Details About the lm Function
Now that we’ve seen a simple example of how models work in
R, let’s describe in detail what lm
does and how you can control it. A linear regression model is appropriate
when the response variable (the thing that you want to predict) can be
estimated from a linear function of the predictor variables (the
information that you know). Technically, we assume that:
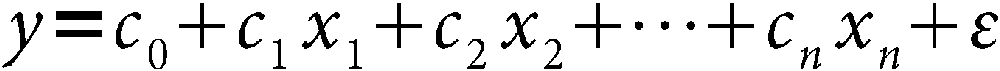
where y is the response variable, x1, x2, ..., xn are the predictor variables (or predictors), c1, c2, ..., cn are the coefficients for the predictor variables, c0 is the intercept, and ε is the error term. (For more details on the assumptions of the least squares model, see Assumptions of Least Squares Regression.) The predictors can be simple variables or even nonlinear functions of variables.
Suppose that you have a matrix of observed predictor variables X and a vector of response variables Y. (In this sentence, I’m using the terms “matrix” and “vector” in the mathematical sense.) We have assumed a linear model, so given a set of coefficients c, we can calculate a set of estimates ŷ for the input data X by calculating ŷ = cX. The differences between the estimates ŷ and the actual values Y are called the residuals. You can think of the residuals as a measure of the prediction error; small residuals mean that the predicted values are close to the actual values. We assume that the expected difference ...
Get R in a Nutshell, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

