Chapter 4. Kubernetes Networking Introduction
Now that we have covered Linux and container networking’s critical components, we are ready to discuss Kubernetes networking in greater detail. In this chapter, we will discuss how pods connect internally and externally to the cluster. We will also cover how the internal components of Kubernetes connect. Higher-level network abstractions around discovery and load balancing, such as services and ingresses, will be covered in the next chapter.
Kubernetes networking looks to solve these four networking issues:
-
Highly coupled container-to-container communications
-
Pod-to-pod communications
-
Pod-to-service communications
-
External-to-service communications
The Docker networking model uses a virtual bridge network by default, which is defined per host and is a private network where containers attach. The container’s IP address is allocated a private IP address, which implies containers running on different machines cannot communicate with each other. Developers will have to map host ports to container ports and then proxy the traffic to reach across nodes with Docker. In this scenario, it is up to the Docker administrators to avoid port clashes between containers; usually, this is the system administrators. The Kubernetes networking handles this differently.
The Kubernetes Networking Model
The Kubernetes networking model natively supports multihost cluster networking. Pods can communicate with each other by default, regardless of which host they are deployed on. Kubernetes relies on the CNI project to comply with the following requirements:
-
All containers must communicate with each other without NAT.
-
Nodes can communicate with containers without NAT.
-
A container’s IP address is the same as those outside the container that it sees itself as.
The unit of work in Kubernetes is called a pod. A pod contains one or more containers, which are always scheduled and run “together” on the same node. This connectivity allows individual instances of a service to be separated into distinct containers. For example, a developer may choose to run a service in one container and a log forwarder in another container. Running processes in distinct containers allows them to have separate resource quotas (e.g., “the log forwarder cannot use more than 512 MB of memory”). It also allows container build and deployment machinery to be separated by reducing the scope necessary to build a container.
The following is a minimal pod definition. We have omitted many options. Kubernetes manages various fields, such as the status of the pods, that are read-only:
apiVersion:v1kind:Podmetadata:name:go-webnamespace:defaultspec:containers:-name:go-webimage:go-web:v0.0.1ports:-containerPort:8080protocol:TCP
Kubernetes users typically do not create pods directly. Instead, users create a high-level workload, such as a deployment, which manages pods according to some intended spec. In the case of a deployment, as shown in Figure 4-1, users specify a template for pods, along with how many pods (often called replicas) that they want to exist. There are several other ways to manage workloads such as ReplicaSets and StatefulSets that we will review in the next chapter. Some provide abstractions over an intermediate type, while others manage pods directly. There are also third-party workload types, in the form of custom resource definitions (CRDs). Workloads in Kubernetes are a complex topic, and we will only attempt to cover the very basics and the parts applicable to the networking stack.
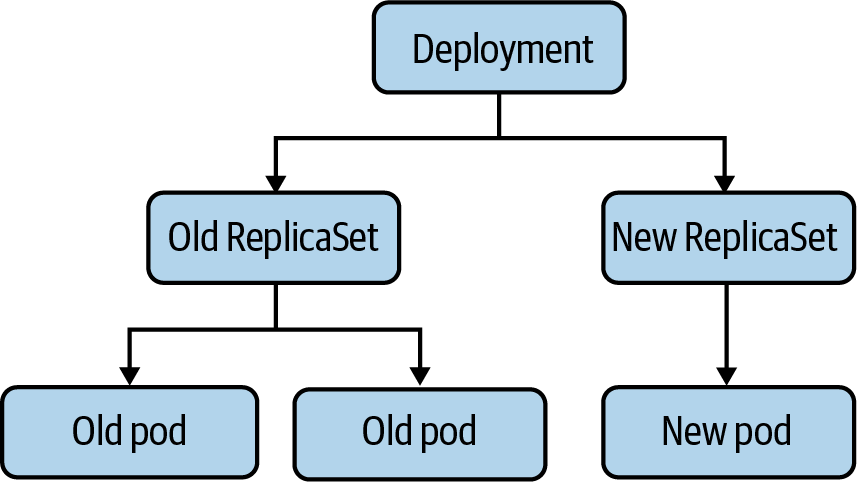
Figure 4-1. The relationship between a deployment and pods
Pods themselves are ephemeral, meaning they are deleted and replaced with new versions of themselves. The short life span of pods is one of the main surprises and challenges to developers and operators familiar with more semipermanent, traditional physical or virtual machines. Local disk state, node scheduling, and IP addresses will all be replaced regularly during a pod’s life cycle.
A pod has a unique IP address, which is shared by all containers in the pod. The primary motivation behind giving
every pod an IP address is to remove constraints around port numbers. In Linux, only one program can listen on a
given address, port, and protocol. If pods did not have unique IP addresses, then two pods on a node could contend
for the same port (such as two web servers, both trying to listen on port 80). If they were the same, it would require a
runtime configuration to fix, such as a --port flag. Alternatively, it would take an ugly script to update a config file in the
case of third-party software.
In some cases, third-party software could not run on custom ports at all, which would require more complex workarounds,
such as iptables DNAT rules on the node. Web servers have the additional problem of expecting conventional port
numbers in their software, such as 80 for HTTP and 443 for HTTPS. Breaking from these conventions requires
reverse-proxying through a load balancer or making downstream consumers aware of the various ports (which is much
easier for internal systems than external ones). Some systems, such as Google’s Borg, use this model. Kubernetes
chose the IP per pod model to be more comfortable for developers to adopt and make it easier to run third-party workloads.
Unfortunately for us, allocating and routing an IP address for every pod adds substantial complexity to a
Kubernetes cluster.
Warning
By default, Kubernetes will allow any traffic to or from any pod. This passive connectivity means, among other things, that any pod in a cluster can connect to any other pod in that same cluster. That can easily lead to abuse, especially if services do not use authentication or if an attacker obtains credentials.
See “Popular CNI Plugins” for more.
Pods created and deleted with their own IP addresses can cause issues for beginners who do not understand this behavior. Suppose we have a small service running on Kubernetes, in the form of a deployment with three pod replicas. When someone updates a container image in the deployment, Kubernetes performs a rolling upgrade, deleting old pods and creating new pods using the new container image. These new pods will likely have new IP addresses, making the old IP addresses unreachable. It can be a common beginner’s mistake to reference pod IPs in config or DNS records manually, only to have them fail to resolve. This error is what services and endpoints attempt to solve, and this is discussed in the next chapter.
When explicitly creating a pod, it is possible to specify the IP address. StatefulSets are a built-in workload type intended for workloads such as databases, which maintain a pod identity concept and give a new pod the same name and IP address as the pod it replaces. There are other examples in the form of third-party CRDs, and it is possible to write a CRD for specific networking purposes.
Note
Custom resources are extensions of the Kubernetes API defined by the writer. It allows software developers to customize the installation of their software in a Kubernetes environment. You can find more information on writing a CRD in the documentation.
Every Kubernetes node runs a component called the Kubelet, which manages pods on the node. The networking functionality in the Kubelet comes from API interactions with a CNI plugin on the node. The CNI plugin is what manages pod IP addresses and individual container network provisioning. We mentioned the eponymous interface portion of the CNI in the previous chapter; the CNI defines a standard interface to manage a container’s network. The reason for making the CNI an interface is to have an interoperable standard, where there are multiple CNI plugin implementations. The CNI plugin is responsible for assigning pod IP addresses and maintaining a route between all (applicable) pods. Kubernetes does not ship with a default CNI plugin, which means that in a standard installation of Kubernetes, pods cannot use the network.
Let’s begin the discussion on how the pod network is enabled by the CNI and the different network layouts.
Node and Pod Network Layout
The cluster must have a group of IP addresses that it controls to assign an IP address to a pod, for example, 10.1.0.0/16. Nodes and pods must have L3 connectivity in this IP address space. Recall from Chapter 1 that in L3, the Internet
layer, connectivity means packets with an IP address can route to a host with that IP address. It is important to
note that the ability to deliver packets is more fundamental than creating connections (an L4 concept). In L4,
firewalls may choose to allow connections from host A to B but reject connections initiating from host B to A. L4 connections from A to B, connections at L3, A to B and B to A, must be allowed. Without L3 connectivity,
TCP handshakes would not be possible, as the SYN-ACK could not be delivered.
Generally, pods do not have MAC addresses. Therefore, L2 connectivity to pods is not possible. The CNI will determine this for pods.
There are no requirements in Kubernetes about L3 connectivity to the outside world. Although the majority of clusters have internet connectivity, some are more isolated for security reasons.
We will broadly discuss both ingress (traffic leaving a host or cluster) and egress (traffic entering a host or cluster). Our use of “ingress” here shouldn’t be confused with the Kubernetes ingress resource, which is a specific HTTP mechanism to route traffic to Kubernetes services.
There are broadly three approaches, with many variations, to structuring a cluster’s network: isolated, flat, and island networks. We will discuss the general approaches here and then get more in-depth into specific implementation details when covering CNI plugins later this chapter.
Isolated Networks
In an isolated cluster network, nodes are routable on the broader network (i.e., hosts that are not part of the cluster can reach nodes in the cluster), but pods are not. Figure 4-2 shows such a cluster. Note that pods cannot reach other pods (or any other hosts) outside the cluster.
Because the cluster is not routable from the broader network, multiple clusters can even use the same IP address space. Note that the Kubernetes API server will need to be routable from the broader network, if external systems or users should be able to access the Kubernetes API. Many managed Kubernetes providers have a “secure cluster” option like this, where no direct traffic is possible between the cluster and the internet.
That isolation to the local cluster can be splendid for security if the cluster’s workloads permit/require such a setup, such as clusters for batch processing. However, it is not reasonable for all clusters. The majority of clusters will need to reach and/or be reached by external systems, such as clusters that must support services that have dependencies on the broader internet. Load balancers and proxies can be used to breach this barrier and allow internet traffic into or out of an isolated cluster.

Figure 4-2. Two isolated clusters in the same network
Flat Networks
In a flat network, all pods have an IP address that is routable from the broader network. Barring firewall rules, any host on the network can route to any pod inside or outside the cluster. This configuration has numerous upsides around network simplicity and performance. Pods can connect directly to arbitrary hosts in the network.
Note in Figure 4-3 that no two nodes’ pod CIDRs overlap between the two clusters, and therefore no two pods will be assigned the same IP address. Because the broader network can route every pod IP address to that pod’s node, any host on the network is reachable to and from any pod.
This openness allows any host with sufficient service discovery data to decide which pod will receive those packets. A load balancer outside the cluster can load balance pods, such as a gRPC client in another cluster.

Figure 4-3. Two clusters in the same flat network
External pod traffic (and incoming pod traffic, when the connection’s destination is a specific pod IP address) has low latency and low overhead. Any form of proxying or packet rewriting incurs a latency and processing cost, which is small but nontrivial (especially in an application architecture that involves many backend services, where each delay adds up).
Unfortunately, this model requires a large, contiguous IP address space for each cluster (i.e., a range of IP addresses where every IP address in the range is under your control). Kubernetes requires a single CIDR for pod IP addresses (for each IP family). This model is achievable with a private subnet (such as 10.0.0.0/8 or 172.16.0.0/12); however, it is much harder and more expensive to do with public IP addresses, especially IPv4 addresses. Administrators will need to use NAT to connect a cluster running in a private IP address space to the internet.
Aside from needing a large IP address space, administrators also need an easily programmable network. The CNI plugin must allocate pod IP addresses and ensure a route exists to a given pod’s node.
Flat networks, on a private subnet, are easy to achieve in a cloud provider environment. The vast majority of cloud provider networks will provide large private subnets and have an API (or even preexisting CNI plugins) for IP address allocation and route management.
Island Networks
Island cluster networks are, at a high level, a combination of isolated and flat networks.
In an island cluster setup, as shown in Figure 4-4, nodes have L3 connectivity with the broader network, but pods do
not. Traffic to and from pods must pass through some form of proxy, through nodes. Most often, this is achieved by
iptables source NAT on a pod’s packets leaving the node. This setup, called masquerading, uses SNAT to rewrite
packet sources from the pod’s IP address to the node’s IP address (refer to Chapter 2 for a refresher on SNAT). In other words, packets
appear to be “from” the node, rather than the pod.
Sharing an IP address while also using NAT hides the individual pod IP addresses. IP address–based firewalling and recognition becomes difficult across the cluster boundary. Within a cluster, it is still apparent which IP address is which pod (and, therefore, which application). Pods in other clusters, or other hosts on the broader network, will no longer have that mapping. IP address-based firewalling and allow lists are not sufficient security on their own but are a valuable and sometimes required layer.
Now let’s see how we configure any of these network layouts with the kube-controller-manager. Control plane refers to all the functions and processes that determine which path to use to send the packet or frame. Data plane refers to all the functions and processes that forward packets/frames from one interface to another based on control plane logic.
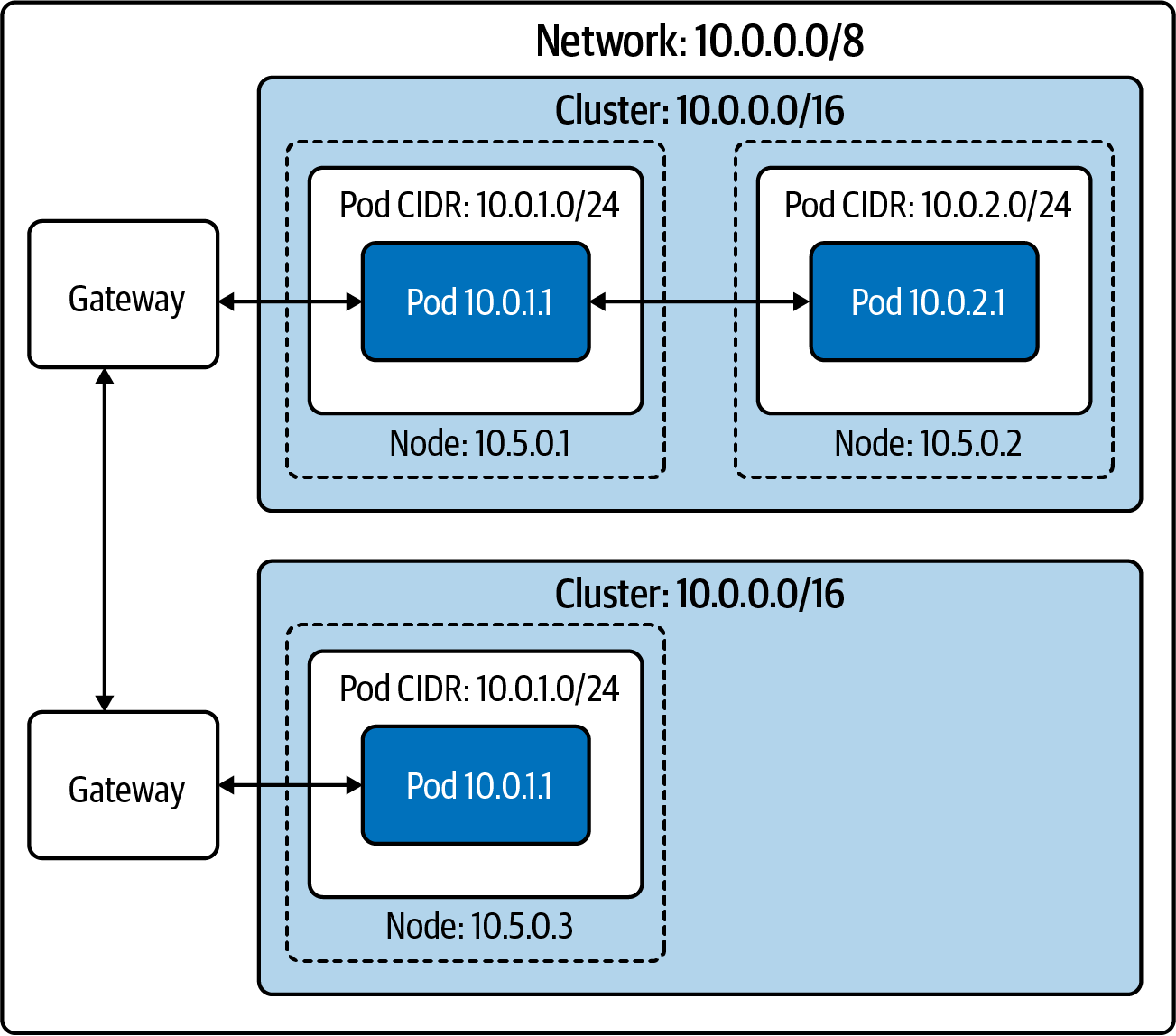
Figure 4-4. Two in the “island network” configuration
kube-controller-manager Configuration
The kube-controller-manager runs most individual Kubernetes controllers in one binary and one process, where most
Kubernetes logic lives. At a high level, a controller in Kubernetes terms is software that watches resources and
takes action to synchronize or enforce a specific state (either the desired state or reflecting the current state as
a status). Kubernetes has many controllers, which generally “own” a specific object type or specific operation.
kube-controller-manager includes multiple controllers that manage the Kubernetes network stack. Notably,
administrators set the cluster CIDR here.
kube-controller-manager, due to running a significant number of controllers, also has a substantial number of flags.
Table 4-1 highlights some notable network configuration flags.
| Flag | Default | Description |
|---|---|---|
|
true |
Sets whether CIDRs for pods should be allocated and set on the cloud provider. |
|
RangeAllocator |
Type of CIDR allocator to use. |
|
CIDR range from which to assign pod IP addresses. Requires |
|
|
true |
Sets whether CIDRs should be allocated by |
|
24 for IPv4 clusters, 64 for IPv6 clusters |
Mask size for the node CIDR in a cluster. Kubernetes will assign each node |
|
24 |
Mask size for the node CIDR in a cluster. Use this flag in dual-stack clusters to allow both IPv4 and IPv6 settings. |
|
64 |
Mask size for the node CIDR in a cluster. Use this flag in dual-stack clusters to allow both IPv4 and IPv6 settings. |
|
CIDR range for services in the cluster to allocate service ClusterIPs. Requires |
Tip
All Kubernetes binaries have documentation for their flags in the online docs. See all kube-controller-manager options in the
documentation.
Now that we have discussed high-level network architecture and network configuration in the Kubernetes control plane, let’s look closer at how Kubernetes worker nodes handle networking.
The Kubelet
The Kubelet is a single binary that runs on every worker node in a cluster. At a high level, the Kubelet is responsible for managing any pods scheduled to the node and providing status updates for the node and pods on it. However, the Kubelet primarily acts as a coordinator for other software on the node. The Kubelet manages a container networking implementation (via the CNI) and a container runtime (via the CRI).
Note
We define worker nodes as Kubernetes nodes that can run pods.
Some clusters technically run the API server and etcd on restricted worker nodes.
This setup can allow control plane components to be managed with the same automation as typical workloads but exposes
additional failure modes and security vulnerabilities.
When a controller (or user) creates a pod in the Kubernetes API, it initially exists as only the pod API object.
The Kubernetes scheduler watches for such a pod and attempts to select a valid node to schedule the pod to.
There are several constraints to this scheduling. Our pod with its CPU/memory requests must not exceed the unrequested
CPU/memory remaining on the node. Many selection options are available, such as affinity/anti-affinity to labeled
nodes or other labeled pods or taints on nodes. Assuming the scheduler finds a node that satisfies all the pod’s
constraints, the scheduler writes that node’s name to our pod’s nodeName field. Let’s say Kubernetes schedules the
pod to node-1:
apiVersion: v1
kind: Pod
metadata:
name: example
spec:
nodeName: "node-1"
containers:
- name: example
image: example:1.0
The Kubelet on node-1 watches for all of the pods scheduled to it. The equivalent
kubectl command would be
kubectl get pods -w --field-selector spec.nodeName=node-1. When the Kubelet observes that our pod exists
but is not present on the node, it creates it. We will skip over the CRI details and the
creation of the container
itself. Once the container exists, the Kubelet makes an ADD call to the CNI, which tells the CNI plugin to create
the pod network. We will cover the interface and plugins in our next section.
Pod Readiness and Probes
Pod readiness is an additional indication of whether the pod is ready to serve traffic.
Pod readiness determines whether the pod address shows up in the Endpoints object from an external source.
Other Kubernetes resources that manage pods, like deployments, take pod readiness into account for decision-making,
such as advancing during a rolling update. During rolling deployment, a new
pod becomes ready, but a service, network policy, or load balancer is not yet prepared for the new pod due to
whatever reason. This may cause service disruption or loss of backend capacity. It should be noted that if a pod spec
does contain probes of any type, Kubernetes defaults to success for all three types.
Users can specify pod readiness checks in the pod spec. From there, the Kubelet executes the specified check and updates the pod status based on successes or failures.
Probes effect the .Status.Phase field of a pod. The following is a list of the pod phases and their descriptions:
- Pending
-
The pod has been accepted by the cluster, but one or more of the containers has not been set up and made ready to run. This includes the time a pod spends waiting to be scheduled as well as the time spent downloading container images over the network.
- Running
-
The pod has been scheduled to a node, and all the containers have been created. At least one container is still running or is in the process of starting or restarting. Note that some containers may be in a failed state, such as in a CrashLoopBackoff.
- Succeeded
-
All containers in the pod have terminated in success and will not be restarted.
- Failed
-
All containers in the pod have terminated, and at least one container has terminated in failure. That is, the container either exited with nonzero status or was terminated by the system.
- Unknown
-
For some reason the state of the pod could not be determined. This phase typically occurs due to an error in communicating with the Kubelet where the pod should be running.
The Kubelet performs several types of health checks for individual containers in a pod: liveness probes (livenessProbe),
readiness probes (readinessProbe), and startup probes (startupProbe).
The Kubelet (and, by extension, the node itself) must be able to connect to
all containers running on that node in order to perform any HTTP health checks.
Each probe has one of three results:
- Success
-
The container passed the diagnostic.
- Failure
-
The container failed the diagnostic.
- Unknown
-
The diagnostic failed, so no action should be taken.
The probes can be exec probes, which attempt to execute a binary within the container, TCP probes, or HTTP probes.
If the probe fails more than the failureThreshold number of times, Kubernetes will consider the check to have failed.
The effect of this depends on the type of probe.
When a container’s readiness probe fails, the Kubelet does not terminate it. Instead, the Kubelet writes the failure to the pod’s status.
If the liveness probes fail, the Kubelet will terminate the container.
Liveness probes can easily cause unexpected failures if misused or misconfigured. The intended use case for
liveness probes is to let the Kubelet know when to restart a container. However, as humans, we quickly learn that if
“something is wrong, restart it” is a dangerous strategy. For example, suppose we create a liveness probe that
loads the main page of our web app. Further, suppose that some change in the system, outside our container’s code,
causes the main page to return a 404 or 500 error. There are frequent causes of such a scenario, such as a backend database
failure, a required service failure, or a feature flag change that exposes a bug. In any of these
scenarios, the liveness probe would restart the container.
At best, this would be unhelpful; restarting the container will not solve a problem elsewhere in the system and
could quickly worsen the problem. Kubernetes has container restart backoffs (CrashLoopBackoff), which add increasing delay
to restarting failed containers. With enough pods or rapid enough failures, the application may go from having an
error on the home page to being hard-down. Depending on the application, pods may also lose cached data upon a
restart; it may be strenuous to fetch or impossible to fetch during the hypothetical degradation.
Because of this, use liveness probes with caution. When pods use them, they only depend on the container they are
testing, with no other dependencies. Many engineers have specific health check endpoints,
which provide minimal validation of criteria, such as “PHP is running and serving my API.”
A startup probe can provide a grace period before a liveness probe can take effect. Liveness probes will not terminate a container before the startup probe has succeeded. An example use case is to allow a container to take many minutes to start, but to terminate a container quickly if it becomes unhealthy after starting.
In Example 4-1, our Golang web server has a liveness probe that performs an HTTP GET on port 8080 to the path /healthz, while the readiness probe uses / on the same port.
Example 4-1. Kubernetes podspec for Golang minimal webserver
apiVersion:v1kind:Podmetadata:labels:test:livenessname:go-webspec:containers:-name:go-webimage:go-web:v0.0.1ports:-containerPort:8080livenessProbe:httpGet:path:/healthzport:8080initialDelaySeconds:5periodSeconds:5readinessProbe:httpGet:path:/port:8080initialDelaySeconds:5periodSeconds:5
This status does not affect the pod itself, but other Kubernetes mechanisms react to it. One key example is
ReplicaSets (and, by extension, deployments). A failing readiness probe causes the ReplicaSet controller to count the
pod as unready, giving rise to a halted deployment when too many new pods are unhealthy. The Endpoints/EndpointsSlice
controllers also react to failing readiness probes. If a pod’s readiness probe fails, the pod’s IP address will not
be in the endpoint object, and the service will not route traffic to it. We will discuss services and endpoints more
in the next
chapter.
The startupProbe will inform the Kubelet whether the application inside the container is started. This probe takes
precedent over the others. If a startupProbe is defined in the pod spec, all other probes are disabled. Once the
startupProbe succeeds, the Kubelet will begin running the other probes. But if the startup probe fails, the Kubelet kills the
container, and the container executes its restart policy. Like the others, if a startupProbe does not exist, the
default state is success.
- initialDelaySeconds
-
Amount of seconds after the container starts before liveness or readiness probes are initiated. Default 0; Minimum 0.
- periodSeconds
-
How often probes are performed. Default 10; Minimum 1.
- timeoutSeconds
-
Number of seconds after which the probe times out. Default 1; Minimum 1.
- successThreshold
-
Minimum consecutive successes for the probe to be successful after failing. Default 1; must be 1 for liveness and startup probes; Minimum 1.
- failureThreshold
-
When a probe fails, Kubernetes will try this many times before giving up. Giving up in the case of the liveness probe means the container will restart. For readiness probe, the pod will be marked Unready. Default 3; Minimum 1.
Application developers can also use readiness gates to help determine when the application inside the
pod is ready. Available and stable since Kubernetes 1.14, to use readiness gates, manifest writers will add
readiness gates in the pod’s spec to specify a list of additional conditions that the Kubelet evaluates for
pod readiness. That is done in the ConditionType attribute of the readiness gates in the pod spec. The ConditionType
is a condition in the pod’s condition list with a matching type. Readiness gates are controlled by the current state
of status.condition fields for the pod, and if the Kubelet cannot find such a condition in the status.conditions
field of a pod, the status of the condition is defaulted to False.
As you can see in the following example, the feature-Y readiness gate is true, while feature-X is false, so the pod’s status
is ultimately false:
kind: Pod
…
spec:
readinessGates:
- conditionType: www.example.com/feature-X
- conditionType: www.example.com/feature-Y
…
status:
conditions:
- lastProbeTime: null
lastTransitionTime: 2021-04-25T00:00:00Z
status: "False"
type: Ready
- lastProbeTime: null
lastTransitionTime: 2021-04-25T00:00:00Z
status: "False"
type: www.example.com/feature-X
- lastProbeTime: null
lastTransitionTime: 2021-04-25T00:00:00Z
status: "True"
type: www.example.com/feature-Y
containerStatuses:
- containerID: docker://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
ready : true
Load balancers like the AWS ALB can use the readiness gate as part of the pod life cycle before sending traffic to it.
The Kubelet must be able to connect to the Kubernetes API server. In Figure 4-5, we can see all the connections made by all the components in a cluster:
- CNI
-
Network plugin in Kubelet that enables networking to get IPs for pods and services.
- gRPC
-
API to communicate from the API server to
etcd. - Kubelet
-
All Kubernetes nodes have a Kubelet that ensures that any pod assigned to it are running and configured in the desired state.
- CRI
-
The gRPC API compiled in Kubelet, allowing Kubelet to talk to container runtimes using gRPC API. The container runtime provider must adapt it to the CRI API to allow Kubelet to talk to containers using the OCI Standard (runC). CRI consists of protocol buffers and gRPC API and libraries.
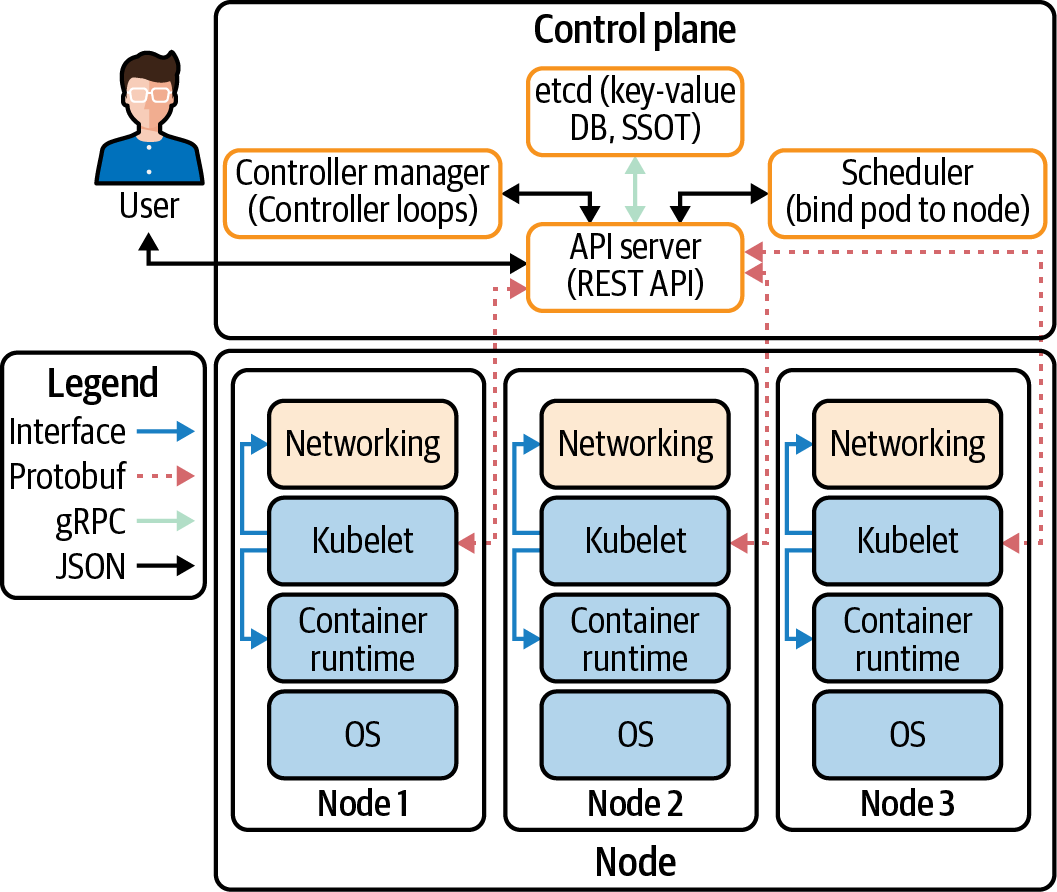
Figure 4-5. Cluster data flow between components
Communication between the pods and the Kubelet is made possible by the CNI. In our next section, we will discuss the CNI specification with examples from several popular CNI projects.
The CNI Specification
The CNI specification itself is quite simple. According to the specification, there are four operations that a CNI plugin must support:
- ADD
-
Add a container to the network.
- DEL
-
Delete a container from the network.
- CHECK
-
Return an error if there is a problem with the container’s network.
- VERSION
-
Report version information about the plugin.
Tip
The full CNI spec is available on GitHub.
In Figure 4-6, we can see how Kubernetes (or the runtime, as the CNI project refers to container orchestrators)
invokes CNI plugin operations by executing binaries. Kubernetes supplies any configuration for the command in JSON to
stdin and receives the command’s output in JSON through stdout. CNI plugins frequently have very simple binaries,
which act as a wrapper for Kubernetes to call, while the binary makes an HTTP or RPC API call to a persistent backend.
CNI maintainers have discussed changing this to an HTTP or RPC model, based on performance issues when frequently
launching Windows processes.
Kubernetes uses only one CNI plugin at a time, though the CNI specification allows for multiplugin setups (i.e., assigning multiple IP addresses to a container). Multus is a CNI plugin that works around this limitation in Kubernetes by acting as a fan-out to multiple CNI plugins.
Note
At the time of writing, the CNI spec is at version 0.4. It has not changed drastically over the years and appears unlikely to change in the future—maintainers of the specification plan to release version 1.0 soon.
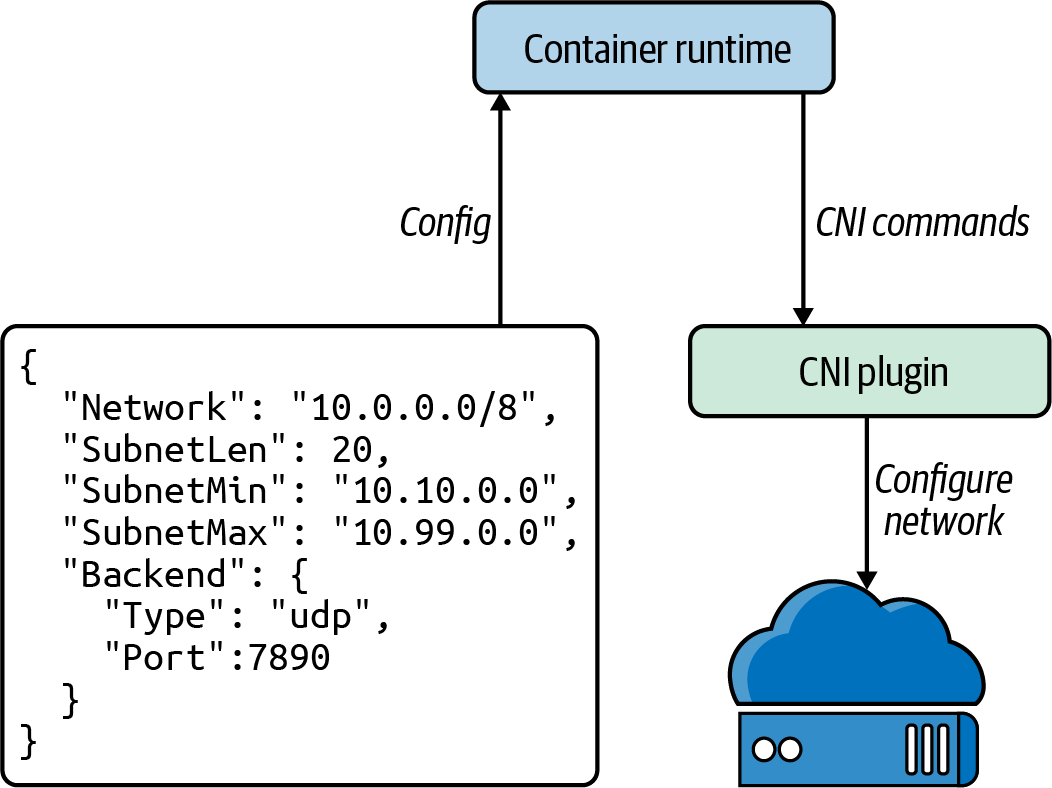
Figure 4-6. CNI configuration
CNI Plugins
The CNI plugin has two primary responsibilities: allocate and assign unique IP addresses for pods and ensure that routes exist within Kubernetes to each pod IP address. These responsibilities mean that the overarching network that the cluster resides in dictates CNI plugin behavior. For example, if there are too few IP addresses or it is not possible to attach sufficient IP addresses to a node, cluster admins will need to use a CNI plugin that supports an overlay network. The hardware stack, or cloud provider used, typically dictates which CNI options are suitable. Chapter 6 will talk about the major cloud platforms and how the network design impacts CNI choice.
To use the CNI, add --network-plugin=cni to the Kubelet’s startup arguments. By default, the Kubelet reads CNI
configuration from the directory /etc/cni/net.d/ and expects to find the CNI binary in /opt/cni/bin/. Admins can
override the configuration location with --cni-config-dir=<directory>, and the CNI binary directory with
--cni-bin-dir=<directory>.
Note
Managed Kubernetes offerings, and many “distros” of Kubernetes, come with a CNI preconfigured.
There are two broad categories of CNI network models: flat networks and overlay networks. In a flat network, the CNI driver uses IP addresses from the cluster’s network, which typically requires many IP addresses to be available to the cluster. In an overlay network, the CNI driver creates a secondary network within Kubernetes, which uses the cluster’s network (called the underlay network) to send packets. Overlay networks create a virtual network within the cluster. In an overlay network, the CNI plugin encapsulates packets. We discussed overlays in greater detail in Chapter 3. Overlay networks add substantial complexity and do not allow hosts on the cluster network to connect directly to pods. However, overlay networks allow the cluster network to be much smaller, as only the nodes must be assigned IP addresses on that network.
CNI plugins also typically need a way to communicate state between nodes. Plugins take very different approaches, such as storing data in the Kubernetes API, in a dedicated database.
The CNI plugin is also responsible for calling IPAM plugins for IP addressing.
The IPAM Interface
The CNI spec has a second interface, the IP Address Management (IPAM) interface, to reduce duplication of IP
allocation code in CNI plugins. The IPAM plugin must determine and output the interface IP address, gateway, and
routes, as shown in Example 4-2. The IPAM interface is similar to the CNI: a binary with JSON input to stdin and JSON
output from stdout.
Example 4-2. Example IPAM plugin output, from the CNI 0.4 specification docs
{"cniVersion":"0.4.0","ips":[{"version":"<4-or-6>","address":"<ip-and-prefix-in-CIDR>","gateway":"<ip-address-of-the-gateway>"(optional)},...],"routes":[(optional){"dst":"<ip-and-prefix-in-cidr>","gw":"<ip-of-next-hop>"(optional)},...]"dns":{(optional)"nameservers":<list-of-nameservers>(optional)"domain":<name-of-local-domain>(optional)"search":<list-of-search-domains>(optional)"options":<list-of-options>(optional)}}
Now we will review several of the options available for cluster administrators to choose from when deploying a CNI.
Popular CNI Plugins
Cilium is open source software for transparently securing network connectivity between application containers.
Cilium is an L7/HTTP-aware CNI and can enforce network policies on L3–L7 using an identity-based security model
decoupled from the network addressing. The Linux technology eBPF, which we discussed in Chapter 2, is what powers
Cilium. Later in this chapter, we will do a deep dive into NetworkPolicy objects; for now know that they are effectively pod-level
firewalls.
Flannel focuses on the network and is a simple and easy way to configure a layer 3 network fabric designed for
Kubernetes. If a cluster requires functionalities like network policies, an admin must deploy
other CNIs, such as Calico. Flannel uses the Kubernetes cluster’s existing etcd to store its state information to
avoid providing a dedicated data store.
According to Calico, it “combines flexible networking capabilities with run-anywhere security enforcement to provide a solution with native Linux kernel performance and true cloud-native scalability.” Calico does not use an overlay network. Instead, Calico configures a layer 3 network that uses the BGP routing protocol to route packets between hosts. Calico can also integrate with Istio, a service mesh, to interpret and enforce policy for workloads within the cluster at the service mesh and network infrastructure layers.
Table 4-2 gives a brief overview of the major CNI plugins to choose from.
| Name | NetworkPolicy support | Data storage | Network setup |
|---|---|---|---|
Cilium |
Yes |
etcd or consul |
Ipvlan(beta), veth, L7 aware |
Flannel |
No |
etcd |
Layer 3 IPv4 overlay network |
Calico |
Yes |
etcd or Kubernetes API |
Layer 3 network using BGP |
Weave Net |
Yes |
No external cluster store |
Mesh overlay network |
Note
Full instructions for running KIND, Helm, and Cilium are in the book’s GitHub repo.
Let’s deploy Cilium for testing with our Golang web server in Example 4-3. We will need a Kubernetes cluster for deploying Cilium. One of the easiest ways we have found to deploy clusters for testing locally is KIND, which stands for Kubernetes in Docker. It will allow us to create a cluster with a YAML configuration file and then, using Helm, deploy Cilium to that cluster.
Example 4-3. KIND configuration for Cilium local deploy
kind: ClusterapiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
- role: worker
networking:
disableDefaultCNI: true
Note
Instructions for configuring a KIND cluster and more can be found in the documentation.
With the KIND cluster configuration YAML, we can use KIND to create that cluster with the following command. If this is the first time you’re running it, it will take some time to download all the Docker images for the working and control plane Docker images:
$kind create cluster --config=kind-config.yaml Creating cluster"kind"... ✓ Ensuring node image(kindest/node:v1.18. 2)Preparing nodes ✓ Writing configuration Starting control-plane Installing StorageClass Joining worker nodes Set kubectl context to"kind-kind"You can now use your cluster with: kubectl cluster-info --context kind-kind Have a question, bug, or feature request? Let us know! https://kind.sigs.k8s.io/#community ߙ⊭--- Always verify that the cluster is up and running with kubectl.
$kubectl cluster-info --context kind-kind Kubernetes master -> control plane is running at https://127.0.0.1:59511 KubeDNS is running at https://127.0.0.1:59511/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy To further debug and diagnose cluster problems, use'kubectl cluster-info dump.'
Note
The cluster nodes will remain in state NotReady until Cilium deploys the network. This is normal behavior for the cluster.
Now that our cluster is running locally, we can begin installing Cilium using Helm, a Kubernetes deployment tool. According to its documentation, Helm is the preferred way to install Cilium. First, we need to add the Helm repo for Cilium. Optionally, you can download the Docker images for Cilium and finally instruct KIND to load the Cilium images into the cluster:
$helm repo add cilium https://helm.cilium.io/# Pre-pulling and loading container images is optional.$docker pull cilium/cilium:v1.9.1 kind load docker-image cilium/cilium:v1.9.1
Now that the prerequisites for Cilium are completed, we can install it in our cluster with Helm. There are many
configuration options for Cilium, and Helm configures options with --set NAME_VAR=VAR:
$helm install cilium cilium/cilium --version 1.10.1\--namespace kube-system NAME: Cilium LAST DEPLOYED: Fri Jan115:39:59 2021 NAMESPACE: kube-system STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: You have successfully installed Cilium with Hubble. Your release version is 1.10.1. For any furtherhelp, visit https://docs.cilium.io/en/v1.10/gettinghelp/
Cilium installs several pieces in the cluster: the agent, the client, the operator, and the cilium-cni plugin:
- Agent
-
The Cilium agent,
cilium-agent, runs on each node in the cluster. The agent accepts configuration through Kubernetes APIs that describe networking, service load balancing, network policies, and visibility and monitoring requirements. - Client (CLI)
-
The Cilium CLI client (Cilium) is a command-line tool installed along with the Cilium agent. It interacts with the REST API on the same node. The CLI allows developers to inspect the state and status of the local agent. It also provides tooling to access the eBPF maps to validate their state directly.
- Operator
-
The operator is responsible for managing duties in the cluster, which should be handled per cluster and not per node.
- CNI Plugin
-
The CNI plugin (
cilium-cni) interacts with the Cilium API of the node to trigger the configuration to provide networking, load balancing, and network policies pods.
We can observe all these components being deployed in the cluster with the kubectl -n kube-system get pods --watch
command:
$ kubectl -n kube-system get pods --watch
NAME READY STATUS
cilium-65kvp 0/1 Init:0/2
cilium-node-init-485lj 0/1 ContainerCreating
cilium-node-init-79g68 1/1 Running
cilium-node-init-gfdl8 1/1 Running
cilium-node-init-jz8qc 1/1 Running
cilium-operator-5b64c54cd-cgr2b 0/1 ContainerCreating
cilium-operator-5b64c54cd-tblbz 0/1 ContainerCreating
cilium-pg6v8 0/1 Init:0/2
cilium-rsnqk 0/1 Init:0/2
cilium-vfhrs 0/1 Init:0/2
coredns-66bff467f8-dqzql 0/1 Pending
coredns-66bff467f8-r5nl6 0/1 Pending
etcd-kind-control-plane 1/1 Running
kube-apiserver-kind-control-plane 1/1 Running
kube-controller-manager-kind-control-plane 1/1 Running
kube-proxy-k5zc2 1/1 Running
kube-proxy-qzhvq 1/1 Running
kube-proxy-v54p4 1/1 Running
kube-proxy-xb9tr 1/1 Running
kube-scheduler-kind-control-plane 1/1 Running
cilium-operator-5b64c54cd-tblbz 1/1 RunningNow that we have deployed Cilium, we can run the Cilium connectivity check to ensure it is running correctly:
$kubectl create ns cilium-test namespace/cilium-test created$kubectl apply -n cilium-test\-f\https://raw.githubusercontent.com/strongjz/advanced_networking_code_examples/ master/chapter-4/connectivity-check.yaml deployment.apps/echo-a created deployment.apps/echo-b created deployment.apps/echo-b-host created deployment.apps/pod-to-a created deployment.apps/pod-to-external-1111 created deployment.apps/pod-to-a-denied-cnp created deployment.apps/pod-to-a-allowed-cnp created deployment.apps/pod-to-external-fqdn-allow-google-cnp created deployment.apps/pod-to-b-multi-node-clusterip created deployment.apps/pod-to-b-multi-node-headless created deployment.apps/host-to-b-multi-node-clusterip created deployment.apps/host-to-b-multi-node-headless created deployment.apps/pod-to-b-multi-node-nodeport created deployment.apps/pod-to-b-intra-node-nodeport created service/echo-a created service/echo-b created service/echo-b-headless created service/echo-b-host-headless created ciliumnetworkpolicy.cilium.io/pod-to-a-denied-cnp created ciliumnetworkpolicy.cilium.io/pod-to-a-allowed-cnp created ciliumnetworkpolicy.cilium.io/pod-to-external-fqdn-allow-google-cnp created
The connectivity test will deploy a series of Kubernetes deployments that will use various connectivity paths. Connectivity paths come with and without service load balancing and in various network policy combinations. The pod name indicates the connectivity variant, and the readiness and liveness gate indicates the success or failure of the test:
$kubectl get pods -n cilium-test -w NAME READY STATUSecho-a-57cbbd9b8b-szn94 1/1 Runningecho-b-6db5fc8ff8-wkcr6 1/1 Runningecho-b-host-76d89978c-dsjm8 1/1 Running host-to-b-multi-node-clusterip-fd6868749-7zkcr 1/1 Running host-to-b-multi-node-headless-54fbc4659f-z4rtd 1/1 Running pod-to-a-648fd74787-x27hc 1/1 Running pod-to-a-allowed-cnp-7776c879f-6rq7z 1/1 Running pod-to-a-denied-cnp-b5ff897c7-qp5kp 1/1 Running pod-to-b-intra-node-nodeport-6546644d59-qkmck 1/1 Running pod-to-b-multi-node-clusterip-7d54c74c5f-4j7pm 1/1 Running pod-to-b-multi-node-headless-76db68d547-fhlz7 1/1 Running pod-to-b-multi-node-nodeport-7496df84d7-5z872 1/1 Running pod-to-external-1111-6d4f9d9645-kfl4x 1/1 Running pod-to-external-fqdn-allow-google-cnp-5bc496897c-bnlqs 1/1 Running
Now that Cilium manages our network for the cluster, we will use it later in this chapter for a NetworkPolicy
overview. Not all CNI plugins will support NetworkPolicy, so that is an important detail when deciding which plugin to use.
kube-proxy
kube-proxy is another per-node daemon in Kubernetes, like Kubelet.
kube-proxy provides basic load balancing functionality
within the cluster.
It implements services and relies on Endpoints/EndpointSlices,
two API objects that we will discuss in detail in the next chapter on networking abstractions.
It may help to reference that section, but the following is the relevant and quick explanation:
-
Services define a load balancer for a set of pods.
-
Endpoints (and endpoint slices) list a set of ready pod IPs. They are created automatically from a service, with the same pod selector as the service.
Most types of services have an IP address for the service, called the cluster IP address, which is not routable outside the
cluster. kube-proxy is responsible for routing requests to a service’s cluster IP address to healthy pods. kube-proxy is by
far the most common implementation for Kubernetes services, but there are alternatives to kube-proxy, such as a
replacement mode Cilium. A substantial amount of our content on routing in Chapter 2 is applicable to kube-proxy,
particularly when debugging service connectivity or performance.
Note
Cluster IP addresses are not typically routable from outside a cluster.
kube-proxy has four modes, which change its runtime mode and exact feature set: userspace, iptables, ipvs, and kernelspace.
You can specify the mode using
--proxy-mode <mode>. It’s worth noting that all modes rely on iptables to some extent.
userspace Mode
The first and oldest mode is userspace mode. In userspace mode, kube-proxy runs a web server and routes all service
IP addresses to the web server, using iptables. The web server terminates connections and proxies the request to a pod in the service’s endpoints.
userspace mode is no longer commonly used, and we suggest avoiding it unless you have a clear reason to use it.
iptables Mode
iptables mode uses iptables entirely. It is the default mode, and the most commonly used
(this may be in part because IPVS mode graduated to GA stability more recently, and iptables is a familiar Linux technology).
iptables mode performs connection fan-out, instead of true load balancing. In other words, iptables mode will route a connection
to a backend pod, and all requests made using that connection will go to the same pod, until the connection is terminated.
This is simple and has predictable behavior in ideal scenarios
(e.g., successive requests in the same connection will be able to benefit from any local caching in backend pods).
It can also be unpredictable when dealing with long-lived connections, such as HTTP/2 connections (notably, HTTP/2 is the transport for gRPC).
Suppose you have two pods, X and Y, serving a service, and you replace X with Z during a normal rolling update.
The older pod Y still has all the existing connections, plus half of the connections that needed to be reestablished when pod X shut down,
leading to substantially more traffic being served by pod Y. There are many scenarios like this that lead to unbalanced traffic.
Recall our examples in the “Practical iptables” section in Chapter 2. In it, we showed that iptables could be configured with a list of IP addresses
and random routing probabilities, such that connections would be made randomly between all IP addresses.
Given a service that has healthy backend pods 10.0.0.1, 10.0.0.2, 10.0.0.3, and 10.0.0.4, kube-proxy would create sequential rules that route connections like so:
-
25% of connections go to
10.0.0.1. -
33.3% of unrouted connections go to
10.0.0.2. -
50% of unrouted connections go to
10.0.0.3. -
All unrouted connections go to
10.0.0.4.
This may seem unintuitive and leads some engineers to assume that kube-proxy is misrouting traffic (especially because
few people look at kube-proxy when services work as expected).
The crucial detail is that each routing rule happens for connections that haven’t been routed in a prior rule.
The final rule routes all connections to 10.0.0.4 (because the connection has to go somewhere), the semifinal rule has a 50%
chance of routing to 10.0.0.3 as a choice of two IP addresses, and so on.
Routing randomness scores are always calculated as 1 / ${remaining number of IP addresses}.
Here are the iptables forwarding rules for the kube-dns service in a cluster.
In our example, the kube-dns service’s cluster IP address is 10.96.0.10.
This output has been filtered and reformatted for clarity:
$sudo iptables -t nat -L KUBE-SERVICES Chain KUBE-SERVICES(2references)target prot optsourcedestination /* kube-system/kube-dns:dns cluster IP */ udp dpt:domain KUBE-MARK-MASQ udp -- !10.217.0.0/16 10.96.0.10 /* kube-system/kube-dns:dns cluster IP */ udp dpt:domain KUBE-SVC-TCOU7JCQXEZGVUNU udp -- anywhere 10.96.0.10 /* kube-system/kube-dns:dns-tcp cluster IP */ tcp dpt:domain KUBE-MARK-MASQ tcp -- !10.217.0.0/16 10.96.0.10 /* kube-system/kube-dns:dns-tcp cluster IP */ tcp dpt:domain KUBE-SVC-ERIFXISQEP7F7OF4 tcp -- anywhere 10.96.0.10 ADDRTYPE match dst-type LOCAL /* kubernetes service nodeports;NOTE: this must be the last rule in this chain */ KUBE-NODEPORTS all -- anywhere anywhere
There are a pair of UDP and TCP rules for kube-dns. We’ll focus on the UDP ones.
The first UDP rule marks any connections to the service
that aren’t originating from a pod IP address (10.217.0.0/16 is the default pod network CIDR)
for masquerading.
The next UDP rule has the chain KUBE-SVC-TCOU7JCQXEZGVUNU as its target.
Let’s take a closer look:
$sudo iptables -t nat -L KUBE-SVC-TCOU7JCQXEZGVUNU Chain KUBE-SVC-TCOU7JCQXEZGVUNU(1references)target prot optsourcedestination /* kube-system/kube-dns:dns */ KUBE-SEP-OCPCMVGPKTDWRD3C all -- anywhere anywhere statistic mode random probability 0.50000000000 /* kube-system/kube-dns:dns */ KUBE-SEP-VFGOVXCRCJYSGAY3 all -- anywhere anywhere
Here we see a chain with a 50% chance of executing, and the chain that will execute otherwise.
If we check the first of those chains, we see it routes to 10.0.1.141, one of our two CoreDNS pods’ IPs:
$sudo iptables -t nat -L KUBE-SEP-OCPCMVGPKTDWRD3C Chain KUBE-SEP-OCPCMVGPKTDWRD3C(1references)target prot optsourcedestination /* kube-system/kube-dns:dns */ KUBE-MARK-MASQ all -- 10.0.1.141 anywhere /* kube-system/kube-dns:dns */ udp to:10.0.1.141:53 DNAT udp -- anywhere anywhere
ipvs Mode
ipvs mode uses IPVS, covered in Chapter 2, instead of iptables, for connection load balancing.
ipvs mode supports six load balancing modes, specified with --ipvs-scheduler:
-
rr: Round-robin -
lc: Least connection -
dh: Destination hashing -
sh: Source hashing -
sed: Shortest expected delay -
nq: Never queue
Round-robin (rr) is the default load balancing mode. It is the closest analog to iptables mode’s behavior (in that connections are made fairly evenly regardless of pod state),
though iptables mode does not actually perform round-robin routing.
kernelspace Mode
kernelspace is the newest, Windows-only mode. It provides an alternative to
userspace mode for Kubernetes on Windows,
as iptables and ipvs are specific to Linux.
Now that we’ve covered the basics of pod-to-pod traffic in Kubernetes,
let’s take a look at NetworkPolicy and securing pod-to-pod traffic.
NetworkPolicy
Kubernetes’ default behavior is to allow traffic between any two pods in the cluster network. This behavior is a
deliberate design choice for ease of adoption and flexibility of configuration, but it is highly undesirable in
practice. Allowing any system to make (or receive) arbitrary connections creates risk.
An attacker can probe systems and can potentially exploit captured credentials or find weakened or missing authentication.
Allowing arbitrary connections also makes it easier to exfiltrate data from a system through a compromised workload.
All in all, we strongly discourage running real clusters without NetworkPolicy. Since all pods can communicate with
all other pods, we strongly recommend that application owners use NetworkPolicy objects along with other application-layer
security measures, such as authentication tokens or mutual Transport Layer Security (mTLS), for any network
communication.
NetworkPolicy is a resource type in Kubernetes that contains allow-based firewall rules. Users can add
NetworkPolicy objects to restrict connections to and from pods. The NetworkPolicy resource acts as a configuration
for CNI plugins, which themselves are responsible for ensuring connectivity between pods. The Kubernetes API declares
that NetworkPolicy support is optional for CNI drivers, which means that some CNI drivers do not support
network policies, as shown in Table 4-3. If a developer creates a NetworkPolicy when using a CNI driver that does not
support NetworkPolicy objects, it does not affect the pod’s network security. Some CNI drivers, such as enterprise products or
company-internal CNI drivers, may introduce their equivalent of a NetworkPolicy. Some CNI drivers may also have
slightly different “interpretations” of the NetworkPolicy spec.
| CNI plugin | NetworkPolicy supported |
|---|---|
Calico |
Yes, and supports additional plugin-specific policies |
Cilium |
Yes, and supports additional plugin-specific policies |
Flannel |
No |
Kubenet |
No |
Example 4-4 details a NetworkPolicy object, which contains a pod selector, ingress rules, and egress rules. The policy
will apply to all pods in the same namespace as the NetworkPolicy that matches the selector label. This use of selector
labels is consistent with other Kubernetes APIs: a spec identifies pods by their labels rather than their names or
parent objects.
Example 4-4. The broad structure of a NetworkPolicy
apiVersion:networking.k8s.io/v1kind:NetworkPolicymetadata:name:demonamespace:defaultspec:podSelector:matchLabels:app:demopolicyTypes:-Ingress-Egressingress:[]NetworkPolicyIngressRule# Not expandedegress:[]NetworkPolicyEgressRule# Not expanded
Before getting deep into the API, let’s walk through a simple example of creating a NetworkPolicy to reduce the scope
of access for some pods. Let’s assume we have two distinct components: demo and demo-DB. As we have no existing
NetworkPolicy in Figure 4-7, all pods can communicate with all other pods (including hypothetically unrelated pods, not
shown).
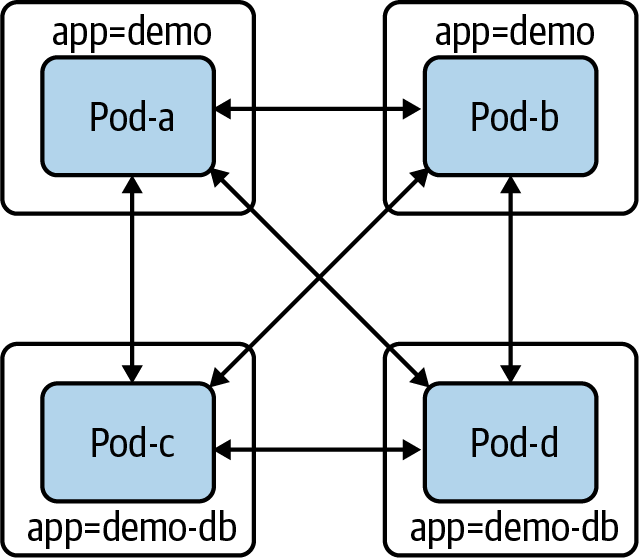
Figure 4-7. Pods without NetworkPolicy objects
Let’s restrict demo-DB’s access level. If we create the following NetworkPolicy that selects demo-DB pods,
demo-DB pods will be unable to send or receive any traffic:
apiVersion:networking.k8s.io/v1kind:NetworkPolicymetadata:name:demo-dbnamespace:defaultspec:podSelector:matchLabels:app:demo-dbpolicyTypes:-Ingress-Egress
In Figure 4-8, we can now see that pods with the label app=demo can no longer create or receive connections.
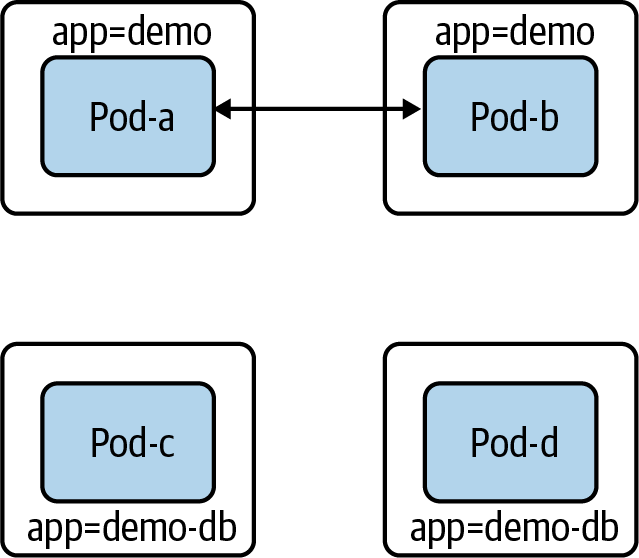
Figure 4-8. Pods with the app:demo-db label cannot receive or send traffic
Having no network access is undesirable for most workloads, including our example database. Our demo-db should
(only) be able to receive connections from demo pods. To do that, we must add an ingress rule to the NetworkPolicy:
apiVersion:networking.k8s.io/v1kind:NetworkPolicymetadata:name:demo-dbnamespace:defaultspec:podSelector:matchLabels:app:demo-dbpolicyTypes:-Ingress-Egressingress:-from:-podSelector:matchLabels:app:demo
Now demo-db pods can receive connections only from demo pods.
Moreover, demo-db pods cannot make connections (as shown in Figure 4-9).
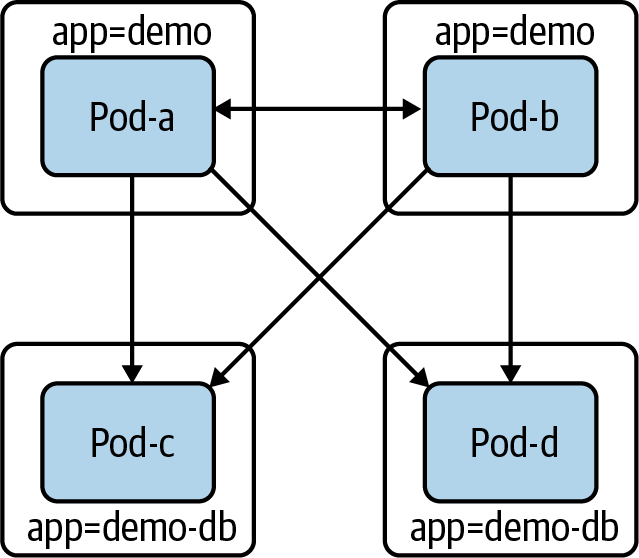
Figure 4-9. Pods with the app:demo-db label cannot create connections, and they can only receive connections from the app:demo pods
Warning
If users can unwittingly or maliciously change labels, they can change how NetworkPolicy objects apply to all pods.
In our prior example, if an attacker was able to edit the app: demo-DB label on a pod in that same namespace, the
NetworkPolicy that we created would no longer apply to that pod. Similarly, an attacker could gain access from
another pod in that namespace if they could add the label app: demo to their compromised pod.
The previous example is just an example; with Cilium we can create these
NetworkPolicy objects for our Golang web server.
NetworkPolicy Example with Cilium
Our Golang web server now connects to a Postgres database with no TLS. Also, with no NetworkPolicy objects in place, any
pod on the network can sniff traffic between the Golang web server and the database, which is a potential security
risk. The following is going to deploy our Golang web application and its database and then deploy NetworkPolicy objects
that will only allow connectivity to the database from the web server. Using the same KIND cluster from the Cilium
install, let’s deploy the Postgres database with the following YAML and kubectl commands:
$ kubectl apply -f database.yaml
service/postgres created
configmap/postgres-config created
statefulset.apps/postgres createdHere we deploy our web server as a Kubernetes deployment to our KIND cluster:
$ kubectl apply -f web.yaml
deployment.apps/app createdTo run connectivity tests inside the cluster network, we will deploy and use a dnsutils pod that has basic
networking tools like ping and curl:
$ kubectl apply -f dnsutils.yaml
pod/dnsutils createdSince we are not deploying a service with an ingress, we can use kubectl port-forward to test connectivity to our
web server:
kubectl port-forward app-5878d69796-j889q 8080:8080
Note
More information about kubectl port-forward can be found in the documentation.
Now from our local terminal, we can reach our API:
$curl localhost:8080/ Hello$curl localhost:8080/healthz Healthy$curl localhost:8080/data Database Connected
Let’s test connectivity to our web server inside the cluster from other pods. To do that, we need to get the IP address of our web server pod:
$kubectl get pods -lapp=app -o wide NAME READY STATUS RESTARTS AGE IP NODE app-5878d69796-j889q 1/1 Running087m 10.244.1.188 kind-worker3
Now we can test L4 and L7 connectivity to the web server from the dnsutils pod:
$kubectlexecdnsutils -- nc -z -vv 10.244.1.188 8080 10.244.1.188(10.244.1.188:8080)open sent 0, rcvd 0
From our dnsutils, we can test the layer 7 HTTP API access:
$kubectlexecdnsutils -- wget -qO- 10.244.1.188:8080/ Hello$kubectlexecdnsutils -- wget -qO- 10.244.1.188:8080/data Database Connected$kubectlexecdnsutils -- wget -qO- 10.244.1.188:8080/healthz Healthy
We can also test this on the database pod. First, we have to retrieve the IP address of the database
pod, 10.244.2.189. We can use kubectl with a combination of labels and options to get this information:
$kubectl get pods -lapp=postgres -o wide NAME READY STATUS RESTARTS AGE IP NODE postgres-0 1/1 Running098m 10.244.2.189 kind-worker
Again, let’s use dnsutils pod to test connectivity to the Postgres database over its default port 5432:
$kubectlexecdnsutils -- nc -z -vv 10.244.2.189 5432 10.244.2.189(10.244.2.189:5432)open sent 0, rcvd 0
The port is open for all to use since no network policies are in place. Now let’s restrict this with a Cilium network policy. The following commands deploy the network policies so that we can test the secure network connectivity. Let’s first restrict access to the database pod to only the web server. Apply the network policy that only allows traffic from the web server pod to the database:
$ kubectl apply -f layer_3_net_pol.yaml
ciliumnetworkpolicy.cilium.io/l3-rule-app-to-db createdThe Cilium deploy of Cilium objects creates resources that can be retrieved just like pods with kubectl. With
kubectl describe ciliumnetworkpolicies.cilium.io l3-rule-app-to-db, we can see all the information about the rule
deployed via the YAML:
$ kubectl describe ciliumnetworkpolicies.cilium.io l3-rule-app-to-db
Name: l3-rule-app-to-db
Namespace: default
Labels: <none>
Annotations: API Version: cilium.io/v2
Kind: CiliumNetworkPolicy
Metadata:
Creation Timestamp: 2021-01-10T01:06:13Z
Generation: 1
Managed Fields:
API Version: cilium.io/v2
Fields Type: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
.:
f:kubectl.kubernetes.io/last-applied-configuration:
f:spec:
.:
f:endpointSelector:
.:
f:matchLabels:
.:
f:app:
f:ingress:
Manager: kubectl
Operation: Update
Time: 2021-01-10T01:06:13Z
Resource Version: 47377
Self Link:
/apis/cilium.io/v2/namespaces/default/ciliumnetworkpolicies/l3-rule-app-to-db
UID: 71ee6571-9551-449d-8f3e-c177becda35a
Spec:
Endpoint Selector:
Match Labels:
App: postgres
Ingress:
From Endpoints:
Match Labels:
App: app
Events: <none>With the network policy applied, the dnsutils pod can no longer reach the database pod; we can see this in the
timeout trying to reach the DB port from the dnsutils pods:
$kubectlexecdnsutils -- nc -z -vv -w510.244.2.189 5432 nc: 10.244.2.189(10.244.2.189:5432): Operation timed out sent 0, rcvd 0commandterminated withexitcode 1
While the web server pod is still connected to the database pod, the /data route connects the web server to the database
and the NetworkPolicy allows it:
$kubectlexecdnsutils -- wget -qO- 10.244.1.188:8080/data Database Connected$curl localhost:8080/data Database Connected
Now let’s apply the layer 7 policy. Cilium is layer 7 aware so that we can block or allow a specific request on the HTTP
URI paths. In our example policy, we allow HTTP GETs on / and /data but do not allow them on /healthz; let’s test that:
$ kubectl apply -f layer_7_netpol.yml
ciliumnetworkpolicy.cilium.io/l7-rule createdWe can see the policy applied just like any other Kubernetes objects in the API:
$kubectl get ciliumnetworkpolicies.cilium.io NAME AGE l7-rule 6m54s$kubectl describe ciliumnetworkpolicies.cilium.io l7-rule Name: l7-rule Namespace: default Labels: <none> Annotations: API Version: cilium.io/v2 Kind: CiliumNetworkPolicy Metadata: Creation Timestamp: 2021-01-10T00:49:34Z Generation: 1 Managed Fields: API Version: cilium.io/v2 Fields Type: FieldsV1 fieldsV1: f:metadata: f:annotations: .: f:kubectl.kubernetes.io/last-applied-configuration: f:spec: .: f:egress: f:endpointSelector: .: f:matchLabels: .: f:app: Manager: kubectl Operation: Update Time: 2021-01-10T00:49:34Z Resource Version: 43869 Self Link:/apis/cilium.io/v2/namespaces/default/ciliumnetworkpolicies/l7-rule UID: 0162c16e-dd55-4020-83b9-464bb625b164 Spec: Egress: To Ports: Ports: Port: 8080 Protocol: TCP Rules: Http: Method: GET Path: / Method: GET Path: /data Endpoint Selector: Match Labels: App: app Events: <none>
As we can see, / and /data are available but not /healthz, precisely what we expect from the NetworkPolicy:
$kubectlexecdnsutils -- wget -qO- 10.244.1.188:8080/data Database Connected$kubectlexecdnsutils -- wget -qO- 10.244.1.188:8080/ Hello$kubectlexecdnsutils -- wget -qO- -T510.244.1.188:8080/healthz wget: error getting responsecommandterminated withexitcode 1
These small examples show how powerful the Cilium network policies can enforce network security inside the cluster. We highly recommend that administrators select a CNI that supports network policies and enforce developers’ use of network policies. Network policies are namespaced, and if teams have similar setups, cluster administrators can and should enforce that developers define network policies for added security.
We used two aspects of the Kubernetes API, labels and selectors; in our next section, we will provide more examples of how they are used inside a cluster.
Selecting Pods
Pods are unrestricted until they are selected by a NetworkPolicy. If selected, the CNI plugin allows pod
ingress or egress only when a matching rule allows it. A NetworkPolicy has a spec.policyTypes field containing a list
of policy types (ingress or egress). For example, if we select a pod with a NetworkPolicy that has ingress listed but
not egress, then ingress will be restricted, and egress will not.
The spec.podSelector field will dictate which pods to apply the NetworkPolicy to. An empty label selector.
(podSelector: {}) will select all pods in the namespace. We will discuss label selectors in more detail shortly.
NetworkPolicy objects are namespaced objects, which means they exist in and apply to a specific namespace. The spec
.podSelector field can select pods only when they are in the same namespace as the NetworkPolicy. This means selecting app:
demo will apply only in the current namespace, and any pods in another namespace with the label app: demo will be
unaffected.
There are multiple workarounds to achieve firewalled-by-default behavior, including the following:
-
Creating a blanket deny-all
NetworkPolicyobject for every namespace, which will require developers to add additionalNetworkPolicyobjects to allow desired traffic. -
Adding a custom CNI plugin that deliberately violates the default-open API behavior. Multiple CNI plugins have an additional configuration that exposes this kind of behavior.
-
Creating admission policies to require that workloads have a
NetworkPolicy.
NetworkPolicy objects rely heavily on labels and selectors; for that reason, let’s dive into more complex examples.
The LabelSelector type
This is the first time in this book that we see a LabelSelector in a resource. It is a ubiquitous configuration
element in Kubernetes and will come up many times in the next chapter, so when you get there, it may be helpful to
look back at this section as a reference.
Every object in Kubernetes has a metadata field, with the type ObjectMeta. That gives every type the same
metadata fields, like labels. Labels are a map of key-value string pairs:
metadata:labels:colour:purpleshape:square
A LabelSelector identifies a group of resources by the present labels (or absent). Very few resources in Kubernetes
will refer to other resources by name. Instead, most resources (NetworkPolicy objects, services, deployments, and other
Kubernetes objects). use label matching with a LabelSelector. LabelSelectors can also be used in API and kubectl
calls and avoid returning irrelevant objects. A LabelSelector has two fields: matchExpressions and matchLabels.
The normal behavior for an empty LabelSelector is to select all objects in scope, e.g., all pods in the same
namespace as a NetworkPolicy. matchLabels is the simpler of the two. matchLabels contains a map of key-value pairs.
For an object to match, each key must be present on the object, and that key must have the corresponding value.
matchLabels, often with a single key (e.g., app=example-thing), is usually sufficient for a selector.
In Example 4-5, we can see a match object that has both the label colour=purple and the label shape=square.
Example 4-5. matchLabels example
matchLabels:colour:purpleshape:square
matchExpressions is more powerful but more complicated. It contains a list of LabelSelectorRequirements.
All requirements must be true in order for an object to match. Table 4-4 shows all the required fields for a
matchExpressions.
| Field | Description |
|---|---|
key |
The label key this requirement compares against. |
operator |
One of
|
values |
A list of string values for the key in question.
It must be empty when the operator is |
Let’s look at two brief examples of matchExpressions.
The matchExpressions equivalent of our prior matchLabels example is shown in Example 4-6.
Example 4-6. matchExpressions example 1
matchExpressions:-key:colouroperator:Invalues:-purple-key:shapeoperator:Invalues:-square
matchExpressions in Example 4-7, will match objects with a color not equal to red, orange, or
yellow, and with a shape label.
Example 4-7. matchExpressions example 2
matchExpressions:-key:colouroperator:NotInvalues:-red-orange-yellow-key:shapeoperator:Exists
Now that we have labels covered, we can discuss rules. Rules will enforce our network policies after a match has been identified.
Rules
NetworkPolicy objects contain distinct ingress and egress configuration sections, which contain a list of ingress rules and egress rules, respectively. NetworkPolicy rules act as exceptions, or an “allow list,” to the default block caused by
selecting pods in a policy. Rules cannot block access; they can only add access. If multiple NetworkPolicy objects select a
pod, all rules in each of those NetworkPolicy objects apply. It may make sense to use multiple NetworkPolicy objects for the same
set of pods (for example, declaring application allowances in one policy and infrastructure allowances like telemetry
exporting in another). However, keep in mind that they do not need to be separate NetworkPolicy objects, and with too
many NetworkPolicy objects it can become hard to reason.
Warning
To support health checks and liveness checks from the Kubelet, the CNI plugin must always allow traffic from a pod’s node.
It is possible to abuse labels if an attacker has access to the node (even without admin privileges). Attackers can spoof a node’s IP and deliver packets with the node’s IP address as the source.
Ingress rules and egress rules are discrete types in the NetworkPolicy API (NetworkPolicyIngressRule and
NetworkPolicyEgressRule). However, they are functionally structured the same way. Each
NetworkPolicyIngressRule/NetworkPolicyEgressRule contains a list of ports
and a list of NetworkPolicyPeers.
A NetworkPolicyPeer has four ways for rules to refer to networked entities: ipBlock, namespaceSelector,
podSelector, and a combination.
ipBlock is useful for allowing traffic to and from external systems. It can be used only on its own in a rule,
without a namespaceSelector or podSelector. ipBlock contains a CIDR and an optional except CIDR. The except
CIDR will exclude a sub-CIDR (it must be within the CIDR range). In Example 4-8, we allow traffic from all IP addresses in
the range 10.0.0.0 to 10.0.0.255, excluding 10.0.0.10. Example 4-9 allows traffic from all pods in any namespace
labeled group:x.
Example 4-8. Allow traffic example 1
from:-ipBlock:-cidr:"10.0.0.0/24"-except:"10.0.0.10"
Example 4-9. Allow traffic example 2
#from:-namespaceSelector:-matchLabels:group:x
In Example 4-10, we allow traffic from all pods in any namespace labeled service: x.. podSelector behaves like the
spec.podSelector field that we discussed earlier.
If there is no namespaceSelector, it selects pods in the same namespace as the
NetworkPolicy.
Example 4-10. Allow traffic example 3
from:-podSelector:-matchLabels:service:y
If we specify a namespaceSelector and a podSelector, the rule selects all pods with the specified pod label
in all namespaces with the specified namespace label. It is common and highly recommended by security experts to keep
the scope of a namespace small; typical namespace scopes are per an app or service group or team. There is a
fourth option shown in Example 4-11 with a namespace and pod selector. This selector behaves like an AND
condition for the namespace and pod selector: pods must have the matching label and be in a namespace with the matching label.
Example 4-11. Allow traffic example 4
from:-namespaceSelector:-matchLabels:group:monitoringpodSelector:-matchLabels:service:logscraper
Be aware this is a distinct type in the API, although the YAML syntax looks extremely similar. As to and from
sections can have multiple selectors, a single character can make the difference between an AND and an OR, so be
careful when writing policies.
Our earlier security warning about API access also applies here. If a user can customize the labels on their namespace,
they can make a NetworkPolicy in another namespace apply to their namespace in a way not intended.
In our previous selector example, if a user can set the label group: monitoring on an arbitrary namespace, they can
potentially send or receive traffic that they are not supposed to. If the NetworkPolicy in question has only a namespace selector, then that namespace label is sufficient to match the policy. If there is also a pod label
in the NetworkPolicy selector, the user will need to set pod labels to match the policy selection. However, in a
typical setup, the service owners will grant create/update permissions on pods in that service’s namespace (directly
on the pod resource or indirectly via a resource like a deployment, which can define pods).
A typical NetworkPolicy could look something like this:
apiVersion:networking.k8s.io/v1kind:NetworkPolicymetadata:name:store-apinamespace:storespec:podSelector:matchLabels:{}policyTypes:-Ingress-Egressingress:-from:-namespaceSelector:matchLabels:app:frontendpodSelector:matchLabels:app:frontendports:-protocol:TCPport:8080egress:-to:-namespaceSelector:matchLabels:app:downstream-1podSelector:matchLabels:app:downstream-1-namespaceSelector:matchLabels:app:downstream-2podSelector:matchLabels:app:downstream-2ports:-protocol:TCPport:8080
In this example, all pods in our store namespace can receive connections only from pods labeled app: frontend
in a namespace labeled app: frontend. Those pods can only create connections to pods in namespaces where the pod
and namespace both have app: downstream-1 or app: downstream-2. In each of these cases, only traffic to port 8080
is allowed. Finally, remember that this policy does not guarantee a matching policy for downstream-1 or
downstream-2 (see the next example). Accepting these connections does not preclude other policies against pods in our
namespace, adding additional exceptions:
apiVersion:networking.k8s.io/v1kind:NetworkPolicymetadata:name:store-to-downstream-1namespace:downstream-1spec:podSelector:app:downstream-1policyTypes:-Ingressingress:-from:-namespaceSelector:matchLabels:app:storeports:-protocol:TCPport:8080
Although they are a “stable” resource (i.e., part of the networking/v1 API), we believe NetworkPolicy objects are still an
early version of network security in Kubernetes. The user experience of configuring NetworkPolicy objects is somewhat rough,
and the default open behavior is highly undesirable.
There is currently a working group to discuss the future of NetworkPolicy and what a v2 API would contain.
CNIs and those who deploy them use labels and selectors to determine which pods are subject to network restrictions. As we have seen in many of the previous examples, they are an essential part of the Kubernetes API, and developers and administrators alike must have a thorough knowledge of how to use them.
NetworkPolicy objects are an important tool in the cluster administrator’s toolbox. They are the only tool available for
controlling internal cluster traffic, native to the Kubernetes API. We discuss service meshes, which will add
further tools for admins to secure and control workloads, in “Service Meshes”.
Next we will discuss another important tool so administrators can understand how it works inside the cluster: the Domain Name System (DNS).
DNS
DNS is a critical piece of infrastructure for any network. In Kubernetes, this is no different, so a brief overview is warranted. In the following “Services” sections, we will see how much they depend on DNS and why a Kubernetes distribution cannot declare that it is a conforming Kubernetes distribution without providing a DNS service that follows the specification. But first, let’s review how DNS works inside Kubernetes.
Note
We will not outline the entire specification in this book. If readers are interested in reading more about it, it is available on GitHub.
KubeDNS was used in earlier versions of Kubernetes. KubeDNS had several containers within a single pod:
kube-dns, dnsmasq, and sidecar. The kube-dns container watches the Kubernetes API and serves DNS records based on the
Kubernetes DNS specification, dnsmasq provides caching and stub domain support, and sidecar provides metrics and
health checks. Versions of Kubernetes after 1.13 now use the separate component CoreDNS.
There are several differences between CoreDNS and KubeDNS:
-
For simplicity, CoreDNS runs as a single container.
-
CoreDNS is a Go process that replicates and enhances the functionality of Kube-DNS.
-
CoreDNS is designed to be a general-purpose DNS server that is backward compatible with Kubernetes, and its extendable plugins can do more than is provided in the Kubernetes DNS specification.
Figure 4-10 shows the components of CoreDNS. It runs a deployment with a default replica of 2, and for it to
run, CoreDNS needs access to the API server, a ConfigMap to hold its Corefile, a service to make DNS available to
the cluster, and a deployment to launch and manage its pods. All of this also runs in the kube-system namespace along
with other critical components in the cluster.
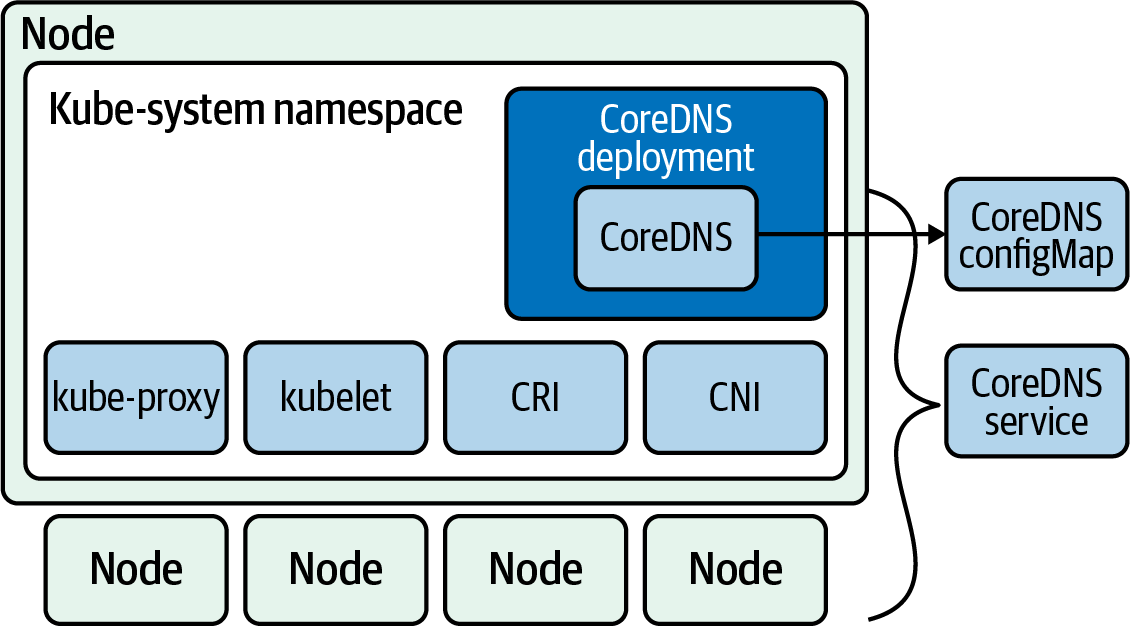
Figure 4-10. CoreDNS components
Like most configuration options, how the pod does DNS queries is in the pod spec under the dnsPolicy attribute.
Outlined in Example 4-12, the pod spec has ClusterFirstWithHostNet as
dnsPolicy.
Example 4-12. Pod spec with DNS configuration
apiVersion:v1kind:Podmetadata:name:busyboxnamespace:defaultspec:containers:-image:busybox:1.28command:-sleep-"3600"imagePullPolicy:IfNotPresentname:busyboxrestartPolicy:AlwayshostNetwork:truednsPolicy:ClusterFirstWithHostNet
There are four options for dnsPolicy that
significantly affect how DNS resolutions work inside a pod:
Default-
The pod inherits the name resolution configuration from the node that the pods run on.
ClusterFirst-
Any DNS query that does not match the cluster domain suffix, such as www.kubernetes.io, is sent to the upstream name server inherited from the node.
ClusterFirstWithHostNet-
For pods running with
hostNetwork, admins should set the DNS policy toClusterFirstWithHostNet. None-
All DNS settings use the
dnsConfigfield in the pod spec.
If none, developers will have to specify name servers in the pod spec. nameservers: is a list of IP addresses that
the pod will use as DNS servers. There can be at most three IP addresses specified. searches: is a list of DNS search
domains for hostname lookup in the pod. Kubernetes allows for at most six search domains. The following is such an example
spec:
apiVersion:v1kind:Podmetadata:namespace:defaultname:busyboxspec:containers:-image:busybox:1.28command:-sleep-"3600"imagePullPolicy:IfNotPresentname:busyboxdnsPolicy:"None"dnsConfig:nameservers:-1.1.1.1searches:-ns1.svc.cluster-domain.example-my.dns.search.suffix
Others are in the options field, which is a list of objects where each object may have a name property and a value property
(optional).
All of these generated properties merge with resolv.conf from the DNS policy. Regular query options have CoreDNS
going through the following search path:
<service>.default.svc.cluster.local
↓
svc.cluster.local
↓
cluster.local
↓
The host search path
The host search path comes from the pod DNS policy or CoreDNS policy.
Querying a DNS record in Kubernetes can result in many requests and increase latency in applications waiting on DNS requests to be answered. CoreDNS has a solution for this called Autopath. Autopath allows for server-side search path completion. It short circuits the client’s search path resolution by stripping the cluster search domain and performing the lookups on the CoreDNS server; when it finds an answer, it stores the result as a CNAME and returns with one query instead of five.
Using Autopath does increase the memory usage on CoreDNS, however. Make sure to scale the CoreDNS replica’s memory with the cluster’s size. Make sure to set the requests for memory and CPU for the CoreDNS pods appropriately. To monitor CoreDNS, it exports several metrics it exposes, listed here:
- coredns build info
-
Info about CoreDNS itself
- dns request count total
-
Total query count
- dns request duration seconds
-
Duration to process each query
- dns request size bytes
-
The size of the request in bytes
- coredns plugin enabled
-
Indicates whether a plugin is enabled on per server and zone basis
By combining the pod metrics along with CoreDNS metrics, plugin administrators will ensure that CoreDNS stays healthy and running inside your cluster.
Tip
This is only a brief overview of the metrics available. The entire list is available.
Autopath and other metrics are enabled via plugins. This allows CoreDNS to focus on its one task, DNS, but still be extensible through the plugin framework, much like the CNI pattern. In Table 4-5, we see a list of the plugins currently available. Being an open source project, anyone can contribute a plugin. There are several cloud-specific ones like router53 that enable serving zone data from AWS route53 service.
| Name | Description |
|---|---|
auto |
Enables serving zone data from an RFC 1035-style master file, which is automatically picked up from disk. |
autopath |
Allows for server-side search path completion. autopath [ZONE…] RESOLV-CONF. |
bind |
Overrides the host to which the server should bind. |
cache |
Enables a frontend cache. cache [TTL] [ZONES…]. |
chaos |
Allows for responding to TXT queries in the CH class. |
debug |
Disables the automatic recovery upon a crash so that you’ll get a nice stack trace. text2pcap. |
dnssec |
Enables on-the-fly DNSSEC signing of served data. |
dnstap |
Enables logging to dnstap. http://dnstap.info golang: go get -u -v github.com/dnstap/golang-dnstap/dnstap. |
erratic |
A plugin useful for testing client behavior. |
errors |
Enables error logging. |
etcd |
Enables reading zone data from an etcd version 3 instance. |
federation |
Enables federated queries to be resolved via the kubernetes plugin. |
file |
Enables serving zone data from an RFC 1035-style master file. |
forward |
Facilitates proxying DNS messages to upstream resolvers. |
health |
Enables a health check endpoint. |
host |
Enables serving zone data from a /etc/hosts style file. |
kubernetes |
Enables the reading zone data from a Kubernetes cluster. |
loadbalancer |
Randomizes the order of A, AAAA, and MX records. |
log enables |
Queries logging to standard output. |
loop detect |
Simple forwarding loops and halt the server. |
metadata |
Enables a metadata collector. |
metrics |
Enables Prometheus metrics. |
nsid |
Adds an identifier of this server to each reply. RFC 5001. |
pprof |
Publishes runtime profiling data at endpoints under /debug/pprof. |
proxy |
Facilitates both a basic reverse proxy and a robust load balancer. |
reload |
Allows automatic reload of a changed Corefile. Graceful reload. |
rewrite |
Performs internal message rewriting. rewrite name foo.example.com foo.default.svc.cluster.local. |
root |
Simply specifies the root of where to find zone files. |
router53 |
Enables serving zone data from AWS route53. |
secondary |
Enables serving a zone retrieved from a primary server. |
template |
Dynamic responses based on the incoming query. |
tls |
Configures the server certificates for TLS and gRPC servers. |
trace |
Enables OpenTracing-based tracing of DNS requests. |
whoami |
Returns resolver’s local IP address, port, and transport. |
Note
A comprehensive list of CoreDNS plugins is available.
CoreDNS is exceptionally configurable and compatible with the Kubernetes model. We have only scratched the surface of what CoreDNS is capable of; if you would like to learn more about CoreDNS, we highly recommend reading Learning CoreDNS by John Belamaric Cricket Liu (O’Reilly).
CoreDNS allows pods to figure out the IP addresses to use to reach applications and servers internal and external to the cluster. In our next section, we will discuss more in depth how IPv4 and 6 are managed in a cluster.
IPv4/IPv6 Dual Stack
Kubernetes has still-evolving support for running in IPv4/IPv6 “dual-stack” mode, which allows a cluster to use both IPv4 and IPv6 addresses. Kubernetes has existing stable support for running clusters in IPv6-only mode; however, running in IPv6-only mode is a barrier to communicating with clients and hosts that support only IPv4. The dual-stack mode is a critical bridge to allowing IPv6 adoption. We will attempt to describe the current state of dual-stack networking in Kubernetes as of Kubernetes 1.20, but be aware that it is liable to change substantially in subsequent releases. The full Kubernetes enhancement proposal (KEP) for dual-stack support is on GitHub.
Warning
In Kubernetes, a feature is “alpha” if the design is not finalized, if the scalability/test coverage/reliability is insufficient, or if it merely has not proven itself sufficiently in the real world yet. Kubernetes Enhancement Proposals (KEPs) set the bar for an individual feature to graduate to beta and then be stable. Like all alpha features, Kubernetes disables dual-stack support by default, and the feature must be explicitly enabled.
IPv4/IPv6 features enable the following features for pod networking:
-
A single IPv4 and IPv6 address per pod
-
IPv4 and IPv6 services
-
Pod cluster egress routing via IPv4 and IPv6 interfaces
Being an alpha feature, administrators must enable IPv4/IPv6 dual-stack; to do so, the IPv6DualStack feature gate for
the network components must be configured for your cluster. Here is a list of those dual-stack cluster network options:
kube-apiserver-
-
feature-gates="IPv6DualStack=true" -
service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR>
-
kube-controller-manager-
-
feature-gates="IPv6DualStack=true" -
cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR> -
service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR> -
node-cidr-mask-size-ipv4|--node-cidr-mask-size-ipv6defaults to /24 for IPv4 and /64 for IPv6
-
kubelet-
-
feature-gates="IPv6DualStack=true"
-
kube-proxy-
-
cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR> -
feature-gates="IPv6DualStack=true"
-
When IPv4/IPv6 is on in a cluster, services now have an extra field in which developers can choose the
ipFamilyPolicy to deploy for their application:
SingleStack-
Single-stack service. The control plane allocates a cluster IP for the service, using the first configured service cluster IP range.
PreferDualStack-
Used only if the cluster has dual stack enabled. This setting will use the same behavior as
SingleStack. RequireDualStack-
Allocates service cluster IP addresses from both IPv4 and IPv6 address ranges.
ipFamilies-
An array that defines which IP family to use for a single stack or defines the order of IP families for dual stack; you can choose the address families by setting this field on the service. The allowed values are
["IPv4"],["IPv6"], and["IPv4","IPv6"](dual stack).
Note
Starting in 1.21, IPv4/IPv6 dual stack defaults to enabled.
Here is an example service manifest that has PreferDualStack set to PreferDualStack:
apiVersion:v1kind:Servicemetadata:name:my-servicelabels:app:MyAppspec:ipFamilyPolicy:PreferDualStackselector:app:MyAppports:-protocol:TCPport:80
Conclusion
The Kubernetes networking model is the basis for how networking is designed to work inside a cluster. The CNI running on the nodes implements the principles set forth in the Kubernetes network model. The model does not define network security; the extensibility of Kubernetes allows the CNI to implement network security through network policies.
CNI, DNS, and network security are essential parts of the cluster network; they bridge the gap between Linux networking, covered in Chapter 2, and container and Kubernetes networking, covered in Chapters 3 and 5, respectively.
Choosing the right CNI requires an evaluation from both the developers’ and administrators’ perspectives. Requirements need to be laid out and CNIs tested. It is our opinion that a cluster is not complete without a discussion about network security and CNI that supports it.
DNS is essential; a complete setup and a smooth-running network require network and cluster administrators to be proficient at scaling CoreDNS in their clusters. An exceptional number of Kubernetes issues stem from DNS and the misconfiguration of CoreDNS.
The information in this chapter will be important when discussing cloud networking in Chapter 6 and what options administrators have when designing and deploying their production cluster networks.
In our next chapter, we will dive into how Kubernetes uses all of this to power its abstractions.
Get Networking and Kubernetes now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

