Chapter 1. Just Enough Microservices
Well, that escalated quickly, really got out of hand fast!
Ron Burgundy, Anchorman
Before we dive into how to work with microservices, it is important that we have a common, shared understanding about what microservice architectures are. I’d like to address some common misconceptions I see on a regular basis, as well as nuances that are often missed. You’ll need this firm foundation of knowledge to get the most out of what follows in the rest of the book. As such, this chapter will provide an explanation of microservice architectures, look briefly at how microservices developed (which means, naturally, taking a look at monoliths), and examine some of the advantages and challenges of working with microservices.
What Are Microservices?
Microservices are independently deployable services modeled around a business domain. They communicate with each other via networks, and as an architecture choice offer many options for solving the problems you may face. It follows that a microservice architecture is based on multiple collaborating microservices.
They are a type of service-oriented architecture (SOA), albeit one that is opinionated about how service boundaries should be drawn, and that independent deployability is key. Microservices also have the advantage of being technology agnostic.
From a technology viewpoint, microservices expose the business capabilities that they encapsulate via one or more network endpoints. Microservices communicate with each other via these networks—making them a form of distributed system. They also encapsulate data storage and retrieval, exposing data, via well-defined interfaces. So databases are hidden inside the service boundary.
There is a lot to unpack in all of that, so let’s dig a bit deeper into some of these ideas.
Independent Deployability
Independent deployability is the idea that we can make a change to a microservice and deploy it into a production environment without having to utilize any other services. More importantly, it’s not just that we can do this; it’s that this is actually how you manage deployments in your system. It’s a discipline you practice for the bulk of your releases. This is a simple idea that is nonetheless complex in execution.
Tip
If there is only one thing you take out of this book, it should be this: ensure you embrace the concept of independent deployability of your microservices. Get into the habit of releasing changes to a single microservice into production without having to deploy anything else. From this, many good things will follow.
To guarantee independent deployability, we need to ensure our services are loosely coupled—in other words, we need to be able to change one service without having to change anything else. This means we need explicit, well-defined, and stable contracts between services. Some implementation choices make this difficult—the sharing of databases, for example, is especially problematic. The desire for loosely coupled services with stable interfaces guides our thinking about how we find service boundaries in the first place.
Modeled Around a Business Domain
Making a change across a process boundary is expensive. If you need to make a change to two services to roll out a feature, and orchestrate the deployment of these two changes, that takes more work than making the same change inside a single service (or, for that matter, a monolith). It therefore follows that we want to find ways of ensuring we make cross-service changes as infrequently as possible.
Following the same approach I used in Building Microservices, this book uses a fake domain and company to illustrate certain concepts when it isn’t possible to share real-world stories. The company in question is Music Corp, a large multi-national organization that somehow remains in business, despite it focusing almost entirely on selling CDs.
We’ve decided to move Music Corp kicking and screaming into the 21st century, and as part of that we’re assessing the existing system architecture. In Figure 1-1, we see a simple three-tiered architecture. We have a web-based user interface, a business logic layer in the form of a monolithic backend, and data storage in a traditional database. These layers, as is common, are owned by different teams.

Figure 1-1. Music Corp’s systems as a traditional three-tiered architecture
We want to make a simple change to our functionality: we want to allow our customers to specify their favorite genre of music. This change requires us to change the user interface to show the genre choice UI, the backend service to allow for the genre to be surfaced to the UI and for the value to be changed, and the database to accept this change. These changes will need to be managed by each team, as outlined in Figure 1-2, and those changes will need to be deployed in the correct order.
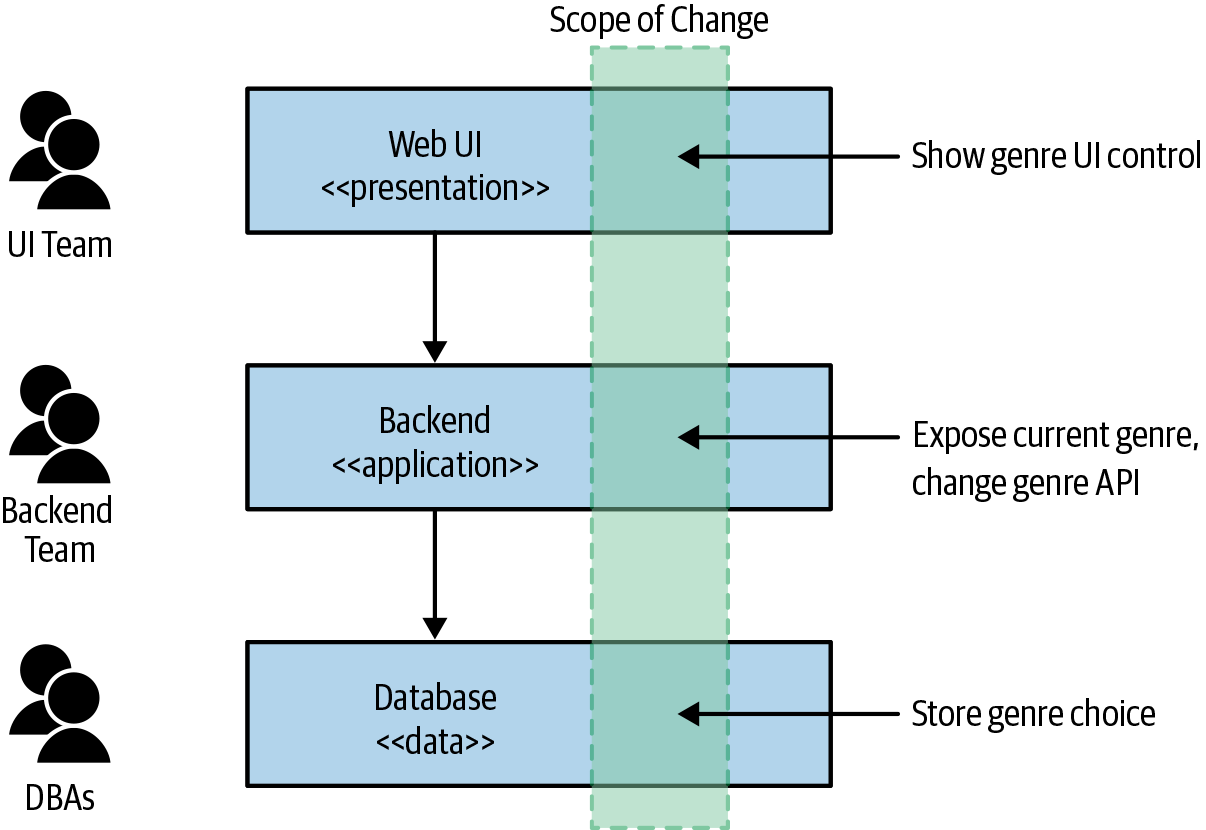
Figure 1-2. Making a change across all three tiers is more involved
Now this architecture isn’t bad. All architecture ends up getting optimized around some set of goals. The three-tiered architecture is so common partly because it is universal—everyone’s heard about it. So picking a common architecture you may have seen elsewhere is often one reason we keep seeing this pattern. But I think the biggest reason we see this architecture again and again is because it is based on how we organize our teams.
The now famous Conway’s law states
Any organization that designs a system…will inevitably produce a design whose structure is a copy of the organization’s communication structure.
Melvin Conway, How Do Committees Invent?
The three-tiered architecture is a good example of this in action. In the past, the primary way IT organizations grouped people was in terms of their core competency: database admins were in a team with other database admins; Java developers were in a team with other Java developers; and frontend developers (who nowadays know exotic things like JavaScript and native mobile application development) were in yet another team. We group people based on their core competency, so we create IT assets that can be aligned to those teams.
So that explains why this architecture is so common. It’s not bad; it’s just optimized around one set of forces—how we traditionally grouped people, around familiarity. But the forces have changed. Our aspirations around our software have changed. We now group people in poly-skilled teams, to reduce hand-offs and silos. We want to ship software much more quickly than ever before. That is driving us to make different choices about how we organize our teams, and therefore in terms of how we break our systems apart.
Changes in functionality are primarily about changes in business functionality. But in Figure 1-1 our business functionality is in effect spread across all three tiers, increasing the chance that a change in functionality will cross layers. This is an architecture in which we have high cohesion of related technology, but low cohesion of business functionality. If we want to make it easier to make changes, instead we need to change how we group code—we choose cohesion of business functionality, rather than technology. Each service may or may not then end up containing a mix of these three layers, but that is a local service implementation concern.
Let’s compare this with a potential alternative architecture illustrated in Figure 1-3. We have a dedicated Customer service, which exposes a UI to allow customers to update their information, and the state of the customer is also stored within this service. The choice of a favorite genre is associated with a given customer, so this change is much more localized. In Figure 1-3 we also show the list of available genres being fetched from a Catalog service, likely something that would already be in place. We also see a new Recommendation service accessing our favorite genre information, something that could easily follow in a subsequent release.

Figure 1-3. A dedicated Customer service may make it much easier to record the favorite musical genre of a customer
In such a situation, our Customer service encapsulates a thin slice of each of the three tiers—it has a bit of UI, a bit of application logic, and a bit of data storage—but these layers are all encapsulated in the single service.
Our business domain becomes the primary force driving our system architecture, hopefully making it easier to make changes, and making it easier for us to organize our teams around our business domain. This is so important that before we finish this chapter, we’ll revisit the concept of modeling software around a domain, so I can share some ideas around domain-driven design that shape how we think about our microservice architecture.
Own Their Own Data
One of the things I see people having the hardest time with is the idea that microservices should not share databases. If one service wants to access data held by another service, then it should go and ask that service for the data it needs. This gives the service the ability to decide what is shared and what is hidden. It also allows the service to map from internal implementation details, which can change for various arbitrary reasons, to a more stable public contract, ensuring stable service interfaces. Having stable interfaces between services is essential if we want independent deployability—if the interface a service exposes keeps changing, this will have a ripple effect causing other services to need to change as well.
Tip
Don’t share databases, unless you really have to. And even then do everything you can to avoid it. In my opinion, it’s one of the worst things you can do if you’re trying to achieve independent deployability.
As we discussed in the previous section, we want to think of our services as end-to-end slices of business functionality, that where appropriate encapsulate the UI, application logic, and data storage. This is because we want to reduce the effort needed to change business-related functionality. The encapsulation of data and behavior in this way gives us high cohesion of business functionality. By hiding the database that backs our service, we also ensure we reduce coupling. We’ll be coming back to coupling and cohesion in a moment.
This can be hard to get your head around, especially when you have an existing monolithic system that has a giant database you have to deal with. Luckily, Chapter 4 is entirely dedicated to moving away from monolithic databases.
What Advantages Can Microservices Bring?
The advantages of microservices are many and varied. The independent nature of the deployments opens up new models for improving the scale and robustness of systems, and allows you to mix and match technology. As services can be worked on in parallel, you can bring more developers to bear on a problem without them getting in each other’s way. It can also be easier for those developers to understand their part of the system, as they can focus their attention on just one part of it. Process isolation also makes it possible for us to vary the technology choices we make, perhaps mixing different programming languages, programming styles, deployment platforms, or databases to find the right mix.
Perhaps, above all, microservice architectures give you flexibility. They open up many more options regarding how you can solve problems in the future.
However, it’s important to note that none of these advantages come for free. There are many ways you can approach system decomposition, and fundamentally what you are trying to achieve will drive this decomposition in different directions. Understanding what you are trying to get from your microservice architecture therefore becomes important.
What Problems Do They Create?
Service-oriented architecture became a thing partly because computers got cheaper, so we had more of them. Rather than deploy systems on single, giant mainframes, it made more sense to make use of multiple cheaper machines. Service-oriented architecture was an attempt to work out how best to build applications that spanned multiple machines. One of the main challenges in all of this is the way in which these computers talk to each other: networks.
Communication between computers over networks is not instantaneous (this apparently has something to do with physics). This means we have to worry about latencies—and specifically, latencies that far outstrip the latencies we see with local, in-process operations. Things get worse when we consider that these latencies will vary, which can make system behavior unpredictable. And we also have to address the fact that networks sometimes fail—packets get lost; network cables are disconnected.
These challenges make activities that are relatively simple with a single-process monolith, like transactions, much more difficult. So difficult, in fact, that as your system grows in complexity, you will likely have to ditch transactions, and the safety they bring, in exchange for other sorts of techniques (which unfortunately have very different trade-offs).
Dealing with the fact that any network call can and will fail becomes a headache, as will the fact that the services you might be talking to could go offline for whatever reason or otherwise start behaving oddly. Adding to all this, you also need to start trying to work out how to get a consistent view of data across multiple machines.
And then, of course, we have a huge wealth of new microservice-friendly technology to take into account—new technology that, if used badly, can help you make mistakes much faster and in more interesting, expensive ways. Honestly, microservices seem like a terrible idea, except for all the good stuff.
It’s worth noting that virtually all of the systems we categorize as “monoliths” are also distributed systems. A single-process application likely reads data from a database that runs on a different machine, and presents data on to a web browser. That’s at least three computers in the mix there, with communication between them over networks. The difference is the extent to which monolithic systems are distributed compared to microservice architectures. As you have more computers in the mix, communicating over more networks, you’re more likely to hit the nasty problems associated with distributed systems. These problems I’ve briefly discussed may not appear initially, but over time, as your system grows, you’ll likely hit most, if not all, of them.
As my old colleague, friend, and fellow microservice-expert James Lewis put it, “Microservices buy you options.” James was being deliberate with his words—they buy you options. They have a cost, and you have to decide if the cost is worth the options you want to take up. We’ll explore this topic in more detail in Chapter 2.
User Interfaces
All too often, I see people focus their work in embracing microservices purely on the server side—leaving the user interface as a single, monolithic layer. If we want an architecture that makes it easier for us to more rapidly deploy new features, then leaving the UI as a monolithic blob can be a big mistake. We can, and should, look at breaking apart our user interfaces too, something we’ll explore in Chapter 3.
Technology
It can be all too tempting to grab a whole load of new technology to go along with your shiny new microservice architecture, but I strongly urge you not to fall into this temptation. Adopting any new technology will have a cost—it will create some upheaval. Hopefully, that will be worth it (if you’ve picked the right technology, of course!), but when first adopting a microservice architecture, you have enough going on.
Working out how to properly evolve and manage a microservice architecture involves tackling a multitude of challenges related to distributed systems—challenges you may not have faced before. I think it’s much more useful to get your head around these issues as you encounter them, making use of a technology stack you are familiar with, and then consider whether changing your existing technology may help address those problems as you find them.
As we’ve already touched on, microservices are fundamentally technology agnostic. As long as your services can communicate with each other via a network, everything else is up for grabs. This can be a huge advantage—allowing you to mix and match technology stacks if you wish.
You don’t have to use Kubernetes, Docker, containers, or the public cloud. You don’t have to code in Go or Rust or whatever else. In fact, your choice of programming language is fairly unimportant when it comes to microservice architectures, over and above how some languages may have a richer ecosystem of supporting libraries and frameworks. If you know PHP best, start building services with PHP!1 There is far too much technical snobbery out there toward some technology stacks that can unfortunately border on contempt for people who work with particular tools.2 Don’t be part of the problem! Choose the approach that works for you, and change things to address problems as and when you see them.
Size
“How big should a microservice be?” is probably the most common question I get. Considering the word “micro” is right there in the name, this comes as no surprise. However, when you get into what makes microservices work as a type of architecture, the concept of size is actually one of the least interesting things.
How do you measure size? Lines of code? That doesn’t make much sense to me. Something that might require 25 lines of code in Java could possibly be written in 10 lines of Clojure. That’s not to say Clojure is better or worse than Java, but rather that some languages are more expressive than others.
The closest I think I get to “size” having any meaning in terms of microservices is something fellow microservices expert Chris Richardson once said—that the goal of microservices is to have “as small an interface as possible.” That chimes with the concept of information hiding (which we’ll discuss in a moment) but does represent an attempt to find meaning after the fact—when we were first talking about these things, our main focus, initially at least, was on these things being really easy to replace.
Ultimately, the concept of “size” is highly contextual. Speak to a person who has worked on a system for 15 years, and they’ll feel that their 100K line code system is really easy to understand. Ask the opinion of someone brand-new to the project, and they’ll feel it’s way too big. Likewise, ask a company that has just embarked on its microservice transition, with perhaps ten of fewer microservices, and you’ll get a different answer than you would from a similar-sized company in which microservices have been the norm for many years, and they now have hundreds.
I urge people not to worry about size. When you are first starting out, it’s much more important that you focus on two key things. First, how many microservices can you handle? As you have more services, the complexity of your system will increase, and you’ll have to learn new skills (and perhaps adopt new technology) to cope with this. It’s for this reason I am a strong advocate for incremental migration to a microservice architecture. Second, how do you define microservice boundaries to get the most out of them, without everything becoming a horribly coupled mess? These are topics we’ll cover throughout the rest of this chapter.
And Ownership
With microservices modeled around a business domain, we see alignment between our IT artifacts (our independently deployable microservices) and our business domain. This idea resonates well when we consider the shift toward technology companies breaking down the divides between “The Business” and “IT.” In traditional IT organizations, the act of developing software is often handled by an entirely separate part of the business from that which actually defines requirements and has a connection with the customer, as Figure 1-4 shows. The dysfunctions of these sorts of organizations are many and varied, and probably don’t need to be expanded upon here.

Figure 1-4. An organizational view of the traditional IT/business divide
Instead, we’re seeing true technology organizations totally combine these previous disparate organizational silos, as we see in Figure 1-5. Product owners now work directly as part delivery teams, with these teams being aligned around customer-facing product lines, rather than around arbitrary technical groupings. Rather than centralized IT functions being the norm, the existence of any central IT function is to support these customer-focused delivery teams.

Figure 1-5. An example of how true technology companies are integrating software delivery
While not all organizations have made this shift, microservice architectures make this change much easier. If you want delivery teams aligned around product lines, and the services are aligned around the business domain, then it becomes easier to clearly assign ownership to these product-oriented delivery teams. Reducing services that are shared across multiple teams is key to minimizing delivery contention—business-domain-oriented microservice architectures make this shift in organizational structures much easier.
The Monolith
We’ve spoken about microservices, but this book is all about moving from monoliths to microservices, so we also need to establish what is meant by the term monolith.
When I talk about the monoliths in this book, I am primarily referring to a unit of deployment. When all functionality in a system had to be deployed together, we consider it a monolith. There are at least three types of monolithic systems that fit the bill: the single-process system, the distributed monolith, and third-party black-box systems.
The Single Process Monolith
The most common example that comes to mind when discussing monoliths is a system in which all of the code is deployed as a single process, as in Figure 1-6. You may have multiple instances of this process for robustness or scaling reasons, but fundamentally all the code is packed into a single process. In reality, these single-process systems can be simple distributed systems in their own right, as they nearly always end up reading data from or storing data into a database.

Figure 1-6. A single-process monolith: all code is packaged into a single process
These single-process monoliths probably represent the vast majority of the monolithic systems that I see people struggling with, and hence are the types of monoliths we’ll focus most of our time on. When I use the term “monolith” from now on, I’ll be talking about these sorts of monoliths unless I say otherwise.
And the modular monolith
As a subset of the single process monolith, the modular monolith is a variation: the single process consists of separate modules, each of which can be worked on independently, but which still need to be combined for deployment, as shown in Figure 1-7. The concept of breaking down software into modules is nothing new; we’ll come back to some of the history around this later in this chapter.

Figure 1-7. A modular monolith: the code inside the process is broken down into modules
For many organizations, the modular monolith can be an excellent choice. If the module boundaries are well defined, it can allow for a high degree of parallel working, but sidesteps the challenges of the more distributed microservice architecture along with much simpler deployment concerns. Shopify is a great example of an organization that has used this technique as an alternative to microservice decomposition, and it seems to work really well for that company.4
One of the challenges of a modular monolith is that the database tends to lack the decomposition we find in the code level, leading to significant challenges that can be faced if you want to pull the monolith in the future. I have seen some teams attempt to push the idea of the modular monolith further, having the database decomposed along the same lines as the modules, as shown in Figure 1-8. Fundamentally, making a change like this to an existing monolith can still be very challenging even if you’re leaving the code alone—many of the patterns we’ll explore in Chapter 4 can help if you want to try to do something similar yourself.
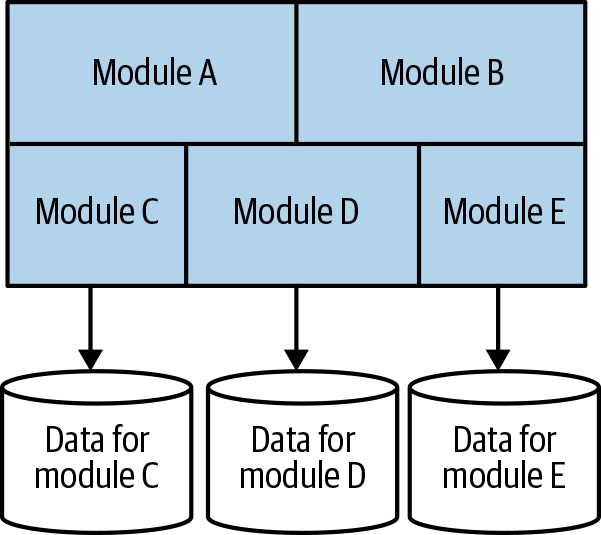
Figure 1-8. A modular monolith with a decomposed database
The Distributed Monolith
A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.5
Leslie Lamport
A distributed monolith is a system that consists of multiple services, but for whatever reason the entire system has to be deployed together. A distributed monolith may well meet the definition of a service-oriented architecture, but all too often fails to deliver on the promises of SOA. In my experience, distributed monoliths have all the disadvantages of a distributed system, and the disadvantages of a single-process monolith, without having enough upsides of either. Encountering distributed monoliths in my work has in large part influenced my own interest in microservice architecture.
Distributed monoliths typically emerge in an environment where not enough focus was placed on concepts like information hiding and cohesion of business functionality, leading instead to highly coupled architectures in which changes ripple across service boundaries, and seemingly innocent changes that appear to be local in scope break other parts of the system.
Third-Party Black-Box Systems
We can also consider some third-party software as monoliths that we may want to “decompose” as part of a migration effort. These might include things like payroll systems, CRM systems, and HR systems. The common factor here is that it’s software developed by other people, and you don’t have the ability to change the code. It could be off-the-shelf software you’ve deployed on your own infrastructure, or could be a Software-as-a-Service (SaaS) product you are using. Many of the decomposition techniques we’ll explore in this book can be used even with systems where you cannot change the underlying code.
Challenges of Monoliths
The monolith, be it a single-process monolith or a distributed monolith, is often more vulnerable to the perils of coupling—specifically, implementation and deployment coupling, topics we’ll explore more shortly.
As you have more and more people working in the same place, they get in each other’s way. Different developers wanting to change the same piece of code, different teams wanting to push functionality live at different times (or delay deployments). Confusion around who owns what, and who makes decisions. A multitude of studies show the challenges of confused lines of ownership.6 I refer to this problem as delivery contention.
Having a monolith doesn’t mean you will definitely face the challenges of delivery contention, any more than having a microservice architecture means that you won’t ever face the problem. But a microservice architecture does give you more concrete boundaries in a system around which ownership lines can be drawn, giving you much more flexibility regarding how you reduce this problem.
Advantages of Monoliths
The single-process monolith, though, has a whole host of advantages, too. Its much simpler deployment topology can avoid many of the pitfalls associated with distributed systems. It can result in much simpler developer workflows; and monitoring, troubleshooting, and activities like end-to-end testing can be greatly simplified as well.
Monoliths can also simplify code reuse within the monolith itself. If we want to reuse code within a distributed system, we have to decide whether we want to copy code, break out libraries, or push the shared functionality into a service. With a monolith, our choices are much simpler, and many people like that simplicity—all the code is there, so just use it!
Unfortunately, people have come to view the monolith as something to be avoided—as something that is inherently problematic. I’ve met multiple people for whom the term monolith is synonymous with legacy. This is a problem. A monolithic architecture is a choice, and a valid one at that. It may not be the right choice in all circumstances, any more than microservices are—but it’s a choice nonetheless. If we fall into the trap of systematically denigrating the monolith as a viable option for delivering our software, then we’re at risk of not doing right by ourselves or the users of our software. We’ll further explore the trade-offs around monoliths and microservices in Chapter 3, and discuss some tools that will help you better assess what is right for your own context.
On Coupling and Cohesion
Understanding the balancing forces between coupling and cohesion is important when defining microservice boundaries. Coupling speaks to how changing one thing requires a change in another; cohesion talks to how we group related code. These concepts are directly linked. Constantine’s law articulates this relationship well:
A structure is stable if cohesion is high, and coupling is low.
Larry Constantine
This seems like a sensible and useful observation. If we have two pieces of tightly related code, cohesion is low as the related functionality is spread across both. We also have tight coupling, as when this related code changes, both things need to change.
If the structure of our code system is changing, that will be expensive to deal with, as the cost of change across service boundaries in distributed systems is so high. Having to make changes across one or more independently deployable services, perhaps dealing with the impact of breaking changes for service contracts, is likely to be a huge drag.
The problem with the monolith is that all too often it is the opposite of both. Rather than tend toward cohesion, and keep things together that tend to change together, we acquire and stick together all sorts of unrelated code. Likewise, loose coupling doesn’t really exist: if I want to make a change to a line of code, I may be able to do that easily enough, but I cannot deploy that change without potentially impacting much of the rest of the monolith, and I’ll certainly have to redeploy the entire system.
We also want system stability because our goal, where possible, is to embrace the concept of independent deployability—that is, we’d like to be able to make a change to our service and deploy that service into production without having to change anything else. For this to work, we need stability of the services we consume, and we need to provide a stable contract to those services that consume us.
Given the wealth of information out there about these terms, it would be silly of me to revisit things too much here, but I think a summary is in order, especially to place these ideas in the context of microservice architectures. Ultimately, these concepts of cohesion and coupling influence hugely how we think about microservice architecture. And this is no surprise—cohesion and coupling are concerns regarding modular software, and what is microservice architecture other than modules that communicate via networks and can be independently deployed?
Cohesion
One of the most succinct definitions I’ve heard for describing cohesion is this: “the code that changes together, stays together.” For our purposes, this is a pretty good definition. As we’ve already discussed, we’re optimizing our microservice architecture around ease of making changes in business functionality—so we want the functionality grouped in such a way that we can make changes in as few places as possible.
If I want to change how invoice approval is managed, I don’t want to have to hunt down the functionality that needs changing across multiple services, and then coordinate the release of those newly changed services in order to roll out our new functionality. Instead, I want to make sure the change involves modifications to as few services as possible to keep the cost of change low.
Coupling
Information Hiding, like dieting, is somewhat more easily described than done.
David Parnas, The Secret History Of Information Hiding
We like cohesion we like, but we’re wary of coupling. The more things are “coupled”, the more they have to change together. But there are different types of coupling, and each type may require different solutions.
There has been a lot of prior art when it comes to categorizing types of coupling, notably work done by Meyer, Yourdan, and Constantine. I present my own, not to say that the work done previously is wrong, more than I find this categorization more useful when helping people understand aspects associated to the coupling of distributed systems. As such, it isn’t intended to be an exhaustive classification of the different forms of coupling.
Implementation coupling
Implementation coupling is typically the most pernicious form of coupling I see, but luckily for us it’s often one of the easiest to reduce. With implementation coupling, A is coupled to B in terms of how B is implemented—when the implementation of B changes, A also changes.
The issue here is that implementation detail is often an arbitrary choice by developers. There are many ways to solve a problem; we choose one, but we may change our minds. When we decide to change our minds, we don’t want this to break consumers (independent deployability, remember?).
A classic and common example of implementation coupling comes in the form of sharing a database. In Figure 1-9, our Order service contains a record of all orders placed in our system. The Recommendation service suggests records to our customers that they might like to buy based on previous purchases. Currently, the Recommendation service directly accesses this data from the database.

Figure 1-9. The Recommendation service directly accesses the data stored in the Order service
Recommendations require information about which orders have been placed. To an extent, this is unavoidable domain coupling, which we’ll touch on in a moment. But in this particular situation, we are coupled to a specific schema structure, SQL dialect, and perhaps even the content of the rows. If the Order service changes the name of a column, splits the Customer Order table apart, or whatever else, it conceptually still contains order information, but we break how the Recommendation service fetches this information. A better choice is to hide this implementation detail, as Figure 1-10 shows—now the Recommendation service accesses the information it needs via an API call.

Figure 1-10. The Recommendation service now accesses order information via an API, hiding internal implementation detail
We could also have the Order service publish a dataset, in the form of a database, which is meant to be used for bulk access by consumers—just as we see in Figure 1-11. As long as the Order service can publish data accordingly, any changes made inside the Order service are invisible to consumers, as it maintains the public contract. This also opens up the opportunity to improve the data model exposed for consumers, tuning to their needs. We’ll be exploring patterns like this in more detail in Chapters 3 and 4.

Figure 1-11. The Recommendation service now accesses order information via an exposed database, which is structured differently from the internal database
In effect, with both of the preceding examples, we are making use of information hiding. The act of hiding a database behind a well-defined service interface allows the service to limit the scope of what is exposed, and can allow us to change how this data is represented.
Another helpful trick is to use “outside-in” thinking when it comes to defining a service interface—drive the service interface by thinking of things from the point of the service consumers first, and then work out how to implement that service contract. The alternative approach (which I have observed is all too common, unfortunately) is to do the reverse. The team working on the service takes a data model, or another internal implementation detail, then thinks to expose that to the outside world.
With “outside-in” thinking, you instead first ask, “What do my service consumers need?” And I don’t mean you ask yourself what your consumers need; I mean you actually ask the people that will call your service!
Tip
Treat the service interfaces that your microservice exposes like a user interface. Use outside-in thinking to shape the interface design in partnership with the people who will call your service.
Think of your service contract with the outside world as a user interface. When designing a user interface, you ask the users what they want, and iterate on the design of this with your users. You should shape your service contract in the same way. Aside from the fact it means you end up with a service that is easier for your consumers to use, it also helps keep some separation between the external contract and the internal implementation.
Temporal coupling
Temporal coupling is primarily a runtime concern that generally speaks to one of the key challenges of synchronous calls in a distributed environment. When a message is sent, and how that message is handled is connected in time, we are said to have temporal coupling. That sounds a little odd, so let’s take a look at an explicit example in Figure 1-12.

Figure 1-12. Three services making use of synchronous calls to perform an operation can be said to be temporally coupled
Here we see a synchronous HTTP call made from our Warehouse service to a downstream Order service to fetch required information about an order. To satisfy the request, the Order service in turn has to fetch information from the Customer service, again via a synchronous HTTP call. For this overall operation to complete, the Warehouse, Order, and Customer services all needed to be up, and contactable. They are temporally coupled.
We could reduce this problem in various ways. We could consider the use of caching—if the Order service cached the information it needed from the Customer service, then the Order service would be able to avoid temporal coupling on the downstream service in some cases. We could also consider the use of an asynchronous transport to send the requests, perhaps using something like a message broker. This would allow a message to be sent to a downstream service, and for that message to be handled after the downstream service is available.
A full exploration of the types of service-to-service communication is outside the scope of this book, but is covered in more detail in Chapter 4 of Building Microservices.
Deployment coupling
Consider a single process, which consists of multiple statically linked modules. A change is made to a single line of code in one of the modules, and we want to deploy that change. In order to do that, we have to deploy the entire monolith—even including those modules that are unchanged. Everything must be deployed together, so we have deployment coupling.
Deployment coupling may be enforced, as in the example of our statically linked process, but can also be a matter of choice, driven by practices like a release train. With a release train, preplanned release schedules are drawn up in advance, typically with a repeating schedule. When the release is due, all changes made since the last release train gets deployed. For some people, the release train can be a useful technique, but I strongly prefer to see it as a transitional step toward proper release-on-demand techniques, rather than viewing it as an ultimate goal. I even have worked in organizations that would deploy all services in a system all at once as part of these release train processes, without any thought to whether those services need to be changed.
Deploying something carries risk. There are lots of ways to reduce the risk of deployment, and one of those ways is to change only what needs to be changed. If we can reduce deployment coupling, perhaps through decomposing larger processes into independently deployable microservices, we can reduce the risk of each deployment by reducing the scope of deployment.
Smaller releases make for less risk. There is less to go wrong. If something does go wrong, working out what went wrong and how to fix it is easier because we changed less. Finding ways to reduce the size of release goes to the heart of continuous delivery, which espouses the importance of fast feedback and release-on-demand methods.9 The smaller the scope of the release, the easier and safer it is to roll out, and the faster feedback we’ll get. My own interest in microservices comes from a previous focus on continuous delivery—I was looking for architectures that made adoption of continuous delivery easier.
Reducing deployment coupling doesn’t require microservices, of course. Runtimes like Erlang allow for the hot-deployment of new versions of modules into a running process. Eventually, perhaps more of us may have access to such capabilities in the technology stacks we use day to day.10
Domain coupling
Fundamentally, in a system that consists of multiple independent services, there has to be some interaction between the participants. In a microservice architecture, domain coupling is the result—the interactions between services model the interactions in our real domain. If you want to place an order, you need to know what items were in a customer’s shopping basket. If you want to ship a product, you need to know where you ship it. In our microservice architecture, by definition this information may be contained in different services.
To give a concrete example, consider Music Corp. We have a warehouse that stores goods. When customers place orders for CDs, the folks working in the warehouse need to understand what items need to be picked and packaged, and where the package needs to be sent. So, information about the order needs to be shared with the people working in the warehouse.
Figure 1-13 shows an example of this: an Order Processing service sends all the details of the order to the Warehouse service, which then triggers the item to be packaged up. As part of this operation, the Warehouse service uses the customer ID to fetch information about the customer from the separate Customer service so that we know how to notify them when the order is sent out.
In this situation, we are sharing the entire order with the warehouse, which may not make sense—the warehouse needs only information about what to package and where to send it. They don’t need to know how much the item cost (if they need to include an invoice with the package, this could be passed along as a pre-rendered PDF). We’d also have problems with information that we have to control access to being too widely shared—if we shared the full order, we could end up exposing credit card details to services that don’t need it, for example.

Figure 1-13. An order is sent to the warehouse to allow packaging to commence
So instead, we might come up with a new domain concept of a Pick Instruction containing just the information the Warehouse service needs, as we see in Figure 1-14. This is another example of information hiding.

Figure 1-14. Using a Pick Instruction to reduce how much information we send to the Warehouse service
We could further reduce coupling by removing the need for the Warehouse service to even need to know about a customer if we wanted to—we could instead provide all appropriate details via the Pick Instruction, as Figure 1-15 shows.

Figure 1-15. Putting more information into the Pick Instruction can avoid the need for a call to the Customer service
For this approach to work, it probably means that at some point Order Processing has to access the Customer service to be able to generate this Pick Instruction in the first place, but it’s likely that Order Processing would need to access customer information for other reasons anyway, so this is unlikely to be much of an issue. This process of “sending” a Pick Instruction implies an API call being made from Order Processing to the Warehouse service.
An alternative could be to have Order Processing emit some kind of event that the Warehouse consumes, in Figure 1-16. By emitting an event that the Warehouse consumes, we effectively flip the dependencies. We go from Order Processing depending on the Warehouse service to be able to ensure an order gets sent, to the Warehouse listening to events from the Order Processing service. Both approaches have their merits, and which I would choose would likely depend on a wider understanding of the interactions between the Order Processing logic and the functionality encapsulated in the Warehouse service—that’s something that some domain modeling can help with, a topic we’ll explore next.

Figure 1-16. Firing an event that the Warehouse service can receive, containing just enough information for the order to be packaged and sent
Fundamentally, some information is needed about an order for the Warehouse service to do any work. We can’t avoid that level of domain coupling. But by thinking carefully about what and how we share these concepts, we can still aim to reduce the level of coupling being used.
Just Enough Domain-Driven Design
As we’ve already discussed, modeling our services around a business domain has significant advantages for our microservice architecture. The question is how to come up with that model—and this is where domain-driven design (DDD) comes in.
The desire to have our programs better represent the real world in which the programs themselves will operate is not a new idea. Object-oriented programming languages like Simula were developed to allow us to model real domains. But it takes more than program language capabilities for this idea to really take shape.
Eric Evans’ Domain-Driven Design,11 presented a series of important ideas that helped us better represent the problem domain in our programs. A full exploration of these ideas is outside the scope of this book, but I’ll provide a brief overview of the most important ideas involved in considering microservice architectures.
Aggregate
In DDD, an aggregate is a somewhat confusing concept, with many different definitions out there. Is it just an arbitrary collection of objects? The smallest unit I should take out of a database? The model that has always worked for me is to first consider an aggregate as a representation of a real domain concept—think of something like an Order, Invoice, Stock Item, etc. Aggregates typically have a life cycle around them, which opens them up to being implemented as a state machine. We want to treat aggregates as self-contained units; we want to ensure that the code that handles the state transitions of an aggregate are grouped together, along with the state itself.
When thinking about aggregates and microservices, a single microservice will handle the life cycle and data storage of one or more different types of aggregates. If functionality in another service wants to change one of these aggregates, it needs to either directly request a change in that aggregate, or else have the aggregate itself react to other things in the system to initiate its own state transitions—examples we see illustrated in Figure 1-17.
The key thing to understand here is that if an outside party requests a state transition in an aggregate, the aggregate can say no. You ideally want to implement your aggregates in such a way that illegal state transitions are impossible.
Aggregates can have relationships with other aggregates. In Figure 1-18, we have a Customer aggregate, which is associated with one or more Orders. We have decided to model Customer and Order as separate aggregates, which could be handled by different services.

Figure 1-17. Different ways in which our Payment service may trigger a Paid transition in our Invoice aggregate

Figure 1-18. One Customer aggregate may be associated with one or more Order aggregates
There are lots of ways to break a system into aggregates, with some choices being highly subjective. You may, for performance reasons or ease of implementation, decide to reshape aggregates over time. To start with, though, I consider implementation concerns to be secondary, initially letting the mental model of the system users be my guiding light on initial design until other factors come into play. In Chapter 2, I’ll introduce Event Storming as a collaborative exercise to help shape these domain models with the help of your nondeveloper colleagues.
Bounded Context
A bounded context typically represents a larger organizational boundary inside an organization. Within the scope of that boundary, explicit responsibilities need to be carried out. That’s all a bit wooly, so let’s look at another specific example.
At Music Corp, our warehouse is a hive of activity—managing orders being shipped out (and the odd return), taking delivery of new stock, having forklift truck races, and so on. Elsewhere, the finance department is perhaps less fun-loving, but still has an important function inside our organization, handling payroll, paying for shipments, and the like.
Bounded contexts hide implementation detail. There are internal concerns—for example, the types of forklift trucks used is of little interest to anyone other than the folks in the warehouse. These internal concerns should be hidden from the outside world—they don’t need to know, nor should they care.
From an implementation point of view, bounded contexts contain one or more aggregates. Some aggregates may be exposed outside the bounded context; others may be hidden internally. As with aggregates, bounded contexts may have relationships with other bounded contexts—when mapped to services, these dependencies become inter-service dependencies.
Mapping Aggregates and Bounded Contexts to Microservices
Both the aggregate and the bounded context give us units of cohesion with well-defined interfaces with the wider system. The aggregate is a self-contained state machine that focuses on a single domain concept in our system, with the bounded context representing a collection of associated aggregates, again with an explicit interface to the wider world.
Both can therefore work well as service boundaries. When starting out, as I’ve already mentioned, I think you want to reduce the number of services you work with. As a result, I think you should probably target services that encompass entire bounded contexts. As you find your feet, and decide to break these services into smaller services, look to split them around aggregate boundaries.
A trick here is that even if you decide to split a service that models an entire bounded context into smaller services later on, you can still hide this decision from the outside world—perhaps by presenting a coarser-grained API to consumers. The decision to decompose a service into smaller parts is arguably an implementation decision, so we might as well hide it if we can!
Further Reading
A thorough exploration of domain-driven design is a worthwhile activity, but outside the scope of this book. If you want to follow this further, I suggest reading either Eric Evans’s original Domain Driven Design or Vaughn Vernon’s Domain-Driven Design Distilled.12
Summary
As we’ve discussed in this chapter, microservices are independently deployable services modeled around a business domain. They communicate with each other via networks. We use the principles of information hiding together with domain-driven design to create services with stable boundaries that are easier to work on independently, and we do what we can to reduce the many forms of coupling.
We also looked at a brief history of where they came from, and even found time to look at a small fraction of the huge amount of prior work that they build upon. We also looked briefly at some of the challenges associated with microservice architectures. This is a topic I’ll explore in more detail in our next chapter, where I will also discuss how to plan a transition to a microservice architecture—as well as providing guidance to help you decide whether they’re even right for you in the first place.
1 For more on this topic, I recommend PHP Web Services by Lorna Jane Mitchell (O’Reilly).
2 After reading Aurynn Shaw’s “Contempt Culture” blog post, I recognized that in the past I have been guilty of showing some degree of contempt toward different technologies, and by extension the communities around them.
3 I can’t recall the first time we actually wrote down the term, but I vividly recall my insistence, in the face of all logic around grammar, that the term should not be hyphenated. In hindsight, it was a hard-to-justify position, which I nonetheless stuck to. I stand by my unreasonable, but ultimately victorious choice.
4 For an overview of Shopify’s thinking behind the use of a modular monolith rather than microservices, Kirsten Westeinde’s talk on YouTube has some useful insights.
5 Email message sent to a DEC SRC bulletin board at 12:23:29 PDT on May 28, 1987 (see https://www.microsoft.com/en-us/research/publication/distribution/ for more).
6 Microsoft Research has carried out studies in this space, and I recommend all of them. As a starting point, I suggest “Don’t Touch My Code! Examining the Effects of Ownership on Software Quality” by Christian Bird et al.
7 Although Parnas’s well known 1972 paper “On the Criteria to be Used in Decomposing Systems into Modules” is often cited as the source, he first shared this concept in “Information Distributions Aspects of Design Methodology”, Proceedings of IFIP Congress ‘71, 1971.
8 See Parnas, David, “The Secret History of Information Hiding.” Published in Software Pioneers, eds. M. Broy and E. Denert (Berlin Heidelberg: Springer, 2002).
9 See Jez Humble and David Farley, Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation (Upper Saddle River: Addison Wesley, 2010) for more details.
10 Greenspun’s 10th rule states, “Any sufficiently complicated C or Fortran program contains an ad hoc, informally specified, bug-ridden, slow implementation of half of Common Lisp.” This has morphed into the newer joke: “Every microservice architecture contains a half-broken reimplementation of Erlang.” I think there is a lot of truth to this.
11 Eric Evans, Domain-Driven Design: Tackling Complexity in the Heart of Software (Boston: Addison-Wesley, 2004).
12 See Vaughn Vernon, Domain-Driven Design Distilled (Boston: Addison-Wesley, 2014).
Get Monolith to Microservices now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

