Kapitel 1. Trends in der Netzwerkbranche
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Mehr als ein Jahrzehnt ist es her, dass der Begriff Software-defined Networking(SDN) geprägt wurde und eine der größten Revolutionen in der Netzwerkbranche seit den 1990er Jahren darstellt, und wahrscheinlich verwirrt dich der Begriff immer noch. Egal, ob du SDN neu kennst oder in den letzten Jahren von der Begeisterung dafür erfasst wurdest, keine Sorge. Dieses Buch führt dich durch die grundlegenden Themen, damit du verstehst, wie Software, die Cloud und Open Source die Art und Weise, wie wir Netzwerke in der heutigen Zeit aufbauen und verwalten, völlig verändert haben.
Dieses Kapitel gibt einen Einblick in die Trends in der Netzwerkbranche, die sich auf SDN, seine Relevanz und seine Auswirkungen in der heutigen Welt der Netzwerke konzentrieren. Wir beginnen mit einem Überblick darüber, wie SDN in den Mainstream Einzug gehalten hat und schließlich zu Netzwerkprogrammierbarkeit und Automatisierungspraktiken geführt hat.
Der Aufstieg des Software-Defined Networking
Wenn man den Wandel in der Netzwerkbranche einer Person zuschreiben könnte, wäre es Martin Casado, ein General Partner des Risikokapitalgebers Andreessen Horowitz. Zuvor war Casado VMware Fellow, Senior Vice President und General Manager in der Networking and Security Business Unit bei VMware. Er hat die Branche tiefgreifend beeinflusst, nicht nur durch seine direkten Beiträge (u. a. OpenFlow und Nicira), sondern auch dadurch, dass er den großen etablierten Netzwerkbetreibern die Augen geöffnet und gezeigt hat, dass sich der Netzwerkbetrieb, die Agilität und die Verwaltbarkeit ändern müssen. Schauen wir uns diese Geschichte ein wenig genauer an.
Die Einführung von OpenFlow
Im Guten wie im Schlechten war OpenFlow das erste wichtige Protokoll der SDN-Bewegung. Casado arbeitete an OpenFlow, während er an der Stanford University unter der Leitung von Nick McKeown promovierte. Das OpenFlow-Protokoll ermöglicht die Entkopplung der Steuerungsebene eines Netzwerkgeräts von der Datenebene (siehe Abbildung 1-1). Vereinfacht ausgedrückt kann man sich die Steuerebene als das Gehirn eines Netzwerkgeräts vorstellen und die Datenebene als die Hardware oder anwendungsspezifischen integrierten Schaltungen (ASICs), die die Weiterleitung der Pakete übernehmen.
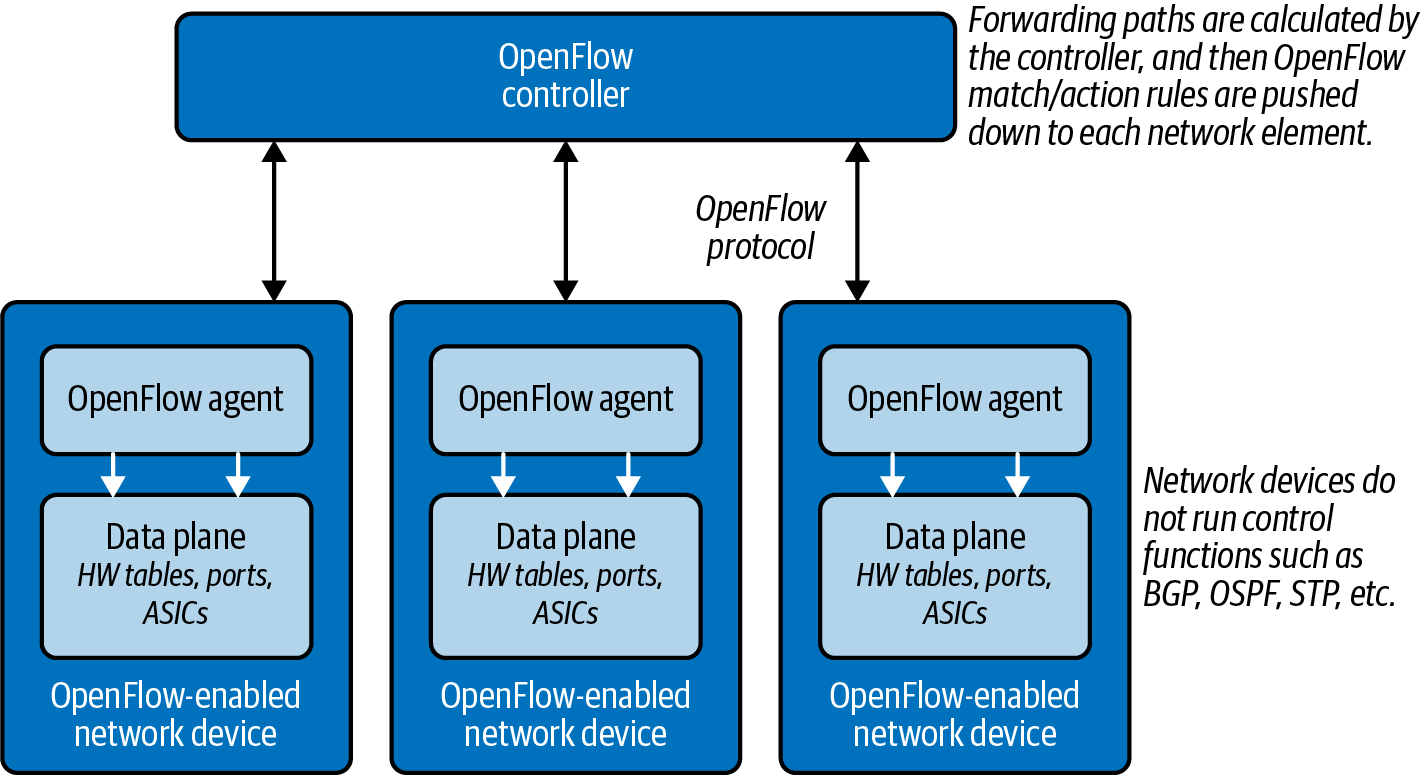
Abbildung 1-1. Entkopplung der Kontroll- und Datenebene mit OpenFlow
Hinweis
In Abbildung 1-1 sind die Netzwerkgeräte ohne Steuerebene dargestellt. Dies stellt einen reinen OpenFlow-Einsatz dar. Viele Geräte unterstützen auch den Betrieb von OpenFlow in einem hybriden Modus, d. h. OpenFlow kann auf einem bestimmten Port, einem virtuellen lokalen Netzwerk (VLAN) oder sogar innerhalb einer normalen Paketweiterleitungs-Pipeline eingesetzt werden. In diesem Fall gibt es keine Übereinstimmung in der OpenFlow-Tabelle, sondern es werden die bestehenden Weiterleitungstabellen verwendet - Media Access Control (MAC)-Routing usw. -, so dass die Paketweiterleitung eher dem Policy-based Routing (PBR) entspricht.
Das bedeutet, dass OpenFlow ein Low-Level-Protokoll ist, das direkt mit den Hardware-Tabellen (z. B. der Forwarding Information Base oder FIB) verbunden ist, die einem Netzwerkgerät vorgeben, wie es den Datenverkehr weiterleiten soll (z. B. "Der Datenverkehr zum Ziel 192.168.0.100 soll über Port 48 abgehen").
Hinweis
OpenFlow ist ein Low-Level-Protokoll, das Flow-Tabellen manipuliert und sich damit direkt auf die Weiterleitung von Paketen auswirkt. OpenFlow ist nicht für die Interaktion mit Attributen der Verwaltungsebene wie Authentifizierung oder SNMP-Parameter (Simple Network Management Protocol) vorgesehen.
Da die von OpenFlow verwendeten Tabellen im Vergleich zu traditionellen Routing-Protokollen mehr als die Zieladresse unterstützen, bietet OpenFlow mehr Granularität (passende Felder im Paket), um den Weiterleitungspfad zu bestimmen. Dies ist nicht unähnlich der Granularität, die PBR bietet, um den nächsten Routing-Hop unter Berücksichtigung der Quelladresse zu bestimmen. Wie OpenFlow viele Jahre später, ermöglicht PBR den Netzwerkadministratoren die Weiterleitung des Datenverkehrs auf der Grundlage von "nicht-traditionellen" Attributen, wie der Quelladresse eines Pakets. Es dauerte jedoch eine ganze Weile, bis die Netzwerkhersteller eine gleichwertige Leistung für den über PBR weitergeleiteten Verkehr anboten, und das Endergebnis war immer noch sehr herstellerspezifisch.
Das Aufkommen von OpenFlow bedeutete, dass wir die gleiche Granularität bei den Entscheidungen zur Weiterleitung des Datenverkehrs erreichen konnten, aber auf eine herstellerneutrale Weise. Es wurde möglich, die Fähigkeiten der Netzwerkinfrastruktur zu verbessern, ohne auf die nächste Version der Hardware des Herstellers zu warten.
Warum OpenFlow?
Es ist zwar wichtig zu verstehen, was OpenFlow ist, aber noch wichtiger ist es, die Gründe für die Forschungs- und Entwicklungsarbeit an der ursprünglichen OpenFlow-Spezifikation zu verstehen, die zum Aufstieg von SDN geführt hat.
Casado arbeitete während seines Studiums in Stanford für die Regierung der Vereinigten Staaten. Zu dieser Zeit musste die Regierung auf Sicherheitsangriffe auf ihre IT-Systeme reagieren (schließlich handelt es sich um die US-Regierung). Casado merkte schnell, dass er in der Lage war, die Computer und Server nach Bedarf zu programmieren und zu manipulieren. Die tatsächlichen Anwendungsfälle wurden nie veröffentlicht, aber es war diese Art der Kontrolle über die Endpunkte, die es ermöglichte, zu reagieren, zu analysieren und möglicherweise einen Host oder eine Gruppe von Hosts bei Bedarf umzuprogrammieren.
Was das Netzwerk angeht, war es fast unmöglich, dies sauber und programmatisch zu tun. Schließlich war jedes Netzwerkgerät gesperrt (z. B. für die Installation von Drittanbietersoftware) und verfügte nur über eine Befehlszeilenschnittstelle (CLI). Obwohl die Befehlszeilenschnittstelle bei Netzwerkadministratoren bekannt und beliebt war und ist, war Casado klar, dass sie nicht die Flexibilität bot, die für die Verwaltung, den Betrieb und die Sicherheit eines Netzwerks erforderlich war.
In Wirklichkeit hatte sich die Art und Weise, wie Netzwerke verwaltet wurden, in mehr als 20 Jahren nicht verändert, abgesehen von der Hinzufügung von CLI-Befehlen für neue Funktionen. Die größte Veränderung war die Umstellung vom Telnet- auf das Secure Shell (SSH)-Protokoll, was ein Scherz war, den das SDN-Unternehmen Big Switch Networks oft in seinen Folien verwendete, wie du in Abbildung 1-2 sehen kannst.

Abbildung 1-2. Was hat sich geändert? Von Telnet zu SSH (Bildquelle: Big Switch Networks, übernommen von Arista Networks)
Spaß beiseite: Die Verwaltung von Netzwerken hinkt anderen Technologien drastisch hinterher, und genau das wollte Casado in den nächsten Jahren ändern. Dieser Mangel an Verwaltbarkeit wird oft besser verstanden, wenn man andere Technologien betrachtet. Andere Technologien verfügen fast immer über modernere Methoden zur Verwaltung vieler Geräte, sowohl für das Konfigurationsmanagement als auch für die Datenerfassung und -analyse - z. B. Hypervisor-Manager, Wireless-Controller, IP-PBXs (d. h. private IP-Telefonanlagen), PowerShell, DevOps-Tools und so weiter. Einige davon sind als kommerzielle Software eng an die Anbieter gekoppelt, andere wiederum sind lockerer abgestimmt, um plattformübergreifende Verwaltung, Betrieb und Agilität zu ermöglichen.
Wenn wir auf das Szenario zurückkommen, auf das Casado bei seiner Arbeit für die Regierung gestoßen ist, welche Fragen tauchten dann bei der Suche nach Antworten auf? War es möglich, den Datenverkehr je nach Anwendung umzuleiten? Hatten die Netzwerkgeräte eine Anwendungsprogrammierschnittstelle (API)? Gab es einen einzigen Kommunikationspunkt zum Netzwerk? Die Antworten lauteten überwiegend nein. Wie sollte es möglich sein, das Netzwerk so zu programmieren, dass es die Weiterleitung von Paketen, Richtlinien und die Konfiguration genauso einfach steuert, wie es möglich war, ein Programm zu schreiben und es auf einem Endrechner laufen zu lassen?
Die ursprüngliche OpenFlow-Spezifikation war das Ergebnis von Casados eigenen Erfahrungen mit dieser Art von Problemen. Der Hype um OpenFlow ist zwar abgeflaut, seit sich die Branche endlich mehr auf Anwendungsfälle und Lösungen als auf Low-Level-Protokolle konzentriert, aber diese erste Arbeit war der Katalysator für die gesamte Branche, um die Art und Weise, wie Netzwerke aufgebaut, verwaltet und betrieben werden, zu überdenken. Ich danke dir, Martin.
Das bedeutet auch, dass dieses Buch vielleicht nie geschrieben worden wäre, wenn es Casado nicht gegeben hätte!
Was ist Software-Defined Networking?
Wir haben OpenFlow vorgestellt, aber was ist Software-defined Networking? Ist das dasselbe, etwas anderes oder nichts von beidem? Um ehrlich zu sein, ist SDN genau das, was die Cloud vor mehr als einem Jahrzehnt war, bevor wir verschiedene Arten von Clouds kannten, wie Infrastructure as a Service (IaaS), Platform as a Service (PaaS) und Software as a Service (SaaS).
Mit Referenzbeispielen und -designs lässt sich die Cloud im Laufe der Zeit besser verstehen, aber schon bevor es diese Begriffe gab, konnte man darüber diskutieren, dass man die Cloud schon kannte, wenn man sie sah. So ähnlich verhält es sich auch mit SDN. Einige Definitionen besagen, dass White-Box-Networking SDN ist oder dass eine API auf einem Netzwerkgerät SDN ist. Ist das wirklich SDN? Nicht wirklich.
In diesem Kapitel wird nicht versucht, SDN zu definieren, sondern es werden die folgenden Technologien und Trends behandelt, die oft als SDN angesehen und in die SDN-Diskussion einbezogen werden:
-
Öffnung der Datenebene
-
Virtualisierung von Netzwerkfunktionen
-
Virtuelle Vermittlung
-
Netzwerkvirtualisierung
-
Geräte-APIs
-
Netzwerk-Automatisierung
-
Bare-Metal-Switching
-
Netzwerkstrukturen für Rechenzentren
-
Software-definiertes WAN
-
Controller Vernetzung
-
Cloud Native Networking
Hinweis
Wir definieren SDN in diesem Buch absichtlich nicht. SDN wird zwar in diesem Kapitel erwähnt, aber wir konzentrieren uns vor allem auf allgemeine Trends, die oft als SDN kategorisiert werden, um sicherzustellen, dass du die einzelnen Trends genauer kennst.
Der Rest des Buches konzentriert sich auf Netzwerkautomatisierung, APIs und periphere Technologien, die wichtig sind, um zu verstehen, wie alle Teile in Netzwerkgeräten zusammenkommen, die programmatische Schnittstellen mit modernen Automatisierungstools und Instrumenten aufweisen.
Neben der oben genannten Liste werden auch andere Technologien und Muster, die nicht direkt mit Netzwerken zu tun haben, weiterhin einen großen Einfluss auf die Art und Weise haben, wie Netzwerke aufgebaut und betrieben werden. Zum Beispiel werden Lösungen für künstliche Intelligenz und maschinelles Lernen (KI/ML) neue Möglichkeiten bieten, um fundierte Entscheidungen zu treffen, wenn es darum geht, ein neues Netzwerk zu entwerfen, Änderungen an der Optimierung vorzuschlagen oder über normale Verkehrsmuster zu lernen, um Ausreißer zu erkennen. Sei offen für alle neuen Möglichkeiten, die in der Technik auftauchen werden, und überlege, wie sie im Netzwerkbereich eingesetzt werden können.
Die Öffnung der Datenebene
OpenFlow war der Hauptgrund dafür, dass die Vorteile der Öffnung der Datenebene und ihrer Steuerung durch externe Steuerungsebenen deutlich wurden. Diese Trennung ermöglichte die Unabhängigkeit des Software-Controllers vom zugrunde liegenden Netzwerk. Um dies zu ermöglichen, kam OpenFlow mit seiner abstrakten Standardmodellierung, die keine Erweiterungen der Anbieter unterstützen konnte, sowie mit vordefinierten Paketverarbeitungspipelines (d. h. wie ein Paket die ASICs durchläuft) und vordefinierten Datenstrukturen, die es OpenFlow ermöglichten, den Weiterleitungspfad während der Laufzeit zu ändern. Diese und andere Einschränkungen machten deutlich, dass OpenFlow nicht in der Lage war, die Entkopplung von Kontroll- und Datenebene zu lösen, da eine zentralisierte Kontrollebene im großen Maßstab eine Herausforderung darstellte.
Hinweis
Seit der Version 1.5.1 im Jahr 2017 wurden keine Änderungen in der Entwicklung des OpenFlow-Standards veröffentlicht, und seine Anwendung ist auf bestimmte Anwendungsfälle beschränkt.
Das Verständnis für einige der Einschränkungen von OpenFlow wirft neue Fragen auf:
-
Warum müssen diese paketverarbeitenden Pipelines repariert werden?
-
Warum können wir keine neuen Datenstrukturen definieren?
Barefoot Networks, das von Intel übernommen wurde, antwortete auf diesen Ruf und entwickelte eine neue Familie von leistungsstarken Chips(Tofino) mit einer vollständig programmierbaren Ausführungspipeline, , sowie eine neue Programmiersprache, Programming Protocol-Independent Packet Processors, kurz P4.
Hinweis
Die P4- und OpenFlow-Protokollspezifikationen werden von derselben Organisation, der Open Networking Foundation (ONF), entwickelt.
Dieser neue, disruptive Ansatz stellte den Status quo des Marktes für Silizium-Switches in Frage. Broadcom, der größte Akteur in diesem Bereich, hat die Network Programming Language (NPL) als alternative programmierbare Lösung eingeführt (mit einer begrenzten Anzahl an konfigurierbaren Optionen) und hat außerdem einen wichtigen Schritt unternommen, um die Programmierung seiner Chips zu vereinfachen, indem er sein OpenBCM SDK im Jahr 2020 öffnete. Auch andere Anbieter haben ein gewisses Maß an Programmierbarkeit eingeführt. So unterstützen die Lösungen Silicon One von Cisco und Trio/Penta von Juniper die P4-Programmierbarkeit.
Hinweis
Traditionell werden ASICs (mit den Einschränkungen einer festen Verarbeitungspipeline) über die SDKs der Chip-Hersteller programmiert, die die vorgefertigten Datenstrukturen und Methoden offenlegen, um zu definieren, wie die Paketweiterleitung ausgeführt wird (unter Berücksichtigung der Weiterleitungsstatusdaten).
Vor einigen Jahren haben Chip-Hersteller begonnen, ihre SDKs zu öffnen, die zuvor nur auf Anfrage und unter Geheimhaltungsvereinbarungen (NDAs) zugänglich waren, um die Programmierbarkeit ihrer Lösungen durch Dritte zu erleichtern. Diese Änderung wurde wahrscheinlich von der Industrie veranlasst, um die Low-Level-Programmierbarkeit von ASICs zu fördern.
Der Markt für diese hochgradig anpassbaren ASICs ist heute aufgrund der höheren Kosten und einiger technischer Einschränkungen begrenzt; einige Marktprognosen gehen von einem deutlichen Anstieg der Verbreitung in den kommenden Jahren aus. Die Zeit wird zeigen, wie sich dieser Markt entwickelt (Intel hat z. B. angekündigt, die Entwicklung des Tofino-Chips im Jahr 2023 einzustellen) und welche Anwendungsfälle am meisten von der Flexibilität dieser programmierbaren Pipelines profitieren werden.
In Abbildung 1-3 siehst du, wie die Kontroll- und die Datenebene des Netzwerks entkoppelt sind und zwei neue Schnittstellen, die Northbound- und Southbound-APIs, zur Verfügung stehen. Die Northbound-API ermöglicht es externen Anwendungen, mit den Netzwerk-Controllern zu interagieren, und die Southbound-API wird vom Netzwerk-Controller verwendet, um die Weiterleitung von Paketen in der Datenebene zu definieren. In der Datenebene gibt es eine Weiterleitungsimplementierung mit einem festen ASIC, der in einen OpenFlow-Agenten integriert ist, und einem programmierbaren ASIC, der über P4 programmiert werden kann.
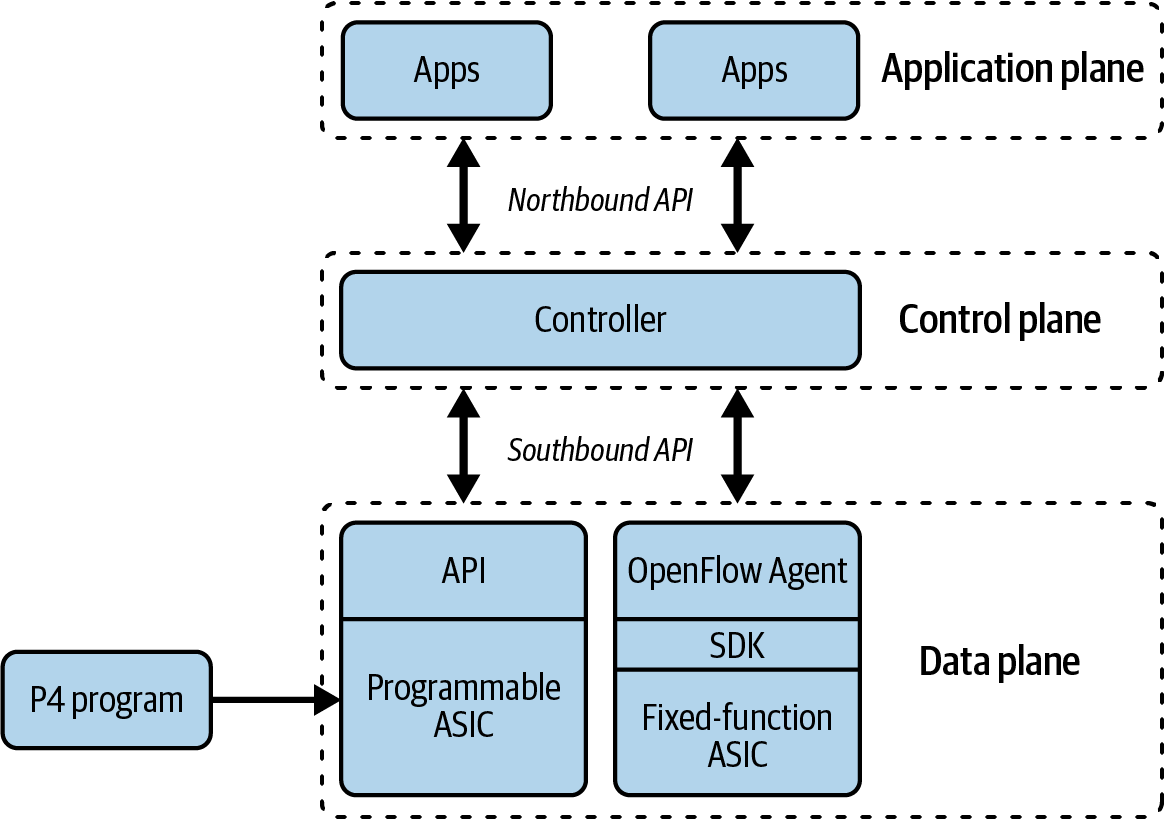
Abbildung 1-3. Programmierbare ASICs
Die Programmierung der Datenebene ermöglicht es uns, die Art und Weise, wie der Datenverkehr das Netzwerk durchläuft, genauer zu definieren, aber diese Flexibilität ist mit zusätzlicher Komplexität verbunden. Das ist toll, wenn du ein Team von Entwicklern hast (in großen Unternehmen wie Google oder Amazon) oder wenn die Programmierung der Datenebene dein Kerngeschäft ist (Netzwerkanbieter und Integratoren). Aber für die meisten Unternehmen ist die Verwendung von OpenFlow, P4 oder eines anderen Protokolls weniger wichtig als das, was eine Gesamtlösung für das zu unterstützende Unternehmen bietet.
Virtualisierung von Netzwerkfunktionen
DieVirtualisierung von Netzwerkfunktionen(NFV) ist kein komplexes Konzept. Es bezieht sich darauf, dass Funktionen, die traditionell als Hardware eingesetzt wurden, stattdessen als Software eingesetzt werden. Die gängigsten Beispiele sind virtuelle Maschinen (VMs), die als Router, Firewalls, Load Balancer, Intrusion Detection Systems und Intrusion Prevention Systems (IDS/IPS), virtuelle private Netzwerke (VPNs), Application Firewalls und andere Dienste/Funktionen fungieren.
Warnung
Verwechsle unsere Beschreibung des NFV-Konzepts nicht mit der konkreten ETSI NFV-Spezifikation für die Telekommunikationsbranche (ETSI ist das Europäische Institut für Telekommunikationsnormen, das sich auf Telekommunikation, Rundfunk und andere elektronische Kommunikationsnetze und -dienste konzentriert). Wir nähern uns NFV von einem abstrakten Standpunkt aus, ohne konkrete Implementierungsdetails.
Mit NFV wird es möglich, ein monolithisches Stück Hardware, das vielleicht zehn- oder hunderttausende von Dollar gekostet hat und Hunderte bis Tausende von Befehlszeilen enthält, in N Stück Software zu zerlegen - nämlich in virtuelle Appliances. Diese kleineren Geräte lassen sich aus der Perspektive eines einzelnen Geräts viel besser verwalten.
Hinweis
Im vorangegangenen Szenario werden virtuelle Appliances als Formfaktor für NFV-fähige Geräte verwendet. Dies ist nur ein Beispiel. Die Bereitstellung von Netzwerkfunktionen als Software kann in vielen Formen erfolgen, z. B. eingebettet in einen Hypervisor (bekannt als virtuelle Netzwerkfunktion, VNF), als Container (bekannt als Container-Netzwerkfunktion, CNF) oder als Anwendung, die auf einem x86-Server läuft.
Es ist üblich, Hardware zu installieren, die in drei bis fünf Jahren benötigt wird, nur für den Fall, dass eine schrittweise Aufrüstung zu kompliziert und noch teurer wäre. Hardware ist also nicht nur kapitalintensiv, sondern wird auch nur für "Was-wäre-wenn"-Szenarien verwendet , wenn es zu einem Wachstum kommt. Der Einsatz von softwarebasierten oder NFV-Lösungen bietet eine bessere Möglichkeit, ein Netzwerk oder eine bestimmte Anwendung zu skalieren und die Fehleranfälligkeit zu minimieren, während ein Pay-as-you-grow-Modell verwendet wird. Anstatt eine einzelne große Cisco ASA zu kaufen, kannst du zum Beispiel nach und nach Cisco ASAv Appliances einsetzen und so bezahlen, wie du wächst. Mit neueren Technologien eines Unternehmens wie Avi Networks, das jetzt zu VMware gehört, kannst du auch problemlos Load Balancer ausbauen.
Obwohl NFV so viele Vorteile bietet, hat die Branche - vor allem Telekommunikationsunternehmen und Managed Service Provider (MSPs) - eine Weile gebraucht, um diese Lösungen in die Produktion zu übernehmen. Dafür gab es einige Gründe. Erstens erforderte die Umstellung ein Umdenken in der Netzwerkarchitektur. Bei einer einzigen monolithischen Firewall (als Beispiel) läuft alles durch diese Firewall, d. h. alle Anwendungen und alle Nutzer oder, wenn nicht alle, dann eine bestimmte Gruppe, die dir bekannt ist. Im NFV-Paradigma könnten viele virtuelle Firewalls eingesetzt werden, mit einer Firewall pro Anwendung oder Mieter im Gegensatz zu einer einzigen großen Firewall. Dadurch wird die Fehlerdomäne pro Firewall oder anderer Service Appliance relativ klein, und wenn eine Änderung vorgenommen oder eine neue Anwendung eingeführt wird, sind keine Änderungen an den anderen Firewalls pro Anwendung (pro Mandant) erforderlich.
Auf der anderen Seite gab es in der traditionellen Welt der monolithischen Geräte nur einen einzigen Verwaltungsbereich für die Sicherheit - ein einziges CLI oder eine grafische Benutzeroberfläche (GUI). Dies kann zu einer immensen Fehlerquote führen, aber es bietet den Administratoren eine optimierte Richtlinienverwaltung, da nur ein einziges Gerät verwaltet wird. Für einige Teams oder Mitarbeiter, die diese Geräte betreuen, könnte dies ein Grund sein, den monolithischen Ansatz beizubehalten.
Mit dem beschleunigten Übergang der IT zu privaten und öffentlichen Cloud-basierten Umgebungen hat die Nachfrage der Kunden nach dynamischeren Architekturen die Netzwerkteams dazu veranlasst, hybride Netzwerke aufzubauen, die verschiedene Arten von NFV-Lösungen erfordern. Das Aufkommen neuer Tools für die Nutzung und Verwaltung von softwarezentrierten Lösungen und die Antwort auf den Ruf von (traditionellen und neuen) Anbietern hat die Nutzung von NFV-Lösungen populär gemacht.
Hinweis
Zu Beginn war ein Faktor, der die Einführung von NFV verzögerte, dass einige Anbieter ihre virtuelle Appliance-Edition nicht mit der gleichen Entschlossenheit verkauften wie den Rest ihres Portfolios. Wir sagen nicht, dass sie keine virtuellen Optionen hatten, aber sie waren in der Regel nicht die bevorzugte Wahl vieler traditioneller Gerätehersteller. Wenn ein Anbieter eine Zeit lang ein Hardware-Geschäft hatte, war das aus Sicht des Vertriebs und der Vergütung ein drastischer Wechsel zu einem softwarebasierten Modell. Heutzutage investieren die Anbieter dagegen in die parallele Entwicklung ihrer Hardware- und Softwarelösungen.
Wie in vielen dieser Technologiebereiche liegt ein großer Vorteil von NFV auch in der Flexibilität. Durch die Abschaffung von Hardware wird die Zeit für die Bereitstellung neuer Dienste verkürzt, da die Zeit für Racking, Stacking, Verkabelung und Integration in eine bestehende Umgebung entfällt. Ein weiterer Vorteil dieses Ansatzes besteht darin, dass die virtuelle Appliance für weitere Tests geklont und gesichert werden kann - zum Beispiel in Disaster-Recovery-Umgebungen (DR) oder bei der Emulation virtueller Labore, wie du in Kapitel 5 sehen wirst. Außerdem spielt diese Flexibilität eine wichtige Rolle bei der Unterstützung neuer Technologien wie Edge Computing oder 5G-Netzwerke.
Schließlich entfällt bei der Einführung von NFV die Notwendigkeit, den Datenverkehr durch ein bestimmtes physisches Gerät zu leiten, um den gewünschten Dienst zu erhalten. Dadurch erhöht sich die Flexibilität, die Netzwerkarchitektur je nach spezifischem Dienst zu ändern und Dienstketten zu erstellen (Verkettung mehrerer NFVs, die ein Netzwerkpaket durchlaufen muss), wie sie beispielsweise das Segment-Routing ermöglicht.
Virtuelles Switching
Zu den gängigsten virtuellen Switches auf dem Markt gehören der VMware vSwitch, der Microsoft Hyper-V Virtual Switch, eine Linux-Bridge und der Open vSwitch (OVS).
Diese Switches werden immer wieder in die SDN-Diskussion mit einbezogen, aber in Wirklichkeit handelt es sich um softwarebasierte Switches, die im Hypervisor-Kernel angesiedelt sind und die Netzwerkkonnektivität zwischen VMs/Containern und dem Knoten selbst, der mit dem externen Netzwerk verbunden ist, bereitstellen. Sie bieten Funktionen wie MAC-Learning und Features wie Link-Aggregation, SPAN und sFlow, genau wie ihre physischen Switches es schon seit Jahren tun. Während diese virtuellen Switches oft in umfassenderen SDN- und Netzwerkvirtualisierungslösungen zu finden sind, handelt es sich bei ihnen selbst um Switches, die nur in Software laufen.
Virtuelle Switches sind zwar keine eigenständige Lösung, aber sie sind extrem wichtig, wenn wir uns als Branche weiterentwickeln. Sie haben eine neue Zugangsebene bzw. einen neuen Rand im Rechenzentrum geschaffen. Der Netzwerkrand ist nicht mehr der physische Top-of-Rack-Switch (ToR), der hardwaredefiniert ist und nur eine begrenzte Flexibilität (in Bezug auf die Entwicklung von Funktionen) bietet. Da der neue Rand durch den Einsatz virtueller Switches softwarebasiert ist, können neue Netzwerkfunktionen schnell in Software erstellt werden, so dass sich die Richtlinien einfacher im gesamten Netzwerk verteilen lassen. Zum Beispiel kann die Sicherheitsrichtlinie an dem virtuellen Switch-Port bereitgestellt werden, der dem eigentlichen Endpunkt am nächsten ist, sei es eine VM oder ein Container, um die Sicherheit des Netzwerks weiter zu erhöhen.
Netzwerk-Virtualisierung
Lösungen, die als Netzwerkvirtualisierung kategorisiert werden, sind zum Synonym für SDN-Lösungen geworden. Für die Zwecke dieses Abschnitts bezieht sich Netzwerkvirtualisierung auf reine Software-Overlay-basierte Lösungen. Einige beliebte Lösungen, die in diese Kategorie fallen, sind VMware NSX, Nuage Networks Virtualized Services Platform (VSP) von Nokia und Contrail von Juniper.
Ein Hauptmerkmal dieser Lösungen ist, dass ein Overlay-basiertes Protokoll wie Virtual Extensible LAN (VXLAN) verwendet wird, um Konnektivität zwischen Hypervisor-basierten virtuellen Switches herzustellen. Dieser Konnektivitäts- und Tunneling-Ansatz bietet Layer-2-Adjazenz zwischen VMs, die auf verschiedenen physischen Hosts existieren, unabhängig vom physischen Netzwerk, d.h. das physische Netzwerk kann Layer 2, Layer 3 oder eine Kombination aus beidem sein. Das Ergebnis ist ein virtuelles Netzwerk, das vom physischen Netzwerk entkoppelt ist und das Wahlmöglichkeiten und Flexibilität bieten soll.
Hinweis
Der Begriff Overlay-Netzwerk wird oft in Verbindung mit Underlay-Netzwerken verwendet. Zur Verdeutlichung: Das Underlay ist das zugrunde liegende physische Netzwerk, das du physisch verkabelst. Das Overlay-Netzwerk wird mit einer Netzwerkvirtualisierungslösung aufgebaut, die dynamisch Tunnel zwischen virtuellen Switches innerhalb eines Rechenzentrums erstellt. Auch hier handelt es sich um eine softwarebasierte Netzwerkvirtualisierungslösung. Beachte auch, dass viele reine Hardware-Lösungen jetzt mit VXLAN als Overlay-Protokoll eingesetzt werden, um Layer-2-Tunnel zwischen ToR-Geräten in einem Layer-3-Rechenzentrum aufzubauen.
Das Overlay ist zwar ein Implementierungsdetail von Netzwerkvirtualisierungslösungen, aber diese Lösungen sind viel mehr als nur virtuelle Switches, die durch Overlays zusammengefügt werden. In der Regel handelt es sich um umfassende Lösungen, die Sicherheit, Lastausgleich und die Integration in das physische Netzwerk bieten, und das alles über einen einzigen Verwaltungspunkt (den Controller). Oft bieten diese Lösungen auch Integrationen mit den besten Anbietern von Layer 4-7-Diensten an, so dass du die Wahl hast, welche Technologie du in deinen Netzwerkvirtualisierungsplattformen einsetzen möchtest.
Diese Lösungen nutzen eine zentrale Steuerungsebene, um die Zuordnungsinformationen zwischen den Overlay- und Underlay-Netzen zu verteilen. Dieser zentralisierte Ansatz führt jedoch zu Einschränkungen in Bezug auf Skalierbarkeit, Interoperabilität und Flexibilität. Ein alternativer Ansatz wurde in Form eines verteilten Protokolls, dem Ethernet VPN (EVPN), entwickelt. Bei EVPN verteilt jedes Netzwerkgerät die Zuordnungsinformationen (über das Border Gateway Protocol oder BGP) an den Rest des Netzwerks, um die VXLAN-Tunnel aufzubauen. Es wird auch als controllerlose VXLAN-Lösung bezeichnet.
Tipp
Eine gute Referenz für VXLAN und EVPN ist Cloud Native Data Center Networking von Dinesh G. Dutt (O'Reilly).
Geräte-APIs
In den letzten Jahren haben die Anbieter erkannt, dass es nicht mehr ausreicht, nur eine Standard-CLI anzubieten, und dass die Verwendung einer CLI den Betrieb stark behindert hat. Wenn du jemals mit einer Programmier- oder Skriptsprache gearbeitet hast, kannst du das wahrscheinlich verstehen. Für diejenigen, die das nicht getan haben, werden wir in Kapitel 10 mehr darüber erfahren.
Das Hauptproblem ist, dass die Skripterstellung mit Legacy- oder CLI-basierten Netzwerkgeräten keine strukturierten Daten zurückgibt. Die Daten werden vom Gerät in einem rohen Textformat an ein Skript zurückgegeben (die Ausgabe von show version), und dann muss die Person, die das Skript schreibt, diesen Text analysieren, um Attribute wie die Betriebszeit oder die Version des Betriebssystems zu extrahieren. Wenn sich die Ausgabe der show Befehle auch nur geringfügig änderte, brachen die Skripte aufgrund falscher Parsing-Regeln ab. Während dieser Ansatz alles war, was Administratoren zur Verfügung stand, war eine Automatisierung technisch möglich, aber jetzt stellen die Anbieter nach und nach auf API-gesteuerte Netzwerkgeräte um.
Durch das Angebot einer API entfällt die Notwendigkeit, Rohtext zu analysieren, da strukturierte Daten von einem Netzwerkgerät zurückgegeben werden, was den Zeitaufwand für das Schreiben eines Skripts erheblich reduziert. Anstatt den Text zu analysieren, um die Betriebszeit oder ein anderes Attribut zu finden, wird ein Objekt zurückgegeben, das genau das liefert, was benötigt wird. Dadurch wird nicht nur der Zeitaufwand für das Schreiben eines Skripts reduziert und die Einstiegshürde für Netzwerktechniker/innen (und andere Nicht-Programmierer/innen) gesenkt, sondern es wird auch eine übersichtlichere Schnittstelle geschaffen, mit der professionelle Softwareentwickler/innen schnell Code entwickeln und testen können, ähnlich wie sie es mit APIs auf Nicht-Netzwerkgeräten tun. "Code testen" kann bedeuten, neue Topologien zu testen, neue Netzwerkfunktionen zu zertifizieren, bestimmte Netzwerkkonfigurationen zu überprüfen und vieles mehr. All dies wird heute manuell durchgeführt und ist zeitaufwändig und fehleranfällig.
Diese Idee ist jedoch nicht neu; das Network Configuration Protocol (NETCONF) wurde 2006 über RFC 4741 veröffentlicht und blieb eine Zeit lang eine der relativ wenigen Optionen, wobei Juniper Networks der Hauptanbieter war, der es propagierte. In jüngerer Zeit begannen andere Anbieter, ihre eigenen APIs zu entwickeln, wie z. B. die eAPI von Arista oder die Cisco Nexus NX API, und später übernahmen sie offene Schnittstellen wie NETCONF, Representational State Transfer Configuration Protocol (RESTCONF) und gRPC Network Management Interface (gNMI). Heutzutage hat fast jeder Anbieter eine Art von API (und die dazugehörige Dokumentation), was zum Teil auf die Nachfrage der Verbraucher zurückzuführen ist. In Kapitel 10 gehen wir näher auf APIs ein und in Kapitel 8 auf die von ihnen verwendeten Datenformate.
Hinweis
Obwohl Juniper mit NETCONF und Arista Networks mit eAPI die APIs als erste eingeführt haben, haben sie auch eine CLI (zusätzlich zu den APIs) bereitgestellt, weil Netzwerkbetreiber daran gewöhnt waren (und immer noch sind), mit dieser Art von Schnittstelle zu arbeiten.
Hyper-Scale-Netzwerke, wie die der großen Public Cloud-Provider, lassen sich nicht manuell betreiben (und erreichen nicht die erforderliche operative Exzellenz). Daher ist das Vorhandensein von APIs (z. B. gNMI oder NETCONF) für die Verwaltung der Netzwerkinfrastruktur für diese Unternehmen schon lange eine wichtige Voraussetzung. Es ist bekannt, dass große Netzbetreiber wie diese die Roadmaps von Netzanbietern mit Forderungen prägen können wie: "Wenn das Modell XYZ die Verwaltungsschnittstelle ABC nicht unterstützt, werde ich es nicht in Betracht ziehen" oder "Wenn dieses Feature nur über CLI verfügbar ist, ist es kein Feature für uns." Du kannst dir vorstellen, wie einflussreich diese Sätze sein können, wenn es um große potenzielle Anschaffungen geht; das ist ein wichtiger Grund, warum die Anbieter in den letzten Jahren ihre Unterstützung für Programmierbarkeit ausgebaut haben.
Netzwerk-Automatisierung
In dem Maße, wie sich die APIs in der Netzwerkwelt weiterentwickeln, werden auch immer mehr interessante Anwendungsfälle auftauchen, um sie zu nutzen. In naher Zukunft ist die Netzwerkautomatisierung ein Hauptkandidat für die Nutzung der programmatischen Schnittstellen, die von modernen Netzwerkgeräten, die eine API anbieten, bereitgestellt werden.
Um es in einen größeren Zusammenhang zu stellen, geht es bei der Netzwerkautomatisierung nicht nur um die Automatisierung der Konfiguration von Netzwerkgeräten. Das ist zwar die gängigste Vorstellung von Netzwerkautomatisierung, aber die Verwendung von APIs und programmatischen Schnittstellen kann viel mehr automatisieren und bieten als nur die Weitergabe von Konfigurationsparametern.
Der Einsatz einer API vereinfacht den Zugriff auf alle Daten, die in den Netzwerkgeräten gespeichert sind. Denk an Daten wie Flow-Level-Daten, Routing-Tabellen, FIB-Tabellen, Schnittstellenstatistiken, MAC-Tabellen, VLAN-Tabellen und Seriennummern - die Liste lässt sich beliebig fortsetzen. Der Einsatz moderner Automatisierungstechniken, die wiederum eine API nutzen, kann die täglichen Abläufe bei der Verwaltung von Netzwerken für die Datenerfassung und die automatische Diagnose und Behebung von Problemen schnell unterstützen. Da eine API verwendet wird, die strukturierte Daten zurückliefert, hast du als Administrator außerdem die Möglichkeit, genau den Datensatz anzuzeigen und zu analysieren, den du willst und brauchst, auch wenn er von verschiedenen show Befehlen stammt, was letztendlich die Zeit für die Fehlersuche und -behebung im Netzwerk reduziert. Anstatt dich mit N Routern zu verbinden, auf denen BGP läuft, um eine Konfiguration zu überprüfen oder ein Problem zu beheben, kannst du Automatisierungstechniken einsetzen, um diesen Prozess zu vereinfachen, oder noch besser, du kannst ihn regelmäßig im Schlaf ausführen.
Außerdem führt der Einsatz von Automatisierungstechniken zu einem berechenbareren und einheitlicheren Netzwerk insgesamt. Dies kann durch die Automatisierung der Erstellung von Konfigurationsdateien, die automatische Verteilung von Firewall-Regeln oder die Automatisierung der Fehlerbehebung erreicht werden. Das vereinfacht den Prozess für alle Benutzer, die eine bestimmte Umgebung unterstützen, anstatt dass jeder Netzwerkadministrator seine eigenen bewährten Methoden anwendet.
Ein weiteres Schlagwort im Zusammenhang mit der Netzwerkautomatisierung ist Intent-based Networking(IBN), das wir als die Fähigkeit zusammenfassen könnten, das Netzwerk über eine Geschäftssprache (den Intent) zu verwalten, ohne sich auf die Low-Level-Details zu konzentrieren, und eine autonome Automatisierung zu ermöglichen, die eine Closed-Loop-Orchestrierung nutzt und auf Ereignisse reagieren kann (auch bekannt als ereignisgesteuerte Automatisierung).
Die Gesamtstrategie zum Aufbau einer Netzwerkautomatisierungslösung ist in Abbildung 1-4 zusammengefasst. Sie beginnt (1) mit der Übersetzung der Nutzerabsichten in Daten, die diese Absichten in strukturierte Daten kodieren(die Quelle der Wahrheit). Dann (2) aktualisiert eine Automatisierungsmaschine anhand dieser Daten den Zustand des Netzwerks. Der Betriebszustand des Netzwerks wird kontinuierlich beobachtet (3), und wenn eine Abweichung vom beabsichtigten Zustand auftritt (z. B. eine Paketverlustspitze auf einer Netzwerkverbindung, die gegen das erwartete Service-Level-Agreement (SLA) verstößt), versucht die Automatisierungs-Engine, die Abweichung entsprechend (4) der Absicht abzumildern (z. B. durch Verlagerung des Datenverkehrs von der betroffenen Verbindung auf eine gesunde).
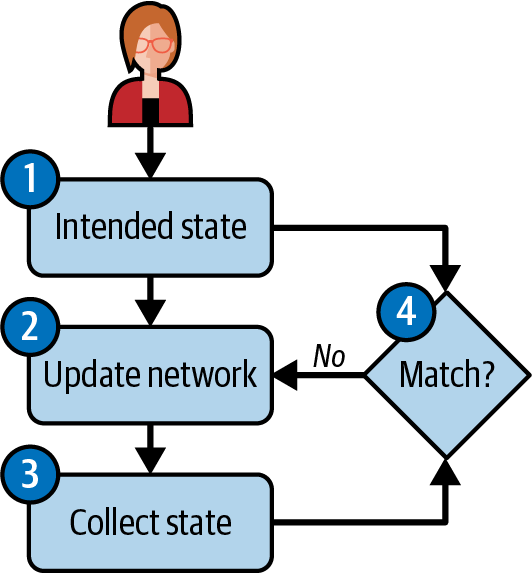
Abbildung 1-4. Intent-basierte Automatisierung
Die Implementierung von IBN-Lösungen kann entsprechend der Komplexität des Netzwerks komplex sein. Es gibt proprietäre Plattformen (in der Regel in Form eines Controllers). Cisco zum Beispiel bietet eine Reihe von IBN-Lösungen für verschiedene Bereiche an: Zugang, Rechenzentrum, Software-definiertes Weitverkehrsnetz (SD-WAN) und Sicherheit. In den meisten Fällen ist jedoch eine gewisse Erweiterbarkeit und Anpassung erforderlich, um bestimmte Anwendungsfälle abzudecken. Eine einzige Lösung reicht selten aus, so dass du wahrscheinlich verschiedene Komponenten zusammenstellen musst, um dein eigenes Automatisierungssystem zu schaffen. In Kapitel 14 haben wir einen Ansatz für den Aufbau kompletter Netzwerkautomatisierungslösungen empfohlen.
Die verschiedenen Arten der Netzwerkautomatisierung werden in Kapitel 2 viel ausführlicher behandelt. Im weiteren Verlauf des Buches lernst du die Konzepte und Werkzeuge kennen, um sie zu implementieren.
Bare-Metal-Switching
Bare-Metal-Switching wird auch oft als SDN bezeichnet, aber das ist es nicht. Das ist es wirklich nicht! Um die verschiedenen Technologietrends, die als SDN wahrgenommen werden, vorzustellen, muss das Thema jedoch behandelt werden. Wenn wir ins Jahr 2014 (und sogar noch früher) zurückspulen, war der Begriff für Bare-Metal-Switching White-Box oder Commodity Switching. Der Begriff hat sich geändert, und das nicht ohne Grund.
Bevor wir uns mit dem Wechsel von White Box zu Bare Metal befassen, ist es wichtig zu verstehen, was dies auf einer hohen Ebene bedeutet, denn es ist eine massive Veränderung in der Art und Weise, wie Netzwerkgeräte betrachtet werden. In den letzten 20 Jahren wurden Netzwerkgeräte immer als physische Geräte gekauft - diese physischen Geräte bestanden aus Hardware-Appliances, einem Betriebssystem und Funktionen/Anwendungen, die auf dem System genutzt werden konnten. Diese Komponenten stammten alle von demselben Anbieter.
Sowohl White-Box- als auch Bare-Metal-Switching nutzen Commodity-basierte Switches, die eher wie x86-Server aussehen (siehe Abbildung 1-5). Dies ermöglicht es dem Nutzer, jede der benötigten Komponenten zu zerlegen. So kann er Hardware von einem Anbieter kaufen, ein Betriebssystem von einem anderen, und dann Funktionen/Anwendungen von anderen Anbietern oder sogar der Open-Source-Community laden.
White-Box-Switching war während des OpenFlow-Hypes eine Zeit lang ein heißes Thema, da die Absicht darin bestand, die Hardware zu standardisieren und das Gehirn des Netzwerks in einem OpenFlow-Controller (heute als SDN-Controller bekannt) zu zentralisieren. Und 2013 gab Google bekannt, dass es seine eigenen Switches gebaut hatte und sie mit OpenFlow steuerte! Das war damals das Thema vieler Gespräche in der Branche, aber in Wirklichkeit ist nicht jeder Endnutzer Google, also wird auch nicht jeder Nutzer seine eigenen Hardware- und Softwareplattformen bauen.
Parallel zu diesen Bemühungen entstanden einige Unternehmen, die sich ausschließlich auf Lösungen für White-Box-Switching konzentrierten. Dazu gehörten Big Switch Networks (jetzt Teil von Arista Networks), Cumulus Networks (jetzt Teil von NVIDIA) und Pica8. Sie alle boten reine Softwarelösungen an und brauchten daher noch Hardware, auf der ihre Software laufen konnte, um eine End-to-End-Lösung anbieten zu können. Ursprünglich stammten diese White-Box-Hardwareplattformen von Original Design Manufacturers (ODMs) wie Quanta Networks, Supermicro, Alpha Networks und Accton Technology Corporation. Selbst wenn du in der Netzwerkbranche tätig bist, hast du höchstwahrscheinlich noch nie von diesen Anbietern gehört.
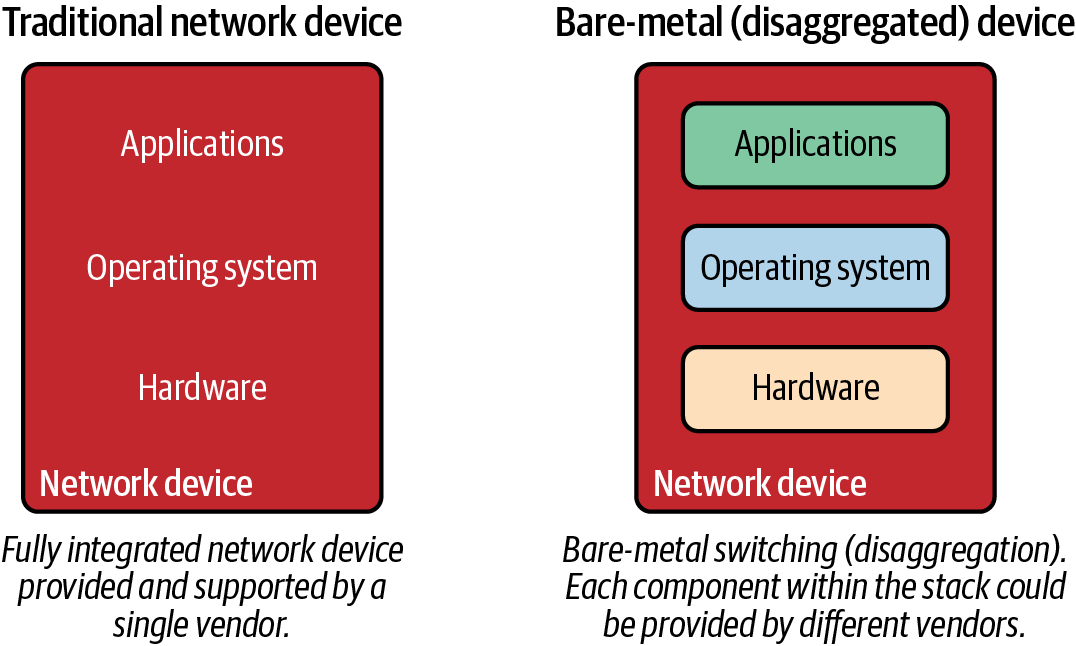
Abbildung 1-5. Traditionelle und Bare-Metal Switching Stacks
Erst als Cumulus und Big Switch Partnerschaften mit Unternehmen wie HP und Dell Technologies ankündigten, ging die Branche dazu über, diesen Trend nicht mehr "White-Box", sondern "Bare-Metal" zu nennen, da nun auch namhafte Hersteller Betriebssysteme von Drittanbietern wie Big Switch und Cumulus auf ihren Hardware-Plattformen unterstützen. Bei Bare-Metal-Switches kombinierst du also Switches von ODMs mit Netzwerkbetriebssystemen (NOSs) von Drittanbietern wie den genannten. Die gleichen Switches von ODMs (die ASICs von Händlern verwenden) wurden auch in die Kataloge der traditionellen Netzwerkanbieter aufgenommen und sind zur Norm für den Massenmarkt geworden.
Es mag immer noch Verwirrung darüber herrschen, warum Bare-Metal technisch gesehen kein SDN ist, weil es Lösungen wie die von Big Switch in beiden Welten gibt. Die Antwort ist einfach. Wenn ein in die Lösung integrierter Controller ein Protokoll wie OpenFlow verwendet (es muss nicht unbedingt OpenFlow sein) und programmatisch mit den Netzwerkgeräten kommuniziert, verleiht das dem Ansatz den Geschmack von SDN. Genau das hat Big Switch getan: Es hat Software auf die Bare-Metal-Hardware geladen, die einen OpenFlow-Agenten ausführt, der dann mit dem Controller als Teil der Lösung kommuniziert.
Auf der anderen Seite bietet ein NOS wie NVIDIA Cumulus Linux eine Linux-Distribution, die speziell für Netzwerk-Switches entwickelt wurde. Diese Distribution bzw. dieses Betriebssystem führt herkömmliche Protokolle wie Link Layer Discovery Protocol (LLDP), Open Shortest Path First (OSPF) und BGP aus, ohne dass ein Controller erforderlich ist, was es vergleichbar und kompatibel mit nicht-SDN-basierten Netzwerkarchitekturen macht.
Mit dieser Beschreibung sollte klar sein, dass Cumulus Linux ein NOS ist, das auf Bare-Metal-Switches läuft, während Big Switch eine Bare-Metal-basierte SDN-Lösung war, die den Einsatz des eigenen SDN-Controllers erfordert, aber auch die Bare-Metal-Switching-Infrastruktur von Drittanbietern nutzt.
Heutzutage stützt sich fast jedes NOS auf Linux als Basisbetriebssystem. Das hat die Innovation in diesem Bereich gefördert, und es sind viele neue Lösungen entstanden. Allerdings sind nicht alle NOSs gleich implementiert. Einige NOS werden zum Beispiel ausschließlich auf dem Linux-Benutzerbereich mit einem unabhängigen Netzwerkstack implementiert. In dieser Gruppe findest du Lösungen, die auf dem Data Plane Development Kit (DPDK) basieren, wie FD.io oder Cisco NX-OS. Beachte, dass die Verwendung eines völlig unabhängigen Netzwerkstacks bedeutet, dass du alle Netzwerkfunktionen des Linux-Kernels neu implementieren musst.
Auf der anderen Seite folgen die meisten Linux-basierten NOSs dem Weg von Cumulus und nutzen den Linux-Kernel-Stack teilweise oder vollständig. In dieser Gruppe gibt es neben Cumulus auch Lösungen von Herstellern wie Arista Extensible Operating System (EOS) und Dell OS10 sowie Open Source-Lösungen wie SONiC, VyOS und OpenWrt. Einige dieser Lösungen (besonders hervorzuheben ist SONiC) haben sich aufgrund ihrer Flexibilität auf verschiedenen Hardware- (Bare-Metal oder traditionelle Anbieter) und virtuellen Plattformen durchgesetzt und werden in Cloud-Umgebungen eingesetzt.
Diese Lösungen ermöglichen das Einbinden anderer Netzwerkanwendungen - zum Beispiel das Hinzufügen eines Routing-Daemons wie FRRouting aus dem Quagga-Projekt, um die Routing-Funktionen zu erweitern, wie es bei Cumulus Linux und VyOS der Fall ist. Ein weiterer Vorteil der Software-Disaggregation ist die Möglichkeit, die Steuerungsebene der Lösung als VM oder sogar als Container zu betreiben, was einfachere Entwicklungs- und Teststrategien ermöglicht, wie wir in Kapitel 5 erläutern. In dem bereits erwähnten Buch Cloud Native Data Center Networking findest du eine ausführlichere Erläuterung der verschiedenen Optionen.
Kurz gesagt, geht es beim Bare-Metal-Switching um Disaggregation und die Möglichkeit, Netzwerkhardware von einem Anbieter zu kaufen und Software von einem anderen zu laden, wenn du dich dafür entscheidest. In diesem Fall haben Administratoren die Möglichkeit, Design, Architektur und Software zu ändern, ohne die Hardware auszutauschen, sondern nur das zugrunde liegende Betriebssystem.
Rechenzentrum Netzwerk Fabrics
Warst du schon einmal in einer Situation, in der du die verschiedenen Geräte in einem Netzwerk nicht einfach austauschen konntest, obwohl sie alle mit Standardprotokollen wie dem Spanning Tree Protocol oder OSPF arbeiten? Wenn ja, bist du nicht allein. Stell dir vor, du hättest ein Rechenzentrumsnetzwerk mit einem zusammengebrochenen Kern und einzelnen Switches oben in jedem Rack. Stell dir vor, was passieren muss, wenn es Zeit für ein Upgrade ist.
Wir können solche Netzwerke auf viele Arten aufrüsten, aber was ist, wenn nur die ToR-Switches aufgerüstet werden müssen und im Evaluierungsprozess für neue ToR-Switches entschieden wird, dass ein neuer Anbieter oder eine neue Plattform verwendet werden soll? Das ist völlig normal und wird immer wieder gemacht. Der Prozess ist einfach: Verbinde die neuen Switches mit dem bestehenden Core (natürlich unter der Annahme, dass der Core über verfügbare Ports verfügt) und konfiguriere 802.1Q Trunking, wenn es sich um eine Layer-2-Verbindung handelt, oder konfiguriere dein bevorzugtes Routing-Protokoll, wenn es sich um eine Layer-3-Verbindung handelt.
Hier kommen die Data Center Network Fabrics ins Spiel. Data Center Network Fabrics zielen darauf ab, die Denkweise von Netzwerkbetreibern zu ändern, indem sie nicht mehr einzelne Boxen verwalten, sondern ein System in seiner Gesamtheit. Wenn wir das frühere Szenario verwenden, wäre es nicht möglich, einen ToR-Switch gegen einen anderen Anbieter auszutauschen, der nur eine einzelne Komponente eines Rechenzentrumsnetzwerks ist. Vielmehr muss das Netzwerk, wenn es als System eingerichtet und verwaltet wird, als ein System betrachtet werden. Das bedeutet, dass der Upgrade-Prozess eine Migration von System zu System oder Fabric zu Fabric ist.
In der Welt der Fabrics können Fabrics ausgetauscht werden, wenn es Zeit für ein Upgrade ist, aber die einzelnen Komponenten innerhalb der Fabric können nicht ausgetauscht werden - zumindest die meiste Zeit. Das kann möglich sein, wenn ein bestimmter Anbieter einen Migrations- oder Upgrade-Pfad anbietet und wenn Bare-Metal-Switching (bei dem nur die Hardware ausgetauscht wird) verwendet wird. Einige Beispiele für Netzwerk-Fabrics in Rechenzentren sind die Application Centric Infrastructure (ACI) von Cisco, die Converged Cloud Fabric (CCF) von Arista (früher Big Switch Big Cloud Fabric (BCF)) oder der Aruba Fabric Composer (früher Plexxi).
Das Netzwerk wird nicht nur als System behandelt, sondern die Netzwerktextilien für Rechenzentren erfüllen auch die folgenden Aufgaben:
-
Bietet eine einzige Schnittstelle zur Verwaltung oder Konfiguration der Fabric, einschließlich der Richtlinienverwaltung
-
Verteilte Standard-Gateways in der gesamten Fabric anbieten
-
Multipathing-Funktionen anbieten
-
Verwende eine Art SDN-Controller, um das System zu verwalten
SD-WAN
Einer der heißesten Trends im Bereich SDN war in den letzten Jahren das Software-defined Wide Area Networking (SD-WAN). In den letzten Jahren wurde eine wachsende Zahl von Unternehmen gegründet, um das Problem der Weitverkehrsnetze anzugehen.
Hinweis
Viele SD-WAN-Startups wurden von marktbeherrschenden Netzwerk- und Sicherheitsanbietern übernommen, wie z. B. Viptela von Cisco, CloudGenix von Palo Alto Networks, VeloCloud von VMware, Silver Peak von Aruba und 128 Technology von Juniper, was zeigt, wie wichtig diese Lösungen im Portfolio aller Anbieter sind.
Seit der Umstellung von Frame Relay auf Multiprotocol Label Switching (MPLS) hat es im WAN keinen radikalen Technologiewandel mehr gegeben. Da die Kosten für Breitband und Internet nur einen Bruchteil der Kosten für entsprechende private Leitungen betragen, hat die Nutzung von Site-to-Site-VPN-Tunneln im Laufe der Jahre zugenommen und damit die Grundlage für das nächste große Ding im WAN gelegt.
Gängige Konzepte für Außenstellen umfassen in der Regel eine private (MPLS-)Leitung und/oder eine öffentliche Internetverbindung. Wenn beides vorhanden ist, wird das Internet in der Regel nur als Backup genutzt, insbesondere für den Datenverkehr von Gästen oder für allgemeine Daten, die über ein VPN zurück zum Unternehmen geleitet werden, während die MPLS-Leitung für Anwendungen mit geringer Latenz wie Sprach- oder Videokommunikation verwendet wird. Wenn der Datenverkehr auf verschiedene Leitungen aufgeteilt wird, erhöht sich die Komplexität der Routing-Protokollkonfiguration und die Granularität des Routings zur Zieladresse wird eingeschränkt. Die Quelladresse, die Anwendung und die Echtzeitleistung des Netzwerks werden bei der Entscheidung über den besten Pfad in der Regel nicht berücksichtigt.
Eine gängige SD-WAN-Architektur, die von vielen modernen Lösungen verwendet wird, ähnelt der Netzwerkvirtualisierung im Rechenzentrum, da ein Overlay-Protokoll die SD-WAN-Kantengeräte miteinander verbindet. Da Overlays verwendet werden, ist die Lösung unabhängig vom zugrundeliegenden physischen Transport, so dass SD-WAN über das Internet oder ein privates WAN funktioniert. Diese Lösungen laufen oft über zwei oder mehr Internetleitungen an Zweigstellen und verschlüsseln den Datenverkehr vollständig mit Internet Protocol Security (IPSec). Darüber hinaus messen viele dieser Lösungen ständig die Leistung jeder genutzten Leitung und sind in der Lage, selbst bei Stromausfällen schnell zwischen den Leitungen für bestimmte Anwendungen fehlzuschlagen. Da die Anwendungsebene sichtbar ist, können Administratoren auch einfach auswählen, welche Anwendung eine bestimmte Route nehmen soll. Diese Funktionen sind in WAN-Architekturen, die ausschließlich auf zielbasiertes Routing mit einem traditionellen Routing-Protokoll wie OSPF oder BGP setzen, oft nicht zu finden.
Aus architektonischer Sicht bieten die SD-WAN-Lösungen der oben genannten Anbieter in der Regel auch eine Form von Zero-Touch-Provisioning (d.h. die Installation neuer Netzwerkgeräte ohne manuelle Eingriffe) und ein zentrales Management mit einem Portal, das vor Ort oder in der Cloud als SaaS-basierte Anwendung zur Verfügung steht, was die Verwaltung und den Betrieb des WAN in Zukunft drastisch vereinfacht.
Ein wertvolles Nebenprodukt der SD-WAN-Technologie ist, dass sie den Endnutzern mehr Auswahlmöglichkeiten bietet, da jeder Anbieter und jede Art von Verbindung im WAN und im Internet genutzt werden kann. Diese Flexibilität vereinfacht die Konfiguration und Komplexität von Carrier-Netzwerken, was wiederum den Carriern ermöglicht, ihr internes Design und ihre Architektur zu vereinfachen und damit hoffentlich ihre Kosten zu senken. Aus technischer Sicht geht es noch einen Schritt weiter: Alle logischen Netzwerkkonstrukte wie virtuelles Routing und Forwarding (VRF) werden über die Benutzeroberfläche (UI) der Controller-Plattform verwaltet, die der SD-WAN-Anbieter bereitstellt.
Controller-Vernetzung
Bei einigen dieser Trends gibt es Überschneidungen, wie du vielleicht schon gemerkt hast. Das ist einer der verwirrenden Punkte, wenn du versuchst, all die neuen Technologien und Trends zu verstehen, die in den letzten Jahren entstanden sind.
Beliebte Netzwerkvirtualisierungsplattformen verwenden zum Beispiel einen Controller, ebenso wie verschiedene Lösungen, die in die Kategorien Data Center Network Fabric, SD-WAN und Bare-Metal-Switch fallen. Verwirrend? Du fragst dich vielleicht, warum Controller-basierte Netzwerke als eigenständige Kategorie aufgeführt werden. In Wirklichkeit handelt es sich oft nur um einen Mechanismus zur Bereitstellung moderner Lösungen, aber nicht alle bisherigen Trends decken alles ab, was Controller aus technologischer Sicht leisten können.
Ein beliebter Open-Source-SDN-Controller ist zum Beispiel OpenDaylight oder ODL von der Linux Foundation, wie in Abbildung 1-6 dargestellt. ODL ist, wie viele andere Controller auch, eine Plattform und kein Produkt. Diese Plattform kann spezialisierte Anwendungen wie Netzwerkvirtualisierung anbieten, aber auch für Netzwerküberwachung, Sichtbarkeit, Tap-Aggregation oder jede andere Funktion in Verbindung mit Anwendungen, die auf der Controller-Plattform aufsetzen, genutzt werden. Das ist der Hauptgrund, warum es wichtig ist, zu verstehen, was Controller über die traditionellen Anwendungen wie Fabrics, Netzwerkvirtualisierung und SD-WAN hinaus bieten können.
ODL ist nicht der einzige Open-Source-Controller. Zu den anderen gehören Open Network Operating System ( ONOS) von der Open Network Foundation und TeraFlow von ETSI. Jede dieser Lösungen hat einen anderen Schwerpunkt und einen anderen Funktionsumfang, der je nach Anwendungsfall bewertet werden muss.
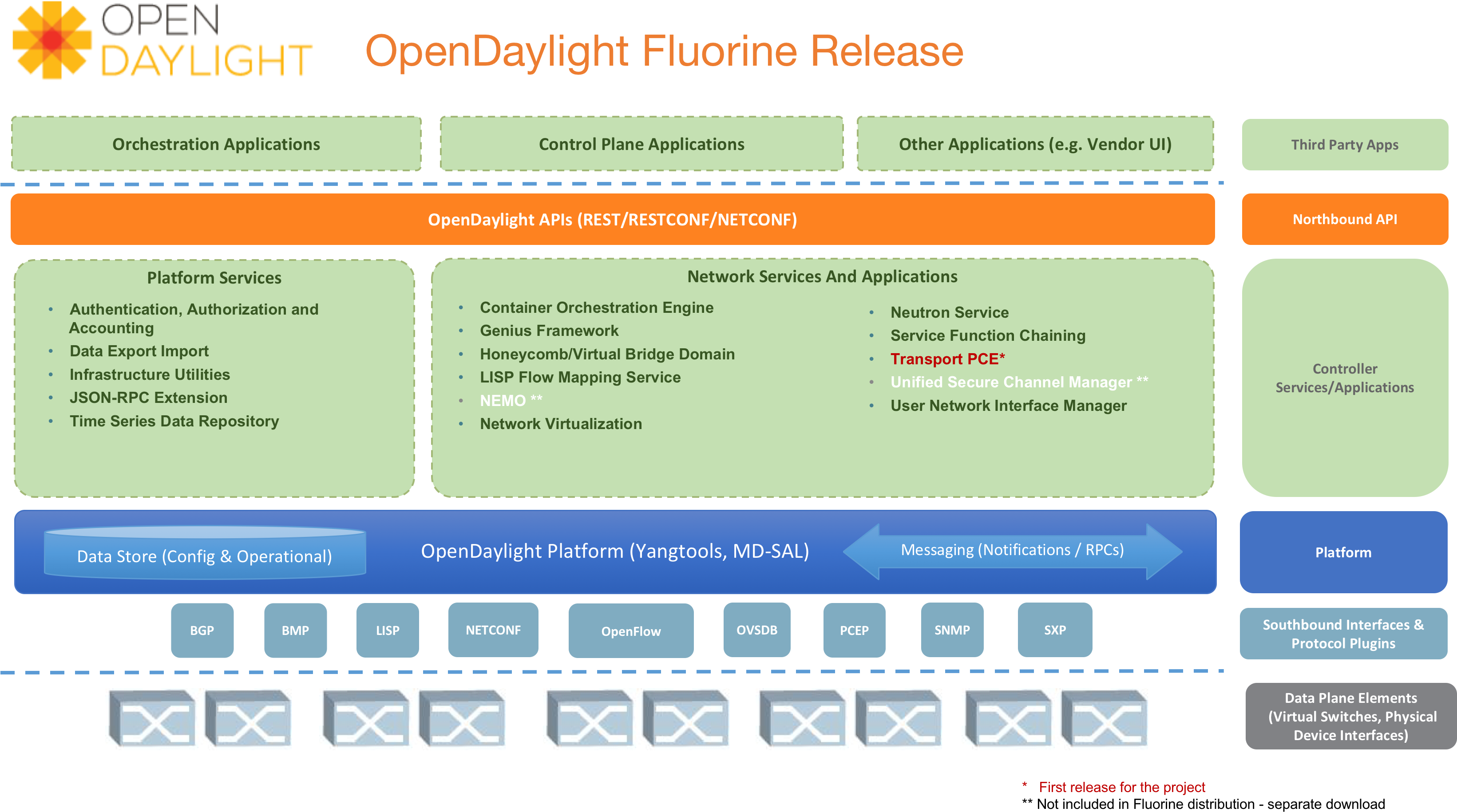
Abbildung 1-6. OpenDaylight Architektur
Cloud Native Networking
Die Art und Weise, wie Anwendungen ausgeführt werden, hat sich seit dem Aufkommen von öffentlichen Cloud-Diensten und Container-Laufzeitumgebungen deutlich verändert. Natürlich hat auch das Netzwerk diesen Trend aufgegriffen und die heutige Netzwerklandschaft ist ein Hybrid aus Container-Netzwerktechnologien und Cloud-Netzwerkdiensten. In Kapitel 4 gehen wir näher auf beides ein.
Container sind leichtgewichtige, portable und einfach zu implementierende Softwareeinheiten, die auf jeder Plattform laufen können. Sie laufen als Prozess, ohne den ganzen Overhead einer VM, und nutzen einige Linux-Funktionen. Docker ist das bekannteste Programm, aber es gibt auch andere Alternativen, wie Podman und LXC. Außerdem kann ein NOS auch als Container laufen (mit einigen Einschränkungen), was die Erstellung von Netzwerklaborszenarien erleichtert, wie wir in Kapitel 5 mit Containerlab zeigen werden.
Die Popularität von Containern kam mit dem Aufkommen von Laufzeitplattformen (das Kubernetes-Projekt ist die bekannteste), die es ermöglichen, diese Container mithilfe des Standard Container Network Interface (CNI) konsistent über verschiedene Infrastrukturen zu verteilen.
Die Cloud-Vernetzung hingegen umfasst verschiedene Netzwerkdienste mit unterschiedlichen Abstraktionsstufen. Plattformen wie Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), DigitalOcean und andere bieten Netzwerkdienste an, die Netzwerkfunktionalitäten emulieren, ohne dass komplexe Konfigurationsartefakte verwendet werden müssen. Mit einigen Unterschieden erlauben alle Cloud-Provider beispielsweise die Einrichtung virtueller regionaler Netzwerke, an die sich andere IT-Infrastrukturdienste anschließen und verbinden können, und andere Netzwerkdienste können sich mit den Rechenzentren vor Ort verbinden (z. B. VPN-Verbindungen). Es gibt viele Netzwerkdienste, aber alle haben einige Merkmale gemeinsam: Die Anpassungseinstellungen sind begrenzter als üblich und nicht so granular, und die Verwaltung erfolgt über HTTP-APIs.
Cloud-Plattformen bieten eine dynamische Infrastruktur, die bei Bedarf bereitgestellt wird. Diese Dynamik bietet mehr Flexibilität und eine kürzere Bereitstellungszeit als der traditionelle Ansatz, bei dem physische Geräte gekauft und installiert werden. Außerdem passt sie perfekt zur DevOps-Kultur, bei der die Anwendung entwickelt, die Infrastruktur bereitgestellt und die Anwendung ausgeführt wird - alles per Code definiert.
Dieser Ansatz wird als Infrastructure as Code(IaC) bezeichnet und besteht darin, den gewünschten Zustand der Infrastruktur in Textdateien zu beschreiben, die dann interpretiert werden, um sie zum Leben zu erwecken. Für die Verwaltung von IaC gibt es viele Lösungen, darunter Terraform von HashiCorp (mehr dazu in Kapitel 12), Pulumi und Cloud-Provider-spezifische Lösungen (z. B. AWS CloudFormation und Google Cloud Deployment Manager).
Die Verwaltung dieser Container- und Cloud-Umgebungen kann anfangs einschüchternd wirken. Nimm es locker. Es handelt sich immer noch um Netzwerkarbeit, also sind deine Fähigkeiten als Netzwerktechniker/in gültig und gefragt. Natürlich brauchst du auch spezifisches Fachwissen und andere Fähigkeiten, wie z.B. Programmiersprachen, domänenspezifische Sprachen und Tools. Dieses Buch wird dir helfen, mit all diesen Dingen zurechtzukommen.
Zusammenfassung
Da hast du es: eine Einführung in die Trends und Technologien, die am häufigsten als SDN kategorisiert werden und den Weg zu einem besseren Netzwerkbetrieb durch Netzwerkprogrammierbarkeit und Automatisierung ebnen. In den letzten sieben Jahren wurden Dutzende von SDN-Startups gegründet, Millionen an Risikokapital investiert und Milliarden für die Übernahme dieser Unternehmen ausgegeben. Die Entwicklung ist unvorstellbar, und wenn wir noch einen Schritt weiter gehen, erkennen wir das gemeinsame Ziel, Softwareprinzipien und Technologien zu nutzen, um den Nutzern mehr Macht, Kontrolle, Flexibilität und Wahlmöglichkeiten zu bieten und gleichzeitig die betriebliche Effizienz zu steigern.
In Kapitel 2 werfen wir einen Blick auf die Netzwerkautomatisierung und tauchen tiefer in ihre verschiedenen Arten ein. Du lernst einige gängige Protokolle und APIs kennen und erfährst, wie sich die Automatisierung in den letzten Jahren weiterentwickelt hat.
Get Netzwerk-Programmierbarkeit und Automatisierung, 2. now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

