Kapitel 1. Falco stellt sich vor
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Das Ziel dieses ersten Kapitels des Buches ist es zu erklären, was Falco ist. Keine Sorge, wir machen es uns leicht! Zunächst werden wir uns ansehen, was Falco macht, und einen Überblick über seine Funktionen und eine einführende Beschreibung der einzelnen Komponenten geben. Wir werden uns mit den Designprinzipien beschäftigen, die Falco inspiriert haben und die auch heute noch seine Entwicklung leiten. Dann werden wir besprechen, was du mit Falco machen kannst, was nicht in seinen Bereich fällt und was du besser mit anderen Tools erreichen kannst. Zum Schluss werden wir einige historische Zusammenhänge aufzeigen, um die Dinge ins rechte Licht zu rücken.
Falco kurz und bündig
Auf der obersten Ebene ist Falco ziemlich einfach: Du installierst mehrere Sensoren in einer verteilten Infrastruktur. Jeder Sensor sammelt Daten (vom lokalen Rechner oder über eine API), führt eine Reihe von Regeln aus und benachrichtigt dich, wenn etwas Schlimmes passiert. Abbildung 1-1 zeigt ein vereinfachtes Diagramm, wie das funktioniert.
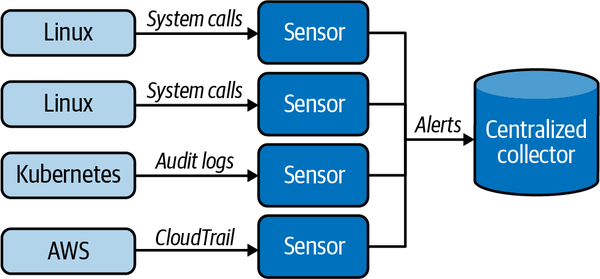
Abbildung 1-1. Die High-Level-Architektur von Falco
Du kannst dir Falco wie ein Netzwerk von Sicherheitskameras für deine Infrastruktur vorstellen: Du platzierst die Sensoren an wichtigen Stellen, sie beobachten, was vor sich geht, und pingen dich an, wenn sie schädliches Verhalten entdecken. Bei Falco wird schädliches Verhalten durch eine Reihe von Regeln definiert, die die Community für dich erstellt und pflegt und die du für deine Bedürfnisse anpassen oder erweitern kannst. Die von deiner Flotte von Falco-Sensoren erzeugten Warnmeldungen können theoretisch auf dem lokalen Rechner verbleiben, aber in der Praxis werden sie normalerweise an einen zentralen Sammler exportiert. Für das zentrale Sammeln von Warnmeldungen kannst du ein allgemeines SIEM-Tool (Security Information and Event Management) oder ein spezielles Tool wie Falcosidekick verwenden. (Wir werden das Sammeln von Warnmeldungen in Kapitel 12 ausführlich behandeln.)
Jetzt wollen wir etwas tiefer in die Falco-Architektur eindringen und ihre wichtigsten Komponenten untersuchen, angefangen bei den Sensoren.
Sensoren
Abbildung 1-2 zeigt, wie die Falco-Sensoren funktionieren.

Abbildung 1-2. Falco Sensor Architektur
Der Sensor besteht aus einer Engine, die zwei Eingänge hat: eine Datenquelle und einen Satz von Regeln. Der Sensor wendet die Regeln auf jedes Ereignis an, das von der Datenquelle kommt. Wenn eine Regel mit einem Ereignis übereinstimmt, wird eine Meldung ausgegeben. Ganz einfach, oder?
Datenquellen
Jeder Sensor kann Eingabedaten aus einer Reihe von Quellen sammeln. Ursprünglich wurde Falco ausschließlich für Systemaufrufe entwickelt, die bis heute eine der wichtigsten Datenquellen sind. Wir werden die Systemaufrufe in den Kapiteln 3 und 4 ausführlich behandeln, aber für den Moment kannst du dir vorstellen, dass ein laufendes Programm sie als Schnittstelle zu seiner Außenwelt nutzt. Das Öffnen oder Schließen einer Datei, das Herstellen oder Empfangen einer Netzwerkverbindung, das Lesen und Schreiben von Daten auf und von der Festplatte oder dem Netzwerk, das Ausführen von Befehlen und die Kommunikation mit anderen Prozessen über Pipes oder andere Arten der Interprozesskommunikation sind alles Beispiele für die Verwendung von Systemaufrufen.
Falco sammelt Systemaufrufe, indem es den Kernel des Linux-Betriebssystems (OS) instrumentiert. Dies kann auf zwei verschiedene Arten geschehen: durch den Einsatz eines Kernelmoduls (d.h. eines ausführbaren Codes, der im Kernel des Betriebssystems installiert werden kann, um die Funktionalität des Kernels zu erweitern) oder durch eine Technologie namens eBPF, die es ermöglicht, Skripte auszuführen, die sicher Aktionen innerhalb des Betriebssystems durchführen. Wir werden in Kapitel 4 ausführlich über Kernelmodule und eBPF sprechen.
Durch den Zugriff auf diese Daten erhält Falco einen unglaublichen Einblick in alles, was in deiner Infrastruktur passiert. Hier sind einige Beispiele für Dinge, die Falco für dich erkennen kann:
-
Privilegienerweiterungen
-
Zugang zu sensiblen Daten
-
Eigentümerschaft und Moduswechsel
-
Unerwartete Netzwerkverbindungen oder Socket-Mutationen
-
Unerwünschte Programmausführung
-
Datenexfiltration
-
Verstöße gegen die Vorschriften
Falco wurde auch erweitert, um neben Systemaufrufen auch andere Datenquellen anzuzapfen (wir zeigen dir im Laufe des Buches Beispiele). Falco kann zum Beispiel deine Cloud-Logs in Echtzeit überwachen und dich benachrichtigen, wenn in deiner Cloud-Infrastruktur etwas Schlimmes passiert. Hier sind einige weitere Beispiele für Dinge, die Falco für dich erkennen kann:
-
Wenn sich ein Benutzer ohne Multifaktor-Authentifizierung anmeldet
-
Wenn eine Cloud-Service-Konfiguration geändert wird
-
Wenn jemand auf eine oder mehrere sensible Dateien in einem Amazon Web Services (AWS) S3-Bucket zugreift
Es werden regelmäßig neue Datenquellen zu Falco hinzugefügt. Daher empfehlen wir, die Website und den Slack-Kanal zu besuchen, um auf dem Laufenden zu bleiben.
Regeln
Regeln sagen der Falco-Engine, was sie mit den Daten aus den Quellen machen soll. Sie ermöglichen es dem Nutzer, Richtlinien in einem kompakten und lesbaren Format zu definieren. Falco wird mit einem umfassenden Satz von Regeln ausgeliefert, die die Sicherheit von Hosts, Containern, Kubernetes und der Cloud abdecken, und du kannst ganz einfach deine eigenen Regeln erstellen, um sie anzupassen. Wir werden viel Zeit auf Regeln verwenden, vor allem in den Kapiteln 7 und 13. Wenn du dieses Buch fertig gelesen hast, wirst du ein absoluter Meister darin sein. Hier ist ein Beispiel, um deinen Appetit zu wecken:
-rule:shell_in_containerdesc:shell opened inside a containercondition:spawned_process and container.id != host and proc.name = bashoutput:shell in a container (user=%user.name container_id=%container.id)Source:syscallpriority:WARNING
Diese Regel erkennt, wenn eine Bash-Shell innerhalb eines Containers gestartet wird, was in einer unveränderlichen containerbasierten Infrastruktur normalerweise nicht gut ist. Die wichtigsten Einträge in einer Regel sind die Bedingung, die Falco mitteilt, worauf es achten soll, und die Ausgabe, die dir Falco mitteilt, wenn die Bedingung ausgelöst wird. Wie du siehst, beziehen sich sowohl die Bedingung als auch die Ausgabe auf Felder, eines der wichtigsten Konzepte in Falco. Die Bedingung ist ein boolescher Ausdruck, der die Überprüfung von Feldern mit Werten kombiniert (im Wesentlichen ein Filter). Die Ausgabe ist eine Kombination aus Text und Feldnamen, deren Werte in der Benachrichtigung ausgedruckt werden. Die Syntax ist ähnlich wie die einer print Anweisung in einer Programmiersprache.
Erinnert dich das an Netzwerk-Tools wie tcpdump oder Wireshark? Gut gesehen: Sie waren eine große Inspiration für Falco.
Datenanreicherung
Umfangreiche Datenquellen und eine flexible Regel-Engine machen Falco zu einem leistungsstarken Sicherheitstool zur Laufzeit. Darüber hinaus bereichern Metadaten von verschiedenen Anbietern die Erkennungen.
Wenn Falco dir mitteilt, dass etwas passiert ist - zum Beispiel, dass eine Systemdatei geändert wurde - brauchst du normalerweise mehr Informationen, um die Ursache und den Umfang des Problems zu verstehen. Welcher Prozess hat das getan? Geschah es in einem Container? Wenn ja, wie lauteten die Namen des Containers und des Images? Welcher Dienst/Namespace war der Ort des Geschehens? War es in der Produktion oder in der Entwicklung? Wurde die Änderung von root vorgenommen?
Die Datenanreicherungs-Engine von Falco hilft bei der Beantwortung all dieser Fragen, indem sie den Zustand der Umgebung aufbaut, einschließlich der laufenden Prozesse und Threads, der geöffneten Dateien, der Container und Kubernetes-Objekte, in denen sie ausgeführt werden, usw. Alle diese Informationen sind für die Regeln und Ausgaben von Falco zugänglich. Du kannst zum Beispiel eine Regel ganz einfach so einschränken, dass sie nur in der Produktion oder in einem bestimmten Dienst ausgelöst wird.
Ausgangskanäle
Jedes Mal, wenn eine Regel ausgelöst wird, gibt die entsprechende Engine eine Benachrichtigung aus. In der einfachsten Konfiguration schreibt die Engine die Meldung auf die Standardausgabe (was, wie du dir vorstellen kannst, normalerweise nicht sehr nützlich ist). Zum Glück bietet Falco ausgeklügelte Möglichkeiten, die Ausgaben an verschiedene Stellen weiterzuleiten, z. B. an Logsammel-Tools, Cloud-Speicherservices wie S3 und Kommunikationstools wie Slack und E-Mail. Zum Ökosystem gehört ein fantastisches Projekt namens Falcosidekick, das speziell dafür entwickelt wurde, Falco mit der Welt zu verbinden und das Sammeln von Ausgaben mühelos zu machen (mehr dazu in Kapitel 12 ).
Container und mehr
Falco wurde für die moderne Welt der Cloud Native Applications entwickelt und bietet daher hervorragende Unterstützung für Container, Kubernetes und die Cloud. Da es in diesem Buch um Cloud Native Security geht, werden wir uns hauptsächlich darauf konzentrieren, aber bedenke, dass Falco nicht auf Container und Kubernetes in der Cloud beschränkt ist. Du kannst es auch als Host-Sicherheitstool verwenden, und viele der vorinstallierten Regeln können dir dabei helfen, deine Linux-Serverflotte zu sichern. Falco bietet auch eine gute Unterstützung für die Netzwerkerkennung, mit der du die Aktivitäten von Verbindungen, IP-Adressen, Ports, Clients und Servern überprüfen und Warnungen erhalten kannst, wenn sie unerwünschtes oder unerwartetes/atypisches Verhalten zeigen.
Falco's Designprinzipien
Nachdem du nun weißt, was Falco macht, lass uns darüber reden, warum es so ist, wie es ist. Wenn du eine Software von nicht zu vernachlässigender Komplexität entwickelst, ist es wichtig, sich auf die richtigen Anwendungsfälle zu konzentrieren und die wichtigsten Ziele zu priorisieren. Manchmal bedeutet das, Kompromisse in Kauf zu nehmen. Falco ist da keine Ausnahme. Bei der Entwicklung von Falco haben wir uns von einer Reihe von Grundsätzen leiten lassen. In diesem Abschnitt werden wir untersuchen, warum diese Prinzipien gewählt wurden und wie sich jedes von ihnen auf die Architektur und die Funktionen von Falco auswirkt. Wenn du diese Prinzipien verstehst, kannst du beurteilen, ob Falco für deine Anwendungsfälle geeignet ist, und du kannst das Beste aus ihm herausholen.
Spezialisiert auf Laufzeit
Die Falco-Engine ist darauf ausgelegt, Bedrohungen zu erkennen, während deine Dienste und Anwendungen laufen. Wenn Falco unerwünschtes Verhalten feststellt, sollte es dich sofort alarmieren (höchstens innerhalb von Sekunden), damit du sofort informiert bist (und reagieren kannst!) und nicht erst, wenn schon Minuten oder Stunden vergangen sind.
Dieses Konstruktionsprinzip kommt in drei wichtigen architektonischen Entscheidungen zum Ausdruck. Erstens ist die Falco-Engine als Streaming-Engine konzipiert, die Daten schnell verarbeiten kann, sobald sie eintreffen, anstatt sie zu speichern und später zu verarbeiten. Das bedeutet, dass die Korrelation verschiedener Ereignisse, selbst wenn sie möglich ist, nicht das primäre Ziel ist und sogar davon abgeraten wird. Drittens wertet Falco die Regeln so nah wie möglich an der Datenquelle aus. Wenn möglich, vermeidet Falco den Transport von Informationen vor ihrer Verarbeitung und bevorzugt den Einsatz umfangreicherer Engines an den Endpunkten.
Geeignet für die Produktion
Du solltest Falco in jeder Umgebung einsetzen können, auch in Produktionsumgebungen, in denen Stabilität und geringer Overhead von größter Bedeutung sind. Es sollte deine Anwendungen nicht zum Absturz bringen und sie so wenig wie möglich verlangsamen.
Dieses Designprinzip wirkt sich auf die Architektur der Datenerfassung aus, insbesondere wenn Falco auf Endpunkten mit vielen Prozessen oder Containern läuft. Die Falco-Treiber (das Kernelmodul und die eBPF-Sonde) wurden in vielen Iterationen und jahrelangen Tests auf ihre Leistung und Stabilität hin überprüft. Das Sammeln von Daten durch Anzapfen des Kernels des Betriebssystems im Gegensatz zur Instrumentierung der überwachten Prozesse/Container garantiert, dass deine Anwendungen nicht aufgrund von Fehlern in Falco abstürzen.
Die Falco-Engine ist in C++ geschrieben und verwendet viele Hilfsmittel, um den Ressourcenverbrauch zu reduzieren. Zum Beispiel vermeidet sie Systemaufrufe, die Festplatten- oder Netzwerkdaten lesen oder schreiben. In gewisser Weise ist das eine Einschränkung, weil es die Benutzer daran hindert, Regeln zu erstellen, die den Inhalt von Nutzdaten untersuchen, aber es stellt auch sicher, dass der CPU- und Speicherverbrauch niedrig bleibt, was viel wichtiger ist.
Intent-Free Instrumentation
Falco wurde entwickelt, um das Anwendungsverhalten zu beobachten, ohne dass die Benutzer Anwendungen neu kompilieren, Bibliotheken installieren oder Container mit Monitoring-Hooks neu erstellen müssen. Das ist in modernen Container-Umgebungen sehr wichtig, in denen Änderungen an jeder einzelnen Komponente einen unrealistischen Arbeitsaufwand bedeuten würden. Es garantiert außerdem, dass Falco jeden Prozess und jeden Container sieht, egal woher er kommt, wer ihn betreibt oder wie lange er schon läuft.
Optimiert für den Einsatz am Rande der Welt
Im Vergleich zu anderen Policy-Engines (z. B. OPA) wurde Falco ausdrücklich mit Blick auf eine verteilte Multisensor-Architektur entwickelt. Die Sensoren sind leichtgewichtig, effizient und portabel und können in verschiedenen Umgebungen eingesetzt werden. Es kann auf einem physischen Host, in einer virtuellen Maschine oder als Container eingesetzt werden. Die Falco-Binärdatei wurde für mehrere Plattformen entwickelt, einschließlich ARM.
Vermeidet das Verschieben und Speichern einer Tonne von Daten
Die meisten derzeit auf dem Markt befindlichen Produkte zur Erkennung von Bedrohungen basieren darauf, eine große Anzahl von Ereignissen an ein zentrales SIEM-Tool zu senden und die gesammelten Daten anschließend auszuwerten. Falco wurde nach einem ganz anderen Prinzip entwickelt: Es bleibt so nah wie möglich am Endpunkt, führt Erkennungen vor Ort durch und sendet nur Warnmeldungen an eine zentrale Sammelstelle. Dieser Ansatz führt zu einer Lösung, die zwar etwas weniger komplexe Analysen durchführen kann, dafür aber einfach zu bedienen, viel kostengünstiger ist und sich sehr gut horizontal skalieren lässt.
Skalierbar
Apropos Skalierung: Ein weiteres wichtiges Entwicklungsziel von Falco ist, dass es in der Lage sein sollte, die größten Infrastrukturen der Welt zu unterstützen. Wenn du sie betreiben kannst, sollte Falco in der Lage sein, sie zu sichern. Wie wir gerade beschrieben haben, sind die Beibehaltung eines begrenzten Zustands und die Vermeidung einer zentralisierten Speicherung wichtige Elemente dafür. Edge Computing ist ebenfalls ein wichtiges Element, denn die Verteilung der Regelauswertung ist der einzige Ansatz, um ein Tool wie Falco wirklich horizontal zu skalieren.
Ein weiterer wichtiger Aspekt der Skalierbarkeit ist die Instrumentierung der Endpunkte. Der Datenerfassungs-Stack von Falco verwendet keine Techniken wie Sidecars, Bibliotheksverknüpfung oder Prozessinstrumentierung. Der Grund dafür ist, dass die Ressourcenauslastung all dieser Techniken mit der Anzahl der zu überwachenden Container, Bibliotheken oder Prozesse steigt. Vielbeschäftigte Rechner haben viele Container, Bibliotheken und Prozesse - zu viele, als dass diese Techniken funktionieren könnten - aber sie haben nur einen Betriebssystemkern. Das Erfassen von Systemaufrufen im Kernel bedeutet, dass du nur einen Falco-Sensor pro Maschine brauchst, egal wie groß die Maschine ist. Das macht es möglich, Falco auf großen Rechnern mit viel Aktivität einzusetzen.
Wahrheitsgemäß
Ein weiterer Vorteil der Verwendung von Systemaufrufen als Datenquelle? Systemaufrufe lügen nie. Falco ist schwer zu umgehen, denn der Mechanismus, mit dem es Daten sammelt, lässt sich nur sehr schwer deaktivieren oder umgehen. Wenn du versuchst, ihn zu umgehen oder zu umgehen, hinterlässt du Spuren, die Falco aufzeichnen kann.
Robuste Standardwerte, reichlich erweiterbar
Ein weiteres wichtiges Ziel bei der Entwicklung war es, die Zeit zu minimieren, die du brauchst, um aus Falco Nutzen zu ziehen. Du solltest in der Lage sein, die Software einfach zu installieren und sie nicht anpassen zu müssen, es sei denn, du hast besondere Anforderungen.
Wann immer jedoch Anpassungen erforderlich sind, bietet Falco Flexibilität. Du kannst zum Beispiel neue Regeln mithilfe einer umfangreichen und ausdrucksstarken Syntax erstellen, neue Datenquellen entwickeln und einsetzen, die den Umfang der Erkennungen erweitern, und Falco in die von dir gewünschten Benachrichtigungs- und Ereignissammlungs-Tools integrieren.
Einfach
Die Einfachheit ist die letzte Designentscheidung, die Falco zugrunde liegt, aber sie ist auch eine der wichtigsten. Die Syntax der Falco-Regeln ist kompakt, leicht zu lesen und einfach zu lernen. Wann immer möglich, sollte eine Falco-Regelbedingung in eine einzige Zeile passen. Jeder, nicht nur Experten, sollte in der Lage sein, eine neue Regel zu schreiben oder eine bestehende Regel zu ändern. Es ist in Ordnung, wenn dadurch die Ausdruckskraft der Syntax eingeschränkt wird: Falco soll eine effiziente Sicherheitsregel-Engine liefern, keine vollwertige domänenspezifische Sprache. Dafür gibt es bessere Werkzeuge.
Die Einfachheit zeigt sich auch in den Prozessen zur Erweiterung von Falco für neue Datenquellen und zur Integration mit einem neuen Cloud-Service oder Containertyp, für die du einfach ein Plugin in einer beliebigen Sprache, einschließlich Go, C und C++, schreiben kannst. Falco lädt diese Plugins ganz einfach und du kannst sie verwenden, um neue Datenquellen oder neue Felder für die Verwendung in Regeln hinzuzufügen.
Was du mit Falco tun kannst
Falco glänzt bei der Erkennung von Bedrohungen, Eindringlingen und Datendiebstahl zur Laufzeit und in Echtzeit. Es funktioniert gut mit Legacy-Infrastrukturen, ist aber besonders gut für Container, Kubernetes und Cloud-Infrastrukturen geeignet. Sie sichert sowohl Workloads (Prozesse, Container, Dienste) als auch die Infrastruktur (Hosts, VMs, Netzwerk, Cloud-Infrastruktur und -Dienste). Sie ist leichtgewichtig, effizient und skalierbar und kann sowohl in der Entwicklung als auch in der Produktion eingesetzt werden. Es kann viele Klassen von Bedrohungen erkennen, aber wenn du mehr brauchst, kannst du es anpassen. Außerdem gibt es eine florierende Community, die es unterstützt und ständig verbessert.
Was du mit Falco nicht tun kannst
Kein einziges Tool kann alle deine Probleme lösen. Zu wissen, was du mit Falco nicht machen kannst, ist genauso wichtig wie zu wissen, wo du es einsetzen kannst. Wie bei jedem Tool gibt es auch hier Kompromisse. Erstens ist Falco keine universelle Regelsprache: Es bietet nicht die Ausdruckskraft einer vollständigen Programmiersprache und kann keine Korrelation zwischen verschiedenen Engines herstellen. Stattdessen ist die Regel-Engine so konzipiert, dass sie relativ zustandslose Regeln in hoher Frequenz an vielen Stellen in deiner Infrastruktur anwendet. Wenn du auf der Suche nach einer leistungsstarken, zentralisierten Policy-Sprache bist, empfehlen wir dir OPA.
Zweitens ist Falco nicht darauf ausgelegt, die gesammelten Daten in einem zentralen Repository zu speichern, damit du sie auswerten kannst. Die Regelvalidierung erfolgt am Endpunkt, und nur die Warnmeldungen werden an einen zentralen Speicherort gesendet. Wenn du dich auf fortgeschrittene Analysen und Big Data-Abfragen konzentrierst, empfehlen wir dir, eines der vielen auf dem Markt erhältlichen Tools für die Logsammlung zu verwenden.
Schließlich prüft Falco aus Effizienzgründen keine Netzwerk-Nutzdaten. Daher ist es nicht das richtige Werkzeug, um Layer 7 (L7) Sicherheitsrichtlinien umzusetzen. Ein herkömmliches netzwerkbasiertes Intrusion Detection System (IDS) oder eine L7-Firewall sind für solche Anwendungsfälle die bessere Wahl.
Hintergrund und Geschichte
Die Autoren dieses Buches haben einen Teil der Geschichte von Falco miterlebt, und in diesem letzten Abschnitt stellen wir unsere Erinnerungen und Perspektiven vor. Wenn du dich nur für den Einsatz von Falco interessierst, kannst du den Rest dieses Kapitels getrost auslassen. Wir sind jedoch der Meinung, dass das Wissen um den Ursprung von Falco dir nützliche Informationen über die Architektur von Falco geben kann, die dir helfen werden, Falco besser zu nutzen. Außerdem ist es eine lustige Geschichte!
Netzwerkpakete: BPF, libpcap, tcpdump und Wireshark
Auf dem Höhepunkt des Internet-Booms Ende der 1990er Jahre wurden Computernetzwerke immer beliebter. Damit wuchs auch die Notwendigkeit, sie zu beobachten, Fehler zu beheben und zu sichern. Leider konnten sich viele Betreiber die damals verfügbaren Tools zur Netzwerküberwachung nicht leisten, da sie alle kommerziell angeboten wurden und sehr teuer waren. Die Folge war, dass viele Leute im Dunkeln tappten.
Schon bald begannen Teams auf der ganzen Welt, an Lösungen für dieses Problem zu arbeiten. In einigen Fällen ging es darum, bestehende Betriebssysteme um Paketaufzeichnungsfunktionen zu erweitern, d. h. einen handelsüblichen Computerarbeitsplatz in ein Gerät zu verwandeln, das in einem Netzwerk sitzt und alle von anderen Arbeitsplätzen gesendeten oder empfangenen Pakete sammeln kann. Eine solche Lösung, der Berkeley Packet Filter (BPF), wurde von Steven McCanne und Van Jacobson an der Universität von Kalifornien in Berkeley entwickelt und soll den BSD-Betriebssystemkern erweitern. Wenn du Linux verwendest, kennst du vielleicht eBPF, eine virtuelle Maschine, mit der sich beliebiger Code im Linux-Kernel sicher ausführen lässt (das e steht für erweitert). eBPF ist eine der angesagtesten modernen Funktionen des Linux-Kernels. Sie hat sich nach vielen Jahren der Verbesserungen zu einer extrem leistungsfähigen und flexiblen Technologie entwickelt, obwohl sie als kleines programmierbares Packet Capture- und Filtering-Modul für BSD Unix begann.
Die BPF wurde mit einer Bibliothek namens libpcap ausgeliefert, mit der jedes Programm rohe Netzwerkpakete aufzeichnen konnte. Ihre Verfügbarkeit löste eine Vielzahl von Netzwerk- und Sicherheitstools aus. Das erste Tool, das auf libpcap basierte, war der Befehlszeilen-Netzwerkanalysator tcpdump, der auch heute noch in fast jeder Unix-Distribution enthalten ist. Im Jahr 1998 wurde jedoch ein GUI-basierter Open-Source-Protokollanalysator namens Ethereal (2006 in Wireshark umbenannt) eingeführt. Es wurde zum Industriestandard für die Paketanalyse und ist es immer noch.
Was tcpdump, Wireshark und viele andere beliebte Netzwerk-Tools gemeinsam haben, ist die Fähigkeit, auf eine reichhaltige, genaue und vertrauenswürdige Datenquelle zuzugreifen, die auf nicht-invasive Weise gesammelt werden kann: rohe Netzwerkpakete. Behalte dieses Konzept im Hinterkopf, während du weiterliest!
Snort und paketbasierte Laufzeitsicherheit
Introspektions-Tools wie tcpdump und Wireshark waren die natürlichen ersten Anwendungen des BPF Packet Capture Stacks. Doch schon bald wurden die Leute kreativ, wenn es um die Verwendung von Paketen ging. Martin Roesch zum Beispiel veröffentlichte 1998 ein Open-Source-Tool zur Erkennung von Eindringlingen in Netzwerke namens Snort. Snort ist eine Regel-Engine, die aus dem Netzwerk erfasste Pakete verarbeitet. Es verfügt über ein umfangreiches Regelwerk, das Bedrohungen und unerwünschte Aktivitäten erkennen kann, indem es die Pakete, die darin enthaltenen Protokolle und die Nutzdaten, die sie enthalten, untersucht. Es inspirierte die Entwicklung ähnlicher Tools wie Suricata und Zeek.
Was Tools wie Snort so leistungsfähig macht, ist ihre Fähigkeit, die Sicherheit von Netzwerken und Anwendungen zu überprüfen , während die Anwendungen laufen. Das ist wichtig, denn es bietet Schutz in Echtzeit, und der Fokus auf das Laufzeitverhalten macht es möglich, Bedrohungen zu erkennen, die auf Schwachstellen beruhen, die noch nicht bekannt geworden sind.
Die Krise der Netzwerkpakete
Du hast gerade gesehen, warum Netzwerkpakete als Datenquelle für Transparenz, Sicherheit und Fehlerbehebung so beliebt sind. Auf ihnen basierende Anwendungen haben mehrere erfolgreiche Branchen hervorgebracht. Es gab jedoch auch Trends, die die Nützlichkeit von Datenpaketen als Quelle der Wahrheit untergruben:
-
Das umfassende Sammeln von Paketen wurde immer komplizierter, vor allem in Umgebungen wie der Cloud, wo der Zugang zu Routern und Netzwerkinfrastrukturen begrenzt ist.
-
Verschlüsselung und Netzwerkvirtualisierung machten es schwieriger, wertvolle Informationen zu extrahieren.
-
Mit dem Aufkommen von Containern und Orchestrierern wie Kubernetes wurden Infrastrukturen elastischer. Gleichzeitig wurde es komplizierter, Netzwerkdaten zuverlässig zu erfassen.
Diese Probleme traten Anfang der 2010er Jahre mit der Popularität von Cloud Computing und Containern zutage. Wieder einmal entwickelte sich ein aufregendes neues Ökosystem, aber niemand wusste so recht, wie man es beheben und sichern sollte.
Systemaufrufe als Datenquelle: sysdig
Hier kommen eure Autoren ins Spiel. Wir haben ein Open-Source-Tool namens sysdig veröffentlicht, zu dessen Entwicklung wir durch eine Reihe von Fragen inspiriert wurden: Wie können wir moderne, native Cloud-Anwendungen am besten transparent machen? Können wir Workflows, die auf der Paketerfassung basieren, auf diese neue Welt anwenden? Was ist die beste Datenquelle?
sysdig konzentrierte sich ursprünglich auf das Sammeln von Systemaufrufen aus dem Kernel des Betriebssystems. Systemaufrufe sind eine reichhaltige Datenquelle - sogar reichhaltiger als Pakete -, weil sie sich nicht ausschließlich auf Netzwerkdaten konzentrieren: Sie umfassen Datei-I/O, Befehlsausführung, Interprozesskommunikation und mehr. Sie sind eine bessere Datenquelle für native Cloud-Umgebungen als Pakete, da sie sowohl für Container als auch für Cloud-Instanzen vom Kernel gesammelt werden können. Außerdem ist es einfach, effizient und minimalinvasiv, sie zu sammeln.
sysdig bestand ursprünglich aus drei separaten Komponenten:
-
Eine Kernel-Erfassungssonde (verfügbar in zwei Varianten, Kernel-Modul und eBPF)
-
Eine Reihe von Bibliotheken, die die Entwicklung von Erfassungsprogrammen erleichtern
-
Ein Befehlszeilen-Tool mit Dekodier- und Filterfunktionen
Mit anderen Worten: Es war die Portierung des BPF-Stacks auf Systemaufrufe. sysdig wurde so entwickelt, dass es die gängigsten Netzwerkpaket-Workflows unterstützt: Trace-Dateien, einfaches Filtern, Skriptfähigkeit und so weiter. Von Anfang an haben wir auch native Integrationen mit Kubernetes und anderen Orchestrierern vorgesehen, um sie in modernen Umgebungen nutzbar zu machen. sysdig wurde in der Community sofort sehr beliebt und bestätigte den technischen Ansatz.
Falco
Was wäre also der nächste logische Schritt? Du hast es erraten: ein Snort-ähnliches Tool für Systemaufrufe! Wir dachten uns, dass eine flexible Regel-Engine, die auf den sysdig-Bibliotheken aufbaut, ein leistungsfähiges Werkzeug wäre, um anormales Verhalten und Eindringlinge in modernen Anwendungen zuverlässig und effizient zu erkennen - im Wesentlichen der Snort-Ansatz, aber angewandt auf Systemaufrufe und entwickelt für den Einsatz in der Cloud.
So wurde Falco also geboren. Die erste (eher einfache) Version wurde Ende 2016 veröffentlicht und enthielt die meisten wichtigen Komponenten, wie z. B. die Rule Engine. Die Falco-Rule-Engine war von der Snort-Engine inspiriert, aber so konzipiert, dass sie mit einem viel umfangreicheren und allgemeineren Datensatz arbeiten konnte, und wurde in die sysdig-Bibliotheken integriert. Es wurde mit einem relativ kleinen, aber nützlichen Satz von Regeln ausgeliefert. Diese erste Version von Falco war hauptsächlich ein Einzelrechner-Tool, das nicht verteilt eingesetzt werden konnte. Wir haben es als Open Source veröffentlicht, weil wir einen großen Bedarf in der Gemeinschaft sahen und natürlich, weil wir Open Source lieben!
Ausweitung auf Kubernetes
Als sich das Tool weiterentwickelte und die Community es annahm, erweiterten die Entwickler von Falco es um neue Anwendungsbereiche. Im Jahr 2018 haben wir zum Beispiel Kubernetes Audit-Logs als Datenquelle hinzugefügt. Mit dieser Funktion kann Falco den Strom von Ereignissen aus dem Audit-Log anzapfen und Fehlkonfigurationen und Bedrohungen erkennen, sobald sie auftreten.
Um diese Funktion zu entwickeln, mussten wir die Engine verbessern, wodurch Falco flexibler wurde und sich besser für eine breitere Palette von Anwendungsfällen eignet.
Beitritt zur Cloud Native Computing Foundation
Im Jahr 2018 hat Sysdig Falco als Sandbox-Projekt zur Cloud Native Computing Foundation (CNCF) beigesteuert. Die CNCF ist die Heimat vieler wichtiger Projekte, die die Grundlage des modernen Cloud Computing bilden, wie Kubernetes, Prometheus, Envoy und OPA. Für unser Team war die Einbindung von Falco in die CNCF eine Möglichkeit, es zu einem wirklich gemeinschaftsgetriebenen Projekt zu machen, um sicherzustellen, dass es sich nahtlos in den Rest des Cloud Native Stacks einfügt, und um eine langfristige Unterstützung zu gewährleisten. Im Jahr 2021 wurden diese Bemühungen durch die Einbringung des sysdig-Kernelmoduls, der eBPF-Probe und der Bibliotheken in die CNCF als Unterprojekt der Falco-Organisation erweitert. Der gesamte Falco-Stack befindet sich nun in den Händen einer neutralen und fürsorglichen Gemeinschaft.
Plugins und die Cloud
Als die Jahre vergingen und Falco reifer wurde, wurden einige Dinge klar. Erstens eignet sich Falco aufgrund seiner ausgefeilten Engine, seiner Effizienz und seiner einfachen Bereitstellung für weit mehr als nur systemaufrufbasierte Laufzeitsicherheit. Zweitens: Da Software immer verteilter und komplexer wird, ist die Laufzeitsicherheit von entscheidender Bedeutung, um erwartete und unerwartete Bedrohungen sofort zu erkennen. Und schließlich glauben wir, dass die Welt einen einheitlichen, standardisierten Ansatz für die Laufzeitsicherheit braucht. Insbesondere besteht eine große Nachfrage nach einer Lösung, die Workloads (Prozesse, Container, Dienste, Anwendungen) und Infrastruktur (Hosts, Netzwerke, Cloud-Dienste) auf konvergente Weise schützen kann.
Der nächste Schritt in der Entwicklung von Falco bestand daher darin, Modularität, Flexibilität und Unterstützung für viele weitere Datenquellen aus verschiedenen Bereichen hinzuzufügen. So wurde 2021 eine neue Plugin-Infrastruktur hinzugefügt, mit der Falco Datenquellen wie die Logs von Cloud-Providern anzapfen kann, um Fehlkonfigurationen, unbefugten Zugriff, Datendiebstahl und vieles mehr zu erkennen.
Eine lange Reise
Die Geschichte von Falco erstreckt sich über mehr als zwei Jahrzehnte und verbindet viele Menschen, Erfindungen und Projekte, die auf den ersten Blick nichts miteinander zu tun haben. Unserer Meinung nach ist diese Geschichte ein Beispiel dafür, warum Open Source so cool ist: Wenn du einen Beitrag leistest, kannst du von den klugen Leuten lernen, die vor dir da waren, auf ihren Innovationen aufbauen und Gemeinschaften auf kreative Weise verbinden.
Get Praktische Cloud Native Sicherheit mit Falco now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

