Chapter 4. Robustness
We know that ML models are not very generalizable—change a few things to the input, and the model breaks. A model’s ability to be resilient to variation in data is called robustness. To put things intuitively, no matter how good your training data is, the model is going to encounter unexpected things in the real world, and robustness is about making sure it’s ready for them.
Tip
At the core of this problem is the fact that you’re almost always training a model to solve for a proxy problem. For example, if you’re trying to make a dog versus cat image classifier, optimizing an image classifier to minimize the error on your limited training set is just a proxy. Your real goal is to distinguish cats and dogs in all possible cases, but the best you can do is this proxy because your computing resources are finite.
Sometimes, optimizing for your proxy won’t bring you very close to your real goal. Sometimes, if you optimize your proxy too much, your overoptimizing will cause you to do worse on your true goal. AI safety researchers have demonstrated that this applies to every single proxy measure ever (whether it’s an AI or human or group of humans doing the optimizing).1 Your best bet is to know what to look out for and spot early the signs that you’re overoptimizing.
There are two kinds of robustness: train-time robustness and test-time robustness. Train-time robustness focuses on the model’s ability to be resilient to adversarial examples added to the training data. Test-time robustness focuses on the model’s ability to generalize during testing to instances not necessarily seen during training. Since unexpected behavior during test time is most important to prevent in production settings, we will focus on test-time robustness in this chapter.
Note that there are also application-specific definitions of robustness. For example, in the NLP setting, researchers often refer to certified robustness. For notation, let’s denote a model as and example sentences as . The model predictions would be , which are many times discrete (or potentially a sequence of discrete for multilabel settings) numbers. Let be the correct label for . Let be modified with word substitutions, in which a word is swapped with its synonyms (usually defined using retrofitted word embeddings). A model is certifiably robust if, for any example sentence , and sentences that consist of modified with word substitutions, . Intuitively, this means that the model , given two examples that are different but semantically equivalent, is able to preserve predictions.
At its core, when a model lacks robustness, it cannot effectively generalize to test distributions that differ from training data distributions. Essentially, no matter how good your training data is, the model is going to encounter unexpected things in the real world, and robustness is about making sure it’s ready to handle noise in the real world.
There are natural parallels between fairness and robustness; specifically, you can think of fairness as robustness to perturbations that stem from demographic factors. For example, in NLP settings, demographic groups can be loosely identified by speech and language patterns. A non-robust model that was largely trained on transcribed examples of spoken utterances by people of a certain demographic would not be able to generalize well outside that group, so it would show low performance on demographic groups with speech and language patterns not seen in the training dataset. Research has empirically shown a relationship between these two trustworthiness goals.
Robustness is important because it shows us what will break the model. It also helps train the model to be ready for inputs that it may see in real life. This is especially important in critical and high-stakes applications like self-driving cars.
Imagine you’re working on a model for a self-driving car system created by a large company. So far, the model has been trained mostly on data from suburban US towns. Now, these cars have a consumer base that covers the United States, including urban, rural, and suburban settings. If this model is not robust, it may not adapt well to the driving patterns and additional visual noise of roads in urban settings. Since problems with self-driving cars could lead to accidents or even deaths, this lack of generalization is dangerous. You need to be confident that the system behaves correctly in any situations the car encounters. You also need to keep it safe from attackers, such as those outlined in Chapters 2 and 3.
Evaluating Robustness
There are several methods for evaluating and improving a model’s robustness. We can group them into two categories:
- Non-adversarial
-
Non-adversarial robustness methods are made up of explicit, predetermined transformations designed to test the ability of classifiers to generalize to low-probability but realistic instances that are present in real-world settings but may not be present in the training data.
- Adversarial
-
Adversarial robustness methods are made up of learned transformations that use machine learning models to modify and create inputs that fool the model. These are designed to develop classifiers that are robust to such attacks.
Adversarial methods include targeted and untargeted attacks. Targeted attacks are designed to fool the model into predicting a particular incorrect class, while untargeted attacks are designed to fool the model into predicting any incorrect class. For example, a targeted attack on an object detection model used in a self-driving car system might try to get the model to classify a dog as a cat; an untargeted attack would try to get it to classify a dog as anything other than a dog. While this may be a less critical error, targeted attacks can also cause models to create more harmful predictions.
Let’s take a look at examples of these transformations.
Non-Adversarial Robustness
First, let’s explore ways to evaluate for robustness by applying explicit, predetermined transformations designed to test the ability of classifiers to generalize to low-probability but realistic instances. There are several steps to applying non-adversarial robustness. First, given an example, apply perturbations. Second, calculate the similarity constraint keeping only perturbations that satisfy the constraint. We will now explain each step in turn.
Step 1: Apply Perturbations
In computer vision, perturbations occur at the pixel level. This may mean inputting pixels into the black-white color space (converting a picture to black-and-white) or zeroing out certain pixels (obscuring certain parts of an image). In NLP, you can add noise by replacing words in a sentence without changing its meaning (such as by adding filler words like “like” or “you know” or by paraphrasing). Let’s look at some examples.
Computer vision
Table 4-1 lists non-adversarial robustness methods for computer vision, with an example image for each.
| Version | Image |
|---|---|
Original |
|
Cropping—only showing a portion of the image |
|
Occlusion—blocking a portion of the image |
|
Shearing—slides one edge of an image along the X or Y axis |
|
Rotate—rotating an image |
|





To see how you can add noise to images, you’ll take code from the Augmentor library.2
importAugmentorp=Augmentor.Pipeline("/path/to/images")p.shear(max_shear_left=20,max_shear_right=20,probability=0.2)p.sample(50)
This will shear all images in the directory by a maximum of 25 degrees to the left or right, with a probability of 0.2, and write 50 images to the /path/to/images/folder/output/ folder. This means that 20% of the time, a sampled and saved image will be sheared. Figure 4-1 shows an example of one of these sampled images.
The image in Figure 4-1 is slightly slanted, or sheared, to the left.

Figure 4-1. Sample output from shearing images
Language
Let’s take a look at examples of data perturbations in NLP.
Here is a question someone might ask Alexa or another AI: "What is the full name of Thailand's capital city?" Table 4-2 shows some different ways you could phrase this question without changing its meaning.
| Perturbation type | Description | Example perturbation | Advantages of perturbation type | Disadvantages of perturbation type |
|---|---|---|---|---|
Token-level perturbation |
Deleting, replacing, or inserting tokens into the original utterance but still preserving the semantic meaning |
“What is the extended name of Thailand’s capital city?” |
Algorithmically more straightforward |
Can be computation-intensive; does not allow more complex perturbations such as phrase substitution or paraphrasing; relies on quality of word synonym lexicon |
Filler word addition |
Including various speech-related noise, such as filler words |
Uh, what’s the full name of Thailand’s capital city? |
Algorithmically more straightforward |
Limited to speech-related applications only |
Paraphrasing |
Rephrasing the original sentence |
“What is Bangkok’s full name?” |
Captures the complexity of variation in the human language |
Relies on the quality of the paraphrasing model |
Speech-to-text errors |
Including phonetically similar words, homophones, or pronunciation in varied accents |
“What is the full mane of Thailand’s capital city?” |
Accurately captures variation in spoken settings |
Can be hard to compute; depending on STT settings used in production, may not reflect real-world variation |
Vernacular change |
In spoken dialogue systems, there may be certain patterns of speech that are prevalent among certain subpopulations |
“Whit’s th’ stowed oot name o’ Thailand’s capital toon?” (Scottish) |
Depending on customer base, can reflect differences in speech patterns seen in production |
Can be difficult to generate examples of |
Step 2: Defining and Applying Constraints
Once we have these perturbations, in order to identify which ones are satisfactory, we need to define constraints. Let’s delve into some popular constraints in both NLP and computer vision.
Natural language processing
For text, it is crucial to ensure that perturbations are fluent: that is, that they are legitimate, natural-sounding sentences and are semantically equivalent to the original sentences. Let’s break down how to evaluate generated sentences for each of these aspects.
Fluency
You can use a language model (LM) to evaluate the fluency of a sentence. Language models will assign high probabilities to grammatically correct sentences and low probabilities to grammatically incorrect or unlikely sentences, so you’ll want to use evaluation metrics that take advantage of this. In terms of choice of language model, pre-trained language models are usually used, although those that have been fine-tuned or trained for the type of language you are evaluating fluency on are preferred (e.g., an LM that has been trained on Twitter if you are evaluating the fluency of a tweet).
Two common metrics are log probability and perplexity. The equations for the two metrics are as follows, where refers to a token at timestep t:
- Log probability
- Perplexity
Perplexity can also be reframed as the exponent of the cross-entropy loss:3
Note that while more performant language models will assign a higher log probability to well-formed sentences, they will have a lower perplexity score. This is because, for perplexity, as log probability increases (in the negative fractional exponent), perplexity decreases.
You might be wondering how you can calculate the probabilities in the definitions for the fluency metrics. It is common practice to use language models to evaluate the fluency of each synonym-substituted sentence and only keep sentences that have a similar fluency score to the original sentence. Note that this comes with limitations, since these language models themselves are imperfect.
Let’s see what it looks like to compute perplexity.
defget_fluency_score(text,tokenizer,model):input_ids=torch.tensor(tokenizer.encode(text)).unsqueeze(0)withtorch.no_grad():outputs=model(input_ids,labels=input_ids)loss,_=outputs[:2]perplexity=math.exp(loss.item())returnperplexity
While for certain scenarios fluency may be a satisfactory constraint, it is not enough for most cases.
Explore your own understanding of fluency: what are some examples of two sentences that are individually fluent, are similar except for noun substitution, but are not similar in meaning?
Preserving semantic meaning
Perplexity does not indicate if the perturbations preserve semantic meaning. Semantic similarity metrics can be used to fill this gap. One popular method to calculate the semantic similarity of two sentences is to embed them both using sentence-level encoders, then calculate their similarity (or other distance measures), such that sentences that are more similar in meaning will have higher similarity than those that are less similar.
A standard metric for textual similarity is cosine similarity of embeddings. Given the embedding A1 and B, the cosine similarity of these embeddings can be computed with the following:
Take the example of ALBERT, a sentence-level encoder. For a particular sentence, you get the embedding by taking the mean of the relevant embeddings to get a fixed vector, regardless of the length of the sentence. We will use the SentenceTransformer package, which allows us to train, evaluate, and run inference on models specifically trained to create useful embeddings. You can read more about the pooling process online.
Then, given the embeddings of both sentences, we can find the cosine similarity.
fromsentence_transformersimportSentenceTransformerfromnumpyimportdotfromnumpy.linalgimportnormdefcosine_similarity(a,b):returndot(a,b)/(norm(a)*norm(b))defget_similarity(sentence,paraphrase):model=SentenceTransformer('paraphrase-albert-small-v2')embs_1=model.encode([sentence])embs_2=model.encode([paraphrase])returncosine_similarity(embs_1,emb_2)
Now let’s test this function out on a valid paraphrased sentence.
get_similarity("Keto diet is a popular diet in the US among fitness enthusiasts","Many fitness communities such as Crossfit follow to the keto diet")0.7476
To compare, let’s do the same thing with two sentences that are not paraphrases of each other.
get_similarity('Keto diet is a popular diet in the US among fitness enthusiasts","You want to minimize carbs on keto")0.57090
You can see that the cosine similarity and semantic meaning are pretty similar. See the notebooks for the full code snippet.
As the name might suggest, ALBERT is part of a family of encoders based on BERT that can detect semantic similarity this way (another example being RoBERTa), and more encoders are released every month. However, for this kind of evaluation, it’s important to use models shown to be highly accurate in evaluating language of the same source and type as the example. An example that contains more formal language, for instance, might not work well with a model trained on tweets.
Semantic similarity also depends on the task at hand. Imagine you are testing the robustness of an intent classification model in a task-oriented dialogue system that allows a user to book a restaurant that serves a specific type of cuisine. To get accurate results, the model might need to perturb utterances while fixing certain attributes, such as type of intent. For example, a person might ask, “Can you find cheap restaurants that serve Indian food?” One way to perturb this sentence is to keep the attributes of Indian food: “Can you bookmark Baar Baar as a great restaurant that serves Indian food?” Another way is to keep the intent (finding restaurants) and perturb the attribute of type of food: “Can you find cheap restaurants that serve Thai food?” Thus, it is important to evaluate a model’s generations based on the task at hand.
Computer vision
For computer vision, instead of embeddings of tokens and sentences, we are concerned with pixel vectors. We can then use metrics such as cosine similarity, as well as L2 distance, which is commonly used in computer vision.
Representing the pixel values of an image by the matrix , we compute the absolute and relative L2 distances:
Table 4-3 lists types of semantic similarity metrics, many of which can be computed for both computer vision and NLP.
| Semantic similarity | Advantages | Disadvantages | Specific to NLP or computer vision |
|---|---|---|---|
Cosine similarity |
|
May not correlate with human notions of similarity |
Both |
L2 distance |
|
May not correlate with human notions of similarity |
Both |
Paraphrase classification |
Correlate more closely with human notions of similarity |
Rely on performance of models |
NLP |
Deep Dive: Word Substitution with Cosine Similarity Constraints
Now let’s return to the word substitution function and tie in the constraints to get acceptable perturbations.
A perturbation is fluent if the perplexity score of the resulting sentence is within 30 points of the score of the original sentence. An increase in perplexity of more than 30 may mean that the generated sentence is gibberish. We only keep a perturbation if it fulfills both fluency and semantic similarity constraints.
importtorchfromnltk.corpusimportwordnetaswnfromtransformersimportGPT2Tokenizer,GPT2LMHeadModelimportmathfromtransformersimportBertModel,BertConfig,BertTokenizerfromnumpyimportdotfromnumpy.linalgimportnormfromtextblobimportTextBlobimportrandomdefget_perturbations(sentence,eval_model_name):tokenizer=GPT2Tokenizer.from_pretrained("gpt2")model=GPT2LMHeadModel.from_pretrained("gpt2")model.eval()tokens=sentence.split(" ")num_to_replace=random.randint(1,len(tokens))blob=TextBlob(sentence)nouns=[nforn,tinblob.tagsif"NN"int]perturbations=[]fornouninnouns:forsynonyminwn.synsets(noun):ifsynonym.pos()!="n":continuesynonym=synonym.lemma_names()[0](synonym)ifsynonym!=noun:if"_"insynonym:synonym=synonym.split("_")[1]perturbation=sentence.replace(noun,synonym)if(get_fluency_score(sentence,tokenizer,model)-get_fluency_score(perturbation,tokenizer,model)<30andcosine_similarity(sentence,perturbation)>0.95):perturbations.append(perturbation)(perturbations)returnperturbations
Try running the following function with the input Hate is the opposite of love. You will get the following perturbations.
Hate is the antonym of love Hate is the reverse of love Hate is the opposition of love Hate is the inverse of love Hate is the opposite of beloved Hate is the opposite of love
Noun-based word substitutions are very computation intensive, especially when done over hundreds of thousands of examples. To address this, we can use methods such as AttackToTrain (a2t) to only substitute important words, or nouns, rather than all nouns. Instead of perturbing every single noun to see the effect on the model prediction, you could perturb only the most important nouns. (Here, importance is based on Yoo and Qi’s definition: “how much the target model’s confidence on the ground truth label changes when the word is deleted from the input.”)4
For example, take the following input.
'Can you find me a pastel dress for a friend's wedding?'
Instead of perturbing both dress and wedding, for an intent classification model, you would perturb dress, since the intent is to buy a particular article of clothing.
This importance can be calculated by the gradient of the loss of the task at hand (in this example, the cross-entropy loss for the intent classification model) with respect to the word.
This speeds up computation by calculating word importance with one pass for each example, rather than multiple passes for each word.
AttackToTrain uses a gradient-based word importance ranking method to replace each word in an input, iteratively, with synonyms generated from a counterfeited word embedding. Let’s use the following sentences as input.
Walmart said it would check all of its million-plus domestic workers to ensure they were legally employed. It has also said it would review all of its domestic employees (more than one million) to ensure they have legal status.
We can use the TextAttack package to find adversarial examples and use paraphrase classification models to identify which perturbations to keep. The tool kit houses a set of attack and constraint evaluation methods, including the a2t adversarial method.
Let’s try it on the Walmart example, which is from the Microsoft Research Paraphrase Corpus (MRPC) dataset. We will use the DistilBERT-based paraphrase model, which has been fine tuned on MRPC, to generate the word-importance rankings.
pip install textattack
textattack attack --model distilbert-base-cased-mrpc \
--recipe a2t \
--dataset-from-huggingface glue^mrpc \
--num-examples 20
Table 4-4 shows some of the paraphrases this generates.
| Input | Output | |
|---|---|---|
Walmart said it would check all of its million-plus domestic workers to ensure they were legally employed. |
Walmart said it would check all of its million-plus domestic workers to ensure they were legitimately employed. |
|
It has also said it would review all of its domestic employees more than 1 million to ensure they have legal status. |
It has also said it would be reviewing all of its domestic employees more than 1 million to ensure they have lawful status. |
You can see more details on how to use the TextAttack tool kit in its documentation.
To summarize, a good generation from a data corruption method is one that (1) maintains a similar level of fluency to the original sentence (similar perplexity or log probability) and (2) preserves the meaning of the original sentence (the sentence embedding has high cosine similarity to that of the original sentence).
These non-adversarial methods, using methods such as Attack2Train, create test data of examples that the model will most likely encounter in production. These examples can then be added to the test data to identify potential weaknesses in a model’s ability to generalize. However, it is impossible (or at best difficult) to ensure a model is robust to all types of inputs that can be expected in very open-domain settings. This is the motivation behind adversarial robustness methods, which use a more automated method to find the data perturbations that are most likely to break the model.
Adversarial Robustness
At the beginning of this chapter, we told you that adversarial robustness methods are learned transformations that use machine learning models to modify and create inputs that fool the model. In short, you train an adversary model that aims to modify inputs to trick the predictor, or the main model (we’ll call it ). The main difference between adversarial and non-adversarial robustness is that adversarial robustness uses gradient-based approaches to create an input that fools the model, whereas non-adversarial robustness methods modify an input (with no guarantee of fooling the model).
Adversarial robustness is helpful in high-stakes environments where users could misuse your model to get particular predictions. The examples these methods create are unlikely to reflect the bulk of your day-to-day inputs, so it helps to use both adversarial and non-adversarial robustness methods to benchmark your ML systems.
Let’s take a neural model with weights and an input . Adversarial robustness aims to maximize the error of model with respect to , to find an that fools the model. There are multiple ways to formulate this, for example, , where is the confidence of the model with weights on the correct label for .
To see how adversarial robustness works, let’s look at an example.
Deep Dive: Adversarial Attacks in Computer Vision
In this section, we’ll dive deeper using two examples from computer vision: a HopSkipJump attack and a simple transparent adversarial attack. The first shows how the effectiveness of typical adversarial attacks varies based on the properties of the test image. The second illustrates how to craft adversarial attacks, even without sophisticated developing expertise.
The HopSkipJump attack on ImageNet
The HopSkipJump adversarial attack on a (non-probabilistic) classification model aims to craft an adversarial sample close to a target test image, as per L2 or Linf distance, that has a different predicted label than the prediction for the target image it is attacking. HopSkipJump works in steps. It initializes at an image of a different label far away from the target image, then iteratively generates adversarial sample images that are closer and closer to the target image, but still have a different label. If you continue this process for a large number of steps, eventually you’ll end up with an image that is visually indistinguishable from the target image, but has a different label predicted by the model being attacked.
We build upon the tutorial notebook part of IBM’s Adversarial Robustness Toolbox documentation. We start by initializing a Keras classifier on a ResNet50 model with pre-trained ImageNet weights.
importnumpyasnpimporttensorflowastftf.compat.v1.disable_eager_execution()importtensorflow.kerasfromtensorflow.keras.applications.resnet50importResNet50fromart.estimators.classificationimportKerasClassifier# modelmean_imagenet=np.zeros([224,224,3])mean_imagenet[...,0].fill(103.939)mean_imagenet[...,1].fill(116.779)mean_imagenet[...,2].fill(123.68)model=ResNet50(weights='imagenet')classifier=KerasClassifier(clip_values=(0,255),model=model,preprocessing=(mean_imagenet,np.ones([224,224,3])))
As test data, we use a group of 16 images from ImageNet Stubs. The code loads the data and obtains predictions for each image.
importpandasaspdimportimagenet_stubsfromimagenet_2012_labelsimportlabel_to_name,name_to_labelall_paths=imagenet_stubs.get_image_paths()all_imgs=[]forpathinall_paths:img=image.load_img(path,target_size=(224,224))img=image.img_to_array(img)all_imgs.append(img)all_names=[os.path.basename(path)forpathinall_paths]all_probs=[np.max(classifier.predict(np.array([img])))forimginall_imgs]all_labels=[np.argmax(classifier.predict(np.array([img])))forimginall_imgs]img_data=pd.DataFrame({"name":[os.path.splitext(name)[0]fornameinall_names],"label":[label_to_name(label)forlabelinall_labels],"prob":[round(p,3)forpinall_probs],"img":all_imgs,}).set_index("name")# check dataimg_data[["label","prob"]].sort_values(["prob"])
Observe in Table 4-5 that the maximum predicted probability varies across the board for different images: from around 0.5 (malamute, beagle, standard_poodle) to very close to 1 (mitten, koala, manhole_cover). So, what happens when we try to craft adversarial attacks for a sure shot image like koala versus something relatively uncertain like beagle? Let’s find out.
| Name | Label | Probability |
|---|---|---|
malamute |
Eskimo dog, husky |
0.494 |
beagle |
beagle |
0.530 |
standard_poodle |
standard poodle |
0.569 |
marmoset |
titi, titi monkey |
0.623 |
tractor |
tractor |
0.791 |
koala |
koala, koala bear, kangaroo bear |
0.99 |
bagle |
bagel, beigel |
0.997 |
We take five images with varying values of predicted probabilities, and perform 40 steps HopSkipJump for each image. At steps 0, 10, 20, 30 and 40, we compute L2 distances between the original and adversarial images to see how different the perturbed image is from the original, as shown in Figure 4-2.
A number of important observations come up.
-
The L2 error is smallest for beagle, which had the most uncertainty, with probability 0.53 for the majority class (Table 4-5). This means that the fewest perturbations had to be applied to the original image to fool the model.
-
Koala had the highest majority-class probability and the highest L2 error.
-
The predicted label for beagle is bluetick, which is a dog breed with a similarly shaped face.
In general, images with smaller majority-class probability generate adversarial images with more similar labels than those with larger majority-class probability.

Figure 4-2. Three images from ImageNet Stubs, with each row showing its original version (left), an adversarial version at step 0 (middle), and an adversarial version at step 40 (right) (arranged top to bottom by increasing values for maximum predicted probability)
The preceding outputs underline the fact that prediction difficulty influences what adversarial images the attack mechanism creates, both in terms of the adversarial image itself and its predicted label. Adversarial versions of more ambiguous, harder-to-predict images are much closer to the original image than those of easier-to-predict images, as shown in Figure 4-3.
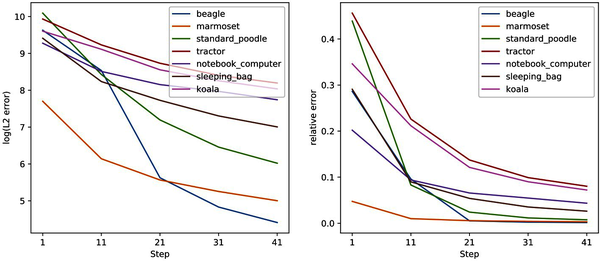
Figure 4-3. Absolute and relative L2 errors for ImageNet Stubs images (absolute errors are in log scale, and relative errors are ratios of the non-log L2 error to the L2 norm of the original image)
Do you notice anything weird about malamute and marmoset in Table 4-5? Use the code in the notebook to examine the HopSkipJump attacks on them. What do you think is going on here?
Creating Adversarial Examples
Many adversarial attack techniques, including HopSkipJump, are computation-intensive and require a basic knowledge of Python programming. However, a 2021 research paper suggests an embarrassingly simple attack known as Simple Transparent Adversarial Examples.5 This method can break publicly deployed image recognition APIs by embedding small amounts of high-transparency text into an image. No coding knowledge is required: there are many free online text-embedding tools available. These tools also allow users to adjust the text’s transparency, size, and angle of rotation.
Let’s check out how this works.
After choosing a font size, rotation angle, and opacity, there are two ways of embedding text: single and repeated.
In single embedding, the phrase is embedded once at a certain coordinate within an image.
In repeated embedding, the phrase is embedded repeatedly at the coordinates of a grid inside the original image.
The following code creates a Python class to embed a given text in an image.
The class SimpleTransparentExamples is initialized with the image, a text to embed, and a font style to embed in.
The text is embedded in the image using parameters in generate, e.g., transparency, angle, and position.
# simple transparent adversarial examplesfromPILimportImage,ImageDraw,ImageFontclassSimpleTransparentExamples:def__init__(self,image,text,font=ImageFont.truetype("sans_serif.ttf",16)):self.image=imageself.text=textself.font=fontdefgenerate(self,alpha=0.3,angle=0,x=0,y=0,image_init=None,resume=False):# watermarkopacity=int(256*alpha)mark_width,mark_height=self.font.getsize(self.text)patch=Image.new("RGBA",(mark_width,mark_height),(0,0,0,0))ImageDraw.Draw(patch).text((0,0),text=self.text,font=self.font,fill=(255,0,0,opacity))patch=patch.rotate(angle,expand=1)# mergewx,wy=patch.sizeifresume==True:img=image.array_to_img(image_init)else:img=self.image.copy()img.paste(patch,(x,y,x+wx,y+wy),patch)img=image.img_to_array(img)returnimg
Figure 4-4 plots the results of running the preceding code on the beagle image. The first one is the original image. While the three images look identical to the human eye, the second and third result in different model predictions. In actuality, the second image has a red “Hello World” embedded at 30 degrees rotation, 16 px font size, and 0.1 opacity at x = 40, y = 20, while the third image has black “Hello World” embedded at 30 degrees rotation, 8 px font size, and 0.5 opacity at 20 px grids.
It takes only seconds to find these adversarial images. You simply pick the alpha (transparency) and angle parameters, then do a grid search across values of the x-y coordinate pairs. For the single-occurrence example, you try placing the phrase at different points in the original image—the two closest points differ by 20 pixels on either the x or y coordinates. For the repeated occurrence example, you continue placing Hello World on this 20-pixel grid of points until the output label changes. You can find the code to do this in this notebook.

Figure 4-4. Simple transparent adversarial examples
The outcomes in this example show that creating adversarial samples is actually really, really easy—you don’t require sophisticated code/ML to do this! We did use Python code to create a mechanism to embed text into the image, but someone with basic computer literacy can instead use one of the many freely available online tools to do that, and they can find an adversarial image that looks basically the same as the original image simply by trial and error.
As you examine Figure 4-4, can you spot the texts? Try to break predictions for other images using this method. Is it less or more difficult? Why?
Adversarial methods for testing robustness in NLP are more difficult than those in computer vision. Words and sentences are more discrete than pixels and cannot be used in a gradient in the same way.6 Additionally, definitions of distance in the input space are more constrained and varied, and perturbations to sentences can be costly. For example, to use word perturbations, you must first build a dictionary of suitable substitutions for each word, then use it to create perturbations for each word in an input.
Improving Robustness
The research we’ve shown you in this chapter has made clear that models trained with certain types of noise are unable to generalize to other types of noise not seen in the training data. Thus, you may need to incorporate robustness methods in your model-training regimes as well. We’ll finish the chapter with a quick look at some ways to do that:
- Simple data augmentation
-
Adding data that encompasses minority samples to training data is a way to improve robustness. Examples from libraries like TextAttack for NLP are a good place to start.
- Regularization methods
-
Regularization can be used to improve robustness in models by encouraging the model to learn features that can more easily generalize to out-of-domain distribution examples. Some work in this vein includes HiddenCut, InfoBert, and causality-based regularization:
-
HiddenCut is a technique that modifies dropout to strike out adjacent words that are more likely to contain similar and redundant information.7 HiddenCut drops hidden units more structurally by masking the entirety of the hidden information of contiguous spans of tokens after every encoding layer. This encourages the models to fully utilize all task-related information instead of learning spurious patterns during training.
-
InfoBERT uses several regularizers, including one that suppresses noisy mutual information between the input and the feature representation and another that increases the mutual information between local robust features and global features.8 Some papers have started to improve robustness (and fairness) with techniques from causal inference (see Chapter 3).9 Others look into integrating loss functions that penalize reliance on spurious features and encourage causal features. We leave the details of this to Chapter 6.
-
- Adversarial training
-
Adversarial training is a natural extension of adversarial attacks. It uses examples created by an adversary to train the model (in addition to the original training set). You can also perform such training in a loop (Figure 4-5), alternating between training the adversary (fixing the model) and training the model (fixing the adversary). The TextAttack library also supports adversarial training (see the documentation for more).

Figure 4-5. Depiction of the adversarial training process
A variety of tool kits have been developed to test the robustness of machine learning systems. Table 4-6 offers a sample to explore.
| Tool kit name | Features | Domain |
|---|---|---|
|
NLP |
|
Has all of the preceding and sentence-level attacks |
NLP |
|
Image augmentation, training, and evaluating CV models |
Computer vision |
|
Image augmentation |
Computer Vision |
|
Attacks based on adversarial examples and defenses to improve the robustness of machine learning models |
Computer vision |
Conclusion
As you’ve seen in this chapter, while models are able to achieve impressive feats such as generating beautiful art or writing poetry, they are still susceptible to noise and biases. Thus, for high-stakes real-world use cases, it is imperative to conduct robustness testing to ensure that models will work well in the wild.
1 Simon Zhaung and Dylan Hadfield-Menell, “Consequences of Misaligned AI”, 34th Conference on Neural Information Processing Systems (2020).
2 Marcus D Bloice et al., “Biomedical Image Augmentation Using Augmentor”, Bioinformatics 35, no. 21 (November 2019): 4522–24.
3 Aerin Kim, “Perplexity Intuition (And Its Derivation)”, Towards Data Science (blog), October 11, 2018.
4 Jin Yong Yoo and Yanjun Qi, “Towards Improving Adversarial Training of NLP Models”, arXiv preprint (2021).
5 Jaydeep Borkar and Pin-Yu Chen, “Simple Transparent Adversarial Examples”, ICLR 2021 Workshop on Security and Safety in Machine Learning Systems (2021).
6 Workaround methods for discrete sampling in text generation, such as Gumbel-Softmax, are advanced topics outside the scope of this book. See Eric Jang et al., “Categorical Reparameterization with Gumbel-Softmax”, arXiv preprint (2016); Matt J. Kusner and José Miguel Hernández-Lobato, “GANS for Sequences of Discrete Elements with the Gumbel-softmax Distribution”, arXiv preprint (2016); and Ivan Fursov et al., “A Differentiable Language Model Adversarial Attack on Text Classifiers”, IEEE Access 10 (2022): 17966-76.
7 Jiaao Chen et al., “HiddenCut: Simple Data Augmentation for Natural Language Understanding with Better Generalizability”, Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (2021): 4380–90.
8 Boxin Wang et al., “InfoBERT: Improving Robustness of Language Models from an Information Theoretic Perspective”, arXiv preprint (2021).
9 Zhao Wang et al., “Enhancing Model Robustness and Fairness with Causality: A Regularization Approach”, arXiv preprint (2021).
Get Practicing Trustworthy Machine Learning now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

