Kapitel 4. Zugriffskontrolle
Diese Arbeit wurde mithilfe von KI übersetzt. Wir freuen uns über dein Feedback und deine Kommentare: translation-feedback@oreilly.com
Nachdem wir uns im vorigen Kapitel ausführlich mit Shells und Skripten beschäftigt haben, konzentrieren wir uns jetzt auf einen speziellen und entscheidenden Sicherheitsaspekt von Linux. In diesem Kapitel geht es um das Thema Benutzer und die Kontrolle des Zugriffs auf Ressourcen im Allgemeinen und Dateien im Besonderen.
Eine Frage, die sich bei einer solchen Mehrbenutzereinrichtung sofort stellt, ist die Frage nach dem Eigentum. Einem Benutzer gehört zum Beispiel eine Datei. Er darf von der Datei lesen, in die Datei schreiben und sie z. B. auch löschen. Wenn es noch andere Benutzer auf dem System gibt, was dürfen diese Benutzer dann tun und wie wird dies definiert und durchgesetzt? Es gibt auch Aktivitäten, die du nicht unbedingt mit Dateien in Verbindung bringen würdest. Zum Beispiel kann es sein, dass ein Benutzer netzwerkbezogeneEinstellungen ändern darf (oder auch nicht).
Um dieses Thema in den Griff zu bekommen, werfen wir zunächst einen Blick auf die grundsätzliche Beziehung zwischen Benutzern, Prozessen und Dateien aus der Perspektive des Zugriffs. Außerdem gehen wir auf Sandboxing und Zugriffskontrolltypen ein. Als Nächstes befassen wir uns mit der Definition eines Linux-Benutzers, was Benutzer tun können und wie man Benutzer entweder lokal oder alternativ von einer zentralen Stelle aus verwaltet.
Danach gehen wir zum Thema Berechtigungen über, wo wir uns ansehen, wie der Zugriff auf Dateien kontrolliert wird und wie sich solche Einschränkungen auf Prozesse auswirken.
Zum Abschluss dieses Kapitels werden wir eine Reihe von fortgeschrittenen Linux-Funktionen im Bereich der Zugriffskontrolle vorstellen, darunter Capabilities, Seccomp-Profile und ACLs. Zum Abschluss stellen wir einige bewährte Sicherheitspraktiken rund um Berechtigungen undZugriffskontrolle vor.
Damit sind wir auch schon beim Thema Benutzer und Ressourcenbesitz, das die Grundlage für den Rest des Kapitels bildet.
Grundlagen
Bevor wir uns mit den Mechanismen der Zugriffskontrolle befassen, sollten wir einen kleinen Schritt zurücktreten und das Thema aus der Vogelperspektive betrachten. Das wird uns helfen, einige Begriffe zu definieren und die Beziehungen zwischen den wichtigsten Konzepten zu klären.
Ressourcen und Eigentümerschaft
Linux ist ein Mehrbenutzer-Betriebssystem und hat als solches das Konzept des Benutzers (siehe "Benutzer") von UNIX geerbt.Jedes Benutzerkonto ist mit einer Benutzer-ID verbunden, die Zugriff auf ausführbare Dateien, Geräte und andere Linux-Assets erhalten kann. Ein menschlicher Benutzer kann sich mit einem Benutzerkonto anmelden, und ein Prozess kann als Benutzerkonto ausgeführt werden. Dann gibt es noch die Ressourcen (die wir einfach als Dateien bezeichnen), also alle Hardware- oder Softwarekomponenten, die dem Benutzer zur Verfügung stehen. Im Allgemeinen bezeichnen wir Ressourcen als Dateien, es sei denn, wir sprechen explizit über den Zugriff auf andere Arten von Ressourcen, wie z. B. bei Syscalls. In Abbildung 4-1und dem darauf folgenden Abschnitt siehst du die Beziehungen zwischen Benutzern, Prozessen und Dateien in Linux auf hoher Ebene.
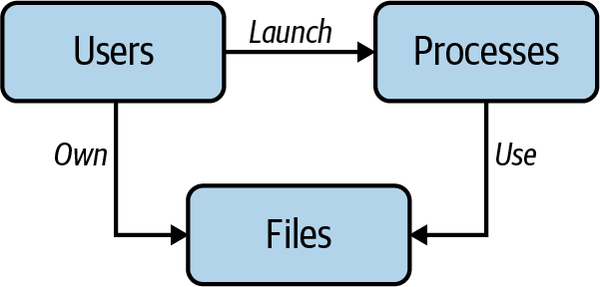
Abbildung 4-1. Benutzer, Prozesse und Dateien in Linux
- Benutzer
-
Prozesse und eigene Dateien starten. Ein Prozess ist ein Programm (ausführbare Datei), das der Kernel in den Hauptspeicher geladen hat und ausführt.
- Dateien
-
Besitzer haben; standardmäßig ist der Benutzer, der die Datei erstellt, der Besitzer.
- Prozesse
-
Verwende Dateien für die Kommunikation und Persistenz. Natürlich können die Benutzer indirekt auch Dateien verwenden, aber sie müssen dies über Prozesse tun.
Diese Darstellung der Beziehungen zwischen Nutzern, Prozessen und Dateien ist natürlich eine sehr vereinfachte Sichtweise, aber sie ermöglicht es uns, die Akteure und ihre Beziehungen zu verstehen und wird uns später nützlich sein, wenn wir die Interaktion zwischen diesen verschiedenen Akteuren genauer besprechen.
Schauen wir uns zunächst den Ausführungskontext eines Prozesses an, um die Frage zu klären, wie eingeschränkt der Prozess ist. Ein Begriff, der uns oft begegnet, wenn wir über den Zugang zu Ressourcen sprechen, ist Sandboxing.
Sandboxing
Sandboxing ist ein vage definierter Begriff und kann sich auf eine Reihe verschiedener Methoden beziehen, von Jails über Container bis hin zu virtuellen Maschinen, die entweder im Kernel oder im Benutzerland verwaltet werden können. In der Regel gibt es etwas, das in der Sandbox läuft - in der Regel eine Anwendung - und der Überwachungsmechanismus erzwingt einen gewissen Grad an Isolation zwischen dem Prozess in der Sandbox und der Hostumgebung. Wenn sich das alles sehr theoretisch anhört, bitte ich dich um ein wenig Geduld. Wir werden Sandboxing später in diesem Kapitel in Aktion sehen, in "seccomp Profiles", und dann wieder in Kapitel 9, wenn wir über VMs und Container sprechen.
Mit einem grundlegenden Verständnis von Ressourcen, Eigentum und Zugang zu diesen Ressourcen im Kopf, wollen wir kurz über einige konzeptionelle Möglichkeiten der Zugriffskontrolle sprechen.
Arten der Zugriffskontrolle
Ein Aspekt der Zugriffskontrolle ist die Art des Zugriffs selbst. Greift ein Benutzer oder ein Prozess direkt auf eine Ressource zu, vielleicht sogar ohne Einschränkung? Oder gibt es vielleicht klare Regeln dafür, auf welche Art von Ressourcen (Dateien oder Systemaufrufe) ein Prozess unter welchen Umständen zugreifen kann. Vielleicht wird sogar der Zugriff selbst aufgezeichnet.
Konzeptionell gibt es verschiedene Arten der Zugriffskontrolle. Die beiden wichtigsten und für unsere Diskussion im Kontext von Linux relevanten sind diediskretionäre und die obligatorische Zugriffskontrolle:
- Diskretionäre Zugriffskontrolle
-
Bei der diskretionären Zugriffskontrolle (DAC) geht es darum, den Zugang zu Ressourcen auf der Grundlage der Identität des Nutzers einzuschränken. Sie ist diskretionär in dem Sinne, dass ein Nutzer mit bestimmten Berechtigungen diese an andere Nutzer weitergeben kann.
- Obligatorische Zugriffskontrolle
-
Die obligatorische Zugriffskontrolle basiert auf einem hierarchischen Modell, das die Sicherheitsstufen darstellt. Die Benutzer/innen erhalten eine Freigabestufe und die Ressourcen ein Sicherheitslabel. Die Benutzer/innen können nur auf die Ressourcen zugreifen, die einer Freigabestufe entsprechen, die gleich (oder niedriger) als ihre eigene ist. In einem Modell mit obligatorischer Zugriffskontrolle kontrolliert ein Administrator den Zugriff streng und ausschließlich, indem er alle Berechtigungen festlegt. Mit anderen Worten: Die Nutzer/innen können die Berechtigungen nicht selbst festlegen, selbst wenn sie die Ressource besitzen.
Außerdem ist Linux traditionell ein Alles-oder-Nichts-System, d.h. entweder bist du ein Superuser, der alles ändern kann, oder du bist ein normaler Benutzer mit eingeschränktem Zugriff. Anfangs gab es keine einfache und flexible Möglichkeit, einem Benutzer oder Prozess bestimmte Privilegien zuzuweisen. Um zum Beispiel zu ermöglichen, dass "Prozess X die Netzwerkeinstellungen ändern darf", musstest du ihm root zuweisen. Das hat natürlich konkrete Auswirkungen auf ein System, in das eingebrochen wird: Ein Angreifer kann diese weitreichenden Privilegien leicht missbrauchen.
Hinweis
Um die "Alles-oder-Nichts-Haltung" in Linux etwas einzuschränken: Die Standardeinstellungen der meisten Linux-Systeme erlauben "anderen" - also allen Benutzern des Systems - den Lesezugriff auf fast alle Dateien und ausführbaren Dateien. Wenn SELinux aktiviert ist, schränkt die obligatorische Zugriffskontrolle den Zugriff nur auf die Dateien ein, für die eine ausdrückliche Genehmigung erteilt wurde. So kann zum Beispiel ein Webserver nur die Ports 80 und 443 benutzen, nur Dateien und Skripte aus bestimmten Verzeichnissen freigeben, nur Protokolle an bestimmte Orte schreiben und so weiter.
Wir werden dieses Thema im Abschnitt "Erweiterte Rechteverwaltung" noch einmal aufgreifen und sehen, wie moderne Linux-Funktionen dabei helfen können, diese binäre Weltsicht zu überwinden und eine feinkörnigere Rechteverwaltung zu ermöglichen.
Die wohl bekannteste Implementierung der obligatorischen Zugriffskontrolle für Linux istSELinux. Es wurde entwickelt, um die hohen Sicherheitsanforderungen von Regierungsbehörden zu erfüllen, und wird in diesen Umgebungen in der Regel eingesetzt, da die Benutzerfreundlichkeit unter den strengen Regeln leidet. Eine weitere Option für die obligatorische Zugriffskontrolle, die seit Version 2.6.36 im Linux-Kernel enthalten und in der Ubuntu-Familie von Linux-Distributionen recht beliebt ist, istAppArmor.
Kommen wir nun zum Thema Benutzer und wie man sie in Linux verwaltet.
Benutzer
In Linux unterscheiden wir oft zwischen zwei Arten von Benutzerkonten, je nach Zweck oder Verwendungszweck:
- Sogenannte Systembenutzer oder Systemkonten
-
Normalerweise verwenden Programme (manchmal auch Daemons genannt) diese Art von Konten, um Hintergrundprozesse auszuführen. Die von diesen Programmen bereitgestellten Dienste können Teil des Betriebssystems sein, wie z. B. Netzwerkdienste (
sshd), oder auf der Anwendungsschicht (z. B.mysql, im Fall einer beliebten relationalen Datenbank). - Regelmäßige Nutzer
-
Zum Beispiel ein menschlicher Benutzer, der Linux interaktiv über die Shell benutzt.
Die Unterscheidung zwischen Systembenutzern und normalen Benutzern ist weniger eine technische als vielmehr eine organisatorische. Um das zu verstehen, müssen wir zunächst das Konzept der Benutzer-ID (UID) einführen, ein 32-Bit-Zahlenwert, der von Linux verwaltet wird.
Linux identifiziert Benutzer über eine UID, wobei ein Benutzer, der zu einer oder mehreren Gruppen gehört, über eine Gruppen-ID (GID) identifiziert wird. Es gibt eine besondere Art von Benutzer mit der UID 0, die normalerweise root genannt wird. Dieser "Superuser" darf alles tun, das heißt, es gelten keine Einschränkungen. Normalerweise solltest du es vermeiden, alsroot Benutzer zu arbeiten, denn er hat einfach zu viel Macht. Du kannst leicht ein System zerstören, wenn du nicht aufpasst (glaub mir, das habe ich schon getan). Wir kommen später in diesem Kapitel darauf zurück.
Verschiedene Linux-Distributionen haben ihre eigenen Methoden, um zu entscheiden, wie sie den UID-Bereich verwalten. Zum Beispiel haben systemd-betriebene Distributionen (siehe "systemd") die folgende Konvention(hier vereinfacht):
- UID 0
-
Ist
root - UID 1 bis 999
-
Sind für Systembenutzer reserviert
- UID 65534
-
Ist der Benutzer
nobody- wird z. B. für die Zuordnung von Remote-Benutzern zu einer bekannten ID verwendet, wie es bei "Network File System" der Fall ist . - UID 1000 bis 65533 und 65536 bis 4294967294
-
Sind regelmäßige Nutzer
Um deine eigenen UIDs herauszufinden, kannst du den Befehl (Überraschung!) id wie folgt verwenden:
$id-u2016796723
Nachdem du nun die Grundlagen über Linux-Benutzer kennst, wollen wir sehen, wie du Benutzer verwalten kannst.
Lokale Benutzerverwaltung
Die erste und traditionell einzig verfügbare Option ist die lokale Verwaltung von Benutzern. Das bedeutet, dass nur die Informationen verwendet werden, die sich auf den Computer beziehen, und dass benutzerbezogene Informationen nicht über ein Netzwerk von Computern verteilt werden.
Für die lokale Benutzerverwaltung verwendet Linux eine einfache dateibasierte Schnittstelle mit einem etwas verwirrenden Namensschema, das leider ein historisches Artefakt ist, mit dem wir leben müssen. In Tabelle 4-1 sind die vier Dateien aufgeführt, die zusammen die Benutzerverwaltung realisieren.
| Zweck | Datei |
|---|---|
Benutzerdatenbank |
/etc/passwd |
Gruppendatenbank |
/etc/group |
Benutzer-Passwörter |
/etc/shadow |
Gruppenpasswörter |
/etc/gshadow |
Stell dir /etc/passwd als eine Art Mini-Benutzerdatenbank vor, in der Benutzernamen, UIDs, Gruppenzugehörigkeit und andere Daten wie das Heimatverzeichnis und die verwendete Anmeldeshell für normale Benutzer gespeichert werden. Werfen wir einen Blick auf ein konkretes Beispiel:
$cat/etc/passwdroot:x:0:0:root:/root:/bin/bashdaemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologinbin:x:2:2:bin:/bin:/usr/sbin/nologinsys:x:3:3:sys:/dev:/usr/sbin/nologinnobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologinsyslog:x:104:110::/home/syslog:/usr/sbin/nologinmh9:x:1000:1001::/home/mh9:/usr/bin/fish
Der Root-Benutzer hat die UID 0.
Ein Systemkonto (
nologinverrät es; siehe weiter unten).
Mein Benutzerkonto.
Schauen wir uns eine der Zeilen in /etc/passwd genauer an, um die Struktur eines Benutzereintrags im Detail zu verstehen:
root:x:0:0:root:/root:/bin/bash^^^^^^^||||||└──|||||└──||||└──|||└──||└──|└──└──
Die zu verwendende Login-Shell. Um interaktive Anmeldungen zu verhindern, verwende /sbin/nologin.
Das Heimatverzeichnis des Benutzers; der Standardwert ist /.
Benutzerinformationen wie der vollständige Name oder Kontaktdaten wie die Telefonnummer. Oft auch als GECOS-Feld bekannt. Beachte, dass die GECOS-Formatierung nicht verwendet wird, sondern das Feld selbst typischerweise für den vollständigen Namen der Person verwendet wird, die mit dem Konto verbunden ist.

Die primäre Gruppe (GID) des Benutzers; siehe auch /etc/group.

Die UID. Beachte, dass Linux UIDs unter 1000 für die Systemnutzung reserviert.

Das Passwort des Benutzers, wobei das Zeichen
xbedeutet, dass das (verschlüsselte) Passwort in /etc/shadow gespeichert wird, was heutzutage die Standardeinstellung ist.
Den Benutzernamen, der höchstens 32 Zeichen lang sein darf.
Eine Sache, die wir in /etc/passwd vermissen, ist das, was wir aufgrund des Namens dort erwarten würden: das Passwort. Passwörter werden aus historischen Gründen in einer Datei namens /etc/shadow gespeichert. Während jeder Benutzer/etc/passwd lesen kann, brauchst du für /etc/shadow normalerweise die Berechtigung root.
Um einen Benutzer hinzuzufügen, kannst du den adduser
Befehl wie folgt:
$sudoaddusermh9Addinguser`mh9' ... Adding new group `mh9'(1001)...Addingnewuser`mh9' (1000) with group `mh9'...Creatinghomedirectory`/home/mh9' ...Copying files from `/etc/skel'...Newpassword:Retypenewpassword:passwd:passwordupdatedsuccessfullyChangingtheuserinformationformh9Enterthenewvalue,orpressENTERforthedefaultFullName[]:MichaelHausenblasRoomNumber[]:WorkPhone[]:HomePhone[]:Other[]:Istheinformationcorrect?[Y/n]Y
Der Befehl
addusererstellt ein Home-Verzeichnis.Außerdem kopiert es eine Reihe von Standardkonfigurationsdateien in das Home-Verzeichnis.
Du musst ein Passwort festlegen.
Gib optionale GECOS-Informationen an.
Wenn du ein Systemkonto erstellen möchtest, gibst du die Option -r an. Dadurch wird die Möglichkeit, eine Login-Shell zu verwenden, ausgeschaltet und die Erstellung eines Home-Verzeichnisses vermieden. Einzelheiten zur Konfiguration findest du in der Datei /etc/adduser.conf, einschließlich Optionen wie dem zu verwendenden UID/GID-Bereich.
Zusätzlich zu den Benutzern gibt es unter Linux auch das Konzept der Gruppen, die gewissermaßen nur eine Sammlung von einem oder mehreren Benutzern sind. Jeder normale Benutzer gehört zu einer Standardgruppe, kann aber Mitglied in weiteren Gruppen sein. Du kannst dich über Gruppen und Zuordnungen in der Datei /etc/group informieren:
$cat/etc/grouproot:x:0:daemon:x:1:bin:x:2:sys:x:3:adm:x:4:syslog...ssh:x:114:landscape:x:115:admin:x:116:netdev:x:117:lxd:x:118:systemd-coredump:x:999:mh9:x:1001:
Zeigt den Inhalt der Gruppenzuordnungsdatei an.
Eine Beispielgruppe für meinen Benutzer mit der GID 1001. Beachte, dass du nach dem letzten Doppelpunkt eine kommagetrennte Liste von Benutzernamen hinzufügen kannst, um mehreren Benutzern die Berechtigung für diese Gruppe zu geben.
Mit diesem grundlegenden Benutzerkonzept und der Benutzerverwaltung im Hinterkopf gehen wir zu einer potenziell besseren Art der Benutzerverwaltung in einer professionellen Einrichtung über, die eine Skalierung ermöglicht.
Zentralisierte Benutzerverwaltung
Wenn du mehr als einen Rechner oder Server hast, für den du Benutzer verwalten musst - z. B. in einer professionellen Einrichtung - dann wird die lokale Benutzerverwaltung schnell alt. Du brauchst eine zentrale Benutzerverwaltung, die du lokal auf einen bestimmten Rechner anwenden kannst. Je nach deinen Anforderungen und deinem (Zeit-)Budget stehen dir verschiedene Ansätze zur Verfügung:
- Verzeichnisbasiert
-
Das Lightweight Directory Access Protocol (LDAP), eine jahrzehntealte Reihe von Protokollen, die jetzt von der IETF formalisiert wurde, definiert, wie man auf ein verteiltes Verzeichnis über das Internet Protocol (IP) zugreift und es verwaltet. Du kannst selbst einen LDAP-Server betreiben - zum Beispiel mit Projekten wie Keycloak - odereinen Cloud-Provider wie Azure Active Directory damit beauftragen.
- Über ein Netzwerk
-
Mit Kerberos können Benutzer auf diese Weise authentifiziert werden. Wir sehen uns Kerberos im Detail unter "Kerberos" an.
- Verwendung von Konfigurationsmanagementsystemen
-
Diese Systeme, wie Ansible, Chef, Puppet oder SaltStack, können verwendet werden, um konsistent Benutzer auf verschiedenen Rechnern anzulegen.
Die tatsächliche Implementierung wird oft von der Umgebung diktiert. So kann es sein, dass ein Unternehmen bereits LDAP einsetzt und die Möglichkeiten daher begrenzt sind. Die Details der verschiedenen Ansätze sowie die Vor- und Nachteile würden jedoch den Rahmen dieses Buches sprengen.
Erlaubnisse
In diesem Abschnitt gehen wir zunächst auf die Linux-Dateiberechtigungen ein, die für die Zugriffskontrolle von zentraler Bedeutung sind, und befassen uns dann mit den Berechtigungen für Prozesse. Das heißt, wir sehen uns die Laufzeitberechtigungen an und wie sie von den Dateiberechtigungen abgeleitet werden.
Dateiberechtigungen
Dateiberechtigungen sind das Herzstück des Linux-Konzepts für den Zugriff auf Ressourcen, denn in Linux ist alles eine Datei, mehr oder weniger. Im Folgenden werden zunächst einige Begriffe erläutert und dann die Darstellung der Metadaten für den Dateizugriff und die Berechtigungen im Detail besprochen.
Es gibt drei Arten von Berechtigungen, von eng bis weit:
- Benutzer
-
Der Eigentümer der Datei
- Gruppe
-
Hat ein oder mehrere Mitglieder
- Andere
-
Die Kategorie für alle anderen
Außerdem gibt es drei Arten von Zugang:
- Lesen (
r) -
Bei einer normalen Datei kann ein Benutzer den Inhalt der Datei einsehen. Bei einem Verzeichnis kann der Benutzer die Namen der Dateien im Verzeichnis anzeigen.
- Schreiben (
w) -
Bei einer normalen Datei kann ein Benutzer die Datei ändern und löschen. Bei einem Verzeichnis kann ein Benutzer Dateien im Verzeichnis erstellen, umbenennen und löschen.
- Ausführen (
x) -
Bei einer normalen Datei kann ein Benutzer die Datei ausführen, wenn er auch Leserechte für die Datei hat. Bei einem Verzeichnis kann ein/e Benutzer/in auf die Dateiinformationen im Verzeichnis zugreifen, d. h. er/sie kann in das Verzeichnis wechseln (
cd) oder dessen Inhalt auflisten (ls).
Schauen wir uns die Dateiberechtigungen in Aktion an (beachte, dass die Leerzeichen, die du hier in der Ausgabe des Befehlsls siehst, zur besseren Lesbarkeit erweitert wurden):
$ls-altotal0-rw-r--r--1mh9devs9Apr1211:42test^^^^^^^||||||└──|||||└──||||└──|||└──||└──|└──└──
Dateiname
Zeitstempel der letzten Änderung
Dateigröße in Bytes
Gruppe, zu der die Datei gehört
Dateibesitzer
Anzahl der harten Verbindungen
Datei-Modus
Wenn wir den Dateimodusvergrößern - alsoden Dateityp und die Berechtigungen, die im vorangegangenen Ausschnitt als ![]() im vorangegangenen Ausschnitt - haben wir Felder mit der folgenden Bedeutung:
im vorangegangenen Ausschnitt - haben wir Felder mit der folgenden Bedeutung:
.rwxrwxrwx^^^^|||└──||└──|└──└──
Erlaubnisse für andere
Berechtigungen für die Gruppe
Berechtigungen für den Dateibesitzer
Der Dateityp(Tabelle 4-2)
Das erste Feld im Dateimodus steht für den Dateityp; siehe Tabelle 4-2für weitere Details. Der Rest des Dateimodus kodiert die Berechtigungen, die für verschiedene Ziele gesetzt wurden, vom Eigentümer bis zu allen, wie in Tabelle 4-3 aufgeführt.
| Symbol | Semantik |
|---|---|
|
Eine normale Datei (z.B. wenn du |
|
Spezialdatei blockieren |
|
Sonderzeichen-Datei |
|
Hochleistungsdatei (zusammenhängende Daten) |
|
Ein Verzeichnis |
|
Ein symbolischer Link |
|
Eine benannte Pipe (mit |
|
Eine Steckdose |
|
Ein anderer (unbekannter) Dateityp |
Es gibt noch einige andere (ältere oder veraltete) Zeichen wie M oderP, die an der Stelle 0 verwendet werden, die du im Großen und Ganzen ignorieren kannst. Wenn du dich dafür interessierst, was sie bedeuten, rufe info ls -n "What information is listed" auf.
In Kombination legen diese Berechtigungen im Dateimodus fest, was für jedes Element des Zielsets (Benutzer, Gruppe, alle anderen) erlaubt ist, wie inTabelle 4-3 gezeigt, und werden durch denZugriff geprüft und durchgesetzt.
| Muster | Wirksame Erlaubnis | Dezimale Darstellung |
|---|---|---|
|
Keine |
0 |
|
Ausführen |
1 |
|
Schreibe |
2 |
|
Schreiben und ausführen |
3 |
|
Lies |
4 |
|
Lesen und ausführen |
5 |
|
Lesen und Schreiben |
6 |
|
Lesen, schreiben, ausführen |
7 |
Schauen wir uns ein paar Beispiele an:
755-
Voller Zugriff für den Besitzer; Lesen und Ausführen für alle anderen
700-
Voller Zugang für den Eigentümer; kein Zugang für alle anderen
664-
Lese-/Schreibzugriff für Eigentümer und Gruppe; Nur-Lese-Zugriff für andere
644-
Lesen/Schreiben für den Besitzer; schreibgeschützt für alle anderen
400-
Schreibgeschützt für den Besitzer
Die 664 hat auf meinem System eine besondere Bedeutung. Wenn ich eine Datei erstelle, ist das die Standardberechtigung, die ihr zugewiesen wird. Du kannst das mit demBefehlumask überprüfen, der mir in meinem Fall 0002 gibt.
Die setuid Berechtigungen werden verwendet, um dem System mitzuteilen, dass eine ausführbare Datei als Eigentümer mit den Berechtigungen des Eigentümers ausgeführt werden soll. Wenn eine Datei root gehört, kann das zu Problemen führen.
Du kannst die Berechtigungen einer Datei mit chmod ändern. Entweder gibst du die gewünschten Berechtigungseinstellungen explizit an (z. B. 644) oder du verwendest Abkürzungen (z. B. +x, um sie ausführbar zu machen). Aber wie sieht das in der Praxis aus?
Lass uns eine Datei mit chmod ausführbar machen:
$ls-al/tmp/masktest-rw-r--r--1mh9dev0Aug2813:07/tmp/masktest$chmod+x/tmp/masktest$ls-al/tmp/masktest-rwxr-xr-x1mh9dev0Aug2813:07/tmp/masktest
Anfangs sind die Dateiberechtigungen
r/wfür den Besitzer und schreibgeschützt für alle anderen, aka644.Mache die Datei ausführbar.
Jetzt sind die Dateiberechtigungen
r/w/xfür den Besitzer undr/xfür alle anderen, auch bekannt als755.
In Abbildung 4-2 siehst du, was unter der Haube vor sich geht. Beachte, dass du vielleicht nicht jedem das Recht geben willst, die Datei auszuführen. Deshalb wäre es hier besser gewesen, eine chmod 744 zu verwenden, die nur dem Eigentümer die richtigen Rechte gibt, während sie für den Rest nicht geändert wird. Wir werden dieses Thema in "Gute Praktiken" weiter besprechen .
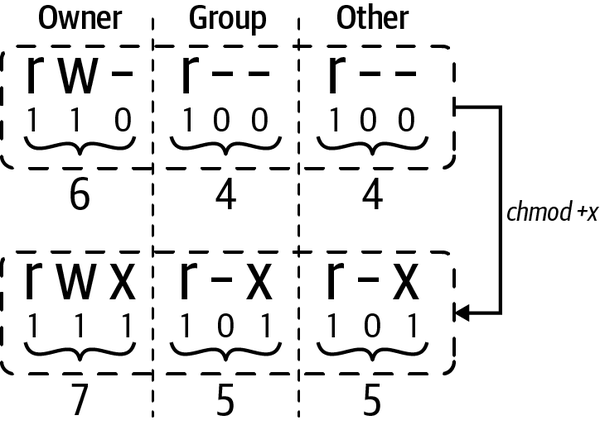
Abbildung 4-2. Eine Datei ausführbar machen und wie sich die Dateiberechtigungen dabei ändern
Du kannst den Besitz auch über chown (und chgrp für die Gruppe) ändern:
$touchmyfile$ls-almyfile-rw-rw-r--1mh9mh90Sep409:26myfile$sudochownrootmyfile-rw-rw-r--1rootmh90Sep409:26myfile
Die Datei myfile, die ich erstellt habe und die mir gehört.
Nach
chownistrootEigentümer dieser Datei.
Nachdem wir uns mit der grundlegenden Rechteverwaltung beschäftigt haben, wollen wir uns nun einige fortgeschrittenere Techniken in diesem Bereich ansehen.
Prozessberechtigungen
Bisher haben wir uns darauf konzentriert, wie menschliche Nutzer auf Dateien zugreifen und welche Berechtigungen dabei eine Rolle spielen. Jetzt wenden wir uns den Prozessen zu. In "Ressourcen und Besitz" haben wir darüber gesprochen, wie Benutzer Dateien besitzen und wie Prozesse Dateien nutzen. Das wirft die Frage auf: Was sind die relevanten Berechtigungen aus der Sicht eines Prozesses?
Wie auf der Handbuchseitecredentials(7) dokumentiert, gibt es verschiedene Benutzer-IDs, die im Zusammenhang mit den Laufzeitberechtigungen relevant sind:
- Echte UID
-
Die echte UID ist die UID des Benutzers, der den Prozess gestartet hat. Sie repräsentiert den Besitz des Prozesses in Bezug auf den menschlichen Benutzer. Der Prozess selbst kann seine reale UID über
getuid(2)abfragen, und du kannst sie über die Shell mitstat -c "%u %g" /proc/$pid/abfragen. - Effektive UID
-
Der Linux-Kernel verwendet die effektive UID, um die Rechte zu bestimmen, die der Prozess beim Zugriff auf gemeinsame Ressourcen wie z. B. Nachrichtenwarteschlangen hat. Auf traditionellen UNIX-Systemen werden sie auch für den Dateizugriff verwendet. Linux hat jedoch früher eine eigene Dateisystem-UID (siehe folgende Diskussion) für Dateizugriffsberechtigungen verwendet, die aus Kompatibilitätsgründen immer noch unterstützt wird. Ein Prozess kann seine effektive UID erhalten über
geteuid(2). - Gespeicherte set-user-ID
-
Gespeicherte set-user-IDs werden in
suidFällen verwendet, in denen ein Prozess Privilegien übernehmen kann, indem er seine effektive UID zwischen der realen UID und der gespeicherten set-user-ID umschaltet. Damit ein Prozess beispielsweise bestimmte Netzwerk-Ports nutzen darf (siehe "Ports"), benötigt er erhöhte Privilegien, wie z.B. alsrootausgeführt zu werden. Ein Prozess kann seine gespeicherten set-user-IDs erhalten übergetresuid(2). - Dateisystem UID
-
Diese Linux-spezifischen IDs werden verwendet, um die Berechtigungen für den Dateizugriff zu bestimmen. Diese UID wurde ursprünglich eingeführt, um Anwendungsfälle zu unterstützen, in denen ein Dateiserver im Namen eines regulären Benutzers agiert und den Prozess von Signalen dieses Benutzers isoliert. Programme manipulieren diese UID normalerweise nicht direkt. Der Kernel merkt sich, wann die effektive UID geändert wird und ändert automatisch die UID des Dateisystems mit. Das bedeutet, dass die Dateisystem-UID normalerweise dieselbe ist wie die effektive UID, aber über
setfsuid(2). Beachte, dass diese UID seit Kernel v2.0 technisch nicht mehr notwendig ist, aber ausKompatibilitätsgründen immer noch unterstützt wird.
Wenn ein Kindprozess über fork(2) erstellt wird, erbt er zunächst Kopien der UIDs seiner Eltern und während eines execve(2) Systemaufrufs bleibt die echte UID des Prozesses erhalten, während sich die effektive UID und die gespeicherte set-user-ID ändern können.
Wenn du zum Beispiel den Befehl passwd ausführst, ist deine effektive UID deine UID, sagen wir 1000. Bei passwd ist suid aktiviert, d.h. wenn du den Befehl ausführst, ist deine effektive UID 0 (auch bekannt als root). Es gibt auch andere Möglichkeiten, die effektive UID zu beeinflussen - zum Beispiel mit chroot und anderen Sandboxing-Techniken.
Hinweis
POSIX-Threads erfordern, dass die Anmeldeinformationen von allen Threads eines Prozesses gemeinsam genutzt werden. Auf der Kernel-Ebene verwaltet Linux jedoch für jeden Thread eigene Benutzer- und Gruppenanmeldeinformationen.
Zusätzlich zu den Dateizugriffsrechten verwendet der Kernel Prozess-UIDs für andere Dinge, einschließlich, aber nicht beschränkt auf die folgenden:
-
Festlegen von Berechtigungen für das Senden von Signalen - zum Beispiel um zu bestimmen, was passiert, wenn du eine
kill -9für eine bestimmte Prozess-ID machst. Darauf kommen wir in Kapitel 6 zurück. -
Berechtigungsverwaltung für Zeitplanung und Prioritäten (z. B.
nice). -
Überprüfung der Ressourcenlimits, die wir im Zusammenhang mit Containern in Kapitel 9 ausführlich besprechen werden.
Während es im Kontext von suid einfach sein kann, mit effektiver UID zu argumentieren, wird es schwieriger, sobald Fähigkeiten ins Spiel kommen.
Erweitertes Berechtigungsmanagement
Obwohl wir uns bisher auf weit verbreitete Mechanismen konzentriert haben, sind die Themen in diesem Abschnitt in gewisser Weise fortgeschritten und nicht unbedingt etwas, was du in einem Gelegenheits- oder Hobby-Setup in Betracht ziehen würdest. Für den professionellen Einsatz, d. h. für Produktionsanwendungen, bei denen geschäftskritische Workloads eingesetzt werden, solltest du zumindest die folgenden fortgeschrittenen Ansätze zur Rechteverwaltung kennen.
Fähigkeiten
Unter Linux hat der Benutzer root, wie in UNIX-Systemen üblich, keine Einschränkungen beim Ausführen von Prozessen. Mit anderen Worten: Der Kernel unterscheidet nur zwischen zwei Fällen:
-
Privilegierte Prozesse, die die Kernel-Berechtigungsprüfungen umgehen, mit einer effektiven UID von 0 (auch bekannt als
root) -
Unprivilegierte Prozesse mit einer effektiven UID ungleich Null, für die der Kernel Berechtigungsprüfungen durchführt, wie in "Prozessberechtigungen" beschrieben
Mit der Einführung derCapabilities syscall in Kernel v2.2 hat sich diese binäre Weltsicht geändert: Die Privilegien, die traditionell mit root verbunden waren, sind nun in verschiedene Einheiten aufgeteilt, die unabhängig voneinander auf der Ebene eines einzelnen Threads zugewiesen werden können.
In der Praxis ist es so, dass ein normaler Prozess null Fähigkeiten hat, die durch die im vorherigen Abschnitt besprochenen Berechtigungen kontrolliert werden. Du kannst sowohl ausführbaren Dateien (Binärdateien und Shell-Skripte) als auch Prozessen Fähigkeiten zuweisen, um nach und nach die für die Ausführung einer Aufgabe erforderlichen Berechtigungen hinzuzufügen (siehe die Diskussion in "Gute Praktiken").
Ein Wort der Warnung: Fähigkeiten sind in der Regel nur für Aufgaben auf Systemebene relevant. Mit anderen Worten: Die meiste Zeit wirst du nicht unbedingt auf sie angewiesen sein.
In Tabelle 4-4 siehst du einige der am häufigsten verwendeten Funktionen.
| Fähigkeit | Semantik |
|---|---|
|
Erlaubt dem Benutzer, beliebige Änderungen an den UIDs/GIDs von Dateien vorzunehmen |
|
Erlaubt das Senden von Signalen an Prozesse, die anderen Benutzern gehören |
|
Erlaubt das Ändern der UID |
|
Ermöglicht die Einstellung der Fähigkeiten eines laufenden Prozesses |
|
Ermöglicht verschiedene netzwerkbezogene Aktionen, wie z. B. die Konfiguration der Schnittstelle |
|
Ermöglicht die Verwendung von RAW- und PACKET-Sockets |
|
Erlaubt den Aufruf |
|
Ermöglicht Systemverwaltungsvorgänge, einschließlich des Einhängens von Dateisystemen |
|
Ermöglicht die Verwendung von |
|
Ermöglicht das Laden von Kernel-Modulen |
Schauen wir uns nun die Fähigkeiten in Aktion an. Für den Anfang kannst du Befehle wie die folgenden verwenden, um die Fähigkeiten zu sehen (die Ausgabe wurde entsprechend angepasst):
$capshCurrent:=Boundingset=cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,...$grepCap/proc/$$/statusCapInh:0000000000000000CapPrm:0000000000000000CapEff:0000000000000000CapBnd:000001ffffffffffCapAmb:0000000000000000
Überblick über alle Funktionen des Systems
Fähigkeiten für den aktuellen Prozess (die Shell)
Mitgetcap undsetcap kannst du die Fähigkeiten detailliert, d.h. für jede einzelne Datei, verwalten (die Details und bewährten Verfahren gehen über den Rahmen dieses Kapitels hinaus).
Fähigkeiten helfen dabei, von einem Alles-oder-Nichts-Ansatz zu feiner abgestuften Berechtigungen auf Dateibasis überzugehen. Kommen wir nun zu einem anderen Thema der erweiterten Zugriffskontrolle: die Sandboxing-Technik von seccomp.
seccomp-Profile
Der Secure Computing Mode (seccomp)ist eine Linux-Kernel-Funktion, die seit 2005 verfügbar ist. Die Grundidee hinter dieser Sandbox-Technik ist, dass du mit einem speziellen Syscall namens seccomp(2) die Syscalls einschränken kannst, die ein Prozess verwenden kann.
Auch wenn du es unbequem findest, seccomp selbst zu verwalten, gibt es Möglichkeiten, es ohne viel Aufwand zu nutzen. Im Zusammenhang mit Containern (siehe "Container") unterstützen zum Beispiel sowohlDocker als auchKubernetes seccomp.
Werfen wir nun einen Blick auf eine Erweiterung der traditionellen, granularen Dateiberechtigung.
Zugriffskontroll-Listen
Mit den Zugriffskontrolllisten (ACLs) gibt es in Linux einen flexiblen Berechtigungsmechanismus, den du zusätzlich zu den "traditionellen" Berechtigungen, die unter "Dateiberechtigungen" besprochen werden , verwenden kannst . ACLs beheben ein Manko der traditionellen Berechtigungen, denn sie ermöglichen es, einem Benutzer oder einer Gruppe, die nicht in der Gruppenliste eines Benutzers enthalten ist, Berechtigungen zu erteilen.
Um zu überprüfen, ob deine Distribution ACLs unterstützt, kannst dugrep -i acl /boot/config* verwenden, wobei du hoffst, irgendwo in der Ausgabe ein POSIX_ACL=Y zu finden, um dies zu bestätigen. Um eine ACL für ein Dateisystem zu verwenden, muss sie beim Einhängen mit der Option acl aktiviert werden. Die Docs-Referenz zuacl enthält viele nützliche Details.
Wir werden hier nicht näher auf ACLs eingehen, da sie den Rahmen dieses Buches sprengen würden. Allerdings kann es von Vorteil sein, sie zu kennen und zu wissen, wo man anfangen muss, wenn man ihnen in freier Wildbahn begegnet.
Daher sollten wir uns einige bewährte Verfahren für die Zugriffskontrolle ansehen.
Bewährte Praktiken
Im Folgenden findest du einige "bewährte Sicherheitsverfahren" im Zusammenhang mit der Zugriffskontrolle. Auch wenn einige davon eher in professionellen Umgebungen anwendbar sind, sollte jeder sie zumindest kennen.
- Geringste Privilegien
-
Das Prinzip der geringsten Privilegien besagt, dass eine Person oder ein Prozess nur die notwendigen Rechte haben sollte, um eine bestimmte Aufgabe zu erfüllen. Wenn eine App zum Beispiel nicht in eine Datei schreiben darf, braucht sie nur Lesezugriff. Im Zusammenhang mit der Zugriffskontrolle kannst du die geringsten Privilegien auf zwei Arten nutzen:
-
In "Dateiberechtigungen" haben wir gesehen, was passiert, wenn du
chmod +xverwendest. Zusätzlich zu den von dir beabsichtigten Berechtigungen werden auch einige zusätzliche Berechtigungen an andere Benutzer vergeben. Die Verwendung expliziter Berechtigungen über den Zahlenmodus ist besser als der symbolische Modus. Mit anderen Worten: Letzterer ist zwar bequemer, aber weniger streng. -
Vermeide es so oft wie möglich, als root zu laufen. Wenn du zum Beispiel etwas installieren musst, solltest du
sudoverwenden und dich nicht alsrootanmelden.
Wenn du eine Anwendung schreibst, kannst du eine SELinux-Richtlinie verwenden, um den Zugriff auf ausgewählte Dateien, Verzeichnisse und andere Funktionen zu beschränken. Im Gegensatz dazu könnte das Standard-Linux-Modell der Anwendung potenziell Zugriff auf alle Dateien geben, die auf dem System geöffnet sind.
-
- Setuid vermeiden
-
Nutze die Möglichkeiten, statt dich auf
setuidzu verlassen. Das ist wie ein Vorschlaghammer und bietet Angreifern eine gute Möglichkeit, dein System zu übernehmen. - Rechnungsprüfung
-
Beim Auditing geht es darum, dass du Aktionen (und die ausführenden Personen) so aufzeichnest, dass das Protokoll nicht manipuliert werden kann. Anhand dieses schreibgeschützten Protokolls kannst du dann überprüfen, wer was wann getan hat. Wir werden dieses Thema in Kapitel 8 vertiefen.
Fazit
Jetzt, wo du weißt, wie Linux Benutzer, Dateien und den Zugriff auf Ressourcen verwaltet, hast du alles zur Hand, um Routineaufgaben sicher und zuverlässig zu erledigen.
Für die praktische Arbeit mit Linux solltest du dich an die Beziehung zwischen Benutzern, Prozessen und Dateien erinnern. Das ist im Zusammenhang mit dem Mehrbenutzer-Betriebssystem, das Linux ist, entscheidend für einen sicheren Betrieb und um Schäden zu vermeiden.
Wir haben die Arten der Zugriffskontrolle besprochen, definiert, was Benutzer in Linux sind, was sie tun können und wie man sie sowohl lokal als auch zentral verwaltet. Das Thema Dateizugriffsrechte und deren Verwaltung kann knifflig sein und ist vor allem eine Frage der Übung.
Fortgeschrittene Berechtigungstechniken wie Capabilities und Seccomp-Profile sind im Kontext von Containern besonders wichtig.
Im letzten Abschnitt haben wir bewährte Praktiken für die Sicherheit bei der Zugriffskontrolle besprochen, insbesondere die Anwendung der geringsten Privilegien.
Wenn du tiefer in die in diesem Kapitel behandelten Themen eintauchen möchtest, findest du hier einige Ressourcen:
- Allgemein
-
-
"A Survey of Access Control Policies" von Amanda Crowell
-
Lynis, ein Werkzeug für Audits und Compliance-Tests
-
- Fähigkeiten
- seccomp
- Zugriffskontroll-Listen
Erinnere dich daran, dass Sicherheit ein fortlaufender Prozess ist, also musst du Benutzer und Dateien im Auge behalten. Darauf werden wir in den Kapiteln 8 und 9 näher eingehen, aber jetzt lass uns erst einmal zum Thema Dateisysteme kommen.
Get Modernes Linux lernen now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

