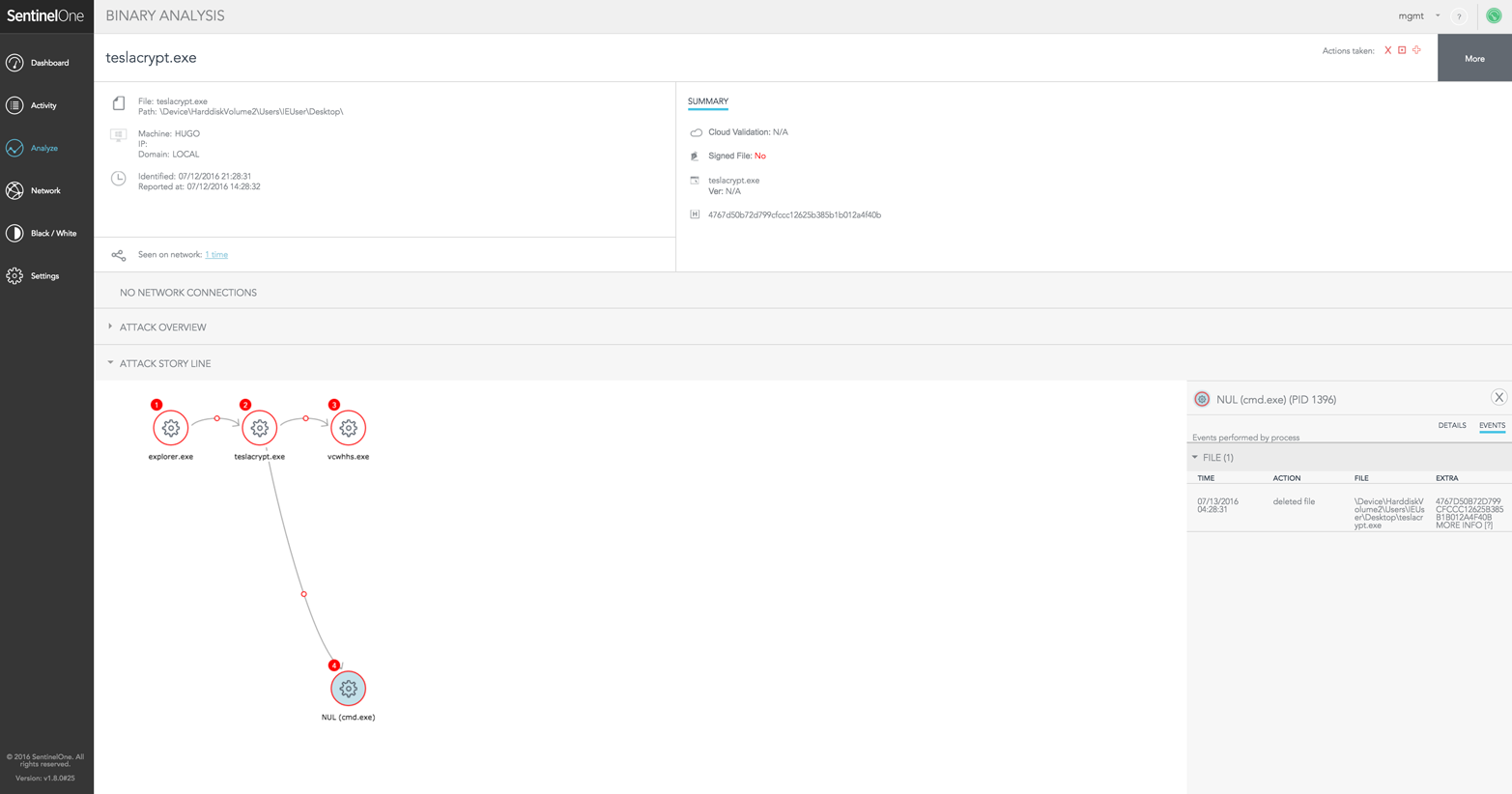
Figure 4-2. SentinelOne blocking a TeslaCrypt attack
Looking at packers and the registry
If the file manages to bypass any execution security in place, the next thing to look at is the packer being used. Some ransomware, like Petya, uses a preferred third-party packer,3 while other ransomware families, like CryptXXX and Locky, create their own custom packers.4 Identifying these packers and preventing them from executing their payload is difficult, which is why so many ransomware families manage to avoid traditional antivirus solutions. Developers also constantly change their methods of obfuscation to avoid detection. Some packers even steal code from other packers to throw off antivirus programs and cause them to mislabel the payloads. So, while identifying a packer and associating it with a specific ransomware family may be a valuable exercise, without a team of researchers to keep up with the constantly evolving environment, it may not be a practical solution to stopping a ransomware installation.
A more practical solution may be preventing the ransomware from accessing the Windows Registry. Ransomware families use the registry to maintain persistence through reboots and to disable system restore on the victim machine. This is pretty consistent across ransomware families as shown in Examples 4-1–4-3, which show three different ransomware families using the registry to maintain persistence between reboots:
Example 4-1. CryptoWall (line break inserted for readability)
\REGISTRY\USER\[Username]\Software\Microsoft\Windows\CurrentVersion\Run\[Fake Name] → C:\Users\admin\AppData\Roaming\29fb37d8\[File Name].exe
Example 4-2. TeslaCrypt (line break inserted for readability)
\REGISTRY\MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Run\[Fake Name] → "C:\Windows\[File Name].exe"
Example 4-3. Cerber (line break inserted for readability)
\REGISTRY\USER\[User Name]\Software\Microsoft\Windows\CurrentVersion\Run\[Fake Name] → "C:\Users\admin\AppData\Roaming\[File Name].exe"
In addition to using the registry to keep the ransomware running between reboots, some ransomware families use it to disable system restore, as shown in Example 4-4.
Example 4-4. CryptoWall (line break inserted for readability)
\REGISTRY\MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\ SystemRestore\DisableSR → 0x00000001
Administrators can disable writing to the registry, or at least to certain registry keys, using Windows Resource Protection. By restricting access to the \Run key and the \SystemRestore key, even for the system and administrator accounts, the ransomware won’t be able to run on start up, and it won’t be able to disable system restore. It is important to note that this will not necessarily stop the ransomware from completing its tasks. Some ransomware families will crash when they cannot write to these Windows Registry keys, but others will continue to run despite the error.
As with restricting where PEs are able to run, locking out local accounts from being able to write to the \Run Windows Registry key means that end users will not be able to install legitimate programs. Again, there is a tradeoff between making the organization’s desktop team responsible for all application installations and the better security offered by restricted access.
On the other hand, there is no legitimate reason a user should want to disable system restore on an organization-issued computer.
Shadow copy
In addition to attempting to disable system restore, most mature ransomware tries to delete everything stored in the VSC using the Volume Shadow Copy Service (VSS). This is another one of those actions that is unique to ransomware; there are no legitimate programs or services that attempt to delete en masse everything stored in the VSC. Example 4-5 shows Cerber issuing the commands to delete all files in the VSS:
Example 4-5. Cerber
"C:\Windows\system32\vssadmin.exe" delete shadows /all /quiet "C:\Windows\system32\wbem\wmic.exe" shadowcopy delete
The example from the Cerber ransomware family is pretty typical. Nestled among a string of commands are strings that will delete all the files stored in the Volume Shadow Copy. These two commands run before the encryption of files on the system starts. One potential way to limit damage done by a ransomware attack might be to deny access to vssadmin.exe and wmic.exe to all local accounts. The loader that installs ransomware is going to attempt to gain either system or local administrator privileges to ensure the install actually works.
An alternative is to use one of the advanced end-point protection tools mentioned in “Preventing ransomware from executing” to spot this type of activity, alert on it, and even kill the process. Again, recommending yet another agent is not always a popular idea. However, used correctly, these advanced end-point protection tools can spot and stop malicious activity that traditional antivirus tools simply cannot.
Figure 4-3 shows an example of this. In this case, SentinelOne is configured in alert mode instead of blocking mode, which allows for a better understanding of how the attack works. In this case, a user downloaded a file called “Click Me For Smiley Faces.exe,” which turned out to be malicious. Once executed, the file accessed a number of files, including vssadmin.exe, and set up an auto-run registry entry (as seen in Figure 4-3). Using the tools available in the platform, an administrator can remotely quarantine the offending file and restore the system.
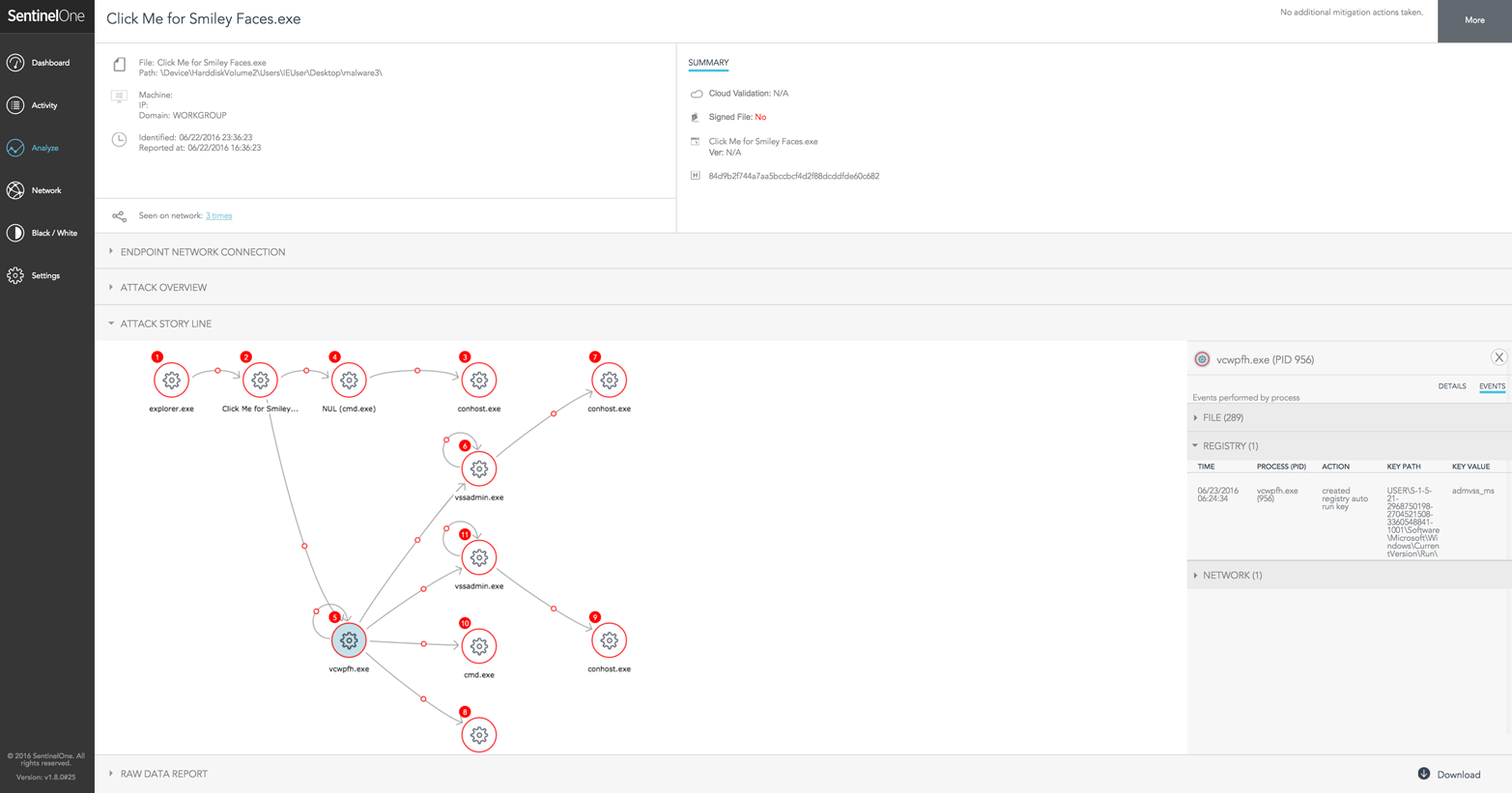
Figure 4-3. SentinelOne alerting to process accessing vssadmin.exe
With the elevated privilege, the attacker will be able to run the commands listed. However, if local and system administrator accounts are denied access to those files, he will not be able to delete the files in the VSC. This will not prevent the ransomware from installing, but it might make it easier to recover from the install.
Figure 4-4 shows Carbon Black stopping a TeslaCrypt ransomware attack by, in part, alerting on its attempt to access wmic.exe.
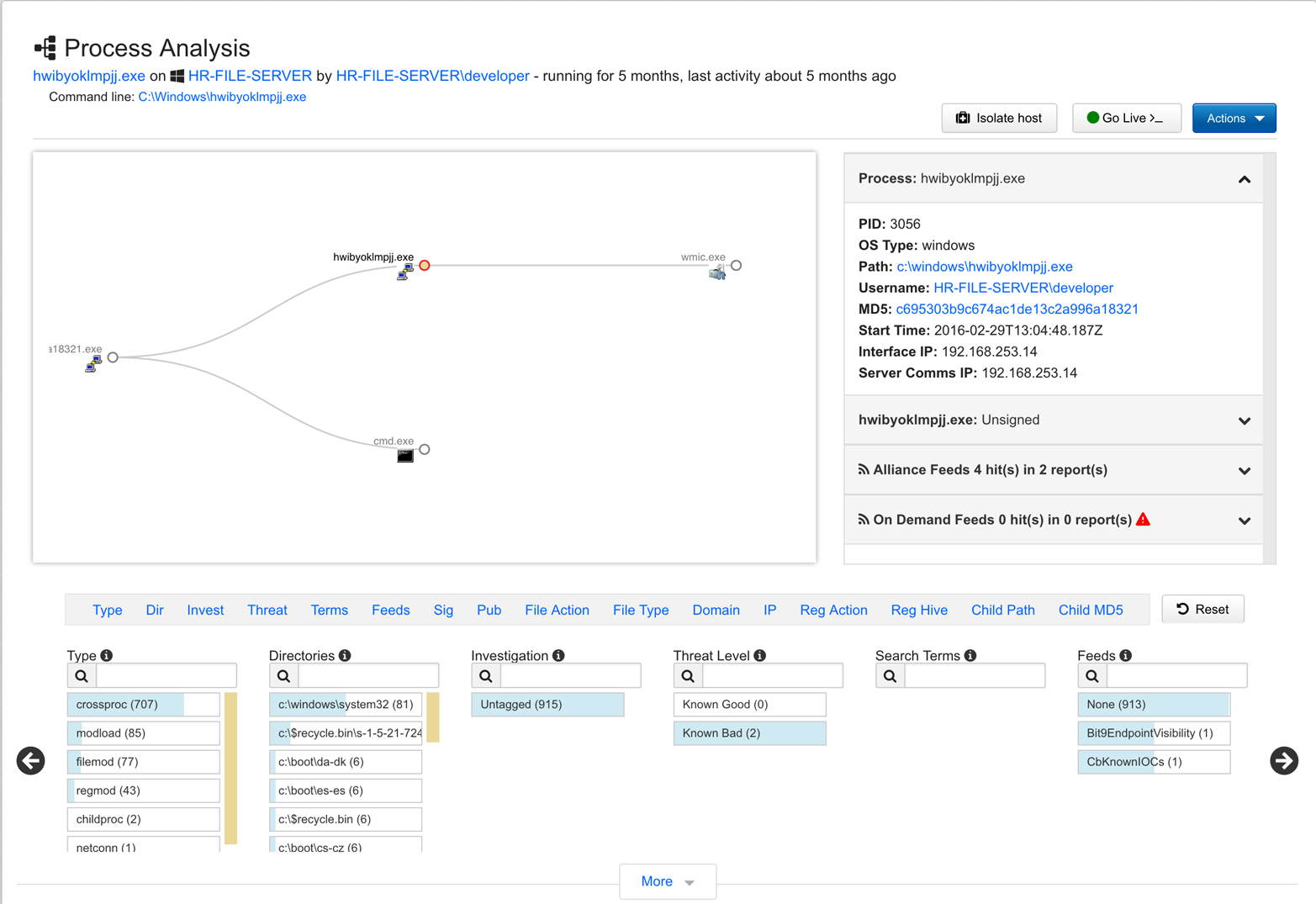
Figure 4-4. Carbon Black stopping TeslaCrypt’s attempt to access wmic.exe
A Word of Caution
There may be internal processes that depend on being able to access vssadmin and wmic, which could be broken by denying access to local and system administrator accounts. It is important to test new security settings thoroughly before implementing them widely.
One alternative to think about is creating an alert on the end-point system. There is no reason that a legitimate process would need to run the two commands listed in Example 4-5. A security team could create an alert that kills any process that executes those programs with those specific flags. This not only lessens any worries about overly restrictive permissions disrupting legitimate processes, but it also stops the ransomware attack before any files are encrypted.
Disrupting command-and-control at the desktop
After the ransomware is installed, but before it starts encrypting the files, it attempts to make a connection to its command-and-control (C&C) host, usually using HTTP over port 80 (unlike other types of malware, ransomware families have not been strong adopters of TLS encryption). For some ransomware families, this is another point in the attack chain where an infection can be stopped. One of the purposes of that initial check-in is to get a unique public key that can be used to encrypt the files. Some ransomware, like early versions of Locky, will not continue if it is not able to get that key. Other families, like the Encryptor ransomware, specifically tout not requiring successful C&C communication in order to encrypt the files.
Disrupting C&C communication can be difficult from the desktop, but if an organization has an advanced end-point protection platform, such as Carbon Black, Cylance, FireEye, or Tanium, network indicators can be fed to the end-point, and communication can be disrupted there. This will be discussed in more detail in Chapter 6.
There are generally two ways that ransomware families manage C&C communication. The first is to load up a list of IP addresses into the binary itself and start connecting down the list looking to see which one of those servers is responding and communicate with that server, which is how Cerber and CryptXXX work. The second method is to use a domain generation algorithm (DGA) to pick a domain and connect to it; Locky and TorrentLocker both work this way. Ransomware that uses embedded lists of domains and IP addresses are easier to disrupt because new samples are quickly decoded and those domains become widely shared. Any organization that has an advanced end-point platform can quickly push down new ransomware-related domains and stop the C&C communication, potentially disrupting the ransomware install. Of course, the end-point is not necessarily the best place to put these indicators. A web proxy, DNS server, or, in some cases, a firewall, a much better fit for DNS and IP address indicators. On the other hand, for organizations that are actively engaged in hunting, the end-point makes more sense for investigative work.
Ransomware that use DGAs to phone home to the C&C server are more difficult but not impossible to stop. A DGA uses some combination of system information with programatic information embedded in the code to create a set of domains that the ransomware can use for C&C purposes. For example, Locky uses the time in conjunction with a frequently updated secret key to generate a list of domains; it also includes a fall-back IP address if none of those domains work. Because that IP address remains static within a Locky variant (but not across all Locky variants), it can be a good indicator to use for blocking purposes, but an indicator with a very short shelf life. However, a number of organizations have reversed engineered the DGA that Locky uses and provide updated lists of C&C domains that Locky will try to provide.
There is also another way to possibly block DGA-generated domains, depending on the capability of an organization’s end-point protection. Take a look at this list of DGA domains from Locky reverse-engineered by Nominum:5
- yslkvbbummq.work
- vinbjwjfuq.su
- rbjuwkqhktemxvk.xyz
- aushewagwr.pw
- ymvbuagowoaucpvc.su
- yjhhhgtp.pw
- csdbxklkbfmljiomg.click
- ksbnorjlt.click
There are a couple of things that pop out right away. The first is that none of the top-level domains (TLDs) used, at least in this subset, are commonly used TLDs. In fact, many of the of the generic TLDs (gTLDs) and country code TLDs (ccTLDs) are well-known for containing malicious content, according to the DomainTools malicious domain report.6 This particular variant of Locky limits domain creation to the following gTLDs and ccTLDS: biz, click, info, org, pl, pw, ru, su, work, and xyz.7
Given the number of malicious domains using these gTLD/ccTLD extensions, it may be a good idea to block all traffic requests to the domains with those gTLDs/ccTLDs; not necessarily all of the potential TLDs, just those that are not required for an organization to maintain legitimate relationships and have a bad reputation.
Separate from the gTLD and ccTLD choices, the domains themselves are suspicious looking. The problem is that the domains are suspicious looking to a human, but not necessarily a computer. Even the most inexperienced security professional would raise an eyebrow at traffic going to the domain rbjuwkqhktemxvk.xyz. This is the problem with DGAs—they generate domains that look odd, but only to a human. However, depending on the end-point protection tool in place, there are ways to write detection rules that look for odd patterns in the domain itself. Writing rules that look for excessive numbers in a domain or that calculate the percentage of the domain that the longest meaningful string (LMS) occupies are ways to potentially filter or block malicious domains created by the DGA. There are other ways to block these domains that are more effective, which will be discussed in Chapter 6.
Remember, none of this blocking matters if the fall-back IP address is not being blocked as well. Of course, this blocking is ideally done at the proxy or firewall level so that the entire network is protected and a single workstation is not overburdened with blocking thousands, or even hundreds of thousands, of domains and IP addresses that change very rapidly. Again, this will be discussed in more detail in Chapter 6.
Stopping the attack during the encryption process
After the public key is retrieved from the C&C server, the next step is for the ransomware to start the encryption process. Most ransomware families, including Locky, CryptoLocker, and Cerber, use the built-in Windows Crypto API to handle the encryption. While this is not a process that can necessarily be blocked, it is a process on which a security team can be alerted. The challenge is to structure alerts in a way that doesn’t generate an overwhelming number of false positives. The Windows Crypto API is used by a wide range of system and third-party applications, so alerting every time a call is made would drown the security teams in alerts.
That being said, creating a threshold alert to trigger when a certain number of calls is made in a short period of time could be an effective warning that ransomware is attacking a system. The way most ransomware families encrypt files is one at a time. One file after another is accessed by the ransomware executable, which then either copies the file and encrypts the copy or it just encrypts the existing file. Each time the ransomware encrypts the file, it has to call the Windows Crypto API again, so it makes a lot of calls in rapid succession. Of course, this alert would be occurring mid-attack, so unless there is very quick response, the only benefit of the alert is knowing that the system is already controlled by ransomware (unless that threshold alert could be fed into an end-point solution and any process that met the threshold could be killed automatically). For example, creating a threshold alert that will kill any nontrusted process that calls the Windows Crypto API (or specifically crypt32.dll) more than four times in a minute. As always, an alert like that would have to be thoroughly tested to ensure the timeframe does not interfere with any legitimate processes or disrupt critical systems. This will still result in some files being lost; but if it works, it will save the majority of the files on the system.
It’s important to note that this will not work on ransomware families that choose to use their own encryption libraries. Right now, the trend in ransomware is to use the Windows Crypto API because it is easy and solid, with no known flaws in its implementation. That could change over time, so it is wise to keep up with changes in the tactics of ransomware developers.
While the encryption calls are going on, the ransomware is also reading and writing a lot of files in rapid succession. The ransomware first enumerates all of the files on the system. Then it starts the process of opening each file, which means that a single process is opening a number of files in rapid succession and copying, modifying, or deleting them. Of course, a user copying a large number of files from one drive to another or one directory to another looks like similar behavior. The difference is that normal copying uses trusted Microsoft Windows processes, while a ransomware executable does not. So, alerting on a large number of files being copied or deleted by a nontrusted Windows process and then killing that process would stop ransomware mid-attack, but not before it most likely inflicted some damage to the system.
A Quick Word on Ransom32
Ransom32 will be discussed in more detail in Chapter 9, but it is worth making a note of it here because of its unique delivery method. Ransom32 is unique because it is developed entirely in JavaScript using the NW.js framework. While Ransom32 behaves a lot like regular ransomware once it is installed, the installation process is a little different.
Because it is delivered as a packed .js file (Ransom32 is often disguised as a .scr file, which should be a red flag in and of itself) it is larger than most ransomware. The packed executable is more than 22 MB, compared to less than 1 MB for other ransomware families. One quick way to alert and block on Ransom32 and other ransomware families built using JavaScript is to flag .js files larger than a certain size. Start with .js files that are larger than 15 MB and move up or down depending on the number of false positives or false negatives.
Looking for the Executable Post-Attack
When an attack is missed, there can be a lot of effort expended in finding the original executable that launched the encryption process. Unfortunately, most of the time that file is long gone. Most modern ransomware will delete the original executable after the ransom note is posted. The following is an example of Cerber ransomware deleting itself (line breaks inserted for readability):
/d /c taskkill /t /f /im "[FILENAME].exe" > NUL & ping -n 1 127.0.0.1 > NUL & del "C:\Documents and Settings\Administrator\Desktop\[FILENAME].exe" > NUL
Of course, with deep forensic analysis, the file can be recovered, but focusing attention on that process takes away from the immediate problem of preventing further encryption. If a ransomware attack is in the process of running, the focus needs to be on stopping it, especially if the files that are being encrypted are on a shared drive. The ransomware process might not even reside on the system that is currently being encrypted. So, if an initial incursion was missed, the first step a security team should take is to isolate the system currently being encrypted. This may not stop the process, but at the very least it might prevent other systems from being infected by the ransomware.
Protecting Public-Facing Servers
While most ransomware security resources revolve around protecting end-points and internal servers, there have been targeted attacks against WordPress sites as well as JBoss servers (mentioned briefly in Chapter 3). As ransomware continues to grow, it is possible that other platforms could come under attack as well.
In early 2016 there was a concerted effort by the team behind CTB-Locker to exploit vulnerabilities in WordPress sites and to encrypt the files on those sites, leaving the site owners (and anyone who visited the site) with a message similar to Figure 4-5.
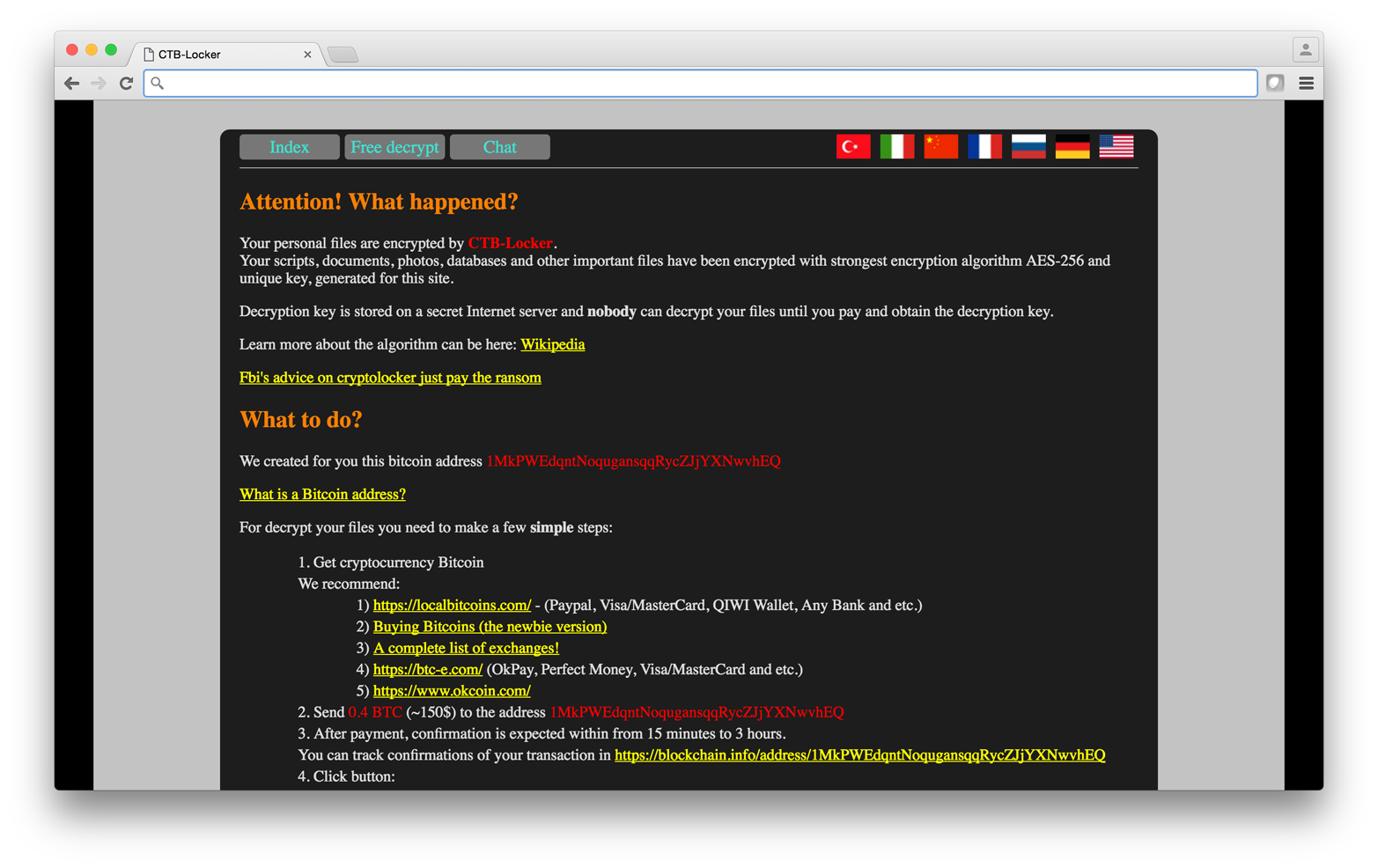
Figure 4-5. A WordPress website compromised by CTB-Locker
At the time, this seemed like a natural evolution for ransomware campaigns. After all, vulnerabilities in WordPress sites have been exploited for years. WordPress is a very extensible platform, with lots of add-ons that are often given very little security scrutiny. Even when vulnerabilities are found and patched, many WordPress site owners are small business owners that lack the time, knowledge, and resources to keep their websites fully patched.
WordPress is not the only content management system (CMS) that suffers from these security risks. Joomla and other CMS platforms are often targeted by hacking teams for exploitation and then used to distribute malware, including ransomware.
But the campaign in early 2016 was different. It specifically targeted vulnerable WordPress sites, and instead of using them to distribute ransomware, the CTB-Locker variant encrypted the files on the site, extorting site owners who wanted to recover their files. A quick Google search of the following text showed that hundreds of sites were compromised as part of this campaign:
Intitle: CTB-Locker
Your scripts, documents, photos, databases and other important files have been encrypted with strongest encryption algorithm AES-256 and unique key, generated for this site.
But the campaign did not last long. After a few weeks it fizzled out. There were a few reasons for this. The first is that most website owners have at least some backup of their website; if they don’t, then their web hosting provider often does. This means that a website is much more likely to be restored from backup, and restored quicker than an end-point would be. The second reason is a more practical one: the hacking team made very little money from the campaign. Several security companies have speculated, based on monitored activity of the Bitcoin address used, that so few people paid the ransom that it was not worth continuing the campaign. In other words, it is more profitable to exploit vulnerable WordPress sites to distribute ransomware that infects the end-point than it is to infect the WordPress site itself with ransomware.
In the case of JBoss servers, the ransomware is not installed on the server itself; instead, the public-facing JBoss server is used to deliver the ransomware to hosts inside the organization. In February 2016, a sophisticated attack group started using this method of delivery. The attackers used a JBoss pentesting tool called JexBoss to scan for vulnerable servers. According to Cisco, there were more than 2,100 publicly accessible vulnerable JBoss servers.8
Once the JBoss server was compromised, the attackers would open a web shell on the server and then use the server to distribute the Samas ransomware to end-points on the system.
As with compromised end-points, the best method for protecting public-facing servers against attacks like these is to make sure they are fully patched. On top of a consistent patching routine, monitoring the servers for suspicious activity can help prevent these servers from being compromised and infected or being used to infect other hosts, irrespective of whether those hosts are internal to the organizations or unsuspecting users visiting the organizations website.
Alerting and Reacting Quickly
The previous section provided a number of potential events that can be alerted on to either warn about a potential ransomware infection or block the activity directly. None of these event alerts will help keep an organization better protected unless they are seen by someone who can act on them and who can act on them quickly and with an understanding of the event they are trying to stop so that the attack can be properly remediated.
In order to truly understand what is happening, the security team has to have a holistic view of an attack. Maintaining that holistic view is a challenge that faces security professionals at all types of organizations since it requires that logs from desktops, servers, networks, and security systems are easily accessible to the security team when they need them. Almost all organizations struggle with being understaffed when it comes to security, but smaller organizations tend to feel the pain more. Many small organizations don’t have a dedicated security person and usually rely on one person to perform triple duty as network, security, and server administrator, not to mention desktop support. Even large organizations who maintain a sizable security staff run into problems because the network team, the security team, and the desktop team don’t always share information. No one team has a complete view of the network.
These obstacles mean that log collection and correlation are often relegated to secondary concerns or are isolated into different groups, so that one group has one view of an incident while another has a different view; but those views aren’t correlated. Or even worse, the team responsible for monitoring logs has to jump from console to console and correlate events manually from one console to another. It is almost understandable; there are always so many competing interests that it is hard for a complex task like log collection and correlation to become a priority. Not to mention that, just as with advanced end-point protection, building out and maintaining a centralized logging infrastructure can be expensive, both in terms of platform investment and man hours. But all of that investment may actually be less expensive than a single ransomware infection.
Effective log correlation in a security information and event management (SIEM) or other log-correlation platform can help an organization detect ransomware faster and help stop the ransomware infection before it can do major damage. But in order to do that, the right logs need to sent to the log-collection platform, and they need to be sent there in a timely manner. At a minimum, an organization needs to be collecting logs from the firewall, IDS, web proxy, end-point protection, operating system, and the DNS server (assuming DNS is maintained in-house). Each of these devices has log data that can be used to identify a point in the ransomware attack chain. As with end-point protection, the earlier in the attack chain the ransomware can be identified, the more likely it is to be stopped before it can infect a victim host.
Of course, to stop the attack, the log-collection platform needs to generate timely alerts, and those alerts need to be monitored. Not only that, but the person monitoring the alerts needs to have access to prevent the attack from continuing. Nothing is worse than catching a ransomware attack in the early stages, but not having the right privileges to kill the process and disrupt the attack. In a smaller organization, this is usually not a problem; the team that is monitoring the logging platform is often responsible for managing the desktops. But in larger organizations, there is a separation of responsibilities, and often a dedicated desktop support team and the security team, responsible for monitoring the alerts from the SIEM, may not have administrative access to the desktop.
For any organization to have a successful monitoring program, the security team has to work closely with the system administrator and the networking team. Providing the right level of access to those responsible for monitoring security alerts, or creating a hand-off process that ensures rapid response to a critical ransomware event, is crucial to stopping these attacks before they cause the organization tens of thousands of dollars. That doesn’t mean that everyone in the organization needs to have administrative access to every system—that would simply create more security headaches. What it does mean is that there should be tools in place that allow security analysts to perform their job as efficiently as possible without disrupting network and system administration workflow. Some of these tools have already been discussed, such as NAC appliances that allows security teams to quickly isolate a potentially infected system to prevent that infection from spreading to the rest of the network. Another example is an incident response platform, such as Carbon Black or Resilient, that allows security teams direct access to an infected system to isolate the ransomware and stop it from doing damage to the network.
Honeyfiles and Honeydirectories
One method of detecting ransomware on a system or a network is the use of a honeyfile. A honeyfile takes the honeypot concept and moves it to the file level. A honeypot is an exposed system that is designed to look vulnerable to attacks. An attacker will compromise the system, and the security team is alerted to the fact that there is a hacker inside their network or attempting to get inside the network. The security team also gets an opportunity to study the attack and perhaps uncover a new exploit that is being used in the wild.
In the context of ransomware, a honeyfile works a little bit differently; it is actually more of a canary file than a honeyfile. The idea is to seed a network with a series of files that a ransomware family would normally encrypt; Microsoft Word documents, Adobe PDF files, image and movie files—it doesn’t really matter what is in the files as long as they have the right extensions. The only caveat to the files is that users in the network have to know not to edit or delete the files. This information can be included in the form of a note inside the file or a warning emailed to all users when this system is implemented (or both, since users don’t always read email).
Before deploying the honeyfiles, create a hash code for each file and make note of each. Once they are in place, start monitoring each of those files. If the hash code changes, or the file is copied or deleted, programmatically kill whatever process initiated the change and alert the security team to investigate the incident.
This should stop the ransomware, but unfortunately it will stop it somewhere mid-encryption. There is no standard way that ransomware reads the list of files on a system and start the encryption process. This means that setting the timestamp on the file to a very early date or making sure the files all start with the letter “A” will not necessarily ensure that these files will be read first. On a file server it is possible to seed multiple files in different locations in the hope that one is identified first, but that is not necessarily a practical solution on a desktop. So while this method will definitely alert to a ransomware attack, it may alert to it too late.
There is another solution that is equally intriguing and potentially more effective. Creating a honeydirectory, or more accurately, a directory sinkhole. This solution was first proposed by the team writing on the Free Forensics blog.9 The idea behind the honeydirectory is to distract the ransomware long enough to be alerted to its presence and stop the process before it can do real damage to the victim system.
What the team at Free Forensics did was use a PowerShell script to create a mount point in the root of the C:\ volume. They labelled that mount point $$, and when ransomware hits that mount point it starts following a loop. The PowerShell script makes recursive directories inside the original directory, so when the ransomware goes into C:\$$ it sees another $$ directory, when it goes into C:\$$\$$ it sees another $$ directory, and so on, up to a maximum path size of 256 characters (this is a Microsoft limit).
Unlike filenames, where it is hard to be sure which file will be read first by the ransomware, directories are enumerated and processed alphabetically, which is why the files in C:\$Recycle.Bin are usually encrypted first, which means this can serve as an early warning system. This won’t stop the ransomware, but it might slow it down enough that the process can be killed before it can encrypt files. The PowerShell script that the team at Free Forensics developed is reprinted, with permission:
#Let's grab the DeviceID for the C volume
$Volume_info_for_C = Get-WMIObject -Class Win32_Volume -Filter "driveletter='c:'"
$Device_ID_of_C = $Volume_info_for_C.DeviceID
#Normally, everything is mounted only to the root (C:\)
#but we are going to get creative.
$Sinkholes = @('$$')
ForEach($Sinkhole in $Sinkholes){
New-Item c:\$Sinkhole -ItemType directory
$Volume_info_for_C.AddMountPoint("c:\$Sinkholes")
}
To take advantage of this sinkhole effectively, the directory needs to be monitored, and any application that is not trusted should be killed and the activity logged while it is traversing the directory. Again, if the ransomware is caught then, it will not have a chance to encrypt real files. If this technique catches on, it would, unfortunately, be trivial for ransomware developers to defeat it by bypassing a directory called “$$” (there are already a number of ransomware families that skip certain directories entirely). Another possible solution is to use the same method, but on the C:\$Recycle.Bin directory. Because the C:\$Recycle.Bin directory is generally enumerated first, it might be possible to create an alert that warns about an untrusted process enumerating the directory and taking action against that process.
Summary
While it is always better to stop a ransomware attack at the edge of the network, it can be stopped at the desktop, often before the ransomware has a chance to encrypt any files. To do this requires understanding the ransomware attack chain, and using tools that are able to interdict and stop the process early in the attack chain. This type of security requires cooperation between the desktop, security, and networking teams. To foster this cooperation, the three teams should meet on a regular basis to share updated information about incoming threats, net vulnerabilities, changes to network architecture, and new tools or systems being deployed within the organization. Even better, if these teams can work together in a tabletop exercise or even a red-teaming drill, everyone will start to have a better grasp of how ransomware attacks work, what to look for in an attack, and how these teams can work together to respond to a ransomware attack. This type of information sharing allows all teams to take appropriate steps to improve the security of the organization and better defend against ransomware. Together the teams can work to better understand the threat and to develop solutions that will enable the security team to respond quickly to a ransomware attack without disrupting the workflow of the desktop and networking teams, as well as users on the network.
1 Staff, “ExxonMobile Introduction Letter Malspam with Macro Enabled Microsoft Publisher Files Distribute Malware,” My Online Security, September 5, 2016.
2 Graham Chantry, “CVE-2012-0158: Anatomy of a Prolific Exploit,” SophosLabs, July 7, 2016.
3 Ehud Shamir, “Reversing Petya – Latest Ransomware Variant,” SentinelOne, April 11, 2016.
4 Deepen Desai, Dhanalakshmi PK, “A Look at Locky Ransomware,” The Zscaler Blog, Zscaler, March 22, 2016.
5 Mikael Kullberg, “Unlocking-Locky,” Nominum Data Science, June 1, 2016.
6 Domain Tools, “Profiling Malicious Domains in The DomainTools Report,” DomainTools Blog, May 5, 2015.
7 Jonell Baltazar and Joonho Sa, “New Downloader for Locky,” Threat Research Blog, FireEye, April 22, 2016.
8 Alexander Chiu, “Widespread JBoss Backdoors a Major Threat,” Cisco Talos Blog, April 15, 2016.
9 Adam Polkosnik, Greg B, Jonathan Glass, and Nick Baronian, “Proactively Reacting to Ransomware,” Free Forensics, March 25, 2016.
Get Ransomware now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

