Chapter 1. A Rapid Introduction to Kafka
The amount of data in the world is growing exponentially and, according to the World Economic Forum, the number of bytes being stored in the world already far exceeds the number of stars in the observable universe.
When you think of this data, you might think of piles of bytes sitting in data warehouses, in relational databases, or on distributed filesystems. Systems like these have trained us to think of data in its resting state. In other words, data is sitting somewhere, resting, and when you need to process it, you run some query or job against the pile of bytes.
This view of the world is the more traditional way of thinking about data. However, while data can certainly pile up in places, more often than not, it’s moving. You see, many systems generate continuous streams of data, including IoT sensors, medical sensors, financial systems, user and customer analytics software, application and server logs, and more. Even data that eventually finds a nice place to rest likely travels across the network at some point before it finds its forever home.
If we want to process data in real time, while it moves, we can’t simply wait for it to pile up somewhere and then run a query or job at some interval of our choosing. That approach can handle some business use cases, but many important use cases require us to process, enrich, transform, and respond to data incrementally as it becomes available. Therefore, we need something that has a very different worldview of data: a technology that gives us access to data in its flowing state, and which allows us to work with these continuous and unbounded data streams quickly and efficiently. This is where Apache Kafka comes in.
Apache Kafka (or simply, Kafka) is a streaming platform for ingesting, storing, accessing, and processing streams of data. While the entire platform is very interesting, this book focuses on what I find to be the most compelling part of Kafka: the stream processing layer. However, to understand Kafka Streams and ksqlDB (both of which operate at this layer, and the latter of which also operates at the stream ingestion layer), it is necessary to have a working knowledge of how Kafka, as a platform, works.
Therefore, this chapter will introduce you to some important concepts and terminology that you will need for the rest of the book. If you already have a working knowledge of Kafka, feel free to skip this chapter. Otherwise, keep reading.
Some of the questions we will answer in this chapter include:
-
How does Kafka simplify communication between systems?
-
What are the main components in Kafka’s architecture?
-
Which storage abstraction most closely models streams?
-
How does Kafka store data in a fault-tolerant and durable manner?
-
How is high availability and fault tolerance achieved at the data processing layers?
We will conclude this chapter with a tutorial showing how to install and run Kafka. But first, let’s start by looking at Kafka’s communication model.
Communication Model
Perhaps the most common communication pattern between systems is the synchronous, client-server model. When we talk about systems in this context, we mean applications, microservices, databases, and anything else that reads and writes data over a network. The client-server model is simple at first, and involves direct communication between systems, as shown in Figure 1-1.
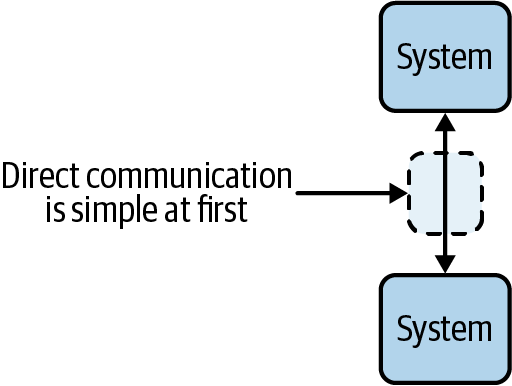
Figure 1-1. Point-to-point communication is simple to maintain and reason about when you have a small number of systems
For example, you may have an application that synchronously queries a database for some data, or a collection of microservices that talk to each other directly.
However, when more systems need to communicate, point-to-point communication becomes difficult to scale. The result is a complex web of communication pathways that can be difficult to reason about and maintain. Figure 1-2 shows just how confusing it can get, even with a relatively small number of systems.
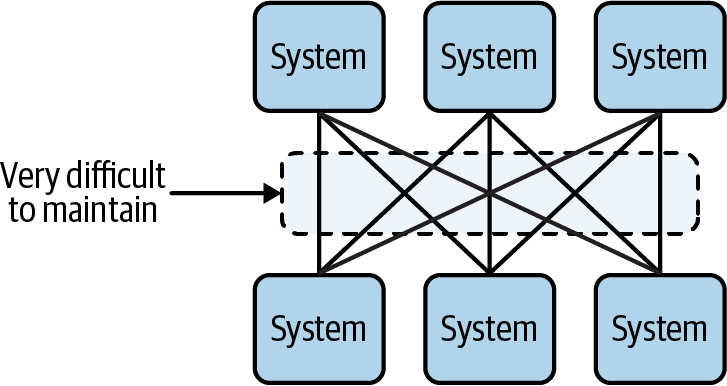
Figure 1-2. The result of adding more systems is a complex web of communication channels, which is difficult to maintain
Some of the drawbacks of the client-server model include:
-
Systems become tightly coupled because their communication depends on knowledge of each other. This makes maintaining and updating these systems more difficult than it needs to be.
-
Synchronous communication leaves little room for error since there are no delivery guarantees if one of the systems goes offline.
-
Systems may use different communication protocols, scaling strategies to deal with increased load, failure-handling strategies, etc. As a result, you may end up with multiple species of systems to maintain (software speciation), which hurts maintainability and defies the common wisdom that we should treat applications like cattle instead of pets.
-
Receiving systems can easily be overwhelmed, since they don’t control the pace at which new requests or data comes in. Without a request buffer, they operate at the whims of the applications that are making requests.
-
There isn’t a strong notion for what is being communicated between these systems. The nomenclature of the client-server model has put too much emphasis on requests and responses, and not enough emphasis on the data itself. Data should be the focal point of data-driven systems.
-
Communication is not replayable. This makes it difficult to reconstruct the state of a system.
Kafka simplifies communication between systems by acting as a centralized communication hub (often likened to a central nervous system), in which systems can send and receive data without knowledge of each other. The communication pattern it implements is called the publish-subscribe pattern (or simply, pub/sub), and the result is a drastically simpler communication model, as shown in Figure 1-3.
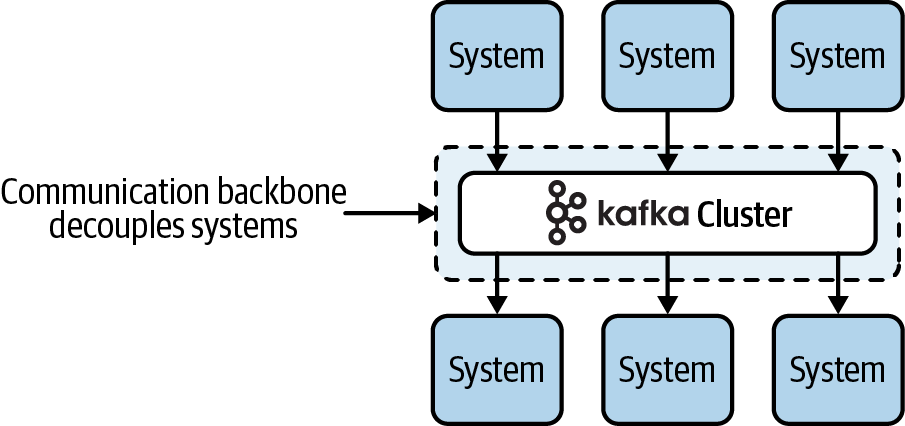
Figure 1-3. Kafka removes the complexity of point-to-point communication by acting as a communication hub between systems
If we add more detail to the preceding diagram, we can begin to identify the main components involved in Kafka’s communication model, as shown in Figure 1-4.
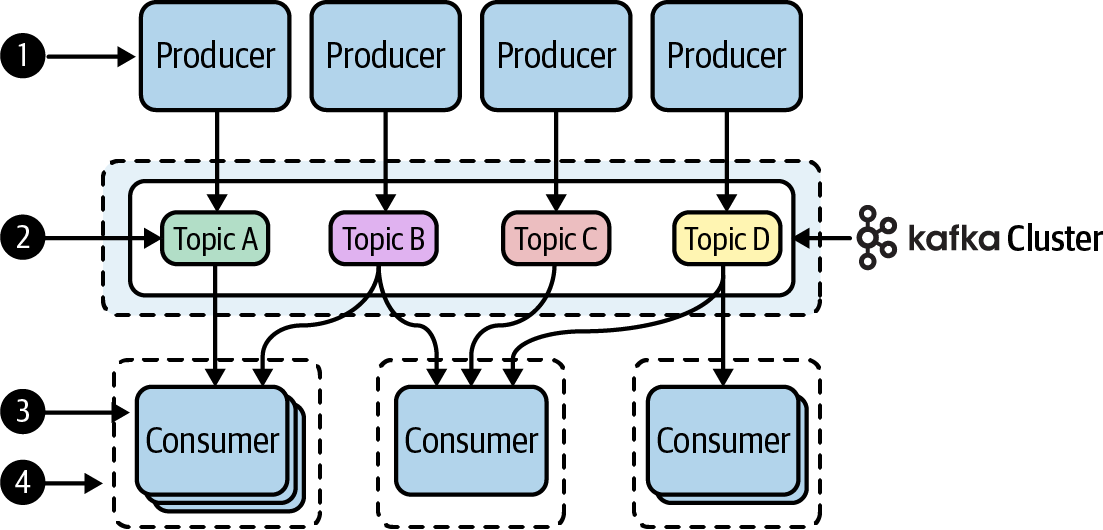
Figure 1-4. The Kafka communication model, redrawn with more detail to show the main components of the Kafka platform
Instead of having multiple systems communicate directly with each other, producers simply publish their data to one or more topics, without caring who comes along to read the data.
Topics are named streams (or channels) of related data that are stored in a Kafka cluster. They serve a similar purpose as tables in a database (i.e., to group related data). However, they do not impose a particular schema, but rather store the raw bytes of data, which makes them very flexible to work with.1

Consumers are processes that read (or subscribe) to data in one or more topics. They do not communicate directly with the producers, but rather listen to data on any stream they happen to be interested in.

Consumers can work together as a group (called a consumer group) in order to distribute work across multiple processes.
Kafka’s communication model, which puts more emphasis on flowing streams of data that can easily be read from and written to by multiple processes, comes with several advantages, including:
-
Systems become decoupled and easier to maintain because they can produce and consume data without knowledge of other systems.
-
Asynchronous communication comes with stronger delivery guarantees. If a consumer goes down, it will simply pick up from where it left off when it comes back online again (or, when running with multiple consumers in a consumer group, the work will be redistributed to one of the other members).
-
Systems can standardize on the communication protocol (a high-performance binary TCP protocol is used when talking to Kafka clusters), as well as scaling strategies and fault-tolerance mechanisms (which are driven by consumer groups). This allows us to write software that is broadly consistent, and which fits in our head.
-
Consumers can process data at a rate they can handle. Unprocessed data is stored in Kafka, in a durable and fault-tolerant manner, until the consumer is ready to process it. In other words, if the stream your consumer is reading from suddenly turns into a firehose, the Kafka cluster will act as a buffer, preventing your consumers from being overwhelmed.
-
A stronger notion of what data is being communicated, in the form of events. An event is a piece of data with a certain structure, which we will discuss in “Events”. The main point, for now, is that we can focus on the data flowing through our streams, instead of spending so much time disentangling the communication layer like we would in the client-server model.
-
Systems can rebuild their state anytime by replaying the events in a topic.
One important difference between the pub/sub model and the client-server model is that communication is not bidirectional in Kafka’s pub/sub model. In other words, streams flow one way. If a system produces some data to a Kafka topic, and relies on another system to do something with the data (i.e., enrich or transform it), the enriched data will need to be written to another topic and subsequently consumed by the original process. This is simple to coordinate, but it changes the way we think about communication.
As long as you remember the communication channels (topics) are stream-like in nature (i.e., flowing unidirectionally, and may have multiple sources and multiple downstream consumers), it’s easy to design systems that simply listen to whatever stream of flowing bytes they are interested in, and produce data to topics (named streams) whenever they want to share data with one or more systems. We will be working a lot with Kafka topics in the following chapters (each Kafka Streams and ksqlDB application we build will read, and usually write to, one or more Kafka topics), so by the time you reach the end of this book, this will be second nature for you.
Now that we’ve seen how Kafka’s communication model simplifies the way systems communicate with each other, and that named streams called topics act as the communication medium between systems, let’s gain a deeper understanding of how streams come into play in Kafka’s storage layer.
How Are Streams Stored?
When a team of LinkedIn engineers2 saw the potential in a stream-driven data platform, they had to answer an important question: how should unbounded and continuous data streams be modeled at the storage layer?
Ultimately, the storage abstraction they identified was already present in many types of data systems, including traditional databases, key-value stores, version control systems, and more. The abstraction is the simple, yet powerful commit log (or simply, log).
Note
When we talk about logs in this book, we’re not referring to application logs, which emit information about a running process (e.g., HTTP server logs). Instead, we are referring to a specific data structure that is described in the following paragraphs.
Logs are append-only data structures that capture an ordered sequence of events. Let’s examine the italicized attributes in more detail, and build some intuition around
logs, by creating a simple log from the command line. For example, let’s create a log called user_purchases, and populate it with some dummy data using the following
command:
# create the logfiletouch users.log# generate four dummy records in our logecho"timestamp=1597373669,user_id=1,purchases=1">> users.logecho"timestamp=1597373669,user_id=2,purchases=1">> users.logecho"timestamp=1597373669,user_id=3,purchases=1">> users.logecho"timestamp=1597373669,user_id=4,purchases=1">> users.log
Now if we look at the log we created, it contains four users that have made a single purchase:
# print the contents of the logcat users.log# outputtimestamp=1597373669,user_id=1,purchases=1timestamp=1597373669,user_id=2,purchases=1timestamp=1597373669,user_id=3,purchases=1timestamp=1597373669,user_id=4,purchases=1
The first attribute of logs is that they are written to in an append-only manner. This means that if user_id=1 comes along and makes a second purchase, we do not update the first record, since each record is immutable in a log. Instead, we just append the new record to the end:
# append a new record to the logecho"timestamp=1597374265,user_id=1,purchases=2">>users.log# print the contents of the logcatusers.log# outputtimestamp=1597373669,user_id=1,purchases=1timestamp=1597373669,user_id=2,purchases=1timestamp=1597373669,user_id=3,purchases=1timestamp=1597373669,user_id=4,purchases=1timestamp=1597374265,user_id=1,purchases=2
Once a record is written to the log, it is considered immutable. Therefore, if we need to perform an update (e.g., to change the purchase count for a user), then the original record is left untouched.
In order to model the update, we simply append the new value to the end of the log. The log will contain both the old record and the new record, both of which are immutable.
Any system that wants to examine the purchase counts for each user can simply read each record in the log, in order, and the last record they will see for user_id=1 will contain the updated purchase amount. This brings us to the second attribute of logs: they are ordered.
The preceding log happens to be in timestamp order (see the first column), but that’s not what we mean by ordered. In fact, Kafka does store a timestamp for each record in the log, but the records do not have to be in timestamp order. When we say a log is ordered, what we mean is that a record’s position in the log is fixed, and never changes. If we reprint the log again, this time with line numbers, you can see the position in the first column:
# print the contents of the log, with line numberscat -n users.log# output1timestamp=1597373669,user_id=1,purchases=1 2timestamp=1597373669,user_id=2,purchases=1 3timestamp=1597373669,user_id=3,purchases=1 4timestamp=1597373669,user_id=4,purchases=1 5timestamp=1597374265,user_id=1,purchases=2
Now, imagine a scenario where ordering couldn’t be guaranteed. Multiple processes could read the user_id=1 updates in a different order, creating disagreement about the actual purchase count for this user. By ensuring the logs are ordered, the data can be processed deterministically3 by multiple processes.4
Furthermore, while the position of each log entry in the preceding example uses line numbers, Kafka refers to the position of each entry in its distributed log as an offset. Offsets start at 0 and they enable an important behavior: they allow multiple consumer groups to each read from the same log, and maintain their own positions in the log/stream they are reading from. This is shown in Figure 1-5.
Now that we’ve gained some intuition around Kafka’s log-based storage layer by creating our own log from the command line, let’s tie these ideas back to the higher-level constructs we identified in Kafka’s communication model. We’ll start by continuing our discussion of topics, and learning about something called partitions.
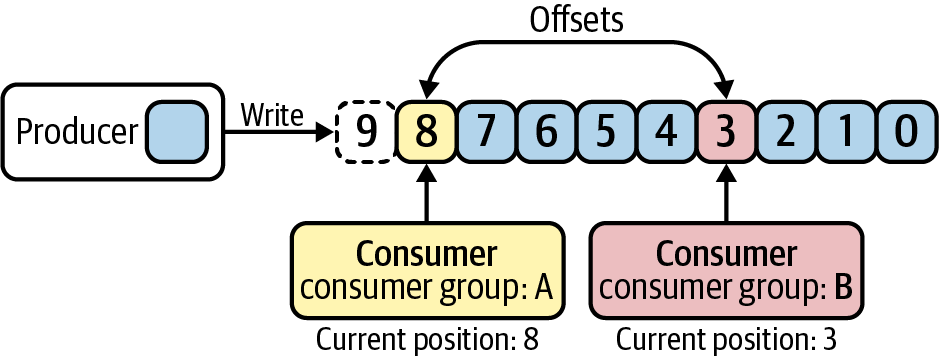
Figure 1-5. Multiple consumer groups can read from the same log, each maintaining their position based on the offset they have read/processed
Topics and Partitions
In our discussion of Kafka’s communication model, we learned that Kafka has the concept of named streams called topics. Furthermore, Kafka topics are extremely flexible with what you store in them. For example, you can have homogeneous topics that contain only one type of data, or heterogeneous topics that contain multiple types of data.5 A depiction of these different strategies is shown in Figure 1-6.
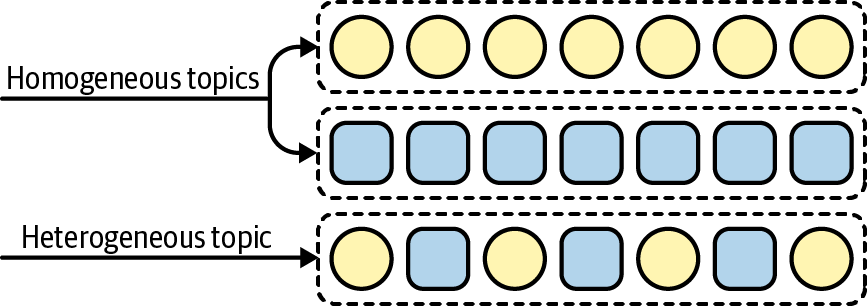
Figure 1-6. Different strategies exist for storing events in topics; homogeneous topics generally contain one event type (e.g., clicks) while heterogeneous topics contain multiple event types (e.g., clicks and page_views)
We have also learned that append-only commit logs are used to model streams in Kafka’s storage layer. So, does this mean that each topic correlates with a log file? Not exactly. You see, Kafka is a distributed log, and it’s hard to distribute just one of something. So if we want to achieve some level of parallelism with the way we distribute and process logs, we need to create lots of them. This is why Kafka topics are broken into smaller units called partitions.
Partitions are individual logs (i.e., the data structures we discussed in the previous section) where data is produced and consumed from. Since the commit log abstraction is implemented at the partition level, this is the level at which ordering is guaranteed, with each partition having its own set of offsets. Global ordering is not supported at the topic level, which is why producers often route related records to the same partition.6
Ideally, data will be distributed relatively evenly across all partitions in a topic. But you could also end up with partitions of different sizes. Figure 1-7 shows an example of a topic with three different partitions.
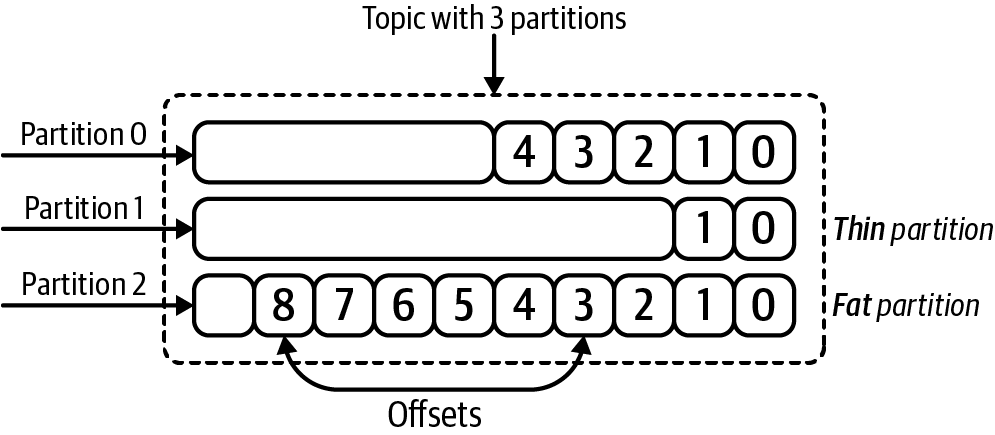
Figure 1-7. A Kafka topic configured with three partitions
The number of partitions for a given topic is configurable, and having more partitions in a topic generally translates to more parallelism and throughput, though there are some trade-offs of having too many partitions.7 We’ll talk about this more throughout the book, but the important takeaway is that only one consumer per consumer group can consume from a partition (individual members across different consumer groups can consume from the same partition, however, as shown in Figure 1-5).
Therefore, if you want to spread the processing load across N consumers in a single consumer group, you need N partitions. If you have fewer members in a consumer group than there are partitions on the source topic (i.e., the topic that is being read from), that’s OK: each consumer can process multiple partitions. If you have more members in a consumer group than there are partitions on the source topic, then some consumers will be idle.
With this in mind, we can improve our definition of what a topic is. A topic is a named stream, composed of multiple partitions. And each partition is modeled as a commit log that stores data in a totally ordered and append-only sequence. So what exactly is stored in a topic partition? We’ll explore this in the next section.
Events
In this book, we spend a lot of time talking about processing data in topics. However, we still haven’t developed a full understanding of what kind of data is stored in a Kafka topic (and, more specifically, in a topic’s partitions).
A lot of the existing literature on Kafka, including the official documentation, uses a variety of terms to describe the data in a topic, including messages, records, and events. These terms are often used interchangeably, but the one we have favored in this book (though we still use the other terms occasionally) is event. An event is a timestamped key-value pair that records something that happened. The basic anatomy of each event captured in a topic partition is shown in Figure 1-8.
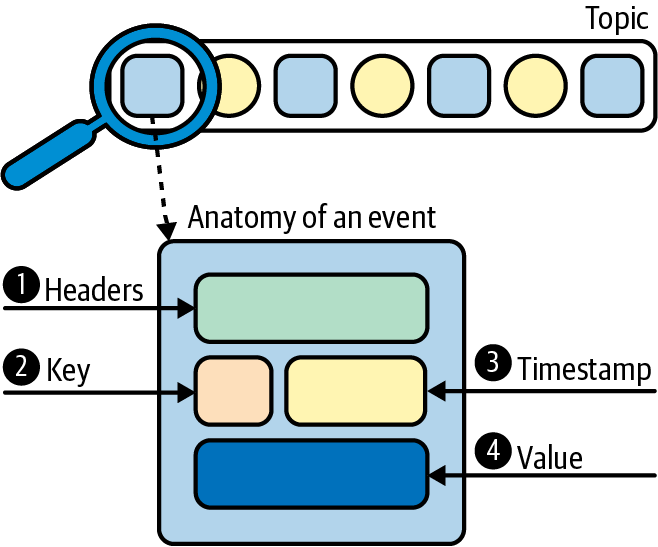
Figure 1-8. Anatomy of an event, which is what is stored in topic partitions
Application-level headers contain optional metadata about an event. We don’t work with these very often in this book.
Keys are also optional, but play an important role in how data is distributed across partitions. We will see this over the next few chapters, but generally speaking, they are used to identify related records.
Each event is associated with a timestamp. We’ll learn more about timestamps in Chapter 5.
The value contains the actual message contents, encoded as a byte array. It’s up to clients to deserialize the raw bytes into a more meaningful structure (e.g., a JSON object or Avro record). We will talk about byte array deserialization in detail in “Serialization/Deserialization”.
Now that we have a good understanding of what data is stored in a topic, let’s get a deeper look at Kafka’s clustered deployment model. This will provide more information about how data is physically stored in Kafka.
Kafka Cluster and Brokers
Having a centralized communication point means reliability and fault tolerance are extremely important. It also means that the communication backbone needs to be scalable, i.e., able to handle increased amounts of load. This is why Kafka operates as a cluster, and multiple machines, called brokers, are involved in the storage and retrieval of data.
Kafka clusters can be quite large, and can even span multiple data centers and geographic regions. However, in this book, we will usually work with a single-node Kafka cluster since that is all we need to start working with Kafka Streams and ksqlDB. In production, you’ll likely want at least three brokers, and you will want to set the replication of your Kafka topic so that your data is replicated across multiple brokers (we’ll see this later in this chapter’s tutorial). This allows us to achieve high availability and to avoid data loss in case one machine goes down.
Now, when we talk about data being stored and replicated across brokers, we’re really talking about individual partitions in a topic. For example, a topic may have three partitions that are spread across three brokers, as shown in Figure 1-9.
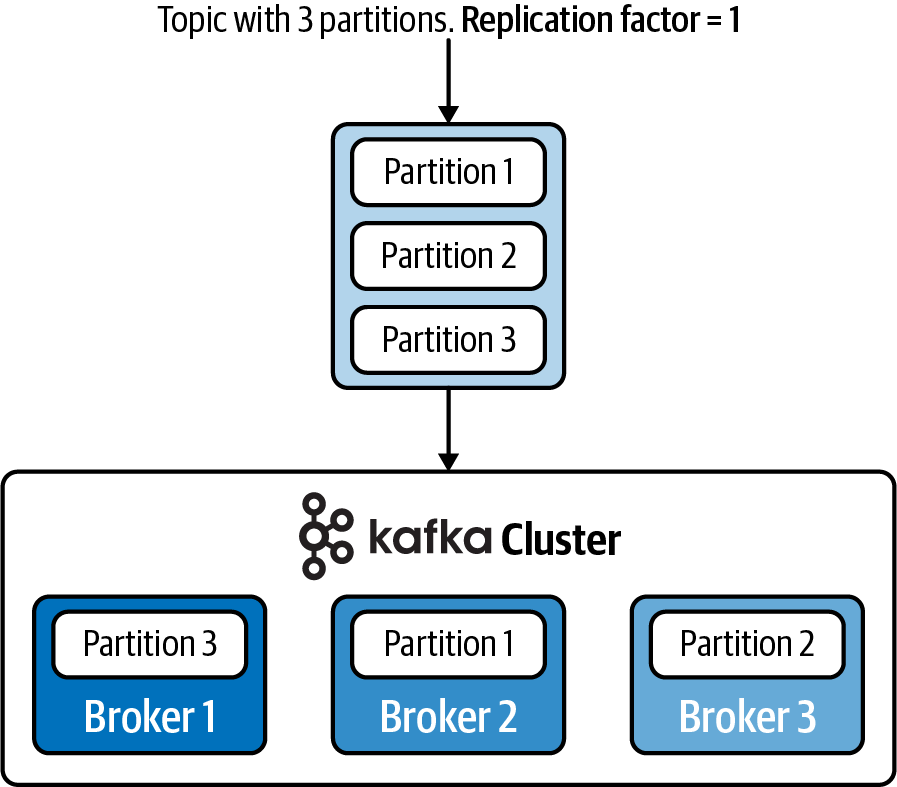
Figure 1-9. Partitions are spread across the available brokers, meaning that a topic can span multiple machines in the Kafka cluster
As you can see, this allows topics to be quite large, since they can grow beyond the capacity of a single machine. To achieve fault tolerance and high availability, you can set a replication factor when configuring the topic. For example, a replication factor of 2 will allow the partition to be stored on two different brokers. This is shown in Figure 1-10.
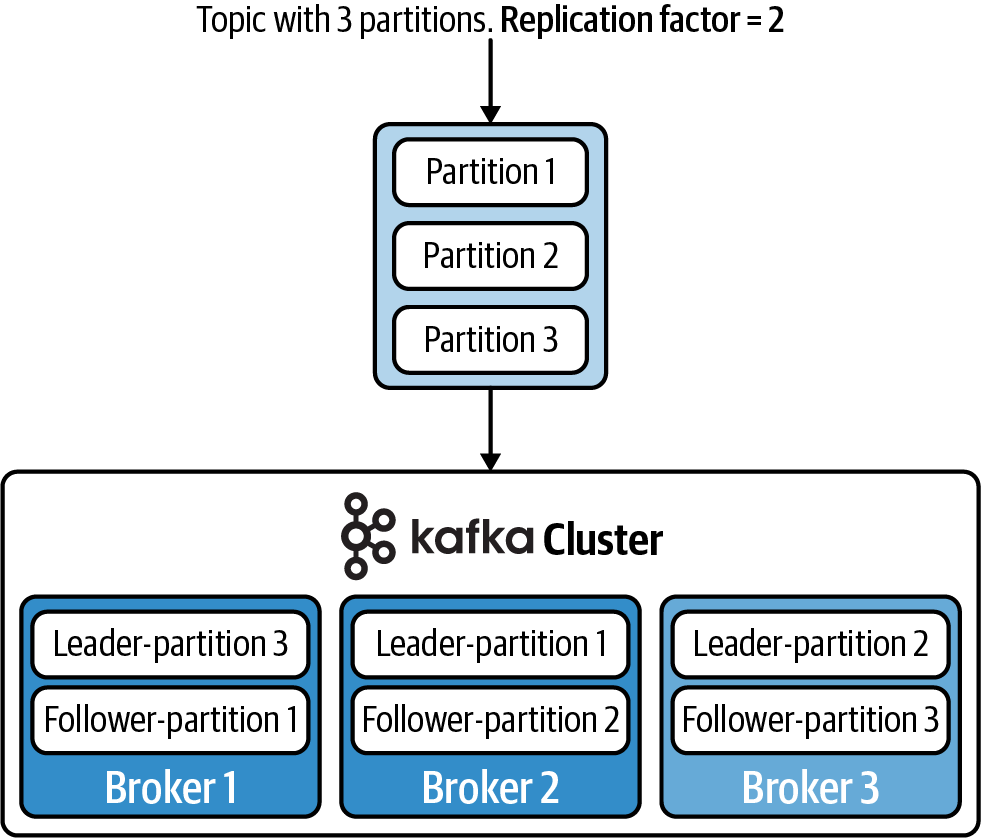
Figure 1-10. Increasing the replication factor to 2 will cause the partitions to be stored on two different brokers
Whenever a partition is replicated across multiple brokers, one broker will be designated as the leader, which means it will process all read/write requests from producers/consumers for the given partition. The other brokers that contain the replicated partitions are called followers, and they simply copy the data from the leader. If the leader fails, then one of the followers will be promoted as the new leader.
Furthermore, as the load on your cluster increases over time, you can expand your cluster by adding even more brokers, and triggering a partition reassignment. This will allow you to migrate data from the old machines to a fresh, new machine.
Finally, brokers also play an important role with maintaining the membership of consumer groups. We’ll explore this in the next section.
Consumer Groups
Kafka is optimized for high throughput and low latency. To take advantage of this on the consumer side, we need to be able to parallelize work across multiple processes. This is accomplished with consumer groups.
Consumer groups are made up of multiple cooperating consumers, and the membership of these groups can change over time. For example, new consumers can come online to scale the processing load, and consumers can also go offline either for planned maintenance or due to unexpected failure. Therefore, Kafka needs some way of maintaining the membership of each group, and redistributing work when necessary.
To facilitate this, every consumer group is assigned to a special broker called the group coordinator, which is responsible for receiving heartbeats from the consumers, and triggering a rebalance of work whenever a consumer is marked as dead. A depiction of consumers heartbeating back to a group coordinator is shown in Figure 1-11.
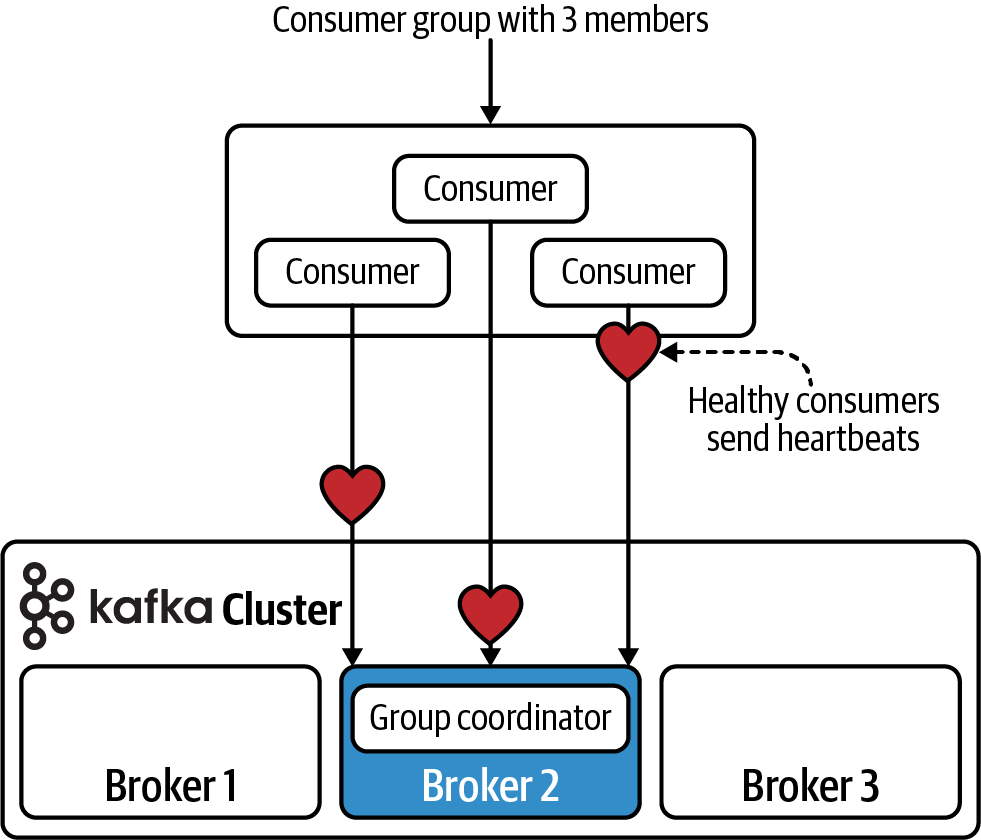
Figure 1-11. Three consumers in a group, heartbeating back to group coordinator
Every active member of the consumer group is eligible to receive a partition assignment. For example, the work distribution across three healthy consumers may look like the diagram in Figure 1-12.
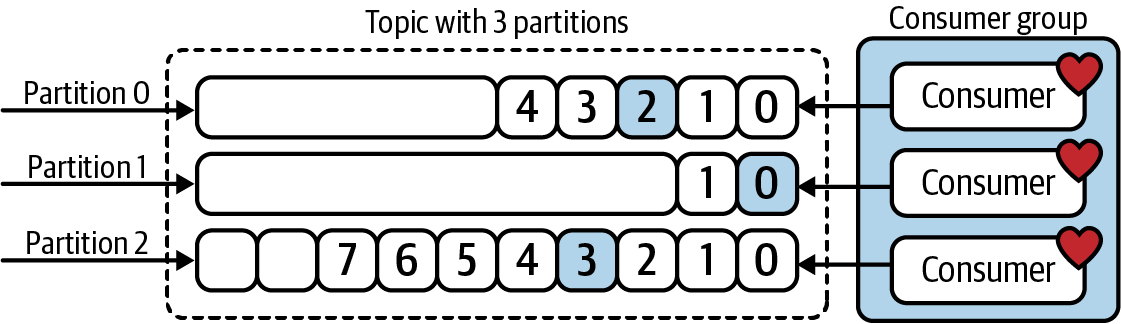
Figure 1-12. Three healthy consumers splitting the read/processing workload of a three-partition Kafka topic
However, if a consumer instance becomes unhealthy and cannot heartbeat back to the cluster, then work will automatically be reassigned to the healthy consumers. For example, in Figure 1-13, the middle consumer has been assigned the partition that was previously being handled by the unhealthy consumer.
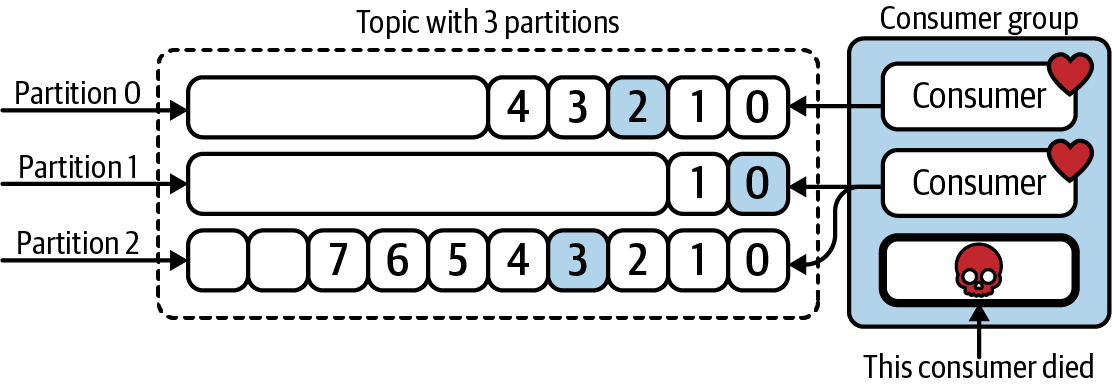
Figure 1-13. Work is redistributed when consumer processes fail
As you can see, consumer groups are extremely important in achieving high availability and fault tolerance at the data processing layer. With this, let’s now commence our tutorial by learning how to install Kafka.
Installing Kafka
There are detailed instructions for installing Kafka manually in the official documentation. However, to keep things as simple as possible, most of the tutorials in this book utilize Docker, which allows us to deploy Kafka and our stream processing applications inside a containerized environment.
Therefore, we will be installing Kafka using Docker Compose, and we’ll be using Docker images that are published by Confluent.8 The first step is to download and install Docker from the Docker install page.
Next, save the following configuration to a file called docker-compose.yml:
---version:'2'services:zookeeper:image:confluentinc/cp-zookeeper:6.0.0hostname:zookeepercontainer_name:zookeeperports:-"2181:2181"environment:ZOOKEEPER_CLIENT_PORT:2181ZOOKEEPER_TICK_TIME:2000kafka:image:confluentinc/cp-enterprise-kafka:6.0.0hostname:kafkacontainer_name:kafkadepends_on:-zookeeperports:-"29092:29092"environment:KAFKA_BROKER_ID:1KAFKA_ZOOKEEPER_CONNECT:'zookeeper:2181'KAFKA_LISTENER_SECURITY_PROTOCOL_MAP:|PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXTKAFKA_ADVERTISED_LISTENERS:|PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR:1KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR:1
The first container, which we’ve named
zookeeper, will contain the ZooKeeper installation. We haven’t talked about ZooKeeper in this introduction since, at the time of this writing, it is being actively removed from Kafka. However, it is a centralized service for storing metadata such as topic configuration. Soon, it will no longer be included in Kafka, but we are including it here since this book was published before ZooKeeper was fully removed.The second container, called
kafka, will contain the Kafka installation. This is where our broker (which comprises our single-node cluster) will run and where we will execute some of Kafka’s console scripts for interacting with the cluster.
Finally, run the following command to start a local Kafka cluster:
docker-compose up
With our Kafka cluster running, we are now ready to proceed with our tutorial.
Hello, Kafka
In this simple tutorial, we will demonstrate how to create a Kafka topic, write data to a topic using a producer, and finally, read data from a topic using a consumer. The first thing we need to do is log in to the container that has Kafka installed. We can do this by running the following command:
docker-compose exec kafka bash
Now, let’s create a topic, called users. We’ll use one of the console scripts (kafka-topics) that is included with Kafka. The following command shows how to do this:
kafka-topics\--bootstrap-serverlocalhost:9092\--create\--topicusers\--partitions4\--replication-factor1# outputCreatedtopicusers.
kafka-topicsis a console script that is included with Kafka.A bootstrap server is the host/IP pair for one or more brokers.
There are many flags for interacting with Kafka topics, including
--list,--describe, and--delete. Here, we use the--createflag since we are creating a new topic.The topic name is
users.
Split our topic into four partitions.

Since we’re running a single-node cluster, we will set the replication factor to 1. In production, you will want to set this to a higher value (such as
3) to ensure high-availability.
Note
The console scripts we use in this section are included in the Kafka source distribution. In a vanilla Kafka installation, these scripts include the .sh file extension (e.g., kafka-topics.sh, kafka-console-producer.sh, etc.). However, the file extension is dropped in Confluent Platform (which is why we ran kafka-topics instead of kafka-topics.sh in the previous code snippet).
Once the topic has been created, you can print a description of the topic, including its configuration, using the following command:
kafka-topics\--bootstrap-serverlocalhost:9092\--describe\--topicusers# outputTopic:usersPartitionCount:4ReplicationFactor:1Configs:Topic:usersPartition:0Leader:1Replicas:1Isr:1Topic:usersPartition:1Leader:1Replicas:1Isr:1Topic:usersPartition:2Leader:1Replicas:1Isr:1Topic:usersPartition:3Leader:1Replicas:1Isr:1
The
--describeflag allows us to view configuration information for a given topic.
Now, let’s produce some data using the built-in kafka-console-producer script:
kafka-console-producer\--bootstrap-serverlocalhost:9092\--propertykey.separator=,\--propertyparse.key=true\--topicusers
The
kafka-console-producerscript, which is included with Kafka, can be used to produce data to a topic. However, once we start working with Kafka Streams and ksqlDB, the producer processes will be embedded in the underlying Java library, so we won’t need to use this script outside of testing and development purposes.We will be producing a set of key-value pairs to our
userstopic. This property states that our key and values will be separated using the,character.
The previous command will drop you in an interactive prompt. From here, we can input several key-value pairs to produce to the users topic. When you are finished, press Control-C on your keyboard to exit the prompt:
>1,mitch >2,elyse >3,isabelle >4,sammy
After producing the data to our topic, we can use the kafka-console-consumer script to read the data. The following command shows how:
kafka-console-consumer\--bootstrap-serverlocalhost:9092\--topicusers\--from-beginning# outputmitchelyseisabellesammy
The
kafka-console-consumerscript is also included in the Kafka distribution. Similar to what we mentioned for thekafka-console-producerscript, most of the tutorials in this book will leverage consumer processes that are built into Kafka Streams and ksqlDB, instead of using this standalone console script (which is useful for testing purposes).The
--from-beginningflag indicates that we should start consuming from the beginning of the Kafka topic.
By default, the kafka-console-consumer will only print the message value. But as we learned earlier, events actually contain more information, including a key, a timestamp, and headers. Let’s pass in some additional properties to the console consumer so that we can see the timestamp and key values as well:9
kafka-console-consumer\--bootstrap-server localhost:9092\--topic users\--property print.timestamp=true\--property print.key=true\--property print.value=true\--from-beginning# outputCreateTime:1598226962606 1 mitch CreateTime:1598226964342 2 elyse CreateTime:1598226966732 3 isabelle CreateTime:1598226968731 4 sammy
That’s it! You have now learned how to perform some very basic interactions with a Kafka cluster. The final step is to tear down our local cluster using the following command:
docker-compose down
Summary
Kafka’s communication model makes it easy for multiple systems to communicate, and its fast, durable, and append-only storage layer makes it possible to work with fast-moving streams of data with ease. By using a clustered deployment, Kafka can achieve high availability and fault tolerance at the storage layer by replicating data across multiple machines, called brokers. Furthermore, the cluster’s ability to receive heartbeats from consumer processes, and update the membership of consumer groups, allows for high availability, fault tolerance, and workload scalability at the stream processing and consumption layer. All of these features have made Kafka one of the most popular stream processing platforms in existence.
You now have enough background on Kafka to get started with Kafka Streams and ksqlDB. In the next section, we will begin our journey with Kafka Streams by seeing how it fits in the wider Kafka ecosystem, and by learning how we can use this library to work with data at the stream processing layer.
1 We talk about the raw byte arrays that are stored in topics, as well as the process of deserializing the bytes into higher-level structures like JSON objects/Avro records, in Chapter 3.
2 Jay Kreps, Neha Narkhede, and Jun Rao initially led the development of Kafka.
3 Deterministic means the same inputs will produce the same outputs.
4 This is why traditional databases use logs for replication. Logs are used to capture each write operation on the leader database, and process the same writes, in order, on a replica database in order to deterministically re-create the same dataset on another machine.
5 Martin Kleppmann has an interesting article on this topic, which can be found at https://oreil.ly/tDZMm. He talks about the various trade-offs and the reasons why one might choose one strategy over another. Also, Robert Yokota’s follow-up article goes into more depth about how to support multiple event types when using Confluent Schema Registry for schema management/evolution.
6 The partitioning strategy is configurable, but a popular strategy, including the one that is implemented in Kafka Streams and ksqlDB, involves setting the partition based on the record key (which can be extracted from the payload of the record or set explicitly). We’ll discuss this in more detail over the next few chapters.
7 The trade-offs include longer recovery periods after certain failure scenarios, increased resource utilization (file descriptors, memory), and increased end-to-end latency.
8 There are many Docker images to choose from for running Kafka. However, the Confluent images are a convenient choice since Confluent also provides Docker images for some of the other technologies we will use in this book, including ksqlDB and Confluent Schema Registry.
9 As of version 2.7, you can also use the --property print.headers=true flag to print the message headers.
Get Mastering Kafka Streams and ksqlDB now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

