Chapter 4. Real-World Security Applications for Machine Intelligence
In many ways, machine intelligence can empower, advance, and transform cybersecurity. Across various cyber domains and missions, machine intelligence has established a foothold and helped enable a more analytically advanced defensive posture for organizations. In the following section, we discuss, highlight, and pull apart the practical and real-world application of machine intelligence for cyber threat hunting, malware detection, and risk scoring.
Hunting for Advanced Threats
Cyber threat hunting is the practice of reviewing security events to identify and prioritize potential threats to a network. When a network has been compromised, cyber threat hunters are frequently brought in to evaluate alerts, explore network devices, and remediate any breaches by applying changes in the network or cleaning up compromised systems. In this role, threat hunters are frequently buried by alerts or are unable to move beyond simple hunting techniques to find advanced adversaries due to the scale of data and the complexity of the threats.
Why Threat Hunting Poses a Challenge for Cyber Operations
Advanced persistent threats are making their way through network defense structures and cybersecurity tools, which look for signatures and behaviors in events. As previously stated, in many organizations, a threat actor can dwell on average 240 days before a threat hunter is able to discover and mitigate a compromise. These actors take advantage of their access to exfiltrate sensitive data, perform espionage activities, or defeat systems and OT.
Threat hunting is a practice to find more advanced persistent threats in networks through Indicators of Compromise (IOC), hunting using threat intelligence data and Tactics, Techniques, and Procedures (TTP) hunting by looking for new intrusion techniques. The latter can be rather challenging, and many teams build hunt analytics, such as filters, queries, or complex logic to address this. But these analytics are frequently not well integrated and quickly become stale as the adversary modifies their tactics. Often, they do not scale to the enterprise level and fail to discover correlations within security event data. More sophisticated analytics are necessary to prioritize analyst activities, detect unknown-unknowns, and reduce “alert fatigue.”
How Machine Intelligence Applies to Threat Hunting
Machine intelligence approaches use machine learning that adapts and learns over time to react not only to the evolving threat, but also can be tuned based on human/analyst inputs as new insights are gleaned. Because threats evolve so rapidly, it’s critical not to engage in a hunt with an outdated set of tools that will miss emerging threats.
Additionally, machine intelligence can be used to consolidate a great deal of human-curated intelligence into robust, simplified machine-curated intelligence. Even though expert analysis is often required for intuition-based analysis, machine intelligence can help comb through large volumes of human intelligence or use human-defined frameworks to speed up the application of expert insight. This can alleviate the labor load on the human analyst, allowing them to focus only on tasks that demand their more complex thinking.
This is particularly important in cyber threat hunting activities after a compromise. Oftentimes, the window between compromise and detrimental effects is small, and hunt actors need to quickly identify where intrusions occurred, what likely attack vectors are moving forward, and how to quickly remediate exploited vulnerabilities. By utilizing machine intelligence, cyber hunt experts can deploy algorithms to sift through large amounts of data, bringing to the front the most applicable and important data. By training algorithms on historical data, machine intelligence can also rapidly uncover relationships in the data that are labor-intensive for a human to detect, helping shrink the latency from compromise to remediation.
How to Build a Machine Intelligence Capability to Support Threat Hunting
In many cases, using IOC or TTP approaches will create large numbers of disparate “haystacks” that contain results from the various joins, filters, rules, or analytics looking for specific known threats. In a large network, these can create an unruly quantity of new data results that a cyber analyst must manually sift through in order to validate true positives and investigate high-priority threats. As a result, it’s necessary to apply machine intelligence approaches that can more succinctly rank and prioritize alerts from diverse sources to optimize the analyst time.
In general, rank aggregation is a method of creating new optimal rankings for a given set of analytics run against a given entity. This machine intelligence approach will generate an aggregation rank resulting from a set of analytic scores by a common entity (e.g., IP, hostname, or domain). The ranked entities provide hunt analyst with the ability to view entities in order of malicious or anomalous behavior derived from a set of analytics provided.
If these analytics measure different dimensions of maliciousness, it should be that low scores across all analytics represent “benign-ness,” or vice versa. Likewise, high scores should represent some indication of maliciousness, or vice versa. The key is that low to high scores across all analytics represent the same thing. For example, Figure 4-1 presents a scenario in which a dataset lists a number of analytics with scores run against a series of IP addresses. Using machine learning, the rationale for how to weight these scores are learned so that optimal weights create a weighted average.
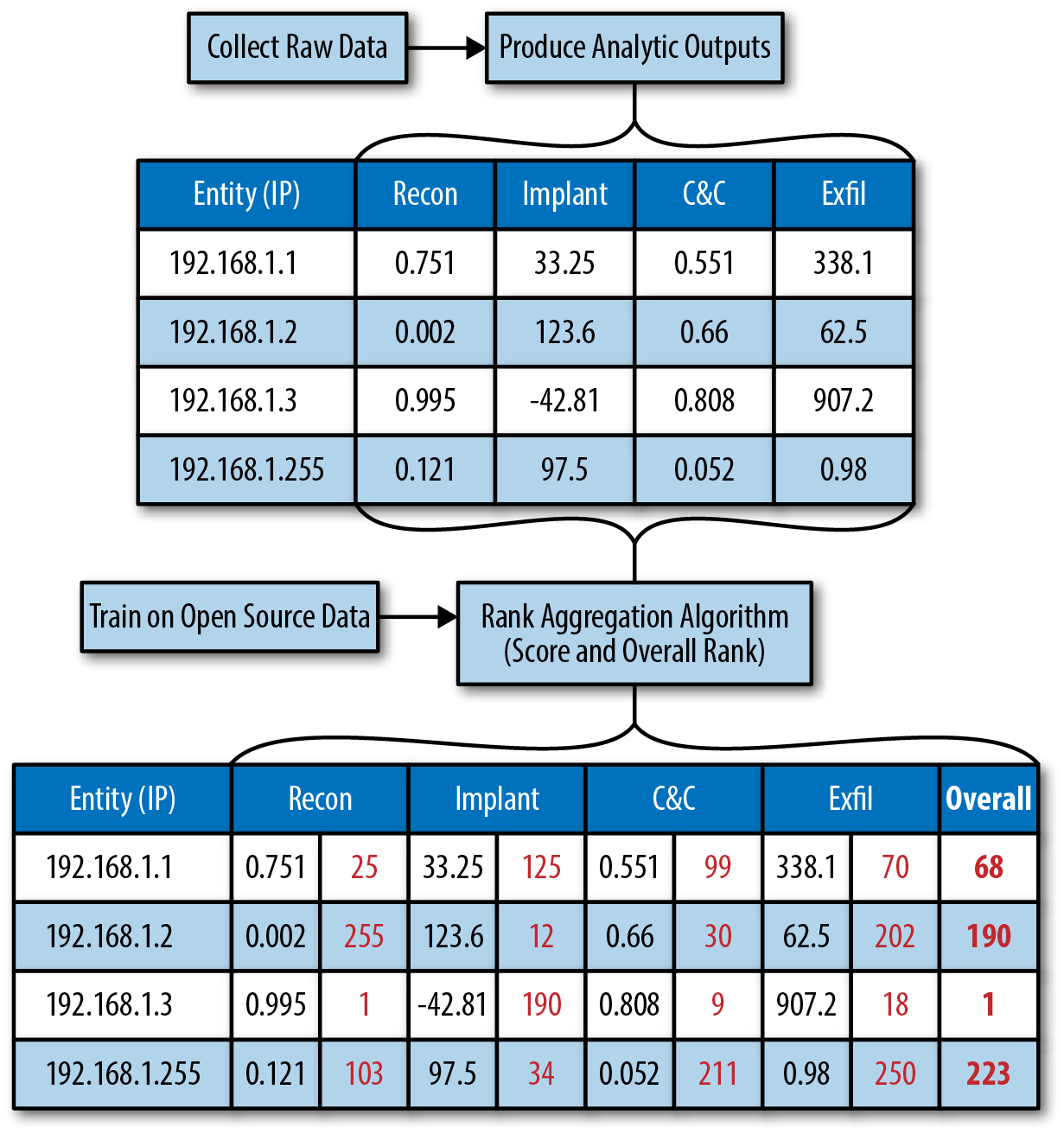
Figure 4-1. Workflow for rank aggregation to optimize threat hunting
This process, in turn, enables analysts to do the following:
-
Take into account all available analytics at once and find entities that rank highly in many analytics in order to direct analysts toward higher value targets of interest
-
Apply the optimum for lots of rank aggregation problems where we have ground truth, which can come from completely unrelated datasets.
-
Compute same features (correlations) as before plus a few others so that we can compare problems of differing size and difficulty and then build a “meta-model” to learn the optimal weights from the correlations, which is technically considered transfer learning.
Utilizing This Machine Intelligence Technique in the Real World
Most organizations currently are able to produce analytic results from IOC filtering or TTP searches and these results reside in a security information and event management (SIEM) product or data mart for display to operators and analysts. After these are available, they can be mined through a rank aggregation pipeline and organized by entity type. In putting rank aggregation into practice to support threat hunting, you could think of the resulting overall ranks as a good starting point for the day for analysts. Consider running rank aggregation as a batch job that runs over night just before the workday begins to produce an ordered set of indicators to hand over to analysts at the beginning of their shift. What is key to this process is that analysts provide feedback based on which indicators result in true positive findings. By validating the true positives and false positives, the machine learning ranking model will improve the weightings over time to better select entities in the future.
Tips and Best Practices
Following are some tips and best practices for building rank aggregation methods for your threat hunting programs.
-
It can take a lot analytic outputs to ensure that rank aggregation works; at a minimum three, but ideally much more than that. It takes time for the model to consistently “get it right” by ranking entities highly, so be patient and make sure that analysts are verifying the outputs.
-
Take advantage of open source such as CRAN,1 UCI,2 Kaggle,3 and Data.gov4 datasets to learn and transfer the optimal weights. The algorithm produces a rank aggregation combining the sets of scores above resulting in a ranked list of indicators.
-
To perform the rank aggregation, the Condorcet method is the gold standard; geometric mean is almost as accurate, but faster and more interpretable. You can build some of these algorithms to scale on massive data volumes, so experiment with different approaches depending on the technology available and quantity of data in the environment.
Detecting and Classifying Malware
Malware, or malicious software, is a broad term encompassing many forms of software, programs, or files that are used for hostile or intrusive purposes in one’s computing environment. Malware can come in many shapes and sizes, and some types are more common or more dangerous than others. For example, a computer virus is the most common type of malware that executes in a computing environment and spreads and infects other programs or files. This can make those files corrupted, inaccessible, or impractical to use. Alternatively, spyware is a malware type that is designed to embed itself within a computing environment and collect information and data on user action, without the user detecting that malicious process. Recently, ransomware has become increasingly publicized following some high-profile, sophisticated malware attacks (e.g., WannaCry and Petya). Here, malware encrypts a user’s data and files, and then the adversarial cyber actor demands a payment in return for unencrypting that data.
For these reasons, detecting existing malware is an incredibly important process because malware can be crippling to a user’s experience, data security, and computing environment. Additionally, there is a need to evaluate new software applications for potential malware embedded within them. This allows the user to preemptively halt the process, preventing intrusion and malicious action on their machine.
Currently, most malware detection techniques are signature based. All objects in a computing environment have unique attributes that define their signature. Current tradecraft in quickly scanning objects and determining their digital signature is quite mature. Therefore, when an organization finds and detects malware, its signature is added to a large database of known malware signatures. This allows anti-malware solutions to scan new objects for known signatures, preventing previously detected malware from entering the computing environment.
Why Malware Detection Poses a Challenge for Cyber Operations
The cost of data breaches from malware attacks continues to grow, presenting enduring threats to networks and organizations. Malware discovery and remediation operations are necessary to understand and manage those risks. The complexity lies in the ability to discover threats at the infection vector and malware exploit campaign levels, pursue intelligence on adversary TTPs, and increase defensive posturing of networks proactively.
As previously discussed, current technologies are robustly able to detect malware using signature-based techniques. Although these approaches are effective for catching well-known malware, they are inherently reactive—they require malware to already have existed, struck an environment, and have been detected by another defensive practitioner. Additionally, the recent Cisco 2017 Annual Cybersecurity Report suggest that 95% of detected malware files are not even 24 hours old, reflecting how fast malware can evolve and how rapidly their malware signatures can change.5 This both speaks to the speed and sophistication of cyber attacks as well as the risks posed by depending on signature-based approaches that prove to be effective only on known and historically recognizable malware.
Highly skilled computer security experts can manually uncover advanced threats using a combination of open source research of exploits or vulnerabilities, network flow, log review, event correlation, and Packet Capture (PCAP) analysis to investigate suspicious software; however, these kinds of operations are both manually intensive and difficult to scale.
Advanced malware affects not only individual users, but can cripple an organization, especially if it infects critical infrastructure or OT.
How Machine Intelligence Applies to Malware Detection
Machine intelligence can identify potential malicious software by applying machine learning such as deep learning models that review and inspect the full software binaries. These models can detect actions that can be characteristic of malicious software and send them off for further review.
As the model reviews more software, the malware detection capability will continue to learn and can detect other similar new attacks as well as completely new malware attacks that would be exposed as anomalies.
Those approaches will have potential to catch malware variants and zero-day attacks that traditional signature-based approaches will never detect. By no means are we suggesting eliminating a traditional antivirus from your security stack, but rather expanding your arsenal to achieve greater detection coverage.
How to Build a Machine Intelligence Capability to Support Malware Detection
Malware can come in all shapes and sizes, in all different forms, and in all different object types. This can be challenging, given that machine intelligence capabilities require some degree of consistency, some common ground, across object types that allows algorithms to compare objects that are known to be malicious with those that are known to be benign. After this common ground is established, models can learn abstract traits that differentiate malicious objects from benign and how these traits can relate to each other to create inherent characteristics that define malware. You can then use these models to look at new objects and assess their likelihood of being malicious.
Luckily for cyber practitioners, all objects can decompose to one common language: their representative byte code or binary file. By converting objects to their binary representation, all types of malware can be seen in a common format, which allows for the deployment of a generalizable machine learning model. From this binary format, a data scientist or machine learning engineer will create an optimized feature representation of this binary code, a feature representation that can be applied to all objects. By training models on this feature vector, models can learn what features are associated with malware. You then can deploy these models on new objects, classifying suspicious objects from objects that are determined to be safe, and blocking those suspicious objects. By doing so, cyber experts can use machine intelligence to abstract away from signatures and conceptualize objects by their underlying byte code structure. These characteristics are inherently more generalizable and can be used to deploy models on new objects in a way that signature-based approaches cannot.
Herein, the “secret sauce” of building malware detectors is determining a creative way to represent raw binary files as a feature vector from which models can learn. This is inherently complex and can be done in a variety of unique ways. In short, there is no one way to create a feature vector for malware detection, but it is in this phase that machine intelligence capabilities can become more advanced and more creative. The more concretely these feature vectors can capture the abstract characteristics of binary files, in a way that can differentiate malware from safe software, the more powerful models can become. As shown in Figure 4-2, after an intelligent feature representation is designed, the machine intelligence development process follows a standard development workflow of architecting, training, validating, and deploying a data-matured analytic.
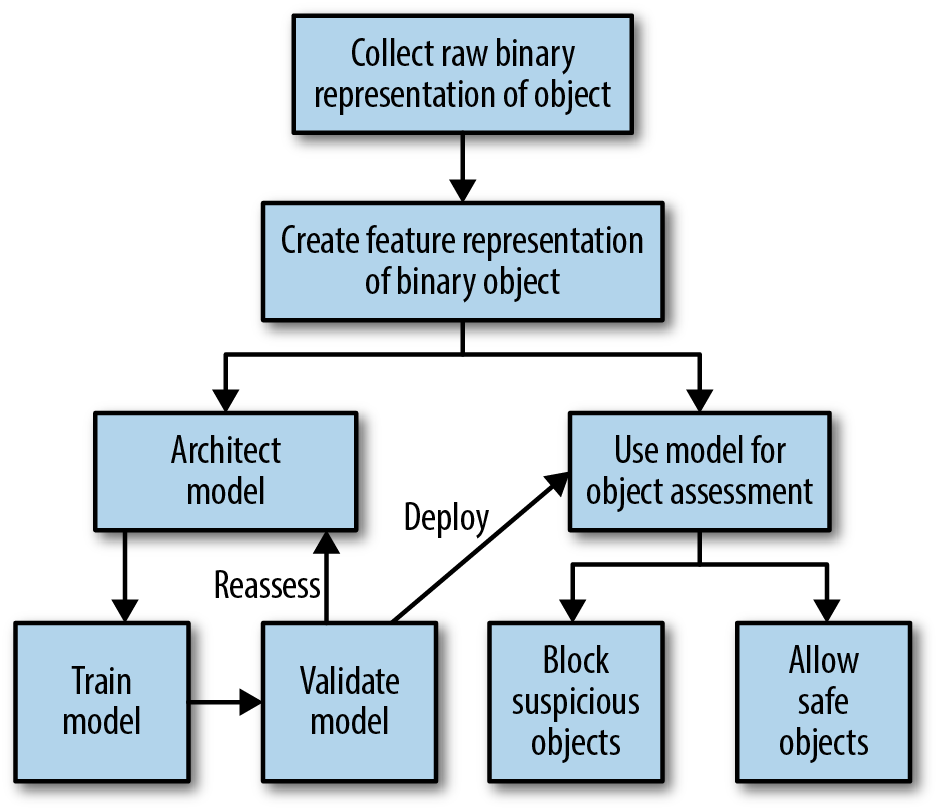
Figure 4-2. Workflow for machine intelligence model development to enable malware detection
Utilizing this Machine Intelligence Technique in the Real World
In practice, building and deploying a machine intelligence capability is challenging. As just described, there are many ways to decompose raw binary files into a coherent set of features. Although we cannot enumerate all approaches here, using minimum hashing and unique binary dictionaries has been proven to be effective in both academia and in industry.
There are a few specific implementations details to consider when employing a machine intelligence-based malware detection capability:
-
If you’re working from scratch, it will be necessary to train a model based on known true positive “goodware” and malware; lots of quality training data is available in open source or from virus data providers (e.g., the CTU-13 data6 set or Kaggle’s “Microsoft Malware Classification Challenge”7).
-
After the model is trained, you can apply it in a few different contexts, with the goal of finding malware that is not currently cataloged by antivirus vendors.
-
One approach is to analyze files that are transferred in SMTP messages in order to detect potentially malicious files that are attached to emails.
-
As an extension of the threat hunting use case, when a hunter detects suspicious files on an endpoint, those files could be put through this model to determine if a file is potentially malicious and to which malware family it could be related.
-
If applied at the network edge, the machine intelligence model can inspect a variety of packet types, such as HTTP sessions, to review the binary content of executable files being transferred across the network.
-
For all of the findings uncovered by these models, they would be considered potential anomalies or suspicious binaries, not a 100% confidence match. In practice, the higher the confidence that the model produces results in stronger indicators of being related to malware and should direct a cyber analyst to perform additional investigation to confirm the findings. This could include decompiling the binaries, enriching features from the features extracted or digging into additional system or network log files to review behaviors.
Tips and Best Practices
Following are some tips and best practices for building malware detection models that will be useful in bringing this capability into your organization.
-
Despite the ubiquity of machine learning models, the challenge lies more upfront in defining and extracting high-quality features from the malware data. Because there are a large number of features (e.g., file metadata, binary information, extracted content, reverse-engineered methods, and dynamic runtime data), it’s particularly important to zero-in on the features that most uniquely identify malware and experiment with many approaches to find an optimal solution.
-
Creativity is essential. Building a machine intelligence capability off a feature vector built from unstructured, binary data cannot be done with rigid rules. Creative and flexible techniques must be used to convert the byte-code to representative, diverse, and powerful features.
-
Large training data for both “goodware” and malware is critical. Oftentimes, the best techniques in this domain require powerful machine learning algorithms that are dependent on large volumes of historical training data. Data collection must begin before the construction of the machine intelligence capability and it must continue throughout the deployment.
-
Algorithms must be regularly and consistently updated on new data and new malware. Even though machine intelligence can help combat the rapid cadence of threat actors, cybersecurity experts must match the same battle rhythm in keeping defensive techniques up to date and mature.
-
Consider training a kernel-based model by exploiting the “kernel trick” such that multiple types of machine learning models can use the same kernel—think of it like a mathematical API. Additionally, train distance-based methods using k-means clustering or k-nearest neighbor (kNN) classifiers.
Scoring Risk in a Network
Cyber risk scoring uses context-defined predictive analytics to provide quantitative, data-driven outputs, allowing organizations to prioritize and focus remediation activities on network areas that are exposed to the greatest risk. As information systems increase in number and connectivity, the attack surfaces in need of strategic and informed cyber defense grow exponentially.
Organizations do not have the time or resources to allocate remediation action to all known and existing vulnerabilities. By providing a predictive risk score, these techniques allow organizations to prioritize defense efforts and focus resources on areas of greatest danger to their overall cybersecurity.
As a comprehensive metric, risk is composed of the following:
-
Attack likelihood
-
The impact of the attack, assuming it is successful
-
The context of the defined vulnerability, given that different network environments can have the same vulnerabilities, but different degrees of exploitability based on their configuration
Accordingly, proactive remediation action is guided by a comprehensive understanding of the intersection of all three criteria, a cyber risk score.
How Risk Scoring Poses a Challenge for Cyber Operations
The growing connectivity among information systems creates increased opportunities for adversaries to take advantage of cyber vulnerabilities, disrupting strategic missions, key systems, and critical infrastructure. Not only are there more ways to enter and exploit an organization’s systems, but adversaries are becoming increasingly creative and innovative in their attack design. Cyber risk scoring’s importance is formed by two core components:
- Attack prevention
-
Now, more than ever, organizations need cutting-edge defensive techniques to counter rapidly evolving cybersecurity threats with the hope of preventing intrusions before they can occur. As organizations depend more and more on information systems, housing secure data and essential systems in linked environments, preventing intrusions and attacks becomes increasingly important. No longer can organizations focus their time responding to existing breaches and mitigating impacts of known attacks with a treatment-centric approach. Rather, they must work to prevent attacks before those attacks can occur, immunizing their systems of risk before adversaries can exploit them. By deploying a risk-informed, predictive, and immunization-centric technique, organizations can move toward strategic cyber resilience and information security. Risk scoring also informs the cyber operational analysts what remediations and tasks are a priority for your enterprise. By focusing on preventing attacks on your mission-critical systems, breaches will become less impactful and response time to them will be reduced until the entire network can be secured to the best point possible while still being able to support mission needs.
- Scope of remediation activity
-
Organizations cannot remediate all their vulnerabilities and cyber risks. With growing IT dependence and interconnectivity creating broader attack surfaces, vulnerabilities are appearing faster than organizations can respond to them. To maintain the highest level of cybersecurity, organizations must intelligently prioritize their resources and time to mitigate vulnerabilities that expose them to the greatest risk. By providing a predictive ranking metric, cyber risk scoring offers a means to decrease organizational cyber vulnerability in the most strategic and efficient manner.
Cyber risk scoring has been performed by domain experts for many years, but subjectively defined metrics often fail to provide the requisite granularity for effective prioritization schemes and are time intensive to generate.
How Machine Intelligence Applies to Risk Scoring
By driving cyber risk assessments with machine learning instead of domain expert interpretation, scores are entirely data-driven and quantitative. These scores can offer both precise point estimates of scaled risk as well as data-driven uncertainty bounds around these scores to better inform decision makers.
Additionally, models can score vulnerabilities and exploit opportunities at scale and efficiently, covering the landscape of known risk in a matter of hours, rather than days, weeks, and months.
That said, machine learning–curated cyber risk scores are not agnostic of domain expertise and subjective input. As natural-language processing (NLP) and data-mining techniques have become more advanced, models have been increasingly capable of structuring and ingesting unstructured expert-curated assessments. This allows for expert-informed machine learning models that can ingest institutional knowledge in a variety of data formats.
In fact, cyber risk scores blend objective characteristics, historical context, and subjective input into one comprehensive machine learning suite for remediation prioritization.
In implementation, machine learning–driven techniques function within proven risk management frameworks such as NIST RMF.8 Here, machine learning models can digest characteristics of vulnerabilities, known historical exploits, attacks, and threat intelligence as well as subjective input.
By using feature engineering, feature generation, and artificial intelligence–driven techniques, these models can return point estimates for all components of cyber risk (i.e., likelihood and impact) framed in the known configuration context. Although these risk scores live at the vulnerability level, they can be rolled up at the system level by marrying historically curated risk scores with known incident data in a predictive manner, prior to the incident.
This allows organizations to develop mature, predictive, system-level scores to better identify systems at the greatest risk, as well as the vulnerabilities that are driving this risk.
With increased risk awareness, organizations can operationalize a framework to efficiently and strategically decrease risk. Here, resources can be mapped to remediation strategies that carry defined financial and labor-time costs and predictively measured risk reductions.
By optimizing resource deployment to activities that maximize the decreased risk, both in magnitude and time, organizations can proactively immunize themselves to the most salient threats in the most efficient manner.
How to Build a Machine Intelligence Capability to Support Risk Scoring
Building a machine intelligence capability for cyber risk scoring isn’t about the recipe for machine learning as much as it’s about the ingredients you put into the pot. Machine intelligence can be incredibly impactful in a predictive framework, allowing organizations to operate proactively rather than reactively. For machine learning algorithms to function in this manner, they require a complete representation of the environment, including the threat landscape, vulnerability characteristics, known impacts, and system configurations prior to an exploit. This allows algorithms to associate these pre-exploit characteristics with whether an exploit occurred and the outcomes of that exploit. In doing so, organizations can develop tailored subscores for cyber risk as well as comprehensive measures for risk. As Figure 4-3 illustrates, these inputs are piped through NLP engines and feature-generation techniques and passed to the machine learning engine that outputs data-driven risk scoring.
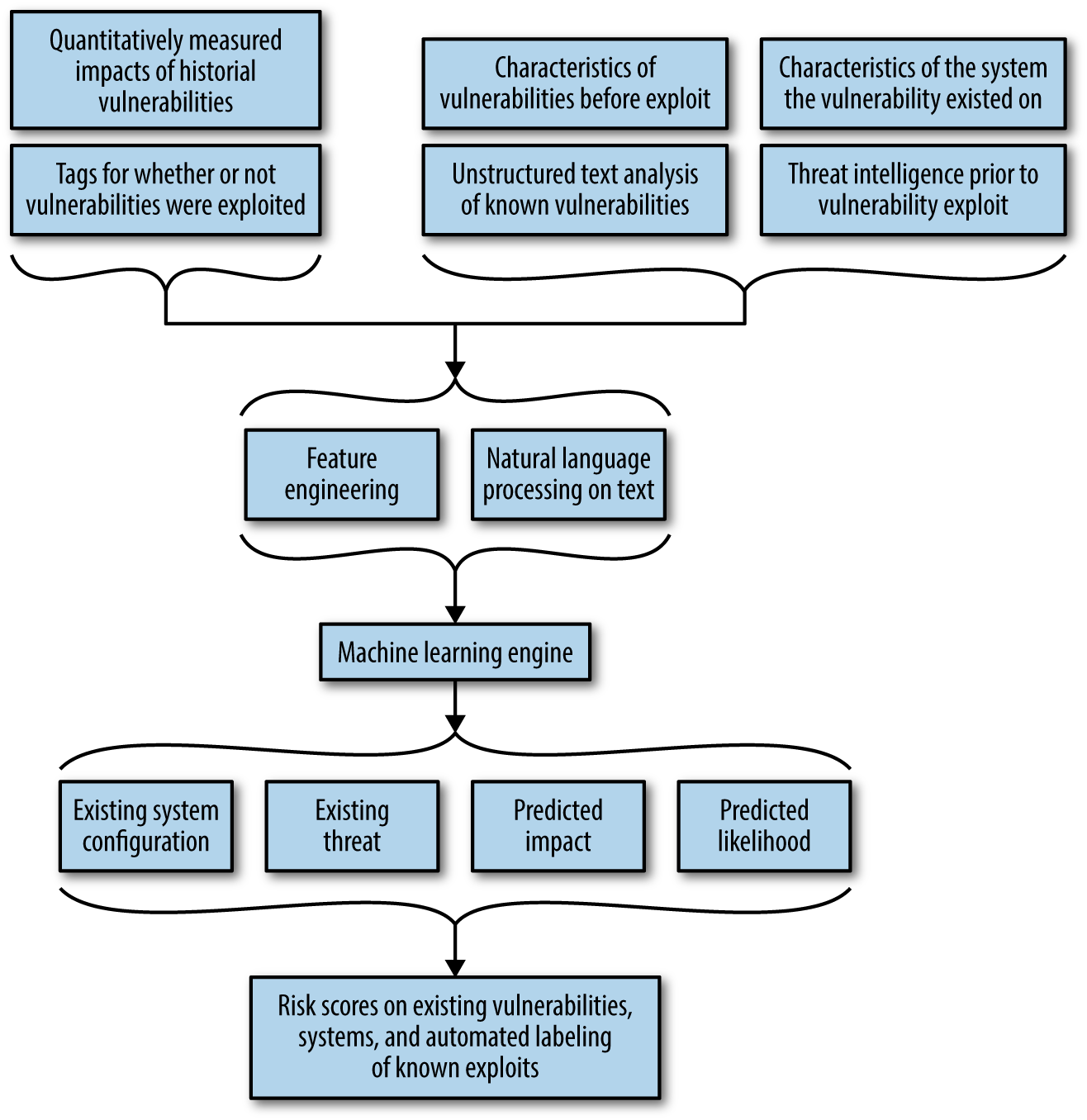
Figure 4-3. Workflow for machine learning model development to enable cyber risk scoring
Utilizing This Machine Intelligence Technique in the Real World
You can utilize risk scoring approaches with machine intelligence to accurately predict the likelihood of a threat actor exploiting a software vulnerability, such as a Common Vulnerability and Exposure (CVE) from the National Vulnerability Database (NVD).9 It’s possible to derive impact scores through close partnership with the organization and an intimate understanding of the mission. Additionally, environment context can be measured and defined only by understanding both an organization’s current and historic system configurations.
Generally speaking, the likelihood of an exploit reflects the ease of exploit. By applying a predictive modeling scheme with machine learning, it’s possible to prioritize known vulnerabilities that have yet to be exploited and flag existing vulnerabilities that have a known exploit available. This allows organizations to immediately harden their defenses with machine intelligence–curated and optimized vulnerability risk scoring, moving from reactive techniques toward proactive techniques.
By blending machine learning scores with organizationally informed impact assessments, framed in the context of environmental configuration, organizations can quickly stand up a cyber risk scoring capability. This moves organizations from treatment-centric cyber defense to immunization-centric cyber defense, where remediation activities can be strategically allocated and precisely targeted to prevent attacks before they can occur.
Tips and Best Practices
Following are some tips and best practices for assessing vulnerabilities and building compliance programs utilizing machine intelligence.
-
Organizations need to proactively begin collecting data. To maintain a predictive capability, machine learning algorithms require both a snapshot of the cyber environment before and after an exploit. This includes data on vulnerabilities, system configurations at the time of exploit, and known threat intelligence at that time.
-
Organizations need to develop tailored impact scores for known exploits. These scores should consider the data one can access with an exploit, the degree to which that exploit can waterfall into subsequent exploits, and the organizational damage that exploit can cause.
-
Don’t forget unstructured data and SME analysis. Robust NLP algorithms can consolidate this unstructured data into more granular and quantitative measures that are easy for machine learning algorithms to digest. Oftentimes, it is the expert-curated insight captured in the text data that differentiates powerful machine intelligence from passable machine intelligence.
-
Organizations need to rigorously document both known exploits in their environment, and log all system-level, exploit-triggered incidents. This allows machine intelligence algorithms to function in a fully supervised manner, which can thus allow for highly predictive and powerful risk scoring.
1 “The Comprehensive R Archive Network”, CRAN.
2 “UCI Machine Learning Repository”, UC Irvine.
3 “The Home of Data Science & Machine Learning”, Kaggle.
4 “The home of the U.S. Government’s open data”, Data.gov.
5 Cisco, “Cisco 2017 Annual Cyber Security Report.”
6 “The CTU-13 Dataset. A Labeled Dataset with Botnet, Normal, and Background Traffic”, Malware Capture Facility Project.
7 “Microsoft Malware Classification Challenge (BIG 2015)”, Kaggle.
8 “Risk Management Framework (RMF) Overview”, National Institute of Standards and Technology: Computer Security Resource Center, February 9, 2018.
9 “National Vulnerability Database”, National Institute of Standards and Technology, February 15, 2018.
Get Modernizing Cybersecurity Operations with Machine Intelligence now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

