Capítulo 4. Preparación de datos textuales para la estadística y el aprendizaje automático
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Técnicamente, cualquier documento de texto no es más que una secuencia de caracteres. Para construir modelos sobre el contenido, necesitamos transformar un texto en una secuencia de palabras o, de forma más general, en secuencias significativas de caracteres llamadas tokens. Pero eso por sí solo no basta. Piensa en la secuencia de palabras Nueva York, que debe tratarse como una única entidad con nombre. Identificar correctamente tales secuencias de palabras como estructuras compuestas requiere un procesamiento lingüístico sofisticado.
La preparación de datos o preprocesamiento de datos en general implica no sólo la transformación de los datos en una forma que pueda servir de base para el análisis, sino también la eliminación del ruido perturbador. Lo que es ruido y lo que no lo es depende siempre del análisis que vayas a realizar. Cuando se trabaja con texto, el ruido tiene distintos sabores. Los datos en bruto pueden incluir etiquetas HTML o caracteres especiales que deben eliminarse en la mayoría de los casos. Pero las palabras frecuentes que tienen poco significado, las llamadas stop words, introducen ruido en el aprendizaje automático y el análisis de datos porque dificultan la detección de patrones.
Lo que aprenderás y lo que construiremos
En este capítulo, desarrollaremos los planos de una tubería de preprocesamiento de texto. El proceso tomará el texto en bruto como entrada, lo limpiará, lo transformará y extraerá las características básicas del contenido textual. Empezaremos con expresiones regulares para la limpieza de datos y la tokenización, y luego nos centraremos en el procesamiento lingüístico de con spaCy. spaCy es una potente biblioteca de PNL con una API moderna y modelos de última generación. Para algunas operaciones haremos uso de textacy, una biblioteca que proporciona algunas buenas funciones adicionales, especialmente para el preprocesamiento de datos. También apuntaremos a NLTK y a otras bibliotecas siempre que parezca útil.
Después de estudiar este capítulo, conocerás los pasos necesarios y opcionales de la preparación de datos. Sabrás cómo utilizar expresiones regulares para la limpieza de datos y cómo utilizar spaCy para la extracción de características. Con los planos proporcionados podrás configurar rápidamente un canal de preparación de datos para tu propio proyecto.
Un proceso de preprocesamiento de datos
El preprocesamiento de datos suele implicar una secuencia de pasos. A menudo, esta secuencia se denomina canalización, porque introduces datos brutos en el canal y obtienes de él los datos transformados y preprocesados. En el Capítulo 1 ya construimos una cadena sencilla de procesamiento de datos que incluía la tokenización y la eliminación de palabras vacías. En este capítulo utilizaremos el término canalización como término general para una secuencia de pasos de procesamiento. La Figura 4-1 ofrece una visión general de los planos que vamos a construir para el canal de preprocesamiento en este capítulo.
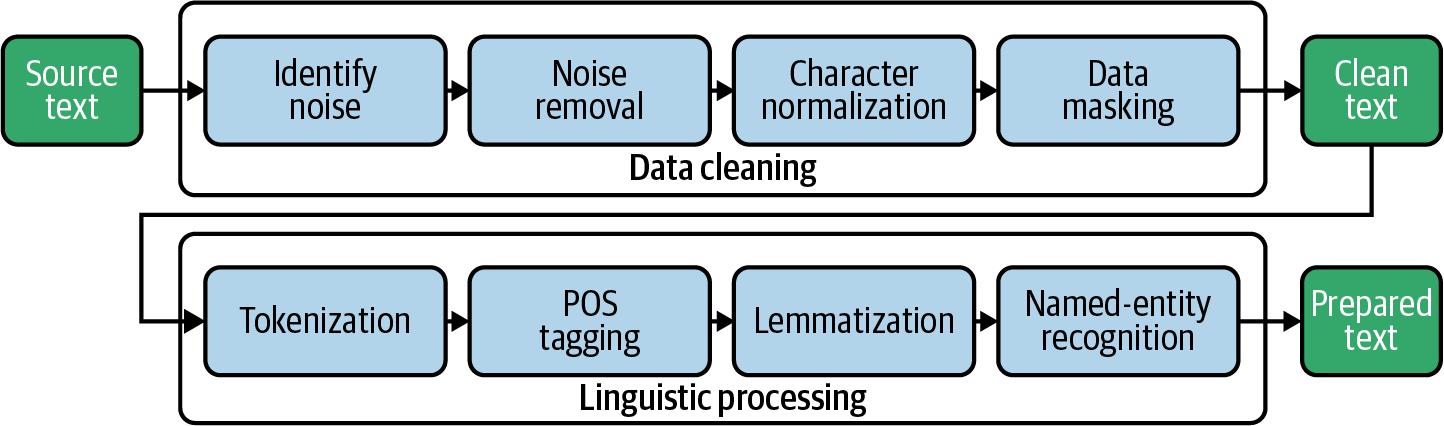
Figura 4-1. Una cadena con los pasos típicos del preprocesamiento de datos textuales.
El primer bloque principal de operaciones de nuestro pipeline es la limpieza de datos. Empezamos por identificar y eliminar el ruido en el texto, como las etiquetas HTML y los caracteres no imprimibles. Durante la normalización de caracteres, los caracteres especiales como acentos y guiones se transforman en una representación estándar. Por último, podemos enmascarar o eliminar identificadores como URL o direcciones de correo electrónico si no son relevantes para el análisis o si hay problemas de privacidad. Ahora el texto está lo suficientemente limpio como para iniciar el procesamiento lingüístico.
Aquí, la tokenización divide un documento en una lista de tokens separados, como palabras y caracteres de puntuación . El etiquetado de la parte del discurso (POS) es el proceso de determinar la clase de palabra, si es un sustantivo, un verbo, un artículo , etc. La lematización asigna las palabras flexionadas a su raíz no flexionada, el lema (por ejemplo, "son" → "ser"). El objetivo del reconocimiento de entidades con nombre es la identificación de referencias a personas, organizaciones, lugares, etc., en el texto.
Al final, queremos crear una base de datos con datos preprarados listos para el análisis y el aprendizaje automático. Por tanto, los pasos de preparación necesarios varían de un proyecto a otro. Depende de ti decidir cuál de los siguientes planos de necesitas incluir en tu pipeline específico del problema.
Presentación del conjunto de datos: Autopublicaciones de Reddit
La preparación de datos textuales es especialmente difícil cuando trabajas con contenido generado por el usuario (CGU). A diferencia del texto bien redactado de informes profesionales, noticias y blogs, las contribuciones de los usuarios en las redes sociales suelen ser breves y contener muchas abreviaturas, hashtags, emojis y erratas. Por lo tanto, utilizaremos el conjunto de datos Reddit Self-Posts, que está alojado en Kaggle. El conjunto de datos completo contiene aproximadamente 1 millón de publicaciones de usuarios con título y contenido, ordenadas en 1.013 subreddits diferentes, cada uno de los cuales tiene 1.000 registros. Utilizaremos un subconjunto de sólo 20.000 posts contenidos en la categoría autos. El conjunto de datos que preparamos en este capítulo es la base para el análisis de las incrustaciones de palabras del Capítulo 10.
Cargar datos en Pandas
El conjunto de datos original consta de dos archivos CSV independientes, uno con las publicaciones y otro con algunos metadatos de los subreddits, incluida la información sobre categorías. Ambos archivos se cargan en un Pandas DataFrame por pd.read_csv() y luego se unen en un único DataFrame.
importpandasaspdposts_file="rspct.tsv.gz"posts_df=pd.read_csv(posts_file,sep='\t')subred_file="subreddit_info.csv.gz"subred_df=pd.read_csv(subred_file).set_index(['subreddit'])df=posts_df.join(subred_df,on='subreddit')
Anteproyecto: Normalizar los nombres de los atributos
Antes de empezar a trabajar con los datos, en cambiaremos los nombres de las columnas específicas del conjunto de datos por nombres más genéricos. Recomendamos nombrar siempre la principal DataFrame df , y nombrar la columna con el texto a analizar text. Estas convenciones de nomenclatura para variables comunes y nombres de atributos facilitan la reutilización del código de los planos en distintos proyectos.
Echemos un vistazo a la lista de columnas de este conjunto de datos:
(df.columns)
Out:
Index(['id', 'subreddit', 'title', 'selftext', 'category_1', 'category_2',
'category_3', 'in_data', 'reason_for_exclusion'],
dtype='object')
Para renombrar y seleccionar columnas, definimos un diccionario column_mapping en el que cada entrada define un mapeo del nombre actual de la columna a un nuevo nombre. Las columnas mapeadas a None y las columnas no mencionadas se eliminan. Un diccionario es la documentación perfecta para una transformación de este tipo y es fácil de reutilizar. Este diccionario se utiliza después para seleccionar y renombrar las columnas que queremos conservar.
column_mapping={'id':'id','subreddit':'subreddit','title':'title','selftext':'text','category_1':'category','category_2':'subcategory','category_3':None,# no data'in_data':None,# not needed'reason_for_exclusion':None# not needed}# define remaining columnscolumns=[cforcincolumn_mapping.keys()ifcolumn_mapping[c]!=None]# select and rename those columnsdf=df[columns].rename(columns=column_mapping)
Como ya se ha dicho, limitamos los datos a la categoría de automóviles:
df=df[df['category']=='autos']
Veamos brevemente un registro de muestra para tener una primera impresión de los datos:
df.sample(1).T
| 14356 | |
|---|---|
| id | 7jc2k4 |
| subreddit | voltios |
| título | Dashcam para volt 2017 |
| texto | Hola.<lb>Estoy pensando en comprarme una dashcam.<lb>¿Alguien tiene alguna recomendación?<lb><lb>En general, busco una recargable para no tener que tender cables hasta el mechero.<lb>A menos que haya instrucciones sobre cómo cablearla correctamente sin que se vean los cables.<lb><lb><lb>¡Gracias! |
| categoría | automóviles |
| subcategoría | chevrolet |
Guardar y cargar un marco de datos
Después de cada paso de la preparación de datos, es útil escribir el DataFrame respectivo en el disco como punto de control. Pandas admite directamente varias opciones de serialización. Los formatos basados en texto, como CSV o JSON, pueden importarse fácilmente a la mayoría de las demás herramientas. Sin embargo, la información sobre los tipos de datos se pierde (CSV) o sólo se guarda rudimentariamente (JSON). El formato de serialización estándar de Python, pickle, está soportado por Pandas y, por tanto, es una opción viable. Es rápido y conserva toda la información, pero sólo puede ser procesado por Python. "Decapar" un marco de datos es fácil; sólo tienes que especificar el nombre del archivo:
df.to_pickle("reddit_dataframe.pkl")
Sin embargo, preferimos almacenar los marcos de datos en bases de datos SQL de , porque te ofrecen todas las ventajas de SQL, como filtros, uniones y fácil acceso desde muchas herramientas. Pero a diferencia de pickle, sólo admiten tipos de datos SQL. Las columnas que contienen objetos o listas, por ejemplo, no pueden guardarse simplemente de esta forma y deben serializarse manualmente.
En nuestros ejemplos, utilizaremos SQLite para persistir marcos de datos. SQLite está bien integrado con Python. Además, es sólo una biblioteca y no requiere un servidor, por lo que los archivos son autocontenidos y pueden intercambiarse fácilmente entre distintos miembros del equipo. Para mayor potencia y seguridad, recomendamos una base de datos SQL basada en servidor.
Utilizamos pd.to_sql() para guardar nuestro DataFrame como tabla posts en una base de datos SQLite. El índice DataFrame no se guarda, y cualquier dato existente se sobrescribe:
importsqlite3db_name="reddit-selfposts.db"con=sqlite3.connect(db_name)df.to_sql("posts",con,index=False,if_exists="replace")con.close()
El DataFrame se puede restaurar fácilmente con pd.read_sql():
con=sqlite3.connect(db_name)df=pd.read_sql("select * from posts",con)con.close()
Limpiar datos de texto
Cuando trabajas con peticiones o comentarios de los usuarios, en lugar de con artículos bien editados, normalmente tienes que enfrentarte a una serie de problemas de calidad:
- Formateo especial y código de programa
- El texto puede contener aún caracteres especiales, entidades HTML, etiquetas Markdown y cosas por el estilo. Estos artefactos deben limpiarse previamente porque complican la tokenización e introducen ruido.
- Saludos, firmas, direcciones, etc.
- La comunicación personal suele contener frases de cortesía sin sentido y saludos por el nombre que suelen ser irrelevantes para el análisis.
- Responde
- Si tu texto contiene respuestas que repiten el texto de la pregunta, debes eliminar las preguntas duplicadas. Conservarlas distorsionará cualquier modelo y estadística.
En esta sección, demostraremos cómo utilizar expresiones regulares para identificar y eliminar patrones no deseados en los datos. Consulta la siguiente barra lateral para obtener más detalles sobre las expresiones regulares en Python.
Echa un vistazo al siguiente ejemplo de texto del conjunto de datos Reddit:
text="""After viewing the [PINKIEPOOL Trailer](https://www.youtu.be/watch?v=ieHRoHUg)it got me thinking about the best match ups.<lb>Here's my take:<lb><lb>[](/sp)[](/ppseesyou) Deadpool<lb>[](/sp)[](/ajsly)Captain America<lb>"""
Sin duda mejorarán los resultados si este texto se limpia y pule un poco. Algunas etiquetas no son más que artefactos del web scraping, así que nos desharemos de ellas. Y como no nos interesan las URL y otros enlaces, también los descartaremos.
Plano: Identificar el ruido con expresiones regulares
La identificación de problemas de calidad en un gran conjunto de datos puede ser complicada. Por supuesto, puedes y debes echar un vistazo a una muestra de los datos. Pero la probabilidad de que no encuentres todos los problemas es alta. Es mejor definir patrones aproximados que indiquen problemas probables y comprobar el conjunto de datos completo mediante programación.
La siguiente función puede ayudarte a identificar el ruido en los datos textuales. Por ruido entendemos todo aquello que no es texto plano y que, por tanto, puede perturbar el análisis posterior. La función utiliza una expresión regular para buscar una serie de caracteres sospechosos y devuelve su proporción de todos los caracteres como puntuación de impureza. Los textos muy cortos (menos de min_len caracteres) se ignoran porque aquí un solo carácter especial provocaría una impureza significativa y distorsionaría el resultado.
importreRE_SUSPICIOUS=re.compile(r'[&#<>{}\[\]\\]')defimpurity(text,min_len=10):"""returns the share of suspicious characters in a text"""iftext==Noneorlen(text)<min_len:return0else:returnlen(RE_SUSPICIOUS.findall(text))/len(text)(impurity(text))
Out:
0.09009009009009009
Casi nunca encontrarás estos caracteres en un texto bien redactado, por lo que las puntuaciones en general deberían ser muy pequeñas. Para el texto de ejemplo anterior, alrededor del 9% de los caracteres son "sospechosos" según nuestra definición. Por supuesto, el patrón de búsqueda puede necesitar una adaptación para corpus que contengan hashtags o tokens similares que contengan caracteres especiales. Sin embargo, no es necesario que sea perfecto; basta con que sea lo suficientemente bueno como para indicar posibles problemas de calidad.
Para los datos de Reddit, podemos obtener los registros más "impuros" con las dos sentencias siguientes. Observa que utilizamos Pandas apply() en lugar del similar map() porque nos permite reenviar parámetros adicionales como min_len a la función aplicada.1
# add new column to data framedf['impurity']=df['text'].apply(impurity,min_len=10)# get the top 3 recordsdf[['text','impurity']].sort_values(by='impurity',ascending=False).head(3)
| texto | impureza | |
|---|---|---|
| 19682 | Mirando a comprar un 335i con 39k millas y 11 meses restantes en la garantía CPO. He preguntado el trato... | 0.21 |
| 12357 | Quiero alquilar un a4 premium plus automatico con el paquete nav.<lb><lb>Precio del vehículo:<ta... | 0.17 |
| 2730 | Desglose a continuación:<lb><lb>Elantra GT<lb><lb>2,0L de 4 cilindros<lb><lb>Transmisión manual de 6 velocidades<lb>... | 0.14 |
Obviamente, hay muchas etiquetas como <lb> (salto de línea) y <tab> incluidas. Comprobemos si hay otras utilizando nuestro modelo de recuento de palabras del Capítulo 1 en combinación con un simple tokenizador regex para dichas etiquetas:
fromblueprints.explorationimportcount_wordscount_words(df,column='text',preprocess=lambdat:re.findall(r'<[\w/]*>',t))
| frec | ficha |
|---|---|
| <lb> | 100729 |
| <tab> | 642 |
Ahora sabemos que, aunque estas dos etiquetas son comunes, son las únicas.
Plano: Eliminar el ruido con expresiones regulares
Nuestro enfoque de la limpieza de datos consiste en definir un conjunto de expresiones regulares e identificar patrones problemáticos y sus correspondientes reglas de sustitución.2 La función blueprint sustituye primero todos los escapes HTML (por ejemplo, &) por su representación en texto plano y, a continuación, sustituye determinados patrones por espacios. Por último, se eliminan las secuencias de espacios en blanco:
importhtmldefclean(text):# convert html escapes like & to characters.text=html.unescape(text)# tags like <tab>text=re.sub(r'<[^<>]*>',' ',text)# markdown URLs like [Some text](https://....)text=re.sub(r'\[([^\[\]]*)\]\([^\(\)]*\)',r'\1',text)# text or code in brackets like [0]text=re.sub(r'\[[^\[\]]*\]',' ',text)# standalone sequences of specials, matches &# but not #cooltext=re.sub(r'(?:^|\s)[&#<>{}\[\]+|\\:-]{1,}(?:\s|$)',' ',text)# standalone sequences of hyphens like --- or ==text=re.sub(r'(?:^|\s)[\-=\+]{2,}(?:\s|$)',' ',text)# sequences of white spacestext=re.sub(r'\s+',' ',text)returntext.strip()
Advertencia
Ten cuidado: si tus expresiones regulares no están definidas con suficiente precisión, ¡puedes eliminar accidentalmente información valiosa durante este proceso sin darte cuenta! Los repetidores + y * pueden ser especialmente peligrosos porque coinciden con secuencias de caracteres no delimitadas y pueden eliminar grandes partes del texto.
Apliquemos la función clean al texto de muestra anterior y comprobemos el resultado:
clean_text=clean(text)(clean_text)("Impurity:",impurity(clean_text))
Out:
After viewing the PINKIEPOOL Trailer it got me thinking about the best match ups. Here's my take: Deadpool Captain America Impurity: 0.0
Tiene muy buena pinta. Una vez que hayas tratado los primeros patrones, debes comprobar de nuevo la impureza del texto limpiado y añadir más pasos de limpieza si es necesario:
df['clean_text']=df['text'].map(clean)df['impurity']=df['clean_text'].apply(impurity,min_len=20)
df[['clean_text','impurity']].sort_values(by='impurity',ascending=False)\.head(3)
| texto_limpio | impureza | |
|---|---|---|
| 14058 | ¿Mustang 2018, 2019 o 2020? ¡Imprescindible! 1. 1. Tener una puntuación crediticia de más de 780 para obtener los mejores tipos de interés. 2. Afíliate a una cooperativa de crédito para financiar el vehículo. 3. O busca un prestamista para financiar el vehículo... | 0.03 |
| 18934 | En el concesionario me ofrecieron una opción para la iluminación de los reposapiés, pero no encuentro ninguna referencia en Internet. ¿Alguien lo ha comprado? ¿Qué aspecto tiene? ¿Alguien tiene fotos? No estoy seguro de si... | 0.03 |
| 16505 | Estoy mirando cuatro Cayman, todos tienen un precio similar. Las principales diferencias son los kilómetros, los años y que uno no es un S. https://www.cargurus.com/Cars/inventorylisting/viewDetailsFilterV... | 0.02 |
Incluso los registros más sucios, según nuestra expresión regular, parecen ahora bastante limpios. Pero además de esos patrones aproximados que buscábamos, también hay variaciones más sutiles de caracteres que pueden causar problemas.
Plano: Normalización de caracteres con textacy
Echa un vistazo a la siguiente frase de , que contiene problemas típicos relacionados con variantes de letras y caracteres de comillas:
text = "The café “Saint-Raphaël” is loca-\nted on Côte dʼAzur."
Los caracteres acentuados pueden ser un problema porque la gente no los utiliza sistemáticamente. Por ejemplo, los tokens Saint-Raphaël y Saint-Raphael no se reconocerán como idénticos. Además, los textos suelen contener palabras separadas por un guión debido a los saltos de línea automáticos. Los guiones y apóstrofes Unicode extravagantes como los utilizados en el texto pueden ser un problema para la tokenización. Para todos estos problemas, tiene sentido normalizar el texto y sustituir los acentos y caracteres extravagantes por equivalentes ASCII.
En utilizaremos textacy para ello. textacy es una biblioteca de PNL creada para trabajar con spaCy. Deja la parte lingüística a spaCy y se centra en el pre y postprocesamiento. Así, su módulo de preprocesamiento comprende una buena colección de funciones para normalizar caracteres y tratar patrones comunes como URL, direcciones de correo electrónico, números de teléfono, etc., que utilizaremos a continuación en . La Tabla 4-1 muestra una selección de las funciones de preprocesamiento de textacy . Todas estas funciones trabajan sobre texto plano, de forma totalmente independiente de spaCy.
| Función | Descripción |
|---|---|
normalize_hyphenated_words |
Reagrupa las palabras separadas por un salto de línea |
normalize_quotation_marks |
Sustituye todo tipo de comillas rebuscadas por un equivalente ASCII |
normalize_unicode |
Unifica los diferentes códigos de caracteres acentuados en Unicode |
remove_accents |
Sustituye los caracteres acentuados por ASCII, si es posible, o elimínalos |
replace_urls |
Similar para URLs como https://xyz.com |
replace_emails |
Sustituye los correos electrónicos por _EMAIL_. |
replace_hashtags |
Similar para etiquetas como #sunshine |
replace_numbers |
Similar para números como 1235 |
replace_phone_numbers |
Similar para los números de teléfono +1 800 456-6553 |
replace_user_handles |
Similar para los nombres de usuario como @pete |
replace_emojis |
Sustituye los emoticonos, etc. por _EMOJI_. |
Nuestra función de plano mostrada aquí normaliza los guiones y comillas de fantasía y elimina los acentos con ayuda de textacy:
importtextacy.preprocessingastprepdefnormalize(text):text=tprep.normalize_hyphenated_words(text)text=tprep.normalize_quotation_marks(text)text=tprep.normalize_unicode(text)text=tprep.remove_accents(text)returntext
Si aplicamos esto a la frase de ejemplo anterior, obtenemos el siguiente resultado:
(normalize(text))
Out:
The cafe "Saint-Raphael" is located on Cote d'Azur.
Nota
Como la normalización Unicode tiene muchas facetas, puedes consultar otras bibliotecas. unidecode, por ejemplo, hace un excelente trabajo aquí.
Plano: Enmascaramiento de datos basado en patrones con textacy
El texto, en particular el contenido de escrito por los usuarios, a menudo contiene no sólo palabras corrientes, sino también varios tipos de identificadores, como URL, direcciones de correo electrónico o números de teléfono. A veces nos interesan especialmente esos elementos, por ejemplo, para analizar las URL que se mencionan con más frecuencia. En muchos casos, sin embargo, puede ser mejor eliminar o enmascarar esta información, ya sea porque no es relevante o por razones de privacidad.
textacy dispone de algunas prácticas funciones replace para el enmascaramiento de datos (véase la Tabla 4-1). La mayoría de las funciones se basan en expresiones regulares de , a las que se puede acceder fácilmente a través del código fuente abierto. Así, siempre que necesites tratar alguno de estos elementos, textacy tiene una expresión regular para ello que puedes utilizar directamente o adaptar a tus necesidades. Ilustremos esto con una simple llamada para encontrar las URL más utilizadas en el corpus:
fromtextacy.preprocessing.resourcesimportRE_URLcount_words(df,column='clean_text',preprocess=RE_URL.findall).head(3)
| ficha | frec |
|---|---|
| www.getlowered.com | 3 |
| http://www.ecolamautomotive.com/#!2/kv7fq | 2 |
| https://www.reddit.com/r/Jeep/comments/4ux232/just_ordered_an_android_head_unit_joying_jeep/ | 2 |
Para el análisis que queremos realizar con este conjunto de datos (en el Capítulo 10), no nos interesan esas URL. Representan más bien un artefacto perturbador. Así pues, sustituiremos todas las URL de nuestro texto por replace_urls, que en realidad no es más que una llamada a RE_URL.sub. La sustitución por defecto para todas las funciones de sustitución de textacy es una etiqueta genérica encerrada entre guiones bajos, como _URL_. Puedes elegir tu propia sustitución especificando el parámetro replace_with. A menudo tiene sentido no eliminar completamente esos elementos porque así se deja intacta la estructura de las frases. La siguiente llamada ilustra la funcionalidad:
fromtextacy.preprocessing.replaceimportreplace_urlstext="Check out https://spacy.io/usage/spacy-101"# using default substitution _URL_(replace_urls(text))
Out:
Check out _URL_
Para finalizar la limpieza de datos de , aplicamos a nuestros datos las funciones de normalización y enmascaramiento de datos:
df['clean_text']=df['clean_text'].map(replace_urls)df['clean_text']=df['clean_text'].map(normalize)
La limpieza de datos es como limpiar tu casa. Siempre encontrarás algunos rincones sucios, y nunca conseguirás que tu casa esté totalmente limpia. Así que dejas de limpiar cuando está suficientemente limpia. Eso es lo que suponemos para nuestros datos en este momento. Más adelante en el proceso, si los resultados del análisis adolecen de ruido remanente, puede que tengamos que volver a limpiar los datos.
Por último, cambiamos el nombre de las columnas de texto para que clean_text pase a ser text, eliminamos la columna de impureza y almacenamos la nueva versión de DataFrame en la base de datos .
df.rename(columns={'text':'raw_text','clean_text':'text'},inplace=True)df.drop(columns=['impurity'],inplace=True)con=sqlite3.connect(db_name)df.to_sql("posts_cleaned",con,index=False,if_exists="replace")con.close()
Tokenización
Ya introdujimos un tokenizador regex en el Capítulo 1, que utilizaba una regla sencilla: . En la práctica, sin embargo, la tokenización puede ser bastante compleja si queremos tratar todo correctamente. Considera el siguiente fragmento de texto como ejemplo:
text="""2019-08-10 23:32: @pete/@louis - I don't have a well-designedsolution for today's problem. The code of module AC68 should be -1.Have to think a bit... #goodnight ;-) 😩😬"""
Obviamente, las reglas para definir los límites de las palabras y las frases no son tan sencillas. Así que ¿qué es exactamente un token? Por desgracia, no existe una definición clara. Podríamos decir que un token es una unidad lingüística semánticamente útil para el análisis. Esta definición implica que la tokenización depende hasta cierto punto de la aplicación. Por ejemplo, en muchos casos podemos descartar simplemente los caracteres de puntuación, pero no si queremos conservar emoticonos como :-) para el análisis de sentimientos. Lo mismo ocurre con los tokens que contienen números o hashtags. Aunque la mayoría de los tokenizadores, incluidos los utilizados en NLTK y spaCy, se basan en expresiones regulares, aplican reglas bastante complejas y a veces específicas de cada idioma.
Primero desarrollaremos nuestro propio modelo de expresiones regulares basadas en la tokenización, antes de presentar brevemente los tokenizadores de NLTK. La tokenización en spaCy se tratará en la siguiente sección de este capítulo como parte del proceso integrado de spaCy.
Plano: Tokenización con expresiones regulares
Las funciones útiles para la tokenización son re.split() y re.findall(). La primera divide una cadena en expresiones coincidentes, mientras que la segunda extrae todas las secuencias de caracteres que coinciden con un determinado patrón. Por ejemplo, en el Capítulo 1 utilizamos la biblioteca regex con el patrón POSIX [\w-]*\p{L}[\w-]* para encontrar secuencias de caracteres alfanuméricos con al menos una letra. La biblioteca scikit-learn CountVectorizer utiliza el patrón \w\w+ para su tokenización por defecto. Coincide con todas las secuencias de dos o más caracteres alfanuméricos. Aplicado a nuestra frase de ejemplo, da el siguiente resultado:3
tokens=re.findall(r'\w\w+',text)(*tokens,sep='|')
Out:
2019|08|10|23|32|pete|louis|don|have|well|designed|solution|for|today problem|The|code|of|module|AC68|should|be|Have|to|think|bit|goodnight
Por desgracia, se pierden todos los caracteres especiales y los emojis. Para mejorar el resultado, añadimos algunas expresiones adicionales para los emojis y creamos una expresión regular reutilizable RE_TOKEN. La opción VERBOSE permite dar un formato legible a expresiones complejas. La siguiente función tokenize y el ejemplo ilustran su uso:
RE_TOKEN=re.compile(r"""( [#]?[@\w'’\.\-\:]*\w # words, hashtags and email addresses| [:;<]\-?[\)\(3] # coarse pattern for basic text emojis| [\U0001F100-\U0001FFFF] # coarse code range for unicode emojis)""",re.VERBOSE)deftokenize(text):returnRE_TOKEN.findall(text)tokens=tokenize(text)(*tokens,sep='|')
Out:
2019-08-10|23:32|@pete|@louis|I|don't|have|a|well-designed|solution for|today's|problem|The|code|of|module|AC68|should|be|-1|Have|to|think a|bit|#goodnight|;-)|😩|😬
Esta expresión debería dar resultados razonablemente buenos en la mayoría de los contenidos generados por los usuarios. Se puede utilizar para tokenizar rápidamente el texto para la exploración de datos, como se explica en el Capítulo 1. También es una buena alternativa para la tokenización por defecto de los vectorizadores de scikit-learn, que se presentará en el próximo capítulo.
Tokenización con NLTK
Echemos un breve vistazo a los tokenizadores de NLTK, ya que NLTK se utiliza frecuentemente para la tokenización. El tokenizador estándar de NLTK puede invocarse mediante el atajo word_tokenize. Produce el siguiente resultado en nuestro texto de muestra:
importnltktokens=nltk.tokenize.word_tokenize(text)(*tokens,sep='|')
Out:
2019-08-10|23:32|:|@|pete/|@|louis|-|I|do|n't|have|a|well-designed solution|for|today|'s|problem|.|The|code|of|module|AC68|should|be|-1|. Have|to|think|a|bit|...|#|goodnight|;|-|)||😩😬
La función utiliza internamente el TreebankWordTokenizer en combinación con el PunktSentenceTokenizer. Funciona bien para texto estándar, pero tiene sus defectos con hashtags o emojis de texto. NLTK también proporciona un RegexpTokenizer, que es básicamente una envoltura de re.findall() con algunas funcionalidades de conveniencia añadidas. Además, hay otros tokenizadores basados en expresiones regulares en NLTK, como el TweetTokenizer o el multilingüe ToktokTokenizer, que puedes consultar en el cuaderno de notas de este capítulo en GitHub.
Recomendaciones para la tokenización
En probablemente necesitarás utilizar expresiones regulares personalizadas si pretendes obtener una gran precisión en los patrones de tokens específicos del dominio. Afortunadamente, puedes encontrar expresiones regulares para muchos patrones comunes en bibliotecas de código abierto y adaptarlas a tus necesidades.4
En general, debes tener en cuenta los siguientes casos problemáticos en tu aplicación y definir cómo tratarlos:5
- Fichas que contienen puntos, como
Dr.,Mrs.,U.,xyz.com - Guiones, como en
rule-based - Clíticos (abreviaturas de palabras conectadas), como en
couldn't,we'veoje t'aime - Expresiones numéricas, como números de teléfono (
(123) 456-7890) o fechas (August 7th, 2019) - Emojis, hashtags, direcciones de correo electrónico o URLs
Los tokenizadores de las bibliotecas comunes difieren especialmente en lo que respecta a a esos tokens.
Procesamiento lingüístico con spaCy
spaCy es una potente biblioteca para el procesamiento de datos lingüísticos. Proporciona una cadena integrada de componentes de procesamiento, por defecto un tokenizador, un etiquetador de partes del discurso, un analizador de dependencias y un reconocedor de entidades con nombre (véase la Figura 4-2). La tokenización se basa en complejas reglas y expresiones regulares dependientes del idioma, mientras que todos los pasos posteriores utilizan modelos neuronales preentrenados.

Figura 4-2. Canal de PNL de spaCy.
La filosofía de spaCy es que el texto original se conserva durante todo el proceso. En lugar de transformarlo, spaCy añade capas de información. El objeto principal para representar el texto procesado es un objeto Doc, que a su vez contiene una lista de objetos Token. Cualquier selección de tokens del rango crea un objeto Span. Cada uno de estos tipos de objeto tiene propiedades que se determinan paso a paso.
En esta sección, explicamos en cómo procesar un documento con spaCy, cómo trabajar con tokens y sus atributos, cómo utilizar etiquetas de parte de discurso y cómo extraer entidades con nombre. Profundizaremos aún más en los conceptos más avanzados de spaCy en el Capítulo 12, donde escribiremos nuestros propios componentes de canalización, crearemos atributos personalizados y trabajaremos con el árbol de dependencias generado por el analizador sintáctico para la extracción de conocimiento.
Advertencia
Para el desarrollo de los ejemplos de este libro, hemos utilizado la versión 2.3.2 de spaCy. Si ya utilizas spaCy 3.0, que aún está en desarrollo en el momento de escribir estas líneas, tus resultados pueden ser ligeramente distintos.
Instanciar una canalización
Empecemos con spaCy. Como primer paso, necesitamos instanciar un objeto de la clase Language de spaCy llamando a spacy.load() junto con el nombre del archivo del modelo a utilizar.6 En este capítulo utilizaremos el pequeño modelo de lengua inglesa en_core_web_sm. La variable del objeto Language suele llamarse nlp:
importspacynlp=spacy.load('en_core_web_sm')
Este objeto Language contiene ahora el vocabulario compartido, el modelo y la tubería de procesamiento. Puedes comprobar los componentes de la tubería a través de esta propiedad del objeto:
nlp.pipeline
Out:
[('tagger', <spacy.pipeline.pipes.Tagger at 0x7fbd766f84c0>),
('parser', <spacy.pipeline.pipes.DependencyParser at 0x7fbd813184c0>),
('ner', <spacy.pipeline.pipes.EntityRecognizer at 0x7fbd81318400>)]
El proceso por defecto consta de un etiquetador, un analizador sintáctico y un reconocedor de entidades con nombre (ner), todos ellos dependientes de la lengua. El tokenizador no se enumera explícitamente porque este paso siempre es necesario.
El tokenizador de spaCy es bastante rápido, pero todos los demás pasos se basan en modelos neuronales y consumen una cantidad de tiempo considerable. Sin embargo, en comparación con otras bibliotecas, los modelos de spaCy son de los más rápidos. Procesar todo el proceso lleva entre 10 y 20 veces más tiempo que sólo la tokenización, donde cada paso consume una parte similar del tiempo total. Si la tokenización de 1.000 documentos tarda, por ejemplo, un segundo, el etiquetado, el análisis sintáctico y el NER pueden tardar cinco segundos más cada uno. Esto puede convertirse en un problema si procesas grandes conjuntos de datos. Por tanto, es mejor desactivar las partes que no necesites.
A menudo sólo necesitarás el tokenizador y el etiquetador de partes del discurso. En este caso, debes desactivar el analizador sintáctico y el reconocimiento de entidades con nombre de esta forma:
nlp=spacy.load("en_core_web_sm",disable=["parser","ner"])
Si sólo quieres el tokenizador y nada más, también puedes llamar simplemente a nlp.make_doc sobre un texto.
Procesar texto
La cadena se ejecuta llamando al objeto nlp. La llamada devuelve un objeto de tipo spacy.tokens.doc.Doc, un contenedor para acceder a los tokens, los spans (rangos de tokens) y sus anotaciones lingüísticas.
nlp=spacy.load("en_core_web_sm")text="My best friend Ryan Peters likes fancy adventure games."doc=nlp(text)
spaCy está orientado a objetos y no es destructivo. Siempre se conserva el texto original. Cuando imprimes el objeto doc, utiliza doc.text, la propiedad que contiene el texto original. Pero doc también es un objeto contenedor de las fichas, y puedes utilizarlo como iterador para ellas:
fortokenindoc:(token,end="|")
Out:
My|best|friend|Ryan|Peters|likes|fancy|adventure|games|.|
Cada token es en realidad un objeto de la clase Token de spaCy. Los tokens, al igual que los documentos, tienen una serie de propiedades interesantes para el procesamiento del lenguaje . La Tabla 4-2 muestra cuáles de estas propiedades crea cada componente de la tubería.7
| Componente | Crea |
|---|---|
| Tokenizador | Token.is_punct, Token.is_alpha, Token.like_email, Token.like_url |
| Etiquetador de parte del discurso | Token.pos_ |
| Analizador sintáctico de dependencias | Token.dep_, Token.head, Doc.sents, Doc.noun_chunks |
| Reconocedor de entidades con nombre | Doc.ents, Token.ent_iob_, Token.ent_type_ |
Proporcionamos una pequeña función de utilidad, display_nlp, para generar una tabla que contenga los tokens y sus atributos. Internamente, creamos un DataFrame para ello y utilizamos la posición del token en el documento como índice. Los caracteres de puntuación se omiten por defecto en esta función. La Tabla 4-3 muestra el resultado de esta función para nuestra frase de ejemplo:
defdisplay_nlp(doc,include_punct=False):"""Generate data frame for visualization of spaCy tokens."""rows=[]fori,tinenumerate(doc):ifnott.is_punctorinclude_punct:row={'token':i,'text':t.text,'lemma_':t.lemma_,'is_stop':t.is_stop,'is_alpha':t.is_alpha,'pos_':t.pos_,'dep_':t.dep_,'ent_type_':t.ent_type_,'ent_iob_':t.ent_iob_}rows.append(row)df=pd.DataFrame(rows).set_index('token')df.index.name=Nonereturndf
| texto | lema_ | is_parada | is_alfa | pos_ | dep_ | tipo_ent | ent_iob_ | |
|---|---|---|---|---|---|---|---|---|
| 0 | Mi | -PRON- | Verdadero | Verdadero | DET | poss | O | |
| 1 | mejor | bien | Falso | Verdadero | ADJ | amod | O | |
| 2 | amigo | amigo | Falso | Verdadero | NOUN | nsubj | O | |
| 3 | Ryan | Ryan | Falso | Verdadero | PROPN | compuesto | PERSONA | B |
| 4 | Peters | Peters | Falso | Verdadero | PROPN | appos | PERSONA | I |
| 5 | le gusta | como | Falso | Verdadero | VERBO | RAÍZ | O | |
| 6 | fantasía | fantasía | Falso | Verdadero | ADJ | amod | O | |
| 7 | aventura | aventura | Falso | Verdadero | NOUN | compuesto | O | |
| 8 | juegos | juego | Falso | Verdadero | NOUN | dobj | O |
Para cada token, encontrarás el lema, algunos indicadores descriptivos, la etiqueta de parte de palabra, la etiqueta de dependencia (que no se utiliza aquí, sino en el Capítulo 12) y, posiblemente, alguna información sobre el tipo de entidad. Los indicadores de is_<something> se crean a partir de reglas, pero todos los atributos de parte de palabra, dependencia y entidad con nombre se basan en modelos de redes neuronales de . Por tanto, siempre hay cierto grado de incertidumbre en esta información. Los corpus utilizados para el entrenamiento contienen una mezcla de artículos de noticias y artículos en línea. Las predicciones del modelo son bastante precisas si tus datos tienen características lingüísticas similares. Pero si tus datos son muy diferentes -si trabajas con datos de Twitter o tickets de servicios informáticos, por ejemplo- debes ser consciente de que esta información no es fiable.
Advertencia
spaCy utiliza la convención según la cual los atributos de token con un guión bajo, como pos_, devuelven la representación textual legible. pos sin guión bajo devuelve el identificador numérico de spaCy de una etiqueta de parte de habla.8 Los identificadores numéricos pueden importarse como constantes, por ejemplo, spacy.symbols.VERB. ¡Asegúrate de no mezclarlos !
Plano: Personalizar la tokenización
La tokenización es el primer paso de la cadena, y todo depende de que los tokens sean correctos. El tokenizador de spaCy hace un buen trabajo en la mayoría de los casos, pero se divide en signos de almohadilla, guiones y guiones bajos, que a veces no es lo que quieres. Por lo tanto, puede ser necesario ajustar su comportamiento. Veamos el siguiente texto como ejemplo:
text="@Pete: choose low-carb #food #eat-smart. _url_ ;-) 😋👍"doc=nlp(text)fortokenindoc:(token,end="|")
Out:
@Pete|:|choose|low|-|carb|#|food|#|eat|-|smart|.|_|url|_|;-)|😋|👍|
El tokenizador de spaCy está completamente basado en reglas. En primer lugar, divide el texto en caracteres de espacio en blanco. A continuación, utiliza el prefijo , el sufijo y las reglas de división infija definidas por expresiones regulares para dividir aún más los tokens restantes. Las reglas de excepción se utilizan para tratar excepciones específicas del idioma, como can't, que debe dividirse en ca y n't con los lemas can y not.9
Como puedes ver en el ejemplo, el tokenizador de inglés de spaCy contiene una regla infija para separar guiones. Además, tiene una regla prefija para separar caracteres como # o _. Sin embargo, funciona bien para tokens prefijados con @ y emojis.
Una opción es fusionar los tokens en un paso posterior al procesamiento utilizando doc.retokenize. Sin embargo, eso no arreglará las etiquetas de parte de discurso mal calculadas ni las dependencias sintácticas, porque éstas dependen de la tokenización. Así que puede ser mejor cambiar las reglas de tokenización y crear los tokens correctos desde el principio.
Para ello, lo mejor es crear tu propia variante del tokenizador con reglas individuales para la división infija, prefija y sufija.10 La siguiente función crea un objeto tokenizador con reglas individuales de una forma "mínimamente invasiva": sólo eliminamos los patrones respectivos de las reglas por defecto de spaCy, pero conservamos la mayor parte de la lógica:
fromspacy.tokenizerimportTokenizerfromspacy.utilimportcompile_prefix_regex,\compile_infix_regex,compile_suffix_regexdefcustom_tokenizer(nlp):# use default patterns except the ones matched by re.searchprefixes=[patternforpatterninnlp.Defaults.prefixesifpatternnotin['-','_','#']]suffixes=[patternforpatterninnlp.Defaults.suffixesifpatternnotin['_']]infixes=[patternforpatterninnlp.Defaults.infixesifnotre.search(pattern,'xx-xx')]returnTokenizer(vocab=nlp.vocab,rules=nlp.Defaults.tokenizer_exceptions,prefix_search=compile_prefix_regex(prefixes).search,suffix_search=compile_suffix_regex(suffixes).search,infix_finditer=compile_infix_regex(infixes).finditer,token_match=nlp.Defaults.token_match)nlp=spacy.load('en_core_web_sm')nlp.tokenizer=custom_tokenizer(nlp)doc=nlp(text)fortokenindoc:(token,end="|")
Out:
@Pete|:|choose|low-carb|#food|#eat-smart|.|_url_|;-)|😋|👍|
Advertencia
Ten cuidado con las modificaciones de tokenización porque sus efectos pueden ser sutiles, y arreglar un conjunto de casos puede romper otro conjunto de casos. Por ejemplo, con nuestra modificación, los tokens como Chicago-based ya no se dividirán. Además, hay varios caracteres Unicode para guiones y rayas que podrían causar problemas si no se han normalizado .
Plano: Trabajar con palabras vacías
spaCy utiliza listas de palabras de parada específicas de cada idioma para establecer la propiedad is_stop de cada token directamente después de la tokenización. Por lo tanto, filtrar las palabras vacías (y los signos de puntuación similares) es fácil:
text="Dear Ryan, we need to sit down and talk. Regards, Pete"doc=nlp(text)non_stop=[tfortindocifnott.is_stopandnott.is_punct](non_stop)
Out:
[Dear, Ryan, need, sit, talk, Regards, Pete]
Se puede acceder a la lista de palabras de parada inglesas con más de 300 entradas importando spacy.lang.en.STOP_WORDS. Cuando se crea un objeto nlp, esta lista se carga y se almacena en nlp.Defaults.stop_words. Podemos modificar el comportamiento por defecto de spaCy configurando la propiedad is_stop de las palabras respectivas en el vocabulario de spaCy:11
nlp=spacy.load('en_core_web_sm')nlp.vocab['down'].is_stop=Falsenlp.vocab['Dear'].is_stop=Truenlp.vocab['Regards'].is_stop=True
Si volvemos a ejecutar el ejemplo anterior, obtendremos el siguiente resultado:
[Ryan, need, sit, down, talk, Pete]
Plano: Extracción de lemas basados en la parte de la oración
La lematización es el mapeo de una palabra a su raíz no flexionada. Tratar palabras como vivienda, alojado y casa como iguales tiene muchas ventajas para la estadística, el aprendizaje automático y la recuperación de información. No sólo puede mejorar la calidad de los modelos, sino también disminuir el tiempo de entrenamiento y el tamaño del modelo, porque el vocabulario es mucho menor si sólo se conservan las formas no flexionadas. Además, a menudo es útil restringir los tipos de palabras utilizadas a determinadas categorías, como sustantivos, verbos y adjetivos. Esos tipos de palabras se denominan etiquetas de parte de discurso.
Veamos primero con más detalle la lematización. Se puede acceder al lema de un token o span mediante la propiedad lemma_, como se ilustra en el siguiente ejemplo:
text="My best friend Ryan Peters likes fancy adventure games."doc=nlp(text)(*[t.lemma_fortindoc],sep='|')
Out:
-PRON-|good|friend|Ryan|Peters|like|fancy|adventure|game|.
La asignación correcta del lema requiere un diccionario de búsqueda y conocimientos sobre la parte de la oración de una palabra. Por ejemplo, el lema del sustantivo reunión es meeting, mientras que el lema del verbo es meet. En inglés, spaCy es capaz de hacer esta distinción. Sin embargo, en la mayoría de las demás lenguas, la lematización se basa puramente en el diccionario, ignorando la dependencia de parte de palabra. Ten en cuenta que los pronombres personales como yo, me, tú y ella siempre reciben el lema -PRON- en spaCy.
El otro atributo de token que utilizaremos en este modelo es la etiqueta de parte de discurso.La Tabla 4-3 muestra que cada token de un documento spaCy tiene dos atributos de parte de discurso: pos_ y tag_. tag_ es la etiqueta del conjunto de etiquetas utilizado para entrenar el modelo. Para los modelos ingleses de spaCy, que se han entrenado con el corpus OntoNotes 5, se trata del conjunto de etiquetas Penn Treebank. Para un modelo alemán, sería el conjunto de etiquetas Stuttgart-Tübingen. El atributo pos_ contiene la etiqueta simplificada del conjunto de etiquetas universales de parte de discurso .12 Recomendamos utilizar este atributo, ya que los valores permanecerán estables en diferentes modelos.La Tabla 4-4 muestra las descripciones completas del conjunto de etiquetas.
| Etiqueta | Descripción | Ejemplos |
|---|---|---|
| ADJ | Adjetivos (describen sustantivos) | grande, verde, africano |
| ADP | Adposiciones (preposiciones y postposiciones) | en, sobre |
| ADV | Adverbios (modifican verbos o adjetivos) | muy, exactamente, siempre |
| AUX | Auxiliar (acompaña al verbo) | puede (hacer), está (haciendo) |
| CCONJ | Conjunción de conexión | y, o, pero |
| DET | Determinante (con respecto a los sustantivos) | la, a, todas (las cosas), tu (idea) |
| INTJ | Interjección (palabra independiente, exclamación, expresión de emoción) | hola, sí |
| NOUN | Sustantivos (comunes y propios) | casa, ordenador |
| NUM | Números cardinales | nueve, 9, IX |
| PROPN | Nombre propio, nombre o parte de un nombre | Peter, Berlín |
| PRON | Pronombre, sustituto del sustantivo | Yo, tú, yo mismo, que |
| PARTE | Partícula (sólo tiene sentido con otra palabra) | |
| PUNTO | Caracteres de puntuación | , . ; |
| SCONJ | Conjunción subordinante | antes, ya que, si |
| SYM | Símbolos (con forma de palabra) | $, © |
| VERBO | Verbos (todos los tiempos y modos) | ir, fue, pensar |
| X | Todo lo que no se pueda asignar | grlmpf |
Las etiquetas de parte de discurso son una excelente alternativa a stop words como filtros de palabras. En la lingüística , los pronombres, las preposiciones, las conjunciones y los determinantes se denominan palabras de función porque su función principal es crear relaciones gramaticales dentro de una frase. Los sustantivos, verbos, adjetivos y adverbios son palabras de contenido, y de ellas depende principalmente el significado de una frase.
A menudo, sólo nos interesan las palabras de contenido. Así, en lugar de utilizar una lista de palabras de parada, podemos utilizar etiquetas de parte de discurso para seleccionar los tipos de palabras que nos interesan y descartar el resto. Por ejemplo, se puede generar así una lista que contenga sólo los sustantivos y nombres propios de un doc:
text="My best friend Ryan Peters likes fancy adventure games."doc=nlp(text)nouns=[tfortindocift.pos_in['NOUN','PROPN']](nouns)
Out:
[friend, Ryan, Peters, adventure, games]
Podríamos definir fácilmente una función de filtro más general para este fin, pero la función extract.words de textacy proporciona convenientemente esta funcionalidad. También nos permite filtrar por parte de la oración y por propiedades adicionales de los tokens, como is_punct o is_stop. Así, la función de filtro permite tanto la selección de parte de la oración como el filtrado de palabras de parada. Internamente, funciona igual que el filtro de sustantivos mostrado anteriormente.
El siguiente ejemplo muestra cómo extraer tokens para adjetivos y sustantivos de la frase de ejemplo:
importtextacytokens=textacy.extract.words(doc,filter_stops=True,# default True, no stopwordsfilter_punct=True,# default True, no punctuationfilter_nums=True,# default False, no numbersinclude_pos=['ADJ','NOUN'],# default None = include allexclude_pos=None,# default None = exclude nonemin_freq=1)# minimum frequency of words(*[tfortintokens],sep='|')
Out:
best|friend|fancy|adventure|games
Nuestra función para extraer una lista filtrada de lemas de palabras no es más que una pequeña envoltura de esa función. Al reenviar los argumentos de la palabra clave (**kwargs), esta función acepta los mismos parámetros que extract.words de textacy.
defextract_lemmas(doc,**kwargs):return[t.lemma_fortintextacy.extract.words(doc,**kwargs)]lemmas=extract_lemmas(doc,include_pos=['ADJ','NOUN'])(*lemmas,sep='|')
Out:
good|friend|fancy|adventure|game
Nota
Utilizar lemas en lugar de palabras flexionadas suele ser una buena idea, pero no siempre. Por ejemplo, puede tener un efecto negativo en el análisis de sentimientos, donde "bueno" y "mejor" marcan la diferencia.
Plano: Extraer frases sustantivas
En el Capítulo 1 ilustramos cómo utilizar los n-gramas para el análisis. Los n-gramas son enumeraciones simples de subsecuencias de n palabras en una frase. Por ejemplo, la frase que hemos utilizado antes contiene los siguientes bigramas:
My_best|best_friend|friend_Ryan|Ryan_Peters|Peters_likes|likes_fancy fancy_adventure|adventure_games
Muchos de esos bigramas no son muy útiles para el análisis, por ejemplo, likes_fancy o my_best. Sería aún peor en el caso de los trigramas. Pero, ¿cómo podemos detectar secuencias de palabras que tengan un significado real? Una forma es aplicar la concordancia de patrones a las etiquetas de parte de habla. spaCy tiene un emparejador basado en reglas bastante potente, y textacy tiene una cómoda envoltura para la extracción de frases basada en patrones. El siguiente patrón extrae secuencias de sustantivos con un adjetivo precedente:
text="My best friend Ryan Peters likes fancy adventure games."doc=nlp(text)patterns=["POS:ADJ POS:NOUN:+"]spans=textacy.extract.matches(doc,patterns=patterns)(*[s.lemma_forsinspans],sep='|')
Out:
good friend|fancy adventure|fancy adventure game
Como alternativa, puedes utilizar la función doc.noun_chunks de spaCy para la extracción de frases nominales. Sin embargo, como los trozos devueltos también pueden incluir pronombres y determinantes, esta función es menos adecuada para la extracción de rasgos:
(*doc.noun_chunks,sep='|')
Out:
My best friend|Ryan Peters|fancy adventure games
Así, definimos nuestro modelo para la extracción de frases sustantivas basado en patrones de parte de discurso. La función toma un doc, una lista de etiquetas de parte de discurso y un carácter separador para unir las palabras de la frase nominal. El patrón construido busca secuencias de sustantivos precedidas por un token con una de las etiquetas de parte de oración especificadas. Se devuelven los lemas. Nuestro ejemplo extrae todas las frases formadas por un adjetivo o un sustantivo seguido de una secuencia de sustantivos :
defextract_noun_phrases(doc,preceding_pos=['NOUN'],sep='_'):patterns=[]forposinpreceding_pos:patterns.append(f"POS:{pos} POS:NOUN:+")spans=textacy.extract.matches(doc,patterns=patterns)return[sep.join([t.lemma_fortins])forsinspans](*extract_noun_phrases(doc,['ADJ','NOUN']),sep='|')
Out:
good_friend|fancy_adventure|fancy_adventure_game|adventure_game
Plano: Extracción de entidades con nombre
Reconocimiento de entidadescon nombre se refiere al proceso de detectar entidades como personas, lugares u organizaciones en un texto. Cada entidad puede constar de uno o varios tokens, como San Francisco. Por lo tanto, las entidades con nombre se representan mediante objetos Span. Al igual que con las frases nominales, puede ser útil recuperar una lista de entidades con nombre para su posterior análisis.
Si vuelves a mirar la Tabla 4-3, verás los atributos de los tokens para el reconocimiento de entidades con nombre, ent_type_ y ent_iob_. ent_iob_ contiene la información de si un token comienza una entidad (B), está dentro de una entidad (I), o está fuera (O). En lugar de iterar a través de los tokens, también podemos acceder directamente a las entidades con nombre con doc.ents. Aquí, la propiedad para el tipo de entidad se llama label_. Vamos a ilustrarlo con un ejemplo:
text="James O'Neill, chairman of World Cargo Inc, lives in San Francisco."doc=nlp(text)forentindoc.ents:(f"({ent.text}, {ent.label_})",end=" ")
Out:
(James O'Neill, PERSON) (World Cargo Inc, ORG) (San Francisco, GPE)
El módulo displacy de spaCy también proporciona la visualización para el reconocimiento de entidades con nombre, lo que hace que el resultado sea mucho más legible y ayuda visualmente a identificar las entidades mal clasificadas:
fromspacyimportdisplacydisplacy.render(doc,style='ent')

Las entidades con nombre se identificaron correctamente como una persona, una organización y una entidad geopolítica (EGP). Pero ten en cuenta que la precisión del reconocimiento de entidades con nombre puede no ser muy buena si tu corpus carece de una estructura gramatical clara. Consulta "Reconocimiento de entidades con nombre" para obtener información detallada en .
Para la extracción de entidades con nombre de determinados tipos, volvemos a utilizar una de las prácticas funciones de textacy:
defextract_entities(doc,include_types=None,sep='_'):ents=textacy.extract.entities(doc,include_types=include_types,exclude_types=None,drop_determiners=True,min_freq=1)return[sep.join([t.lemma_fortine])+'/'+e.label_foreinents]
Con esta función podemos, por ejemplo, recuperar las entidades con nombre de los tipos PERSON y GPE (entidad geopolítica) así:
(extract_entities(doc,['PERSON','GPE']))
Out:
["James_O'Neill/PERSON", 'San_Francisco/GPE']
Extracción de características en un gran conjunto de datos
Ahora que conocemos las herramientas que nos proporciona spaCy, podemos construir por fin nuestro extractor de rasgos lingüísticos. La Figura 4-3 ilustra lo que vamos a hacer. Al final, queremos crear un conjunto de datos que pueda utilizarse como entrada para análisis estadísticos y diversos algoritmos de aprendizaje automático. Una vez extraídos, conservaremos los datos preprocesados "listos para usar" en una base de datos.
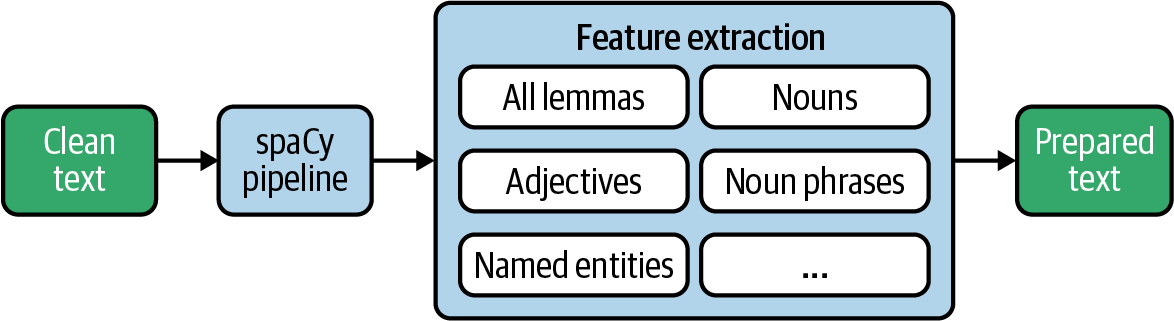
Figura 4-3. Extracción de rasgos de un texto con spaCy.
Plano: Crear una función para conseguirlo todo
Esta función del plano combina todas las funciones de extracción de la sección anterior. Pone ordenadamente todo lo que queremos extraer en un solo lugar del código, de forma que no sea necesario ajustar los pasos posteriores si añades o cambias algo aquí:
defextract_nlp(doc):return{'lemmas':extract_lemmas(doc,exclude_pos=['PART','PUNCT','DET','PRON','SYM','SPACE'],filter_stops=False),'adjs_verbs':extract_lemmas(doc,include_pos=['ADJ','VERB']),'nouns':extract_lemmas(doc,include_pos=['NOUN','PROPN']),'noun_phrases':extract_noun_phrases(doc,['NOUN']),'adj_noun_phrases':extract_noun_phrases(doc,['ADJ']),'entities':extract_entities(doc,['PERSON','ORG','GPE','LOC'])}
La función devuelve un diccionario con todo lo que queremos extraer, como se muestra en este ejemplo:
text="My best friend Ryan Peters likes fancy adventure games."doc=nlp(text)forcol,valuesinextract_nlp(doc).items():(f"{col}: {values}")
Out:
lemmas: ['good', 'friend', 'Ryan', 'Peters', 'like', 'fancy', 'adventure', \
'game']
adjs_verbs: ['good', 'like', 'fancy']
nouns: ['friend', 'Ryan', 'Peters', 'adventure', 'game']
noun_phrases: ['adventure_game']
adj_noun_phrases: ['good_friend', 'fancy_adventure', 'fancy_adventure_game']
entities: ['Ryan_Peters/PERSON']
La lista de nombres de columnas devuelta es necesaria para los pasos siguientes. En lugar de codificarla, simplemente llamamos a extract_nlp con un documento vacío para recuperar la lista:
nlp_columns=list(extract_nlp(nlp.make_doc('')).keys())(nlp_columns)
Out:
['lemmas', 'adjs_verbs', 'nouns', 'noun_phrases', 'adj_noun_phrases', 'entities']
Plano: Utilizar spaCy en un gran conjunto de datos
Ahora podemos utilizar esta función para extraer características de todos los registros de un conjunto de datos. Tomamos los textos depurados que creamos y guardamos al principio de este capítulo y añadimos los títulos:
db_name="reddit-selfposts.db"con=sqlite3.connect(db_name)df=pd.read_sql("select * from posts_cleaned",con)con.close()df['text']=df['title']+': '+df['text']
Antes de iniciar el procesamiento PNL, inicializamos las nuevas columnas DataFrame que queremos rellenar con valores:
forcolinnlp_columns:df[col]=None
Los modelos neuronales de spaCy se benefician de ejecutándose en la GPU. Por tanto, intentamos cargar el modelo en la GPU antes de empezar:
ifspacy.prefer_gpu():("Working on GPU.")else:("No GPU found, working on CPU.")
Ahora tenemos que decidir qué modelo y qué componentes de la tubería utilizar. Recuerda desactivar los componentes innecesarios para mejorar el tiempo de ejecución. Nos ceñimos al modelo inglés pequeño con la canalización por defecto y utilizamos nuestro tokenizador personalizado que separa los guiones:
nlp=spacy.load('en_core_web_sm',disable=[])nlp.tokenizer=custom_tokenizer(nlp)# optional
Al procesar conjuntos de datos más grandes, se recomienda utilizar el procesamiento por lotes de spaCy para obtener una ganancia de rendimiento significativa (aproximadamente un factor 2 en nuestro conjunto de datos). La función nlp.pipe toma un iterable de textos, los procesa internamente como un lote, y devuelve una lista de objetos Doc procesados en el mismo orden que los datos de entrada.
Para utilizarlo, primero tenemos que definir un tamaño de lote. Luego podemos hacer un bucle sobre los lotes y llamar a nlp.pipe.
batch_size=50foriinrange(0,len(df),batch_size):docs=nlp.pipe(df['text'][i:i+batch_size])forj,docinenumerate(docs):forcol,valuesinextract_nlp(doc).items():df[col].iloc[i+j]=values
En el bucle interno extraemos las características del doc procesado y escribimos los valores de nuevo en el DataFrame. Todo el proceso tarda entre seis y ocho minutos en el conjunto de datos sin utilizar una GPU y entre tres y cuatro minutos con la GPU en Colab.
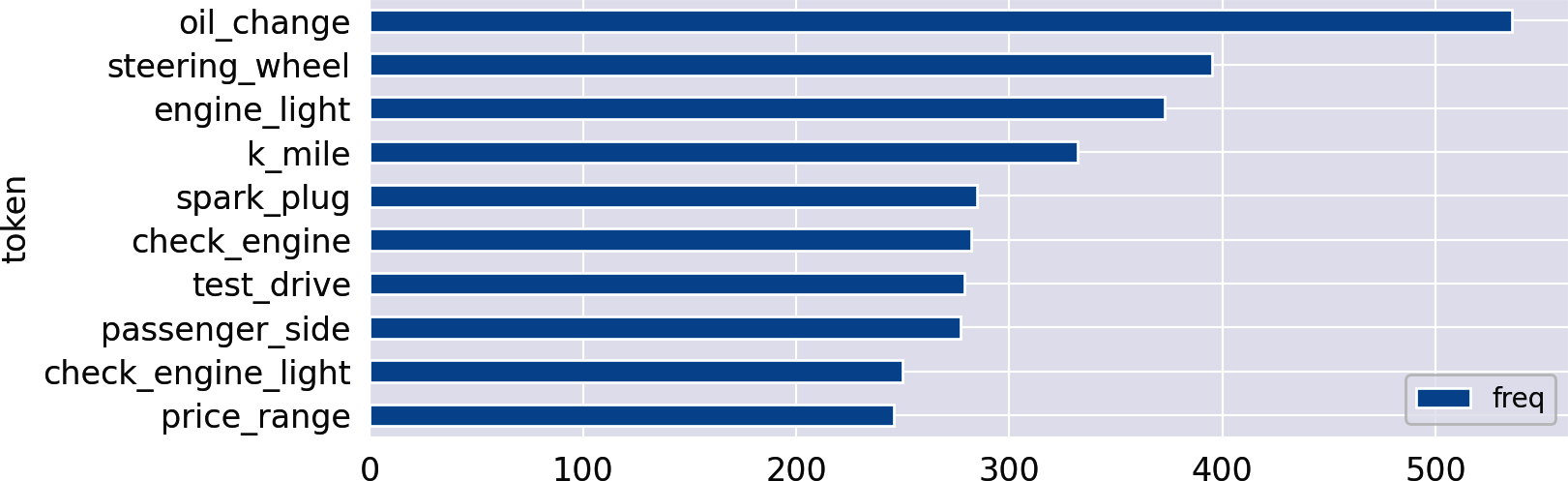
Las columnas recién creadas son perfectamente adecuadas para el análisis de frecuencias con las funciones del Capítulo 1. Comprobemos cuáles son las frases sustantivadas más frecuentes en la categoría autos:
count_words(df,'noun_phrases').head(10).plot(kind='barh').invert_yaxis()
Out:
Persistir en el resultado
Por último, guardamos la DataFrame completa en SQLite. Para ello, tenemos que serializar las listas extraídas en cadenas separadas por espacios, ya que la mayoría de las bases de datos no admiten listas:
df[nlp_columns]=df[nlp_columns].applymap(lambdaitems:' '.join(items))con=sqlite3.connect(db_name)df.to_sql("posts_nlp",con,index=False,if_exists="replace")con.close()
La tabla resultante proporciona una base sólida y lista para usar en posteriores análisis. De hecho, volveremos a utilizar estos datos en el Capítulo 10 para entrenar incrustaciones de palabras en los lemas extraídos. Por supuesto, los pasos de preprocesamiento dependen de lo que vayas a hacer con los datos. Trabajar con conjuntos de palabras como los producidos por nuestro plano es perfecto para cualquier tipo de análisis estadístico sobre frecuencias de palabras y aprendizaje automático basado en una vectorización de bolsas de palabras. Tendrás que adaptar los pasos para los algoritmos que se basan en el conocimiento de las secuencias de palabras.
Nota sobre el tiempo de ejecución
El procesamiento lingüístico completo lleva mucho tiempo. De hecho, procesar sólo las 20.000 entradas de Reddit con spaCy lleva varios minutos. En cambio, un simple tokenizador regexp sólo tarda unos segundos en tokenizar todos los registros en la misma máquina. Lo que resulta caro es el etiquetado, el análisis de y el reconocimiento de entidades con nombre de , aunque spaCy es realmente rápido en comparación con otras bibliotecas. Así que si no necesitas entidades con nombre, deberías desactivar el analizador sintáctico y el reconocimiento de entidades con nombre para ahorrar más del 60% del tiempo de ejecución.
Procesar los datos por lotes con nlp.pipe y utilizando GPUs es una forma de acelerar el procesamiento de datos para spaCy. Pero la preparación de datos en general también es una candidata perfecta para la paralelización. Una opción de para paralelizar tareas en Python es utilizar la biblioteca multiprocessingEspecialmente para la paralelización de operaciones sobre marcos de datos, hay algunas alternativas escalables a Pandas que merece la pena consultar, concretamente Dask, Modin y Vaex. pandarallel es una biblioteca que añade operadores de aplicación paralela directamente a Pandas.
En cualquier caso, es útil observar el progreso y obtener una estimación del tiempo de ejecución. Como ya se mencionó en en el Capítulo 1, la biblioteca tqdm es una gran herramienta para ese fin, porque proporciona barras de progreso para los iteradores y las operaciones con marcos de datos. Nuestros cuadernos en GitHub utilizan tqdm siempre que es posible.
Hay más
Empezamos con la limpieza de datos y pasamos por todo un proceso de tratamiento lingüístico. Aun así, hay algunos aspectos que no cubrimos en detalle pero que pueden ser útiles o incluso necesarios en tus proyectos.
Detección de idiomas
Muchos corpus contienen texto en lenguas diferentes. Siempre que trabajes con un corpus multilingüe, tendrás que decidirte por una de estas opciones:
- Ignora otras lenguas si representan una minoría insignificante, y trata cada texto como si fuera de la lengua principal del corpus, por ejemplo, el inglés.
- Traduce todos los textos a la lengua principal, por ejemplo, utilizando Google Translate.
- Identifica la lengua y realiza el preprocesamiento dependiente de la lengua en los pasos siguientes.
Existen buenas bibliotecas para la detección de idiomas. Nuestra recomendación es La biblioteca fastText de Facebook. fastText proporciona un modelo preentrenado que identifica 176 idiomas de forma realmente rápida y precisa. Proporcionamos un modelo adicional para la detección de idiomas con fastText en el repositorio de GitHub de este capítulo.
La función make_spacy_doc de textacy te permite cargar automáticamente el modelo de lenguaje correspondiente para el procesamiento lingüístico, si está disponible. Por defecto, utiliza un modelo de detección de idiomas basado en el Detector Compacto de Idiomas v3 de Google, pero también podrías enganchar cualquier función de detección de idiomas (por ejemplo, fastText).
Corrector ortográfico
El contenido generado por los usuarios de adolece de muchos errores ortográficos. Sería estupendo que un corrector ortográfico pudiera corregir automáticamente estos errores. SymSpell es un popular corrector ortográfico con un puerto a Python. Sin embargo, como sabes por tu smartphone, la corrección ortográfica automática puede introducir por sí misma artefactos extraños. Por tanto, deberías comprobar si la calidad mejora realmente.
Normalización de tokens
A menudo, hay diferentes grafías para términos idénticos o variaciones de términos que quieres tratar y, sobre todo, contar de forma idéntica. En este caso, es útil normalizar estos términos y asignarlos a una norma común. He aquí algunos ejemplos:
- EE.UU. o EE.UU. → EE.UU.
- burbuja puntocom → burbuja puntocom
- Múnich → Múnich
Podrías utilizar el comparador de frases de spaCy para integrar este tipo de normalización como un paso de postprocesamiento en su pipeline. Si no utilizas spaCy, puedes usar un simple diccionario de Python para asignar las distintas grafías a sus formas normalizadas.
Observaciones finales y recomendaciones
"Basura dentro, basura fuera" es un problema frecuentemente citado en los proyectos de datos. Esto es especialmente cierto en el caso de los datos textuales, que son intrínsecamente ruidosos. Por lo tanto, la limpieza de datos es una de las tareas más importantes en cualquier proyecto de análisis de texto. Dedica el esfuerzo suficiente a garantizar una alta calidad de los datos y compruébala sistemáticamente. En esta sección hemos mostrado muchas soluciones para identificar y resolver los problemas de calidad.
El segundo requisito para realizar análisis fiables y modelos robustos es la normalización. Muchos algoritmos de aprendizaje automático para texto se basan en el modelo de bolsa de palabras , que genera una noción de similitud entre documentos basada en las frecuencias de las palabras. En general, es mejor que utilices texto lematizado cuando hagas clasificación de textos, modelado de temas o agrupamiento basado en TF-IDF. Deberías evitar o utilizar con moderación esos tipos de normalización o eliminación de palabras vacías para tareas de aprendizaje automático más complejas, como el resumen de textos, la traducción automática o la respuesta a preguntas, en las que el modelo debe reflejar la variedad del lenguaje.
1 Las operaciones Pandas map y apply se explicaron en "Blueprint: Construir una tubería sencilla de preprocesamiento de textos".
2 Las bibliotecas especializadas en la limpieza de datos HTML, como Beautiful Soup, se presentaron en el Capítulo 3.
3 El operador asterisco (*) descomprime la lista en argumentos separados para print.
4 Por ejemplo, consulta el tokenizador de tweets de NLTK para expresiones regulares para emoticonos de texto y URL, o consulta las expresiones regulares de compilación de textacy.
5 Un buen resumen es "El arte de la tokenización", de Craig Trim.
6 Consulta el sitio web de spaCy para ver la lista de modelos disponibles.
7 Consulta la API de spaCy para obtener una lista completa.
8 Consulta la API de spaCy para ver una lista completa de atributos.
9 Consulta la documentación de spaCy sobre el uso de la tokenización para obtener más detalles y un ejemplo ilustrativo.
10 Para más detalles, consulta la documentación sobre el uso del tokenizador de spaCy.
11 Modificar la lista de palabras de parada de esta forma probablemente quedará obsoleto con spaCy 3.0. En su lugar, se recomienda crear una subclase modificada de la clase de idioma correspondiente. Para más detalles, consulta el cuaderno GitHub de este capítulo.
12 Para más información, consulta Etiquetas universales de parte de discurso.
Get Planos para el análisis de textos con Python now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

