Chapter 4. CRUD and CQRS
Two of the most popular patterns for dealing with data manipulation are Create, Read, Update, and Delete (CRUD) and Command and Query Responsibility Segregation (CQRS). Most developers are familiar with CRUD because the majority of the material and tools available try to support this pattern in one way or another. Any tool or framework that is promoted as a fast way to deliver your software to market provides some sort of scaffolding or dynamic generation of CRUD operations.
Things start to get blurry when we talk about CQRS. Certainly the subject of microservices will usually invoke CQRS in many different discussions between people at conferences and among members of development teams, but personal experience shows that we still have plenty of room for clarification. If you look for the term “CQRS” on a search engine, you will find many good definitions. But even after reading those, it might be difficult to grasp exactly the “why” or even the “how” of CQRS.
This chapter will try to present clear distinction between and motivation behind using both CRUD and CQRS patterns. And any discussion about CQRS won’t be complete if we do not understand the different consistency models that are involved in distributed systems—how these systems handle read and write operations on the data state in different nodes. We’ll start our explanation with these concepts.
Consistency Models
When we’re talking about consistency in distributed systems, we are referring to the concept that you will have some data distributed in different nodes of your system, and each one of those might have a copy of your data. If it’s a read-only dataset, any client connecting to any of the nodes will always receive the same data, so there is no consistency problem. When it comes to read-write datasets, some conflicts can arise. Each one of the nodes can update its own copy of the data, so if a client connects to different nodes in your system, it might receive different values for the same data.
The way that we deal with updates on different nodes and how we propagate the information between them leads to different consistency models. The description presented in the next sections about eventual consistency and strong consistency is an over-simplification of the concepts, but it should paint a sufficiently complete picture of them within the context of information integration between microservices and relational databases.
Eventual Consistency
Eventual consistency is a model in distributed computing that guarantees that given an update to a data item in your dataset, eventually, at a point in the future, all access to this data item in any node will return the same value. Because each one of the nodes can update its own copy of the data item, if two or more nodes modify the same data item, you will have a conflict. Conflict resolution algorithms are then required to achieve convergence.1 One example of a conflict resolution algorithm is last write wins. If we are able to add a synchronized timestamp or counter to all of our updates, the last update always wins the conflict.
One special case for eventual consistency is when you have your data distributed in multiple nodes, but only one of them is allowed to make updates to the data. If one node is the canonical source of information for the updates, you won’t have conflicts in the other nodes as long as they are able to apply the updates in the exact same order as the canonical information source. You add the possibility of write unavailability, but that’s a bearable trade-off for some business use cases. We explore this subject in greater detail in “Event Sourcing”.
Strong Consistency
Strong consistency is a model that is most familiar to database developers, given that it resembles the traditional transaction model with its Atomicity, Consistency, Isolation, and Durability (ACID) properties. In this model, any update in any node requires that all nodes agree on the new value before making it visible for client reads. It sounds naively simple, but it also introduces the requirement of blocking all the nodes until they converge. It might be especially problematic depending on network latency and throughput.
Applicability
There are always exceptions to any rule, but eventual consistency tends to be favored for scenarios in which high throughput and availability are more important requirements than immediate consistency. Keep in mind that most real-world business use cases are already eventual consistency. When you read a web page or receive a spreadsheet or report through email, you are already looking at information as it was some seconds, minutes, or even hours ago. Eventually all information converges, but we’re used to this eventuality in our lives. Shouldn’t we also be used to it when developing our applications?
CRUD
CRUD architectures are certainly the most common architectures in traditional data manipulation applications. In this scenario, we use the same data model for both read and write operations, as shown in Figure 4-1. One of the key advantages of this architecture is its simplicity—you use the same common set of classes for all operations. Tools can easily generate the scaffolding code to automate its implementation.
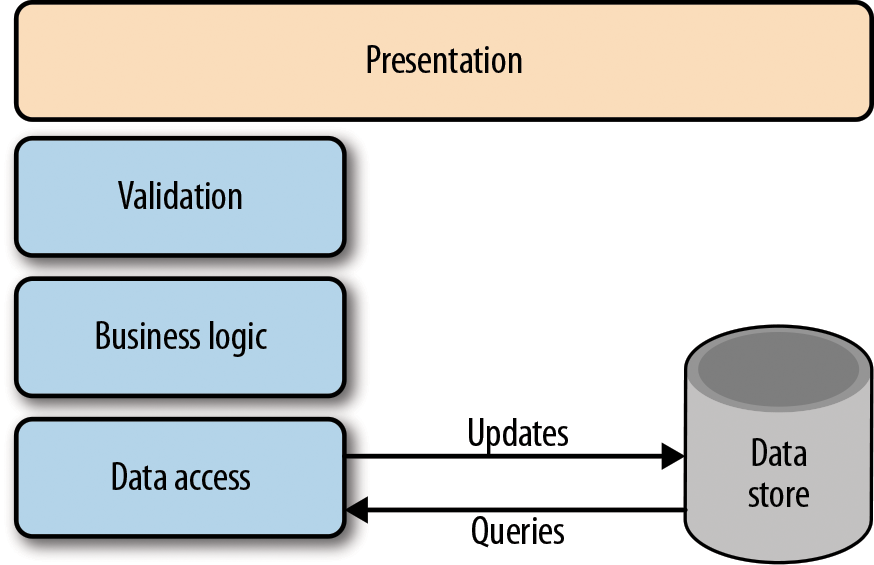
Figure 4-1. A traditional CRUD architecture (Source)
If we implemented a Customer class in our project and wanted to change the Customer’s name, we would retrieve a Customer entity from our data store, change the property, and then issue an update statement to our data store to have the representation persisted.
It’s a very common practice nowadays to see a CRUD architecture being implemented through REST endpoints exposed over HTTP.
Probably the majority of basic data manipulation operations will be best served using a CRUD architecture, and in fact that’s our recommended approach for that. However, when complexity begins to arise in your use cases, you might want to consider something different. One of the things missing in a CRUD architecture is intent.
Suppose that we wanted to change the Customer’s address. In a CRUD architecture, we just update the property and issue an update statement. We can’t figure out if the change was motivated by an incorrect value or if the customer moved to another city. Maybe we have a business scenario in which we were required to trigger a notification to an external system in case of a relocation. In this case, a CQRS architecture might be a better fit.
CQRS
CQRS is a fancy name for an architecture that uses different data models to represent read and write operations.
Let’s look again at the scenario of changing the Customer’s address. In a CQRS architecture (see Figure 4-2), we could model our write operations as Commands. In this case, we can implement a WrongAddressUpdateCommand and a RelocationUpdateCommand. Internally, both would be changing the Customer data store. But now that we know the intent of the update, we can fire the notification to the external system only in the RelocationUpdateCommand code.
For the read operations, we will be invoking some query methods on a read interface, such as CustomerQueryService, and we would be returning Data Transfer Objects (DTOs)2 to be exposed to our presentation layer.
Things start to become even more interesting when we realize that we don’t need to use the same data store for both models. We can use a simple CQRS architecture, such as the one represented in Figure 4-2, or we can split the read and write data stores into separate tables, schemas, or even database instances or technologies, as demonstrated in Figure 4-3. The possibility of using data stores in different nodes with different technologies sounds tempting for a microservices architecture.
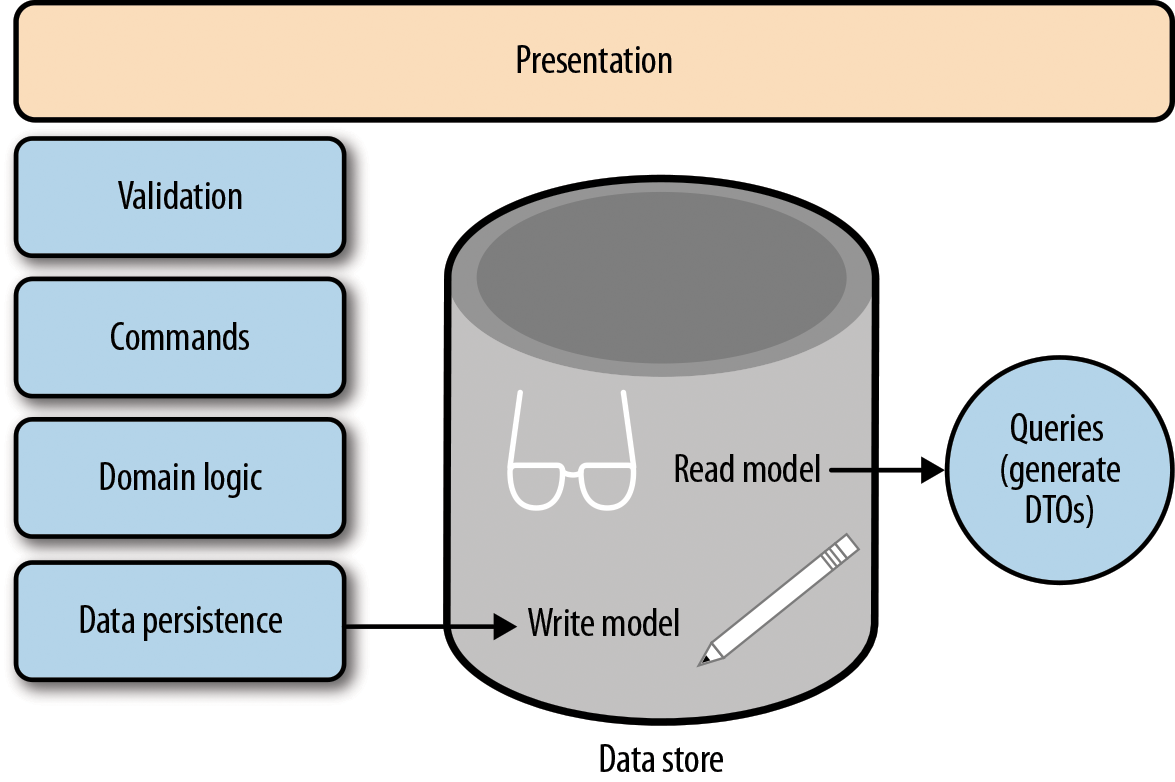
Figure 4-2. A basic CQRS architecture (Source)
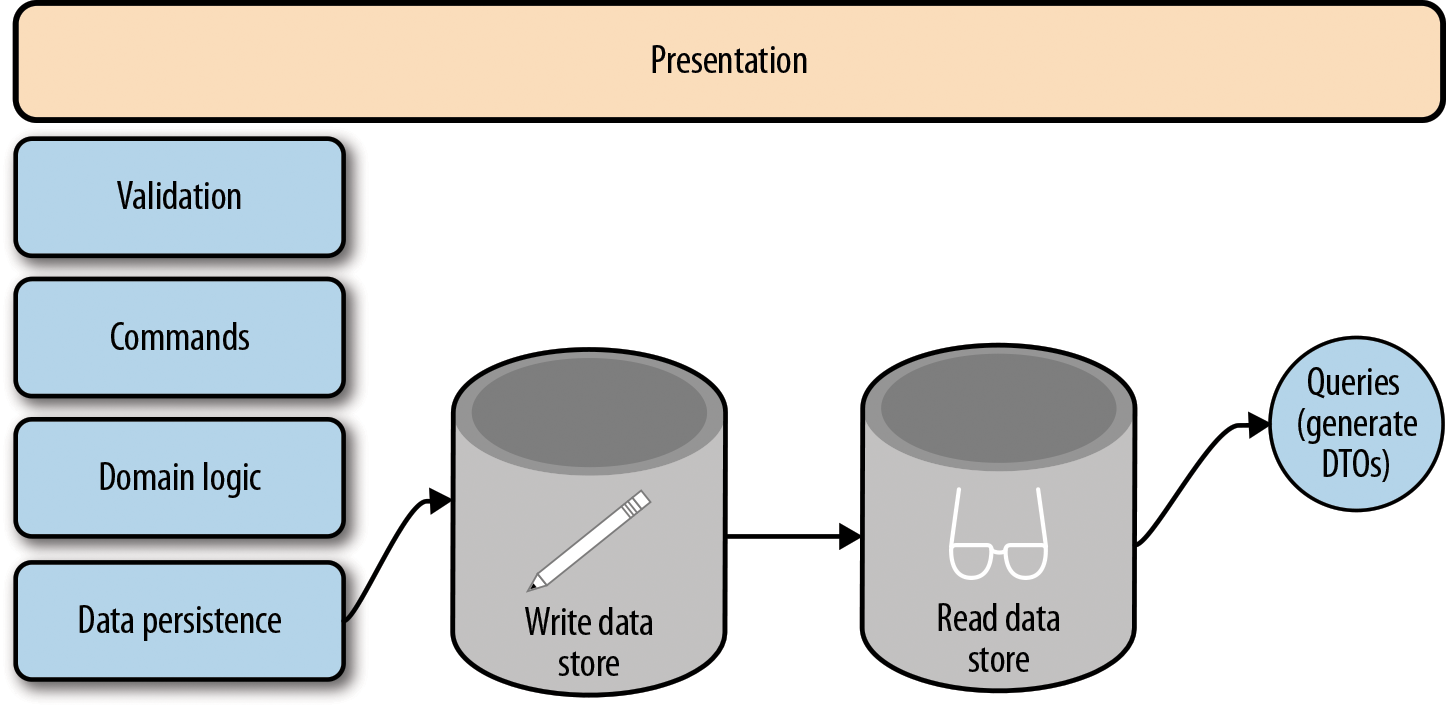
Figure 4-3. A CQRS architecture with separate read and write stores (Source)
Some motivations for using separate data stores for read and write operations are performance and distribution. Your write operations might generate a lot of contention on the data store. Or your read operations may be so intensive that the write operations degrade significantly. You also might need to consolidate the information of your model using information provided by other data stores. This can be time consuming and won’t perform well if you try to update the read model together with your write model. You might want to consider doing that asynchronously. Your read operations could be implemented in a separate service (remember microservices?), so you would need to issue the update request to the read model in a remote data store.
CQRS and Multiple Read Data Stores
It’s not unusual for an application to use the same information in a number of different ways. Sometimes you need one subset of the information; at other times, you might need another subset of the information. Sometimes different features of your application consume different aggregate information from the same data store. Different requirements also allow you to have different consistency models between read data stores, even though the write data store might be the same.
When you design your application with CQRS, you’re not tied to having a single read data store in your model. If you have different requirements for different features of your application, you can create more than one read data store, each one with a read model optimized for the specific use case being implemented.
Whenever we’re issuing the update requests to another component of our system, we are creating an event. It’s not a strict requirement, but when events come to play, that’s the moment we strongly consider adding a message broker to our architecture. You could be storing the events in a separate table and keep polling for new records, but for most implementations, a message broker will be the wisest choice because it favors a decoupled architecture. And if you’re using a Java Platform, Enterprise Edition (Java EE) environment, you already have that for free anyway.
Event Sourcing
Sometimes one thing leads to another, and now that we’ve raised the concept of events, we will also want to consider the concept of event sourcing.
Event sourcing is commonly used together with CQRS. Even though neither one implies the use of the other, they fit well together and complement each other in interesting ways. Traditional CRUD and CQRS architectures store only the current state of the data in the data stores. It’s probably OK for most situations, but this approach also has its limitations:
-
Using a single data store for both operations can limit scalability due to performance problems.
-
In a concurrent system with multiple users, you might run into data update conflicts.
-
Without an additional auditing mechanism, you have neither the history of updates nor its source.
Other Auditing Approaches
Event sourcing is just one of the possible solutions when auditing is a requirement for your application. Some database patterns implemented by your application or through triggers can keep an audit trail of what has changed and when, creating some sort of event sourcing in the sense that the change events are recorded.
You can add triggers to the database in order to create these change events, or you can use an open source tool like Hibernate Envers to achieve that if you’re already using Hibernate in your project. With Hibernate Envers, you even have the added benefit of built-in query capabilities for you versioned entities.
To solve this limitation in event sourcing, we model the state of the data as a sequence of events. Each one of these events is stored in an append-only data store. In this case, the canonical source of information is the sequence of events, not a single entity stored in the data store.
We’ll use the classic example of the amount of money stored in a bank account. Without using event sourcing, a credit() operation to the amount of a bank account would need to do the following:
-
Query the bank account to get the current value
-
Add the supplied amount to the current value of the entity
-
Issue an update to the data store with the new value
All of the preceding operations would probably be executed inside a single method within the scope of a single transaction.
With event sourcing, there’s no single entity responsible for the amount of money stored in the bank account. Instead of updating the bank account directly, we would need to create another entity that represents the credit() operation. We can call it CreditOperation and it contains the value to be credited. Then we would be required to do the following:
-
Create a
CreditOperationwith the amount to be credited -
Issue an insert to the data store with the
CreditOperation
Assuming that all bank accounts start with a zero balance, it’s just a matter of sequentially applying all the credit() and debit() operations to compute the current amount of money. You probably already noticed that this is not a computational-intensive operation if the number of operations is small, but the process tends to become very slow as the size of the dataset grows. That’s when CQRS comes to the assistance of event sourcing.
With CQRS and event sourcing, you can store the credit() and debit() operations (the write operations) in a data store and then store the consolidated current amount of money in another data store (for the read operations). The canonical source of information will still be the set of credit() and debit() operations, but the read data store is created for performance reasons. You can update the read data store synchronously or asynchronously. In a synchronous operation, you can achieve strong or eventual consistency; in an asynchronous operation, you will always have eventual consistency. There are many different strategies for populating the read data store, which we cover in Chapter 5.
Notice that when you combine CQRS and event sourcing you get auditing for free: in any given moment of time, you can replay all the credit() and debit() operations to check whether the amount of money in the read data store is correct. You also get a free time machine: you can check the state of your bank account at any given moment in the past.
Get Migrating to Microservice Databases now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

