To make the most of the server-side JavaScript environment, it’s important to understand some core concepts behind the design choices that were made for Node.js and JavaScript in general. Understanding the decisions and trade-offs will make it easier for you to write great code and architect your systems. It will also help you explain to other people why Node.js is different from other systems they’ve used and where the performance gains come from. No engineer likes unknowns in her system. “Magic” is not an acceptable answer, so it helps to be able to explain why a particular architecture is beneficial and under what circumstances.
This chapter will cover the coding styles, design patterns, and production know-how you need to write good, robust Node code.
A fundamental part of Node is the event loop, a concept underlying the behavior of JavaScript as well as most other interactive systems. In many languages, event models are bolted onto the side, but JavaScript events have always been a core part of the language. This is because JavaScript has always dealt with user interaction. Anyone who has used a modern web browser is accustomed to web pages that do things “onclick,” “onmouseover,” etc. These events are so common that we hardly think about them when writing web page interaction, but having this event support in the language is incredibly powerful. On the server, instead of the limited set of events based on the user-driven interaction with the web page’s DOM, we have an infinite variety of events based on what’s happening in the server software we use. For example, the HTTP server module provides an event called “request,” emitted when a user sends the web server a request.
The event loop is the system that JavaScript uses to deal with these incoming requests from various parts of the system in a sane manner. There are a number of ways people deal with “real-time” or “parallel” issues in computing. Most of them are fairly complex and, frankly, make our brains hurt. JavaScript takes a simple approach that makes the process much more understandable, but it does introduce a few constraints. By having a grasp of how the event loop works, you’ll be able to use it to its full advantage and avoid the pitfalls of this approach.
Node takes the approach that all I/O activities should be nonblocking (for reasons we’ll explain more later). This means that HTTP requests, database queries, file I/O, and other things that require the program to wait do not halt execution until they return data. Instead, they run independently, and then emit an event when their data is available. This means that programming in Node.js has lots of callbacks dealing with all kinds of I/O. Callbacks often initiate other callbacks in a cascading fashion, which is very different from browser programming. There is still a certain amount of linear setup, but the bulk of the code involves dealing with callbacks.
Because of this somewhat unfamiliar programming style, we need to look for patterns to help us effectively program on the server. That starts with the event loop. We think that most people intuitively understand event-driven programming because it is like everyday life. Imagine you are cooking. You are chopping a bell pepper and a pot starts to boil over (Figure 3-1). You finish the slice you are working on, and then turn down the stove. Rather than trying to chop and turn down the stove at the same time, you achieve the same result in a much safer manner by rapidly switching contexts. Event-driven programming does the same thing. By allowing the programmer to write code that only ever works on one callback at a time, the program is both understandable and also able to quickly perform many tasks efficiently.

In everyday life, we are used to having all sorts of internal callbacks for dealing with events, and yet, like JavaScript, we always do just one thing at once. Yes, yes, we can see that you are rubbing your tummy and patting your head at the same time—well done. But if you try to do any serious activities at the same time, it goes wrong pretty quickly. This is like JavaScript. It’s great at letting events drive the action, but it’s “single-threaded” so that only one thing happens at once.
This single-threaded concept is really important. One of the criticisms leveled at Node.js fairly often is its lack of “concurrency.” That is, it doesn’t use all of the CPUs on a machine to run the JavaScript. The problem with running code on multiple CPUs at once is that it requires coordination between multiple “threads” of execution. In order for multiple CPUs to effectively split up work, they would have to talk to each other about the current state of the program, what work they’d each done, etc. Although this is possible, it’s a more complex model that requires more effort from both the programmer and the system. JavaScript’s approach is simple: there is only one thing happening at once. Everything that Node does is nonblocking, so the time between an event being emitted and Node being able to act on that event is very short because it’s not waiting on things such as disk I/O.
Another way to think about the event loop is to compare it to a postman (or mailman). To our event-loop postman, each letter is an event. He has a stack of events to deliver in order. For each letter (event) the postman gets, he walks to the route to deliver the letter (Figure 3-2). The route is the callback function assigned to that event (sometimes more than one). Critically, however, because our postman has only a single set of legs, he can walk only a single code path at a time.
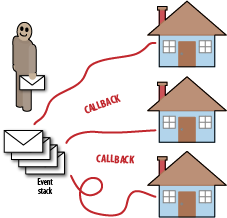
Sometimes, while the postman is walking a code route, someone will give him another letter. This is the callback function he is visiting at the moment. In this case, the postman delivers the new message immediately (after all, someone gave it to him directly instead of going via the post office, so it must be urgent). The postman will diverge from his current code path and walk the proper code path to deliver the new event. He then carries on walking the original code path emitted by the previous event.
Let’s look at the behavior of our postman in a
typical program by picking something simple. Suppose we have a web (HTTP)
server that gets requests, retrieves some data from a database, and
returns it to the user. In this scenario, we have a few events to deal
with. First (as in most cases) comes the request event from the
user asking the web server for a web page. The callback that deals with
the initial request (let’s call it callback A) looks at the request object
and figures out what data it needs from the database. It then makes a
request to the database for that data, passing another function, callback
B, to be called on the response event. Having
handled the request, callback A
returns. When the database has found the data, it issues the response event. The event loop then calls
callback B, which sends the data back to the user.
This seems fairly straightforward. The obvious thing to note here is the “break” in the code, which you wouldn’t get in a procedural system. Because Node.js is a nonblocking system, when we get to the database call that would make us wait, we instead issue a callback. This means that different functions must start handling the request and finish handling it when the data is ready to return. So we need to make sure that we either pass any state we need to the callback or make it available in some other way. JavaScript programming typically does it through closures. We’ll discuss that in more detail later.
Why does this make Node more efficient? Imagine ordering food at a fast food restaurant. When you get in line at the counter, the server taking your order can behave in two ways. One of them is event-driven, and one of them isn’t. Let’s start with the typical approach taken by PHP and many other web platforms. When you ask the server for your order, he takes it but won’t serve any other customers until he has completed your order. There are a few things he can do after he’s typed in your order: process your payment, pour your drink, and so on. However, the server is still going to have to wait an unknown amount of time for the kitchen to make your burger (one of us is vegetarian, and orders always seem to take ages). If, as in the traditional approach of web application frameworks, each server (thread) is allocated to just one request at a time, the only way to scale up is to add more threads. However, it’s also very obvious that our server isn’t being very efficient. He’s spending a lot of time waiting for the kitchen to cook the food.
Obviously, real-life restaurants use a much more efficient model. When a server has finished taking your order, you receive a number that he can use to call you back. You could say this is a callback number. This is how Node works. When slow things such as I/O start, Node simply gives them a callback reference and then gets on with other work that is ready now, like the next customer (or event, in Node’s case). It’s important to note that as we saw in the example of the postman, at no time do restaurant servers ever deal with two customers at the same time. When they are calling someone back to collect an order, they are not taking a new one, and vice versa. By acting in an event-driven way, the servers are able to maximize their throughput.
This analogy also illustrates the cases where Node fits well and those where it doesn’t. In a small restaurant where the kitchen staff and the wait staff are the same people, no improvement can be made by becoming event-driven. Because all the work is being done by the same people, event-driven architectures don’t add anything. If all (or most) of the work your server does is computation, Node might not be the ideal model.
However, we can also see when the architecture fits. Imagine there are two servers and four customers in a restaurant (Figure 3-3). If the servers serve only one customer at a time, the first two customers will get the fastest possible order, but the third and fourth customers will get a terrible experience. The first two customers will get their food as soon as it is ready because the servers have dedicated their whole attention to fulfilling their orders. That comes at the cost of the other two customers. In an event-driven model, the first two customers might have to wait a short amount of time for the servers to finish taking the orders of the third and fourth customers before they get their food, but the average wait time (latency) of the system will be much, much lower.

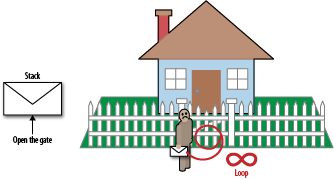
Let’s look at another example. We’ve given the event-loop postman a letter to deliver that requires a gate to be opened. He gets there and the gate is closed, so he simply waits and tries again and again. He’s trapped in an endless loop waiting for the gate to open (Figure 3-4). Perhaps there is a letter on the stack that will ask someone to open the gate so the postman can get through. Surely that will solve things, right? Unfortunately, this will only help if the postman gets to deliver the letter, and currently he’s stuck waiting endlessly for the gate to open. This is because the event that opens the gate is external to the current event callback. If we emit the event from within a callback, we already know our postman will go and deliver that letter before carrying on, but when events are emitted outside the currently executing piece of code, they will not be called until that piece of code has been fully evaluated to its conclusion.
As an illustration, the code in Example 3-1 creates a loop that Node.js (or a browser) will never break out of.
In this example, console.log will never be called, because the
while loop stops Node from ever getting a chance to
call back the timeout and emit the die event. Although
it’s unlikely we’d program a loop like this that relies on an external
condition to exit, it illustrates how Node.js can do only one thing at
once, and getting a fly in the ointment can really screw up the whole
server. This is why nonblocking I/O is an essential part of event-driven
programming.
Let’s consider some numbers. When we run an operation in the CPU
(not a line of JavaScript, but a single machine code operation), it takes
about one-third of a nanosecond (ns). A 3Ghz processor runs
3×109 instructions a second, so each
instruction takes 10-9/3 seconds each. There
are typically two types of memory in a CPU, L1 and L2 cache, each of which
takes approximately 2–5ns to access. If we get data from memory (RAM), it
takes about 80ns, which is about two orders of magnitude slower than
running an instruction. However, all of these things are in the same
ballpark. Getting things from slower forms of I/O is not quite so good.
Imagine that getting data from RAM is equivalent to the weight of a cat.
Retrieving data from the hard drive, then, could be considered to be the
weight of a whale. Getting things from the network is like 100 whales.
Think about how running var foo = "bar"
versus a database query is a single cat versus 100 blue whales. Blocking
I/O doesn’t put an actual gate in front of the event-loop postman, but it
does send him via Timbuktu when he is delivering his events.
Given a basic understanding of the event loop, let’s look at the standard Node.js code for creating an HTTP server, shown in Example 3-2.
This code is the most basic example from the
Node.js website (but as we’ll see soon, it’s not the ideal way to code).
The example creates an HTTP server using a factory method in the http library. The factory method creates a new
HTTP server and attaches a callback to the request event. The callback is specified as the
argument to the createServer method.
What’s interesting here is what happens when this code is run. The first
thing Node.js does is run the code in the example from top to bottom. This
can be considered the “setup” phase of Node programming. Because we
attached some event listeners, Node.js doesn’t exit, but instead waits for
an event to be fired. If we didn’t attach any events, Node.js would exit
as soon as it had run the code.
So what happens when the server gets an HTTP
request? Node.js emits the request
event, which causes the callbacks attached to that event to be run in
order. In this case, there is only one callback, the anonymous function we
passed as an argument to createServer.
Let’s assume it’s the first request the server has had since setup.
Because there is no other code running, the request event is handled immediately and the
callback is run. It’s a very simple callback, and it runs pretty
fast.
Let’s assume that our site gets really popular and we get lots of requests. If, for the sake of argument, our callback takes 1 second and we get a second request shortly after the first one, the second request isn’t going to be acted on for another second or so. Obviously, a second is a really long time, and as we look at the requirements of real-world applications, the problem of blocking the event loop becomes more damaging to the user experience. The operating system kernel actually handles the TCP connections to clients for the HTTP server, so there isn’t a risk of rejecting new connections, but there is a real danger of not acting on them. The upshot of this is that we want to keep Node.js as event-driven and nonblocking as possible. In the same way that a slow I/O event should use callbacks to indicate the presence of data that Node.js can act on, the Node.js program itself should be written in such a way that no single callback ties up the event loop for extended periods of time.
This means that you should follow two strategies when writing a Node.js server:
Taking the event-driven approach works effectively with the event loop (the name is a hint that it would), but it’s also important to write event-driven code in a way that is easy to read and understand. In the previous example, we used an anonymous function as the event callback, which makes things hard in a couple of ways. First, we have no control over where the code is used. An anonymous function’s call stack starts from when it is used, rather than when the callback is attached to an event. This affects debugging. If everything is an anonymous event, it can be hard to distinguish similar callbacks when an exception occurs.
Get Node: Up and Running now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

