Capítulo 1. Programación reactiva con RxJava
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
RxJava es una implementación específica de la programación reactiva para Java y Android que está influenciada por la programación funcional. Favorece la composición de funciones, evita el estado global y los efectos secundarios, y piensa en flujos para componer programas asíncronos y basados en eventos. Comienza con el patrón observador de devoluciones de llamada productor/consumidor y lo amplía con docenas de operadores que permiten componer, transformar, programar, estrangular, gestionar errores y gestionar el ciclo de vida.
RxJava es una biblioteca madura de código abierto que ha encontrado una amplia adopción tanto en el servidor como en los dispositivos móviles Android. Junto con la biblioteca, se ha creado una comunidad activa de desarrolladores en torno a RxJava y la programación reactiva para contribuir al proyecto, hablar, escribir y ayudarse mutuamente.
Este capítulo proporcionará una visión general de RxJava -qué es y cómo funciona- y el resto de este libro te llevará a través de todos los detalles de cómo utilizarlo y aplicarlo en tus aplicaciones. Puedes empezar a leer este libro sin experiencia previa en programación reactiva, pero empezaremos por el principio y te llevaremos a través de los conceptos y prácticas de RxJava para que puedas aplicar sus puntos fuertes a tus casos de uso.
Programación Reactiva y RxJava
Programación reactiva es un término general de programación que se centra en reaccionar ante cambios, como valores de datos o eventos. Puede hacerse, y a menudo se hace, de forma imperativa. Una devolución de llamada es una aproximación a la programación reactiva hecha de forma imperativa. Una hoja de cálculo es un gran ejemplo de programación reactiva: las celdas que dependen de otras celdas "reaccionan" automáticamente cuando esas otras celdas cambian.
En los ordenadores actuales, todo acaba siendo imperativo en algún momento, ya que llega al sistema operativo y al hardware. Hay que decir explícitamente al ordenador lo que hay que hacer y cómo hacerlo. Los humanos no pensamos como las CPU y los sistemas relacionados, así que añadimos abstracciones. La programación reactiva-funcional es una abstracción, igual que nuestros lenguajes de programación imperativa de alto nivel son abstracciones de las instrucciones binarias y de ensamblaje subyacentes. El hecho de que todo acabe siendo imperativo es importante recordarlo y comprenderlo porque nos ayuda con el modelo mental de a qué se dirige la programación reactivo-funcional y cómo se ejecuta en última instancia: no hay magia.
Por tanto, la programación reactiva-funcional es un enfoque de la programación -una abstracción sobre los sistemas imperativos- que nos permite programar casos de uso asíncronos y basados en eventos sin tener que pensar como el propio ordenador y definir imperativamente las complejas interacciones del estado, en particular a través de los límites de los hilos y la red. No tener que pensar como el ordenador es un rasgo útil cuando se trata de sistemas asíncronos y basados en eventos, porque intervienen la concurrencia y el paralelismo, que son características muy difíciles de utilizar correcta y eficazmente. Dentro de la comunidad Java, los libros Java Concurrency in Practice de Brian Goetz y Concurrent Programming in Java de Doug Lea (Addison-Wesley), y foros como "Mechanical Sympathy " son representativos de la profundidad, amplitud y complejidad del dominio de la concurrencia. Mis interacciones con expertos de estos libros, foros y comunidades desde que empecé a utilizar RxJava me han convencido aún más que antes de lo difícil que es realmente escribir software concurrente de alto rendimiento, eficiente, escalable y correcto. Y ni siquiera hemos mencionado los sistemas distribuidos, que llevan la concurrencia y el paralelismo a otro nivel.
Así pues, la respuesta breve a lo que resuelve la programación reactiva-funcional es la concurrencia y el paralelismo. Más coloquialmente, está resolviendo el infierno de las devoluciones de llamada, que resulta de abordar casos de uso reactivos y asíncronos de forma imperativa. La programación reactiva, como la que implementa RxJava, está influida por la programación funcional y utiliza un enfoque declarativo para evitar los típicos escollos del código reactivo-imperativo.
Cuando necesitas programación reactiva
La programación reactiva es útil en situaciones como las siguientes:
-
Procesar eventos del usuario, como movimientos y clics del ratón, pulsaciones del teclado, señales GPS que cambian con el tiempo a medida que el usuario se mueve con su dispositivo, señales del giroscopio del dispositivo, eventos táctiles, etc.
-
Responder y procesar todos y cada uno de los eventos de E/S con latencia desde el disco o la red, dado que la E/S es intrínsecamente asíncrona (se hace una petición, pasa el tiempo, se recibe o no una respuesta, lo que desencadena más trabajo).
-
Manejar eventos o datos enviados a una aplicación por un productor que no puede controlar (eventos del sistema procedentes de un servidor, los eventos del usuario antes mencionados, señales del hardware, eventos desencadenados por el mundo analógico procedentes de sensores, etc.).
Ahora bien, si el código en cuestión sólo maneja un flujo de eventos, la programación reactiva-imperativa con una devolución de llamada va a estar bien, e introducir la programación reactiva-funcional no te va a aportar muchos beneficios. Puedes tener cientos de flujos de eventos diferentes, y si todos son completamente independientes entre sí, no es probable que la programación imperativa suponga un problema. En casos de uso tan sencillos, los enfoques imperativos van a ser los más eficientes porque eliminan la capa de abstracción de la programación reactiva y se acercan más a aquello para lo que están optimizados los sistemas operativos, lenguajes y compiladores actuales.
Sin embargo, si tu programa es como la mayoría, necesitas combinar eventos (o respuestas asíncronas de funciones o llamadas de red), tener lógica condicional interactuando entre ellos, y debes manejar escenarios de fallo y limpieza de recursos en todos y cada uno de ellos. Aquí es donde el enfoque reactivo-imperativo comienza a aumentar drásticamente su complejidad y la programación reactiva-funcional empieza a brillar. Una opinión no científica que he llegado a aceptar es que la programación reactiva-funcional tiene una curva de aprendizaje y una barrera de entrada inicialmente mayores, pero que el techo de complejidad es mucho menor que con la programación reactiva-imperativa.
De ahí el eslogan de Reactive Extensions (Rx) en general y de RxJava en concreto: "una biblioteca para componer programas asíncronos y basados en eventos". RxJava es una implementación concreta de los principios de la programación reactiva influida por la programación funcional y de flujo de datos. Hay diferentes enfoques para ser "reactivo", y RxJava no es más que uno de ellos. Veamos cómo funciona.
Cómo funciona RxJava
Un elemento central de RxJava es el tipo Observable, que representa un flujo de datos o eventos. Está pensado para push (reactivo), pero también puede utilizarse para pull (interactivo). Es perezoso y no ansioso. Puede utilizarse de forma asíncrona o síncrona. Puede representar 0, 1, muchos o infinitos valores o eventos en el tiempo.
Son muchas palabras de moda y detalles, así que vamos a desgranarlos. Tendrás todos los detalles en "Anatomía de rx.Observable".
Empujar frente a tirar
Todo el sentido de que RxJava sea reactivo es que admita el empuje, por lo que Observable y las firmas de tipo Observer relacionadas admiten que se le empujen eventos. Esto, a su vez, suele ir acompañado de asincronía, de la que hablaremos en la siguiente sección. Pero el tipo Observable también admite un canal de retroalimentación asíncrono (también denominado a veces asíncrono-tirón o reactivo-tirón), como una aproximación al control de flujo o contrapresión en los sistemas asíncronos. En una sección posterior de este capítulo se abordará el control de flujo y cómo encaja este mecanismo.
Para soportar la recepción de eventos mediante push, un par Observable/Observer se conecta mediante suscripción. El Observable representa el flujo de datos y puede ser suscrito por un Observer (del que aprenderás más en "Capturar todas las notificaciones mediante el observador<T>"):
interfaceObservable<T>{Subscriptionsubscribe(Observers)}
Al suscribirte, Observer puede recibir tres tipos de eventos:
-
Datos a través de la función
onNext() -
Errores (excepciones o lanzables) mediante la función
onError() -
Finalización del flujo mediante la función
onCompleted()
interfaceObserver<T>{voidonNext(Tt)voidonError(Throwablet)voidonCompleted()}
El método onNext() puede no llamarse nunca o llamarse una, muchas o infinitas veces. Los onError() y onCompleted() son eventos terminales, lo que significa que sólo se puede llamar a uno de ellos y una sola vez. Cuando se llama a un evento terminal, el flujo Observable se termina y no se pueden enviar más eventos a través de él. Los eventos terminales pueden no producirse nunca si el flujo es infinito y no falla.
Como se verá en "Control de flujo" y "Contrapresión", existe un tipo adicional de firma para permitir la tracción interactiva:
interfaceProducer{voidrequest(longn)}
Se utiliza con un Observer más avanzado llamado Subscriber (con más detalles en "Control de los oyentes mediante la suscripción y el suscriptor<T>"):
interfaceSubscriber<T>implementsObserver<T>,Subscription{voidonNext(Tt)voidonError(Throwablet)voidonCompleted()...voidunsubscribe()voidsetProducer(Producerp)}
La función unsubcribe, que forma parte de la interfaz Subscription, se utiliza para permitir que un suscriptor se dé de baja de un flujo Observable. La función setProducer y los tipos Producer se utilizan para formar un canal de comunicación bidireccional entre el productor y el consumidor utilizado para el control de flujo.
Asíncrono frente a síncrono
Generalmente, un Observable va a ser asíncrono, pero no tiene por qué serlo. Un Observable puede ser síncrono y, de hecho, es síncrono por defecto. RxJava nunca añade concurrencia a menos que se le pida. Un Observable síncrono se suscribiría, emitiría todos los datos utilizando el hilo del suscriptor y se completaría (si es finito). Un Observable respaldado por una E/S de red bloqueante bloquearía sincrónicamente el hilo suscriptor y luego emitiría mediante onNext() cuando volviera la E/S de red bloqueante.
Por ejemplo, lo siguiente es completamente síncrono:
Observable.create(s->{s.onNext("Hello World!");s.onCompleted();}).subscribe(hello->System.out.println(hello));
Aprenderás más sobre Observable.create en "Dominar Observable.create()" y sobre Observable.subscribe en "Suscribirse a notificaciones desde Observable".
Ahora bien, como probablemente estés pensando, éste no suele ser el comportamiento deseado de un sistema reactivo, y tienes razón. Es una mala forma de utilizar un Observable con E/S de bloqueo síncrono (si es necesario utilizar E/S de bloqueo, hay que hacerla asíncrona con hilos). Sin embargo, a veces es apropiado obtener datos de forma sincrónica de una caché en memoria y devolverlos inmediatamente. El caso "Hola Mundo" mostrado en el ejemplo anterior no necesita concurrencia, y de hecho será mucho más lento si se le añade una programación asíncrona. Así pues, el criterio real que suele ser importante es si la producción del evento Observable es bloqueante o no bloqueante, no si es síncrona o asíncrona. El ejemplo "Hola Mundo" es no bloqueante porque nunca bloquea un hilo, por lo que es un uso correcto (aunque superfluo) de un Observable.
El RxJava Observable es intencionadamente agnóstico con respecto a async frente a sync, y a si existe concurrencia o de dónde procede. Esto es por diseño y permite que la implementación del Observable decida qué es lo mejor. ¿Por qué puede ser útil?
En primer lugar, la concurrencia puede proceder de múltiples lugares, no sólo de threadpools. Si la fuente de datos ya es asíncrona porque está en un bucle de eventos, RxJava no debería añadir más sobrecarga de programación ni forzar una implementación de programación concreta. La concurrencia puede proceder de threadpools, bucles de eventos, actores, etcétera. Puede añadirse o puede originarse en la fuente de datos. RxJava es agnóstico con respecto a dónde se origina la asincronía.
En segundo lugar, hay dos buenas razones para utilizar el comportamiento síncrono, que veremos en los siguientes subapartados.
Datos en memoria
Si los datos existen en una caché local en memoria (con tiempos de búsqueda constantes de microsegundos/nanosegundos), no tiene sentido pagar el coste de programación para hacerla asíncrona. El Observable puede simplemente obtener los datos de forma sincrónica y emitirlos en el subproceso suscriptor, como se muestra aquí:
Observable.create(s->{s.onNext(cache.get(SOME_KEY));s.onCompleted();}).subscribe(value->System.out.println(value));
Esta opción de programación es potente cuando los datos pueden estar o no en memoria. Si están en memoria, emítelos de forma síncrona; si no lo están, realiza la llamada a la red de forma asíncrona y devuelve los datos cuando lleguen. Esta elección puede residir condicionalmente dentro de Observable:
// pseudo-codeObservable.create(s->{TfromCache=getFromCache(SOME_KEY);if(fromCache!=null){// emit synchronouslys.onNext(fromCache);s.onCompleted();}else{// fetch asynchronouslygetDataAsynchronously(SOME_KEY).onResponse(v->{putInCache(SOME_KEY,v);s.onNext(v);s.onCompleted();}).onFailure(exception->{s.onError(exception);});}}).subscribe(s->System.out.println(s));
Cálculo sincrónico (como los operadores)
La razón más común para seguir siendo síncrono es la composición y transformación de flujos mediante operadores. RxJava utiliza sobre todo la gran API de operadores utilizados para manipular, combinar y transformar datos, como map(), filter(), take(), flatMap() y groupBy(). La mayoría de estos operadores son síncronos, lo que significa que realizan sus cálculos de forma síncrona dentro de onNext() a medida que pasan los eventos.
Estos operadores son síncronos por razones de rendimiento. Toma esto como ejemplo:
Observable<Integer>o=Observable.create(s->{s.onNext(1);s.onNext(2);s.onNext(3);s.onCompleted();});o.map(i->"Number "+i).subscribe(s->System.out.println(s));
Si el operador map fuera asíncrono por defecto, cada número (1, 2, 3) se programaría en un hilo donde se realizaría la concatenación de la cadena ("Número " + i). Esto es muy ineficiente y generalmente tiene una latencia no determinista debido a la programación, el cambio de contexto, etc.
Lo importante aquí es comprender que la mayoría de las canalizaciones de funciones de Observable son síncronas (a menos que un operador específico necesite ser asíncrono, como timeout o observeOn), mientras que el propio Observable puede ser asíncrono. Estos temas reciben un tratamiento más profundo en "Concurrencia declarativa con observeOn()" y "Temporización cuando no se producen eventos".
El siguiente ejemplo demuestra esta mezcla de sincronización y asincronización:
Observable.create(s->{...asyncsubscriptionanddataemission...}).doOnNext(i->System.out.println(Thread.currentThread())).filter(i->i%2==0).map(i->"Value "+i+" processed on "+Thread.currentThread()).subscribe(s->System.out.println("SOME VALUE =>"+s));System.out.println("Will print BEFORE values are emitted")
En este ejemplo, el Observable es asíncrono (emite en un hilo distinto al del suscriptor), por lo que subscribe es no bloqueante, y el println del final emitirá antes de que se propaguen los eventos y se muestre la salida "ALGÚN VALOR ⇒".
Sin embargo, las funciones filter() y map() se ejecutan sincrónicamente en el hilo de llamada que emite los eventos. En general, éste es el comportamiento que deseamos: una canalización asíncrona (los operadores Observable y composed) con un cálculo síncrono eficaz de los eventos.
Así, el propio tipo Observable admite implementaciones concretas tanto sync como async, y esto es así por diseño.
Concurrencia y paralelismo
Los flujos individuales Observable no permiten ni concurrencia ni paralelismo. En su lugar, se consiguen mediante la composición de asínc Observables.
El paralelismo es la ejecución simultánea de tareas, normalmente en diferentes CPUs o máquinas. La concurrencia, en cambio, es la composición o intercalación de múltiples tareas. Si una sola CPU tiene múltiples tareas (como hilos) en ella, se ejecutan concurrentemente pero no en paralelo por "corte de tiempo". Cada subproceso obtiene una parte del tiempo de la CPU antes de cederlo a otro subproceso, aunque éste aún no haya terminado.
La ejecución paralela es concurrente por definición, pero la concurrencia no es necesariamente paralelismo. En la práctica, esto significa que ser multihilo es concurrencia, pero el paralelismo sólo se produce si esos hilos se programan y ejecutan en distintas CPU exactamente al mismo tiempo. Así pues, genéricamente hablamos de concurrencia y de ser concurrente, pero el paralelismo es una forma específica de concurrencia.
El contrato de un RxJava Observable es que los eventos (onNext(), onCompleted(), onError()) nunca pueden emitirse simultáneamente. En otras palabras, un único flujo Observable debe ser siempre serializado y a prueba de hilos. Cada evento puede emitirse desde un hilo diferente, siempre que las emisiones no sean concurrentes. Esto significa que no hay intercalación ni ejecución simultánea de onNext(). Si onNext() se sigue ejecutando en un hilo, otro hilo no puede empezar a invocarlo de nuevo (intercalación).
He aquí un ejemplo de lo que está bien:
Observable.create(s->{newThread(()->{s.onNext("one");s.onNext("two");s.onNext("three");s.onNext("four");s.onCompleted();}).start();});
Este código emite datos secuencialmente, por lo que cumple el contrato. (Sin embargo, ten en cuenta que, en general, se aconseja no iniciar un hilo como éste dentro de un Observable. En su lugar, utiliza planificadores, como se explica en "Multihilo en RxJava").
Aquí tienes un ejemplo de código ilegal:
// DO NOT DO THISObservable.create(s->{// Thread AnewThread(()->{s.onNext("one");s.onNext("two");}).start();// Thread BnewThread(()->{s.onNext("three");s.onNext("four");}).start();// ignoring need to emit s.onCompleted() due to race of threads});// DO NOT DO THIS
Este código es ilegal porque tiene dos hilos que pueden invocar simultáneamente a onNext(). Esto rompe el contrato. (Además, tendría que esperar de forma segura a que ambos hilos se completaran para llamar a onComplete, y como se ha mencionado antes, en general es una mala idea iniciar manualmente hilos de este tipo).
Entonces, ¿cómo se aprovecha la concurrencia y/o el paralelismo con RxJava? Composición.
Un único flujo Observable siempre se serializa, pero cada flujo Observable puede funcionar independientemente uno de otro, y por tanto concurrentemente y/o en paralelo. Esta es la razón por la que merge y flatMap acaban siendo tan utilizados en RxJava: para componer flujos asíncronos de forma concurrente. (Puedes obtener más información sobre los detalles de merge y flatMap en "Envolver utilizando flatMap()" y "Tratar varios observables como uno solo utilizando merge()").
He aquí un ejemplo artificial que muestra la mecánica de dos Observables asíncronos que se ejecutan en hilos separados y se fusionan:
Observable<String>a=Observable.create(s->{newThread(()->{s.onNext("one");s.onNext("two");s.onCompleted();}).start();});Observable<String>b=Observable.create(s->{newThread(()->{s.onNext("three");s.onNext("four");s.onCompleted();}).start();});// this subscribes to a and b concurrently,// and merges into a third sequential streamObservable<String>c=Observable.merge(a,b);
Observable c recibirá elementos tanto de a como de b, y debido a su asincronía, ocurren tres cosas:
-
"uno" aparecerá antes que "dos"
-
"tres" aparecerá antes que "cuatro"
-
El orden entre uno/dos y tres/cuatro no está especificado
Entonces, ¿por qué no permitir que se invoque simultáneamente a onNext()?
Principalmente porque onNext() está pensado para que lo utilicemos los humanos, y la concurrencia es difícil. Si onNext() pudiera invocarse de forma concurrente, significaría que cada Observer tendría que codificar de forma defensiva para la invocación concurrente, incluso cuando no se esperara o no se quisiera.
Una segunda razón es porque algunas operaciones simplemente no son posibles con la emisión concurrente; por ejemplo, scan y reduce, que son comportamientos comunes e importantes. Operadores como scan y reduce requieren la propagación secuencial de eventos para que el estado pueda acumularse en flujos de eventos que no sean a la vez asociativos y conmutativos. Permitir flujos Observable concurrentes (con onNext() concurrente) limitaría los tipos de eventos que se pueden procesar y requeriría estructuras de datos a prueba de hilos.
Nota
El tipo Stream de Java 8 admite la emisión concurrente. Por eso java.util.stream.Stream requiere que las funciones reduce sean asociativas, porque deben soportar la invocación concurrente en flujos paralelos. La documentación del paquete java.util.stream sobre paralelismo, ordenación (relacionada con la conmutatividad), operaciones de reducción y asociatividad ilustra aún más la complejidad de que el mismo tipo Stream permita tanto la emisión secuencial como la concurrente.
Una tercera razón es que el rendimiento se ve afectado por la sobrecarga de sincronización, porque todos los observadores y operadores tendrían que ser seguros para los hilos, aunque la mayor parte del tiempo los datos lleguen secuencialmente. A pesar de que la JVM suele ser buena eliminando la sobrecarga de sincronización, no siempre es posible (sobre todo con algoritmos no bloqueantes que utilizan atómicos), por lo que esto acaba siendo un impuesto sobre el rendimiento que no se necesita en los flujos secuenciales.
Además, suele ser más lento hacer paralelismo genérico de grano fino. Normalmente, el paralelismo debe hacerse de forma gruesa, como en lotes de trabajo, para compensar la sobrecarga de cambiar de hilo, programar el trabajo y recombinarlo. Es mucho más eficiente ejecutar sincrónicamente en un único hilo y aprovechar las muchas optimizaciones de memoria y CPU para el cálculo secuencial. En List o array, es bastante fácil tener unos valores predeterminados razonables para el paralelismo por lotes, porque todos los elementos se conocen de antemano y pueden dividirse en lotes (aunque incluso entonces suele ser más rápido procesar la lista completa en una sola CPU, a menos que la lista sea muy grande o el cálculo por elemento sea significativo). Un flujo, sin embargo, no conoce el trabajo de antemano, sólo recibe los datos a través de onNext() y, por tanto, no puede dividir el trabajo en lotes automáticamente.
De hecho, antes de RxJava v1, se añadió un operador .parallel(Function f) para intentar comportarse como java.util.stream.Stream.parallel() porque se consideraba una buena comodidad. Se hizo de forma que no se rompiera el contrato de RxJava al dividir un único Observable en muchos Observables que se ejecutaban cada uno en paralelo, y luego volver a unirlos. Sin embargo, se acabó eliminando de la biblioteca antes de la v1 porque era muy confuso y casi siempre daba lugar a un peor rendimiento. Añadir paralelismo computacional a un flujo de eventos casi siempre debe razonarse y probarse. Tal vez podría tener sentido un ParallelObservable, para el que los operadores estén restringidos a un subconjunto que asuma la asociatividad, pero en los años de uso de RxJava, nunca ha acabado mereciendo la pena el esfuerzo, porque la composición con merge y flatMap son bloques de construcción eficaces para abordar los casos de uso.
El Capítulo 3 enseñará a utilizar operadores para componer Observables y beneficiarse de la concurrencia y el paralelismo.
Pereza frente a Ansia
El tipo Observable es perezoso, lo que significa que no hace nada hasta que se le suscribe. Esto difiere de un tipo ansioso como Future, que cuando se crea representa trabajo activo. La pereza permite componer Observables sin pérdida de datos debido a condiciones de carrera sin almacenamiento en caché. En un Future, esto no es un problema, porque el valor único puede almacenarse en caché, de modo que si el valor se entrega antes de la composición, el valor se recuperará. Con un flujo ilimitado, se necesitaría un búfer ilimitado para ofrecer esta misma garantía. Así, el Observable es perezoso y no se iniciará hasta que se suscriba, de modo que toda la composición pueda realizarse antes de que empiecen a fluir los datos.
En la práctica, esto significa dos cosas:
- La suscripción, no la construcción inicia los trabajos
-
Debido a la pereza de un
Observable, crear uno en realidad no provoca que se realice ningún trabajo (ignorando el "trabajo" de asignar el propio objetoObservable). Lo único que hace es definir qué trabajo debe realizarse cuando finalmente se suscriba. Considera unObservabledefinido así:Observable<T>someData=Observable.create(s->{getDataFromServerWithCallback(args,data->{s.onNext(data);s.onCompleted();});})La referencia
someDataexiste ahora, perogetDataFromServerWithCallbackaún no se está ejecutando. Lo único que ha sucedido es que la envolturaObservablese ha declarado alrededor de una unidad de trabajo a realizar, la función que vive dentro deObservable.La suscripción a
Observablehace que se realice el trabajo:someData.subscribe(s->System.out.println(s));Esto ejecuta perezosamente el trabajo representado por el
Observable. - Los observables se pueden reutilizar
-
Como
Observablees perezoso, también significa que una instancia concreta puede invocarse más de una vez. Siguiendo con el ejemplo anterior, esto significa que podemos hacer lo siguiente:someData.subscribe(s->System.out.println("Subscriber 1: "+s));someData.subscribe(s->System.out.println("Subscriber 2: "+s));Ahora habrá dos suscripciones distintas, cada una de las cuales llamará a
getDataFromServerWithCallbacky emitirá eventos.Esta pereza difiere de los tipos asíncronos como
Future, en los queFuturese crea para representar trabajo ya iniciado. UnFutureno puede reutilizarse (suscribirse varias veces para desencadenar trabajo). Si existe una referencia a unFuture, significa que el trabajo ya está ocurriendo. Puedes ver en el código de ejemplo anterior exactamente dónde está el afán; el métodogetDataFromServerWithCallbackestá ansioso porque se ejecuta inmediatamente cuando se invoca. Envolver unObservablealrededor degetDataFromServerWithCallbackpermite utilizarlo perezosamente.
Esta pereza es poderosa a la hora de componer. Por ejemplo:
someData.onErrorResumeNext(lazyFallback).subscribe(s->System.out.println(s));
En este caso, lazyFallback Observable representa un trabajo que se puede hacer, pero que sólo se hará si algo se suscribe a él, y que sólo queremos que se suscriba si someData falla. Por supuesto, los tipos ansiosos pueden hacerse perezosos utilizando llamadas a funciones (como getDataAsFutureA()).
El afán y la pereza tienen cada uno sus puntos fuertes y débiles, pero RxJava Observable es perezoso. Por lo tanto, si tienes un Observable no hará nada hasta que te suscribas a él.
Este tema se trata con más detalle en "Abrazar la pereza".
Dualidad
Un Observable Rx es el "dual" asíncrono de un Iterable. Por "dual", queremos decir que el Observable proporciona toda la funcionalidad de un Iterable excepto en el flujo inverso de datos: es push en lugar de pull. En la tabla siguiente se muestran los tipos que tienen funciones push y pull:
| Tirar (Iterable) | Empujar (Observable) |
|---|---|
T siguiente() |
onSiguiente(T) |
lanza una excepción |
onError(Throwable) |
devuelve |
onCompletado() |
Según la tabla, en lugar de que el consumidor extraiga los datos a través de next(), el productor los envía a onNext(T). La finalización con éxito se señala a través de la llamada de retorno onCompleted(), en lugar de bloquear el hilo hasta que se hayan iterado todos los elementos. En lugar de lanzar excepciones a la pila de llamadas, los errores se emiten como eventos a la llamada de retorno onError(Throwable).
El hecho de que se comporte como un dual significa efectivamente que cualquier cosa que puedas hacer de forma síncrona mediante pull con un Iterable y Iterator se puede hacer de forma asíncrona mediante push con un Observable y Observer. Esto significa que el mismo modelo de programación puede aplicarse a ambos.
Por ejemplo, a partir de Java 8 se puede actualizar un Iterable para que tenga composición de funciones mediante el tipo java.util.stream.Stream para que funcione así:
// Iterable<String> as Stream<String>// that contains 75 stringsgetDataFromLocalMemorySynchronously().skip(10).limit(5).map(s->s+"_transformed").forEach(System.out::println)
Esto recuperará 75 cadenas de getDataFromLocalMemorySynchronously(), obtendrá los elementos 11-15 e ignorará el resto, transformará las cadenas y las imprimirá. (Obtén más información sobre operadores como take, skip y limit en "Rebanar y cortar utilizando skip(), takeWhile() y otros").
Un RxJava Observable se utiliza de la misma manera:
// Observable<String>// that emits 75 stringsgetDataFromNetworkAsynchronously().skip(10).take(5).map(s->s+"_transformed").subscribe(System.out::println)
Esto recibirá 5 cadenas (se emitieron 15, pero se descartaron las 10 primeras), y luego se dará de baja (ignorando o deteniendo el resto de cadenas que se iban a emitir). Transforma e imprime las cadenas igual que en el ejemplo anterior Iterable/Stream.
En otras palabras, el Rx Observable permite programar con datos asíncronos mediante push, igual que Streams en torno a Iterables y Lists mediante pull síncrono.
Cardinalidad
El Observable admite el envío asíncrono de múltiples valores. Esto encaja perfectamente en la parte inferior derecha de la siguiente tabla, el dual asíncrono de Iterable (o Stream, List, Enumerable, etc.) y la versión multivalor de un Future:
| Una | Muchos | |
|---|---|---|
Sincrónico |
T obtenerDatos() |
Iterable<T> getData() |
Asíncrono |
Futuro<T> getData() |
Observable<T> getData() |
Ten en cuenta que esta sección se refiere a Future de forma genérica. Utiliza la sintaxis Future.onSuccess(callback) para representar su comportamiento. Existen diferentes implementaciones, como CompletableFuture, ListenableFutureo la de Scala Future. Pero hagas lo que hagas, no utilices java.util.Future, que requiere un bloqueo para recuperar un valor.
Entonces, ¿por qué podría ser valioso un Observable en lugar de sólo Future? La razón más obvia es que se trata de un flujo de eventos o de una respuesta multivaluada. La razón menos obvia es la composición de múltiples respuestas de un solo valor. Veamos cada una de ellas.
Flujo de eventos
El flujo de eventos es sencillo. Con el tiempo, el productor envía eventos al consumidor, como se muestra aquí:
// producerObservable<Event>mouseEvents=...;// consumermouseEvents.subscribe(e->doSomethingWithEvent(e));
Esto no funciona muy bien con un Future:
// producerFuture<Event>mouseEvents=...;// consumermouseEvents.onSuccess(e->doSomethingWithEvent(e));
La llamada de retorno onSuccess podría haber recibido el "último evento", pero quedan algunas preguntas: ¿Necesita ahora el consumidor hacer un sondeo? ¿Los pondrá en cola el productor? ¿O se perderán entre cada obtención? El Observable es sin duda beneficioso en este caso. En ausencia de Observable, un enfoque de devolución de llamada sería mejor que modelar esto con un Future.
Valores múltiples
Las respuestas multivaluadas son el siguiente uso de Observable. Básicamente, en cualquier lugar en el que se utilizaría un List, Iterable, o Stream, se puede utilizar Observable en su lugar:
// producerObservable<Friend>friends=...// consumerfriends.subscribe(friend->sayHello(friend));
Ahora bien, esto puede funcionar con un Future, así:
// producerFuture<List<Friend>>friends=...// consumerfriends.onSuccess(listOfFriends->{listOfFriends.forEach(friend->sayHello(friend));});
Entonces, ¿por qué utilizar el enfoque Observable<Friend>?
Si la lista de datos a devolver es pequeña, probablemente no importe para el rendimiento y se convierta en una elección subjetiva. Sin embargo, si la lista es grande, o la fuente de datos remota debe obtener diferentes partes de la lista desde diferentes ubicaciones, utilizar el enfoque Observable<Friend> puede suponer una ventaja de rendimiento o latencia.
La razón más convincente es que los elementos se pueden procesar a medida que se reciben, en lugar de esperar a que llegue toda la colección. Esto es especialmente cierto cuando las diferentes latencias de red en el backend pueden afectar a cada elemento de forma diferente, lo que en realidad es bastante común debido a las latencias de cola larga (como en las arquitecturas orientadas a servicios o microservicios) y a los almacenes de datos compartidos. Si espera toda la colección, el consumidor siempre experimentará la latencia máxima del trabajo agregado realizado para la colección. Si los elementos se devuelven como un flujo Observable, el consumidor los recibe inmediatamente y el "tiempo hasta el primer elemento" puede ser significativamente menor que el del último y más lento. Para que esto funcione, hay que sacrificar el orden del flujo para que los elementos puedan emitirse en cualquier orden en que el servidor los reciba. Si al final el orden es importante para el consumidor, se puede incluir una clasificación o posición en los datos o metadatos del elemento, y el cliente puede entonces ordenar o posicionar los elementos según necesite.
Además, mantiene el uso de memoria limitado al necesario por elemento, en lugar de tener que asignar y acumular memoria para toda la colección.
Composición
Un tipo Observable multivaluado también es útil cuando se componen respuestas de un solo valor, como las de Futures.
Al fusionar varios Futures, emiten otro Future con un único valor, como éste:
CompletableFuture<String>f1=getDataAsFuture(1);CompletableFuture<String>f2=getDataAsFuture(2);CompletableFuture<String>f3=f1.thenCombine(f2,(x,y)->{returnx+y;});
Eso podría ser exactamente lo que se quiere, y de hecho está disponible en RxJava a través de Observable.zip (sobre lo que aprenderás más en "Composición por pares utilizando zip() y zipWith()"):
Observable<String>o1=getDataAsObservable(1);Observable<String>o2=getDataAsObservable(2);Observable<String>o3=Observable.zip(o1,o2,(x,y)->{returnx+y;});
Sin embargo, implica esperar a que se completen todos los Futures antes de emitir nada. A menudo, es preferible emitir cada valor Future devuelto a medida que se completa. En este caso, es preferible Observable.merge (o el relacionado flatMap). Permite componer los resultados (incluso si cada uno es sólo un Observable que emite un valor) en un flujo de valores que se emiten tan pronto como están listos:
Observable<String>o1=getDataAsObservable(1);Observable<String>o2=getDataAsObservable(2);// o3 is now a stream of o1 and o2 that emits each item without waitingObservable<String>o3=Observable.merge(o1,o2);
Único
Ahora bien, a pesar de que Rx Observable es genial para manejar flujos multivaluados, la simplicidad de una representación de un solo valor es muy agradable para el diseño y el consumo de API. Además, el comportamiento básico de solicitud/respuesta es muy común en las aplicaciones. Por esta razón, RxJava proporciona un tipo Single, que es un equivalente perezoso a un Future. Piensa en él como un Future con dos ventajas: en primer lugar, es perezoso, por lo que puede suscribirse varias veces y componerse fácilmente, y en segundo lugar, se ajusta a la API de RxJava, por lo que puede interactuar fácilmente con un Observable.
Por ejemplo, considera estos accesorios:
publicstaticSingle<String>getDataA(){returnSingle.<String>create(o->{o.onSuccess("DataA");}).subscribeOn(Schedulers.io());}publicstaticSingle<String>getDataB(){returnSingle.just("DataB").subscribeOn(Schedulers.io());}
A continuación, se pueden utilizar y, opcionalmente, componer así:
// merge a & b into an Observable stream of 2 valuesObservable<String>a_merge_b=getDataA().mergeWith(getDataB());
Observa cómo dos Singles se fusionan en un Observable. Esto podría dar lugar a una emisión de [A, B] o [B, A], dependiendo de cuál se complete primero.
Volviendo al ejemplo anterior, ahora podemos utilizar Single en lugar de Observable para representar la obtención de datos, pero fusionándolos en un flujo de valores:
// Observable<String> o1 = getDataAsObservable(1);// Observable<String> o2 = getDataAsObservable(2);Single<String>s1=getDataAsSingle(1);Single<String>s2=getDataAsSingle(2);// o3 is now a stream of s1 and s2 that emits each item without waitingObservable<String>o3=Single.merge(s1,s2);
Utilizar Single en lugar de Observable para representar un "flujo de uno" simplifica el consumo porque un desarrollador sólo debe tener en cuenta los siguientes comportamientos para el tipo Single:
-
Puede responder con un error
-
Nunca respondas
-
Responde con éxito
Compáralo con los estados adicionales que un consumidor debe tener en cuenta con un Observable:
-
Puede responder con un error
-
Nunca respondas
-
Responde con éxito sin datos y finaliza
-
Responde con éxito con un único valor y termina
-
Responde con éxito con varios valores y termina
-
Responde con éxito con uno o más valores y nunca termina (esperando más datos)
Al utilizar Single, el modelo mental es más sencillo para consumir la API, y sólo después de que se produzca la composición en un Observable debe el desarrollador considerar los estados adicionales. A menudo es mejor que esto ocurra porque normalmente el desarrollador controla ese código, mientras que la API de datos suele ser de un tercero.
Obtendrás más información sobre Single en "Observable versus Único".
Completable
Además de Single, RxJava también tiene un tipo Completable que aborda el caso de uso sorprendentemente común de no tener ningún tipo de retorno, sólo la necesidad de representar la finalización con éxito o sin éxito. A menudo se acaba utilizando Observable<Void> o Single<Void>. Esto es incómodo, así que surgió Completable, como se demuestra aquí:
Completablec=writeToDatabase("data");
Este caso de uso es habitual cuando se realizan escrituras asíncronas para las que no se espera ningún valor de retorno, pero se necesita una notificación de finalización correcta o fallida. El código anterior con Completable es similar a éste:
Observable<Void>c=writeToDatabase("data");
El propio Completable es una abstracción para dos llamadas de retorno, finalización y fallo, como ésta:
staticCompletablewriteToDatabase(Objectdata){returnCompletable.create(s->{doAsyncWrite(data,// callback for successful completion()->s.onCompleted(),// callback for failure with Throwableerror->s.onError(error));});}
De cero a infinito
Observable puede admitir cardinalidades de cero a infinito (lo que se explora más en "Flujos infinitos"). Pero por simplicidad y claridad, Single es un "Observable de Uno", y Completable es un "Observable de Ninguno".
Con estos tipos recién introducidos, nuestra tabla acaba teniendo este aspecto:
| Cero | Una | Muchos | |
|---|---|---|---|
Sincrónico |
void hacerAlgo() |
T obtenerDatos() |
Iterable<T> getData() |
Asíncrono |
Completable hacerAlgo() |
Single<T> getData() |
Observable<T> getData() |
Simpatía mecánica: E/S bloqueante frente a no bloqueante
Hasta ahora, el argumento a favor del estilo de programación reactivo-funcional ha consistido principalmente en proporcionar una abstracción sobre las devoluciones de llamada asíncronas para permitir una composición más manejable. Y, es bastante obvio que realizar solicitudes de red no relacionadas de forma concurrente en lugar de secuencial es beneficioso para la latencia experimentada, de ahí la razón para adoptar la asincronía y necesitar la composición.
Pero, ¿hay alguna razón de eficiencia para adoptar el enfoque reactivo (ya sea imperativo o funcional) en la forma en que realizamos la E/S? ¿Hay ventajas en utilizar E/S no bloqueantes, o está bien bloquear hilos de E/S para esperar una única solicitud de red? Las pruebas de rendimiento en las que participé en Netflix demostraron que existen ventajas de eficiencia objetivas y cuantificables al adoptar la E/S no bloqueante y los bucles de eventos frente a la E/S bloqueante de hilos por petición. En esta sección se exponen las razones por las que esto es así, así como los datos que te ayudarán a tomar tu propia decisión.
Como se indica en "La búsqueda de respuestas", se hicieron pruebas para comparar el rendimiento de la E/S bloqueante y no bloqueante con Tomcat y Netty en Linux. Como este tipo de pruebas siempre son controvertidas y difíciles de hacer bien, seré muy claro al decir que estas pruebas sólo son relevantes para lo siguiente:
-
Comportamiento en sistemas Linux típicos utilizados en torno a 2015/2016
-
Java 8 (OpenJDK y Oracle)
-
Tomcat y Netty sin modificar, tal como se utilizan en entornos de producción típicos
-
Carga de trabajorepresentativa de solicitud/respuesta de servicios web que implique la composición de otros múltiples servicios web
Teniendo en cuenta ese contexto, aprendimos lo siguiente:
-
El código de Netty es más eficiente que el de Tomcat, lo que le permite consumir menos CPU por petición.
-
La arquitectura de bucle de eventos de Netty reduce las migraciones de hilos bajo carga, lo que mejora la calidez de la caché de la CPU y la localidad de la memoria, lo que mejora las instrucciones por ciclo (IPC) de la CPU, que reduce el consumo de ciclos de la CPU por petición.
-
El código de Tomcat tiene mayores latencias bajo carga debido a su arquitectura de pool de hilos, que implica bloqueos de pool de hilos (y contención de bloqueos) y migraciones de hilos para dar servicio a la carga.
El siguiente gráfico ilustra mejor la diferencia entre las arquitecturas:
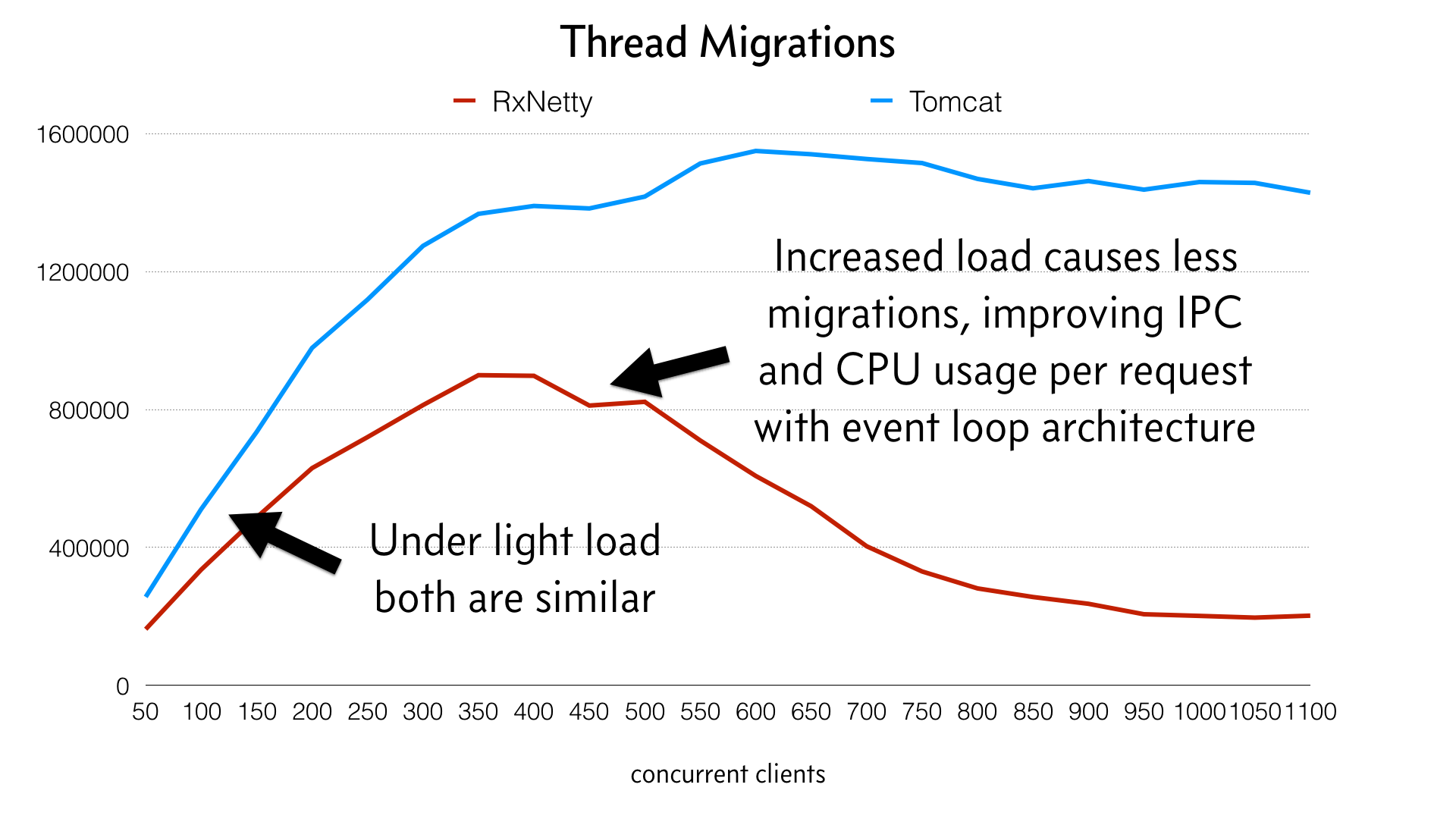
Observa cómo las líneas divergen a medida que aumenta la carga. Éstas son las migraciones de los hilos. Lo más interesante que aprendí fue que la aplicación Netty en realidad se vuelve más eficiente a medida que se somete a carga y los hilos se "calientan" y se pegan a un núcleo de la CPU. Tomcat, por otro lado, tiene un hilo independiente por cada solicitud y, por tanto, no puede obtener este beneficio y conserva mayores migraciones de hilos debido a que cada hilo debe programarse para cada solicitud.
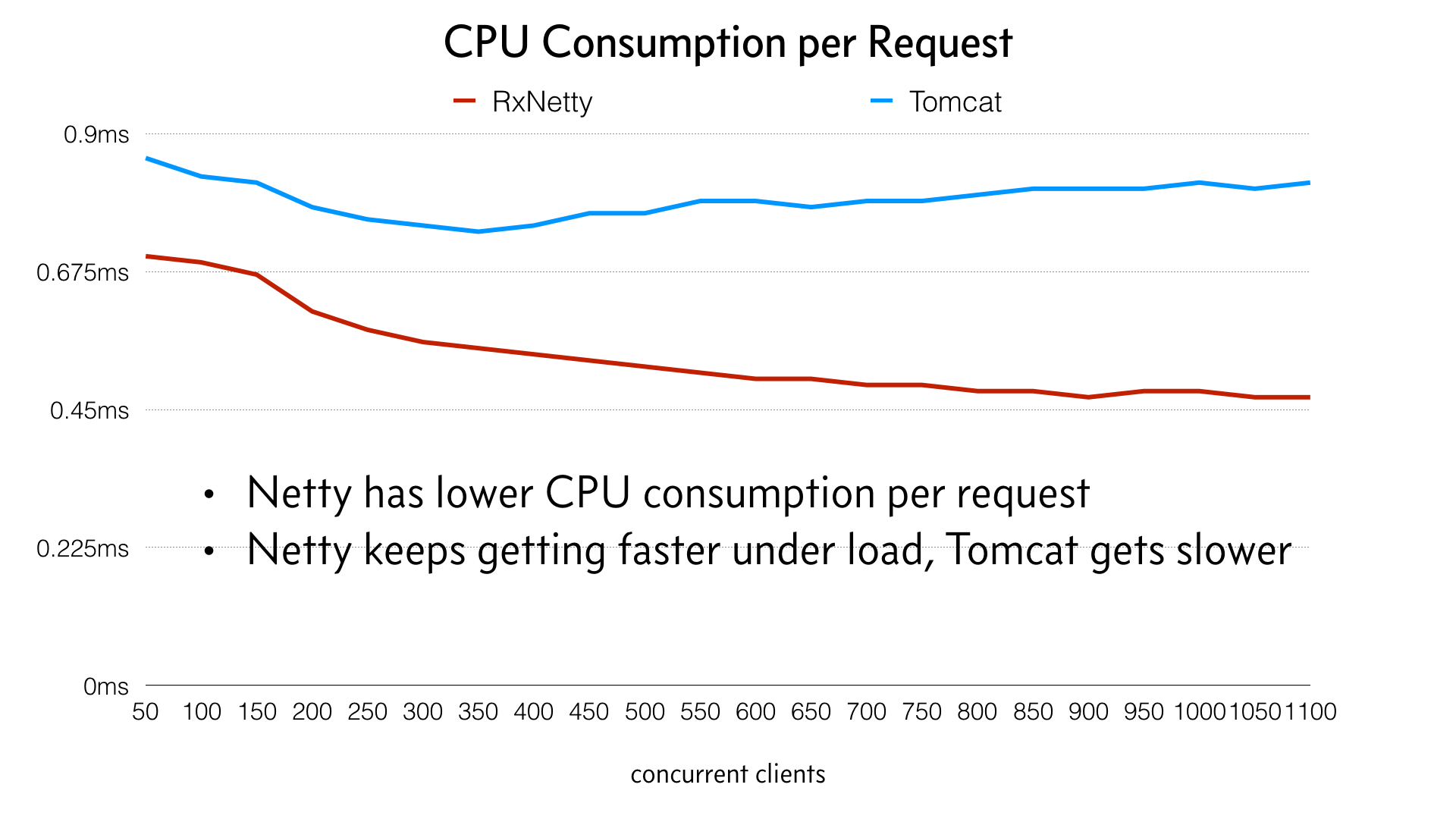
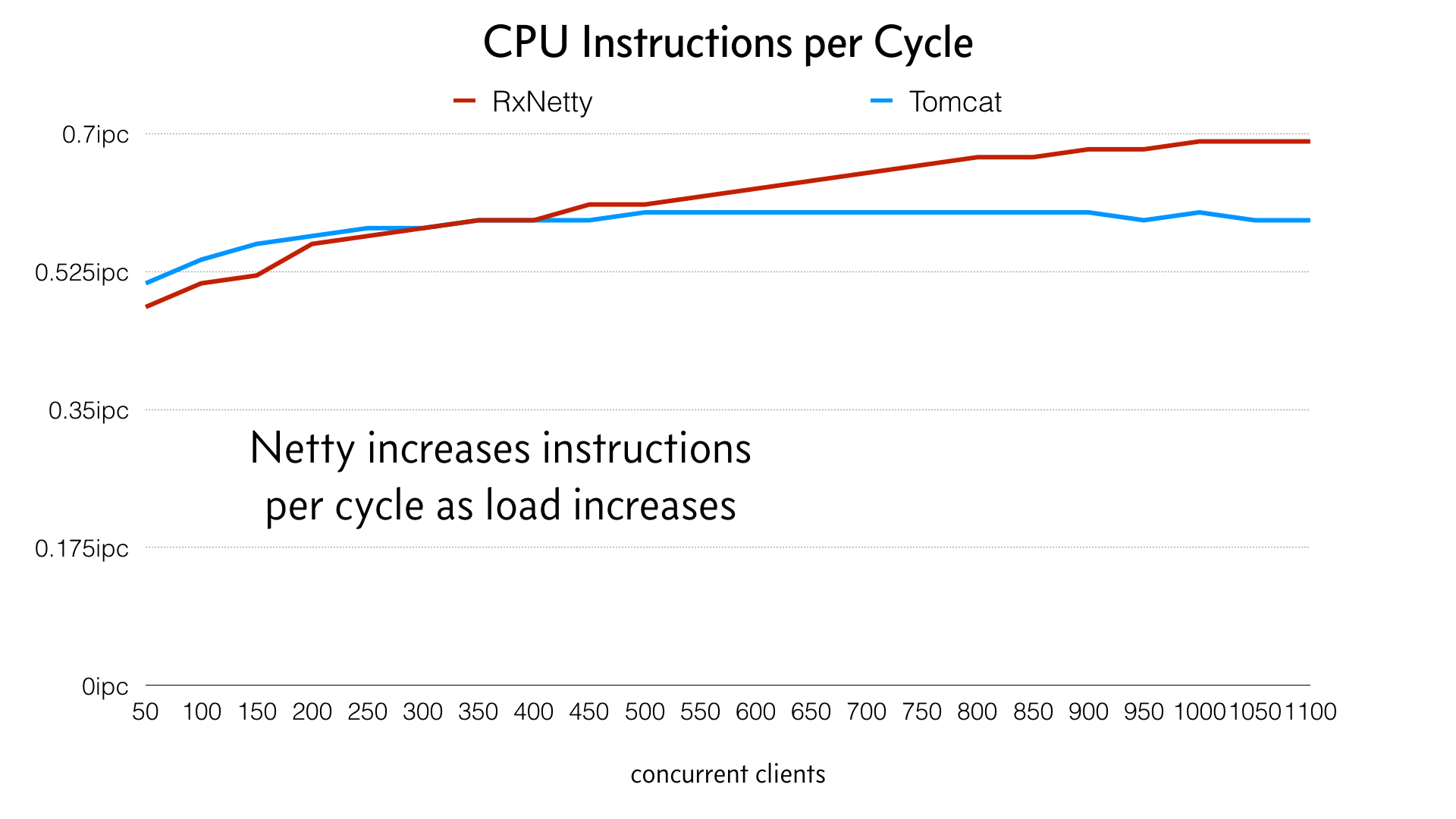
El consumo de CPU de Netty se mantiene prácticamente plano a medida que aumenta la carga y, de hecho, se vuelve ligeramente más eficiente a medida que la carga llega al máximo, a diferencia de Tomcat, que se vuelve menos eficiente.
El impacto resultante en la latencia y el rendimiento se ve en el siguiente gráfico:
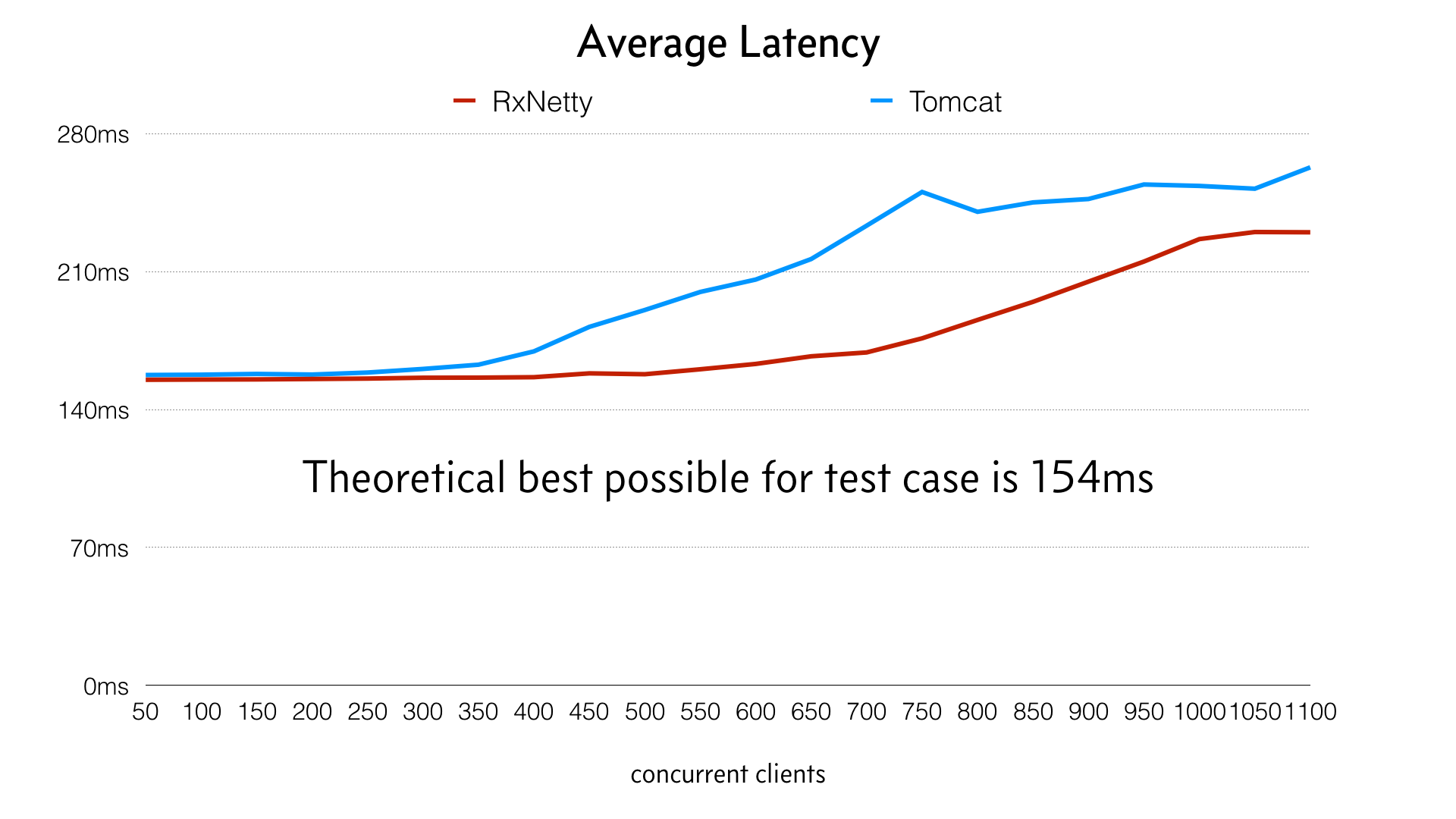
A pesar de que las medias no son muy valiosas (a diferencia de los percentiles), este gráfico muestra cómo ambos tienen una latencia similar con poca carga, pero divergen significativamente a medida que aumenta la carga. Netty es capaz de utilizar mejor la máquina hasta que aumenta la carga, con menor impacto en la latencia:
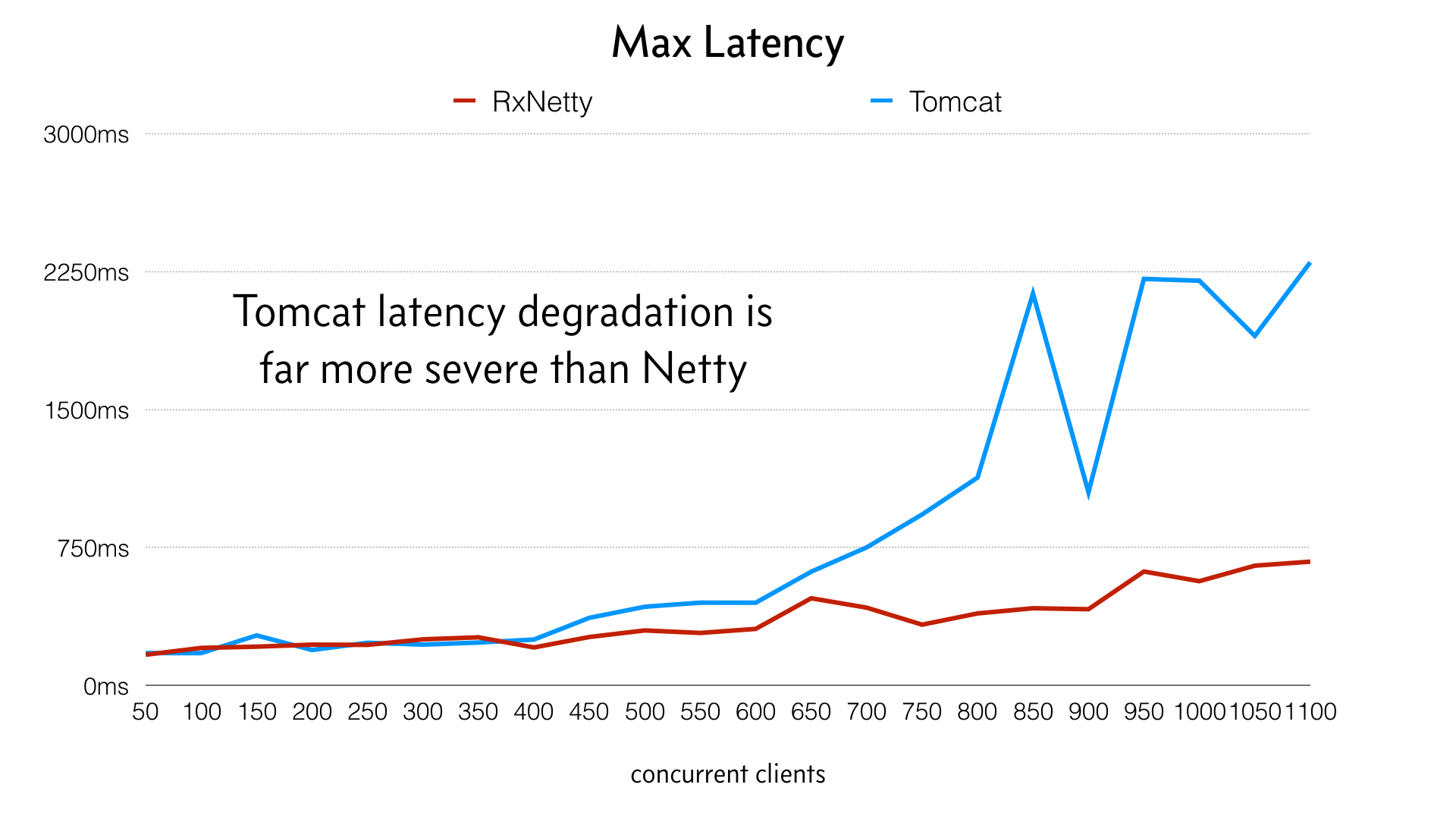
Este gráfico de latencia máxima se eligió para mostrar cómo los valores atípicos afectan a los usuarios y a los recursos del sistema. Netty maneja la carga con mucha más elegancia y evita los valores atípicos del peor caso.
La siguiente imagen muestra el rendimiento:
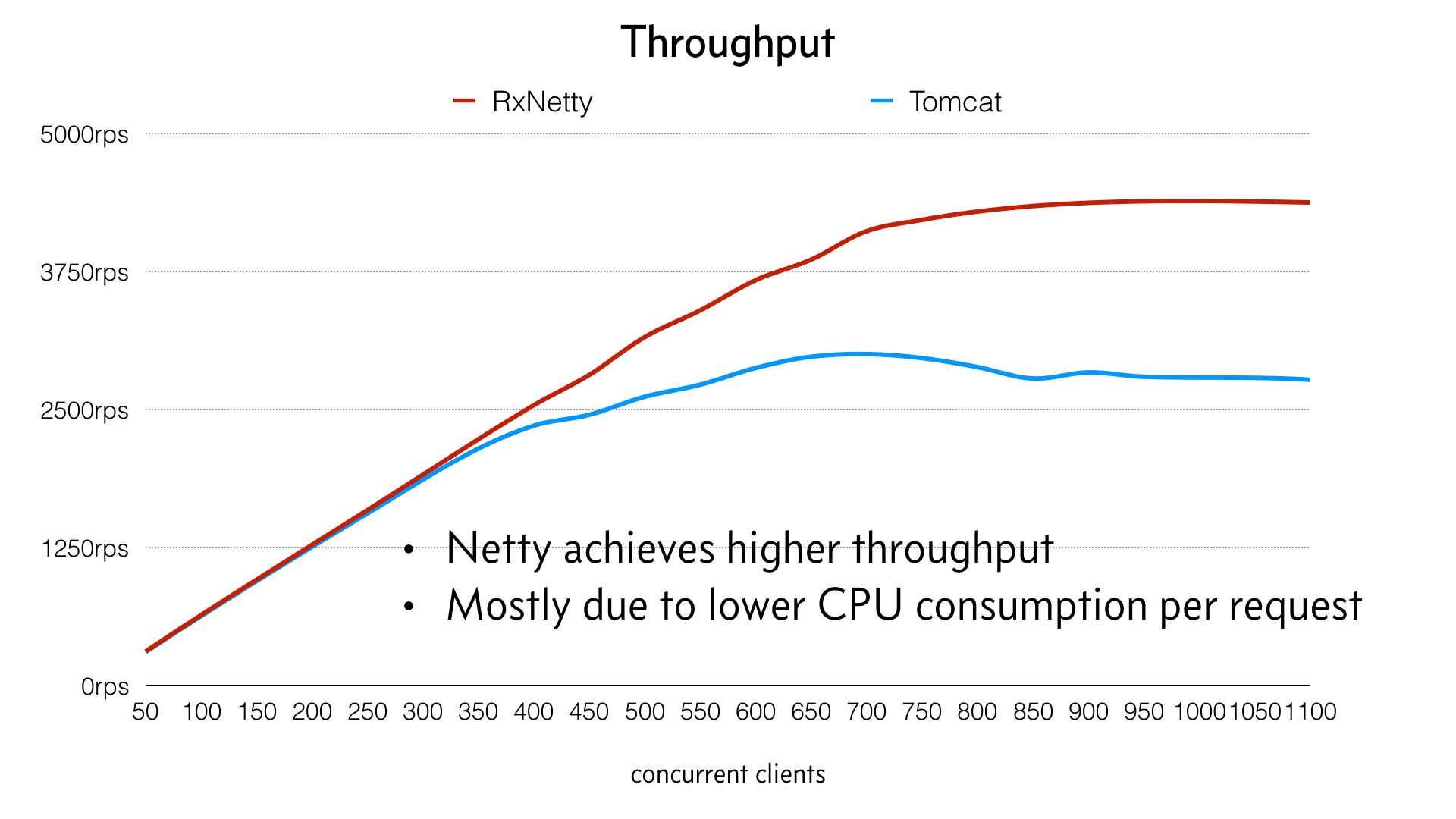
De estos resultados se desprenden dos grandes ventajas. En primer lugar, una mejor latencia y rendimiento significa tanto una mejor experiencia de usuario como un menor coste de infraestructura. En segundo lugar, la arquitectura de bucle de eventos es más resistente bajo carga. En lugar de venirse abajo cuando aumenta la carga, la máquina puede ser llevada a su límite y manejarlo con elegancia. Éste es un argumento muy convincente para los sistemas de producción a gran escala que necesitan manejar picos inesperados de tráfico y seguir respondiendo.
También me pareció que la arquitectura de bucle de eventos era más fácil de manejar. No requiere1 requiere un ajuste para obtener un rendimiento óptimo, mientras que la arquitectura de hilos por petición a menudo requiere ajustar el tamaño de los grupos de hilos (y, por consiguiente, la recolección de basura) en función de la carga de trabajo.
Esto no pretende ser un estudio exhaustivo del tema, pero encontré que este experimento y los datos resultantes son una prueba convincente de que hay que perseguir la arquitectura "reactiva" en forma de E/S no bloqueante y bucles de eventos. En otras palabras, con el hardware, el núcleo Linux y la JVM de 2015/2016, la E/S no bloqueante mediante bucles de eventos tiene ventajas.
El uso de Netty con RxJava se analizará más adelante en "Servidor HTTP no bloqueante con Netty y RxNetty".
Abstracción reactiva
En última instancia, los tipos y operadores de RxJava no son más que una abstracción sobre las devoluciones de llamada imperativas. Sin embargo, esta abstracción cambia completamente el estilo de codificación y proporciona herramientas muy potentes para hacer programación asíncrona y no bloqueante. Cuesta aprenderlo y requiere un cambio de mentalidad para sentirse cómodo con la composición de funciones y el pensamiento en secuencias, pero cuando lo has conseguido es una herramienta muy eficaz junto a nuestros estilos típicos de programación orientada a objetos e imperativa.
El resto de este libro te lleva a través de los muchos detalles de cómo funciona RxJava y cómo utilizarlo. El Capítulo 2 explica de dónde vienen los Observabley cómo puedes consumirlos. El Capítulo 3 te guiará a través de varias docenas de transformaciones declarativas y potentes.
1 Más allá quizás de debatir cuándo se dimensiona el número de bucles de eventos a 1x, 1,5x o 2x el número de núcleos. Sin embargo, no he encontrado grandes diferencias entre estos valores y, por lo general, elijo por defecto 1x.
Get Programación Reactiva con RxJava now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

