Capítulo 1. ¿Por qué debería migrar a Amazon Web Services?
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Me pregunté si poner una pregunta tan cargada como primer capítulo de mi libro era una buena idea. La lista real de razones para migrar a AWS podría ser tan larga como este libro, pero como dice Simon Sinek, "Empieza siempre por el porqué".1 Así pues, me pareció prudente. El mayor obstáculo que encontrarás es la reticencia de la gente al cambio. Migrar a AWS desde tu plataforma actual supone un cambio en la forma de operar de las personas y en las habilidades necesarias. Una narrativa sólida en torno al porqué te permitirá inspirar a las personas que te rodean y obtener mejores resultados, al tiempo que eliminas las reticencias. Este capítulo profundizará en muchas ventajas tecnológicas y empresariales que se obtienen al migrar a la nube. Con esta información, podrás proporcionar el porqué a los niveles superiores de la dirección y al personal.
Mientras lees este capítulo, te animo a que pienses en las situaciones que vive tu empresa y en cómo se relacionan estos beneficios.
Una forma que ha funcionado bien en el pasado para comunicar el porqué a los compañeros de trabajo es a través de un conjunto de preguntas frecuentes (FAQ). Más adelante, en este mismo capítulo, explicaremos cómo elaborar tus FAQ para comunicar el porqué a la alta dirección y al personal. Puedes conseguirlo anticipándote a las preguntas que te harán y elaborando respuestas basadas en los beneficios que obtendrá tu empresa. Completando este ejercicio, ganarás aceptación y disminuirán los detractores. Aumentarás la probabilidad de éxito y la eficacia de la transición.
Ventajas de la tecnología en la nube
AWS ofrece varias ventajas con las últimas tecnologías de perímetro. Sin embargo, no todas estas tecnologías y sus ventajas se aplican a todas las empresas. En lugar de recorrer todas las ventajas, recorreremos las ventajas técnicas que se aplican a todas las empresas. Puede que no sean llamativas, pero crean una base sólida sobre la que construir tu infraestructura. Si aprovechas estas ventajas mientras migras a AWS, obtendrás suficientes ahorros de capital y tiempo para financiar la prueba de tecnologías más avanzadas. He podido ahorrar a empresas millones de dólares utilizando estos métodos, que luego pueden reinvertir en innovación. Estoy de acuerdo en que transcribir automáticamente las llamadas de atención al cliente y analizar el sentimiento de los clientes es una herramienta impresionante y poderosa para tu empresa. Sin embargo, creo que la migración es una de las situaciones de "arrastrarse antes de andar". Como gestor, tu principal preocupación es asegurarte de que la migración satisface las necesidades y normativas de tu empresa. Implantar la última IA de perímetro es secundario; al fin y al cabo, la infraestructura que tienes hoy es la que paga las facturas y proporciona valor a tu cliente actual.
Escalabilidad y consumo dinámico
Cuando migras a AWS, tienes que centrarte en desviar tu forma de pensar de cómo solías operar la infraestructura on-premise. Muchos de los patrones de diseño y procesos operativos convencionales son antipatrones en la nube. Para la escalabilidad y el consumo , muchos de estos antipatrones aparecen al principio de tu migración. Lo mejor es identificarlos y superarlos rápidamente. Cambiar tu actual proceso de pensamiento en torno a la escalabilidad en las instalaciones te proporcionará inmediatamente ahorro de costes y agilidad al compararla con la escalabilidad en la nube. Antes de tratar estos nuevos patrones y por qué los patrones locales son antipatrones, repasaremos la escalabilidad que te ofrece AWS. De nuevo, mientras lees, puede tener sentido que apuntes algunas notas sobre tus aplicaciones y sobre cómo estos métodos de escalado podrían mejorar tus capacidades.
Escalado vertical
El escalado vertical es la práctica de añadir computación y memoria a un servidor para aumentar el rendimiento disponible para la carga de trabajo. Yo lo comparo con ser Amish y arar mi campo. Estoy arando una nueva hilera, pero la tierra se endurece. Para terminar de arar, desengancho mi caballo de cuarto de milla, voy al granero y consigo un caballo de tiro más grande. La escalada vertical no es una idea novedosa para la nube. Ha estado ahí todo el tiempo en tu centro de datos y, según mi experiencia, es el método al que se recurre para mejorar el rendimiento y aumentar la capacidad. Sin embargo, la migración a AWS conlleva algunas diferencias clave.
Cuando tienes tu infraestructura funcionando en AWS, tienes un modelo de consumo dinámico de pago por uso, en lugar de un modelo de prepago. Me gusta explicarlo como las mareas: la gravedad de la luna tira de la tierra y eleva el nivel del agua del océano a su paso. Esta analogía refleja el uso de tu infraestructura a lo largo del día: tu carga de recursos fluye y refluye. Al igual que la marea, acabas teniendo un nivel de agua alto y otro bajo. La diferencia con la nube es que sólo pagas por lo que utilizas; sólo debes comprar en la marca de agua baja. Luego pagas incrementalmente por más consumo durante los momentos de mayor uso. En las instalaciones, tienes que precomprar en la marca de agua alta. Para complicar aún más la cuestión, debes prever tu consumo durante la vida útil del hardware, que estará por encima o por debajo del consumo real. Los recursos infrautilizados son una sangría para la financiación de tu empresa, y los recursos sobreutilizados proporcionan una mala experiencia al usuario. En mi analogía, la compra de equipos locales puede imaginarse como la construcción de un muelle. Si colocas el muelle demasiado alto, tendrás que poner escaleras para que la gente llegue a sus barcos. Si colocas el muelle demasiado bajo, estarán chapoteando en el agua. AWS es un muelle flotante y elimina ambos problemas; sube y baja, proporcionando unas condiciones óptimas. La Figura 1-1 muestra el aspecto de la compra y el consumo de prepago a lo largo de su vida útil.
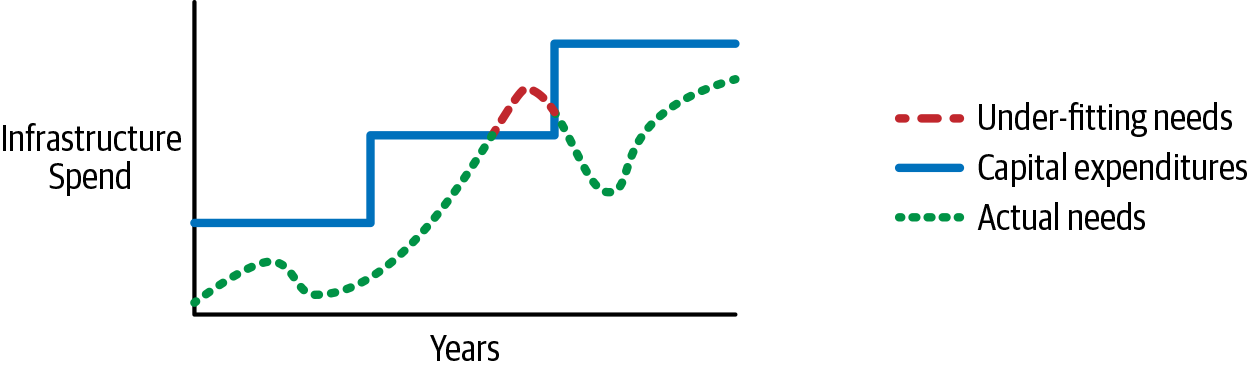
Figura 1-1. Costes de las infraestructuras a lo largo del tiempo
La Figura 1-1 muestra muy bien cómo la compra de equipos in situ se ajusta demasiado o demasiado poco a las necesidades de tu empresa. Si comparas la línea de puntos, que representa tu necesidad, y la línea continua, que representa tus gastos de capital, verás hasta qué punto la diferencia entre ambas fluye y refluye. En un momento dado, la demanda supera la capacidad de la infraestructura, lo que se indica cuando la línea está discontinua, lo que significa que no tienes capacidad suficiente para dar servicio a los clientes. Yo diría que no tener capacidad suficiente no es habitual. La mayoría de la gente, incluido yo, compra más de lo que necesita, por lo que nunca se produce una situación así. Tener constantemente recursos informáticos de bajo rendimiento es una buena razón para que tu jefe te pida que vacíes tu mesa. Lo importante que muestra este gráfico es cómo debes comprar no sólo para la marca de agua alta, sino también para bastante más. El exceso garantiza una capacidad suficiente, y todo el espacio entre las líneas punteada y continua es capital desperdiciado. La capacidad dinámica de AWS elimina este exceso y el capital perdido, permitiéndote utilizar esos fondos para otras necesidades empresariales.
Si piensas en tu historia reciente, tal vez recuerdes una conversación muy parecida al siguiente escenario.
Este es un escenario frecuente, tanto en las instalaciones como en la nube. Hay algunas cosas sobre las que me gustaría llamar la atención y que cambiarán después de migrar a AWS. En primer lugar, instancia es la nomenclatura de AWS para un servidor o máquina virtual del servicio Elastic Compute Cloud (EC2), y estos términos pueden utilizarse indistintamente. Sin embargo, utilizaré instancia siempre que hable de un servidor en AWS, y servidor o máquina virtual para indicar un servidor en las instalaciones. La segunda es la afirmación "el uso de memoria está dentro de los límites". Cuando trabajas con el dimensionamiento de instancias en AWS, no puedes ajustar la CPU y la memoria por separado. Debes encontrar la instancia más pequeña que cumpla el objetivo de memoria o CPU, y la que no sea tu objetivo se queda en el camino. En este ejemplo, la capacidad de la CPU es tu objetivo. Cuando aumentes en dos CPU más en AWS, tu memoria también aumentará. En tercer lugar, puede ser mejor utilizar el escalado horizontal, para hacer girar más instancias cuando sea necesario para hacer frente a la carga, en lugar de hacer un cambio vertical permanente. Hablaremos del escalado horizontal en la siguiente sección.
Nota
AWS ofrece una capacidad llamada Optimizar CPUs para las instancias de Amazon EC2. Esta capacidad te permite establecer el número de CPUs cuando lanzas una instancia. El ajuste no puede modificarse posteriormente y no altera la tasa de ejecución de la instancia. Estas limitaciones pueden no ser evidentes inmediatamente al leer la documentación y hacer que parezca que AWS funciona como las capacidades locales. La razón principal de la función Optimizar CPUs es la licencia de software basada en el recuento de CPU y los casos de uso de perímetro cuando la CPU es baja y a la vez se requiere mucha RAM.
Veamos otro escenario posible.
En esta situación, AWS puede brillar reduciendo tus costes de operación. Como ya se ha mencionado, mientras estés en las instalaciones, deberás comprar equipos para cumplir con tu alto nivel de exigencia, por lo que ya has comprometido fondos para hacer funcionar tu entorno. Asignar más potencia de CPU para abordar el procesamiento por lotes es irrelevante para los costes de funcionamiento. Sin embargo, en AWS, estás comprando en la marca de agua baja, y es mejor quedarse ahí.
Te estarás preguntando cómo resolver el problema del rendimiento. Lo mejor es resolver este escenario utilizando un escalado vertical temporal. Sabes cuándo surgirá esta carga de trabajo, y sabes que sólo es temporal. No tendría sentido aumentar la capacidad para abordar el proceso por lotes de forma permanente. Utilizando eventos programados o software de terceros, puedes programar el escalado de este servidor antes de la carga de trabajo y volver a escalarlo después de que termine el trabajo. El escalado temporal te proporcionaría la operación más rentable.
Escala horizontal
Aunque el escalado vertical añade más capacidad a un único servidor, el escalado horizontal te permite añadir más servidores para satisfacer la carga de tu aplicación. Utilizando de nuevo mi analogía Amish, si la tierra se pusiera demasiado dura, engancharía un segundo caballo para terminar de arar en lugar de conseguir un caballo más grande. De nuevo, con el modelo de pago por uso de AWS, puedes obtener una reducción significativa de los costes utilizando el escalado horizontal. Para lograr el escalado horizontal, AWS ofrece dos servicios cruciales, Elastic Load Balancing y AWS Auto Scaling.
Consejo
Empieza siempre con el escalado horizontal y trabaja a partir de ahí para encontrar razones técnicas por las que no funcione. Sólo entonces vuelve a la escala vertical.
Advertencia
Los servidores Windows que están unidos a un dominio requieren una consideración especial. Estos servidores necesitan una secuencia de comandos especial para añadirse y eliminarse del dominio durante los eventos de escalado horizontal.
Equilibrio de carga elástico
Recordarás que dije que el escalado vertical era el método más utilizado para escalar en las instalaciones. Para aplicar el escalado horizontal in situ, tendrías que comprar un equilibrador de carga. El aumento de los costes de capital, mantenimiento y cuidado son un factor disuasorio importante a la hora de utilizar equilibradores de carga para las necesidades de capacidad. La implantación de equilibradores de carga en las instalaciones se ve más a menudo cuando existe una preocupación específica de alta disponibilidad, o hay una capacidad limitada para escalar verticalmente. Con el equilibrio de carga, el consumo dinámico en AWS proporciona de nuevo una ventaja considerable. Sólo pagas por el equilibrio de carga que necesitas, así que no hay costes iniciales. También te beneficiarás de una tecnología sin servidor. El Elastic Load Balancing en AWS no tiene ningún servidor que debas mantener o parchear, lo que reduce tus costes blandos. Como puedes ver, el equilibrio de carga en AWS es más atractivo, haciendo más accesible el escalado horizontal para el rendimiento.
Nota
El término "sin servidor" significa muchas cosas para distintas personas y empresas. En el contexto en que yo lo utilizo, tal como se representa en este libro, se refiere a cualquier servicio que no requiere que gestiones servidores o infraestructura. Obviamente, hay servidores en algún lugar haciendo el trabajo; simplemente no necesitas preocuparte de ellos.
Autoescalado de AWS
Mientras que el servicio Elastic Load Balancing proporciona la conectividad de red entre los usuarios de tu aplicación y los servidores, el servicio AWS Auto Scaling contiene la lógica necesaria para controlar la expansión y contracción del conjunto de servidores. Sin esta expansión y contracción, tus costes volverían a ser estáticos y menos eficientes. El Autoescalado dispone de múltiples activadores para añadir y eliminar capacidad de tu grupo de servidores de aplicaciones. Puedes utilizar el uso de CPU, el uso de memoria y las operaciones de entrada/salida de disco por segundo (IOPS) para una opción basada en las necesidades. Otra opción, si sabes cuándo se producirá tu carga, es el autoescalado mediante una programación. El servicio AWS Auto Scaling también te permite establecer un número mínimo de servidores y puede actuar como orquestador de alta disponibilidad, garantizando que una cantidad mínima de computación esté disponible para dar servicio a tus clientes. La forma de ver la disponibilidad y la recuperación de desastres (DR) también cambia, pero hablaré de ello más adelante en "Recuperación de desastres/Continuidad empresarial".
Tomémonos un segundo para recordar la conversación con Tom sobre las necesidades de capacidad de CPU para la aplicación generadora de memes del "Escenario 1-1". En este escenario, tiene mucho sentido cambiar de una solución de escalado vertical utilizada en las instalaciones a un escalado horizontal en la nube. Utilizar este método producirá la mejor experiencia para tus clientes, al tiempo que proporcionará a tu empresa el mejor consumo de costes disponible. Cuando el uso de la CPU aumenta a medida que más gente genera memes, el servicio de autoescalado añade un servidor para hacer frente a la carga. Cuando el servidor esté en línea y disponible, el autoescalado lo añadirá al equilibrador de carga para atender las peticiones de los clientes. El proceso funciona a la inversa cuando la carga disminuye, volviendo a tu configuración de referencia. Sin embargo, el uso del escalado horizontal tiene algunas advertencias. Tus servidores tienen que ser sin estado. Sin estado significa que ninguna configuración o dato específico vive en el servidor, y que el servidor puede eliminarse sin efectos adversos en el funcionamiento general. Otra advertencia puede ser que necesites crear imágenes de instancia preconfiguradas para reducir el tiempo de lanzamiento de la instancia.
Diversidad geográfica
Ahora que hemos cubierto la escalabilidad, vamos a cubrir otra ventaja clave de AWS: la diversidad geográfica. Piensa en tu(s) centro(s) de datos. ¿Dónde están? ¿A qué distancia están? ¿Cuántos hay? Si gestionas una operación más pequeña, probablemente la respuesta sea pocos, y si tienes más de uno, probablemente no estén muy separados. Por mi experiencia, puedo decirte que los centros de datos de una empresa estaban separados por sólo 11 km. No es exactamente diversidad geográfica, pero es mejor que la solución anterior, tener un único centro de datos. Si eres una gran empresa, probablemente tengas dos o más centros de datos, y lo más probable es que estén más separados. Sin embargo, ¿cómo de cerca están de tus usuarios? ¿Cómo está conectada la oficina remota de Brasil con tu centro de datos de Nueva York?
He migrado muchas empresas de Fortune 500 y algunas empresas más pequeñas a AWS. A lo largo de mi experiencia, puedo decirte que, sea cual sea tu configuración, cuando migras a AWS, puedes hacerlo mejor. AWS tiene una diversidad geográfica impresionante, y puedes utilizarla a tu favor para cuestiones de alta disponibilidad y recuperación de desastres, y acercar los servicios a tus clientes para una experiencia de usuario más rápida. Para destacar cómo puedes aprovechar esta capacidad, recorreremos cómo implementa AWS su infraestructura. Existen los conceptos de regiones y zonas de disponibilidad (AZ), como se muestra en la Figura 1-2. AWS proporciona un sitio web con un globo terráqueo interactivo en el que se detallan sus regiones, conectividad de red y puntos de presencia.
Consejo
No intentes extender tu empresa a muchas regiones en aras de la diversidad. Debe haber una razón empresarial convincente, porque puede haber costes adicionales asociados.
Regiones
Las regiones de AWS son un conjunto de zonas de disponibilidad que tienen centros de datos en un área geográfica. El concepto de regiones es muy extraño en comparación con las operaciones locales. En las instalaciones no tienes la capacidad de crear un diseño de infraestructura comparable. No tienes la economía de escala para crear una infraestructura tan vasta.
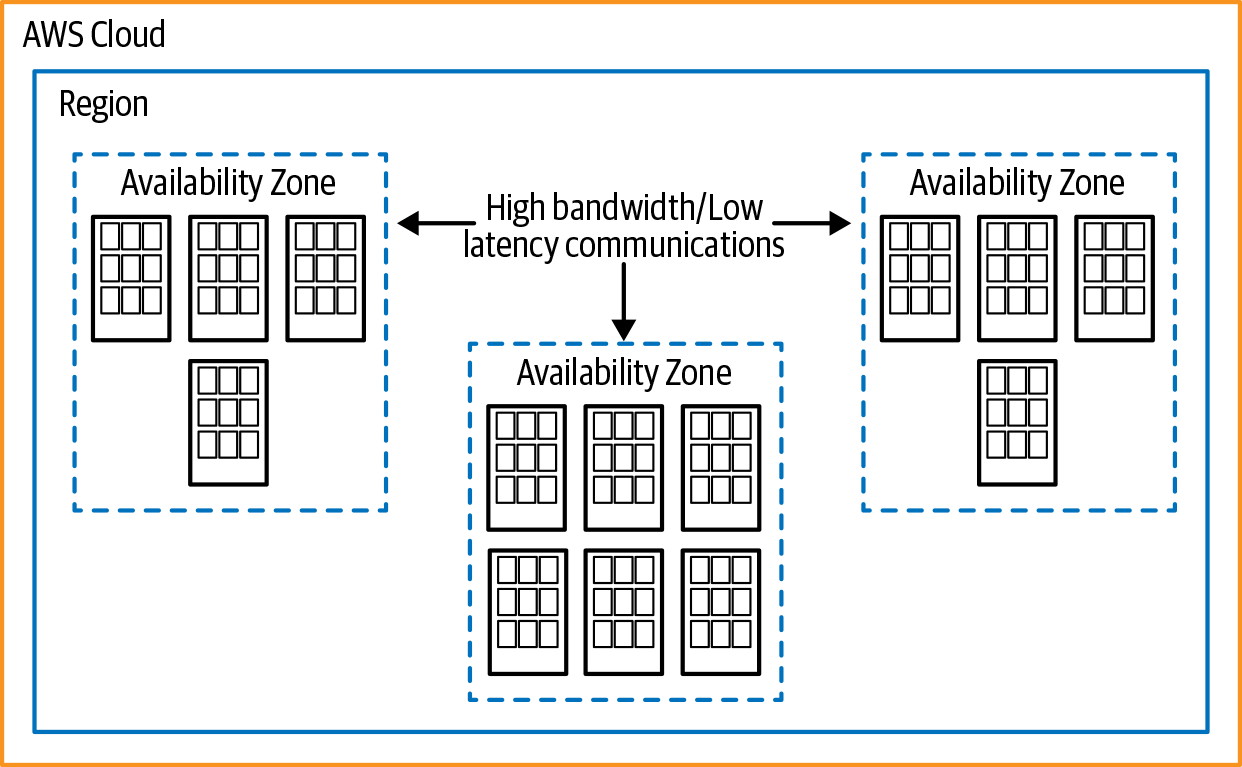
Para ayudar a entender el concepto, podemos establecer una similitud con la forma en que se segmenta Estados Unidos. Una región podría estar representada por un estado individual. Dentro de un estado hay condados(parroquias si vives en Luisiana, o boroughs en Alaska), y representan zonas de disponibilidad. El último aspecto de una región en AWS son los centros de datos; puedes pensar en ellos como las ciudades dentro de un condado. En el momento de escribir estas líneas, la infraestructura de AWS consta de las regiones que se muestran en la Tabla 1-1.
| Nombre de la región | Región |
|---|---|
Este de EEUU (N. Virginia) |
us-este-1 |
Este de EEUU (Ohio) |
us-este-2 |
Oeste de EEUU (N. California) |
us-oeste-1 |
Oeste de EEUU (Oregón) |
us-oeste-2 |
África (Ciudad del Cabo) |
af-sur-1 |
Asia Pacífico (Hong Kong) |
ap-este-1 |
Asia Pacífico (Mumbai) |
ap-sur-1 |
Asia-Pacífico (Osaka-Local) |
ap-noreste-3 |
Asia Pacífico (Seúl) |
ap-nordeste-2 |
Asia Pacífico (Singapur) |
ap-sureste-1 |
Asia Pacífico (Sidney) |
ap-sureste-2 |
Asia Pacífico (Tokio) |
ap-noreste-1 |
Canadá (Central) |
ca-central-1 |
China (Pekín) |
cn-norte-1 |
China (Ningxia) |
cn-noroeste-1 |
UE (Frankfurt) |
eu-oeste-1 |
UE (Irlanda) |
eu-central-1 |
UE (Londres) |
eu-oeste-2 |
UE (Milán) |
eu-sur-1 |
UE (París) |
eu-oeste-3 |
UE (Estocolmo) |
eu-norte-1 |
Oriente Medio (Bahréin) |
me-sur-1 |
América del Sur (São Paulo) |
sa-este-1 |
Advertencia
AWS no ofrece todos los servicios en todas las regiones. Consulta la Tabla de regiones de AWS para asegurarte de que todos los servicios que necesitas están disponibles antes de la migración.
Proximidad de los datos
Cuando te estés preparando para migrar a AWS, querrás pensar en tus usuarios y su ubicación, y seleccionar la región más cercana a ellos. Puede tratarse de usuarios internos o externos, o de ambos. La ventaja que aporta AWS sobre los centros de datos locales convencionales es que no tienes que limitarte a una o dos regiones. Tienes a tu disposición todas las regiones de AWS del mundo. No hay costes irrecuperables asociados al lanzamiento de una nueva región, como ocurre con un centro de datos. No tienes que alquilar espacio ni comprar acondicionamiento de energía, extinción de incendios, seguridad, bastidores y todas las demás cosas necesarias para poner en marcha un centro de datos adecuadamente. AWS se ha ocupado de esto por ti. Gracias a los modelos multiinquilino y de pago por uso, sólo tienes que pagar por la infraestructura que utilices en esa región. Veamos algunos escenarios para ayudarte a hacerte una idea de cómo podrías utilizar las regiones en tu migración.
Tomémonos un segundo para recorrer este escenario como si fuéramos Sam. La mayoría de los usuarios corporativos están en Washington, DC. Lo primero que quieres hacer es elegir una región de AWS cercana a tu personal para reducir la latencia. Una elección obvia sería la región us-east-1 en Virginia. Seleccionar Virginia garantiza que el grueso de los usuarios internos tenga la latencia más baja posible. La velocidad de la luz es fija; no hay mucho que podamos hacer para que la transmisión de datos sea más rápida. Seleccionar algo cercano como Virginia no es exclusivo de la nube; probablemente su centro de datos ya se encuentre a unos cientos de kilómetros de la sede corporativa. Sin embargo, cuando piensas en la segunda afirmación, cómo el mayor cliente está en Seattle, es aquí donde cambia la planificación del diseño en AWS. AWS tiene regiones por todo EEUU; tendría sentido colocar alguna infraestructura para dar soporte a su mayor cliente en Seattle. Elegiría la región us-west-2 en Oregón como segunda ubicación de implementación, específicamente para su aplicación online. Lo mejor es que Sam no tiene que preocuparse de todos los componentes de un centro de datos. Sólo tiene que concentrarse y pagar los servidores necesarios para su mayor cliente. Una implementación de este tipo en dos regiones sería muy costosa.
En la situación de Bill, yo recomendaría empezar con la latencia para saber cómo sería la implementación base. Como los servidores de las oficinas sólo dan servicio a la oficina local en la que se encuentran, no habrá mucho tráfico cruzando el país. Yo recomendaría a Bill que utilizara la región us-east-2 de Ohio para los servidores de Chicago y us-east-1 para sus servidores de Nueva York. Con esta configuración, sus usuarios tendrán la latencia más baja hacia sus respectivos servidores. Como su empresa tiene un sitio web, pero no es una aplicación esencial para los clientes, yo sugeriría que Bill lo colocara en una sola región en AWS. Bill puede hacer que su sitio web sea más rápido para los clientes utilizando Amazon CloudFront, una red de distribución de contenidos (CDN). Utilizando CloudFront aumentará el rendimiento sin la complejidad de más servidores en otras regiones. Por último, Bill tiene una aplicación desarrollada internamente que utilizan ambas oficinas. Como esta aplicación es de construcción privada, Bill puede aprovechar las dos regiones con una pequeña reprogramación. Este diseño proporciona una solución multimáster (puedes escribir datos en ambos lugares) y multirregión, que ofrecería el mejor rendimiento y disponibilidad.
Brittany tiene el proceso de selección más sencillo. Toda su base de usuarios se encuentra en Columbus, OH. Yo le sugeriría que utilizara la región us-east-2 de Ohio para alojar su infraestructura, ya que un tercero aloja su sitio web. Dónde ubicar su sitio no afecta a su decisión. Es posible que Brittany quiera replicar sus datos en una segunda región con fines de recuperación ante catástrofes, pero hablaré de ello en la sección "Recuperación ante catástrofes/Continuidad empresarial".
Localidad de datos y normativa sobre privacidad
Se ha hablado mucho del Reglamento General de Protección de Datos (RGPD) en la Unión Europea (UE). Este reglamento, junto con otros, ha suscitado preocupación en la dirección de TI sobre cómo cumplir los requisitos de soberanía de datos que impone. Como AWS tiene regiones repartidas por todo el mundo, es fácil controlar la soberanía del almacenamiento de datos según el país donde exista la normativa. La localidad de datos es sólo una parte del rompecabezas. También puedes necesitar validar que los datos no crucen fronteras durante las transacciones. El mero hecho de almacenar los datos en el país correcto no garantiza toda tu infraestructura y operaciones si tienes procesamiento fuera de la región designada. Sin embargo, tener todas las regiones de AWS a tu disposición te da una ventaja significativa sobre las implementaciones en las instalaciones, donde puede que tengas que adquirir nuevos centros de datos para cumplir la normativa.
Una advertencia importante que quiero señalar para la soberanía de los datos es que algunos países no tienen más de una región. Por ejemplo, si tienes normativas en Canadá que exigen que los datos se almacenen en el país, en este momento tendrás opciones limitadas para la implementación multirregión. Actualmente, AWS sólo dispone de la región central de Canadá (ca-central-1). AWS sigue añadiendo nuevas regiones continuamente, y puede que éste no sea siempre el caso de Canadá, pero es esencial tener en cuenta tus requisitos de RD para la soberanía. AWS ha cubierto suficientemente EE.UU. y la UE, pero zonas como Sudamérica y Asia-Pacífico pueden requerir una consideración añadida. Es importante tener en cuenta que cada región tiene al menos dos zonas de disponibilidad. Para la mayoría de las empresas, esto puede suministrar suficiente disponibilidad para cubrir tus necesidades de RD, manteniendo la soberanía.
Zonas de disponibilidad
Volviendo a mi analogía del estado, las ciudades representaban los centros de datos reales; los condados eran las zonas de disponibilidad (AZ) en una región de AWS. Las AZ desempeñan un papel clave en la alta disponibilidad dentro de una región. AWS conecta las AZ con redes de fibra óptica de baja latencia, lo que permite que los datos se muevan entre ellas con facilidad. Las zonas también están separadas geográficamente, por lo que un suceso como una inundación o un tornado en una zona no afectará a las demás. Para que sea más fácil de visualizar, puedes pensar en una zona de disponibilidad como un único centro de datos. La mayoría de las regiones tienen tres zonas de disponibilidad entre las que elegir para la implementación de la infraestructura. Para ayudar a solidificar el concepto, vamos a recorrer una hipotética región de AWS.
Las AZ y su separación son una ventaja significativa respecto a los centros de datos convencionales. Muchas empresas tienen el equivalente a dos regiones en su implementación local, pero sólo una AZ. Lo normal es que haya un centro de datos cerca de la oficina principal y un segundo en un lugar distante, con fines de recuperación ante desastres. El concepto de zonas de disponibilidad rara vez existe en las instalaciones. De forma similar al cambio de mentalidad con el escalado y las regiones, también es necesario un cambio de mentalidad sobre cómo abordar la disponibilidad en el diseño de tu infraestructura. Cambiar tu proceso de pensamiento te permite aprovechar las ventajas de las zonas de disponibilidad. Veamos un escenario para ayudarte a hacerte una idea de cómo podrías utilizar las AZ en tu migración.
Jim ha aumentado su disponibilidad, pero no ha mejorado su diversidad geográfica. Si su centro de datos primario se desconecta, Jim seguirá teniendo que conmutar por error al centro de recuperación ante desastres de California. No sé a ti, pero a mí pensar en la recuperación ante desastres solía darme ardor de estómago. Nuestra DR estaba diseñada y verificada, y habíamos hecho pruebas de conmutación por error. Sin embargo, las pruebas suelen ser de una pieza cada vez, no de todo un centro de datos. ¿Funcionaría todo en caso de desastre? Debería es la respuesta. No me gusta que funcione. Quiero cosas seguras, y la mejor manera de tener algo seguro en caso de desastre es cambiar tu forma de pensar de RD a continuidad del negocio (BC) . En las instalaciones, Jim tendría dificultades para incorporar la BC a su aplicación y hacerla altamente disponible. La continuidad del negocio es mucho más fácil de conseguir en AWS gracias a las zonas de disponibilidad. Las zonas de disponibilidad están separadas geográficamente dentro de una región, lo que les permite disponer de fuentes de alimentación y comunicación independientes. También están lo suficientemente separadas como para que un tornado sólo afecte a una AZ. Jim podría reconfigurar su aplicación cuando migre a AWS. Puede utilizar dos AZ para su servidor espejo SQL y sus servidores web. Su objetivo debería ser crear un funcionamiento continuo y de alta disponibilidad si una AZ se quedara sin conexión.
AZs y recuperación de desastres
Las AZ de AWS son uno de los cambios más críticos que ayudan a las empresas cuando migran a AWS. La recuperación ante desastres en las instalaciones es un problema difícil de resolver; nunca recibe el amor, la atención y la financiación que debería. Acaba siendo una sangría de recursos y una fuente importante de estrés para la dirección. Pienso en mis días en la banca, donde la RD es crítica. Sería mucho más fácil cambiar la conversación a BC y volver a añadir algunos años a mi vida. Cuando migres a AWS, te animo a que prestes especial atención a cómo puedes implementar tu infraestructura en varias AZ para lograr la continuidad empresarial.
Quiero llamar la atención sobre un patrón de diseño que aparece muchas veces con la implementación de AZ. No debes caer en la misma trampa. Muchas empresas implementan y configuran dos AZ en una región y piensan que tienen toda la disponibilidad que necesitan. ¿Quién puede criticar su lógica? Tienen dos Implementaciones; cuando una falla, la otra toma el relevo. Te animo a que pienses a largo plazo. ¿Qué ocurre cuando falla una AZ, pero ha sido a causa de un desastre natural? La AZ que ha fallado no volverá a funcionar pronto. En esta situación, tendrías que volver a desplegar el segundo conjunto de infraestructura en otra AZ. Si sólo has configurado dos AZ y una está ahora desconectada, tendrías que construir una nueva implementación de AZ. Mientras tanto, seguirás sintiendo las presiones de estar en un estado fallido. Recomiendo desplegar al menos tres AZ desde el principio, para hacer frente a cualquier posible fallo de AZ.
Fácil acceso a las nuevas tecnologías
Con la escalabilidad y la diversidad geográfica, hemos tocado los beneficios físicos de AWS; ahora, vamos a cubrir un beneficio lógico con el fácil acceso a tecnologías más nuevas. En los primeros días de AWS, los servicios se limitaban a unos pocos, como Simple Storage Service (S3) para almacenamiento de objetos y Elastic Compute Cloud (EC2) para computación. Ahora AWS ofrece docenas de servicios, desde plataformas de bases de datos gestionadas como Relational Database Service (RDS) hasta herramientas de IA como SageMaker. El acceso a las nuevas tecnologías permite a las empresas adoptar y ampliar sus capacidades e innovar para sus clientes con mayor facilidad. Para destacar cómo el acceso a estas tecnologías puede mejorar cualquier empresa, quiero mostrarlo utilizando una comparación muy drástica. La incorporación de estos servicios más avanzados, junto con el modelo de pago por uso, ha cambiado la capacidad de las pequeñas startups para competir con las organizaciones de Fortune 500. Piensa en un combate de boxeo. En una esquina está la startup, pequeña pero rápida. En la otra esquina está la empresa Fortune, grande pero lenta. En este combate de boxeo, los contrincantes no están igualados. La empresa más pequeña y ágil puede superar en maniobrabilidad a la gran empresa, pero su éxito depende de que dé suficientes golpes antes de que la gran empresa le dé cuerda y la derribe.
Para dar un ejemplo de cómo podría ser esto, veamos algunas tecnologías que AWS puede proporcionar económicamente a las startups. Un ejemplo de tecnología costosa de implementar en las instalaciones es el almacenamiento y análisis de datos. Para que una startup se adentre en la analítica, tendría que generar una cantidad sustancial de inversión para comprar el hardware necesario para almacenar y procesar cantidades masivas de datos. Un gasto de esta envergadura resta financiación a funciones vitales de la empresa, como pagar los salarios del personal. El primer día de operaciones de una startup que realice análisis en sus instalaciones podría costar decenas o cientos de miles de dólares en gastos iniciales de hardware. La adquisición de grandes cantidades de hardware por parte de una gran empresa ya establecida es fácil. Pagar cientos de miles no es difícil; la dificultad para una gran empresa está en el tiempo de ejecución.
Al lanzarse en AWS, esta misma startup tendría un acceso más fácil a nuevas tecnologías como la analítica por dos razones. La primera es que AWS tiene muchos servicios tecnológicos avanzados disponibles para que una startup elija en el espacio de la analítica. Existe el almacenamiento de objetos Amazon S3 para almacenar grandes cantidades de datos de forma rentable. Amazon QuickSight ofrece herramientas de inteligencia empresarial, y servicios como Amazon Athena y AWS Glue proporcionan capacidades de procesamiento y consulta de datos. Ofrecer los servicios por sí solos no es una salsa especial. Cuando combinas estos servicios de tecnología avanzada con el modelo de pago por uso, tienes los ingredientes adecuados para incitar a la competencia, al suprimir el importante gasto de capital y eliminar la barrera de entrada.
El acceso barato y fácil a estas nuevas tecnologías permite a cualquier empresa probar, experimentar e innovar de formas nunca antes posibles. Lo que más impide a las empresas experimentar e innovar es el miedo al fracaso. El fracaso en las instalaciones es un esfuerzo muy costoso, que deja hardware y software extra o especializado en las estanterías en lugar de dinero en efectivo en el banco. Tras migrar a AWS, la accesibilidad de la tecnología y el bajo coste del fracaso pueden permitir a tu empresa innovar y ofrecer mejores resultados a tus clientes. Veamos cómo podría ser la accesibilidad a las nuevas tecnologías para tu empresa.
En las instalaciones, Amy tendría mucho trabajo para hacer realidad esta petición. Tendría que implementar algunos servidores para realizar el entrenamiento del modelo de IA. Dependiendo del algoritmo de aprendizaje automático elegido, Amy podría tener que comprar hardware especializado para realizar los cálculos. Amy también tendrá que resolver el problema de quién programará y mantendrá esta aplicación de IA, lo que requiere un conjunto de habilidades especializadas. Todos estos elementos crean un importante obstáculo para la adopción. Amy no tiene fácil acceso a las nuevas tecnologías. Sin embargo, después de que la empresa de Amy migre a AWS, le resultaría mucho más sencillo implementar esta solicitud. AWS tiene un servicio llamado Amazon Forecast que realiza este cálculo de IA. Amy no tendría que preocuparse de servidores, hardware o un conjunto de habilidades de programación de IA especializadas para probar esta tecnología. Amy podría utilizar su personal informático y sus programadores actuales para poner en marcha una prueba de concepto (POC) y sólo pagaría por el tiempo de entrenamiento en horas, el almacenamiento de datos en gigabytes (GB) y las previsiones generadas (0,238 $, 0,088 $ y 0,60 $ por 1.000, respectivamente).
Disponibilidad
Ya hemos hablado de la diversidad geográfica y el escalado y de cómo pueden aumentar tu disponibilidad. Sin embargo, éstas no son las únicas capacidades que ofrece AWS para aumentar tu disponibilidad. Hay muchas formas tecnológicas de que AWS aumente la disponibilidad, pero centrémonos en unas pocas seleccionadas que tienen más probabilidades de ser relevantes para tus necesidades.
Si echas un vistazo a la historia de AWS, verás que se siguen creando ofertas sin servidor, como los equilibradores de carga elásticos de los que hemos hablado antes. Como no estás desplegando ningún servidor, no controlas la cantidad ni la ubicación de la implementación. AWS diseña estos servicios para que estén altamente disponibles para ti, aliviando esta carga de trabajo y estrés de tu vida. Estoy seguro de que apreciarás menos trabajo y estrés. No estarás sentado en la playa sorbiendo piñas coladas, pero es una cosa menos de la que preocuparte tras la migración. La forma en que AWS consigue este mayor nivel de disponibilidad para estas ofertas sin servidor es explotando al máximo el concepto de zona de disponibilidad para ofrecerlas. Aquí tienes dos escenarios que detallan cómo podrías utilizar estos servicios en tu entorno para obtener una mayor disponibilidad en comparación con tu configuración local.
En la implementación de Keith, hay una forma mejor de arquitecturar esta solución en AWS para aumentar su disponibilidad. En esta situación, mi recomendación sería trasladar los archivos de informes a Amazon S3. S3 es un almacén de objetos y es perfecto para almacenar datos que deben descargarse de Internet. S3 es también una de las ofertas sin servidor de AWS y está diseñado para una alta disponibilidad. S3 replica tus archivos entre todas las AZ de una región automáticamente y proporciona 11 nueves de durabilidad. ¿Qué son 11 nueves de durabilidad? Significa que hay una probabilidad del 99,999999999% de que tu archivo siga existiendo en el almacenamiento. He oído que es probable que los datos de S3 sobrevivan a la humanidad. No soy matemático, así que no puedo validar la afirmación. Sin embargo, haciendo algunas matemáticas de servilleta, parece plausible. Haciendo unas pequeñas modificaciones en la aplicación, Keith puede conseguir una alta disponibilidad, una durabilidad casi inimaginable y confianza en la carga de trabajo continua de su personal.
Nota
AWS proporciona 11 nueves de durabilidad, no de disponibilidad. Es importante recordar la diferencia. El acuerdo de nivel de servicio (SLA) de AWS garantiza que los datos existen en el almacenamiento, no que estén siempre disponibles para ser recuperados. Ten por seguro que su historial ha sido bastante bueno.
La situación de Kathy no es única. Basé este escenario en mi experiencia real con uno de mis centros de datos. Que llueva agua en un centro de datos no es nada bueno, y es algo que nunca pensaste en abordar. Ahora que lo pienso, se trata del mismo centro de datos en el que se derrumbó parte de la pared. Los obreros de la construcción estaban retirando un puente peatonal que había al lado. Una grúa estrelló un enorme trozo de hormigón contra el muro. Estas son las situaciones en las que la vida es más extraña que la ficción. Yo no podría inventarme estas cosas, y tú tampoco, de eso se trata. No puedes pensar en todas las cosas que pueden ocurrirle a tu centro de datos y, como Kathy, lo mejor es que lo tengas en cuenta en tu implementación. Para la implementación de Kathy, tendría sentido utilizar el Sistema de Archivos Elástico de Amazon (EFS) para almacenar los datos de su clúster HPC. EFS es compatible con el protocolo NFS necesario para el funcionamiento de su clúster y ofrece almacenamiento de datos redundante en todas las AZ. Este servicio es una oferta sin servidor y no requiere ninguna entrada para esta disponibilidad.
Mayor seguridad
Siguiendo con la tendencia de las ventajas lógicas, AWS ofrece otra con mayor seguridad. Hace unos años, la gente temía la seguridad de sus datos en la nube. Puedo entender en parte su reticencia. Digo parcialmente porque los grandes proveedores de software como servicio (SaaS) como Box tenían un negocio en auge. La gente no tenía miedo de poner sus datos empresariales en esas plataformas. Me resulta irónico que esas mismas personas temieran colocar el resto de sus datos en AWS. Para la mayoría, el miedo a trasladar sus datos a AWS ya ha pasado. Tras las brechas, grandes empresas han declarado que si estuvieran en AWS, la brecha no se habría producido, o habría tenido menos impacto. La confianza cero y el mínimo privilegio son buenas prácticas en AWS. Estas dos metodologías son bastante eficaces para proteger tu entorno. La ventaja de AWS es que facilita la aplicación de estos principios.
Confianza cero
La seguridad de la confianza en las instalaciones ha permanecido prácticamente inalterada durante las últimas décadas. La mayoría de las redes tienen una implementación en tres zonas. Existe una zona de Internet para conectarse a Internet y alojar otros dispositivos, como cortafuegos y controladores de redes privadas virtuales (VPN). Detrás, hay una zona de perímetro o zona desmilitarizada (DMZ) que aloja los servidores web y de correo electrónico.
Más adentro de tu red, hay una zona interna que aloja tus servidores y datos privados. Algunas empresas implementan una cuarta zona donde se encuentran las impresoras y los puestos de trabajo, lo que permite una mayor separación de los servidores privados. Tener zonas era un buen diseño de seguridad para las redes hace 20 años. El problema de este diseño es que hay un nivel de confianza para cada zona. No confías en Internet, confías un poco en el perímetro y confías plenamente en la zona privada. Este concepto suena bien cuando lo piensas, pero después de todas las recientes brechas corporativas que se han producido, puedes ver por qué está anticuado. Una vez que atraviesas el velo del perímetro o de las zonas internas, puedes saltar como Dorothy por el camino de baldosas amarillas. Este diseño implementa la seguridad perimetral. Atraviesa el perímetro, y hay poco que te impida hurgar y pinchar en el resto de los servidores hasta que irrumpas en ellos.
Laconfianza cero es cuando ningún servidor confía en ningún otro servidor. Si puedes entrar en un servidor de la zona de perímetro, no podrás comunicarte con ningún otro servidor de esa zona, a menos que lo permita el diseño. En lugar de la feliz Dorothy, acabas en una fría y oscura celda, como Al Capone, contemplando tu salud en rápido declive. La confianza cero restringe tu radio de explosión de cualquier ataque, con lo que tu entorno es más seguro. Nada dice que no puedas hacer esto in situ. Implementé esta seguridad para un banco en el que trabajaba. Llevó mucho tiempo implantarla, y costó decenas de miles de dólares en tecnología y decenas de miles más en esfuerzo de los empleados.
Grupos de Seguridad de AWS son un beneficio significativo para la seguridad de confianza cero y no cuestan decenas de miles de dólares. Los grupos de seguridad no cuestan nada. Los grupos de seguridad son la forma en que AWS implementa los cortafuegos en AWS. Un grupo de seguridad proporciona un cortafuegos externo a tu instancia o grupo de instancias; no es un software que se ejecute en la propia instancia. Como un cortafuegos, controla todo el tráfico que fluye hacia tu instancia y bloquea todo lo que no hayas permitido explícitamente. Para facilitar aún más la gestión, tampoco tienes que controlar el tráfico sólo por direcciones IP. Los grupos de seguridad te permiten hacer referencia a otros grupos de seguridad. Esta referenciabilidad hace que la gestión de la seguridad sea aún menos pesada que en las instalaciones. Cuando asignas o desasignas instancias de un grupo de seguridad, el grupo de seguridad se ajusta automáticamente sin intervención manual, mientras que cambiar servidores y direcciones IP en las instalaciones se convierte en un problema si las reglas del cortafuegos no se actualizan y se vuelven obsoletas. Al hacer referencia a un grupo de seguridad como fuente cuando se añade o elimina un servidor, éste se inserta o elimina automáticamente del grupo de seguridad. Esta automatización garantiza que no haya referencias antiguas y estáticas.
Consejo
Asegúrate de que tu equipo rompe el hábito de utilizar direcciones IP para los recursos de AWS y cambia a referencias de grupos de seguridad.
Veamos un escenario en el que esto ocurriría en las instalaciones.
Si los servidores de John hubieran estado en AWS, se habría bloqueado la mayor parte de este ataque. El compromiso del servidor web se habría producido igualmente: John no gestionó eficazmente la seguridad ni eliminó la vulnerabilidad. Sin embargo, una vez que el atacante hubiera entrado en el servidor web, no habría podido saltar del servidor a otro con tanta facilidad. Al implantar reglas de grupo de seguridad de confianza cero, el pirata informático no habría podido desplazarse a los demás servidores de la zona del perímetro. No tendrían forma de llegar hasta allí, y en el momento en que John eliminara el tercer servidor de base de datos, éste ya no estaría en el grupo de seguridad. Por tanto, también se habría bloqueado el acceso al servidor de base de datos de nóminas.
Menor privilegio
El mínimo privilegio es controlar la autorización al nivel más pequeño de acceso para hacer el trabajo necesario. Puedes pensar en ello como en la seguridad de un aeropuerto. Como pasajero, puedes pasar el control de seguridad, pero no puedes equivocarte de avión ni entrar en un almacén. La mujer que trabaja en el mostrador de Starbucks puede pasar el control de seguridad y entrar en el almacén, pero no puede subir a ningún avión ni a la pista. Un manipulador de equipajes puede entrar en la pista y en las salas de tratamiento de equipajes, pero no puede subir a un avión ni entrar en un almacén. Esto es un privilegio mínimo: cada uno tiene el acceso que necesita para hacer su trabajo, nada más.
AWS considera la seguridad el trabajo cero, con lo que quiere decir que es incluso más importante que la prioridad número uno. Se ha pensado mucho en cómo funcionan los controles de acceso. AWS ofrece un control muy preciso de las capacidades de cada servicio a través de un servicio llamado Gestión de Identidad y Acceso (IAM). Este control te permite, al igual que al aeropuerto, conceder sólo el acceso necesario para el funcionamiento de un servicio concreto. Los innumerables permisos que ofrecen los servicios de AWS se segmentan en lista, lectura, etiquetado y escritura. La Tabla 1-2 detalla las capacidades asociadas a estos permisos.
Utilizando estos controles de acceso individuales, puedes conceder acceso a un subconjunto mínimo de acciones. ¿Por qué querrías hacer esto, y por qué es una ventaja para la seguridad en AWS? Se reduce al radio de explosión. Si un atacante consiguiera acceder a un conjunto de credenciales, querrías limitar las acciones que puede realizar para limitar la cantidad de daño que puede causar. Veamos un escenario sin configurar el mínimo privilegio y veamos lo que puede ocurrir.
Una situación como la de Rob no es exclusiva de la nube. Al igual que es posible escalar en las instalaciones, también lo es el mínimo privilegio. Sólo que es más difícil de aplicar en las instalaciones. Cuando trabajas in situ, hay docenas de lugares en los que tienes que implantar la seguridad: cortafuegos, conmutadores, hipervisores, y la lista continúa. Es como una oficina llena de mesas, y tienes que ir a cada mesa y cerrar los cajones. Después de migrar y empezar a utilizar los servicios de AWS, tu tarea de asegurar se vuelve mucho más fácil. En lugar de centrarte en asegurar cada escritorio de la oficina, sólo tienes que asegurar la oficina. IAM funciona como la puerta de entrada a tu infraestructura. Cada usuario que pasa por esa puerta obtiene su autorización al atravesarla. IAM te permite asignar los permisos de lista, lectura, etiquetado y escritura a medida que entran tus usuarios, para darte un control granular.
Beneficios empresariales de la nube
Aunque migrar a AWS tiene importantes ventajas técnicas, también hay una serie de ventajas empresariales. Considero que los beneficios empresariales son significativamente más atractivos que los técnicos. Es un poco como empezar una relación. Los beneficios técnicos te atraen en primer lugar, mientras que los aspectos empresariales son las atracciones mentales que mantienen la relación creciente e interesante. Aunque las ventajas técnicas puedan ser un por qué cuando empieces a migrar a AWS, se convertirán rápidamente en un cómo una vez resueltos los obstáculos técnicos. Al igual que en el mundo del amor, el lado físico de la ecuación puede decaer a medida que se convierte en algo habitual y esperado. Claro que AWS sacará nuevos servicios y capacidades para animar el lado técnico; sin embargo, todo vuelve al lado empresarial de la casa. No se implementa la tecnología por la tecnología, siempre hay un motor empresarial detrás. Por eso quiero poner en primer plano las ventajas empresariales que te ofrecerá migrar a AWS.
Los beneficios empresariales van a tener poder de permanencia como motivación de tu empresa durante mucho más tiempo que cualquier motivación técnica. Debido a la longevidad de estas motivaciones, tiene sentido dedicar un tiempo extra a evaluar y pensar cómo se relacionan directamente con tu empresa. Elaborar un gran por qué en torno a estos beneficios proporcionará una historia convincente para impulsar y mantener la motivación de las partes interesadas y el personal para tu migración.
Reducción de gastos y ayudas
Ya hemos tratado el concepto de pago por uso y la compra de tu infraestructura a la baja, así que no queremos sumergirnos más en esas aguas (valga el juego de palabras). Sin embargo, éstas no son las únicas formas en que AWS puede ayudarte a reducir tus costes relacionados con los gastos en TI. Cuando hablo de las ventajas de AWS en relación con los costes, me gusta desglosarlas en dos cubos. En el primer cubo, tenemos los costes duros asociados al funcionamiento de tu entorno. Son los costes de equipos, software, servicios, energía, extinción de incendios y similares. Son muy tangibles y fáciles de medir. En el otro lado de la cuestión, el segundo cubo contiene los costes blandos asociados a tu patrimonio. Estos costes, como el tiempo del personal para parchear, montar equipos, realizar copias de seguridad y otros, son difíciles de medir. Estos costes blandos son el parásito adherido a tu presupuesto de TI que le chupa la vida. Si se ahorraran, tu empresa dispondría de más fondos de TI para innovar y ofrecer valor a tus clientes.
Costes duros
Acabo de decir que los costes duros son fáciles de medir, pero ahora voy a matizarlo mucho. Son fáciles de medir si los mides. Cuando hablas de hardware, como servidores y conmutadores, estoy seguro de que tienes una medida exacta. Los has comprado, están en tus libros como activos amortizables, y probablemente puedas decirme exactamente cuánto te cuestan. Una vez que vas más allá del hardware, las cosas se complican un poco. Por ejemplo, si no tienes un centro de datos externo o dedicado, la contabilidad de los costes individuales se complica. He detallado aquí dos ejemplos que muestran lo drástica que puede ser la diferencia en la imputación de costes.
Andrea tiene un trabajo bastante fácil. Todo lo que Andrea necesita para dirigir un centro de datos se lo venden con un bonito lacito encima. Ella sabe exactamente lo que le cuestan todos esos artículos, y no tiene que preocuparse de contabilizarlos. AWS no ofrece ninguna simplificación a Andrea en cuanto a la forma de contabilizar los costes. El coste del funcionamiento de sus sistemas en AWS también se le entregará en una sola factura con un bonito lazo. Andrea podría tener alguna capacidad no utilizada en su bastidor si no está repleto de equipos. Podría beneficiarse de AWS porque no tendría que pagar por esa capacidad extra. Al comparar la relación coste-beneficio con AWS, a Andrea le resultará fácil realizar el análisis.
Lo creas o no, me encuentro con la situación de Jim todo el tiempo. Muchas empresas no tienen ni idea de cuáles son los costes reales del funcionamiento de su infraestructura. Como Jim, las cosas crecieron orgánicamente en las instalaciones, y no hubo una separación real desde el punto de vista contable. A Jim le resultará difícil hacer una comparación de costes entre los gastos on-premise y los de AWS. Como sus costes no se imputan directamente, Jim tendrá que hacer algunas suposiciones. Puede basarlos en los metros cuadrados de estos centros de datos o utilizar un estándar del sector como referencia. AWS puede ayudar en este aspecto utilizando la herramienta de coste total de propiedad (TCO) disponible en línea. He descubierto que algunos directivos no ven con buenos ojos las estimaciones que proporciona AWS. Les parece más material de marketing que datos cualitativos, y preferirían datos de un tercero imparcial. Si quieres hacer tus estimaciones a mano, puedes utilizar la Calculadora de precios de AWS.
Nota
La calculadora de precios de AWS no admite el cálculo de costes en todos los servicios de AWS, pero sus capacidades siguen creciendo con el tiempo.
La economía de escala que AWS ofrece a las empresas en costes duros es una ventaja sustancial. Tiene más servidores de los que podría tener una sola empresa. Utiliza equipos especializados y puede reducir los costes de adquisición y operativos. Este ahorro se traslada a sus clientes. Incluso las mayores empresas del mundo, las que tienen infraestructuras a gran escala, deciden migrar a AWS y cerrar sus centros de datos. La razón es muy sencilla: no están en el negocio de los centros de datos. Su negocio es ofrecer algún otro servicio o producto a sus clientes. Como los centros de datos no son su negocio, no pueden tener la escala de AWS y, por tanto, el ahorro de costes. Si estas enormes empresas no pueden hacerlo tan eficazmente como AWS, imagina lo que la migración puede hacer por tu empresa.
Costes blandos
Una de las ventajas más interesantes de AWS está relacionada con los costes blandos. Cuando migras a AWS, hay un montón de servicios disponibles para ayudar a reducir los costes blandos del funcionamiento de tu entorno. Además de eliminar los costes, los servicios también pueden ayudar a reducir el riesgo. Uno de los mejores servicios para reducir los costes blandos tras la migración es RDS, un servicio de base de datos gestionado. Esta gestión significa que AWS se encarga de parchear el sistema operativo, hacer copias de seguridad de las bases de datos y parchear el motor de la base de datos. Esta automatización elimina gran parte del esfuerzo necesario de tu personal para realizar estas funciones. Muchas horas al año del personal se dedicarían a instalar los parches y a comprobar que se realizan las copias de seguridad. Operaciones como éstas son una pérdida de tiempo y no aportan ningún valor a los clientes. Los clientes quieren copias de seguridad de sus datos, pero no les importa cómo se hagan, ni están dispuestos a pagar por ellas. Lo consideran inevitable y parte de tu problema, no del suyo. Los clientes buscan capacidades del producto, actualizaciones y corrección de errores. AWS te ayuda con estas funciones que no añaden valor, como el parcheado de la base de datos, y libera tiempo para que tu personal trabaje en aquellos elementos que añaden valor y que los clientes desean.
Esta forma de ahorro de costes blandos prevalece en toda la plataforma. Si piensas en todos los elementos necesarios para hacer funcionar un centro de datos, empezarás a ver estos ahorros. Por ejemplo, el funcionamiento de un centro de datos implica sistemas de baterías de reserva. Estos sistemas necesitan mantenimiento y pruebas. Si diriges tu propio centro de datos, estas tareas recaen sobre tus hombros. Dependiendo de tu perfil de riesgo, podrías estar probando tus sistemas de copia de seguridad cada año, trimestre o mes. De nuevo, esto no aporta ningún valor a tus clientes, aparte de que esperen que tus sistemas estén en línea cuando los necesiten. Puedes profundizar un poco más y pensar en el tiempo necesario para negociar los contratos de tus líneas de comunicaciones y los contratos de asistencia de climatización. Todos estos elementos consumen tu tiempo y esfuerzo, y el coste real de este tiempo es difícil de cuantificar. Cuando pienso en mis centros de datos y en el tiempo necesario para gestionarlos, hubiera preferido externalizar todo eso y preocuparme de ejecutar mi software. Si utilizas un centro de datos de colocación, muchas de estas tareas ya están externalizadas para ti, y no tienes que preocuparte de ellas.
Si damos un paso más allá de los requisitos operativos de un centro de datos y empezamos a fijarnos en cosas como la red y los hipervisores, verás una tendencia en la que AWS puede ahorrarte aún más tiempo. Por ejemplo, en AWS no tienes que preocuparte de administrar el hipervisor. Parchear tu entorno VMware o Microsoft Hyper-V se convierte en algo obsoleto. El hipervisor forma parte del producto EC2 en el que ya no tienes que pensar. Tú consumes las instancias EC2. AWS se preocupa del hardware y el sistema operativo subyacentes y de los parches. Lo mismo ocurre con el equilibrio de carga elástico. En tu entorno local, tendrías que parchear tu equilibrador de carga y mantener toda la seguridad y la actualización del hardware cuando caduque. Lo mismo ocurre con tu subsistema de almacenamiento, porque AWS gestiona el subsistema de almacenamiento por ti. Tú consumes los volúmenes del almacén elástico de bloques (EBS). No tienes que preocuparte de gestionar cuánta capacidad de disco hay disponible, cuánto almacenamiento se necesitará o cuánto cuestan los contratos de mantenimiento.
Nota
La reducción de los costes blandos puede superar fácilmente el ahorro en costes duros. Los salarios de los empleados son probablemente el mayor gasto de tu empresa. Ahora bien, esto no significa que debas repartir cartas de despido como si fueran caramelos en Halloween, pero sí que tu personal tendrá más tiempo para añadir valor empresarial.
El último componente importante que cubriremos y que reduce los costes blandos de las operaciones es el cortafuegos. Los cortafuegos son otro dispositivo crítico de comunicación de red que debes gestionar, parchear y actualizar. Utilizando los Grupos de Seguridad de AWS, eliminas una cantidad significativa de costes blandos relacionados con el mantenimiento de tu entorno. Además, AWS dispone de un servicio de red llamado Network ACLs que ofrece una segunda capa de seguridad mediante la implementación de un cortafuegos de Capa 3.
Podría seguir hablando de todas las capacidades de AWS que pueden ahorrarte estos costes. Quería destacar algunas de las más importantes para que pienses en otras áreas en las que tus empleados emplean gran parte de su tiempo en realizar tareas mundanas, tareas que puedes externalizar y dejar que las gestione otra persona. Tu producto o servicio es lo que tu empresa hace mejor; es lo que la hace única. Por eso estás en el negocio. Lo repetiré varias veces a lo largo del libro. Es un concepto esencial, que quiero que arraigue en tu ser. Te ayudará con los detractores más adelante. Algunos empleados serán reacios a los cambios y temerán la obsolescencia y la carga de trabajo adicional. Podrás mostrarles cómo mejorará su vida laboral si se dedican a tareas más interesantes, lo que disminuirá su reticencia a seguir adelante. Me gusta decirlo así: nadie fue a la universidad o a clases de formación para aprender a realizar tareas monótonas. Aprendieron por otra razón: para construir un producto, para crear magníficas bases de datos o para ganar un buen dinero. Te aseguro que ninguno de ellos soñaba con el trabajo que podría hacer un robot.
Hay muchos más servicios disponibles en AWS para ayudarte a reducir tu carga de trabajo en tareas de bajo coste que no vamos a revisar. Hay herramientas para hacer copias de seguridad de tus datos, hay herramientas para aplicar parches e incluso hay herramientas para gestionar licencias. Cuando se utilizan juntas, son un arma formidable contra la pérdida de tiempo y esfuerzo. Tendrás que determinar dónde tiene tu empresa un despilfarro significativo en tareas operativas y determinar si hay algún servicio o capacidad que ayude a disminuirlo. La Tabla 1-3 es una lista de algunos servicios adicionales que podrían disminuir tus costes blandos tras la migración.
Advertencia
No utilices costes blandos en tu justificación empresarial a menos que puedas cuantificarlos absolutamente. Si no lo haces, podrían desestimarlos y poner en peligro tu migración. He visto a directivos meterse en situaciones complicadas en las que la alta dirección pensaba que estaban impulsando una agenda al proporcionar cifras"blandas".
Sin compromiso
Cuando construyes en tus propias instalaciones, es muy parecido a comprar un coche nuevo. Te esfuerzas mucho en la evaluación para asegurarte de que encaja bien. Estaréis juntos durante los próximos tres a cinco años, y será mejor que lo aprovechéis al máximo. Es el segundo mayor gasto que tendréis después de la casa. Es un compromiso importante que tiene un gran impacto en tu vida. Al igual que con tu coche, el compromiso es lo que hace que las empresas sean aprensivas a la hora de probar cosas nuevas. Da mucho más miedo fracasar rápido cuando fracasar cuesta duros que son difíciles de recuperar. Seamos realistas: el hardware informático se deprecia más rápido que tu último coche. Un coche al menos tocará fondo en algún punto de la curva porque sigue cumpliendo la función de conducir de A a B. No es el caso del hardware informático; el valor puede seguir bajando hasta cero porque el software diseñado para ejecutarse en él ya no puede funcionar. Esta depreciación provoca mucho miedo a fallar rápido. Fallar rápido significa que el hardware que compras hoy puede no funcionar como esperabas con el concepto que estabas probando, y ahora tienes este hardware por ahí acumulando polvo. Haz esto unas cuantas veces, y tendrás decenas, cientos o miles de piezas de equipo por ahí tiradas. ¿Qué ocurre? No fallas rápido. No quieres fracasar en absoluto, así que no innovas, y a tu empresa se la come una startup.
No se lo digas a mi mujer de 17 años, pero el compromiso es malo. Al menos cuando se trata de TI. AWS no tiene compromisos. Puedes poner en marcha un servidor, o probar un concepto de negocio o una mejora del producto. Si no funciona, destrúyelo y deja de pagar. Ahora tu capacidad de probar y fallar supone un bocado mucho menor de tu presupuesto. Fracasar rápido significa que gastas cantidades insignificantes de dinero varias veces hasta que encuentras algo que funciona y ofrece el producto o la función que quieren tus clientes. Es como un nuevo producto que ves en la web y que quieres probar, pero temes que no cumpla lo que promete. Sin embargo, entonces ves que hay una garantía de devolución del dinero si no quedas satisfecho. Ahora tu miedo al fracaso ha desaparecido, así que sigues adelante con tu compra. El aspecto de no compromiso de AWS es la misma cálida manta de seguridad en la que te gusta envolverte antes de probar ese nuevo producto.
Una de las ventajas que puedes aprovechar es en torno a las pruebas de los empleados. A lo largo de mi carrera, he tenido muchos empleados a los que les encantaba trastear y probar cosas. Lo considero una excelente ventaja empresarial. La gente puede resolver problemas de formas nunca esperadas o pensadas mediante la experimentación. Sin embargo, lo mejor sería que pusieras algunas barandillas en torno a la experimentación. Debes asegurarte de que tus datos están seguros y de que tus costes no se te van de las manos. En AWS, puedes configurar una cuenta sandbox que permita a tu personal probar cosas nuevas, aprender y experimentar de forma controlada. Puedes establecer límites de gasto y alarmas para esta cuenta para mantener los costes bajos. Desde el punto de vista de la seguridad, puedes impedir el acceso a los datos de producción para limitar la fuga de datos.
Además, puedes ejecutar scripts de limpieza automatizados para purgar la infraestructura implementada y mantener los costes bajos y la TI en la sombra al mínimo. Todos estos elementos proporcionan un lugar seguro donde tu personal puede ayudarte a ofrecer un mejor valor a tus clientes, al tiempo que se desafían a sí mismos y se mantienen mentalmente comprometidos con su trabajo. Todos salimos ganando.
Agilidad empresarial
Otra ventaja empresarial que puedes aprovechar al migrar es la agilidad empresarial, que es excepcionalmente crítica para la supervivencia a largo plazo. Si te fijas en las empresas que han luchado y fracasado recientemente -Sears, Kodak, Toys R Us y Blockbuster, por nombrar algunas-, su incapacidad para adaptarse y cambiar es lo que aceleró su desaparición. La conclusión es que la agilidad empresarial se traduce en una mayor competitividad, una mayor capacidad de adaptación a las condiciones cambiantes del mercado y un aumento de los ingresos.
Consejo
La agilidad es la ventaja número uno de la migración. Asegúrate de abordarlo en tus FAQ sobre el porqué.
Me he dado cuenta de que en todas las empresas a las que he ayudado a migrar a AWS, obtener agilidad empresarial era el beneficio más difícil de conseguir, y sin embargo el más fructífero. Es difícil porque hay muchas personas implicadas, normalmente diferentes departamentos y diferentes equipos dentro de los departamentos. Necesitan cooperar como un todo cohesionado para cosechar los beneficios de la agilidad. Tradicionalmente, estos equipos están muy aislados en una empresa. Por desgracia, cuando se trabaja con personas y con estos silos, el cambio no se produce rápidamente. Muchas veces, la reticencia al cambio provoca bloqueos considerables. Una de las razones por las que considero vital plantear las narrativas del porqué es que ayudará a hacer avanzar el proceso e impulsará las sinergias entre los silos.
Si retrocedieras unos cinco años, no oirías mencionar las palabras agilidad empresarial en el contexto de las TI. Las TI estaban ahí para proporcionar los servicios tecnológicos que necesitaba la empresa. Normalmente, tenías largos ciclos de desarrollo con metodologías de diseño en cascada, o utilizabas software comercial listo para usar. Sin embargo, las cosas han cambiado en los últimos años. La combinación de la metodología de desarrollo de software ágil y los canales de implementación automatizados ha cambiado la forma en que las empresas ven las TI. Hoy en día no es inaudito que las empresas lancen diez actualizaciones de producción cada día. Si comparas eso con tu sistema local, verás la enorme diferencia que facilitan estas herramientas. AWS ha creado un conjunto de productos para la automatización de la creación e implementación de infraestructura y software. Sin embargo, estos servicios por sí solos no son especialmente útiles. Por ejemplo, AWS CodePipeline te permite automatizar la construcción e implementación de software. Por desgracia, si el software no puede instalarse automáticamente y requiere la intervención del usuario, una canalización de implementación automatizada no es extremadamente útil.
Dicho de otro modo, la agilidad es la combinación de herramientas y procesos humanos. Por desgracia, como responsable de TI, recaerá sobre ti la responsabilidad de abordar esta desconexión. TI será el punto central de contacto entre todos los demás equipos, divisiones y unidades de negocio de una organización. Esta centralización da al responsable de TI una perspectiva única para crear un modo de funcionamiento uniforme en toda la empresa. Sumerjámonos en el siguiente escenario, que muestra cómo puede afectar la agilidad a una empresa.
He visto algunas empresas excepcionalmente grandes y de éxito en una situación comparable a la de Judy. Crearon sus herramientas internas mucho antes de la actual ola de tecnologías. Su competencia es más reciente y se creó en un estado nativo en la nube, lo que les da varias ventajas. En el caso de Judy, la competencia utiliza análisis e IA y puede enviar actualizaciones al menos semanalmente. Para que su empresa pueda competir en igualdad de condiciones, tendrá que introducir bastantes cambios:
-
Implanta una canalización de integración continua y desarrollo continuo (CI/CD)
-
Prueba de regresión de dos años de cambios antes de actualizar el entorno de producción
-
Formar al personal y a los clientes sobre los dos años de cambios
Una vez que la actualización se lleve a producción, podrán pensar en cambiar a una metodología de desarrollo ágil. Mientras tanto, Judy tendrá que asegurarse de que la tutoría, la formación y la motivación del personal están en marcha para garantizar el éxito del resultado.
Recuperación en caso de catástrofe/Continuidad empresarial
Cuando empecé mi carrera, muchas empresas no pensaban en la RD. Durante muchos años, el alcance de mis planes de RD era una copia de seguridad en cinta que se guardaba en una caja fuerte a prueba de incendios. Ni siquiera debería haber utilizado el término a prueba: era más bien un retardo al fuego y no garantizaba que la temperatura del incendio no derritiera mis cintas. A medida que pasaban los años, también aumentaba la importancia de la RD. La TI pasó de limitarse a gestionar un sistema de contabilidad a convertirse en una parte fundamental del negocio. Hoy en día, la TI puede ser tu negocio, y sin ella, no estarás mucho tiempo en activo. La RD es una gran parte de tu presupuesto actual y una parte crítica de tus procesos.
Cuando las empresas migran a AWS, deben intentar desplazar el foco de atención de la RD a la BC. La continuidad del negocio se ocupa más de que las operaciones continúen que de recuperarse de un fallo completo. Estoy seguro de que estarás de acuerdo conmigo en que la continuidad es mejor que la recuperación. ¿Quién quiere recuperarse cuando es mucho más fácil continuar? Con las capacidades de la infraestructura de AWS a tus espaldas, es más fácil crear un plan de BC que pueda cumplir tus objetivos requeridos. Esos objetivos son el objetivo de punto de recuperación (RPO) y el objetivo de tiempo de recuperación (RTO). Para ayudar a recordar estos conceptos, yo siempre pienso en el objetivo RPO como la fecha de caducidad de mi leche. ¿Qué edad pueden tener (los datos) antes de que ya no me sirvan? Recuerdo el RTO como el tiempo que tardo en ir a la tienda a por más leche, o el tiempo que puedo estar desconectado.
El uso de las AWS AZ en tu diseño te permite alcanzar un RTO y un RPO próximos a cero mediante la implementación de tus aplicaciones en una configuración activa/activa o activa/pasiva. Activa/activa significa que tus aplicaciones se ejecutan en al menos dos servidores al mismo tiempo. Podrías hacerlo con un equilibrador de carga delante de los servidores. Activa/pasiva es similar, pero uno de los servidores responde a las solicitudes en cada momento. En caso de fallo en una implementación activa/pasiva, el segundo servidor sustituye al principal. Enhorabuena, ahora tienes un diseño de BC RPO/RTO casi nulo en AWS. Este diseño te permitirá sobrevivir al fallo de una AZ y continuar las operaciones sin interrupción. La pregunta que debes hacerte es si esto es suficiente protección para tu negocio. ¿Y si se cae una región entera? Si te haces esa pregunta y la respuesta es: " Eso es inaceptable", entonces hay más trabajo de BC/DR que hacer.
Aprovechando las ventajas de las regiones de AWS, puedes ampliar tu infraestructura para dar cuenta del fallo de toda una región. Sin embargo, según tu implementación y tus requisitos, puede haber una diferencia significativa en el coste, dependiendo de tu implementación. Tendrás que decidir si tu empresa quiere una RD entre regiones o una BC. La DR interregional es menos costosa, pero tiene un RTO y un RPO mucho mayores, mientras que la BC interregional cuesta más porque debe haber más infraestructura activa en funcionamiento para adaptarse al menor RTO/RPO. Veamos dos escenarios para mostrar cómo podría ser tu DR/BC tras migrar a AWS.
Cumplir los requisitos del distrito no será una tarea difícil de lograr, dadas las capacidades de AWS. Dado que el RTO y el RPO son tan elevados, no tiene mucho sentido implementar BC y seguir con una estrategia de DR. Kevin podrá instantanear (hacer una copia de los datos a nivel de bloque) los servidores mediante un sistema automatizado llamado Data Lifecycle Manager (DLM). DLM admite un OPR de tan sólo 2 horas, lo que es mejor que el requisito de 168 horas. Como Kevin sólo tiene 12 servidores, no le resultaría tan difícil redistribuir manualmente las instancias a otra AZ dentro del RTO requerido de 24 horas. Si fallara una AZ, Kevin podría poner en marcha nuevos servidores y adjuntarles las últimas instantáneas en unas seis horas, lo que le dejaría mucho tiempo libre. Lo mejor sería que Kevin desplegara sus 12 servidores en tres AZ. Esta configuración garantiza que sólo puedan caerse 4 servidores a la vez, en lugar de 12. La implementación con esta configuración le ahorraría cuatro horas más de redistribución de instancias.
Amelia debería plantearse pasar de una RD a una BC. Tiene suficientes sistemas de alta criticidad empresarial como para necesitarlo. Aprovechando algunas de las ventajas de AWS, Amelia puede implementar sus aplicaciones en tres AZ y utilizar el equilibrio de carga y el autoescalado para proporcionar disponibilidad. Trasladando su backend de base de datos a Amazon RDS, puede beneficiarse de la disponibilidad activa/pasiva de la base de datos. Con esta configuración, Amelia reducirá su RTO/RPO a prácticamente instantáneo. Para añadir otra capa de protección, puede implementar DLM con instantáneas de cuatro horas y replicarlas en otra región para la capacidad de DR. Puede restaurar sus servidores si toda una región se cae durante un periodo prolongado.
La BC no es un concepto que asocies con el ahorro de costes, pero con AWS y las regiones con tres AZ, puedes reducir un 25% tus costes sin dejar de ofrecer el mismo nivel de disponibilidad. Depende de las capacidades de tu aplicación, pero si tus aplicaciones pueden soportarlo, puedes ahorrar una cantidad considerable. Este ahorro es otra ventaja de AWS en relación con la BC.
Jimmy ahorrará algo de dinero trasladando su aplicación a AWS. Digamos que el funcionamiento del servidor de producción de Jimmy cuesta 100 dólares al mes. Para cumplir sus requisitos de disponibilidad y BC, Jimmy tiene un segundo servidor en otro centro de datos. Este servidor también cuesta 100 $ al mes tenerlo en línea para recibir actualizaciones de la base de datos y estar preparado para servir tráfico. Jimmy está pagando el 200% por su aplicación: 100% para servir la aplicación, y 100% para estar disponible en caso de fallo. Como Jimmy está en Estados Unidos, tiene al menos tres AZ a su disposición. Cuando migre sus servidores, puede utilizar el autoescalado y un equilibrador de carga para cambiar su aplicación a un clúster activo/activo. En esta configuración, Jimmy puede desplegar tres servidores que sirvan al 50% de la carga, lo que significa que pagará 50 $ al mes por cada servidor, con lo que su total será de 150 $ en lugar de 200 $. En esta configuración, Jimmy puede hacer que falle un servidor o AZ y seguir sirviendo toda su carga, incluso ahorrando un 25% de sus costes corrientes.
Reducción de la dependencia del proveedor
Cada vez que oigo las palabras "dependencia del proveedor" en relación con la migración a AWS, tengo que rascarme la cabeza. En todo caso, migrar a AWS abre más opciones en lugar de restringirlas. Cuando construías tu infraestructura in situ, aceptabas muchas limitaciones de proveedores. Podías cambiar de proveedor de red de área de almacenamiento (SAN) o de proveedor de hardware de servidor, pero lo hacías cuando tenías que renovar el hardware. Cuando comprabas ese hardware, quedabas atado a él de tres a cinco años. No podías comprar una SAN a Dell EMC y un año después comprar capacidad de disco a Hewlett-Packard para ampliarla. Simplemente no funciona así, y lo mismo ocurre con tu hipervisor. Claro que puedes cambiar de VMware a Hyper-V, pero el nivel de esfuerzo para conseguirlo es elevado.
Cuando migras a AWS, cambias tu hardware por bits y bytes. Si subieras mi servidor a AWS y lo hicieras funcionar allí, al día siguiente podrías coger ese servidor y trasladarlo a Azure. Al trasladarte a la nube, cortas las ataduras a tu hardware. Hay algunos costes de salida de datos de los proveedores de la nube que generan un pequeño coste de traslado, pero esos costes de traslado existen en todas partes, incluso en las instalaciones, así que los considero discutibles. Convertir tus sistemas en puramente de datos los hace más móviles que nunca. Ejecutar instancias en AWS te ofrece más ventajas de movilidad de las que jamás podrías tener en las instalaciones; todo se debe al modelo de pago por uso y a la falta de compromisos.
El verdadero bloqueo del proveedor entra en juego cuando utilizas servicios propietarios que sólo ofrece un proveedor. He oído a muchos directivos afirmar que sólo quieren utilizar servicios disponibles en todas las nubes para tener movilidad y poder cambiar de proveedor. Esta mentalidad no es un buen augurio para tu carrera a largo plazo. Mantener tu infraestructura al ritmo del mínimo común denominador te garantiza que nunca tendrás una ventaja competitiva en tu mercado. Tu competencia avanzará adoptando tecnologías lock-in para añadir valor a sus negocios. Es como comprar un Corvette y no salir nunca de la primera marcha. Cierto grado de bloqueo es inevitable, y cuando surge una situación de bloqueo, es importante que te preguntes si es bueno para tu negocio.
Advertencia
Sé cauteloso cuando las discusiones pasen a la multi-nube. Es la forma más segura de que tus costes se disparen. Tienes que empezar a pagar por todo dos veces. El doble de herramientas de seguridad, el doble de auditorías y, potencialmente, el doble de personal, dependiendo de los conjuntos de habilidades.
Cambio en los gastos operativos
Una ventaja de migrar a AWS y adoptar un modelo de pago por uso es que pasas de un gasto de capital a un gasto operativo. A primera vista, no se ve inmediatamente por qué esto es una ventaja, y algunos lo ven como algo negativo. Si compras un servidor in situ y lo amortizas, es decir, gastas el desgaste del activo a lo largo de varios años, acabas teniendo un gasto mensual fijo por ese hardware. Tras la migración, cambias esta forma de contabilidad por un coste operativo variable. Este cambio no parece algo bueno desde el punto de vista contable; pasas de un gasto mensual fijo a un gasto variable. Mucha gente prefiere una variable fija y conocida para los gastos, y la adición de un gasto variable les inquieta.
Aunque el gasto sea variable, sigo viéndolo como una ventaja frente a las instalaciones. Para tener la ventaja de un gasto mensual fijo en el servidor, tienes que comprarlo. La compra de hardware significa que recurres a tu cuenta de efectivo, para la que luego creas una cuenta de activos en mi sistema contable. Una vez creada la cuenta de activos, puedes dividir el coste total del servidor por el número de meses que piensas conservarlo. Muchas empresas utilizan 36 meses o 3 años como calendario de amortización. Tienes que disponer de tu cuenta de efectivo. Ese dinero desaparece, y no está disponible para hacer otras cosas como pagar al personal o comprar más publicidad. No es el caso de AWS:no tienes esa detracción, y tu efectivo sigue estando disponible para impulsar el negocio.
Puede que sigas preguntándote por el coste variable y su imprevisibilidad. Yo lo considero una ventaja. No siempre es fácil entender por qué es una ventaja, así que veamos el siguiente escenario para comprenderlo mejor.
Para explicar cómo la situación de Duke y el coste variable suponen un beneficio, desglosemos algunos números. La plataforma de Duke funciona en estado estacionario sin usuarios a unos 850 $ al mes. Este coste se traduce en el coste fijo de Duke para su producto. No importa cuántos usuarios haya en la plataforma, producir el producto para que lo consuman costará unos 850 $ al mes. El coste variable es el coste por usuario de 0,55 $. La suma del coste variable aumenta por cada usuario añadido linealmente. Ahora viene lo mejor: como el coste se basa en el consumo -los usuarios-, los ingresos también aumentan linealmente. Estas cifras ayudan a la empresa de Duke a crear predicciones sobre cuánto le costará y cuánto ganará. No les dirá nada sobre su penetración en el mercado, ni sobre a cuántos usuarios no les gustó la aplicación y cancelaron el servicio. Sin embargo, el director financiero de Duke se sentirá mucho más cómodo con un coste variable sabiendo que está vinculado a su base de usuarios. Si comparásemos este escenario con el de Duke ejecutando su aplicación in situ, tendría que comprar una gran cantidad de hardware para su demanda prevista. El coste sería fijo, pero también sería más costoso y fijo, aunque la empresa sólo obtuviera diez mil usuarios en el lanzamiento en lugar de cien mil.
Si quieres más previsibilidad en tu factura y tienes un consumo relativamente estático, puedes comprar instancias reservadas de AWS . Una instancia reservada es una instancia EC2 prepagada en lugar del modelo de pago por uso y te ofrece un precio con descuento. Pagas una instancia reservada por adelantado y luego amortizas el coste a lo largo del año. Forma una función notablemente similar a la amortización, porque pagas por adelantado y luego amortizas 1/12 parte de ese coste cada mes. AWS también ofrece instancias reservadas de tres años, pero no las veo con buenos ojos por muchas razones que trataré en "Modelado de la tasa de ejecución".
Nota
A veces, el modelo de pago por uso no funciona para todos; limita algunas capacidades de las pequeñas y medianas empresas para acelerar la amortización. Puede que tu contable quiera reducir tu carga fiscal, utilizando la Sección 179 del IRS. Antes de migrar, será esencial que hables con tu contable o director financiero y determines el curso de acción correcto en estas circunstancias y cómo abordar la cuestión.
Convertir tu porqué en una FAQ
En este capítulo, hemos cubierto mucho terreno sobre cómo, con un pequeño cambio, puedes cosechar un número significativo de beneficios técnicos y empresariales al migrar a AWS. Espero que al leer los distintos escenarios que explican algunos de estos cambios, hayas podido reflexionar sobre tu experiencia personal y extraer similitudes. Deberías tener una buena base de referencia para elaborar tus preguntas frecuentes sobre la migración a AWS, utilizando tus notas como guía.
¿Por qué estamos creando un FAQ para la migración? Bueno, la gente hará preguntas; es un hecho. Me gusta crear un FAQ por adelantado con respuestas a las preguntas que creo que es más probable que la gente haga. Por un lado, demuestra que has dedicado mucho tiempo a ver el proyecto a través de sus ojos. Esta conexión les da la sensación de que sientes su dolor y comprendes su punto de vista. La empatía te hará ganar apoyo rápidamente. El hecho es que, haciendo este ejercicio, ¡comprenderás su punto de vista! Lo siguiente que hacen las preguntas frecuentes es eliminar de inmediato las preocupaciones generales y permitirte ponerte a trabajar más rápidamente. Estoy seguro de que no quieres estar en más reuniones discutiendo repetidamente las mismas detracciones. A medida que trabajes y te comuniques con los equipos, puede que te des cuenta de que no has captado todos los pensamientos e ideas que tiene la gente. No pasa nada. Todo forma parte del proceso. Será importante captar sus preguntas y responder a ellas también. Hay muchas posibilidades de que otra persona de tu organización vuelva a preguntar.
Cómo construir las FAQ
El primer paso para elaborar tus FAQ es decidir a qué público van dirigidas. Este público puede ser la dirección, un equipo de desarrollo, tu personal o una unidad de negocio. Realizarás este ejercicio varias veces utilizando un público diferente para dar forma a tus FAQ. Para este ejercicio, utilizaremos la alta dirección. Ahora que tenemos nuestro público, tienes que ponerte en su lugar y pensar en las preguntas u objeciones que podrían tener sobre la migración a AWS. Repasemos dos preguntas que podrían hacerte los altos cargos y pensemos cómo elaboraríamos una respuesta basándonos en los conocimientos que hemos adquirido en este capítulo.
¿Cuánto más nos va a costar AWS?
CIO
Puedes apostar a que te harán esta pregunta, y es una pregunta muy justa. El problema con esta pregunta es que tienen una actitud predispuesta a pensar que AWS será más en lugar de menos. Sería una excelente idea reescribir esta pregunta con una postura más neutral. Quieres que la gente decida por sí misma y no se deje influenciar en ningún sentido por las preguntas de tu FAQ. "¿Cómo cambiarán nuestros costes de infraestructura tras la migración?" sería una forma mejor de formular esta pregunta.
Para responder a esta pregunta, sería importante que te centraras en los aspectos de compra de alta y baja rentabilidad de tu infraestructura. Para mayor apoyo, también puedes incluir cualquier aplicación que pueda ahorrar costes mediante un modelo de BC actualizado y ahorrar el 25% de esos costes. Es importante extraer la visión del funcionamiento interno de tu empresa tanto como sea posible para personalizarla y hacerla real para ellos.
¿Cómo afectará esta migración a nuestros gastos de personal y operativos?
DIRECTOR FINANCIERO
Esta es otra pregunta muy común que viene de la alta dirección. Es más difícil de responder. Técnicamente, tus costes operativos aumentarán desde una perspectiva contable debido al cambio de un modelo capex a un modelo opex para tu infraestructura. Sería una excelente idea separar esto en otra pregunta y respuesta para las FAQ. Entonces puedes reformular esta pregunta en "¿Cómo afectará esta migración a la productividad de nuestro personal?". Ahora puedes responder a esta pregunta con todos los ahorros de costes blandos en los que has pensado antes.
El siguiente paso en el proceso es seguir iterando con todos los equipos y departamentos a los que afectará tu migración a AWS. Será un proceso que llevará tiempo, pero ayudará en general al reducir la fricción al cambio. A medida que pases por más equipos, el número de preguntas nuevas netas disminuirá porque muchos de los grupos tendrán las mismas preocupaciones. Los puntos de vista y las motivaciones de sus preguntas cambiarán en función de su posición. Basándote en este punto de vista diferente, puede que no añadas otro elemento a las FAQ, sino que añadas más a la respuesta para abordar la preocupación adicional en su lugar.
Para terminar
Hemos cubierto mucho terreno en este capítulo, revisando los beneficios tecnológicos y empresariales de migrar a AWS. Lo cierto es que sólo hemos arañado la superficie, y hay muchas más formas de beneficiarse de la migración. De nuevo, estos son los beneficios que se aplican universalmente a cualquiera que migre y eran los más importantes de cubrir. Cada empresa que he migrado a la nube ha aprovechado AWS para beneficiarse de su aspecto y escenario únicos. AWS podría considerarse como el mayor Juego de Erector del mundo. Te permite construir un número Shannon de soluciones posibles.
Nota
Claude Shannon fue un matemático que teorizó el límite inferior de la complejidad del árbol de partidas en el ajedrez, que da como resultado unas10120 partidas únicas posibles. Este número se conoce como número de Shannon.
A estas alturas, deberías tener una comprensión sólida de cómo tu empresa puede aprovechar de forma única los beneficios de AWS, relacionando los escenarios y las explicaciones con tu experiencia. Deberías tener construidas unas preguntas frecuentes sólidas que ayuden a abordar las preocupaciones de los usuarios y a hacer avanzar la conversación. Por último, puede que tengas algunas ideas sobre lo que depara el futuro en cuanto a beneficios adicionales tras la migración.
1 Simon Sinek, Empieza por qué: Cómo los grandes líderes inspiran a todos a actuar (Nueva York: Porfolio, 2011).
Get Migrar a AWS: Guía del administrador now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

