Kapitel 1. Einführung
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Computer waren früher viel einfacher. Das heißt nicht, dass sie einfach zu bedienen oder zu programmieren waren, aber konzeptionell gab es viel weniger zu tun. PCs in den 1980er Jahren hatten in der Regel einen einzigen 8-Bit-CPU-Kern und nicht viel Speicherplatz. In der Regel konnte man nur ein einziges Programm auf einmal ausführen. Das, was wir heute als Betriebssystem bezeichnen, würde nicht einmal gleichzeitig mit dem Programm laufen, mit dem der Benutzer interagiert.
Schließlich wollten die Menschen mehr als ein Programm gleichzeitig ausführen, und das Multitasking war geboren. Damit konnten Betriebssysteme mehrere Programme gleichzeitig ausführen, indem sie die Ausführung zwischen ihnen umschalteten. Die Programme konnten entscheiden, wann sie ein anderes Programm laufen lassen wollten, indem sie die Ausführung dem Betriebssystem überließen. Dieser Ansatz wird kooperatives Multitasking genannt.
Wenn in einer kooperativen Multitasking-Umgebung ein Programm aus irgendeinem Grund fehlschlägt, kann kein anderes Programm weiter ausgeführt werden. Da diese Unterbrechung anderer Programme nicht erwünscht ist, ging schließlich zu einem präemptiven Multitasking über. Bei diesem Modell legt das Betriebssystem selbst fest, welches Programm zu welchem Zeitpunkt auf der CPU ausgeführt wird, und verlässt sich nicht darauf, dass die Programme selbst entscheiden, wann sie die Ausführung wechseln. Bis heute verwenden fast alle Betriebssysteme diesen Ansatz, sogar auf Systemenmit mehreren Kernen, weil wir in der Regel mehr Programme laufen lassen als wirCPU-Kerne haben.
Mehrere Aufgaben gleichzeitig laufen zu lassen, ist sowohl für Programmierer als auch für Benutzer äußerst nützlich. Vor der Einführung von Threads konnte ein einzelnes Programm (d.h. ein einzelner Prozess) nicht mehrere Aufgaben zur gleichen Zeit ausführen. Stattdessen mussten Programmiererinnen und Programmierer, die Aufgaben gleichzeitig ausführen wollten, die Aufgabe entweder in kleinere Teile aufteilen und diese innerhalb des Prozesses einplanen oder separate Aufgaben in separaten Prozessen ausführen und diese miteinander kommunizieren lassen.
Auch heute noch ist in einigen Hochsprachen die geeignete Methode, um mehrere Aufgaben gleichzeitig auszuführen, die Ausführung zusätzlicher Prozesse. In einigen Sprachen wie Ruby und Python gibt es eine globale Interpretersperre (GIL), was bedeutet, dass nur ein Thread zu einem bestimmten Zeitpunkt ausgeführt werden kann. Das macht die Speicherverwaltung zwar viel praktischer, macht aber die Multithread-Programmierung für Programmierer/innen nicht so attraktiv, sodass stattdessen mehrere Prozesse eingesetzt werden.
Bis vor kurzem war JavaScript eine Sprache, in der die einzigen verfügbaren Multitasking-Mechanismen darin bestanden, Aufgaben aufzuteilen und ihre Teile für eine spätere Ausführung einzuplanen oder - im Fall von Node.js - zusätzliche Prozesse zu starten. Normalerweise haben wir den Code mit Hilfe von Callbacks oder Promises in asynchrone Einheiten unterteilt. Ein typisches Stück Code, das auf diese Weise geschrieben wurde, könnte etwa so aussehen wie in Beispiel 1-1, wobei die Operationen durch Callbacks oder await aufgeteilt werden.
Beispiel 1-1. Ein typisches Stück asynchroner JavaScript-Code, das zwei verschiedene Muster verwendet
readFile(filename,(data)=>{doSomethingWithData(data,(modifiedData)=>{writeFile(modifiedData,()=>{console.log('done');});});});// orconstdata=awaitreadFile(filename);constmodifiedData=awaitdoSomethingWithData(data);awaitwriteFile(filename);console.log('done');
Heutzutage haben wir in allen wichtigen JavaScript-Umgebungen Zugriff auf Threads, und im Gegensatz zu Ruby und Python haben wir keine GIL, die sie für die Ausführung von CPU-intensiven Aufgaben praktisch nutzlos macht. Stattdessen werden andere Kompromisse eingegangen, z. B. dass JavaScript-Objekte nicht über Threads hinweg geteilt werden (zumindest nicht direkt). Dennoch sind Threads für JavaScript-Entwickler/innen nützlich, um CPU-intensive Aufgaben abzugrenzen. Im Browser gibt es auch spezielle Threads, die über andere Funktionen verfügen als der Hauptthread. Die Details, wie wir das machen können, sind Thema späterer Kapitel, aber um dir eine Vorstellung zu geben, kann das Erzeugen eines neuen Threads und die Bearbeitung einer Nachricht in einem Browser so einfach sein wie in Beispiel 1-2.
Beispiel 1-2. Einen Browser-Thread starten
constworker=newWorker('worker.js');worker.postMessage('Hello, world');// worker.jsself.onmessage=(msg)=>console.log(msg.data);
Das Ziel dieses Buches ist es, JavaScript-Threads als Programmierkonzept und -werkzeug zu erkunden und zu erklären. Du lernst, wie du sie nutzen kannst und vor allem, wann du sie nutzen solltest. Nicht jedes Problem muss mit Threads gelöst werden. Nicht einmal jedes CPU-intensive Problem muss mit Threads gelöst werden. Es ist die Aufgabe von Softwareentwicklern, Probleme und Tools zu bewerten, um die am besten geeigneten Lösungen zu finden. Hier geht es darum, dir ein weiteres Werkzeug an die Hand zu geben und dir genug Wissen zu vermitteln, um zu wissen, wann und wie du es einsetzen solltest.
Was sind Fäden?
In allen modernen Betriebssystemen sind alle Ausführungseinheiten außerhalb des Kernels in Prozessen und Threads organisiert. Entwickler können Prozesse und Threads und die Kommunikation zwischen ihnen nutzen, um einem Projekt mehr Gleichzeitigkeit zu verleihen. Auf Systemen mit mehreren CPU-Kernen bedeutet dies auch, dass sie Parallelität hinzufügen.
Wenn du ein Programm ausführst, z. B. Node.js oder einen Code-Editor, startest du einen Prozess. Das bedeutet, dass der Code von in einen Speicherbereich geladen wird, der nur für diesen Prozess bestimmt ist, und dass das Programm keinen anderen Speicherbereich ansprechen kann, ohne den Kernel entweder um mehr Speicher oder um einen anderen Speicherbereich zu bitten. Ohne das Hinzufügen von Threads oder zusätzlichen Prozessen wird jeweils nur eine Anweisung in der vom Programmcode vorgeschriebenen Reihenfolge ausgeführt. Wenn du damit nicht vertraut bist, kannst du dir die Anweisungen als eine einzelne Codeeinheit vorstellen, wie eine Codezeile. (Tatsächlich entspricht eine Anweisung in der Regel einer Zeile im Assemblercode deines Prozessors!)
Ein Programm kann zusätzliche Prozesse erzeugen, die ihren eigenen Speicherplatz haben. Diese Prozesse teilen sich den Speicher nicht (es sei denn, er wird über zusätzliche Systemaufrufe zugewiesen) und haben ihre eigenen Befehlszeiger, d. h. jeder Prozess kann zur gleichen Zeit einen anderen Befehl ausführen. Wenn die Prozesse auf demselben Kern ausgeführt werden, kann der Prozessor zwischen den Prozessen hin- und herschalten und die Ausführung des einen Prozesses vorübergehend unterbrechen, während ein anderer ausgeführt wird.
Ein Prozess kann auch Threads erzeugen, die keine vollwertigen Prozesse sind. Ein Thread ist genau wie ein Prozess, nur dass er sich den Speicherplatz mit dem Prozess teilt, zu dem er gehört. Ein Prozess kann viele Threads haben, und jeder Thread hat seinen eigenen Befehlszeiger. Alle Eigenschaften, die für die Ausführung von Prozessen gelten, treffen auch auf Threads zu. Da sie sich einen Speicherplatz teilen, ist es einfach, Programmcode und andere Werte zwischen Threads auszutauschen. Das macht sie wertvoller als Prozesse, wenn es darum geht, die Gleichzeitigkeit von Programmen zu erhöhen, allerdings um den Preis einer gewissen Komplexität bei der Programmierung, die wir später in diesem Buch behandeln werden.
Eine typische Art, die Vorteile von Threads zu nutzen, besteht darin, rechenintensive Arbeiten wie mathematische Operationen auf einen zusätzlichen Thread oder einen Pool von Threads auszulagern, während der Hauptthread frei ist, um extern mit dem Benutzer oder anderen Programmen zu interagieren, indem er in einer Endlosschleife auf neue Interaktionen prüft. Viele klassische Webserver-Programme wie der Apache verwenden ein solches System, um große Mengen an HTTP-Anfragen zu verarbeiten. Das könnte in etwa so aussehen wie in Abbildung 1-1. In diesem Modell werden die HTTP-Anfragedaten zur Verarbeitung an einen Worker-Thread weitergeleitet. Wenn die Antwort fertig ist, wird sie an den Haupt-Thread zurückgegeben, der sie an den User-Agent zurückschickt.
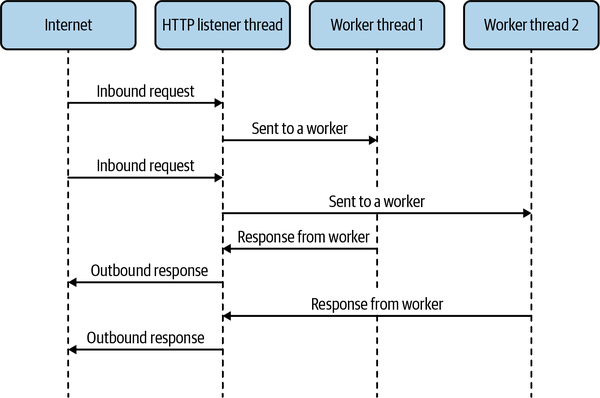
Abbildung 1-1. Worker-Threads, wie sie in einem HTTP-Server verwendet werden können
Damit Threads nützlich sind, müssen sie sich untereinander koordinieren können. Das bedeutet, dass sie in der Lage sein müssen, Dinge zu tun, wie auf andere Threads zu warten und Daten von ihnen zu erhalten. Wie bereits erwähnt, haben wir einen gemeinsamen Speicherbereich für Threads, und mit einigen anderen grundlegenden Primitiven können Systeme zur Weitergabe von Nachrichten zwischen Threads erstellt werden. In vielen Fällen sind solche Konstrukte auf der Sprach- oder Plattformebene verfügbar.
Gleichzeitigkeit vs. Parallelität
Es ist wichtig, zwischen Gleichzeitigkeit und Parallelität zu unterscheiden, da diese beiden Begriffe bei der Multithreading-Programmierung ziemlich häufig vorkommen. Es handelt sich um eng verwandte Begriffe, die je nach Situation sehr ähnliche Dinge bedeuten können. Beginnen wir mit einigen Definitionen.
- Gleichzeitigkeit
-
Die Aufgaben werden zeitlich überlappend ausgeführt.
- Parallelität
-
Die Aufgaben werden genau zur gleichen Zeit ausgeführt.
Auch wenn es den Anschein hat, dass dies dasselbe bedeutet, solltest du bedenken, dass Aufgaben in kleinere Teile aufgeteilt und dann verschachtelt werden können. In diesem Fall kann Gleichzeitigkeit ohne Parallelität erreicht werden, weil sich die Zeiträume, in denen die Aufgaben laufen, überschneiden können. Damit Aufgaben parallel ausgeführt werden können, müssen sie genau zur gleichen Zeit laufen. Im Allgemeinen bedeutet das, dass sie auf verschiedenen CPU-Kernen genau zur gleichen Zeit laufen müssen.
Betrachte Abbildung 1-2. Darin haben wir zwei Aufgaben, die parallel und gleichzeitig laufen. Im Fall der Gleichzeitigkeit wird nur eine Aufgabe zu einem bestimmten Zeitpunkt ausgeführt, aber während des gesamten Zeitraums wechselte die Ausführung zwischen den beiden Aufgaben. Das bedeutet, dass sich die beiden Aufgaben zeitlich überschneiden und somit der Definition von Gleichzeitigkeit entsprechen. Im parallelen Fall werden beide Aufgaben gleichzeitig ausgeführt, sie laufen also parallel zueinander. Da sie sich auch zeitlich überschneiden, laufen sie auch gleichzeitig ab. Parallelität ist eine Teilmenge der Gleichzeitigkeit.
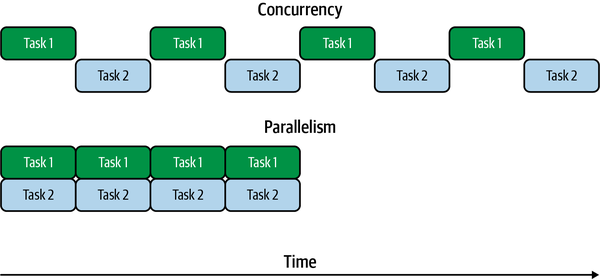
Abbildung 1-2. Gleichzeitigkeit versus Parallelität
Threads sorgen nicht automatisch für Parallelität. Die Systemhardware muss dies ermöglichen, indem sie über mehrere CPU-Kerne verfügt, und das Zeitplannungsprogramm des Betriebssystems muss entscheiden, ob die Threads auf separaten CPU-Kernen laufen sollen. Auf Systemen mit nur einem Kern oder Systemen, auf denen mehr Threads als CPU-Kerne laufen, können mehrere Threads gleichzeitig auf einer einzigen CPU ausgeführt werden, indem zu geeigneten Zeiten zwischen ihnen umgeschaltet wird. In Sprachen mit einer GIL wie Ruby und Python werden Threads außerdem explizit daran gehindert, Parallelität zu bieten, da während der gesamten Laufzeit immer nur eine Anweisung gleichzeitig ausgeführt werden kann.
Es ist wichtig, auch über das Timing nachzudenken, denn Threads werden normalerweise zu einem Programm hinzugefügt, um die Leistung zu steigern. Wenn dein System nur Gleichzeitigkeit zulässt, weil nur ein einziger CPU-Kern zur Verfügung steht oder es bereits mit anderen Aufgaben ausgelastet ist, kann es sein, dass die Verwendung zusätzlicher Threads keine Vorteile bringt. Der Overhead durch die Synchronisierung und den Kontextwechsel zwischen den Threads kann sogar dazu führen, dass das Programm noch schlechter läuft. Miss immer die Leistung deiner Anwendung unter den Bedingungen, unter denen sie laufen soll. Auf diese Weise kannst du überprüfen, ob ein Multithreading-Programmiermodell für dich tatsächlich von Vorteil ist .
Single-Threaded JavaScript
Historisch gesehen boten die Plattformen, auf denen JavaScript lief, keine Thread-Unterstützung, sodass die Sprache als Single-Thread-Sprache angesehen wurde. Wenn du jemanden sagen hörst, dass JavaScript single-threaded ist, bezieht er sich auf diesen historischen Hintergrund und den Programmierstil, den er von Natur aus mit sich bringt. Es stimmt, dass die Sprache trotz des Titels dieses Buches keine eingebaute Funktion zur Erstellung von Threads hat. Das ist nicht weiter verwunderlich, denn die Sprache hat auch keine eingebauten Funktionen für die Interaktion mit dem Netzwerk, den Geräten oder dem Dateisystem oder für Systemaufrufe. Sogar so grundlegende Funktionen wie setTimeout() sind nicht in JavaScript enthalten. Stattdessen bieten die Umgebungen, in die die virtuelle Maschine (VM) eingebettet ist, wie Node.js oder Browser, diese Funktionen über umgebungsspezifische APIs an.
Anstelle von Threads als Gleichzeitigkeitsprimitiv wird der meiste JavaScript-Code ereignisorientiert geschrieben und in einem einzigen Ausführungs-Thread ausgeführt. Wenn verschiedene Ereignisse wie Benutzerinteraktionen oder E/A eintreten, lösen sie die Ausführung von Funktionen aus, die zuvor für die Ausführung dieser Ereignisse festgelegt wurden. Diese Funktionen werden in der Regel Callbacks genannt und sind das Herzstück der asynchronen Programmierung in Node.js und im Browser. Sogar in Promises oder der async/await Syntax sind Callbacks das zugrunde liegende Primitiv. Es ist wichtig zu wissen, dass Callbacks nicht parallel oder neben anderem Code ausgeführt werden. Wenn der Code in einem Callback läuft, ist das der einzige Code, der gerade läuft. Mit anderen Worten: Es ist immer nur ein Callback-Stack aktiv.
Oft denkt man, dass Operationen parallel ablaufen, aber in Wirklichkeit laufen sie gleichzeitig ab. Stell dir zum Beispiel vor, du willst drei Dateien mit Zahlen öffnen, die 1.txt, 2.txt und 3.txt heißen, und dann die Ergebnisse addieren und ausdrucken. In Node.js könntest du etwas wie in Beispiel 1-3 machen.
Beispiel 1-3. Gleichzeitiges Lesen aus Dateien in Node.js
importfsfrom'fs/promises';asyncfunctiongetNum(filename){returnparseInt(awaitfs.readFile(filename,'utf8'),10);}try{constnumberPromises=[1,2,3].map(i=>getNum(`${i}.txt`));constnumbers=awaitPromise.all(numberPromises);console.log(numbers[0]+numbers[1]+numbers[2]);}catch(err){console.error('Something went wrong:');console.error(err);}
Um diesen Code auszuführen, speichere ihn in einer Datei namens reader.js. Stelle sicher, dass du Textdateien mit den Namen 1.txt, 2.txt und 3.txt hast, die jeweils ganze Zahlen enthalten, und führe das Programm dann mit node reader.js aus.
Da wir Promise.all() verwenden, warten wir darauf, dass alle drei Dateien gelesen und geparst werden. Wenn du die Augen zusammenkneifst, sieht das vielleicht sogar ähnlich aus wie die pthread_join() aus dem C-Beispiel weiter unten in diesem Kapitel. Aber nur weil die Versprechen zusammen erstellt werden und zusammen auf sie gewartet wird, bedeutet das nicht, dass der Code, der sie auflöst, zur gleichen Zeit läuft, sondern nur, dass sich ihre Zeitrahmen überschneiden. Es gibt immer noch nur einen Anweisungszeiger und es wird immer nur eine Anweisung auf einmal ausgeführt.
Da es keine Threads gibt, gibt es nur eine JavaScript Umgebung, mit der du arbeiten kannst. Das bedeutet eine Instanz der VM, einen Anweisungszeiger und eine Instanz des Garbage Collectors. Mit einem Anweisungszeiger meinen wir, dass der JavaScript-Interpreter zu jedem Zeitpunkt nur eine Anweisung ausführt. Das bedeutet aber nicht, dass wir auf ein globales Objekt beschränkt sind. Sowohl im Browser als auch in Node.js stehen uns Realms zur Verfügung.
Realms kann man sich als Instanzen der JavaScript-Umgebung vorstellen, die dem JavaScript-Code zur Verfügung gestellt werden. Das bedeutet, dass jeder Realm sein eigenes globales Objekt und alle zugehörigen Eigenschaften des globalen Objekts erhält, wie z.B. eingebaute Klassen wie Date und andere Objekte wie Math. Das globale Objekt wird in Node.js und windowin Browsern als global bezeichnet, aber in modernen Versionen beider Programme kann man das globale Objekt auch alsglobalThis.
In Browsern hat jeder Frame in einer Webseite einen Realm für das gesamte JavaScript darin. Da jeder Frame seine eigene Kopie von Object und anderen Primitiven hat, werden Sie feststellen, dass sie ihre eigenen Vererbungsbäume haben und instanceof möglicherweise nicht so funktioniert, wie Sie es erwarten, wenn Sie mit Objekten aus verschiedenen Realms arbeiten. Dies wird in Beispiel 1-4 gezeigt.
Beispiel 1-4. Objekte aus einem anderen Frame in einem Browser
constiframe=document.createElement('iframe');document.body.appendChild(iframe);constFrameObject=iframe.contentWindow.Object;console.log(Object===FrameObject);console.log(newObject()instanceofFrameObject);console.log(FrameObject.name);
Das globale Objekt innerhalb der
iframeist über die EigenschaftcontentWindowzugänglich.
Das Ergebnis ist false, d.h. die
Objectinnerhalb des Rahmens ist nicht dieselbe wie im Hauptrahmen.
instanceofergibtfalse, wie erwartet, da es sich nicht um dieselbeObjecthandelt.
Trotz alledem haben die Konstruktoren die gleiche
nameEigenschaft.
In Node.js können Realms mit der Funktion vm.createContext() erstellt werden, wie in Beispiel 1-5 gezeigt. In der Node.js-Sprache werden die Realms Contexts genannt. Alle Regeln und Eigenschaften, die für Browser-Frames gelten, gelten auch für Contexts, aber in Contexts hast du keinen Zugriff auf globale Eigenschaften oder andere Dinge, die in deinen Node.js-Dateien im Geltungsbereich liegen könnten. Wenn du diese Funktionen nutzen willst, musst du sie manuell an den Context übergeben.
Beispiel 1-5. Objekte aus einem neuen Context in Node.js
constvm=require('vm');constContextObject=vm.runInNewContext('Object');console.log(Object===ContextObject);console.log(newObject()instanceofContextObject);console.log(ContextObject.name);
Mit
runInNewContextkönnen wir Objekte aus einem neuen Kontext holen.Dies gibt false zurück. Wie bei iframes im Browser ist
Objectinnerhalb des Kontexts nicht dasselbe wie im Hauptkontext.Ähnlich verhält es sich mit
instanceof, dasfalseauswertet.Auch hier haben die Konstruktoren die gleiche
nameEigenschaft.
In jedem dieser Realm-Fälle ist es wichtig zu beachten, dass wir immer noch nur einen Befehlszeiger haben und der Code von nur einem Realm gleichzeitig ausgeführt wird, da wir immer noch von einer Single-Thread-Ausführung sprechen .
Threads in C: Reich werden mit Happycoin
Threads gibt es natürlich nicht nur in JavaScript. Sie sind ein seit langem bestehendes Konzept auf der Ebene des Betriebssystems, unabhängig von Sprachen. Sehen wir uns an, wie ein Programm mit Threads in C aussehen könnte. C bietet sich hier an, weil die C-Schnittstelle für Threads den meisten Thread-Implementierungen in höheren Sprachen zugrunde liegt, auch wenn es scheinbar unterschiedliche Semantiken gibt.
Beginnen wir mit einem Beispiel. Stell dir einen Proof-of-Work-Algorithmus für eine einfache und unpraktische Kryptowährung namens Happycoin vor, der wie folgt aussieht:
-
Erzeuge eine zufällige 64-Bit-Ganzzahl ohne Vorzeichen.
-
Stelle fest, ob die ganze Zahl glücklich ist oder nicht.
-
Wenn sie nicht glücklich ist, ist sie keine Happycoin.
-
Wenn sie nicht durch 10.000 teilbar ist, ist sie keine Happycoin.
-
Ansonsten ist es eine Happycoin.
Eine Zahl ist glücklich, wenn sie schließlich 1 wird, wenn man sie durch die Summe der Quadrate ihrer Ziffern ersetzt und so lange wiederholt, bis entweder die 1 eintritt oder eine zuvor gesehene Zahl entsteht. Wikipedia definiert dies klar und weist auch darauf hin, dass, wenn eine zuvor gesehene Zahl auftritt, auch die 4 auftritt und umgekehrt. Vielleicht merkst du, dass unser Algorithmus unnötig teuer ist, denn wir könnten erst auf Teilbarkeit und dann auf Glück prüfen. Das ist gewollt, denn wir versuchen, eine hohe Arbeitsbelastung zu demonstrieren.
Erstellen wir ein einfaches C-Programm, das den Proof-of-Work-Algorithmus 10.000.000 Mal durchläuft und alle gefundenen Happycoins sowie deren Anzahl ausgibt.
Hinweis
Das cc in den Kompilierungsschritten hier kann durch gcc oder clang ersetzt werden, je nachdem, was dir zur Verfügung steht. Auf den meisten Systemen ist cc ein Alias für gcc oder clang, also werden wir das hier verwenden.
Windows-Benutzer müssen hier möglicherweise etwas mehr Arbeit leisten, um dies in Visual Studio zum Laufen zu bringen, und das Thread-Beispiel wird unter Windows nicht sofort funktionieren, da es POSIX-Threads (Portable Operating System Interface) und nicht Windows-Threads verwendet, die anders sind. Um das Ausprobieren unter Windows zu vereinfachen, empfiehlt es sich, das Windows Subsystem für Linux zu verwenden, damit du eine POSIX-kompatible Umgebung hast, mit der du arbeiten kannst.
Nur mit dem Hauptfaden
Erstelle eine Datei namens happycoin.c in einem Verzeichnis namens ch1-c-threads/. Wir werden diese Datei im Laufe dieses Abschnitts aufbauen. Füge zu Beginn den Code aus Beispiel 1-7 ein.
Beispiel 1-7. ch1-c-threads/happycoin.c
#include <inttypes.h>#include <stdbool.h>#include <stdio.h>#include <stdlib.h>#include <time.h>uint64_trandom64(uint32_t*seed){uint64_tresult;uint8_t*result8=(uint8_t*)&result;for(size_ti=0;i<sizeof(result);i++){result8[i]=rand_r(seed);}returnresult;}
In dieser Zeile werden Zeiger verwendet, was für dich vielleicht ungewohnt ist, wenn du hauptsächlich aus JavaScript kommst. Die Kurzfassung ist, dass
result8ein Array aus acht vorzeichenlosen 8-Bit-Ganzzahlen ist, das auf demselben Speicher wieresultbasiert, der eine einzelne vorzeichenlose 64-Bit-Ganzzahl ist.
Wir haben eine Reihe von includes hinzugefügt, die uns praktische Dinge wie Typen, E/A-Funktionen und die Zeit- und Zufallszahlenfunktionen zur Verfügung stellen, die wir brauchen werden. Da derAlgorithmusdie Erzeugung einer zufälligen 64-Bit-Ganzzahl ohne Vorzeichenerfordert (d.h. eine uint64_t), benötigen wir acht Zufallsbytes, die uns random64() durch den Aufruf von rand_r() liefert, bis wir genügend Bytes haben. Da rand_r() auch einen Verweis auf einen Seed benötigt, übergeben wir diesen auch an random64().
Fügen wir nun unsere Berechnung der Glückszahl hinzu, wie in Beispiel 1-8 gezeigt.
Beispiel 1-8. ch1-c-threads/happycoin.c
uint64_tsum_digits_squared(uint64_tnum){uint64_ttotal=0;while(num>0){uint64_tnum_mod_base=num%10;total+=num_mod_base*num_mod_base;num=num/10;}returntotal;}boolis_happy(uint64_tnum){while(num!=1&&num!=4){num=sum_digits_squared(num);}returnnum==1;}boolis_happycoin(uint64_tnum){returnis_happy(num)&&num%10000==0;}
Um die Summe der Quadrate der Ziffern in sum_digits_squared zu erhalten, verwenden wir den Mod-Operator %, um jede Ziffer von rechts nach links zu ermitteln, sie zu quadrieren und sie dann zu unserer laufenden Summe zu addieren. Dann verwenden wir diese Funktion in is_happy in einer Schleife und halten an, wenn die Zahl 1 oder 4 ist. Wir halten bei 1 an, weil das bedeutet, dass die Zahl glücklich ist. Wir halten auch bei 4 an, weil das ein Zeichen für eine Endlosschleife ist, bei der wir nie bei 1 landen. In is_happycoin() überprüfen wir schließlich, ob eine Zahl glücklich und durch 10.000 teilbar ist.
Lass uns das alles in unserer main() Funktion zusammenfassen, wie in Beispiel 1-9 gezeigt.
Beispiel 1-9. ch1-c-threads/happycoin.c
intmain(){uint32_tseed=time(NULL);intcount=0;for(inti=1;i<10000000;i++){uint64_trandom_num=random64(&seed);if(is_happycoin(random_num)){printf("%"PRIu64" ",random_num);count++;}}printf("\ncount %d\n",count);return0;}
Zuerst brauchen wir einen Seed für den Zufallszahlengenerator. Die aktuelle Uhrzeit eignet sich am besten als Startwert, also verwenden wir sie über time(). Dann ziehen wir in einer Schleife 10.000.000 Mal eine Zufallszahl von random64() ab und prüfen, ob es sich um eine Happycoin handelt. Wenn ja, erhöhen wir den Zähler und geben die Zahl aus. Die seltsame PRIu64 Syntax im printf() Aufruf ist notwendig, um 64-Bit-Ganzzahlen ohne Vorzeichen korrekt auszudrucken. Wenn die Schleife beendet ist, geben wir den Zählerstand aus und beenden das Programm.
Um dieses Programm zu kompilieren und auszuführen, verwende die folgenden Befehle in deinem ch1-c-threads Verzeichnis.
$ cc -o happycoin happycoin.c $ ./happycoin
Du erhältst eine Liste der gefundenen Happycoins in einer Zeile und die Anzahl der Münzen in der nächsten Zeile. Bei einem bestimmten Programmdurchlauf könnte das etwa so aussehen:
11023541197304510000 ... [ 167 more entries ] ... 770541398378840000 count 169
Die Ausführung dieses Programms nimmt eine nicht unerhebliche Zeit in Anspruch, etwa 2 Sekunden auf einem gewöhnlichen Computer. Dies ist ein Fall, in dem Threads nützlich sein können, um die Dinge zu beschleunigen, weil viele Iterationen der gleichen, weitgehend mathematischen Operation ausgeführt werden.
Machen wir weiter und wandeln wir dieses Beispiel in ein Multithreading-Programm um.
Mit vier Worker Threads
Wir werden vier Threads einrichten, die jeweils ein Viertel der Iterationen der Schleife ausführen, die eine Zufallszahl generiert und prüft, ob sie eine Happycoin ist.
In POSIX C werden Threads mit der pthread_* Familie von Funktionen verwaltet. Die Funktion pthread_create() wird verwendet, um einen Thread zu erstellen. Es wird eine Funktion übergeben, die in diesem Thread ausgeführt wird. Der Programmablauf wird auf dem Hauptthread fortgesetzt. Das Programm kann auf die Beendigung eines Threads warten, indem es pthread_join() aufruft. Du kannst der Funktion, die auf dem Thread ausgeführt wird, über pthread_create() Argumente übergeben und von pthread_join() Rückgabewerte erhalten.
In unserem Programm werden wir die Erzeugung von Happycoins in einer Funktion namens get_happycoins() isolieren, die in unseren Threads laufen wird. Wir erstellen die vier Threads und warten dann sofort auf ihre Fertigstellung. Wenn wir die Ergebnisse von einem Thread zurückbekommen, geben wir sie aus und speichern die Anzahl, damit wir am Ende die Gesamtsumme ausgeben können. Damit wir die Ergebnisse zurückgeben können, erstellen wir ein einfaches struct mit dem Namen happy_result.
Erstelle eine Kopie deiner bestehenden happycoin.c und nenne sie happycoin-threads.c. Füge dann in der neuen Datei den Code aus Beispiel 1-10 unter der letzten #include in die Datei ein.
Beispiel 1-10. ch1-c-threads/happycoin-threads.c
#include <pthread.h>structhappy_result{size_tcount;uint64_t*nums;};
Die erste Zeile enthält pthread.h, die uns Zugriff auf die verschiedenen Thread-Funktionen gibt, die wir benötigen. Dann wird struct happy_result definiert, das wir später als Rückgabewert für unsere Thread-Funktion get_happycoins() verwenden werden. Sie speichert ein Array der gefundenen Happycoins, das hier durch einen Zeiger repräsentiert wird, und die Anzahl dieser Münzen.
Jetzt kannst du die gesamte Funktion main() löschen, denn wir werden sie jetzt ersetzen. Zuerst fügen wir die Funktion get_happycoins() in Beispiel 1-11 hinzu, die der Code ist, der in unseren Worker-Threads laufen wird.
Beispiel 1-11. ch1-c-threads/happycoin-threads.c
void*get_happycoins(void*arg){intattempts=*(int*)arg;intlimit=attempts/10000;uint32_tseed=time(NULL);uint64_t*nums=malloc(limit*sizeof(uint64_t));structhappy_result*result=malloc(sizeof(structhappy_result));result->nums=nums;result->count=0;for(inti=1;i<attempts;i++){if(result->count==limit){break;}uint64_trandom_num=random64(&seed);if(is_happycoin(random_num)){result->nums[result->count++]=random_num;}}return(void*)result;}
Dieses seltsame Zeiger-Casting besagt im Grunde: "Behandle diesen beliebigen Zeiger als Zeiger auf ein
intund gib mir dann den Wert diesesint."
Du wirst feststellen, dass diese Funktion eine einzelne void * aufnimmt und eine einzelne void * zurückgibt. Das ist die Funktionssignatur, die von pthread_create() erwartet wird, also haben wir hier keine Wahl. Das bedeutet, dass wir unsere Argumente so umwandeln müssen, wie wir sie haben wollen. Da wir die Anzahl der Versuche übergeben, wandeln wir das Argument in ein int um. Dann setzen wir den Seed wie im vorherigen Beispiel, aber dieses Mal geschieht das in unserer Thread-Funktion, sodass wir für jeden Thread einen anderen Seed erhalten.
Nachdem wir genügend Platz für unser Array und struct happy_result reserviert haben, beginnen wir mit der gleichen Schleife wie in main() im Single-Thread-Beispiel, nur dass wir dieses Mal die Ergebnisse in struct speichern, anstatt sie zu drucken. Wenn die Schleife beendet ist, geben wir struct als Zeiger zurück, den wir in void * umwandeln, um die Funktionssignatur zu erfüllen. Auf diese Weise werden die Informationen an den Hauptthread zurückgegeben, der sie dann auswertet.
Dies verdeutlicht eine der wichtigsten Eigenschaften von Threads, die wir bei Prozessen nicht haben, nämlich den gemeinsamen Speicherbereich. Wenn wir zum Beispiel Prozesse statt Threads und einen Interprozess-Kommunikationsmechanismus (IPC) für die Rückübertragung von Ergebnissen verwenden würden, könnten wir nicht einfach eine Speicheradresse an den Hauptprozess zurückgeben, weil der Hauptprozess keinen Zugriff auf den Speicher des Worker-Prozesses hätte. Dank virtuellem Speicher könnte die Speicheradresse auf etwas ganz anderes im Hauptprozess verweisen. Anstatt einen Zeiger zu übergeben, müssten wir den gesamten Wert über den IPC-Kanal zurückgeben, was zu Leistungseinbußen führen kann. Da wir Threads anstelle von Prozessen verwenden, können wir nur den Zeiger benutzen, so dass der Hauptthread ihn genauso benutzen kann.
Shared Memory ist jedoch nicht ohne seine Kompromisse. In unserem Fall muss der Worker-Thread den Speicher, den er jetzt an den Haupt-Thread weitergegeben hat, nicht nutzen. Das ist bei Threads nicht immer der Fall. In vielen Fällen ist es notwendig, den Zugriff von Threads auf den gemeinsamen Speicher über die Synchronisation richtig zu steuern, da sonst unvorhersehbare Ergebnisse auftreten können. Wie das in JavaScript funktioniert, werden wir in den Kapiteln 4 und 5 genauer erklären.
Lass uns das mit der Funktion main() in Beispiel 1-12 abschließen.
Beispiel 1-12. ch1-c-threads/happycoin-threads.c
#define THREAD_COUNT 4intmain(){pthread_tthread[THREAD_COUNT];intattempts=10000000/THREAD_COUNT;intcount=0;for(inti=0;i<THREAD_COUNT;i++){pthread_create(&thread[i],NULL,get_happycoins,&attempts);}for(intj=0;j<THREAD_COUNT;j++){structhappy_result*result;pthread_join(thread[j],(void**)&result);count+=result->count;for(intk=0;k<result->count;k++){printf("%"PRIu64" ",result->nums[k]);}}printf("\ncount %d\n",count);return0;}
Zuerst deklarieren wir unsere vier Threads als Array auf dem Stack. Dann teilen wir die gewünschte Anzahl der Versuche (10.000.000) durch die Anzahl der Threads. Dieses Ergebnis wird als Argument an get_happycoins() übergeben, das wir in der ersten Schleife sehen, die jeden der Threads mit pthread_create() erstellt und dabei die Anzahl der Versuche pro Thread als Argument angibt. In der nächsten Schleife warten wir mit pthread_join() darauf, dass jeder der Threads seine Ausführung beendet. Dann können wir die Ergebnisse und die Gesamtzahl aller Threads ausdrucken, genau wie im Beispiel mit einem Thread.
Hinweis
In diesem Programm geht Speicher verloren. Eine Schwierigkeit bei der Multithreading-Programmierung in C und einigen anderen Sprachen ist, dass man leicht den Überblick darüber verlieren kann, wo und wann Speicher zugewiesen wird und wo und wann er wieder freigegeben werden sollte. Versuche, den Code hier zu ändern, um sicherzustellen, dass das Programm beendet wird, wenn der gesamte vom Heap zugewiesene Speicher wieder freigegeben wurde.
Wenn die Änderungen abgeschlossen sind, kannst du das Programm mit den folgenden Befehlen in deinem ch1-c-threads Verzeichnis kompilieren und ausführen.
$ cc -pthread -o happycoin-threads happycoin-threads.c $ ./happycoin-threads
Die Ausgabe sollte in etwa so aussehen:
2466431682927540000 ... [ 154 more entries ] ... 15764177621931310000 count 156
Du wirst feststellen, dass die Ausgabe ähnlich wie beim Beispiel mit einem Thread ist.1 Du wirst auch feststellen, dass es ein bisschen schneller ist. Auf einem normalen Computer ist es in etwa 0,8 Sekunden fertig. Das ist nicht ganz viermal so schnell, denn es gibt einen gewissen anfänglichen Overhead im Haupt-Thread und auch die Kosten für das Drucken der Ergebnisse. Wir könnten die Ergebnisse ausdrucken, sobald sie in dem Thread, der die Arbeit erledigt, fertig sind, aber dann könnten sich die Ergebnisse in der Ausgabe gegenseitig überlagern, denn nichts hält zwei Threads davon ab, gleichzeitig in den Ausgabestrom zu drucken. Indem wir die Ergebnisse an den Hauptthread senden, können wir den Druck der Ergebnisse dort koordinieren, damit nichts durcheinanderkommt.
Dies verdeutlicht den Hauptvorteil und einen Nachteil von threaded Code. Einerseits ist es nützlich, rechenintensive Aufgaben aufzuteilen, damit sie parallel ausgeführt werden können. Andererseits müssen wir sicherstellen, dass einige Ereignisse richtig synchronisiert werden, damit keine seltsamen Fehler auftreten. Wenn du deinem Code in einer beliebigen Sprache Threads hinzufügst, solltest du dich vergewissern, dass die Verwendung angemessen ist. Wie bei allen Versuchen, schnellere Programme zu erstellen, solltest du auch hier immer messen. Du willst nicht die Komplexität von Threads in deiner Anwendung haben, wenn sie dir keinen wirklichen Nutzen bringt.
Jede Programmiersprache, die Threads unterstützt, bietet einige Mechanismen, um Threads zu erstellen und zu zerstören, Nachrichten zwischen den Threads weiterzuleiten und mit Daten zu interagieren, die von den Threads gemeinsam genutzt werden. Das sieht nicht in jeder Sprache gleich aus, denn so wie die Paradigmen der Sprachen und unterschiedlich sind, sind es auch die programmatischen Modelle der parallelen Programmierung. Nachdem wir uns nun angeschaut haben, wie Thread-Programme in einer Low-Level-Sprache wie C aussehen, wenden wir uns nun JavaScript zu. Die Dinge werden ein wenig anders aussehen, aber wie du sehen wirst, bleiben die Prinzipien dieselben.
1 Die Tatsache, dass sich die Gesamtzahl des Multithreading-Beispiels von der des Single-Thread-Beispiels unterscheidet, ist irrelevant, weil die Zahl davon abhängt, wie viele Zufallszahlen zufällig Happycoins sind. Das Ergebnis wird zwischen zwei verschiedenen Durchläufen völlig unterschiedlich sein.
Get Multithreading-Javascript now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

