Kapitel 4. Datenquellen
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
In diesem Kapitel tauchen wir tief in den Kern des Betriebssystems und den Datenerfassungsstapel von Falco ein. Du erfährst, wie Falco die verschiedenen Arten von Ereignissen erfasst, die in die Regel-Engine einfließen, wie der Datenerfassungsprozess im Vergleich zu anderen Ansätzen funktioniert und warum er so aufgebaut ist, wie er ist. Du wirst die Details so gut verstehen, dass du am Ende dieses Kapitels in der Lage sein wirst, die richtigen Treiber und Plugins für deine Bedürfnisse auszuwählen und einzusetzen.
Als Erstes musst du verstehen, welche Datenquellen du in Falco nutzen kannst. Die Datenquellen von Falco können in zwei Hauptgruppen eingeteilt werden: Systemaufrufe und Plugins. Systemaufrufe sind die ursprüngliche Datenquelle von Falco. Sie stammen aus dem Kernel des Betriebssystems und bieten Einblick in die Aktivitäten von Prozessen, Containern, virtuellen Maschinen und Hosts. Falco nutzt sie, um Workloads und Anwendungen zu schützen. Die zweite Familie von Datenquellen, die Plugins, ist relativ neu: Die Unterstützung wurde 2022 hinzugefügt. Plugins verbinden verschiedene Arten von Inputs mit Falco, z. B. Cloud-Logs und APIs.
Falco unterstützte früher Kubernetes-Audit-Logs als dritten, separaten Quellentyp; seit Falco 0.32 wurde diese Datenquelle jedoch als Plugin neu implementiert, sodass wir sie in diesem Kapitel nicht mehr behandeln werden.
Systemaufrufe
Wie wir bereits mehrfach erwähnt haben, sind Systemaufrufe eine wichtige Datenquelle für Falco und eine der Zutaten, die es einzigartig machen. Aber was genau ist ein Systemaufruf? Beginnen wir mit einer allgemeinen Definition, die wir von Wikipedia übernommen haben:
In der Informatik ist ein Systemaufruf (üblicherweise als Syscall abgekürzt) die programmatische Art und Weise, in der ein Computerprogramm einen Dienst vom Kernel des Betriebssystems anfordert, auf dem es ausgeführt wird. Dazu können hardwarebezogene Dienste (z. B. der Zugriff auf eine Festplatte oder die Kamera des Geräts), die Erstellung und Ausführung neuer Prozesse und die Kommunikation mit integrierten Kernel-Diensten wie der Prozessplanung gehören.
Packen wir das mal aus. Auf der höchsten Abstraktionsebene besteht ein Computer aus einem Haufen Hardware, auf dem ein Haufen Software läuft. In der modernen Computerwelt ist es jedoch äußerst ungewöhnlich, dass ein Programm direkt auf der Hardware läuft. In den allermeisten Fällen laufen die Programme über einem Betriebssystem. Die Treiber von Falco konzentrieren sich speziell auf das Betriebssystem, das die Cloud und das moderne Rechenzentrum antreibt: Linux.
Ein Betriebssystem ist ein Stück Software, das dafür entwickelt wurde, die Ausführung anderer Software zu steuern und zu unterstützen. Neben vielen anderen Dingen, kümmert sich das Betriebssystem um:
-
Zeitplanungsprogramme
-
Speicher verwalten
-
Vermittlung von Hardware-Zugang
-
Implementierung von Netzwerkkonnektivität
-
Umgang mit Gleichzeitigkeit
Es ist klar, dass die meisten dieser Funktionen den Programmen, die auf dem Betriebssystem laufen, zur Verfügung gestellt werden müssen, damit sie etwas Sinnvolles tun können. Und der beste Weg für eine Software, diese Funktionen bereitzustellen, ist natürlich eine Anwendungsprogrammierschnittstelle (API): eine Reihe von Funktionen, die Client-Programme aufrufen können. Genau das sind die Systemaufrufe: APIs für die Interaktion mit dem Betriebssystem.
Warte, warum fast?
Nun, das Betriebssystem ist ein einzigartiges Stück Software und du kannst es nicht einfach wie eine Bibliothek aufrufen. Das Betriebssystem läuft in einem separaten Ausführungsmodus, dem so genannten privilegierten Modus, der vom Benutzermodus, dem Kontext für die Ausführung normaler Prozesse (d. h. laufender Programme), getrennt ist. Diese Trennung macht das Aufrufen des Betriebssystems komplizierter. Bei einigen CPUs rufst du einen Systemaufruf auf, indem du einen Interrupt auslöst. Bei den meisten modernen CPUs musst du jedoch einen bestimmten CPU-Befehl verwenden. Wenn wir diese zusätzliche Ebene der Komplexität ausklammern, kann man sagen, dass Systemaufrufe APIs für den Zugriff auf die Funktionen des Betriebssystems sind. Es gibt viele von ihnen, jeder mit seinen eigenen Eingangsargumenten und Rückgabewerten.
Jedes Programm, ohne Ausnahme, nutzt die Systemaufrufschnittstelle ausgiebig und ständig für alles, was keine reine Berechnung ist: Eingaben lesen, Ausgaben erzeugen, auf die Festplatte zugreifen, im Netzwerk kommunizieren, ein neues Programm starten und so weiter. Das bedeutet, wie du dir vorstellen kannst, dass die Beobachtung der Systemaufrufe ein sehr detailliertes Bild davon vermittelt, was jeder Prozess tut.
Betriebssystementwickler haben die Systemaufrufschnittstelle lange Zeit als stabile API behandelt. Das bedeutet, dass du davon ausgehen kannst, dass sie gleich bleibt, auch wenn sich der Kernel drastisch ändert. Das ist wichtig, denn es garantiert Konsistenz über Zeit und Ausführungsumgebungen hinweg und macht die Systemaufruf-API zur idealen Wahl, um zuverlässige Sicherheitssignale zu sammeln. Falco-Regeln können zum Beispiel auf bestimmte Systemaufrufe verweisen und davon ausgehen, dass deren Verwendung auf jeder Linux-Distribution funktioniert.
Beispiele
Linux bietet viele Systemaufrufe - mehr als 300 an der Zahl. Sie alle aufzuzählen, wäre fast unmöglich und sehr langweilig, deshalb ersparen wir dir das. Wir wollen dir aber einen Eindruck davon vermitteln, welche Arten von Systemaufrufen es gibt.
Tabelle 4-1 enthält einige der Systemaufrufkategorien, die für ein Sicherheitstool wie Falco am wichtigsten sind. Für jede Kategorie enthält die Tabelle Beispiele für repräsentative Systemaufrufe. Du kannst mehr Informationen zu jeder Kategorie finden, indem du man 2 Xeingibst, wobei X der Name des Systemaufrufs ist, in ein Linux-Terminal oder in die Suchleiste deines Browsers eingibst.
| Kategorie | Beispiele |
|---|---|
| Datei E/A | open, creat, close, read, write, ioctl, link, unlink, chdir, chmod, stat, seek, mount, rename, mkdir, rmdir |
| Netzwerk | socket, bind, connect, listen, accept, sendto, recvfrom, getsockopt, setsockopt, shutdown |
| Kommunikation zwischen Prozessen | pipe, futex, inotify_add_watch, eventfd, semop, semget, semctl, msgctl |
| Prozessmanagement | clone, execve, fork, nice, kill, prctl, exit, setrlimit, setpriority, capset |
| Speicherverwaltung | brk, mmap, mprotect, mlock, madvise |
| Benutzerverwaltung | setuid, getuid, setgid, getgid |
| System | sethostname, setdomainname, reboot, syslog, uname, swapoff, init_module, delete_module |
Tipp
Wenn du einen Blick auf die vollständige Liste der Linux-Systemaufrufe werfen möchtest, gib man syscalls in ein Linux-Terminal oder eine Suchmaschine ein. Daraufhin wird die offizielle Seite des Linux-Handbuchs angezeigt, die eine umfassende Liste der Systemaufrufe mit Hyperlinks enthält, über die du dir viele von ihnen genauer ansehen kannst. Außerdem bietet der Softwareentwickler Filippo Valsorda eine übersichtliche und durchsuchbare Liste auf seiner persönlichen Homepage an.
Systemaufrufe beobachten
Da Systemaufrufe für Falco und für die Laufzeitsicherheit im Allgemeinen so wichtig sind, ist es wichtig, dass du lernst, wie man sie erfasst, beobachtet und interpretiert. Dies ist eine wertvolle Fähigkeit, die dir in vielen Situationen nützlich sein wird. Wir zeigen dir zwei verschiedene Tools, die du zu diesem Zweck verwenden kannst: strace und sysdig.
strace
strace ist ein Tool, das du auf so gut wie jedem Rechner mit einem Unix-kompatiblen Betriebssystem finden kannst. In seiner einfachsten Form benutzt du es, um ein Programm auszuführen, und es gibt jeden Systemaufruf, den das Programm ausführt, im Standardfehler aus. In anderen Worten: Füge strace an den Anfang einer beliebigen Befehlszeile und du siehst alle Systemaufrufe, die diese Befehlszeile erzeugt:
$ strace echo hello world
execve("/bin/echo", ["echo", "hello", "world"], 0x7ffc87eed490 /* 32 vars */) = 0
brk(NULL) = 0x558ba22bf000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=121726, ...}) = 0
mmap(NULL, 121726, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f289009c000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\20\35\2\0\0\0\0\0" ...
fstat(3, {st_mode=S_IFREG|0755, st_size=2030928, ...}) = 0
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) ...
mmap(NULL, 4131552, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) ...
mprotect(0x7f288fc87000, 2097152, PROT_NONE) = 0
mmap(0x7f288fe87000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED| ...
mmap(0x7f288fe8d000, 15072, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED| ...
close(3) = 0
arch_prctl(ARCH_SET_FS, 0x7f289009b540) = 0
mprotect(0x7f288fe87000, 16384, PROT_READ) = 0
mprotect(0x558ba2028000, 4096, PROT_READ) = 0
mprotect(0x7f28900ba000, 4096, PROT_READ) = 0
munmap(0x7f289009c000, 121726) = 0
brk(NULL) = 0x558ba22bf000
brk(0x558ba22e0000) = 0x558ba22e0000
openat(AT_FDCWD, "/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=3004224, ...}) = 0
mmap(NULL, 3004224, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f288f7c2000
close(3) = 0
fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 2), ...}) = 0
write(1, "hello world\n", 12hello world
) = 12
close(1) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++
Beachte, dass die Ausgabe von strace die C-Syntax nachahmt und wie ein Strom von Funktionsaufrufen aussieht, wobei der Rückgabewert nach dem = Symbol am Ende jeder Zeile hinzugefügt wird. Sieh dir zum Beispiel den Syscall write (fett gedruckt) an, der die Zeichenkette "hello world" auf der Standardausgabe (Dateideskriptor 1) ausgibt. Er gibt den Wert 12 zurück, also die Anzahl der Bytes, die erfolgreich geschrieben wurden. Beachte, wie die Zeichenkette "hello world" auf die Standardausgabe gedruckt wird , bevor der Systemaufruf write zurückkehrt und strace seinen Rückgabewert auf dem Bildschirm ausgibt.
Eine zweite Möglichkeit, strace zu verwenden, ist, es auf einen laufenden Prozess zu richten, indem du die Prozess-ID (PID) in der Befehlszeile angibst:
$ sudo strace -p`pidof vi`
strace: Process 16472 attached
select(1, [0], [], [0], NULL) = 1 (in [0])
read(0, "\r", 250) = 1
select(1, [0], [], [0], {tv_sec=0, tv_usec=0}) = 0 (Timeout)
select(1, [0], [], [0], {tv_sec=0, tv_usec=0}) = 0 (Timeout)
write(1, "\7", 1) = 1
select(1, [0], [], [0], {tv_sec=4, tv_usec=0}) = 0 (Timeout)
select(1, [0], [], [0], NULL
^C
strace: Process 16472 detached
<detached ...>
strace hat einige Vor- und einige Nachteile. Es wird auf breiter Basis unterstützt, sodass es entweder bereits verfügbar ist oder nur ein einfaches Paket installiert werden muss. Außerdem ist es einfach zu benutzen und ideal, wenn du einen einzelnen Prozess untersuchen musst, was es perfekt für Debugging-Anwendungen macht.
Nachteilig ist, dass strace einzelne Prozesse instrumentiert, was es ungeeignet macht, die Aktivität des gesamten Systems zu untersuchen oder wenn du keinen bestimmten Prozess hast, von dem du ausgehen kannst. Außerdem basiert strace auf ptrace für die Sammlung von Systemaufrufen, was es sehr langsam macht und für den Einsatz in Produktionsumgebungen ungeeignet ist. Du solltest damit rechnen, dass ein Prozess erheblich langsamer wird (manchmal um Größenordnungen), wenn du strace an ihn anhängst.
sysdig
Wir haben sysdig in der Diskussion über Trace-Dateien in Kapitel 3vorgestellt. sysdig ist anspruchsvoller als strace und enthält mehrere erweiterte Funktionen. Die gute Nachricht ist jedoch, dass sysdig das Datenmodell, das Ausgabeformat und die Filtersyntax von Falco teilt - du kannst also vieles von dem, was du über Falco gelernt hast, in sysdig anwenden und umgekehrt.
Das erste, was du beachten musst, ist, dass du sysdig nicht auf einen einzelnen Prozess richtest, wie du es mit strace machst. Stattdessen lässt du es einfach laufen und es erfasst jeden Systemaufruf, der auf dem Rechner aufgerufen wird, egal ob innerhalb oder außerhalb von Containern:
$ sudo sysdig 1 17:41:13.628568857 0 prlcp (4358) < write res=0 data=.N;.n... 2 17:41:13.628573305 0 prlcp (4358) > write fd=6(<p>pipe:[43606]) size=1 4 17:41:13.609136030 3 gmain (2935) < poll res=0 fds= 5 17:41:13.609146818 3 gmain (2935) > write fd=4(<e>) size=8 6 17:41:13.609149203 3 gmain (2935) < write res=8 data=........ 9 17:41:13.626956525 0 Xorg (3214) < epoll_wait res=1 10 17:41:13.626964759 0 Xorg (3214) > setitimer 11 17:41:13.626966955 0 Xorg (3214) < setitimer
Deshalb kannst du die Anzeige von sysdig mit Hilfe von Filtern einschränken. sysdig akzeptiert die gleiche Filtersyntax wie Falco (was es übrigens zu einem großartigen Werkzeug macht, um Falco-Regeln zu testen und Fehler zu beheben). Im folgenden Beispiel beschränken wir sysdig auf die Erfassung von Systemaufrufen für Prozesse mit dem Namen "cat":
$ sudo sysdig proc.name=cat & cat /etc/hosts 47190 14:40:39.913809700 12 cat (377163.377163) < execve res=0 exe=cat args=/etc/hosts. tid=377163(cat) pid=377163(cat) ptid=5860(zsh) cwd= fdlimit=1024 pgft_maj=0 pgft_min=60 vm_size=424 vm_rss=4 vm_swap=0 comm=cat cgroups=cpuset=/user.slice.cpu=/user.slice.cpuacct=/.io=/user.slice.memory= /user.slic... env=SYSTEMD_EXEC_PID=3558.GJS_DEBUG_TOPICS=JS ERROR;JS LOG.SESSION_MANAGER=local/... tty=34817 pgid=377163(cat) loginuid=1000 flags=0 47194 14:40:39.913846153 12 cat (377163.377163) > brk addr=0 47196 14:40:39.913846951 12 cat (377163.377163) < brk res=55956998C000 vm_size=424 vm_rss=4 vm_swap=0 47205 14:40:39.913880404 12 cat (377163.377163) > arch_prctl 47206 14:40:39.913880871 12 cat (377163.377163) < arch_prctl 47207 14:40:39.913896493 12 cat (377163.377163) > access mode=4(R_OK) 47208 14:40:39.913900922 12 cat (377163.377163) < access res=-2(ENOENT) name=/etc/ld.so.preload 47209 14:40:39.913903872 12 cat (377163.377163) > openat dirfd=-100(AT_FDCWD) name=/etc/ld.so.cache flags=4097(O_RDONLY|O_CLOEXEC) mode=0 47210 14:40:39.913914652 12 cat (377163.377163) < openat fd=3(<f>/etc/ld.so.cache) dirfd=-100(AT_FDCWD) name=/etc/ld.so.cache flags=4097(O_RDONLY|O_CLOEXEC) mode=0 dev=803
Diese Ausgabe erfordert ein wenig mehr Erklärung als die von strace. Die Felder, die sysdig ausgibt, sind:
-
Inkrementelle Ereignisnummer
-
Zeitstempel des Ereignisses
-
CPU-ID
-
Befehlsname
-
Prozess-ID und Thread-ID (TID), getrennt durch einen Punkt
-
Richtung des Ereignisses (
>bedeutet Eintritt, während<Austritt bedeutet) -
Ereignistyp (für unsere Zwecke ist dies der Name des Systemaufrufs)
-
Systemaufruf-Argumente
Im Gegensatz zu strace gibt sysdig für jeden Systemaufruf zwei Zeilen aus: Die enter-Zeile wird erzeugt, wenn der Systemaufruf startet, und die exit-Zeile wird gedruckt, wenn der Systemaufruf zurückkehrt. Dieser Ansatz eignet sich gut, wenn du herausfinden willst, wie lange ein Systemaufruf gedauert hat oder einen Prozess ausfindig machen willst, der in einem Systemaufruf stecken geblieben ist.
Beachte auch, dass sysdig standardmäßig zusätzlich zu den Prozess-IDs auch Thread-IDs ausgibt. Threads sind die zentrale Ausführungseinheit des Betriebssystems und damit auch von sysdig. Mehrere Threads können innerhalb desselben Prozesses oder Befehls existieren und sich Ressourcen wie z. B. den Speicher teilen. Die TID ist die grundlegende Kennung, der du folgen musst, wenn du die Ausführungsaktivität auf deinem Rechner verfolgen willst. Das kannst du tun, indem du dir einfach die TID-Nummer ansiehst oder indem du das Rauschen mit einer Befehlszeile wie dieser herausfilterst:
$ sysdig thread.tid=1234
die den Ausführungsfluss nur für Thread 1234 beibehält.
Threads leben innerhalb von Prozessen, die durch eine Prozess-ID identifiziert werden. Viele der Prozesse, die auf einem durchschnittlichen Linux-Rechner laufen, sind Single-Thread-Prozesse, und in diesem Fall ist thread.tid dasselbe wie proc.pid. Die Filterung nach proc.pid ist nützlich, um zu beobachten, wie Threads innerhalb eines Prozesses miteinander interagieren.
Trace-Dateien
Wie du in Kapitel 3 gelernt hast, kannst du sysdig anweisen, die Systemaufrufe, die es aufzeichnet, in einer Trace-Datei zu speichern:
$ sudo sysdig -w testfile.scap
Du wirst wahrscheinlich einen Filter verwenden wollen, um die Dateigröße unter Kontrolle zu halten. Zum Beispiel:
$ sudo sysdig -w testfile.scap proc.name=cat
Du kannst auch Filter beim Lesen von Trace-Dateien verwenden:
$ sysdig -r testfile.scap proc.name=cat
Die Filter von sysdig sind so wichtig, dass wir ihnen ein ganzes Kapitel(Kapitel 6) widmen werden.
Wir empfehlen dir, mit sysdig zu spielen und die Aktivität gängiger Programme in Linux zu erkunden. Das wird später hilfreich sein, wenn du Falco Regeln erstellst oder interpretierst.
Systemaufrufe erfassen
Also gut, Systemaufrufe sind cool und wir müssen sie erfassen. Wie machen wir das also am besten?
Weiter oben in diesem Kapitel haben wir beschrieben, wie Systemaufrufe den Übergang des Ausführungsflusses von einem laufenden Prozess zum Kernel des Betriebssystems bewirken. Intuitiv und wie in Abbildung 4-1 dargestellt, gibt es zwei Orte, an denen Systemaufrufe erfasst werden können: im laufenden Prozess oder im Betriebssystemkern.
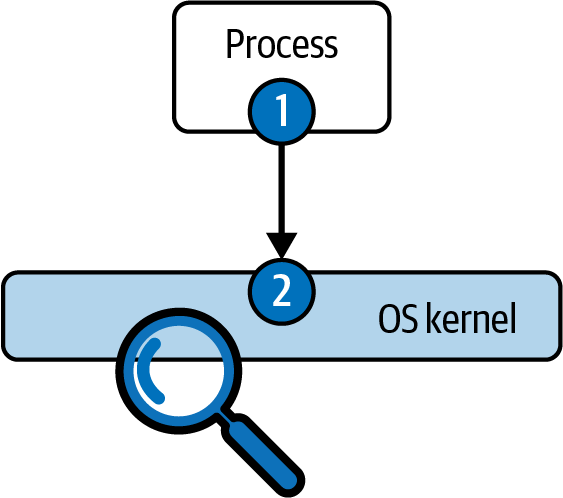
Abbildung 4-1. Optionen für die Erfassung von Systemaufrufen
Um Systemaufrufe in einem laufenden Prozess zu erfassen, muss normalerweise entweder der Prozess oder eine seiner Bibliotheken mit einer Art von Instrumentierung modifiziert werden. Die Tatsache, dass die meisten Programme in Linux die C-Standardbibliothek, auch bekannt als glibc, verwenden, um Systemaufrufe auszuführen, macht die Instrumentierung dieser Bibliothek sehr reizvoll. Daher gibt es zahlreiche Tools und Frameworks, um die glibc (und andere Systembibliotheken) für die Instrumentierung zu modifizieren. Diese Techniken können statisch sein, indem sie den Quellcode der Bibliothek ändern und neu kompilieren, oder dynamisch, indem sie ihre Position im Adressraum des Zielprozesses finden und Haken einfügen.
Hinweis
Eine andere Methode, um Systemaufrufe zu erfassen, ohne den Betriebssystemkern zu instrumentieren, ist die Verwendung der Debugging-Funktionen des Betriebssystems. strace verwendet zum Beispiel eine Funktion namens ptrace,1 die die Grundlage für Tools wie den GNU Debugger (gdb) bildet.
Die zweite Möglichkeit besteht darin, die Ausführung des Systemaufrufs abzufangen, nachdem er an das Betriebssystem weitergeleitet wurde. Dazu muss ein Teil des Codes im Betriebssystem-Kernel selbst ausgeführt werden. Das ist in der Regel heikler und risikoreicher, denn die Ausführung von Code im Kernel erfordert erhöhte Berechtigungen. Alles, was im Kernel läuft, hat potenziell die Kontrolle über den Rechner, seine Prozesse, seine Benutzer und seine Hardware. Daher kann ein Fehler in einem Programm, das im Kernel läuft, zu großen Sicherheitsrisiken, Datenbeschädigung oder in manchen Fällen sogar zum Absturz des Computers führen. Aus diesem Grund wählen viele Sicherheitstools die Instrumentierungsoption 1 und erfassen Systemaufrufe auf Benutzerebene, innerhalb des Prozesses.
Falco macht genau das Gegenteil: Es ist auf der Seite der Kernel-Instrumentierung angesiedelt. Die Gründe für diese Entscheidung lassen sich in drei Worten zusammenfassen: Genauigkeit, Leistung und Skalierbarkeit. Gehen wir der Reihe nach darauf ein.
Genauigkeit
Instrumentierungstechniken auf Benutzerebene - insbesondere solche, die auf der glibc-Ebene arbeiten - haben ein paar große Probleme. Erstens kann ein motivierter Angreifer sie umgehen, indem er die glibc nicht benutzt! Du musst keine Bibliothek verwenden, um Systemaufrufe zu tätigen, und Angreifer können stattdessen eine einfache Abfolge von CPU-Befehlen erstellen und so die glibc-Instrumentierung vollständig umgehen. Das ist nicht gut.
Noch schlimmer ist, dass es große Kategorien von Software gibt, die die Glibc überhaupt nicht laden. Statisch gelinkte C-Programme zum Beispiel, die häufig in Containern verwendet werden, importieren Glibc-Funktionen zur Kompilierzeit und betten sie in ihre ausführbaren Dateien ein. Bei diesen Programmen hast du nicht die Möglichkeit, die Bibliothek zu ersetzen oder zu ändern. Das Gleiche gilt für Programme, die in Go geschrieben wurden, das seine eigene statisch gelinkte Systemaufruf-Schnittstellenbibliothek hat.
Die Erfassung auf Kernel-Ebene leidet nicht unter diesen Einschränkungen. Sie unterstützt jede Sprache, jeden Stack und jedes Framework, da die Erfassung von Systemaufrufen auf einer Ebene unterhalb aller Bibliotheken und Abstraktionsschichten stattfindet. Das bedeutet, dass es für Angreifer viel schwieriger ist, die Instrumentierung auf Kernel-Ebene zu umgehen.
Leistung
Einige Erfassungsmethoden auf Benutzerebene, wie z.B. ptrace, haben einen erheblichen Overhead, weil sie eine hohe Anzahl von Kontextwechseln erzeugen. Jeder einzelne Systemaufruf muss eindeutig an einen separaten Prozess übergeben werden, wodurch die Ausführung zwischen den Prozessen hin- und hergeschoben werden muss. Das ist so langsam, dass es ein Hindernis für den Einsatz solcher Techniken in der Produktion ist, wo eine so große Auswirkung auf die instrumentierten Prozesse nicht akzeptabel ist.
Es stimmt, dass die glibc-basierte Erfassung effizienter sein kann, aber sie führt immer noch zu einem hohen Overhead für grundlegende Operationen wie die Zeitstempelung von Ereignissen. Bei der Erfassung auf Kernel-Ebene sind dagegen keine Kontextwechsel erforderlich, und der gesamte erforderliche Kontext, wie z. B. Zeitstempel, wird innerhalb des Kernels gesammelt. Dadurch ist sie viel schneller als jede andere Technik und daher am besten für die Produktion geeignet.
Skalierbarkeit
Wie der Name schon sagt, muss bei der Erfassung auf Prozessebene für jeden einzelnen Prozess "etwas getan" werden. Was das ist, kann variieren, aber es entsteht ein Overhead, der proportional zur Anzahl der beobachteten Prozesse ist. Das ist bei der Instrumentierung auf Kernel-Ebene nicht der Fall. Sieh dir Abbildung 4-2 an.
Wenn du die Kernel-Instrumentierung an der richtigen Stelle einsetzt, ist es möglich, einen einzigen Instrumentierungspunkt zu haben (in Abbildung 4-2 mit 2 gekennzeichnet), egal wie viele Prozesse laufen. Das garantiert nicht nur maximale Effizienz, sondern auch die Gewissheit, dass dir nichts entgeht, denn kein Prozess entgeht der Erfassung auf Kernel-Ebene.
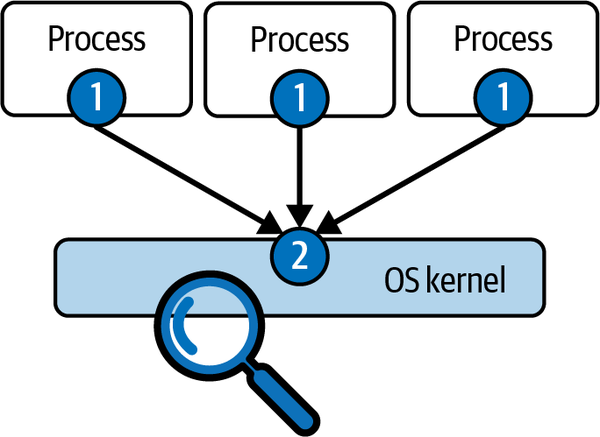
Abbildung 4-2. Skalierbarkeit der Systemaufruferfassung, Prozessebene versus Kernel
Und was ist mit Stabilität und Sicherheit?
Wir haben erwähnt, dass die Instrumentierung auf Kernel-Ebene heikler ist, weil ein Fehler ernsthafte Probleme verursachen kann. Du fragst dich vielleicht: "Gehe ich ein zusätzliches Risiko ein, wenn ich mich für ein Tool wie Falco entscheide, das auf Kernel-Instrumentierung basiert, anstatt für ein Produkt, das auf User-Level-Instrumentierung beruht?"
Nicht wirklich. Zunächst einmal profitiert die Instrumentierung auf Kernel-Ebene von gut dokumentierten, stabilen Hooking-Schnittstellen, während Ansätze wie das glibc-basierte Capture weniger sauber und von Natur aus riskanter sind. Sie können den Rechner nicht zum Absturz bringen, aber sie können den instrumentierten Prozess durchaus zum Absturz bringen, was in der Regel zu schlechten Ergebnissen führt. Darüber hinaus reduzieren Technologien wie eBPF das Risiko, Code im Kernel auszuführen, erheblich und machen die Instrumentierung auf Kernel-Ebene auch für risikoscheue Benutzer/innen praktikabel.
Instrumentierungsansätze auf Kernel-Ebene
Wir hoffen, dich davon überzeugt zu haben, dass die Kernel-Instrumentierung, wann immer sie verfügbar ist, der richtige Weg für die Sicherheit zur Laufzeit ist. Nun stellt sich die Frage, welcher Mechanismus am besten geeignet ist, um sie zu implementieren. Von den verschiedenen verfügbaren Ansätzen sind zwei für ein Tool wie Falco relevant: Kernelmodule oder eBPF-Sonden. Werfen wir einen Blick auf jeden dieser Ansätze.
Kernel Module
Ladbare Kernelmodule sind Codeteile, die zur Laufzeit in den Kernel geladen werden können. In der Vergangenheit wurden Module in Linux (und vielen anderen Betriebssystemen) häufig verwendet, um den Kernel erweiterbar, effizient und kleiner zu machen.
Kernelmodule erweitern den Funktionsumfang des Kernels, ohne dass das System neu gestartet werden muss. Sie werden normalerweise verwendet, um Gerätetreiber, Netzwerkprotokolle und Dateisysteme zu implementieren. Kernel-Module sind in C geschrieben und werden für den jeweiligen Kernel kompiliert, in dem sie ausgeführt werden sollen. Mit anderen Worten: Es ist nicht möglich, ein Modul auf einem Rechner zu kompilieren und es dann auf einem anderen zu verwenden (es sei denn, die beiden Rechner haben genau denselben Kernel). Kernelmodule können auch entladen werden, wenn der Benutzer sie nicht mehr braucht, um Speicherplatz zu sparen.
Linux unterstützt Kernel-Module schon seit langer Zeit, sodass sie auch mit sehr alten Versionen von Linux funktionieren. Außerdem haben sie weitreichenden Zugriff auf den Kernel, was bedeutet, dass es nur sehr wenige Einschränkungen gibt, was sie tun können. Das macht sie zu einer guten Wahl, um die detaillierten Informationen zu sammeln, die ein Laufzeit-Sicherheitstool wie Falco benötigt. Da sie in C geschrieben sind, sind Kernel-Module auch sehr effizient und daher eine gute Wahl, wenn die Leistung wichtig ist.
Wenn du die Liste der Module sehen willst, die in deiner Linux-Box geladen sind, benutze diesen Befehl:
$ sudo lsmod
eBPF
Wie in Kapitel 1 erwähnt, ist der eBPF die "nächste Generation" des Berkeley Packet Filter (BPF). Der BPF wurde 1992 für das Filtern von Netzwerkpaketen mit BSD-Betriebssystemen entwickelt und wird auch heute noch von Tools wie Wireshark verwendet. Die Innovation des BPF war die Möglichkeit, beliebigen Code im Kernel des Betriebssystems auszuführen. Da ein solcher Code jedoch mehr oder weniger unbegrenzte Rechte auf dem Rechner hat, ist dies potenziell riskant und muss mit Vorsicht geschehen.
Abbildung 4-3 zeigt, wie BPF beliebige Paketfilter sicher im Kernel ausführt.
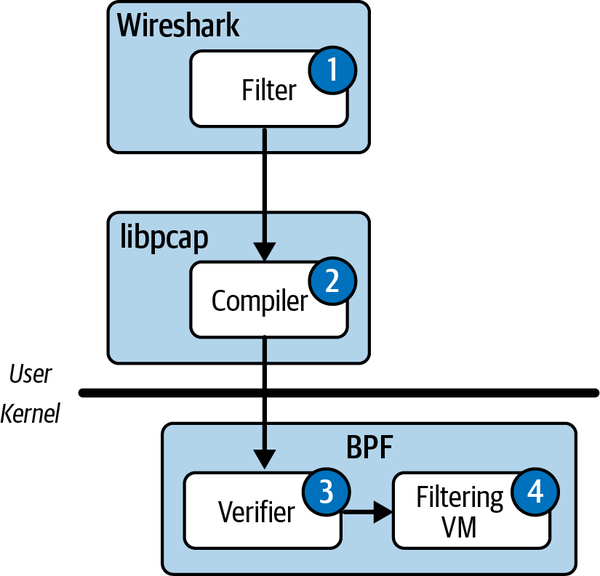
Abbildung 4-3. Schritte zum Einsatz des BPF-Filters
Schauen wir uns die hier dargestellten Schritte an:
-
Der Nutzer gibt einen Filter in ein Programm wie Wireshark ein (z. B.
port 80). -
Der Filter wird an einen Compiler weitergeleitet, der ihn in Bytecode für eine virtuelle Maschine umwandelt. Dies ist vom Konzept her ähnlich wie das Kompilieren eines Java-Programms, aber sowohl das Programm als auch der Befehlssatz der virtuellen Maschine (VM) sind bei der BPF viel einfacher. So sieht zum Beispiel unser
port 80Filter aus, nachdem er kompiliert wurde:(000) ldh [12] (001) jeq #0x86dd jt 2 jf 10 (002) ldb [20] (003) jeq #0x84 jt 6 jf 4 (004) jeq #0x6 jt 6 jf 5 (005) jeq #0x11 jt 6 jf 23 (006) ldh [54] (007) jeq #0x50 jt 22 jf 8 (008) ldh [56] (009) jeq #0x50 jt 22 jf 23 (010) jeq #0x800 jt 11 jf 23 (011) ldb [23] (012) jeq #0x84 jt 15 jf 13 (013) jeq #0x6 jt 15 jf 14 (014) jeq #0x11 jt 15 jf 23 (015) ldh [20] (016) jset #0x1fff jt 23 jf 17 (017) ldxb 4*([14]&0xf) (018) ldh [x + 14] (019) jeq #0x50 jt 22 jf 20 (020) ldh [x + 16] (021) jeq #0x50 jt 22 jf 23 (022) ret #262144 (023) ret #0
-
Um zu verhindern, dass ein kompilierter Filter Schaden anrichtet, wird er von einem Verifier analysiert, bevor er in den Kernel injiziert wird. Der Verifier prüft den Bytecode und stellt fest, ob der Filter gefährliche Eigenschaften hat (z. B. Endlosschleifen, die dazu führen würden, dass der Filter nie zurückkehrt und viel Kernel-CPU verbraucht).
-
Wenn der Filtercode nicht sicher ist, lehnt der Verifier ihn ab, meldet dem Benutzer einen Fehler und stoppt den Ladevorgang. Ist der Verifizierer zufrieden, wird der Bytecode an die virtuelle Maschine weitergeleitet, die ihn auf jedes eingehende Paket anwendet.
eBPF ist eine neuere (und viel leistungsfähigere) Version von BPF, die 2014 zu Linux hinzugefügt wurde und erstmals in der Kernel-Version 3.18 enthalten war. eBPF hebt die Konzepte von BPF auf ein neues Niveau, bietet mehr Effizienz und nutzt die Vorteile neuerer Hardware. Vor allem aber ermöglicht eBPF mit Hooks im gesamten Kernel Anwendungsfälle, die über das einfache Filtern von Paketen hinausgehen, z. B. Tracing, Leistungsanalyse, Debugging und Sicherheit. Es handelt sich im Wesentlichen um eine Allzweck-VM für die Codeausführung, die garantiert, dass die von ihr ausgeführten Programme keinen Schaden anrichten.
Hier sind einige der Verbesserungen, die eBPF gegenüber der klassischen BPF mit sich bringt:
-
Ein erweiterter Befehlssatz, d.h. eBPF kann viel anspruchsvollere Programme ausführen.
-
Ein Just-in-Time-Compiler (JIT). Während die klassische BPF interpretiert wurde, werden eBPF-Programme nach der Validierung in native CPU-Befehle umgewandelt. Das bedeutet, dass sie viel schneller laufen, fast mit der Geschwindigkeit der CPU.
-
Die Möglichkeit, echte C-Programme zu schreiben, anstatt nur einfache Paketfilter.
-
Eine ausgereifte Reihe von Bibliotheken, mit denen du eBPF aus Sprachen wie Go steuern kannst.
-
Die Möglichkeit, Unterprogramme und Hilfsfunktionen auszuführen.
-
Sicherer Zugriff auf verschiedene Kernel-Objekte. eBPF-Programme können gefahrlos in Kernel-Strukturen "spähen", um Informationen und Kontext zu sammeln, die für Tools wie Falco Gold wert sind.
-
Das Konzept der Maps, Speicherbereiche, die genutzt werden können, um Daten mit der Benutzerebene effizient und einfach auszutauschen.
-
Ein viel ausgefeilterer Verifizierer, der eBPF-Programmen mehr Möglichkeiten bietet, ohne ihre Sicherheit zu beeinträchtigen.
-
Die Fähigkeit, an viel mehr Stellen im Kernel als nur im Netzwerkstack zu arbeiten, unter Verwendung von Funktionen wie Tracepoints, kprobes, uprobes, Linux Security Modules Hooks und Userland Statically Defined Tracing (USDT).
eBPF entwickelt sich schnell weiter und wird immer mehr zum Standard für die Erweiterung des Linux-Kernels. eBPF-Skripte sind flexibel und sicher und laufen extrem schnell, so dass sie sich perfekt für die Erfassung der Laufzeit Aktivität eignen.
Die Falco-Treiber
Falco bietet zwei verschiedene Treiber-Implementierungen an, die die beiden gerade beschriebenen Ansätze umsetzen: ein Kernel-Modul und eine eBPF-Sonde. Die beiden Implementierungen haben die gleiche Funktionalität und sind bei der Verwendung von Falco austauschbar. Daher können wir beschreiben, wie sie funktionieren, ohne uns auf eine bestimmte Implementierung zu konzentrieren.
Der High-Level-Erfassungsablauf ist in Abbildung 4-4 dargestellt.

Abbildung 4-4. Der Fluss der Erfassung des Treibers
Der Ansatz, den die Falco-Treiber verwenden, um einen Systemaufruf zu erfassen, umfasst drei Hauptschritte, die in der Abbildung gekennzeichnet sind:
-
Eine Kernel-Funktion namens Tracepoint fängt die Ausführung des Systemaufrufs ab. Der Tracepoint ermöglicht es, an einer bestimmten Stelle im Betriebssystemkern einen Haken zu setzen, so dass jedes Mal, wenn die Kernelausführung diesen Punkt erreicht, eine Callback-Funktion aufgerufen wird.2 Die Falco-Treiber installieren zwei Tracepoints für Systemaufrufe: einen, an dem Systemaufrufe in den Kernel eintreten, und einen weiteren, an dem sie den Kernel verlassen und die Kontrolle an den aufrufenden Prozess zurückgeben.
-
Während des Tracepoint-Callbacks "packt" der Treiber die Systemaufrufargumente in einen gemeinsamen Speicherpuffer. In dieser Phase wird der Systemaufruf auch mit einem Zeitstempel versehen und zusätzlicher Kontext vom Betriebssystem eingeholt (z. B. die Thread-ID oder die Verbindungsdetails für einige Socket-Syscalls). Diese Phase muss besonders effizient sein, denn der Systemaufruf kann erst ausgeführt werden, wenn der Tracepoint-Callback des Treibers zurückkehrt.
-
Der gemeinsam genutzte Puffer enthält nun die Systemaufrufdaten und Falco kann über libscap (vorgestellt in Kapitel 3) direkt darauf zugreifen. In dieser Phase werden keine Daten kopiert, was die CPU-Auslastung minimiert und die Cache-Kohärenz optimiert.
Bei der Erfassung von Systemaufrufen in Falco gibt es ein paar Dinge zu beachten. Zunächst einmal ist die Art und Weise, wie Systemaufrufe in den Puffer gepackt werden, flexibel und spiegelt nicht unbedingt die Argumente der ursprünglichen Aufrufe wider. In manchen Fällen lässt der Treiber nicht benötigte Argumente weg, um die Leistung zu erhöhen. In anderen Fällen fügt der Treiber Felder hinzu, die den Status, nützlichen Kontext oder zusätzliche Informationen enthalten. Ein clone -Ereignis in Falco enthält zum Beispiel viele Felder, die Informationen über den neu erstellten Prozess enthalten, z. B. die Umgebungsvariablen.
Der zweite Punkt, den du beachten solltest, ist, dass Systemaufrufe zwar die mit Abstand wichtigsten Datenquellen sind, die die Treiber erfassen, aber nicht die einzigen. Mit Hilfe von Tracepoints greifen die Treiber auf andere Stellen im Kernel zu, wie z. B. das Zeitplannungsprogramm, um Kontextwechsel und Signalübergaben zu erfassen. Wirf einen Blick auf diesen Befehl:
$ sysdig evt.type=switch
Diese Codezeile zeigt Ereignisse an, die über den Kontextwechsel-Tracepoint erfasst wurden.
Welchen Treiber solltest du verwenden?
Wenn du dir nicht sicher bist, welchen Treiber du verwenden solltest, findest du hier einige einfache Richtlinien:
-
Verwende das Kernel-Modul, wenn du eine E/A-intensive Arbeitslast hast und darauf achtest, den Overhead der Instrumentierung so gering wie möglich zu halten. Das Kernel-Modul hat einen geringeren Overhead als die eBPF-Sonde und auf Rechnern, die viele Systemaufrufe generieren, hat es weniger Auswirkungen auf die Leistung der laufenden Prozesse. Es ist nicht einfach abzuschätzen, wie viel besser das Kernel-Modul abschneidet, da dies davon abhängt, wie viele Systemaufrufe ein Prozess tätigt, aber man kann davon ausgehen, dass der Unterschied bei platten- oder netzwerkintensiven Arbeitslasten, die viele Systemaufrufe pro Sekunde erzeugen, spürbar ist.
-
Du solltest das Kernelmodul auch verwenden, wenn du einen Kernel unterstützen musst, der älter als Linux Version 4.12 ist.
-
Verwende die eBPF-Sonde in allen anderen Situationen.
Das war's!
Systemaufrufe innerhalb von Containern erfassen
Das Schöne an der Tracepoint-basierten Erfassung auf Kernel-Ebene ist, dass sie alles sieht, was auf einem Rechner innerhalb oder außerhalb eines Containers läuft. Nichts entgeht ihm. Außerdem ist es einfach zu implementieren, da nichts in den überwachten Containern ausgeführt werden muss und keine Sidecars benötigt werden.
Abbildung 4-5 zeigt, wie du Falco in einer containerisierten Umgebung einsetzt, mit einem vereinfachten Diagramm eines Rechners, auf dem drei Container (mit 1, 2 und 3 gekennzeichnet) laufen, die auf unterschiedlichen Container-Laufzeiten basieren.

Abbildung 4-5. Einsatz von Falco in einer containerisierten Umgebung
In einem solchen Szenario wird Falco normalerweise als Container installiert. Orchestratoren wie Kubernetes machen es einfach, Falco auf jedem Host zu installieren, mit Funktionen wie DaemonSets und Helm-Charts.
Wenn der Falco-Container startet, installiert er den Treiber im Betriebssystem. Sobald er installiert ist, kann der Treiber die Systemaufrufe jedes Prozesses in jedem Container sehen, ohne dass eine weitere Benutzeraktion erforderlich ist, da alle diese Systemaufrufe über denselben Tracepoint laufen. Eine fortschrittliche Logik im Treiber kann jeden erfassten Systemaufruf dem entsprechenden Container zuordnen, so dass Falco immer weiß, welcher Container einen Systemaufruf erzeugt hat. Falco holt auch Metadaten von der Container-Laufzeit ab, so dass es einfach ist, Regeln zu erstellen, die auf Container-Labels, Bildnamen und anderen Metadaten basieren. (Falco bietet eine weitere Anreicherung auf der Grundlage von Kubernetes-Metadaten, die wir im nächsten Kapitel besprechen werden).
Ausführen der Falco-Treiber
Nachdem du nun eine Vorstellung davon hast, wie sie funktionieren, schauen wir uns an, wie du die beiden Falco-Treiber auf einem lokalen Rechner einsetzen und verwenden kannst. (Wenn du Falco in Produktionsumgebungen installieren willst, lies Kapitel 9 und 10).
Kernel Modul
Falco wird standardmäßig mit dem Kernelmodul ausgeführt, sodass keine weiteren Schritte erforderlich sind, wenn du es als Treiber verwenden möchtest. Starte einfach Falco, und es wird das Kernelmodul übernehmen. Wenn du das Kernelmodul entladen und eine andere Version laden willst, zum Beispiel weil du ein eigenes, angepasstes Modul gebaut hast, verwende die folgenden Befehle:
$ sudo rmmod falco $ sudo insmod path/to/your/module/falco.ko
eBPF-Sonde
Um die eBPF-Unterstützung in Falco zu aktivieren, musst du die Umgebungsvariable FALCO_BPF_PROBE setzen. Wenn du sie auf einen leeren Wert setzt (FALCO_BPF_PROBE=""), lädt Falco die eBPF-Sonde aus ~/.falco/falco-bpf.o. Andernfalls kannst du explizit auf den Pfad verweisen, in dem sich die eBPF-Sonde befindet:
export FALCO_BPF_PROBE="path/to/your/ebpf/probe/falco-bpf.o"
Nachdem du die Umgebungsvariable gesetzt hast, kannst du Falco ganz normal starten und es wird die eBPF-Sonde verwenden.
Tipp
Um sicherzustellen, dass die eBPF-Sonde von Falco (und jedes andere eBPF-Programm) mit der besten Leistung läuft, stelle sicher, dass dein Kernel CONFIG_BPF_JIT aktiviert hat und net.core.bpf_jit_enable auf 1 eingestellt ist. Dadurch wird der BPF JIT-Compiler im Kernel aktiviert, was die Ausführung von eBPF-Programmen erheblich beschleunigt.
Falco in Umgebungen verwenden, in denen kein Kernel-Zugriff möglich ist: pdig
Die Instrumentierung des Kernels ist, wann immer möglich, die beste Lösung. Was aber, wenn du Falco in Umgebungen einsetzen willst, in denen der Zugriff auf den Kernel nicht erlaubt ist? Das ist häufig in verwalteten Container-Umgebungen wie AWS Fargate der Fall. In solchen Umgebungen ist es nicht möglich, ein Kernel-Modul zu installieren, weil der Cloud-Provider es blockiert.
Für diese Situationen haben die Falco-Entwickler einen Instrumentierungstreiber auf Benutzerebene namens pdig entwickelt. Er baut auf ptrace auf, verwendet also den gleichen Ansatz wie strace. Wie strace kann auch pdig auf zwei Arten arbeiten: Es kann ein Programm ausführen, das du auf der Kommandozeile angibst, oder es kann sich an einen laufenden Prozess anhängen. In jedem Fall instrumentiert pdig den Prozess und seine Kinder so, dass ein Falco-kompatibler Strom von Ereignissen entsteht.
Beachte, dass pdig genau wie strace erfordert, dass du CAP_SYS_PTRACE für die Container-Laufzeit aktivierst. Stelle sicher, dass du deinen Container mit dieser Fähigkeit startest, sonst schlägt pdig fehl.
Die eBPF-Sonde und das Kernel-Modul arbeiten auf der globalen Host-Ebene, während pdig auf der Prozess-Ebene arbeitet. Das kann die Instrumentierung von Containern erschweren. Glücklicherweise kann pdig die Kinder eines instrumentierten Prozesses verfolgen. Das heißt, wenn du den Einstiegspunkt eines Containers mit pdig ausführst, kannst du jeden Systemaufruf erfassen, der von einem Prozess für diesen Container erzeugt wird.
Die größte Einschränkung von pdig ist die Leistung. ptrace ist vielseitig, aber es verursacht einen erheblichen Overhead bei den instrumentierten Prozessen. pdig wendet mehrere Tricks an, um diesen Overhead zu reduzieren, ist aber immer noch deutlich langsamer als die Falco-Treiber auf Kernel-Ebene.
Falco mit pdig betreiben
Du führst pdig mit dem Pfad (und den Argumenten, falls vorhanden) des Prozesses aus, den du verfolgen willst, ähnlich wie bei strace. Hier ist ein Beispiel:
$ pdig [-a] curl https://example.com/
Die Option -a aktiviert den vollständigen Filter, der eine größere Anzahl von instrumentierten Systemaufrufen bietet. Aus Leistungsgründen solltest du diese Option wahrscheinlich nicht mit Falco verwenden.
Du kannst dich auch mit der Option -p an einen laufenden Prozess anhängen:
$ pdig [-a] -p 1234
Um einen Effekt zu beobachten, musst du Falco in einem separaten Prozess laufen lassen. Verwende das Kommandozeilen-Flag -u:
$ falco -u
Falco Plugins
Zusätzlich zu den Systemaufrufen kann Falco viele andere Datentypen sammeln und verarbeiten, z. B. Anwendungsprotokolle und Cloud-Aktivitätsströme. Zum Abschluss dieses Kapitels wollen wir uns den Mechanismus ansehen, der diesen Funktionen zugrunde liegt: Das Plugin-Framework von Falco.
Plugins sind eine modulare, flexible Möglichkeit, die Falco-Ingestion zu erweitern. Jeder kann sie nutzen, um Falco eine neue Datenquelle hinzuzufügen, lokal oder remote. Abbildung 4-6 zeigt, wo Plugins im Falco-Capture-Stack sitzen: Sie sind Inputs für libscap und dienen als Alternative zu den Treibern, die beim Capturing von Systemaufrufen verwendet werden.
Plugins sind als gemeinsam genutzte Bibliotheken implementiert, die einer dokumentierten API entsprechen. Sie ermöglichen es dir, neue Ereignisquellen hinzuzufügen, die du dann mit Filterausdrücken und Falco-Regeln auswerten kannst. Außerdem kannst du mit ihnen neue Felder definieren, die Informationen aus Ereignissen extrahieren können.

Abbildung 4-6. Falco-Plugins
Konzepte der Plugin-Architektur
Plugins sind dynamische Shared Libraries (.so-Dateien unter Unix, .dll-Dateien unter Windows), die Funktionen der C-Aufrufkonvention exportieren. Falco lädt diese Bibliotheken dynamisch und ruft die exportierten Funktionen auf. Plugins werden mit Hilfe der semantischen Versionierung versioniert, um Regressionen und Kompatibilitätsprobleme zu minimieren. Sie können in jeder Sprache geschrieben werden, solange sie die benötigten Funktionen exportieren. Go ist die bevorzugte Sprache zum Schreiben von Plugins, gefolgt von C/C++.
Plugins enthalten zwei Hauptfunktionen, auch Capabilities genannt:
- Ereignisbeschaffung
-
Diese Fähigkeit wird verwendet, um eine neue Ereignisquelle zu implementieren. Eine Ereignisquelle kann einen Strom von Ereignissen "öffnen" und "schließen" und kann ein Ereignis über eine
nextMethode an libscap zurückgeben. Mit anderen Worten, sie wird verwendet, um Falco mit neuem "Material" zu versorgen. - Feld-Extraktion
-
Die Feldextraktion konzentriert sich darauf, Felder aus Ereignissen zu erzeugen, die von anderen Plugins oder den Kernbibliotheken generiert werden. Felder sind die grundlegenden Komponenten von Falco-Regeln. Wenn du also neue Felder bereitstellst, kannst du die Anwendbarkeit von Falco-Regeln auf neue Bereiche ausweiten. Ein Beispiel ist das JSON-Parsing, bei dem ein Plugin in der Lage ist, Felder aus beliebigen JSON-Nutzdaten zu extrahieren. Mehr über Felder erfährst du in Kapitel 6.
Ein einzelnes Plugin kann die Fähigkeit der Ereignisbeschaffung, die Fähigkeit der Feldextraktion oder beides gleichzeitig anbieten. Die Fähigkeiten werden durch die Implementierung bestimmter Funktionen in der Plugin-API-Schnittstelle exportiert.
Um das Schreiben von Plugins zu erleichtern, gibt es Go- und C++-SDKs, die sich um die Details der Speicherverwaltung und Typkonvertierung kümmern. Sie bieten eine schlanke Möglichkeit, Plugins zu implementieren, ohne sich mit den Details der Funktionen auf unterer Ebene, die die Plugin-API ausmachen, auseinandersetzen zu müssen.
Die Bibliotheken tun alles, was möglich ist, um die von den Plugins stammenden Daten zu überprüfen, um Falco und andere Verbraucher vor beschädigten Daten zu schützen. Aus Leistungsgründen wird den Plugins jedoch vertraut, und da sie im selben Thread und Adressraum wie Falco laufen, könnten sie das Programm zum Absturz bringen. Falco geht davon aus, dass du als Nutzer die Kontrolle hast und stellt sicher, dass nur von dir geprüfte Plugins geladen oder gepackt werden.
Wie Falco Plugins verwendet
Falco lädt Plugins basierend auf der Konfiguration in falco.yaml. Seit Sommer 2022, als dieses Buch in Druck ging, werden, wenn ein Quell-Plugin geladen ist, nur noch Ereignisse von diesem Plugin verarbeitet, und die Erfassung von Systemaufrufen ist deaktiviert. Außerdem kann eine laufende Falco-Instanz nur ein Plugin verwenden. Wenn du möchtest, dass Falco auf einem einzigen Rechner Daten von mehreren Plugins oder von Plugins und Treibern sammelt, musst du mehrere Falco-Instanzen laufen lassen und für jede davon eine andere Quelle verwenden.3
Falco konfiguriert Plugins über die Eigenschaft plugins in falco.yaml. Hier ist ein Beispiel:
plugins:-name:cloudtraillibrary_path:libcloudtrail.soinit_config:"..."open_params:"..."load_plugins:[cloudtrail]
Die Eigenschaft plugins in falco.yaml definiert die Menge der Plugins, die Falco laden kann, und die Eigenschaft load_plugins steuert, welche Plugins beim Start von Falco geladen werden.
Die Mechanismen zum Laden eines Plugins sind in libscap implementiert und nutzen die dynamischen Bibliotheksfunktionen des Betriebssystems.4 Der Plugin-Ladecode stellt außerdem sicher, dass:
-
Das Plugin ist gültig (d. h., es exportiert die erwarteten Symbole).
-
Die API-Versionsnummer des Plugins ist mit dem Plugin-Framework kompatibel.
-
Für eine bestimmte Ereignisquelle wird jeweils nur ein Quellen-Plugin geladen.
-
Wenn für eine bestimmte Ereignisquelle eine Mischung aus Quell- und Extraktor-Plugins geladen wird, haben die exportierten Felder eindeutige Namen, die sich nicht mit den Plugins überschneiden.
Eine aktuelle Liste der verfügbaren Falco-Plugins findest du im Plugins-Repository unter der Falcosecurity-GitHub-Organisation. Zum jetzigen Zeitpunkt unterhält die Falcosecurity-Organisation offiziell Plugins für CloudTrail, GitHub, Okta, Kubernetes Audit-Logs und JSON. Darüber hinaus gibt es Plugins von Drittanbietern für seccomp und Docker.
Wenn du daran interessiert bist, deine eigenen Plugins zu schreiben, findest du alles, was du wissen musst, in Kapitel 14. Wenn du ungeduldig bist und einfach nur den Code sehen willst, findest du den Quellcode für alle derzeit verfügbaren Plugins im Plugins-Repository.
Fazit
Herzlichen Glückwunsch, dass du es bis zum Ende dieses Kapitels geschafft hast, das eine Menge Informationen enthält! Was du hier gelernt hast, ist die Grundlage für das Verständnis und den Betrieb von Falco. Außerdem bildet es eine solide architektonische Grundlage, die dir jedes Mal nützlich sein wird, wenn du ein Sicherheitstool unter Linux ausführen oder einsetzen musst.
Als Nächstes erfährst du, wie der Kontext zu den erfassten Daten hinzugefügt wird, um Falco noch leistungsfähiger zu machen.
1 Lauf man 2 ptrace für weitere Informationen dazu.
2 Weitere Informationen findest du in dem Artikel "Using the Linux Kernel Tracepoints" von Mathieu Desnoyer.
3 Beachte, dass die Falco-Entwickler daran arbeiten, diese Einschränkung zu beseitigen. Daher wird Falco in Zukunft in der Lage sein, Daten von mehreren Plugins gleichzeitig zu empfangen oder Systemaufrufe zu erfassen und gleichzeitig Plugins zu verwenden.
4 Eine dynamische Bibliothek wird mit dlopen/dlsym unter Unix oder LoadLibrary/GetProcAddress unter Windows geladen.
Get Praktische Cloud Native Sicherheit mit Falco now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

