Chapter 1. Machine Learning for Computer Vision
Imagine that you are sitting in a garden, observing what’s going on around you. There are two systems in your body that are at work: your eyes are acting as sensors and creating representations of the scene, while your cognitive system is making sense of what your eyes are seeing. Thus, you might see a bird, a worm, and some movement and realize that the bird has walked down the path and is eating a worm (see Figure 1-1).

Figure 1-1. Human vision involves our sensory and cognitive systems.
Computer vision tries to imitate human vision capabilities by providing methods for image formation (mimicking the human sensory system) and machine perception (mimicking the human cognitive system). Imitation of the human sensory system is focused on hardware and on the design and placement of sensors such as cameras. The modern approach to imitating the human cognitive system consists of machine learning (ML) methods that are used to extract information from images. It is these methods that we cover in this book.
When we see a photograph of a daisy, for example, our human cognitive system is able to recognize it as a daisy (see Figure 1-2). The machine learning models for image classification that we build in this book imitate this human capability by starting from photographs of daisies.
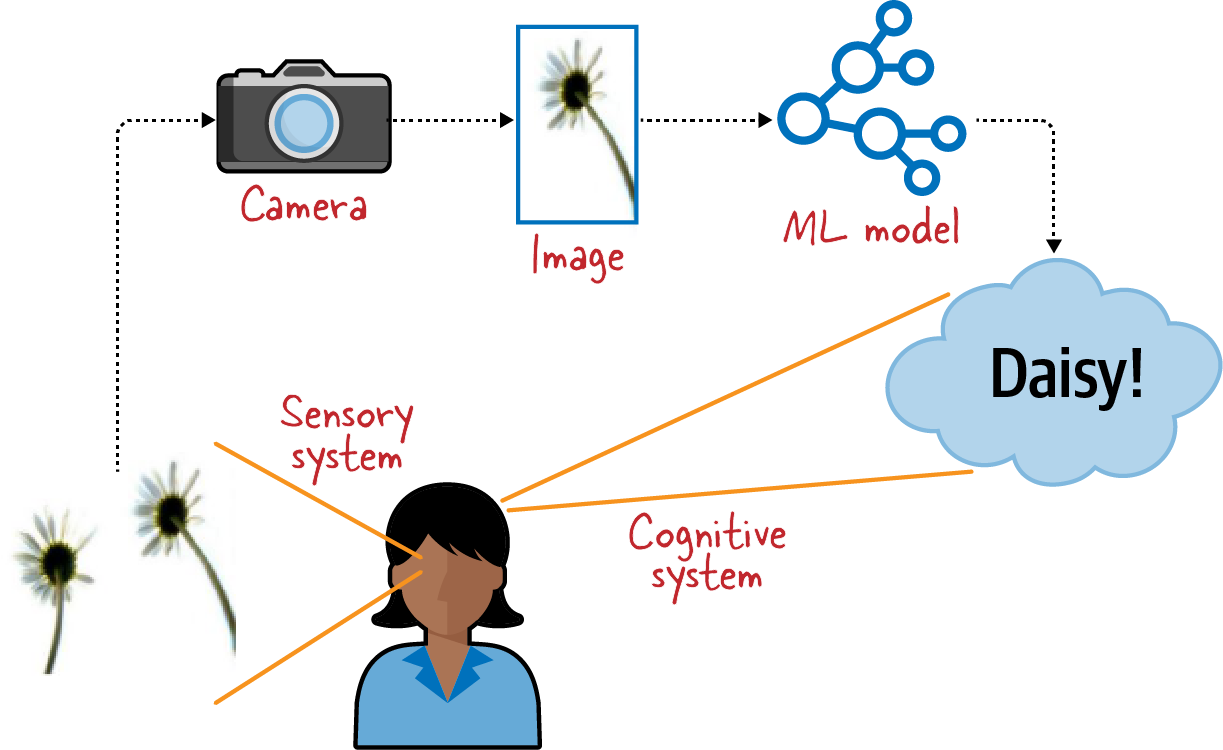
Figure 1-2. An image classification machine learning model imitates the human cognitive system.
Machine Learning
If you were reading a book on computer vision in the early 2010s, the methods used to extract information from photographs would not have involved machine learning. Instead, you would have been learning about denoising, edge finding, texture detection, and morphological (shape-based) operations. With advancements in artificial intelligence (more specifically, advances in machine learning), this has changed.
Artificial intelligence (AI) explores methods by which computers can mimic human capabilities. Machine learning is a subfield of AI that teaches computers to do this by showing them a large amount of data and instructing them to learn from it. Expert systems is another subfield of AI—expert systems teach computers to mimic human capabilities by programming the computers to follow human logic. Prior to the 2010s, computer vision tasks like image classification were commonly done by building bespoke image filters to implement the logic laid out by experts. Nowadays, image classification is achieved through convolutional networks, a form of deep learning (see Figure 1-3).
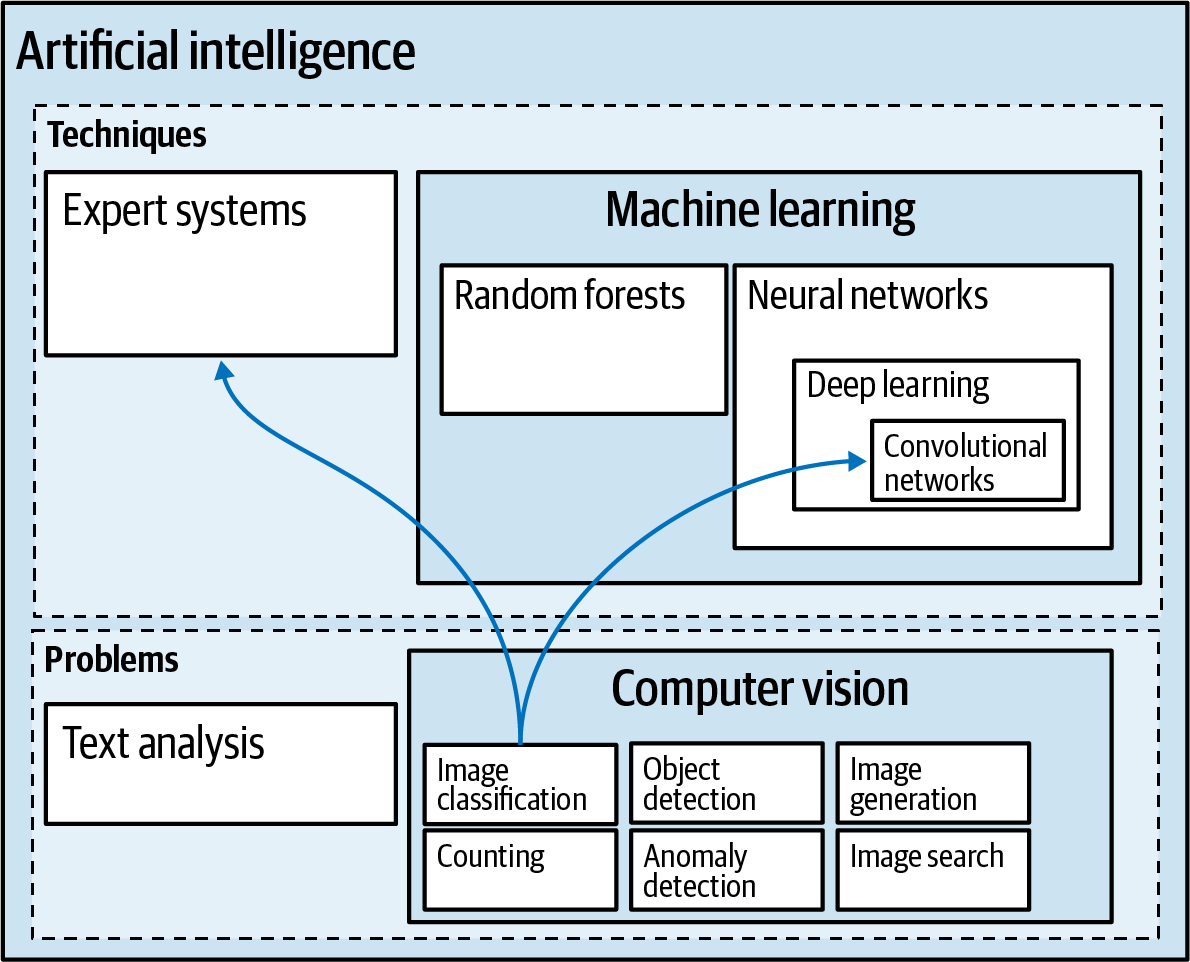
Figure 1-3. Computer vision is a subfield of AI that tries to mimic the human visual system; while it used to rely on an expert systems approach, today it’s done with machine learning.
Take, for example, the image of the daisy in Figure 1-2. A machine learning approach teaches a computer to recognize the type of flower in an image by showing the computer lots of images along with their labels (or correct answers). So, we’d show the computer lots of images of daisies, lots of images of tulips, and so on. Based on such a labeled training dataset, the computer learns how to classify an image that it has not encountered before. How this happens is discussed in Chapters 2 and 3.
In an expert system approach, on the other hand, we would start by interviewing a human botanist on how they classify flowers. If the botanist explained that bellis perennis (the scientific name for a daisy) consists of white elongated petals around a yellow center and green, rounded leaves, we would attempt to devise image processing filters to match these criteria. For example, we’d look for the prevalence of white, yellow, and green in the image. Then we’d devise edge filters to identify the borders of the leaves and matched morphological filters to see if they match the expected rounded shape. We might smooth the image in HSV (hue, saturation, value) space to determine the color of the center of the flower as compared to the color of the petals. Based on these criteria, we might come up with a score for an image that rates the likelihood that it is a daisy. Similarly, we’d design and apply different sets of rules for roses, tulips, sunflowers, and so on. To classify a new image, we’d pick the category whose score is highest for that image.
This description illustrates the considerable bespoke work that was needed to create image classification models. This is why image classification used to have limited applicability.
That all changed in 2012 with the publication of the AlexNet paper. The authors—Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton—were able to greatly outperform any existing image classification method by applying convolutional networks (covered in Chapter 3) to the benchmark dataset used in the ImageNet Large-Scale Visual Recognition Challenge (ILSVRC). They achieved a top-51 error of 15.3%, while the error rate of the runner-up was over 26%. Typical improvements in competitions like this are on the order of 0.1%, so the improvement that AlexNet demonstrated was one hundred times what most people expected! This was an attention-grabbing performance.
Neural networks had been around since the 1970s, and convolutional neural networks (CNNs) themselves had been around for more than two decades by that point—Yann LeCun introduced the idea in 1989. So what was new about AlexNet? Four things:
- Graphics processing units (GPUs)
-
Convolutional neural networks are a great idea, but they are computationally very expensive. The authors of AlexNet implemented a convolutional network on top of the graphics rendering libraries provided by special-purpose chips called GPUs. GPUs were, at the time, being used primarily for high-end visualization and gaming. The paper grouped the convolutions to fit the model across two GPUs. GPUs made convolutional networks feasible to train (we’ll talk about distributing model training across GPUs in Chapter 7).
- Rectified linear unit (ReLU) activation
-
AlexNet’s creators used a non-saturating activation function called ReLU in their neural network. We’ll talk more about neural networks and activation functions in Chapter 2; for now, it’s sufficient to know that using a piecewise linear non-saturating activation function enabled their model to converge much faster.
- Regularization
-
The problem with ReLUs—and the reason they hadn’t been used much until 2012—was that, because they didn’t saturate, the neural network’s weights became numerically unstable. The authors of AlexNet used a regularization technique to keep the weights from becoming too large. We’ll discuss regularization in Chapter 2 too.
- Depth
-
With the ability to train faster, they were able to train a more complex model that had more neural network layers. We say a model with more layers is deeper; the importance of depth will be discussed in Chapter 3.
It is worth recognizing that it was the increased depth of the neural network (allowed by the combination of the first three ideas) that made AlexNet world-beating. That CNNs could be sped up using GPUs had been proven in 2006. The ReLU activation function itself wasn’t new, and regularization was a well-known statistical technique. Ultimately, the model’s exceptional performance was due to the authors’ insight that they could combine all of these to train a deeper convolutional neural network than had been done before.
Depth is so important to the resurging interest in neural networks that the whole field has come to be referred to as deep learning.
Deep Learning Use Cases
Deep learning is a branch of machine learning that uses neural networks with many layers. Deep learning outperformed the previously existing methods for computer vision, and has now been successfully applied to many other forms of unstructured data: video, audio, natural language text, and so on.
Deep learning gives us the ability to extract information from images without having to create bespoke image processing filters or code up human logic. When doing image classification using deep learning, we need hundreds or thousands or even millions of images (the more, the better), for which we know the correct label (like “tulip” or “daisy”). These labeled images can be used to train an image classification deep learning model.
As long as you can formulate a task in terms of learning from data, it is possible to use computer vision machine learning methods to address the problem. For example, consider the problem of optical character recognition (OCR)—taking a scanned image and extracting the text from it. The earliest approaches to OCR involved teaching the computer to do pattern matching against what individual letters look like. This turns out to be a challenging approach, for various reasons. For example:
-
There are many fonts, so a single letter can be written in many ways.
-
Letters come in different sizes, so the pattern matching has to be scale-invariant.
-
Bound books cannot be laid flat, so the scanned letters are distorted.
-
It is not enough to recognize individual letters; we need to extract the entire text. The rules of what forms a word, a line, or a paragraph are complex (see Figure 1-4).
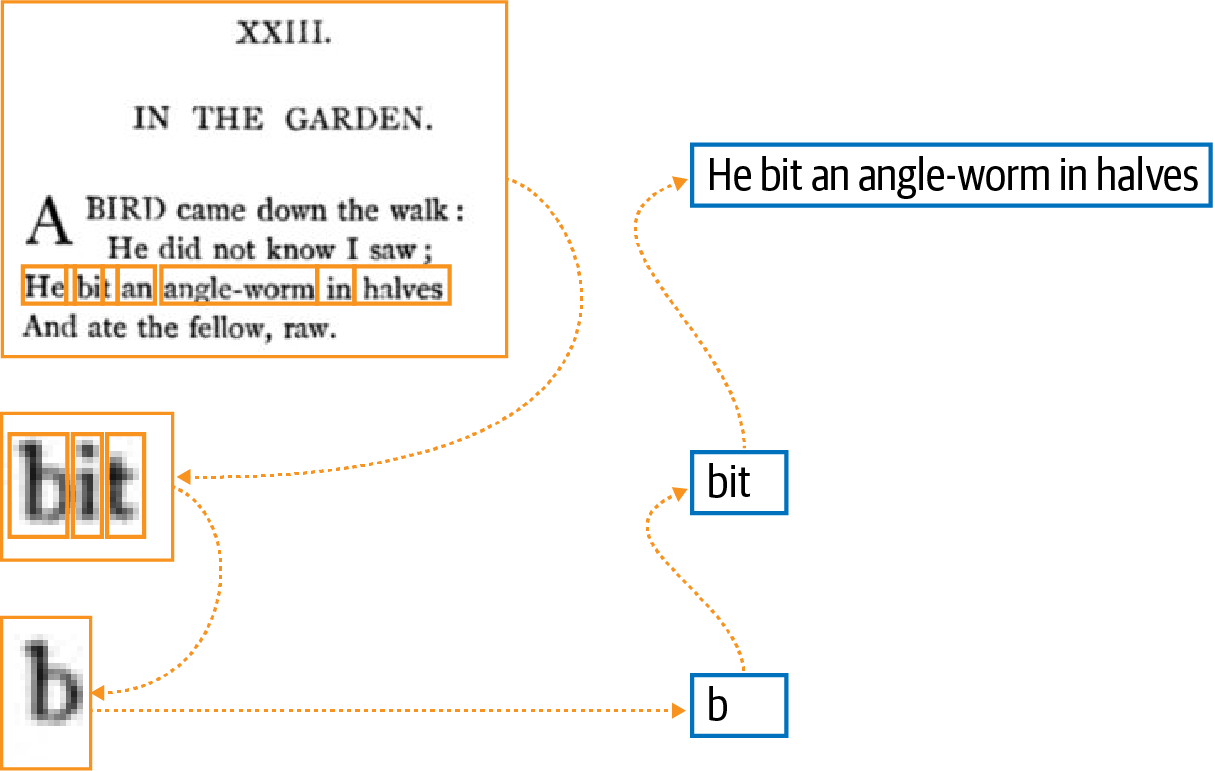
Figure 1-4. Optical character recognition based on rules requires identifying lines, breaking them into words, and then identifying the component letters of each word.
On the other hand, with the use of deep learning, OCR can be quite easily formulated as an image classification system. There are many books that have already been digitized, and it’s possible to train the model by showing it a scanned image from a book and using the digitized text as a label.
Computer vision methods provide solutions for a variety of real-world problems. Besides OCR, computer vision methods have been successfully applied to medical diagnosis (using images such as X-rays and MRIs), automating retail operations (such as reading QR codes, recognizing empty shelves, checking the quality of vegetables, etc.), surveillance (monitoring crop yield from satellite images, monitoring wildlife cameras, intruder detection, etc.), fingerprint recognition, and automotive safety (following cars at a safe distance, identifying changes in speed limits from road signs, self-parking cars, self-driving cars, etc.).
Computer vision has found use in many industries. In government, it has been used for monitoring satellite images, in building smart cities, and in customs and security inspections. In healthcare, it has been used to identify eye disease and to find early signs of cancer from mammograms. In agriculture, it has been used to spot malfunctioning irrigation pumps, assess crop yields, and identify leaf disease. In manufacturing, it finds a use on factory floors for quality control and visual inspection. In insurance, it has been used to automatically assess damage to vehicles after an accident.
Summary
Computer vision helps computers understand the content of digital images such as photographs. Starting with a seminal paper in 2012, deep learning approaches to computer vision have become wildly successful. Nowadays, we find successful uses of computer vision across a large number of industries.
We’ll start our journey in Chapter 2 by creating our first machine learning models.
1 Top-5 accuracy means that we consider the model to be correct if it returns the correct label for an image within its top five results.
Get Practical Machine Learning for Computer Vision now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

