Kapitel 4. Datenkataloge
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Die Speicherung innerhalb der Lakehouse-Architektur ist wichtig, da sie die Daten für die gesamte Plattform speichert. Um diese gespeicherten Daten zu suchen, zu erkunden und zu entdecken, brauchen die Nutzer einen Datenkatalog. In diesem Kapitel geht es darum, einen Datenkatalog und den gesamten Prozess der Metadatenverwaltung zu verstehen, der es den Nutzern der Lakehouse-Plattform ermöglicht, die Daten zu suchen und darauf zuzugreifen.
Im ersten Abschnitt dieses Kapitels erkläre ich grundlegende Konzepte wie Metadaten, Metaspeicher und Datenkataloge. Diese Konzepte sind nicht neu; Unternehmen setzen schon seit langem Datenkataloge sowohl in traditionellen Data Warehouses als auch in modernen Datenplattformen ein. Ich erkläre diese grundlegenden Konzepte zuerst, um die Diskussion über die fortgeschrittenen Funktionen im weiteren Verlauf des Kapitels vorzubereiten.
Wir werden erörtern, wie sich Datenkataloge in der Lakehouse-Architektur von den traditionellen und kombinierten Architekturen unterscheiden und wie sie den Nutzern helfen, eine einheitliche Sicht auf alle Metadaten zu erhalten. Außerdem werden wir die zusätzlichen Vorteile von Datenkatalogen in der Lakehouse-Architektur erörtern, die es den Nutzern ermöglichen, Metadaten zu nutzen, um eine einheitliche Datenverwaltung, Berechtigungskontrolle, Abstammung und Freigabemechanismen zu implementieren.
Im letzten Abschnitt dieses Kapitels gehe ich auf einige der gängigen Datenkatalog-Technologien ein, die auf Cloud-Plattformen verfügbar sind. Du erfährst, welche Überlegungen zum Design und zu den praktischen Einschränkungen es gibt, die dir helfen, eine fundierte Entscheidung zu treffen, wenn du die Datenkataloge für deine Lakehouse-Plattform entwirfst.
Metadaten verstehen
Genauso wie wir Prozesse brauchen, um die Daten innerhalb der Plattform zu verwalten, brauchen wir auch gut definierte Ansätze für die Verwaltung der Metadaten. Ein solider Prozess zur Verwaltung von Metadaten vereinfacht die Suche und Entdeckung von Daten für die Nutzer der Plattform.
Metadaten werden oft als "Daten über Daten" definiert. Sie sind genauso wichtig wie die Daten selbst. Metadaten helfen, die Daten zu definieren, indem sie zusätzliche Informationen liefern, die die Daten beschreiben, wie z. B. Attributname, Datentyp, Dateiname und Dateigröße.
Metadaten liefern die erforderliche Struktur und andere relevante Informationen, damit die Daten einen Sinn ergeben. Sie helfen den Nutzern, genau die Daten zu entdecken, zu verstehen und zu finden, die sie für ihre spezifischen Anforderungen benötigen.
Metadaten werden grob in technische Metadaten und geschäftliche Metadaten eingeteilt.
Technische Metadaten
Technische Metadaten liefern technische Informationen über die Daten. Ein einfaches Beispiel für technische Metadaten sind die Schemadetails einer beliebigen Tabelle. Das Schema umfasst Attributnamen, Datentypen, Längen und andere zugehörige Informationen. Tabelle 4-1 zeigt das Schema einer Produkttabelle mit drei Attributen.
| Name des Attributs | Attribut Typ | Attribut Länge | Attribut-Beschränkung |
|---|---|---|---|
| produkt_id | Ganzzahl | Nicht Null | |
| produkt_name | String | 100 | Null |
| Produkt_Kategorie | String | 50 | Null |
Ähnlich wie bei Tabellen gibt es auch bei anderen Objekten (wie Dateien) Metadaten. Dateimetadaten enthalten Details wie den Dateinamen, die Erstellungs- oder Aktualisierungszeit, die Dateigröße und die Zugriffsberechtigung. Dateien wie CSV-Dateien haben manchmal einen Header-Datensatz, der die Attributnamen der Daten definiert. Auch JSON- und XML-Dateien enthalten Attributnamen. Wie in Kapitel 3 beschrieben, enthalten auch Dateiformate wie Apache Parquet, Apache ORC und Apache Avro Metadaten.
Geschäftliche Metadaten
Geschäftliche Metadaten helfen den Nutzern, die geschäftliche Bedeutung der Daten zu verstehen. Fachliche Metadaten ergänzen die technischen Metadaten, um den Daten einen fachlichen Kontext zu geben. In Tabelle 4-2 sind die geschäftlichen Metadaten der Produkttabelle aufgeführt.
| Technischer Name des Attributs | Attribut Geschäftsname | Attribut geschäftliche Bedeutung |
|---|---|---|
| produkt_id | Produktidentifikator | Eindeutiger Bezeichner des Produkts |
| produkt_name | Produktname | Name des Produkts |
| Produkt_Kategorie | Produktkategorie | Kategorie des Produkts |
In diesem Beispiel sind die technischen Attributnamen selbsterklärend und du kannst ihre geschäftliche Bedeutung leicht verstehen. Das ist jedoch nicht immer der Fall.
Stell dir ein Szenario vor, in dem du SAP als Quellsystem und das SAP-Logistikmodul Materialwirtschaft (MM) verwendest. MARA, die die allgemeinen Materialdaten enthält, ist eine der am häufigsten verwendeten Tabellen in diesem SAP-Modul. Wie in Tabelle 4-3 dargestellt, sind die technischen Namen dieser Attribute nicht selbsterklärend, und du müsstest einen betriebswirtschaftlichen Kontext hinzufügen, damit die Benutzer verstehen, welche Daten jedes Attribut enthält.
| Technischer Name des Attributs | Attribut Geschäftsname | Attribut geschäftliche Bedeutung |
|---|---|---|
| MANDT | Kunde | Name des Kunden |
| MATNR | Materialnummer | Eindeutige Kennung des Materials |
| ERSDA | Erstellt am | Datum, an dem der Materialeintrag erstellt wurde |
Technische und geschäftliche Metadaten sind wichtig, um die Daten auf deiner Plattform besser zu verstehen. Ein solides Metadatenmanagement sollte die Möglichkeit bieten, technische und geschäftliche Metadaten zu pflegen und zu verwalten. Es sollte Governance- und Sicherheitsfunktionen wie die Zugriffskontrolle, den Umgang mit sensiblen Daten und die gemeinsame Nutzung von Daten unterstützen, auf die wir später in diesem Kapitel eingehen werden.
Wie Metaspeicher und Datenkataloge zusammenarbeiten
Das Metadatenmanagement ist ein Prozess , um die Metadaten zu verwalten und sie den Nutzern zur Verfügung zu stellen, aber wir brauchen Lösungen und Werkzeuge, um diesen Prozess umzusetzen. Metaspeicher und Datenkataloge sind die Lösungen, die dabei helfen, einen soliden Metadatenmanagementprozess aufzubauen.
Ein Metaspeicher ist ein Repository innerhalb der Datenplattform, in dem die Metadaten physisch gespeichert werden. Er dient als zentrale Speicherung von Metadaten. Von dieser zentralen Speicherung aus kannst du auf alle Metadaten zugreifen.
Ein Datenkatalog bietet einen Mechanismus für den Zugriff auf die im Metaspeicher gespeicherten Metadaten. Er bietet die erforderliche Benutzeroberfläche, um die Metadaten zu erkunden und nach verschiedenen Tabellen und Attributen zu suchen.
Abbildung 4-1 zeigt, wie Metaspeicher und Datenkataloge zusammenhängen und wie sie den Nutzern den Zugriff auf Metadaten ermöglichen.

Abbildung 4-1. Flussdiagramm der Metadaten
In den traditionellen Hadoop-Ökosystemen vor Ort stellte Hive beispielsweise den Hive Metastore (HMS) für zum Speichern von Metadaten (für Hive-Tabellen, die auf HDFS-Daten erstellt wurden) und den Hive-Katalog (HCatalog) für den Zugriff auf die HMS-Tabellen aus Spark- oder MapReduce-Anwendungen bereit.
Moderne Datenkataloge bieten einen Mechanismus, um Metadaten besser zu verwalten. Sie ermöglichen es dir, die richtigen Zugriffskontrollen für die richtigen Nutzer/innen einzurichten, damit diese sicher auf deine Daten zugreifen können. Du kannst die Kataloge logisch in Datenbanken oder Schemata unterteilen, die Tabellen, Ansichten und andere Objekte enthalten. Du kannst die Zugriffsrechte der Benutzer auf Katalogebene oder auf der detaillierteren Schema- oder Tabellenebene verwalten.
Abbildung 4-2 zeigt ein realistisches Szenario, wie ein Benutzer auf der Grundlage seiner Rollen und Rechte auf bestimmte Kataloge zugreifen kann.
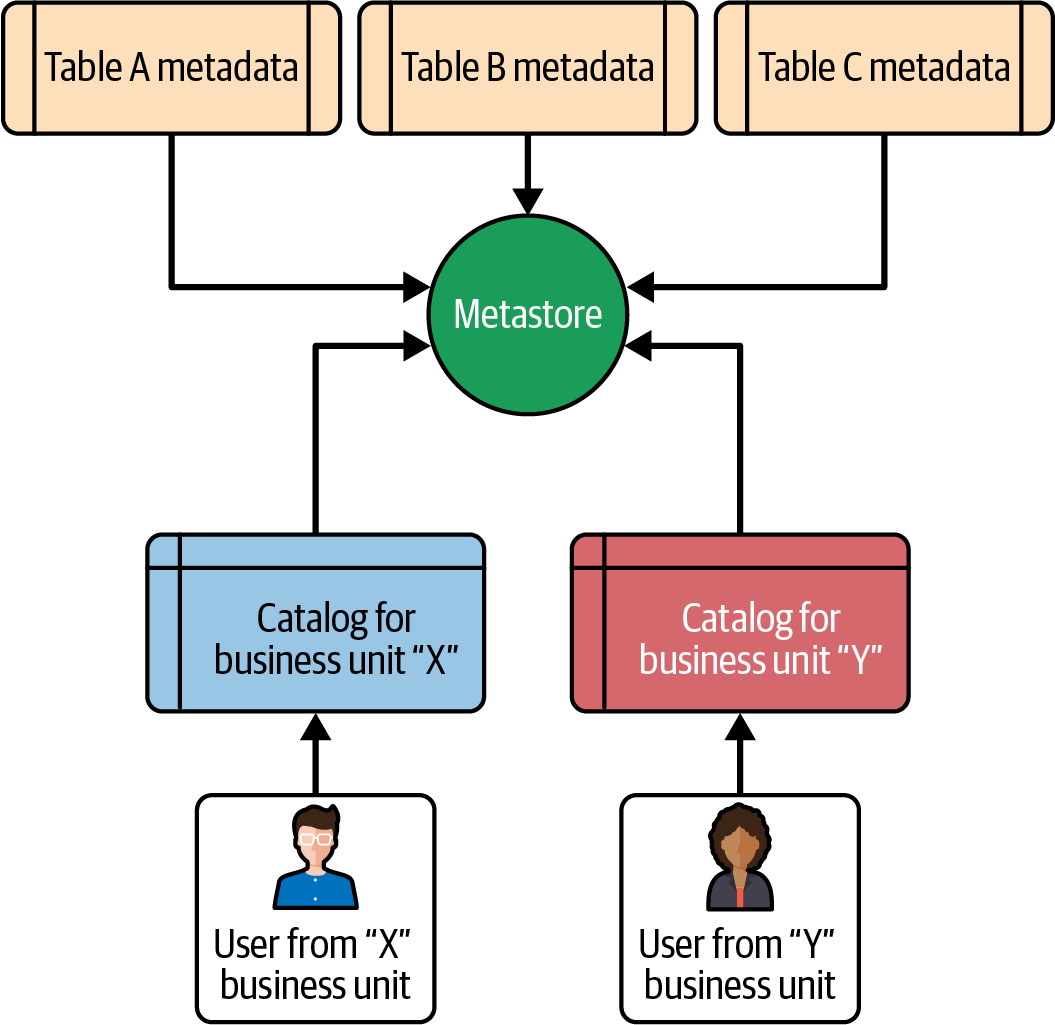
Abbildung 4-2. Katalog auf Basis von Geschäftsbereichen
Wie in Abbildung 4-2 dargestellt, können Benutzer aus dem Geschäftsbereich "X" nur auf den Katalog des Geschäftsbereichs "X" zugreifen und Benutzer aus dem Geschäftsbereich "Y" nur auf den Katalog des Geschäftsbereichs "Y".
Es ist nicht immer notwendig, die Kataloge nach Geschäftsbereichen zu kategorisieren. Es gibt verschiedene Ansätze und du kannst wählen, was für dich am besten funktioniert. Du kannst Kataloge auf der Grundlage der verschiedenen Umgebungen erstellen - z. B. Entwicklung, Test und Produktion - oder du kannst einen einzigen Katalog erstellen und die Berechtigungen auf Schema- oder Tabellenebene steuern.
Hinweis
Viele Datenexperten verwenden die Begriffe Metaspeicher und Datenkataloge synonym, um Systeme zur Speicherung von Metadaten zu beschreiben. Die meisten modernen Cloud-Dienste, die Datenkataloge anbieten, abstrahieren die physische Speicherung von Metadaten und stellen die Datenkataloge nur zur Verfügung, damit die Nutzer/innen Schemata, Tabellen und Attribute durchsuchen und darauf zugreifen können. Hinter jedem Katalog verbirgt sich eine physische Speicherung , in der die eigentlichen Metadaten gespeichert sind.
Merkmale eines Datenkatalogs
Datenkataloge bieten mehrere wichtige Funktionen, mit denen Plattformadministratoren Daten organisieren, verwalten und kontrollieren können. Die in diesem Abschnitt beschriebenen Funktionen helfen den Nutzern der Plattform, relevante Daten schnell zu suchen, zu erkunden und zu entdecken.
Daten suchen, erforschen und entdecken
Datenkataloge bieten den Nutzern einen einfachen Mechanismus, um die benötigten Daten zu suchen und zu verstehen, wo (in welchem Schema, in welcher Tabelle oder in welchem Attribut) Daten vorhanden sind, damit sie sie abfragen können. Datenkataloge bieten auch die Möglichkeit, den Tabellen und Attributen Geschäftsbeschreibungen hinzuzufügen.
Die Nutzer können den Katalog durchforsten, den geschäftlichen Kontext verstehen und Daten entdecken, die ihnen bei der weiteren Analyse helfen könnten.
Datenklassifizierung
Klassifizierung ist der Prozess der Kategorisierung von Attributen auf der Grundlage bestimmter Spezifikationen oder Standards. Du kannst die Attribute von nach Domänen (wie Kunde, Produkt und Vertrieb) oder nach Sensibilität (wie vertraulich, intern oder öffentlich) klassifizieren. Die Klassifizierung hilft den Nutzern, die Daten besser zu verstehen und zu nutzen. Ein Attribut, das als "intern" klassifiziert ist, bedeutet zum Beispiel, dass die Nutzer die Daten nicht außerhalb ihres Unternehmens weitergeben sollten.
Als Teil des Klassifizierungsprozesses kannst du Tags zu deinen Metadaten hinzufügen. Stell dir zum Beispiel ein Szenario vor, in dem du ein Lakehouse für einen Versicherungsanbieter implementierst. Du hättest mehrere Tabellen mit Kundendaten wie Kundenname, Geburtsdatum und nationale Kennung. Alle diese Attribute sind personenbezogene Daten ( PII-Attribute ). Du kannst diese Attribute in deinem Katalog als "pii_attributes" kennzeichnen und diese Tags verwenden, um Governance-Richtlinien zu implementieren, die diese sensiblen Daten vor nicht berechtigten oder externen Nutzern schützen. Wie du mit sensiblen Daten umgehst, wird in Kapitel 6 näher erläutert.
Hinweis
PII-Attribute sind Teile von Daten, die zur Identifizierung einer bestimmten Person verwendet werden können, z. B. nationale IDs, E-Mail-IDs, Telefonnummern und Geburtsdaten.
Aus Compliance-Gründen ist es zwingend erforderlich, solche Informationen von den Datenkonsumenten zu abstrahieren. Du solltest den Zugriff auf PII-Attribute nur einer bestimmten Gruppe von Nutzern auf der Grundlage ihrer organisatorischen Rolle erlauben.
Du solltest auch Data-Governance-Richtlinien einführen, um solche PII-Attribute vor nicht berechtigten Nutzern zu verbergen oder zu maskieren, die nicht berechtigt sind, die Werte in den PII-Attributen zu sehen.
Die Datenklassifizierung hilft bei der Verwaltung von Daten, der Umsetzung von Governance-Richtlinien und der Sicherung von Daten auf der Plattform.
Data Governance und Sicherheit
Datenkataloge fungieren als Gatekeeper für Daten und helfen bei der Umsetzung der Data Governance- und Sicherheitsrichtlinien, die für die Verwaltung, Steuerung und Sicherung der Daten im gesamten Unternehmen erforderlich sind.
Datenkataloge bieten folgende Governance- und Sicherheitsfunktionen:
-
Unterstützung bei der Implementierung von Standardregeln und -beschränkungen zur Erhaltung der Datenqualität
-
Implementierung des Audit-Prozesses, wie z.B. die Nachverfolgung von Benutzern, die auf bestimmte Tabellen oder Attribute zugreifen, die für die Compliance-Berichterstattung erforderlich sind
-
Unterstützung für eine fein abgestufte Berechtigungskontrolle für Benutzer, die auf die Daten zugreifen
-
Sichern Sie die Plattformdaten, indem Sie Funktionen zum Filtern oder Abstrahieren sensibler Daten bereitstellen, die auf der Plattform gespeichert sind.
-
Ermöglicht den sicheren Datenaustausch mit Datenkonsumenten
Data Governance ist ein umfassendes Thema, das wir in Kapitel 6 ausführlicher behandeln werden.
Datenabfolge
Jedes Daten- und Analyse-Ökosystem besteht aus mehreren Aufträgen, die die Daten aus den Quellsystemen aufnehmen, umwandeln und schließlich in die Zielspeicherung laden, damit die Nutzer sie nutzen können. Innerhalb dieser Speicherung kann es Hunderte von Tabellen mit Tausenden von Attributen geben, durch die die Daten über verschiedene Komponenten hinweg fließen. Wenn das System wächst, werden auch die Datenbestände immer größer. Um den Datenfluss zwischen den einzelnen Komponenten deiner Plattform zu verfolgen, brauchst du einen Tracking-Mechanismus, der dir einen Überblick darüber verschafft, wie die Daten durch diese Attribute navigieren. Data Lineage ist ein Prozess, der Informationen über diesen Datenfluss zwischen den verschiedenen Komponenten liefert.
Die Datenabfolge kann auch dabei helfen, eine Auswirkungsanalyse durchzuführen, wenn sich der Name, der Typ oder die Länge eines Attributs ändert. Und es kann dir helfen, Datenbestände wie Tabellen zu prüfen, die redundant sind oder von keinem Verbraucher verwendet werden. Datenkataloge helfen dir bei der Implementierung einer Data-Lineage-Lösung, um die Beziehung zwischen Quell- und Zielattributen zu verfolgen. Wir werden dies in Kapitel 6 näher erläutern.
Die Funktionen eines Datenkatalogs ermöglichen die Zusammenarbeit zwischen verschiedenen Datenteams und Data Personas innerhalb eines Unternehmens, so dass Geschäftsanwender/innen selbständig Analysen durchführen können, indem sie die Daten entdecken und nutzen, die sie für bessere Entscheidungen benötigen.
Vereinheitlichter Datenkatalog
Wie in Kapitel 2 erläutert, stößt die kombinierte Architektur an ihre Grenzen, da sie zwei verschiedene Speicherebenen verwendet - eine für den Data Lake und eine für das Data Warehouse. In solchen Systemen ist es außerdem schwierig, getrennte Metaspeicher und Kataloge für den Data Lake und das Data Warehouse zu verwalten.
Die Herausforderungen eines siloartigen Metadatenmanagements
Die meisten Herausforderungen, die mit der isolierten, individuellen Speicherung von Daten in der kombinierten Architektur verbunden sind, gelten auch für das Metadatenmanagement. Zu diesen Herausforderungen gehören:
- Wartung
-
Du musst separate Metadaten für Data-Lake-Objekte und Data-Warehouse-Tabellen pflegen, was den gesamten Wartungsaufwand erhöht. Du musst häufig Metadaten zwischen den beiden Systemen replizieren, um Änderungen von einem System zum anderen zu synchronisieren.
- Datenentdeckung
-
Die Datenermittlung wird in einer kombinierten Architektur zur Herausforderung, da die Nutzer zwei verschiedene Datenkataloge durchsuchen müssen. Einige Objekte, wie z. B. zusammengefasste Tabellen und aggregierte Ansichten, sind möglicherweise nur im Data Warehouse verfügbar. In solchen Fällen sollten die Nutzer der Plattform wissen, in welchem System sich die gesuchten Daten befinden.
- Datenmanagement und Sicherheit
-
Aufgrund der isolierten Speicherung auf Ebenen wird die Umsetzung von Data Governance- und Sicherheitsrichtlinien wie Zugriffskontrolle, Umgang mit sensiblen Daten und sichere Freigabe zur Herausforderung. In solchen Umgebungen gibt es keine einheitliche Data-Governance-Richtlinie, die einfach und praktisch zu implementieren und zu pflegen ist.
- Datenherkunft
-
Bei jeder Änderung des Namens, des Datentyps oder der Länge einer bestimmten Spalte musst du eine Auswirkungsanalyse durchführen, um die Tabellen zu identifizieren, in denen die betreffende Spalte vorhanden ist. In kombinierten Architekturen ist die Sicht auf die Datenabfolge auf einzelne Ökosysteme (Data Lake oder Data Warehouse) beschränkt; ein durchgängiges Verständnis des Datenflusses ist nicht möglich.
In Anbetracht dieser Herausforderungen ist es von Vorteil, einen einheitlichen Datenkatalog zu verwenden, der das Metadatenmanagement, die Datenermittlung und die Governance-Prozesse vereinfachen kann. Die Lakehouse-Architektur ermöglicht es dir, diesen einheitlichen Datenkatalog zu implementieren.
Was ist ein Unified Data Catalog?
Ein einheitlicher Datenkatalog ist ein Katalog, der Metadaten aller Datenbestände wie Tabellen, Ansichten, Berichte und Funktionen sowie KI-Bestände wie ML-Modelle und Feature-Tabellen enthalten kann. Ein einheitlicher Datenkatalog ermöglicht es seinen Nutzern, alle ihre Daten und KI-Assets von einer einzigen, zentralen Plattform aus zu verwalten. In der Lakehouse-Architektur befinden sich alle Daten- und KI-Workloads in einer einzigen Cloud-Speicherebene, so dass Plattformadministratoren einen einheitlichen Datenkatalog zur Verwaltung und Steuerung des gesamten Ökosystems implementieren können.
Abbildung 4-3 zeigt einen einheitlichen Datenkatalog innerhalb einer Lakehouse-Plattform und die wichtigsten Funktionen, die er bietet.
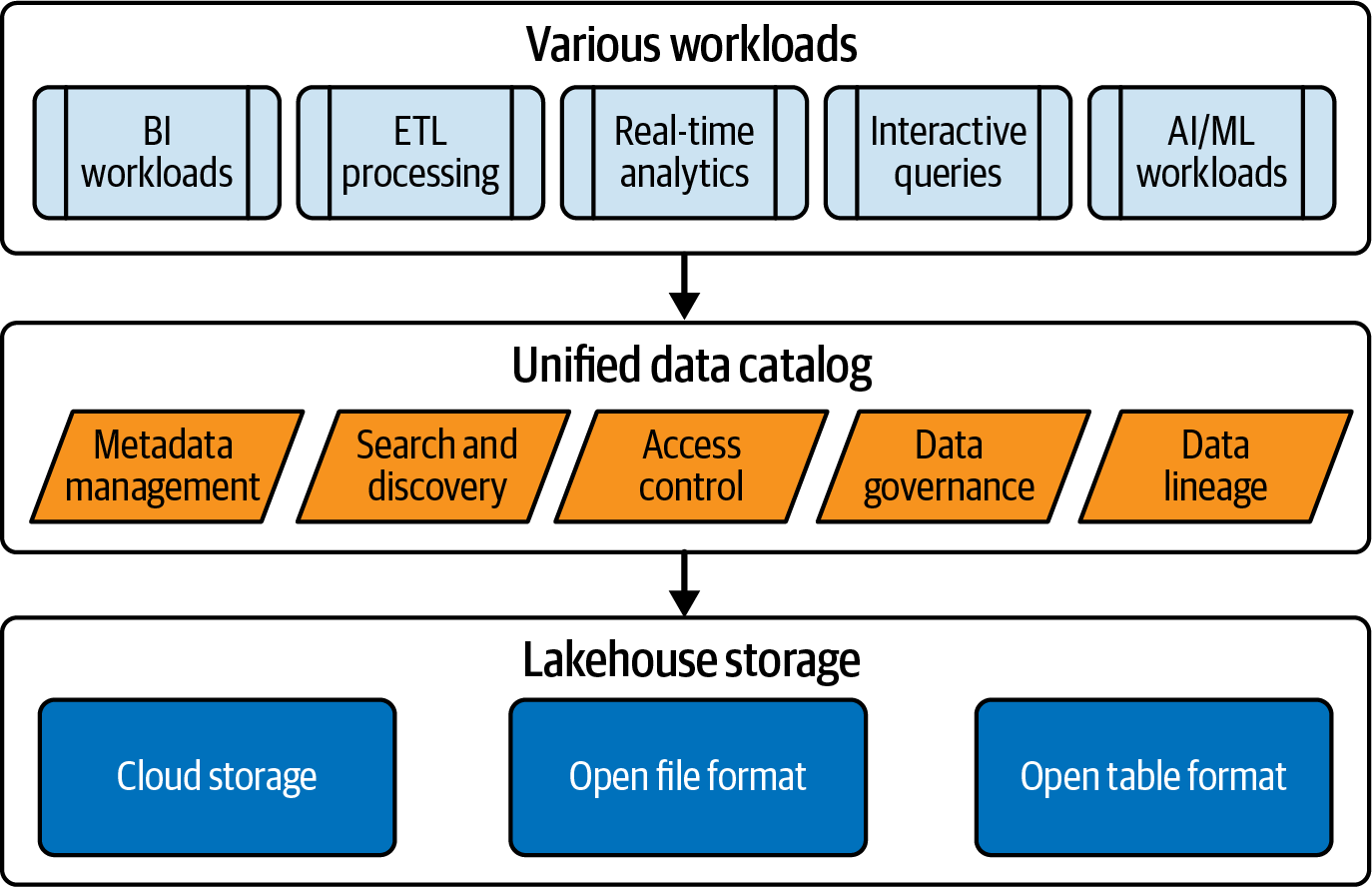
Abbildung 4-3. Vereinheitlichter Datenkatalog in einer Lakehouse-Plattform
Wie bereits erwähnt, bietet ein Datenkatalog wichtige Funktionen wie Suche, Erkennung, Governance und Abstammung. In einem einheitlichen Datenkatalog können Unternehmen diese Funktionen für alle Datenobjekte wie Tabellen, Ansichten und Berichte sowie für alle in KI-Workloads verwendeten Assets wie Modelle und Feature Stores implementieren.
Ein vereinheitlichter Datenkatalog bietet eine einzige Schnittstelle für verschiedene Daten-Personen wie Dateningenieure, Analysten und Wissenschaftler, um effizient zusammenzuarbeiten und gemeinsam Daten zu erforschen und zu nutzen. Er dient sowohl technischen als auch geschäftlichen Nutzern als zentrales Repository zum Suchen und Entdecken von Daten.
Zusammenfassend lässt sich sagen, dass ein einheitlicher Datenkatalog dein Fenster ist, um die gesamten Daten und KI-Assets innerhalb der Plattform zu erkunden, die technischen Metadaten dieser Assets zu durchsuchen und den geschäftlichen Kontext der Daten zu verstehen.
Vorteile eines Unified Data Catalog
Die wichtigsten Vorteile eines einheitlichen Datenkatalogs sind folgende:
- Vereinheitlichte Suche und Datenermittlung
-
In der Lakehouse-Architektur kannst du eine einzige Metaspeicherschicht implementieren, die alle Metadaten des gesamten Ökosystems enthält. Anders als bei der kombinierten Architektur können die Nutzer/innen die Metadaten aller Datenbestände mithilfe eines einheitlichen Datenkatalogs durchsuchen und erkunden. So können sie schnell die gewünschten Tabellen oder Attribute suchen, ohne zu wissen, wo sich die Daten im System befinden.
-
Datenkataloge bieten auch Funktionen, um technische Daten mit geschäftlichem Kontext zu ergänzen. Dateneigentümer können Attribute mit Geschäftsbeschreibungen und geschäftlichen Bedeutungen versehen. Auf diese Weise können Fachanwender und technische Benutzer Daten leicht finden.
- Konsistente Zugriffskontrollen
-
Die Verwaltung und Aufrechterhaltung des Zugangs zu Daten ist schwierig. Noch schwieriger wird es, wenn du auf deiner gesamten Plattform einheitliche Zugriffsebenen einführen willst. Einheitliche Datenkataloge helfen dabei, eine einheitliche Zugriffskontrolle über das gesamte Datenökosystem hinweg zu implementieren.
-
Du kannst eine einheitliche Zugriffskontrolle für verschiedene Personen einführen, unabhängig davon, welche Compute Engines sie nutzen. Stell dir ein Szenario vor, in dem du möchtest, dass die Data Engineers und Data Scientists deines Vertriebsteams auf ihre geschäftsbereichsspezifischen Datenbestände zugreifen können. Die Dateningenieure könnten Notebooks verwenden, während die Datenwissenschaftler die Tabellen des Feature Stores abfragen möchten, um auf die Daten zuzugreifen. Mit der einheitlichen Zugriffskontrolle kannst du beiden Personas die gleichen Zugriffsrechte gewähren.
- Einheitliche Datenverwaltung und -sicherheit
-
Mit einem einheitlichen Datenkatalog kannst du einheitliche Data Governance- und Sicherheitsrichtlinien umsetzen, die für alle Assets gelten, einschließlich Tabellen, Dateien, Funktionen, ML-Modelle und Feature-Tabellen. Du kannst deine Daten schützen, indem du die konsistenten Maskierungsrichtlinien auf sensible Daten im Lakehouse anwendest. Jede Persona kann unabhängig von dem Tool, mit dem sie auf die Daten zugreift, nur die Daten sehen, für die sie eine Zugriffsberechtigung hat.
- Durchgängige Datenabfolge
-
Mit einem Lakehouse, das einen einheitlichen Metaspeicher und Katalog verwendet, kannst du ganz einfach die End-to-End-Abstammung über alle Komponenten hinweg sehen. Einige der fortschrittlichen Datenkataloge bieten auch die Möglichkeit, Verbundkataloge zu implementieren, in denen die Metadaten von Quellen außerhalb deiner Datenplattform sowie die Abstammung dieser Quellen angezeigt werden können.
-
Durch die Vereinheitlichung verschiedener Aspekte der Datenverwaltungsprozesse über alle Assets hinweg erhalten die Nutzer/innen der Lakehouse-Plattform eine einheitliche Erfahrung, egal wo sie auf die Daten zugreifen.
Implementierung eines Datenkatalogs: Wichtige Designüberlegungen und Optionen
Es gibt mehrere Tools und Plattformen, die dir bei der Implementierung von Datenkatalogen in einem Lakehouse helfen können. Jeder Cloud-Provider hat seine eigenen Dienste und die meisten führenden Produkte von Drittanbietern verfügen über Funktionen zur Implementierung von Datenkatalogen.
Du kannst einen einheitlichen Datenkatalog auf der Grundlage deines Anwendungsfalls und der gesamten technischen Landschaft entwerfen und implementieren. In diesem Abschnitt gehe ich auf einige der führenden Datenkatalog-Tools, Designüberlegungen, mögliche Designentscheidungen und die wichtigsten Einschränkungen bei der Implementierung eines Datenkatalogs in einer Lakehouse-Plattform ein.
Wir besprechen den weit verbreiteten Hive-Metaspeicher, Cloud-native Datenkataloge von AWS, Azure und GCP sowie Datenkatalogangebote von Drittanbietern wie Databricks.
Hive Metaspeicher verwenden
Hive ist seit den Hadoop-Tagen sehr beliebt. Viele Unternehmen haben den Hive-Metaspeicher (HMS) eingeführt, um ihre Anforderungen an die Metadatenverwaltung zu erfüllen, während sie Hadoop-Ökosysteme oder moderne Datenplattformen implementieren. Traditionelle Hadoop-Ökosysteme verwendeten MapReduce als Berechnungsmaschine und HCatalog als Datenkatalog für den Zugriff auf HMS. Spark verfügt ebenfalls über eine Datenkatalog-API für den Zugriff auf die im HMS gespeicherten Metadaten.
Du kannst HMS für die Speicherung der Metadaten für deine Datenplattform verwenden. HMS bietet den Nutzern die Flexibilität, ein externes RDBMS zu verwenden, um Metadaten wie Tabellentypen, Spaltennamen und Spalten-Datentypen zu speichern. Es dient als zentrales Repository für die Speicherung und Verwaltung der Metadaten von Tabellen, die mit verschiedenen Compute Engines wie Hive, Spark oder Flink erstellt wurden. Native Cloud-Dienste wie AWS Glue und Drittanbieter wie Databricks und viele andere bieten Optionen zur Nutzung von HMS für die Speicherung von Metadaten.
Obwohl viele Organisationen HMS als ihren primären Metaspeicher eingeführt haben, gibt es eine Reihe von Herausforderungen:
-
Du musst ein separates RDBMS bereitstellen und verwalten, um die Metadaten zu speichern, was den Wartungsaufwand erhöht.
-
Da es sich nicht um einen nativen Cloud-Dienst handelt, musst du im Vergleich zu Cloud-nativen Datenkatalogdiensten zusätzlichen Aufwand für seine Integration betreiben.
In Anbetracht dieser Herausforderungen haben CSPs native Katalogisierungsdienste eingeführt, um die Verwaltung von Metadaten einfach und unkompliziert zu gestalten.
AWS-Dienste nutzen
AWS bietet zwei Optionen für die Speicherung von Metadaten - HMS und Glue Data Catalog.
Glue Data Catalog, ein nativer AWS-Service, lässt sich problemlos mit Services wie AWS Glue ETL, Amazon EMR, Amazon Athena und AWS Lake Formation integrieren. Du würdest die meisten dieser Dienste nutzen, wenn du eine Lakehouse-Plattform in AWS implementierst.
Hinweis
Hier ist eine kurze Beschreibung der eben erwähnten AWS-Services. Ich werde sie in den folgenden Kapiteln dieses Buches im Detail besprechen:
-
AWS Glue ETL ist ein serverloser Datenintegrationsdienst zur Erstellung von Spark-Aufträgen für die Datenverarbeitung.
-
Amazon EMR bietet eine Big-Data-Plattform zur Ausführung von Frameworks wie Spark, Hive, Presto, HBase und anderen Big-Data-Frameworks für Datenverarbeitung, interaktive Analysen und maschinelles Lernen.
-
Amazon Athena ist ein serverloser Service für die interaktive Analyse von Daten, die auf S3 gespeichert sind.
-
AWS Lake Formation bietet Funktionen zur Sicherung und Verwaltung von Daten in S3.
Abbildung 4-4 zeigt ein einfaches Flussdiagramm, wie du Hudi-Dateien in S3 erstellst, sie parst, um Metadaten im Glue Data Catalog zu erstellen, Hudi-Tabellen mit Lake Formation verwaltest und sie mit der Amazon Athena Engine abfragst. Du kannst auch andere offene Tabellenformate wie Iceberg oder Delta Lake anstelle von Hudi verwenden.
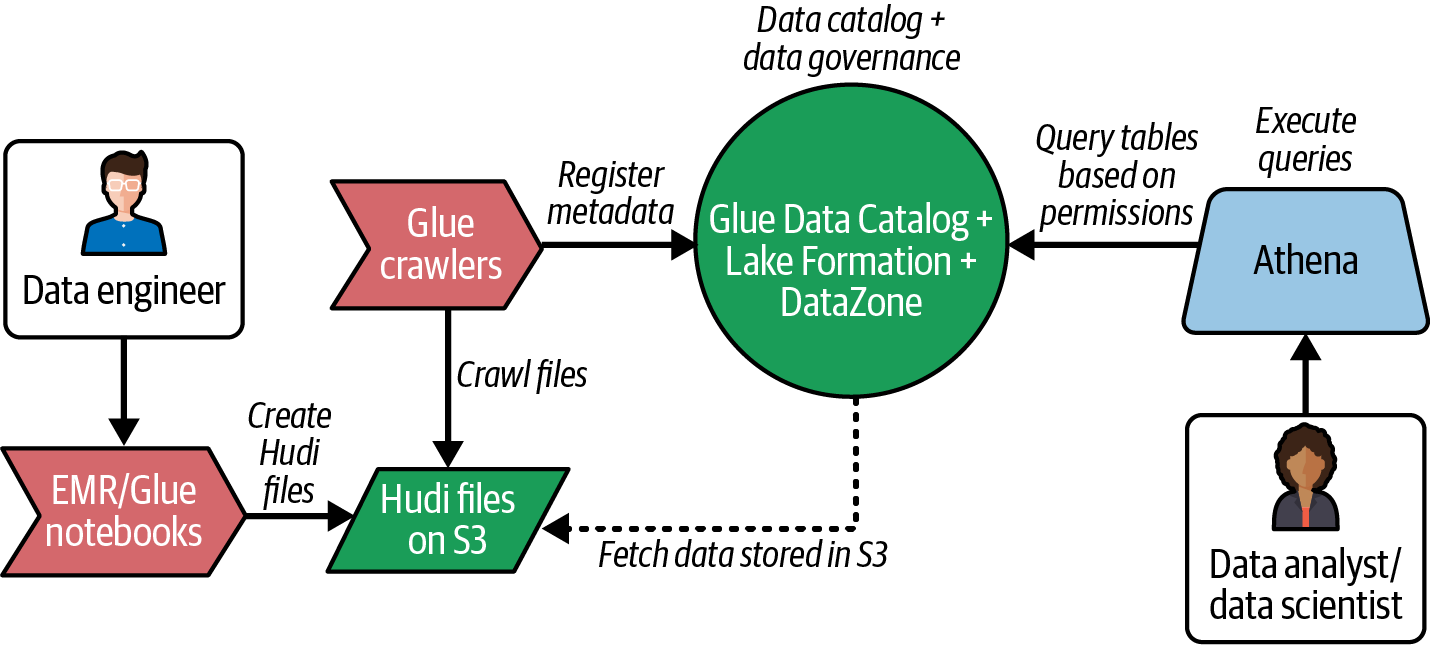
Abbildung 4-4. Lakehouse-Datenfluss im AWS-Ökosystem
Wie das Diagramm zeigt, spielt der Glue Data Catalog eine wichtige Rolle in der Lakehouse-Architektur, um verschiedenen Personas das Erstellen, den Zugriff und die Abfrage von Daten auf S3 zu ermöglichen.
Wie HMS bietet auch der Glue Data Catalog ein zentrales Metadaten-Repository für alle Datenbestände. Die wichtigsten Funktionen von AWS Glue Data Catalog sind folgende:
-
Es verfügt über umfassende Integrationen mit anderen AWS-Diensten.
-
Es handelt sich um einen vollständig verwalteten, serverlosen Dienst, der nicht vom Nutzer bereitgestellt oder gewartet werden muss.
-
Du kannst Glue Crawler verwenden, um die Datendateien aus S3 zu analysieren und Metadaten im Katalog zu erstellen.
-
Die Integration mit Amazon Athena bietet eine Benutzeroberfläche, mit der du das Schema, die Tabellen und die Attribute leicht erkunden kannst.
-
Tabellen, die mit Open-Source-Frameworks wie Spark, Hive und Presto innerhalb des EMR-Clusters erstellt wurden, können Glue Data Catalog zum Speichern ihrer Metadaten verwenden.
-
Sie ist mit AWS Lake Formation integriert, um den Nutzern eine fein abgestufte Zugriffskontrolle zu ermöglichen.
Amazon bietet auch einen Service mit dem Namen Amazon DataZone an, der dir bei der Implementierung eines Datenkatalogs helfen kann, der die technischen Metadaten mit geschäftlichen Metadaten anreichert. Du kannst die in Glue Data Catalog gespeicherten Metadaten in DataZone importieren und den technischen Attributen Geschäftsbeschreibungen hinzufügen, um ihnen einen geschäftlichen Kontext zu geben. Mit DataZone, das intern Lake Formation für das Berechtigungsmanagement und die gemeinsame Nutzung von Daten nutzt, kannst du deine Daten weiter verwalten und freigeben.
Beachte die folgenden wichtigen Punkte, wenn du AWS-Services nutzt, um einen Datenkatalog für deine Lakehouse-Plattform zu implementieren:
- Datenkatalog anstelle von HMS einkleben
-
Glue Data Catalog ist eine Alternative zu HMS. Du kannst Glue Data Catalog als Metaspeicher für die Metadaten der Tabellen verwenden, die mit Abfrage-Engines wie Hive, Spark und Presto innerhalb des Amazon EMR-Clusters erstellt werden. Glue Data Catalog unterstützt die Speicherung von Metadaten für Hudi, Iceberg und Delta Lake Tabellen. Die Fähigkeit, dein bevorzugtes offenes Tabellenformat zu unterstützen, ist eine der wichtigsten Überlegungen bei der Auswahl eines Datenkatalogdienstes.
- Glue Crawler für die automatische Erstellung von Metadaten
-
Du kannst AWS Glue Crawler verwenden, um die Datendateien in S3 zu crawlen und die Metadaten zu holen (zu parsen). Glue Crawler speichern die Metadaten im Glue Data Catalog und erstellen die Tabellen auf der Grundlage der aus den Dateien geparsten Datensätze. Du kannst Crawler verwenden, um die Metadaten für alle deine in S3 gespeicherten Dateien zu generieren. Glue Crawler können auch Schemaänderungen im S3-Datenspeicher erkennen. Du kannst die Crawler so konfigurieren, dass sie die Tabellenänderungen im Datenkatalog entweder aktualisieren oder ignorieren.
- Unterstützung von Tabellenformaten
-
Glue Crawler unterstützen jetzt auch Hudi, Iceberg und Delta Lake Dateien, um automatisch Tabellen im Glue Data Catalog zu erstellen. Je nachdem, welches Tabellenformat du wählst, kannst du bei der Erstellung der Crawler die entsprechende Option auswählen.
- Lake Formation für Data Governance
-
Glue Data Catalog ist gut in Lake Formation integriert, mit dem du fein abgestufte Zugriffskontrollen und andere Data Governance-Funktionen wie rollenbasierte Datenfilterung und sichere Datenfreigabe implementieren kannst.
- Athena für die Datenexploration
-
Glue Data Catalog verfügt über eine tiefe Integration mit Amazon Athena, einem Dienst zur Abfrage von Daten im S3 Data Lake. Wir werden dies in Kapitel 5 im Detail besprechen. Mit Athena kannst du alle Datenbanken, Tabellen und Spalten im Glue Data Catalog abfragen.
Azure-Dienste nutzen
Wenn du planst, ein Lakehouse mit dem Azure-Ökosystem zu implementieren, wirst du Dienste wie Azure Synapse Analytics als Rechenschicht und ADLS als Speicherschicht nutzen.
Synapse Analytics bietet zwei Compute Engines zur Verarbeitung der in ADLS gespeicherten Daten: Synapse Spark-Pools und Synapse serverlose SQL-Pools. Dateningenieure, die mit der Spark-Programmierung vertraut sind, können die Spark-Pools nutzen. Für Datenanalysten, die sich mit SQL besser auskennen, bietet Synapse serverlose SQL-Pools. Du kannst beide Pools nutzen, um in ADLS gespeicherte Daten zu verarbeiten. Wir werden diese Compute Engines in Kapitel 5 genauer besprechen.
Abbildung 4-5 zeigt die beiden Optionen, die Synapse Analytics für die Pflege und Verwaltung der Metadaten für die in ADLS gespeicherten Daten anbietet - die Lake-Datenbank und die SQL-Datenbank:
- See-Datenbank
-
Die Synapse Spark-Pools verwalten die Lake-Datenbanken. Du kannst Lake-Datenbanken verwenden, um die Metadaten der Objekte zu speichern, die mit den Synapse-Notebooks erstellt wurden. Dazu gehören auch die Metadaten von Deltatabellen, die mit Spark-Pools erstellt wurden.
- SQL-Datenbank
-
Serverlose SQL-Pools verwalten die Synapse-SQL-Datenbanken. Du kannst mit Synapse Serverless SQL Pools in der SQL-Datenbank Tabellen erstellen und die Serverless SQL Endpunkte verwenden, um Management Studio oder Power BI mit den Tabellen in der SQL-Datenbank zu verbinden und Daten abzufragen.
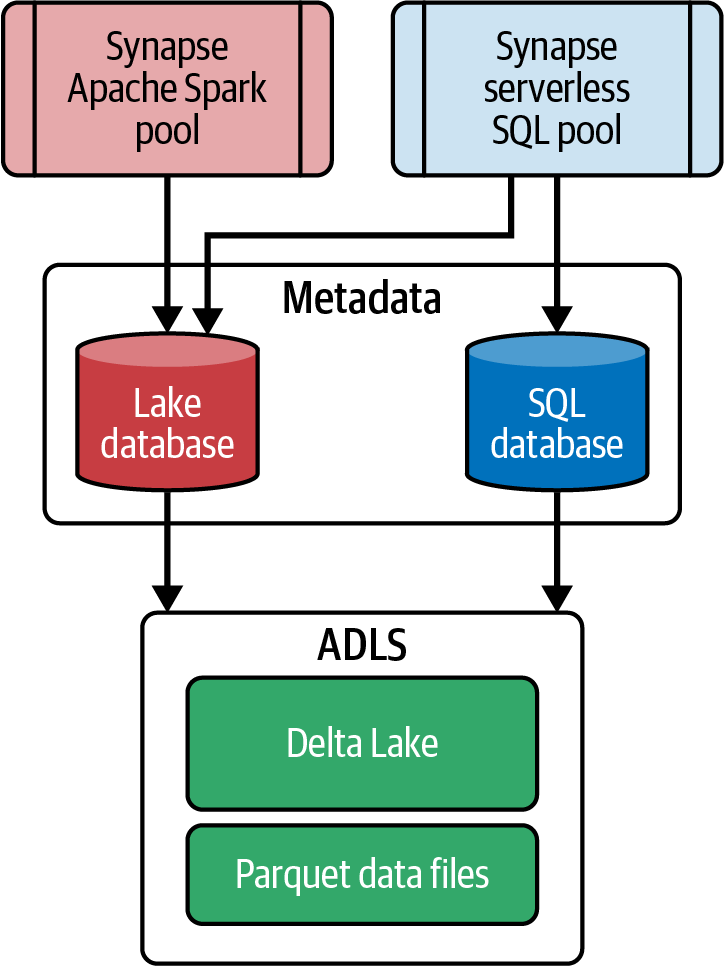
Abbildung 4-5. Verwaltung von Metadaten mit Synapse Analytics
Hinweis
Die Synapse-SQL-Datenbank unterscheidet sich vom Azure-SQL-Datenbankdienst (relationale Datenbank). Die Synapse SQL-Datenbank enthält die Metadaten von Tabellen, die mit den Synapse Serverless SQL-Pools erstellt wurden. Sie enthält nicht die eigentlichen Daten, da diese auf ADLS gespeichert sind.
Je nachdem, welche Compute Engine du verwendest, kannst du die Lake Database (für Spark-Pools) oder die SQL Database (für serverlose SQL-Pools) auswählen. Wie in Abbildung 4-5 dargestellt, liegt der Vorteil der Lake Database darin, dass du sowohl von Synapse-Notebooks als auch von Synapse-Serverless-SQL-Pools aus auf sie zugreifen kannst.
Abbildung 4-6 zeigt, wie du Deltatabellen in ADLS und Metadaten in einer Lake-Datenbank erstellen und einen einheitlichen Katalog mit Microsoft Purview implementieren kannst, um ihn sicher mit Synapse serverlosen SQL-Pools für weitere Analysen abzufragen.
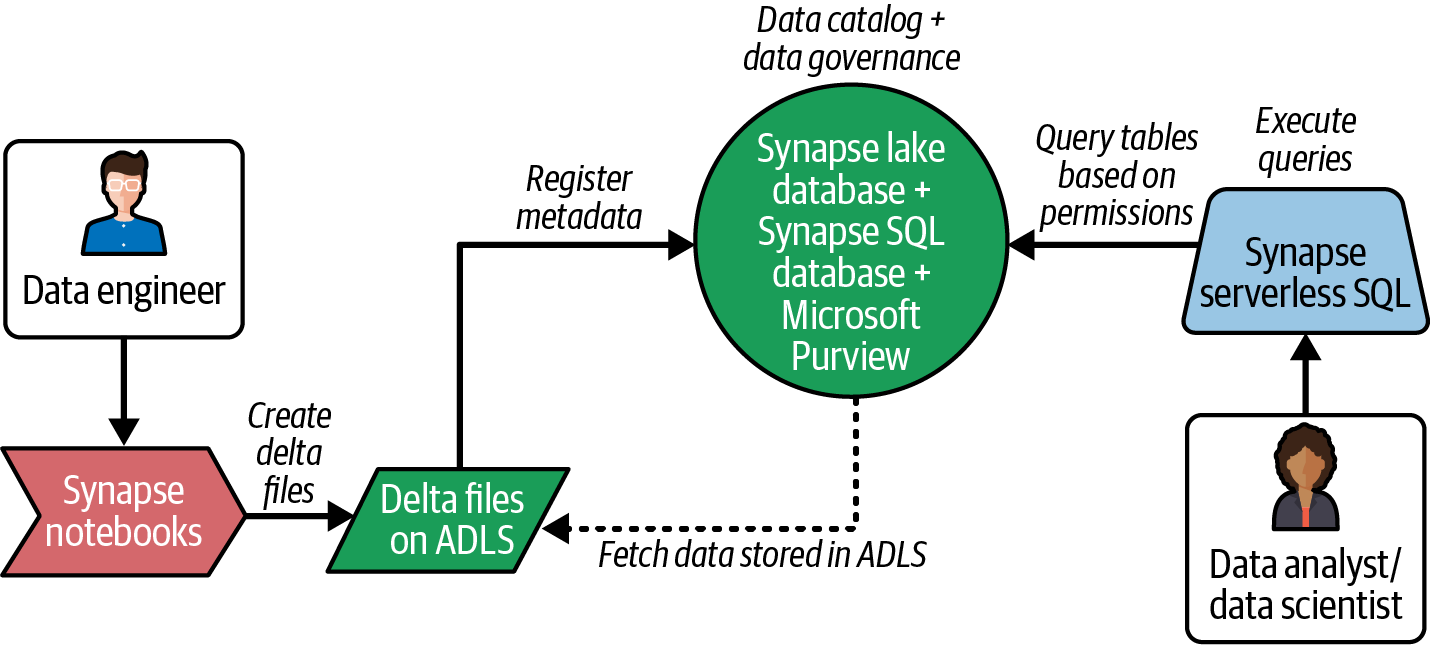
Abbildung 4-6. Lakehouse-Datenfluss im Azure-Ökosystem
Wie in Abbildung 4-6 dargestellt, kannst du mit Synapse-Notebooks Deltatabellen erstellen und dann den serverlosen SQL-Pool-Endpunkt verwenden, um die Daten mit Power BI oder einem anderen Datenbankabfrage-Editor wie SQL Server Management Studio (SSMS) abzufragen.
Die Synapse-See-Datenbank und die SQL-Datenbank bewahren zwar die Metadaten auf, sind aber keine vollwertigen Katalogisierungslösungen. Azure bietet einen Dienst namens Microsoft Purview, der Katalogfunktionen bereitstellt. Du kannst ihn nutzen, um einen Datenkatalog für dein Lakehouse zu erstellen.
Microsoft Purview bietet Unterstützung für eine einheitliche Data Governance auf lokalen, nativen Azure- und Multi-Cloud-Plattformen sowie Unterstützung für die Datenklassifizierung und den Umgang mit sensiblen Daten. Darüber hinaus bietet es Funktionen wie Data Lineage, Zugriffskontrolle und Datenfreigabe sowie Funktionen zur Erstellung und Pflege eines Geschäftsglossars für Geschäftsanwender. Du kannst die Metadaten aus der Synapse SQL-Datenbank in Microsoft Purview importieren und diese Funktionen in deiner Plattform nutzen.
GCP-Dienste nutzen
Wie bei AWS und Azure kannst du deinen Datenkatalog in GCP nach einem ähnlichen Muster erstellen und ihn als zentrale, einheitliche Ebene für das Metadatenmanagement nutzen.
Abbildung 4-7 zeigt, wie du Iceberg-Tabellen in GCS und Metadaten in BigLake erstellst, die Metadaten mit Dataplex zentral verwaltest und sie mit BigQuery für weitere Analysen sicher abfragst.
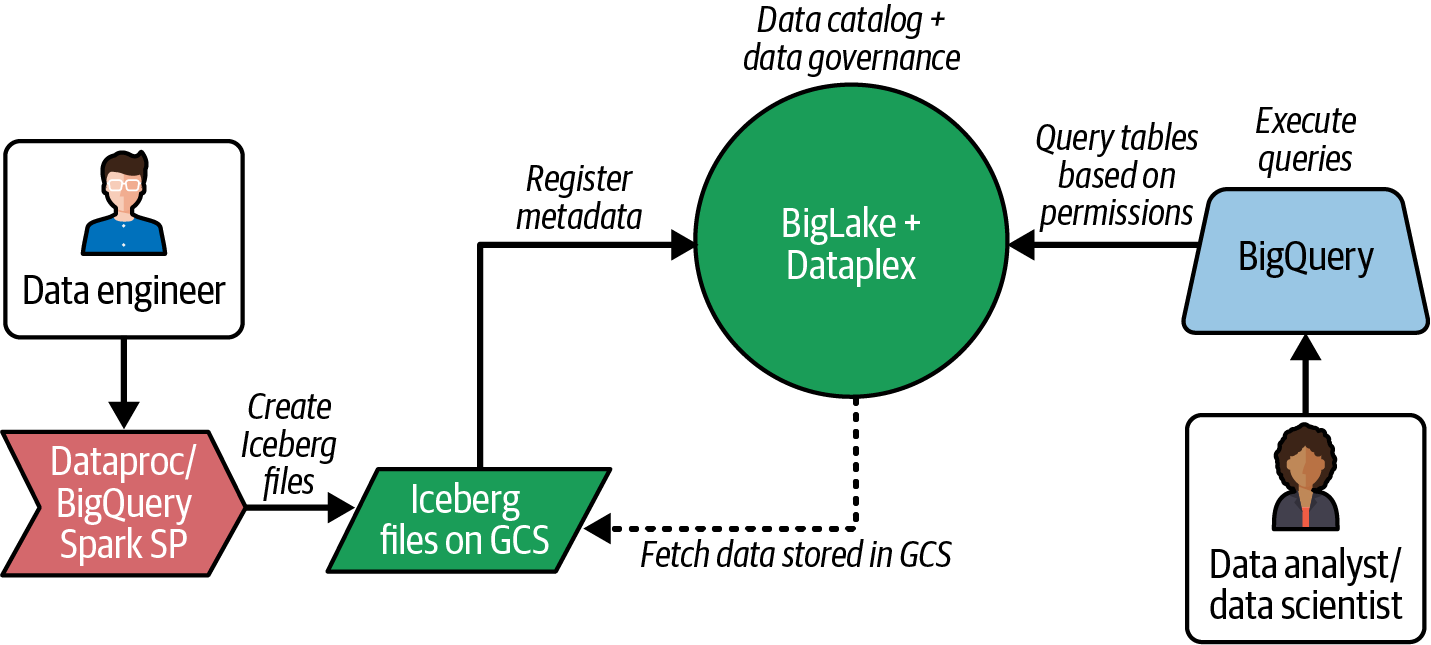
Abbildung 4-7. Datenfluss des Seehauses im GCP-Ökosystem
Hinweis
Hier ist eine kurze Beschreibung der in Abbildung 4-7 gezeigten Compute Services, die ich in den folgenden Kapiteln im Detail besprechen werde:
- BigLake
-
BigLake ist ein GCP-Dienst, der es BigQuery und anderen Open-Source-Frameworks wie Spark ermöglicht, mit einer feinkörnigen Zugriffskontrolle auf die in GCS gespeicherten Daten zuzugreifen. Er unterstützt das offene Iceberg-Tabellenformat und ermöglicht es BigQuery-Nutzern, Iceberg-Daten abzufragen, die in GCS als BigLake-Tabellen mit kontrollierten Berechtigungen gespeichert sind.
-
Die wichtigsten Merkmale von BigLake sind:
-
Es bietet einen Metastore, um auf Iceberg-Tabellen aus BigQuery zuzugreifen.
-
Es kann Iceberg-Tabellen, die in Dataproc oder BigQuery erstellt wurden, synchronisieren und sie den Nutzern über die BigQuery-SQL-Schnittstelle zur Verfügung stellen.
-
Sie ermöglicht es Administratoren, eine fein abgestufte Zugriffskontrolle für Iceberg-Tabellen zu implementieren.
BigLake unterstützt derzeit nur Parquet-Dateien für Iceberg und hat noch ein paar weitere Einschränkungen.
-
- Dataplex
-
Dataplex ist ein GCP-Dienst, der es Unternehmen ermöglicht, ihre Datenbestände zu entdecken und zu verwalten. Er bietet die Möglichkeit, Daten zu erforschen, den Lebenszyklus von Daten zu verwalten und den Datenfluss mithilfe der End-to-End-Abstammung zu verstehen.
BigLake ist mit Dataplex integriert, um eine zentrale Zugriffskontrolle für BigLake-Tabellen zu ermöglichen. Du kannst Dataplex für deine Plattform in Betracht ziehen, wenn du alle deine Datenbestände von einem einzigen Fenster aus verwalten willst.
Databricks verwenden
Mit dem Aufkommen des Multi-Cloud-Gedankens haben viele Unternehmen begonnen, nach Produkten von Drittanbietern zu suchen, die sich gut in ihre Multi-Cloud-Strategie integrieren lassen. Databricks bietet ein solches Produkt an, das es Unternehmen ermöglicht, eine Multi-Cloud-Strategie zu verfolgen, da es die AWS-, Azure- und GCP-Infrastruktur für die Berechnung und Speicherung nutzen kann.
Hinweis
Die Multi-Cloud-Strategie ist ein Ansatz zur Nutzung mehrerer Cloud-Plattformen, um die besten Funktionen und Kostenvorteile zu nutzen, die von verschiedenen CSPs angeboten werden. Viele Unternehmen entscheiden sich heute für mehr als einen Cloud-Provider, um ihre Datenökosysteme zu implementieren.
Databricks bietet mehrere Optionen für die Katalogisierung von Metadaten. Du kannst HMS oder einen eigenen Dienst namens Databricks Unity Catalog für die Verwaltung, Pflege und Steuerung von Metadaten nutzen. Unity Catalog hilft dabei, eine einheitliche Governance-Lösung für alle Daten und KI-Assets in einem Lakehouse zu implementieren.
Ähnlich wie AWS Glue Data Catalog ist Unity Catalog ein nativer Service innerhalb von Databricks und bietet einfache Integrationen mit Databricks-Funktionen wie Notebooks und Databricks SQL.
Hinweis
Databricks SQL ist eine serverlose Compute Engine innerhalb der Databricks Lakehouse Plattform. Du kannst sie nutzen, um interaktive Abfragen im Lakehouse auszuführen. In Kombination mit einem Abfrage-Editor (ein Dienst, der in der Databricks UI für die Erstellung von Abfragen zur Verfügung steht) kannst du ganz einfach Datenbestände aus dem HMS oder dem Unity-Katalog durchsuchen und Abfragen mit SQL-Befehlen ausführen.
Abbildung 4-8 zeigt ein einfaches Flussdiagramm innerhalb eines mit Azure Databricks implementierten Lakehouse. Du kannst die Deltadateien mit Databricks Notebooks erstellen und über Databricks SQL auf die Deltatabellen zugreifen.
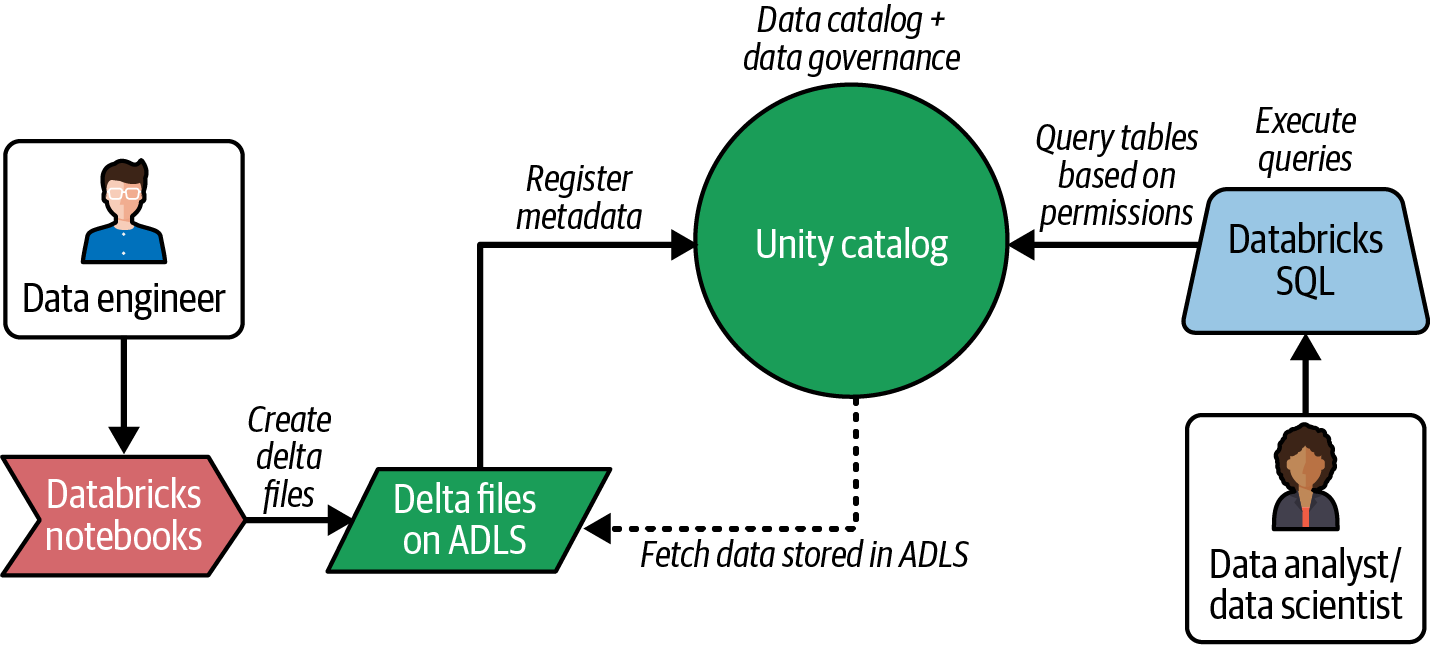
Abbildung 4-8. Lakehouse Datenfluss im Databricks Ökosystem
Unity Catalog spielt eine wichtige Rolle, denn er bietet Funktionen zur Verwaltung von Metadaten an einem zentralen Ort, auf den sowohl Databricks Notebooks als auch Databricks SQL zugreifen können. Außerdem bietet er einen zentralen Mechanismus für die Zugriffskontrolle zur Umsetzung von Data Governance-Richtlinien.
Die wichtigsten Funktionen des Unity-Katalogs sind folgende:
-
Fähigkeit, alle Daten und KI-Assets wie Tabellen, Ansichten, Notebooks, ML-Modelle, Feature-Tabellen und Dashboards zu verwalten und zu steuern
-
Die Möglichkeit, geschäftlichen Kontext hinzuzufügen, erleichtert die Suche und das Auffinden von Daten
-
Die Möglichkeit, föderierte Kataloge (zum Zeitpunkt der Erstellung dieses Buches in der Vorschau) für externe Quellen wie MySQL, PostgreSQL/Postgres, Snowflake und Redshift bereitzustellen
-
End-to-End-Datenabgleich über die Databricks-Ökosysteme, einschließlich KI-Komponenten
-
Sichere Datenfreigabe durch fein abgestufte Zugriffskontrollen für Datenfreigaben
-
Alle Schema- und Metadatenänderungen in Notebooks werden sofort und ohne Verzögerung in Databricks SQL übernommen (im Vergleich zu Azure Synapse Analytics mit Delta Lake).
Unity Catalog wurde vor kurzem von Databricks als Open Source zur Verfügung gestellt und wird bald verschiedene Daten- und KI-Produkte unterstützen.
Unity Catalog ist eine hervorragende Option für die Implementierung eines Lakehouse innerhalb des Databricks-Ökosystems. Wenn du jedoch auch außerhalb von Databricks auf Metadaten zugreifen und diese verwalten möchtest, kannst du auch andere Kataloge in Erwägung ziehen, die Daten aus Databricks Unity Catalog aufnehmen und sie Nutzern außerhalb von Databricks für eine einfachere Suche und zentrale Verwaltung zur Verfügung stellen können.
Tipp
Viele Funktionen und Dienste, die in diesem Abschnitt beschrieben werden, sind relativ neu oder befinden sich noch im Vorschaumodus. Sie werden sich allmählich weiterentwickeln und ausgereift sein, und für einige der hier besprochenen Einschränkungen werden Workarounds oder Lösungen angeboten werden. Wenn du diese Tools für deinen Anwendungsfall untersuchst, solltest du die aktuelle Dokumentation lesen und die neuesten Versionen testen.
Neben den cloud nativen Katalogen gibt es Open-Source-Kataloge wie Project Nessie und Enterprise-Katalogisierungstools wie Alation, Collibra und Atlan, die zusätzliche Funktionen und Vorteile bieten, die du für deine spezifischen Anforderungen untersuchen kannst.
Die wichtigsten Erkenntnisse
In diesem Kapitel haben wir besprochen, wie du die Metadaten für alle deine Datenbestände in einem Metaspeicher speichern und mit Hilfe von Datenkatalogen basierend auf Zugriffsberechtigungen darauf zugreifen kannst. Die Lakehouse-Architektur ermöglicht es dir, einen einheitlichen Datenkatalog zu implementieren, um alle deine Daten und KI-Assets zu verwalten, zu steuern und gemeinsam zu nutzen.
Tabelle 4-4 fasst die verschiedenen Dienste zusammen, die auf den Cloud-Plattformen für die Implementierung von Metadaten-Managementprozessen zur Verfügung stehen.
| Anbieter | Verwaltung technischer Metadaten | Management von Unternehmensmetadaten und Data Governance |
|---|---|---|
| AWS | HMS, Leimdatenkatalog | DataZone |
| Azurblau | Synapse Lake Datenbank, Synapse SQL Datenbank | Microsoft Blickwinkel |
| GCP | BigLake | Dataplex |
| Databricks | HMS, Einheits-Katalog | Einheits-Katalog |
Tabelle 4-5 fasst die wichtigsten Designüberlegungen für jedes Ökosystem zusammen, wenn ein Datenkatalog in einer Lakehouse-Architektur implementiert wird.
In diesem Kapitel haben wir uns auf Metaspeicher und Datenkataloge sowie deren Funktionen und Vorteile in der Lakehouse-Architektur konzentriert. Im nächsten Kapitel werden wir die verschiedenen Rechen- und Datenverbrauchsoptionen in der Lakehouse-Architektur besprechen und wie sie den verschiedenen Personas helfen, Daten- und Analyseaufgaben effizient zu erledigen.
Referenzen
- AWS
- Azurblau
- GCP
- Databricks
- Andere
Get Praktische Seehaus-Architektur now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

