Chapter 4. Exposition
In Chapter 3 we mainly focused on adding instrumentation to your code. But all the instrumentation in the world isn’t much use if the metrics produced don’t end up in your monitoring system. The process of making metrics available to Prometheus is known as exposition.
Exposition to Prometheus is done over HTTP. Usually you expose metrics under the /metrics path, and the request is handled for you by a client library. Prometheus supports two human-readable text formats: the Prometheus text format and OpenMetrics. You have the option of producing the exposition format by hand, in which case it will be easier with the Prometheus text format, which is less strict. You may choose to do this if there is no suitable library for your language, but it is recommended you use a library as it’ll get all the little details like escaping correct. Most of the libraries will also provide the ability to produce metrics using both the OpenMetrics and Prometheus text format.
Exposition is typically done either in your main function or another top-level function and only needs to be configured once per application.
Metrics are usually registered with the default registry when you define them. If one of the libraries you are depending on has Prometheus instrumentation, the metrics will be in the default registry and you will gain the benefit of that additional instrumentation without having to do anything. Some users prefer to explicitly pass a registry all the way down from the main function, so you’d have to rely on every library between your application’s main function and the Prometheus instrumentation being aware of the instrumentation. This presumes that every library in the dependency chain cares about instrumentation and agrees on the choice of instrumentation libraries.
This design allows for instrumentation for Prometheus metrics with no exposition at all.1 In that case, aside from still paying the (tiny) resource cost of instrumentation, there is no impact on your application. If you are the one writing a library, you can add instrumentation for your users using Prometheus without requiring extra effort for your users who don’t monitor. To better support this use case, the instrumentation parts of client libraries try to minimize their dependencies.
Let’s take a look at exposition in some of the popular client libraries. We are going to presume here that you know how to install the client libraries and any other required dependencies.
Python
You have already seen start_http_server in Chapter 3. It
starts up a background thread with an HTTP server that only serves
Prometheus metrics, as follows:
fromprometheus_clientimportstart_http_serverif__name__=='__main__':start_http_server(8000)//Yourcodegoeshere.
start_http_server is very convenient to get up and running quickly. But it is
likely that you already have an HTTP server in your application that you
would like your metrics to be served from.
In Python there are various ways this can be done depending on which frameworks you are using.
WSGI
Web Server Gateway Interface (WSGI) is a Python standard for web applications.
The Python client provides a WSGI app that you can use with your existing WSGI
code. In Example 4-1, the metrics_app is delegated to by my_app if
the /metrics path is requested; otherwise, it performs its usual logic. By
chaining WSGI applications, you can add middleware such as authentication, which
client libraries do not offer out of the box.
Example 4-1. Exposition using WSGI in Python
fromprometheus_clientimportmake_wsgi_appfromwsgiref.simple_serverimportmake_servermetrics_app=make_wsgi_app()defmy_app(environ,start_fn):ifenviron['PATH_INFO']=='/metrics':returnmetrics_app(environ,start_fn)start_fn('200 OK',[])return[b'Hello World']if__name__=='__main__':httpd=make_server('',8000,my_app)httpd.serve_forever()
Twisted
Twisted is a Python event-driven network engine. It supports WSGI so you can
plug in make_wsgi_app, as shown in Example 4-2.
Example 4-2. Exposition using Twisted in Python
fromprometheus_clientimportmake_wsgi_appfromtwisted.web.serverimportSitefromtwisted.web.wsgiimportWSGIResourcefromtwisted.web.resourceimportResourcefromtwisted.internetimportreactormetrics_resource=WSGIResource(reactor,reactor.getThreadPool(),make_wsgi_app())classHelloWorld(Resource):isLeaf=Falsedefrender_GET(self,request):returnb"Hello World"root=HelloWorld()root.putChild(b'metrics',metrics_resource)reactor.listenTCP(8000,Site(root))reactor.run()
Multiprocess with Gunicorn
Prometheus assumes that the applications it is monitoring are long-lived and multithreaded. But this can fall apart a little with runtimes such as CPython.2 CPython is effectively limited to one processor core due to the Global Interpreter Lock (GIL). To work around this, some users spread the workload across multiple processes using a tool such as Gunicorn.
If you were to use the Python client library in the usual fashion, each worker would track its own metrics. Each time Prometheus went to scrape the application, it would randomly get the metrics from only one of the workers, which would be only a fraction of the information and would also have issues such as counters appearing to be going backward. Workers can also be relatively short-lived.
The solution to this problem offered by the Python client is to have each
worker track its own metrics. At exposition time all the metrics of all the
workers are combined in a way that provides the semantics you would get from a
multithreaded application. There are some limitations to the approach used: the
process_ metrics and custom collectors will not be exposed, and the
Pushgateway cannot be used.3
Using Gunicorn, you need to let the client library know when a worker process exits.4 This is done in a config file like the one in Example 4-3.
Example 4-3. Gunicorn config.py to handle worker processes exiting
fromprometheus_clientimportmultiprocessdefchild_exit(server,worker):multiprocess.mark_process_dead(worker.pid)
You will also need an application to serve the metrics. Gunicorn uses WSGI, so you can use
make_wsgi_app. You must create a custom registry containing only a
MultiProcessCollector for exposition, so that it does not include both the
multiprocess metrics and metrics from the local default registry (Example 4-4).
Example 4-4. Gunicorn application in app.py
fromprometheus_clientimportmultiprocess,make_wsgi_app,CollectorRegistryfromprometheus_clientimportCounter,GaugeREQUESTS=Counter("http_requests_total","HTTP requests")IN_PROGRESS=Gauge("http_requests_inprogress","Inprogress HTTP requests",multiprocess_mode='livesum')@IN_PROGRESS.track_inprogress()defapp(environ,start_fn):REQUESTS.inc()ifenviron['PATH_INFO']=='/metrics':registry=CollectorRegistry()multiprocess.MultiProcessCollector(registry)metrics_app=make_wsgi_app(registry)returnmetrics_app(environ,start_fn)start_fn('200 OK',[])return[b'Hello World']
As you can see in Example 4-4, counters work normally, as do
summaries and histograms. For gauges there is additional optional configuration
using multiprocess_mode. You can configure the gauge based on how you intended to
use it, as follows:
all-
The default, which returns a time series from each process, whether it is alive or dead. This allows you to aggregate the series as you wish in PromQL. They will be distinguished by a
pidlabel. liveall-
Returns a time series from each alive process.
livesum-
Returns a single time series that is the sum of the value from each alive process. You would use this for things like in-progress requests or resource usage across all processes. A process might have aborted with a nonzero value, so dead processes are excluded.
max-
Returns a single time series that is the maximum of the value from each alive or dead process. This is useful if you want to track the last time something happened, such as a request being processed, which could have been in a process that is now dead.
min-
Returns a single time series that is the minimum of the value from each alive or dead process.
There is a small bit of setup before you can run Gunicorn, as shown in
Example 4-5. You must set an environment variable called
prometheus_multiproc_dir. This points to an empty directory the client
library uses for tracking metrics. Before starting the application, you should
always wipe this directory to handle any potential changes to your
instrumentation.
Example 4-5. Preparing the environment before starting Gunicorn with two workers
hostname $ export prometheus_multiproc_dir=$PWD/multiproc hostname $ rm -rf $prometheus_multiproc_dir hostname $ mkdir -p $prometheus_multiproc_dir hostname $ gunicorn -w 2 -c config.py app:app [2018-01-07 19:05:30 +0000] [9634] [INFO] Starting gunicorn 19.7.1 [2018-01-07 19:05:30 +0000] [9634] [INFO] Listening at: http://127.0.0.1:8000 (9634) [2018-01-07 19:05:30 +0000] [9634] [INFO] Using worker: sync [2018-01-07 19:05:30 +0000] [9639] [INFO] Booting worker with pid: 9639 [2018-01-07 19:05:30 +0000] [9640] [INFO] Booting worker with pid: 9640
When you look at the /metrics path, you will see the two defined metrics, but
python_info and the process_ metrics will not be there.
Tip
Each process creates several files that must be read at exposition time in
prometheus_multiproc_dir. If your workers stop and start a lot, this can make
exposition slow when you have thousands of files.
It is not safe to delete individual files as that could cause counters to incorrectly go backward, but you can either try to reduce the churn (for example, by increasing or removing a limit on the number of requests workers handle before exiting5), or regularly restarting the application and wiping the files.
These steps are for Gunicorn. The same approach also works with other Python
multiprocess setups, such as using the multiprocessing module.
Go
In Go, http.Handler is the standard interface for providing HTTP handlers, and
promhttp.Handler provides that interface for the Go client library. To
demonstrate how this works, place the code in Example 4-6 in a file called example.go.
Example 4-6. A simple Go program demonstrating instrumentation and exposition
packagemainimport("log""net/http""github.com/prometheus/client_golang/prometheus""github.com/prometheus/client_golang/prometheus/promauto""github.com/prometheus/client_golang/prometheus/promhttp")var(requests=promauto.NewCounter(prometheus.CounterOpts{Name:"hello_worlds_total",Help:"Hello Worlds requested.",}))funchandler(whttp.ResponseWriter,r*http.Request){requests.Inc()w.Write([]byte("Hello World"))}funcmain(){http.HandleFunc("/",handler)http.Handle("/metrics",promhttp.Handler())log.Fatal(http.ListenAndServe(":8000",nil))}
You can fetch dependencies and run this code in the usual way:
hostname $ go get -d -u github.com/prometheus/client_golang/prometheus hostname $ go run example.go
This example uses promauto, which will automatically register your metric
with the default registry. If you do not wish to do so, you can use
prometheus.NewCounter instead and then use MustRegister in an init
function:
func init() {
prometheus.MustRegister(requests)
}
This is a bit more fragile, as it is easy for you to create and use the metric
but forget the MustRegister call.
Java
The Java client library is also known as the simpleclient. It replaced the original client, which was developed before many of the current practices and guidelines around how to write a client library were established. The Java client should be used for any instrumentation for languages running on a Java Virtual Machine (JVM).
HTTPServer
Similar to start_http_server in Python, the HTTPServer class in the Java
client gives you an easy way to get up and running (Example 4-7).
Example 4-7. A simple Java program demonstrating instrumentation and exposition
importio.prometheus.client.Counter;importio.prometheus.client.hotspot.DefaultExports;importio.prometheus.client.exporter.HTTPServer;publicclassExample{privatestaticfinalCountermyCounter=Counter.build().name("my_counter_total").help("An example counter.").register();publicstaticvoidmain(String[]args)throwsException{DefaultExports.initialize();HTTPServerserver=newHTTPServer(8000);while(true){myCounter.inc();Thread.sleep(1000);}}}
You should generally have Java metrics as class static fields, so that they are only registered once.
The call to DefaultExports.initialize is needed for the various process and
jvm metrics to work. You should generally call it once in all of your Java
applications, such as in the main function. However, DefaultExports.initialize
is idempotent and thread safe, so additional calls are harmless.
In order to run the code in Example 4-7, you will need the
simpleclient dependencies. If you are using Maven,
Example 4-8 is what the dependencies in your pom.xml
should look like.
Example 4-8. pom.xml dependencies for Example 4-7
<dependencies><dependency><groupId>io.prometheus</groupId><artifactId>simpleclient</artifactId><version>0.16.0</version></dependency><dependency><groupId>io.prometheus</groupId><artifactId>simpleclient_hotspot</artifactId><version>0.16.0</version></dependency><dependency><groupId>io.prometheus</groupId><artifactId>simpleclient_httpserver</artifactId><version>0.16.0</version></dependency></dependencies>
Servlet
Many Java and JVM frameworks support using subclasses of HttpServlet in their
HTTP servers and middleware. Jetty is one such server, and you can see how to
use the Java client’s MetricsServlet in Example 4-9.
Example 4-9. A Java program demonstrating exposition using MetricsServlet and Jetty
importio.prometheus.client.Counter;importio.prometheus.client.exporter.MetricsServlet;importio.prometheus.client.hotspot.DefaultExports;importjavax.servlet.http.HttpServlet;importjavax.servlet.http.HttpServletRequest;importjavax.servlet.http.HttpServletResponse;importjavax.servlet.ServletException;importorg.eclipse.jetty.server.Server;importorg.eclipse.jetty.servlet.ServletContextHandler;importorg.eclipse.jetty.servlet.ServletHolder;importjava.io.IOException;publicclassExample{staticclassExampleServletextendsHttpServlet{privatestaticfinalCounterrequests=Counter.build().name("hello_worlds_total").help("Hello Worlds requested.").register();@OverrideprotectedvoiddoGet(finalHttpServletRequestreq,finalHttpServletResponseresp)throwsServletException,IOException{requests.inc();resp.getWriter().println("Hello World");}}publicstaticvoidmain(String[]args)throwsException{DefaultExports.initialize();Serverserver=newServer(8000);ServletContextHandlercontext=newServletContextHandler();context.setContextPath("/");server.setHandler(context);context.addServlet(newServletHolder(newExampleServlet()),"/");context.addServlet(newServletHolder(newMetricsServlet()),"/metrics");server.start();server.join();}}
You will also need to specify the Java client as a dependency. If you are using Maven, this will look like Example 4-10.
Example 4-10. pom.xml dependencies for Example 4-9
<dependencies><dependency><groupId>io.prometheus</groupId><artifactId>simpleclient</artifactId><version>0.16.0</version></dependency><dependency><groupId>io.prometheus</groupId><artifactId>simpleclient_hotspot</artifactId><version>0.16.0</version></dependency><dependency><groupId>io.prometheus</groupId><artifactId>simpleclient_servlet</artifactId><version>0.16.0</version></dependency><dependency><groupId>org.eclipse.jetty</groupId><artifactId>jetty-servlet</artifactId><version>11.0.11</version></dependency></dependencies>
Pushgateway
Batch jobs are typically run on a regular schedule, such as hourly or daily. They start up, do some work, and then exit. As they are not continuously running, Prometheus can’t exactly scrape them.6 This is where the Pushgateway comes in.
The Pushgateway7 is a metrics cache for service-level batch jobs. Its architecture is shown in Figure 4-1. It remembers only the last push that you make to it for each batch job. You use it by having your batch jobs push their metrics just before they exit. Prometheus scrapes these metrics from your Pushgateway and you can then alert and graph them. Usually you run a Pushgateway beside a Prometheus.

Figure 4-1. The Pushgateway architecture
A service-level batch job is one where there isn’t really an instance label
to apply to it. That is to say it applies to all of one of your services, rather
than being innately tied to one machine or process instance.8 If you don’t particularly care where a batch job runs
but do care that it happens (even if it happens to currently be set up to run
via cron on one machine), it is a service-level batch job. Examples include a per-datacenter batch job to check for bad machines, or one that performs garbage collection across a whole service.
Note
The Pushgateway is not a way to convert Prometheus from pull to push. If, for example, there are several pushes between one Prometheus scrape and the next, the Pushgateway will only return the last push for that batch job. This is discussed further in “Networks and Authentication”.
You can download the Pushgateway from the Prometheus download page. It is an
exporter that runs by default on port 9091, and Prometheus should be set up to
scrape it. However, you should also provide the honor_labels: true setting
in the scrape config, as shown in Example 4-11. This is
because the metrics you push to the Pushgateway should not have an instance
label, and you do not want the Pushgateway’s own instance target label to end
up on the metrics when Prometheus scrapes them.9 honor_labels is discussed in
“Label Clashes and honor_labels”.
Example 4-11. prometheus.yml scrape config for a local Pushgateway
scrape_configs:-job_name:pushgatewayhonor_labels:truestatic_configs:-targets:-localhost:9091
You can use client libraries to push to the Pushgateway. Example 4-12 shows the structure you would use for a Python batch job. A custom registry is created so that only the specific metrics you choose are pushed. The duration of the batch job is always pushed,10 and the time it ended is pushed only if the job is successful.
There are three different ways you can write to the Pushgateway. In Python
these are the push_to_gateway, pushadd_to_gateway, and delete_from_gateway
functions:
push-
Any existing metrics for this job are removed and the pushed metrics added. This uses the PUT HTTP method under the covers.
pushadd-
The pushed metrics override existing metrics with the same metric names for this job. Any metrics that previously existed with different metric names remain unchanged. This uses the POST HTTP method under the covers.
delete-
The metrics for this job are removed. This uses the DELETE HTTP method under the covers.
As Example 4-12 is using pushadd_to_gateway, the value of my_job_duration_seconds will always get replaced. However,
my_job_last_success_seconds# will only get replaced if there are no
exceptions; it is added to the registry and then pushed.
Example 4-12. Instrumenting a batch job and pushing its metrics to a Pushgateway
fromprometheus_clientimportCollectorRegistry,Gauge,pushadd_to_gatewayregistry=CollectorRegistry()duration=Gauge('my_job_duration_seconds','Duration of my batch job in seconds',registry=registry)try:withduration.time():# Your code here.pass# This only runs if there wasn't an exception.g=Gauge('my_job_last_success_seconds','Last time my batch job successfully finished',registry=registry)g.set_to_current_time()finally:pushadd_to_gateway('localhost:9091',job='batch',registry=registry)
You can see pushed data on the status page, as Figure 4-2 shows.
An additional metric push_time_seconds has been added by the Pushgateway because Prometheus will always use the time at which it scrapes as the
timestamp of the Pushgateway metrics. push_time_seconds gives you a way to
know the actual time the data was last pushed. Another metric, push_failure_time_seconds, has been introduced, which represents the last time when an update to this group in the Pushgateway failed.
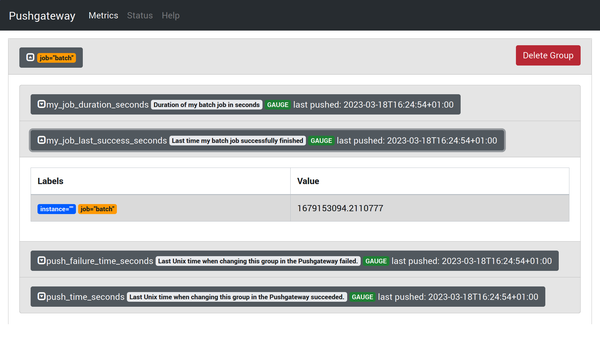
Figure 4-2. The Pushgateway status page showing metrics from a push
You might have noticed in Figure 4-2 that the push is referred to
as a group. You can provide labels in addition to the job label when
pushing, and all of these labels are known as the grouping key. In Python
this can be provided with the grouping_key keyword argument. You would use
this if a batch job was sharded or split up somehow. For example, if you have 30
database shards and each had its own batch job, you might distinguish them with
a shard label.
Tip
Once pushed, groups stay forever in the Pushgateway. You should avoid using grouping keys that vary from one batch job run to the next, as this will make the metrics difficult to work with and cause performance issues. When decommissioning a batch job, don’t forget to delete its metrics from the Pushgateway.
Bridges
Prometheus client libraries are not limited to outputting metrics in the Prometheus format. There is a separation of concerns between instrumentation and exposition so that you can process the metrics in any way you like.
For example, the Go, Python, and Java clients each include a Graphite bridge. A bridge takes metrics output from the client library registry and outputs it to something other than Prometheus. So the Graphite bridge will convert the metrics into a form that Graphite can understand11 and write them out to Graphite, as shown in Example 4-13.
Example 4-13. Using the Python GraphiteBridge to push to Graphite every 10 seconds
importtimefromprometheus_client.bridge.graphiteimportGraphiteBridgegb=GraphiteBridge(['graphite.your.org',2003])gb.start(10)whileTrue:time.sleep(1)
This works because the registry has a method that allows you to get a snapshot
of all the current metrics. This is CollectorRegistry.collect in Python,
CollectorRegistry.metricFamilySamples in Java, and Registry.Gather in Go.
This is the method that HTTP exposition uses, and you can use it too. For example,
you could use this method to feed data into another non-Prometheus instrumentation
library.12
Tip
If you ever want to hook into direct instrumentation, you should instead use
the metrics output by a registry. Wanting to know every time a counter is
incremented does not make sense in terms of a metrics-based monitoring system.
However, the count of increments is already provided for you by
CollectorRegistry.collect and works for custom collectors.
Parsers
In addition to a client library’s registry allowing you to access metric output, the Go13 and Python clients also feature a parser for the Prometheus and OpenMetrics exposition formats. Example 4-14 only prints the samples, but you could feed Prometheus metrics into other monitoring systems or into your local tooling.
Example 4-14. Parsing the Prometheus text format with the Python client
fromprometheus_client.parserimporttext_string_to_metric_familiesforfamilyintext_string_to_metric_families(u"counter_total 1.0\n"):forsampleinfamily.samples:("Name:{0}Labels:{1}Value:{2}".format(*sample))
DataDog, InfluxDB, Sensu, and Metricbeat14 are some of the monitoring systems that have components that can parse the text format. Using one of these monitoring systems, you could take advantage of the Prometheus ecosystem without ever running the Prometheus server. We believe that this is a good thing, as there is currently a lot of duplication of effort between the various monitoring systems. Each of them has to write similar code to support the myriad custom metric outputs provided by the most commonly used software.
Text Exposition Format
The Prometheus text exposition format is relatively easy to produce and parse. Although you should almost always rely on a client library to handle it for you, there are cases such as with the Node Exporter textfile collector (discussed in “Textfile Collector”) where you may have to produce it yourself.
We will be showing you version 0.0.4 of the text format, which has the content type header:
Content-Type: text/plain; version=0.0.4; charset=utf-8
In the simplest cases, the text format is just the name of the metric followed
by a 64-bit floating-point number. Each line is terminated with a line-feed
character (\n):
my_counter_total 14 a_small_gauge 8.3e-96
Metric Types
More
complete Prometheus text format output would include the HELP and TYPE of the metrics, as
shown in Example 4-15. HELP is a description of what the metric is,
and should not generally change from scrape to scrape. TYPE is one of
counter, gauge, summary, histogram, or untyped. untyped is used when
you do not know the type of the metric, and is the default if no type is
specified. It is invalid for you to have a duplicate metric, so make sure all the time series that belong to a metric are grouped together.
Example 4-15. Exposition format for a gauge, counter, summary, and histogram
# HELP example_gauge An example gauge
# TYPE example_gauge gauge
example_gauge -0.7
# HELP my_counter_total An example counter
# TYPE my_counter_total counter
my_counter_total 14
# HELP my_summary An example summary
# TYPE my_summary summary
my_summary_sum 0.6
my_summary_count 19
# HELP latency_seconds An example histogram
# TYPE latency_seconds histogram
latency_seconds_bucket{le="0.1"} 7  latency_seconds_bucket{le="0.2"} 18
latency_seconds_bucket{le="0.4"} 24
latency_seconds_bucket{le="0.8"} 28
latency_seconds_bucket{le="+Inf"} 29
latency_seconds_sum 0.6
latency_seconds_count 29
latency_seconds_bucket{le="0.2"} 18
latency_seconds_bucket{le="0.4"} 24
latency_seconds_bucket{le="0.8"} 28
latency_seconds_bucket{le="+Inf"} 29
latency_seconds_sum 0.6
latency_seconds_count 29 
For histograms, the
lelabels have floating-point values and must be sorted. You should note how the histogram buckets are cumulative, aslestands for less than or equal to.The
_countmust match the+Infbucket, and the+Infbucket must always be present. Buckets should not change from scrape to scrape, as this will cause problems for PromQL’shistogram_quantilefunction.
Labels
The histogram in the preceding example also shows how labels are represented. Multiple labels are separated by commas, and it is OK to have a trailing comma before the closing brace.
The ordering of labels does not matter, but it is a good idea to have the ordering consistent from scrape to scrape. This will make writing your unit tests easier, and consistent ordering ensures the best ingestion performance in Prometheus.
Here is an example of a summary in text format:
# HELP my_summary An example summary
# TYPE my_summary summary
my_summary_sum{foo="bar",baz="quu"} 1.8
my_summary_count{foo="bar",baz="quu"} 453
my_summary_sum{foo="blaa",baz=""} 0
my_summary_count{foo="blaa",baz="quu"} 0
It is possible to have a metric with no time series, if no children have been initialized, as discussed in “Child”:
# HELP a_counter_total An example counter # TYPE a_counter_total counter
Escaping
The text exposition format is encoded in UTF-8, and full UTF-815 is permitted in both HELP and label values. Thus you need to use backslashes to escape characters that would cause issues using backslashes. For HELP this
is line feeds and backslashes. For label values this is line feeds,
backslashes, and double quotes.16 The format ignores extra whitespace.
Here is an example demonstrating escaping in the text exposition format:
# HELP escaping A newline \\n and backslash \\ escaped
# TYPE escaping gauge
escaping{foo="newline \\n backslash \\ double quote \" "} 1
Timestamps
It is possible to specify a timestamp on a time series. It is an integer value in milliseconds since the Unix epoch,17 and it goes after the value. Timestamps in the exposition format should generally be avoided as they are only applicable in certain limited use cases (such as federation) and come with limitations. Timestamps for scrapes are usually applied automatically by Prometheus. It is not defined as to what happens if you specify multiple lines with the same name and labels but different timestamps.
# HELP foo I'm trapped in a client library # TYPE foo gauge foo 1 15100992000000
check metrics
Prometheus 2.0 uses a custom parser for efficiency. So, just because a /metrics endpoint can be scraped doesn’t mean that the metrics are compliant with the format.
Promtool is a utility included with Prometheus that among other things can verify that your metric output is valid and perform lint checks:
curl http://localhost:8000/metrics | promtool check metrics
Common mistakes include forgetting the line feed on the last line, using carriage return and line feed rather than just line feed,18 and invalid metric or label names. As a brief reminder, metric and label names cannot contain hyphens, and cannot start with a number.
You now have a working knowledge of the text format. You can find the full specification in the official Prometheus documentation.
OpenMetrics
The OpenMetrics format is similar to the Prometheus text exposition format but contains several incompatible changes with the Prometheus text format. Even if they look similar, for a given set of metrics, the output they generate would generally be different.
We will be showing you version 1.0.0 of the OpenMetrics format, which has the content type header:
Content-Type: application/openmetrics-text; version=1.0.0; charset=utf-8
In the simplest cases, the text format is just the name of the metric followed
by a 64-bit floating-point number. Each line is terminated with a line-feed
character (\n). The file is terminated by # EOF:
my_counter_total 14 a_small_gauge 8.3e-96 # EOF
Metric Types
The metric types supported by the Prometheus text exposition format are also supported in OpenMetrics. In addition to counters, gauges, summaries, and histograms, specific types have been added: StateSet, GaugeHistograms, and Info.
StateSets represent a series of related boolean values, also called a bitset. A value of 1 means true and 0 means false.
GaugeHistograms measure current distributions. The difference with histograms is that buckets values and sum can go up and down.
Info metrics are used to expose textual information that does not change during process lifetime. An application’s version, revision control commit, and the version of a compiler are good candidates. The value of these metrics is always 1.
In addition to HELP and TYPE, metric families in OpenMetrics have an optional UNIT metadata that specifies a metric’s unit.
All the types are demonstrated in Example 4-16.
Example 4-16. Exposition format for different types of metrics
# HELP example_gauge An example gauge
# TYPE example_gauge gauge
example_gauge -0.7
# HELP my_counter An example counter
# TYPE my_counter counter
my_counter_total 14
my_counter_created 1.640991600123e+09
# HELP my_summary An example summary
# TYPE my_summary summary
my_summary_sum 0.6
my_summary_count 19
# HELP latency_seconds An example histogram
# TYPE latency_seconds histogram
# UNIT latency_seconds seconds
latency_seconds_bucket{le="0.1"} 7
latency_seconds_bucket{le="0.2"} 18
latency_seconds_bucket{le="0.4"} 24
latency_seconds_bucket{le="0.8"} 28
latency_seconds_bucket{le="+Inf"} 29
latency_seconds_sum 0.6
latency_seconds_count 29
# TYPE my_build_info info
my_build_info{branch="HEAD",version="0.16.0rc1"} 1.0
# TYPE my_stateset stateset
# HELP my_stateset An example stateset
my_stateset{feature="a"} 1
my_stateset{feature="b"} 0
# TYPE my_gaugehistogram gaugehistogram
# HELP my_gaugehistogram An example gaugehistogram
my_gaugehistogram_bucket{le="1.0"} 0
my_gaugehistogram_bucket{le="+Inf"} 3
my_gaugehistogram_gcount 3
my_gaugehistogram_gsum 2
# EOFIn OpenMetrics, as shown in Example 4-16, GaugeHistograms use distinct _gcount and _gsum suffixes for counts and sums, differentiating them from Histograms’ _count and _sum.
Timestamps
It is possible to specify a timestamp on a time series. It is a float value in seconds since the Unix epoch,19 and it goes after the value, as shown in this example:
# HELP foo I'm trapped in a client library # TYPE foo gauge foo 1 1.5100992e9
Warning
Timestamps are expressed in seconds since epoch in OpenMetrics, while in the Prometheus text format they are expressed in milliseconds since epoch.
You now have a working knowledge of the OpenMetrics format. You can find the full specification in the OpenMetrics GitHub repository.
We have mentioned labels a few times now. In the following chapter you’ll learn what they are in detail.
1 No exposition means that the metrics are not scraped by a Prometheus server.
2 CPython is the official name of the standard Python implementation. Do not confuse it with Cython, which can be used to write C extensions in Python.
3 The Pushgateway is not suitable for this use case, so this is not a problem in practice.
4 child_exit was added in Gunicorn version 19.7 released in March 2017.
5 Gunicorn’s --max-requests flag is one example of such a limit.
6 Though for batch jobs that take more than a few minutes to run, it may also make sense to scrape them normally over HTTP to help debug performance issues.
7 You may see it referenced as pgw in informal contexts.
8 For batch jobs such as database backups that are tied to a machine’s lifecycle, the Node Exporter textfile collector is a better choice. This is discussed in “Textfile Collector”.
9 The Pushgateway explicitly exports empty instance labels for metrics without an instance label. Combined with honor_labels: true, this results in Prometheus not applying an instance label to these metrics. Usually, empty labels and missing labels are the same thing in Prometheus, but this is the exception.
10 Just like summaries and histograms, gauges have a time function decorator and context manager. It is intended only for use in batch jobs.
11 The labels are flattened into the metric name. Tag (i.e., label) support for Graphite was only recently added in 1.1.0.
12 This works both ways. Other instrumentation libraries with an equivalent feature can have their metrics fed into a Prometheus client library. This is discussed in “Custom Collectors”.
13 The Go client’s parser is the reference implementation.
14 Part of the Elasticsearch stack.
15 The null byte is a valid UTF-8 character.
16 Yes, there are two different sets of escaping rules within the text format. In OpenMetrics, this has been unified to just one rule, as double quotes must be escaped in HELP as well.
17 Midnight January 1st 1970 UTC.
18 \r\n is the line ending on Windows, while on Unix, \n is used. Prometheus has a Unix heritage, so it uses \n.
19 Midnight January 1st 1970 UTC.
Get Prometheus: Up & Running, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

